1. Introduction
We are currently witnessing the rise of the Internet of Things (IoT) paradigm as a result of the proliferation of the number and type of internet-connected devices. IoT deployments with the highest business value are in most cases found in the scope of industrial environments and are conveniently called Industrial IoT (IIoT) deployments. IIoT is the cornerstone of the fourth industrial revolution (Industry 4.0), which is characterized by the digitization of physical processes in industrial environments such as manufacturing shop floors, energy plants and oil refineries. The latter digitization is primarily based on the deployment of Cyber Physical Systems (CPS), such as sensors, automation devices and smart objects like drones and automated guided vehicles.
The vast majority of IIoT use cases involve collection and processing of data from a variety of distributed data sources, including processing and analytics over data streams with very high ingestion rates. As a prominent example, predictive maintenance applications involve the application of machine learning and artificial intelligence algorithms over multisensory data (e.g., vibration, temperature, ultrasonic, thermal imaging) towards predicting the end of life of machines and equipment. Likewise, Zero Defect Manufacturing (ZDM) applications analyze large amounts of digital data from various automation devices in order to proactively identify the causes of defects. As another example, digital twin applications apply advanced analytics over real and simulated data sources in order to experiment with what-if scenarios and take optimal production planning and industrial automation decisions. Therefore, Distributed Data Analytics (DDA) infrastructures are at the heart of IIoT systems and applications, which must deal with BigData problems, notably problems that analyze very large numbers of distributed and heterogeneous data streams that usually exhibit high velocity as well.
In this context, DDA infrastructures for IIoT applications must provide support for:
High-performance and low-latency operations, i.e., low overhead, near real-time processing of data streams.
Scalability, i.e., ability to process an arbitrarily large number of streams, with only marginal upgrades to the underlying hardware infrastructure.
Dynamicity, i.e., ability to dynamically update the results of the analytics functions, upon changes in their configuration, which is essential in cases of in volatile industrial environments where data sources may join or leave dynamically.
Stream handling, i.e., effective processing of streaming data in addition to transactional static or semi-static data (i.e., data at rest).
Configurability, i.e., flexible adaptation to different business and factory automation requirements, such as the calculation of various KPIs (Key Performance Indicators) for production processes involving various data sources on diverse industrial environments that may even leverage different streaming middleware platforms and toolkits.
The importance of streaming analytics for IoT and BigData applications has given rise to several research and industry efforts towards producing high performance stream processing engines. A first generation of streaming analytics applications used centralized stream processing engines such as Aurora [
1] and TelegraphCQ [
2]. These engines provided window-based query operators that execute continuous queries over relational data streams. They supported the relational query model (e.g., such as the CQL (Continuous Query Language) [
3]) but lacked support for parallel data processing. The increase of stream rates and query complexity drove another generation of stream processing engines, which were distributed and could harness the processing power of a cluster of stream processors. Typical examples of such systems are Borealis [
4] and InfoSphere Streams [
5], which permit parallelism for continuous queries i.e., one query can be executed on multiple machines. Such systems exploit task parallelism, i.e., they execute different operators on different machines and allow the execution of many different continuous queries in parallel.
Systems like InfoSphere Streams support intraquery parallelism, which specifies stream connections, but management and configuration is manual. This poses limitations for BigData applications, where a single continuous query must in several cases process a large volume of streaming data. To alleviate this limitation, stream processing engines that focus on intraquery parallelism emerged. The latter parallelize the execution of individual query operations. Typical examples include StreamCloud [
6] and the popular Apache S4 and Apache Storm systems, which express queries as directed acyclic graphs with parallel operators interconnect by data streams. However, these systems cannot scale out the computation at runtime and therefore are not effective in supporting unknown BigData analytics jobs when the computational resources needed are not known ahead of time. To this end, systems like Spark Streaming [
7] that parallelize streaming queries by running them on the Spark-distributed dataflow framework using microbatching have emerged. Microbatching permits the execution of streaming computations as a series of short-running Spark jobs that output incremental results based on the most recent input data. Nevertheless, these execution models have limitations when it comes to supporting sliding windows in the streaming process. In recent years, the Apache Flink engine [
8] incorporated a distributed dataflow framework that can execute data-parallel batch and streaming processing jobs on the same platform. Computation is described as dataflow graphs, which are optimized using existing database techniques. This is the reason why Apache Flink and Apache Spark are currently two of the most popular streaming engines for Big Data systems. However, these platforms assume that stream processing operators are stateless. While this simplifies scalability and failure recovery, it is a setback to expressing complex analytic tasks such as data mining and machine learning algorithms that need to refine a model incrementally. To address this problem, some of the state-of-the-art stream processing engines adopt a stateful stream processing model. This is for example the case with Apache Samza [
9] and Naiad [
10], which execute streaming operators in a data-parallel fashion. More recent streaming engines implement the concept of Stateful Dataflow Graphs (SDGs), which are graphs containing vertices that are data-parallel stream processing operators with arbitrary amounts of mutable in-memory state, and edges that represent the stream. SDGs can be executed in a pipelined fashion and have a low processing latency. When processing SDGs, the machines take checkpoints of the in-memory state of processing operators in a cluster, which are persisted to disk. Therefore, in case a machine in the cluster fails, the failed operator instances can be restored on other machines, recovering their state from the most recent checkpoint, and reprocessing buffered stream data in order to restore the operator’s state in a way that ensures it is up to date.
Recently, IIoT vendors and solution integrators make also extensive use of the Kafka Streams framework [
11], which incorporates many of the previous listed functionalities and addresses many of the stream processing challenges in IIoT environments. It supports event-at-a-time processing with millisecond latency, which alleviates the limitations of microbatching, while at the same time, providing the means for stateful processing including distributed joins and aggregations. Moreover, it supports distributed processing and failover, while at the same time offering a convenient DSL (Domain Specific Language) for defining queries.
