A Novel Approach to Working Memory Training Based on Robotics and AI


Abstract
:1. Introduction
2. Related Work
2.1. Educational Robotics
2.2. Working Memory and the N-back Task
2.3. BDI Intelligent Agents
2.4. DDA Systems
3. Proposed System
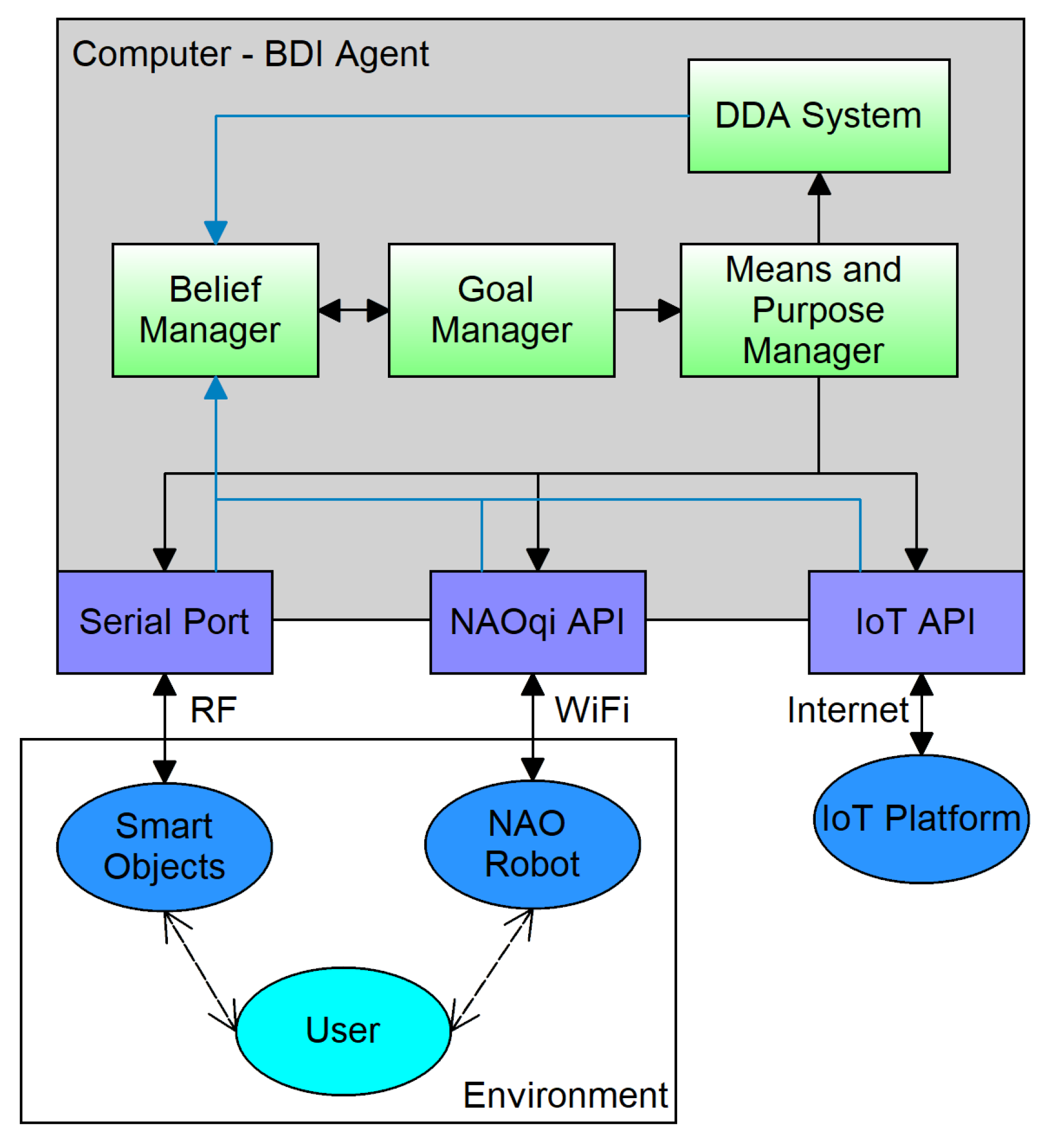
3.1. Components
- User: Obviously the user/student is the center of our system. The user can receive instructions and feedback from the robot, and physically interact with the smart objects (electronic cubes) to provide inputs to the system.
- Robot: A Nao platform running our artificial intelligence algorithm, based on BDI agents, acts as the tutor in the N-back game. The robot has movement and speech capabilities, allowing it to command instructions and provide feedback.
- Smart Objects: Four cubes that are touch-sensitive provide inputs to the system and have actuators (LEDs and buzzer) as a feedback for the user during the game. By touching one of the cubes, the robot can generate a stimulus to the user, represented by the color of the LED of the cube (red, green, blue or yellow).
