
Is the Spatial-Temporal Dependence Model Reliable for the Short-Term Freight Volume Forecast of Inland Ports? A Case Study of the Yangtze River, China




Abstract
:1. Introduction
2. Related Work
2.1. Analysis of Port Freight Volume Relationships
2.2. Forecasting Methods for Freight Volume
2.3. Motivation
3. Data and Methods
3.1. Ports and Data
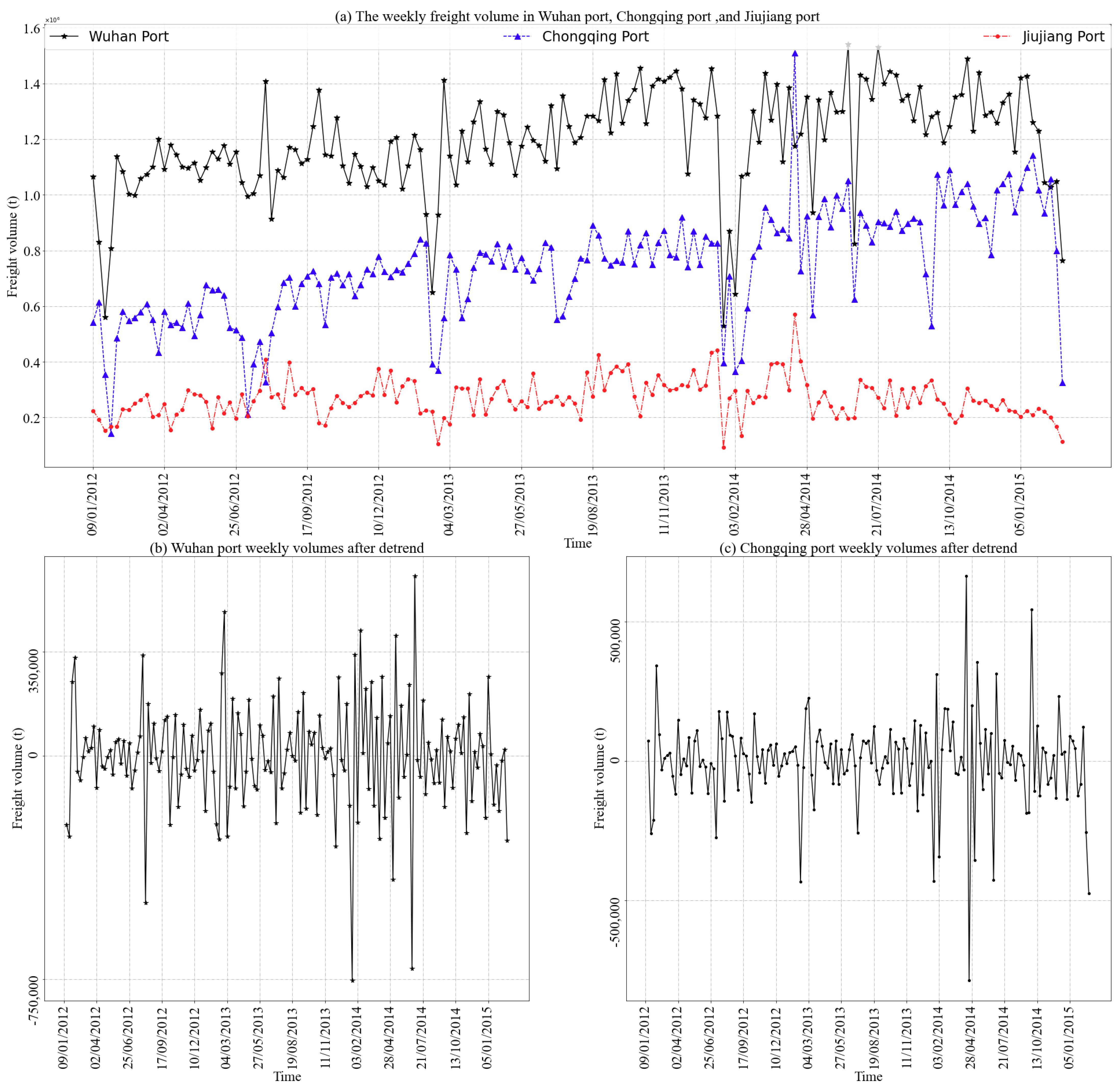
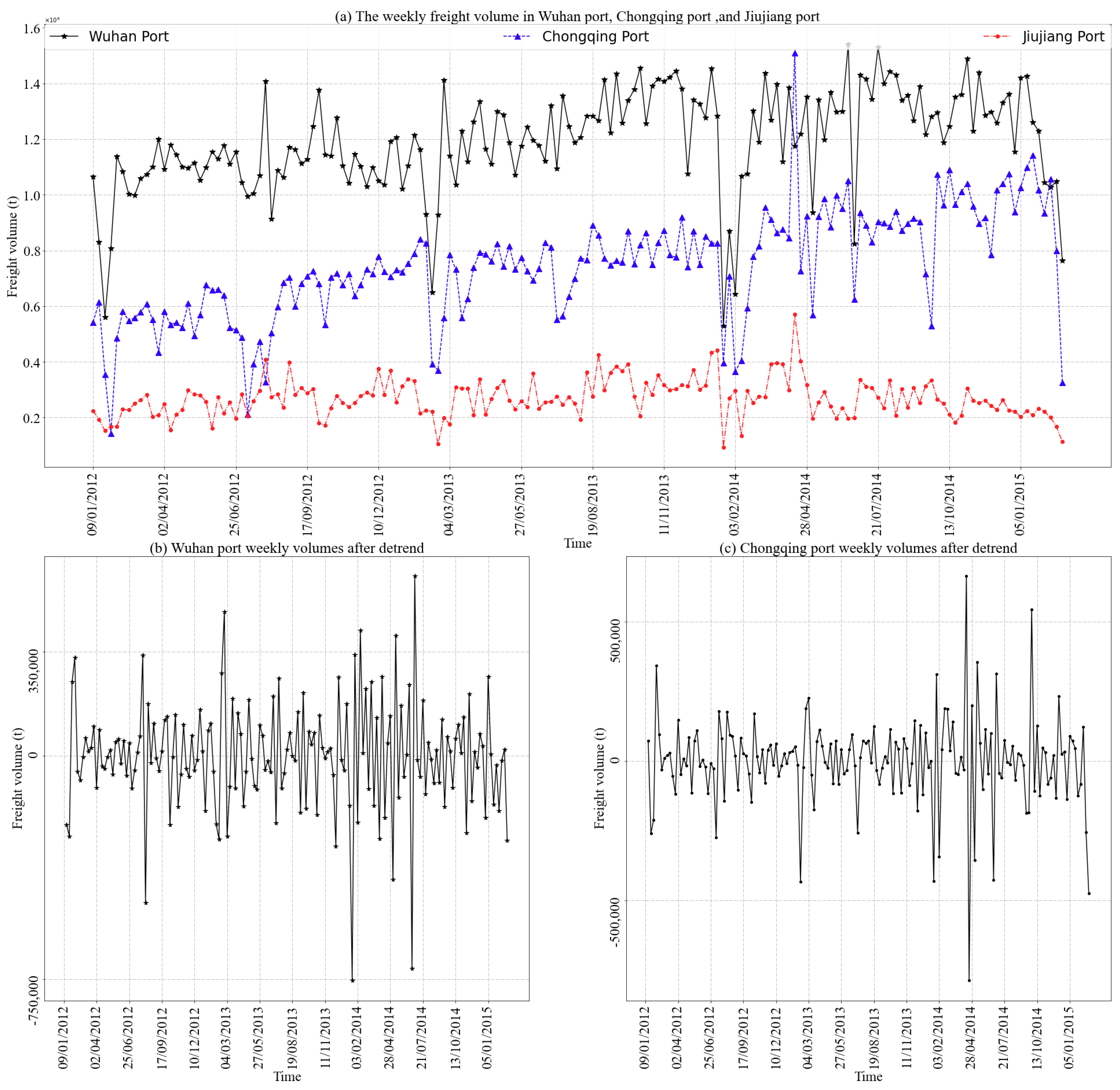
3.1.1. Port Locations and Freight Volume Data
3.1.2. Trend Analysis and Stationary Detection
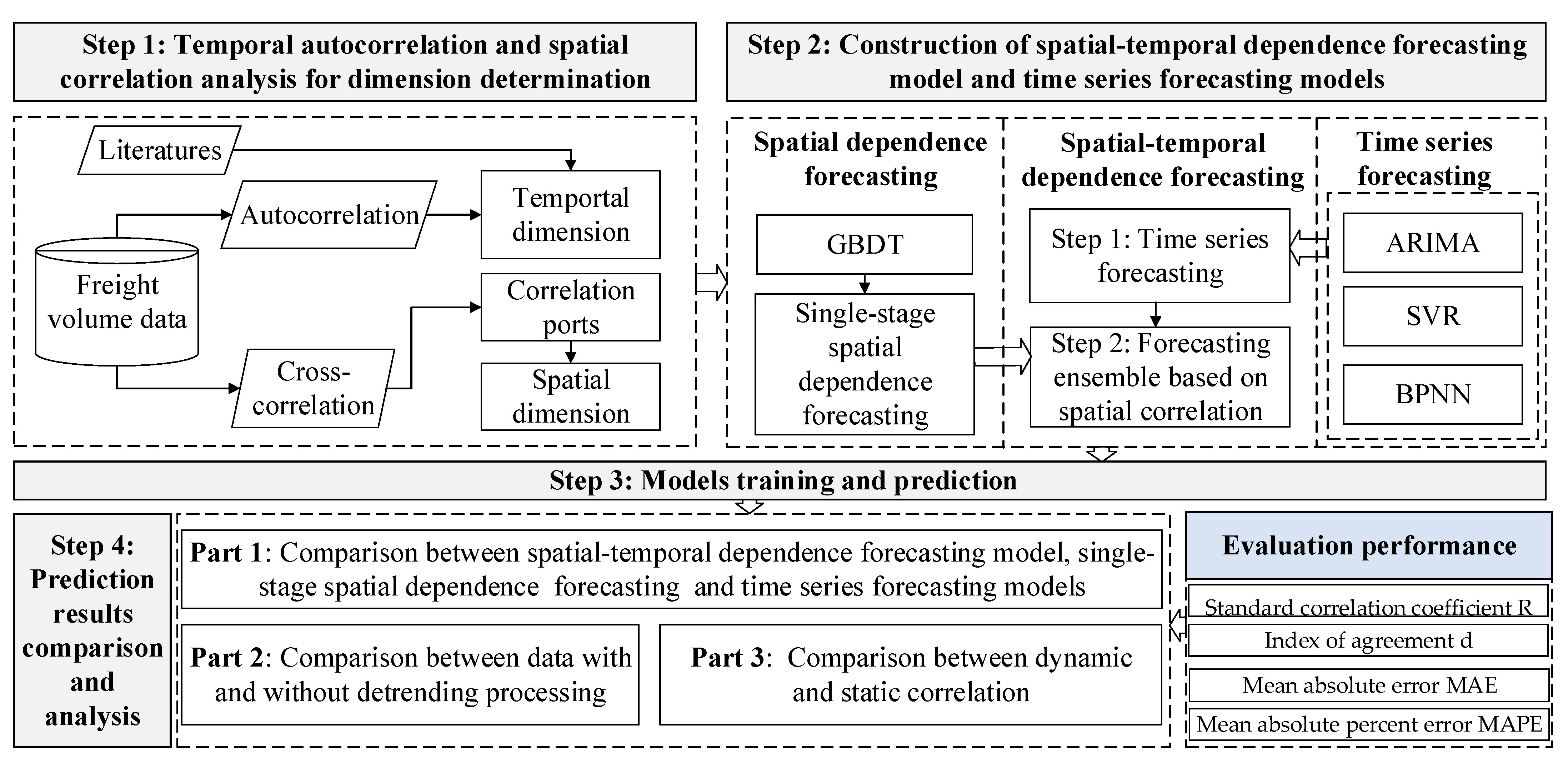
3.2. The Framework for Spatial-Temporal Dependence Forecasting and Analysis
3.2.1. Correlation Analysis of Freight Volume Data
3.2.2. Autocorrelation Analysis
3.2.3. Cross-Correlation Analysis
