Text and Data Quality Mining in CRIS


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Motivation
2. Fundamentals
2.1. Data Quality in CRIS
- Completeness
- Correctness
- Consistency
- Timeliness
- Measurements must be understandable to serve their purpose. The results cannot help in decision-making when no one understands what has been measured and what the results mean exactly. This underlines the importance of metadata that documents the measurements and the results. This helps the data consumer understand the context and interpret the results.
- Measurements must be reproducible. Inconsistent measurements mean that the results have little or no significance. To show if the quality in a record improves or deteriorates, the same data must be measured using the same methods. As a result, comparisons between different objects are possible.
- Measurements must be expedient. It should measure what helps to reduce the uncertainty of a decision. Measurements serve a purpose and help with concrete problems.
2.2. Definition of the Term TDM
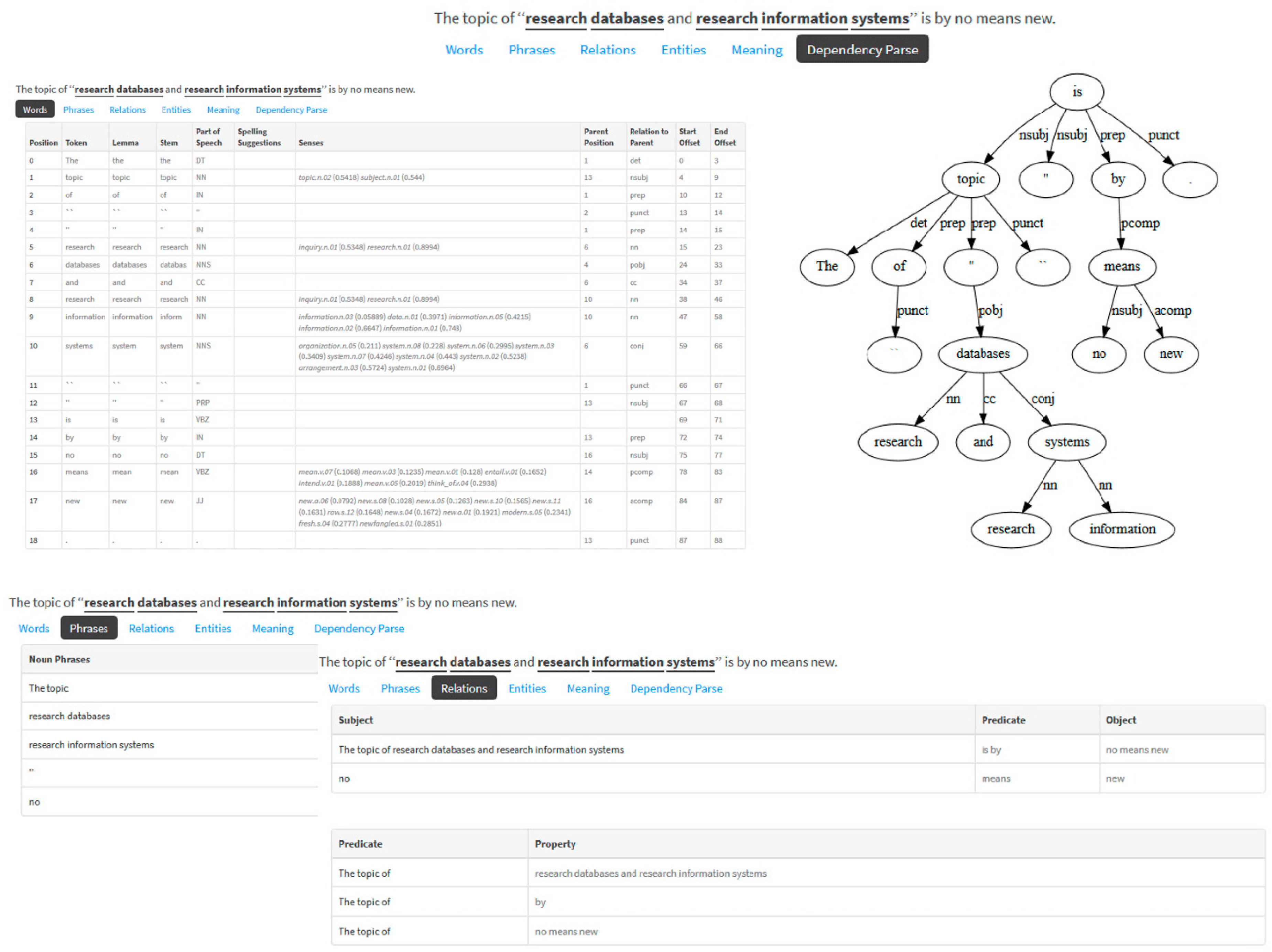
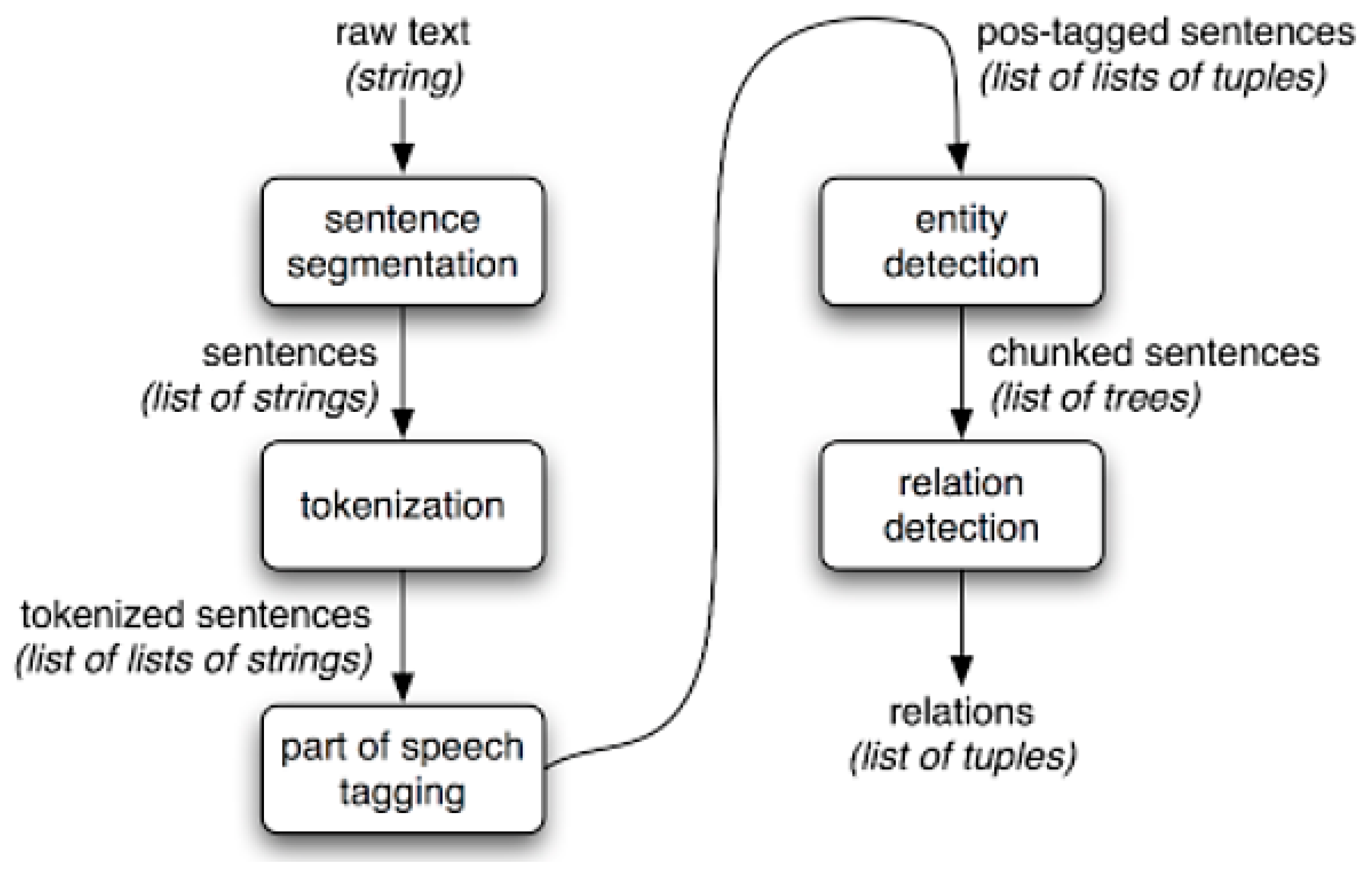
2.3. Problems of Unstructured Data in CRIS
- The availability of the data must be guaranteed.
