Hybrid LSTM Neural Network for Short-Term Traffic Flow Prediction


Abstract
:1. Introduction
2. Related Works
3. Hybrid LSTM Neural Network
3.1. Network Structure
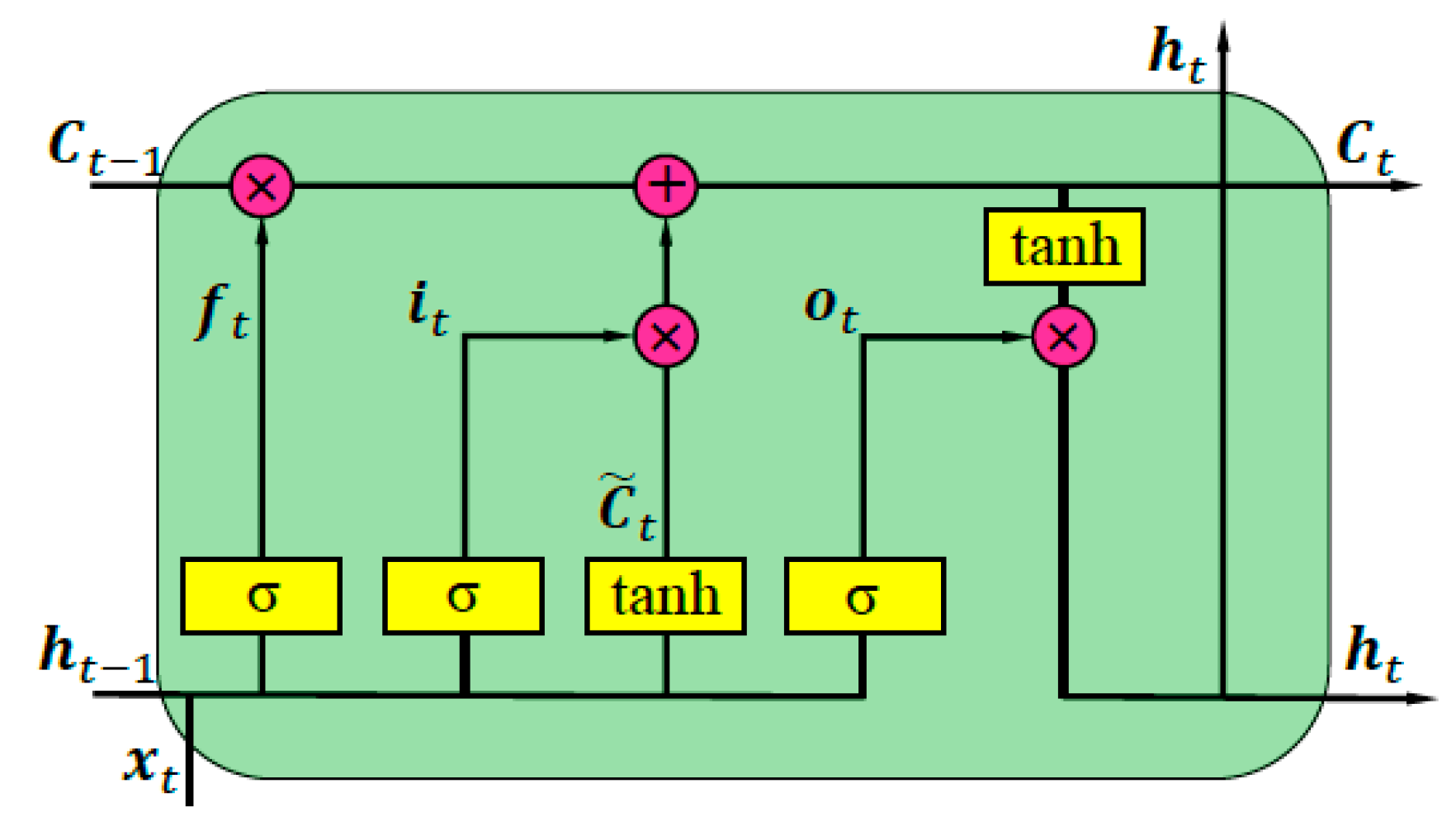
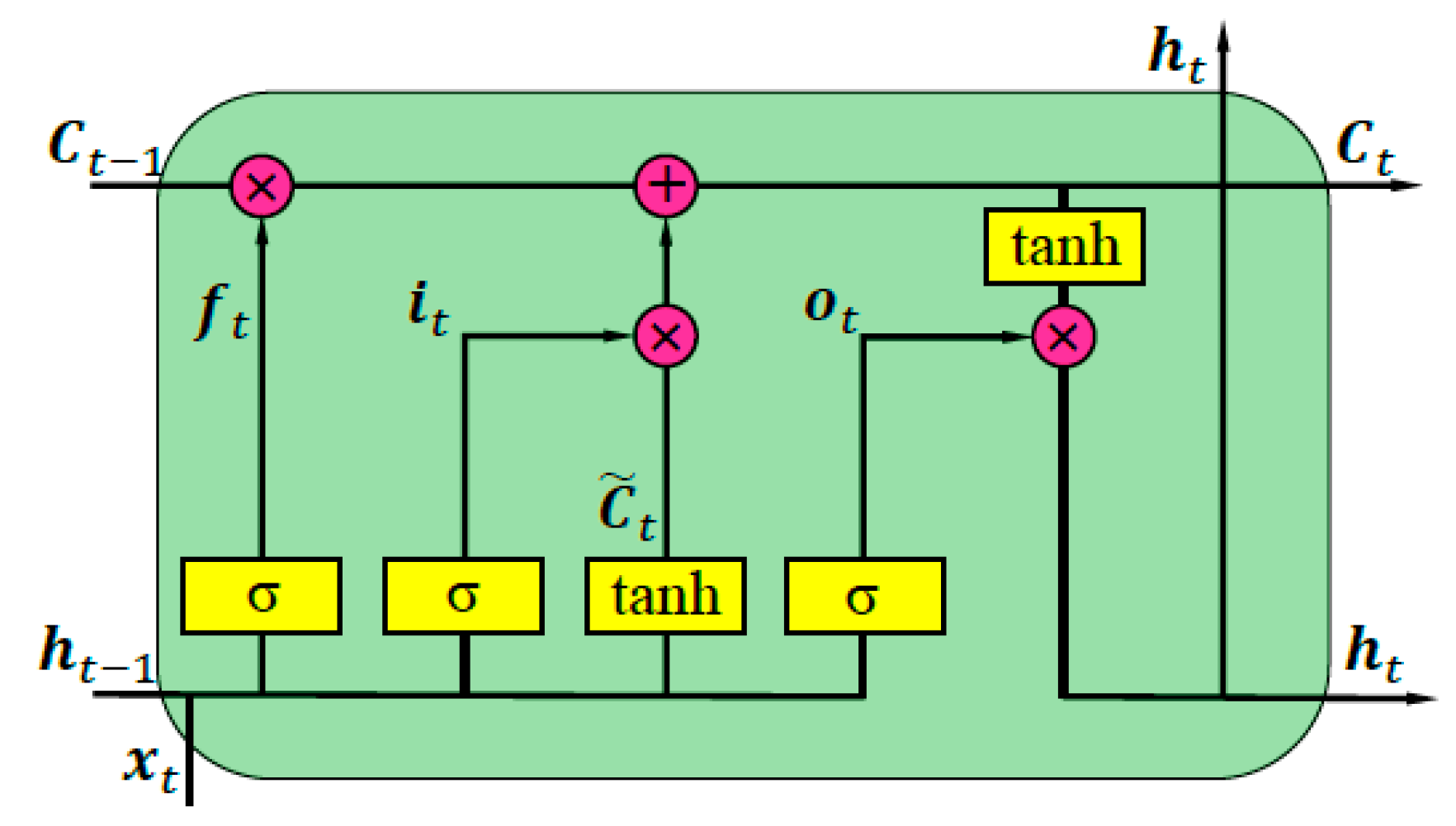
3.2. LSTM Layer
3.3. Activation Layer
3.4. Dense Layer
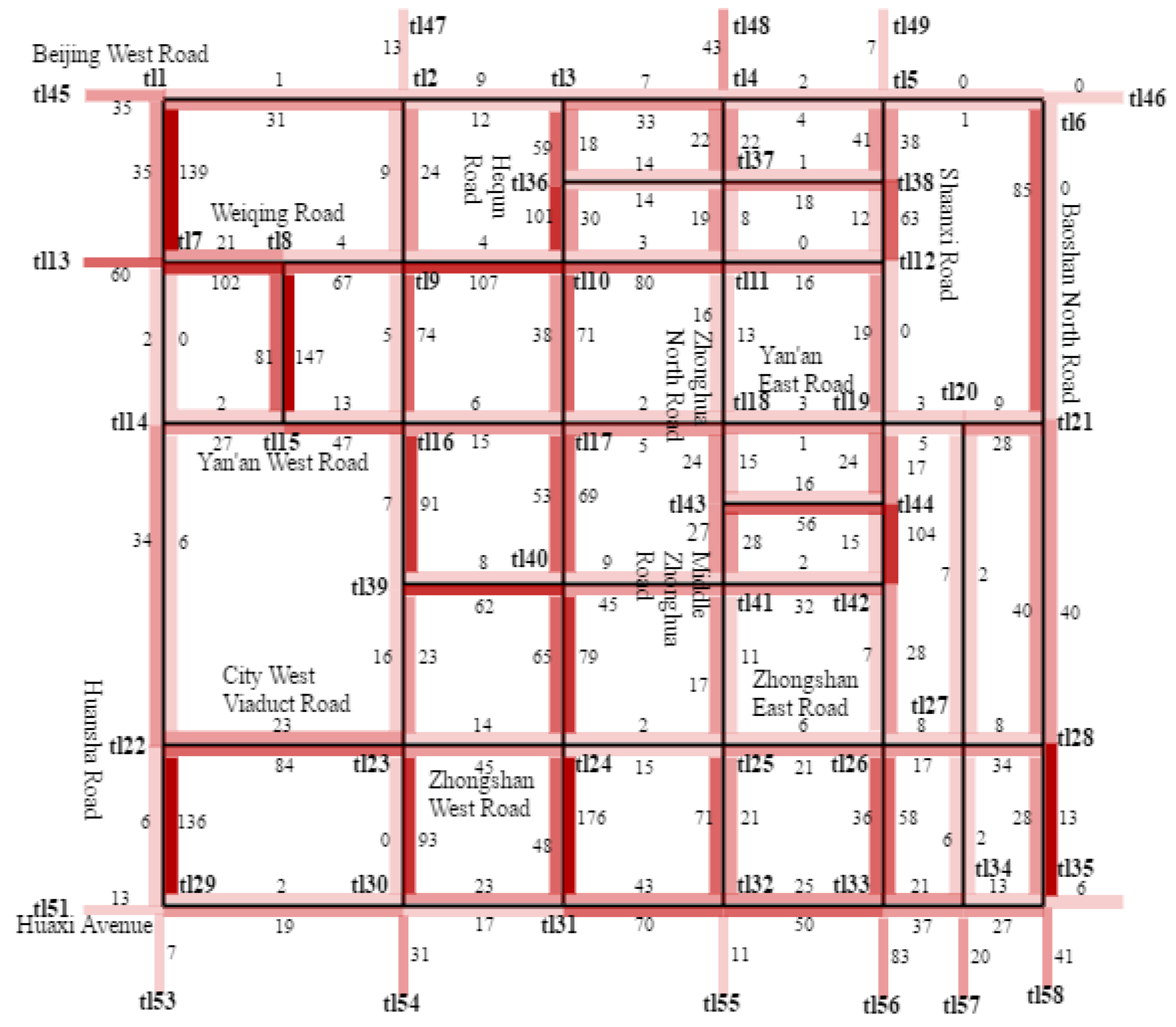
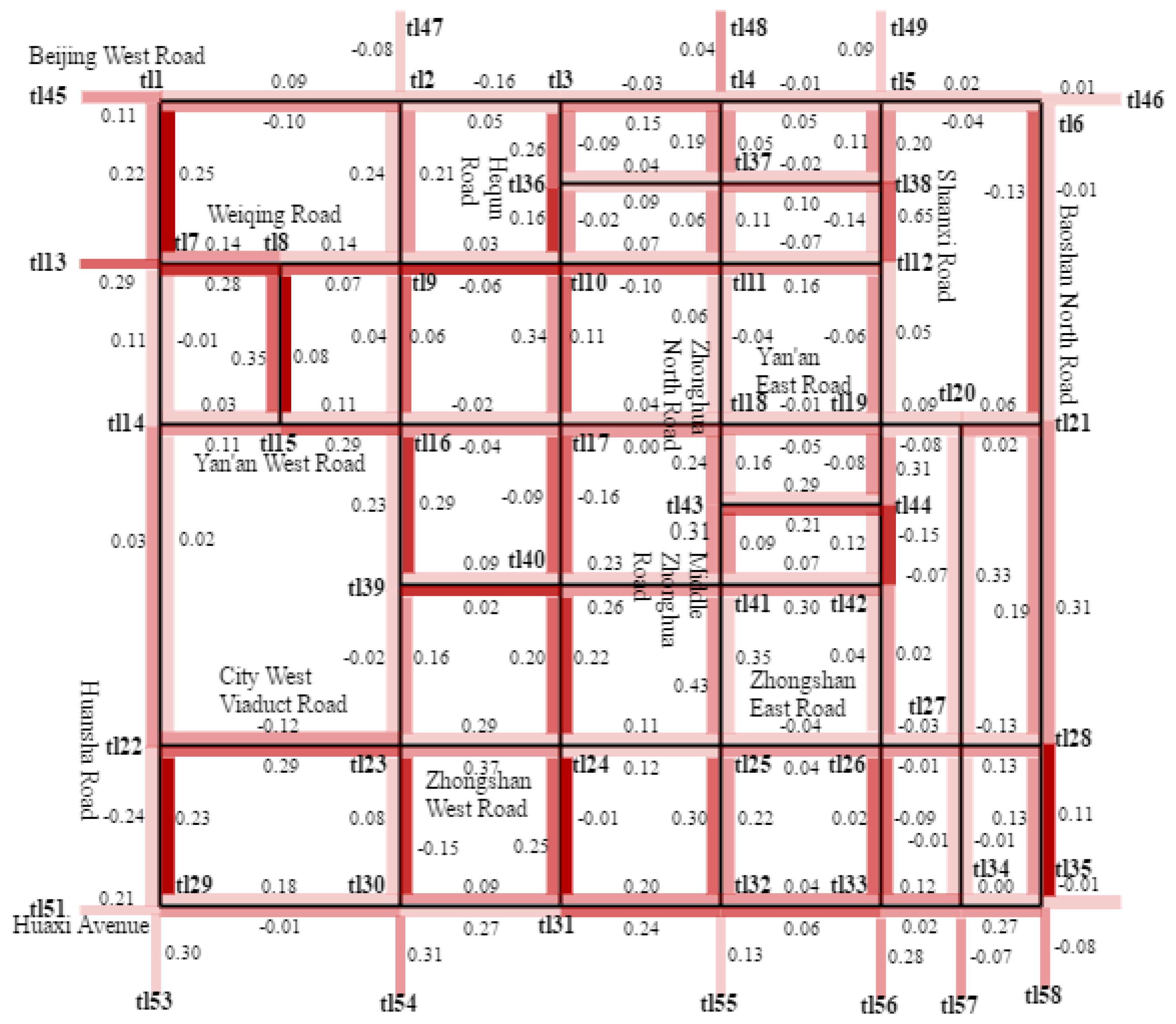
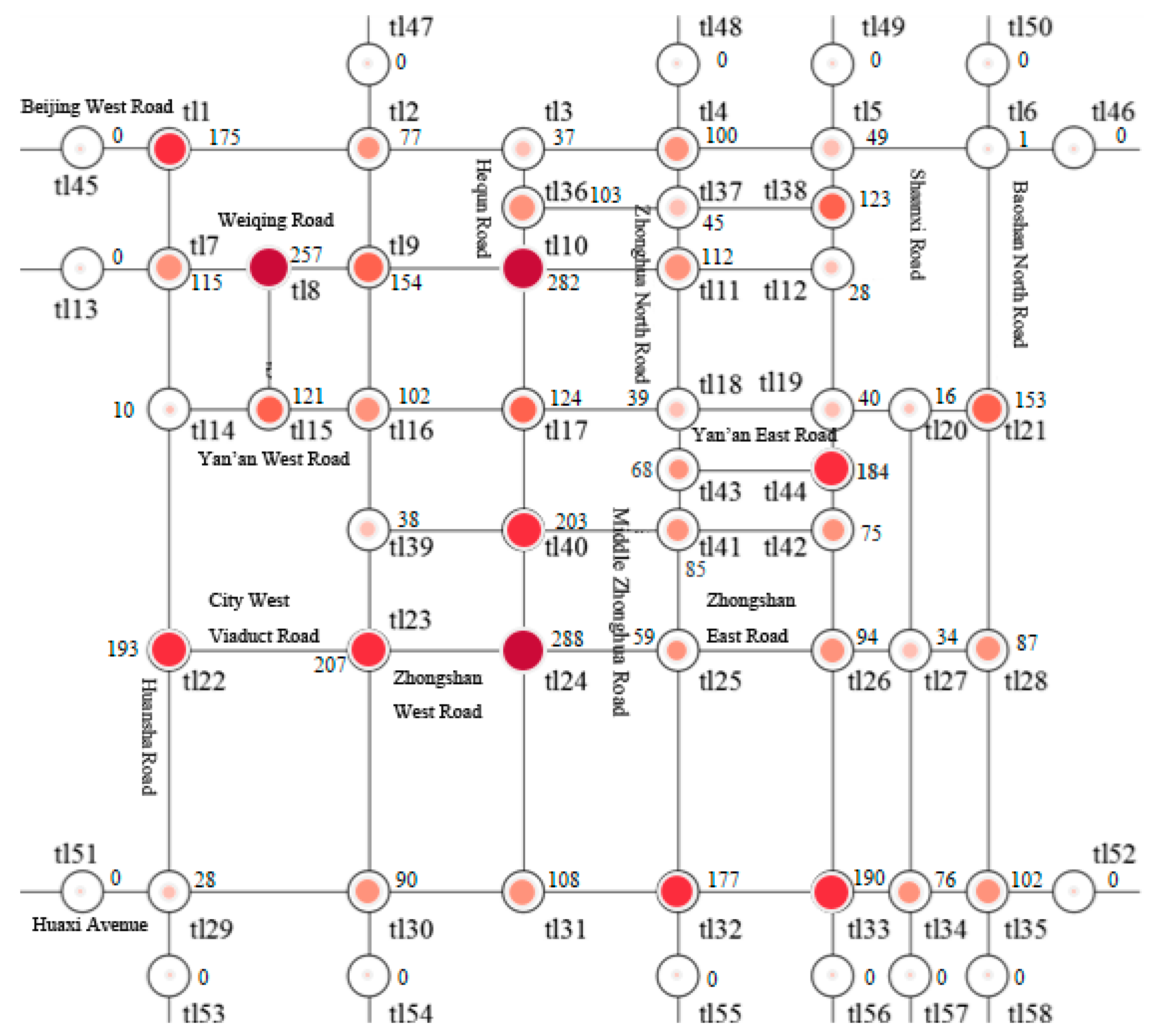
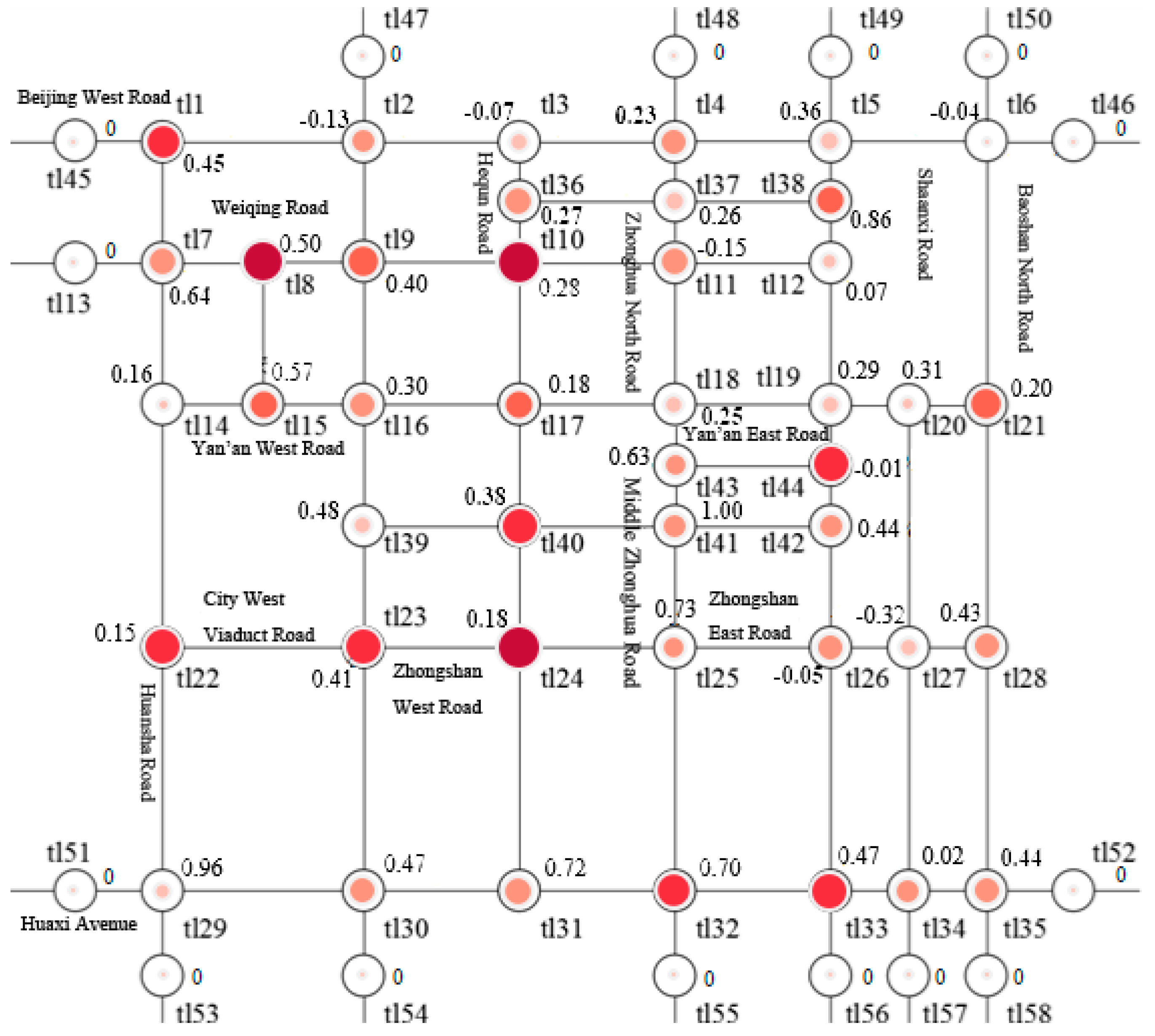
4. Experimental Process
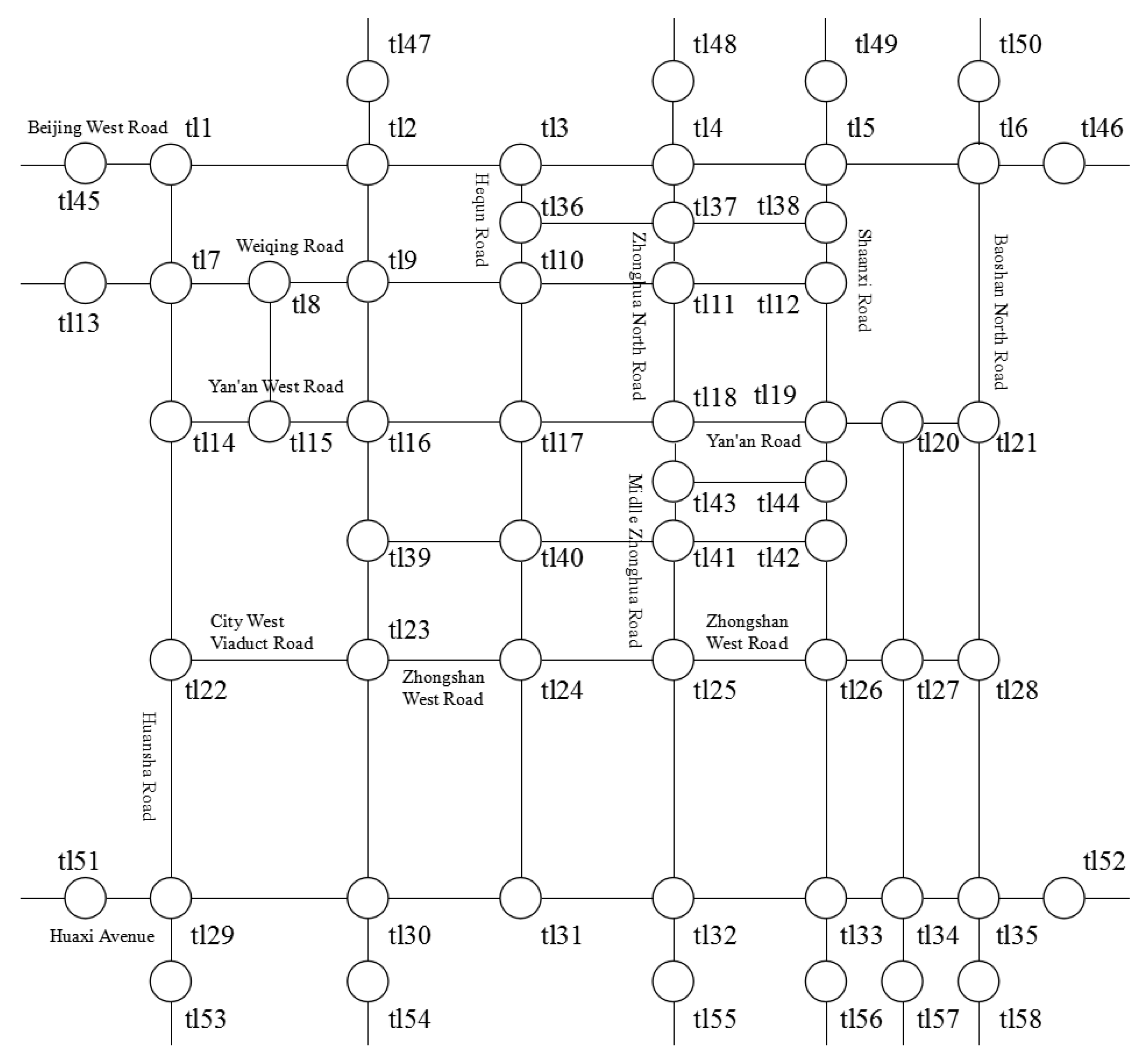
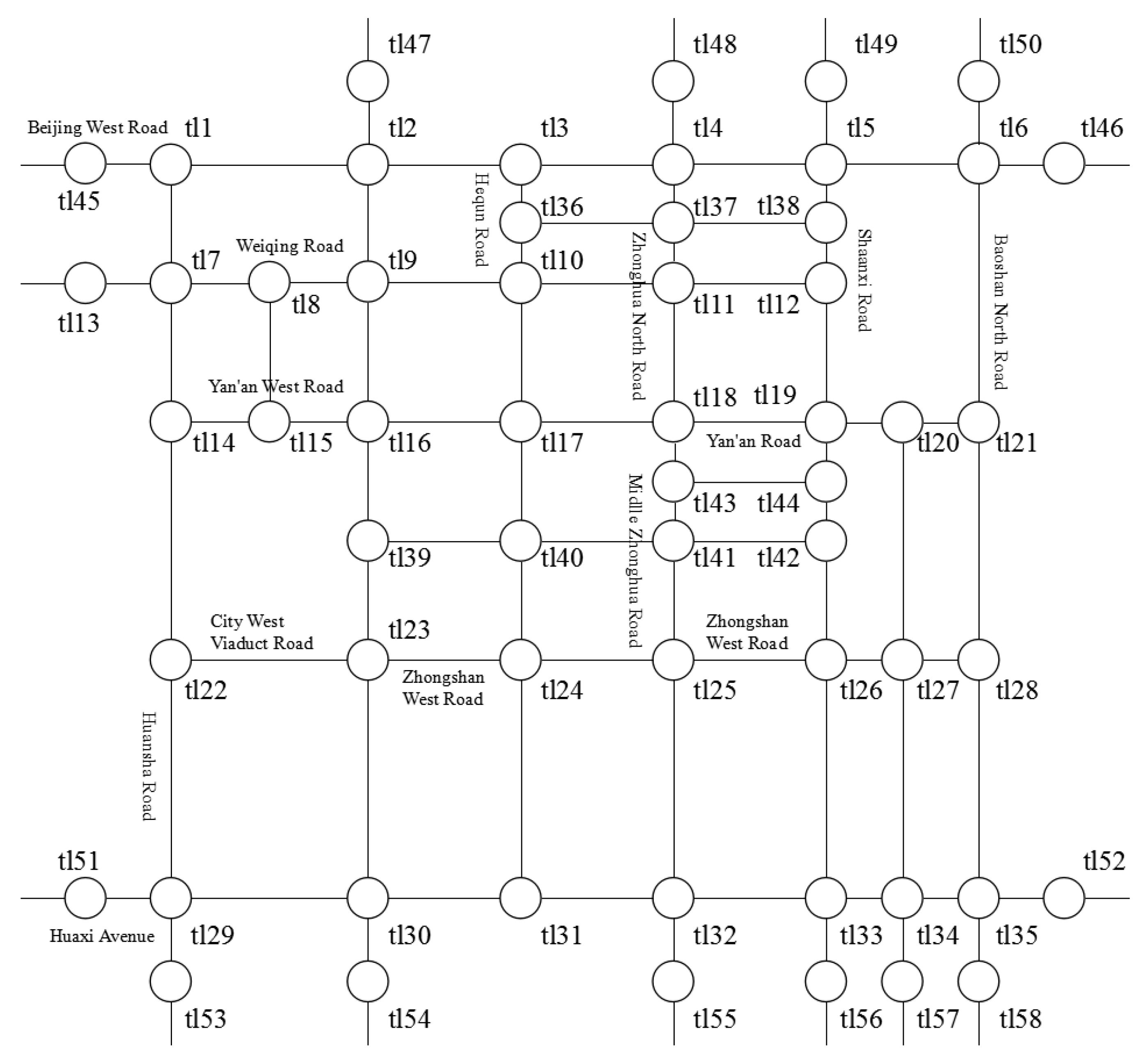
4.1. Experimental Environment and Data Set
4.2. Experimental Evaluation Indicators
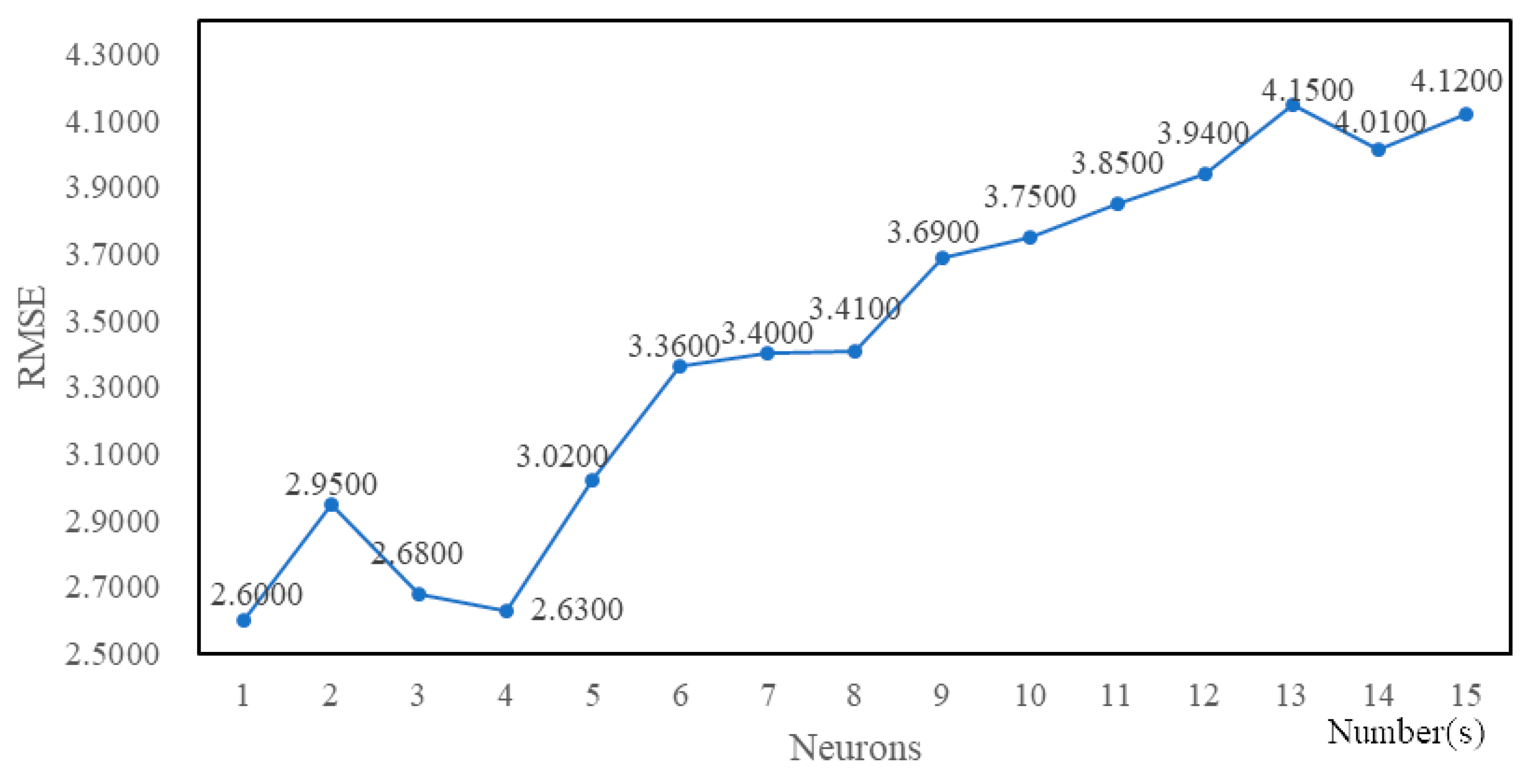
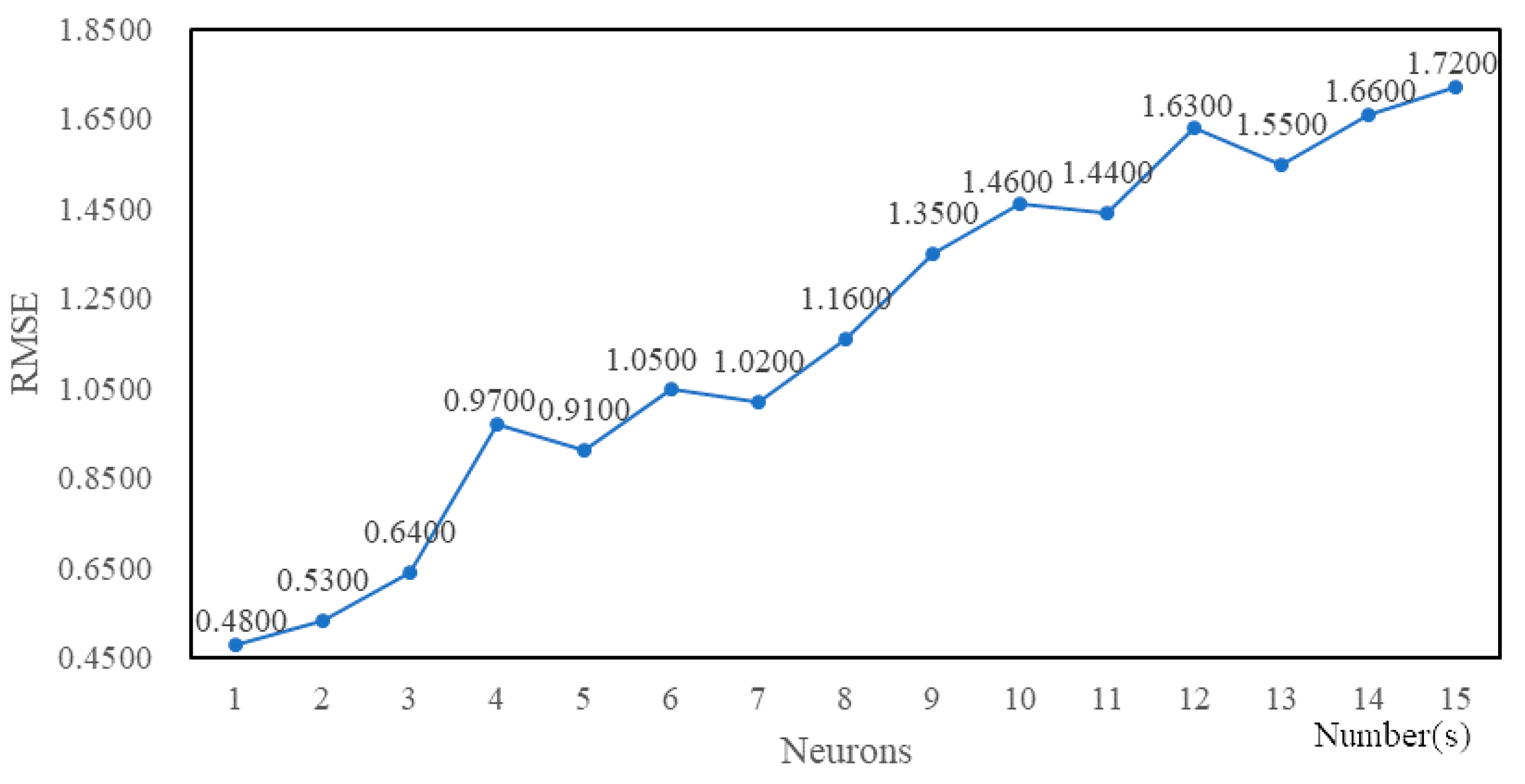
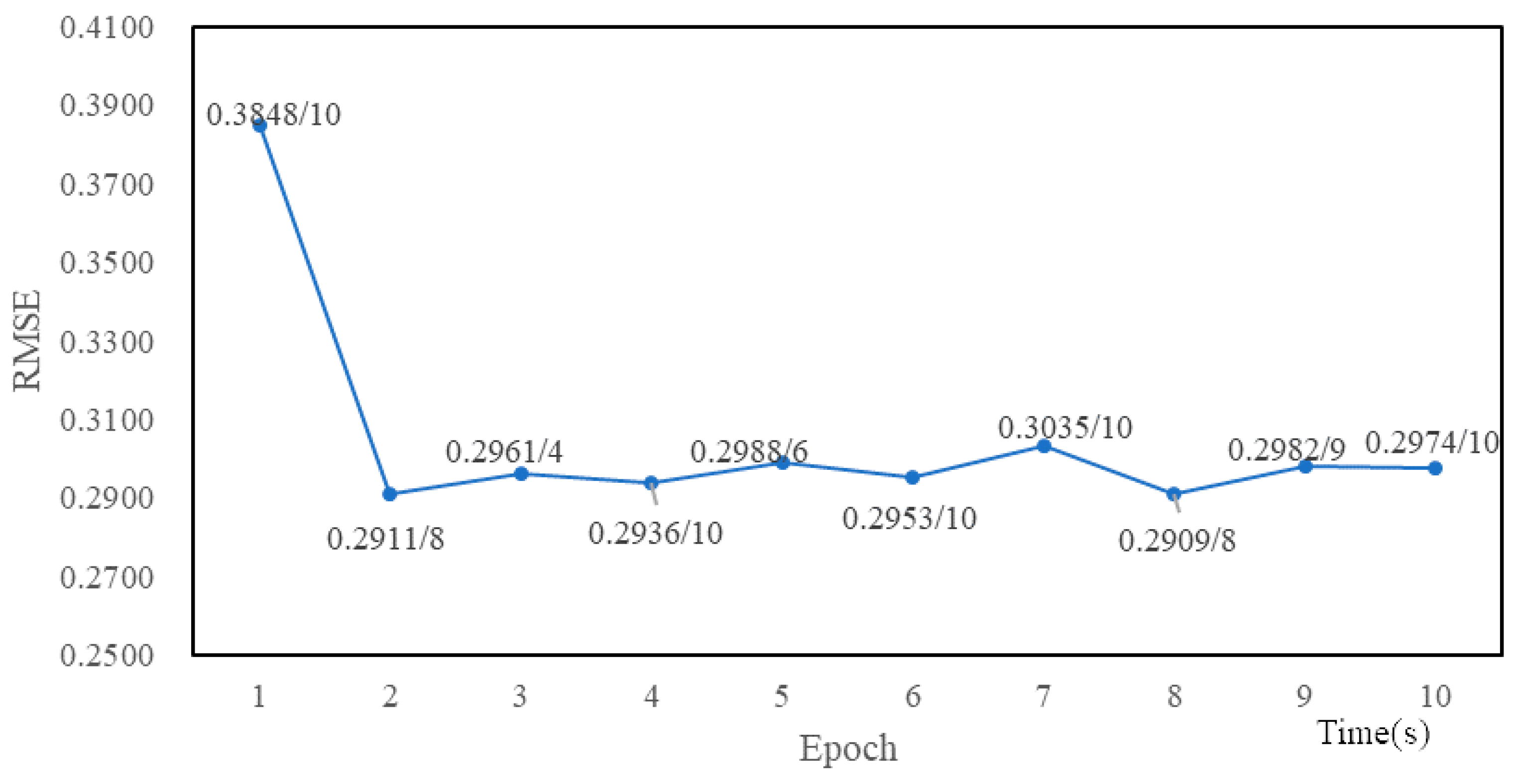
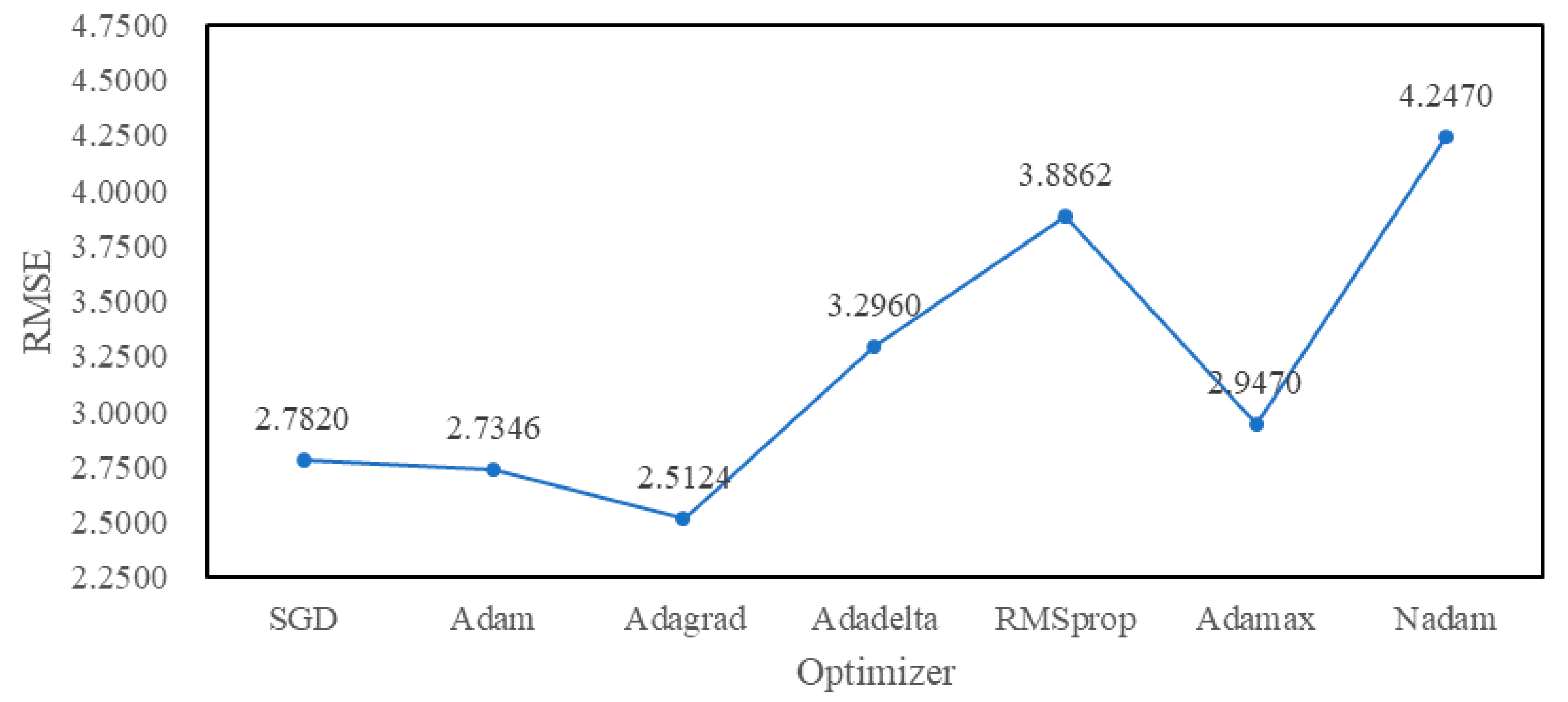
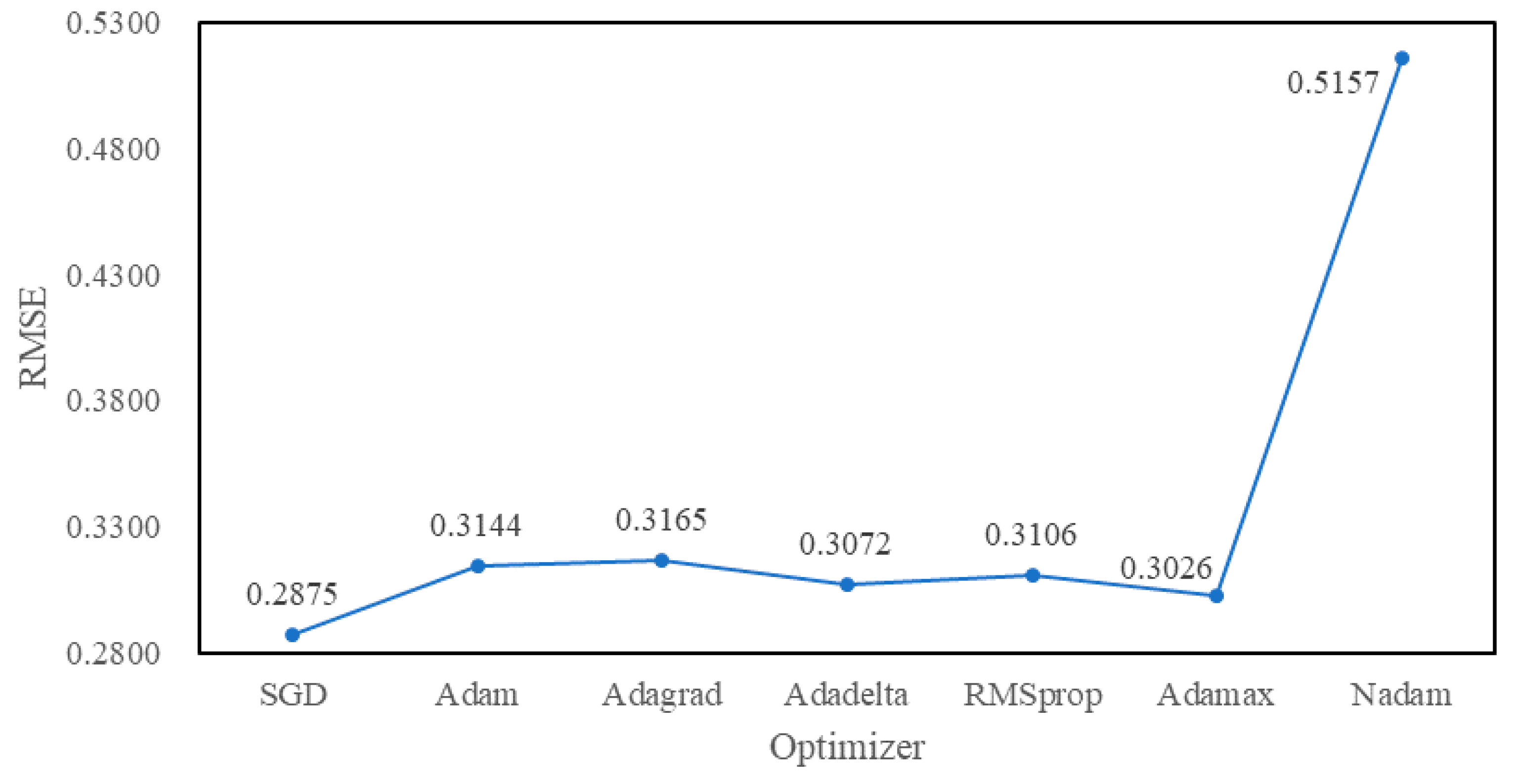
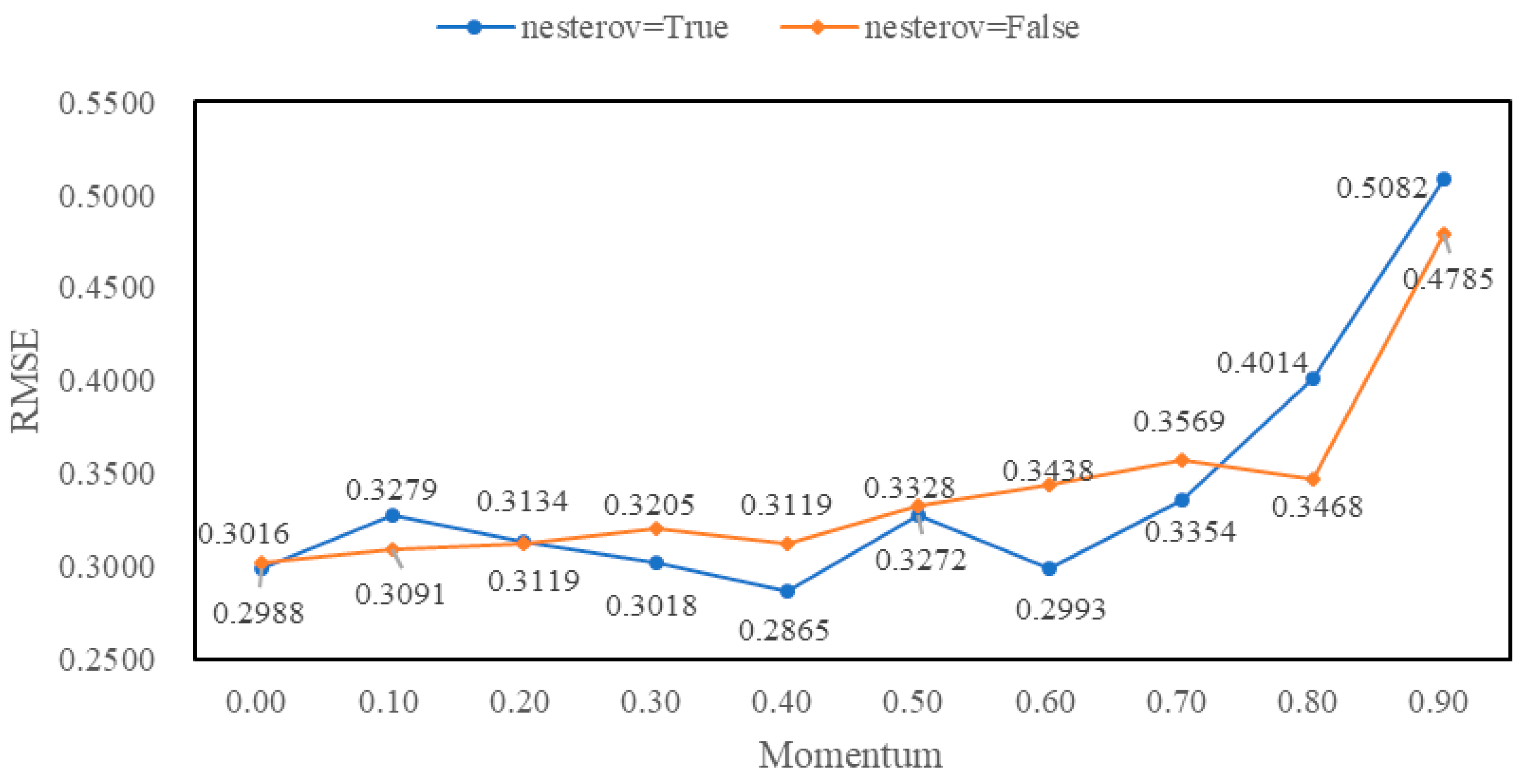
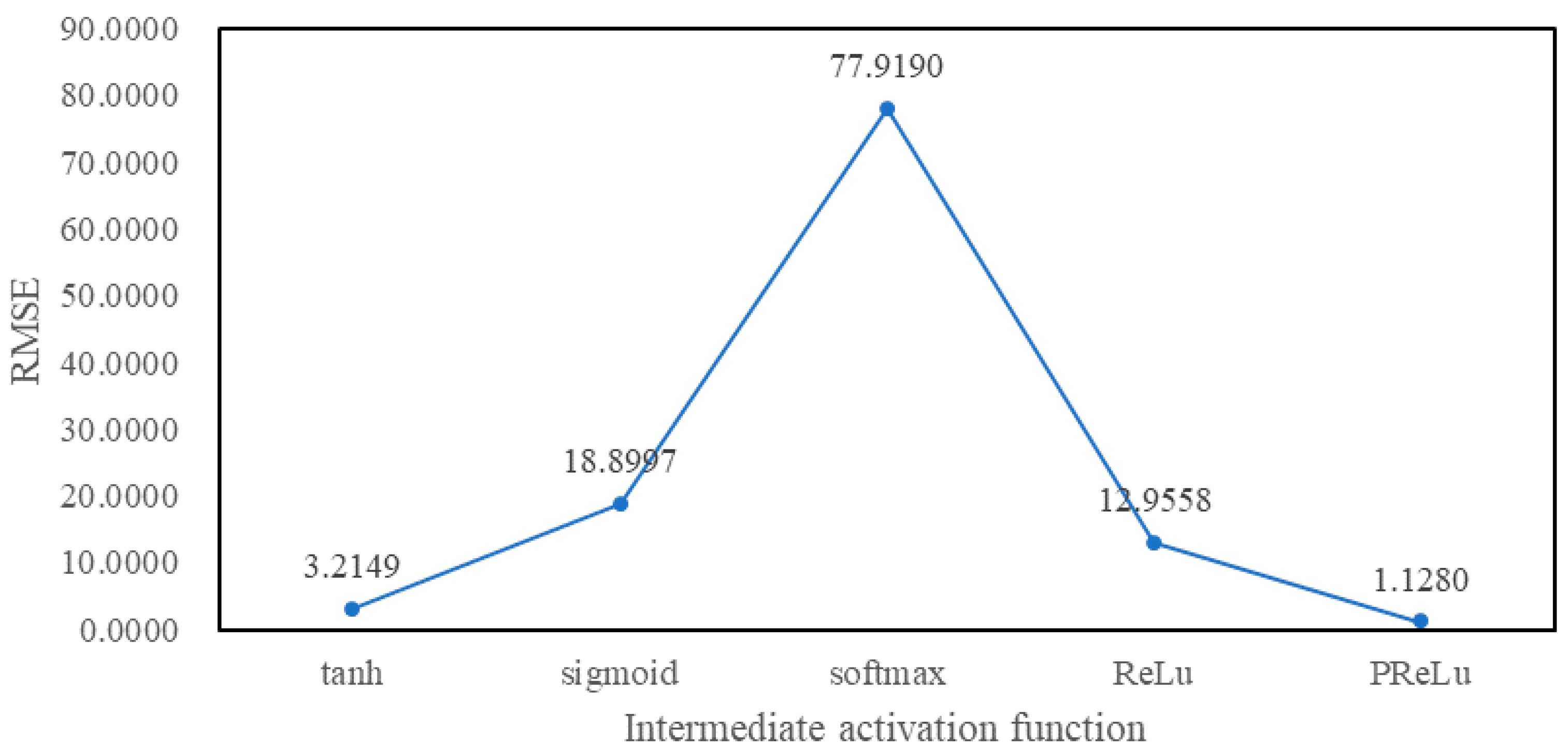
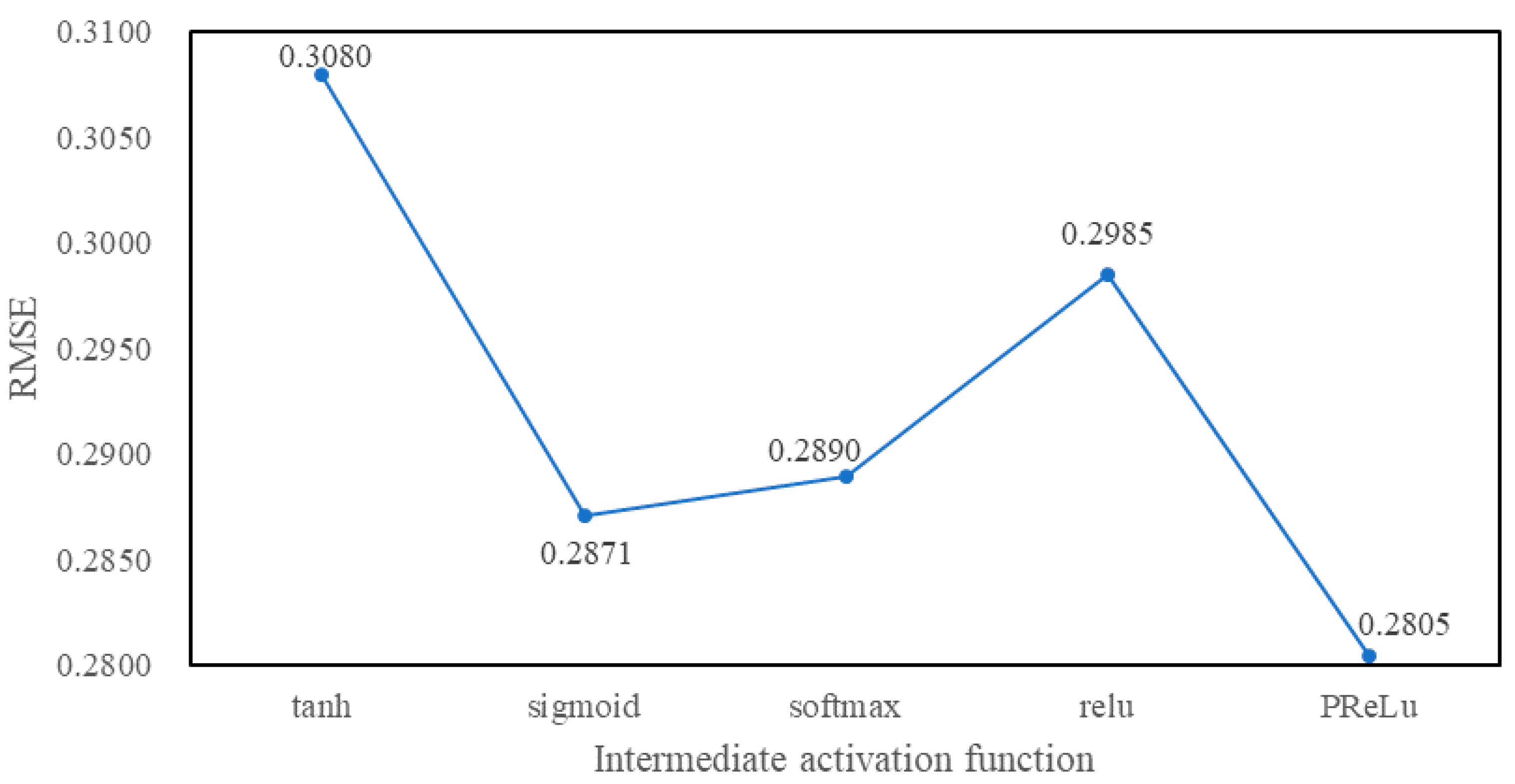
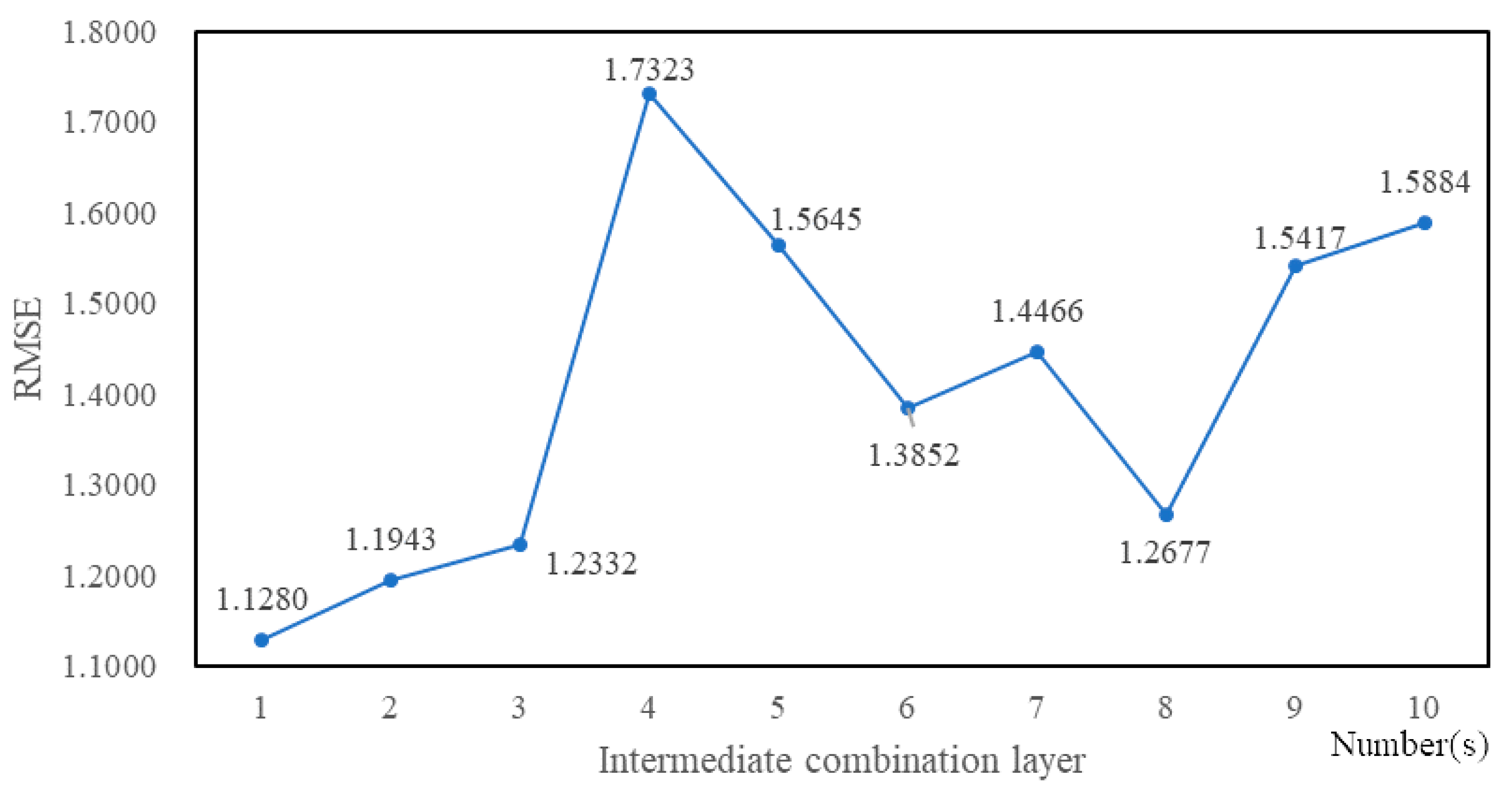
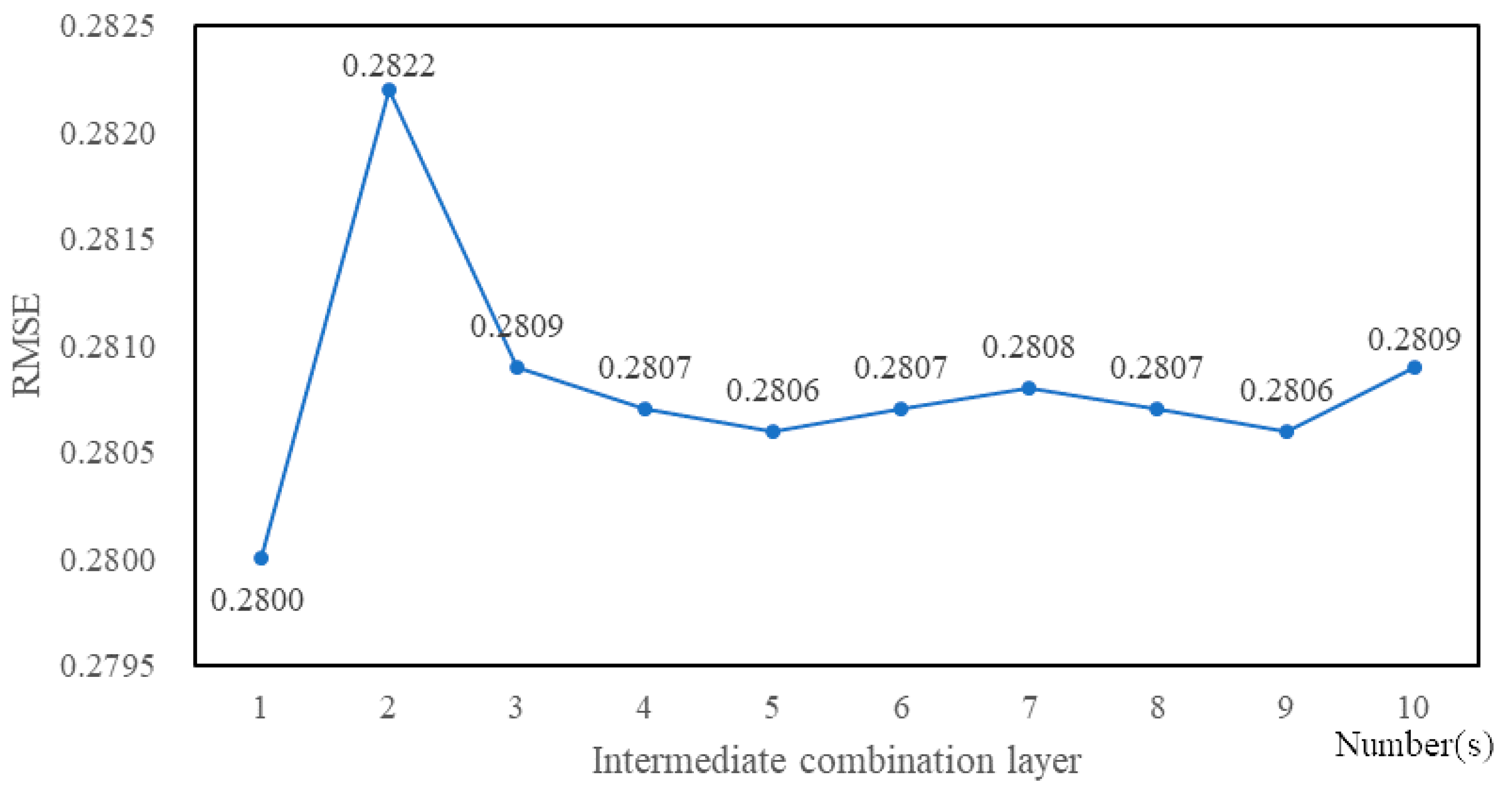
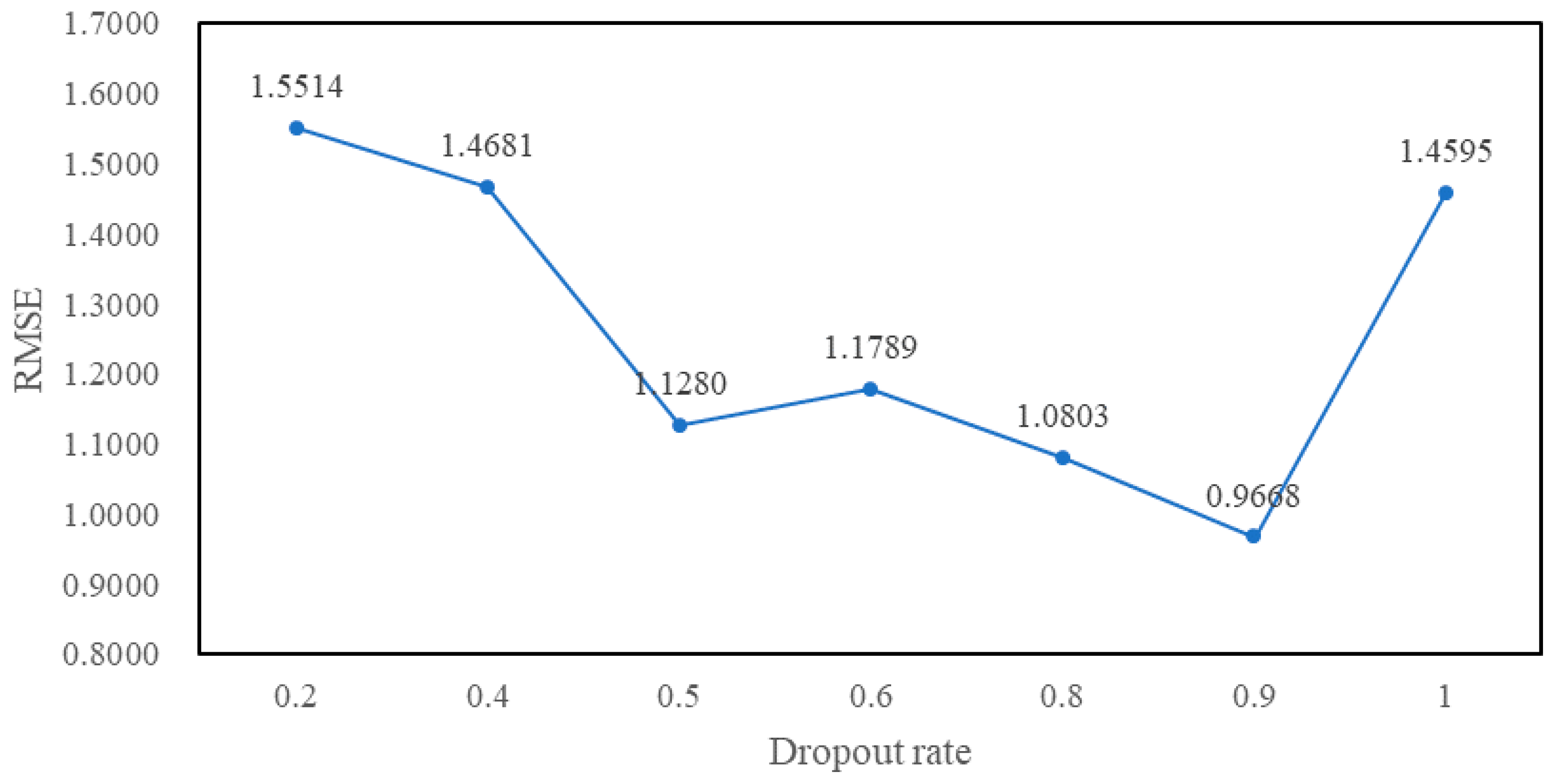
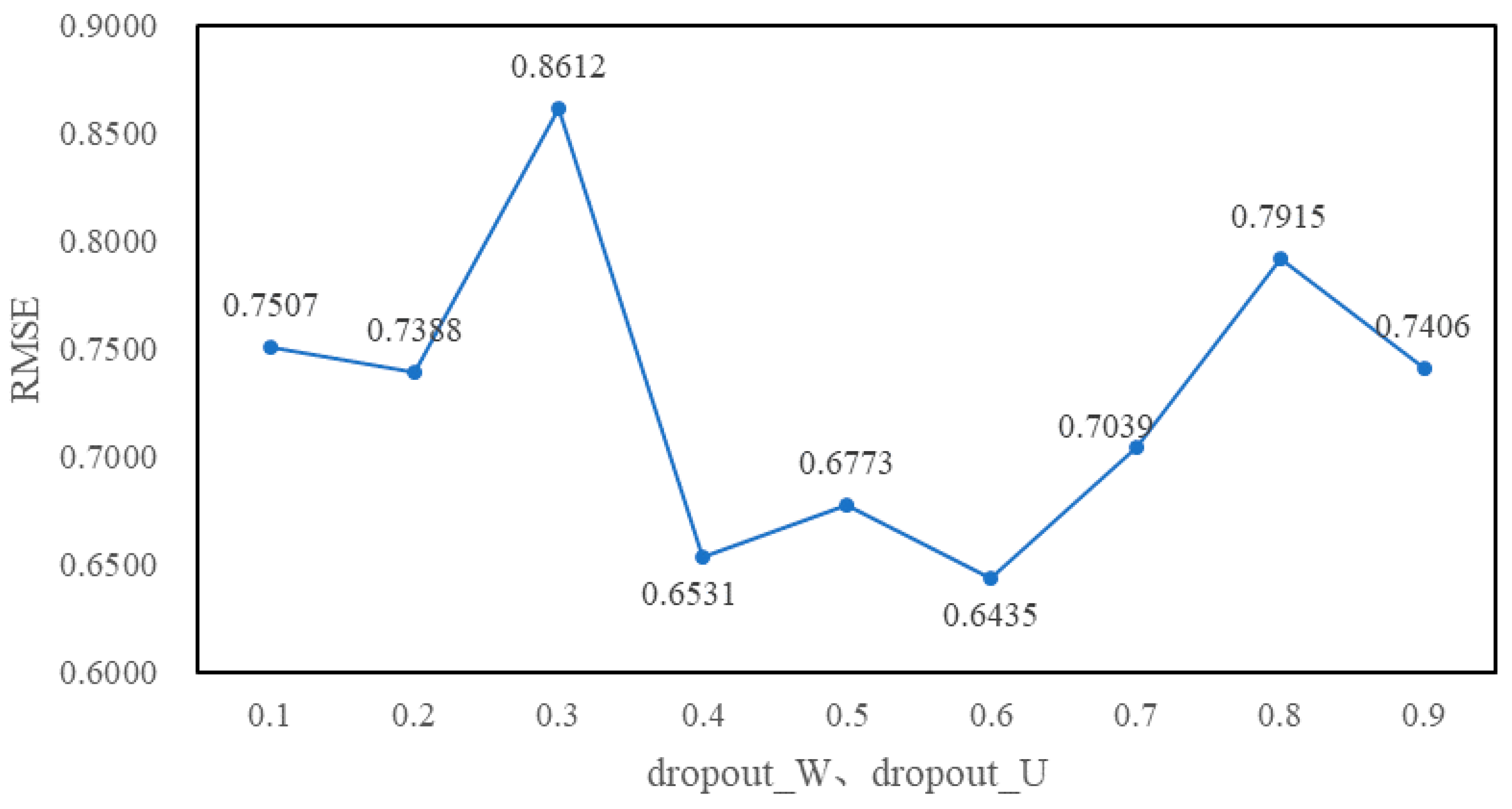
