Dynamic Top-K Interesting Subgraph Query on Large-Scale Labeled Graphs

Abstract
:1. Introduction
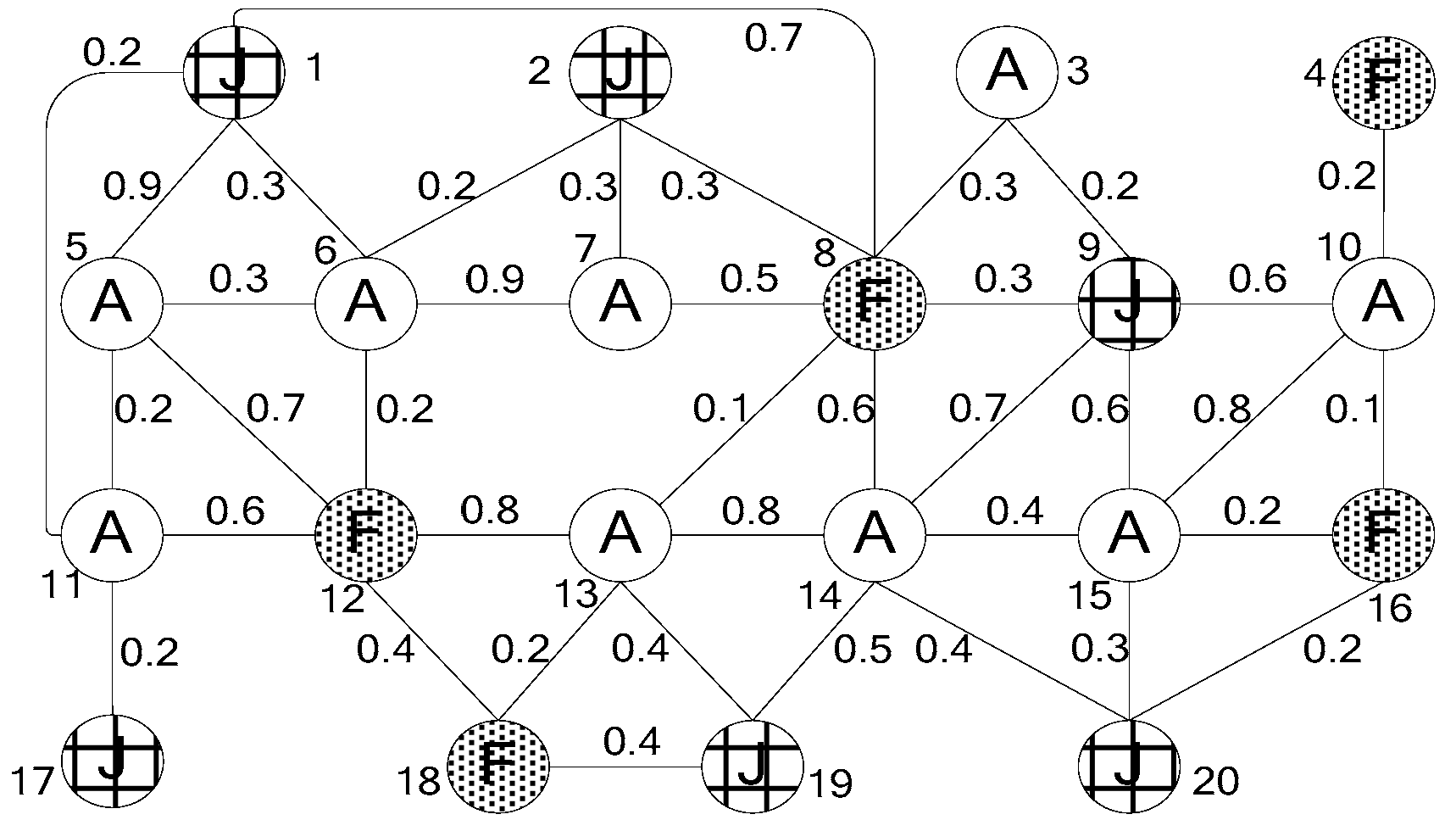
- A graph topology structure feature index (GTSF index) is proposed. It consists of a node topology feature index (NTF index) and an edge feature index (EF index), which uses the topology structure of nodes and the edge feature information to prune and filter invalid nodes, to obtain a relatively small set of candidate node sets and candidate edge sets.
- A multi-factor candidate set filtering strategy based on the GTSF is proposed, and this strategy is used to further prune the candidate set of the query graph to avoid redundant computation in the matching-validation phase.
- We propose a dynamic Top-K interesting subgraph query method based on the sliding window. First, in the matching-verification phase, a query matching order setting method is given to improve the matching-verification efficiency. Then because dynamic changes in the graph may influence matching results, we divide the matching process into two phase: initial matching and dynamic modified. In the initial matching phase, the initial result set is achieved by matching one by one the candidate set according to the matching order; in the dynamic modified phase, the initial result set is dynamically updated by using the dynamic change of the graph as far as possible to ensure that the real-time and accuracy of query results.
- Taking into account some factors, such as the frequent I/O and network communication, we propose an incremental dynamic maintenance strategy for indexes. As there may be some relationship among the various types of graph change operations in the update interval, the optimization mechanism of graph changes is proposed. By using optimized change operations, indexes are made by local updates to avoid the huge overheads caused by global updates.
2. Preliminaries
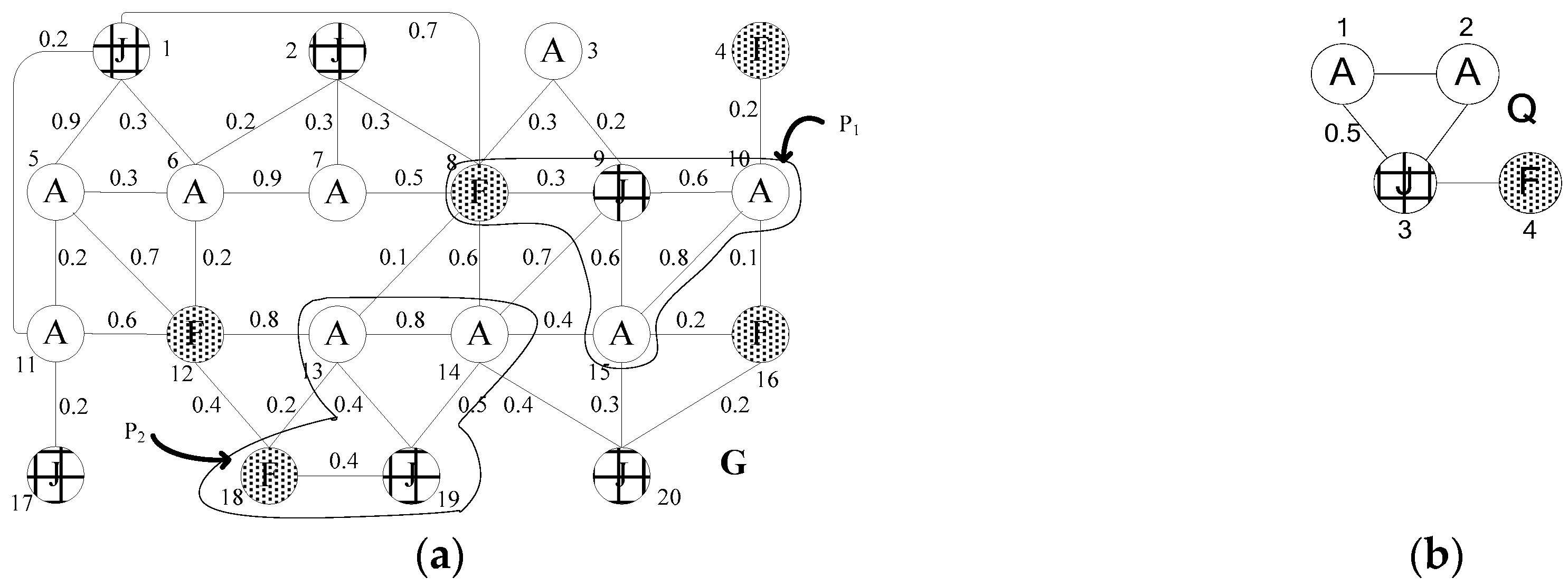
3. GTSF Index Construction
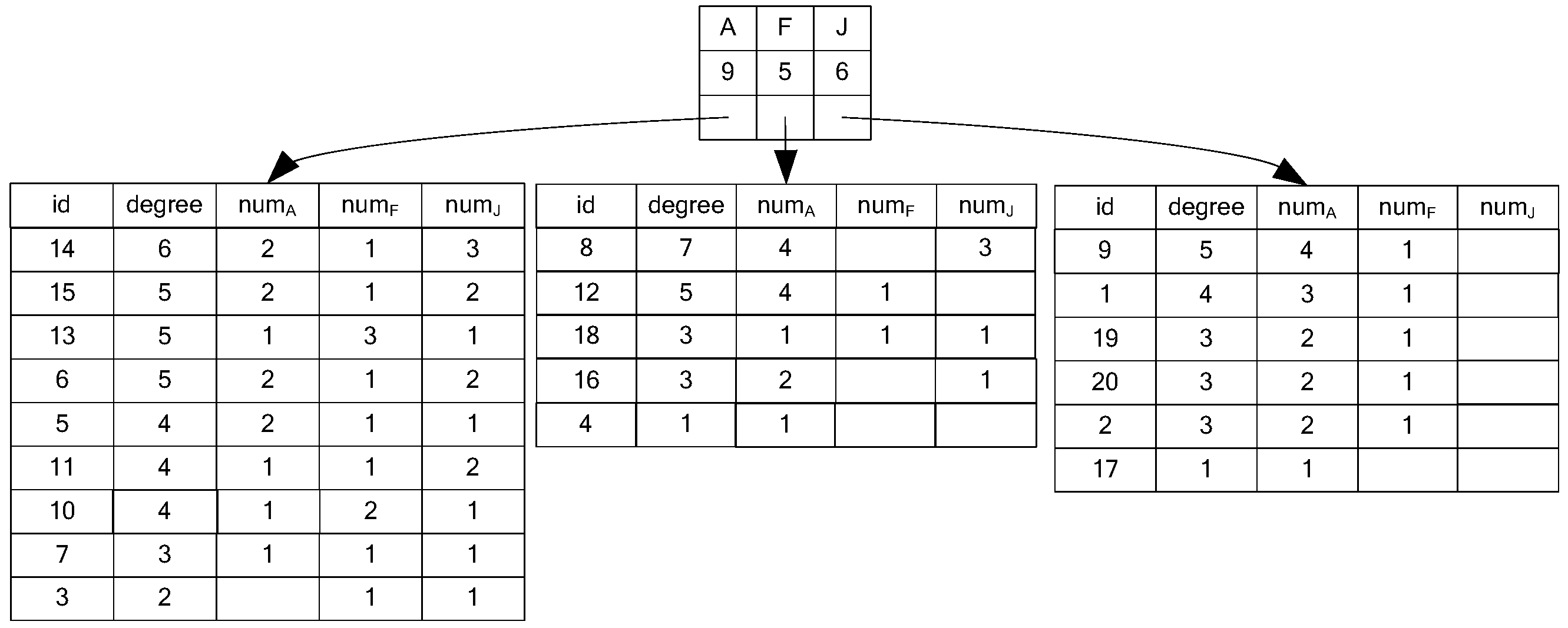
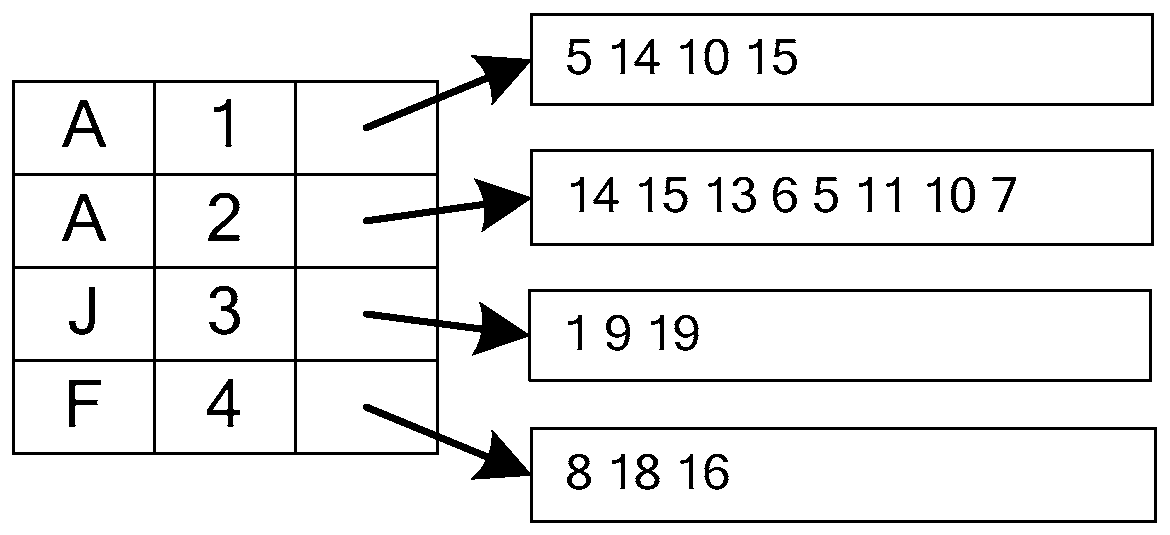
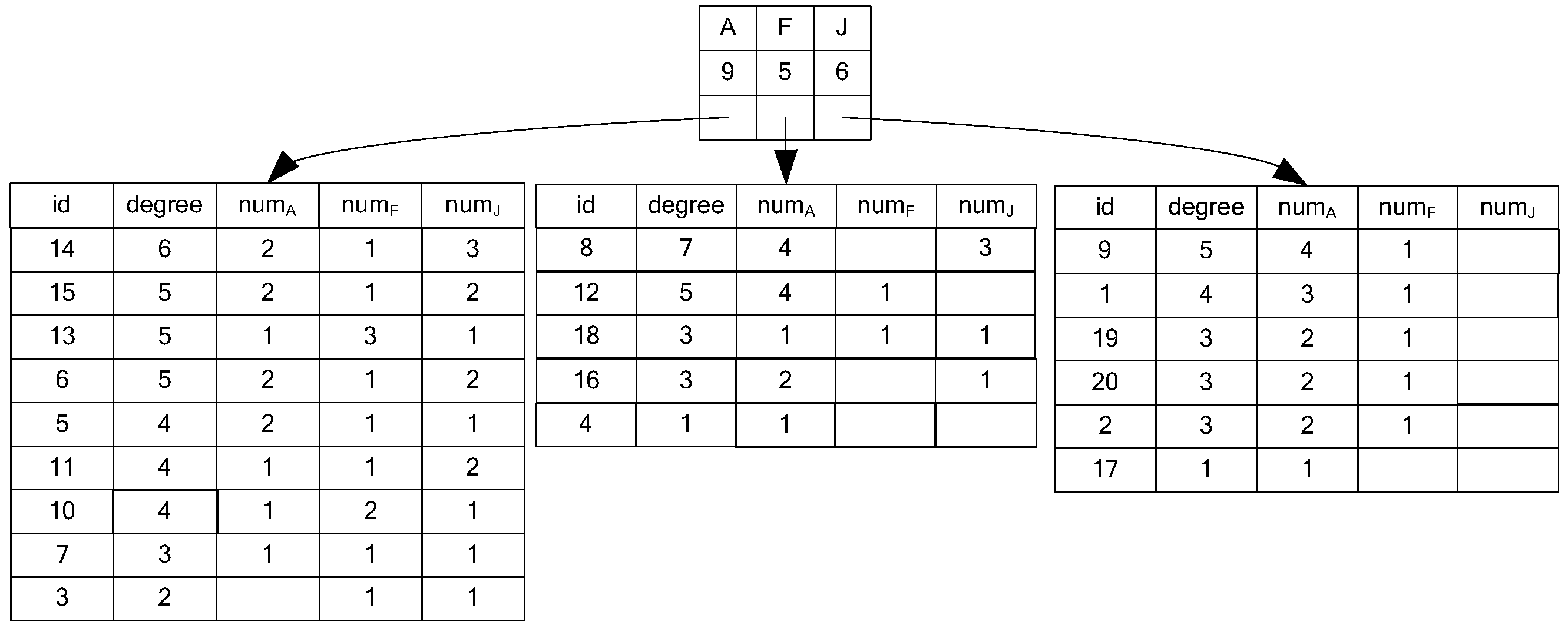
3.1. NTF Index
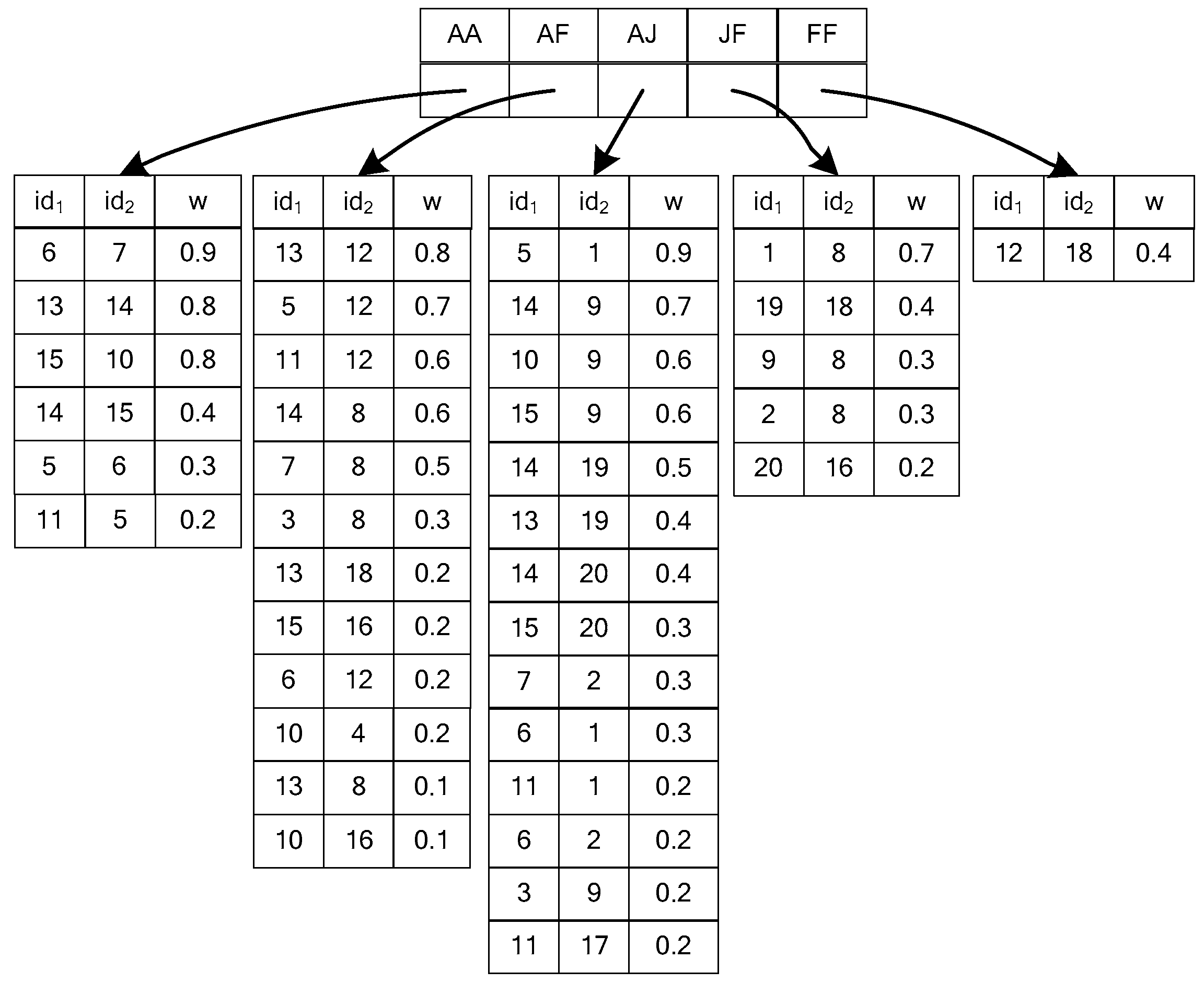
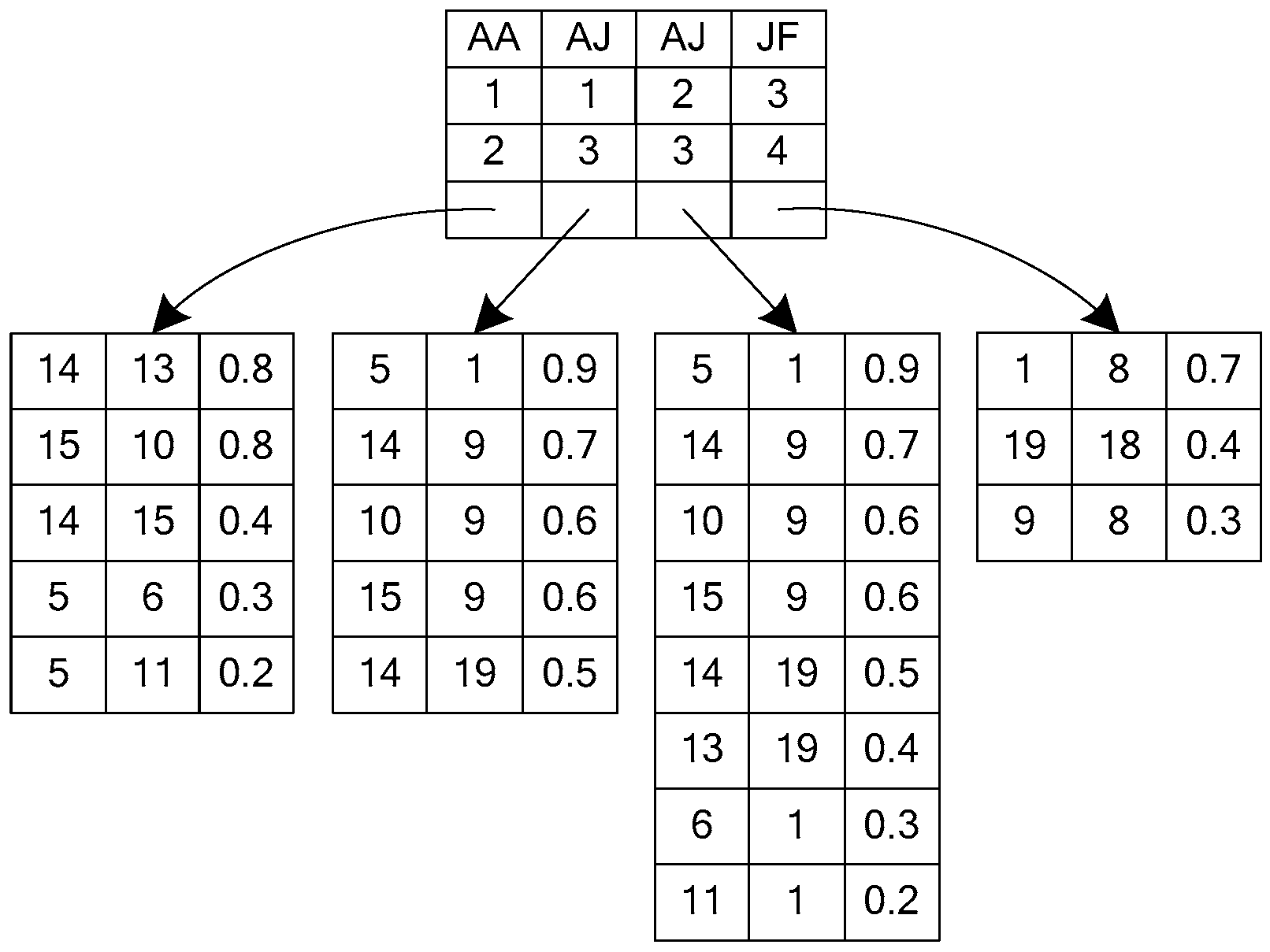
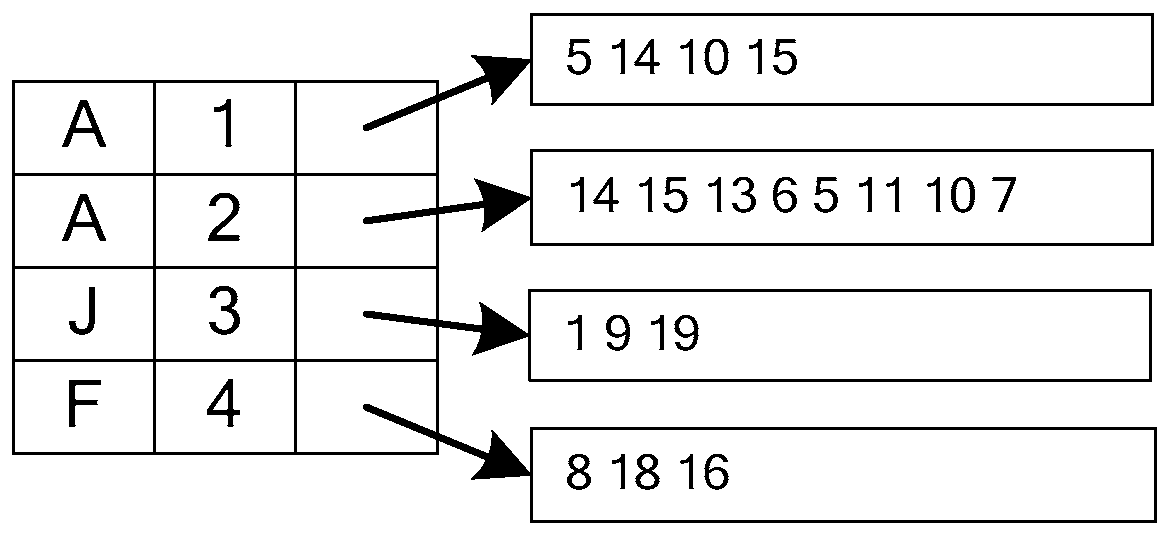
3.2. EF Index
4. Dynamic Top-K Interesting Subgraph Approximate Query based on The Sliding Window
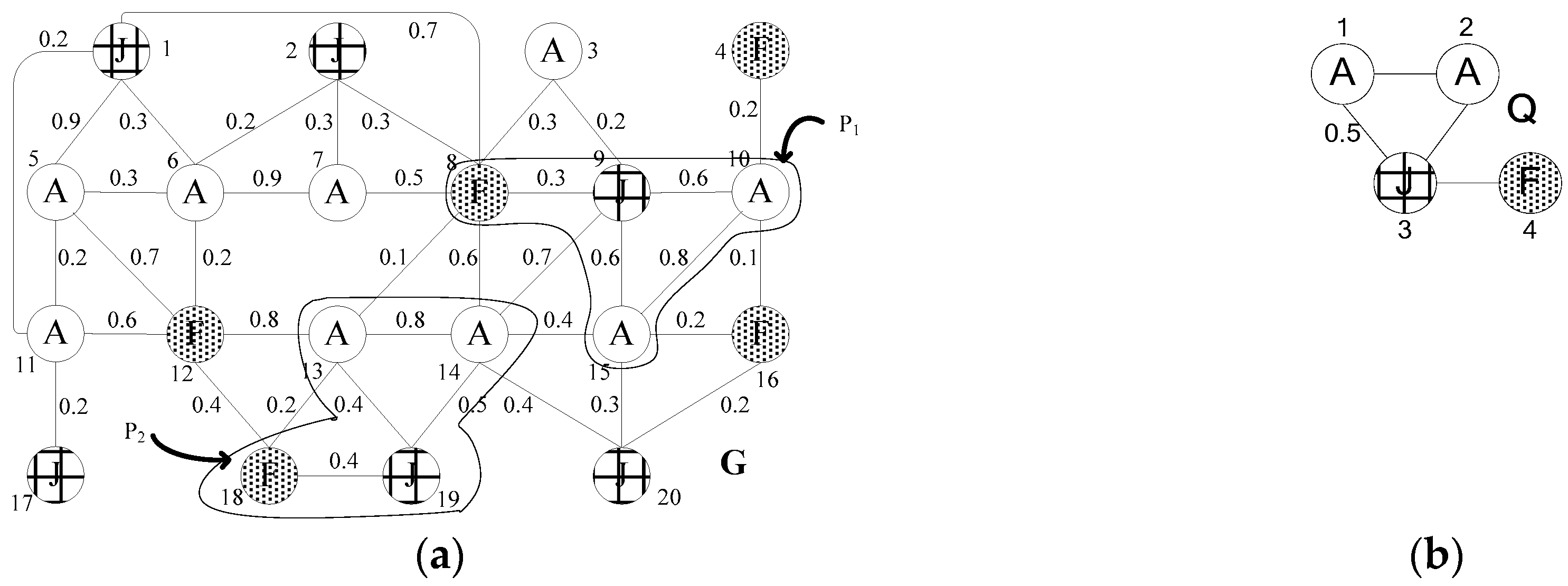
4.1. Multi-Factor Candidate Set Filtering Based on GTSF Index
4.1.1. Multi-factor Candidate Node Set Filtering
| Algorithm 1 CNFiltering algorithm |