- The quality of the data must be good.
- Responsibilities in universities and academic institutions must be regulated.
- Data know-how must be available.
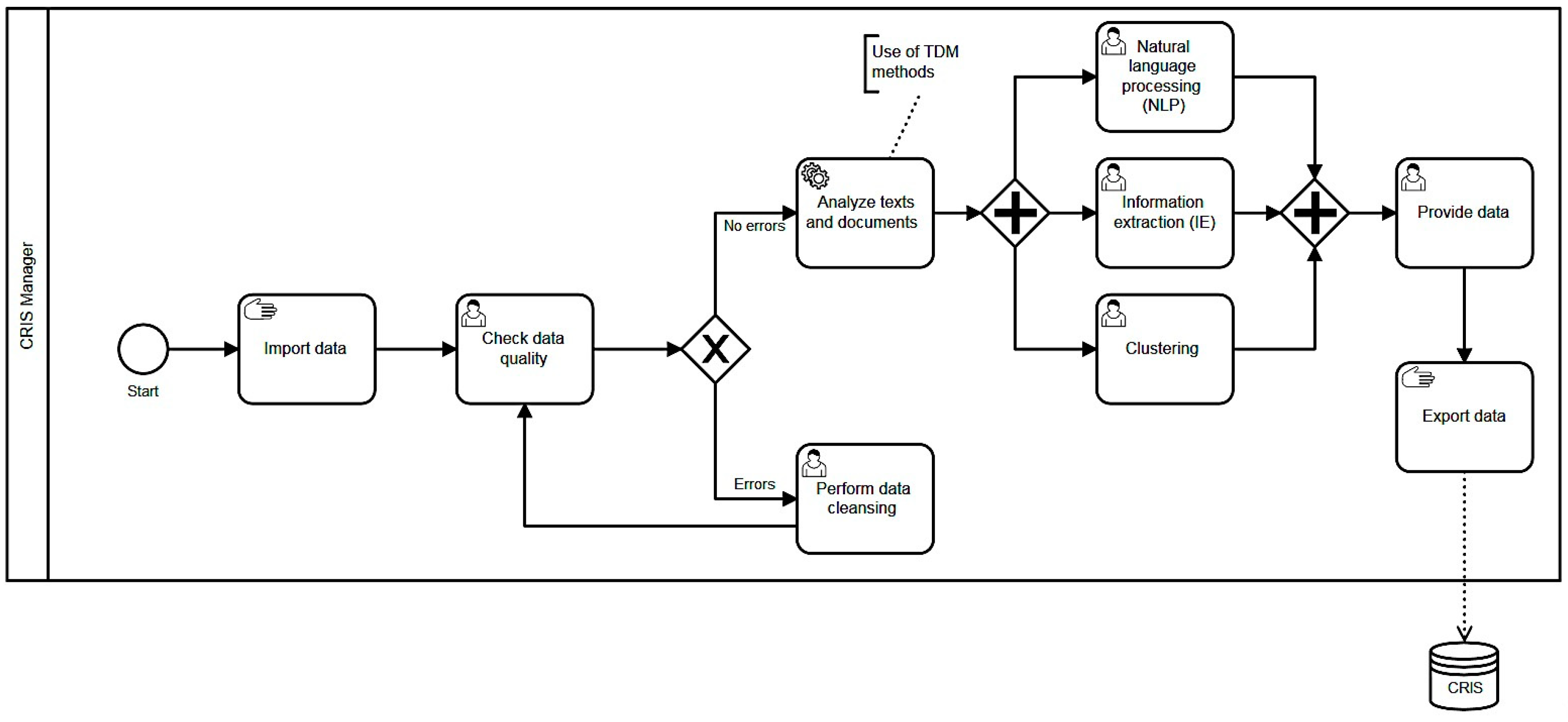
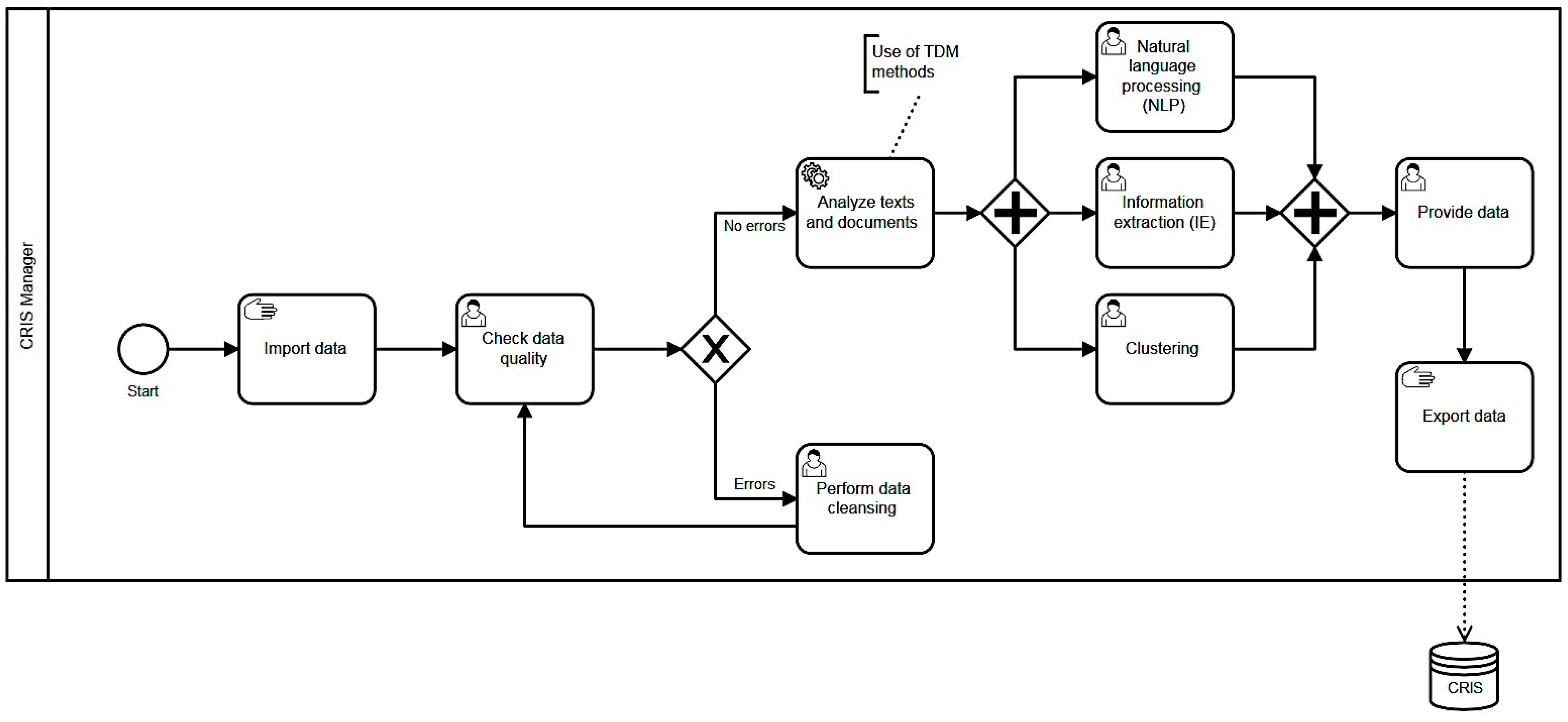
3. Employing TDM Methods in CRIS
- Application of pre-processing routines on heterogeneous data sources.
- Application of algorithms for the discovery of patterns.
- Present and visualize the results.