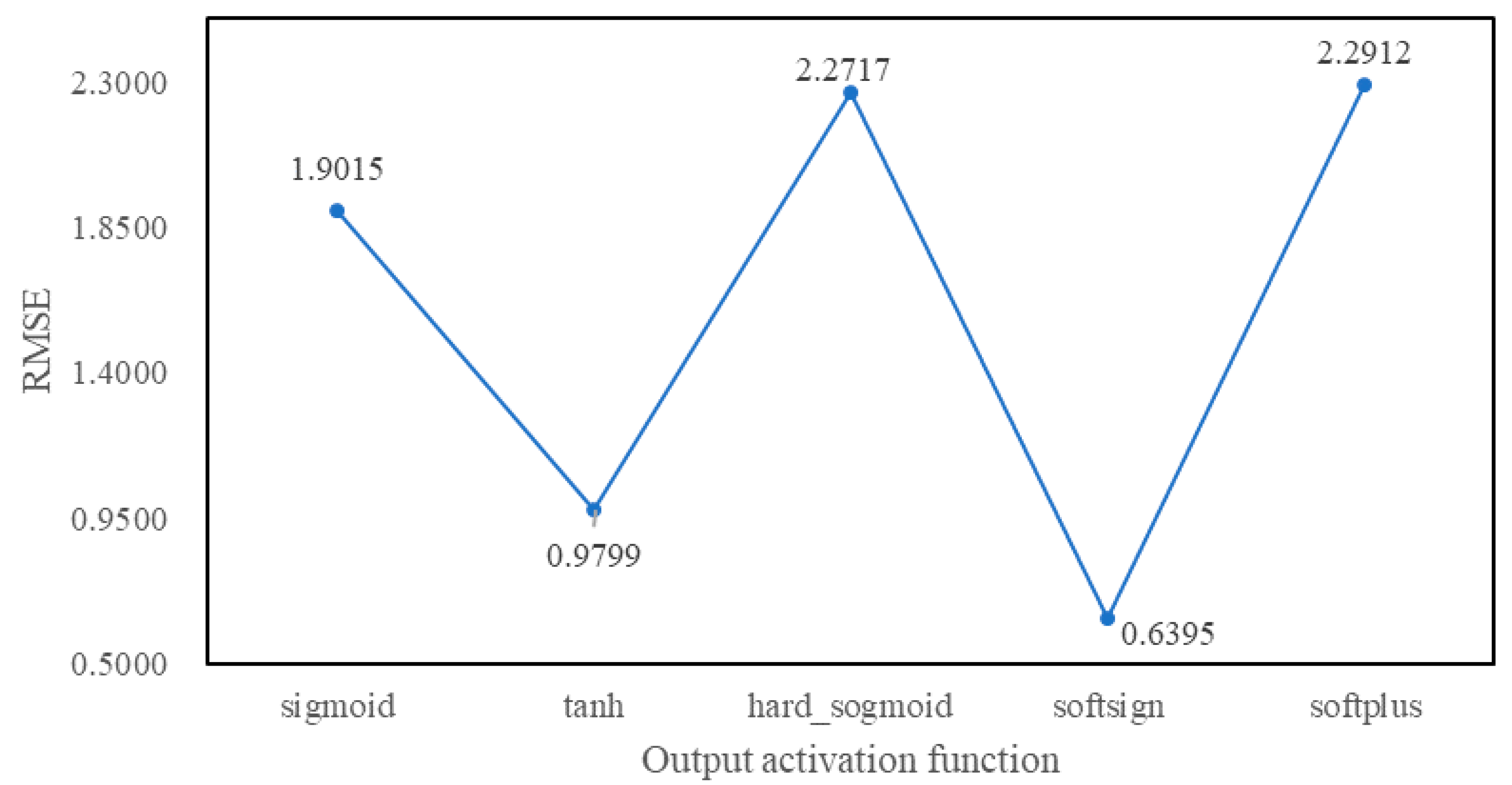
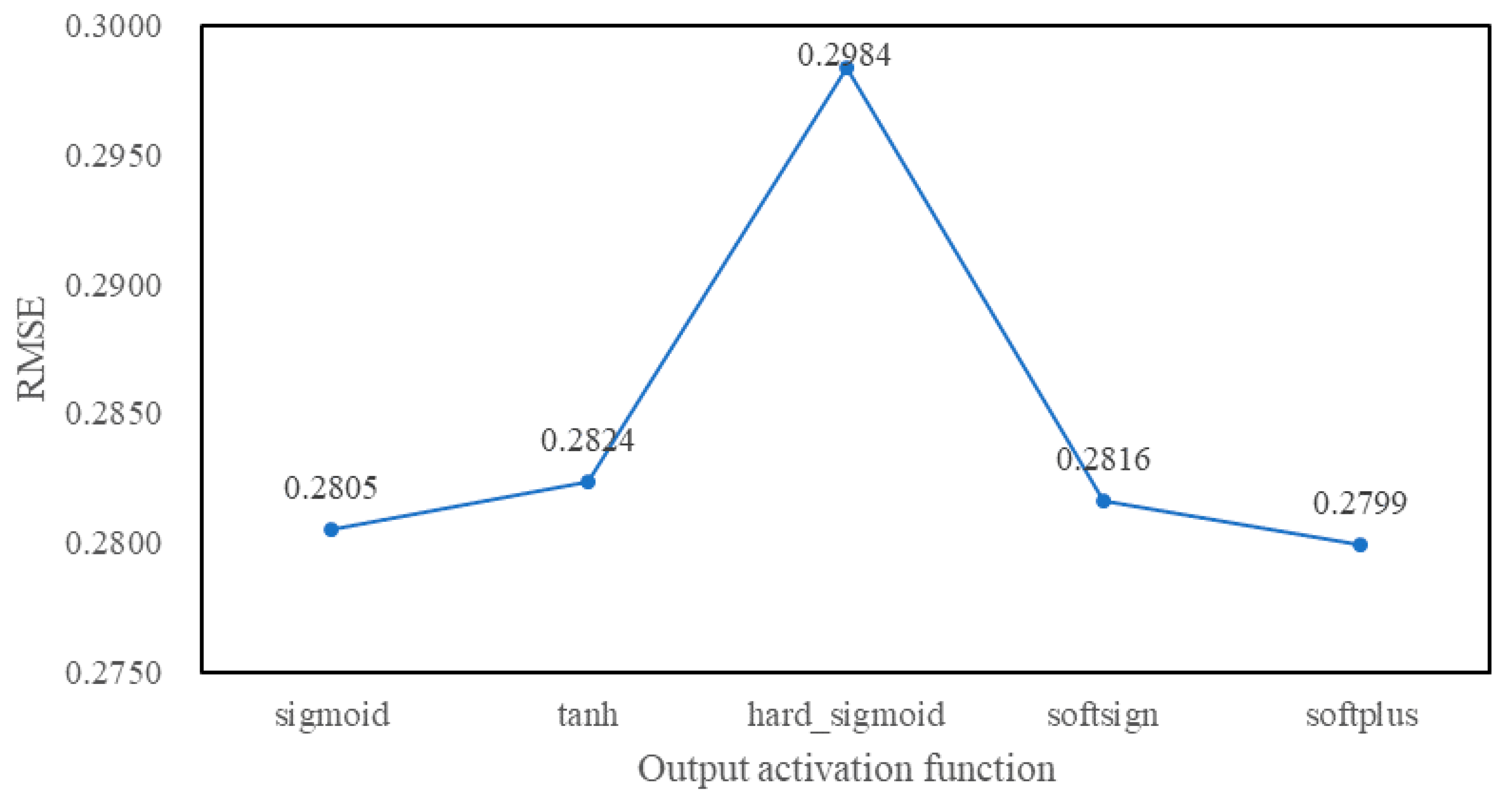
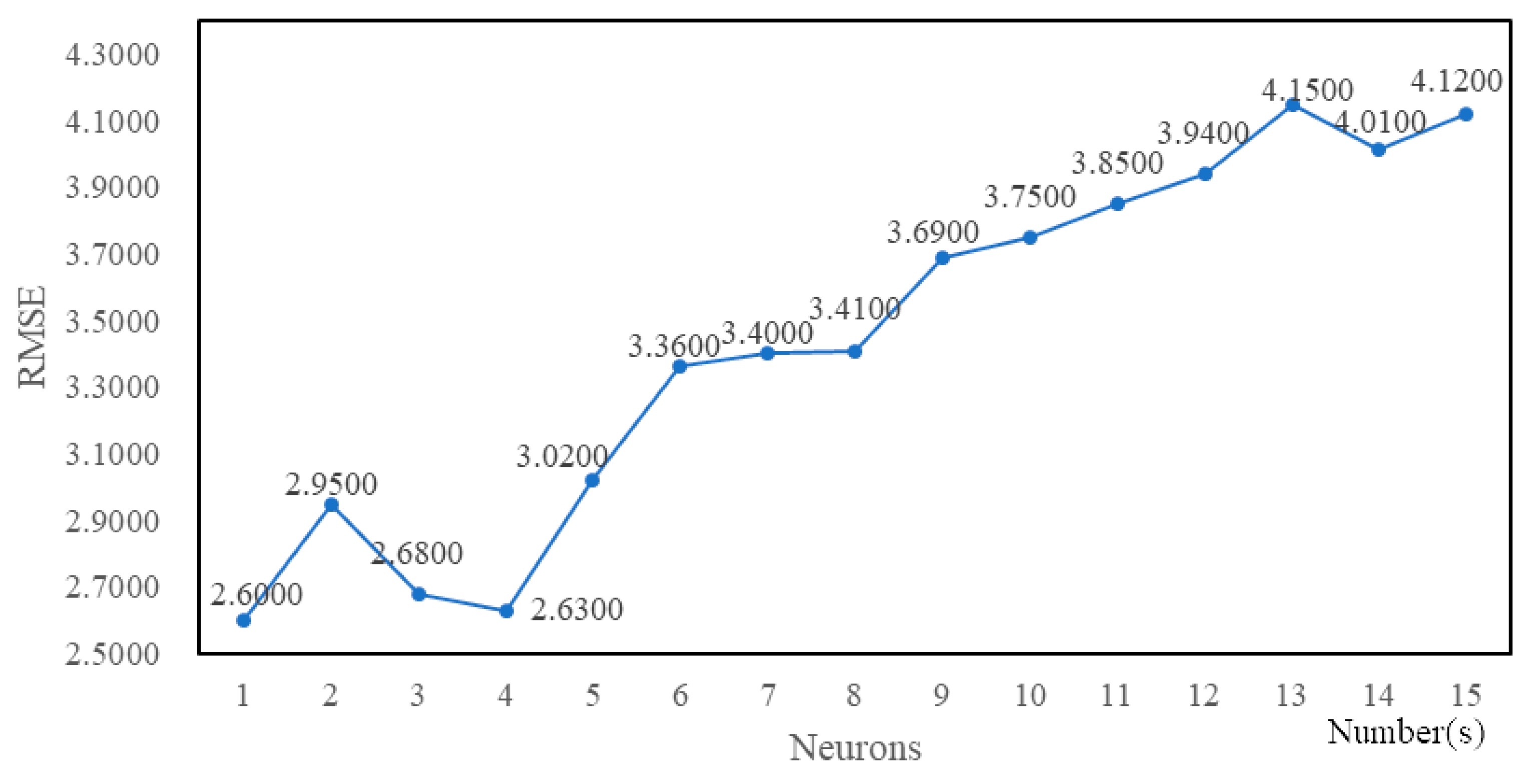
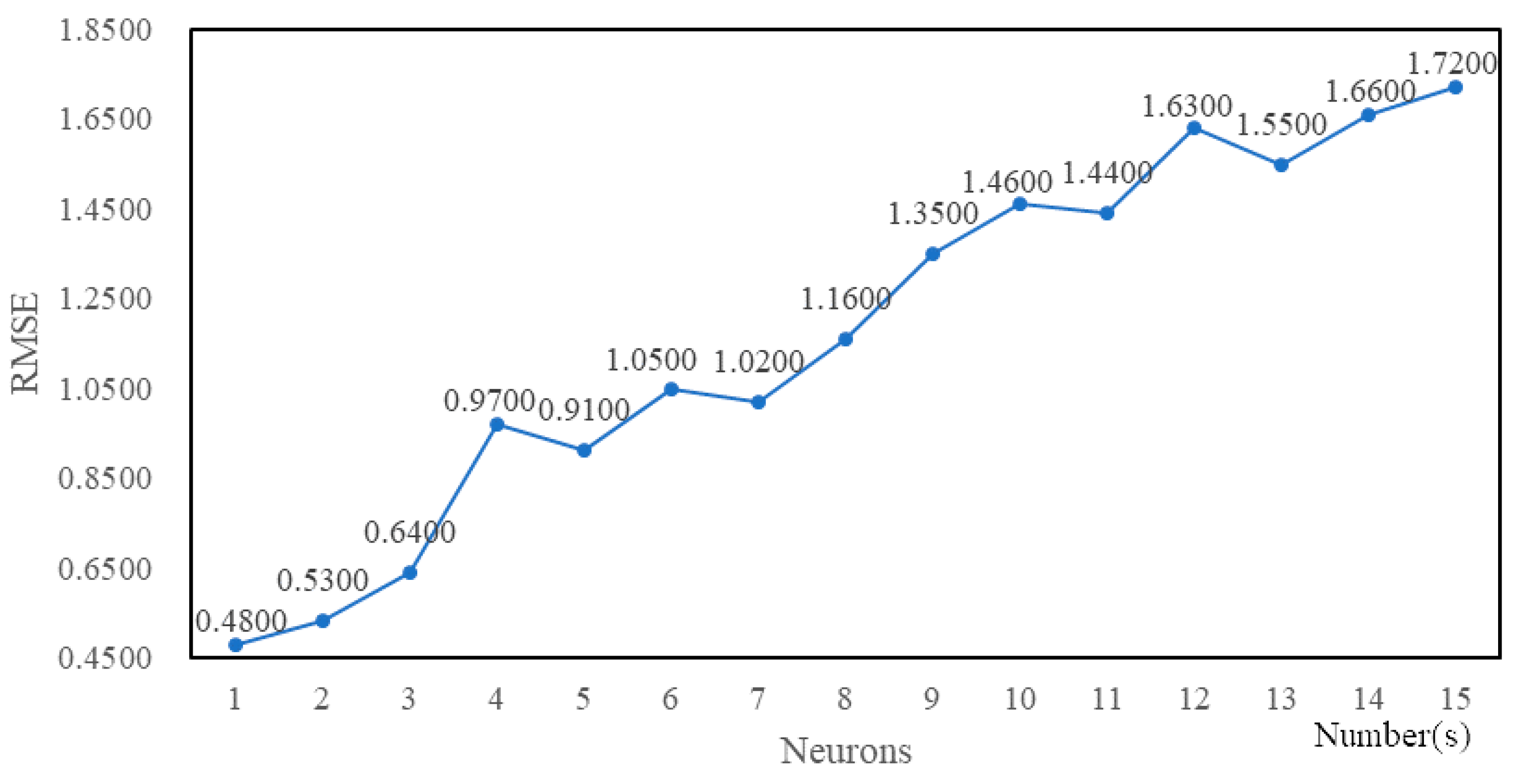
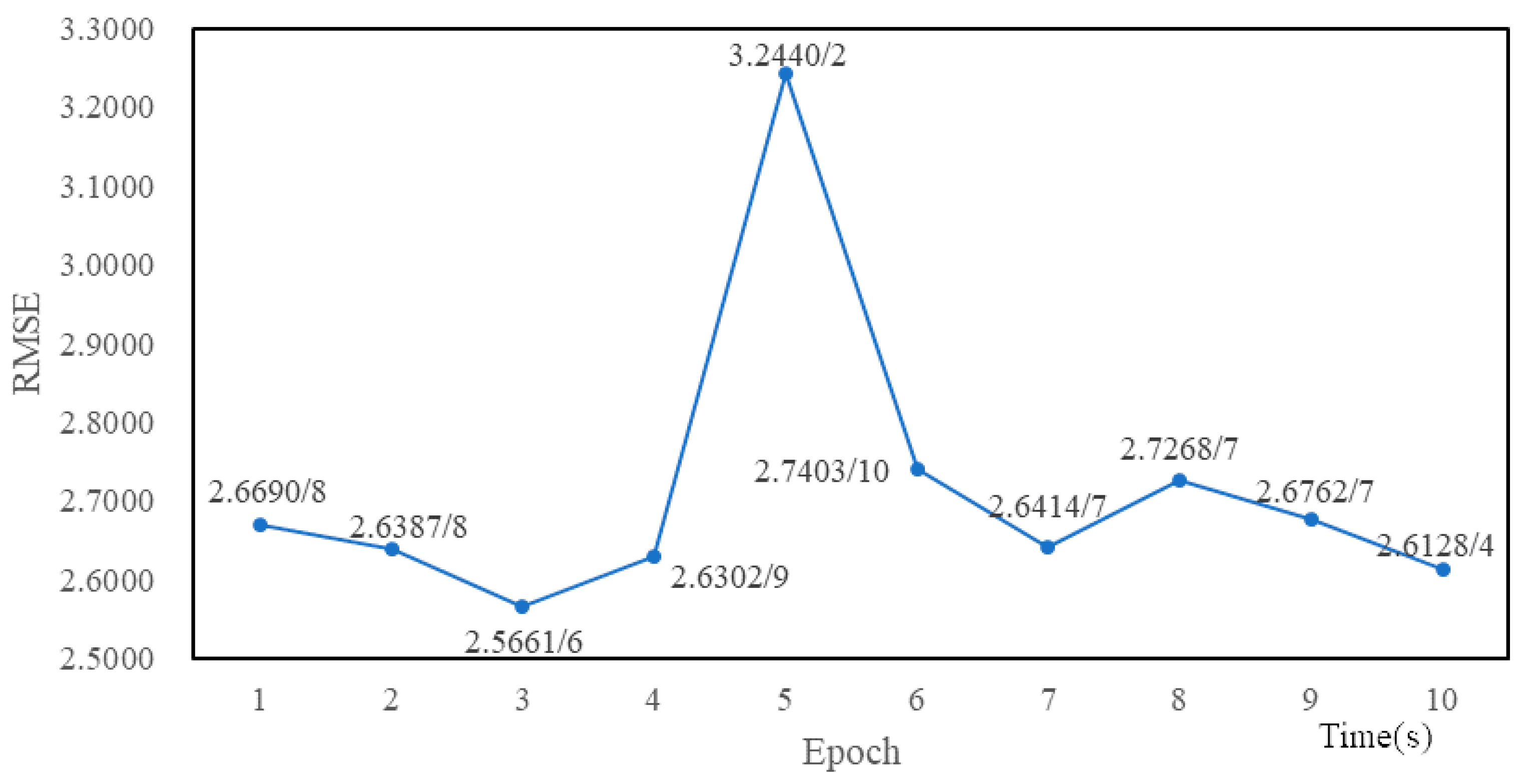
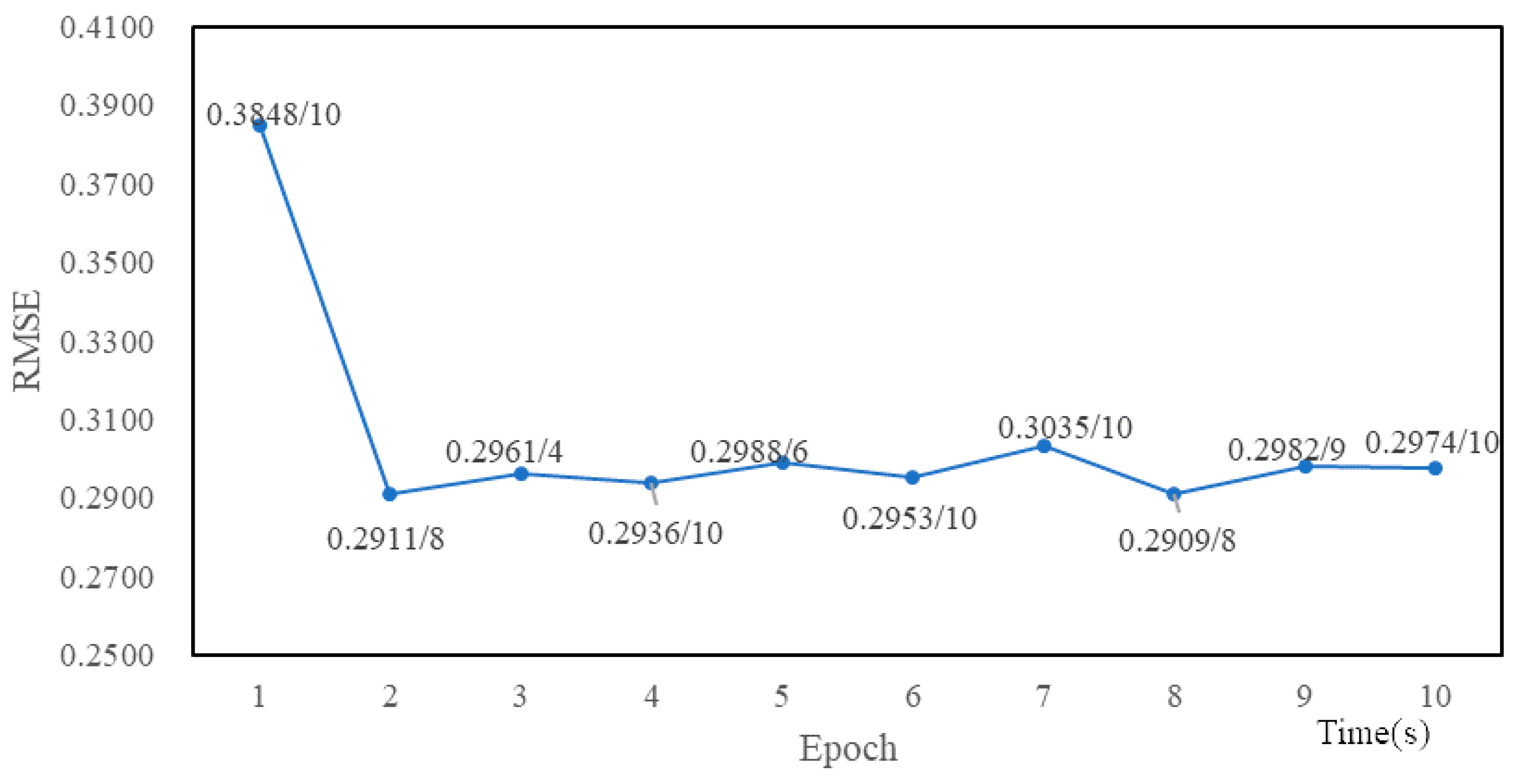
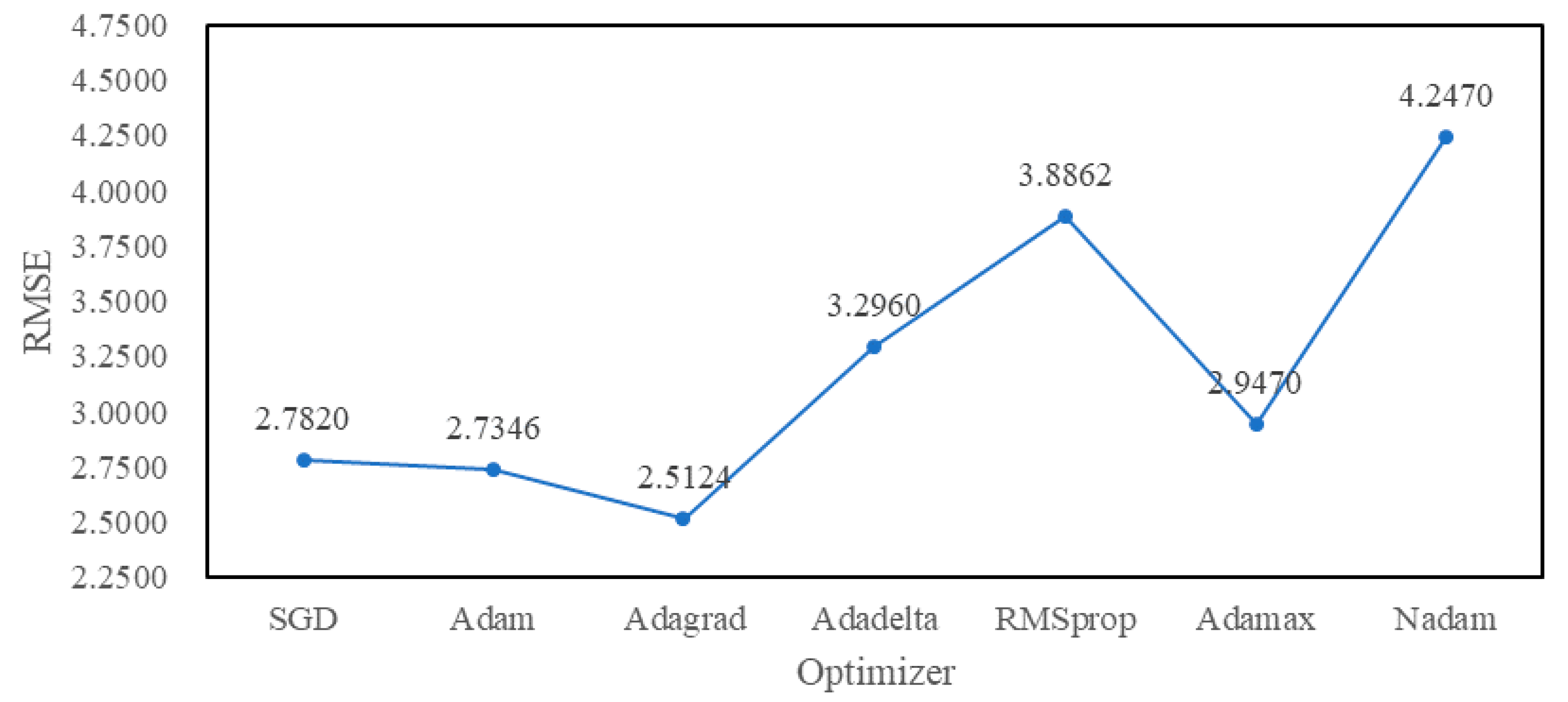
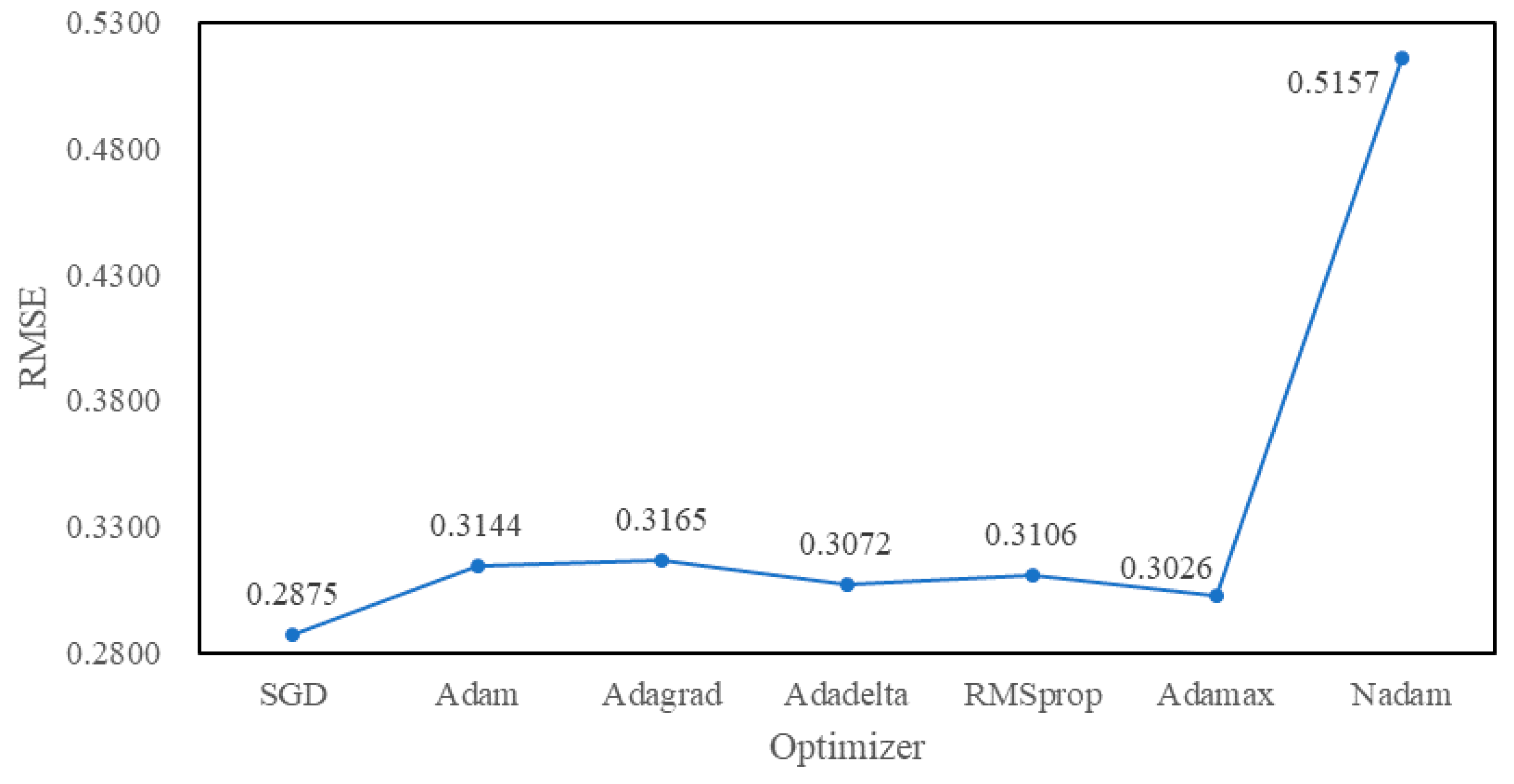
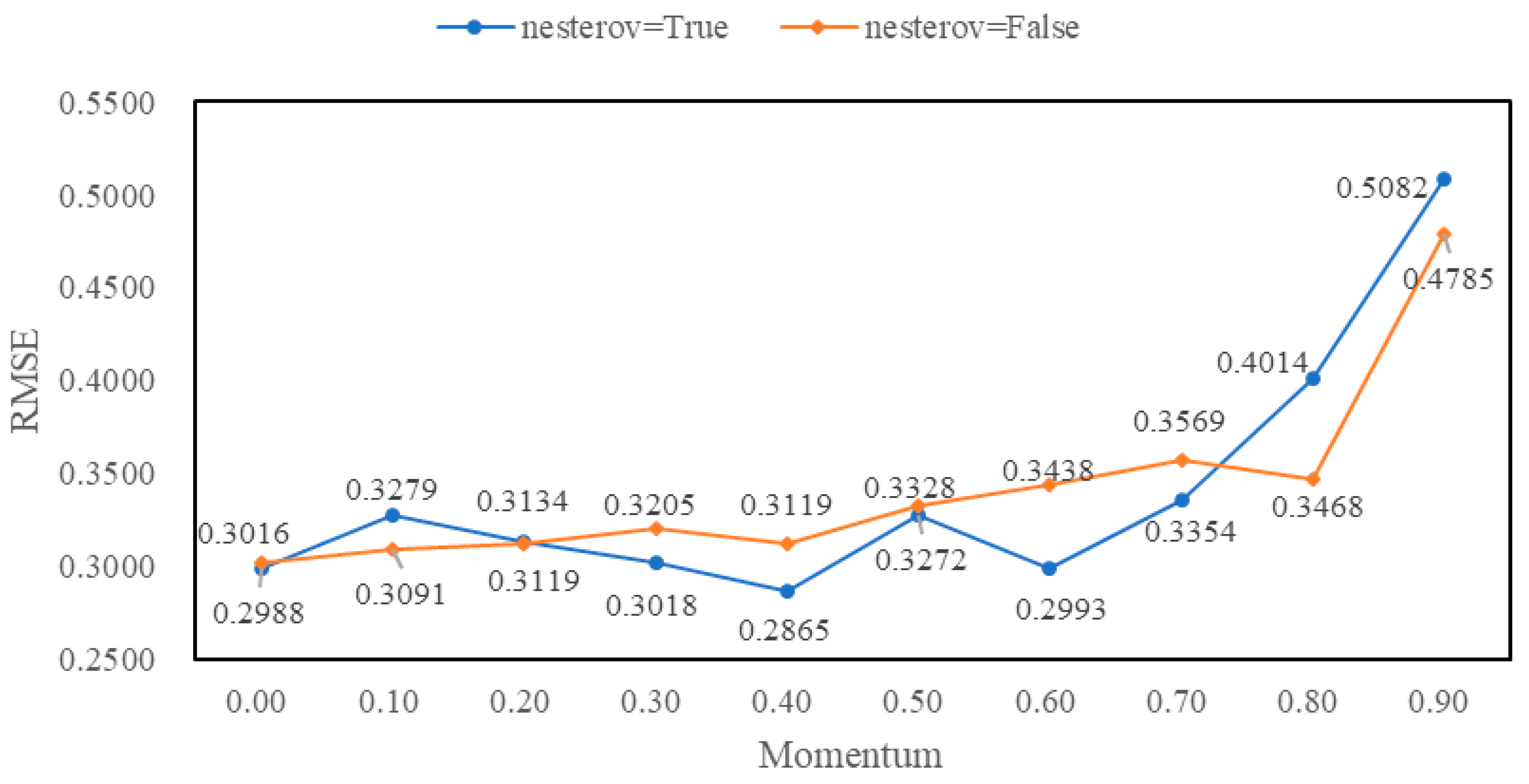
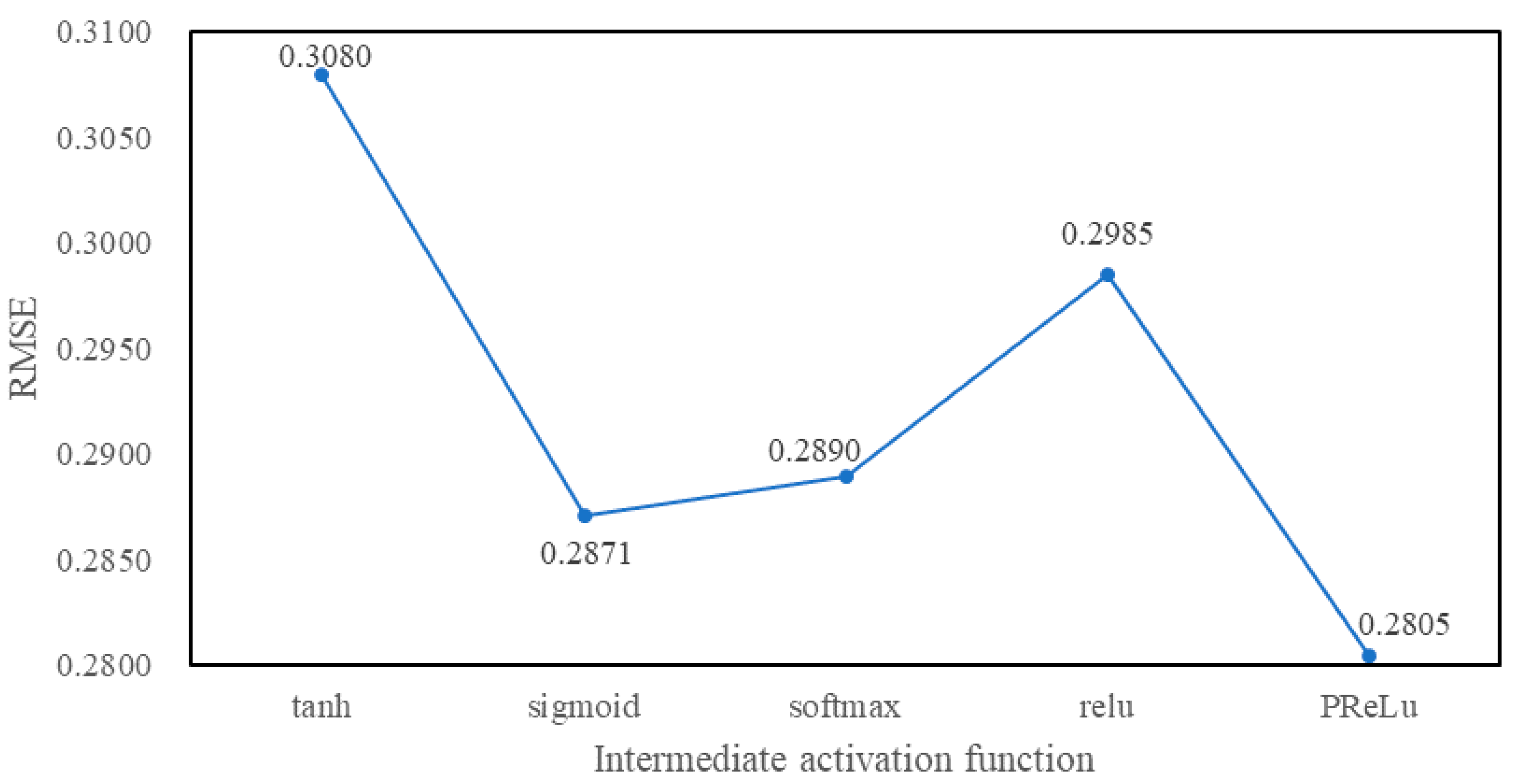
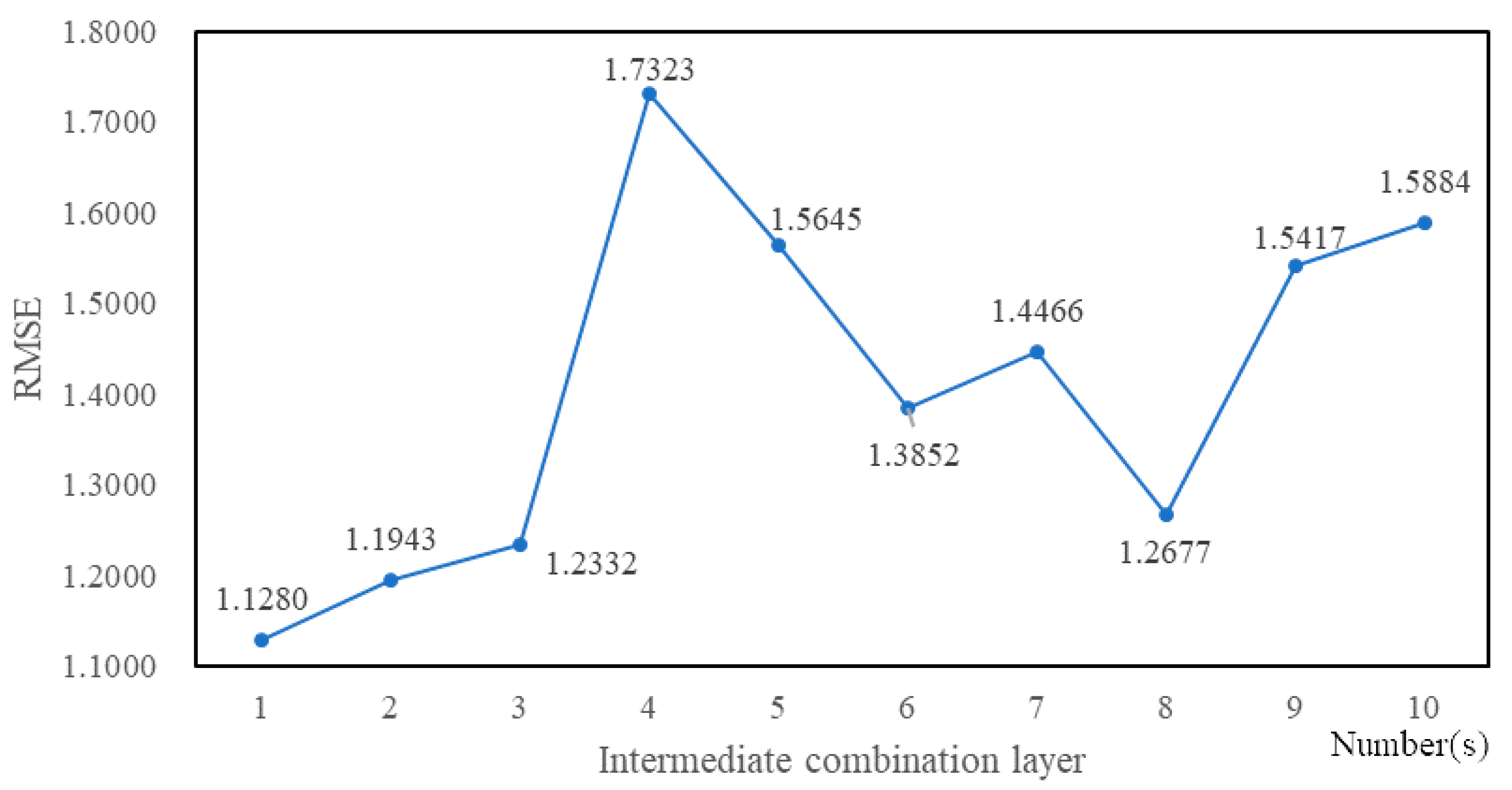
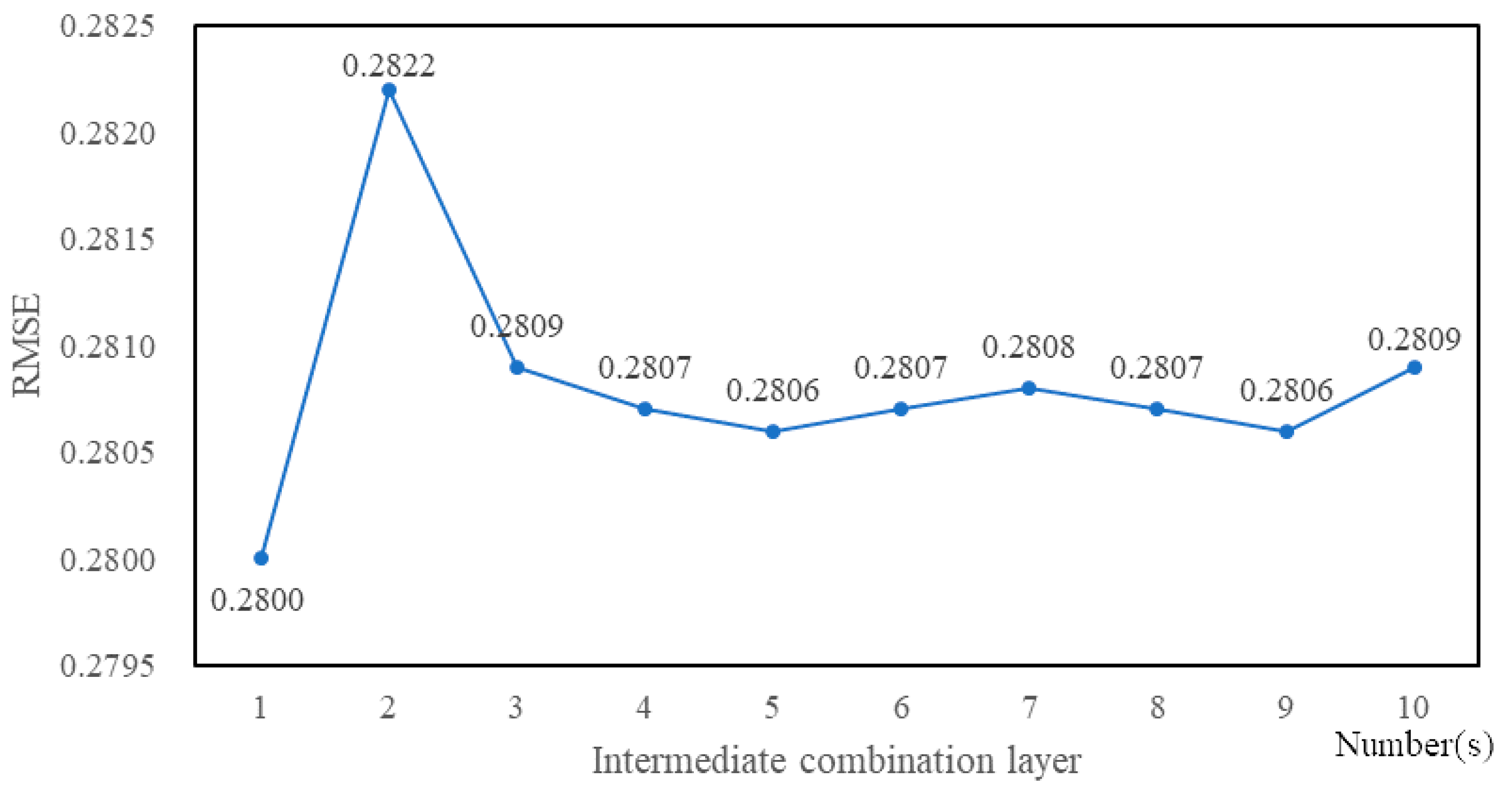
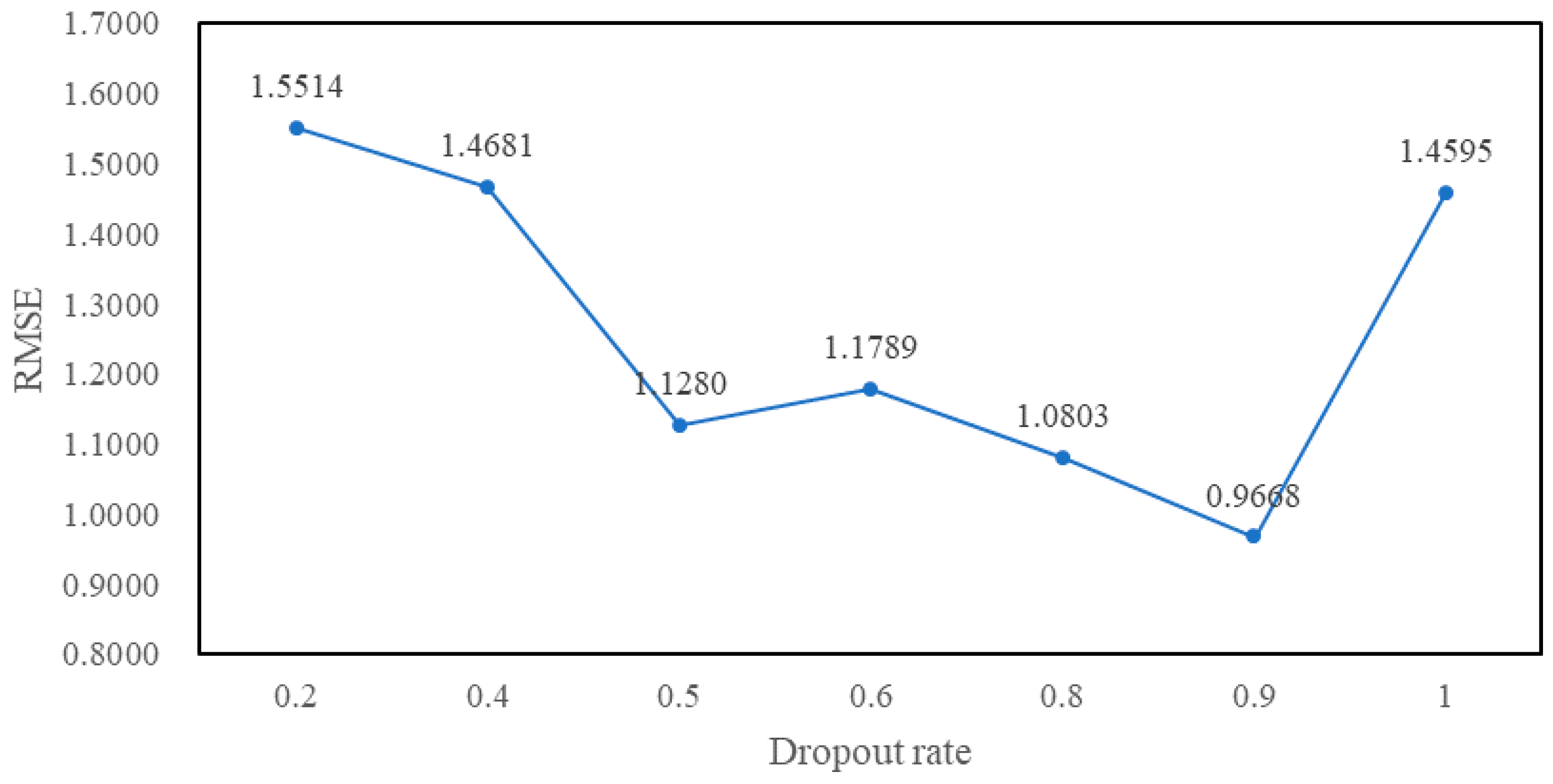
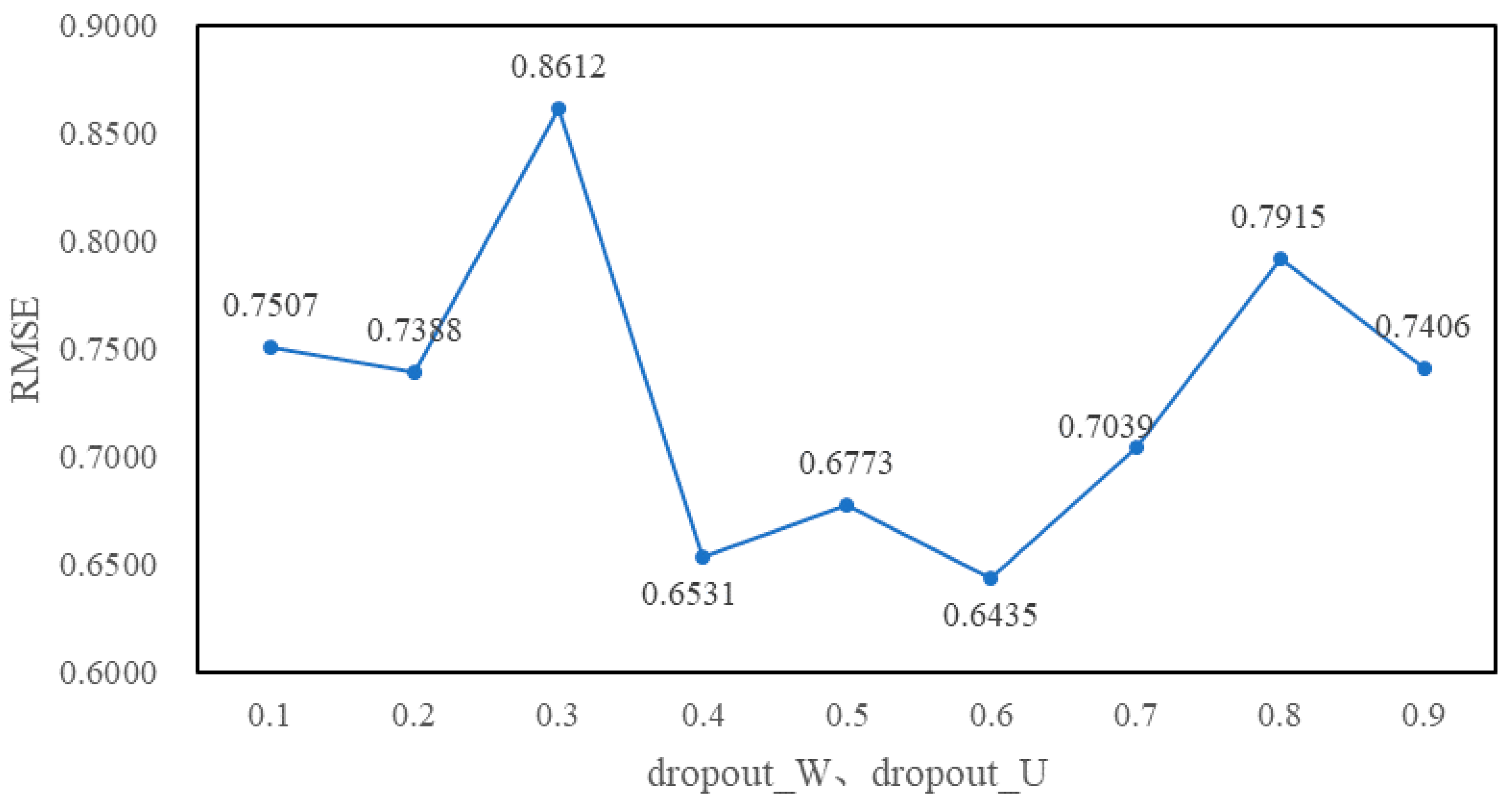
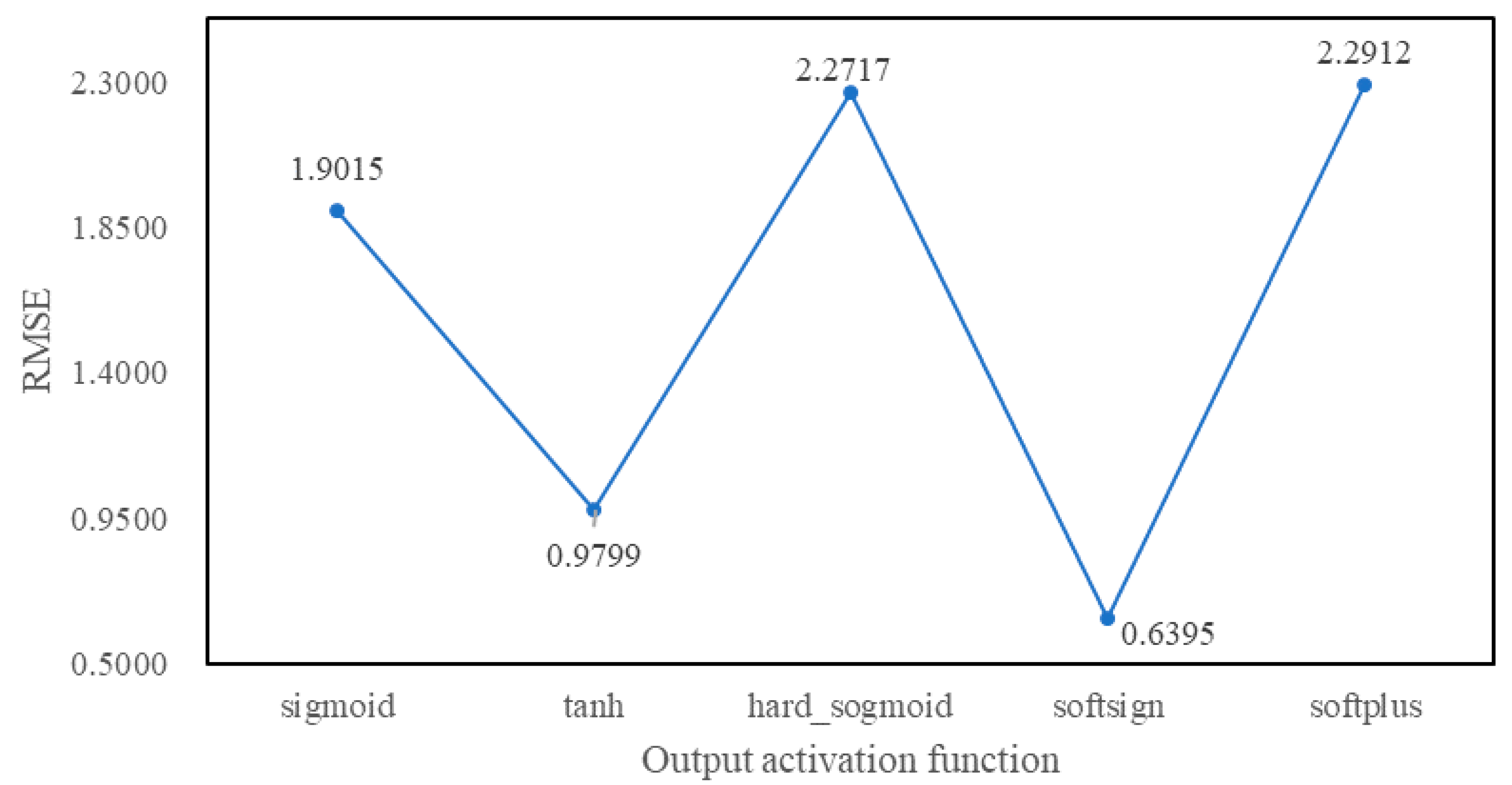
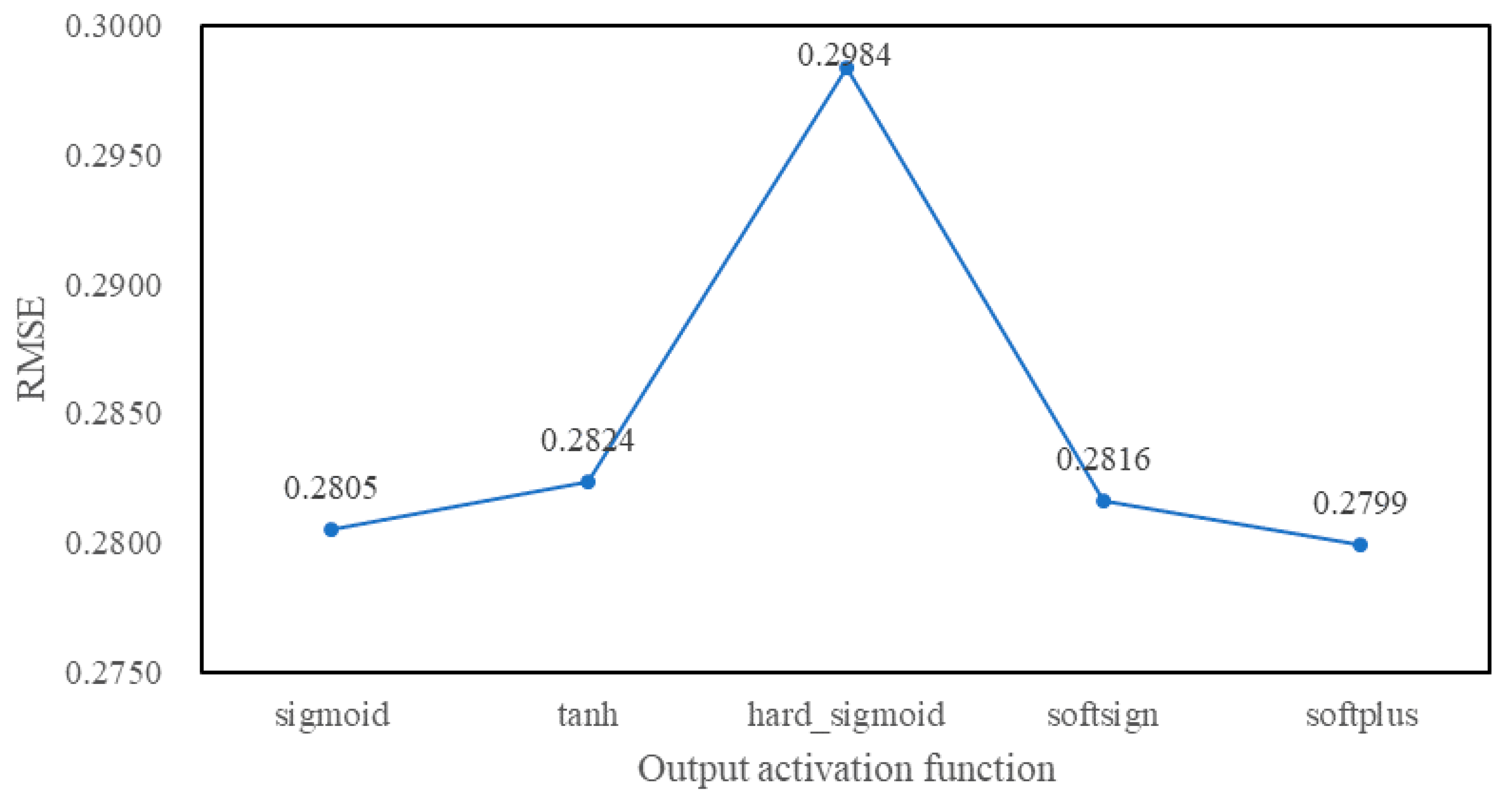
4.3. Experimental Tuning Process
5. Experimental Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Okutani, I.; Stephanedes, Y.J. Dynamic prediction of traffic volume through kalman filtering theory. Transp. Res. Part B Methodol. 1984, 18, 1–11. [Google Scholar] [CrossRef]
- Perera, L.P.; Soares, C.G. Ocean vessel trajectory estimation and prediction based on extended kalman filter. In Proceedings of the Second International Conference on Adaptive and Self-Adaptive Systems and Applications, Lisbon, Portugal, 14–20 November 2010. [Google Scholar]
