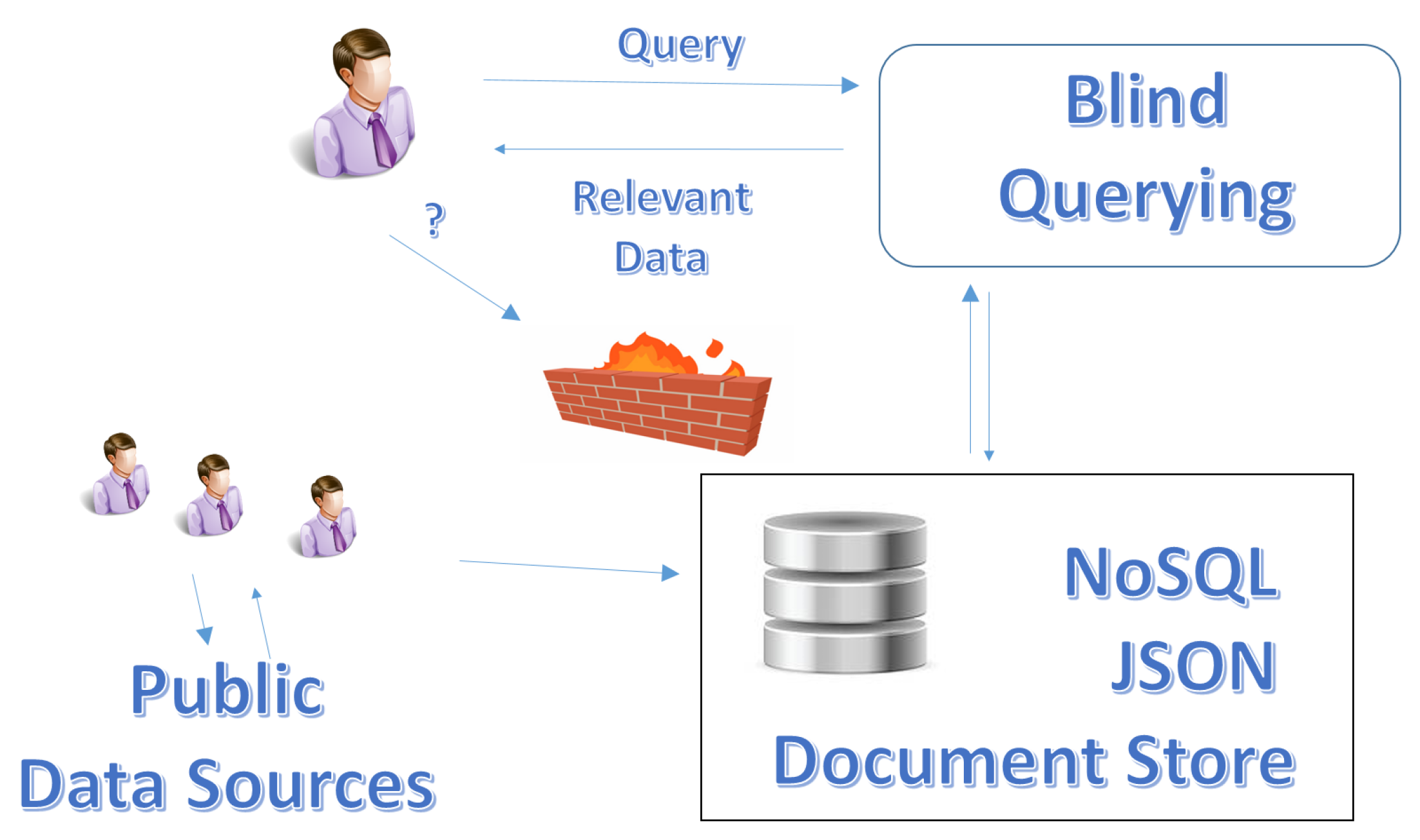
Blind Queries Applied to JSON Document Stores



Abstract
:1. Introduction
- Conceptual definition of the problem. In order to move from the context of querying Open Data portals to the context of querying private JSON document stores, the problem has been conceptually reformulated. We studied which previous concepts were still suitable and we defined some new concepts.
- Development of the HammerJDB framework. We developed new connectors to document stores and implemented new concepts, by keeping the core query rewriting technique developed within the former Hammer framework.
- Evaluation. The novel HammerJDB framework has been tested, in order to evaluate its capability to retrieve JSON documents of interest and validate the feasibility of the approach.
2. Related Works
- Any adopted technique should be able to process large volumes of data in a relatively short time.
- Approaches relying on Machine Learning often require a significantly large training set of manually labeled Web pages or JSON data sets. In general, labeling pages/data sets is a time-expensive and error prone task. As a consequence, in many cases we cannot assume the existence of labeled items.
- Oftentimes, any Web portal extraction tool has to routinely extract data from a source which can evolve over time. Web sources are continuously evolving and structural changes happen with no forewarning, thus are unpredictable. Eventually, in real-world scenarios it emerges the need of maintaining these systems, that might stop working correctly if the are not enough flexible to detect and face the structural modifications of the Web sources they have to interact with.
- a method able to prevent tf-idf failure caused by the presence of sets of correlated features;
- an improved spatial verification and re-ranking step that incrementally builds a statistical model of the query object;
- the concept of relevant spatial context to boost performance of retrieval.
3. Basic Concepts on NoSQL Databases for JSON Documents
3.1. JSON Documents
- A JSON document is enclosed within a pair of braces { and }, that encompasses a list of comma-separated fields.
- Syntactically, a field is a name: value pair, where the name is a string contained within a pair of " characters.
