Facial Expression Recognition Based on Random Forest and Convolutional Neural Network


Abstract
:1. Introduction
2. Related Work
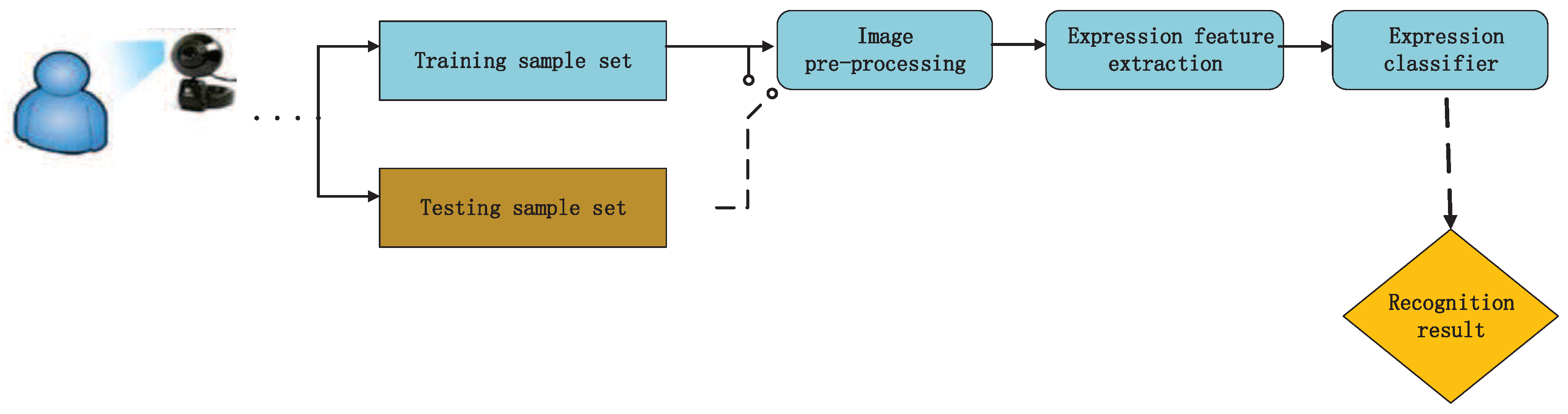
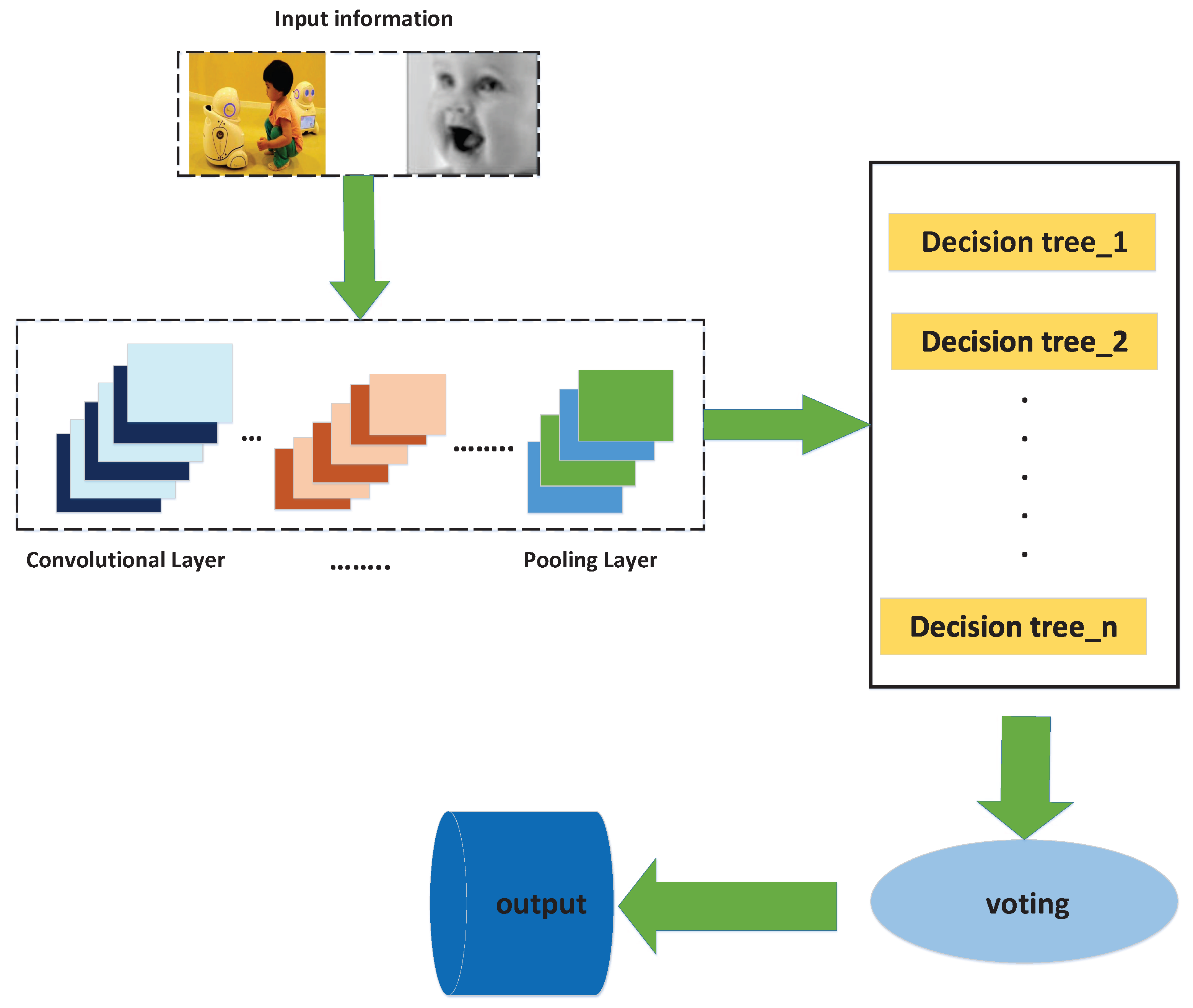
3. Proposed Method
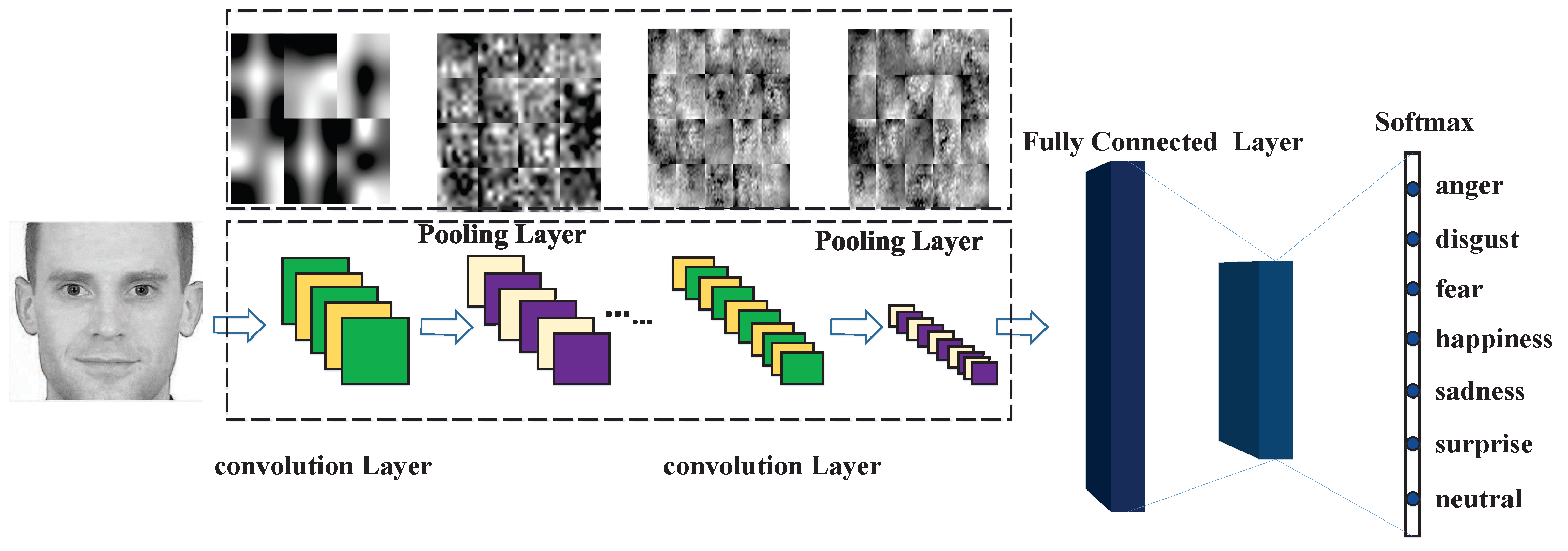
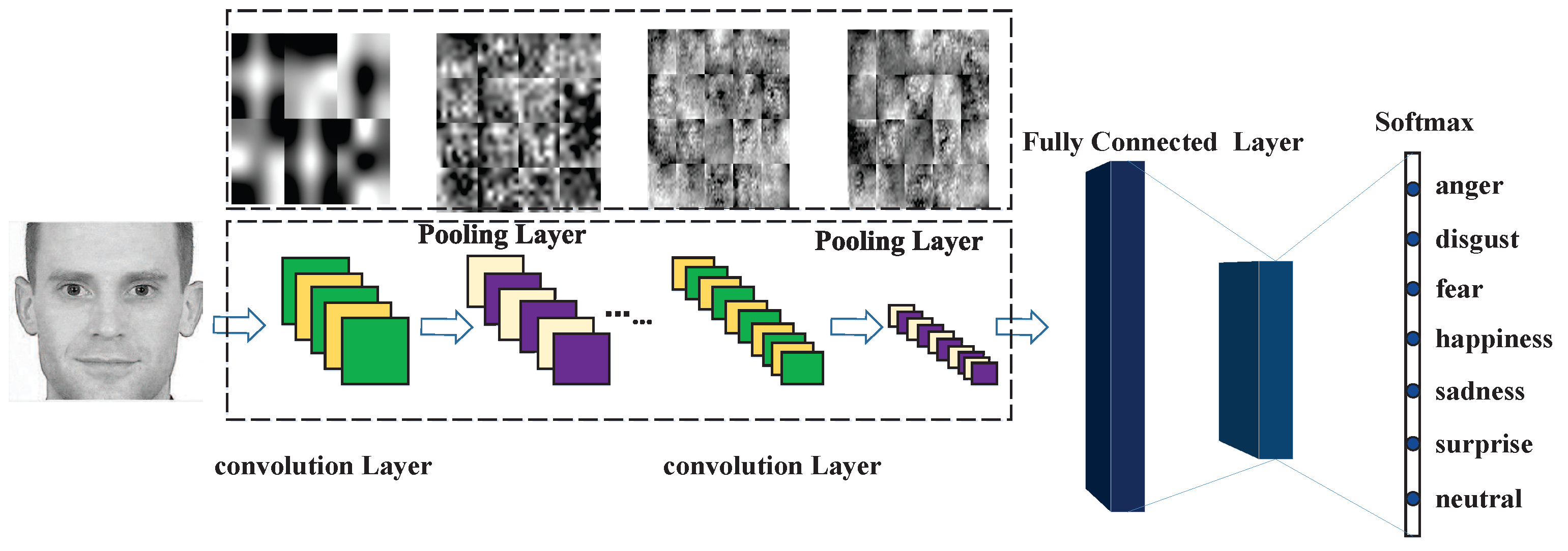
3.1. The Acquisition of Features Based on Convolutional Neural Network
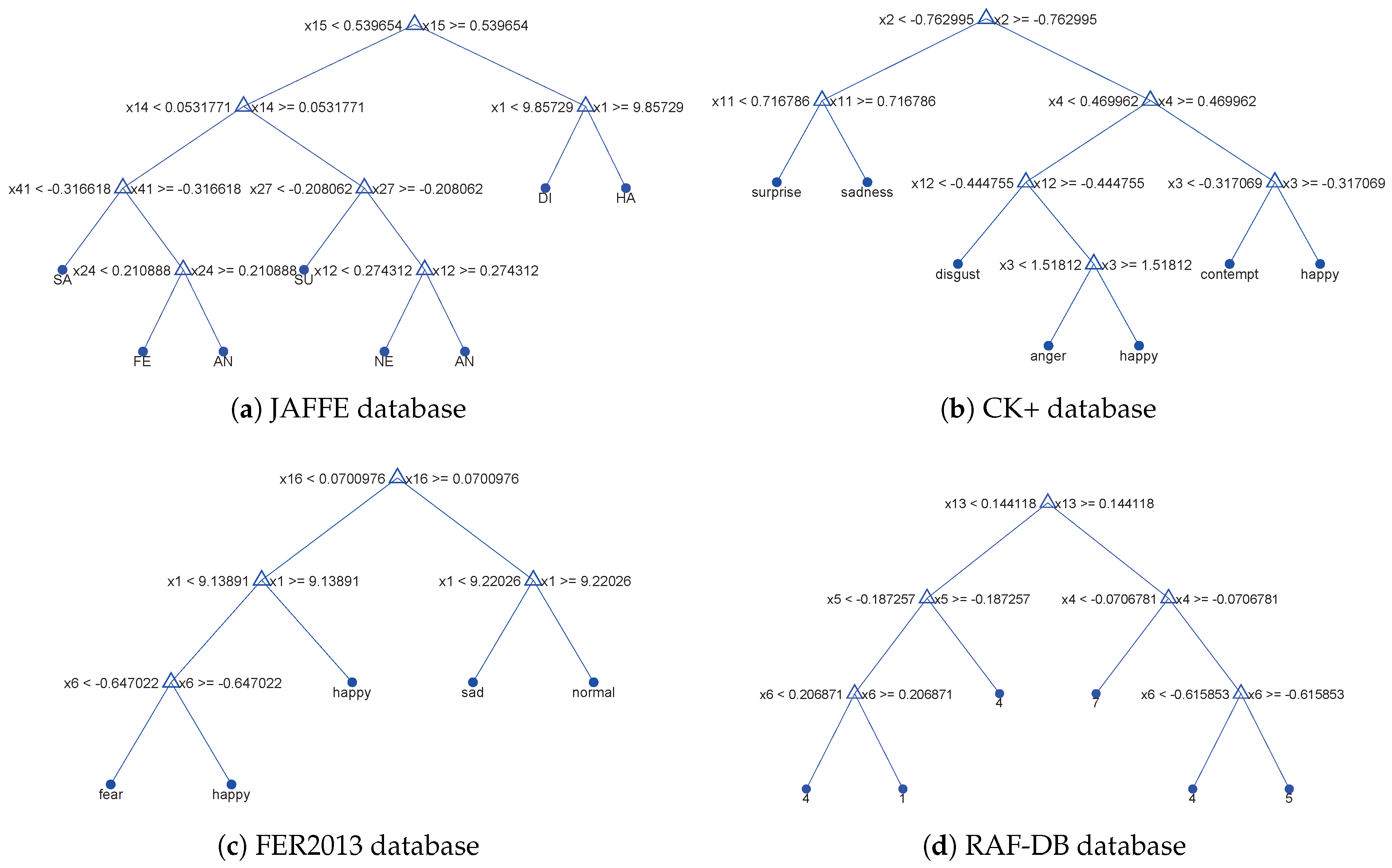
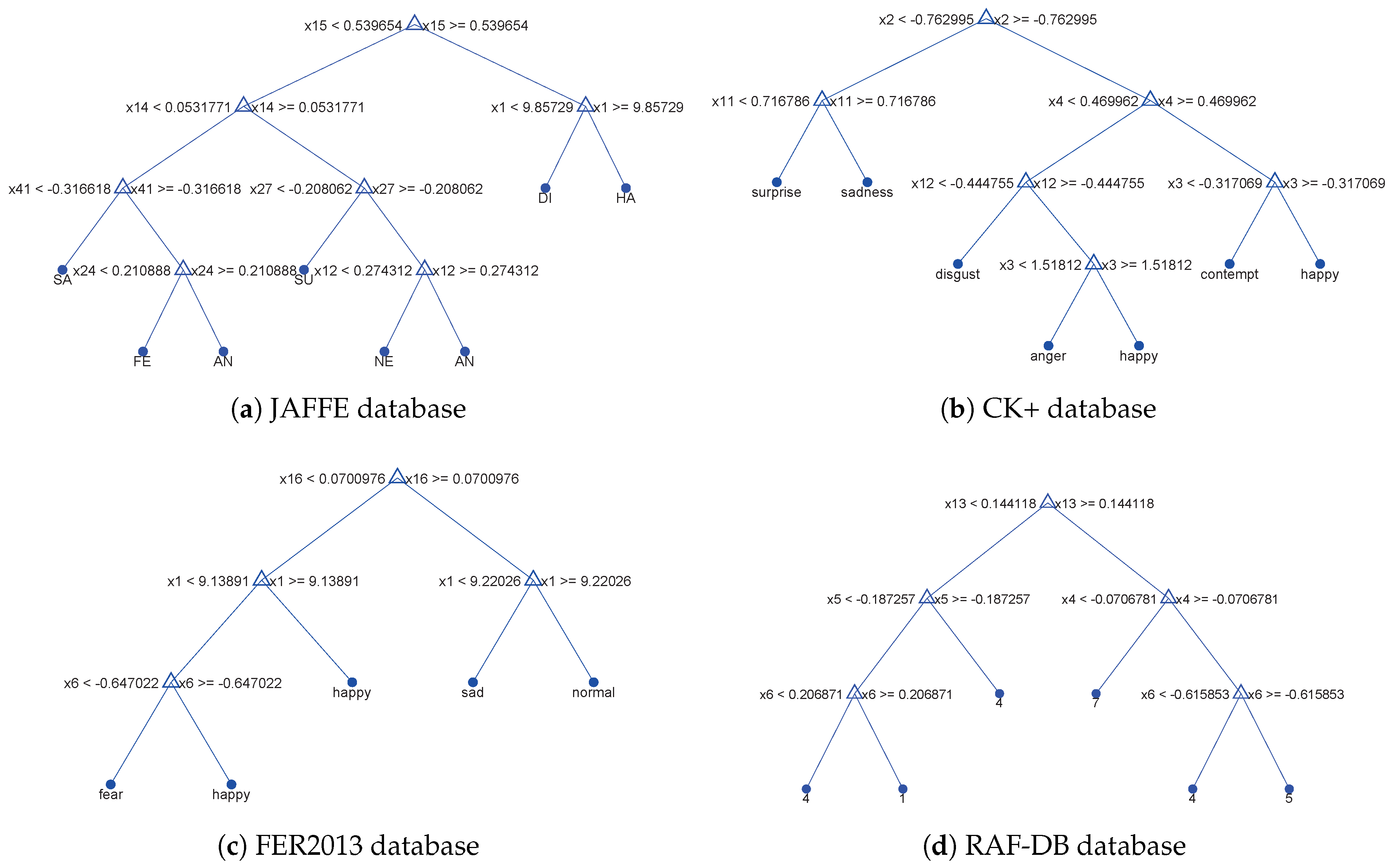
3.2. Introduction and Improvement of C4.5 Decision Tree
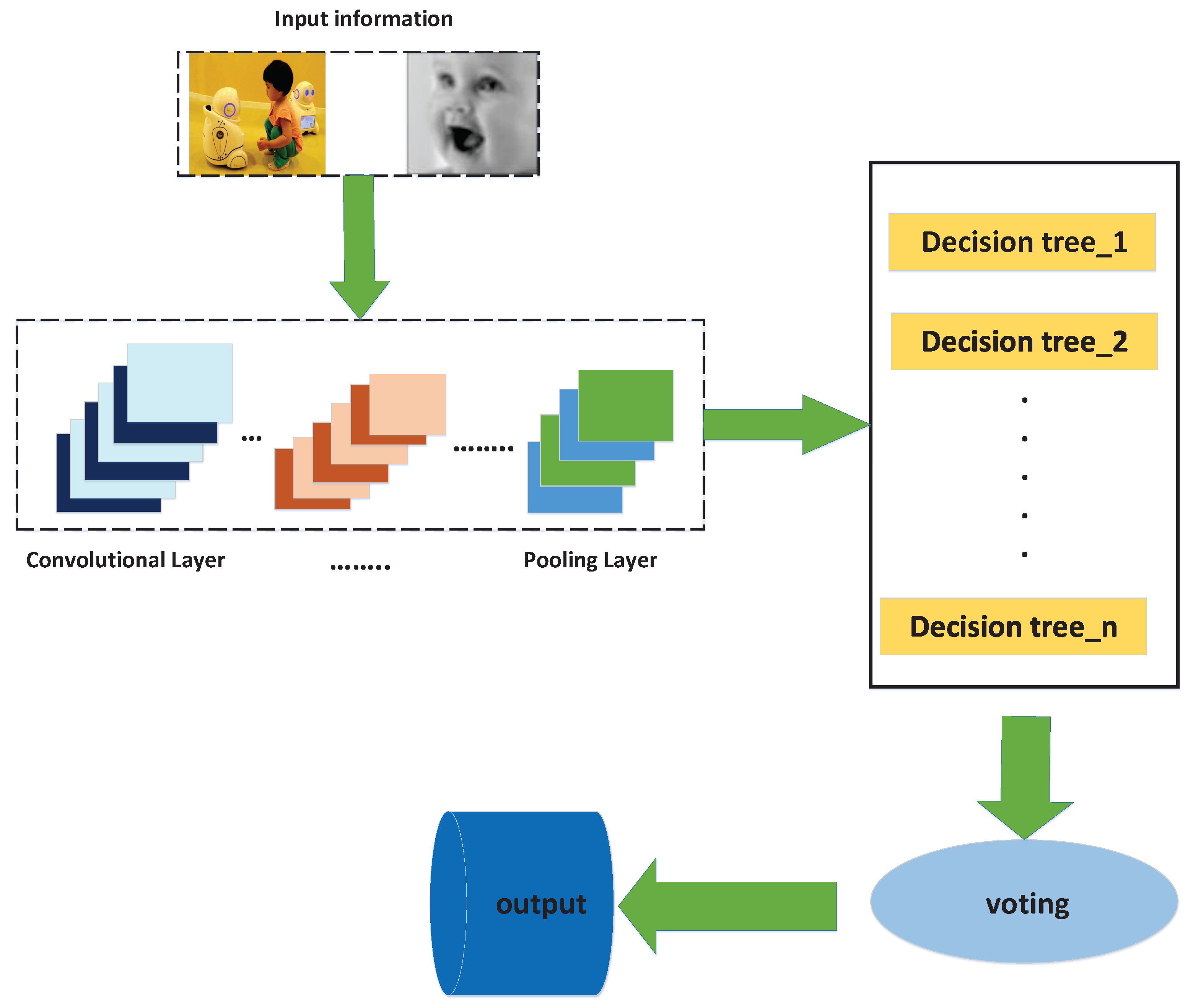
3.3. Generation of the New Random Forest
| Algorithm 1. Generate new random forest |
| Input: training set D; attribute set A |
| Output: multiple expression classification decision trees; |
| 1 : Count=0; number=0; |
| 2 : Create the root node node; |
| 3 : If all samples in D belong to the same category C, then, |
| 4 : Mark node as class C leaf node, return, |
| 5 : end if |
| 6 : If A=, OR the sample values on A are the same, then |
| 7 : Mark node as a leaf node and its category as the class with the largest number of samples, return |
| 8 : end if |
| 9 : For each attribute, information gain rate is calculated by Equation (2). |
| 10 : Select the optimal partition attribute from A, and assume that the test attribute A * has |
| the highest information gain rate during the experiment. |
| 11 : Find the segmentation point of the attribute; |
| 12 : A new leaf node is separated from node a*; |
| 13 : If the sample subset corresponding to this leaf node is empty, then this leaf node is |
| divided to generate a new leaf node, which is marked as the expression with the highest number. |
| 14 : Else, |
| 15 continue to split this leaf node; |