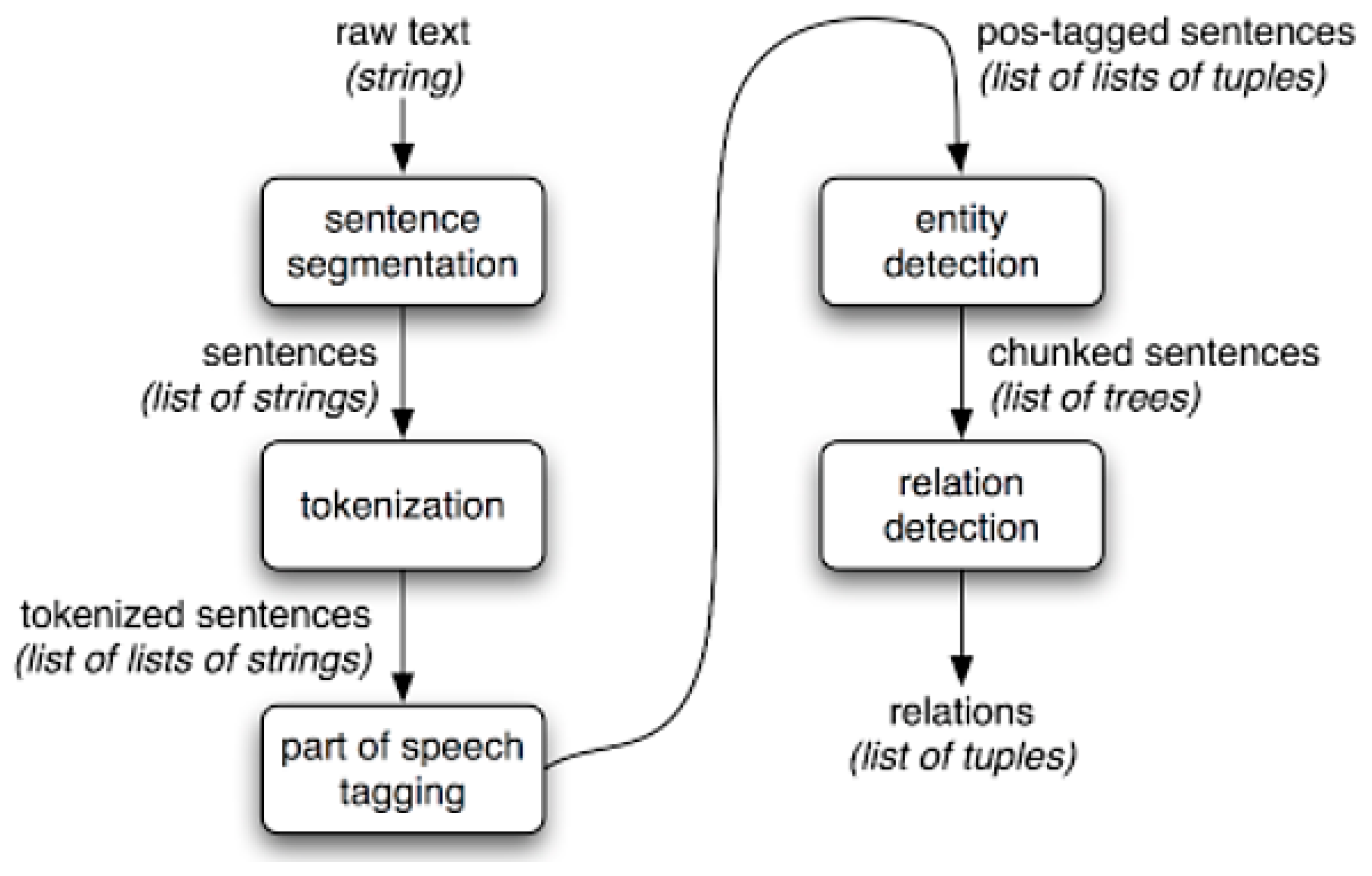
3.1. Natural Language Processing (NLP)
- Spell checking and correction: By spelling the word and identifying the meaning of a word in context, a correct spelling checker is possible.
- Information gathering: By recognizing syntactic and semantic dependencies, it is possible to extract specific information from a text.
