1. Introduction
The 21st century has been widely recognized as “A Century of Ocean”. Ocean, as the main space of marine development and security strategy, plays a significant role in safeguarding national security, alleviating resource shortages and expanding the development space for economy and society. It is well known that the marine environment involves numerous oceanic and meteorological factors, which are constantly changing and have complex mutual actions between each other. With climate change, marine disasters are occurring more frequently and disaster losses are heavier. Risk assessment is taken increasingly seriously. However, the risk mechanism of marine disasters is nonlinear and uncertain. Besides this, statistical information of disasters is usually scarce, causing an obstacle to risk assessment. It is difficult to evaluate disaster risk under uncertain knowledge and lacking information conditions. Therefore, developing new assessment models becomes an important subject to be studied urgently.
Marine environment is complicated and varied, producing varieties of marine disasters, such as marine geologic disaster, red tide, wave disaster, sea ice disaster and storm surge disaster. Many scholars have carried out risk assessment studies on different types of marine disasters: Qiao focused on the hazard assessment of geologic disaster sources in coastal areas [
1]. He constructed the evaluation system by classifying features of different risk sources such as fault and earthquake, then adopted the analytic hierarchy process (AHP) to assess the marine geologic hazard quantitatively. Wen [
2] analyzed characteristics of risk-causing factors and risk-on bodies to set up the assessment index system and developed a new red tide risk assessment model. Yuan [
3] selected systematic assessment indicators of the sea ice disaster with consideration of natural and anthropogenic environment, and put forward the theoretical basis and concrete method of disaster assessment and zoning. Ericken [
4] applied the fuzzy clustering and fuzzy reasoning algorithm to deal with the fuzziness of sea ice disaster information, achieving the reasoning of uncertain information and the regional division of sea ice risk. Zhao [
5] summarized the research progress of storm surge disaster assessment and constructed a multi-level indicator system from the aspects of nature, society and economy, then applied the principal component analysis and geographic information system to the risk assessment of storm surge disaster.
Marine disasters, occurring in the form of cluster, concurrence and contingency, usually cause considerable disaster losses. However, it is difficult to express these forms through the risk assessment of a single type of marine disaster. Several studies have been devoted to the comprehensive risk assessment of multiple marine disasters: Ye [
6] analyzed the temporal–spatial characteristics of oceanic and meteorological variables and established the general risk management system of comprehensive marine disaster. Zhang [
7] elaborated marine environmental features in the South China Sea from the perspectives of marine geography, marine meteorology and marine hydrology, and adopted the fuzzy synthetic evaluation method to evaluate the marine hazard. Dubois [
8] designed an integrated risk analysis frame of multiple marine disasters in coastal areas, including unit division, identification of disaster-causing factors and vulnerability analysis of disaster bearing body. In addition, the Earth System Science Partnership started the proposal of integrated risk governance to analyze internal relations between marine disasters and climate change at different spatial–temporal scales [
9]. The Federal Emergency Administration of the USA developed a natural hazard loss estimation software to evaluate and predict the risk losses caused by multiple marine disasters, including storm surges, sea waves and typhoons. Comprehensive risk assessment of multiple marine disasters, emphasizing systematization and interdisciplinarity, can integrate and analyze different types of marine disasters to establish a more comprehensive assessment index system. With the index system set up, varieties of mathematical models are combined for quantitative assessment. In our research, we lay emphasis on analyzing the hazard of disaster-causing factors and focus on the comprehensive hazard evaluation of marine disasters.
