A High Throughput Hardware Architecture for Parallel Recursive Systematic Convolutional Encoders


Abstract
1. Introduction
2. Materials and Methods
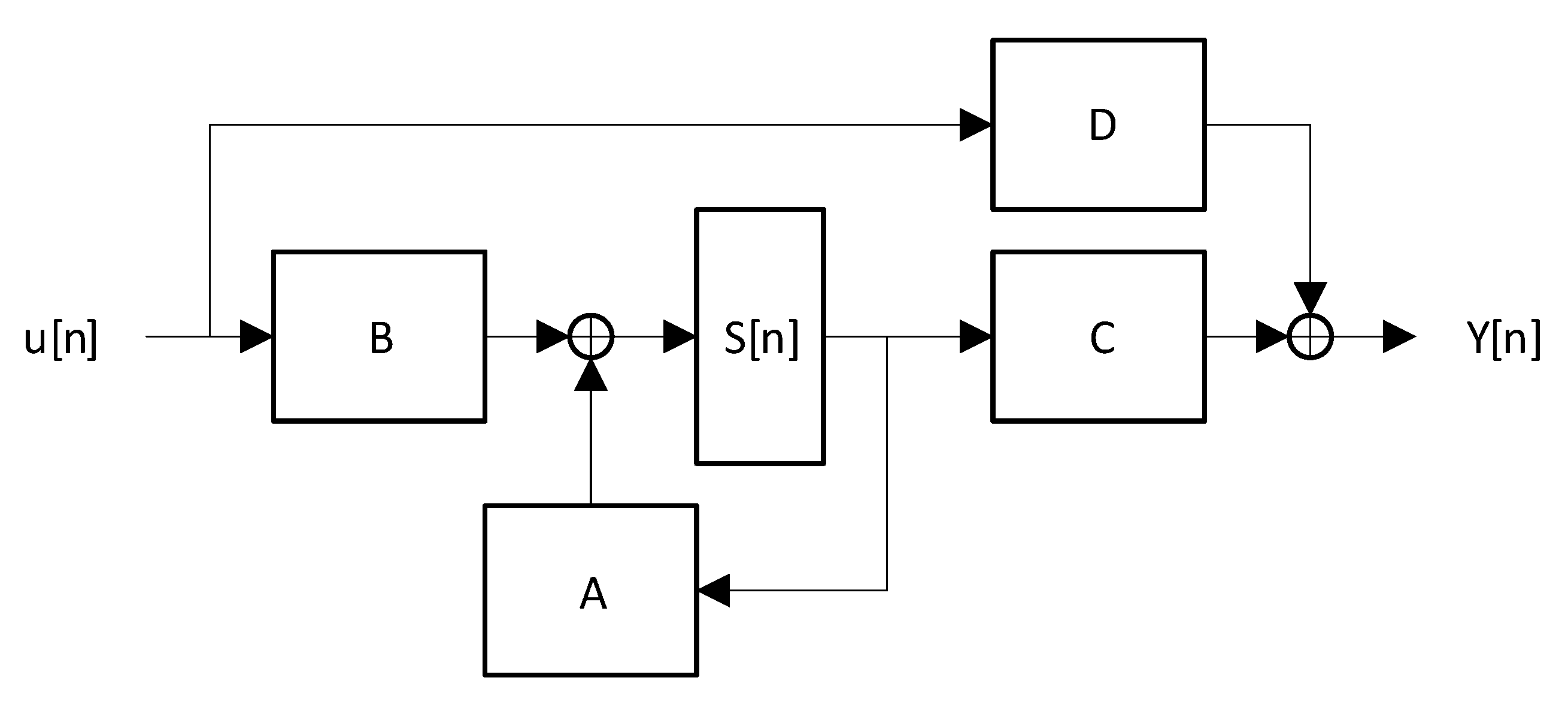
2.1. RSC Encoders Introduction
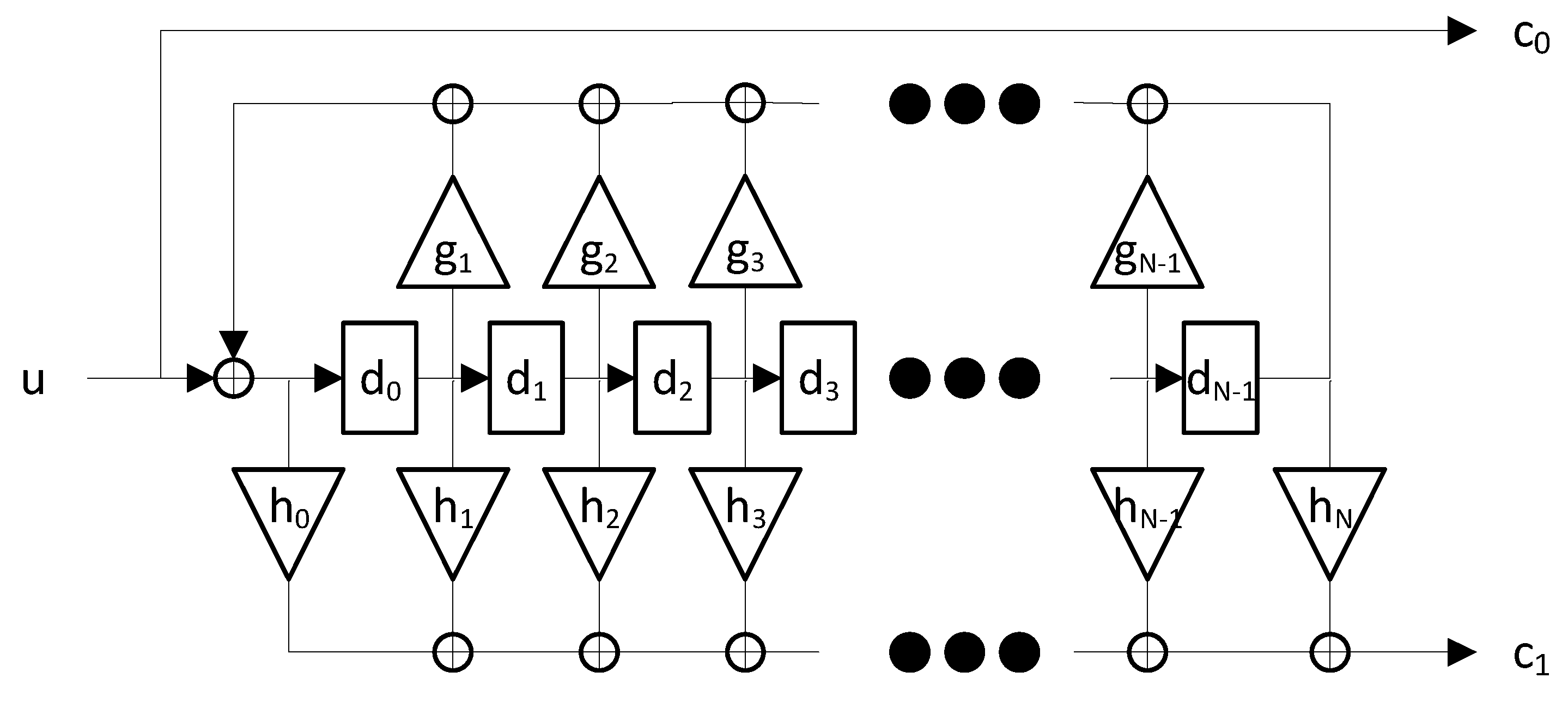
2.2. RSC Encoders Parallelization Approach
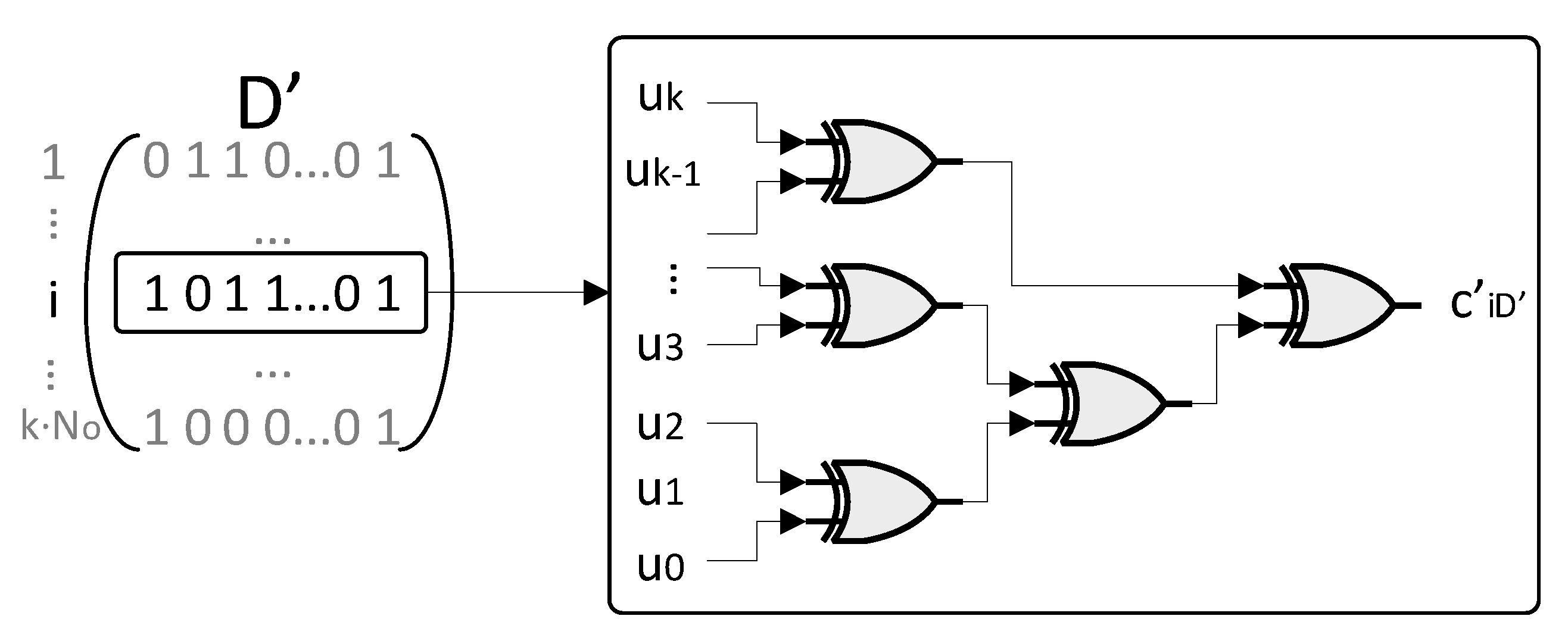
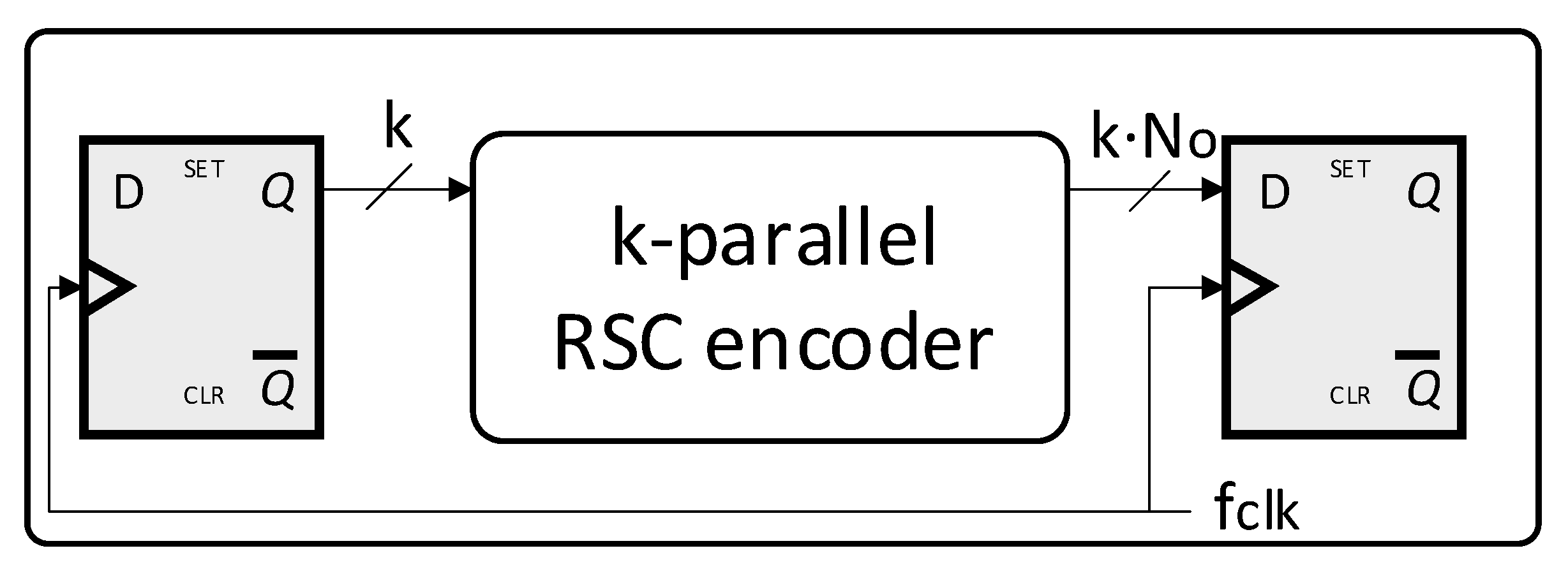
2.3. Parallel RSC Encoders Hardware Architecture
2.4. Analysis of the Tree Network Topology as a Function of the Parallelism Degree
3. Results
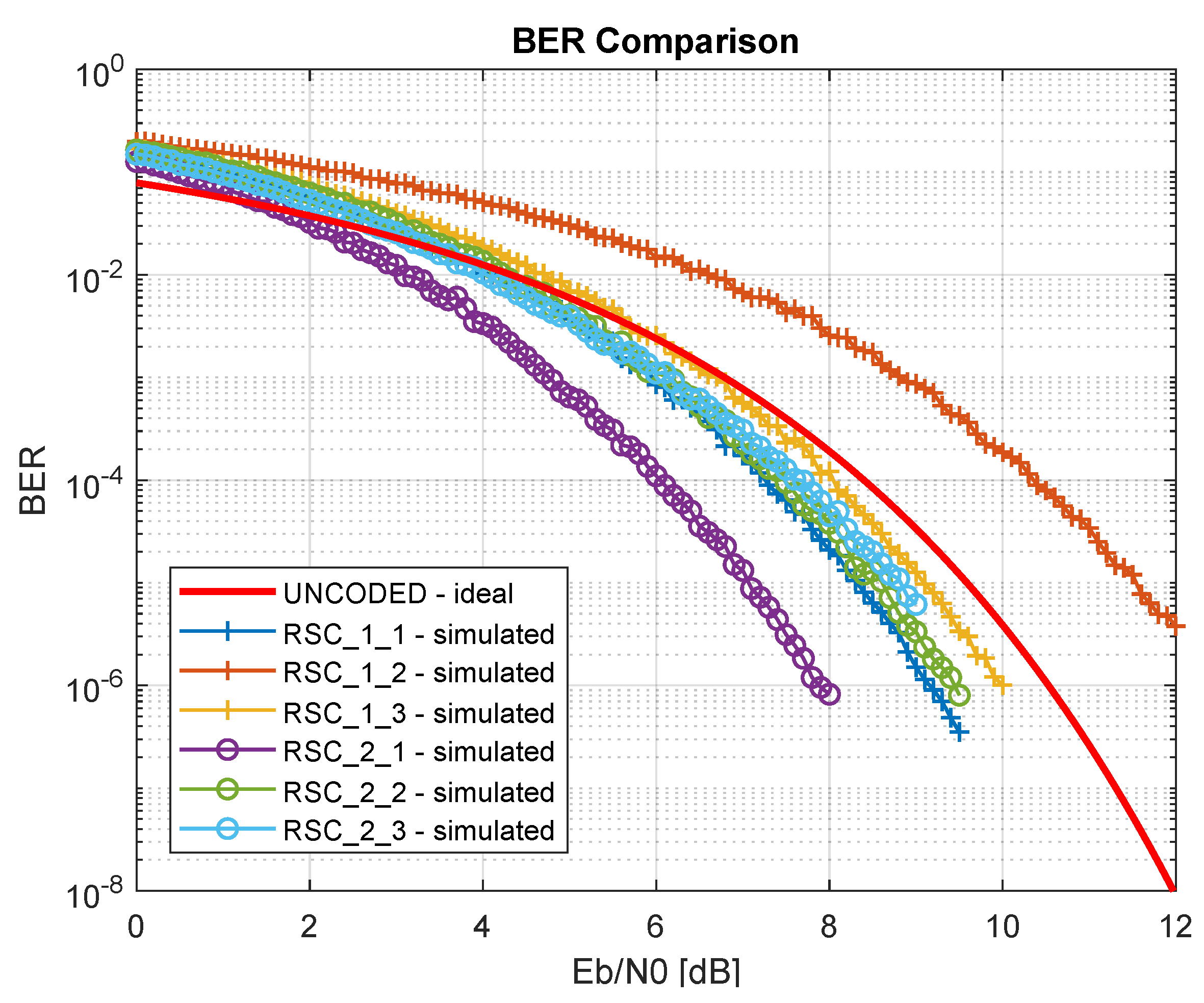
3.1. BER Performance Analysis and Implementation Results of some RSC Codes
- RSC encoder
- Binary phase shift keying (BPSK) modulation
- Additive white Gaussian noise (AWGN) channel
- Soft-viterbi decoder
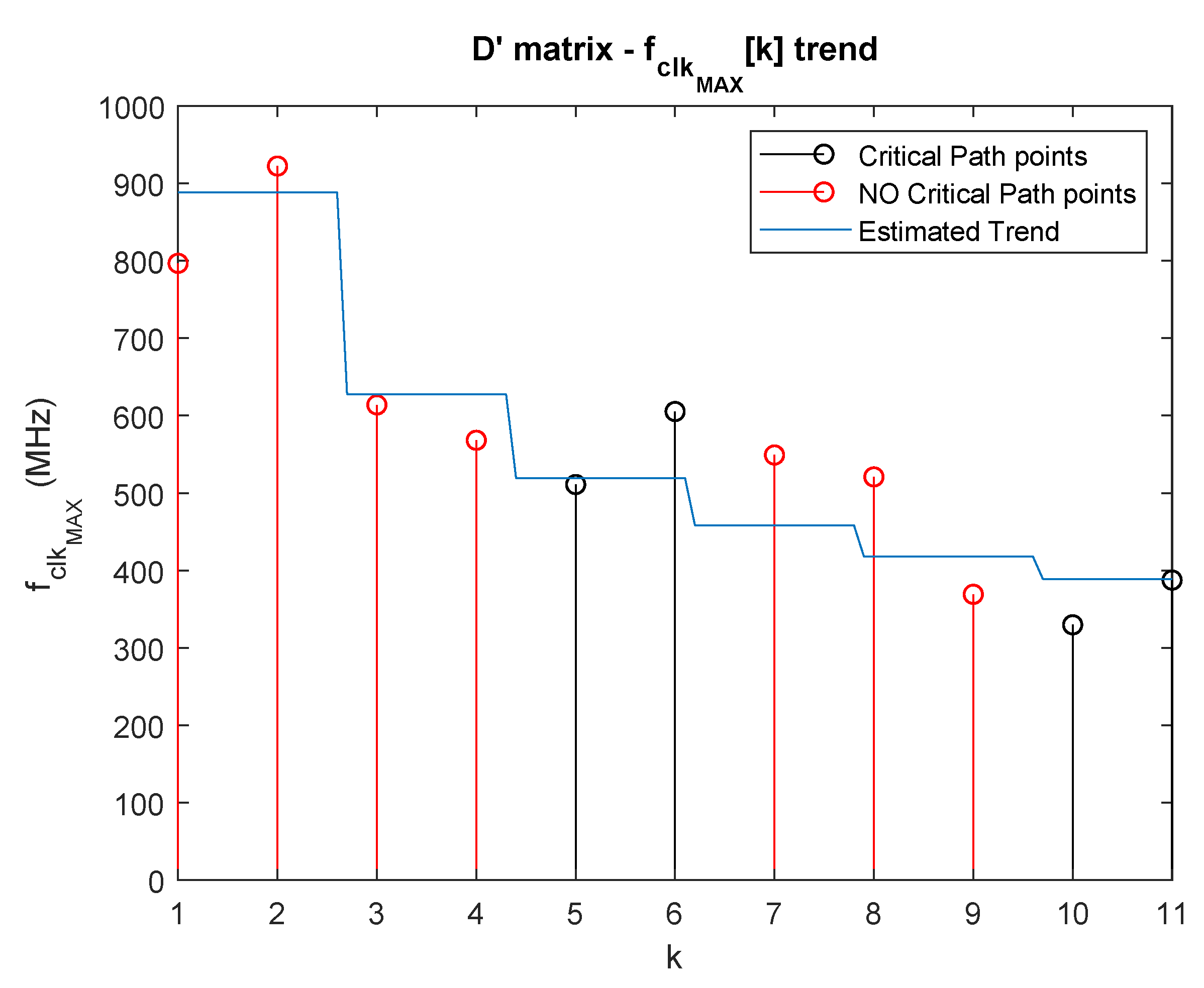
