
Bridge Crack Semantic Segmentation Based on Improved Deeplabv3+

Abstract
1. Introduction
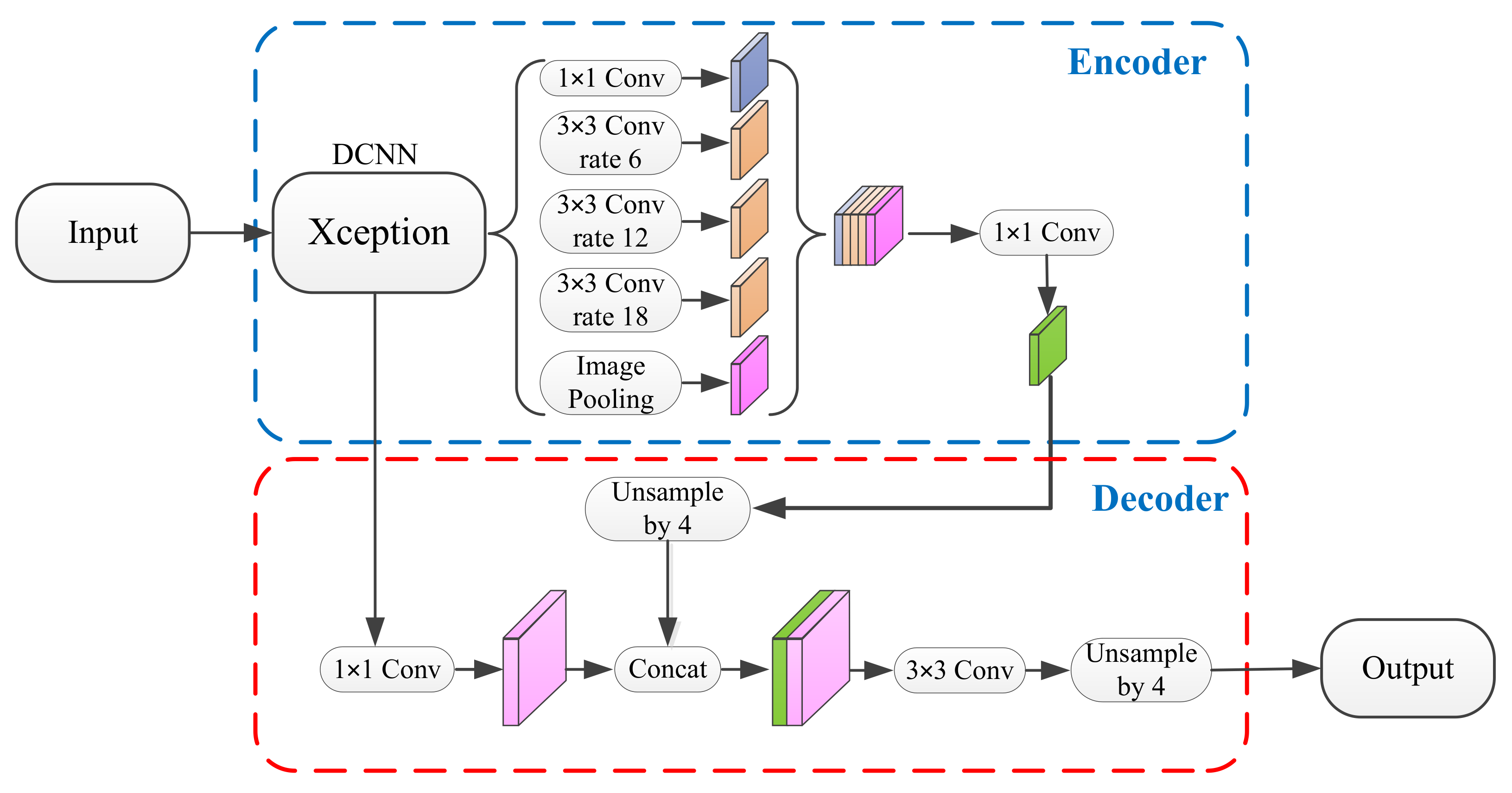
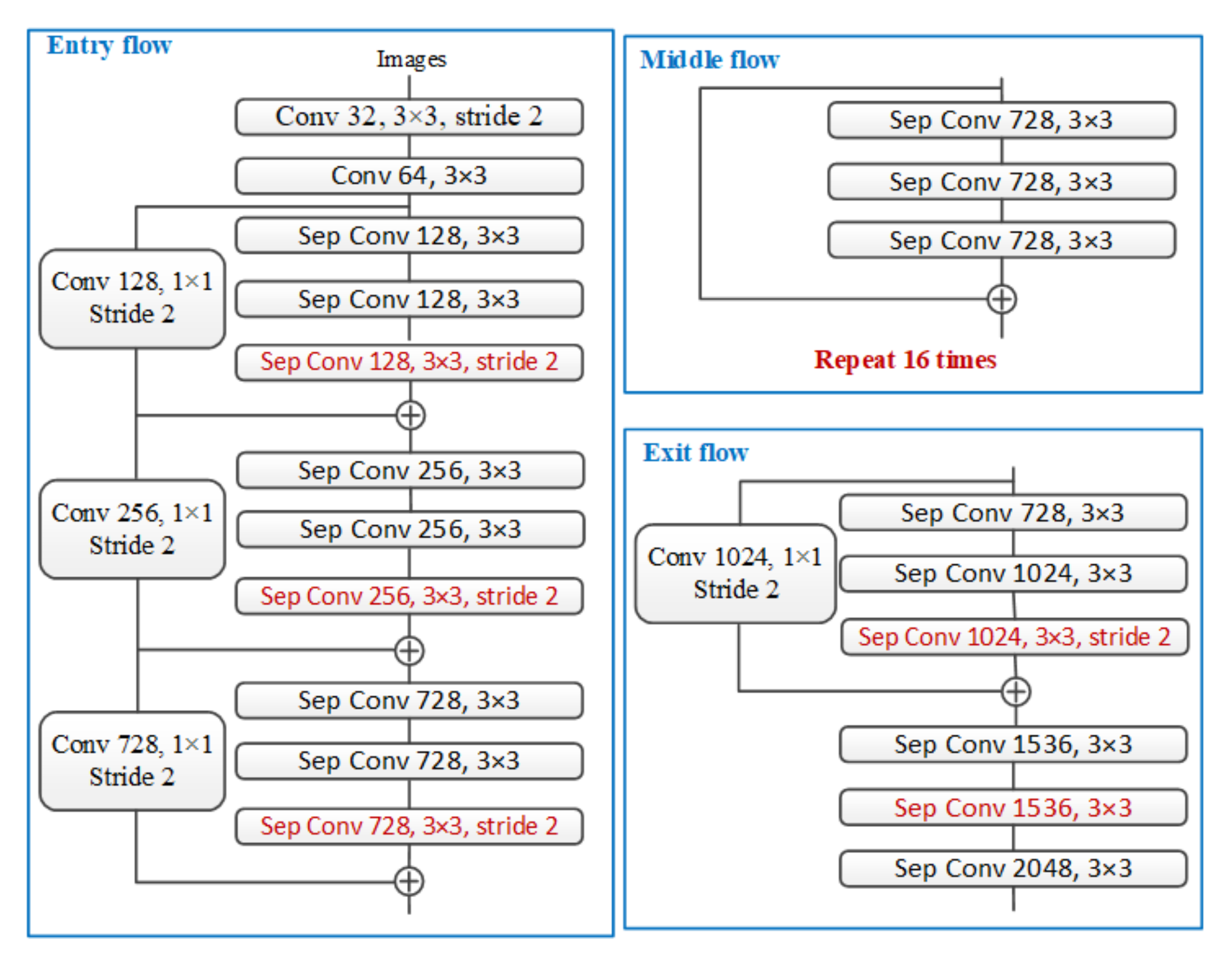
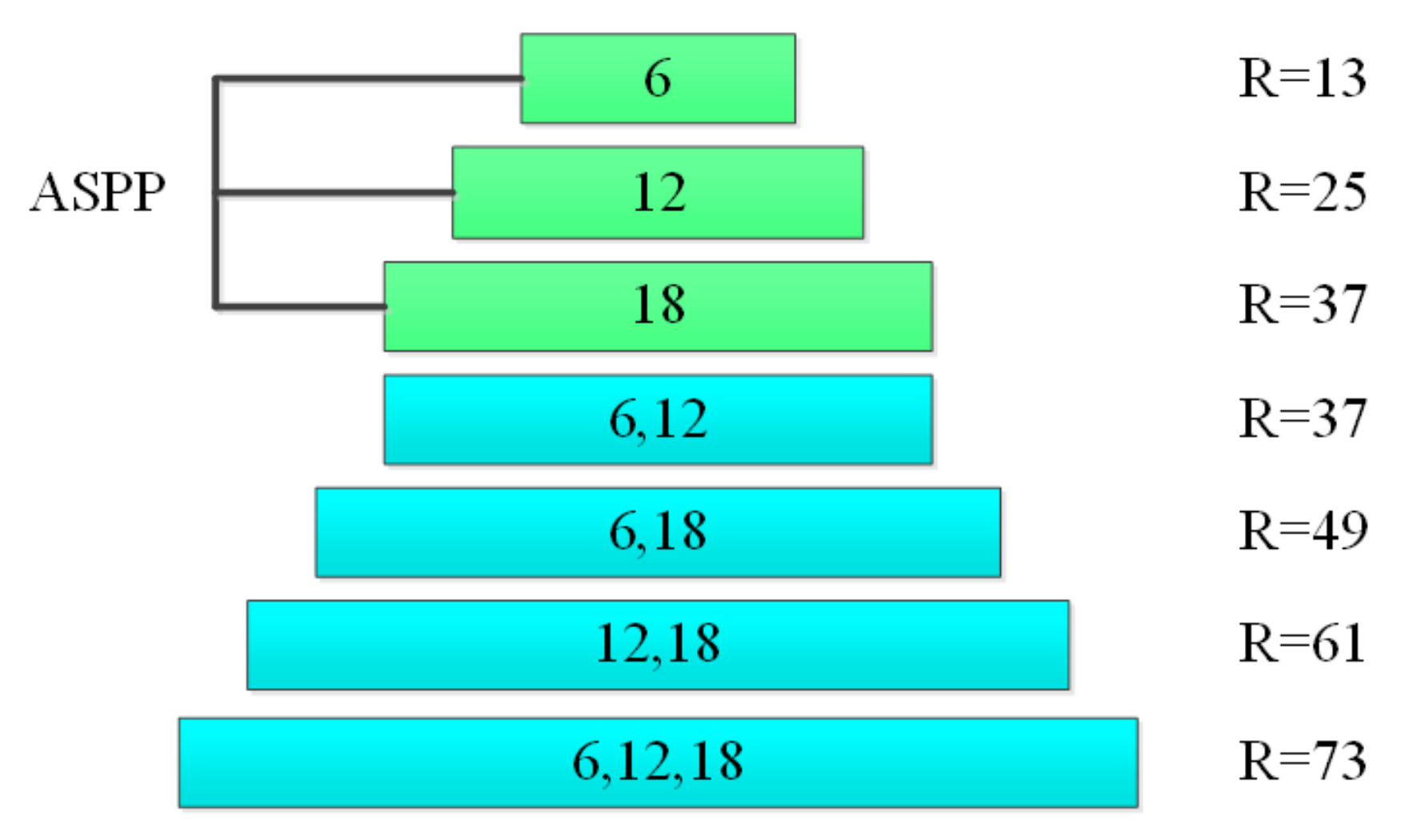
2. DeepLabv3+ Algorithm
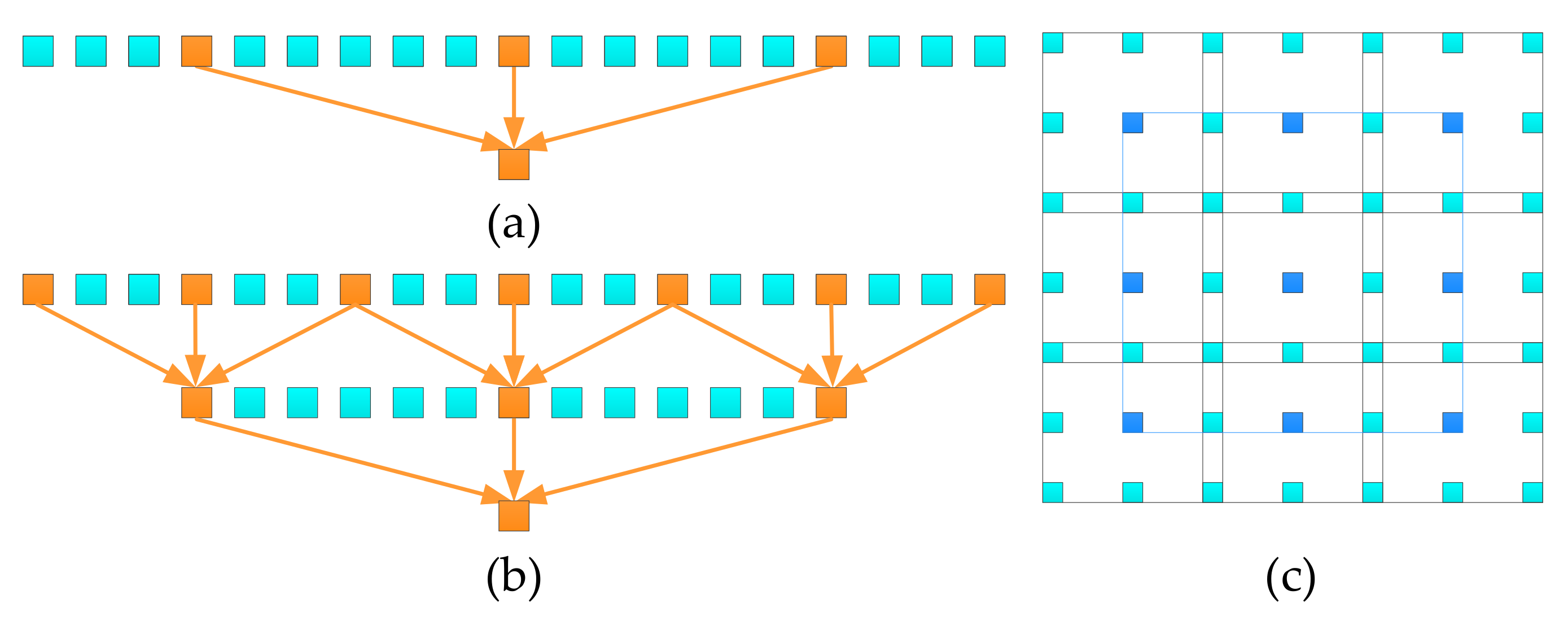
3. Dense-DeepLabv3+ Semantic Segmentation Algorithm
4. Crack Segmentation Results and Analysis
4.1. Evaluation Metrics
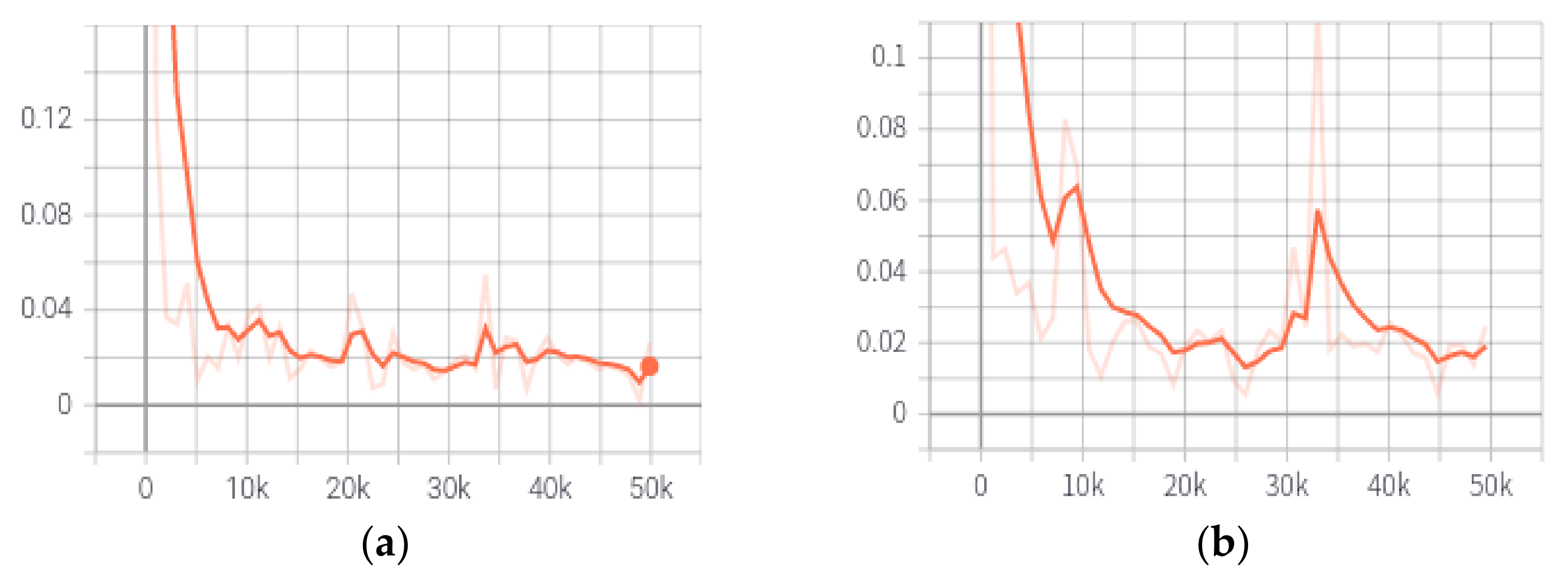
4.2. Experimental Conditions and Model Training
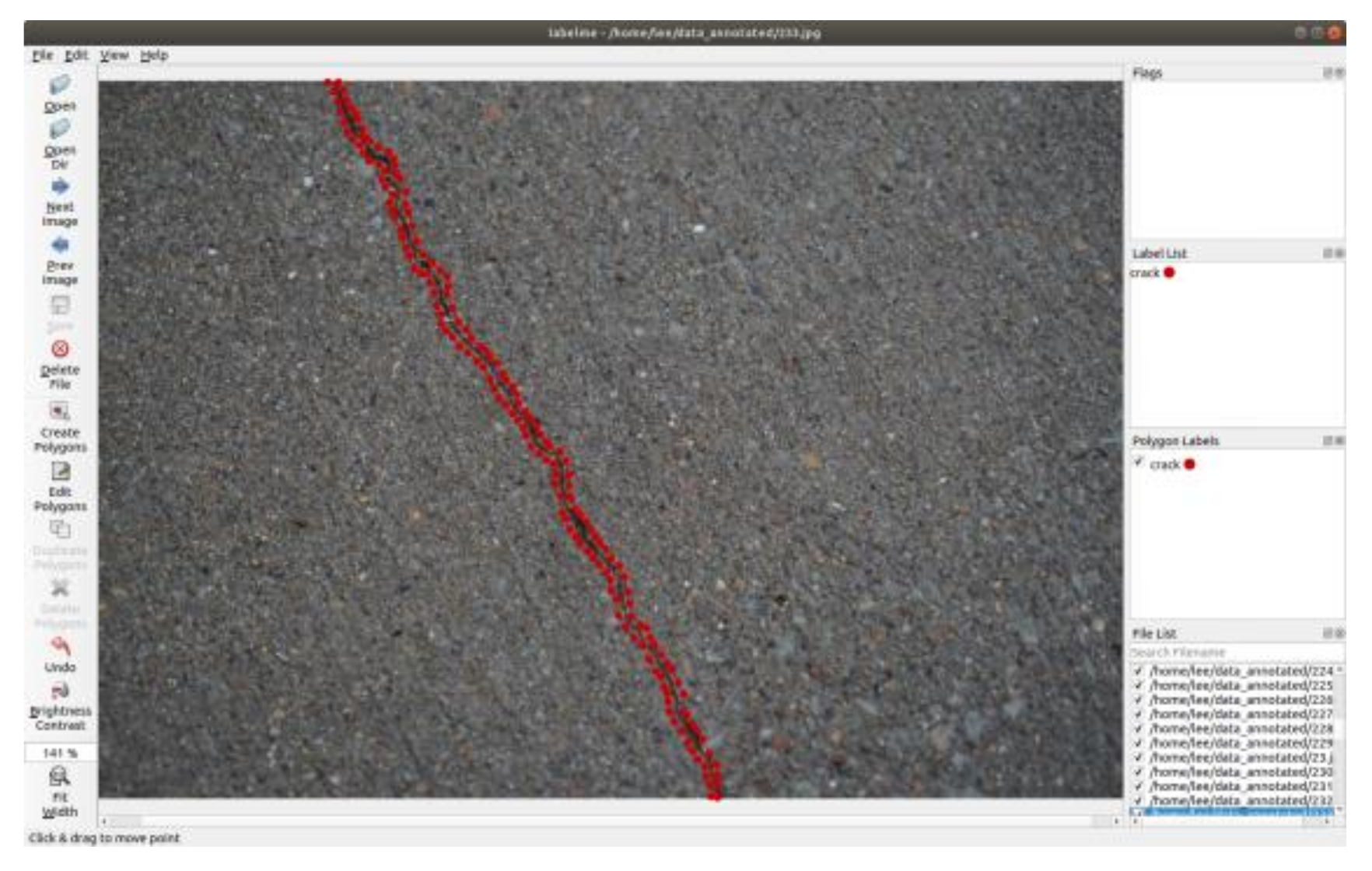
4.3. Crack Segmentation Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sabatino, S.; Frangopol, D.M.; Dong, Y. Sustainability-informed maintenance optimization of highway bridges considering multi-attribute utility and risk attitude. Eng. Struct. 2015, 102, 310–321. [Google Scholar] [CrossRef]
- Cheng, H.D.; Shi, X.J.; Glazier, C. Real-time image thresholding based on sample space reduction and interpolation approach. J. Comput. Civ. Eng. 2003, 17, 264–272. [Google Scholar] [CrossRef]