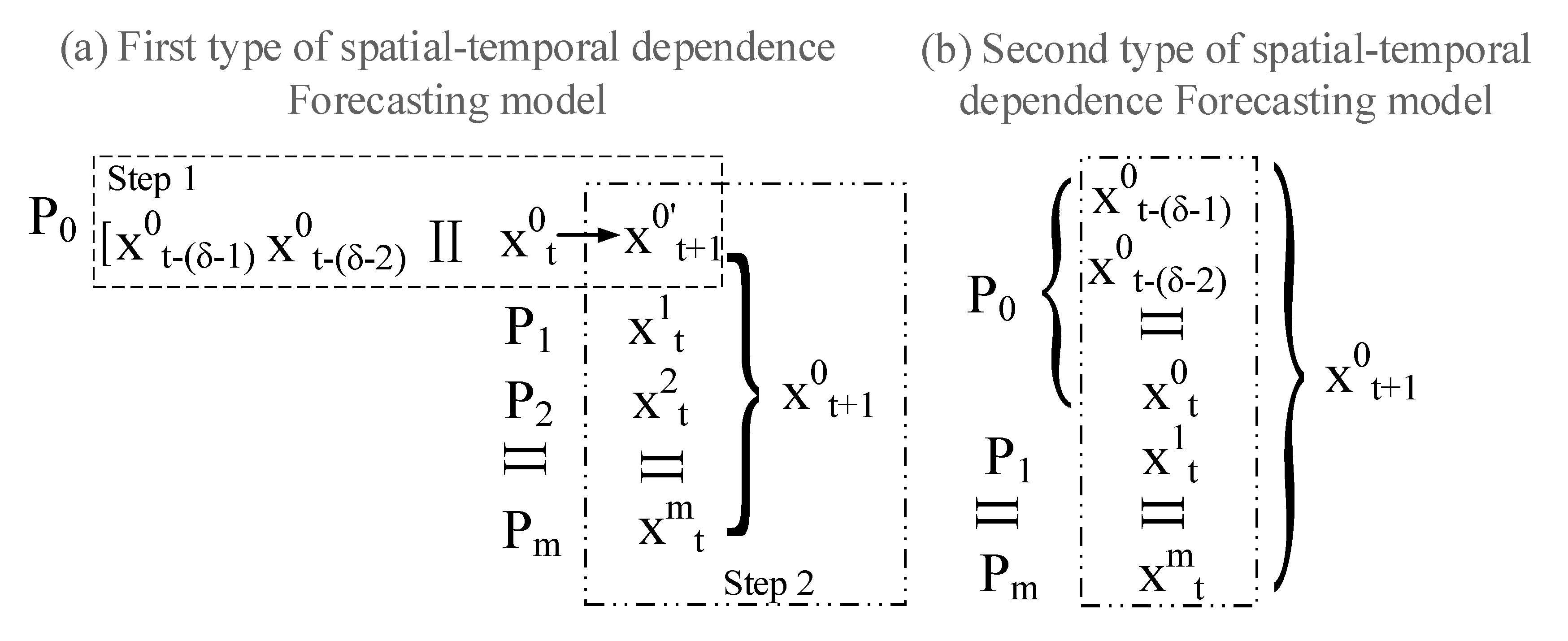
3.2.4. Spatial-Temporal Dependence Forecasting Model for Port Freight Volumes
3.2.5. GBDT Forecasting Process
- We calculated the average of as the initial learner ;
- We calculated the residuals , where is the lost function, and is the training data;
- We built a tree with a goal of predicting the residuals, which takes as the training data of the new tree;
- We calculated the best-fitting value for leaf node area , where is the number of leaf nodes of the tree;
- We updated with ;
- We repeated step 2 to step 4 until the number of iterations matches the number specified by the hyperparameter;
- We used the last to make a final prediction as to the value of the freight volume of the target port.
