Machine Reading Comprehension for Answer Re-Ranking in Customer Support Chatbots

Abstract
1. Introduction
2. Related Work
2.1. Conversational Agents
2.2. Answer Combination
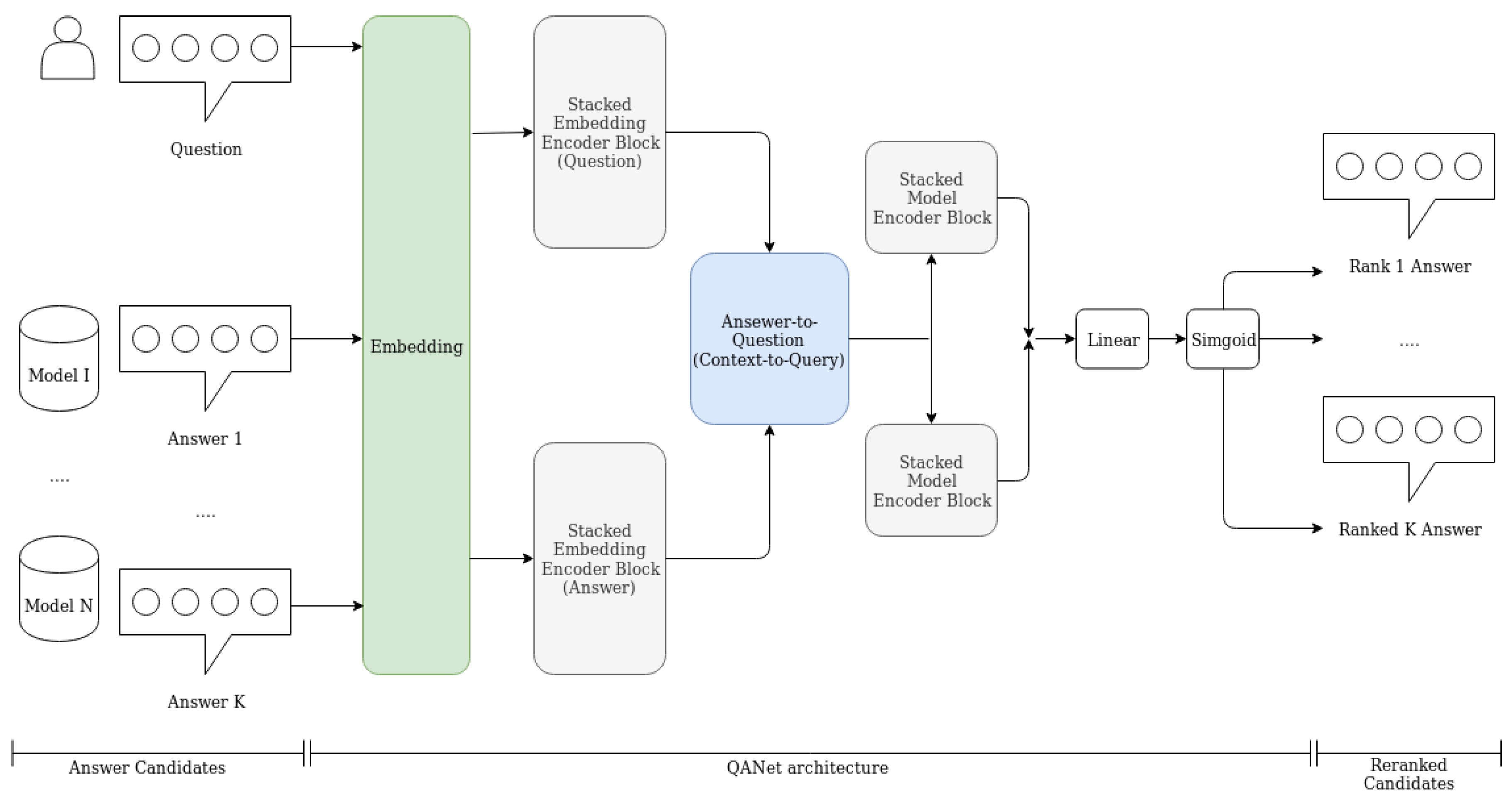
3. Re-Ranking Model
3.1. Negative Sampling
3.2. QANet Architecture
3.3. Answer Selection
4. Data
5. Experiments
5.1. Preprocessing
5.2. Training Setup
5.3. Individual Models
5.4. Evaluation Measures
6. Evaluation Results
6.1. Auxiliary Task: Question–Answer Goodness Classification
6.2. Answer Selection/Generation: Individual Models
6.3. Main Task: Multi-Source Answer Re-Ranking
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Yu, A.W.; Dohan, D.; Luong, M.T.; Zhao, R.; Chen, K.; Norouzi, M.; Le, Q.V. QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension. In Proceedings of the 2018 International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Seo, M.; Kembhavi, A.; Farhadi, A.; Hajishirzi, H. Bi-directional attention flow for machine comprehension. In Proceedings of the 2017 International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Chen, D.; Fisch, A.; Weston, J.; Bordes, A. Reading Wikipedia to Answer Open-Domain Questions. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1870–1879. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the ACL Workshop on Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Lowe, R.; Pow, N.; Serban, I.; Pineau, J. The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems. In Proceedings of the 16th Annual Meeting of the Special Interest Group on Discourse and Dialogue, Prague, Czech Republic, 2–4 September 2015; pp. 285–294. [Google Scholar]
- Lison, P.; Tiedemann, J. OpenSubtitles2016: Extracting Large Parallel Corpora from Movie and TV Subtitles. In Proceedings of the Tenth International Conference on Language Resources and Evaluation, Portorož, Slovenia, 23–28 May 2016. [Google Scholar]
- Reddy, S.; Chen, D.; Manning, C.D. CoQA: A conversational question answering challenge. arXiv, 2018; arXiv:1808.07042. [Google Scholar]
- Microsoft Research Social Media Conversation Corpus. Available online: http://research.microsoft.com/convo/ (accessed on 20 February 2019).
- Luong, T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1412–1421. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv, 2014; arXiv:1409.0473. [Google Scholar]