| Input:node topology feature index TG, edge feature index EG, node topology feature index TQ, edge feature index EQ |
| Output:the candidate node set CN 1 CN=NULL; 2 for(traverse e in EQ) do /* Obtain the candidate node set CN of the query graph Q */ 3 if (w(e)!=0) /* Filter special nodes */ 4 CN←SNF (EG,e,CN); 5 CN←DF(TG,e,CN); 6 CN←ANLFF(TG,e,CN); 7 else /* Filter common nodes */ 8 CN←DF(TG,e,CN); 9 CN←ANLFF(TG,e,CN); 10 end for 11 Output C; |
4.1.2. Candidate Edge Set Filtering
| Algorithm 2 CEFiltering algorithm |
| Input:edge feature index EG, edge feature index EQ, the candidate node set CN |
| Output :the candidate edge set CE 1 CE=NULL; 2 for(traverse e in EQ) do /* Filter out invalid edges in the query graph Q by using the EF index and candidate node set CN */ 3 for (traverse in CN[e]) do 4 if (w( )<w(e)) 5 return false; 6 else 7 (v, u)←e′; 8 if (v CN || u CN) 9 return false; 10 else 11 return true; 12 output CE; |
4.2. Dynamic Top-K Interesting Subgraph Query
4.2.1. Sliding Window
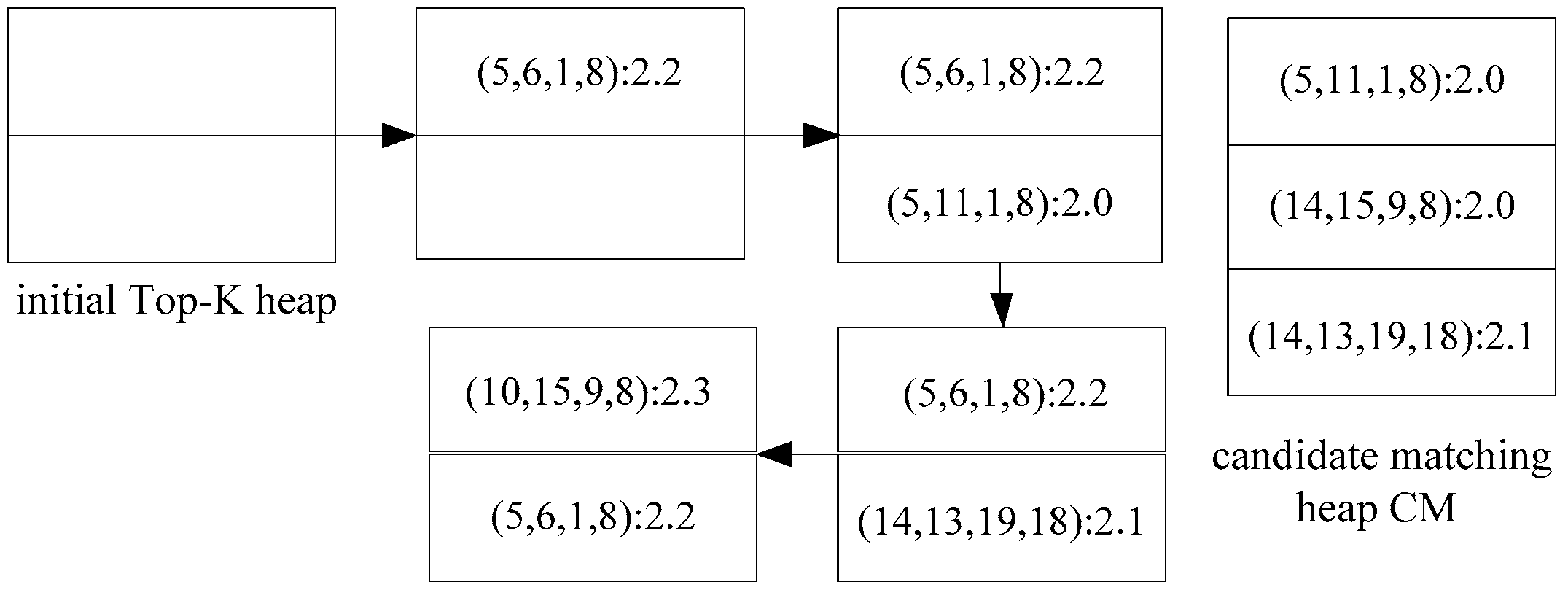
4.2.2. Top-K Interesting Subgraph Matching-validation
| Algorithm 3 FirstSubMatching algorithm |
| Input:edge feature index EQ, the candidate edge set CE, number of interest subgraph K |
| Output:Top-K interest subgraph F, the candidate matching heap CM 1 CM =NULL; F=NULL; 2 int CP, N =| EQ |,Top-K=K,O[|EQ|]; 3 O[0]←First(CE); /*to determine the initial edge (u,v)*/ 4 O[ ]←traverse EQ from CE; /* to determine the matching order of edges */ 5 for ((u,v)′ ← traverse CE[O[0]]) do /*to instantiate the query graph Q and get the initial Top-K heap */ 6 CP←Size-1((u,v)′); 7 if (US(Size-1)<I(Top-K.bottom)) 8 return false; 9 else 10 for (c = 2……N) do 11 (u,v)″← traverse O[c] in |CP|; 12 if ((u,v)″ != null) 13 (u,v)″← traverse|CP|; 14 CP←Size-c( ); 15 else return false; 16 end for 17 if (I(Size-n())<=I(Top-K.bottom)) 18 CM←Size-n(); 19 update(CM); 20 return false; 21 else 22 CM←Top-K.bottom; 23 update(CM); 24 Delete(Top-K.bottom); 25 Top-K ←Size-n(); 26 update(Top-K); 27 end for 28 F ← Top-K; 29 Output F, CM; |
- To collect the awaiting matching operation set W. When the size of the sliding window is Tw = nΔt and the query time interval is Tm = mΔt, the sliding window collects ECO once every Δt to form an ECOS. When the query time arrives each time, the awaiting matching operation set W will be formed by the ECOS that has not been updated to CE in the sliding window. That is, the awaiting matching operation set during Tm can be represented as WTm = {ECOS1, ECOS2, …, ECOSi, …, ECOSm} (ECOSi