Subunits Inference and Lexicon Development Based on Pairwise Comparison of Utterances and Signs


Abstract
:1. Introduction
2. Relevant Literature
- (i)
- Most of the methods for subword units extraction in speech processing employ or presume some form of prior knowledge, e.g., existence of writing system, availability of transcription, and linguistic knowledge to preset number of clusters. Zero resource speech processing, although alleviates the necessity of such prior knowledge, is still an emerging field. As stated in [16], the main focus is on “finding speech features that emphasize linguistically relevant properties of the speech signal (phoneme structure) and de-emphasize the linguistically irrelevant ones”.
- (ii)
- Unlike speech processing, in sign language processing, the acquisition methods have evolved such as from the use of hand gloves to camera systems. In addition, most of the subunits extraction investigations have been carried out in a signer dependent manner.
3. Proposed Approach
- Step 1:
- A sequence of feature vectors is extracted for each utterance or sign. In the case of speech signal, the feature vectors are short-term cepstral features, which tend to model information related to vocal tract system. In the case of signs, the feature vectors for hand movement are based on the 3D skeletal information.
- Step 2:
- Given the sequence of feature vectors for each utterance or sign, a HMM is obtained for each unknown word or sign in the set. This step exploits the idea that HMMs inherently segment a time series into stationary segments and speech/sign recognition can be performed with word level HMMs.
- Step 3:
- The states are clustered into subunits by pairwise comparison and a sequence model in terms of clustered subunits is obtained for each unknown word or sign.
- Step 4:
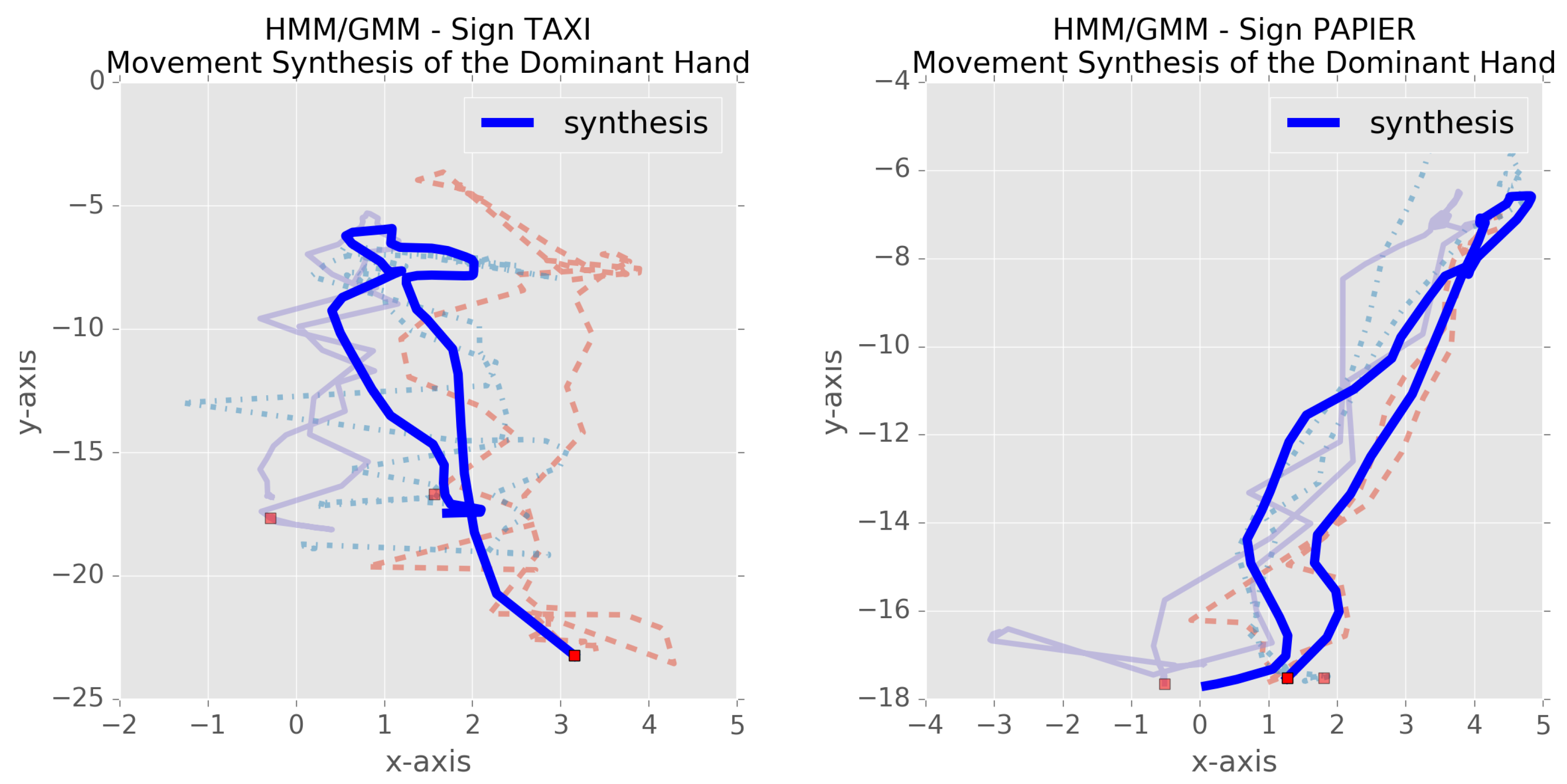
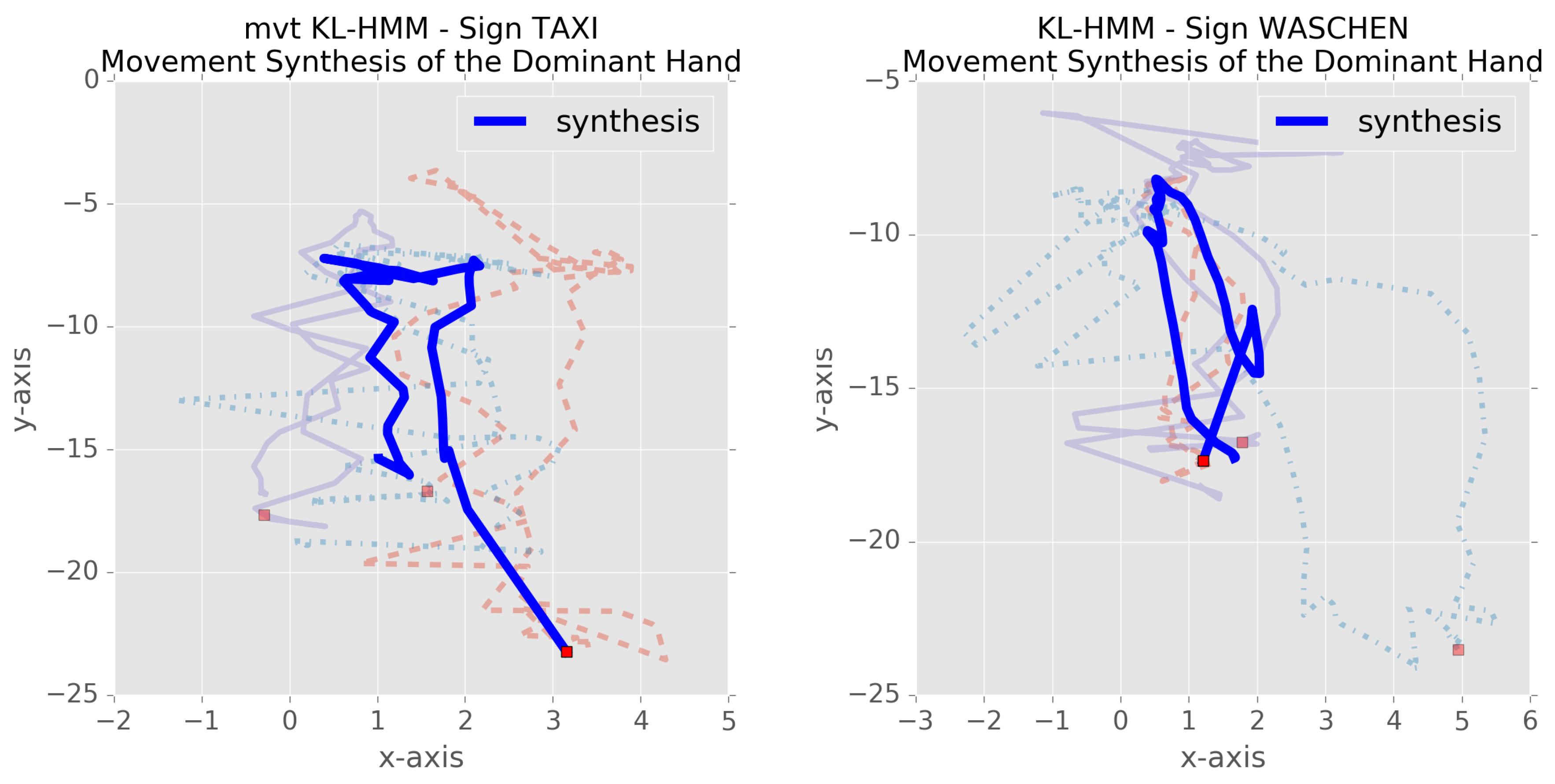
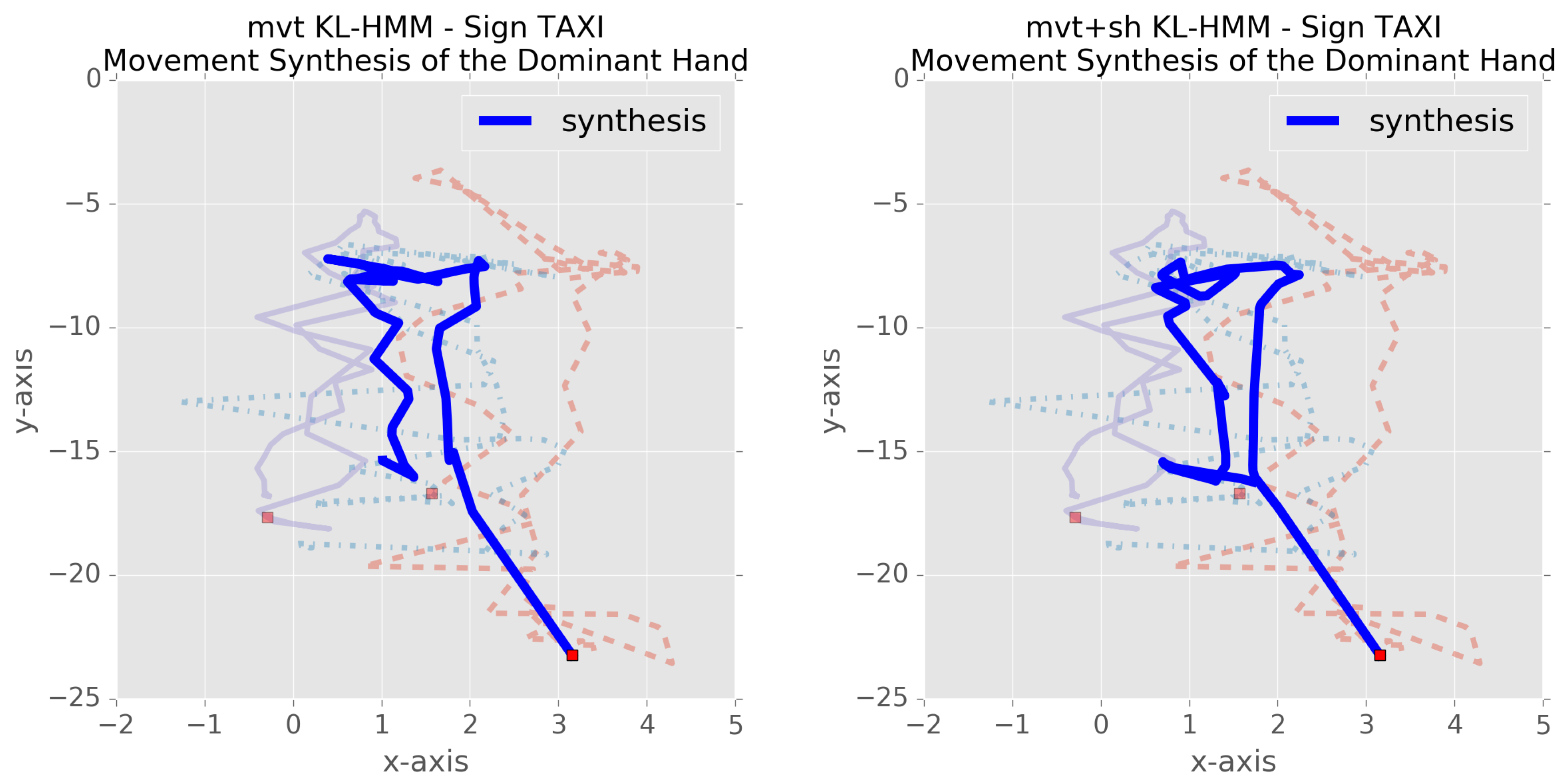
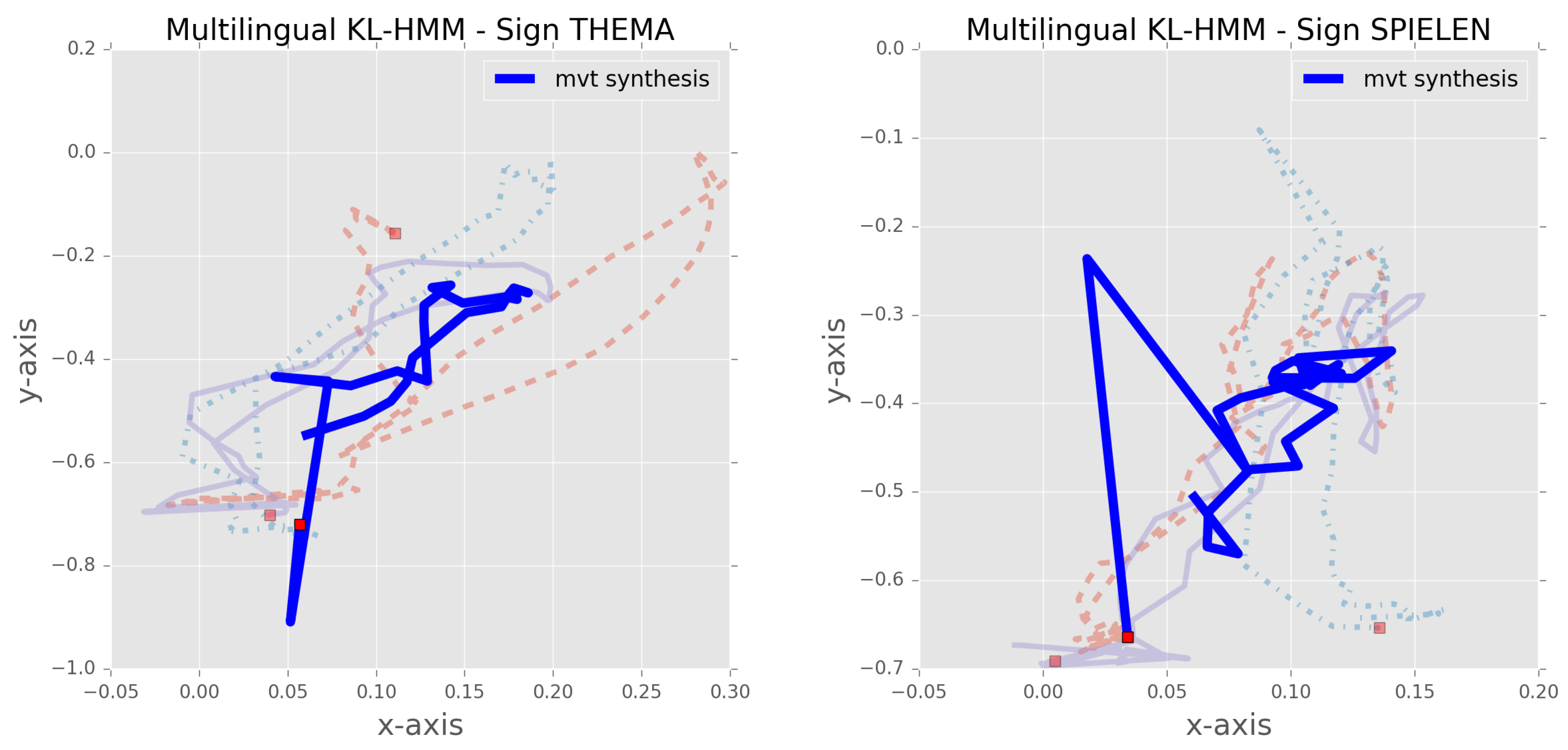
- In the case of spoken language, phone set and pronunciation model for the unknown words are inferred by learning a probabilistic subunit-to-phone relationship exploiting auxiliary speech data with linguistic resources. As noted above, unlike speech processing, prior knowledge about how to model sign as a sequence of subunits is still emerging. Thus, in the context of sign language, visualization based on HMM-based synthesis is employed.
3.1. Automatic Subword Unit Based Lexicon Development
- First, multiple automatic subword units based lexicons corresponding to different values of are obtained.