- Vinyals, O.; Le, Q.V. A Neural Conversational Model. arXiv, 2015; arXiv:1506.05869. [Google Scholar]
- Serban, I.V.; Sordoni, A.; Bengio, Y.; Courville, A.C.; Pineau, J. Hierarchical neural network generative models for movie dialogues. arXiv, 2015; arXiv:1507.04808. [Google Scholar]
- Sordoni, A.; Galley, M.; Auli, M.; Brockett, C.; Ji, Y.; Mitchell, M.; Nie, J.Y.; Gao, J.; Dolan, B. A Neural Network Approach to Context-Sensitive Generation of Conversational Responses. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015; pp. 196–205. [Google Scholar]
- Sordoni, A.; Bengio, Y.; Vahabi, H.; Lioma, C.; Grue Simonsen, J.; Nie, J.Y. A Hierarchical Recurrent Encoder-Decoder for Generative Context-Aware Query Suggestion. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 18–23 October 2015; pp. 553–562. [Google Scholar]
- Boyanov, M.; Nakov, P.; Moschitti, A.; Da San Martino, G.; Koychev, I. Building Chatbots from Forum Data: Model Selection Using Question Answering Metrics. In Proceedings of the International Conference Recent Advances in Natural Language Processing, Varna, Bulgaria, 2–8 September 2017; pp. 121–129. [Google Scholar]
- Nakov, P.; Hoogeveen, D.; Màrquez, L.; Moschitti, A.; Mubarak, H.; Baldwin, T.; Verspoor, K. SemEval-2017 Task 3: Community Question Answering. In Proceedings of the 11th International Workshop on Semantic Evaluation, Vancouver, BC, Canada, 3–4 August 2017; pp. 27–48. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the 30th Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Hardalov, M.; Koychev, I.; Nakov, P. Towards Automated Customer Support. In Proceedings of the 18th International Conference on Artificial Intelligence: Methodology, Systems, and Applications, Varna, Bulgaria, 12–14 September 2018; pp. 48–59. [Google Scholar]
- Li, Y.; Miao, Q.; Geng, J.; Alt, C.; Schwarzenberg, R.; Hennig, L.; Hu, C.; Xu, F. Question Answering for Technical Customer Support. In Proceedings of the 7th CCF International Conference, NLPCC 2018, Hohhot, China, 26–30 August 2018; pp. 3–15. [Google Scholar]
- Feng, M.; Xiang, B.; Glass, M.R.; Wang, L.; Zhou, B. Applying deep learning to answer selection: A study and an open task. Proceedings of IEEE Workshop on Automatic Speech Recognition and Understanding, Scottsdale, AZ, USA, 13–17 December 2015; pp. 813–820. