Multivariate Maps—A Glyph-Placement Algorithm to Support Multivariate Geospatial Visualization



Abstract
:1. Introduction
- 1.
- A multivariate map with scalable glyph rendering and presentation (in the form of scale-aware maps) (C1—size perceivability, C2—multivariate geospatial data, C4—glyph placement).
- 2.
- Dynamic hierarchical glyphs that support zooming, and user-controlled level of detail. (C2—multivariate geospatial data, C3—occlusion, C4—glyph placement).
- 3.
- Interactive filters to improve analysis and exploration of multivariate data and comparison of geo-spatial areas. (C2—multivariate geospatial data).
2. Related Work
3. Design Goals and Tasks
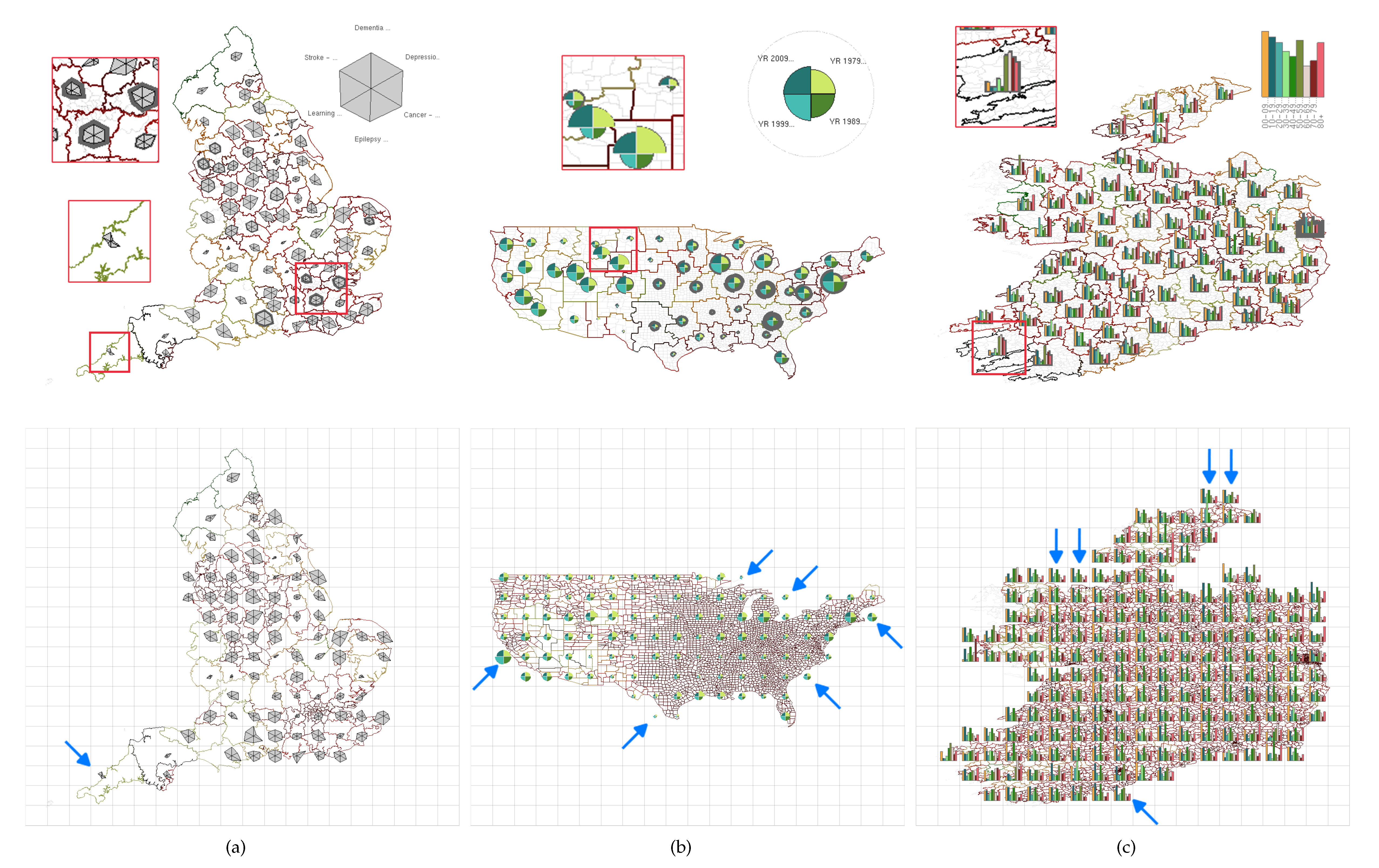
- T1—Visualization Overview: Provide a glyph-based overview of multivariate data on a map free from occlusion (C3—occlusion).
- T2—Multivariate Map: Offer a selection of informative multivariate glyphs to compare trends between regions (C2—multivariate geospatial data).