- The value of a field can alternatively be:
- -
- A constant (possibly negative) integer or real number;
- -
- a constant string, enclosed either within a pair of " characters;
- -
- a nested document, enclosed within { and }, arbitrarily complex;
- -
- an array of values, uncolored within characters [ and ], where an item can be either a numerical value or a string value or a document or an array.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| { |
| ‘‘a’’: 1, |
| ‘‘b’’: { |
| ‘‘c n’’: ‘‘c1’’, |
| ‘‘d’’: ‘‘d1’’ |
| }, |
| ‘‘f’’: { ‘‘f1’’: { |
| ‘‘c n’’: ‘‘c2’’, |
| ‘‘d’’: ‘‘d2’’ |
| }, |
| ‘‘f2’’: { |
| ‘‘c n’’: ‘‘c3’’, |
| ‘‘d’’: ‘‘d3’’ |
| } |
| } |
| } |
3.2. Document Databases
| { ‘‘ID’’: 1, |
| ‘‘Offer’’: { ‘‘Title’’: ‘‘Finance Manager ’’, |
| ‘‘Description’’: ‘‘Department’s finances’’, |
| ‘‘Country’’: ‘‘IT’’, |
| ‘‘Salary’’: ‘‘To be defined’’ }, |
| ‘‘Publish date’’: ‘‘03/09/2018’’ } |
| { ‘‘ID’’: 2, |
| ‘‘Profession’’: ‘‘International Export/Sales Manager’’, |
| ‘‘Profile’’: ‘‘An International Export / Sales Manager’’, |
| ‘‘Place’’: { ‘‘Location’’: ‘‘Valencia’’, |
| ‘‘Country’’: ‘‘Spain’’ }, |
| ‘‘Release date’’: ‘‘13/09/2018’’ } |
| { ‘‘ID’’: 3, |
| ‘‘Profession’’: ‘‘Solution Services Marketing Manager ’’, |
| ‘‘Profile’’: ‘‘8--10 years of experience in Marketing.’’, |
| ‘‘Place’’: { ‘‘Location’’: ‘‘Barcelona’’, |
| ‘‘Country’’: ‘‘Spain’’ }, |
| ‘‘Release date’’: ‘‘17/09/2018’’ } |
| { ‘‘ID’’: 1, |
| ‘‘Job Title’’: ‘‘Junior project controller’’, |
| ‘‘Area’’: { ‘‘City’’: ‘‘Berlin’’, |
| ‘‘Country’’: ‘‘DE’’ }, |
| ‘‘Offer’’: { ‘‘Contract’’: ‘‘Permanent’’, |
| ‘‘Working Hours’’: ‘‘Full Time’’}, |
| ‘‘Release date’’: ‘‘19/09/2018’’ } |
| { ‘‘ID’’: 2, |
| ‘‘Offer’’: { ‘‘Job Title’’: ‘‘Supplier Engineer’’, |
| ‘‘Place’’: { ‘‘City’’: ‘‘Berlin’’, |
| ‘‘Country’’: ‘‘DE’’ } }, |
| ‘‘Release date’’: ‘‘17/09/2018’’ |
| } |
4. Blind Querying on Open Data: Definitions and Approach
4.1. Basic Concepts and Definitions
- [Job-Offers],
- P [Company], [Requirements], [Contract] },
- sc [City]=“My City” AND [Profession]=“Software Developer”.
- [Jobs],
- [Company], [Requirements], [Contract]},
- [City]=“My City” AND [Profession]=“Software Developer”.
- [Job-Offers],
- [Company], [Requirements], [Contract]},
- [Job-Location]=“My City” AND [Profession]=“Software Developer”
- [Jobs],
- [Company], [Requirements], [Contract]},
- [Job-Location]=“My City” AND [Profession]=“Software Developer”
4.2. Hammer, the Blind Querying Framework
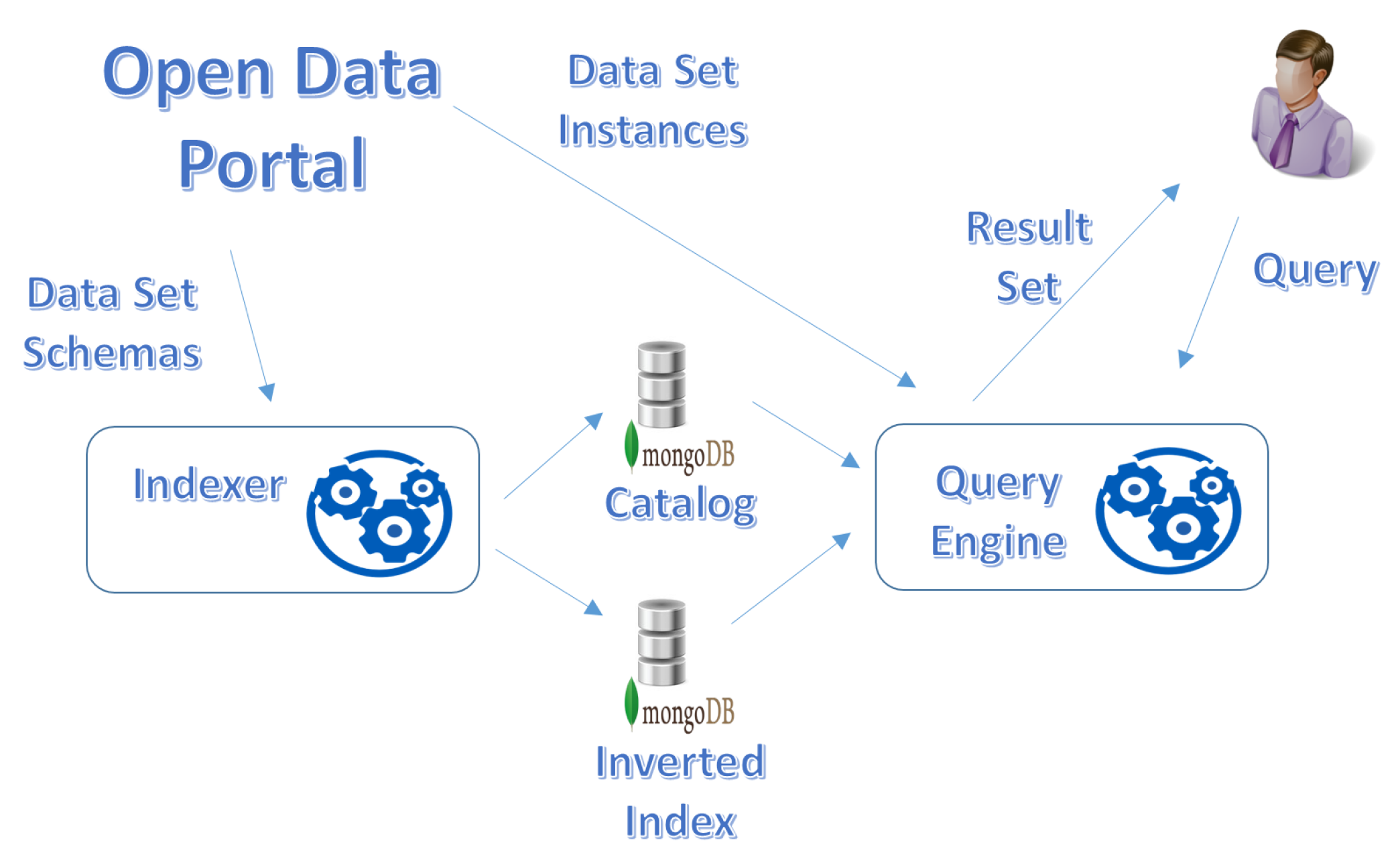
4.2.1. Indexer
- Crawling. the Indexer crawls the Open Data portal, in order to gather the list of published data sets, and for each of them its schema and auxiliary meta-data are extracted.
- The data set descriptions are stored into the catalog of the corpus; among several choices, we employed MongoDB to store the catalog, for the sake of flexibility.
- Indexing. The schema and the meta-data of the gathered data sets are indexed by means of an Inverted Index, a key-value data structure where the key is a term appearing in the data set descriptor (typically, the data set name and the field names), while the value is a list of data set identifiers (see Definition 4) that are associated with the term. Again, for the sake of flexibility, we adopted MongoDB to store the inverted index too.
4.2.2. Query Engine
- Step 1: Term Extraction and Retrieval of Alternative Terms. The set of terms is extracted from within , and . Then, for each term , the set of similar terms is built. A term if is present in the catalog and either if it is lexicographically similar (based on the Jaro-Winkler similarity measure) or semantically similar (synonym) based on WordNet dictionary, or a combination of both.