From a physical standpoint, marine disasters are the presence of interactions of geographical, meteorological and hydrological factors. The influence is nonlinear, and the action mechanism is fuzzy between each two environmental variables, causing the randomness in temporal-spatial distribution, occurring frequency and hazard intensity of marine disasters. Therefore, marine disasters have significant uncertainties, which concretely manifest in self-uncertainty, information uncertainty and cognitive uncertainty [
10]. In the above assessment of marine disasters, whether for a single marine disaster or multiple marine disasters, most studies use qualitative and semi-quantitative assessment methods, mainly including Delphi method, AHP, grey comprehensive evaluation method (GCE) and fuzzy comprehensive evaluation method (FCE). The subjectivity and experience are too strong in the expert investigation method. The analytical function is a linear model with strict mathematical assumptions, which is difficult to model with large-scale evaluation indicators and nonlinear relationships in marine environments. Besides this, GCE and FCE can only deal with one kind of uncertainty, such as randomness or fuzziness, but they are hard to achieve the uncertainty reasoning comprehensively. In conclusion, the existing assessment approaches hardly process uncertain information and are incapable of achieving assessment with complex influencing mechanism. Therefore, developing new risk assessment models propitious to the marine environment would be impressive.
Bayesian Network (BN), on the basis of probability theory and graph theory, shows great advantage in the expression of uncertain knowledge and the reasoning of complex relationships. The abilities of prior knowledge combination, multi-source information fusion and uncertainty reasoning make BN an effective model to solve uncertain problems in complex systems. In recent years, some studies have applied BN in assessment with nonlinear uncertain problems and made some achievements. Aguilera [
11] adopted the clustering analysis to grade indicators and determine node states. Then the hierarchical BN is constructed for groundwater quality evaluation. Li [
12] improved the BN with the genetic algorithm and applied it to the risk assessment of sea ice disasters. Boutkhamouin [
13] used the BN to identify causal relationships between evaluation indicators and targets, and adopted the uncertainty reasoning mechanism for probabilistic assessment of floods. Liu [
14] introduced the BN to the hazard evaluation and management of flood disaster, and proposed the weighted BN to deal with correlated variables. Application of BN in risk assessment has become an inevitable development trend. However, to the best of our knowledge, the use of BN in the marine hazard assessment is very limited.
It should be noted that, as an emerging artificial intelligence algorithm, a large number of objective data is essential for BN to mine the influence relationships among variables quantitatively. Unfortunately, marine disaster data are mainly collected by means of social statistical surveys. The time series of these data are not long enough, and the continuity is poor, especially in the lack of associated information between disaster losses and environmental conditions. The limited sample size cannot effectively support BN training and disaster assessment modeling. Huang [
15,
16] proposed a small sample expansion algorithm based on information matrix, that is the information diffusion algorithm, and successfully applied it to natural disaster assessment, which effectively improved the accuracy in assessment with small sample numbers. Zhang [
17] improved the diffusion function of the information diffusion algorithm and proposed a more universal non-uniform information diffusion algorithm. It is an effective method of processing the incomplete information. In addition, the information diffusion model has also been effectively applied to the evaluation modeling of earthquake risk and water shortage risk [
18,
19]. Therefore, we will use the information diffusion algorithm to expand samples and complete the objective construction of BN, given the advantage of the model in dealing with the scarcity of disaster samples.
Aiming at the problem of high uncertainty and scarcity of disaster data in marine hazard assessment, this paper combines information diffusion and BN to construct a comprehensive hazard assessment model of marine disasters. The information diffusion algorithm is used to expand small samples in order to obtain sufficient disaster data for BN training. Then the BN-based assessment model is constructed through structural learning, parameter learning and probabilistic reasoning. For the model verification, we apply the model to the monthly hazard assessment of marine disasters in Shanghai. The remainder of the paper is organized as follows:
Section 2 presents the theory of BN and information diffusion.
Section 3 introduces the specific techniques of the assessment model. The obtained results and analysis are shown in
Section 4.
Section 5 draws conclusions and summarizes the main findings.
4. Model Construction
It is well-known that the risk includes the hazard of risk-causing factors, the vulnerability of risk-bearing body and the risk-prevention capacity. We focus on the hazard assessment in our research. The proposed assessment model is used to evaluate and predict the monthly comprehensive hazard of marine disasters in Shanghai, which borders the Yangtze River and the East China Sea. There are many kinds of marine disasters in Shanghai with a high occurrence frequency and activity intensity. The marine environment is complicated, and disaster hazard has tremendous uncertainty. Detailed evaluation and prediction of overall marine hazard are of great significance for ensuring personal security, economic and social development, and city operation.