- T3—Glyph Placement: Clearly couple encoded glyphs to their geo-spatial contexts (C4—glyph placement).
- T4—Level-of-detail Leverage scale-aware maps to enable exploration of the data at multiple levels of detail (C1—size perceivability).
- T5—Filtering: Support the exploration of multivariate geo-spatial data with user options with varying glyph designs and filters (C2—multivariate geospatial data).
- T6—Smooth Interaction: To provide smooth and fluid transitions between the different levels of detail (C4—glyph placement).
4. Overview
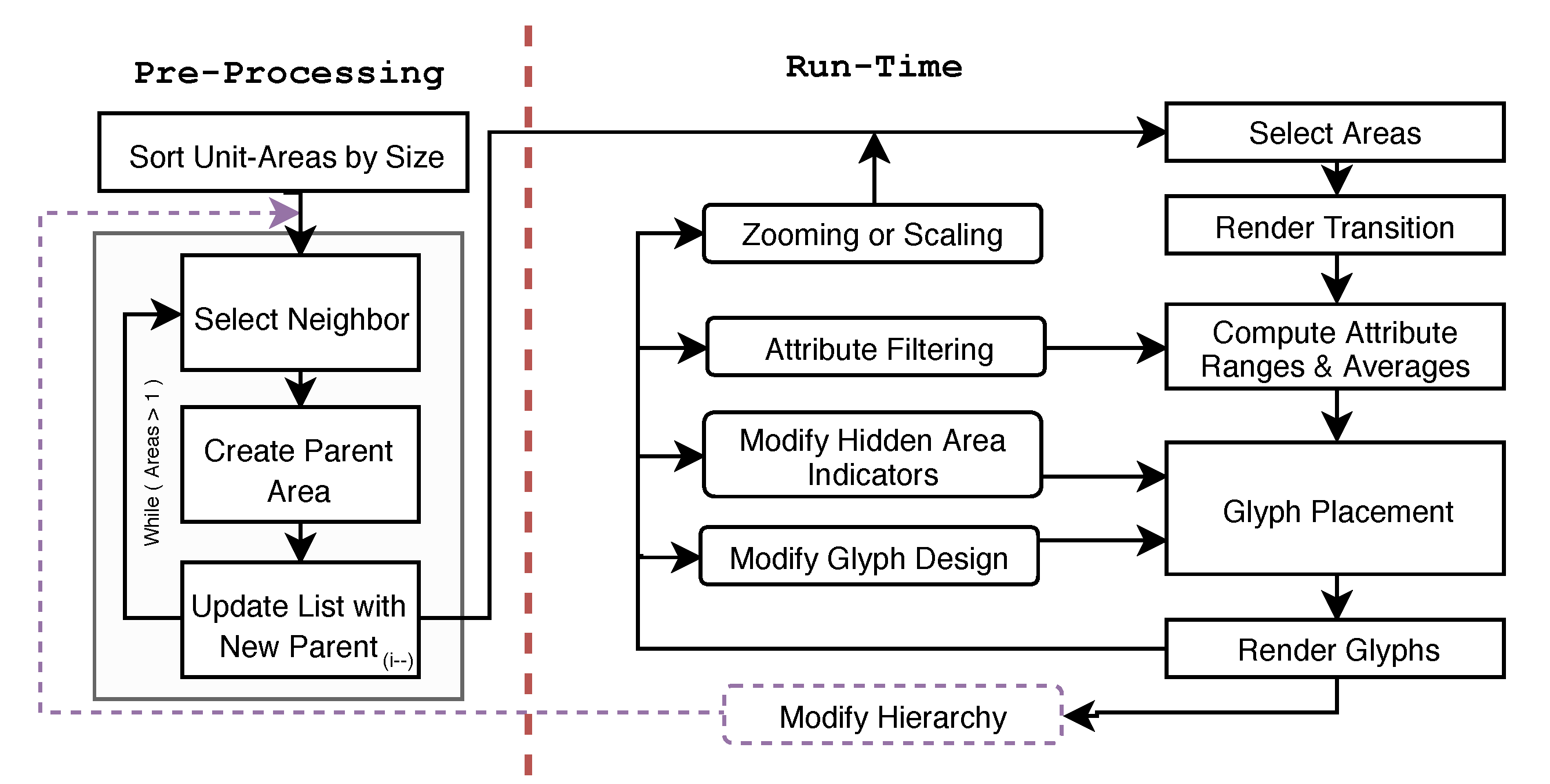
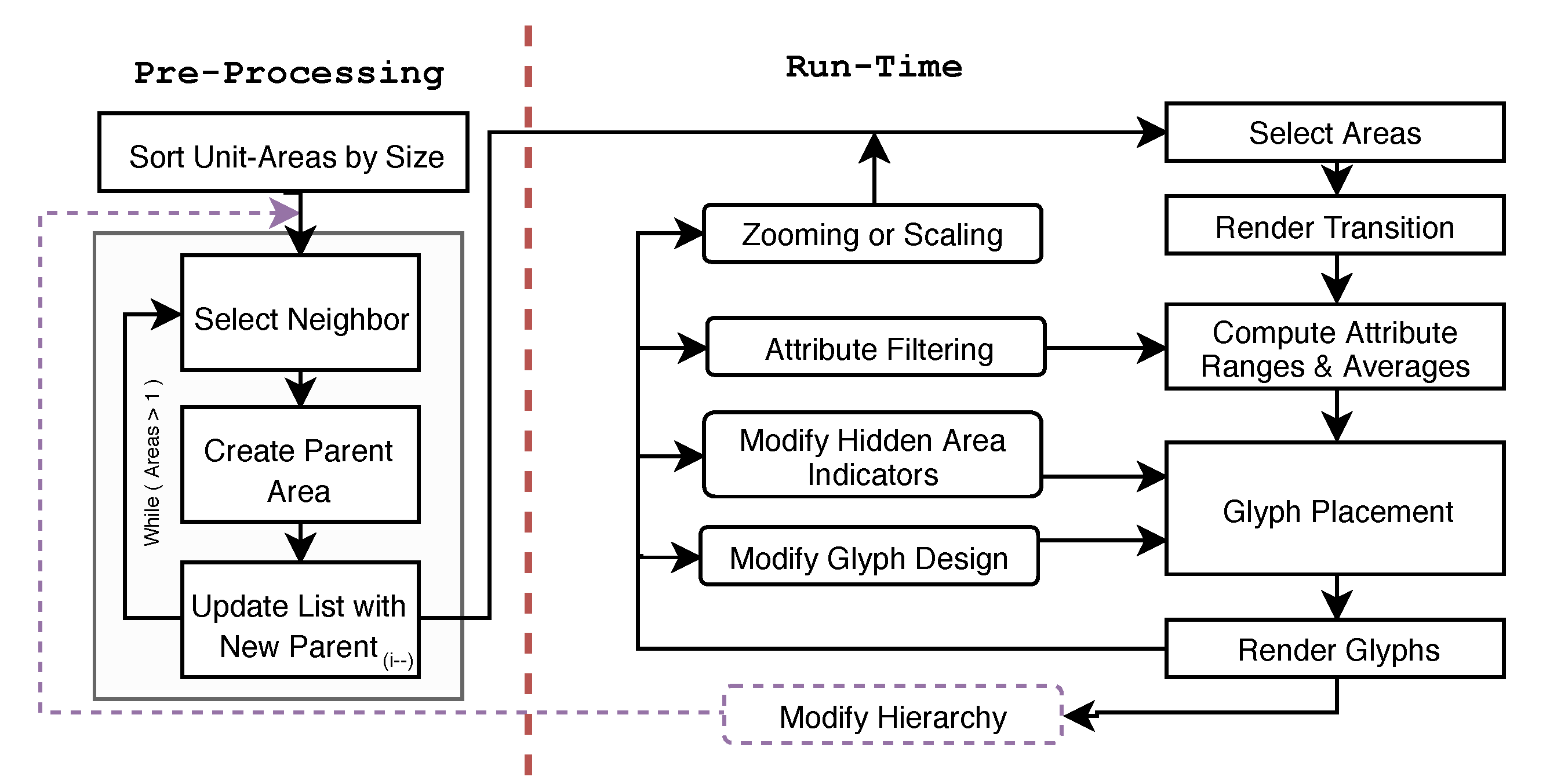
4.1. Pre-Processing
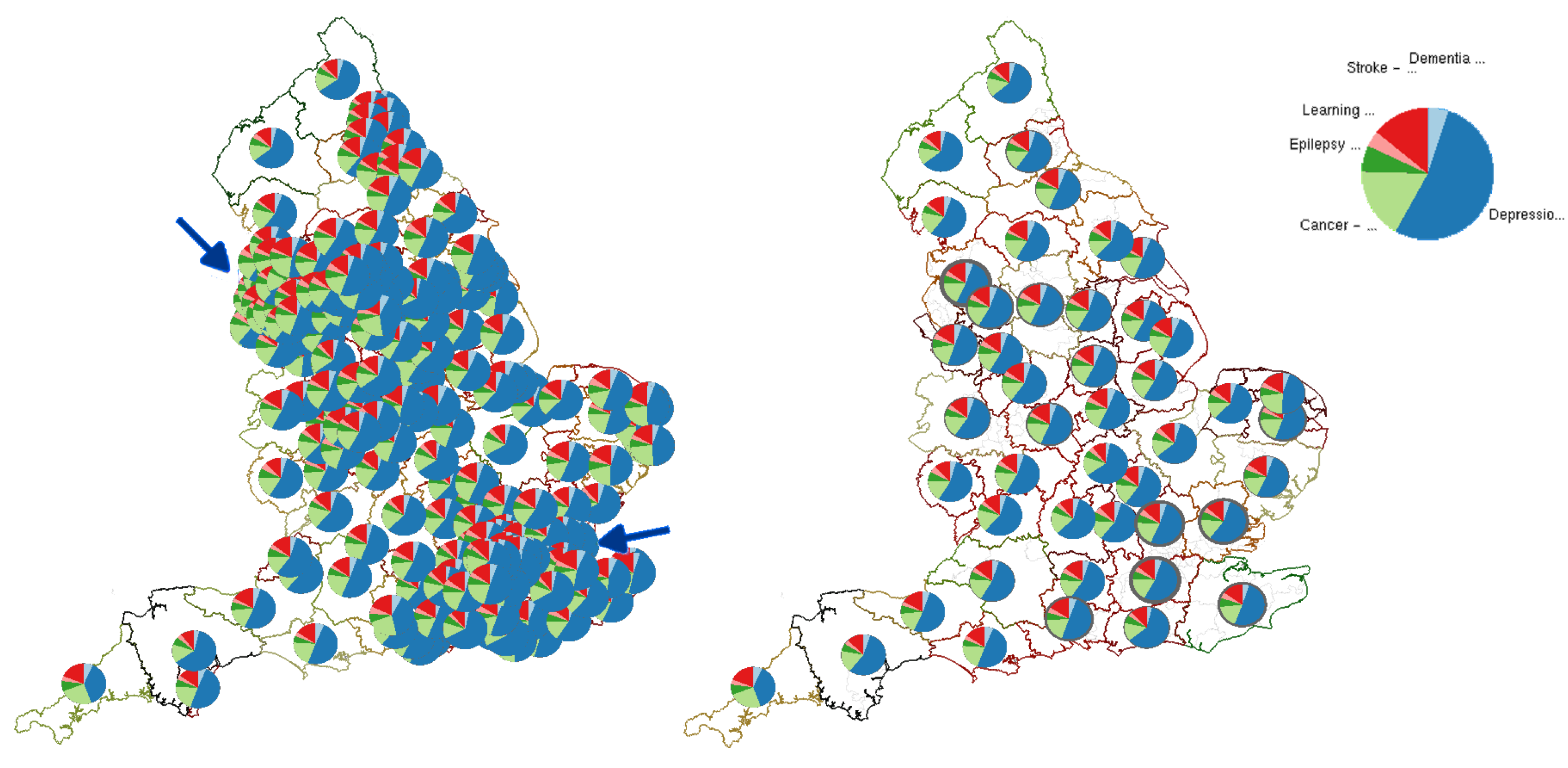
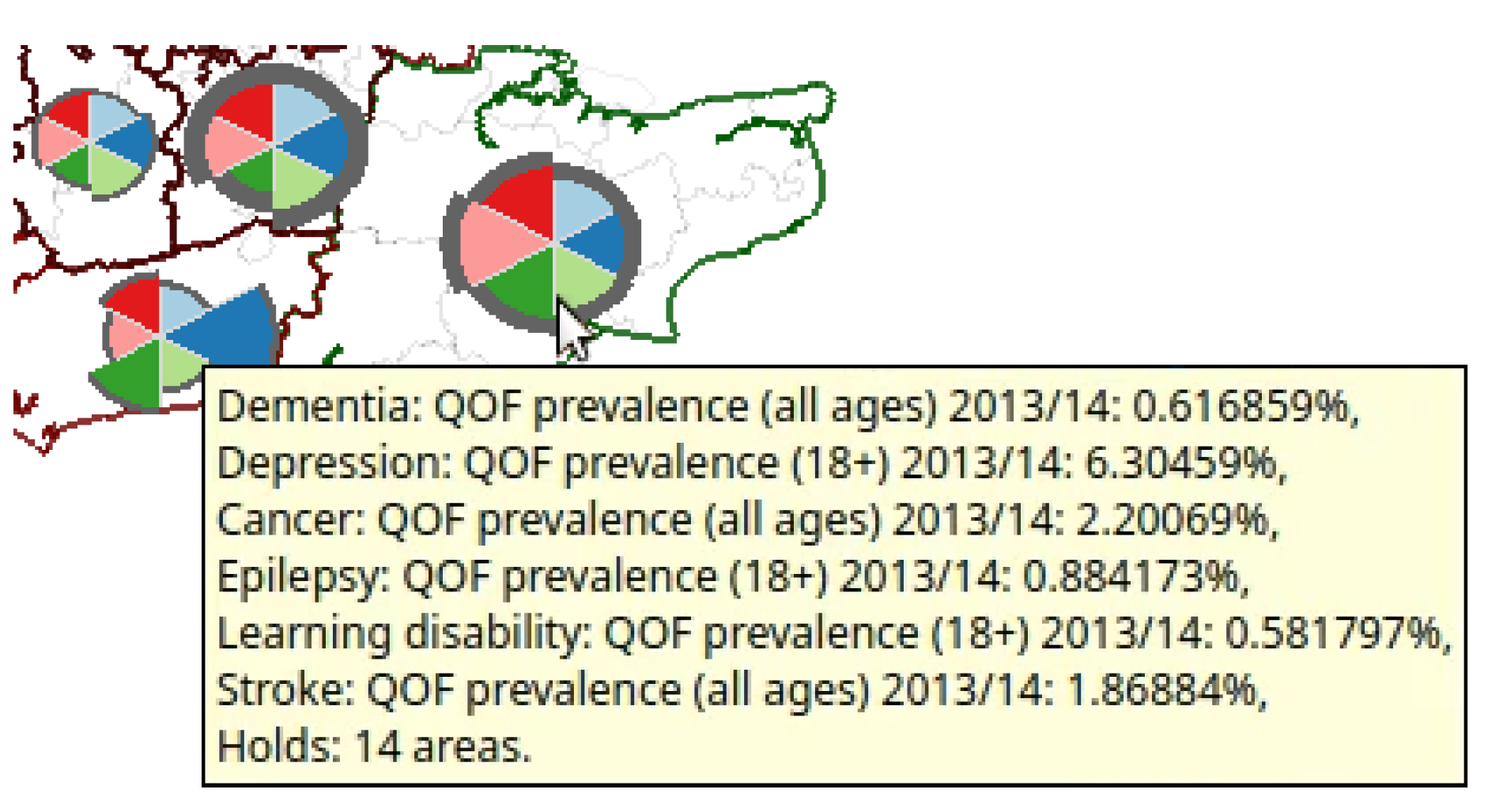
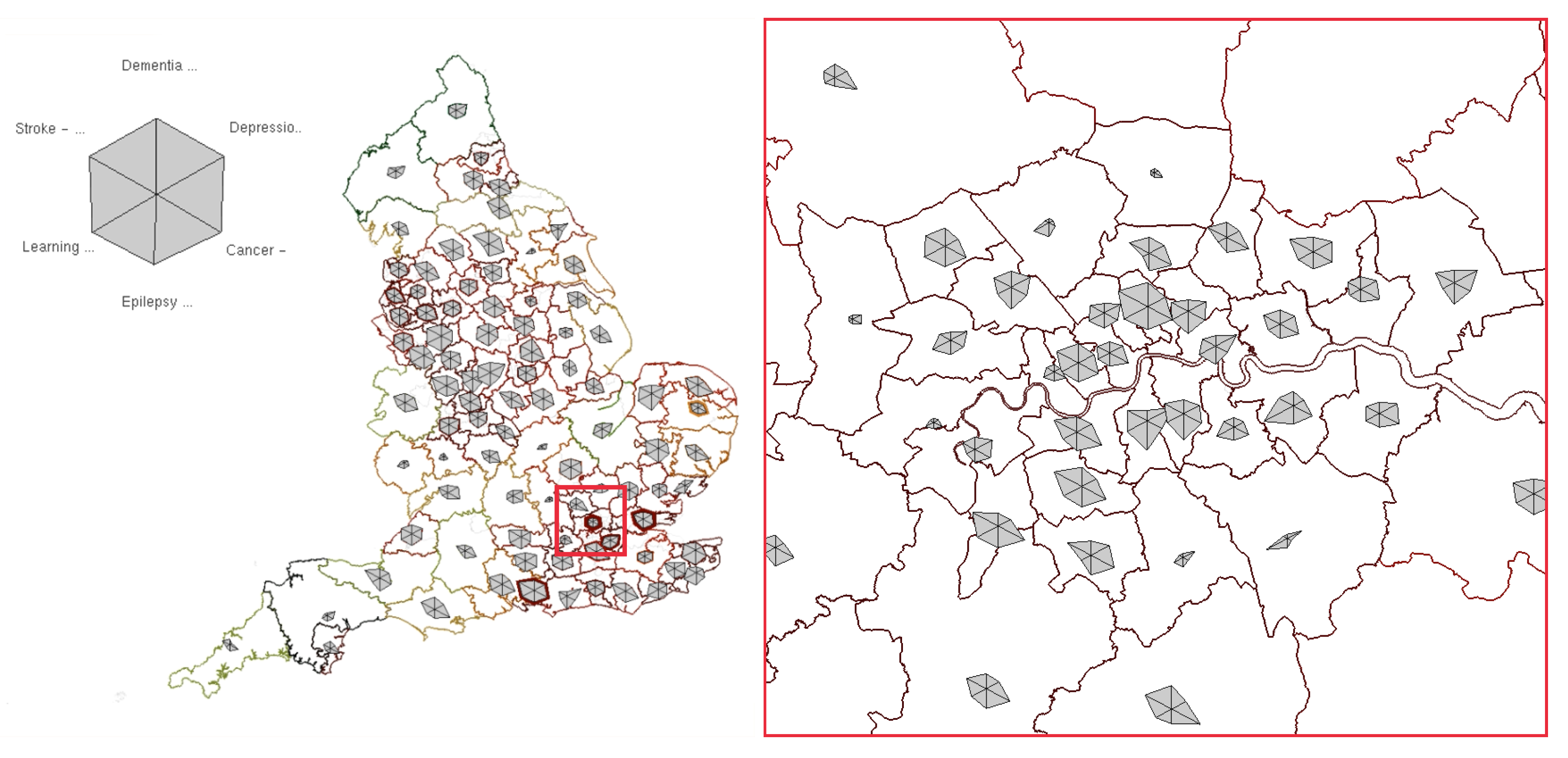
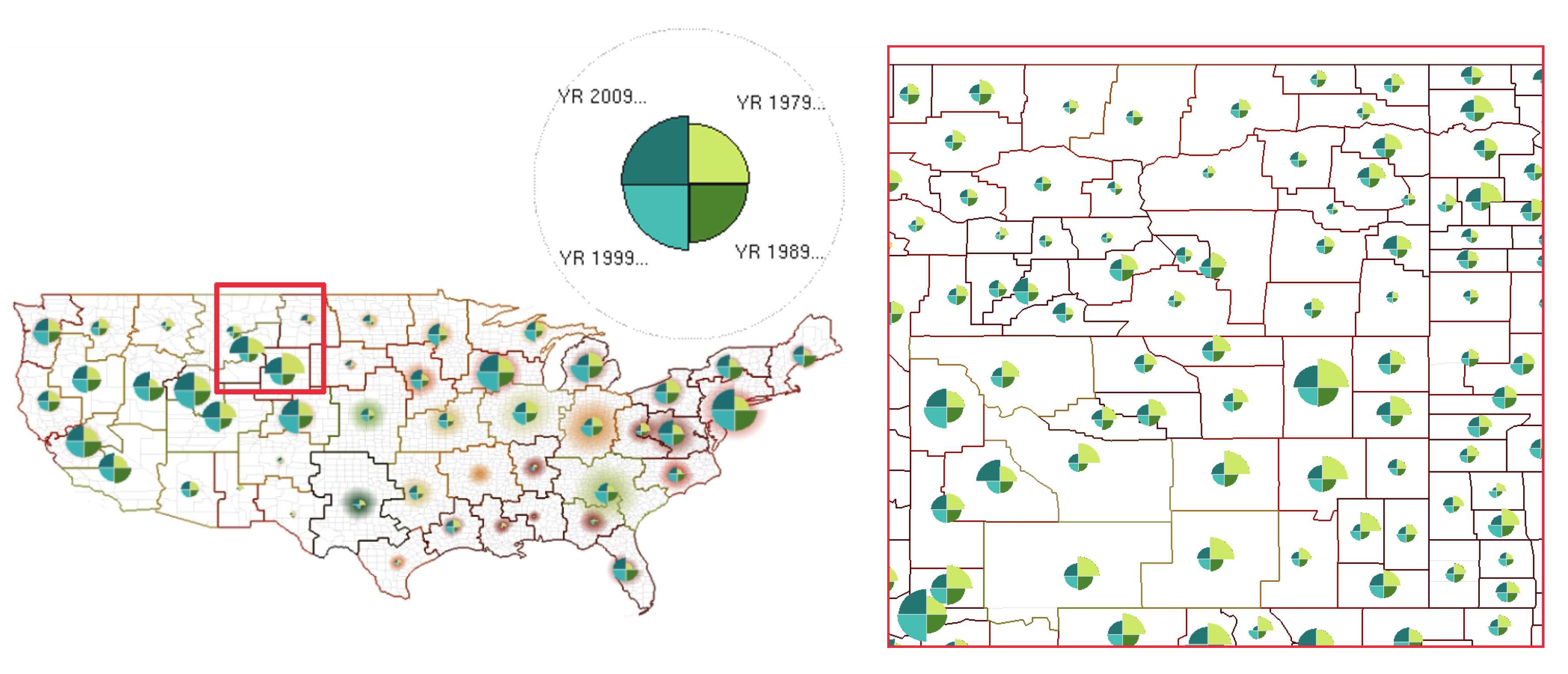
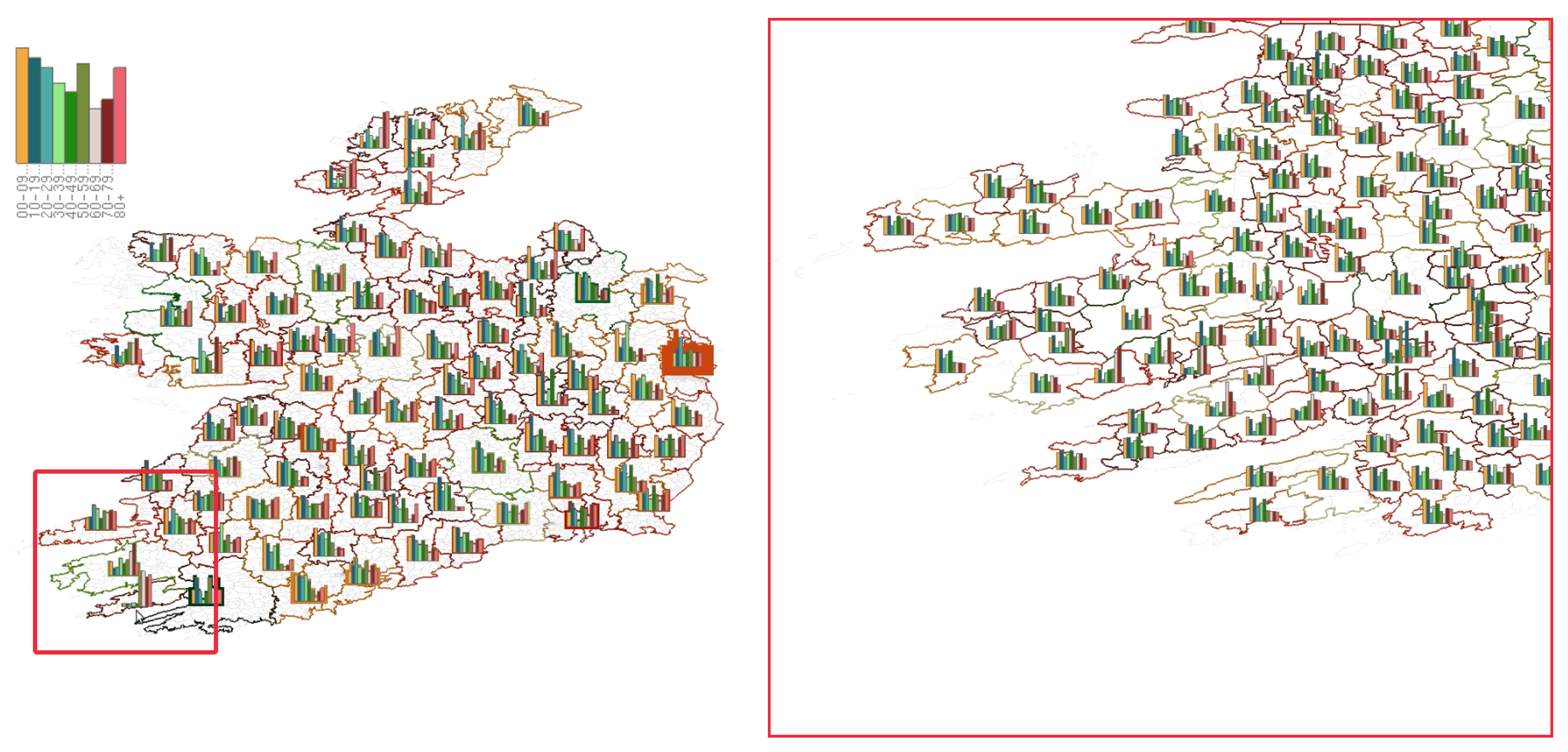
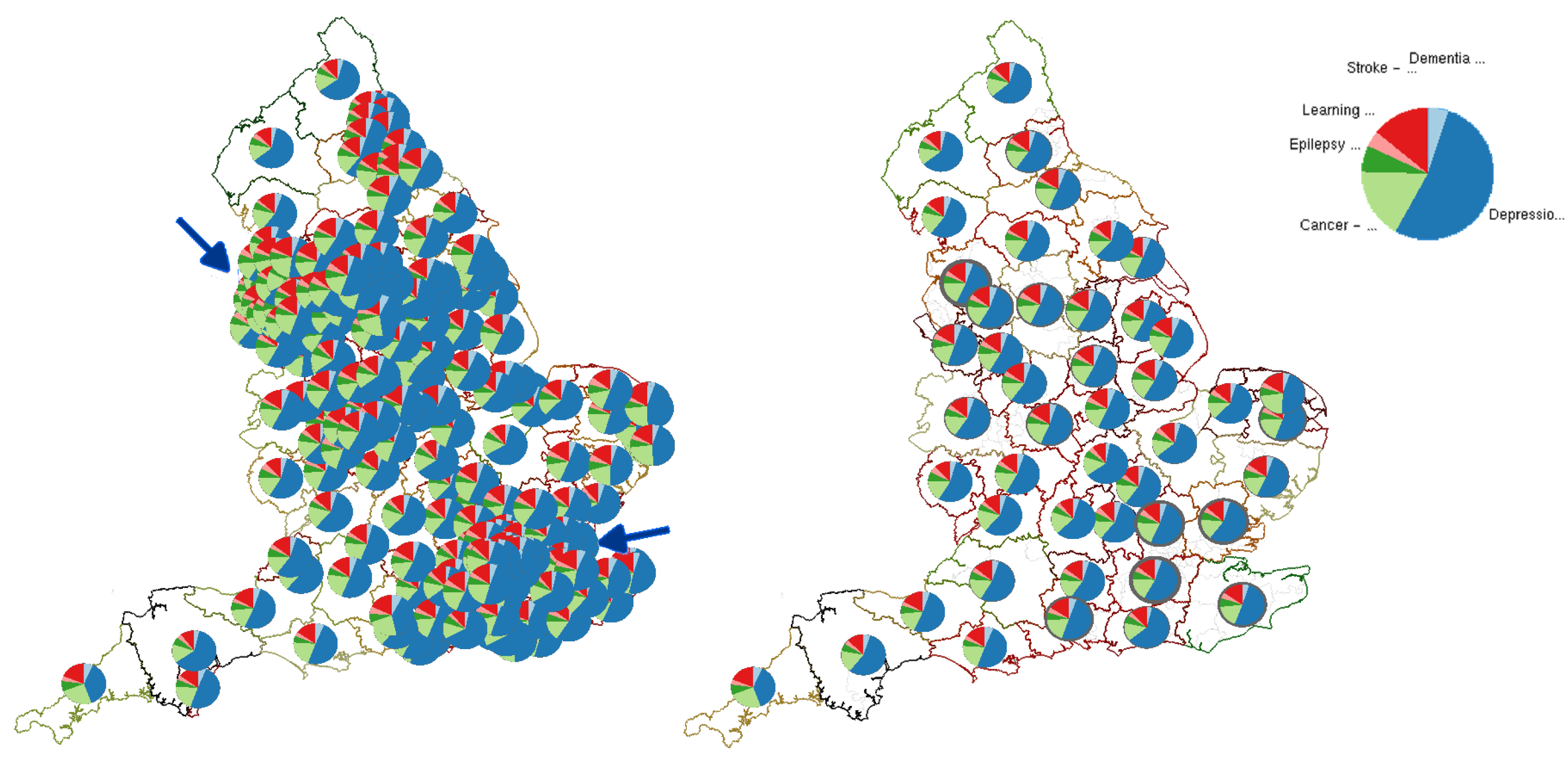
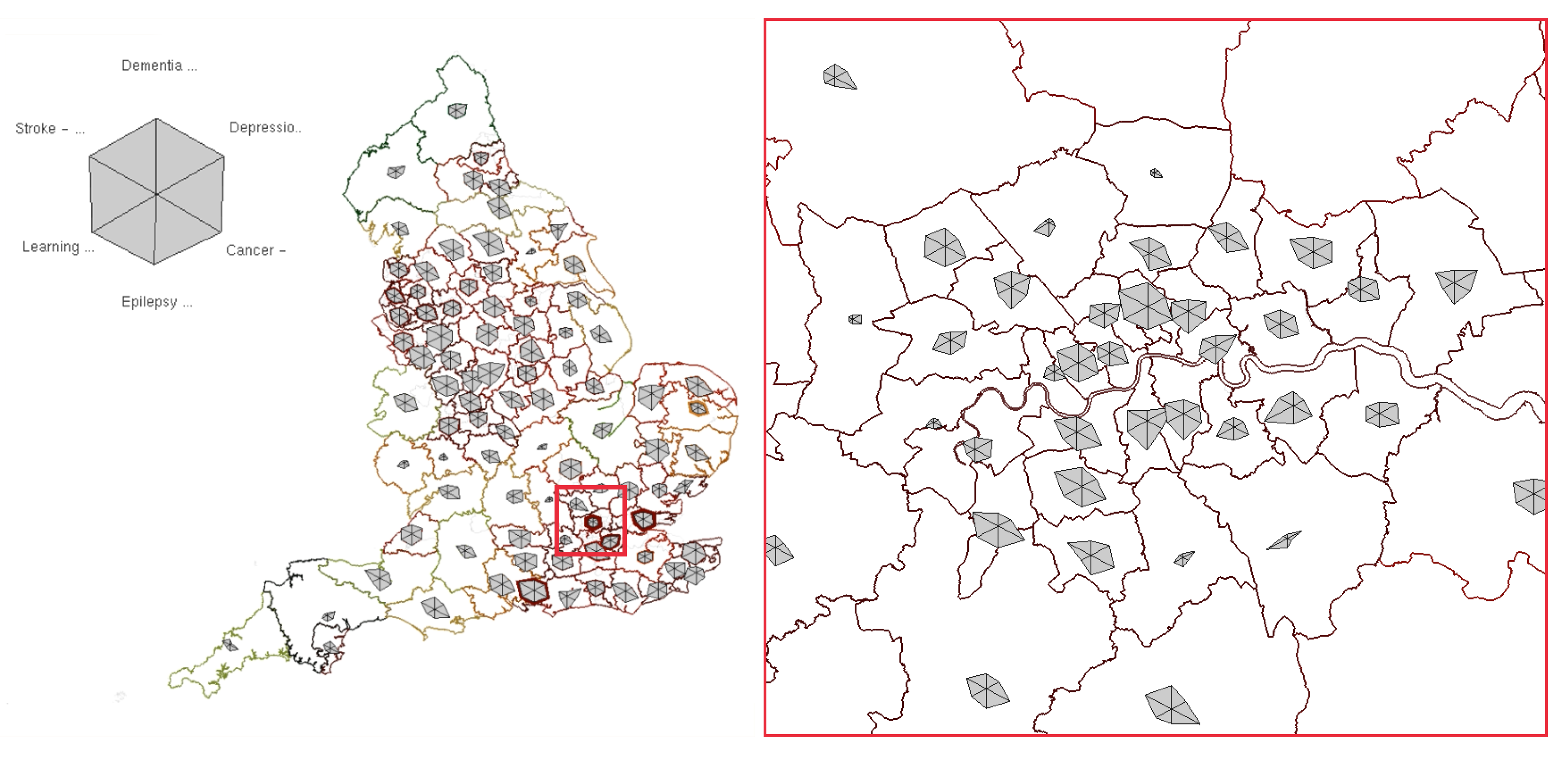
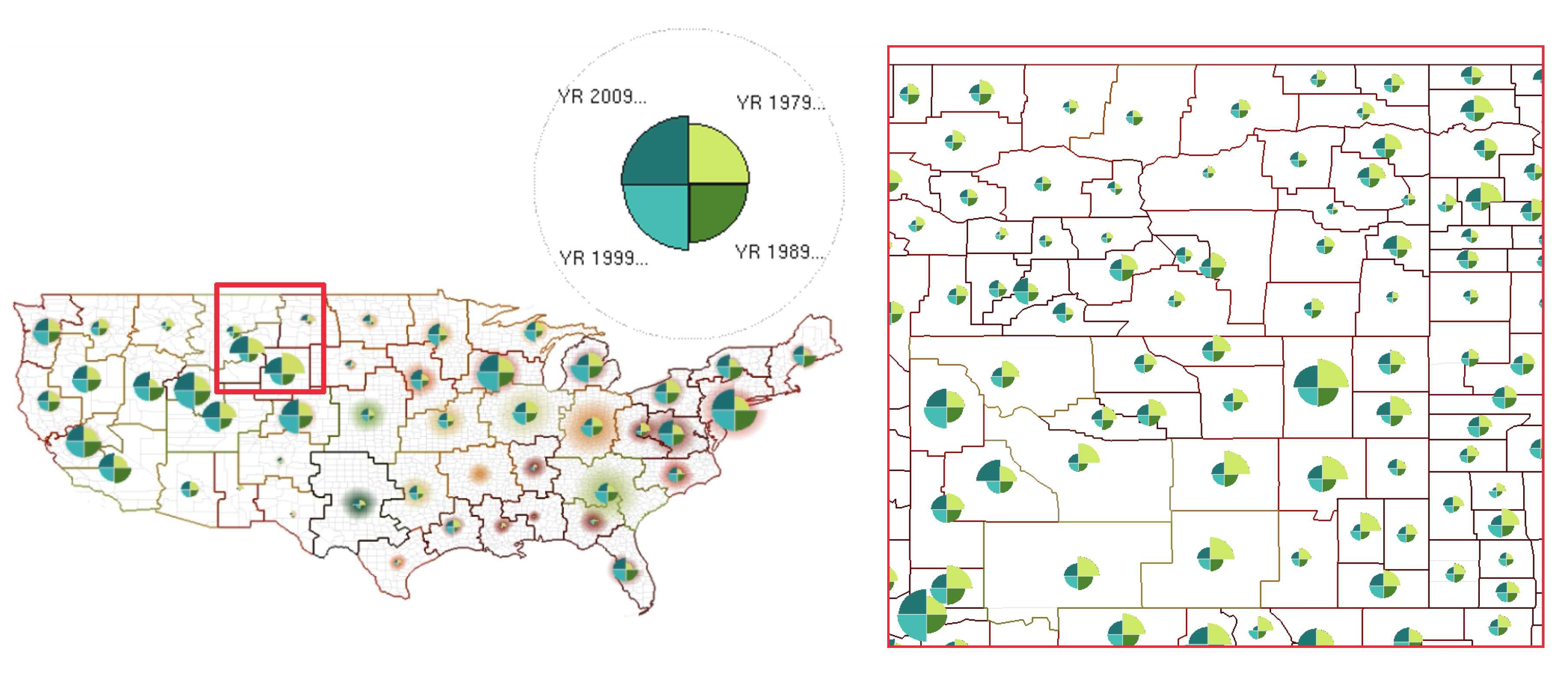
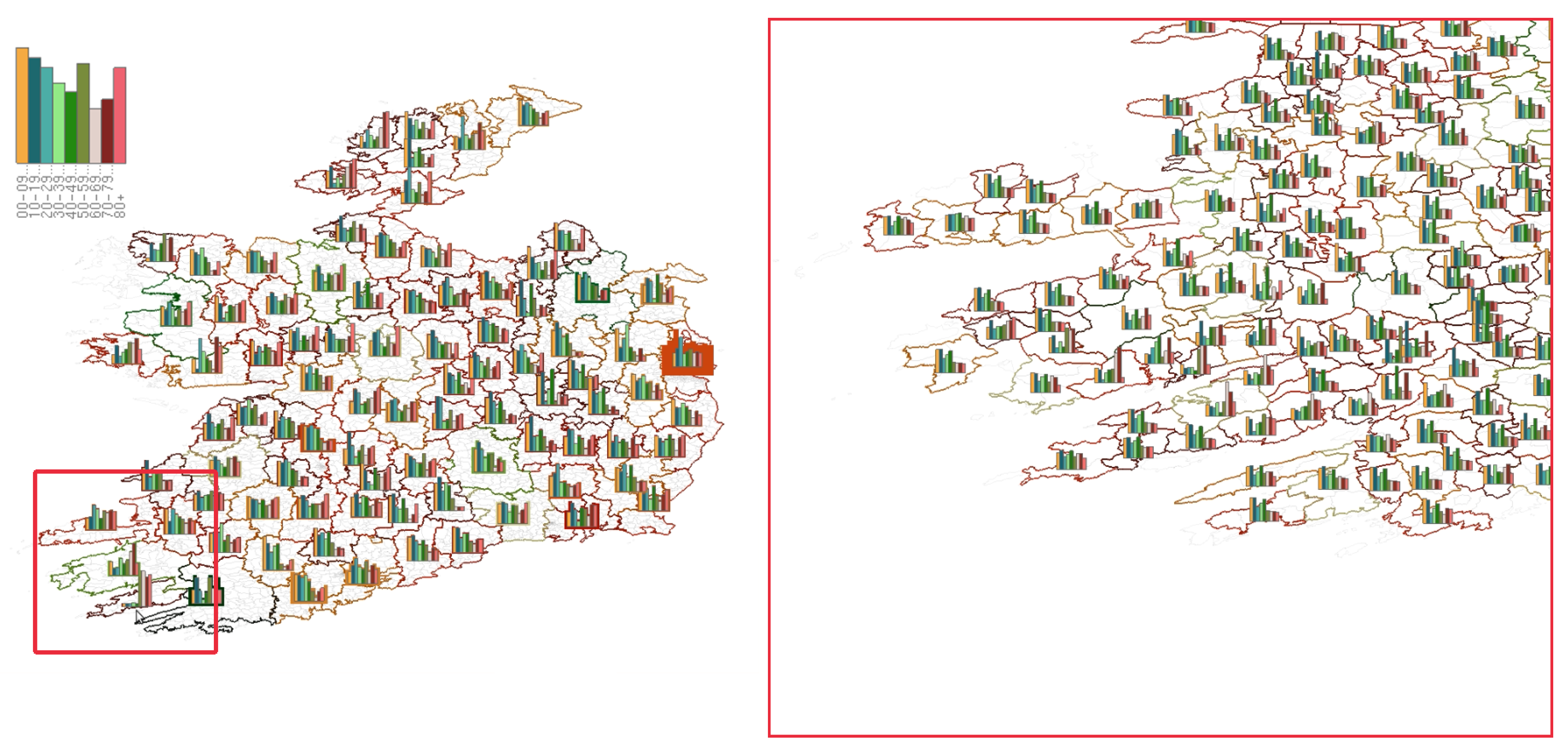
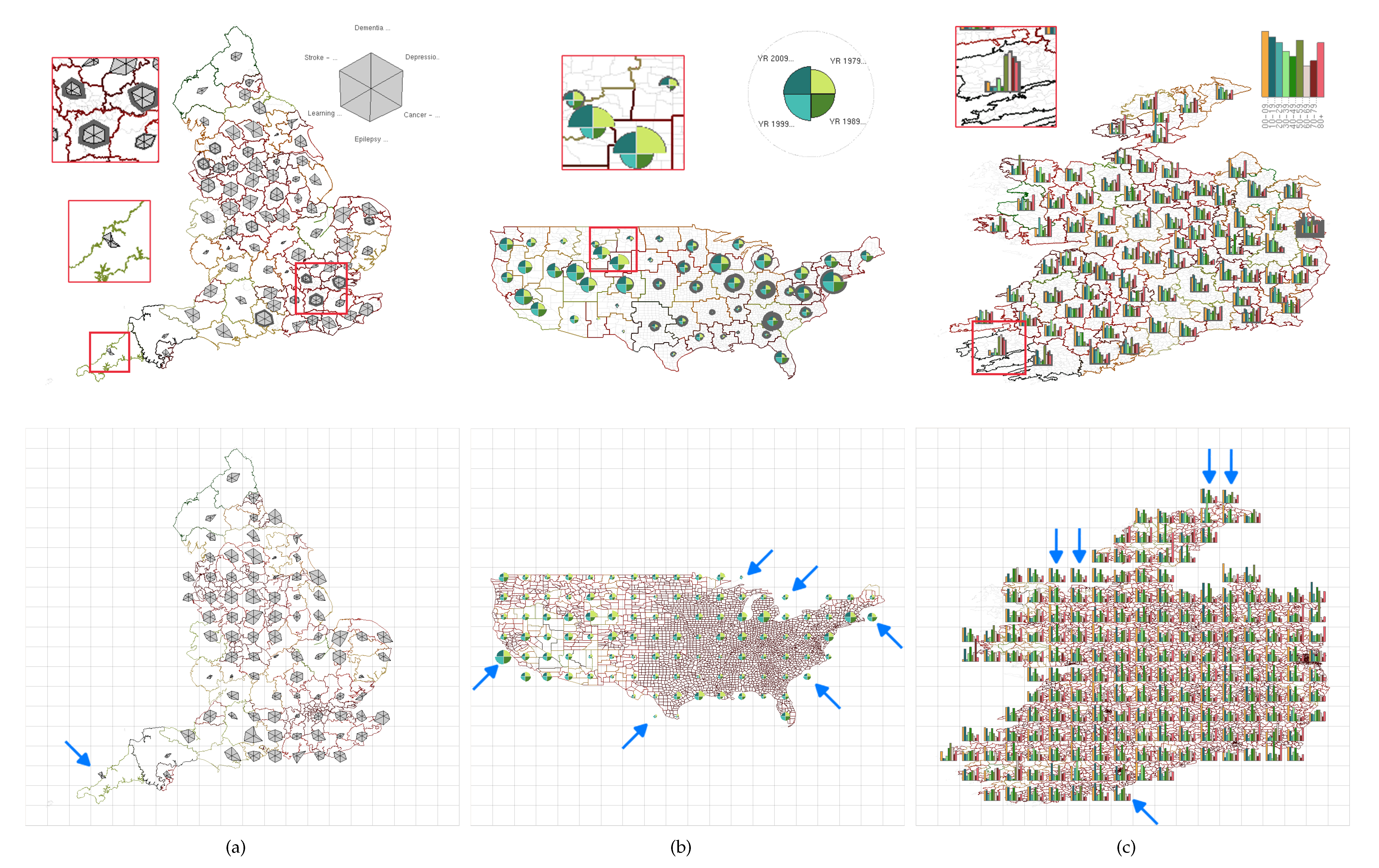
4.2. Geospatial Glyph Placement