- Chen, C.; Hu, J.; Meng, Q.; Zhang, Y. Short-time traffic flow prediction with ARIMA-GARCH model. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011; pp. 607–612. [Google Scholar]
- Shen, G.; Zhu, Y. Short-term traffic flow forecasting based on hybrid model. J. Nanjing Univ. Technol. 2014, 38, 246–251. [Google Scholar]
- Zhu, Z.; Liu, L.; Cui, M. Short-term traffic flow forecasting model combining SVM and kalman filter. Comput. Sci. 2013, 40, 248–251. [Google Scholar]
- Yang, G.; Xu, R.; Qin, M.; Zheng, K.; Zhang, B. Short-term traffic volume forecasting based on ARMA and kalman filter. J. Zhengzhou Univ. (Eng. Sci.) 2017, 38, 36–40. [Google Scholar]
- Tang, J.; Xu, G.; Wang, Y.; Wang, H.; Zhang, S.; Liu, F. Traffic flow prediction based on hybrid model using double exponential smoothing and support vector machine. In Proceedings of the 16th International IEEE Conference on Intelligent Transportation Systems (ITSC 2013), Hague, The Netherlands, 6–9 October 2013; pp. 130–135. [Google Scholar]
- Li, S.; Liu, L.; Zhai, M. Prediction for short-term traffic flow based on modified PSO optimized BP neural network. Syst. Eng. Theory Pract. 2012, 32, 2045–2049. [Google Scholar]