3.2.6. The Single-Stage GBDT Forecasting Model
3.3. Time Series Forecasting Models of Port Freight Volumes
3.3.1. Auto-Regression Integrated Moving Average
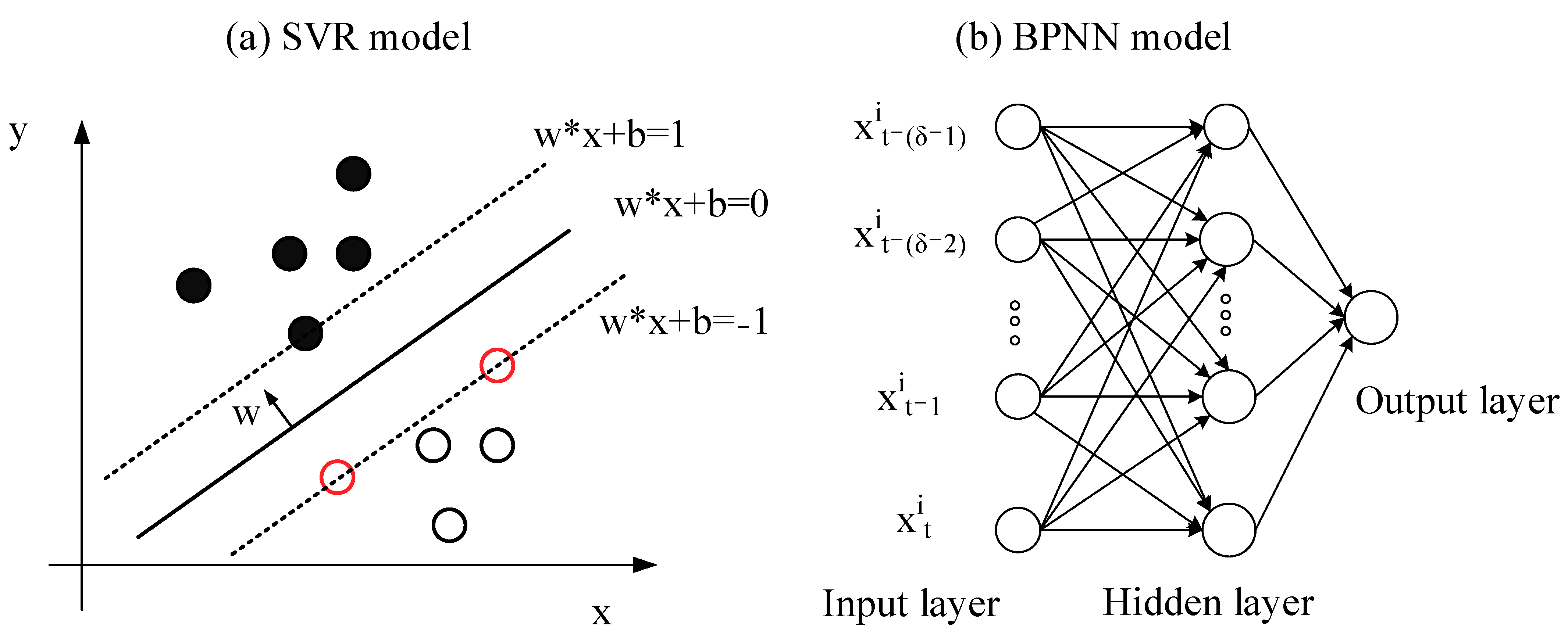
3.3.2. Support Vector Regression
- (a)
- data standardization to prevent local features from being too large or too small, and to speed up the calculation;
- (b)
- the determination of the kernel function and the parameters , and the construction of the SVR model;
- (c)
- training of the SVR model based on training data;
- (d)
- the prediction of the target value after obtaining the model.
3.3.3. Back-Propagation Neural Network
3.3.4. Evaluation Methods for Forecasting Results
3.4. Experimental Design
3.4.1. Dataset Partitioning
3.4.2. Parameter Selection
4. Results
4.1. Correlation Analysis of Port Freight Volume
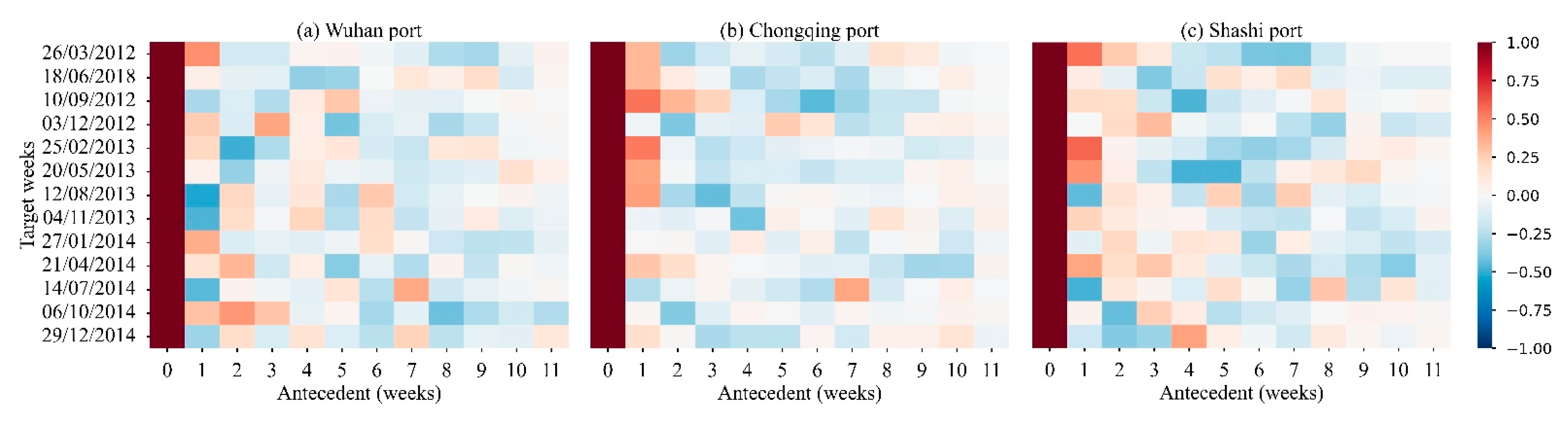
4.1.1. Autocorrelation Analysis of Port Freight Volume
- (a)
- There was no obvious periodic pattern in the time series of weekly freight volume;
- (b)
- With the increase of the time interval between the current week and the previous week, the correlation decreased gradually;
- (c)
- The weeks with higher correlation are the antecedent 1–3 weeks, but there is both positive and negative autocorrelation.