represents the edge change operation set within the ith Δt in Tm). If n < m, a buffer (Buffer) is allocated for each continuous query request, which is used to store ECOSfirst = {ECOS1, ECOS2, …, ECOS(m-n)} in first T1 = (m-n) Δt minutes during twice the query result of the time interval. When the next query time arrives, the ECOSfirst in Buffer is merged into WTm and the Buffer is cleared.
- To update the candidate edge set CE dynamically. Traversing WTm to determine the operate of each ECO. If it belongs to the delete type, then go to 3; if it belongs to the update type, then go to 4; else go to 5.
- The modification of the delete type record. First, the CM heap is retrieved. If the matching item in the CM heap includes the awaiting deleted edges, they are deleted. Second, the Top-K heap is retrieved. If there are corresponding records, their corresponding matching is directly deleted. The Top-K heap is filled with CM.bottom, and then the CM.bottom is removed until the Top-K heap is full. Go to 2.
- The modification of the update type record. Taking an example of DBLP, with the increase of cooperation between authors, their relationship becomes closer, or contact frequently. So, the edge weight between them is in slow growth. So, a record whose weight is not greater than the weight of the query edge in a certain time, it is likely to meet the condition at some future moment. To avoid inserting and deleting records in the CE frequently, the record of each candidate edge is set as a flag (flag). If the weight is less than the weight of the corresponding query edge, its flag is 0; else its flag is 1. The w0 is the weight of the corresponding query edge; w1 is the new weight of the update type record; w2 is the old weight of the new update type record. If the candidate edge set includes the edge to be updated, then ① When the flag of a record to be updated in the CE is 0: if w0 w1, the weight of this record is updated and its flag is set to 1, then go to 6; else it is not processed. ② When the flag is 1: if w1 ≥ w0, the weight of this record is updated, and the CE of the corresponding edge is reordered; and then the Top-K and CM heap are retrieved, if there is a corresponding record, the corresponding interesting score plus (w1-w2); finally, the Top-k and CM heap is repeatedly updated to ensure INT (CM.bottom) INT (Top-K.bottom), and if INT (CM.bottom) > INT (Top-K.bottom), CM.bottom, and Top-K.bottom is exchanged. Else the weight of this record is updated, and its flag is set to 0, and then the update record is then processed according to the processing method of the deletion record in 3. Go to 2.