- Rao, S.R.; Mobahi, H.; Yang, A.Y.; Sastry, S.S.; Yi, M. Natural image segmentation with adaptive texture and boundary encoding. In Proceedings of the Asian Conference on Computer Vision, Xi’an, China, 23–27 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 135–146. [Google Scholar]
- Xu, J.X.; Zhang, X.N. Crack detection of reinforced concrete bridge using video image. J. Cent. South Univ. 2013, 20, 2605–2613. [Google Scholar] [CrossRef]
- Mokhtari, S.; Wu, L.L.; Yun, H.B. Comparison of Supervised Classification Techniques for Vision-Based Pavement Crack Detection. Transp. Res. Rec. 2016, 2595, 119–127. [Google Scholar] [CrossRef]
- Hoang, N.D.; Nguyen, Q.L. A novel method for asphalt pavement crack classification based on image processing and machine learning. Eng. Comput. 2019, 35, 487–498. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.L.; Wang, X.G.; Fieguth, P.; Chen, J.; Liu, X.W.; Pietikinen, M. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.Q.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.M.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 318–327. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 642–656. [Google Scholar]
- Zhou, X.Y.; Zhuo, J.C.; Krahenbuhl, P. Bottom-up Object Detection by Grouping Extreme and Center Points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 850–859. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 357–361. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. arXiv 2016, arXiv:1606.00915v2. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.K.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]
- Zhao, H.S.; Shi, J.P.; Qi, X.J.; Wang, X.G.; Jia, J.Y. Pyramid Scene Parsing Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Comput. Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- An, Y.K.; Jang, K.; Kim, B.; Cho, S. Deep learning-based concrete crack detection using hybrid images. In Proceedings of the Conference on Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems, Denver, CA, USA, 5–8 March 2018; p. 10598. [Google Scholar]
- Zhang, A.; Wang, K.C.; Fei, Y.; Liu, Y.; Tao, S.; Chen, C.; Li, J.Q.; Li, B. Deep Learning-Based Fully Automated Pavement Crack Detection on 3D Asphalt Surfaces with an Improved CrackNet. J. Comput. Civ. Eng. 2018, 32, 04018041. [Google Scholar] [CrossRef]
- Nie, M.; Wang, C. Pavement Crack Detection based on yolo v3. In Proceedings of the 2nd International Conference on Safety Produce Informatization, Chongqing, China, 28–30 November 2019; pp. 327–330. [Google Scholar]
- Lee, D.; Kim, J.; Lee, D. Robust Concrete Crack Detection Using Deep Learning-Based Semantic Segmentation. Int. J. Aeronaut. Space Sci. 2019, 20, 287–299. [Google Scholar] [CrossRef]
- Lyu, P.H.; Wang, J.; Wei, R.Y. Pavement Crack Image Detection based on Deep Learning. In Proceedings of the International Conference on Deep Learning Technologies, Xiamen, China, 5–7 July 2019; pp. 6–10. [Google Scholar]