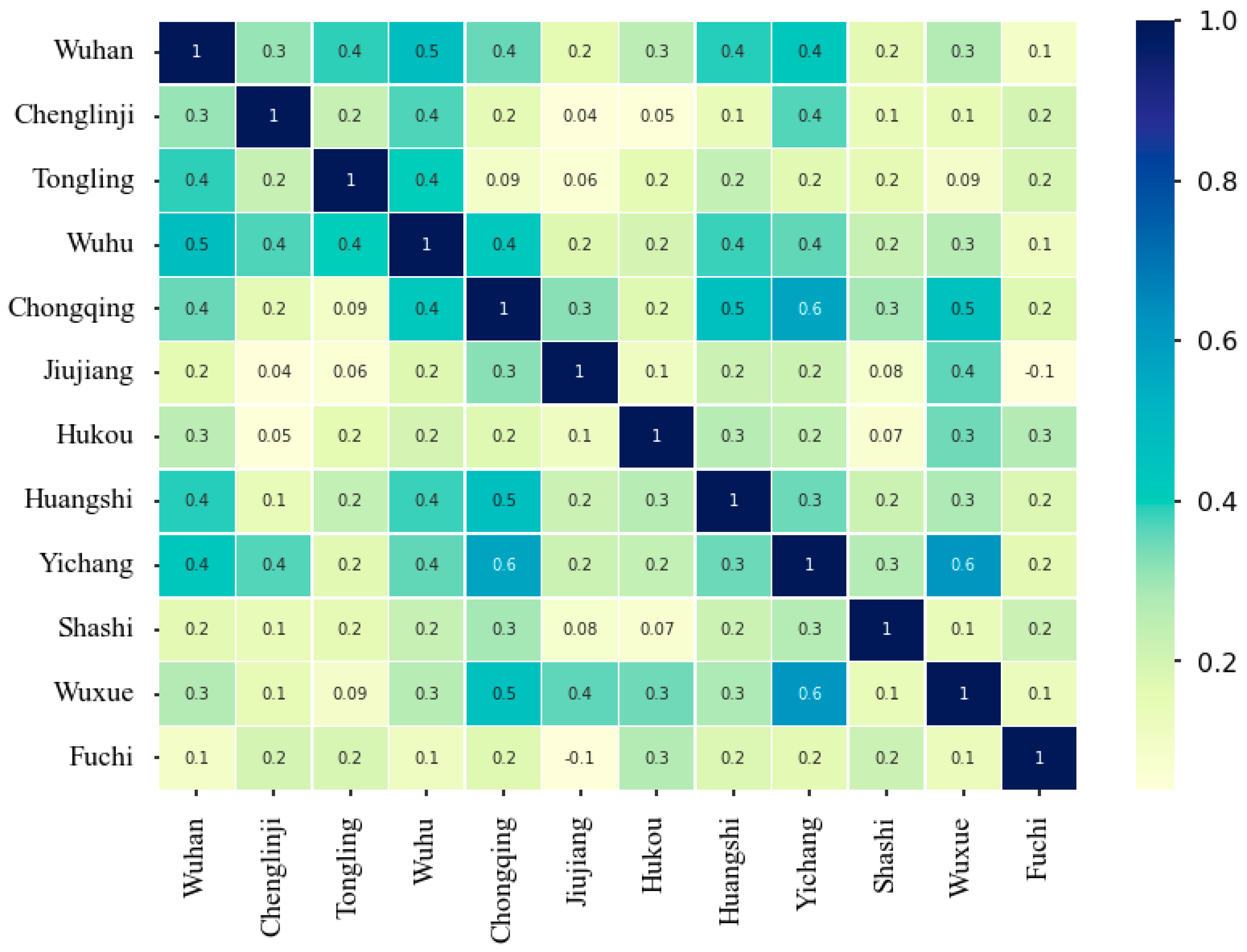
4.1.2. Freight Volume Correlation Analysis between Ports
4.1.3. Was There a Lag between the Weekly Freight Volumes of Different Ports?
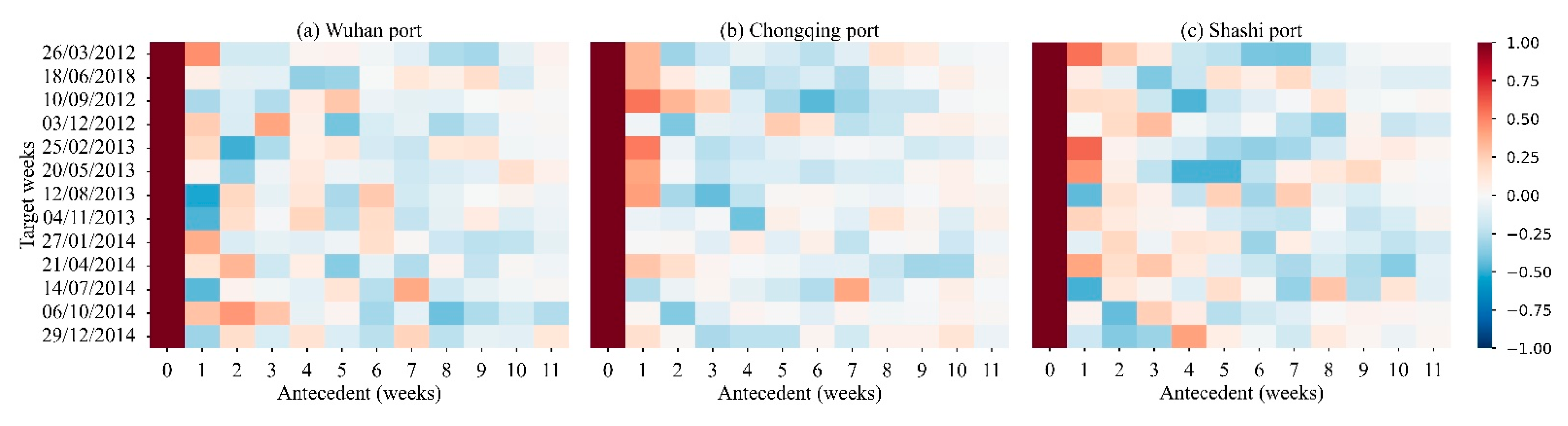
4.1.4. Is the Correlation of Ports’ Weekly Freight Volume Dynamic?
4.1.5. Is the Correlation of Ports’ Weekly Freight Volume Related to Ports’ Grades?
4.2. Prediction Comparison between Different Forecasting Models
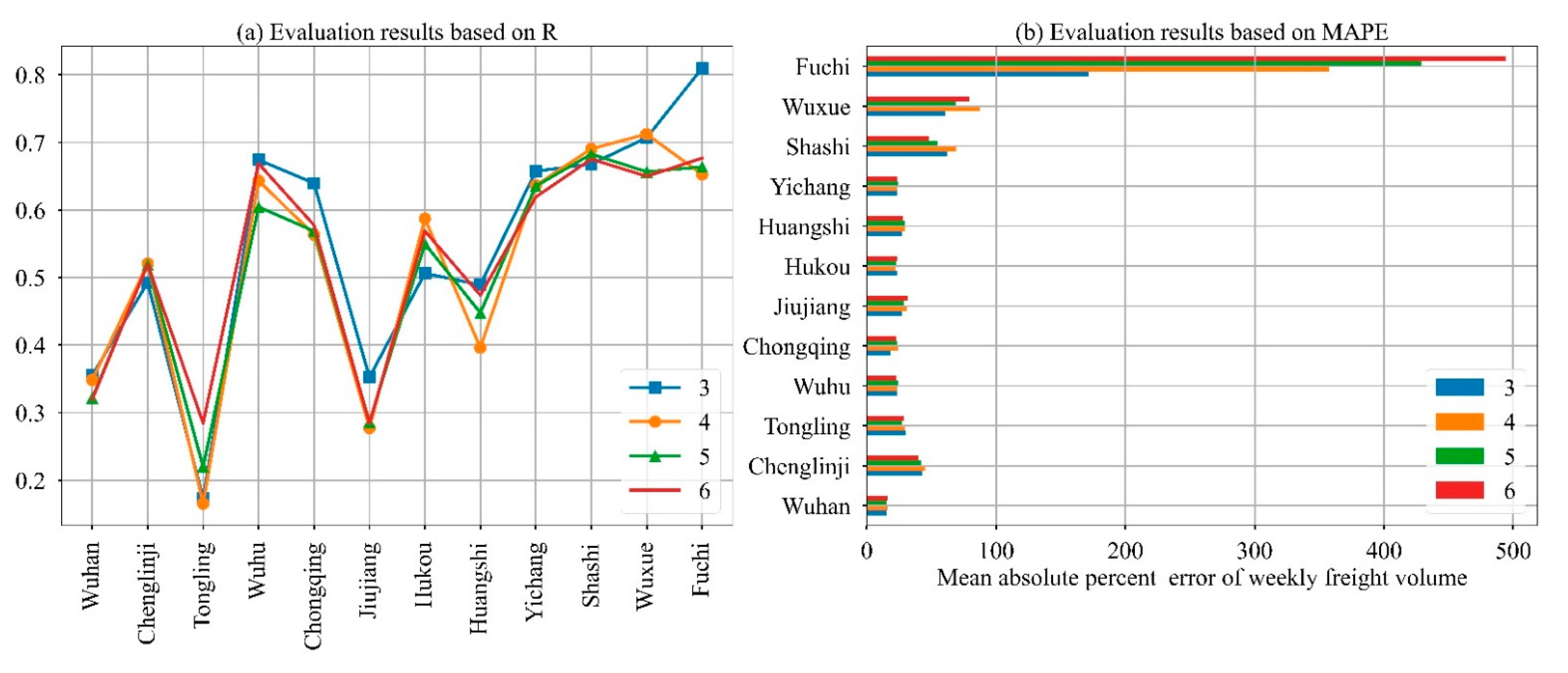
