Credit Scoring Using Machine Learning by Combing Social Network Information: Evidence from Peer-to-Peer Lending

Abstract
1. Introduction
2. Literature Review
3. Hypothesis Development
4. Empirical Study
4.1. Data and Variables
4.2. Statistical Significance of Social Network Information
4.3. Default Prediction Models
4.3.1. Random Forest
4.3.2. AdaBoost
4.3.3. LightGBM
| Algorithm 1. Gradient boosting decision tree algorithm procedure. |
| Input: N samples: {xi, yi}, K, L, … |
| Initialize f0 |
| for k = 1 to K: |
| , i = 1, 2, …, N |
| fk = ρ∗fk, Fk = Fk−1 + fk |
| Output: Fk |
4.3.4. Parameter Selection
4.4. Results
4.4.1. Default Prediction Models and Discussion
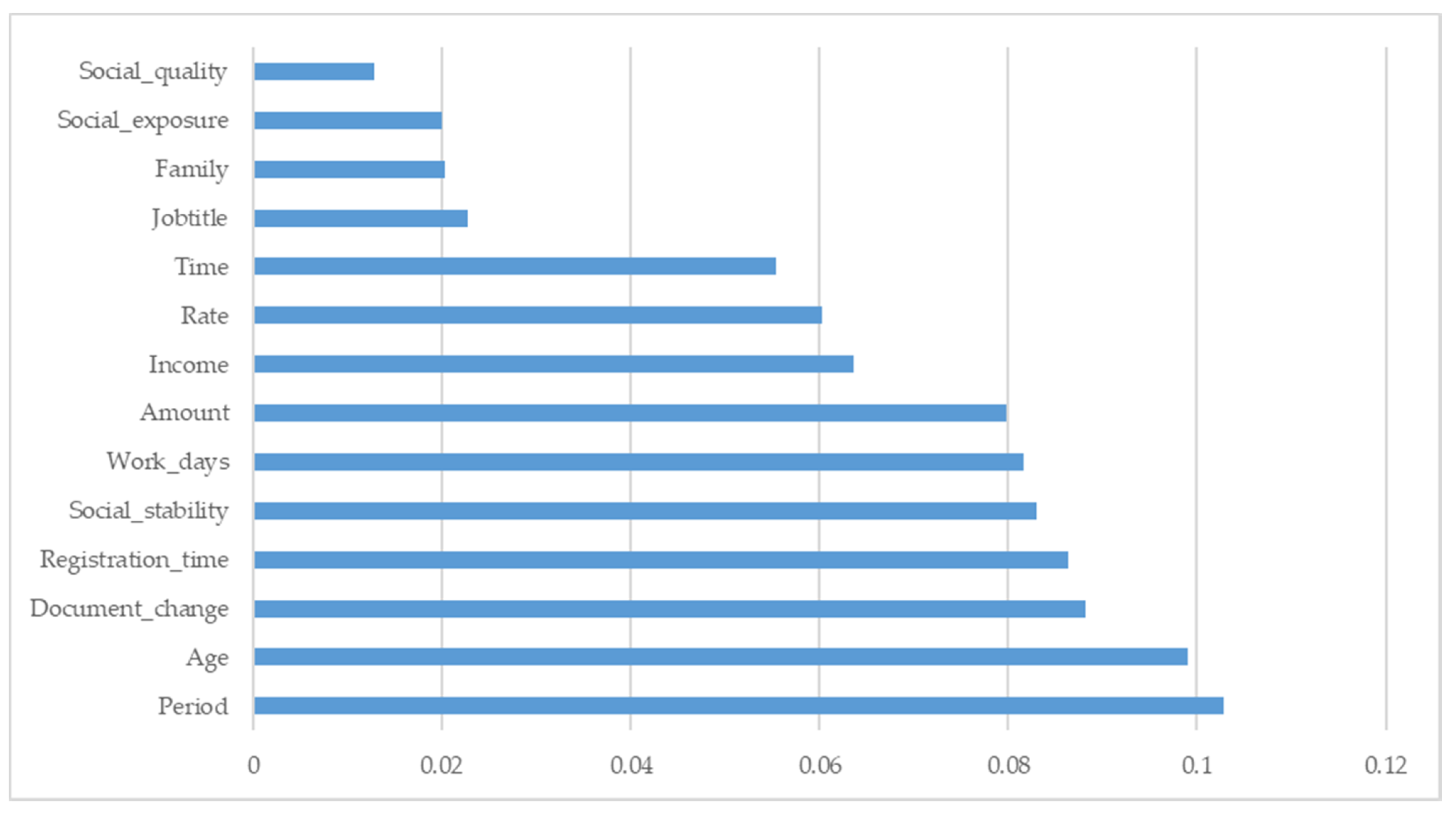
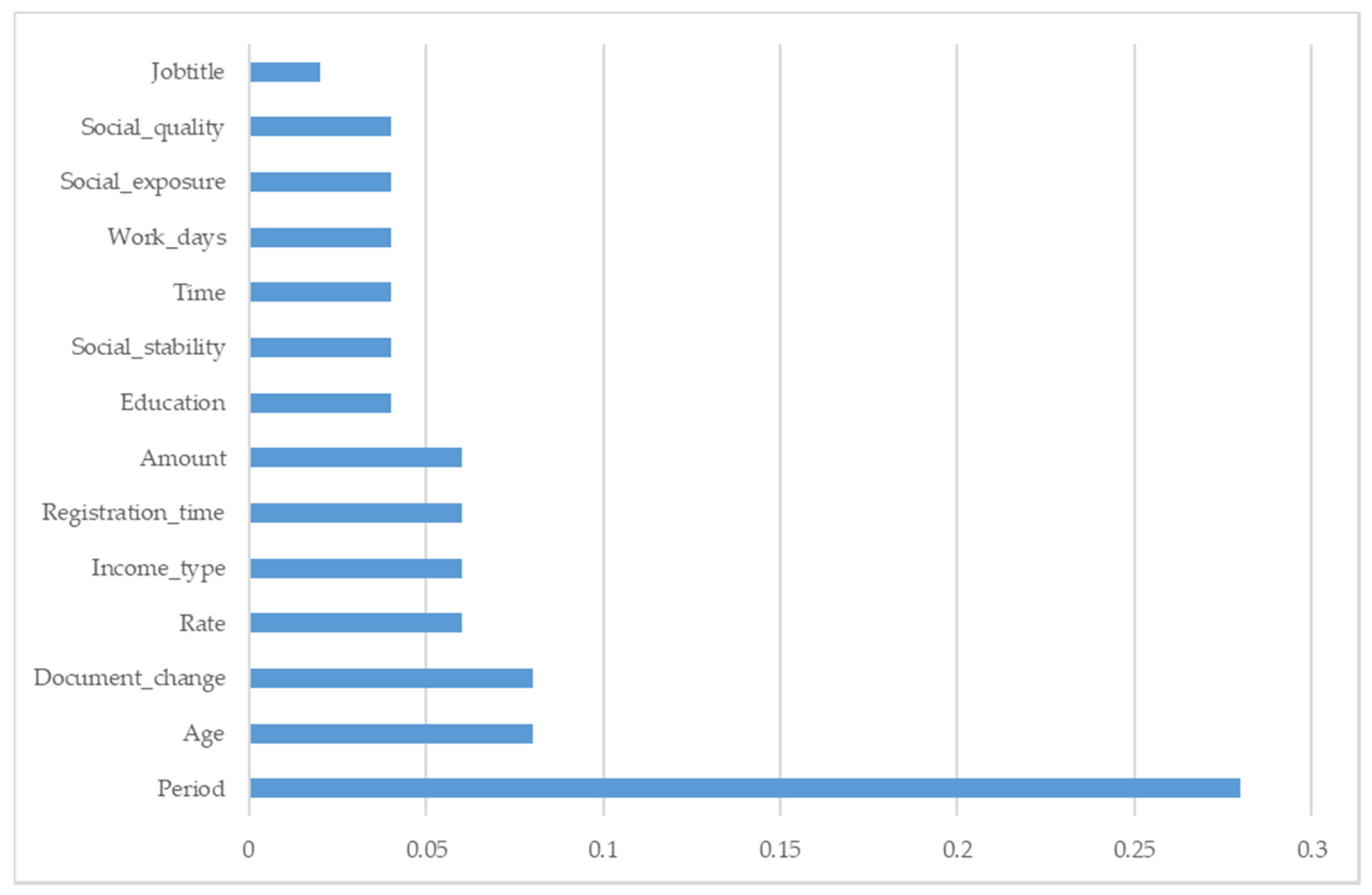
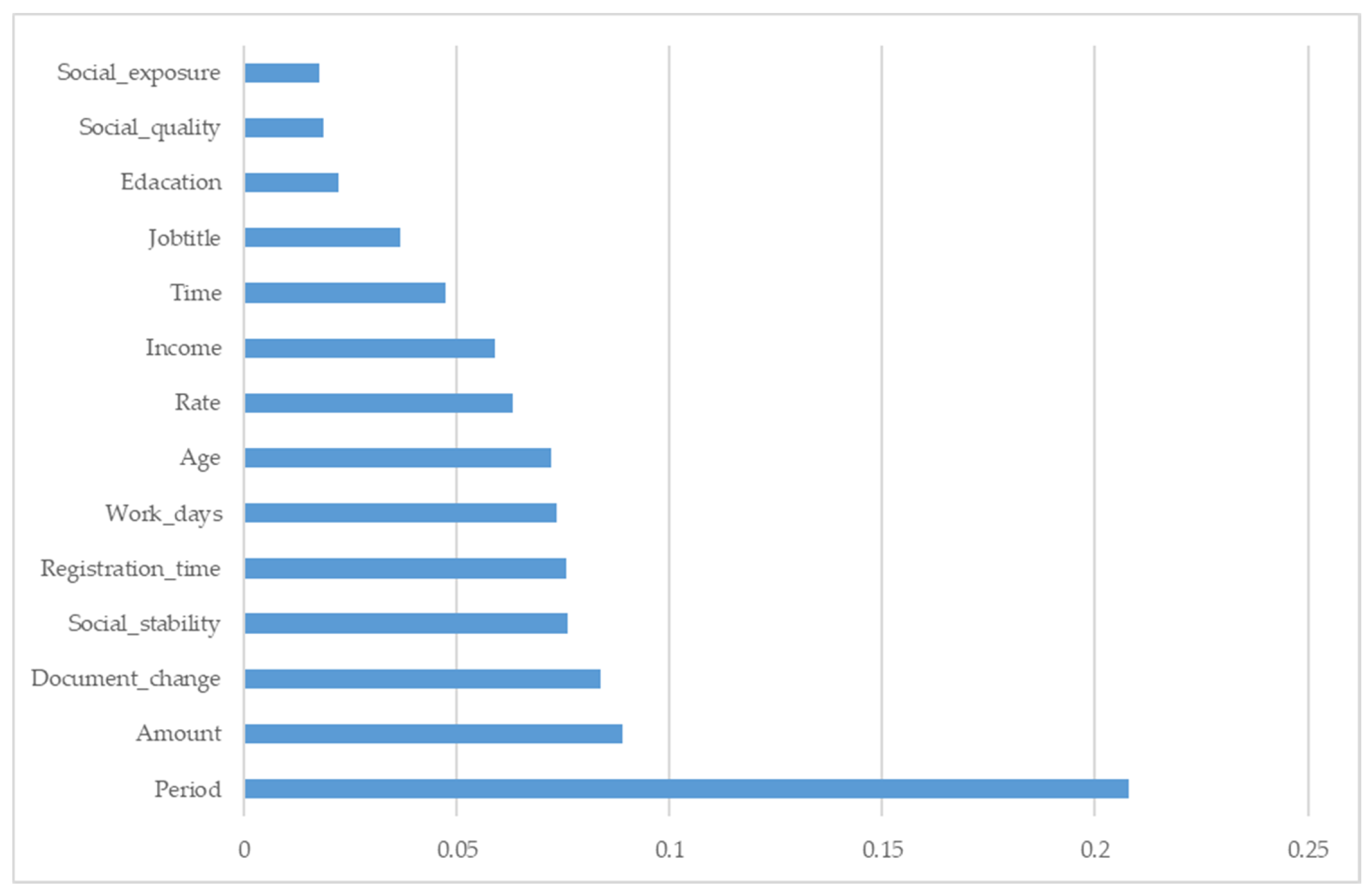
4.4.2. Feature Importance
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Einav, L.; Jenkins, M.; Levin, J. The impact of credit scoring on consumer lending. Rand J. Econ. 2013, 44, 249–274. [Google Scholar] [CrossRef]
- Blöchlinger, A.; Leippold, M. Economic benefit of powerful credit scoring. J. Bank Financ. 2006, 30, 851–873. [Google Scholar] [CrossRef]