| 16 : end if; |
| 17 : One decision tree is created. |
| 18 : make the test sample into the established tree and calculate the recognition rate, |
| 19 : if accuracy<0.6, count=count, |
| 20 : else |
| 21 : count=count+1; |
| 22 : end if |
| 23 : if count <M, |
| 24 : repeat step(2)-step(22) |
| 25 : else |
| 26 : count =M, |
| 27 : break; |
| 28 : end if |
| 29 : Set the threshold value |
| 30 : If random < |
| 31 : Select the optimal decision tree from all the currently established decision trees |
| as the alternative decision tree. number=number+1; |
| 32 : else |
| 33 : The decision tree is randomly selected from all the currently established decision trees |
| as an alternative decision tree. number=number+1; |
| 34 : if number<m, |
| 35 repeat step(29)-step(33) |
| 36 : if number=m, |
| 37 : break |
| 38 :end if |
| 36 : All the selected decision trees are combined to form a random forest |
| 39 : The test samples are put into the random forest, and the classification results of each decision tree are collected. |
| The results with the most votes will be used as the prediction classification of the current sample. |
4. Experiments and Results
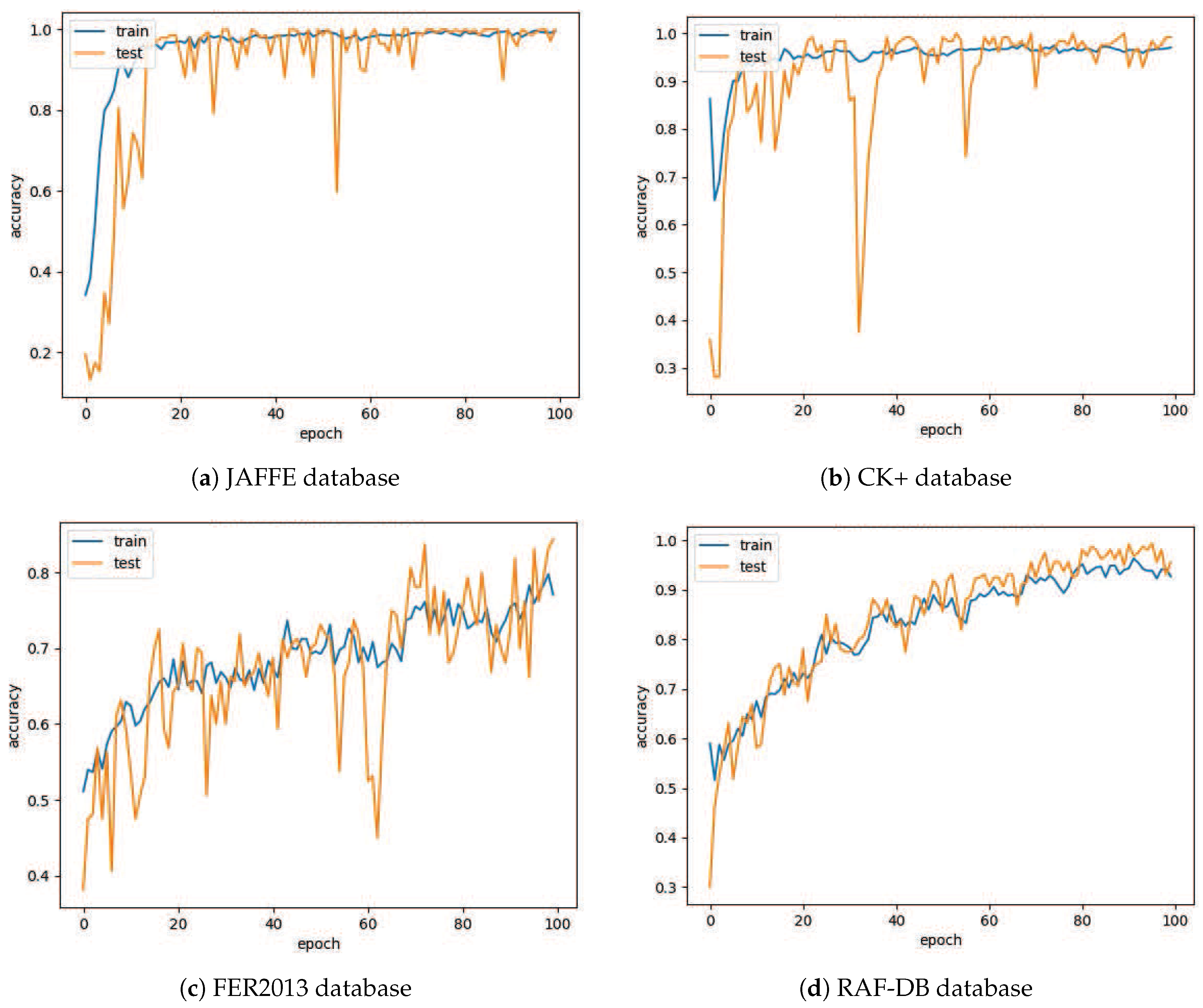
4.1. Database
4.2. Data Augmentation
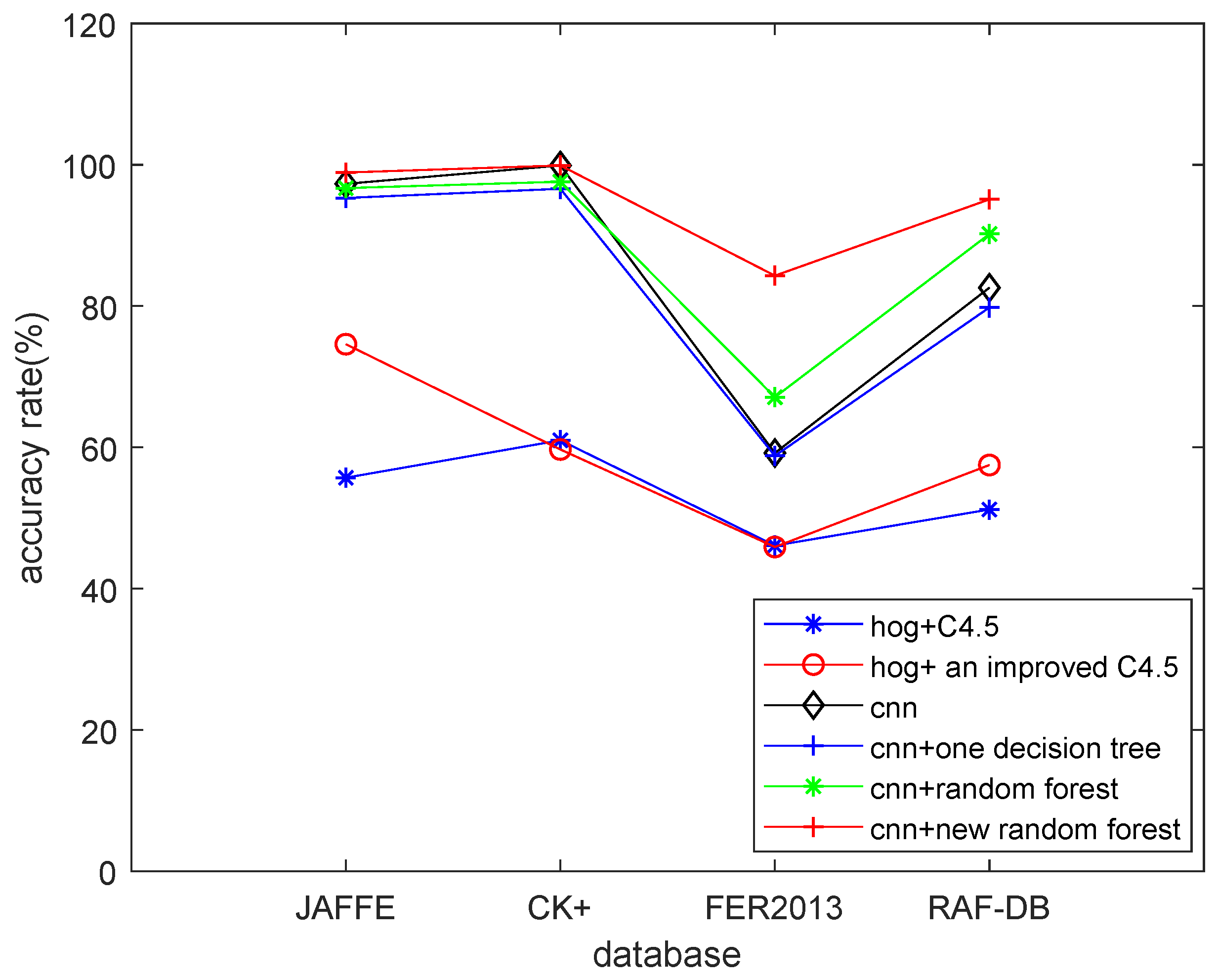
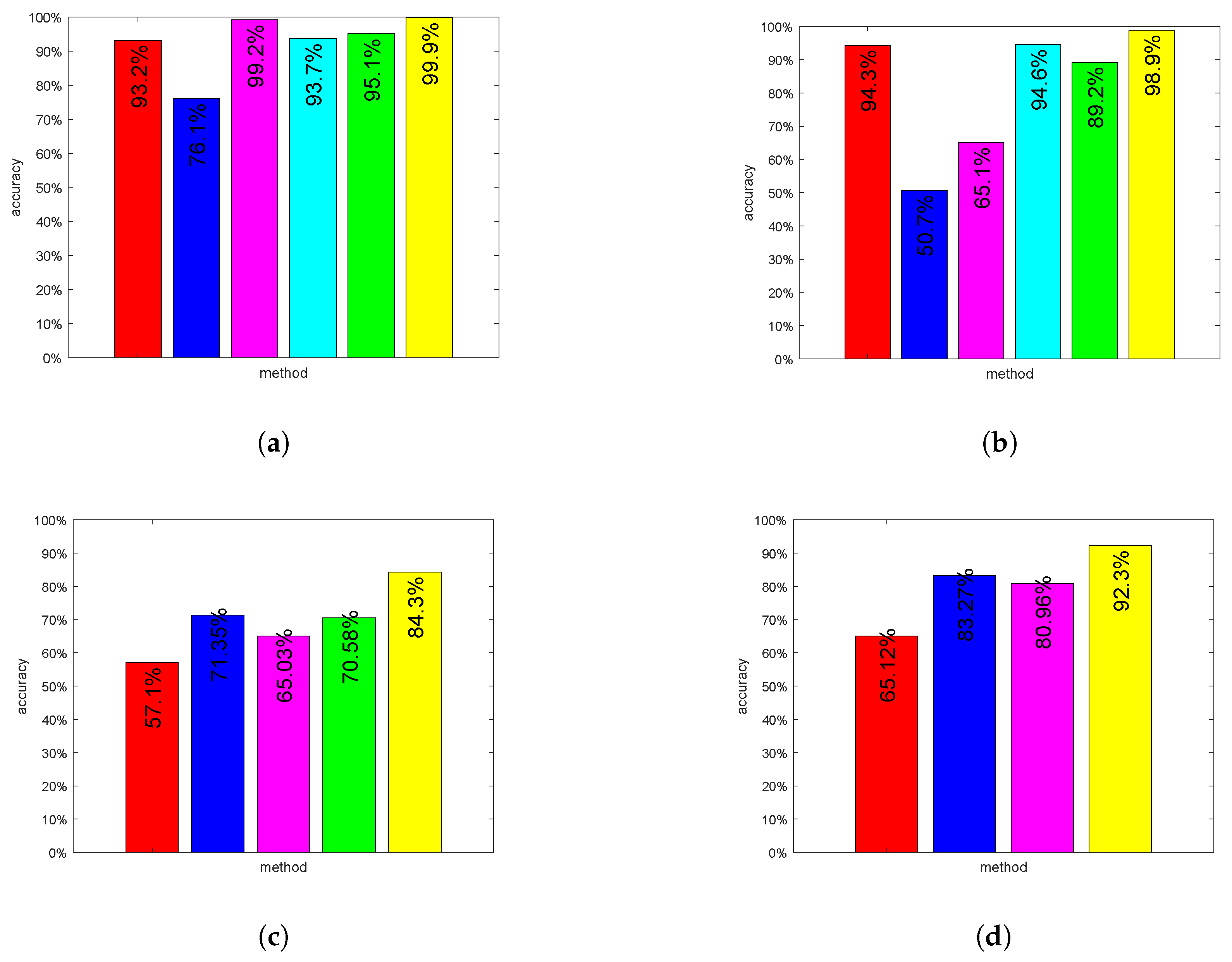
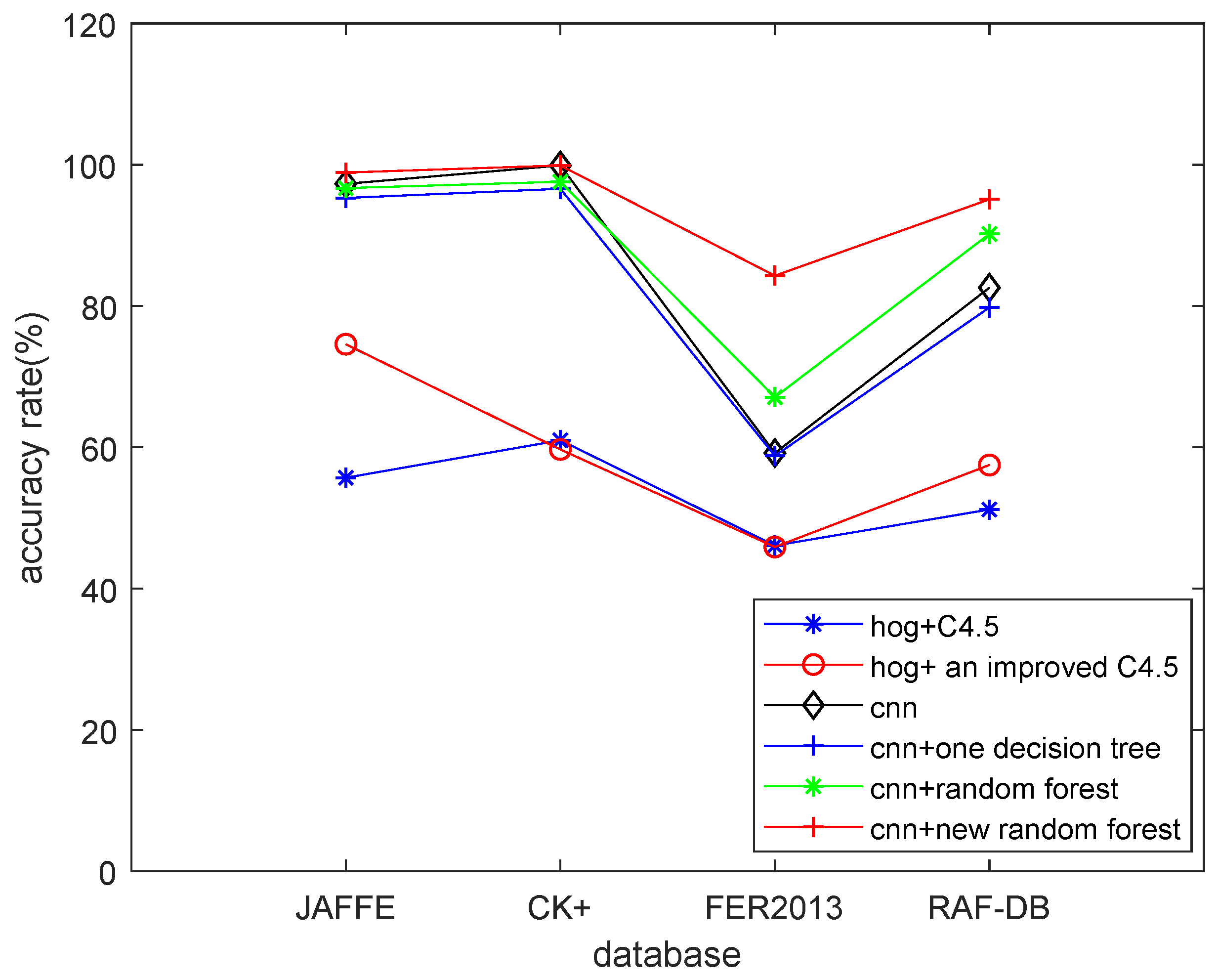
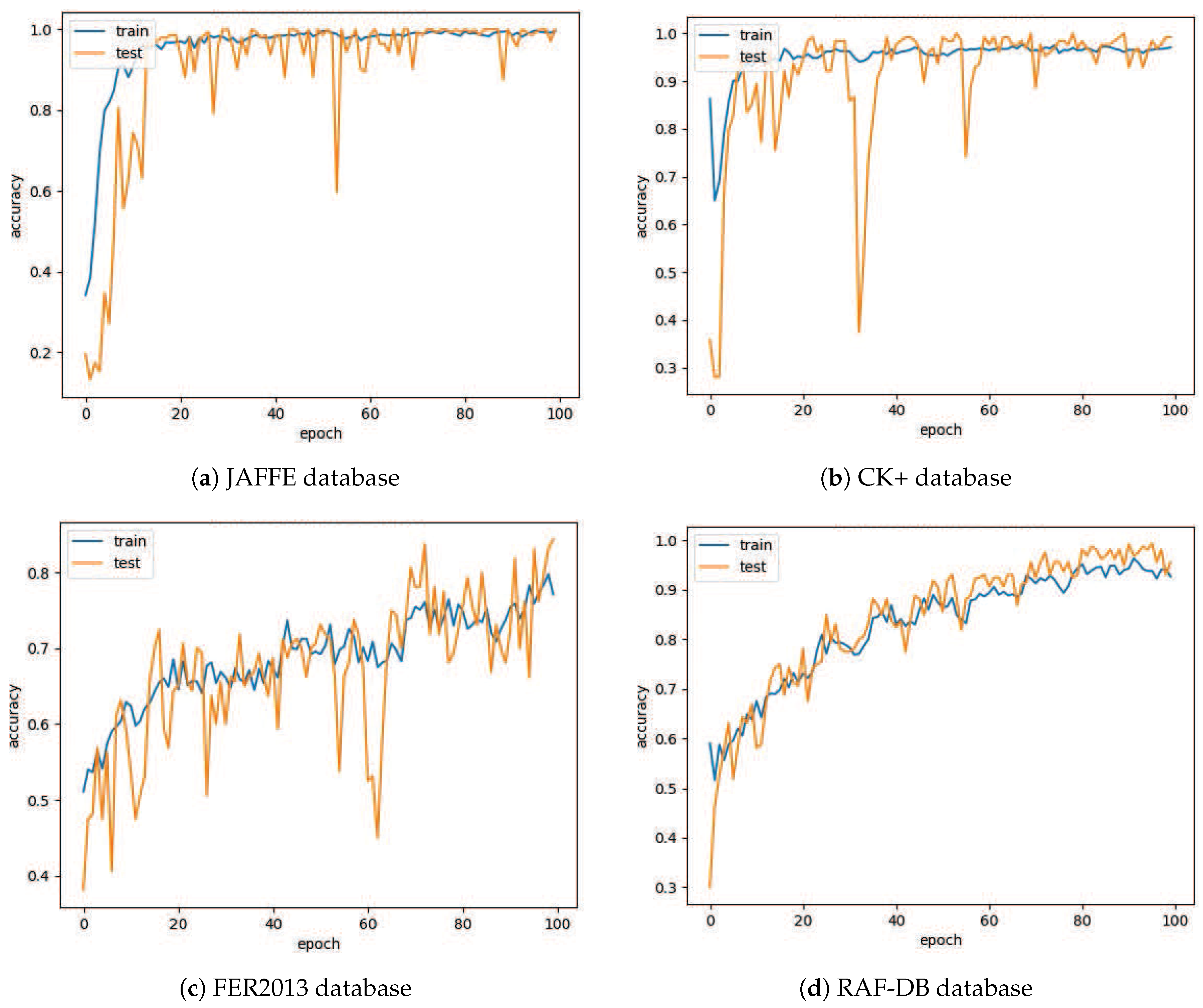
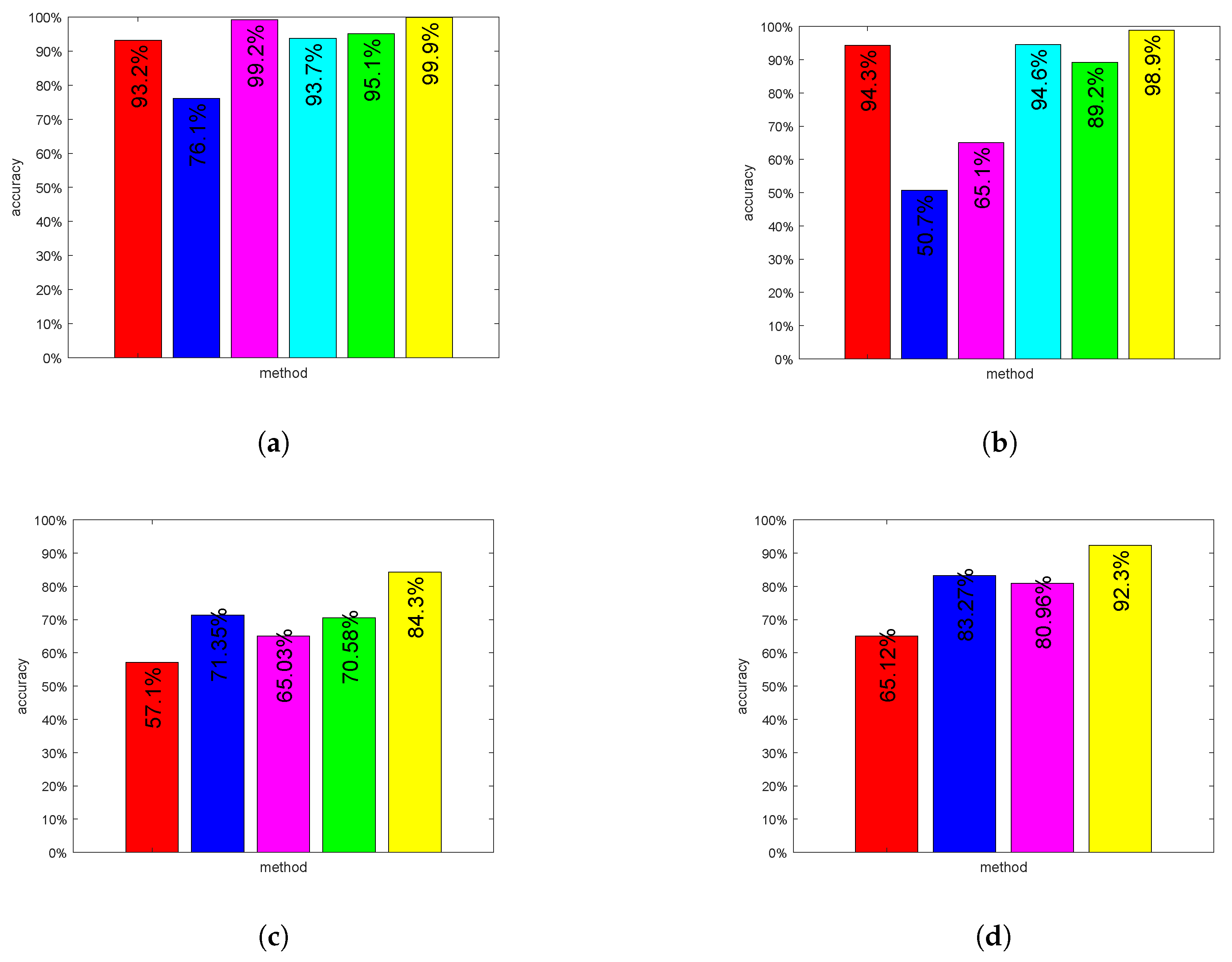
4.3. Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mehrabian, A. Communication without words. Psychol. Today 1968, 2, 4. [Google Scholar]
- Darwin, C.; Ekman, P. Expression of the emotions in man and animals. Portable Darwin 2003, 123, 146. [Google Scholar]