- A recognition system is then trained on the training data based on each of those lexicons.
- The lexicon that yields best recognition accuracy on the development data is chosen.
3.2. Linking Derived Subwords Units to Linguistic Knowledge
- A phone posterior probability estimator on auxiliary data or languages that have well developed phonetic resources is trained.
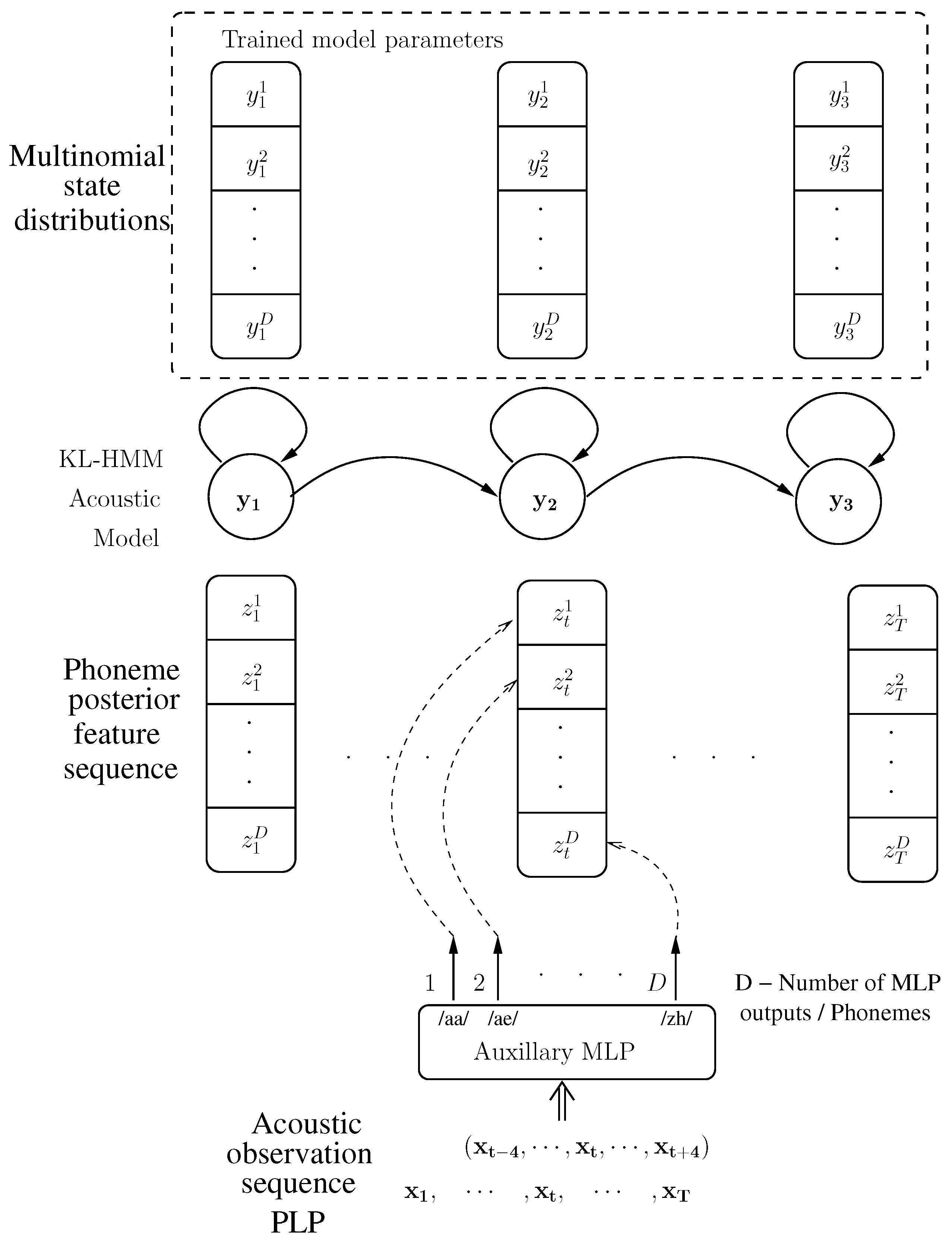
- A Kullback–Leibler divergence based HMM [39,40] (KL-HMM) with the phone posterior probability is trained as feature observations and the states being represented by the derived automatic subword units. Each state of the KL-HMM is parameterized by a categorical distribution of the same dimension as phone probability feature vector, which capture a probabilistic relationship between the automatic subword units and the phones. For a brief introduction about KL-HMM, the reader is referred to Appendix A. (The present paper builds upon different capabilities of KL-HMM: (a) modeling different subword units [41,42]; (b) handling resource constraints by exploiting multilingual or auxiliary resources [43]; and (c) modeling multichannel visual information in sign language [44]. For the sake of brevity, we do not go into very details of these works.)