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Back-propagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Li, X.; Li, L.; Gao, J.; He, X.; Chen, J.; Deng, L.; He, J. Recurrent reinforcement learning: A hybrid approach. In Proceedings of the 2016 International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Qiu, M.; Li, F.L.; Wang, S.; Gao, X.; Chen, Y.; Zhao, W.; Chen, H.; Huang, J.; Chu, W. AliMe Chat: A Sequence to Sequence and Rerank based Chatbot Engine. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 498–503. [Google Scholar]
- Cui, L.; Huang, S.; Wei, F.; Tan, C.; Duan, C.; Zhou, M. SuperAgent: A Customer Service Chatbot for E-commerce Websites. In Proceedings of the Association for Computational Linguistics 2017, System Demonstrations, Vancouver, BC, Cananda, 30 July–4 August 2017; pp. 97–102. [Google Scholar]
- Pang, L.; Lan, Y.; Guo, J.; Xu, J.; Xu, J.; Cheng, X. DeepRank: A New Deep Architecture for Relevance Ranking in Information Retrieval. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, Singapore, 6–10 November 2017; pp. 257–266. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Highway networks. arXiv, 2015; arXiv:1505.00387. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Association for Computational Linguistics. New Orleans, LA, USA, 1–6 June 2018; pp. 2227–2237. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv, 2016; arXiv:1607.06450. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Serban, I.V.; Lowe, R.; Henderson, P.; Charlin, L.; Pineau, J. A Survey of Available Corpora For Building Data-Driven Dialogue Systems: The Journal Version. Dialog. Discourse 2018, 9, 1–49. [Google Scholar]
- Customer Support on Twitter. Available online: http://www.kaggle.com/thoughtvector/customer-support-on-twitter (accessed on 18 February 2019).
- Codebase of Towards Automated Customer Support. Available online: https://github.com/mhardalov/customer-support-chatbot (accessed on 12 February 2019).
- Manning, C.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.; McClosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. Proceedings of 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MA, USA, 22–27 June 2014; pp. 55–60. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 2015 International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. OSDI 2016, 16, 265–283. [Google Scholar]
- ElasticSearch. Available online: http://www.elastic.co/products/elasticsearch (accessed on 20 February 2019).
