Word Sense Disambiguation Studio: A Flexible System for WSD Feature Extraction †



Abstract
:1. Introduction
2. Related Work
- A huge number of classes: for example, a WordNet-based dictionary used for sense annotating a text contains about 150,000 open class words with about 210 000 different senses (classes).
- Data sparseness: it is practically impossible to have a training set of adequate size that covers all open class words in the dictionary, which (for the supervised approach to WSD) makes it impossible to create a good classification model for disambiguating all words.
- Necessity to construct separate classification models for each open class word (or even for each word POS category).
- Relying on rather complicated procedures for extracting binary features and their integration with word embeddings.
- Ignoring the order of words in the context.
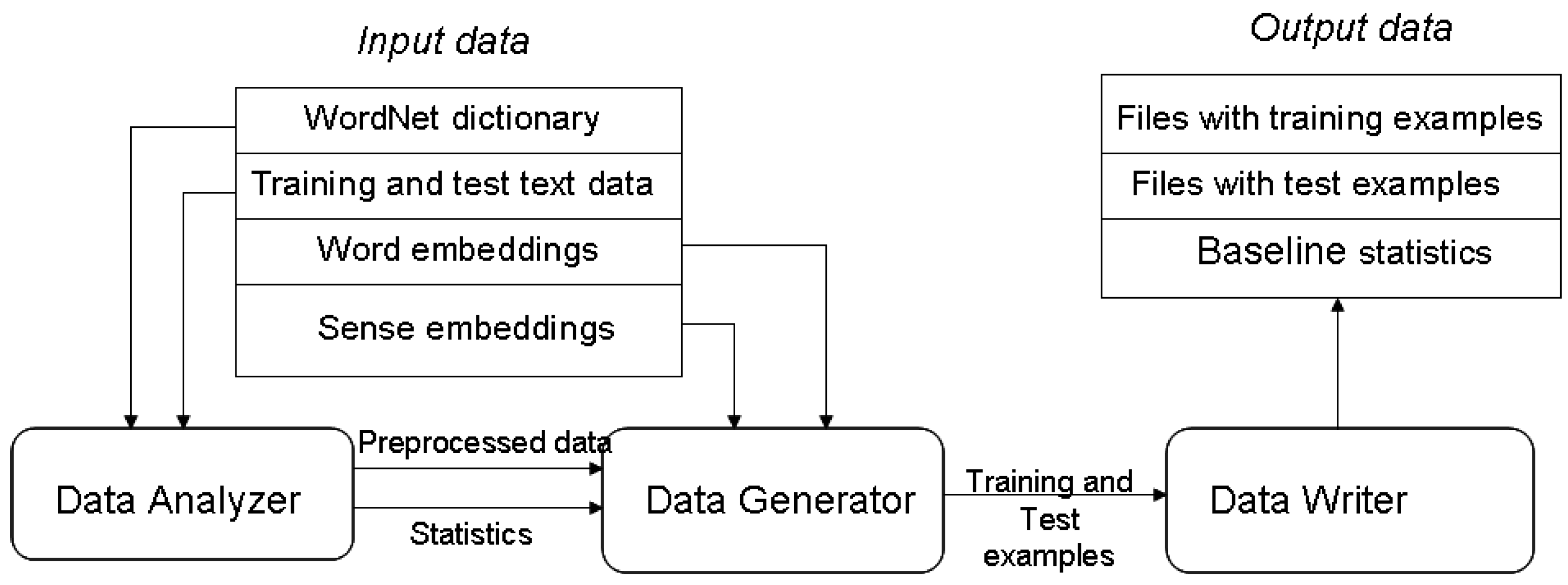
3. WSD Studio—Architecture and Functionality
- A WordNet-based dictionary—a file that relates open class words (in their lemma forms) to their possible senses. The dictionary is expected to be a text file, where each line represents a word and its senses in the following format:{word} {sense1}:{tag-count1} {sense2}:{tag-count2} … {sensen}:{tag-countn}
- where {word} is a WordNet word, {sense} is the synset_id of the sense in the WordNet and {tag-count} is the tag count of the sense in the WordNet. Currently the WSD Studio supports a variation of the synset_id, where the first digit of the synset_id that represents the POS category is removed and instead a dash and the Word-Net indicator ss_type are appended at the end. An example of synset_id transformation looks like this: 105,820,620 -> 05820620−n.