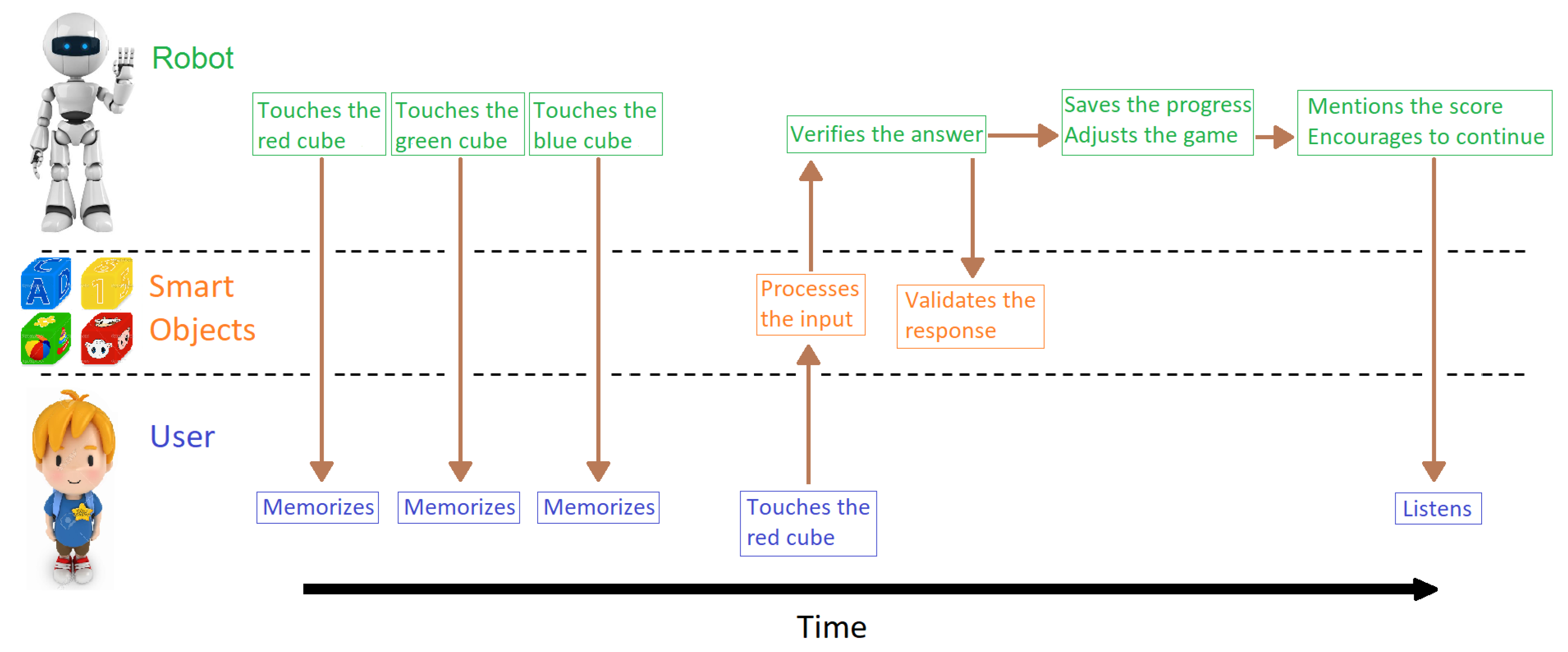
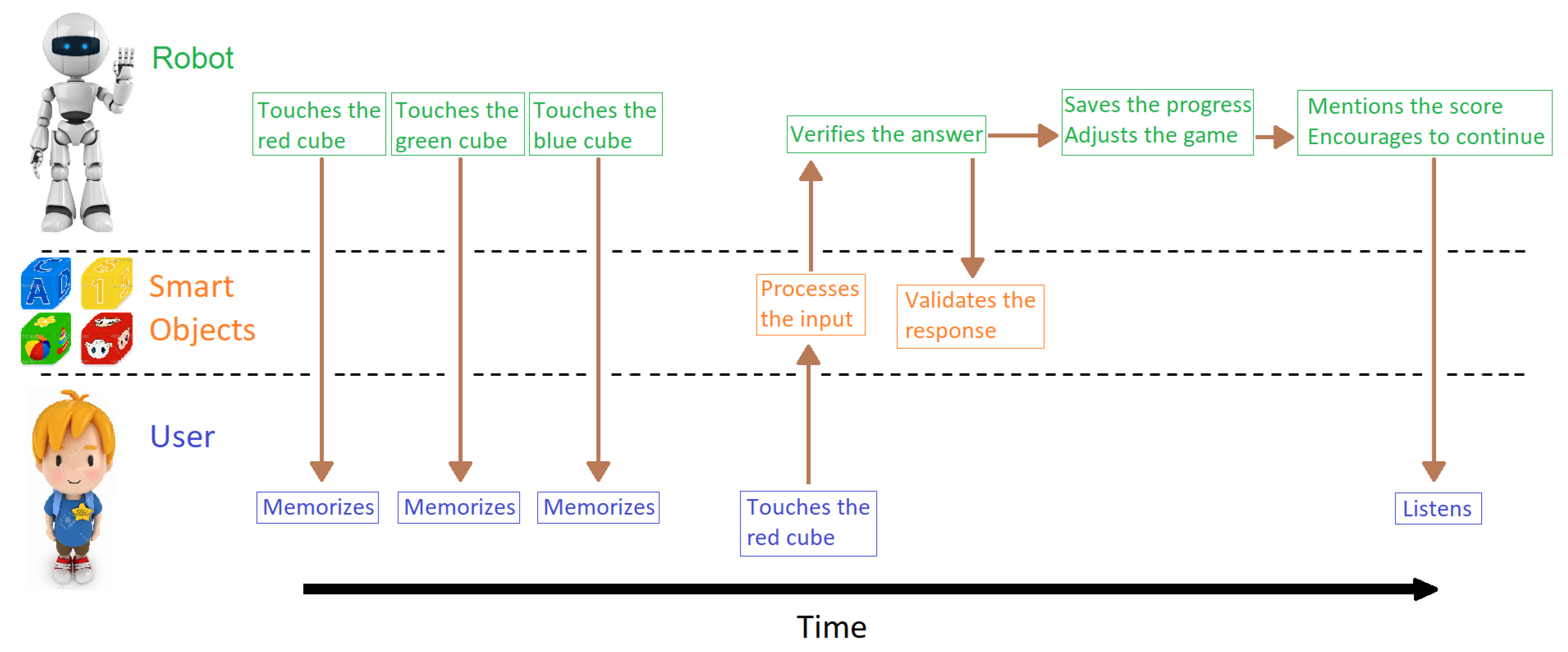
3.2. Human–Robot Interaction
- First, the robot sends a red stimulus, then a green stimulus, and finally a blue stimulus, each generated by touching the corresponding cube (smart object) with its hand. The robot mentions that now it is the user’s turn.
- Since it is a two-back game, the user must touch the red smart object to answer correctly. The smart object processes the input and sends information to the computer when it is touched.
- The system receives the information and validates the response, and sends the validation to the smart objects.
- When the round ends, the score is saved and uploaded to a central server in order to analyze the data. The robot mentions the score to the user and asks if he wants to continue with another round.
- If the answer is positive, the system uses the DDA system, also running on the computer, to adjust the parameters for a new round. On the contrary, the robots says goodbye and goes into sleep mode.