- Step 2: Neighbour Queries. For each term , the alternative terms are used to compute, from the original query q, the Neighbour Queries (see Definition 8) The set of queries to process contains both q and the derived neighbour queries.
- Step 3: VSM Data Set Retrieval. For each query , the set of terms is used to retrieve the data sets, represented by means of the Vector Space Model [34]. The cosine similarity is computed as relevance measure of a data set with respect to terms in the query ; the relevance measure is denoted as ; only data sets with (where is a pre-defined minimum threshold) are selected for next steps. The Inverted Index (Figure 2) is essential to efficiently select data sets by computing . The set of extracted data sets is denoted as .To sum up, this step extracts the data sets that own the largest number of terms in common with the query, because the greater the number of the common terms, the higher the relevance of the data set with respect to the query.
- Step 4: Schema Fitting. In this step, a comparison between the set of field names in each query and the schema of each selected data set in is performed, in order to compute the Schema Fitting Degree (see [3] for its definition): the data set whose schema better fits the list of terms in query is the most relevant (higher ) with respect to the other data sets; for example, if some field appearing in the selection condition is missing in the data set, the query cannot be executed.The overall relevance measure of a data set with respect to a query is obtained as a linear combination of the keyword relevance measure and the schema fitting degree :This step returns the set of result data sets : a data set if its global relevance measure is greater than or equal to a minimum threshold , that is, for at least one query .
- Step 5: Instance Filtering. The Query Engine retrieves and downloads the instances of the data sets returned by Step 4 (see Figure 2) in . The queries are evaluated on the downloaded instances, in order to find out those data items that satisfy at least one query . These data items constitute the result set produced by the Query Engine and provided to the user (see Problem 1).
5. Blind Querying on NoSQL Databases for JSON Documents
5.1. Novel Concepts
| JSON Data Set |
| 1, |
| collection_name=“SouthernCountriesAds”, |
| schema|.“ID”|, “ID”, “number”〉, |
| 〈|.“Offer”.“Title”|, “Title”, “String”〉, |
| 〈|.“Offer”.“Description”|, “Description”, “String”〉, |
| 〈|.“Offer”.“Country”|, “Country”, “String”〉, |
| 〈|.“Offer”.“Salary”|, “Salary”, “String”〉, |
| 〈|.“Publish date”|, “Publish Date”, “String” |
| Instance |
| { ‘‘ID’’: 1, |
| ‘‘Offer’’: { ‘‘Title’’: ‘‘Finance Manager ’’, |
| ‘‘Description’’: ‘‘Department’s finances’’, |
| ‘‘Country’’: ‘‘IT’’, |
| ‘‘Salary’’: ‘‘To be defined’’ }, |
| ‘‘Publish date’’: ‘‘03/09/2018’’ } |
| JSON Data Set |
| 2, |
| collection_name=“SouthernCountriesAds”, |
| schema|.“ID|”, “ID”, “number”〉, |
| 〈|.“Profession”|, “Profession”, “String”〉, |
| 〈|.“Profile”|, “Profile”, “String”〉, |
| 〈|.“Place”.“Location”|, “Location”, “String”〉, |
| 〈|.“Place”.“Country”|, “Country”, “String”〉, |
| 〈|.“Release date”|, “Release Date”, “String” |
| Instance |
| { ‘‘ID’’: 2, |
| ‘‘Profession’’: ‘‘International Export/Sales Manager’’, |
| ‘‘Profile’’: ‘‘An International Export / Sales Manager’’, |
| ‘‘Place’’: { ‘‘Location’’: ‘‘Valencia’’, |
| ‘‘Country’’: ‘‘Spain’’ }, |
| ‘‘Release date’’: ‘‘13/09/2018’’ } |
| { ‘‘ID’’: 3, |
| ‘‘Profession’’: ‘‘Solution Services Marketing Manager ’’, |
| ‘‘Profile’’: ‘‘8--10 years of experience in Marketing.’’, |
| ‘‘Place’’: { ‘‘Location’’: ‘‘Barcelona’’, |
| ‘‘Country’’: ‘‘Spain’’ }, |
| ‘‘Release date’’: ‘‘17/09/2018’’ } |
| JSON Data Set |
| 3, |
| collection_name=“NorthernCountriesAds”, |
| schema|.“ID”|, “ID”, “number”〉, |
| 〈|.“Job Title”|, “Job Title”, “String”〉, |
| 〈|.“Area”.“City”|, “City”, “String”〉, |
| 〈|.“Area”.“Country”|, “Country”, “String”〉, |
| 〈|.“Offer”.“Contract”|, “Contract”, “String”〉, |
| 〈|.“Offer”.“Working Hours”|, “Working Hours”, “String”〉, |
| 〈|.“Release date”|, “Release Date”, “String” |
| Instance |
| { ‘‘ID’’: 1, |
| ‘‘Job Title’’: ‘‘Junior project controller’’, |
| ‘‘Area’’: { ‘‘City’’: ‘‘Berlin’’, |
| ‘‘Country’’: ‘‘DE’’ }, |
| ‘‘Offer’’: { ‘‘Contract’’: ‘‘Permanent’’, |
| ‘‘Working Hours’’: ‘‘Full Time’’}, |
| ‘‘Release date’’: ‘‘19/09/2018’’ } |
| JSON Data Set |
| 4, |
| collection_name=“NorthernCountriesAds”, |
| schema|.“ID”|, “ID”, “number”〉, |
| 〈|.“Offer”.“Job Title”|, “Job Title”, “String”〉, |
| 〈|.“Offer”.“Place”.“City”|, “City”, “String”〉, |
| 〈|.“Offer”.“Place”.“Country”|, “Country”, “String”〉, |
| 〈|.“Release date”|, “Release Date”, “String” |
| Instance |
| { ‘‘ID’’: 2, |
| ‘‘Offer’’: { ‘‘Job Title’’: ‘‘Supplier Engineer’’, |
| ‘‘Place’’: { ‘‘City’’: ‘‘Berlin’’, |
| ‘‘Country’’: ‘‘DE’’ } }, |
| ‘‘Release date’’: ‘‘17/09/2018’’ |
| } |
- 2,
- |.“ID”|, |.“Profession”|, |.“Place”.“Location”|},
- |.“Place”.“Location”|=“Valencia” AND |.“Place”.“Country”|=“Spain”.
- [Ads],
- [ID], [Profession], [Location]},
- [Location]=“Valencia” AND [Country]=“Spain”.