4.1. Indicator Analysis
The marine disasters threatening the security of Shanghai mainly include storm surges, ocean waves, sea level rise and tsunamis. Given the disaster-causing mechanism of different types of marine disasters and relevant literatures [
6,
7], we select five representative environmental variables that have a remarkable effect on maritime activities for assessment modeling: wind speed, wave height, flow velocity, sea surface height and sea surface temperature. Studies have shown that wind speed can pose a serious threat to navigation safety. Wave height and sea surface height can bring harm to coastal constructions. Sea surface temperature may cause the malfunction of devices in ships. The mode of action of these variables is summarized in
Table 2. We will then construct the hazard assessment indicators for marine disasters based on the above meteorological and oceanic variables.
- (1)
Gale hazard indicator ()
The hazard of gale is described in two aspects: average wind speed and extreme wind speed. Calculate the monthly average wind speed and the monthly maximum wind speed. The indicator is constructed based on Equation (4) coming from Ref. [
7].
where:
and
respectively represent the monthly average wind speed and the monthly maximum wind speed.
- (2)
Wave hazard indicator ()
The hazard of sea wave is described in two aspects: sea wave intensity and frequency of occurrence. According to the classification of wave intensity (
Table 3) presented in Ref. [
28], the monthly average number of different level of wave height (I, II, III, IV) are calculated respectively.
The indicator is constructed according to Ref. [
28].
where:
represent the monthly average number of I, II, III, IV wave height respectively.
- (3)
Flow velocity hazard indicator ()
The hazard of flow velocity is described in two aspects: average flow velocity and extreme flow velocity. Calculate the monthly average flow velocity and the monthly maximum flow velocity. The indicator is constructed based on Equation (6).
where:
and
represent the monthly average flow velocity and the monthly maximum flow velocity respectively. The weight configuration comes from Ref. [
7].
- (4)
Sea level rise hazard indicator ()
The hazard of sea level rise is described in two aspects: intensity and frequency of sea level rise. According to the classification of sea level rise intensity (
Table 4) in Ref. [
28], the monthly average number of different grade of sea level rise (I, II, III) are calculated respectively.
The indicator is constructed according to Equation (7).
where:
represent the monthly average number of I, II, III sea level rise respectively. The weight configuration comes from Ref. [
28].
- (5)
Sea surface temperature hazard indicator ()
The hazard of sea surface temperature is described in two aspects: average sea surface temperature and extreme sea surface temperature. Calculate the monthly average sea surface temperature and the monthly maximum sea surface temperature. The indicator is constructed based on Ref. [
7].
where:
and
respectively represent the monthly average sea surface temperature and the monthly maximum sea surface temperature.
Considering the characteristics of the meteorological and oceanic environment in Shanghai, April to November is a peak period for various marine disasters. Therefore, we focus on the monthly assessment of comprehensive marine hazard in this period. Data sets required for the indicator construction come from observation in Sheng Shan Station (National Marine Data Center:
http://mds.nmdis.org.cn/, accessed on 31 May 2021).
In addition to constructing evaluation indicators, we need to quantitatively express the evaluation object. The objective of our research is the comprehensive hazard of marine disasters, denoted as
. In almost all references, the severity of the hazard of marine disasters is usually quantified by the direct economic loss. These data come from the China Marine Disaster Bulletin (
http://www.soa.gov.cn/zwgk/hygb/zghyzhgb/) (accessed on 20 February 2021) and Shanghai Statistical Yearbook. On account of limited data recording and data storage, the time series of these data are not long enough and discontinuous. We looked up the statistical yearbook from 2005 to 2019 and only obtained 80 complete samples.