3.2. Impact of the Parallelism Degree on the Data Rate: Case Study
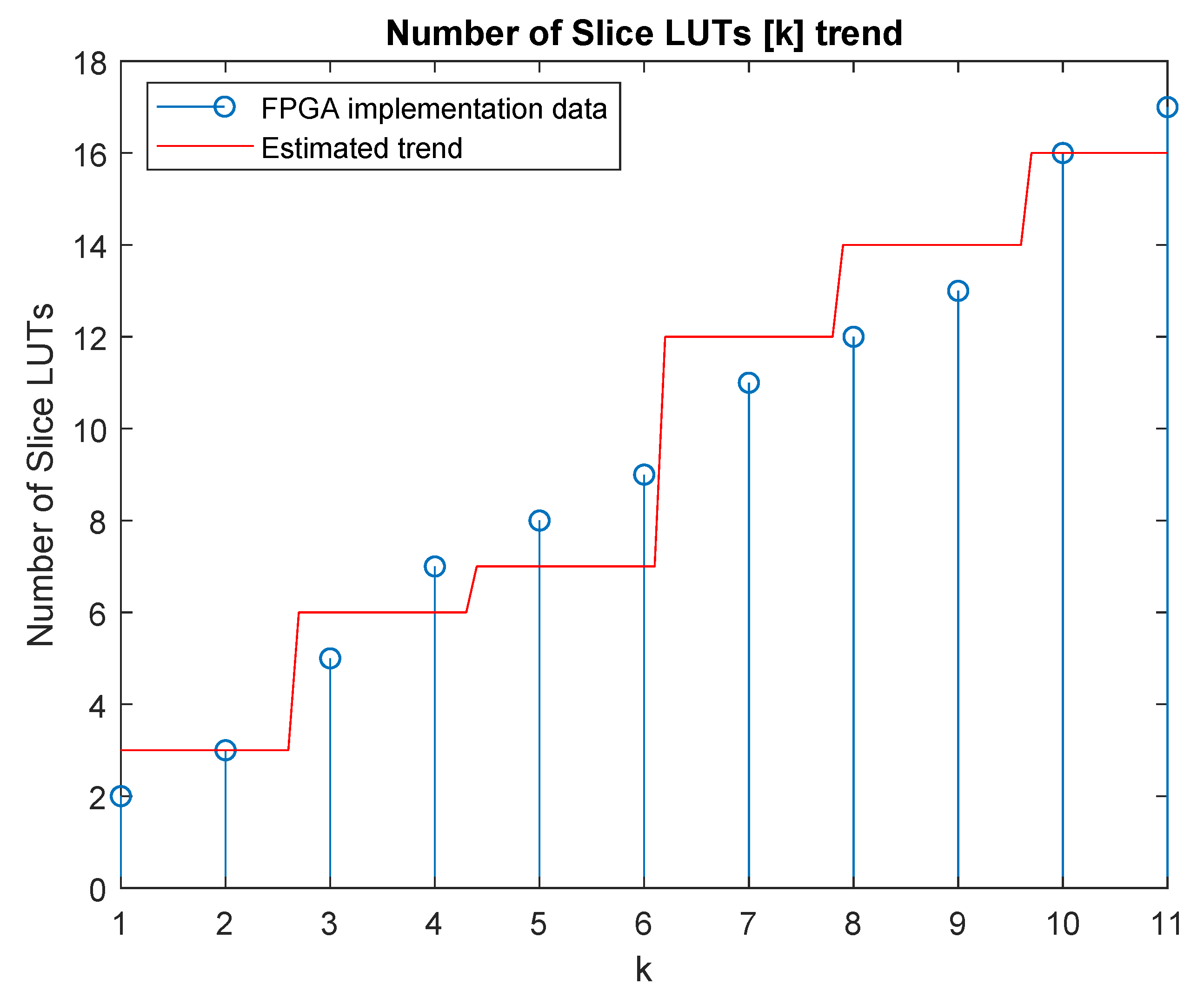
3.3. Impact of the Parallelism Degree on the Source Utilization: Case Study
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| BER | Bit error rate |
| FEC | Forward error correcting |
| RSC | Recursive systematic convolutional |
| CTC | Convolutional turbo code |
| VHDL | Very high speed integrated circuits hardware description language |
| FPGA | Field programmable gate array |
| LUT | Lookup table |
| LSFR | Linear feedback shift register |
| IP | Intellectual property |
| XOR | Exclusive OR |
| BPSK | Binary phase shift keying |
| AWGN | Additive white Gaussian noise |
| MSE | Mean square error |
References
- CCSDS. Flexible Advanced Coding And Modulation Scheme For High Rate Telemetry Applications; Recommendation for Space Data System Standards, CCSDS 131.2-B-1; CCSDS: Washington, DC, USA, 2012. [Google Scholar]