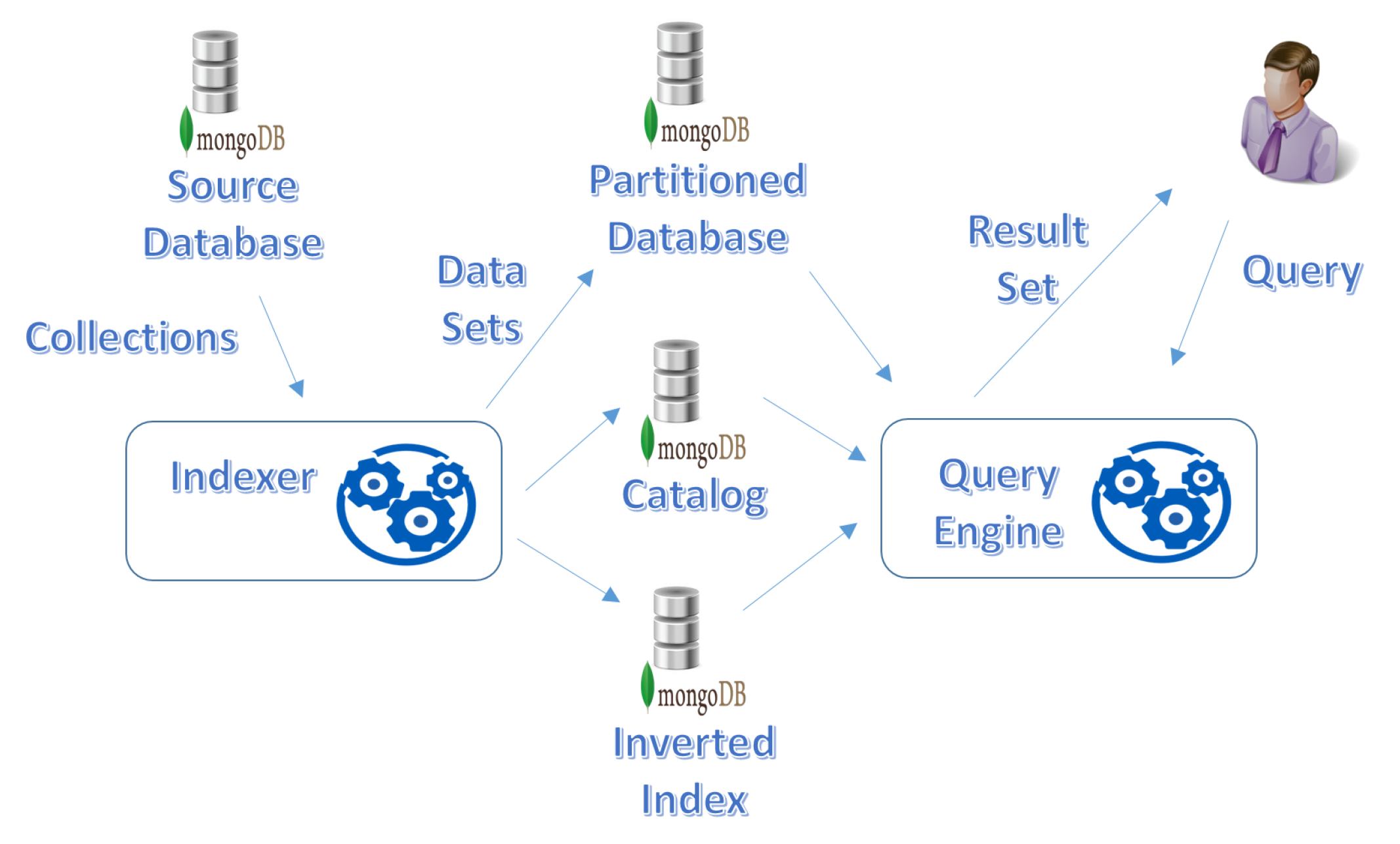
5.2. Indexer
- Task 1: Database Scanning. First of all, as illustrated in Figure 3, the Source Database is scanned, in order to find out all the collections stored in it.
- Task 2: Schema Extraction and Identification of JSON Data Sets. Each collection in the Source Database is fully read; for each document, its schema is extracted, in order to identify the JSON data set which the document belongs to.The output of this task is the Partitioned Database (see Figure 3): the original collections in the Source Database are partitioned; in the Partitioned Database, we have one collection for each single JSON data set identified in the Source Database. This design choice is motivated by the need for efficiently evaluating JSON queries on JSON data sets (to select documents).
- Task 3: Catalog Construction. The JSON data sets identified in the previous task and their schemas are described in the Catalog (see Figure 3), so that the Query Engine can exploit it to drive the query process.
- Task 4: Indexing. The catalog is used to generate the Inverted Index (see Figure 3). Specifically, keys in the inverted index are names of collections and names of leaf fields (we do not consider field paths, because they cannot be expressed in the blind query q).
- The procedure receives, as input parameter, a string denoting the name of the collection to scan.
- At lines 1 and 2, the variable is defined and initialized to the empty set; its role is to collect the full set of JSON data sets identified by the procedure.
- The For Each loop at lines 3 to 20 reads each single document d from the collection. On this document, many tasks are performed.
- -
- At line 4, the ExtractSchema function is called, to get a set of descriptors constituting the schema of the document. This function is reported in Algorithm 2.
- -
- The nested For Each loop at lines 6 to 11 checks for a JSON data set already present in set having the same schema as document d. If there exists such a JSON data set (line 6), the variable is set to true (line 8) and the variable is assigned with the descriptor of this JSON data set (line 9).
- -
- If there not exists a previous JSON data set in having the same schema as document d (line 12), a new JSON data set must be created. In details: a new identifier is generated (line 13), that is used to generate the name of the database collection (to create in the Partitioned Database) to store documents belonging to this JSON data set (line 14); the new collection is created (line 15) and the descriptor of this new JSON data set is assigned to the variable (line 16) to be added to the set (line 17).
- -
- Document d is copied into the collection storing the documents of the JSON data set which d belongs to (line 19).
- The last task performed by the Partition_Collection procedure is to add the descriptors of the JSON data sets so far generated into the Catalog database (line 21).
| Algorithm 1: Procedure Partition_Collection. | |
| Procedure Partition_Collection(: String) | |
| Begin | |
| 1. | : Set-of( data_set_descriptor ) |
| 2. | |
| 3. | For EachCollection( ) Do |
| 4. | ExtractSchema(d, ||) |
| 5. | ; |
| 6. | For EachDo |
| 7. | If AND Then |
| 8. | |
| 9. | |
| 10. | End If |
| 11. | End For Each |
| 12. | IfThen |
| 13. | GenId() |
| 14. | |
| 15. | CreateCollection() |
| 16. | |
| 17. | |
| 18. | End If |
| 19. | SaveToCollection(d, ) |
| 20. | End For Each |
| 21. | AddToCatalog() |
| End Procedure | |
| Algorithm 2: Function ExtractSchema. | |
| Function ExtractSchema(d: document, : path): Set-of( FieldDescriptor) | |
| Begin | |
| 1. | S: Set-of( FieldDescriptor) |
| 2. | |
| 3. | For Each Fields-of(d) Do |
| 4. | |
| 5. | If“document”Then |
| 6. | ExtractSchema( Vale-of( d, ), ) |
| 7. | Else |
| 8. | |
| 9. | |
| 10. | End If |
| 11. | End For Each |
| 12. | ReturnS |
| End Function | |
- At lines 1 and 2, the S variable is defined and initialized to the empty set; its role is to collect fields descriptors.