- The modification of the insert type record. For an edge to be inserted, if there is a query edge whose type is the same as it, the insert record is inserted the candidate set of the corresponding query edge is based on its weight. If its weight is less than the weight of the corresponding query edge, the flag of this insert record is set to 0, else the flag is set to 1. Then go to 6. However, if there is not a query edge whose type is the same as its type, the insert operation is not performed, go to 2 directly.
- To determine the matching-verification order of edges. The edge of the weight change or the new insert edge is used as the initial edge. Starting from the initial edge, the breadth-first traversal is implemented according to the label of edges to obtain the matching-verification order of edges.
- Size-c matching: According to the matching-verification order of edges, Size-c (c = 1, …, n, n is the edge number of the query graph Q). In the matching process, if the flag of the record is 0, this record does not participate in matching. Size-n is the final matching subgraph.Size-c matching: According to the matching-verification order of edges, Size-c (c = 1, …n, n is the edge number of the query graph Q). In the matching process, if the flag of the record is 0, this record does not participate in matching. Size-n is the final matching subgraph.
5. Dynamic Maintenance of the GTSF Index
5.1. ECOS Optimization
5.2. Incremental Update Based on Optimized ECOS
- The update of the insert record. When an edge (u, v) is inserted, the topological structure information of the two endpoints u and v will change. The degree of two nodes is added 1, and the v/u type adjacency node number of the u/v node is added 1. First, the NTF index is retrieved, and the topological structure information of the u and v is modified. If there is no u or v in the NTF index, the u or v is inserted in the NTF index as the newly inserted node. Second, the EF index is retrieved, and then (u, v) is inserted to the EF index table according to the type and weight of (u, v).
- The update of the delete record. When an edge (u, v) is deleted, the degrees of two nodes and the v/u type adjacency node number of the u/v node are subtracted 1. The NTF index is retrieved, and the topological structure information of the u and v is modified. And then the EF index is retrieved, and the corresponding item of the edge (u, v) is deleted.