- Aitken, R. ‘All data is credit data’: Constituting the unbanked. Compet. Chang. 2017, 21, 274–300. [Google Scholar] [CrossRef]
- Ma, L.; Zhao, X.; Zhou, Z.; Liu, Y. A new aspect on P2P online lending default prediction using meta-level phone usage data in China. Decis. Support. Syst. 2018, 111, 60–71. [Google Scholar] [CrossRef]
- Jiang, C.; Wang, Z.; Wang, R.; Ding, Y. Loan default prediction by combining soft information extracted from descriptive text in online peer-to-peer lending. Ann. Oper. Res. 2018, 266, 511–529. [Google Scholar] [CrossRef]
- Dorfleitner, G.; Priberny, C.; Schuster, S.; Stoiber, J.; Weber, M.; de Castro, I.; Kammler, J. Description-text related soft information in peer-to-peer lending—Evidence from two leading European platforms. J. Bank. Financ. 2016, 64, 169–187. [Google Scholar] [CrossRef]
- Ge, R.; Feng, J.; Gu, B.; Zhang, P. Predicting and Deterring Default with Social Media Information in Peer-to-Peer Lending. J. Manag. Inform. Syst. 2017, 34, 401–424. [Google Scholar] [CrossRef]
- Wei, Y.; Yildirim, P.; Van den Bulte, C.; Dellarocas, C. Credit scoring with social network data. Market. Sci. 2015, 35, 234–258. [Google Scholar] [CrossRef]