- The For Each loop at lines 3 to 11 scans each (root) field f in document d. For each field, it performs several actions.
- -
- At line 4, the path of the field is generated, by appending the field name to the base path (by means of operator •).
- -
- If the (data) type of the field is “document” (line 5), this means that the value of the field is a nested document: the Extract_Schema function is recursively called (at line 6), by providing the value of the field and the new base path.
- -
- If the type of the field is not “document” (line 7), this means that its descriptor can be inserted into S: line 8 generates the descriptor, that is inserted into S at line 9.
- The function terminates by returning the set S of generated descriptors (line 12).
5.3. Query Engine
- Step 1: Generation of Neighbour Queries. First of all, the blind query q is rewritten on the basis of the meta-data contained in the catalog, in order to obtain the set of queries to process Q, i.e., q and neighbour queries, as in Step 1 of the classical blind query process described in Section 4.2.2.In this step, we only exploit lexical and/or semantic similarities of terms in the catalog, in particular of field names, independently of their path (and, consequently, independently of the current, possibly complex, structure of documents).In a few words, we rewrite the original blind query q into a pool of partially-blind queries Q, that are likely to find some documents. These queries are partially blind, in the sense that they are obtained by considering terms actually present in the catalog, but still do not consider JSON data sets and their actual (possibly complex) structure.
- Step 2: VSM. Formalized by means of the Vector Space Model approach, each query is used to search the Inverted Index. For each query , we obtain the set of JSON data sets that possibly match . Only the JSON data sets having a term relevance measure ( is the minimum threshold introduced in Section 4.2.2 for term relevance) are considered.The idea is that partially-blind queries obtained by rewriting the original blind query q are exploited to find out those JSON data sets that possibly can contain relevant documents.
- Step 3: Schema Fitting and Generation of JSON Queries. For each query and each JSON data set , the schema fitting degree is computed and the overall relevance measure is computed. If a JSON data set is such that (where is the minimum threshold for the overall relevance measure, see Section 4.2.2), the new JSON query is generated by assigning , as well as and are obtained, respectively, from and by replacing all field names with the corresponding field path (in case of a field name corresponding to multiple fields, the comparison predicate is replaced by a disjunction of predicates, one for each alternative field path). The final set of JSON queries is obtained.In this step, we perform a second rewriting process—partially-blind queries in Q are rewritten into a set of exact queries, that perfectly match the JSON data sets to query. This way, the next step can actually retrieve the JSON documents.
- Step4: Execution of JSON Queries. Each JSON query is executed. The result set of JSON documents that satisfy the query is obtained. The final result set is generated, as the result set of the original blind query q (as asked by Problem 2).
| Blind Query |
| [Ads], |
| [ID], [Profession], [City]}, |
| [City]=“Valencia” AND [Country]=“Spain” |
| Queries to Process |
| [Ads], |
| [ID], [Profession], [City]}, |
| [City]=“Valencia” AND [Country]=“Spain” |
| [Ads], |
| [ID], [Job Title], [City]}, |
| [City]=“Valencia” AND [Country]=”Spain“ |
| [Ads], |
| [ID], [Profession], [Location]}, |
| [Location]=”Valencia” AND [Country]=“Spain” |
| Selected JSON Data Sets |
| , , |
| JSON Queries |
| 3, |
| |.“ID”|, |.“Job Title”|, |.“Area”.“City”|}, |
| |.“Area”.“City”|=“Valencia” AND |.“Area”.“Country”|=“Spain” |
| 4, |
| |.“ID”|, |.“Offer”.“Job Title”|, |.“Offer”.“Place”.“City”|}, |
| |.“Offer”.“Place”.“City”|=“Valencia” AND |
| |.“Offer”.“Place”.“Country”|=“Spain“ |
| 2, |
| |.“ID”|, |.“Profession”|, |.“Place”.“Location”|}, |
| |.“Place”.“Location”|=“Valencia” AND |.“Place”.“Country”|=“Spain” |
6. Benchmark and Experiments
6.1. Application Context and Datas St
- Online job portals of Public Employment Services;
- Private online job portals operated either by national actors or by international consortia (e.g., Axel Springer Media);
- Aggregators gathering advertisements from other job portals and re-posting them on their own Web site (e.g., Jobrapido, Adzuna);
- Employment and recruiting agencies (e.g., Adecco, Randstad and Manpower);
- Newspapers maintaining their own online portals for job advertisements (e.g., Guardian Jobs);
- Online portals for classified ads, that is, small advertisements in categories such as “for sale”, “services”, “jobs” (e.g. Ebay and Subito).
- The German data set is composed by 1000 documents sampled from the data scraped from an Employment agency. This job offers are stored within the test database in a collection named “Jobs”.
- The second data set contains ads from the Spanish Public Employment Service. It contains 1000 documents. It is stored within the test database in the collection named “Spanish-jobs”.
- The data set from the international job search engine contains only job ads related to the Italian labour market. In the test database, the sample 1000 documents are stored in the collection named “Job-offers”.
6.2. Experiments
| [jobs], |
| [title], [place]}, |
| [lang] = “it” AND [publishdate] >= “2018-01-01” |
| [jobs], |
| [title], [place], [country]}, |
| [description] = “Java” OR [title] = “Java” |
| [vacancies], |
| [title], [description],[place], [country]}, |
| [place] = “Madrid” OR[place] = “Bilbao” |
| [jobs], |
| {} , |
| [contract] = “Permanent” AND[place] = “Milan” |
| [jobs], |
| [title], [description],[place], [country]}, |
| [title] = “SAP Finance Expert” AND[country] = “DE” |
| [joboffers], |
| [title], [description],[skills], [country]}, |
| [description] = “Oracle” OR[skills] = “Oracle” |
| [jobS], |
| [title], [description],[contract], [place], [company]}, |
| [title] = “Fertigungsplaner” OR[title] = “Production Planner” OR |
| [title] = “Pianificatore della produzione” OR |
| [title] = “Planificador de Producción” |
| [job-offer], |
| [title], [description],[industry], [place], [company]}, |
| [place] = “Berlin” OR[industry] = “IT” |
- Query looks for job offers that are written in Italian, posted in the year 2018. We are interested in the properties named [title] and [place] (i.e., job location). Notice that the date is written as “2018-01-01”, to check and stress the search of similar terms.
- Query looks for job offers concerning Java developers. In particular, we are interested in job titles containing the term Java, as well as the job location. In fact, our goal (as analysts) may be to build a map with the distribution of vacancies and check the mismatching problem between supply and demand of Java developers. Notice the field named [description], that is not present in any data set stored in the database; we chose it because we wanted to specify a very generic field name.
- In query we look for job vacancies in Madrid and Bilbao.
- Query looks for data about Permanent position in Milan, in order to evaluate the type of contracts in the Italian labour market.
- In query , we look for job offers in Germany, concerning experts in SAP Finance.
- Query is designed to obtain all job vacancies that contain the skill Oracle (related to Oracle Database or other Oracle products). Notice that, also in this case we use the [description] field name in the selection conditions, to stress our framework.
- To check the capability of our approach to scale over the corpus of the data, query looks for data about “Production Planner” in different languages on the same field ([title]).