- Zou, Y.; Cao, W.; Luo, M.; Zhang, P.; Wang, W.; Huang, W. Deep Learning-based Pavement Cracks Detection via Wireless Visible Light Camera-based Network. In Proceedings of the IEEE International Conference on Computing, Communications and IoT Applications, Shenzhen, China, 26–28 October 2019; pp. 47–52. [Google Scholar]
- Huyan, J.; Li, W.; Tighe, S.; Xu, Z.C.; Zhai, J.Z. CrackU-net: A novel deep convolutional neural network for pixelwise pavement crack detection. Struct. Control Health Monit. 2020, 27, e2551. [Google Scholar] [CrossRef]
- Park, S.E.; Eem, S.H.; Jeon, H. Concrete crack detection and quantification using deep learning and structured light. Constr. Build. Mater. 2020, 252, 119096. [Google Scholar] [CrossRef]
- Yang, Q.; Shi, W.; Chen, J.; Lin, W. Deep convolution neural network-based transfer learning method for civil infrastructure crack detection. Autom. Constr. 2020, 116, 103199. [Google Scholar] [CrossRef]
- Kalfarisi, R.; Wu, Z.Y.; Soh, K. Crack Detection and Segmentation Using Deep Learning with 3D Reality Mesh Model for Quantitative Assessment and Integrated Visualization. J. Comput. Civ. Eng. 2020, 34, 04020010. [Google Scholar] [CrossRef]
- Billah, U.H.; La, H.M.; Tavakkoli, A. Deep Learning-Based Feature Silencing for Accurate Concrete Crack Detection. Sensors 2020, 20, 4403. [Google Scholar] [CrossRef]
- Fang, F.; Li, L.; Gu, Y.; Zhu, H.; Lim, J.H. A Novel Hybrid Approach for Crack Detection. Pattern Recogn. 2020, 107, 107474. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Parameters | Original DeepLabv3+ | Dense-DeepLabv3+ |
|---|---|---|
| Atrous rates | 6, 12, 18 | 6, 12, 18 |
| Base learning rate | 0.001 | 0.001 |
| Output stride | 16 | 16 |
| Train crop size | 513, 513 | 513, 513 |
| Train batch size | 4 | 4 |
| Training number of steps | 50,000 | 50,000 |
| Class_0 [%] | Class_1 [%] | Overall [%] | |
|---|---|---|---|
| original Deeplabv3+ | 99.12 | 58.74 | 78.93 |
| Dense-DeepLabv3+ | 99.30 | 65.44 | 82.37 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, H.; Meng, D.; Li, W.; Wang, Y. Bridge Crack Semantic Segmentation Based on Improved Deeplabv3+. J. Mar. Sci. Eng. 2021, 9, 671. https://doi.org/10.3390/jmse9060671
Fu H, Meng D, Li W, Wang Y. Bridge Crack Semantic Segmentation Based on Improved Deeplabv3+. Journal of Marine Science and Engineering. 2021; 9(6):671. https://doi.org/10.3390/jmse9060671
Chicago/Turabian StyleFu, Huixuan, Dan Meng, Wenhui Li, and Yuchao Wang. 2021. "Bridge Crack Semantic Segmentation Based on Improved Deeplabv3+" Journal of Marine Science and Engineering 9, no. 6: 671. https://doi.org/10.3390/jmse9060671
APA StyleFu, H., Meng, D., Li, W., & Wang, Y. (2021). Bridge Crack Semantic Segmentation Based on Improved Deeplabv3+. Journal of Marine Science and Engineering, 9(6), 671. https://doi.org/10.3390/jmse9060671