Different indicators have different orders of magnitude. In order to eliminate the impact of dimension and to speed up the training of BN, all indicators need to be normalized according to Equation (9).
where:
is the normalized value;
is the original value;
,
denote maximum and minimum of original data.
Table 5 shows the normalized data, whose sample size is very small. The structural learning and parameter learning of BN rely on big data to explore causal relationships among variables. However, the sample size is too small to be directly used for either conventional statistical analysis methods or data mining techniques for BN modeling. Next, we will expand the samples.
4.2. Sample Expansion
The non-normal information diffusion algorithm based on the string vibration equation is adopted to expand the disaster samples. The detailed algorithm principle is elaborated in Ref. [
27], and we will not repeat it here. The specific implementation steps of sample expansion are presented as follows:
Step 1: The first 50 samples in
Table 3 are taken as modeling samples, and the last 30 samples are taken as testing samples. Each sample is denoted as
.
respectively represents assessment indicators
and assessment target
. The information injection points are set as follows:
Step 2: The bandwidth of the information diffusion algorithm are calculated using the modeling samples, as shown in
Table 6.
Step 3: It is calculated the amount of information
diffused by each sample (the ordinal number is
) to the information injection point
:
where:
represents the diffusion function;
represents the bandwidth corresponding to different evaluation indicators.
Step 4: The information matrix
is formed by the superposition of information volume
:
Step 5: can generate fuzzy relation matrix
. The conversion relationship from
to
is:
Step 6: Suppose the input sample is denoted as
, and the five-dimensional linear information distribution is performed on it. The fuzzy set can be obtained:
where:
.
Step 7: The fuzzy inference is realized based on the fuzzy set and fuzzy relation matrix, then the output can be obtained after defuzzification:
where:
.
Finally, the 500 virtual samples displayed in
Table 7 are generated through the above process, and 50 modeling samples are also combined to obtain the final training data sets (550 samples) for BN learning.
4.3. BN-Based Model Construction
In this section, the structural learning and parameter learning of BN are carried out based on the expanded training samples, and the BN for comprehensive hazard assessment of marine disasters can be established under the condition of small samples.
4.3.1. Indicator Discretization
BN is more suitable for modeling with discrete data but the indicator data are all continuous, so the data need to be discretized to determine different levels of each indicator, namely the states taken by network nodes. We adopt the equal interval division method to discretize indicator data and the discrete interval is 0.2. Thus, each node can take five states, represented by 1, 2, 3, 4 and 5 respectively.
Table 8 shows discrete training samples.
4.3.2. Structural Learning
There are two main approaches to learn BN structure from objective data: search scoring method and dependency analysis method [
29]. The search scoring method is standardized and complicated, which is suitable for BN structural learning with a small handful of nodes, while the process of dependency analysis method is easy to operate and suitable for BN modeling with a large number of nodes. As for our experiment, there are few network nodes and clear relationships existing. K2 algorithm, one of the search scoring methods, is adopted to learn the network structure, which is a typical greedy search algorithm proposed by Cooper [
30]. It combines Bayesian scoring and hill-climbing search strategy to optimize the network topology and can effectively mine the BN structure from data sets.
This algorithm needs to determine the prior order of nodes. We use the classic greedy search algorithm to obtain the topological order of network nodes: [
,
,
,
,
,
]. Based on the expanded training samples, the network structure is established with the help of the FULL_BNT toolbox in MATALB, as shown in
Figure 2. In the network used for marine hazard assessment, the evaluation indicators are taken as the observation node, and the comprehensive hazard is taken as the target node.
4.3.3. Parameter Learning
After the network structure is constructed, parameter learning is conducted to determine the conditional probability distribution of nodes. In this research, we combine the Monte Carlo algorithm and expectation-maximization (EM) algorithm [
31,
32,
33] presented in
Table 9 for parameter learning. The parameter learning principle goes as follows: We use the Monte Carlo algorithm to conduct 300 random number experiments to generate the conditional probability of each child node as the initial probability of the EM algorithm. Then, on the basis of the expanded dataset, the EM algorithm is used to modify the conditional probability.