- Finally, we wanted to specify another very generic field name, that is, [company]. In query , we look for jobs posting in the IT industry sector in “Berlin”, in order to evaluate job offers in the ICT sector in the city of Berlin.
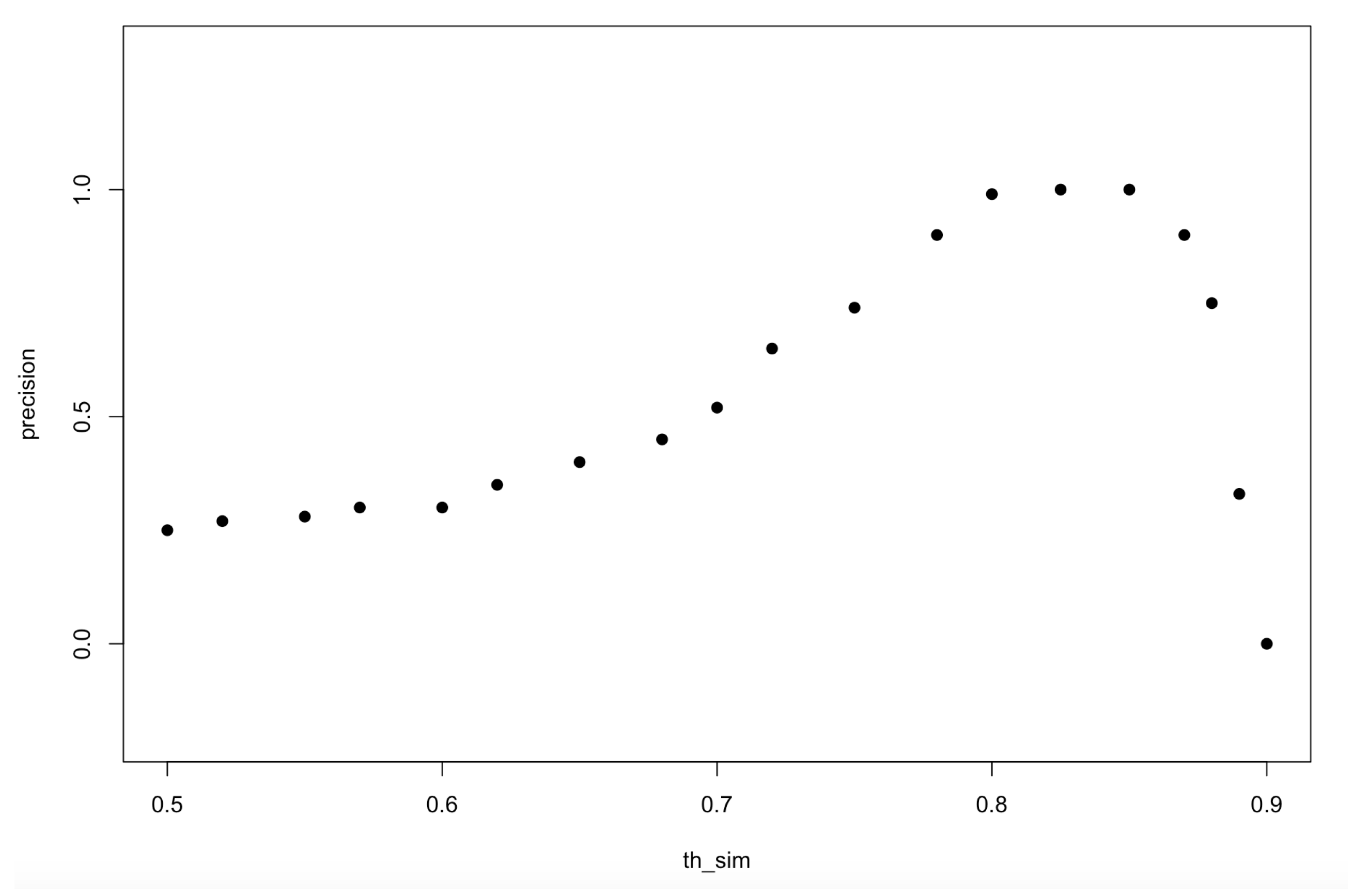
6.2.1. Sensitivity Analysis
- th_sim: it is the minimum threshold for the lexical similarity, we chose two distinct values, i.e., 0.8 and 0.9.
- th_krm: it is the minimum threshold for the Term-based Relevance Measure; we considered two different values, that is, 0.2 and 0.3.
- th_rm: it is the minimum threshold for the global relevance of data sets; we considered two different values, that is, 0.2 and 0.3.
- For Test, th_sim, th_krm and th_rm;
- For Test, th_sim, th_krm and th_rm;
- For Test, th_sim, th_krm and th_rm;
- For Test, th_sim, th_krm and th_rm;
6.2.2. Comparison
7. Discussion
- Stability of Sources. The application context described in Section 6.1 may suggest that data sources are stable in time; so, if we store documents coming from one single data source into a specific collection, they necessarily have the same structure.In practice, this is not true, in particular when the time window for gathering may span over years. In fact, if APIs are exploited to get documents, they could change the structure of the provided documents. Furthermore, if screen scraping techniques are used to get data from web sites that do not provide APIs, the situation may be even worse, because web interfaces change more frequently than APIs (sometimes they add more information, sometimes they reduce it); as an effect, JSON documents obtained by scraping the same site in different times may have different structures. Consequently, documents in the same collection may have different structures, due to the fact that the source is unstable.
- No control on choices. Why has a JSON document database been chosen? Why have other NoSQL databases like Entity Databases not been considered by the organization? For many reasons, that often are not technical. For example, one could be that analysts are already more familiar with the document database technology or, specifically, with MongoDB. A second reason could be that at the beginning of the gathering they had only JSON documents to deal with. A third reason could be that they inherited the choice from previous projects and so on.The cost of transforming (possibly partially unknown) heterogeneous databases into a homogeneous and simplified representation could be very high, both in terms of time (necessary to accurately inspect the data sets, and select, extract, restructure and load data) and in terms of money (the cost of people with the necessary skills, such as programmers, database experts, and so on, involved in the process).
- Neighbour Queries and Execution Times. Neighbour queries and related JSON queries must be executed and this, of course, significantly increases the execution times if compared to the execution of one single query.But in order to execute one single query, it would be necessary to have no heterogeneity in the data, that is, data should be pre-processed and collected into one single collection. However, as stated in the previous point, pre-processing could be very expensive. The goal of blind querying based on neighbour queries and JSON queries is to save pre-processing steps: in fact, even though the user had to wait for (let us say) 10 min, this would certainly be more convenient than spending working days in pre-processing. This is perfectly aligned with the spirit of information retrieval.