- Douillard, C.; Jézéquel, M.; Berrou, C.; Brengarth, N.; Tousch, J.; Pham, N. The turbo code standard for DVB-RCS. In Proceedings of the 2nd International Symposium on Turbo Codes Related Topics, Brest, France, 4–7 September 2000; pp. 535–538. [Google Scholar]
- Park, S.J.; Jeon, J.H. Interleaver optimization of convolutional turbo code for 802.16 systems. IEEE Commun. Lett. 2009, 13, 339–341. [Google Scholar] [CrossRef]
- Viterbi, A. Error bounds for convolutional codes and an asymptotically optimum decoding algorithm. IEEE Trans. Inf. Theory 1967, 13, 260–269. [Google Scholar] [CrossRef]
- Bahl, L.; Cocke, J.; Jelinek, F.; Raviv, J. Optimal decoding of linear codes for minimizing symbol error rate (corresp.). IEEE Trans. Inf. Theory 1974, 20, 284–287. [Google Scholar] [CrossRef]
- Benedetto, S.; Montorsi, G. Role of recursive convolutional codes in turbo codes. Electron. Lett. 1995, 31, 858–859. [Google Scholar] [CrossRef]
- Berrou, C.; Glavieux, A.; Thitimajshima, P. Near Shannon limit error-correcting coding and decoding: Turbo-codes. In Proceedings of the ICC’93-IEEE International Conference on Communications, Geneva, Switzerland, 23–26 May 1993; pp. 1064–1070. [Google Scholar]
- Benedetto, S.; Divsalar, D.; Montorsi, G.; Pollara, F. Serial concatenation of interleaved codes: Performance analysis, design, and iterative decoding. IEEE Trans. Inf. Theory 1998, 44, 909–926. [Google Scholar] [CrossRef]
- Berrou, C.; Pyndiah, R.; Adde, P.; Douillard, C.; Le Bidan, R. An overview of turbo codes and their applications. In Proceedings of the European Conference on Wireless Technology, Paris, France, 3–5 October 2005; pp. 1–9. [Google Scholar]