The configurability functionalities of state-of-the-art streaming engines fall short when it comes to routing data streams across the different data producers and data consumers of IIoT environments. Indeed, most streaming engines are configured based on low-level APIs (Application Programming Interfaces), which incur significant programming effort. Moreover, zero-programming options functionalities like the Kafka Streams DSL are very versatile when there is a need to dynamically select data sources from the shop floor and to define queries over them. Nevertheless, they are not very effective when there is a need to define how data should be routed across many different data consumers (e.g., predictive analytics algorithms, digital twins) in industrial environments. In other words, they are very good for defining low-level tasks (e.g., configuration of window sizes and stateful graphs), but do not make provisions for the preprocessing and routing of the data across different producers and consumers. Likewise, they are also very much tailored to clustered environments, yet they provide no ready to use facilities for configuring and deploying streaming applications in edge computing environments, which are very common in the case of IIoT [
12]. Specifically, the concepts of edge/fog nodes and how to collect and analyze data across them are not directly supported in the configuration capabilities of state-of-the-art streaming engines.
Most important, it is quite common for IIoT environments to deploy different streaming engines and toolkits e.g., Spark, Kafka and Storm can be used for different applications running in different parts of the plant. In such cases, the need for routing data streams from different streaming middleware platforms to consumers and applications is likely to arise. Hence, there is a need for a meta-streaming engine for streaming data routing and processing, which can make sure that data streams