- HammerJDB versus ElasticSearch and Apache Solr. The reader could observe that the gain in accuracy obtained by HammerJDB with respect to ElasticSearch and Apache Solr could be not so relevant, so why not to use them? In fact, ElasticSearch and Apache Solr are famous to return results quite immediately.However, the reader should consider a different aspect of the problem; they have their own storage systems and data must be transferred from the JSON document store to them, thus causing the duplication of the data sets. Furthermore, performing this transfer is a trouble when the JSON store is continuously fed, because only incremental data must by transferred. Consequently, the version of the data sets in the JSON document store could be not aligned with the version queried by ElasticSearch or Apache Solr.The adoption of HammerJDB avoids this possibly expensive trasfer, because it directly works on the original JSON document database to query.
- Arrays are not supported. At the current stage of development of the blind query technique, array fields in JSON documents are not supported. Clearly, this is a sever limitation, in particular when documents describing GeoJSON [38] layers are stored. Transformations of JSON documents suggested in Section 5 totally or partially loose the original documents; in many applications, this loss could be a problem for further analysis activities. In this paper, we demonstrated that concepts defined in our previous work can be adapted to query JSON document databases, provided that array fields are not considered. In future work, we will deeply investigate how to effectively deal with array fields.
8. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Boselli, R.; Cesarini, M.; Marrara, S.; Mercorio, F.; Mezzanzanica, M.; Pasi, G.; Viviani, M. WoLMIS: A labor market intelligence system for classifying web job vacancies. J. Intell. Inf. Syst. 2018, 51, 477–502. [Google Scholar] [CrossRef]
- Pelucchi, M.; Psaila, G.; Toccu, M.P. Building a query engine for a corpus of open data. In Proceedings of the WEBIST 2017, 13th International Conference on Web Information Systems and Technologies, Porto, Portugal, 25–27 April 2017; pp. 126–136. [Google Scholar]
- Pelucchi, M.; Psaila, G.; Toccu, M. Enhanced Querying of Open Data Portals. In Proceedings of the International Conference on Web Information Systems and Technologies, Porto, Portugal, 25–27 April 2017; pp. 179–201. [Google Scholar]
- Zadeh, L.A. Fuzzy sets as a basis for a theory of possibility. Fuzzy Sets Syst. 1978, 1, 3–28. [Google Scholar] [CrossRef]
- Damiani, E.; Tanca, L. Blind Queries to XML Data. In Proceedings of the 11th International Conference on Database and Expert Systems Applications, DEXA 2000, London, UK, 4–8 September 2000; pp. 345–356. [Google Scholar]
- Damiani, E.; Lavarini, N.; Marrara, S.; Oliboni, B.; Pasini, D.; Tanca, L.; Viviani, G. The APPROXML Tool Demonstration. In Proceedings of the Advances in Database Technology—EDBT 2002, 8th International Conference on Extending Database Technology, Prague, Czech Republic, 25–27 March 2002; pp. 753–755. [Google Scholar]
- Campi, A.; Damiani, E.; Guinea, S.; Marrara, S.; Pasi, G.; Spoletini, P. A fuzzy extension of the XPath query language. J. Intell. Inf. Syst. 2009, 33, 285–305. [Google Scholar] [CrossRef]
- Marrara, S.; Pasi, G. Fuzzy Approaches to Flexible Querying in XML Retrieval. Int. J. Comput. Intell. Syst. 2016, 9, 95–103. [Google Scholar] [CrossRef] [Green Version]
- Baumgartner, R.; Gatterbauer, W.; Gottlob, G. Web Data Extraction System. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: Boston, MA, USA, 2009; pp. 3465–3471. [Google Scholar] [CrossRef]
- Ferrara, E.; De Meo, P.; Fiumara, G.; Baumgartner, R. Web data extraction, applications and techniques: A survey. Knowl. Based Syst. 2014, 70, 301–323. [Google Scholar] [CrossRef] [Green Version]
- Azad, H.K.; Deepak, A. Query expansion techniques for information retrieval: A survey. Inf. Process. Manag. 2019, 56, 1698–1735. [Google Scholar] [CrossRef] [Green Version]
- Lee, H.M.; Lin, S.K.; Huang, C.W. Interactive query expansion based on fuzzy association thesaurus for web information retrieval. In Proceedings of the 10th IEEE International Conference on Fuzzy Systems, Melbourne, Australia, 2–5 December 2001; Volume 2, pp. 724–727. [Google Scholar]
- Theobald, M.; Weikum, G.; Schenkel, R. Top-k query evaluation with probabilistic guarantees. In Proceedings of the Thirtieth International Conference on Very Large Data Bases-Volume 30, VLDB Endowment, Toronto, ON, Canada, 31 August–3 September 2004; pp. 648–659. [Google Scholar]
- Cui, H.; Wen, J.R.; Nie, J.Y.; Ma, W.Y. Probabilistic query expansion using query logs. In Proceedings of the 11th International Conference on World Wide Web, Honolulu, HI, USA, 7–11 May 2002; ACM: New York, NY, USA, 2002; pp. 325–332. [Google Scholar]
- Chum, O.; Mikulik, A.; Perdoch, M.; Matas, J. Total recall II: Query expansion revisited. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 889–896. [Google Scholar]
- Chum, O.; Philbin, J.; Sivic, J.; Isard, M.; Zisserman, A. Total recall: Automatic query expansion with a generative feature model for object retrieval. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Liu, J.; Dong, X.; Halevy, A.Y. Answering Structured Queries on Unstructured Data; WebDB 2006; Citeseer: Chicago, IL, USA, 2006; Volume 6, pp. 25–30. [Google Scholar]
- Kononenko, O.; Baysal, O.; Holmes, R.; Godfrey, M. Mining Modern Repositories with Elasticsearch; MSR: Hyderabad, India, 2014. [Google Scholar]
- Białecki, A.; Muir, R.; Ingersoll, G.; Imagination, L. Apache Lucene 4. In Proceedings of the SIGIR 2012 Workshop on Open Source Information Retrieval, Portland, OR, USA, 16 August 2012; p. 17. [Google Scholar]
- Nagi, K. Bringing search engines to the cloud using open source components. In Proceedings of the 2015 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K), Lisbon, Portugal, 12–14 November 2015; Volume 1, pp. 116–126. [Google Scholar]
- Pelucchi, M.; Psaila, G.; Maurizio, T. The challenge of using map-reduce to query open data. In Proceedings of the 6th International Conference on Data Science, Technology and Applications (DATA 2017), Madrid, Spain, 24–26 July 2017; pp. 331–342. [Google Scholar]
- Dean, J.; Ghemawat, S. MapReduce: A flexible data processing tool. Commun. ACM 2010, 53, 72–77. [Google Scholar] [CrossRef]
- Vavilapalli, V.K.; Murthy, A.C.; Douglas, C.; Agarwal, S.; Konar, M.; Evans, R.; Graves, T.; Lowe, J.; Shah, H.; Seth, S.; et al. Apache hadoop yarn: Yet another resource negotiator. In Proceedings of the 4th Annual Symposium on Cloud Computing, Santa Clara, CA, USA, 1–3 October 2013; ACM: New York, NY, USA; p. 5. [Google Scholar]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster computing with working sets. HotCloud 2010, 10, 95. [Google Scholar]
- Pelucchi, M.; Psaila, G.; Toccu, M. Hadoop vs. Spark: Impact on Performance of the Hammer Query Engine for Open Data Corpora. Algorithms 2018, 11, 209. [Google Scholar] [CrossRef]
- Davoudian, A.; Chen, L.; Liu, M. A survey on NoSQL stores. ACM Comput. Surv. (CSUR) 2018, 51, 40. [Google Scholar] [CrossRef]
- Bray, T. The Javascript Object Notation (Json) Data Interchange Format. 2014. Available online: https://buildbot.tools.ietf.org/html/rfc7158 (accessed on 15 March 2019).