- Phone-based pronunciation is inferred by using the trained KL-HMM as a generative model and decoding the resulting sequence of probability through an ergodic HMM of phones.
4. Spoken Language Study
4.1. Experimental Setup
4.1.1. Database
4.1.2. Systems
4.2. Results and Analysis
4.2.1. ASR Level Validation
4.2.2. Lexical Level Validation
4.2.3. Further Analysis
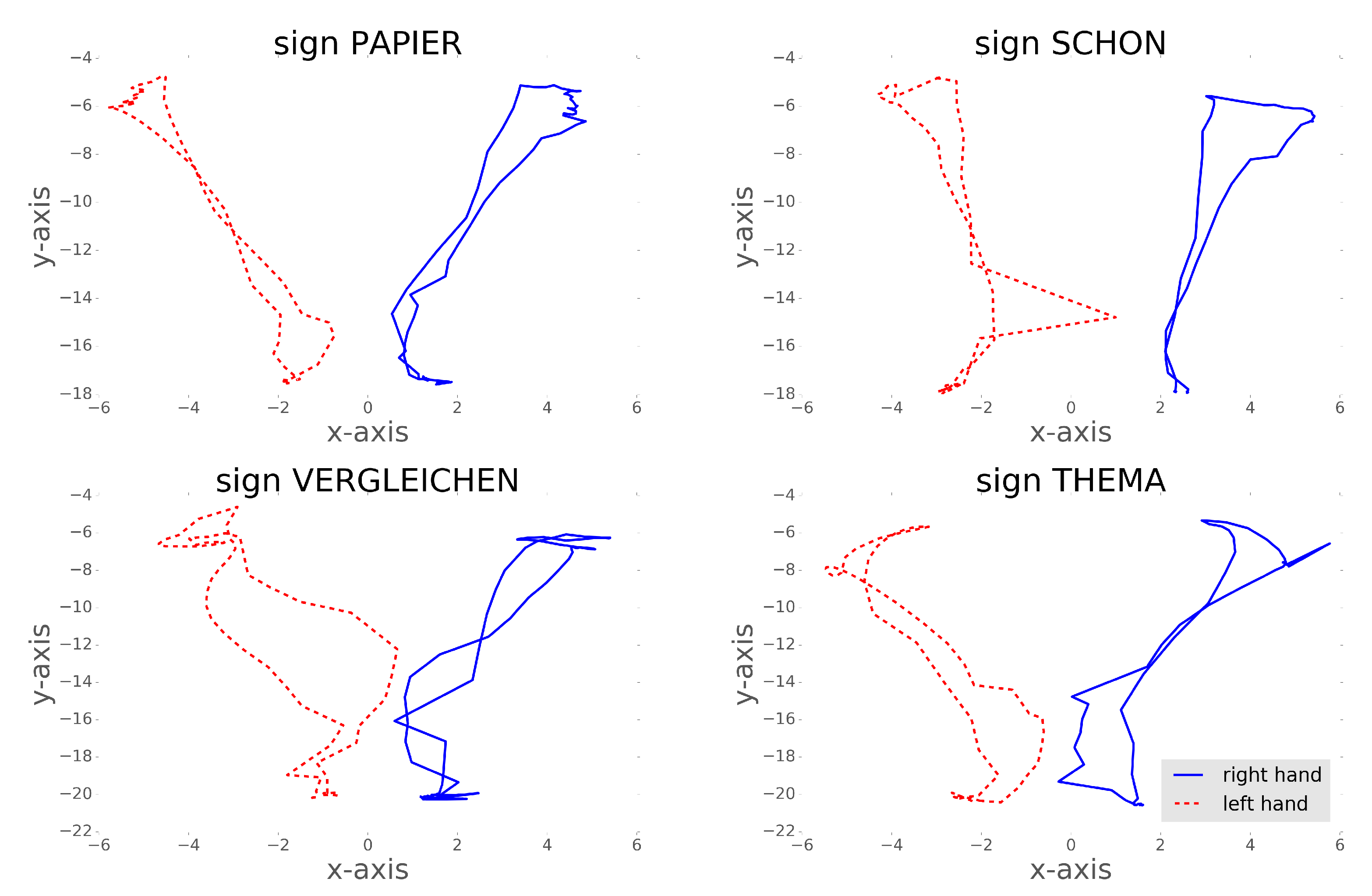
5. Sign Language Study
5.1. Experimental Setup
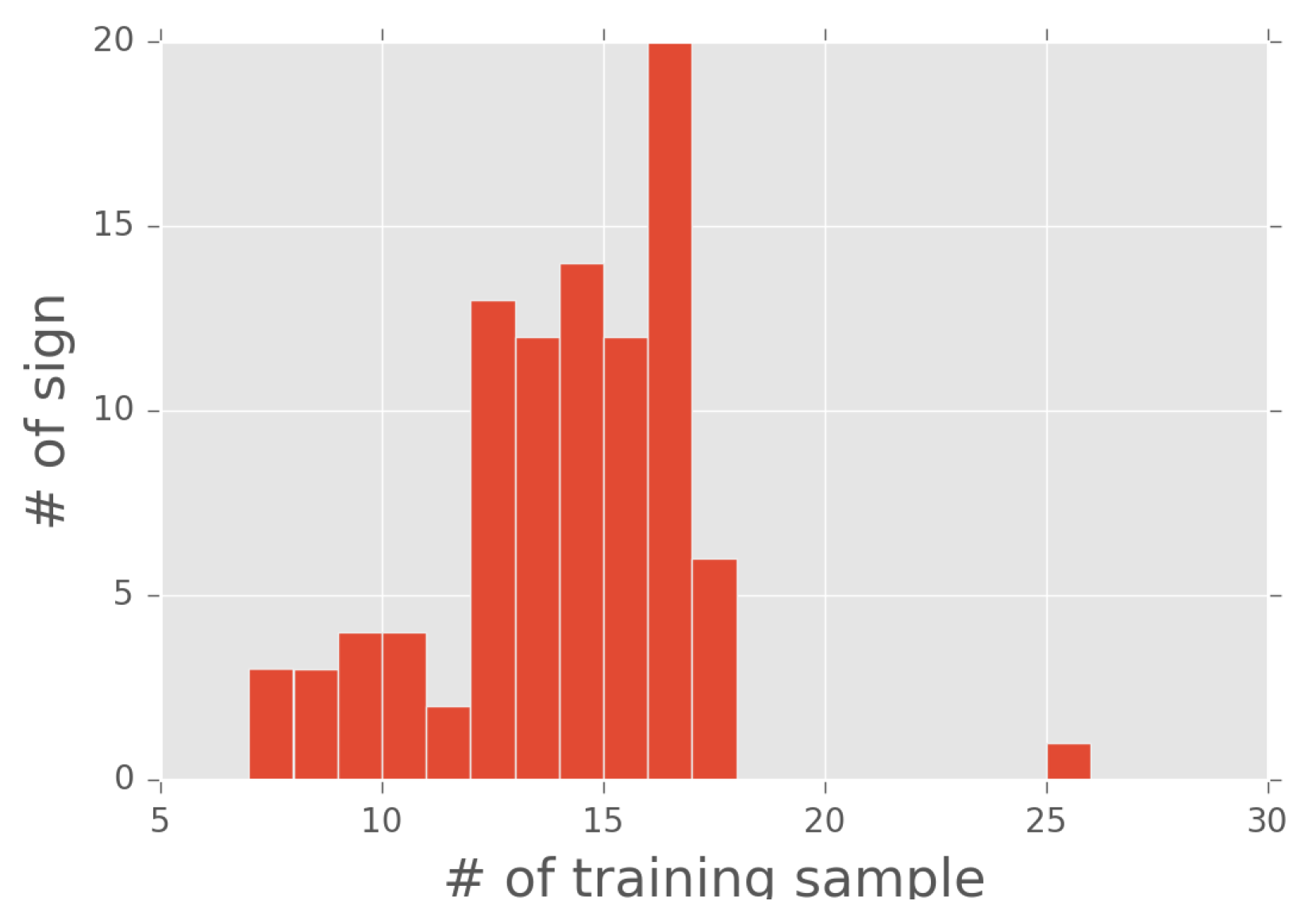
5.1.1. Database
5.1.2. Feature Extraction
5.1.3. Systems
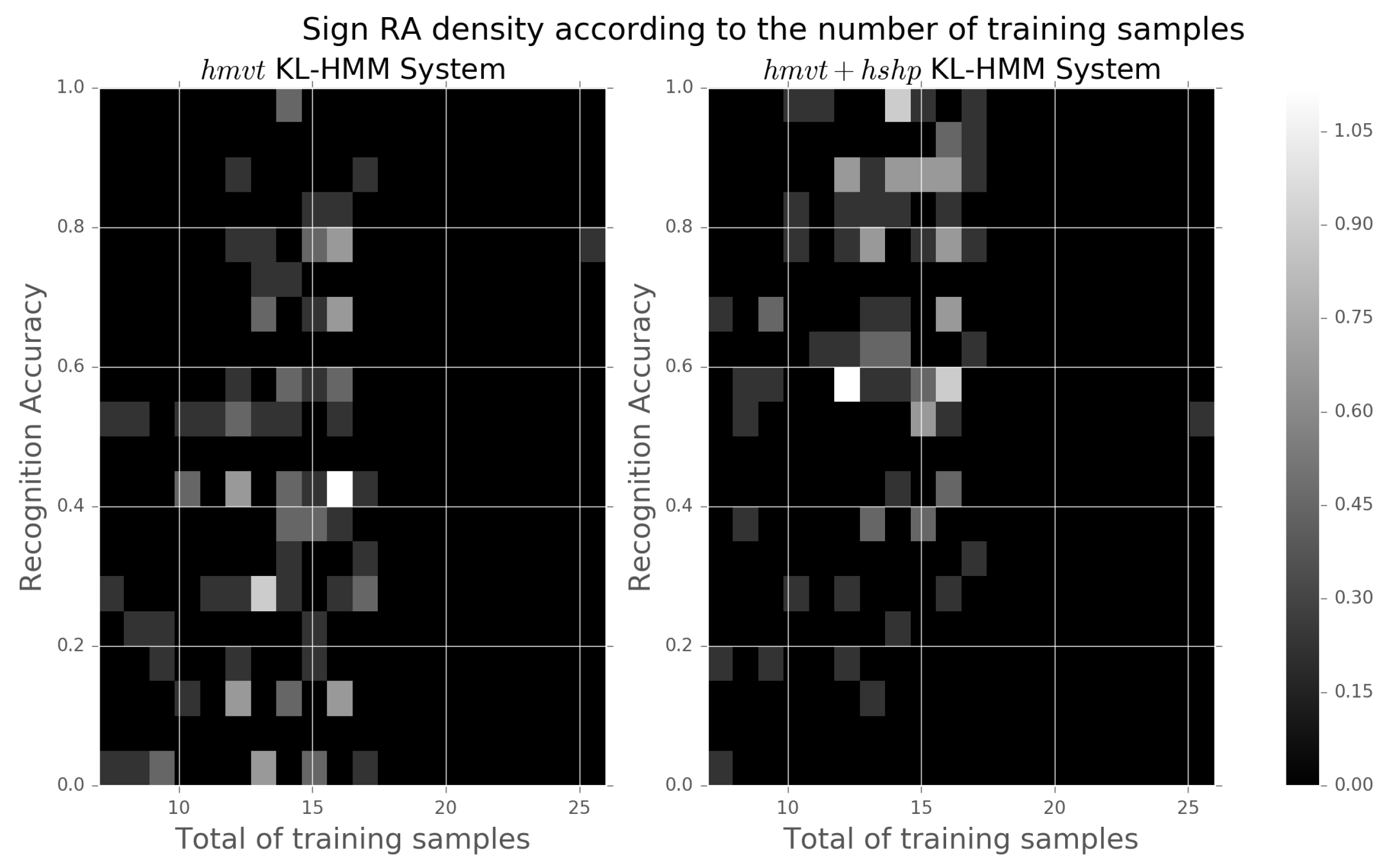
- Monolingual KL-HMM system: In this case, the hand movement subunits posterior probabilities estimated by the MLP of hybrid HMM/ANN system are used as feature observations. The KL-HMM states represent the hand movement subunits.
- Cross-lingual KL-HMM system: In this case, the hand movement subunits are derived on TSL HospiSign database (Steps 2 and 3); an MLP is trained on the HospiSign data to estimate TSL subunits posterior probabilities; and the states model DSGS subunits and the parameters are trained by using the TSL subunits posterior probabilities estimated on the DSGS data as feature observations. In doing so, the KL-HMM learns a probabilistic relationship between DSGS subunits and TSL subunits, and allows us to examine language-independence of derived subunits. To compensate the difference in the coordinate system recording in between both databases, a skeleton alignment is applied before the feature extraction. To do so, all the signer skeletons of both databases are aligned at the neck joint with respect to a reference Hospisign signer skeleton and then scaled by the shoulder width.
5.2. Results and Analysis
5.2.1. Monolingual Study
5.2.2. Cross-Lingual Study
6. Discussion and Conclusions
- Further ground the methodology linguistically by: (a) modeling articulatory features [60,61] instead of cepstral features in the case of spoken language; and (b) modeling both hand movement and hand shape in the case of sign language for deriving subunits. In both cases, it can be achieved by employing KL-HMM in Step 2 and Step 3. In the case of sign language, it will help in connecting to linguistic research that are trying to understand the high level units formed by hand movement and hand shape [4,5].
- Extend the cross-lingual investigations on sign language to multilingual scenario by pooling resources from other sign languages, with the ultimate aim of handling resource constraints in sign language processing.