acquired by different streaming engines are delivered in the target application. Consider for example a predictive maintenance application, which should typically combine data streams from multiple sensor-based applications, along with data streams and data at rest from business information systems (e.g., quality data from an Enterprise Resource Planning (ERP) system). The concept of such a meta-level streaming engine is perfectly in-line with edge computing systems, as the latter are likely to combine different streaming middleware platforms in their edge nodes.
Meta-level streaming functionalities can be defined by means of a domain specific language [
13], which provides versatility in configuring domain-specific data operations in ways that ease programming and lower development times [
14]. There are various DSL languages for IoT systems, which focus however on the needs of different types of systems and applications like RFID and multisensory applications for supply chain management (e.g., [
15,
16]). Moreover, there are various approaches to designing DSL, which vary in terms of efficiency [
17,
18]. Nevertheless, existing DSL do not adequately cover the domain of routing and preprocessing of heterogeneous streams for IIoT applications, which is one of the main motivations behind the work presented in this manuscript. Note also that DSLs provide a foundation for almost zero-programming applications in the domains that they target, since they can be coupled with programming environments and can be amenable by visual tools [
19]. In this context, the DSL that is presented in the paper lowers the effort required for development of IIoT data analytics applications and aligns with model driven engineering concepts and principles [
20,
21].
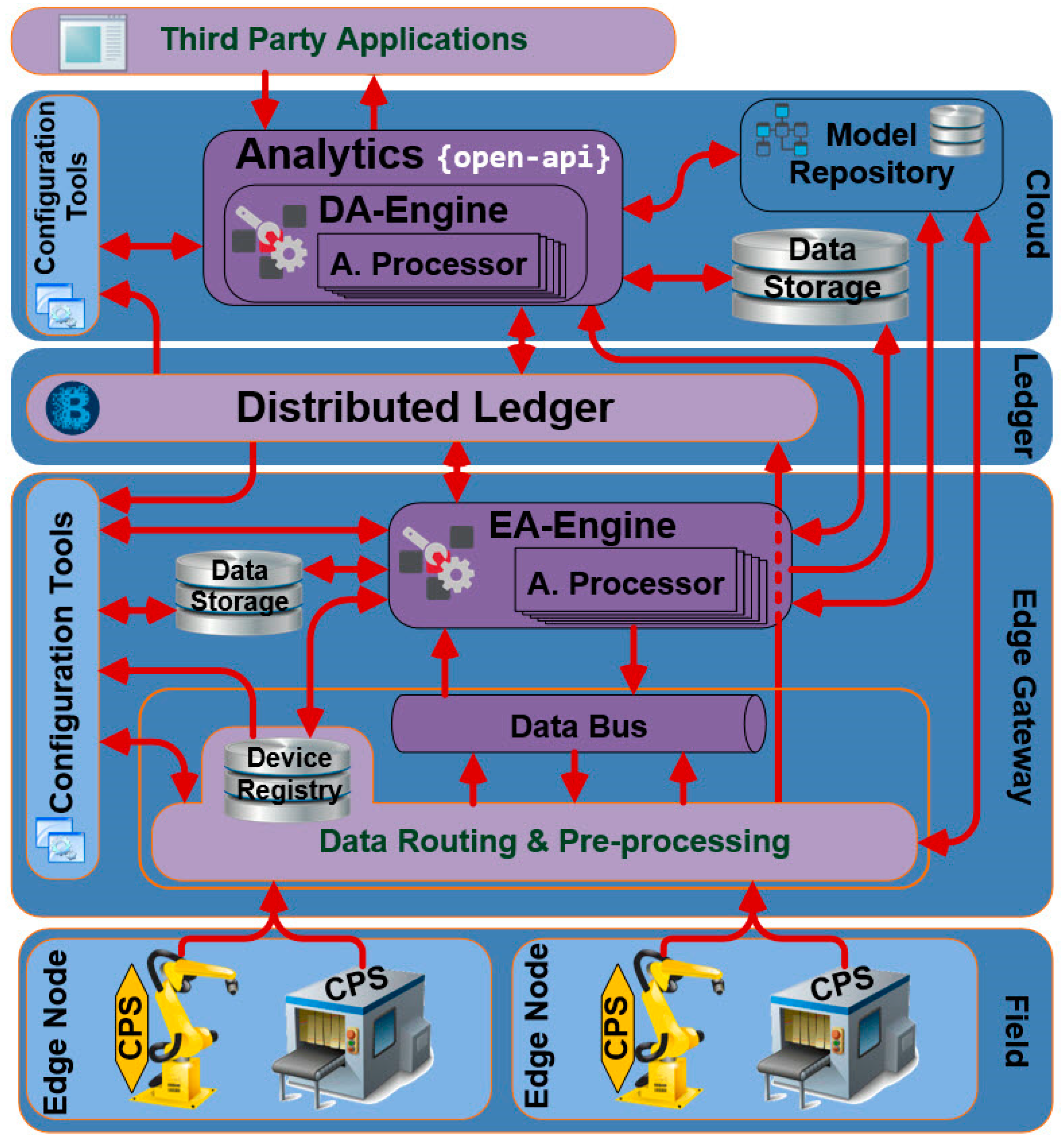
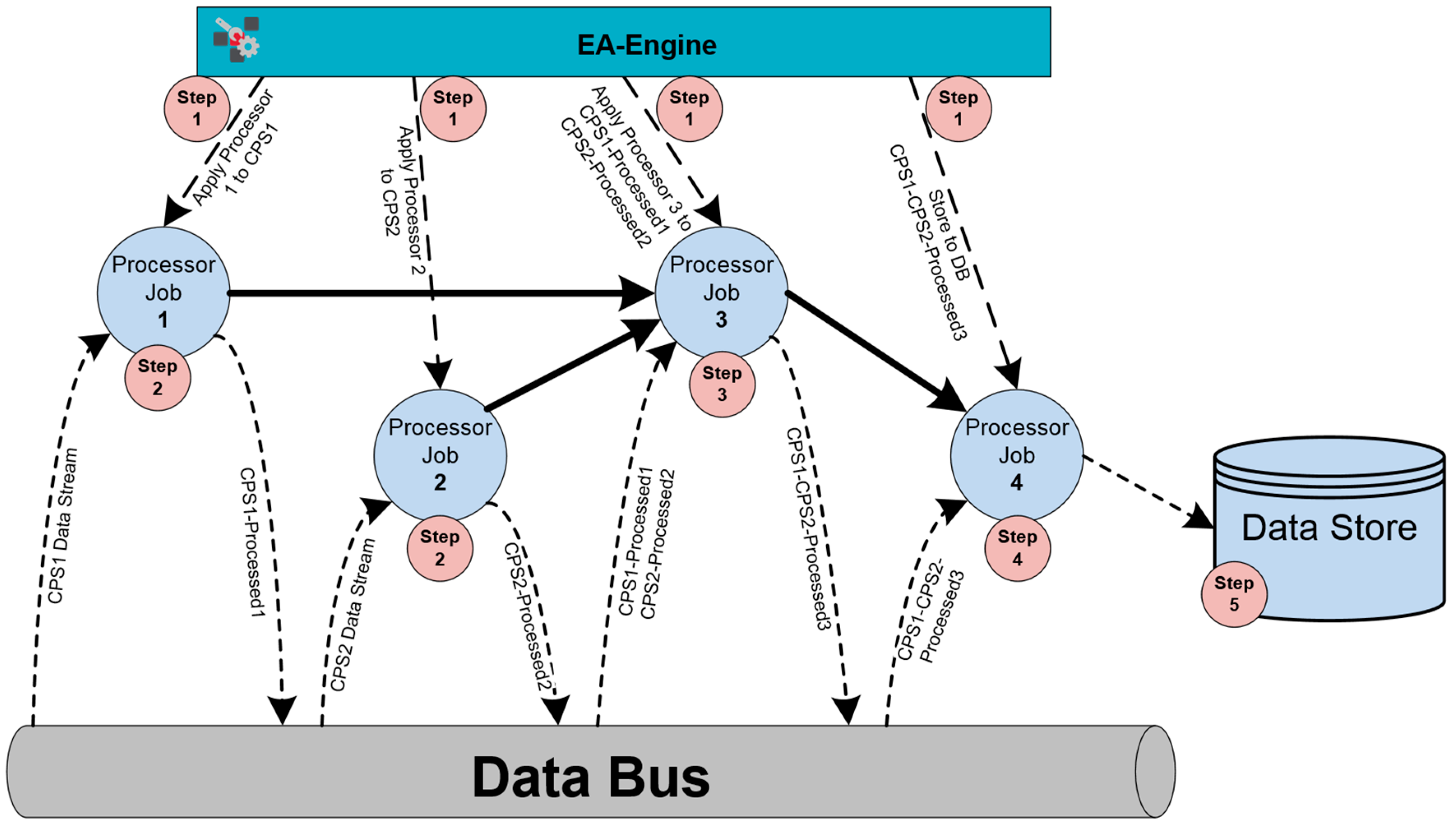
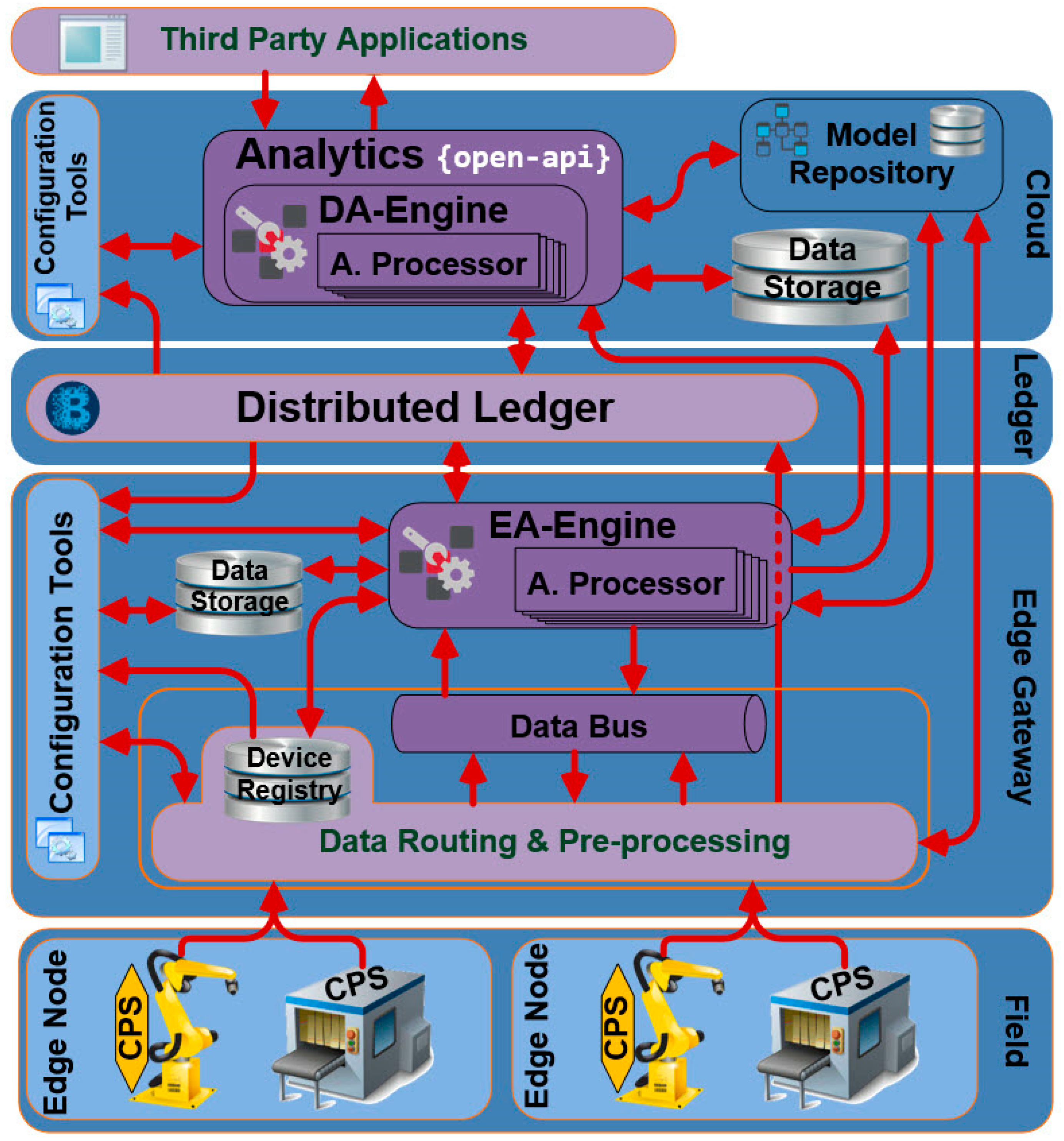