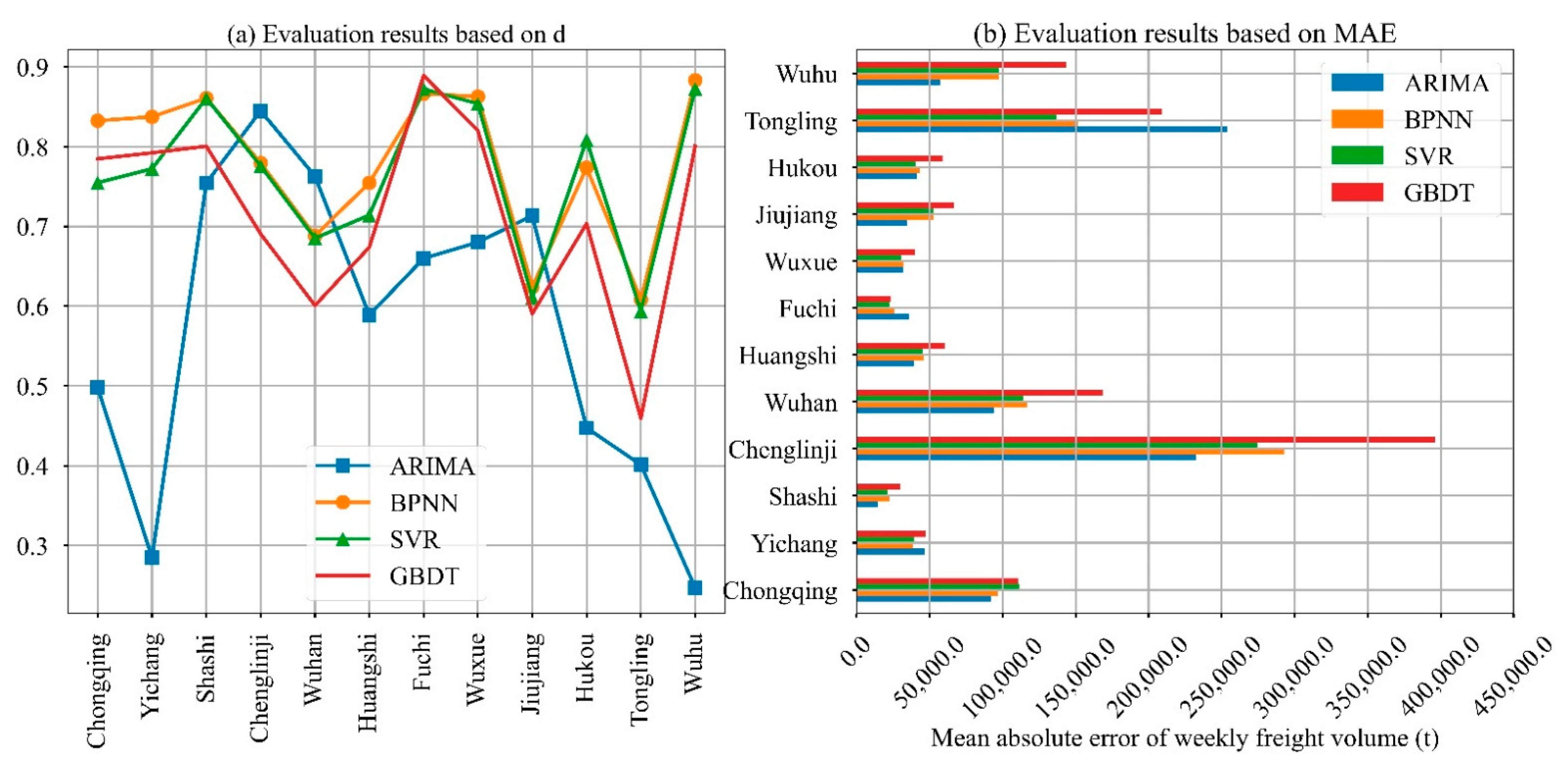
4.2.1. Comparison between Spatial-Temporal Dependence Forecasting and Time Series Forecasting
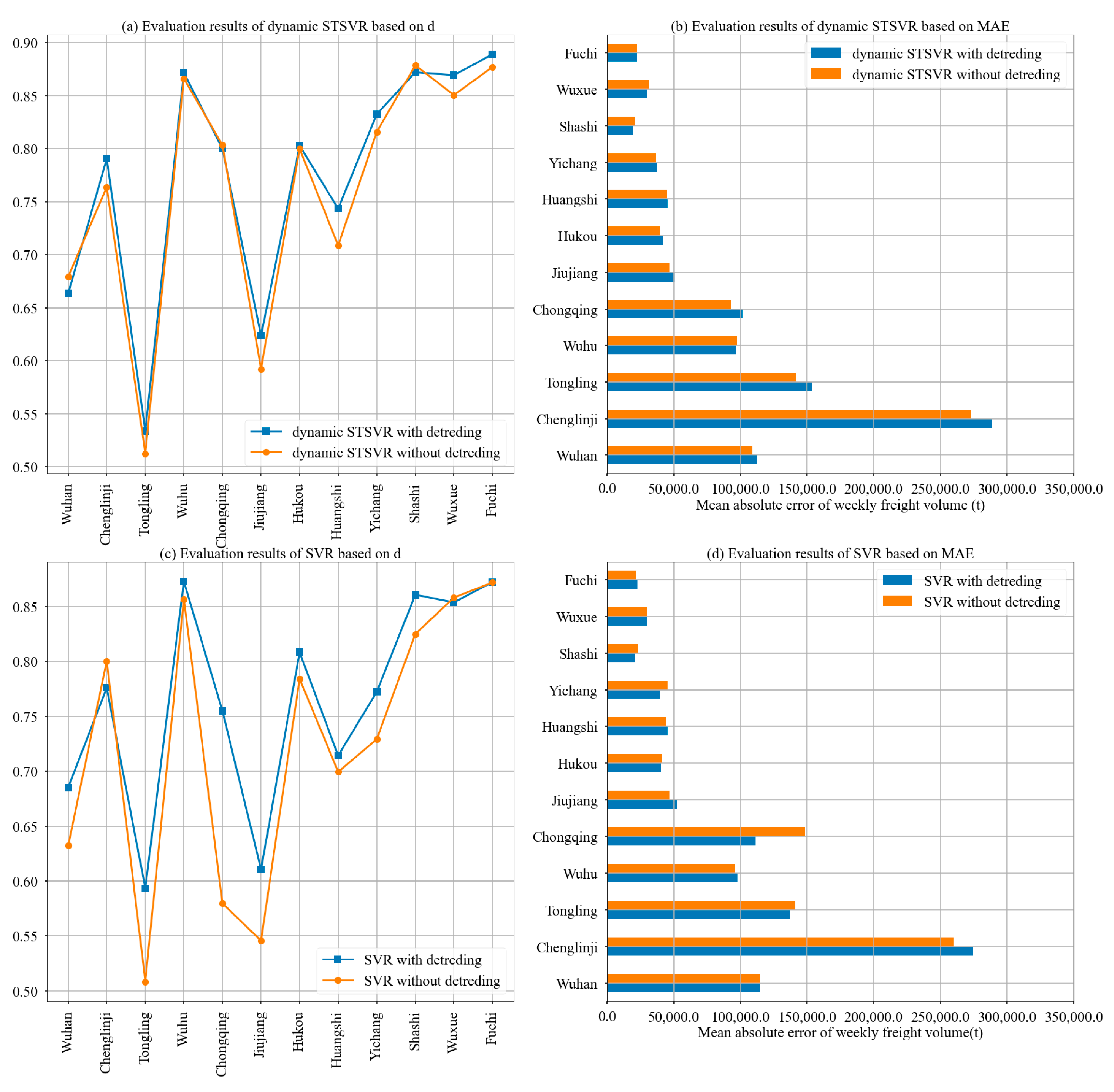
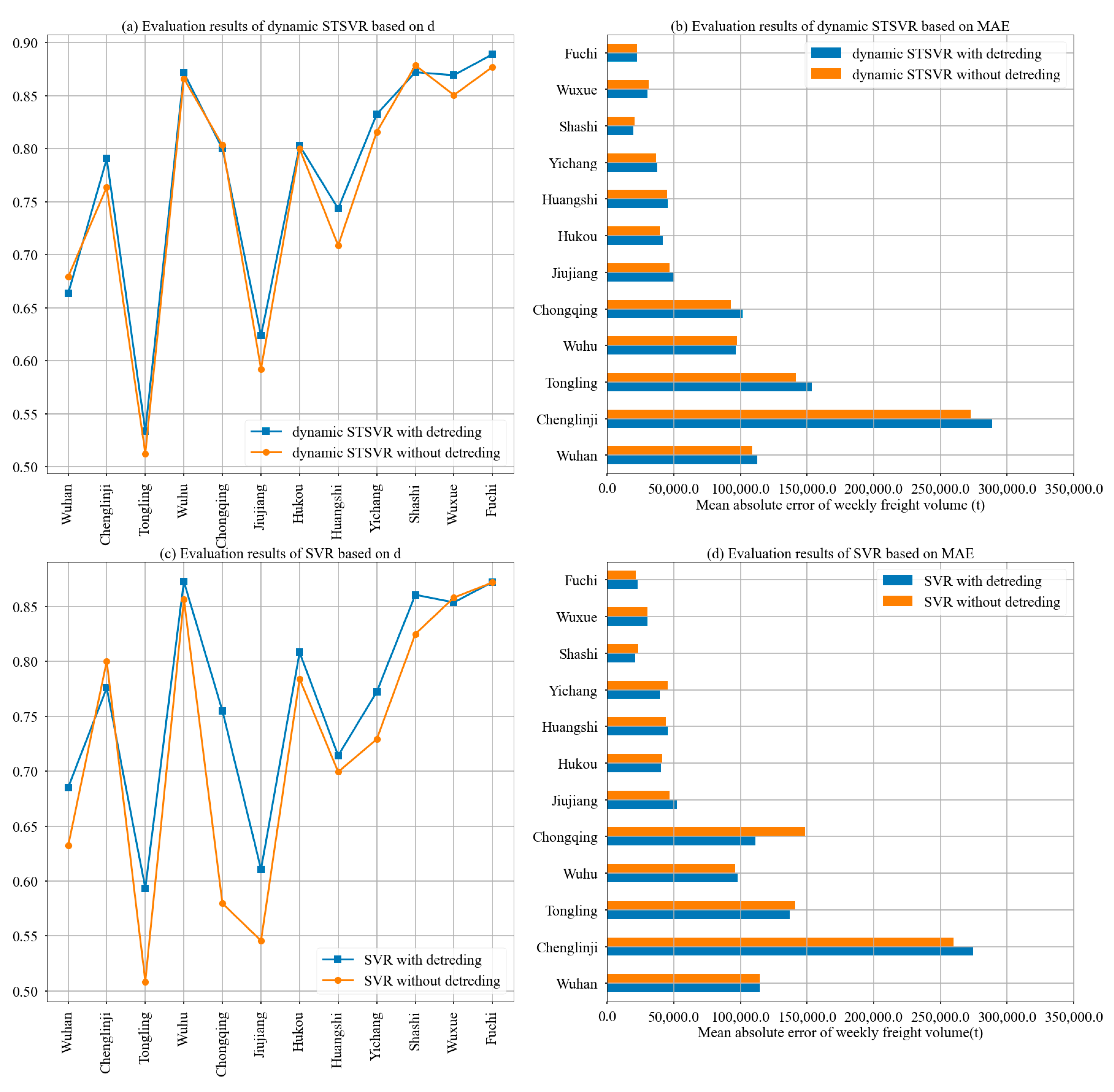
4.2.2. Comparison between Static Spatial Dependence and Dynamic Spatial Dependence
4.2.3. Comparison between Time Series with and without Stationary Processing
5. Discussion
6. Conclusions
- The weekly freight volume of an inland port is higher depending on its past data.