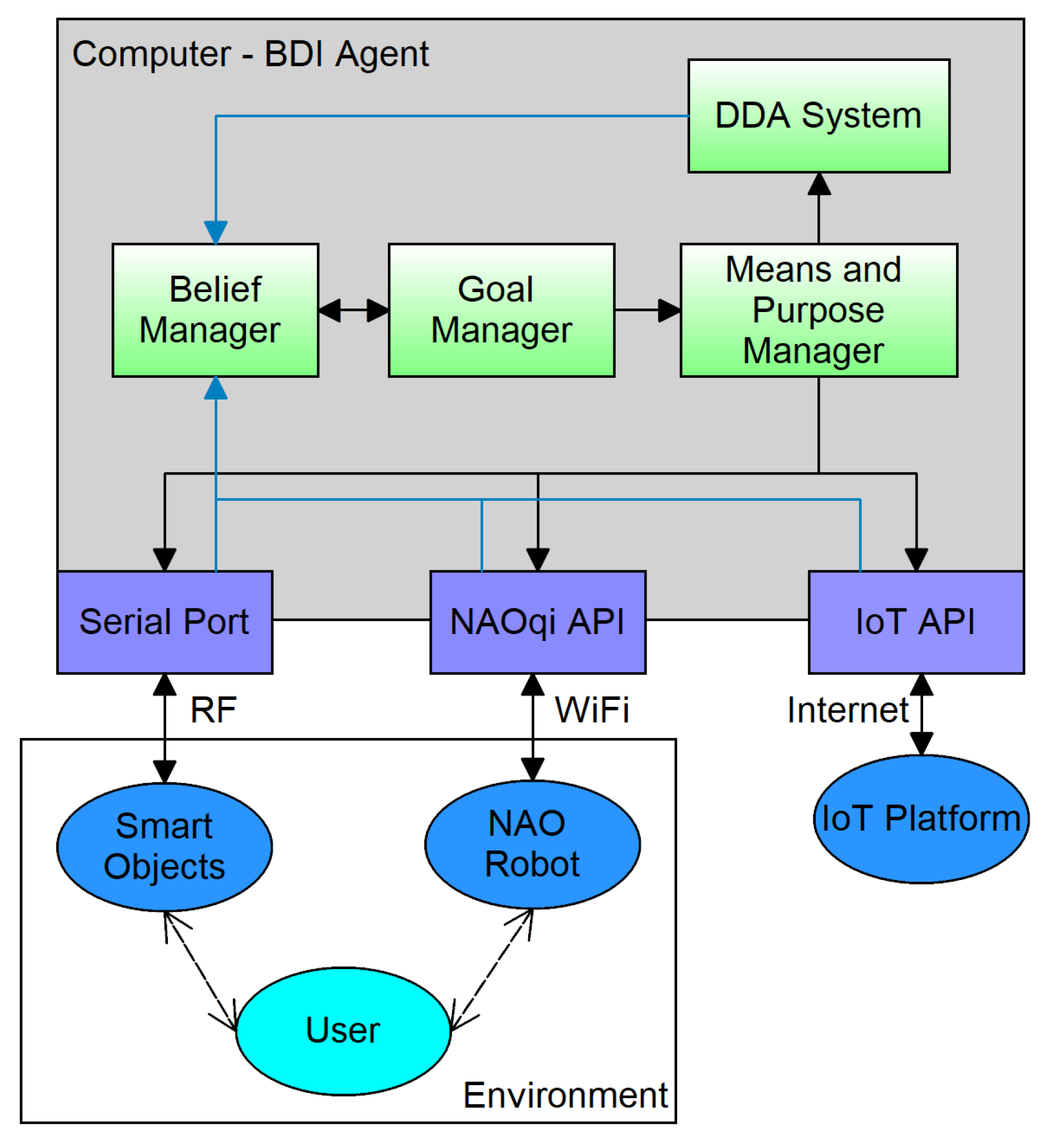
4. Design and Implementation
- The External Devices are constituted by the smart objects that receive the inputs from the user and provide feedback, and the Nao robotic platform that interacts with the user.
- The BDI Agent is composed by the belief, goal and means and purpose managers, and is in charge of the development of the N-back game and the control of the other components.
- The Fuzzy DDA System is also part of the intelligent agent, and is used to balance the levels of the game.
- The IoT Platform is incorporated to collect data on the progress of the user.
4.1. Smart Objects
4.2. BDI Agent for the N-Back Game
4.2.1. Belief Manager
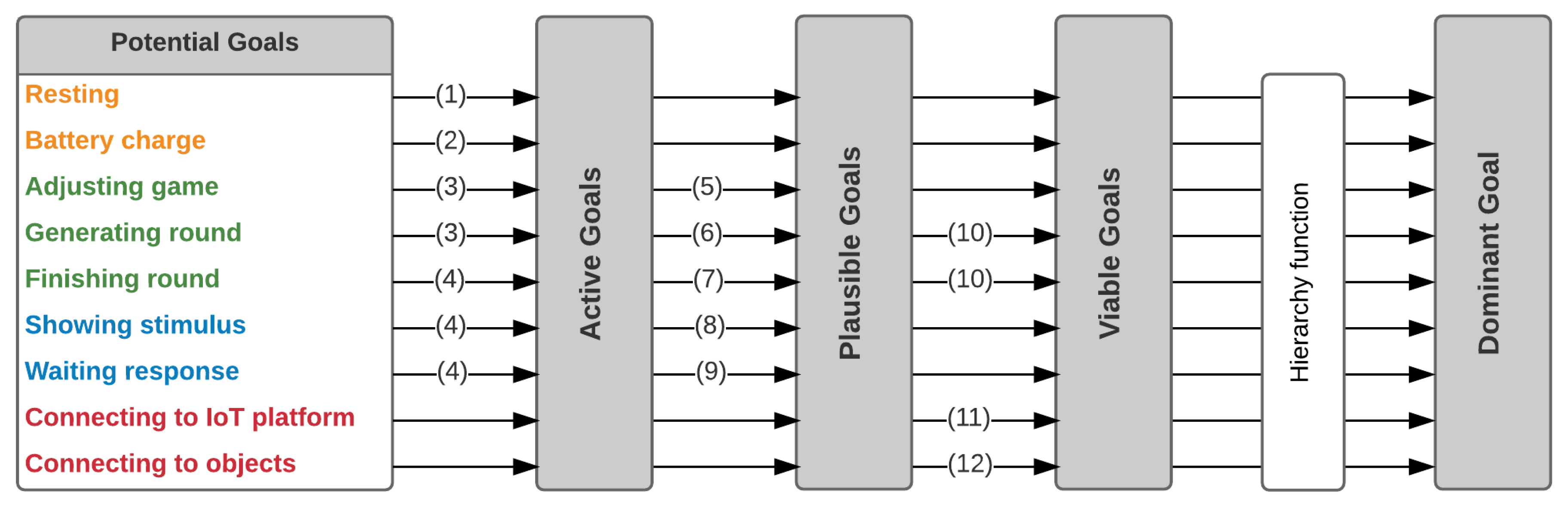
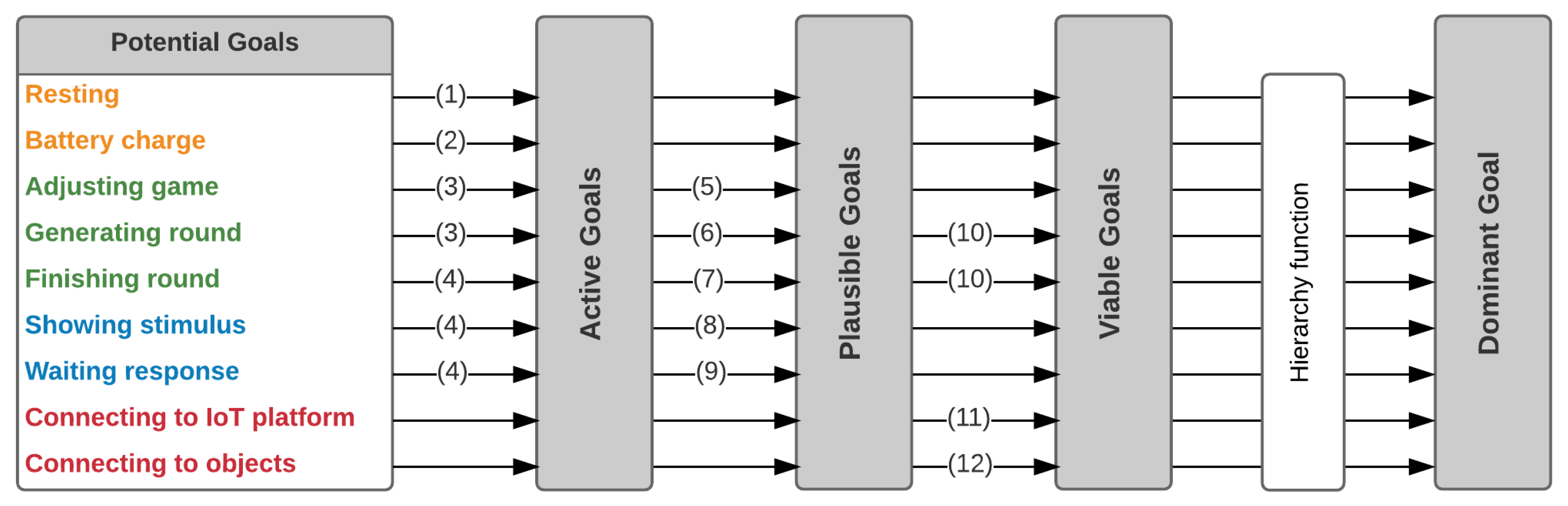
4.2.2. Goal Manager
- Survival: Resting, Battery charge.
- Obligation: Adjusting game, Generating round and Finishing round.
- Requirement: Showing stimulus, Waiting for response.
- Needs: Connecting to IoT platform, Connecting to objects and Waiting for the presence of the user.
4.2.3. Means and Purpose Manager
- Resting: The system deactivates all functions and the robot goes into idle mode.
- Battery charge: The robot mentions that its battery level is low, and requests to be plugged to a power supply if the user wants to continue playing.
- Adjusting game: The system inputs all the parameters of the last round into the DDA system to generate the new suitable parameters for the user.
- Generating round: The system takes the new parameters given by the DDA system and generates a new level.
- Finishing round: All game variables are reset and the progress of the user is uploaded to the central server.
- Showing stimulus: The robot moves its arms to touch a smart object, and the touched smart object reacts turning its LEDs on.
- Waiting for response: For a limited time, the robot waits for the user to touch one of the smart objects.
- Connecting to IoT platform: The system checks its Internet connection, and, if the connectivity is down, the robot requests the user to verify the connection.
- Connecting to objects: The system verifies its connection with the smart objects, and, if the link is down, the robot requests the user to verify the connection.