- In the speech community, there is interest in modeling articulatory measurements obtained through electromagnetic articulography [62,63]. In the present work, the hand movement subunits were extracted by modeling skeletal information, i.e., measurements in 3D coordinate system. We will investigate whether such a method can be adopted to derive subunits from articulatory measurements, which in turn could be related well to the acoustic signal and phones.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| ASL | American Sign Language |
| ASR | Automatic Speech Recognition |
| BSL | British Sign Language |
| DGS | German Sign Language |
| DSGS | Swiss German Sign Language |
| DTW | Dynamic Time Warping |
| GMM | Gaussian Mixture Model |
| HamNoSys | Hamburg Notation System |
| HMM | Hidden Markov Model |
| HTK | Hidden Markov Model ToolKit |
| KL-HMM | Kullback–Leibler divergence-based HMM |
| LEV | Levenshtein distance |
| LQR | Linear-Quadratic Regulator |
| MLP | MultiLayer Perceptron |
| PLP | Perceptual linear prediction |
| PRR | Phone Recognition Rate |
| RA | Recognition Accuracy |
| SAMPA | Speech Assessment Methods Phonetic Alphabet |
| SLR | Sign Language Recognition |
| TSL | Turkish Sign Language |
| TTS | Text-to-speech Synthesis |
Appendix A. Kullback–Leibler Divergence Based HMM
- Reverse KL-divergence ():
- Symmetric KL-divergence (SKL):
References
- Sutton-Spence, R.; Woll, B. The Linguistics of British Sign Language: An Introduction; Cambridge University Press: Cambridge, UK, 1999. [Google Scholar] [CrossRef]
- Cooper, H.; Holt, B.; Bowden, R. Sign Language Recognition. In Visual Analysis of Humans; Moeslund, T.B., Hilton, A., Kräger, V., Sigal, L., Eds.; Springer: London, UK, 2011; pp. 539–562. [Google Scholar] [CrossRef] [Green Version]
- Adda-Decker, M.; Lamel, L. Multilingual Dictionaries. In Multilingual Speech Proceesing; Schultz, T., Kirchhoff, K., Eds.; Academic Press: Cambridge, MA, USA, 2006; Chapter 5; pp. 123–168. [Google Scholar]
- Baus, C.; Gutiérrez, E.; Carreiras, M. The role of syllables in sign language production. Front. Psychol. 2014, 5, 1254. [Google Scholar] [CrossRef] [PubMed]
- Boyes Braem, P.; Sutton-Spence, R. (Eds.) The Hands Are the Head of the Mouth: The Mouth as Articulator in Sign Languages; Signum: Hamburg, Germany, 2001. [Google Scholar]
- Kaplan, R.; Kay, M. Regular models of phonological rule systems. Comput. Linguist. 1994, 20, 331–378. [Google Scholar]
- Davel, M.; Barnard, E. Pronunciation prediction with Default&Refine. Comput. Speech Lang. 2008, 22, 374–393. [Google Scholar]
- Dedina, M.; Nusbaum, H. PRONOUNCE: A program for pronunciation by analogy. Comput. Speech Lang. 1991, 5, 55–64. [Google Scholar] [CrossRef]
- Pagel, V.; Lenzo, K.; Black, A. Letter to Sound Rules for Accented Lexicon Compression. In Proceedings of the International Conference on Spoken Language Processing, Sydney, Australia, 30 November–4 December 1998. [Google Scholar]
- Bisani, M.; Ney, H. Joint-sequence Models for Grapheme-to-phoneme Conversion. Speech Commun. 2008, 50, 434–451. [Google Scholar] [CrossRef]
- Wang, D.; King, S. Letter-to-Sound Pronunciation Prediction Using Conditional Random Fields. IEEE Signal Process. Lett. 2011, 18, 122–125. [Google Scholar] [CrossRef]
- Park, A.; Glass, J.R. Towards unsupervised pattern discovery in speech. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding, San Juan, Puerto Rico, 27 November–1 December 2005; pp. 53–58. [Google Scholar]
- Park, A.S.; Glass, J.R. Unsupervised Pattern Discovery in Speech. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 186–197. [Google Scholar] [CrossRef]
- Varadarajan, B.; Khudanpur, S.; Dupoux, E. Unsupervised Learning of Acoustic Sub-word Units. In Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics on Human Language Technologies: Short Papers, Columbus, OH, USA, 16–17 June 2008; pp. 165–168. [Google Scholar]
- Jansen, A.; Church, K.; Hermansky, H. Towards spoken term discovery at scale with zero resources. In Proceedings of the Interspeech, Makuhari, Chiba, Japan, 26–30 September 2010; pp. 1676–1679. [Google Scholar]
- Versteegh, M.; Thiollière, R.; Schatz, T.; Cao Kam, X.N.; Anguera, X.; Jansen, A.; Dupoux, E. The Zero Resource Speech Challenge 2015. In Proceedings of the Interspeech, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Dunbar, E.; Cao, X.N.; Benjumea, J.; Karadayi, J.; Bernard, M.; Besacier, L.; Anguera, X.; Dupoux, E. The zero resource speech challenge 2017. In Proceedings of the IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 323–330. [Google Scholar]
- Lee, C.H.; Juang, B.H.; Soong, F.; Rabiner, L. Word recognition using whole word and subword models. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Glasgow, UK, 23–26 May 1989; Volume 1, pp. 683–686. [Google Scholar]
- Svendsen, T.; Paliwal, K.K.; Harborg, E.; Husoy, P.O. An improved sub-word based speech recognizer. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Glasgow, UK, 23–26 May 1989; Volume 1, pp. 108–111. [Google Scholar]
- Paliwal, K. Lexicon-building methods for an acoustic sub-word based speech recognizer. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Albuquerque, NM, USA, 3–6 April 1990; pp. 729–732. [Google Scholar]
- Svendsen, T.; Soong, F.; Purnhagen, H. Optimizing baseforms for HMM-based speech recognition. In Proceedings of the EUROSPEECH, Madrid, Spain, 18–21 September 1995. [Google Scholar]
- Holter, T.; Svendsen, T. Combined optimisation of baseforms and model parameters in speech recognition based on acoustic subword units. In Proceedings of the ASRU, Santa Barbara, CA, USA, 17 December 1997; pp. 199–206. [Google Scholar]
- Bacchiani, M.; Ostendorf, M. Joint lexicon, acoustic unit inventory and model design. Speech Commun. 1999, 29, 99–114. [Google Scholar] [CrossRef]
- Singh, R.; Raj, B.; Stern, R.M. Automatic generation of subword units for speech recognition systems. IEEE Trans. Speech Audio Process. 2002, 10, 89–99. [Google Scholar] [CrossRef] [Green Version]