- Ying, Z.; Fang, X. Combining LBP and Adaboost for facial expression recognition. In Proceedings of the International Conference on Signal Processing, Beijing, China, 26–29 October 2008. [Google Scholar]
- Ekman, P.; Friesen, W.V. Constants across cultures in the face and emotion. J. Pers. Soc. Psychol. 1971, 17, 124–129. [Google Scholar] [CrossRef] [PubMed]
- Kalansuriya, T.R.; Dharmaratne, A.T. Facial image classification based on age and gender. In Proceedings of the Fourteenth International Conference on Advances in ICT for Emerging Regions, Colombo, Sri Lanka, 10–14 December 2014. [Google Scholar]
- Pang, Y.; Liu, Z.; Yu, N. A new nonlinear feature extraction method for face recognition. Neurocomputing 2006, 69, 949–953. [Google Scholar] [CrossRef]
- Lopes, A.T.; Aguiar, E.D.; Souza, A.F.D.; Oliveira-Santos, T. Facial Expression Recognition with Convolutional Neural Networks: Coping with Few Data and the Training Sample Order. Pattern Recog. 2017, 61, 610–628. [Google Scholar] [CrossRef]
- Liu, W.; Song, C.; Wang, Y. Facial expression recognition based on discriminative dictionary learning. In Proceedings of the 21st International Conference on Pattern Recognition, Tsukuba Science City, Japan, 11–15 November 2012. [Google Scholar]
- Ali, G.; Iqbal, M.A.; Choi, T.S. Boosted NNE collections for multicultural facial expression recognition. Pattern Recog. 2016, 55, 14–27. [Google Scholar] [CrossRef]
- Zhang, Z.; Lyons, M.; Schuster, M.; Akamatsu, S. Comparison between geometry-based and Gabor-wavelets-based facial expression recognition using multi-layer perceptron. In Proceedings of the 3rd IEEE International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998. [Google Scholar]