- Liu, J. Short-term traffic flow prediction model of phase space reconstruction and support vector regression with combination optimization. Comput. Eng. Appl. 2014, 50, 13–17. [Google Scholar]
- Gao, S. Short time traffic flow prediction model based on neural network and cuckoo search algorithm. Comput. Eng. Appl. 2013, 49, 106–109. [Google Scholar]
- Zhang, J.; Wang, Y.; Zhu, X. Short-term prediction of traffic flow based on neural network optimized improved particle swarm optimization. Comput. Eng. Appl. 2017, 53, 227–231. [Google Scholar]
- Hou, Y.; Zhao, H. Traffic flow prediction based on T-S fuzzy neural network optimized improved particle swarm optimization. Comput. Eng. Appl. 2014, 50, 236–239. [Google Scholar]
- Shen, Y.; Yan, J.; Wang, W. Short-term traffic flow forecasting based on WNN optimized by CPSO. Comput. Appl. Softw. 2014, 31, 84–90. [Google Scholar]
- Zang, Y.; Ni, F.; Feng, Z.; Cui, S.; Ding, Z. Wavelet transform processing for cellular traffic prediction in machine learning networks. In Proceedings of the 2015 IEEE China Summit and International Conference on Signal and Information Processing (ChinaSIP), Chengdu, China, 12–15 July 2015; pp. 458–462. [Google Scholar]