- Training and test text data that may consist of one or several text files containing a set of sentences (If the training text data is not available, the system uses SemCor [3] as the default training set). Each sentence is a sequence of words in their lemma forms that may be annotated by their POS categories. Each open class word in a sentence should be annotated by a sense from the corresponding WordNet-based dictionary. The system accepts two formats for representing training and test text data: the Unified Evaluation Framework (UEF) XML format [16] and a plain text alternative. Compared to the UEF XML, in the plain text format each annotated text is expected to be in a different text file. Each word occupies one line, where each open class word is followed by an interval and the synset_id of its sense. Each sentence ends with an empty line. When datasets in the UEF XML format are used, an additional text file containing mappings from sense_index to synset_id must be provided. Each line must contain one mapping pair with the sense_index at the beginning of the line followed by an interval and the synset_id.
- Word embeddings—a file relating words with their embeddings.
- Word sense embeddings (optional)—a file relating word sense identifiers with their embeddings.
3.1. Data Analyzer Module
- The process of data generation becomes format independent and the specifics of input format parsing are encapsulated only in the project creation algorithm.
- Any potential problems related to data parsing are avoided since all data used by the data generation algorithm is saved in an easy processable/parsable way.
- The bundling of input data into a data project allows the user to easily create several data configurations and to reuse them multiple times.
3.2. Data Generator Module
3.2.1. Representation of Examples
3.2.2. Representation of Target and Context Words
3.2.3. Representation of the Target Word Class
3.3. Data Writer Module
4. Experiments
4.1. Comparison with a Knowledge-Based WSD System
4.2. What Words Should be Included into the Context Window?
4.3. Evaluation of the Influence of Word Embedding Compression
4.4. Evaluation of the Influence of the Data Set Granularity
4.5. Comparison with the State-of-the-Art Supervised WSD Systems
5. Discussion
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Navigli, R. Word sense disambiguation: A survey. ACM Comput. Surv. 2009, 41, 2. [Google Scholar] [CrossRef]
- Fellbaum, C. WordNet and wordnets. In Encyclopedia of Language and Linguistics, 2nd ed.; Elsevier: Oxford, UK, 2005; pp. 665–670. [Google Scholar]
- Miller, G.A.; Leacock, C.; Tengi, R.; Bunker, R.T. A semantic concordance. In Proceedings of the ARPA Workshop on Human Language Technology, Princeton, NJ, USA, 21–24 March 1993; pp. 303–308. [Google Scholar]
- Pilehvar, M.T.; Navigli, R. A large-scale pseudoword-based evaluation framework for state-of-the-art Word Sense Disambiguation. Comput. Linguist. 2014, 40, 837–881. [Google Scholar] [CrossRef]
- Pasini, T.; Navigli, R. Train-O-Matic: Large-Scale Supervised Word Sense Disambiguation in Multiple Languages without Manual Training Data. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 77–88. [Google Scholar]
- Lesk, M. Automatic sense disambiguation using machine readable dictionaries: How to tell a pine cone from an ice cream cone. In Proceedings of the 5th SIGDOC; ACM: New York, NY, USA, 1986; pp. 24–26. [Google Scholar]
- Camacho-Collados, J.; Pilehvar, M.H.; Navigli, R. Nasari: Integrating explicit knowledge and corpus statistics for a multilingual representation of concepts and entities. Artif. Intell. 2016, 240, 36–64. [Google Scholar] [CrossRef]