- Harari, G.M.; Müller, S.R.; Aung, M.S.; Rentfrow, P.J. Smartphone sensing methods for studying behavior in everyday life. Curr. Opin. Behav. Sci. 2017, 18, 83–90. [Google Scholar] [CrossRef]
- Blumenstock, J.; Cadamuro, G.; On, R. Predicting poverty and wealth from mobile phone metadata. Science 2015, 350, 1073–1076. [Google Scholar] [CrossRef]
- Hand, D.J.; Henley, W.E. Statistical classification methods in consumer credit scoring: a review. J. R. Stat. Soc. A. Stat. 1997, 160, 523–541. [Google Scholar] [CrossRef]
- Baesens, B.; van Gestel, T.; Viaene, S.; Stepanova, M.; Suykens, J.; Vanthienen, J. Benchmarking State-of-the-Art Classification Algorithms for Credit Scoring. J. Oper. Res. Soc. 2003, 54, 627–635. [Google Scholar] [CrossRef]
- Harris, T. Credit scoring using the clustered support vector machine. Expert. Syst. Appl. 2015, 42, 741–750. [Google Scholar] [CrossRef]
- Zhao, Z.; Xu, S.; Kang, B.H.; Kabir, M.M.J.; Liu, Y.; Wasinger, R. Investigation and improvement of multi-layer perceptron neural networks for credit scoring. Expert. Syst. Appl. 2015, 42, 3508–3516. [Google Scholar] [CrossRef]