- Question answering: Through syntactic and semantic analysis of a question, a computer can automatically find appropriate answers.
- Machine translation: By clarifying the meaning of words as a single or in context, a correct translation is feasible.
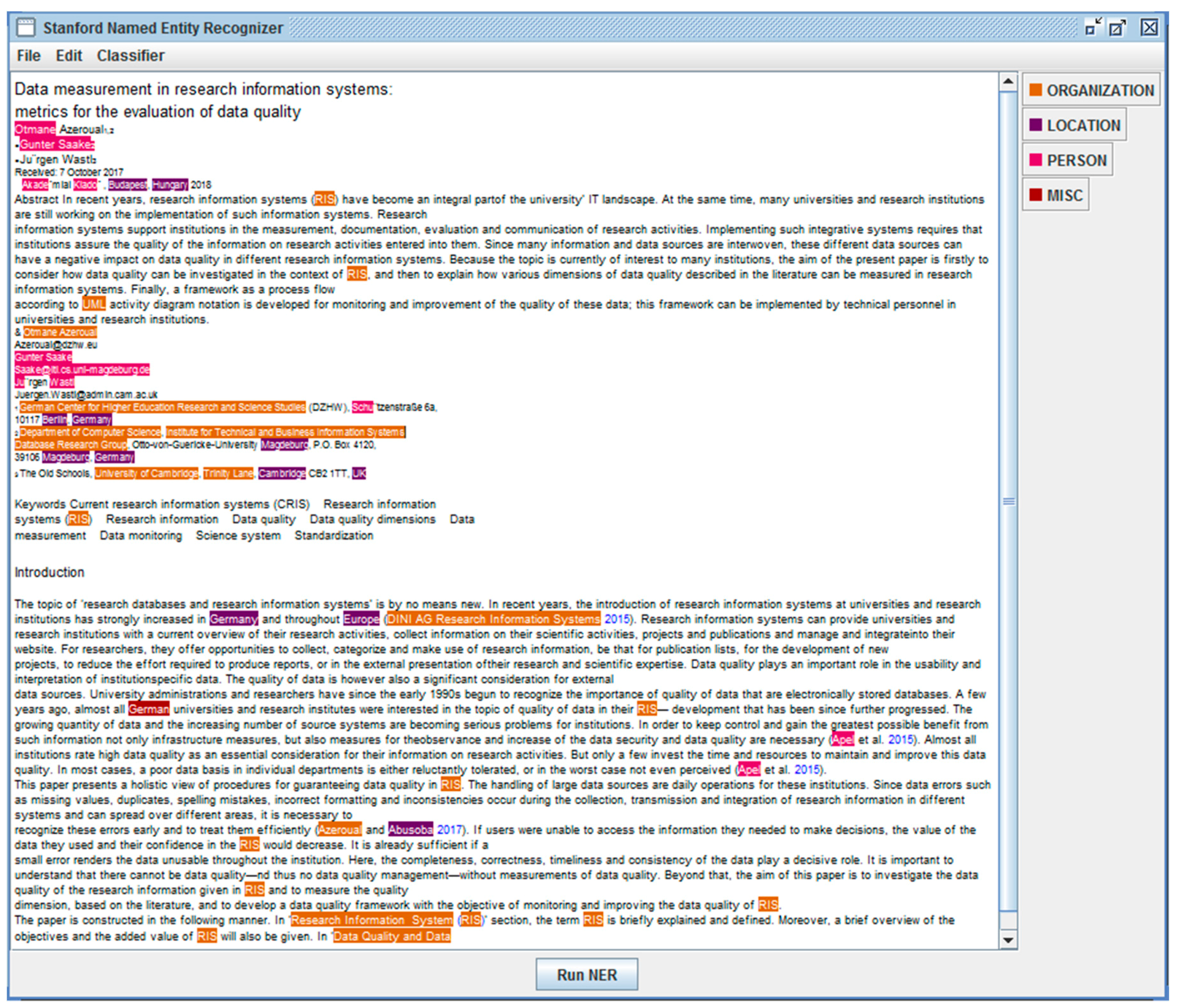
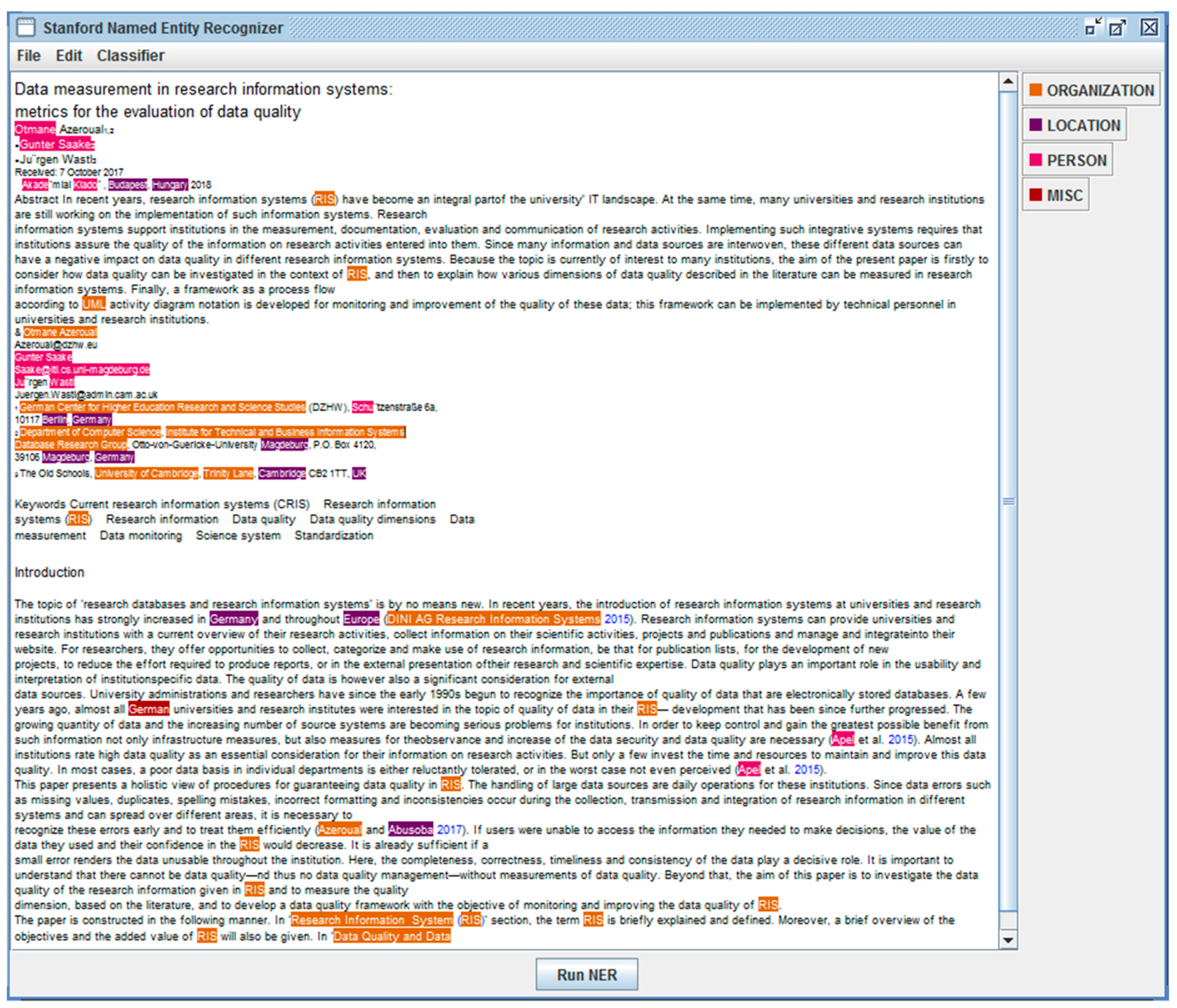
3.2. Information Extraction (IE)
- Named Entities (ENAMEX) with PERSON, LOCATION, and ORGANIZATION;