Each network node has its own conditional probability distribution, which quantitatively expresses the causal relationship with other nodes. For example,
Table 10 shows the conditional probability distribution
of nodes
. So far, based on the expanded training samples, a complete BN for the comprehensive hazard assessment of marine disasters has been constructed.
4.3.4. Probabilistic Assessment
Based on the information of observation nodes, the comprehensive hazard of marine disasters is evaluated and predicted by probabilistic reasoning to verify the effectiveness of our proposed assessment technique. The reasoning algorithm of BN includes the exact reasoning algorithm and approximate reasoning algorithm. Considering the small scale of network nodes and the simple network structure in our research, we choose the joint tree reasoning mechanism, one of the most widely used exact reasoning algorithms, to calculate the posterior probability distribution of the target node. We input the testing samples, and the hazard level is determined according to the maximum probability, as shown in
Table 11.
The evaluation results are expressed in the posterior probability distribution, clearly showing the probabilities of different levels. The assessment has richer information and expresses the uncertainty of disaster hazard. Compared with the actual hazard level, the prediction accuracy of our proposed assessment model is 90.11%, which can effectively evaluate and predict the comprehensive hazard of marine disasters based on limited marine environmental information.
4.4. Model Verification
In the marine disaster assessment, associated samples between disaster losses and environmental conditions are scarce, which causes difficulties in building an assessment and prediction model. To solve this problem, we combine the information diffusion algorithm and BN to construct the assessment model. In order to further discuss the performance of our evaluation model and verify its effectiveness under the conditions of uncertain knowledge and incomplete samples, we design multiple sets of comparative experiments.
(1) Sample expansion vs. Sample non-expansion
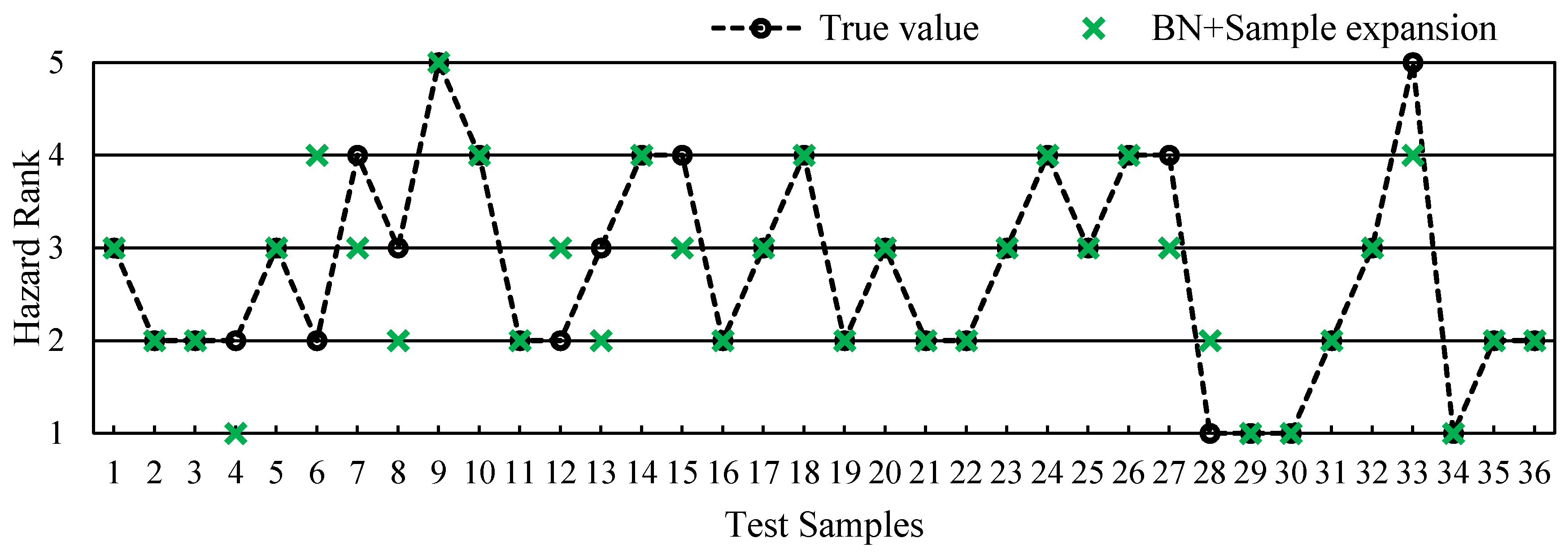
In order to verify the effectiveness of sample expansion, we use the data sets before and after the sample expansion to construct two different BN-based evaluation models. The assessment results of marine disaster hazard with testing samples are illustrated in
Figure 3.