- Malekipirbazari, M.; Aksakalli, V. Risk assessment in social lending via random forests. Expert. Syst. Appl. 2015, 42, 4621–4631. [Google Scholar] [CrossRef]
- Ala’Raj, M.; Abbod, M.F. A new hybrid ensemble credit scoring model based on classifiers consensus system approach. Expert. Syst. Appl. 2016, 64, 36–55. [Google Scholar] [CrossRef]
- Thomas, L.C. Consumer finance: challenges for operational research. J. Oper. Res. Soc. 2010, 61, 41–52. [Google Scholar] [CrossRef]
- Emekter, R.; Tu, Y.; Jirasakuldech, B.; Lu, M. Evaluating credit risk and loan performance in online Peer-to-Peer (P2P) lending. Appl. Econ. 2015, 47, 54–70. [Google Scholar] [CrossRef]
- Gao, Q.; Lin, M. Words Matter: The Role of Texts in Online Credit Markets. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2446114 (accessed on 27 September 2019).
- Hill, S.; Provost, F.; Volinsky, C. Network-Based Marketing: Identifying Likely Adopters via Consumer Networks. Stat. Sci. 2006, 21, 256–276. [Google Scholar] [CrossRef]
- Everett, C.R. Group Membership, Relationship Banking and Loan Default Risk: The Case of Online Social Lending. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1114428 (accessed on 27 September 2019).