- Robertson, S.; Zaragoza, H. The Probabilistic Relevance Framework: BM25 and Beyond. Found. Trends Inf. Retr. 2009, 3, 333–389. [Google Scholar] [CrossRef]
- Liu, C.W.; Lowe, R.; Serban, I.; Noseworthy, M.; Charlin, L.; Pineau, J. How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 2122–2132. [Google Scholar]
- Lowe, R.; Noseworthy, M.; Serban, I.V.; Angelard-Gontier, N.; Bengio, Y.; Pineau, J. Towards an Automatic Turing Test: Learning to Evaluate Dialogue Responses. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1116–1126. [Google Scholar]
- Rus, V.; Lintean, M. A Comparison of Greedy and Optimal Assessment of Natural Language Student Input Using Word-to-Word Similarity Metrics. In Proceedings of the Seventh Workshop on Building Educational Applications Using NLP, Montreal, QC, Canada, 7 June 2012; pp. 157–162. [Google Scholar]
- Forgues, G.; Pineau, J.; Larchevêque, J.M.; Tremblay, R. Bootstrapping dialog systems with word embeddings. In Proceedings of the NIPS Workshop on Modern Machine Learning and Natural Language Processing, Montreal, QC, Canada, 12 December 2014. [Google Scholar]
- Lin, C.Y.; Och, F.J. Automatic Evaluation of Machine Translation Quality Using Longest Common Subsequence and Skip-Bigram Statistics. In Proceedings of the 42nd Annual Conference of the Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; pp. 605–612. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Introduction to Reinforcement Learning; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]


{kind=link}
| Questions | Answers | |
| Avg. # words | 21.31 | 25.88 |
| Min # words | ||
| 1st quantile (#words) | ||
| Mode (# words) | ||
| 3rd quantile (#words) | ||
| Max # words | ||
| Overall | ||
| # question–answer pairs | 49,626 | |
| # words (in total) | 26,140 | |
| Min # turns per dialog | ||
| Max # turns per dialog | ||
| Avg. # turns per dialog | 2.6 | |
| Training set: # of dialogs | 45,582 | |
| Testing set: # of dialogs | 4044 | |
| Model | Embedding Type | d_model | Heads | Accuracy |
|---|---|---|---|---|
| Majority class | – | – | – | |
| QANet | GloVe | 64 | 4 | |
| 64 | 8 | |||
| 128 | 8 | |||
| QANet | ELMo (token level) | 64 | 4 | |
| 64 | 8 | |||
| 128 | 8 | |||
| QANet | ELMo (sentence level) | 64 | 8 | |
| 128 | 8 | 85.45 |
| Model | Word Overlap | Semantic Similarity | |||
|---|---|---|---|---|---|
| BLEU@2 | ROUGE_L | Emb Avg | Greedy Match | Vec Extr | |
| Transformer [20] | |||||
| IR-BM25 [20] | |||||
| seq2seq [20] | |||||
| QANet on IR (Individual) | |||||
| Model | Word Overlap | Semantic Similarity | |||
|---|---|---|---|---|---|
| BLEU@2 | ROUGE_L | Emb Avg | Greedy Match | Vec Extr | |
| Random Top Answer | |||||
| QANet+GloVe | |||||
| d = 64, h = 4 | 40.85 | ||||
| Softmax | |||||
| d = 64, h = 8 | |||||
| Softmax | |||||
| d = 128, h = 8 | |||||
| Softmax | |||||
| QANet+ELMo (Token) | |||||
| d = 64, h = 4 | |||||
| Softmax | |||||
| d = 64, h = 8 | 78.54 | ||||
| Softmax | |||||
| d = 128, h = 8 | |||||
| Softmax | |||||
| QANet+ELMo (Sentence) | |||||
| d = 64, h = 8 | |||||
| Softmax | |||||
| d = 128, h = 8 | |||||
| Softmax | 16.05 ± 0.06 | 24.81 ± 0.08 | 31.20 ± 0.06 | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hardalov, M.; Koychev, I.; Nakov, P. Machine Reading Comprehension for Answer Re-Ranking in Customer Support Chatbots. Information 2019, 10, 82. https://doi.org/10.3390/info10030082
Hardalov M, Koychev I, Nakov P. Machine Reading Comprehension for Answer Re-Ranking in Customer Support Chatbots. Information. 2019; 10(3):82. https://doi.org/10.3390/info10030082
Chicago/Turabian StyleHardalov, Momchil, Ivan Koychev, and Preslav Nakov. 2019. "Machine Reading Comprehension for Answer Re-Ranking in Customer Support Chatbots" Information 10, no. 3: 82. https://doi.org/10.3390/info10030082
APA StyleHardalov, M., Koychev, I., & Nakov, P. (2019). Machine Reading Comprehension for Answer Re-Ranking in Customer Support Chatbots. Information, 10(3), 82. https://doi.org/10.3390/info10030082