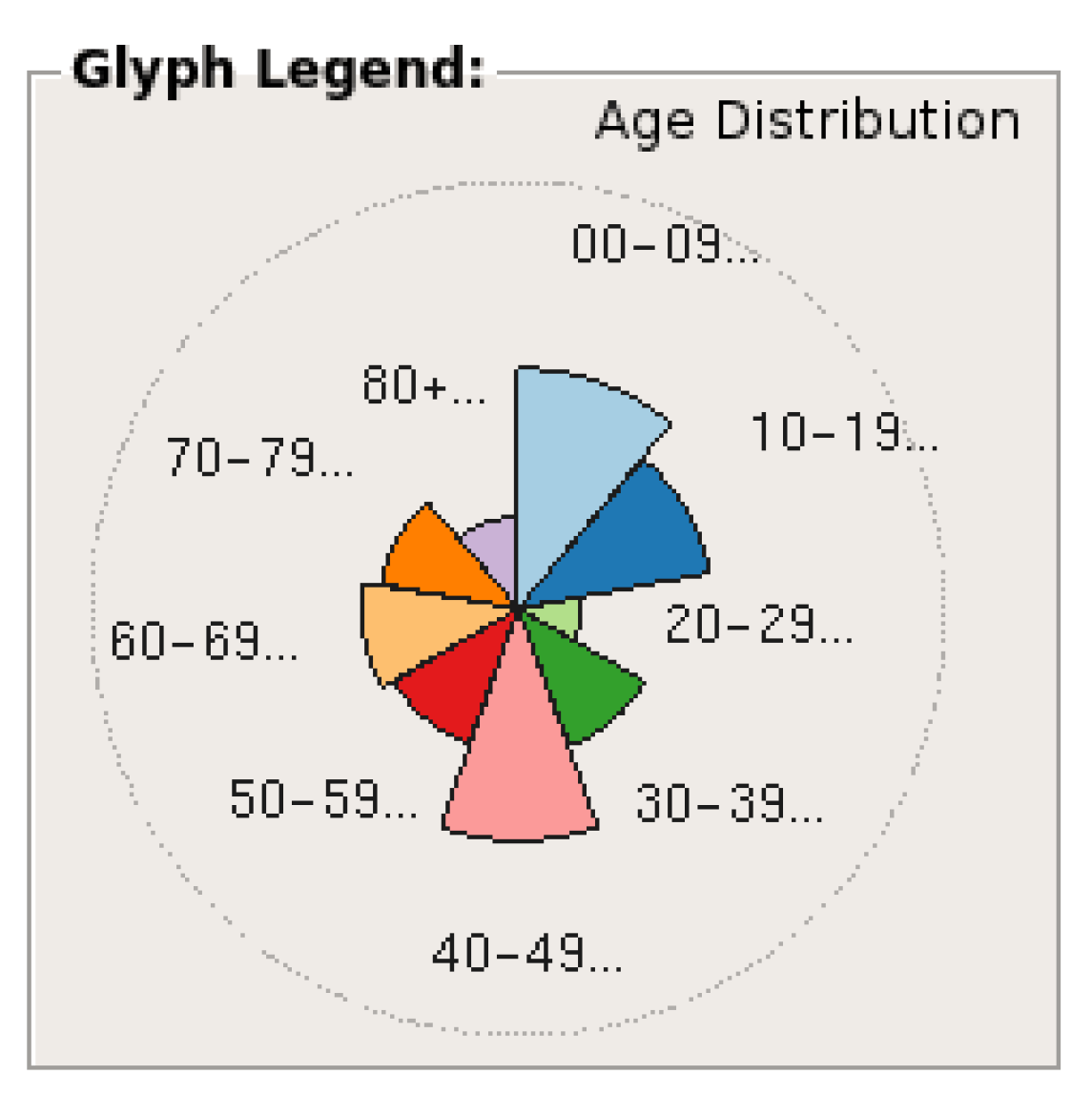
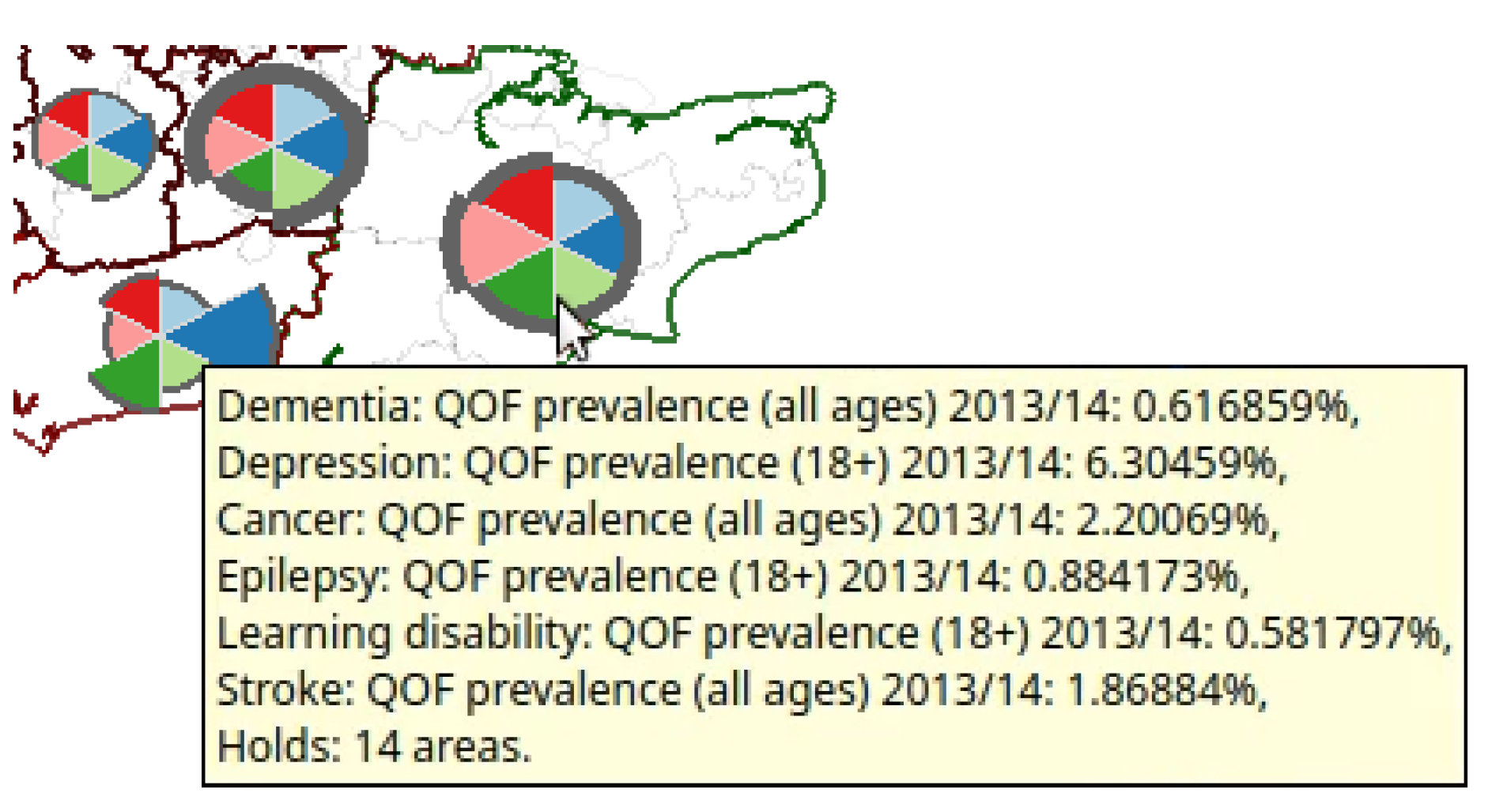
4.3. Glyph Selection
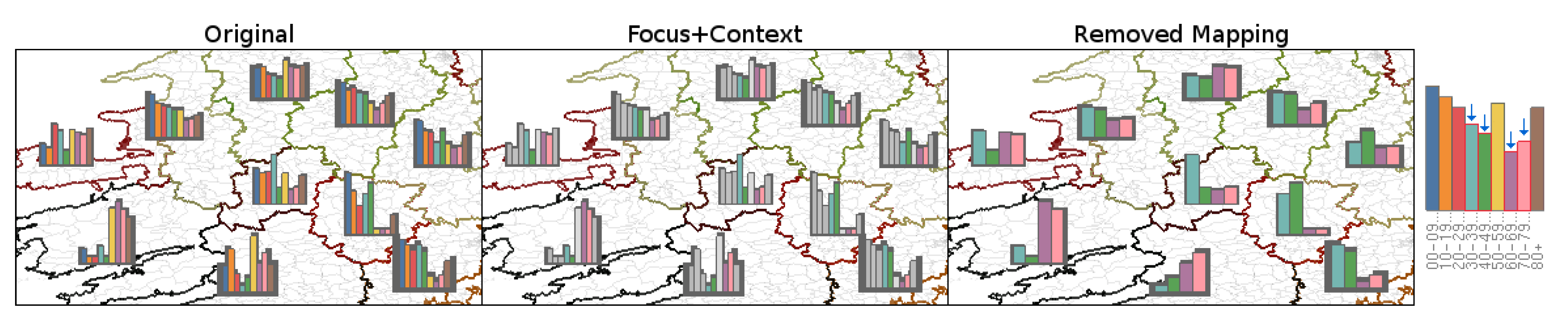
4.4. Adjusting Level-of-Detail with Glyph Density
4.5. Smooth Merging and Splitting Transitions
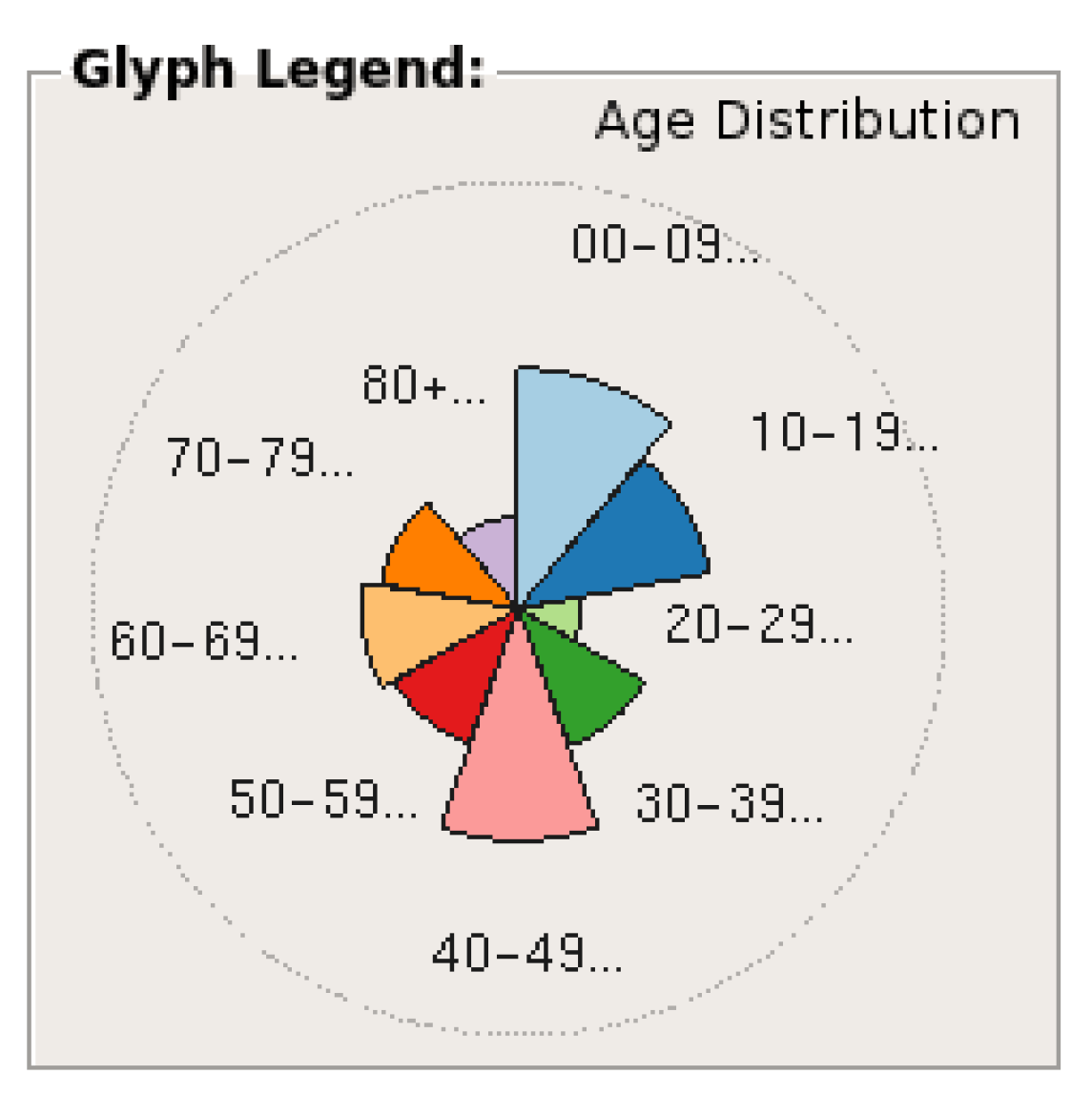
4.6. Dynamic Average Glyph Legend
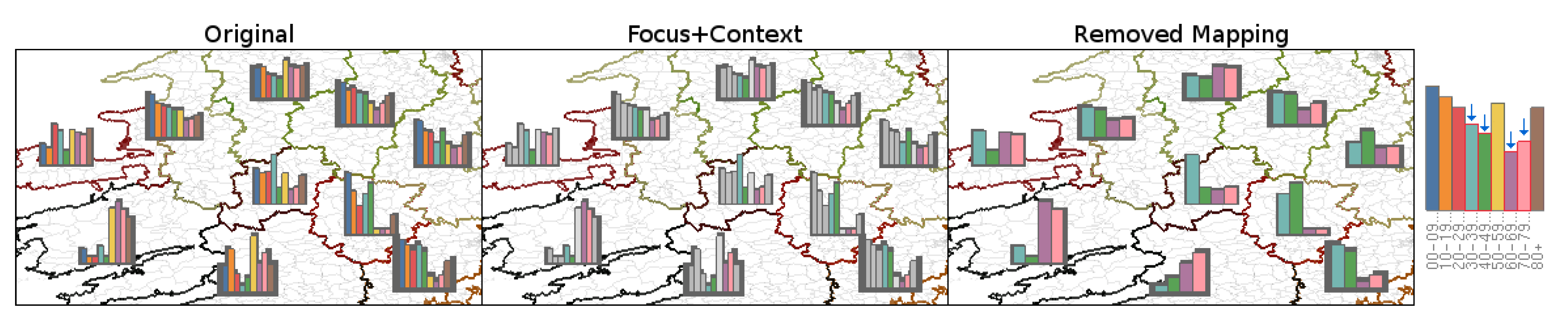
4.7. Attribute Filtering
4.8. Unit Area Density Indicators
4.9. Interactive User Options
5. Evaluation
5.1. Video and Images
5.2. Case Studies
5.3. Comparative Evaluation—Grid-Placement Versus Dynamic Placement
6. Future Work
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fairbairn, D.; Andrienko, G.; Andrienko, N.; Buziek, G.; Dykes, J. Representation and its relationship with cartographic visualization. Cartogr. Geogr. Inf. Sci. 2001, 28, 13–28. [Google Scholar] [CrossRef]
- Ward, M.O.; Lipchak, B.N. A visualization tool for exploratory analysis of cyclic multivariate data. Metrika 2000, 51, 27–37. [Google Scholar] [CrossRef]