In the remaining of the paper we introduce a configurable infrastructure for distributed data analytics environments, which caters for the flexible and almost zero-programming configuration of data routing and preprocessing functions. The presented DDA (i.e., the FAR-EDGE DDA) is a meta-level streaming engine that provides the means for routing and preprocessing data streams regardless of the streaming middleware/engine used to capture them. The FAR-EDGE DDA is configurable in the scope of edge computing environments, as it defines an Edge Analytics Engine (EAE) that handles analytics within the scope of an edge node, while at the same time providing mechanisms for combining and synchronizing analytics functionalities across multiple edge nodes. The latter functionalities are very common in IIoT environments, where several processes (e.g., production scheduling, supply chain management) are likely to involve multiple stations or entire plants i.e., multiple edge nodes using different streaming middleware toolkits (e.g., Kafka or Spark). The configurability of the FAR-EDGE DDA hinges on an abstract modelling of data sources and data processing functions, along with their structuring against edge nodes, edge analytics functions and analytics spanning multiple edge nodes. The management of the respective data models is what facilitates configurability. In principle, the FAR-EDGE DDA offers its own DSL for managing routing and processing of data streams from any streaming engine (e.g., Kafka, Spark, Storm) to any type of consuming application (e.g., rule engine, machine learning, artificial intelligence). This paper is a significantly extended version of a conference paper of the co-authors. It enhances the conference paper in three main directions:
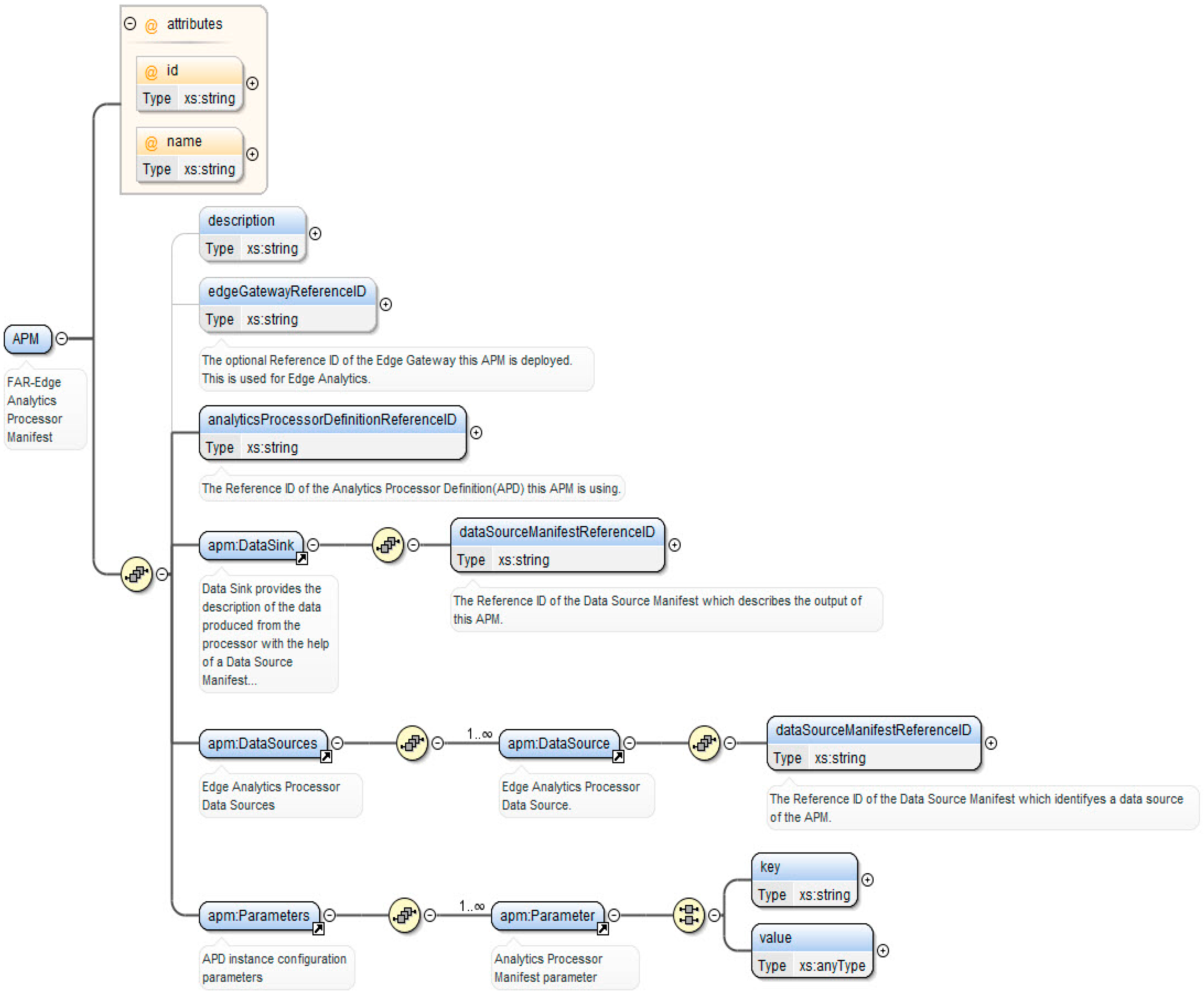
First, it introduces some of the foundational concepts of the DDA, such as the DSL for describing analytics pipelines. The latter DSL is also illustrated through a practical example.