- Shannon, C.E. Communication in the presence of noise. Proc. IEEE 1998, 86, 447–457. [Google Scholar] [CrossRef]
- Weithoffer, S.; Nour, C.A.; Wehn, N.; Douillard, C.; Berrou, C. 25 Years of Turbo Codes: From Mb/s to beyond 100 Gb/s. In Proceedings of the 2018 IEEE 10th International Symposium on Turbo Codes Iterative Information Processing (ISTC), Hong Kong, China, 3–7 December 2018; pp. 1–6. [Google Scholar]
- Ilango, P.; Chokkalingam, A. A Novel Architecture of Modified Turbo Codes with an area efficient high speed interleaver. Concurr. Comput. Pract. Exp. 2018, e5067. [Google Scholar] [CrossRef]
- Fowdur, T.P.; Beeharry, Y.; Soyjaudah, S.K. Performance of modified asymmetric LTE Turbo codes with reliability-based hybrid ARQ. In Proceedings of the 2014 9th International Symposium on Communication Systems, Networks Digital Sign (CSNDSP), Manchester, UK, 23–25 July 2014; pp. 928–933. [Google Scholar]
- Kumar, M.S.; Shameem, S.S.; Raghu Sai, M.N.V.; Nikhil, D.; Kartheek, P.; Kishore, K.H. Efficient and low latency turbo encoder design using Verilog-Hdl. Int. J. Eng. Technol. 2018, 7, 37–41. [Google Scholar] [CrossRef][Green Version]
- Jiang, S.; Zhang, P.W.; Lau, F.C.M.; Sham, C.W.; Huang, K. A Turbo-Hadamard Encoder/Decoder System with Hundreds of Mbps Throughput. In Proceedings of the 2018 IEEE 10th International Symposium on Turbo Codes Iterative Information Processing (ISTC), Hong Kong, China, 3–7 December 2018; pp. 1–5. [Google Scholar]
- Pilato, L.; Meoni, G.; Fanucci, L. Design Optimization for High Throughput Recursive Systematic Convolutional Encoders. In Proceedings of the 2018 22nd International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 10–12 October 2018; pp. 806–809. [Google Scholar]
- Singh, B.; Singh, I.P. Performance enhancement of LOG MAP Turbo Decoder for mobile applications. In Proceedings of the 2015 International Conference on Recent Developments in Control, Automation and Power Engineering (RDCAPE), Noida, India, 12–13 March 2015; pp. 259–264. [Google Scholar]
- Thul, M.J.; Wehn, N. FPGA implementation of parallel turbo-decoders. In Proceedings of the SBCCI 2004, 17th Symposium on Integrated Circuits and Systems Design (IEEE Cat. No. 04TH8784), Pernambuco, Brazil, 7–11 September 2004; pp. 198–203. [Google Scholar]
- Zynq7000 Datasheet. Available online: https://www.xilinx.com/support/documentation/data_sheets/ds190-Zynq-7000-Overview (accessed on 23 April 2019).