- Ellis, G.; Dix, A. A taxonomy of clutter reduction for information visualisation. IEEE Trans. Vis. Comput. Graph. 2007, 13, 1216–1223. [Google Scholar] [CrossRef] [PubMed]
- Borgo, R.; Kehrer, J.; Chung, D.H.; Maguire, E.; Laramee, R.S.; Hauser, H.; Ward, M.; Chen, M. Glyph-based Visualization: Foundations, Design Guidelines, Techniques and Applications. In Proceedings of the Eurographics State of the Art Reports, Girona, Spain, 6–10 May 2013; pp. 39–63. [Google Scholar]
- Public Health England. FingerTips PHE. Available online: https://fingertips.phe.org.uk (accessed on 20 November 2018).
- McNabb, L.; Laramee, R.S. Survey of Surveys (SoS)-Mapping The Landscape of Survey Papers in Information Visualization. Comput. Graph. Forum 2017, 36, 589–617. [Google Scholar] [CrossRef]
- Fuchs, J.; Isenberg, P.; Bezerianos, A.; Keim, D. A Systematic Review of Experimental Studies on Data Glyphs. IEEE Trans. Vis. Comput. Graph. 2017, 23, 1863–1879. [Google Scholar] [CrossRef] [PubMed]
- Ward, M.O. A taxonomy of glyph placement strategies for multidimensional data visualization. Inf. Vis. 2002, 1, 194–210. [Google Scholar] [CrossRef]
- Tobler, W. Thirty five years of computer cartograms. Ann. Assoc. Am. Geogr. 2004, 94, 58–73. [Google Scholar] [CrossRef]
- Nusrat, S.; Kobourov, S. Task taxonomy for cartograms. In Proceedings of the 17th IEEE Eurographics Conference on Visualization (EUROVIS—Short papers), Cagliari, Italy, 25–29 May 2015. [Google Scholar]
- Nusrat, S.; Kobourov, S. The State of the Art in Cartograms. Comput. Graph. Forum 2016, 35, 619–642. [Google Scholar] [CrossRef] [Green Version]
- Tominski, C.; Gladisch, S.; Kister, U.; Dachselt, R.; Schumann, H. A survey on interactive lenses in visualization. In Proceedings of the EuroVis State-of-the-Art Reports, Swansea, UK, 9–13 June 2014; Volume 3. [Google Scholar]
- Tominski, C.; Gladisch, S.; Kister, U.; Dachselt, R.; Schumann, H. Interactive lenses for visualization: An extended survey. Comput. Graph. 2017, 36, 173–200. [Google Scholar] [CrossRef]