- The update of the update record. Because the topological structure information of the graph node is not changed when the weight of an edge is changed, the NTF index does not need to be updated. That is, only the EF index needs to be retrieved and then the weight item of the changed edge is modified.
| Algorithm 4 DISQtop-k algorithm |
| Input:date graph G, query graph Q, number of interest subgraph K, total query time Tt, interval time T to initialize the Top-K heap, query interval time Tm, run time t Output :Top-K interest subgraph F 1 F=NULL; 2 The3-12 linesare executed circularly and the cycle time isTt; /*to execute query during total query time Tt */ 3 The 4-12 lines are executed circularly and the cycle time T; /*to initialize the Top-K heap at n times of T and n is non-negative integer */ 4 The NTF and EF indexes were established offline according to data graph G : TG and EG; 5 The NTF and EF indexes were established online according to query graph Q:TQ and EQ; 6 CN ←CNFiltering(TG,EG,TQ,EQ); /*to gain the candidate node set CN by the CNFiltering algorithm */ 7 CE ←CEFiltering(CN,EG,EQ); /*to gain the candidate edge set CE by the CEFiltering algorithm */ 8 F, CM←FirstSubMatching (EQ ,CE,K); /*to gain the Top-K interest subgraph F and the candidate matching heap CM by the FirstSubMatching algorithm */ 9 If t % Tm == 0 10 ECOS←ECOS-OS(ECOS); /*to gain the optimized ECOS by the ECOS-OS strategy */ 11 TG, EG←IDM (EQ ,CE,K, ECOS); /*to incrementally update TG and EG of data graph G based on the IDM strategy and the optimized ECOS */ 12 end If 13 F, CM, CE←DynSubMatching (EQ,CE,K,F,CM,Tm); 14 Output F; |
6. Experiments
6.1. Experimental Environment and Datasets
6.2. Experimental Analysis
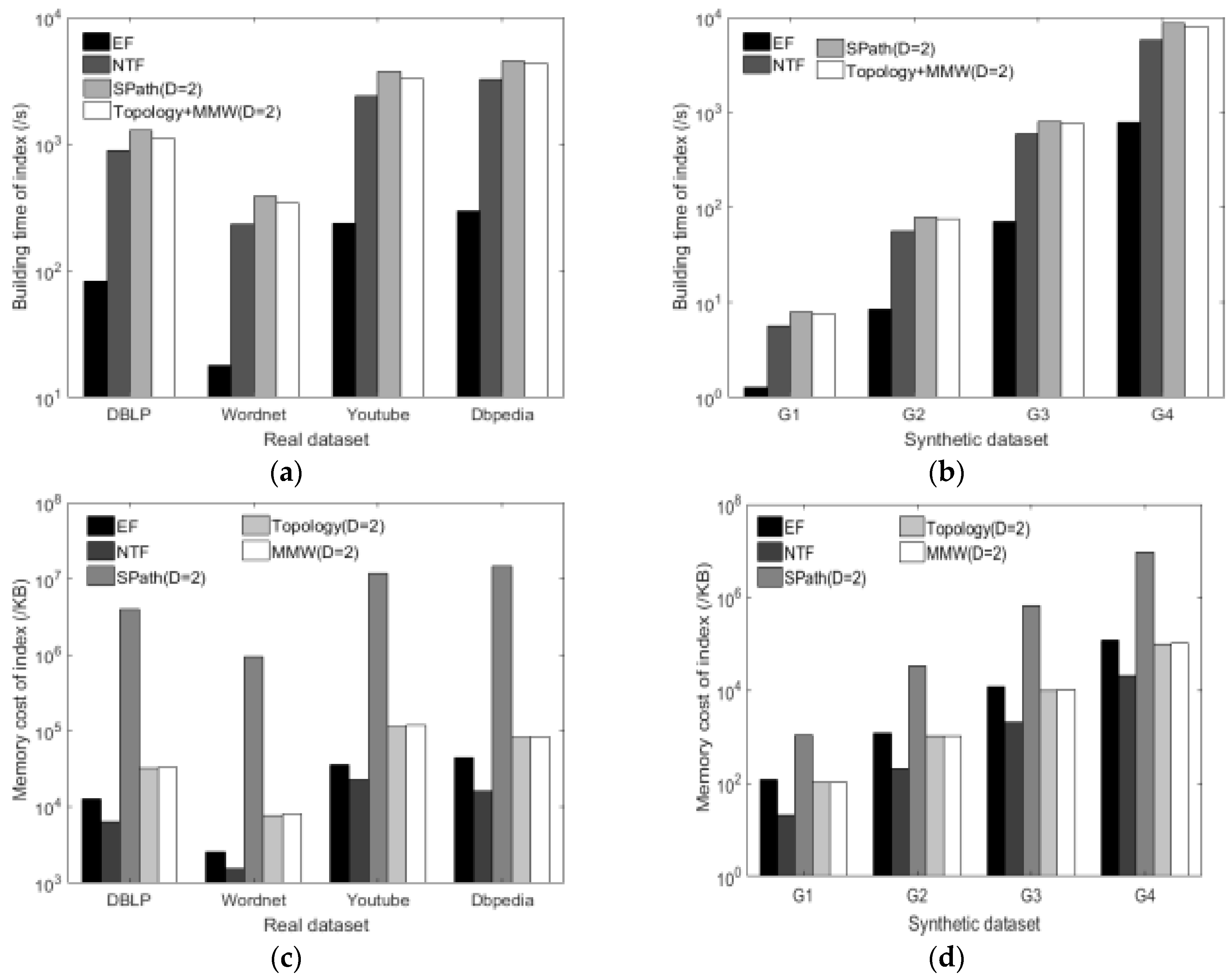
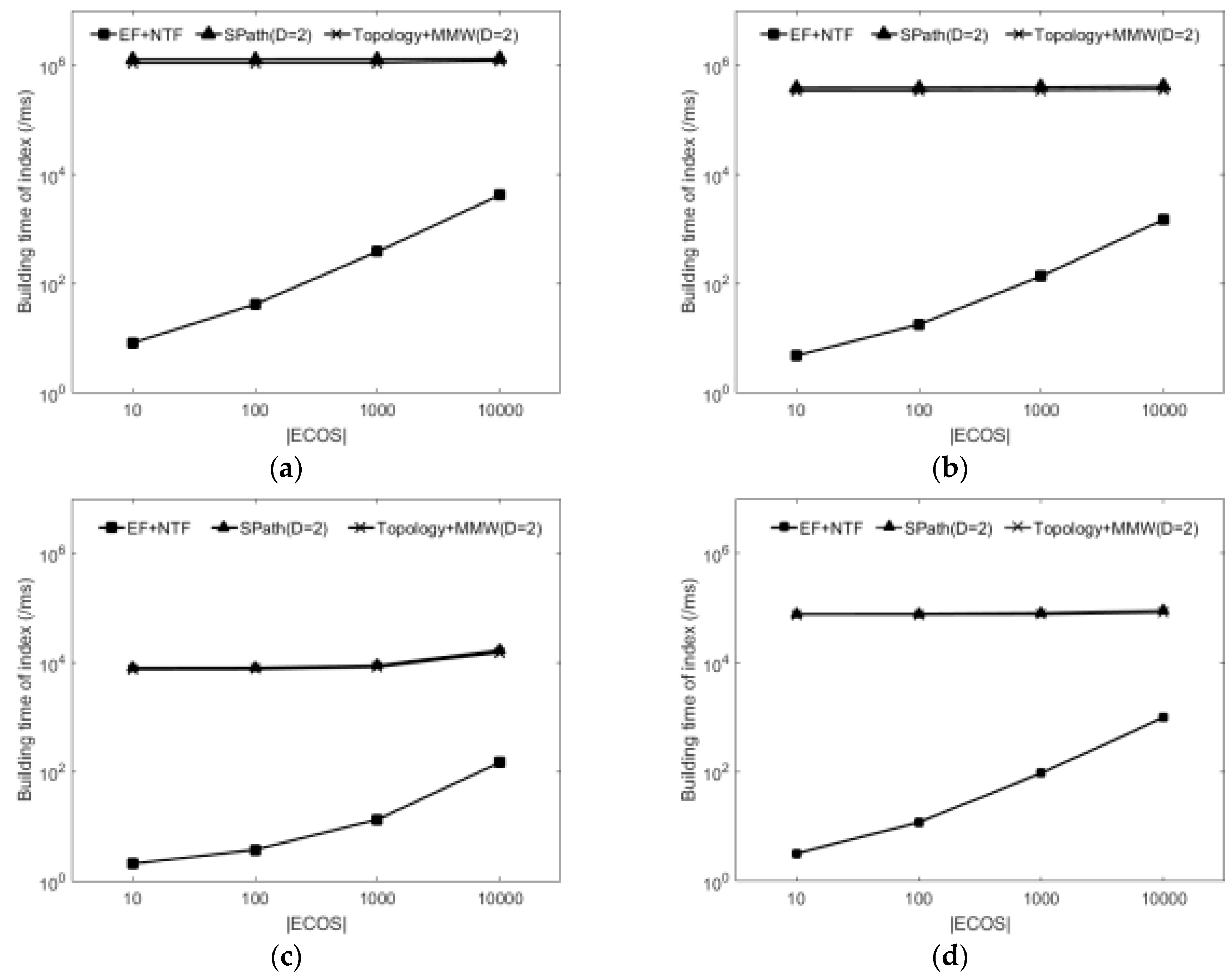
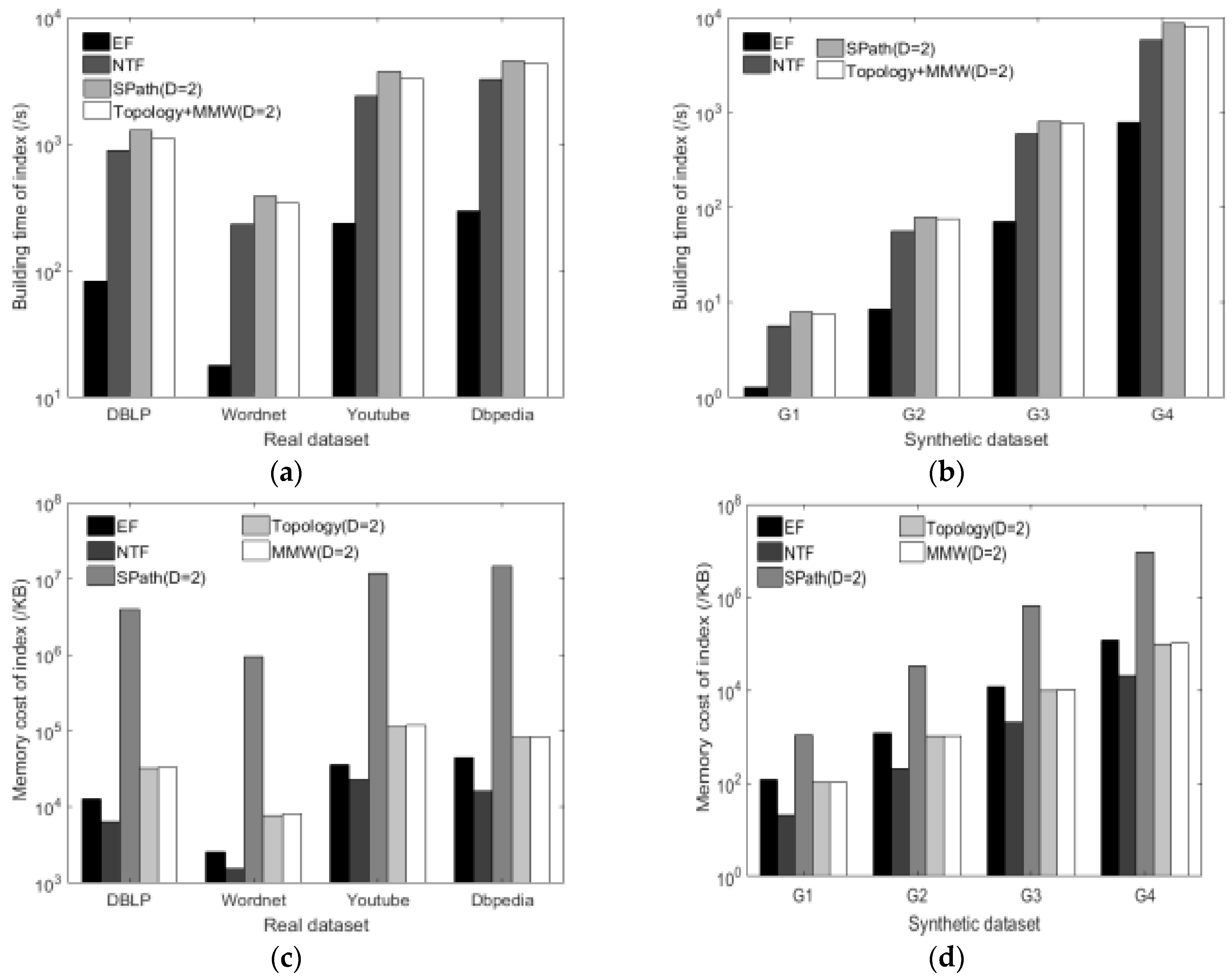
6.2.1. Construction Time and Memory Cost of Index
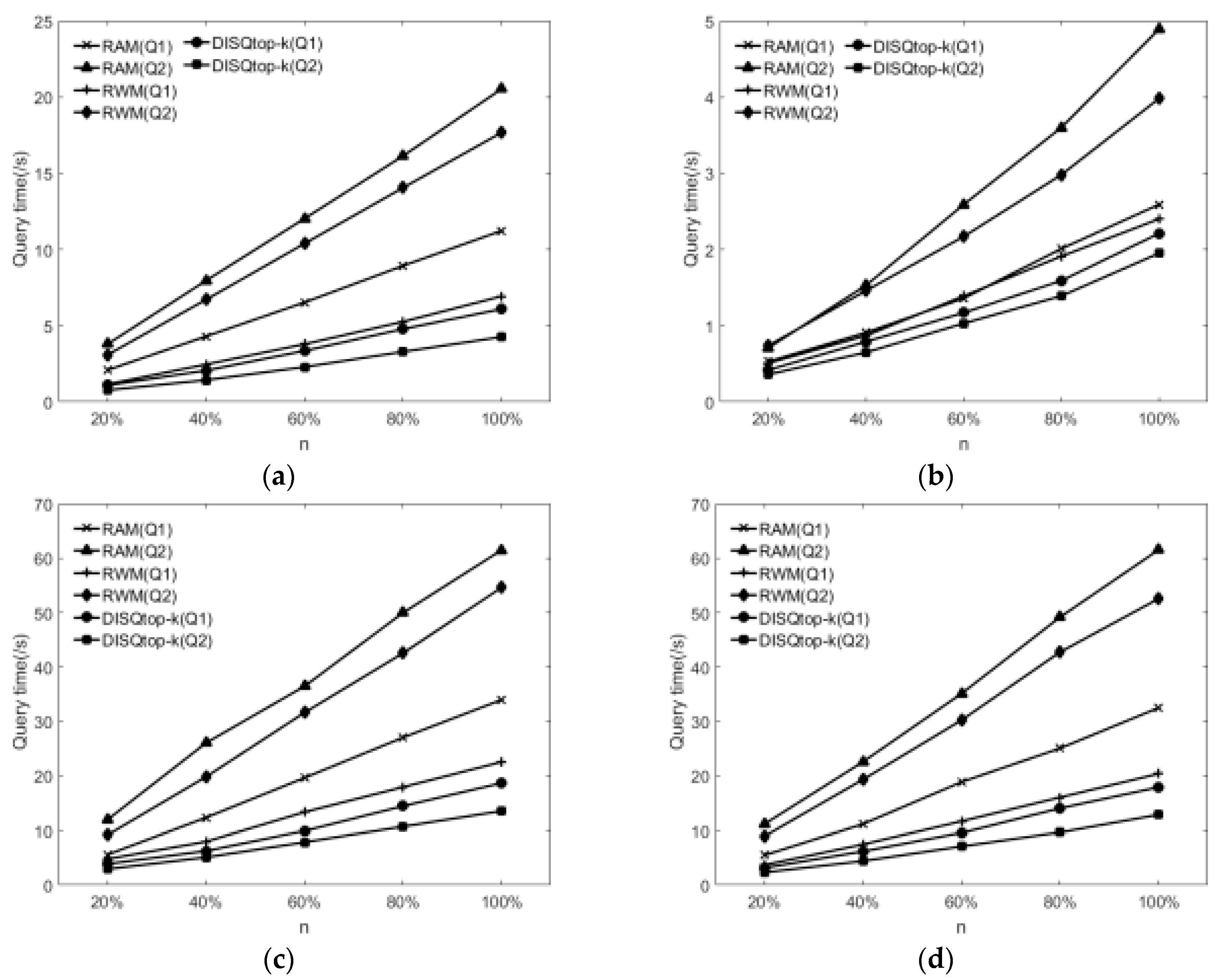
6.2.2. Interesting Subgraph Query Efficiency Evaluation
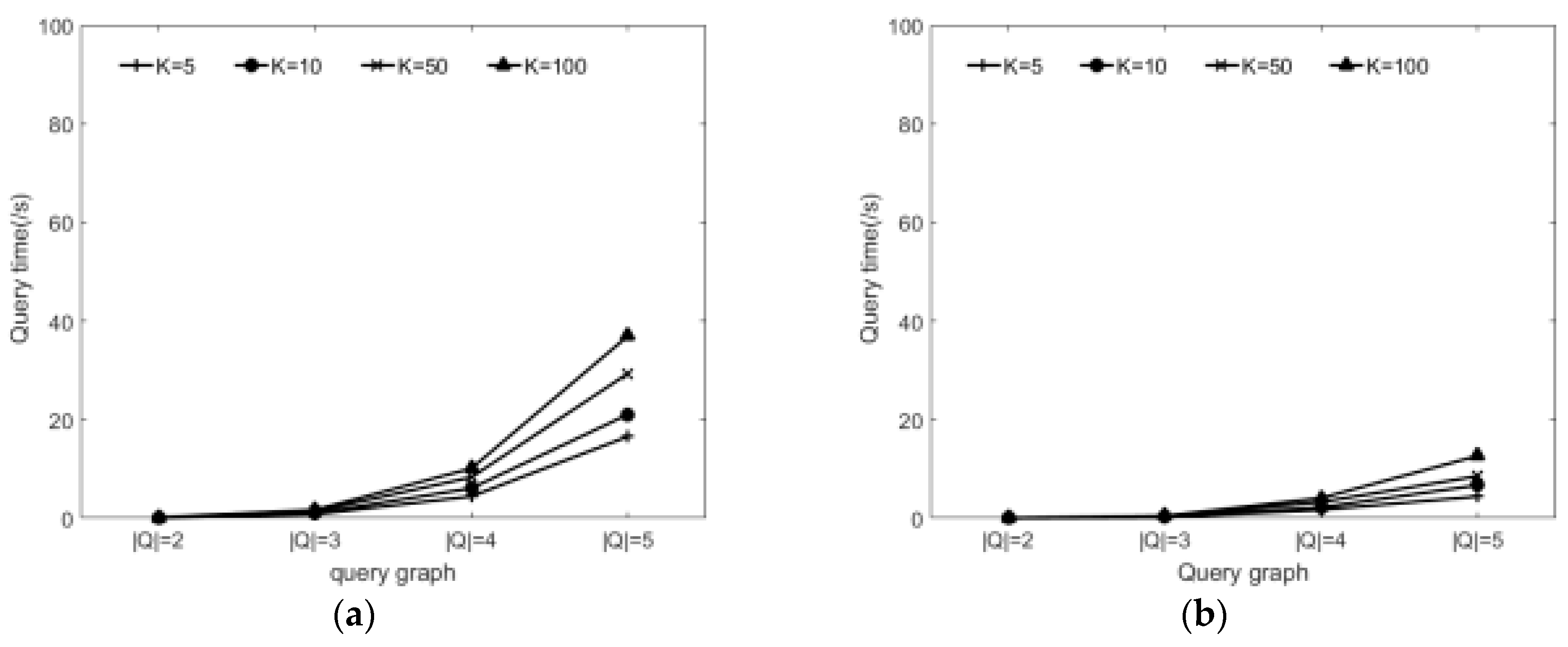
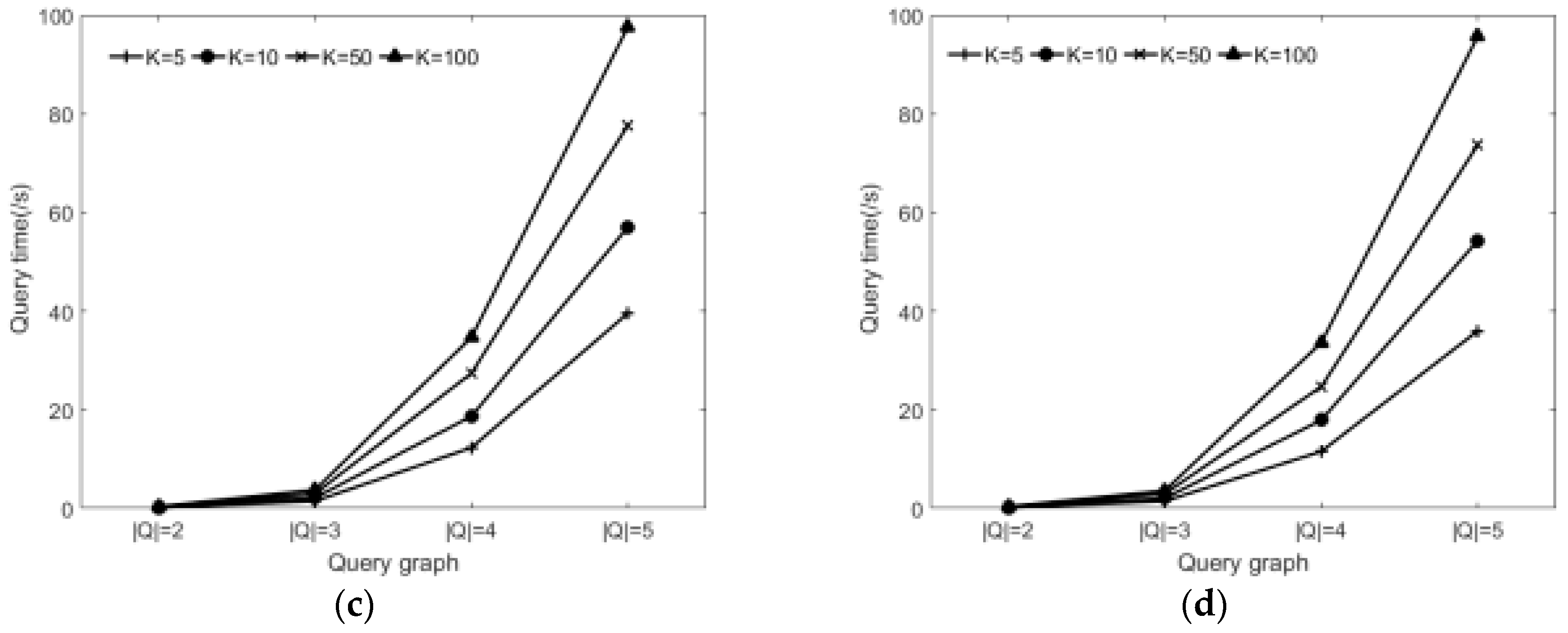
6.2.3. Effect of Varying Query Graph and the K
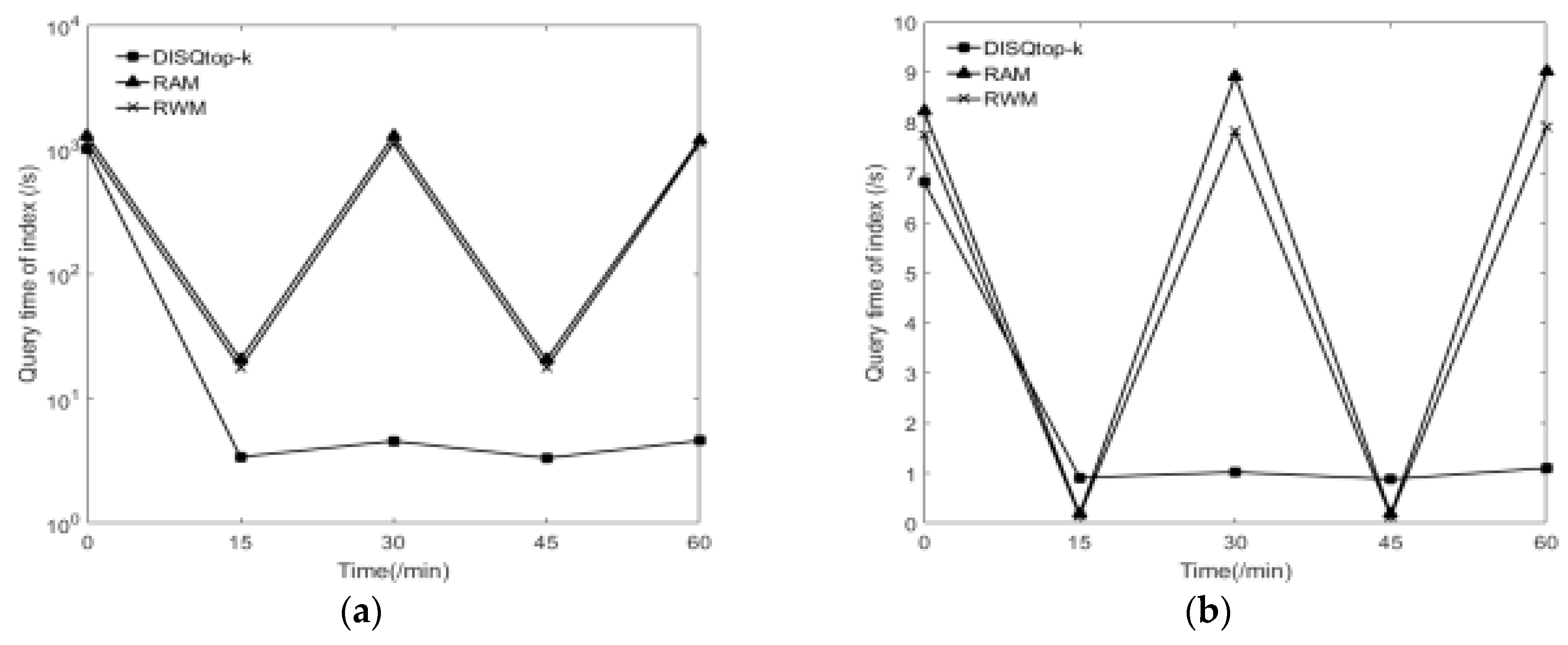
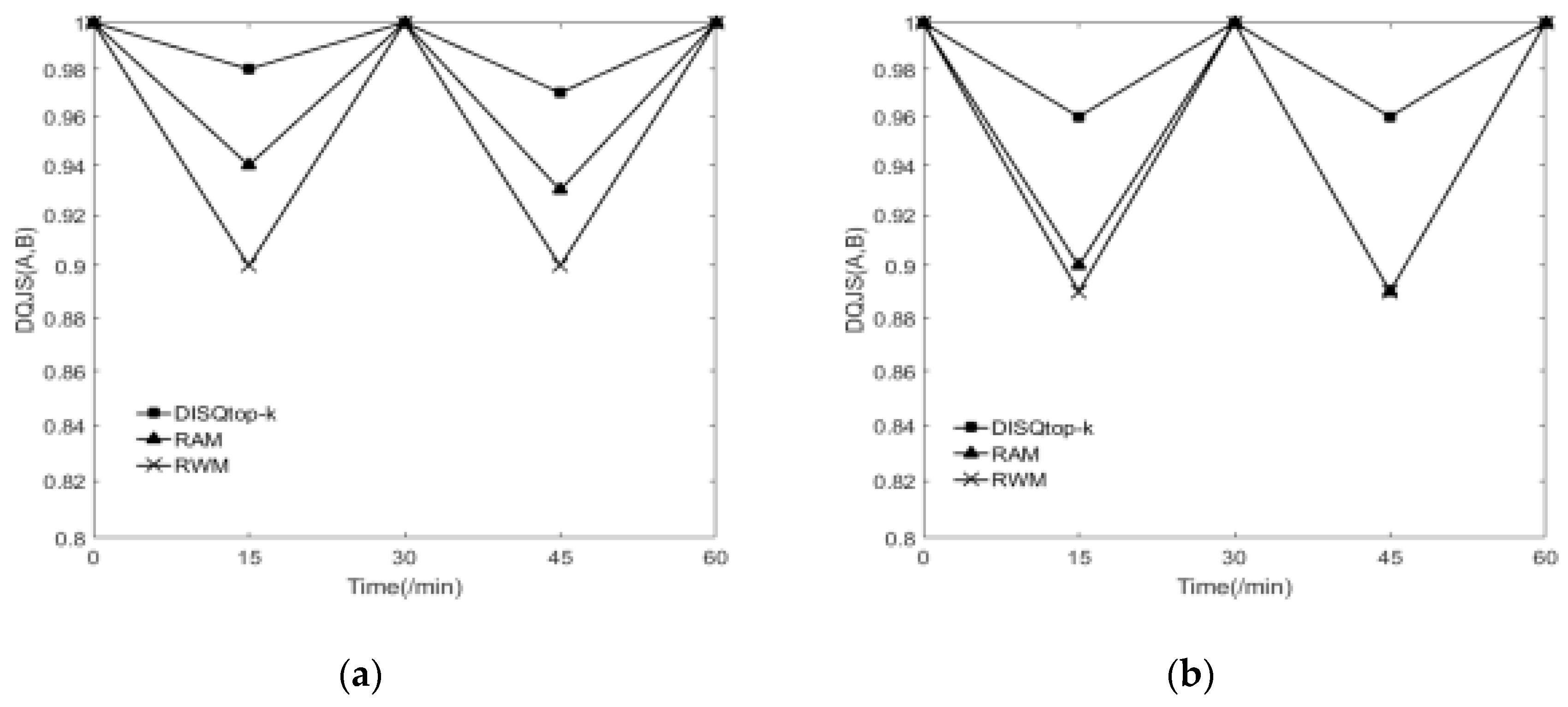
6.2.4. Effect of Dynamic Update and Query
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Sonmez, A.B.; Can, T. Comparison of tissue/disease specific integrated networks using directed graphlet signatures. Bmc Bioinf. 2017, 18, 135. [Google Scholar] [CrossRef] [PubMed]