4.3. Fuzzy DDA System
4.3.1. Inputs
4.3.2. Outputs
4.3.3. Fuzzy Rules
5. Experimental Results and Analysis
5.1. Verification of the BDI Agent
5.2. Experimental Setup
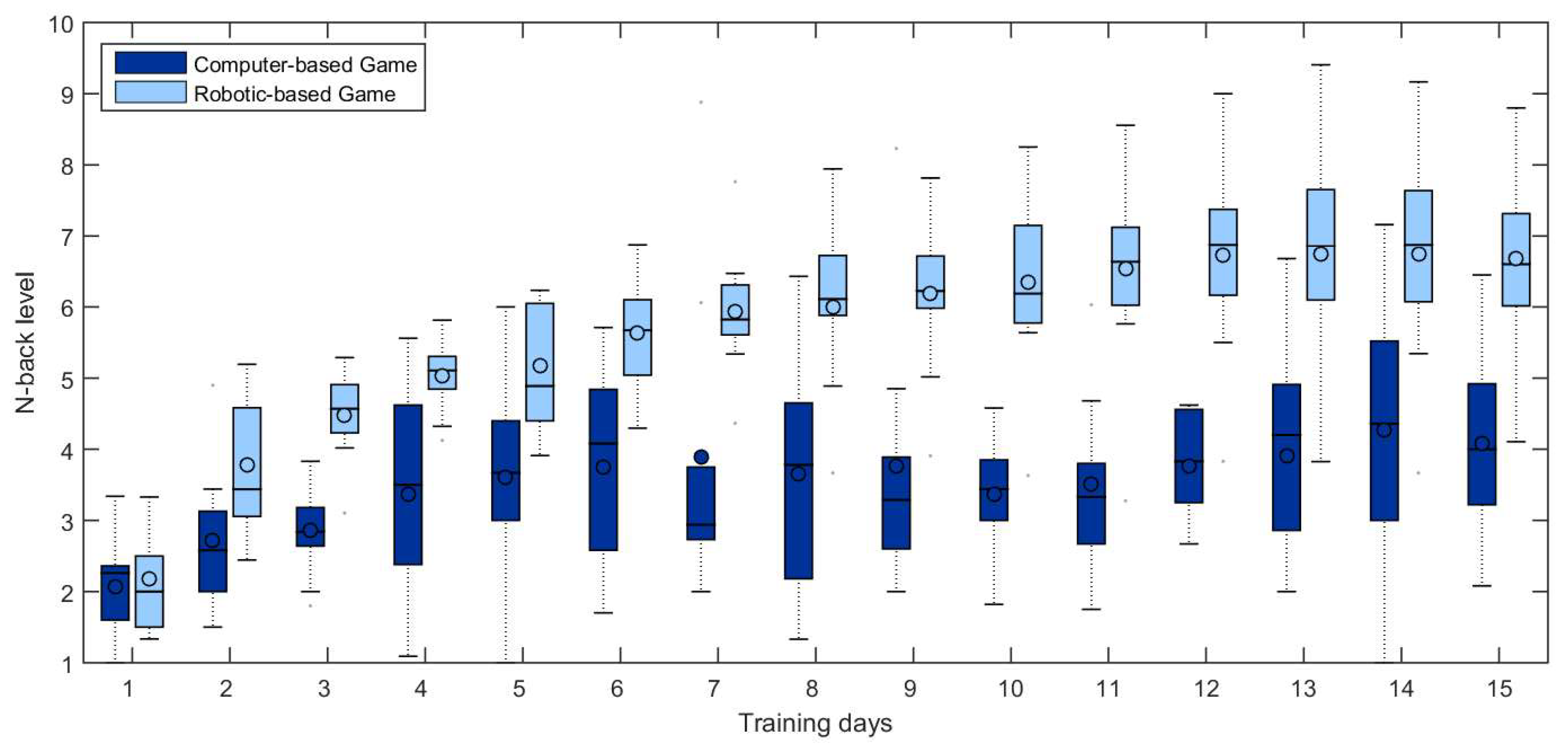
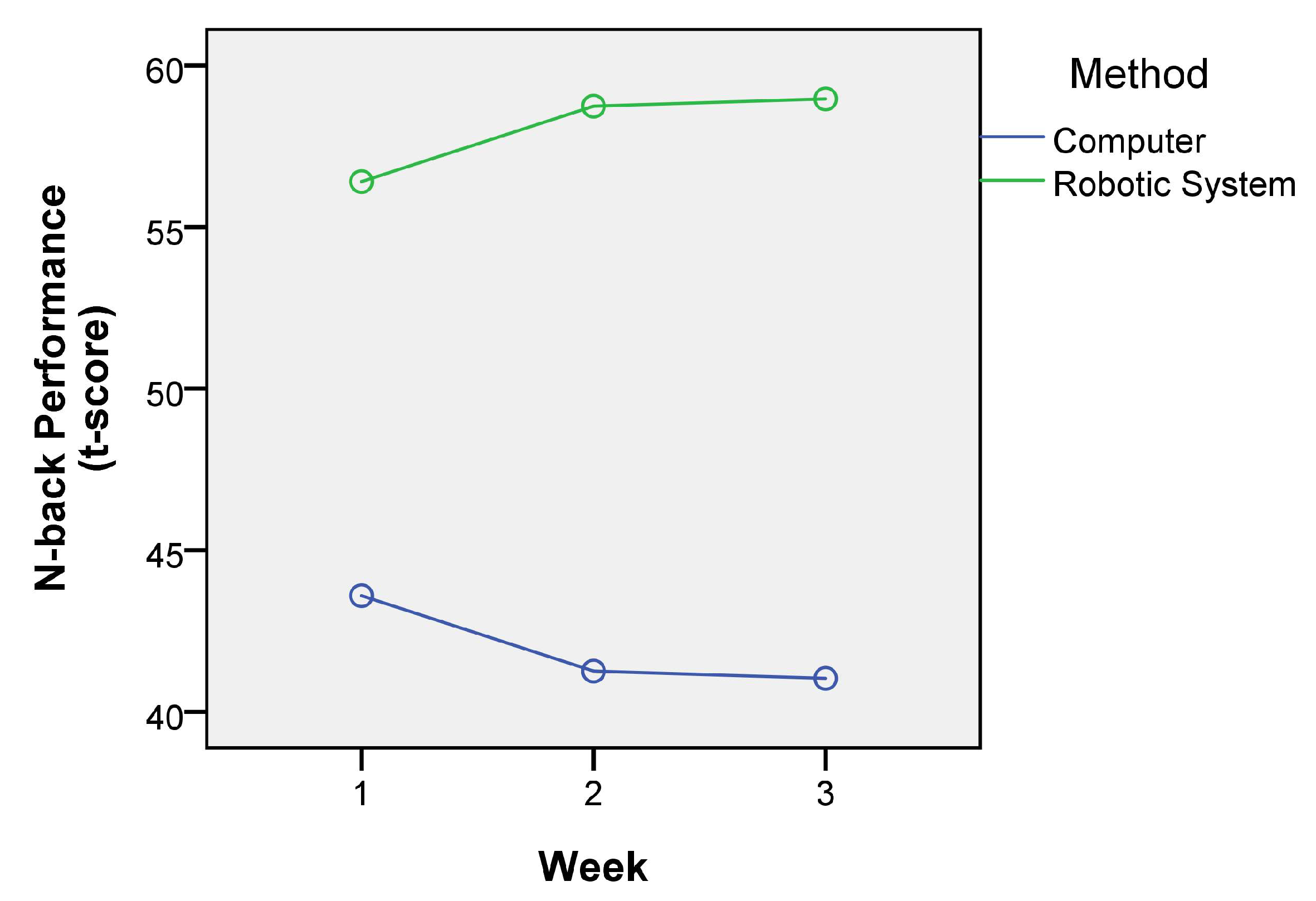
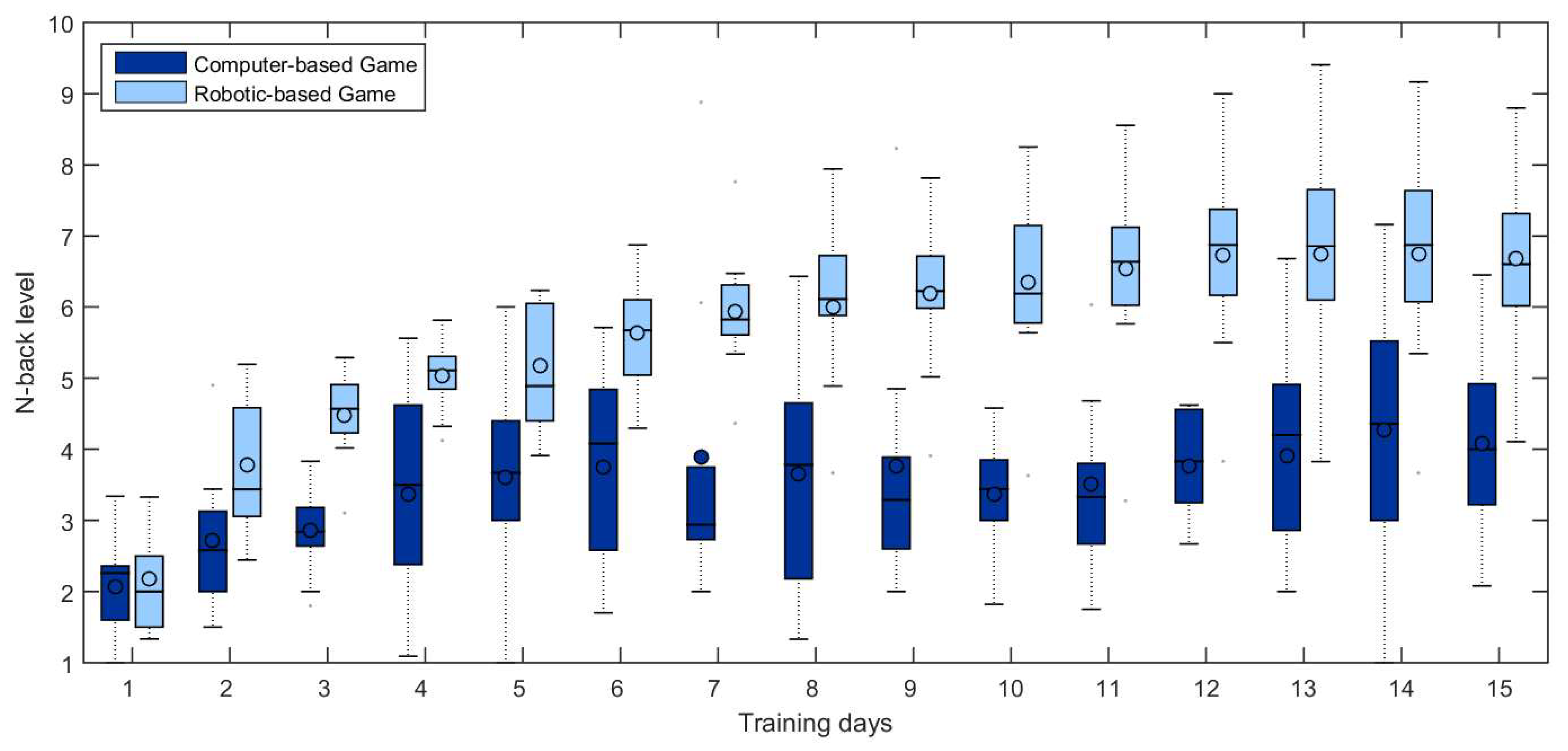
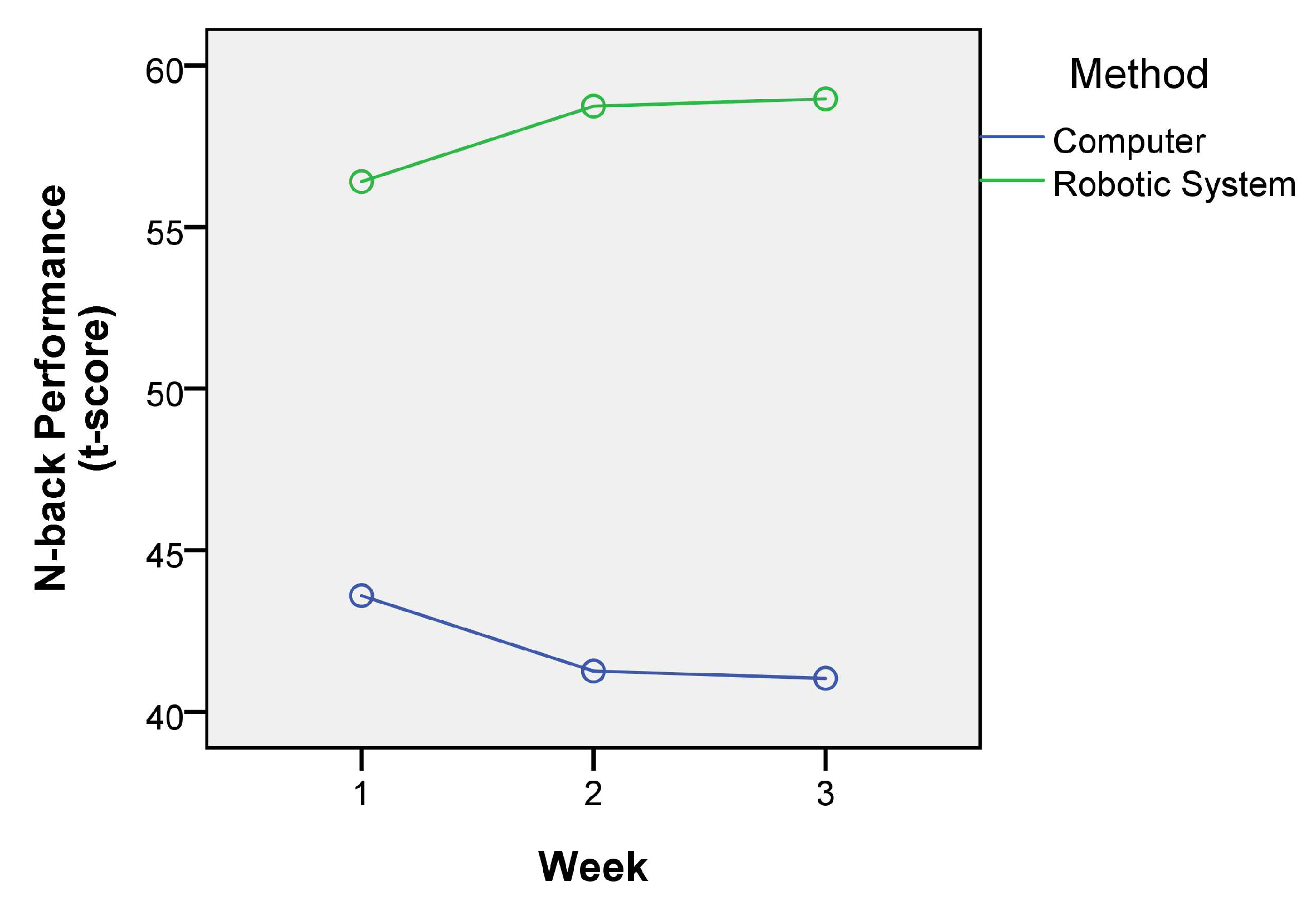
5.3. Training Results
5.4. Survey Results
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Jaeggi, S.M.; Buschkuehl, M.; Jonides, J.; Perrig, W.J. Improving fluid intelligence with training on working memory. Proc. Natl. Acad. Sci. USA 2008, 105, 6829–6833. [Google Scholar] [CrossRef] [PubMed]
- Gutiérrez-Martínez, F.; Ramos, M. La memoria operativa como capacidad predictora del rendimiento escolar. Estudio de adaptación de una medida de memoria operativa para niños y adolescentes. Psicología Educativa 2014, 20, 1–10. [Google Scholar] [CrossRef]
- McNab, F.; Zeidman, P.; Rutledge, R.B.; Smittenaar, P.; Brown, H.R.; Adams, R.A.; Dolan, R.J. Age-related changes in working memory and the ability to ignore distraction. Proc. Natl. Acad. Sci. USA 2015, 112, 6515–6518. [Google Scholar] [CrossRef] [PubMed]
- Pugin, F.; Metz, A.J.; Stauffer, M.; Wolf, M.; Jenni, O.G.; Huber, R. Working memory training shows immediate and long-term effects on cognitive performance in children. F1000 Res. 2015. [Google Scholar] [CrossRef]
- Borella, E.; Carretti, B.; Riboldi, F.; De Beni, R. Working memory training in older adults: evidence of transfer and maintenance effects. Psychol. Aging 2010, 25, 767–778. [Google Scholar] [CrossRef] [PubMed]
- Deveau, J.; Jaeggi, S.M.; Zordan, V.; Phung, C.; Seitz, A.R. How to build better memory training games. Front. Syst. Neurosci. 2015, 8, 243. [Google Scholar] [CrossRef] [PubMed]
- Chin, K.Y.; Hong, Z.W.; Chen, Y.L. Impact of Using an Educational Robot-Based Learning System on Students’; Motivation in Elementary Education. IEEE Trans. Learn. Technol. 2014, 7, 333–345. [Google Scholar] [CrossRef]
- Bravo Sánchez, F.A.; González Correal, A.M.; Guerrero, E.G. Interactive Drama with Robots for Teaching Non-technical Subjects. J. Hum.-Robot Interact. 2017, 6, 48–69. [Google Scholar] [CrossRef]
- Brown, L.; Howard, A. Engaging children in math education using a socially interactive humanoid robot. In Proceedings of the 2013 13th IEEE-RAS International Conference on Humanoid Robots (Humanoids), Atlanta, GA, USA, 15–17 October 2013; pp. 183–188. [Google Scholar] [CrossRef]