- Dhaliwal, S.; Singh, N.; Kaur, G. Performance analysis of convolutional code over different code rates and constraint length in wireless communication. In Proceedings of the 2017 International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 10–11 February 2017; pp. 464–468. [Google Scholar]
- Bolinth, E. On the equivalence of rate R= k/n non-systematic feed-forward convolutional codes and recursive systematic convolutional codes. In Proceedings of the 11th European Wireless Conference 2005-Next Generation wireless and Mobile Communications and Services, Nicosia, Cyprus, 10–13 April 2005; pp. 1–7. [Google Scholar]
- Rabaey, J.M.; Chandrakasan, A.P.; Nikolic, B. Digital Integrated Circuits; Prentice-Hall: Upper Saddle River, NJ, USA, 2002; Volume 2. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | L | Generators | Paral. (k) | Puncturing | Code Rate | (MHz) | (Mb/s) | Slice LUTs | Slice egs |
|---|---|---|---|---|---|---|---|---|---|
| RSC_1_1 | 3 | 1 | No | 770.4 | 770.4 | 2 | 2 | ||
| RSC_1_2 | 3 | 2 | [1 1 1 0] | 640.6 | 1281.2 | 2 | 1 | ||
| RSC_1_3 | 3 | 3 | [1 1 1 1 1 0] | 648.9 | 1946.7 | 3 | 2 | ||
| RSC_2_1 | 4 | 1 | No | 784.9 | 784.9 | 2 | 2 | ||
| RSC_2_2 | 4 | 2 | [1 1 1 0] | 781.8 | 1563.7 | 3 | 3 | ||
| RSC_2_3 | 4 | 3 | [1 1 1 1 1 0] | 613.1 | 1839.3 | 4 | 3 |
| Parallel. | Matrix Containing | Parallel. | Matrix Containing | ||
|---|---|---|---|---|---|
| (k) | (MHz) | the Critical Path | (k) | (MHz) | the Critical Path |
| 1 | 784.9293564 | B | 7 | 523.5602094 | B |
| 2 | 545.2562704 | A | 8 | 489.2367906 | B |
| 3 | 564.6527386 | C | 9 | 366.9724771 | B |
| 4 | 548.5463522 | C | 10 | 329.7065612 | D |
| 5 | 510.9862034 | D | 11 | 387.4467261 | D |
| 6 | 605.3268765 | D |
| 0.988904449419594 | |
| 0.571261448964218 |
| [s] | 3.25590031598599e-10 |
| [s] | 7.99924552672264e-10 |
| Parallel. | Number of | Parallel. | Number of |
|---|---|---|---|
| (k) | Slice LUTs | (k) | Slice LUTs |
| 1 | 2 | 7 | 11 |
| 2 | 3 | 8 | 12 |
| 3 | 5 | 9 | 13 |
| 4 | 6 | 10 | 16 |
| 5 | 8 | 11 | 17 |
| 6 | 9 |
| 1.91672252010724 | |
| 0.655328418230563 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meoni, G.; Giuffrida, G.; Fanucci, L. A High Throughput Hardware Architecture for Parallel Recursive Systematic Convolutional Encoders. Information 2019, 10, 151. https://doi.org/10.3390/info10040151
Meoni G, Giuffrida G, Fanucci L. A High Throughput Hardware Architecture for Parallel Recursive Systematic Convolutional Encoders. Information. 2019; 10(4):151. https://doi.org/10.3390/info10040151
Chicago/Turabian StyleMeoni, Gabriele, Gianluca Giuffrida, and Luca Fanucci. 2019. "A High Throughput Hardware Architecture for Parallel Recursive Systematic Convolutional Encoders" Information 10, no. 4: 151. https://doi.org/10.3390/info10040151
APA StyleMeoni, G., Giuffrida, G., & Fanucci, L. (2019). A High Throughput Hardware Architecture for Parallel Recursive Systematic Convolutional Encoders. Information, 10(4), 151. https://doi.org/10.3390/info10040151