- Li, X.J.; Yang, G.H. Graph Theory-Based Pinning Synchronization of Stochastic Complex Dynamical Networks. IEEE Trans. Neural Netw. Learn Syst. 2017, 28, 427–437. [Google Scholar] [CrossRef] [PubMed]
- Ma, S.; Li, J.; Hu, C.; Lin, X.; Huai, J. Big Graph Search: Challenges and Techniques. Front. Comput. Sci. 2016, 10, 387–398. [Google Scholar] [CrossRef]
- Wu, B.; Shen, H. Exploiting Efficient Densest Subgraph Discovering Methods for Big Data. IEEE Trans. Big Data. 2017, 3, 334–348. [Google Scholar] [CrossRef]
- Zhang, H.W.; Xie, X.F.; Duan, Y.Y.; Wen, Y.L. An algorithm for subgraph matching based on adaptive structural summary of labeled directed graph data. Chin. J. Comput. 2017, 40, 52–71. [Google Scholar] [CrossRef]
- Lee, J.; Han, W.S.; Kasperovics, R.; Lee, J.H. An in-depth comparison of subgraph isomorphism algorithms in graph databases. Proc. VLDB Endowment 2012, 6, 133–144. [Google Scholar] [CrossRef]
- Kim, J.; Shin, H.; Han, W.S.; Hong, S. Taming Subgraph Isomorphism for RDF Query Processing. Proc. VLDB Endowment 2015, 8, 1238–1249. [Google Scholar] [CrossRef]
- Shang, H.C.; Zhang, Y.; Lin, X.M.; Yu, J.X. Taming verification hardness: An efficient algorithm for testing subgraph isomorphism. Proc. VLDB Endowment 2008, 1, 364–375. [Google Scholar] [CrossRef]
- Yan, X.; He, B.; Zhu, F.; Han, J. Top-K aggregation queries over large networks. In Proceedings of the IEEE International Conference on Data Engineering, California, CA, USA, 1–6 March 2010; pp. 377–380. [Google Scholar] [CrossRef]
- Gupta, M.; Gao, J.; Yan, X.; Cam, H. Top-K interesting subgraph discovery in information networks. In Proceedings of the International Conference on Data Engineering, Chicago, IL, USA, 31 March–4 April 2014; pp. 820–831. [Google Scholar] [CrossRef]
- Fan, W.; Wang, X.; Wu, Y. Diversified top-k graph pattern matching. Proc. VLDB Endowment 2013, 6, 1510–1521. [Google Scholar] [CrossRef]
- Ju, W.; Li, J.; Yu, W.; Zhang, R. iGraph: An incremental data processing system for dynamic graph. Front. Comput. Sci. 2016, 10, 462–476. [Google Scholar] [CrossRef]
- Zhang, L.; Lin, J.; Karim, R. Sliding Window-Based Fault Detection From High-Dimensional Data Streams. IEEE Trans. Syst. Man Cybern. Syst. 2017, 47, 289–303. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, Y.; Zhang, W.; Lin, X. Skype: Top-k spatial-keyword publish/subscribe over sliding window. Proc. VLDB Endowment 2016, 9, 1–26. [Google Scholar] [CrossRef]
- Ullmann, J.R. An Algorithm for Subgraph Isomorphism. J. ACM 1976, 23, 31–42. [Google Scholar] [CrossRef]