- Phamduy, P.; LeGrand, R.; Porfiri, M. Robotic Fish: Design and Characterization of an Interactive iDevice-Controlled Robotic Fish for Informal Science Education. IEEE Robot. Autom. Mag. 2015, 22, 86–96. [Google Scholar] [CrossRef]
- Plaza, P.; Sancristobal, E.; Carro, G.; Castro, M. Home-made robotic education, a new way to explore. In Proceedings of the 2017 IEEE Global Engineering Education Conference (EDUCON), Athens, Greece, 26–28 April 2017; pp. 132–136. [Google Scholar] [CrossRef]
- McNab, F.; Varrone, A.; Farde, L.; Jucaite, A.; Bystritsky, P.; Forssberg, H.; Klingberg, T. Changes in Cortical Dopamine D1 Receptor Binding Associated with Cognitive Training. Science 2009, 323, 800–802. [Google Scholar] [CrossRef] [PubMed]
- Jaeggi, S.M.; Buschkuehl, M.; Perrig, W.J.; Meier, B. The concurrent validity of the N-back task as a working memory measure. Memory 2010, 18, 394–412. [Google Scholar] [CrossRef] [PubMed]
- Bouker, J.; Scarlatos, A. Investigating the impact on fluid intelligence by playing N-Back games with a kinesthetic modality. In Proceedings of the 2013 10th International Conference and Expo on Emerging Technologies for a Smarter World (CEWIT), Melville, NY, USA, 21–22 October 2013; pp. 1–3. [Google Scholar] [CrossRef]
- Wooldridge, M.; Jennings, N.R. Intelligent Agents: Theory and Practice. Knowl. Eng. Rev. 1995, 10, 115–152. [Google Scholar] [CrossRef]
- Gottifredi, S.; Tucat, M.; Corbatta, D.; García, A.; Simari, G.R. A BDI Architecture for High Level Robot Deliberation. Inteligencia Artificial: Revista Iberoamericana de Inteligencia Artificial 2010, 14, 74–83. [Google Scholar] [CrossRef]
- Taillandier, P.; Therond, O.; Gaudou, B. A new BDI agent architecture based on the belief theory. Application to the modelling of cropping plan decision-making. In Proceedings of the International Environmental Modelling and Software Society (iEMSs), Leipzig, Germany, 1–5 July 2012. [Google Scholar]
- Lin, Y.; Min, H.; Zhou, H.; Pei, F. A Human–Robot-Environment Interactive Reasoning Mechanism for Object Sorting Robot. IEEE Trans. Cogn. Dev. Syst. 2018, 10, 611–623. [Google Scholar] [CrossRef]
- Liu, L.; Li, B.; Chen, I.; Goh, T.J.; Sung, M. Interactive robots as social partner for communication care. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 2231–2236. [Google Scholar] [CrossRef]