- Lin, M.; Prabhala, N.R.; Viswanathan, S. Judging borrowers by the company they keep: Friendship networks and information asymmetry in online peer-to-peer lending. Manag. Sci. 2013, 59, 17–35. [Google Scholar] [CrossRef]
- De Cnudde, S.; Moeyersoms, J.; Stankova, M.; Tobback, E.; Javaly, V.; Martens, D. What does your Facebook profile reveal about your creditworthiness? Using alternative data for microfinance. J. Oper. Res. Soc. 2019, 70, 353–363. [Google Scholar] [CrossRef]
- Li, S.M.; Lin, Z.X.; Qiu, J.X.; Safi, R.; Xiao, Z.Y. How friendship networks work in online P2P lending markets. Nankai Bus. Rev. Int. 2015, 6, 42–67. [Google Scholar] [CrossRef]
- Zhang, Y.; Jia, H.; Diao, Y.; Hai, M.; Li, H. Research on Credit Scoring by Fusing Social Media Information in Online Peer-to-Peer Lending. Procedia Comput. Sci. 2016, 91, 168–174. [Google Scholar] [CrossRef]
- Guo, G.; Zhu, F.; Chen, E.; Liu, Q.; Wu, L.; Guan, C. From Footprint to Evidence: An Exploratory Study of Mining Social Data for Credit Scoring. ACM T. Web. 2016, 10, 1–38. [Google Scholar] [CrossRef]
- Zeng, Z.; Xie, Y. A preference-opportunity-choice framework with applications to intergroup friendship. Am. J. Social. 2008, 114, 615–648. [Google Scholar] [CrossRef] [PubMed][Green Version]
- McPherson, M.; Smith-Lovin, L.; Cook, J.M. Birds of a Feather: Homophily in Social Networks. Annu. Rev. Social. 2001, 27, 415–444. [Google Scholar] [CrossRef]
- Pokhriyal, N.; Jacques, D.C. Combining disparate data sources for improved poverty prediction and mapping. Proc. Natl. Acad. Sci. USA 2017, 114, E9783–E9792. [Google Scholar] [CrossRef] [PubMed]
- Lessmann, S.; Baesens, B.; Seow, H.; Thomas, L.C. Benchmarking state-of-the-art classification algorithms for credit scoring: An update of research. Eur. J. Oper. Res. 2015, 247, 124–136. [Google Scholar] [CrossRef]
- Baumeister, R.F.; Leary, M.R. The need to belong: Desire for interpersonal attachments as a fundamental human motivation. Psychol. Bull. 1995, 117, 497–529. [Google Scholar] [CrossRef]
- Herzenstein, M.; Sonenshein, S.; Dholakia, U.M. Tell Me a Good Story and I May Lend You Money: The Role of Narratives in Peer-to-Peer Lending Decisions. J. Market. Res. 2011, 48, S138–S149. [Google Scholar] [CrossRef]
- Iyer, R.; Khwaja, A.I.; Luttmer, E.F.P.; Shue, K. Screening Peers Softly: Inferring the Quality of Small Borrowers. Manag. Sci. 2015, 62, 1554–1577. [Google Scholar] [CrossRef]
- Delong, E.R.; Delong, D.M.; Clarke-Pearson, D.L. Comparing the areas under two or more correlated receiver operating characteristic curves: A nonparametric approach. Biometrics 1988, 44, 837–845. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Variables | Description |
|---|---|
| Age | 21–69 years |
| Gender | {male (0.63), female (0.37)} |
| Marriage | {married (0.73), unmarried (0.15), divorced (0.07), widow (0.05)} |
| Children | {have (0.31), don’t have (0.69)} |
| Family | {Number of family members the borrower has: 1 (0.22), 2 (0.50), 3 (0.18), 4 (0.09), 5 or above (0.01)} |
| Education | {Junior high school or below (0.76), senior high school (0.03), bachelor/junior college or above (0.21)} |
| Income | The annual income of the borrower |
| Car | {yes (0.33), no (0.67)} |
| Income_type | Income type, six types |
| House | {own (0.88), parent’s house (0.06), rent (0.06),} |
| Work_days | 0–16,061 days |
| Registration_time | Numbers of minutes before the application the borrower started registration in this platform |
| Document_change | Numbers of minutes before the application the borrower changed his/her document |