- Bartlett, M.S.; Littlewort, G.; Frank, M.; Lainscsek, C. Recognizing facial expression: machine learning and application to spontaneous behavior. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Qi, W.; Jaja, J. From Maxout to Channel-Out: Encoding Information on Sparse Pathways. In Proceedings of the 24th International Conference on Artificial Neural Networks, Hamburg, Germany, 15–19 September 2014. [Google Scholar]
- Quinlan, J.R. Induction on decision tree. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Setsirichok, D.; Piroonratana, T.; Wongseree, W.; Usavanarong, T.; Paulkhaolarn, N.; Kanjanakorn, C.; Sirikong, M.; Limwongse, C.; Chaiyaratana, N. Classification of complete blood count and haemoglobin typing data by a C4.5 decision tree, a naïve Bayes classifier and a multilayer perceptron for thalassaemia screening. Biomed. Signal Process. Control 2012, 7, 202–212. [Google Scholar] [CrossRef]
- Luo, Y.; Wu, C.; Zhang, Y. Facial expression recognition based on fusion feature of PCA and LBP with SVM. Optik-Int. J. Light Electron Optics 2013, 124, 2767–2770. [Google Scholar] [CrossRef]
- Chen, J.; Chen, Z.; Chi, Z.; Fu, H. Facial expression recognition based on facial components detection and hog features. In Proceedings of the International Workshops on Electrical and Computer Engineering Subfields, Istanbul, Turkey, 22–23 August 2014; pp. 884–888. [Google Scholar]
- Mollahosseini, A.; Chan, D.; Mahoor, M.H. Going Deeper in Facial Expression Recognition using Deep Neural Networks. In Proceeding of the IEEE Winter Conference on Applications of Computer Vision, Lake Placid, NY, USA, 7–9 March 2016. [Google Scholar]
- Wen, G.; Zhi, H.; Li, H.; Li, D.; Jiang, L.; Xun, E. Ensemble of Deep Neural Networks with Probability-Based Fusion for Facial Expression Recognition. Cognit. Comput. 2017, 9, 1–14. [Google Scholar] [CrossRef]