- Ayerbe, M.A.B.; Gonzalez, D.S.A.; Jiménez, F.A.M.; Guerrero, E.G.; Correal, A.M.G. AIO robot: A EDI modular robotic dramatization platform. In Proceedings of the 2017 18th International Conference on Advanced Robotics (ICAR), Hong Kong, China, 10–12 July 2017; pp. 262–268. [Google Scholar] [CrossRef]
- Kaptein, F.; Broekens, J.; Hindriks, K.; Neerincx, M. Personalised self-explanation by robots: The role of goals versus beliefs in robot-action explanation for children and adults. In Proceedings of the 2017 26th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), Lisbon, Portugal, 28–31 August 2017; pp. 676–682. [Google Scholar] [CrossRef]
- Silva, M.P.; do Nascimento Silva, V.; Chaimowicz, L. Dynamic Difficulty Adjustment through an Adaptive AI. In Proceedings of the 2015 14th Brazilian Symposium on Computer Games and Digital Entertainment (SBGames), Piauí, Brazil, 11–13 November 2015; pp. 173–182. [Google Scholar] [CrossRef]
- Sun, Q.; He, S. Artificial neural network using the training set of DTS for Pacman game. In Proceedings of the 2014 11th International Computer Conference on Wavelet Actiev Media Technology and Information Processing(ICCWAMTIP), Chengdu, China, 19–21 December 2014; pp. 209–213. [Google Scholar] [CrossRef]
- Pratama, N.P.H.; Nugroho, S.M.S.; Yuniarno, E.M. Fuzzy controller based AI for dynamic difficulty adjustment for defense of the Ancient 2 (DotA2). In Proceedings of the 2016 International Seminar on Intelligent Technology and Its Applications (ISITIA), Lombok, Indonesia, 28–30 July 2016; pp. 95–100. [Google Scholar] [CrossRef]
- Andrade, K.D.O.; Pasqual, T.B.; Caurin, G.A.P.; Crocomo, M.K. Dynamic difficulty adjustment with Evolutionary Algorithm in games for rehabilitation robotics. In Proceedings of the 2016 IEEE International Conference on Serious Games and Applications for Health (SeGAH), Orlando, FL, USA, 11–13 May 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Araujo, V.; Gonzalez, A.; Mendez, D. Dynamic Difficulty Adjustment for a Memory Game. In Communications in Computer and Information Science; Springer International Publishing: New York, NY, USA, 2018; pp. 605–616. [Google Scholar] [CrossRef]
- Wang, K.; Liu, X. Particle Filtering-based tracking and localization on context-aware robotic system. In Proceedings of the 2014 9th International Conference on Computer Science Education (ICCSE), Vancouver, BC, Canada, 22–24 August 2014; pp. 229–234. [Google Scholar] [CrossRef]