- Minal, D.; Preeti, R.B. Short term traffic flow prediction based on neuro-fuzzy hybrid system. In Proceedings of the 2016 IEEE International Conference on ICT in Business Industry & Government (ICTBIG), Indore, India, 1–3 November 2016. [Google Scholar]
- Kumar, A. Novel multi input parameter time delay neural network model for traffic flow prediction. In Proceedings of the 2016 IEEE Online International Conference on Green Engineering and Technologies (IC-GET), Coimbatore, India, 1–6 November 2016. [Google Scholar]
- Yu, B.; Duan, X.; Wu, Y. Establishment and application of data prediction model based on BP neural network. Comput. Digit. Eng. 2016, 44, 482–486. [Google Scholar]
- Zhang, C.; Liu, S.; Tan, T. Research on short-term traffic flow prediction methods based on modified genetic algorithm optimized BP neural network. J. Tianjin Chengjian Univ. 2017, 23, 143–148. [Google Scholar]
- Zhang, Q.; Zhu, X. Short-term traffic flow forecasting method based on GA-elman neural network. J. Lanzhou Univ. Technol. 2013, 39, 95–98. [Google Scholar]
- Yi, H.; Jung, H.; Bae, S. Deep neural networks for traffic flow prediction. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju, Korea, 13–16 February 2017; pp. 328–331. [Google Scholar]
- Yin, L.; He, Y.; Dong, X.; Lu, Z. Research on the multi-step prediction of volterra neural network for traffic flow. Acta Autom. Sin. 2014, 40, 2066–2072. [Google Scholar]
- Emilian, N. Dynamic traffic flow prediction based on GPS data. In Proceedings of the 2014 IEEE 26th International Conference on Tools with Artificial Intelligence (ICTAI), Limassol, Cyprus, 10–12 November 2014; pp. 922–929. [Google Scholar]
- Surya, S.; Rakesh, N. Flow based traffic congestion prediction and intelligent signaling using markov decision process. In Proceedings of the 2016 IEEE International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 1–6 August 2016. [Google Scholar]
- Luo, X.; Jiao, Q.; Niu, L.; Sun, Z. Short-term traffic flow prediction based on deep learning. Appl. Res. Comput. 2017, 34, 91–97. [Google Scholar]
- Zhang, M. Short-term traffic flow prediction of non-detector intersections based on FCM. Comput. Technol. Dev. 2017, 27, 39–45. [Google Scholar]