- Lawrence, S.; Giles, C.L.; Tsoi, A.C.; Back, A.D. Face recognition: a convolutional neural-network approach. IEEE Trans. Neural Netw. 1997, 8, 98–113. [Google Scholar] [CrossRef] [PubMed]
- Kim, P. Convolutional Neural Network. In MATLAB Deep Learning; Apress: Berkeley, CA, USA, 2017. [Google Scholar]
- Ming, L.; Hu, X. Recurrent convolutional neural network for object recognition. In Proceedings of the Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3367–3375. [Google Scholar]
- Xu, M.; Wang, J.L.; Chen, T. Improved Decision Tree Algorithm: ID3 +. In Intelligent Computing in Signal Processing and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2006; pp. 141–149. [Google Scholar]
- Butaye, J.; Jacquemyn, H.; Hermy, M. Differential colonization causing non-random forest plant community structure in a fragmented agricultural landscape. Ecography 2001, 24, 369–380. [Google Scholar] [CrossRef]
- Oza, N.C. Online Ensemble Learning. In Proceedings of the Seventeenth National Conference on Artificial Intelligence and Twelfth Conference on on Innovative Applications of Artificial Intelligence, Austin, TX, USA, 30 July–3 August 2000. [Google Scholar]
- Shih, F.Y.; Chuang, C.F.; Wang, P.S.P. Performance comparisons of facial expression recognition in JAFFE database. Int. J. Pattern Recog. Artif. Intell. 2011, 22, 445–459. [Google Scholar] [CrossRef]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J. The Extended Cohn-Kanade Dataset (CK+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the Computer Vision and Pattern Recognition Workshops, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Kankanamge, S.; Fookes, C.; Sridharan, S. Facial analysis in the wild with LSTM networks. In Proceedings of the 25th IEEE International Conference on Image Processing, Athens, Greece, 7–10 October 2018. [Google Scholar]