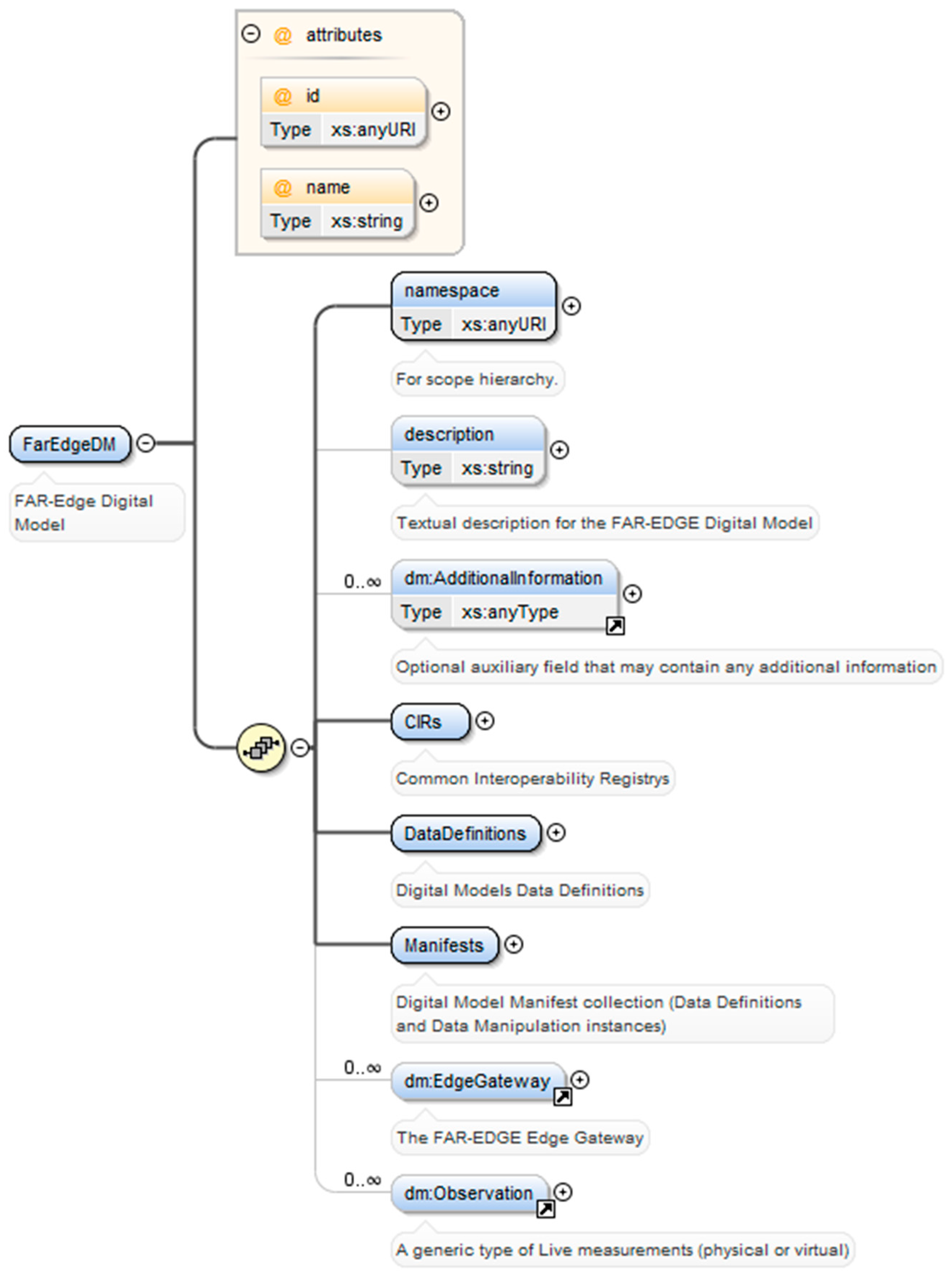
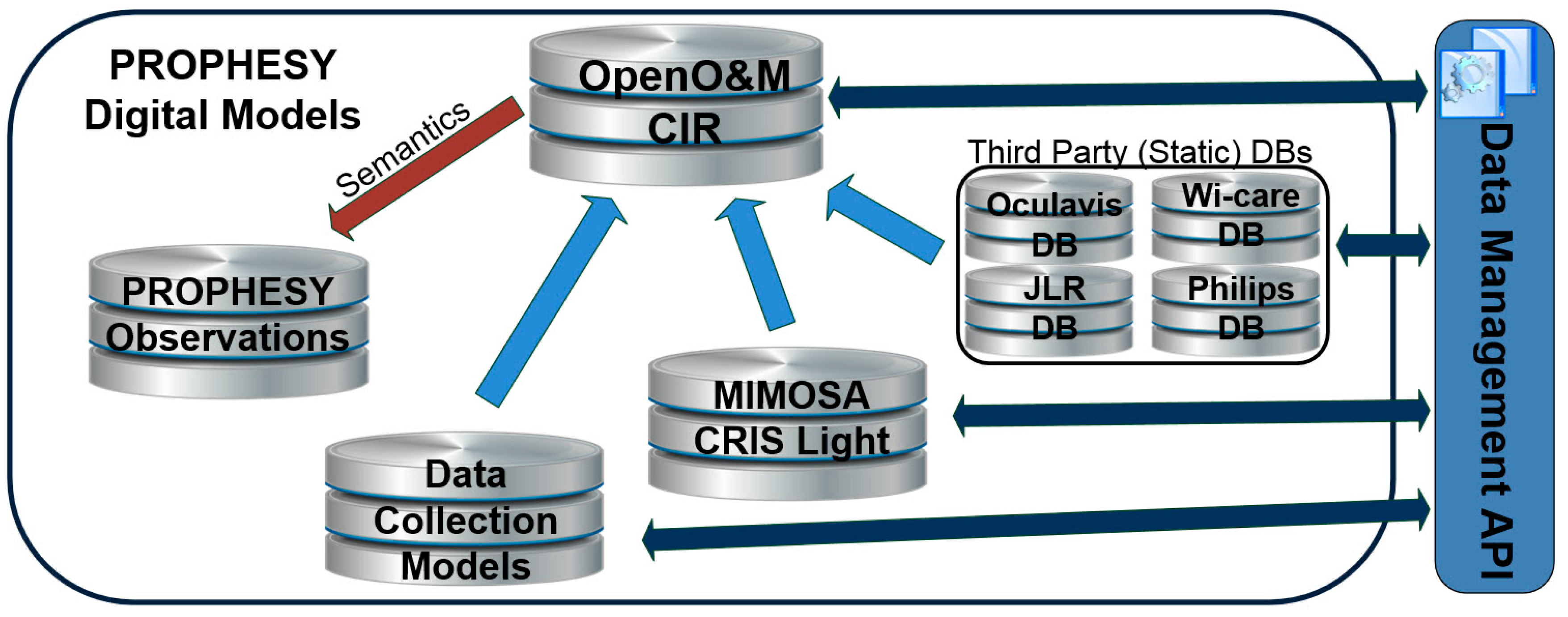
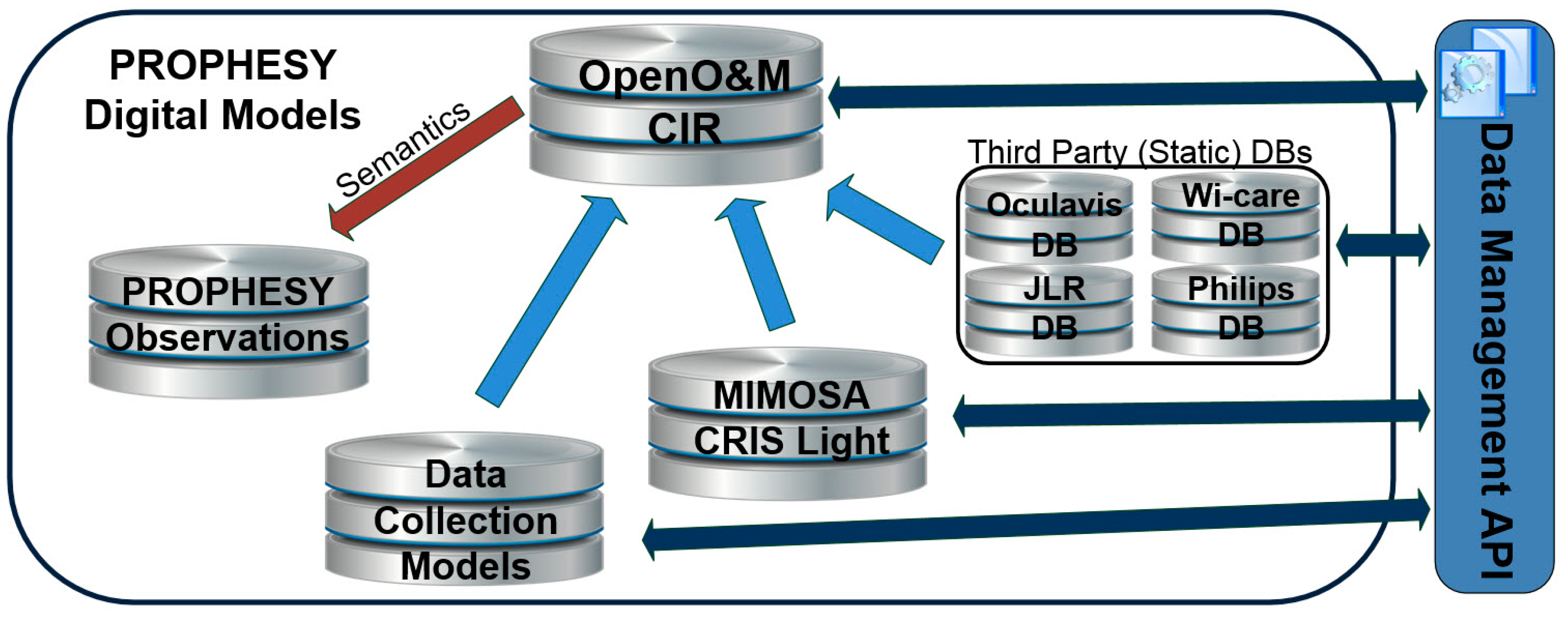
Second, it also introduces the concept of the Common Interoperability Registry (CIR) for linking data sources that are described based on other schemes, different that the project’s DSLs. The CIR concept was not part of the conference paper.