- Rui, L.; Li, Q. Short-term traffic flow prediction algorithm based on combined model. J. Electron. Inf. Technol. 2016, 38, 1227–1233. [Google Scholar]
- Pascale, A.; Nicoli, M. Adaptive bayesian network for traffic flow prediction. In Proceedings of the 2011 IEEE Statistical Signal Processing Workshop (SSP), Nice, France, 28–30 June 2011; pp. 177–180. [Google Scholar]
- Wen, M.; Yu, W.; Peng, J.; Zhang, X. A traffic flow prediction algorithm based on adaptive particle filter. In Proceedings of the 2014 26th Chinese Control and Decision Conference (CCDC), Changsha, China, 31 May–2 June 2014; pp. 4736–4740. [Google Scholar]
- Borkowski, P. The ship movement trajectory prediction algorithm using navigational data fusion. Sensors 2017, 17, 1432. [Google Scholar] [CrossRef]
- Shao, H.; Soong, B.H. Traffic flow prediction with long short-term memory networks (LSTMs). In Proceedings of the 2016 IEEE Region 10 Conference (TENCON), Singapore, 22–25 November 2016; pp. 2986–2989. [Google Scholar]
- Lipton, Z.C. A Critical Review of Recurrent Neural Networks for Sequence Learning. Available online: https://arxiv.org/pdf/1506.00019v2.pdf (accessed on 2 February 2019).