- Cordella, L.P.; Foggia, P.; Sansone, C.; Vento, M. A (sub)graph isomorphism algorithm for matching large graphs. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1367–1372. [Google Scholar] [CrossRef] [PubMed]
- Sun, Z.; Wang, H.; Wang, H.; Shao, B.; Li, J. Efficient subgraph matching on billion node graphs. Proc. VLDB Endowment 2012, 5, 788–799. [Google Scholar] [CrossRef]
- Han, W.S.; Lee, J.; Lee, J.H. TurboISO: Towards ultrafast and robust subgraph isomorphism search in large graph databases. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22–27 June 2013; pp. 337–348. [Google Scholar] [CrossRef]
- Ren, X.; Wang, J. Exploiting Vertex Relationships in Speeding up Subgraph Isomorphism over Large Graphs. Proc. VLDB Endowment 2015, 8, 617–628. [Google Scholar] [CrossRef]
- Bi, F.; Chang, L.; Lin, X.; Qin, L.; Zhang, W. Efficient Subgraph Matching by Postponing Cartesian Products. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; pp. 1199–1214. [Google Scholar] [CrossRef]
- Holder, L.B.; Cook, D.J.; Djoko, S. Substructure discovery in the SUBDUE system. In Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 31 July–1 August 1994; pp. 169–180. [Google Scholar]
- Zhu, F.D.; Qu, Q.; Lo, D.; Yan, X.; Han, J.; Yu, P.S. Mining Top-K large structural patterns in a massive network. Proc. VLDB Endowment 2011, 4, 807–818. [Google Scholar]
- Zhao, P.X.; Han, J.W. On graph query optimization in large networks. Proc. VLDB Endowment 2010, 3, 340–351. [Google Scholar] [CrossRef]
- He, H.; Singh, A.K. Query language and access methods for graph databases. In Proceedings of the Acm Sigmod International Conference on Management of Data, Indianapolis, IN, USA, 6–11 June 2010; pp. 125–160. [Google Scholar] [CrossRef]
- Pietracaprina, A.; Riondato, M.; Upfla, E.; Vandin, F. Mining top-k frequent itemsets through progressive sampling. Data Min. Knowl. Discovery 2010, 21, 310–326. [Google Scholar] [CrossRef]
- Wu, C.W.; Shie, B.E.; Tseng, V.S.; Yu, P.S. Mining top-k high utility itemsets. In Proceedings of the 18th ACM International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 78–86. [Google Scholar] [CrossRef]
- Yang, Z.; Fu, W.C.; Liu, R. Diversified Top-k Subgraph Querying in a Large Graph. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; pp. 1167–1182. [Google Scholar] [CrossRef]
- Wang, L.; Han, J.; Chen, H.; Lu, J. Top-k probabilistic prevalent co-location mining in spatially uncertain data sets. Front. Comput. Sci. 2016, 10, 488–503. [Google Scholar] [CrossRef]
- Zhang, X.; Meng, X. Discovering top-k patterns with differential privacy-an accurate approach. Front. Comput. Sci. 2014, 8, 816–827. [Google Scholar] [CrossRef]