Third, it provides more details and richer information about the architecture of the DDA and its use in the scope of cloud/edge deployments.
The rest of paper is structured as follows:
Section 2 introduces the architecture, main elements and principles of operation of the DDA.
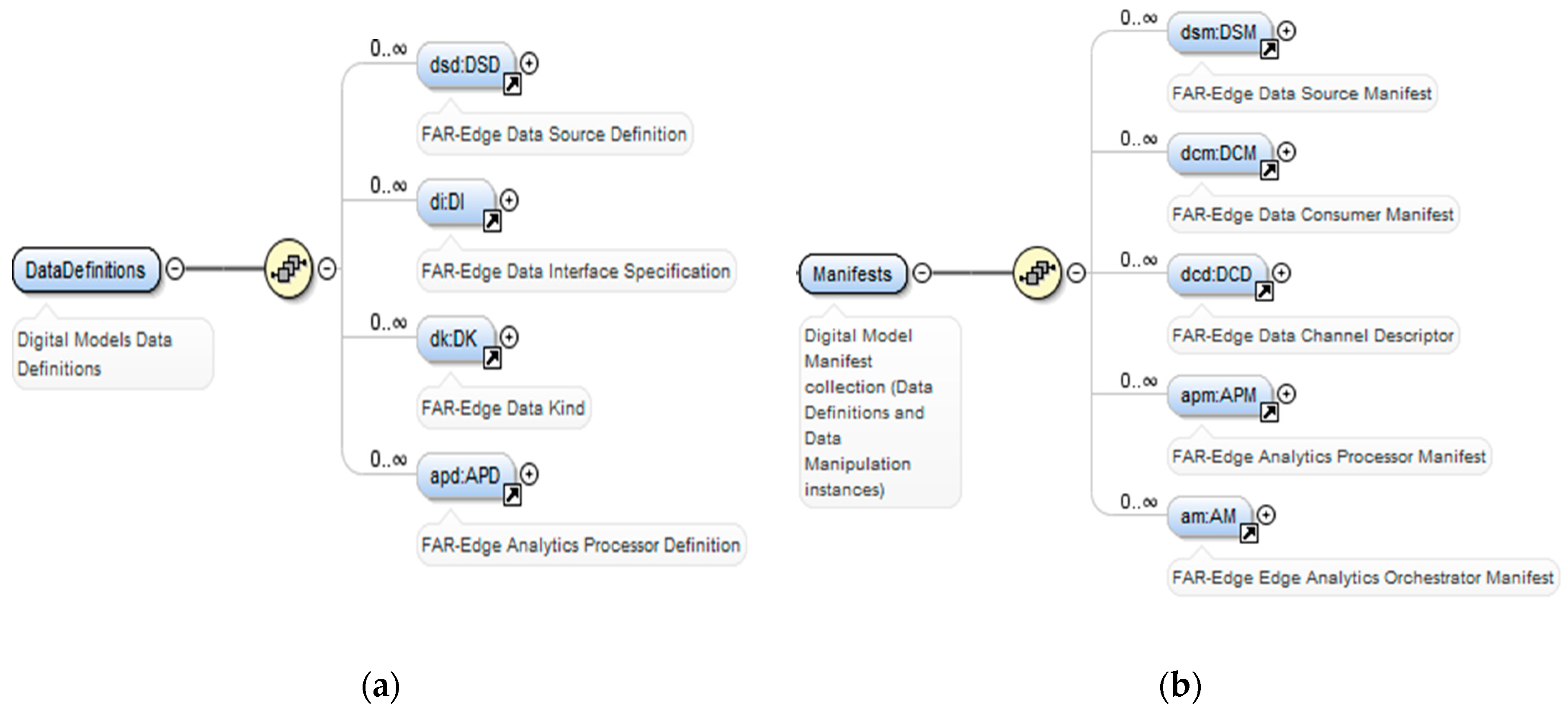
Section 3 present the underlying data models that enable its configurability, including flexible ways for ensuring the interoperability of different data