- Bordogna, G.; Capelli, S.; Psaila, G. A big geo data query framework to correlate open data with social network geotagged posts. In Proceedings of the The Annual International Conference on Geographic Information Science, Buffalo, NY, USA, 2–4 August 2017; Springer: Cham, Germany, 2017; pp. 185–203. [Google Scholar]
- Bordogna, G.; Ciriello, D.E.; Psaila, G. A flexible framework to cross-analyze heterogeneous multi-source geo-referenced information: The J-CO-QL proposal and its implementation. In Proceedings of the International Conference on Web Intelligence, Leipzig, Germany, 23–26 August 2017; ACM: New York, NY, USA, 2017; pp. 499–508. [Google Scholar]
- Bordogna, G.; Capelli, S.; Ciriello, D.E.; Psaila, G. A cross-analysis framework for multi-source volunteered, crowdsourced, and authoritative geographic information: The case study of volunteered personal traces analysis against transport network data. Geo-Spat. Inf. Sci. 2018, 21, 257–271. [Google Scholar] [CrossRef]
- Psaila, G.; Fosci, P. Toward an Analist-Oriented Polystore Framework for Processing JSON Geo-Data. In Proceedings of the IADIS International Conference Applied Computing, Budapest, Hungaria, 21–23 October 2018; pp. 213–222. [Google Scholar]
- Winkler, W.E. String Comparator Metrics and Enhanced Decision Rules in the Fellegi-Sunter Model of Record Linkage. In Proceedings of the Section on Survey Research Methods; American Statistical Association: Alexandria, VA, USA, 1990; pp. 354–359. [Google Scholar]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; Volume 1. [Google Scholar]
- Tabulaex; Tabulaex: Milano, Italy, 2018.
- Amato, F.; Boselli, R.; Cesarini, M.; Mercorio, F.; Mezzanzanica, M.; Moscato, V.; Persia, F.; Picariello, A. Challenge: Processing web texts for classifying job offers. In Proceedings of the 2015 IEEE International Conference on Semantic Computing (ICSC), Anaheim, CA, USA, 7–9 February 2015; pp. 460–463. [Google Scholar]
- Shahi, D. Apache Solr: An Introduction. In Apache Solr; Springer: Berlin, Germany, 2015; pp. 1–9. [Google Scholar]
- Butler, H.; Daly, M.; Doyle, A.; Gillies, S.; Schaub, T.; Schmidt, C. Geojson Specification. Geojson.org. 2008. Available online: https://tools.ietf.org/html/rfc7946 (accessed on 15 March 2019).
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
| Precision (%) for JSON Data Sets | ||||
|---|---|---|---|---|
| Query | Test | Test | Test | Test |
| 100.00 | 33.33 | 100.00 | 33.33 | |
| 100.00 | 100.00 | 100.00 | 100.00 | |
| 100.00 | 33.33 | 33.33 | 33.33 | |
| 33.33 | 33.33 | 33.33 | 33.33 | |
| 33.33 | 33.33 | 33.33 | 33.33 | |
| 100.00 | 100.00 | 100.00 | 100.00 | |
| 100.00 | 100.00 | 100.00 | 100.00 | |
| 33.33 | 33.33 | 33.33 | 33.33 | |
| Recall (%) for Documents | ||||
| Query | Test | Test | Test | Test |
| 100.00 | 100.00 | 100.00 | 100.00 | |
| 100.00 | 100.00 | 100.00 | 100.00 | |
| n.c. | n.c. | 100.00 | 100.00 | |
| n.c. | n.c. | 100.00 | 100.00 | |
| 100.00 | 100.00 | 100.00 | 100.00 | |
| n.c. | 100.00 | 100.00 | 100.00 | |
| n.c. | 100.00 | 50.00 | 50.00 | |
| 100.00 | 100.00 | 100.00 | 100.00 | |
| Precision (%) for Documents | ||||
| Query | Test | Test | Test | Test |
| 100.00 | 100.00 | 100.00 | 100.00 | |
| 100.00 | 100.00 | 100.00 | 100.00 | |
| n.c. | n.c. | 100.00 | 100.00 | |
| n.c. | n.c. | 70.37 | 70.37 | |
| 100.00 | 100.00 | 100.00 | 100.00 | |
| n.c. | 27.78 | 27.78 | 27.78 | |
| n.c. | 100.00 | 100.00 | 100.00 | |
| 4.44 | 4.44 | 4.55 | 4.55 | |
| Precision (%) for JSON Data Sets | |||
|---|---|---|---|
| Query | Elasticsearch | Apache Solr | Test |
| 33.33 | 33.33 | 100.00 | |
| 100.00 | 100.00 | 100.00 | |
| 33.33 | 33.33 | 33.33 | |
| 33.33 | 33.33 | 33.33 | |
| 100.00 | 100.00 | 33.33 | |
| 100.00 | 100.00 | 100.00 | |
| 100.00 | 100.00 | 100.00 | |
| 33.33 | 33.33 | 33.33 | |
| Recall (%) for Documents | |||
| Query | Elasticsearch | Apache Solr | Test |
| 100.00 | 100.00 | 100.00 | |
| 100.00 | 100.00 | 100.00 | |
| 100.00 | 91.77 | 100.00 | |
| 33.09 | 90.23 | 100.00 | |
| 100.00 | 100.00 | 100.00 | |
| 40.00 | 80.00 | 100.00 | |
| 50.00 | 100.00 | 100.00 | |
| 100.00 | 100.00 | 100.00 | |
| Precision (%) for Documents | |||
| Query | Elasticsearch | Apache Solr | Test |
| 100.00 | 100.00 | 100.00 | |
| 71.43 | 50.00 | 100.00 | |
| 72.83 | 70.97 | 100.00 | |
| 84.21 | 93.02 | 70.37 | |
| 100.00 | 100.00 | 100.00 | |
| 10.00 | 18.18 | 27.78 | |
| 50.00 | 40.00 | 100.00 | |
| 4.00 | 4.00 | 4.55 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marrara, S.; Pelucchi, M.; Psaila, G. Blind Queries Applied to JSON Document Stores. Information 2019, 10, 291. https://doi.org/10.3390/info10100291
Marrara S, Pelucchi M, Psaila G. Blind Queries Applied to JSON Document Stores. Information. 2019; 10(10):291. https://doi.org/10.3390/info10100291
Chicago/Turabian StyleMarrara, Stefania, Mauro Pelucchi, and Giuseppe Psaila. 2019. "Blind Queries Applied to JSON Document Stores" Information 10, no. 10: 291. https://doi.org/10.3390/info10100291