- Agirre, E.; Soroa, A. Personalizing Pagerank for Word Sense Disambiguation. In Proceedings of the 12th Conference of the European Chapter of the Association for Computational Linguistics, Athens, Greece, 30 March–3 April 2009; pp. 33–41. [Google Scholar]
- Agre, G.; Petrov, D.; Keskinova, S. A new approach to the supervised word sense disambiguation. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2018; Volume 11089, pp. 3–15. [Google Scholar]
- Zhong, Z.; Ng, H.T. It Makes Sense: A wide-coverage Word Sense Disambiguation system for free text. In Proceedings of the ACL System Demonstrations, Uppsala, Sweden, 13 July 2010; pp. 78–83. [Google Scholar]
- Cortes, C.; Vapnik, V.N. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv, 2013; arXiv:1301.3781. [Google Scholar]
- Taghipour, K.; Ng, H.T. Semisupervised word sense disambiguation using word embed-dings in general and specific domains. In Proceedings of the NAACL HLT, Denver, CO, USA, 31 May–5 June 2015; pp. 314–323. [Google Scholar]
- Rothe, S.; Schutze, H. Autoextend: Extending word embeddings to embeddings for syn-sets and lexemes. In Proceedings of the ACL 2015, Beijing, China, 26 July 2015; pp. 1793–1803. [Google Scholar]
- Iacobacci, I.; Pilehvar, M.H.; Navigli, R. Embeddings for word sense disambiguation: An evaluation study. In Proceedings of the ACL, Berlin, Germany, 7–12 August 2016; pp. 897–907. [Google Scholar]
- Koprinkova-Hristova, P.; Popov, A.; Simov, K.; Osenova, P. Echo state network for word sense disambiguation. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2018; Volume 11089, pp. 73–82. [Google Scholar]
- Popov, A. Neural Network Models forWord Sense Disambiguation: An Overview. Cybern. Inf. Technol. 2018, 18, 139–151. [Google Scholar]
- Melamud, O.; Goldberger, J.; Dagan, I. Learning Generic Context Embedding with Bidirectional LSTM. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning (CoNLL), Berlin, Germany, 7–12 August 2016; pp. 51–61. [Google Scholar]
- Kageback, M.; Salomonsson, H. Word sense disambiguation using a bidirectional lstm. arXiv, 2016; arXiv:1606.03568. [Google Scholar]
- Yuan, D.; Richardson, J.; Doherty, R.; Evans, C.; Altendorf, E. Semi-supervised word sense disambiguation with neural models. In Proceedings of the 26th International Conference on Computational Linguistics (COLING 2016), Osaka, Japan, 11–16 December 2016; pp. 1374–1385. [Google Scholar]
- Raganato, A.; Camacho-Collados, J.; Navigli, R. Word Sense Disambiguation: A Unified Evaluation Framework and Empirical Comparison. In Proceedings of the EACL 2017, Valencia, Spain, 3–7 April 2017; pp. 99–110. [Google Scholar]
- Zhou, Z.-H.; Feng, J. Deep Forest: Towards an Alternative to Deep Neural Networks. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17), Melbourne, Australia, 19–25 August 2017; pp. 3553–3559. [Google Scholar]
- Simov, K.; Osenova, P.; Popov, A. Using context information for knowledge-based word sense disambiguation. In Lecture Notes in Artificial Intelligence; Springer: Berlin, Germany, 2016; Volume 9883, pp. 130–139. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; Volume 14, pp. 1532–1543. [Google Scholar]
- Postma, M.; Izquierdo, R.; Agirre, E.; Rigau, G.; Vossen, P. Addressing the MFS Bias in WSD systems. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), Portorož, Slovenia, 23–26 May 2016; pp. 1695–1700. [Google Scholar]
- Cohen, J. Fast effective rule induction. In Proceedings of the Twelfth International Conference on Machine Learning, Tahoe City, CA, USA; 9–12 July 1995; pp. 115–123. [Google Scholar]