- Shan, C.; Gong, S.; McOwan, P.W. Facial expression recognition based on local binary patterns: A comprehensive study. Image Vision Comput. 2009, 27, 803–816. [Google Scholar] [CrossRef]
- Liu, M.; Li, S.; Shan, S.; Chen, X. Au-inspired deep networks for facial expression feature learning. Neurocomputing 2015, 159, 126–136. [Google Scholar] [CrossRef]
- Ahmed, H.; Rashid, T.; Sidiq, A. Face Behavior Recognition through Support Vector Machines. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 101–108. [Google Scholar]
- Rashid, T.A. Convolutional Neural Networks based Method for Improving Facial Expression Recognition. In The International Symposium on Intelligent Systems Technologies and Applications; Springer: Cham, Switzerland, 2016; pp. 73–84. [Google Scholar]
- Tumen, V.; Soylemez, O.F.; Ergen, B. Facial emotion recognition on a dataset using convolutional neural network. In Proceedings of the 2017 International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 16–17 September 2017. [Google Scholar]
- Chang, T.; Wen, G.; Yang, H.; Ma, J.J. Facial Expression Recognition Based on Complexity Perception Classification Algorithm. arXiv 2018, arXiv:1803.00185. [Google Scholar]
- Kuang, L.; Zhang, M.; Pan, Z. Facial Expression Recognition with CNN Ensemble. In Proceedings of the International Conference on Cyberworlds, Chongqing, China, 28–30 September 2016. [Google Scholar]
- Kim, B.K. Hierarchical committee of deep convolutional neural networks for robust facial expression recognition. J. Multimodal User Interfaces 2016, 10, 173–189. [Google Scholar] [CrossRef]