- The spatial-temporal dependence model is not sensitive enough to offer a major improvement in the forecasting of the weekly freight volume forecasting for inland river ports, although it does offer a minor improvement.
- Dynamic freight volume correlation and stationary processing help to make predictions more accurate.
- The weekly freight volume forecasts of different ports show obvious differences.
- In order to make more accurate predictions, for the benefit of port management departments, these freight volume forecasting models and results should be taken into account when carrying out related research.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Akbulaev, N.; Bayramli, G. Maritime transport and economic growth: Interconnection and influence (an example of the countriesin the Caspian sea coast; Russia, Azerbaijan, Turkmenistan, Kazakhstan and Iran). Mar. Policy 2020, 118, 104005. [Google Scholar] [CrossRef]
- Bagoulla, C.; Guillotreau, P. Maritime transport in the French economy and its impact on air pollution: An input-output analysis. Mar. Policy 2020, 116, 103818. [Google Scholar] [CrossRef]
- Pasha, J.; Dulebenets, M.A.; Fathollahi-Fard, A.M.; Tian, G.; Lau, Y.; Singh, P.; Liang, B. An integrated optimization method for tactical-level planning in liner shipping with heterogeneous ship fleet and environmental considera-tions. Adv. Eng. Inform. 2021, 48, 101299. [Google Scholar] [CrossRef]
- Dulebenets, M.A. A comprehensive multi-objective optimization model for the vessel scheduling problem in liner ship-ping. Int. J. Prod. Econ. 2018, 196, 293–318. [Google Scholar] [CrossRef]
- Dui, H.; Zheng, X.; Wu, S. Resilience analysis of maritime transportation systems based on importance measures. Reliab. Eng. Syst. Saf. 2021, 209, 107461. [Google Scholar] [CrossRef]
- Sahu, P.K.; Padhi, A.; Patil, G.R.; Mahesh, G.; Sarkar, A.K. Spatial temporal analysis of freight flow through Indian major seaport system. Asian J. Shipp. Logist. 2019, 35, 77–85. [Google Scholar] [CrossRef]
- Makridakis, S.; Merikas, A.; Merika, A.; Tsionas, M.; Izzeldin, M. A novel forecasting model for the Baltic dry index utilizing optimal squeezing. J. Forecast. 2020, 39, 56–68. [Google Scholar] [CrossRef]
- Awah, P.; Nam, H.; Kim, S. Short term forecast of container throughput: New variables application for the Port of Douala. J. Mar. Sci. Eng. 2021, 9, 720. [Google Scholar] [CrossRef]
- Yi-Mei, C.; Xiao-Ning, Z.; Li, W. Review on integrated scheduling of container terminals. J. Traffic Transp. Eng. 2019, 19, 136–146. [Google Scholar]
- Olba, X.B.; Daamen, W.; Vellinga, T.; Hoogendoorn, S.P. Risk assessment methodology for vessel traffic in ports by defining the nautical port risk index. J. Mar. Sci. Eng. 2019, 8, 10. [Google Scholar] [CrossRef] [Green Version]
- Ruiz-Aguilar, J.J.; Urda, D.; Moscoso-López, J.; González-Enrique, J.; Turias, I.J. A freight inspection volume forecasting ap-proach using an aggregation/disaggregation procedure, machine learning and ensemble models. Neurocomputing 2019, 391, 282–291. [Google Scholar] [CrossRef]
- Moscoso-López, J.A.; Turias, I.; Jimenez-Come, M.J.; Ruiz-Aguilar, J.J.; Cerbán, M.D.M. A two-stage forecasting approach for short-term intermodal freight prediction. Int. Trans. Oper. Res. 2016, 26, 642–666. [Google Scholar] [CrossRef]
- Jiang, L.; Wang, J.; Jiang, H.; Feng, X. Prediction model of port throughput based on game theory and multimedia Bayesian regression. Multimed. Tools Appl. 2019, 78, 4397–4416. [Google Scholar] [CrossRef]
- Tovar, B.; Wall, A. The impact of demand uncertainty on port infrastructure costs: Useful information for regulators? Transp. Policy 2014, 33, 176–183. [Google Scholar] [CrossRef]
- Farhan, J.; Ong, G.P. Forecasting seasonal container throughput at international ports using SARIMA models. Marit. Econ. Logist. 2018, 20, 131–148. [Google Scholar] [CrossRef]
- Gosasang, V.; Chandraprakaikul, W.; Kiattisin, S. A comparison of traditional and neural networks forecasting techniques for container throughput at Bangkok Port. Asian J. Shipp. Logist. 2011, 27, 463–482. [Google Scholar] [CrossRef] [Green Version]
- Ruiz Aguilar, J.J.; Turias, I.; Moscoso López, J.A.; Jiménez Come, M.J.; Cerbán Jiménez, M. Efficient goods inspection demand at ports: A comparative forecasting approach. Int. T. Oper. Res. 2019, 26, 1906–1934. [Google Scholar] [CrossRef]
- Khashei, M.; Bijari, M. A novel hybridization of artificial neural networks and ARIMA models for time series forecasting. Appl. Soft Comput. 2011, 11, 2664–2675. [Google Scholar] [CrossRef]
- Van der Voort, M.; Dougherty, M.; Watson, S. Combining kohonen maps with arima time series models to forecast traffic flow. Transp. Res. Part C Emerg. Technol. 1996, 4, 307–318. [Google Scholar] [CrossRef] [Green Version]
- Yin, S.; Jiang, Y.; Tian, Y.; Kaynak, O. A data-driven fuzzy information granulation approach for freight volume fore-casting. IEEE T. Ind. Electron. 2017, 64, 1447–1456. [Google Scholar] [CrossRef]
- Ermagun, A.; Levinson, D. Spatiotemporal traffic forecasting: Review and proposed directions. Transp. Rev. 2018, 38, 786–814. [Google Scholar] [CrossRef]
- Cai, P.; Wang, Y.; Lu, G.; Chen, P.; Ding, C.; Sun, J. A spatiotemporal correlative k-nearest neighbor model for short-term traffic multistep forecasting. Transp. Res. Part C Emerg. Technol. 2016, 62, 21–34. [Google Scholar] [CrossRef]
- Ermagun, A.; Levinson, D. Spatiotemporal short-term traffic forecasting using the network weight matrix and systematic detrending. Transp. Res. Part C Emerg. Technol. 2019, 104, 38–52. [Google Scholar] [CrossRef]
- Merkel, A. Spatial competition and complementarity in European port regions. J. Transp. Geogr. 2017, 61, 40–47. [Google Scholar] [CrossRef]
- Verhoeff, J.M. Seaport competition: Some fundamental and political aspects. Marit. Policy Manag. 1981, 8, 49–60. [Google Scholar] [CrossRef]
- Goss, R. On the distribution of economic rent in seaports. Int. J. Marit. Econ. 1999, 1, 1–9. [Google Scholar] [CrossRef]
- Fleming, D.K.; Baird, A.J. Comment some reflections on port competition in the United States and western Europe. Marit. Policy Manag. 1999, 26, 383–394. [Google Scholar] [CrossRef]