- Time expressions (TIMEX) with DATE and TIME;
- Number expressions (NUMEX) with MONEY (financial terms) and PERCENT (percentages).
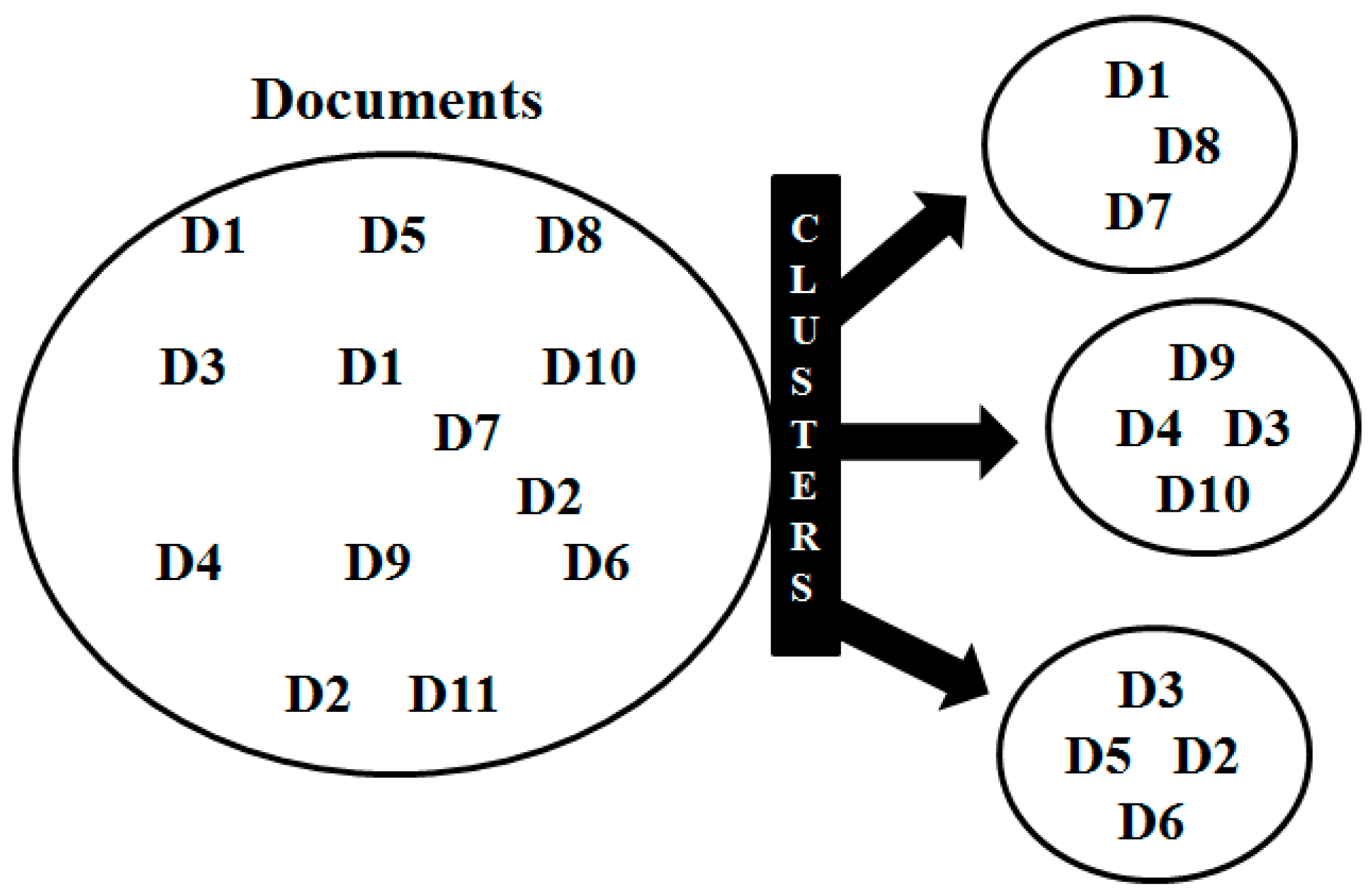
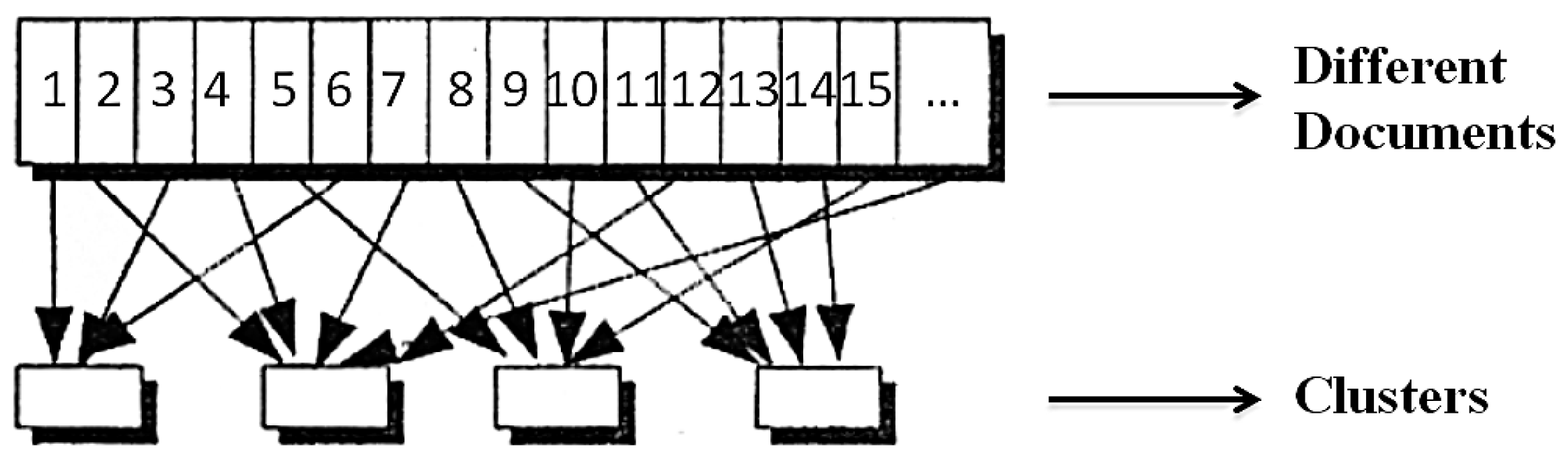
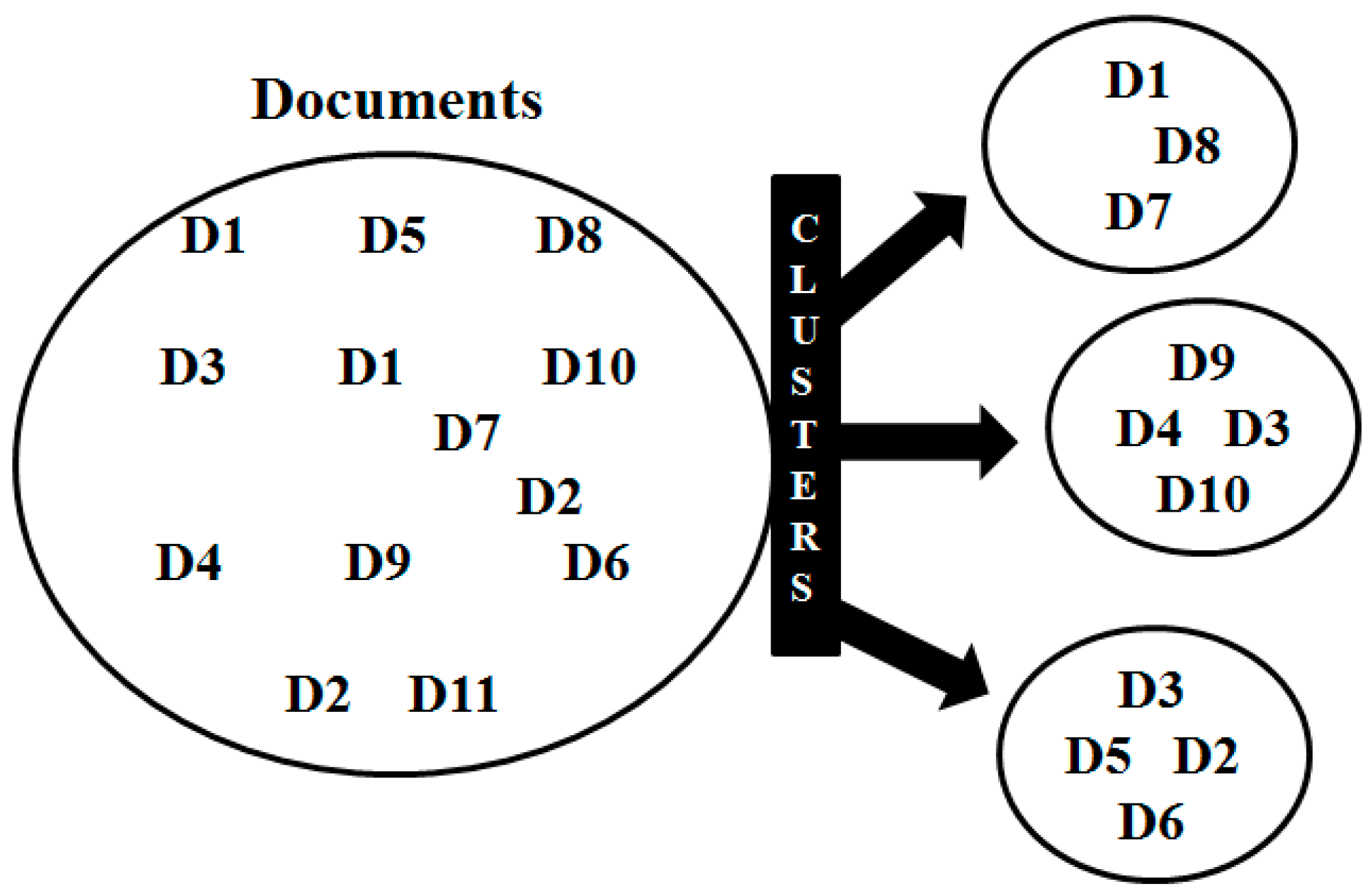
3.3. Clustering
- Preparation of data.
- Determination of similarities between data objects or document representations.
- Grouping of data objects or document representations.