- Cockburn, A.; Karlson, A.K.; Bederson, B.B. A review of overview+ detail, zooming, and focus+ context interfaces. ACM Comput. Surv. 2008, 41, 2. [Google Scholar] [CrossRef]
- Luboschik, M.; Schumann, H.; Cords, H. Particle-based labeling: Fast point-feature labeling without obscuring other visual features. IEEE Trans. Vis. Comput. Graph. 2008, 14, 1237–1244. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jänicke, S.; Heine, C.; Stockmann, R.; Scheuermann, G. Comparative Visualization of Geospatial-temporal Data. In Proceedings of the 3rd International Conference on Information Visualization Theory and Applications, IVAPP, Rome, Italy, 24–26 February 2012; pp. 613–625. [Google Scholar]
- Rohrdantz, C.; Krstajic, M.; El Assady, M.; Keim, D. What is Going On? How Twitter and Online News Can Work in Synergy to Increase Situational Awareness. In Proceedings of the 2nd IEEE Workshop on Interactive Visual Text Analytics Task-Driven Analysis of Social Media, Seattle, WA, USA, 15 October 2012. [Google Scholar]
- Jo, J.; Vernier, F.; Dragicevic, P.; Fekete, J.D. A Declarative Rendering Model for Multiclass Density Maps. IEEE Trans. Vis. Comput. Graph. 2019, 25, 470–480. [Google Scholar] [CrossRef] [PubMed]
- Guo, D. Regionalization with dynamically constrained agglomerative clustering and partitioning (REDCAP). Int. J. Geogr. Inf. Sci. 2008, 22, 801–823. [Google Scholar] [CrossRef]
- Dorling, D. The visualization of local urban change across Britain. Environ. Plan. B Plan. Des. 1995, 22, 269–290. [Google Scholar] [CrossRef]
- Slingsby, A.; Wood, J.; Dykes, J. Treemap cartography for showing spatial and temporal traffic patterns. J. Maps 2010, 6, 135–146. [Google Scholar] [CrossRef]
- Slingsby, A.; Dykes, J.; Wood, J. Rectangular hierarchical cartograms for socio-economic data. J. Maps 2010, 6, 330–345. [Google Scholar] [CrossRef]
- Tong, C.; Roberts, R.; Laramee, R.S.; Berridge, D.; Thayer, D. Cartographic Treemaps for Visualization of Public Healthcare Data. Available online: https://core.ac.uk/download/pdf/132203033.pdf (accessed on 20 September 2019).