- Yap, W.Y.; Lam, J.S.L. An interpretation of inter-container port relationships from the demand perspective. Marit. Policy Manag. 2004, 31, 337–355. [Google Scholar] [CrossRef]
- Ishii, M.; Lee, P.T.-W.; Tezuka, K.; Chang, Y.-T. A game theoretical analysis of port competition. Transp. Res. Part E Logist. Transp. Rev. 2013, 49, 92–106. [Google Scholar] [CrossRef]
- De Oliveira, G.F.; Cariou, P. The impact of competition on container port (in)efficiency. Transp. Res. Part A Policy Pract. 2015, 78, 124–133. [Google Scholar] [CrossRef]
- Sayal, M. Detecting time correlations in time-series data streams. In Technical Report HPL-2004-103; HP Laboratories Palo Alto: Santa Clara, CA, USA, 2004. [Google Scholar]
- Su, Y.; Zhao, Y.; Xia, W.; Liu, R.; Bu, J.; Zhu, J.; Cao, Y.; Li, H.; Niu, C.; Zhang, Y.; et al. CoFlux: Robustly corre-lating KPIs by fluctuations for service troubleshooting. In Proceedings of the International Symposium on Quality of Service, Phoenix, AZ, USA, 24–25 June 2019; Association for Computing Machinery (ACM): New York, NY, USA, 2019; pp. 1–10. [Google Scholar]
- Pfeifer, P.E.; Deutsch, S.J. A STARIMA model-building procedure with application to description and regional forecasting. Trans. Inst. Br. Geogr. 1980, 5, 330–349. [Google Scholar] [CrossRef]
- Pfeifer, P.E. The promise of pick-the-winners contests for producing crowd probability forecasts. Theory Decis. 2016, 81, 255–278. [Google Scholar] [CrossRef]
- Li, H.; Liu, J.; Yang, Z.; Liu, R.W.; Wu, K.; Wan, Y. Adaptively constrained dynamic time warping for time series classification and clustering. Inform. Sci. 2020, 534, 97–116. [Google Scholar] [CrossRef]
- Chen, Y. A new methodology of spatial cross-correlation analysis. PLoS ONE 2015, 10, e0126158. [Google Scholar] [CrossRef]
- Zhang, M.; Montewka, J.; Manderbacka, T.; Kujala, P.; Hirdaris, S. A big data analytics method for the evaluation of ship–ship collision risk reflecting hydrometeorological conditions. Reliab. Eng. Syst. Saf. 2021, 213, 107674. [Google Scholar] [CrossRef]
- Doong, D.; Chen, S.; Chen, Y.; Tsai, C. Operational probabilistic forecasting of coastal freak waves by using an artificial neural network. J. Mar. Sci. Eng. 2020, 8, 165. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Li, J.; Zhang, T. A machine-learning model for zonal ship flow prediction using AIS data: A case study in the south atlantic states region. J. Mar. Sci. Eng. 2019, 7, 463. [Google Scholar] [CrossRef] [Green Version]
- Vlahogianni, E.I.; Karlaftis, M.G.; Golias, J.C. Short-term traffic forecasting: Where we are and where we’re going. Transp. Res. Part C Emerg. Technol. 2014, 43, 3–19. [Google Scholar] [CrossRef]
- Lam, W.H.K.; Ng, P.L.P.; Seabrooke, W.; Hui, E.C.M. Forecasts and reliability analysis of port cargo throughput in Hong Kong. J. Urban Plan. Dev. 2004, 130, 133–144. [Google Scholar] [CrossRef]
- Kourentzes, N.; Barrow, D.K.; Crone, S.F. Neural network ensemble operators for time series forecasting. Expert Syst. Appl. 2014, 41, 4235–4244. [Google Scholar] [CrossRef] [Green Version]
- Tsai, F.-M.; Huang, L.J. Using artificial neural networks to predict container flows between the major ports of Asia. Int. J. Prod. Res. 2017, 55, 5001–5010. [Google Scholar] [CrossRef]
- Gökkuş, Ü.; Yıldırım, M.S.; Aydin, M.M. Estimation of container traffic at seaports by using several soft computing methods: A case of Turkish Seaports. Discret. Dyn. Nat. Soc. 2017, 2017, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Barua, L.; Zou, B.; Zhou, Y. Machine learning for international freight transportation management: A comprehensive review. Res. Transp. Bus. Manag. 2020, 34, 100453. [Google Scholar] [CrossRef]
- Moscoso-López, J.A.; Turias, I.J.; Aguilar, J.J.R.; Gonzalez-Enrique, F.J. SVR-Ensemble Forecasting Approach for Ro-Ro Freight at Port of Algeciras (Spain); Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2018; pp. 357–366. [Google Scholar]
- Puech, T.; Boussard, M.; D’Amato, A.; Millerand, G. A Fully Automated Periodicity Detection in Time Series; Springer International Publishing: Cham, Switzerland, 2020; pp. 43–54. [Google Scholar]
- Box, G.E.P.; Jenkins, G.M.; Reinsel, G.C. Time Series Analysis Forecasting and Control; John Wiley & Sons, INC.: Hoboken, NJ, USA, 1976. [Google Scholar]
- Wang, J.; Shi, Q. Short-term traffic speed forecasting hybrid model based on chaos—Wavelet analysis-support vector machine theory. Transp. Res. Part C Emerg. Technol. 2013, 27, 219–232. [Google Scholar] [CrossRef]
- Rossi, F.; Villa, N. Support vector machine for functional data classification. Neurocomputing 2006, 69, 730–742. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.Y.; Liu, J. LSTM network: A deep learning approach for short-term traffic forecast. IET Intell. Transp. Syst. 2017, 11, 68–75. [Google Scholar] [CrossRef] [Green Version]
- Ai, Y.; Li, Z.; Gan, M.; Zhang, Y.; Yu, D.; Chen, W.; Ju, Y. A deep learning approach on short-term spatiotemporal distri-bution forecasting of dockless bike-sharing system. Neural Comput. Appl. 2019, 31, 1665–1677. [Google Scholar] [CrossRef]
- Liu, Q.; Zhang, R.; Wang, Y.; Yan, H.; Hong, M. Daily prediction of the Arctic sea ice concentration using reanalysis data based on a convolutional LSTM network. J. Mar. Sci. Eng. 2021, 9, 330. [Google Scholar] [CrossRef]
- Bergmeir, C.; Hyndman, R.J.; Koo, B. A note on the validity of cross-validation for evaluating autoregressive time series pre-diction. Comput. Stat. Data Anal. 2018, 120, 70–83. [Google Scholar] [CrossRef]
- Homosombat, W.; Ng, A.K.Y.; Fu, X. Regional transformation and port cluster competition: The case of the Pearl River Delta in South China. Growth Chang. 2015, 47, 349–362. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Port | Province/ City | Distance from Wuhan Port (km) | Average Freight Volume per Week (t) | Average Freight Volume per Year (t) | Rank |
|---|---|---|---|---|---|
| Chongqing Port | Chongqing | 1286 | 743,147.4 | 31,168,095.0 | 5 |
| Yichang Port | Hubei | 626 | 231,196.2 | 9,781,418.3 | 9 |