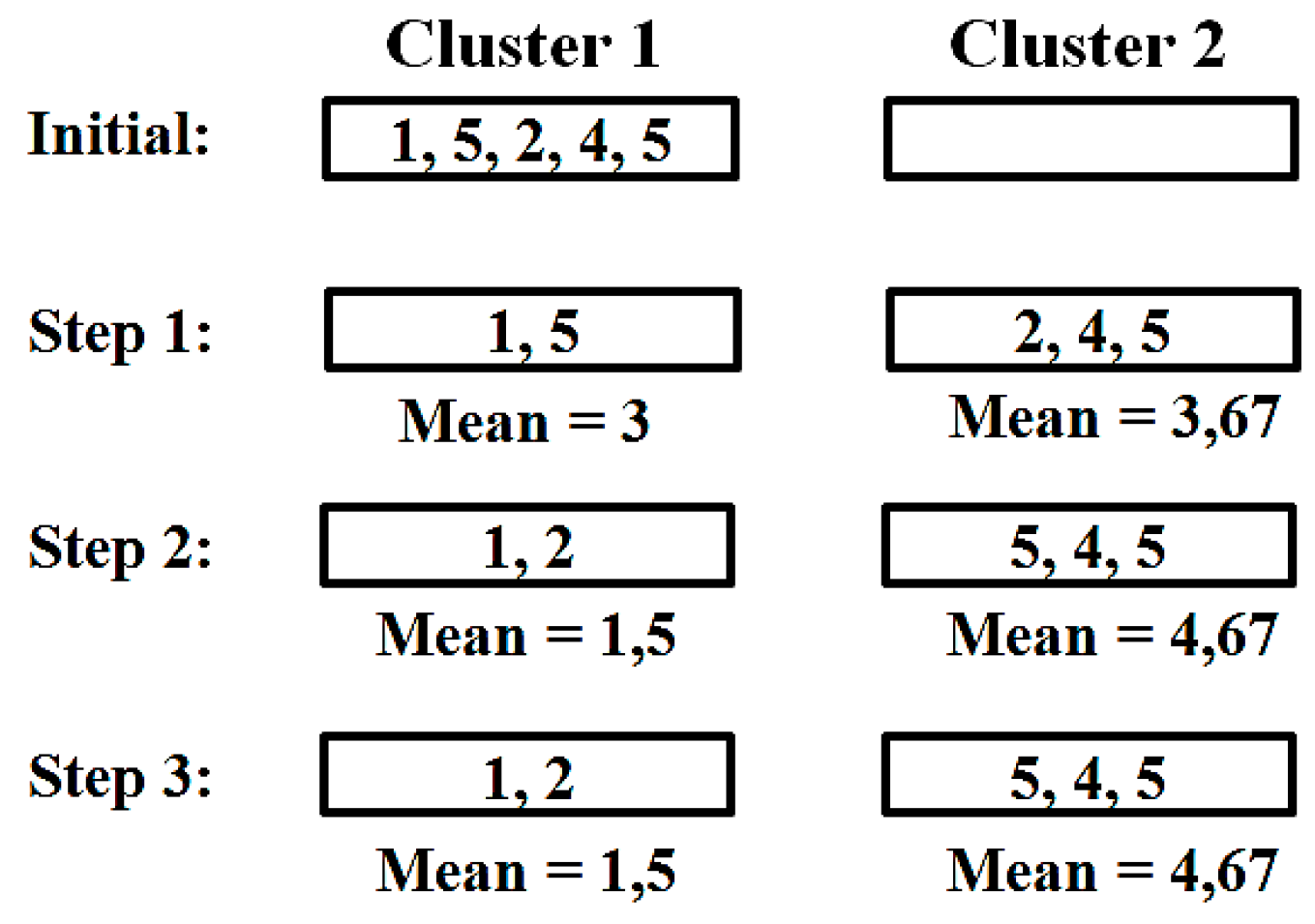
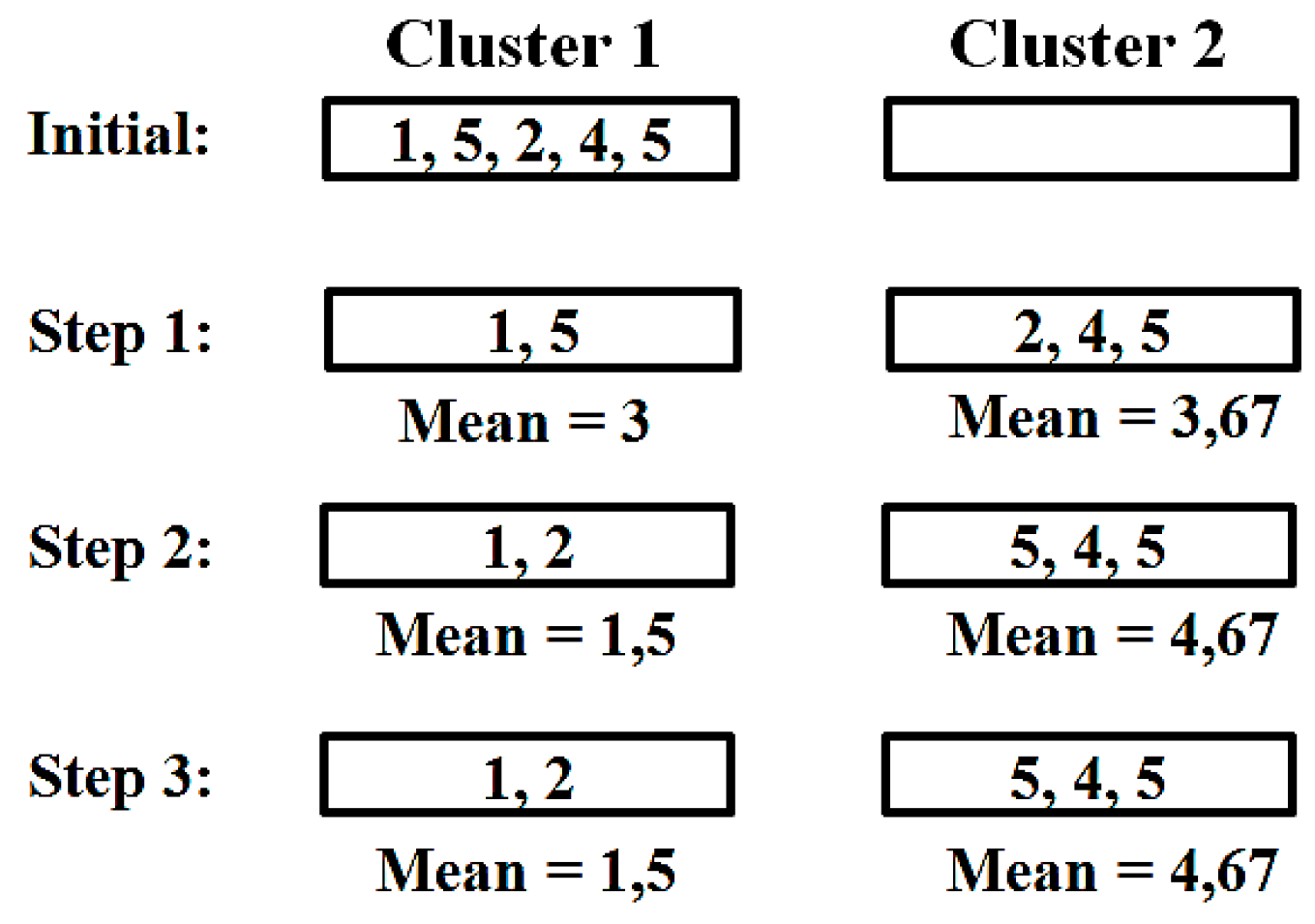
- Distribute all documents on k clusters.
- Compute the mean vector for each cluster using the following formula.
- Compare all documents with the average vectors of all clusters and note the most similar for each document.
- Move all documents into the most similar clusters.
- If no documents have been moved to another cluster, hold; otherwise go to point (2).