sources and databases that contain data of interest to IIoT applications.
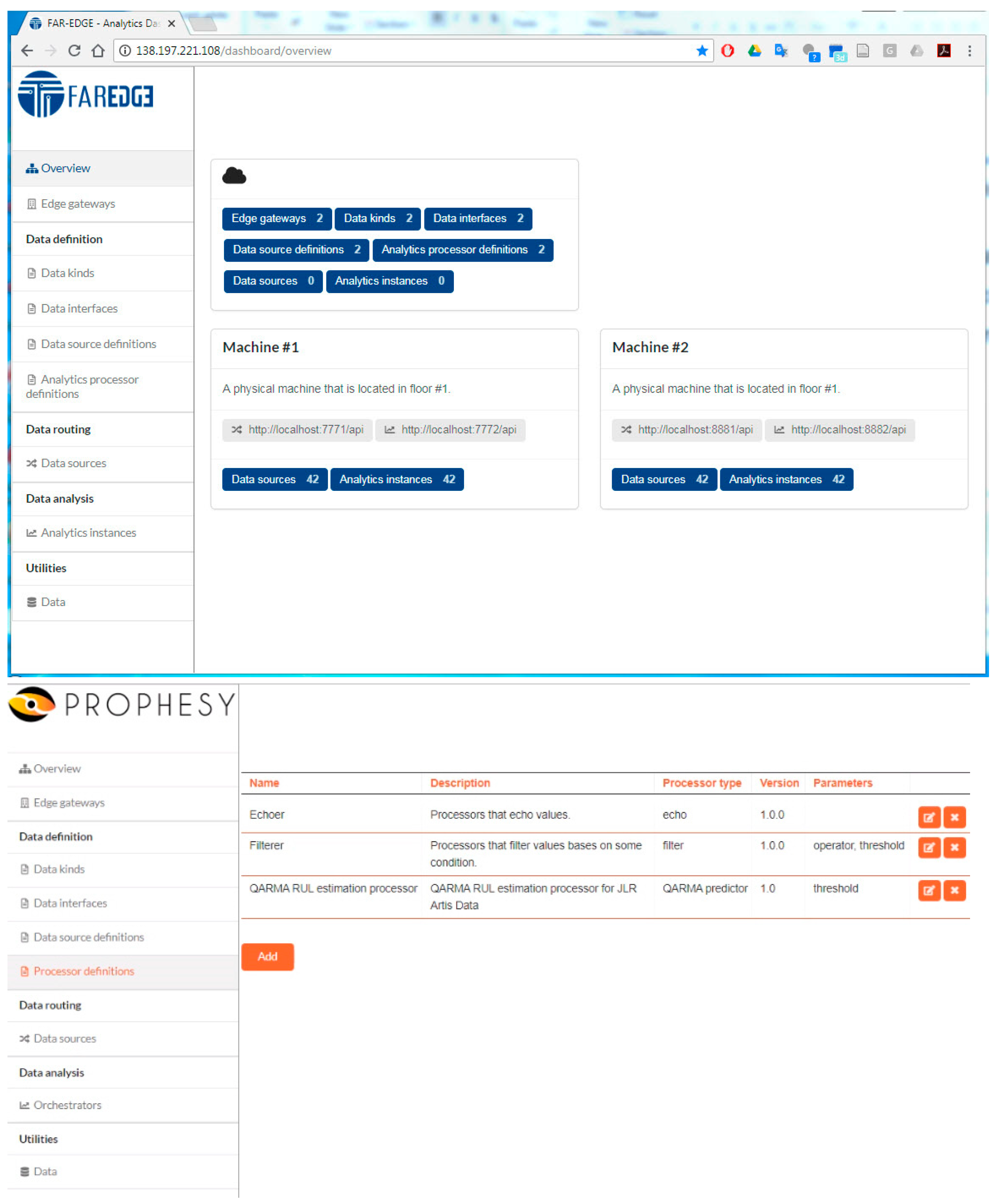
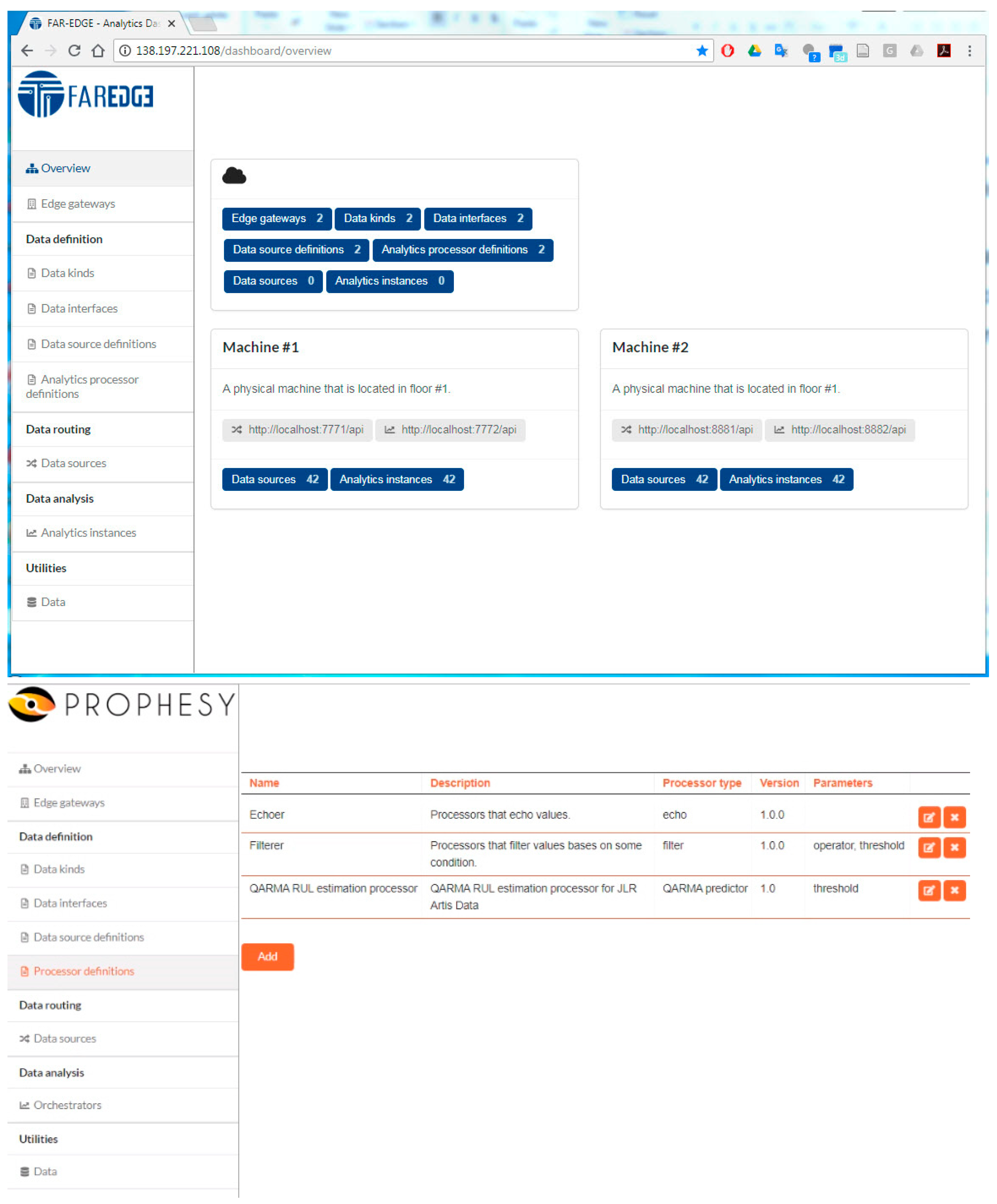
Section 4 provides information on the open source implementation of the DDA, along with its deployment in several applications. The latter applications serve as a basis for the technical validation of the DDA. Finally,
Section 5 is the concluding section of the paper.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}