{kind=link}
| Data Set | Number of Word Occurrences | Number of Occurrences of Polysemous Words | Number of Occurrences of Monosemous Words | Maximum Number of Senses Per Word | Number of Occurrences of “Test-Only” Words | Number of Occurrences of “Unsolvable” Words |
|---|---|---|---|---|---|---|
| Training text data | 134,372 | 115,095 | 19,277 | 31 | - | - |
| Test text data | 49,541 | 42,296 | 7245 | 23 | 2042 | 3594 |
| Classifier | Random Forest(100) + “Full” Word Embeddings + WordNet-Based Class Ordering | Random Forest(100) + “Compressed” Word Embeddings + WordNet-Based Class Ordering | Knowledge-Based Classifier [23] | WNFS |
|---|---|---|---|---|
| Accuracy (%) | 75.85 | 75.67 | 68.77 | 75.71 |
| POS of the Target Word | GCForest | FCNN | WNFS Baseline | ||
|---|---|---|---|---|---|
| Context: Open Class Words Only | Context: All Words | Context: Open Class Words Only | Context: All Words | ||
| ADJ | 81.35 | 81,46 | 81,20 | 81.24 | 81.20 |
| NOUN | 73.06 | 73.45 | 73.38 | 73.35 | 73.38 |
| VERB | 57.20 | 59.31 | 56.66 | 56.93 | 56.66 |
| ADV | 77.47 | 79.39 | 75.84 | 76.71 | 75.84 |
| Overall | 70.59 | 71.54 | 70.49 | 70.62 | 70.49 |
| POS of the Target Word | GCForest | FCNN | WNFS Baseline | ||
|---|---|---|---|---|---|
| Compressed | Uncompressed | Compressed | Uncompressed | ||
| ADJ | 81.20 | 81.46 | 81.20 | 81.24 | 81.20 |
| NOUN | 73.38 | 73.45 | 73.38 | 73.35 | 73.38 |
| VERB | 57.08 | 59.31 | 57.26 | 56.93 | 56.66 |
| ADV | 76.20 | 79.39 | 75.84 | 76.71 | 75.84 |
| Overall | 70.63 | 71.54 | 70.65 | 70.62 | 70.49 |
| GCforest | FCNN | JRIP | Examples | WNFS Baseline | |
|---|---|---|---|---|---|
| ADJ | 81.20 | 81.20 | 81.20 | 7196 | 81.20 |
| NOUN | 73.38 | 73.38 | 73.38 | 19450 | 73.38 |
| VERB | 57.08 | 57.26 | 62.53 | 10781 | 56.66 |
| ADV | 76.20 | 75.84 | 77.68 | 2989 | 75.84 |
| Overall | 70.63 | 70.65% | 72.20 | 40416 | 70.49 |
| Word Experts (256 FCNN Classifiers) | POS Experts (4 FCNN Classifiers) | WNFS Baseline | |||
|---|---|---|---|---|---|
| Uncompressed | Compressed | Uncompressed | Compressed | ||
| ADJ | 81.80 | 81.61 | 81.24 | 81.20 | 81.20 |
| ADV | 78.82 | 78.45 | 76.71 | 75.84 | 75.84 |
| NOUN | 73.56 | 73.23 | 73.35 | 73.38 | 73.38 |
| VERB | 59.18 | 58.66 | 56.93 | 57.26 | 56.66 |
| Overall | 71.58 | 71.22 | 70.62 | 70.65 | 70.49 |
| Training Corpus | Test Corpus | Systems | Accuracy (%) |
|---|---|---|---|
| SemCor | Concatenation of Senseval and SemEval collections | IMS | 68.4 |
| IMS + emb | 69.1 | ||
| IMS-s + emb | 69.6 | ||
| Context2Vec | 69.0 | ||
| MFS | 64.8 | ||
| WNFS | 65.2 | ||
| WSD Studio + JRip (POS experts) | 65.3 | ||
| WSD Studio + FCNN (Word experts) | 66.8 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Agre, G.; Petrov, D.; Keskinova, S. Word Sense Disambiguation Studio: A Flexible System for WSD Feature Extraction. Information 2019, 10, 97. https://doi.org/10.3390/info10030097
Agre G, Petrov D, Keskinova S. Word Sense Disambiguation Studio: A Flexible System for WSD Feature Extraction. Information. 2019; 10(3):97. https://doi.org/10.3390/info10030097
Chicago/Turabian StyleAgre, Gennady, Daniel Petrov, and Simona Keskinova. 2019. "Word Sense Disambiguation Studio: A Flexible System for WSD Feature Extraction" Information 10, no. 3: 97. https://doi.org/10.3390/info10030097
APA StyleAgre, G., Petrov, D., & Keskinova, S. (2019). Word Sense Disambiguation Studio: A Flexible System for WSD Feature Extraction. Information, 10(3), 97. https://doi.org/10.3390/info10030097