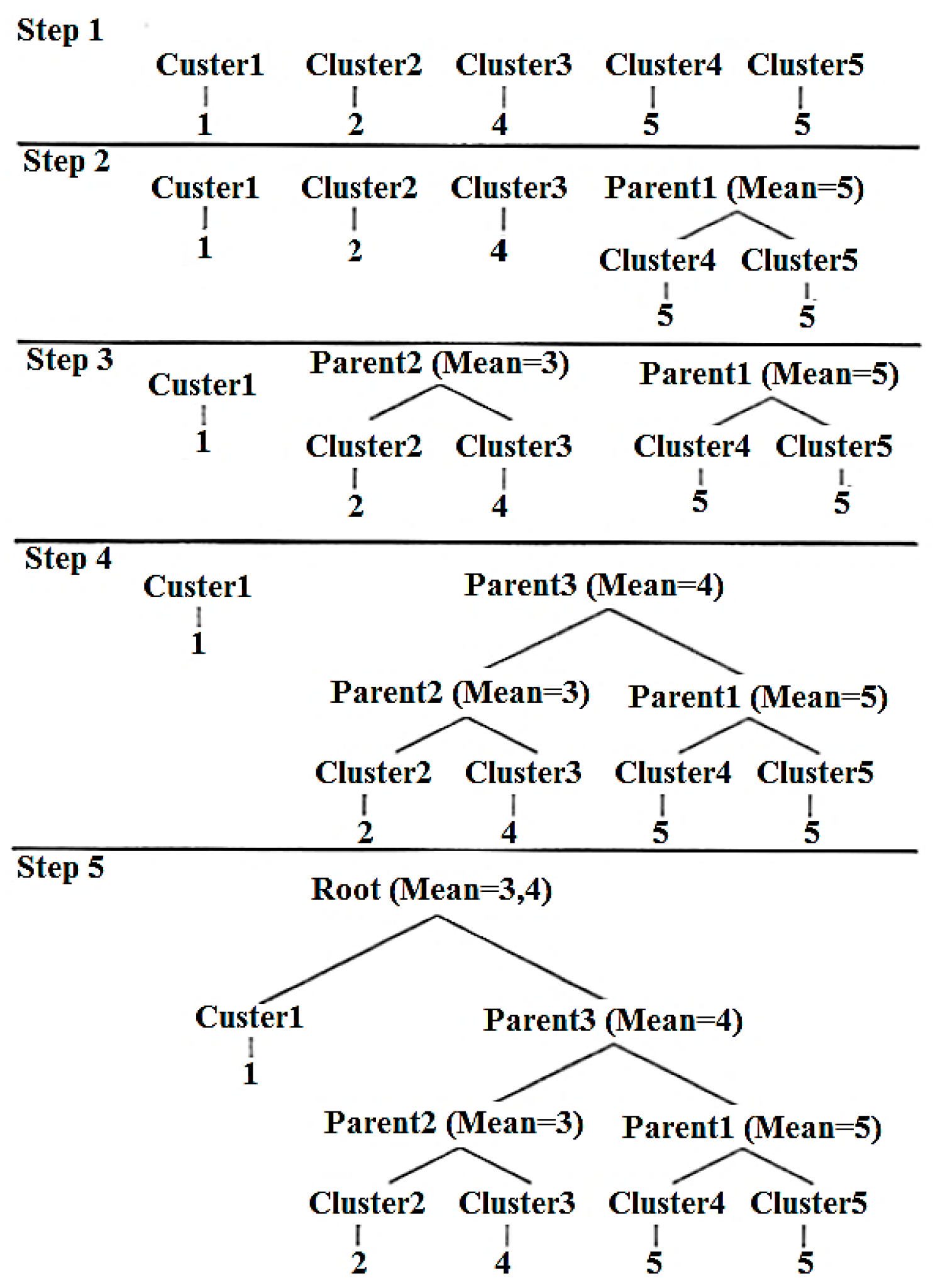
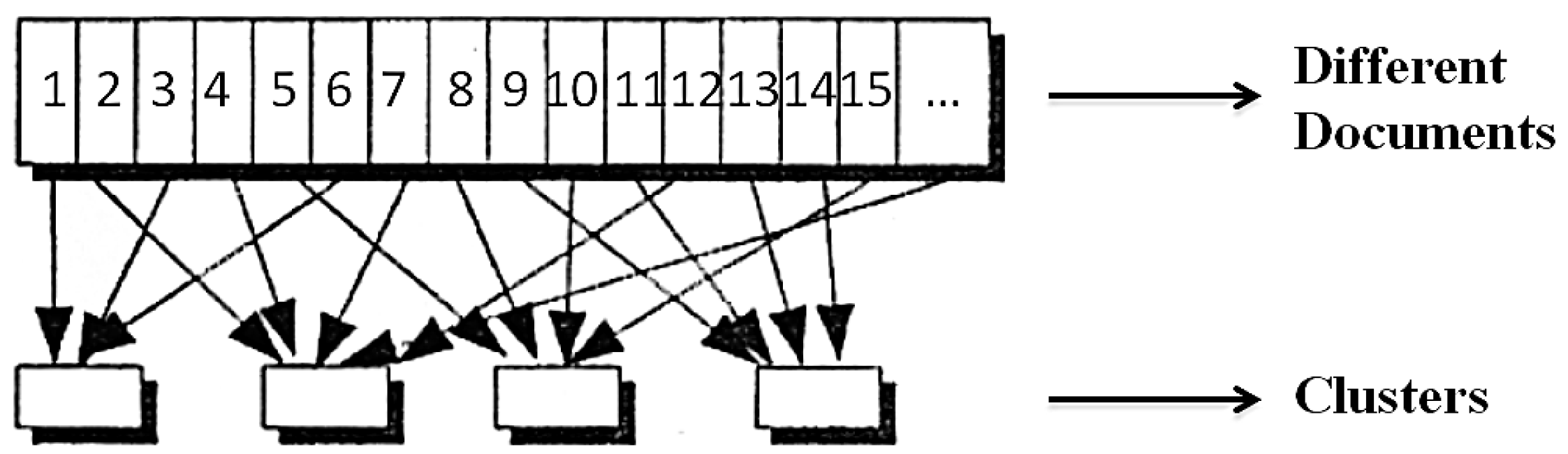
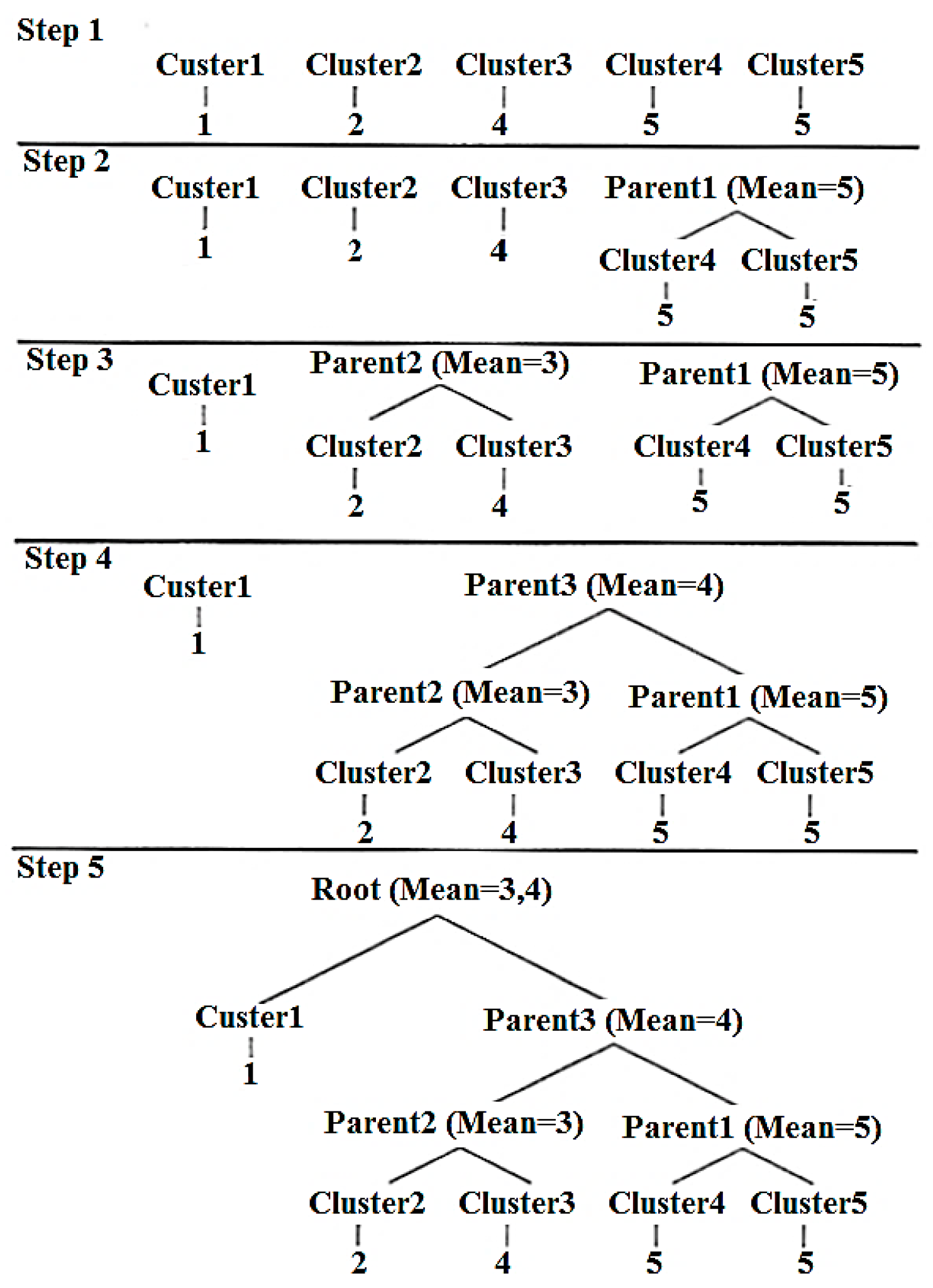
- Start with many clusters, each containing exactly one document.
- Find the most similar pair B and C of clusters that do not have a parent node.
- Combine B and C into a parent cluster A.
- If more than one cluster is left without parents, go to (2).