- Hartmann, W.; Roy, A.; Lamel, L.; Gauvain, J. Acoustic unit discovery and pronunciation generation from a grapheme-based lexicon. In Proceedings of the ASRU, Olomouc, Czech Republic, 8–12 December 2013; pp. 380–385. [Google Scholar]
- Lee, C.; Zhang, Y.; Glass, J.R. Joint Learning of Phonetic Units and Word Pronunciations for ASR. In Proceedings of the EMNLP, Seattle, WA, USA, 18–21 October 2013; pp. 182–192. [Google Scholar]
- Razavi, M.; Rasipuram, R.; Magimai.-Doss, M. Towards Weakly Supervised Acoustic Subword Unit Discovery and Lexicon Development Using Hidden Markov Models. Speech Commun. 2018, 96, 168–183. [Google Scholar] [CrossRef]
- Hanke, T. HamNoSys—Representing sign language data in language resources and language processing contexts. In Proceedings of the 4th International Conference on Language Resources and Evaluation (LREC 2004), Lisbon, Portugal, 26–28 May 2004; pp. 1–6. [Google Scholar]
- Pitsikalis, V.; Theodorakis, S.; Vogler, C.; Maragos, P. Advances in phonetics-based sub-unit modeling for transcription alignment and sign language recognition. In Proceedings of the IEEE CVPR Workshops, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Cooper, H.; Ong, E.; Pugeault, N.; Bowden, R. Sign language recognition using sub-units. J. Mach. Learn. Res. 2012, 13, 2205–2231. [Google Scholar]
- Koller, O.; Ney, H.; Bowden, R. May the force be with you: Force-aligned signwriting for automatic subunit annotation of corpora. In Proceedings of the 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (AFGR), Shanghai, China, 22–26 April 2013; pp. 1–6. [Google Scholar] [CrossRef]
- Bauer, B.; Kraiss, K.F. Towards an Automatic Sign Language Recognition System Using Subunits. In Gesture and Sign Language in Human-Computer Interaction: International Gesture Workshop; Springer: Berlin/Heidelberg, Germany, 2002; pp. 64–75. [Google Scholar] [CrossRef]
- Junwei, H.; George, A.; Alistair, S. Modelling and segmenting subunits for sign language recognition based on hand motion analysis. Pattern Recognit. Lett. 2009, 30, 623–633. [Google Scholar] [CrossRef]
- Fang, G.; Gao, X.; Gao, W.; Chen, Y. A novel approach to automatically extracting basic units from Chinese sign language. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 23–26 August 2004; Volume 4, pp. 454–457. [Google Scholar] [CrossRef]
- Theodorakis, S.; Pitsikalis, V.; Maragos, P. Model-level data-driven sub-units for signs in videos of continuous Sign Language. In Proceedings of the IEEE ICASSP, Dallas, TX, USA, 14–19 March 2010; pp. 2262–2265. [Google Scholar] [CrossRef]
- Sako, S.; Kitamura, T. Subunit modeling for Japanese sign language recognition based on phonetically depend multi-stream hidden Markov models. In Universal Access in Human-Computer Interaction. Design Methods, Tools, and Interaction Techniques for eInclusion; Springer: Berlin/Heidelberg, Germany, 2013; pp. 548–555. [Google Scholar]
- Miller, G.A. The Science of Words; W. H. Freeman and Company: New York, NY, USA, 1996. [Google Scholar]
- Bhattacharyya, A. On a Measure of Divergence between Two Multinomial Populations. Sankhyā Indian J. Stat. 1946, 7, 401–406. [Google Scholar]
- Aradilla, G.; Vepa, J.; Bourlard, H. An acoustic model based on Kullback-Leibler divergence for posterior features. In Proceedings of the ICASSP, Honolulu, HI, USA, 15–20 April 2007. [Google Scholar]
- Aradilla, G.; Bourlard, H.; Magimai.-Doss, M. Using KL-based acoustic models in a large vocabulary recognition task. In Proceedings of the Interspeech, Brisbane, Australia, 22–26 September 2008. [Google Scholar]
- Magimai.-Doss, M.; Rasipuram, R.; Aradilla, G.; Bourlard, H. Grapheme-based Automatic Speech Recognition using KL-HMM. In Proceedings of the Interspeech, Florence, Italy, 27–31 August 2011. [Google Scholar]
- Razavi, M.; Rasipuram, R.; Magimai.-Doss, M. Acoustic data-driven grapheme-to-phoneme conversion in the probabilistic lexical modeling framework. Speech Commun. 2016, 80, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Rasipuram, R.; Magimai.-Doss, M. Acoustic and Lexical Resource Constrained ASR using Language-Independent Acoustic Model and Language-Dependent Probabilistic Lexical Model. Speech Commun. 2015, 68, 23–40. [Google Scholar] [CrossRef]
- Tornay, S.; Razavi, M.; Camgoz, N.C.; Bowden, R.; Magimai.-Doss, M. HMM-based Approaches to Model Multichannel Information in Sign Language inspired from Articulatory Features-based Speech Processing. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Pignat, E.; Calinon, S. Learning adaptive dressing assistance from human demonstration. Robot. Auton. Syst. 2017, 93, 61–75. [Google Scholar] [CrossRef] [Green Version]
- Bohner, M.; Wintz, N. The Linear Quadratic Tracker on time scales. Int. J. Dyn. Syst. Differ. Equ. 2011, 3. [Google Scholar] [CrossRef]
- Hermansky, H. Perceptual Linear Predictive (PLP) Analysis of Speech. J. Acoust. Soc. Am. 1990, 57, 1738–1752. [Google Scholar] [CrossRef]
- Pitrelli, J.F.; Fong, C.; Wong, S.H.; Spitz, J.R.; Leung, H.C. PhoneBook: A phonetically-rich isolated-word telephone-speech database. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Detroit, MI, USA, 9–12 May 1995; Volume 1, pp. 101–104. [Google Scholar] [CrossRef]
- Dupont, S.; Bourlard, H.; Deroo, O.; Fontaine, V.; Boite, J.M. Hybrid HMM/ANN Systems for Training Independent Tasks: Experiments on ‘Phonebook’ and Related Improvements. In Proceedings of the ICASSP, Munich, Germany, 21–24 April 1997. [Google Scholar]
- Rabiner, L.R. A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Bourlard, H.; Morgan, N. Connectionist Speech Recognition: A Hybrid Approach; Kluwer Academic Publishers: Norwell, MA, USA, 1993. [Google Scholar]
- Young, S.; Evermann, G.; Gales, M.; Hain, T.; Kershaw, D.; Liu, X.; Moore, G.; Odell, J.; Ollason, D.; Povey, D.; et al. The HTK Book; Cambridge University Engineering Department: Cambridge, UK, 2002. [Google Scholar]
- Johnson, D.; Ellis, D.; Oei, C.; Wooters, C.; Faerber, P.; Morgan, N.; Asanovic, K. ICSI Quicknet Software Package. 2004. Available online: http://www.icsi.berkeley.edu/Speech/qn.html (accessed on 8 January 2018).