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Graves, A. Supervised Sequence Labelling with Recurrent Neural Networks Book; Springer: Berlin/Heidelberg, Germany, 2012; pp. 31–38. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. Available online: https://arxiv.org/pdf/1502.01852.pdf (accessed on 18 February 2019).
- Xavier, G.; Yoshua, B. Understanding the difficulty of training deep feedforward neural networks. J. Mach. Learn. Res. 2010, 9, 249–256. [Google Scholar]
- Xavier, G.; Yoshua, B.; Bengio, Y. Deep sparse rectifier neural networks. J. Mach. Learn. Res. 2011, 15, 315–323. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Wang, W.; Guo, X. Jiaotong Gongchengxue, 1st ed.; Southeast University Press: Nan Jing, China, 2000; p. 37. ISBN 7-81050-680-3. [Google Scholar]
- Keras Documentation. Available online: https://keras.io/ (accessed on 2 February 2019).
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]


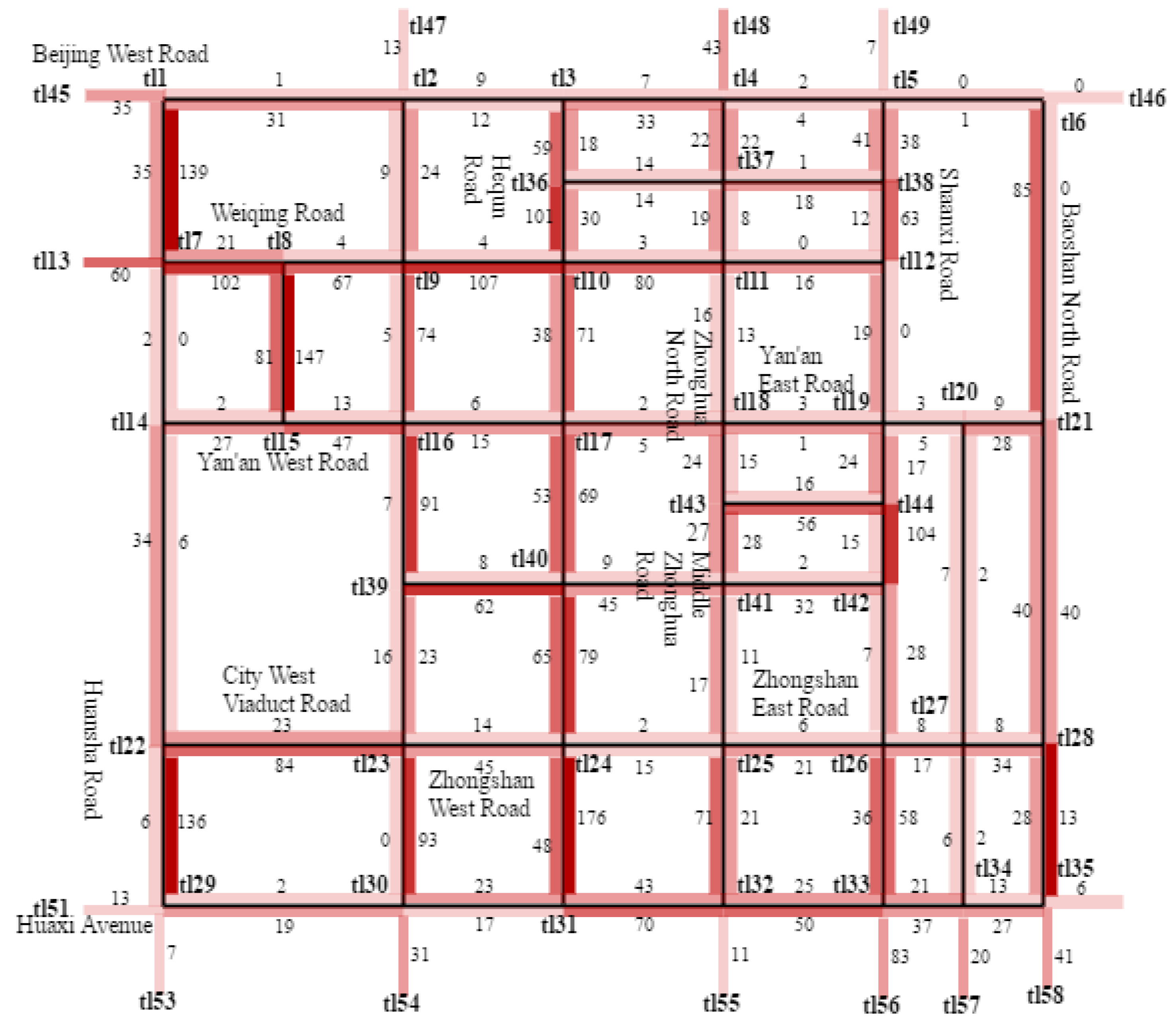
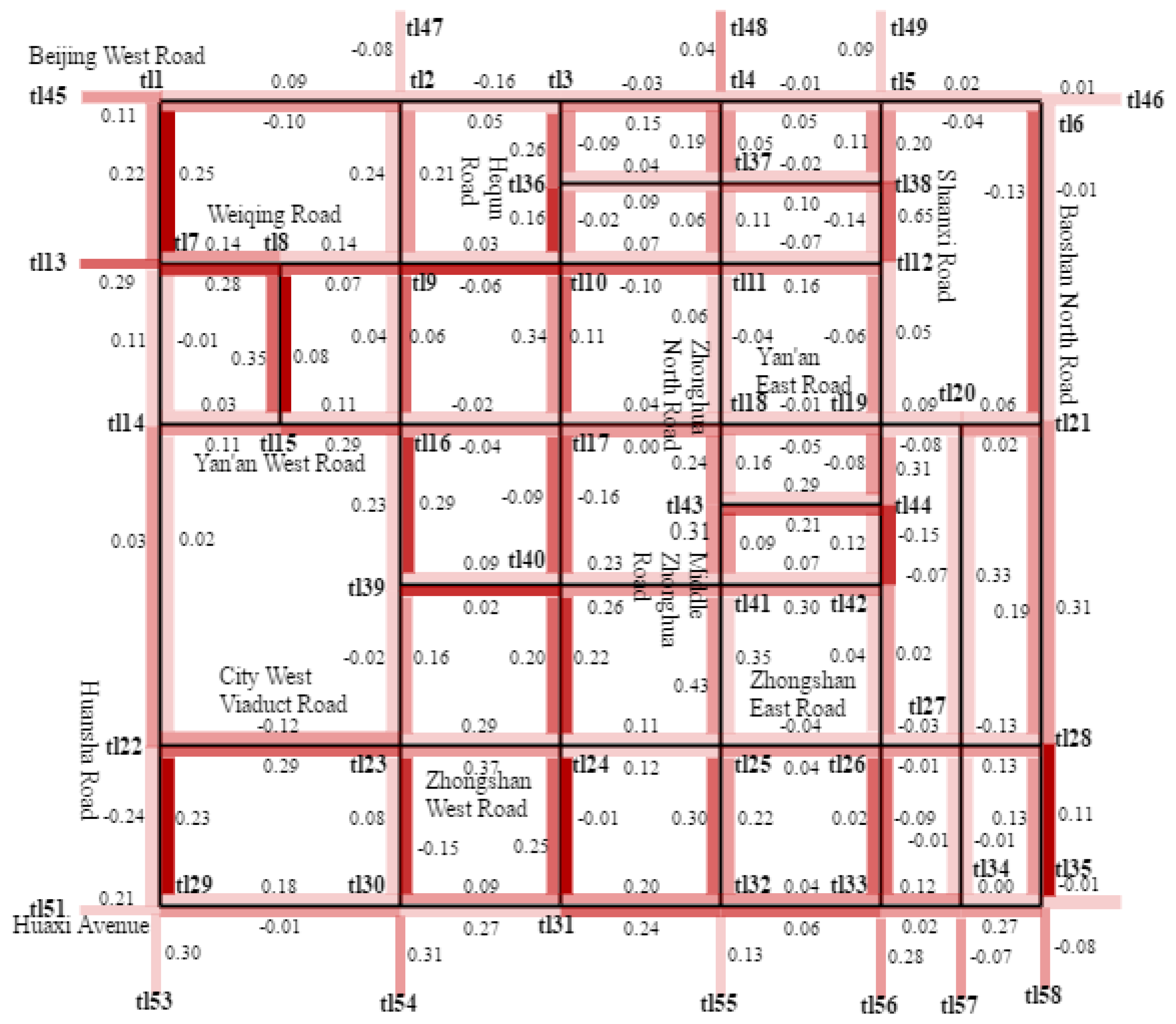
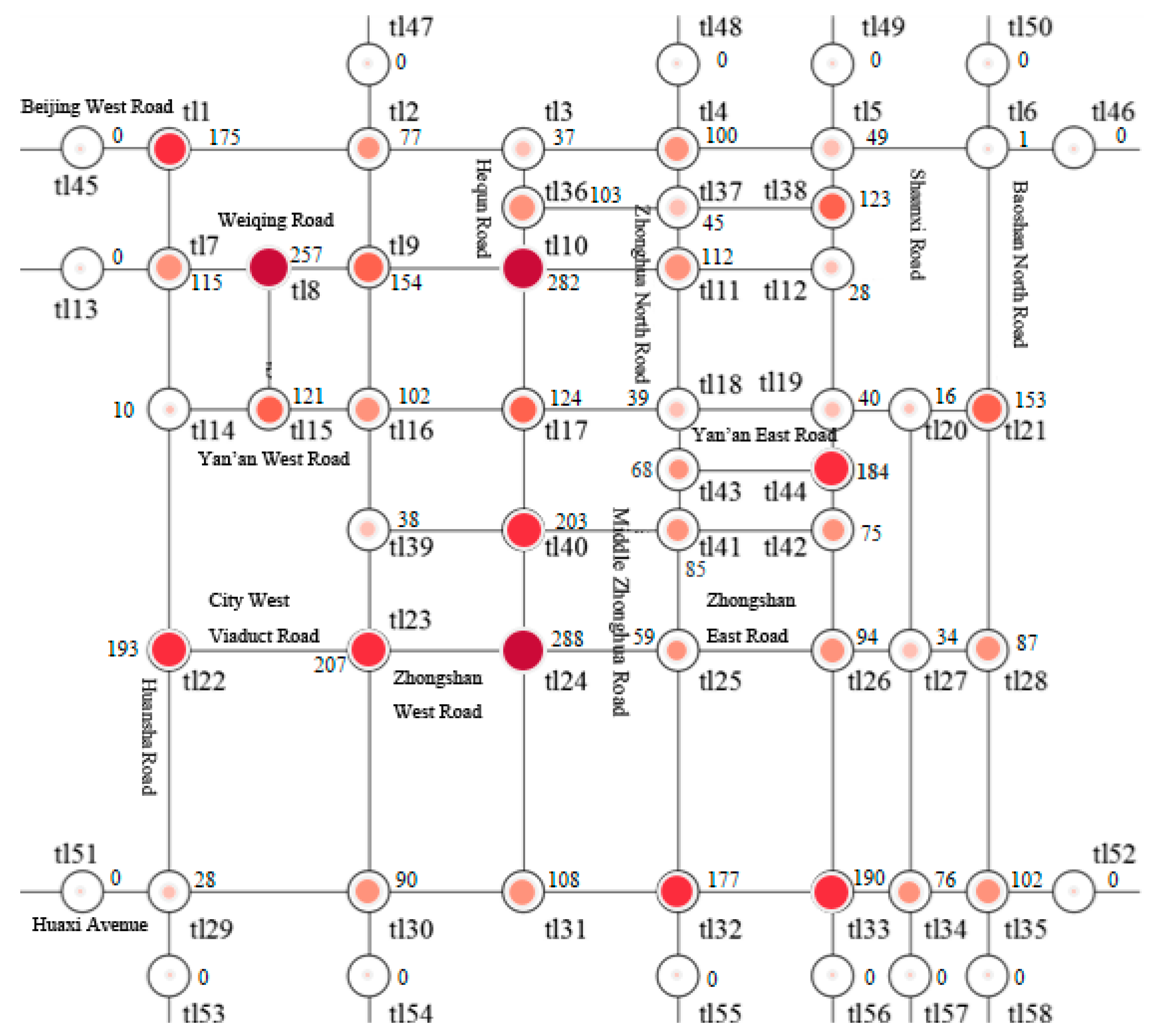
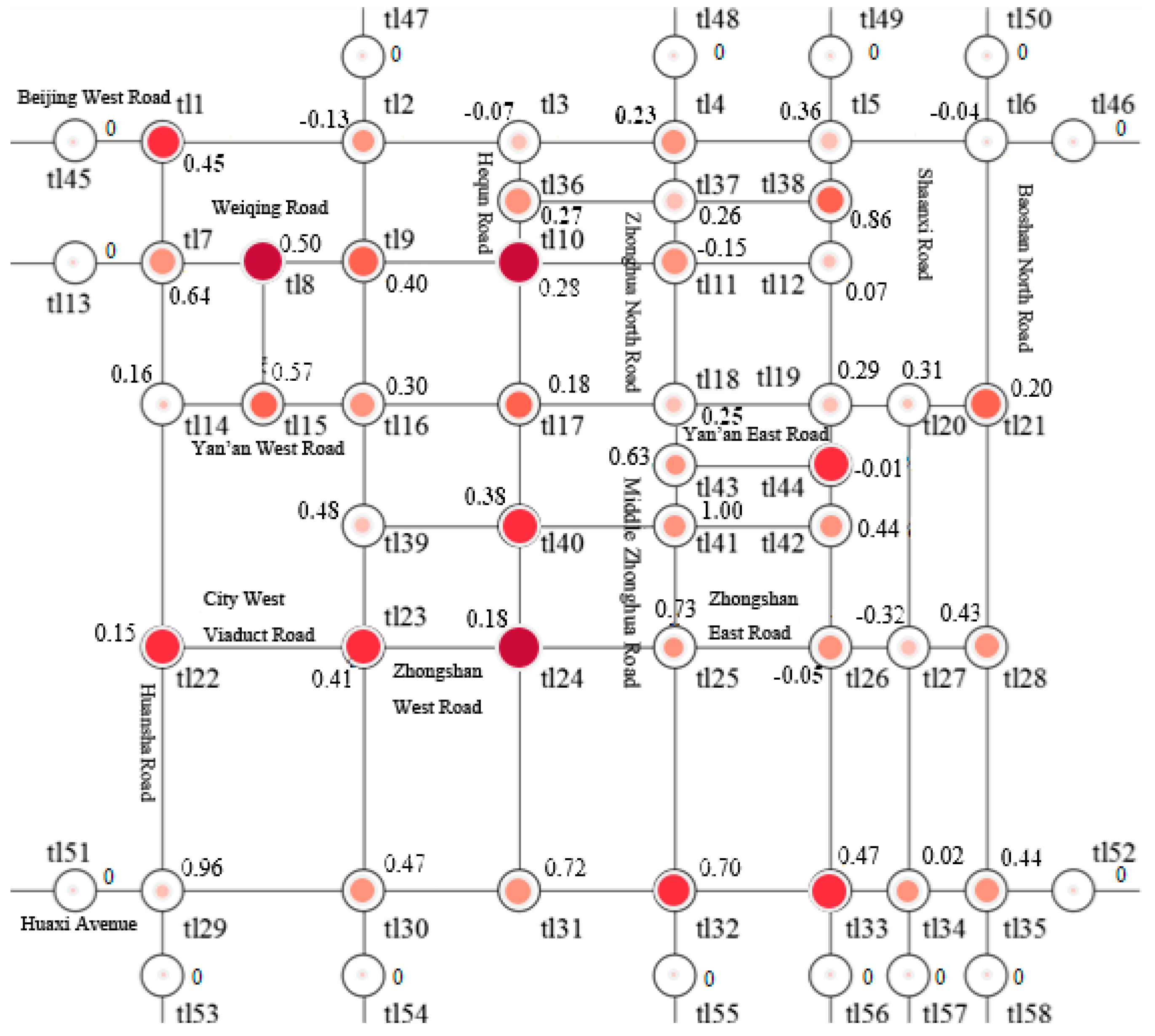

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Current Node (TrafficLightID) | Source Node (FromID) | Traffic Flow (traffic_flow) |
|---|---|---|
| tl4 | tl1 | [10, 8, 5, 0, 0, 23, 13, …, 23] |
| tl4 | tl2 | [23, 15, 12, 12, 9, 9, 9, …, 9] |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, Y.; Yin, Y. Hybrid LSTM Neural Network for Short-Term Traffic Flow Prediction. Information 2019, 10, 105. https://doi.org/10.3390/info10030105
Xiao Y, Yin Y. Hybrid LSTM Neural Network for Short-Term Traffic Flow Prediction. Information. 2019; 10(3):105. https://doi.org/10.3390/info10030105
Chicago/Turabian StyleXiao, Yuelei, and Yang Yin. 2019. "Hybrid LSTM Neural Network for Short-Term Traffic Flow Prediction" Information 10, no. 3: 105. https://doi.org/10.3390/info10030105
APA StyleXiao, Y., & Yin, Y. (2019). Hybrid LSTM Neural Network for Short-Term Traffic Flow Prediction. Information, 10(3), 105. https://doi.org/10.3390/info10030105