4. Conclusions
Funding
Conflicts of Interest
References
- Azeroual, O.; Saake, G.; Abuosba, M. Data quality measures and data cleansing for research information systems. J. Digit. Inf. Manag. 2018, 16, 12–21. [Google Scholar]
- Azeroual, O.; Saake, G.; Schallehn, E. Analyzing data quality issues in research information systems via data profiling. Int. J. Inf. Manag. 2018, 41, 50–56. [Google Scholar] [CrossRef]
- Azeroual, O.; Saake, G.; Wastl, J. Data measurement in research information systems: Metrics for the evaluation of data quality. Scientometrics 2018, 115, 1271–1290. [Google Scholar] [CrossRef]
- Azeroual, O.; Schöpfel, J. Quality issues of CRIS data: An exploratory investigation with universities from twelve countries. Publications 2019, 7, 14. [Google Scholar] [CrossRef]
- Azeroual, O. A text and data analytics approach to enrich the quality of unstructured research information. Comput. Inf. Sci. 2019, 12, 84–95. [Google Scholar] [CrossRef]
- Azeroual, O.; Abuosba, M. Improving the data quality in the research information systems. Int. J. Comput. Sci. Inf. Secur. 2017, 15, 82–86. [Google Scholar]
- Azeroual, O.; Saake, G.; Abuosba, M.; Schöpfel, J. Text data mining and data quality management for research information systems in the context of open data and open science. In Proceedings of the 3rd International Colloquium on Open Access—Open Access to Science Foundations, Issues and Dynamics, Rabat, Morocco, 28–30 November 2018; pp. 29–46. [Google Scholar]
- Azeroual, O.; Saake, G.; Abuosba, M.; Schöpfel, J. Quality of research information in RIS databases: A multidimensional approach. In Proceedings of the 22nd International on Business Information Systems, BIS 2019, Seville, Spain, 26–28 June 2019; Volume 353, pp. 337–349. [Google Scholar]
- Mehler, A.; Wolff, C. Perspektiven und Positionen des Text Mining. LDV Forum 2005, 20, 1–18. [Google Scholar]
- Nahm, U.Y.; Mooney, R.J. Text mining with information extraction. In Proceedings of the AAAI-2002 Spring Symposium on Mining Answers from Texts and Knowledge Bases, Stanford, CA, USA, 25–27 March 2002. [Google Scholar]
- Rajman, M.; Besançon, R. Text mining: Natural language techniques and text mining applications. In Proceedings of the Data Mining and Reverse Engineering. IFIP—The International Federation for Information Processing, Leysin, Switzerland, 7–10 October 1998; Springer: Boston, MA, USA, 1998; pp. 50–64. [Google Scholar]
- Feldman, R.; Sanger, J. The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Wang, R.Y.; Strong, D.M. Beyond accuracy: What data quality means to data consumers. J. Manag. Inf. Syst. 1996, 12, 5–33. [Google Scholar] [CrossRef]
- Redman, T.C. Data Driven: Profiting from your Most Important Business Asset; Harvard Business Publishing: Brighton, MA, USA, 2013. [Google Scholar]
- Redman, T.C. Data quality management past, present, and future: Towards a management system for data. In Handbook of Data Quality; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Aggarwal, C.C.; Zhai, C.X. Mining Text Data; Springer: Berlin, Germany, 2012. [Google Scholar]
- Feldman, R.; Dagan, I. Knowledge discovery in textual databases (KDT). In Proceedings of the First International Conference on Knowledge Discovery and Data Mining (KDD-95), Montreal, QC, Canada, 20–21 August 1995; AAAI Press: Palo Alto, CA, USA, 1995; pp. 112–117. [Google Scholar]
- Van der Aalst, W. Process Mining: Discovery, Conformance and Enhancement of Business Processes; Springer: Berlin, Germany, 2011. [Google Scholar]
- He, W. Improving user experience with case-based reasoning systems using text mining and Web 2.0. Expert Syst. Appl. 2013, 40, 500–507. [Google Scholar] [CrossRef]
- Natarajan, M. Role of text mining in information extraction and information management. DESIDOC Bull. Inf. Technol. 2005, 25, 31–38. [Google Scholar] [CrossRef]
- Kao, A.; Poteet, S. (Hrsg.): Natural Language Processing and Text Mining; 1. Auflage; Springer: London, UK, 2007; pp. 1–7. [Google Scholar]
- Miller, T.W. Data and Text Mining; Internat. ed.; Pearson Prentice Hall: Upper Saddle River, NJ, USA, 2005. [Google Scholar]
- Weiss, S.; Indurkhya, N.; Zhang, T. Fundamentals of PreZdictive Text Mining; Springer: London, UK; New York, NY, USA, 2010. [Google Scholar]
- Asahara, M.; Matsumoto, Y. Japanese named entity extraction with redundant morphological analysis. In Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology, NAACL’03, Edmonton, AB, Canada, 27 May–1 June 2003; Volume 1, pp. 8–15. [Google Scholar]
- Collins, M.; Singer, Y. Unsupervised models for named entity classification. In Proceedings of the Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora, College Park, MD, USA, 21–22 June 1999; pp. 100–110. [Google Scholar]
- Cucerzan, S.; Yarowsky, D. Language independent NER using a unified model of internal and contextual evidence. In Proceedings of the 6th Conference on Natural Language Learning, COLING’02, Stroudsburg, PA, USA, 31 August 2002; Volume 20, pp. 1–4. [Google Scholar]
- McCallum, A.; Li, W. Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, CONLL’03, Edmonton, AB, Canada, 27 May–1 June 2003; Volume 4, pp. 188–191. [Google Scholar]
- Nadeau, D.; Sekine, S. A survey of named entity recognition and classification. Linguist. Investig. 2007, 30, 3–26. [Google Scholar]
- Rao, D.; McNamee, P.; Dredze, M. Entity linking: Finding extracted Entities in a knowledge base. In Multi-Source, Multilingual Information Extraction and Summarization. Theory and Applications of Natural Language Processing; Springer: Berlin/Heidelberg, Germany, 2012; Volume 18, pp. 93–115. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media: Newton, MA, USA, 2009. [Google Scholar]
- Cassisi, C.; Montalto, P.; Aliotta, M.; Cannata, A.; Pulvirenti, A. Similarity measures and dimensionality reduction techniques for time series data mining. In Advances in Data Mining Knowledge Discovery and Application; Karahoca, A., Ed.; IntechOpen: London, UK, 2012. [Google Scholar]
- Yadav, N.; Kobren, A.; Monath, N.; McCallum, A. Supervised hierarchical clustering with exponential linkage. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; Volume 97, pp. 6973–6983. [Google Scholar]
- Gan, Q.; Wei, W.C.; Johnstone, D. A faster estimation method for the probability of informed trading using hierarchical agglomerative clustering. Quant. Financ. 2015, 15, 1805–1821. [Google Scholar] [CrossRef]
- Ieva, C.; Gotlieb, A.; Kaci, S.; Lazaar, N. Discovering program topoi via hierarchical agglomerative clustering. IEEE Trans. Reliab. 2019, 67, 73–80. [Google Scholar] [CrossRef]
- Tie, J.; Chen, W.; Sun, C.; Mao, T.; Xing, G. The application of agglomerative hierarchical spatial clustering algorithm in tea blending. Clust. Comput. 2018, 22, 6059–6068. [Google Scholar] [CrossRef]
- Xu, Z.; Xuan, J.; Lui, J.; Cui, X. MICHAC: Defect prediction via feature selection based on maximal information coefficient with hierarchical agglomerative clustering. In Proceedings of the IEEE 23rd International Conference on Software Analysis, Evaluation and Reengineering (SANER), Suita, Japan, 14–18 March 2016. [Google Scholar]
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Azeroual, O. Text and Data Quality Mining in CRIS. Information 2019, 10, 374. https://doi.org/10.3390/info10120374
Azeroual O. Text and Data Quality Mining in CRIS. Information. 2019; 10(12):374. https://doi.org/10.3390/info10120374
Chicago/Turabian StyleAzeroual, Otmane. 2019. "Text and Data Quality Mining in CRIS" Information 10, no. 12: 374. https://doi.org/10.3390/info10120374
APA StyleAzeroual, O. (2019). Text and Data Quality Mining in CRIS. Information, 10(12), 374. https://doi.org/10.3390/info10120374