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- Ong, S.C.W.; Ranganath, S. Automatic Sign Language Analysis: A Survey and the Future Beyond Lexical Meaning. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 873–891. [Google Scholar] [CrossRef] [PubMed]
- Ebling, S.; Camgoz, N.C.; Braem, P.B.; Tissi, K.; Sidler-Miserez, S.; Stoll, S.; Hadfield, S.; Haug, T.; Bowden, R.; Tornay, S.; et al. SMILE Swiss German sign language dataset. In Proceedings of the Language Resources and Evaluation Conference, Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Camgöz, N.C.; Kındıroğlu, A.A.; Akarun, L. Sign Language Recognition for Assisting the Deaf in Hospitals. In Proceedings of the Human Behavior Understanding: 7th International Workshop, Amsterdam, The Netherlands, 16 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 89–101. [Google Scholar] [CrossRef]
- Koller, O.; Ney, H.; Bowden, R. Deep Hand: How to Train a CNN on 1 Million Hand Images When Your Data Is Continuous and Weakly Labelled. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Jachova, Z.; Olivera, K.; Karovska Ristovska, A. Differences between American Sign Language (ASL) and British Sign Language (BSL). J. Spec. Educ. Rehabil. 2008, 9, 41–52. [Google Scholar] [CrossRef]
- King, S.; Frankel, J.; Livescu, K.; McDermott, E.; Richmond, K.; Wester, M. Speech production knowledge in automatic speech recognition. J. Acoust. Soc. Am. 2007, 121, 723–742. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rasipuram, R.; Magimai.-Doss, M. Articulatory feature based continuous speech recognition using probabilistic lexical modeling. Comput. Speech Lang. 2016, 36, 233–259. [Google Scholar] [CrossRef] [Green Version]
- Wrench, A.; Richmond, K. Continuous Speech Recognition Using Articulatory Data. In Proceedings of the ICSLP, Beijing, China, 16–20 October 2000. [Google Scholar]
- Richmond, K.; Hoole, P.; King, S. Announcing the Electromagnetic Articulography (Day 1) Subset of the mngu0 Articulatory Corpus. In Proceedings of the Interspeech, Florence, Italy, 27–31 August 2011. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Clustered Subword Unit-Based System | Word Level System | |
|---|---|---|
| HMM/GMM | 94.1 ± 5.6 | 96.1 ± 4.0 |
| Hybrid HMM/ANN | 97.8 ± 2.0 | 98.3 ± 2.1 |
| Average # units | 810 | 1125 |
| Context-Independent System | Context-Dependent System | |
| Baseline HMM/GMM | 97.7 ± 2.5 | 96.1 ± 4.8 |
| # phonemes | 39 | 114 |
| Clustered Subword Unit-Based System | Word Level System | |
|---|---|---|
| KL-HMM | 99.0 ± 1.8 | 99.4 ± 1.2 |
| Context-Independent System | Context-Dependent System | |
| Baseline KL-HMM | 98.1 ± 3.4 | 99.7 ± 0.9 |
| Clustered Subword Unit-Based System | Word Level System | |
|---|---|---|
| LEV ± std | 1.9 ± 0.2 | 1.5 ± 0.1 |
| PRR ± std | 70.3 ± 2.6 | 76.4 ± 1.1 |
| HMM/GMM-Based System | |||
|---|---|---|---|
| Lexicon | Average RA ± std | Average # Units | |
| Clustered subword unit-based system | all-train-utterances | 94.1 ± 5.6 | 810 (−28%) |
| six-utterances | 95.7 ± 4.5 | 1365 (−9%) | |
| four-utterances | 95.4 ± 5.9 | 1019 (−3%) | |
| Word level system | all-train-utterances | 96.1 ± 4.0 | 1125 |
| six-utterances | 96.3 ± 4.0 | 1500 | |
| four-utterances | 96.0 ± 5.5 | 1050 | |
| Monolingual KL-HMM-Based System | ||||
|---|---|---|---|---|
| Lexicon | Average RA ± std | LEV ± std | PRR ± std | |
| Clustered subword unit-based system | all-train-utterances | 99.0 ± 1.8 | 1.9 ± 0.2 | 70.3 ± 2.6 |
| six-utterances | 99.3 ± 1.2 | 1.5 ± 0.1 | 76.2 ± 1.7 | |
| four-utterances | 99.0 ± 1.4 | 1.8 ± 0.1 | 71.5 ± 1.0 | |
| Word level system | all-train-utterances | 99.4 ± 1.2 | 1.5 ± 0.1 | 76.4 ± 1.1 |
| six-utterances | 99.3 ± 1.2 | 1.4 ± 0.0 | 77.5 ± 0.7 | |
| four-utterances | 99.1 ± 1.4 | 1.8 ± 0.1 | 72.1 ± 0.8 | |
| Multilingual KL-HMM-Based System | ||
|---|---|---|
| Lexicon | Average RA ± std | |
| Clustered subword unit-based system | all-train-utterances | 98.4 ± 1.5 |
| six-utterances | 98.5 ± 1.6 | |
| four-utterances | 98.4 ± 2.5 | |
| Word level system | all-train-utterances | 98.7 ± 2.1 |
| six-utterances | 98.5 ± 1.6 | |
| four-utterances | 98.4 ± 2.5 | |
| Word | True | Monolingual-Based Inferrence | Multilingual-Based Inferrence |
|---|---|---|---|
| yarns | y a r n z | y a r n z | j o n |
| speechwriter | s p i C r Y t X | s p i C r Y t X | s p i tS u a OY e l |
| infrequently | I n f r i k w x n t l i | I n f r i k w x t l i | i e n f w i k u e |
| oops | u p s | w u p t s | n u |
| quail | k w e l | k w e l | u w e i o |
| bonbon | b a n b a n | b @ a n b a x n | o n b o n |
| Clustered Subunit-Based System | Sign Level System | |
|---|---|---|
| HMM/GMM | 51.3 | 49.4 |
| Hybrid HMM/ANN | 51.6 | 53.0 |
| KL-HMM | 55.8 | 57.4 |
| Average # subunits | 1945 | 2256 |
| hmvt KL-HMM | hshp KL-HMM | hmvt+hshp KL-HMM | |
|---|---|---|---|
| Sign RA | 55.8 | 38.2 | 74.3 |
| Cross-Lingual System | Monolingual System | |
|---|---|---|
| Sign RA | 41.5 | 55.8 |
| hmvt KL-HMM | hmvt+hshp KL-HMM | |
|---|---|---|
| Sign RA | 41.5 | 66.1 |
| Lexicon | Sign RA | |
|---|---|---|
| hmvt KL-HMM System | ten-sample-signs | 35.9 |
| eight-sample-signs | 33.7 | |
| six-sample-signs | 33.8 | |
| hmvt+hshp KL-HMM System | ten-sample-signs | 62.6 |
| eight-sample-signs | 60.1 | |
| six-sample-signs | 55.0 |
| Ref. | Features Based | Segment. | Clustering Algorithm | Recognition Study | Signer Indep. Study | Monolingual/ Cross-Lingual |
|---|---|---|---|---|---|---|
| Sako and Kitamura [36] | images processing | multi-stream HMM | tree based algorithm | ✓ | ✓ | Monolingual |
| Bauer and Kraiss [32] | gloves | HMM | k-means | ✓ | ✗ | Monolingual |
| Han et al. [33] | images processing | discontinuity detector | DTW | ✓ | ✗ | Monolingual |
| Fang et al. [34] | gloves | HMM | modified k-means | ✗ | ✗ | Monolingual |
| Theodorakis et al. [35] | images processing | HMM | HMM hierarchical clustering | ✗ | ✗ | Monolingual |
| Our approach | skeleton | HMM | pair-wise clustering with Bhatt. dist. | ✓ | ✓ | Mono- and cross-lingual |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tornay, S.; Magimai.-Doss, M. Subunits Inference and Lexicon Development Based on Pairwise Comparison of Utterances and Signs. Information 2019, 10, 298. https://doi.org/10.3390/info10100298
Tornay S, Magimai.-Doss M. Subunits Inference and Lexicon Development Based on Pairwise Comparison of Utterances and Signs. Information. 2019; 10(10):298. https://doi.org/10.3390/info10100298
Chicago/Turabian StyleTornay, Sandrine, and Mathew Magimai.-Doss. 2019. "Subunits Inference and Lexicon Development Based on Pairwise Comparison of Utterances and Signs" Information 10, no. 10: 298. https://doi.org/10.3390/info10100298