| Jobtitle | Job title, five types |
| Amount | Loan amount |
| Rate | Loan rate |
| Period | 8–45 months |
| Time | When the borrower applies for a loan during the day |
| Social_stability | {1 year or below (0.32), 1–3 years (0.31), >3 years (0.37)} |
| Social_exposure | {1 (0.12), 2 (0.56), 3 (0.21), 4 (0.11)} |
| Social_quality | {0 (0.87), 1 (0.10), 2 or above (0.03)} |
| Default (N = 9025) | Non-Default (N = 12011) | p-Value | |||||
|---|---|---|---|---|---|---|---|
| Mean | Median | Std. | Mean | Median | Std. | ||
| Social_quality | 0.190 | 0 | 0.511 | 0.141 | 0 | 0.440 | 0.000(<0.01) |
| Social_stability | 824.67 | 610 | 770.81 | 998.47 | 809 | 843.52 | 0.000(<0.01) |
| Social_exposure | 2.366 | 2 | 0.803 | 2.278 | 2 | 0.832 | 0.000(<0.01) |
| Variable | Model 1 | Model 2 | ||
|---|---|---|---|---|
| Coefficient | Std. | Coefficient | Std. | |
| Age | −0.2550 *** | (0.020) | −0.2212 *** | (0.021) |
| Gender | −0.3797 *** | (0.033) | −0.3802 *** | (0.033) |
| Marriage | - | - | - | - |
| Children | 0.0180 | (0.040) | 0.0139 | (0.040) |
| Family | −0.0205 | (0.046) | −0.0125 | (0.049) |
| Education | −0.2233 *** | (0.016) | −0.2193 *** | (0.016) |
| Income | −0.0116 | (0.018) | 0.0008 | (0.017) |
| Car | −0.1296 *** | (0.016) | −0.1238 *** | (0.016) |
| Income_type | 0.0123 | (0.020) | −0.0191 | (0.021) |
| House | −0.0328 ** | (0.015) | −0.0367 ** | (0.015) |
| Work_days | −0.1448 *** | (0.017) | −0.1470 *** | (0.017) |
| Registration_time | −0.1054 *** | (0.016) | −0.1007 *** | (0.016) |
| Document_change | −0.1466 *** | (0.015) | −0.1369 *** | (0.015) |
| Jobtitle | −0.0476 *** | (0.017) | −0.0473 *** | (0.017) |
| Amount | 0.0037 | (0.023) | 0.0165 | (0.023) |
| Rate | 0.1986 *** | (0.015) | 0.2114 *** | (0.015) |
| Period | 0.0559 *** | (0.021) | −0.0631 *** | (0.021) |
| Time | −0.0560 *** | (0.015) | −0.0604 *** | (0.015) |
| Social_stability | - | - | −0.1287 *** | (0.015) |
| Social_exposure | - | - | 0.1162 *** | (0.017) |
| Social_quality | - | - | 0.1020 *** | (0.014) |
| Random Forest | AdaBoost | LightGBM | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Accuracy | AUC | F1 | Accuracy | AUC | F1 | Accuracy | AUC | F1 | |
| Not contain | 63.57% | 0.674 | 0.635 | 63.91% | 0.681 | 0.642 | 65.50% | 0.692 | 0.649 |
| Contain | 63.92% | 0.689 | 0.644 | 64.40% | 0.697 | 0.651 | 66.22% | 0.711 | 0.659 |
| Do Not Contain | Contain | p-Value | |
|---|---|---|---|
| Random Forest | 0.674 (0.001099) | 0.689 (0.001287) | 0.018 |
| AdaBoost | 0.681 (0.001141) | 0.697 (0.001327) | 0.014 |
| LightGBM | 0.692 (0.001328) | 0.711 (0.001535) | 0.009 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niu, B.; Ren, J.; Li, X. Credit Scoring Using Machine Learning by Combing Social Network Information: Evidence from Peer-to-Peer Lending. Information 2019, 10, 397. https://doi.org/10.3390/info10120397
Niu B, Ren J, Li X. Credit Scoring Using Machine Learning by Combing Social Network Information: Evidence from Peer-to-Peer Lending. Information. 2019; 10(12):397. https://doi.org/10.3390/info10120397
Chicago/Turabian StyleNiu, Beibei, Jinzheng Ren, and Xiaotao Li. 2019. "Credit Scoring Using Machine Learning by Combing Social Network Information: Evidence from Peer-to-Peer Lending" Information 10, no. 12: 397. https://doi.org/10.3390/info10120397
APA StyleNiu, B., Ren, J., & Li, X. (2019). Credit Scoring Using Machine Learning by Combing Social Network Information: Evidence from Peer-to-Peer Lending. Information, 10(12), 397. https://doi.org/10.3390/info10120397