- Li, S.; Deng, W. Reliable Crowdsourcing and Deep Locality-Preserving Learning for Unconstrained Facial Expression Recognition. IEEE Trans. Image Process. 2018, 28, 356–370. [Google Scholar] [CrossRef]
- Li, Y.; Zeng, J.; Shan, S.; Chen, X. Occlusion aware facial expression recognition using CNN with attention mechanism. IEEE Trans. Image Process. 2018, 28, 2439–2450. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Input | Kernel Size | Output |
|---|---|---|---|
| Conv | 96 × 96 | 5 × 5 | 92 × 92 |
| Conv | 92 × 92 | 5 × 5 | 88 × 88 |
| Pool | 88 × 88 | 2 × 2 | 44 × 44 |
| Conv | 44 × 44 | 3 × 3 | 42 × 42 |
| Pool | 42 × 42 | 2 × 2 | 21 × 21 |
| Conv | 21 × 21 | 3 × 3 | 19 × 19 |
| Conv | 19 × 19 | 3 × 3 | 17 × 17 |
| Conv | 17 × 17 | 5 × 5 | 13 × 13 |
| Conv | 11 × 11 | 2 × 2 | 5 × 5 |
| FC | |||
| Softmax |
| Ck+ Expression Label | Number | JAFFE Expression Label | Number |
|---|---|---|---|
| anger | 5941 | anger | 4840 |
| contempt | 2970 | disgust | 4840 |
| disgust | 9735 | fear | 4842 |
| fear | 4125 | happy | 4842 |
| happy | 12,420 | neutral | 4840 |
| sadness | 3696 | sad | 4841 |
| surprise | 14,619 | surprise | 4840 |
| FER2013 Expression Label | Number | RAF-DB Expression Label | Number |
| anger | 4953 | 1 | 1619 |
| normal | 6198 | 2 | 355 |
| disgust | 547 | 3 | 877 |
| fear | 5121 | 4 | 5957 |
| happy | 8989 | 5 | 2460 |
| sadness | 6077 | 6 | 867 |
| surprise | 4022 | 7 | 3204 |
| Method (JAFFE) | Accuracy(%) | Running Time (s) |
|---|---|---|
| hog+C4.5 | 55.7 | 689.5 |
| hog+an improved C4.5 | 74.6 | 384.6 |
| cnn | 97.3 | 11,940.2 |
| cnn+one decision tree | 95.3 | 13,229.4 |
| cnn+random forest | 96.7 | 13,158.9 |