- González, A.; Angel, R.; González, E. BDI concurrent architecture orientedto goal managment. In Proceedings of the 2013 8th Computing Colombian Conference (8CCC), Armenia, Colombia, 21–23 August 2013; pp. 1–6. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Type | |
|---|---|---|
| Sensors | Battery level () | percentage |
| Robot’s motors high temperature () | boolean | |
| User’s presence sensor () | boolean | |
| Objects connection () | boolean | |
| IoT platform connection () | boolean | |
| Process | Game over () | boolean |
| Round initiated () | boolean | |
| Stimuli number () | integer | |
| Continue game () | boolean | |
| Game turn () | assignment | |
| Loops () | integer | |
| Game balanced () | boolean | |
| Emotional | Mood () | percentage |
| RTI/PRI | LP | MLP | MP | MHP | HP |
|---|---|---|---|---|---|
| FR | HT | HT | MT | LT | LT |
| NR | HT | MT | MT | MT | LT |
| HP | HT | HT | MT | MT | LT |
| RTI/PRI | LP | MLP | MP | MHP | HP |
|---|---|---|---|---|---|
| FR | FS | NS | NS | MS | MS |
| NR | FS | NS | NS | NS | MS |
| HP | FS | FS | FS | NS | NS |
| RTI/PRI | LP | MLP | MP | MHP | HP |
|---|---|---|---|---|---|
| FR | LD | KL | KL | KL | LU |
| NR | LD | KL | KL | KL | LU |
| HP | LD | LD | KL | KL | KL |
| Training Group (n = 9) | Control Group (n = 9) | |
|---|---|---|
| Average age | 20.25 | 20.4 |
| Gender | 55.5% Female | 55.5% Female |
| Average years of education | 15.25 | 15.4 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Araujo, V.; Mendez, D.; Gonzalez, A. A Novel Approach to Working Memory Training Based on Robotics and AI. Information 2019, 10, 350. https://doi.org/10.3390/info10110350
Araujo V, Mendez D, Gonzalez A. A Novel Approach to Working Memory Training Based on Robotics and AI. Information. 2019; 10(11):350. https://doi.org/10.3390/info10110350
Chicago/Turabian StyleAraujo, Vladimir, Diego Mendez, and Alejandra Gonzalez. 2019. "A Novel Approach to Working Memory Training Based on Robotics and AI" Information 10, no. 11: 350. https://doi.org/10.3390/info10110350
APA StyleAraujo, V., Mendez, D., & Gonzalez, A. (2019). A Novel Approach to Working Memory Training Based on Robotics and AI. Information, 10(11), 350. https://doi.org/10.3390/info10110350