- Sha, C.; Wang, K.; Zhang, D.; Wang, X.; Zhou, A. Optimizing top-k retrieval: submodularity analysis and search strategies. Front. Comput. Sci. 2016, 10, 477–487. [Google Scholar] [CrossRef]
- Xu, J.; Zhang, Q.Z.; Zhao, X.; Lu, P.; Li, T.S. Survey on Dynamic Graph Pattern Matching Technologies. J. Softw. 2018, 29, 663–688. [Google Scholar] [CrossRef]
- Wang, S.P.; Wen, Y.Y.; Zhao, H.; Meng, Y.H. An Incremental Processing Algorithm about Disjoint Query Based on Sliding Window over Data Stream. Chin. J. Comput. 2017, 40, 2381–2403. [Google Scholar] [CrossRef]
- Wang, W.P.; Li, J.Z.; Zhang, D.D.; Guo, L.J. Sliding Window Based Method for Processing Continuous J-A Queries on Data Streams. J. Softw. 2006, 17, 740–749. [Google Scholar] [CrossRef]
- Khan, A.; Wu, Y.; Aggarwal, C.C.; Yan, X. NeMa: Fast graph search with label similarity. In Proceedings of the International Conference on Very Large Data Bases, Riva del Garda, Italy, 26–30 August 2013; pp. 181–192. [Google Scholar] [CrossRef]
- Sun, Y.Z.; Yu, Y.T.; Han, J.W. Ranking-Based clustering of heterogeneous information networks with star network schema. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 29 June–2 July 2009; pp. 797–806. [Google Scholar] [CrossRef]
- Chakrabarti, D.; Zhan, Y.; Faloutsos, C. R-MAT: A recursive model for graph mining. In Proceedings of the Fourth SIAM International Conference on Data Mining, Lake Buena Vista, FL, USA, 22–24 April 2004; pp. 442–446. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset(G) | |V| | |E| | Avg.degree |
|---|---|---|---|
| Youtube | 1.14M | 2.99M | 5.26 |
| DBLP | 317080 | 1.05M | 6.62 |
| Wordnet | 76854 | 213308 | 5.55 |
| Dbpedia | 809597 | 3.72M | 9.19 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shan, X.; Jia, C.; Ding, L.; Ding, X.; Song, B. Dynamic Top-K Interesting Subgraph Query on Large-Scale Labeled Graphs. Information 2019, 10, 61. https://doi.org/10.3390/info10020061
Shan X, Jia C, Ding L, Ding X, Song B. Dynamic Top-K Interesting Subgraph Query on Large-Scale Labeled Graphs. Information. 2019; 10(2):61. https://doi.org/10.3390/info10020061
Chicago/Turabian StyleShan, Xiaohuan, Chunjie Jia, Linlin Ding, Xingyan Ding, and Baoyan Song. 2019. "Dynamic Top-K Interesting Subgraph Query on Large-Scale Labeled Graphs" Information 10, no. 2: 61. https://doi.org/10.3390/info10020061
APA StyleShan, X., Jia, C., Ding, L., Ding, X., & Song, B. (2019). Dynamic Top-K Interesting Subgraph Query on Large-Scale Labeled Graphs. Information, 10(2), 61. https://doi.org/10.3390/info10020061