- Tong, C.; McNabb, L.; Laramee, R.S.; Lyons, J.; Walters, A.; Berridge, D.; Thayer, D. Time-oriented Cartographic Treemaps for Visualization of Public Healthcare Data. Available online: https://core.ac.uk/download/pdf/132203032.pdf (accessed on 20 September 2019).
- Beecham, R.; Slingsby, A.; Brunsdon, C. Locally-varying explanations behind the United Kingdom’s vote to leave the European Union. J. Spat. Inf. Sci. 2018, 2018, 117–136. [Google Scholar] [CrossRef]
- Nusrat, S.; Alam, M.J.; Scheidegger, C.; Kobourov, S. Cartogram visualization for bivariate geo-statistical data. IEEE Trans. Vis. Comput. Graph. 2018, 24, 2675–2688. [Google Scholar] [CrossRef]
- Palsky, G. Des chiffres et des cartes-la cartographie quantitative au XIXe siècle, Paris, èditions du CTHS, coll. Géographie 1996, 19, 331. [Google Scholar]
- Kahrl, W.L.; Bowen, W.A.; Brand, S.; Shelton, M.L.; Fuller, D.L.; Ryan, D.A. The California Water Atlas; Governor’s Office of Planning and Research: Sacramento, CA, USA, 1979.
- Olson, J.M. Spectrally encoded two-variable maps. Ann. Assoc. Am. Geogr. 1981, 71, 259–276. [Google Scholar] [CrossRef]
- Dunn, R. A dynamic approach to two-variable color mapping. Am. Stat. 1989, 43, 245–252. [Google Scholar]
- Brewer, C.; Campbell, A.J. Beyond graduated circles: Varied point symbols for representing quantitative data on maps. Cartogr. Perspect. 1998, 6–25. [Google Scholar] [CrossRef]
- Andrienko, N.; Andrienko, G. Exploratory Analysis of Spatial and Temporal Data: A Systematic Approach; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar] [CrossRef]
- Slocum, T.A.; McMaster, R.B.; Kessler, F.C.; Howard, H.H. Thematic Cartography and Geovisualization; Pearson Prentice Hall: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Bertin, J. Semiology of Graphics: Diagrams, Networks, Maps; University of Wisconsin Press: Madison, WI, USA, 1983. [Google Scholar]
- Elmer, M.E. Symbol Considerations for Bivariate Thematic Mapping. Ph.D. Thesis, University of Wisconsin–Madison, Madison, WI, USA, 2012. [Google Scholar]
- Kresse, W.; Danko, D.M. Springer Handbook of Geographic Information; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Tsorlini, A.; Sieber, R.; Hurni, L.; Klauser, H.; Gloor, T. Designing a Rule-based Wizard for Visualizing Statistical Data on Thematic Maps. Cartogr. Perspect. 2017. [Google Scholar] [CrossRef]
- Ward, M.O. Multivariate data glyphs: Principles and practice. In Handbook of Data Visualization; Springer: Berlin/Heidelberg, Germany, 2008; pp. 179–198. [Google Scholar]
- Ropinski, T.; Preim, B. Taxonomy and usage guidelines for glyph-based medical visualization. In Proceedings of the SimVis, Magdeburg, Germany, 18–29 February 2008; pp. 121–138. [Google Scholar]
- Chung, D.H.; Legg, P.A.; Parry, M.L.; Bown, R.; Griffiths, I.W.; Laramee, R.S.; Chen, M. Glyph sorting: Interactive visualization for multi-dimensional data. Inf. Vis. 2015, 14, 76–90. [Google Scholar] [CrossRef]
- McNabb, L.; Laramee, R.S.; Fry, R. Dynamic Choropleth Maps—Using Amalgamation to Increase Area Perceivability. In Proceedings of the The 22nd International Conference on Information Visualization (IV), Fisciano, Italy, 10–13 July 2018; pp. 284–293. [Google Scholar] [CrossRef]
- McNabb, L.; Laramee, R.S.; Wilson, M. When Size Matters—Towards Evaluating Pereivability of Choropleths. In The Computer Graphics & Visual Computing (CGVC) Conference 2018; The Eurographics Association: Swansea, UK, 2018; pp. 163–171. [Google Scholar] [CrossRef]
- Openshaw, S. The Modifiable Areal Unit Problem. In Concepts and Techniques in Modern Geography; Geo Books: Norwich, UK, 1984. [Google Scholar]
- Nightingale, F. Notes on Matters Affecting the Health, Efficiency, and Hospital Administration of the British Army: Founded Chiefly on the Experience of the Late War; Harrison and Sons, St. Martin’s Lane: London, UK, 1858. [Google Scholar]
- Siegel, J.H.; Farrell, E.J.; Goldwyn, R.M.; Friedman, H.P. The surgical implications of physiologic patterns in myocardial infarction shock. Surgery 1972, 72, 126–141. [Google Scholar]
- Brewer, C.A. A Transition in Improving Maps: The ColorBrewer Example. Cartogr. Geogr. Inf. Sci. 2003, 30, 159–162. [Google Scholar] [CrossRef]
- Gramazio, C.C.; Laidlaw, D.H.; Schloss, K.B. Colorgorical: Creating discriminable and preferable color palettes for information visualization. IEEE Trans. Vis. Comput. Graph. 2017, 23, 521–530. [Google Scholar] [CrossRef]
- U.S. Department of Commerce. USA Counties Data File Downloads. Available online: https://www.census.gov/support/USACdataDownloads.html (accessed on 20 November 2018).
- Ordnance Survey Ireland. Open Data for Census 2016 Ireland. Available online: https://bit.ly/2Dyg7Ac (accessed on 20 November 2018).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature | Placement Algorithm | Max No. of Variates | Level-of-Detail | Dynamic Zooming | Smooth Transitions | |
|---|---|---|---|---|---|---|
| Aggregation | Janicke et al. [16] | Coordinate-based | 1 | ✓ | ✓ | ✗ |
| Rohrdantz et al. [17] | Coordinate-based | 5 | ✗ | ✗ | ✗ | |
| Jo et al. [18] | Region centroid | 10 | ✗ | ✗ | ✗ | |
| Guo [19] | No glyphs | 1 | ✓ | ✗ | ✗ | |
| Minard [27] | Manual | 3 | ✗ | ✗ | ✗ | |
| Kahrl et al. [28] | Manual | 6 | ✗ | ✗ | ✗ | |
| Olson [29] | No glyphs | 2 | ✗ | ✗ | ✗ | |
| Dunn [30] | No glyphs | 2 | ✗ | ✗ | ✗ | |
| Brewer [31] | Region centroid | 2 | ✗ | ✗ | ✗ | |
| Multivariate Maps | Andrienko and Andrienko [32] | Region centroid/ Grid-based | 6 | ✗ | ✗ | ✗ |
| Slocum et al. [33] | Region centroid/ Grid-based | 8 | ✗ | ✗ | ✗ | |
| Bertin [34] | Coordinate-based/ Grid-based | 6 | ✗ | ✗ | ✗ | |
| GGP | Elmer [35] | Region centroid | 2 | ✗ | ✗ | ✗ |
| Kresse and Danko [36] | Coordinate-based | 2 | ✗ | ✗ | ✗ | |
| Tsorlini et al. [37] | Region centroid | 6 | ✗ | ✗ | ✗ | |
| Chung et al. [40] | Scatterplot | 9 | ✗ | ✗ | ✗ | |
| McNabb et al. [41] | No glyphs | 1 | ✓ | ✓ | ✗ | |
| This | Dynamic Region centroid | 9 | ✓ | ✓ | ✓ | |
| Glyph Design | Hidden Density Indicators | ||||
|---|---|---|---|---|---|
| No Indicator | Outline | Size | Shadow | Size + Outline | |
| Pie Chart |  |  |  |  |  |
| Polar Area Chart |  |  |  |  |  |
| Bar Chart |  |  |  |  |  |
| Star Chart |  |  |  |  |  |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
McNabb, L.; Laramee, R.S. Multivariate Maps—A Glyph-Placement Algorithm to Support Multivariate Geospatial Visualization. Information 2019, 10, 302. https://doi.org/10.3390/info10100302
McNabb L, Laramee RS. Multivariate Maps—A Glyph-Placement Algorithm to Support Multivariate Geospatial Visualization. Information. 2019; 10(10):302. https://doi.org/10.3390/info10100302
Chicago/Turabian StyleMcNabb, Liam, and Robert S. Laramee. 2019. "Multivariate Maps—A Glyph-Placement Algorithm to Support Multivariate Geospatial Visualization" Information 10, no. 10: 302. https://doi.org/10.3390/info10100302