| cnn+new random forest | 98.9 | 12,715.5 |
| Method (CK+) | Accuracy(%) | Running Time (s) |
| hog+C4.5 | 61.0 | 2595.3 |
| hog+an improved C4.5 | 59.7 | 1597.7 |
| cnn | 99.9 | 19,604.4 |
| cnn+one decision tree | 96.6 | 25,398.6 |
| cnn+random forest | 97.6 | 22,369.1 |
| cnn+new random forest | 99.9 | 20,606.4 |
| Method (FER2013) | Accuracy(%) | Running Time (s) |
| hog+C4.5 | 46.1 | 2061.6 |
| hog+an improved C4.5 | 45.9 | 1290.8 |
| cnn | 59.2 | 14,720.3 |
| cnn+one decision tree | 58.8 | 17,880.5 |
| cnn+random forest | 67.1 | 17,601.9 |
| cnn+new random forest | 84.3 | 15,860.5 |
| Method (RAF-DB) | Accuracy(%) | Running Time (s) |
| hog+C4.5 | 51.2 | 351.6 |
| hog+an improved C4.5 | 57.5 | 140.8 |
| cnn | 82.6 | 6509.2 |
| cnn+one decision tree | 79.8 | 7122.5 |
| cnn+random forest | 90.2 | 6997.8 |
| cnn+new random forest | 92.3 | 6729.1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Li, Y.; Song, Y.; Rong, X. Facial Expression Recognition Based on Random Forest and Convolutional Neural Network. Information 2019, 10, 375. https://doi.org/10.3390/info10120375
Wang Y, Li Y, Song Y, Rong X. Facial Expression Recognition Based on Random Forest and Convolutional Neural Network. Information. 2019; 10(12):375. https://doi.org/10.3390/info10120375
Chicago/Turabian StyleWang, Yingying, Yibin Li, Yong Song, and Xuewen Rong. 2019. "Facial Expression Recognition Based on Random Forest and Convolutional Neural Network" Information 10, no. 12: 375. https://doi.org/10.3390/info10120375
APA StyleWang, Y., Li, Y., Song, Y., & Rong, X. (2019). Facial Expression Recognition Based on Random Forest and Convolutional Neural Network. Information, 10(12), 375. https://doi.org/10.3390/info10120375