| Shashi Port | Hubei | 478 | 87,369.9 | 5,681,884.9 | 10 |
| Chenglingji Port | Hunan | 231 | 1,290,178.1 | 57,570,284.1 | 2 |
| Wuhan Port | Hubei | 0.0 | 1,194,259.3 | 57,803,446.1 | 1 |
| Huangshi Port | Hubei | 133 | 240,774.6 | 9,994,258.5 | 8 |
| Fuchi Port | Hubei | 195 | 55,721.4 | 988,158.1 | 12 |
| Wuxue Port | Hubei | 204 | 132,642.0 | 3,566,179.7 | 11 |
| Jiujiang Port | Jiangxi | 250 | 269,118.6 | 13,426,721.4 | 6 |
| Hukou Port | Jiangxi | 260 | 264,441.0 | 12,746,637.7 | 7 |
| Tongling Port | Anhui | 496 | 878,022.6 | 45,468,097.5 | 3 |
| Wuhu Port | Anhui | 600 | 691,657.1 | 38,161,639.8 | 4 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0.572 | 0.293 | 0.157 | 0.353 | 0.464 | 0.173 | 0.457 | 0.321 | 0.173 | 0.094 | 0.425 |
| 2 | 0.572 | 1 | 0.266 | 0.367 | 0.432 | 0.347 | 0.164 | 0.615 | 0.219 | 0.237 | 0.169 | 0.356 |
| 3 | 0.293 | 0.266 | 1 | 0.139 | 0.164 | 0.219 | 0.221 | 0.139 | 0.079 | 0.068 | 0.152 | 0.230 |
| 4 | 0.157 | 0.367 | 0.139 | 1 | 0.308 | 0.141 | 0.203 | 0.148 | 0.040 | 0.0490 | 0.227 | 0.370 |
| 5 | 0.3523 | 0.432 | 0.164 | 0.308 | 1 | 0.392 | 0.095 | 0.271 | 0.160 | 0.254 | 0.390 | 0.473 |
| 6 | 0.464 | 0.347 | 0.219 | 0.141 | 0.392 | 1 | 0.185 | 0.280 | 0.221 | 0.265 | 0.237 | 0.384 |
| 7 | 0.173 | 0.164 | 0.221 | 0.203 | 0.095 | 0.185 | 1 | 0.130 | −0.108 | 0.270 | 0.190 | 0.113 |
| 8 | 0.457 | 0.615 | 0.139 | 0.148 | 0.271 | 0.280 | 0.130 | 1 | 0.360 | 0.345 | 0.092 | 0.262 |
| 9 | 0.321 | 0.219 | 0.079 | 0.040 | 0.160 | 0.220 | −0.108 | 0.360 | 1 | 0.114 | 0.060 | 0.175 |
| 10 | 0.173 | 0.237 | 0.068 | 0.0490 | 0.254 | 0.265 | 0.269 | 0.345 | 0.114 | 1 | 0.160 | 0.201 |
| 11 | 0.094 | 0.169 | 0.152 | 0.227 | 0.390 | 0.237 | 0.190 | 0.092 | 0.060 | 0.160 | 1 | 0.402 |
| 12 | 0.425 | 0.356 | 0.230 | 0.370 | 0.473 | 0.384 | 0.113 | 0.262 | 0.175 | 0.201 | 0.402 | 1 |
| Ports | Models and Hyper-Parameters | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| ARIMA | SVR | BPNN | GBDT | ||||||
| Kernel | Activation | Number of Neurons | Estimators | Learning Rate | Max Depth | ||||
| Chenglingli | 2 | 0 | 8.01 | linear | relu | 7 | 97 | 0.0266 | 18 |
| Chongqing | 3 | 3 | 8.53 | poly | relu | 10 | 103 | 0.0012 | 21 |
| Fuchi | 0 | 1 | 5.43 | rbf | tanh | 5 | 95 | 0.0018 | 20 |
| Huangshi | 0 | 1 | 6.96 | linear | tanh | 9 | 97 | 0.0567 | 19 |
| Hukou | 0 | 1 | 7.52 | linear | relu | 9 | 99 | 0.0777 | 20 |
| Jiujiang | 1 | 0 | 12.28 | linear | identity | 8 | 103 | 0.0216 | 23 |
| Shashi | 0 | 2 | 5.06 | rbf | relu | 8 | 93 | 0.0315 | 22 |
| Tongling | 2 | 1 | 10.05 | linear | relu | 9 | 100 | 0.1166 | 21 |
| Wuhan | 2 | 0 | 9.2 | rbf | tanh | 9 | 99 | 0.1235 | 22 |
| Wuhu | 2 | 0 | 6.63 | linear | tanh | 7 | 98 | 0.1042 | 22 |
| Wuxue | 1 | 0 | 9.33 | linear | relu | 10 | 98 | 0.1672 | 20 |
| Yichang | 2 | 2 | 9.81 | poly | relu | 8 | 97 | 0.05378 | 18 |
| Ports | Models | ||||
|---|---|---|---|---|---|
| Chongqing Port | SVR-GBDT | 0.6142 | 0.7645 | 114814 | 17.5140 |
| STSVT | 0.6354 | 0.7793 | 109594 | 17.2641 | |
| SVR | 0.6271 | 0.7549 | 111383 | 17.1492 | |
| Yichang Port | SVR-GBDT | 0.6318 | 0.7860 | 46907.8 | 23.0705 |
| STSVT | 0.7110 | 0.8323 | 37346.2 | 18.8978 | |
| SVR | 0.6131 | 0.7723 | 39594.2 | 18.6422 | |
| Shashi Port | SVR-GBDT | 0.6629 | 0.7979 | 27866.8 | 71.2912 |
| STSVT | 0.7717 | 0.8652 | 20955.1 | 62.7795 | |
| SVR | 0.7619 | 0.8609 | 21156 | 52.5459 | |
| Chenglingji Port | SVR-GBDT | 0.4909 | 0.6913 | 388887 | 43.795 |
| STSVT | 0.6209 | 0.7776 | 295815 | 35.539 | |
| SVR | 0.6197 | 0.7759 | 274525 | 30.2371 | |
| Wuhan Port | SVR-GBDT | 0.3544 | 0.6002 | 150934 | 14.3819 |
| STSVT | 0.4212 | 0.6399 | 112476 | 11.1286 | |
| SVR | 0.4685 | 0.6852 | 114343 | 10.6734 | |
| Huangshi Port | SVR-GBDT | 0.4383 | 0.6420 | 62257.2 | 20.0887 |
| STSVT | 0.5985 | 0.7533 | 45119.9 | 20.1444 | |
| SVR | 0.5276 | 0.7141 | 45383 | 21.4577 | |
| Fuchi Port | SVR-GBDT | 0.8013 | 0.8817 | 23504.5 | 124.399 |
| STSVT | 0.7941 | 0.8727 | 24230.3 | 335.966 | |
| SVR | 0.7912 | 0.8724 | 22878.8 | 268.399 | |
| Wuxue Port | SVR-GBDT | 0.6732 | 0.7971 | 43535.6 | 44.4348 |
| STSVT | 0.7878 | 0.8699 | 29921.2 | 29.4547 | |
| SVR | 0.7589 | 0.8534 | 30449 | 32.8891 | |
| Jiujiang Port | SVR-GBDT | 0.2311 | 0.5185 | 69281.1 | 28.7139 |
| STSVT | 0.3651 | 0.6139 | 49234.8 | 20.9561 | |
| SVR | 0.3922 | 0.6107 | 52461.3 | 22.0805 | |
| Hukou Port | SVR-GBDT | 0.4671 | 0.6751 | 62505.6 | 25.4328 |
| STSVT | 0.6364 | 0.7829 | 43338.2 | 18.0239 | |
| SVR | 0.6780 | 0.8084 | 40370 | 16.5361 | |
| Tongling Port | SVR-GBDT | 0.1231 | 0.4481 | 220966 | 30.5405 |
| STSVT | 0.2423 | 0.5294 | 156148 | 24.1003 | |
| SVR | 0.3308 | 0.5934 | 137192 | 20.0258 | |
| Wuhu Port | SVR-GBDT | 0.6333 | 0.7758 | 143389 | 23.1780 |
| STSVT | 0.6627 | 0.7838 | 126290 | 20.5344 | |
| SVR | 0.7797 | 0.8729 | 97741.1 | 15.9640 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, L.; Zhang, Y.; Chen, C.; Hu, Y.; Liu, C.; Chen, J. Is the Spatial-Temporal Dependence Model Reliable for the Short-Term Freight Volume Forecast of Inland Ports? A Case Study of the Yangtze River, China. J. Mar. Sci. Eng. 2021, 9, 985. https://doi.org/10.3390/jmse9090985
Liu L, Zhang Y, Chen C, Hu Y, Liu C, Chen J. Is the Spatial-Temporal Dependence Model Reliable for the Short-Term Freight Volume Forecast of Inland Ports? A Case Study of the Yangtze River, China. Journal of Marine Science and Engineering. 2021; 9(9):985. https://doi.org/10.3390/jmse9090985
Chicago/Turabian StyleLiu, Lei, Yong Zhang, Chen Chen, Yue Hu, Cong Liu, and Jing Chen. 2021. "Is the Spatial-Temporal Dependence Model Reliable for the Short-Term Freight Volume Forecast of Inland Ports? A Case Study of the Yangtze River, China" Journal of Marine Science and Engineering 9, no. 9: 985. https://doi.org/10.3390/jmse9090985
APA StyleLiu, L., Zhang, Y., Chen, C., Hu, Y., Liu, C., & Chen, J. (2021). Is the Spatial-Temporal Dependence Model Reliable for the Short-Term Freight Volume Forecast of Inland Ports? A Case Study of the Yangtze River, China. Journal of Marine Science and Engineering, 9(9), 985. https://doi.org/10.3390/jmse9090985