It can be seen from the figure that the BN trained with the original sample (sample size is 50) has a large deviation between the evaluation and reality, and the prediction accuracy of the hazard level is only 56.67%. With the BN trained with expanded samples (sample size is 550), the evaluation accuracy is up to 90.11%, increased by 33.44%. It demonstrates that the expanded samples based on the information diffusion algorithm effectively extract the data structure information from limited samples, improving the performance of BN. The sample augment method provides a technical approach for disaster assessment in a data-scarce environment.
(2) BN vs. BPNN and ELM
In order to verify the effectiveness of BN, based on the expanded samples, we use BN and two, frequently used machine learning (ML) algorithms, Back-Propagation neural network (BPNN) and extreme learning machine (ELM), to build different hazard assessment models and compare their assessing performance. In modeling with BPNN and ELM, the number of network layers is three in both cases.
Figure 4 shows the assessment results of three models. The prediction accuracy of BPNN and ELM are 73.34% and 76.67%, respectively, which are significantly lower than the accuracy of BN (90.11%). More importantly, BPNN and ELM are ML algorithms with deterministic outputs, and the assessment results are single certain value, which cannot handle and express the uncertainty in disaster assessment. In contrast, BN not only obtains high accuracy in evaluation and prediction with mining the influence relationship among indicators, but also can deal with uncertainty through the probabilistic reasoning.
(3) Information Diffusion vs. Bootstrap
In order to further illustrate the effectiveness of the sample expansion based on the information diffusion algorithm, we compare it with the most commonly used sample expansion algorithm, Bootstrap, also known as the self-service statistical method.
The Bootstrap algorithm is a statistical method for expanding samples [
34]. Its core idea is to use the distribution of samples to simulate the statistical characteristics of the unknown probability distribution, and then obtain approximate location parameters. The small samples are expanded by the information diffusion algorithm and Bootstrap algorithm respectively, and then different BN-based assessment models are constructed based on the two expanded samples.
Figure 5 shows the evaluation results.
It can be seen from the figure that the BN trained with expanded samples from the information diffusion has the highest prediction accuracy (90.11%); the expanded samples with the Bootstrap algorithm can slightly improve the probabilistic reasoning accuracy of BN (72.23%), which is obviously lower than that of information diffusion. We also use BPNN and ELM to carry out the same evaluation and prediction experiments, as shown in
Table 12.
For BN, BPNN and ELM, the samples expanded by information diffusion result in greater improvement of assessing performance than the Bootstrap algorithm, indicating that the information diffusion algorithm can effectively extract and expand the data structure information from incomplete limited samples. Our proposed model provides a solution to the hazard assessment with small samples.
(4) Generality Test
Generalization ability is usually known in the ML community, used to describe the algorithm’s adaptive capacity to new samples. In order to test the generality of our proposed model, we input different testing samples into the BN-based assessment model established in
Section 4.3. Environment and disaster data from another time period (April to November of 2001–2005) are selected as new testing samples to verify the performance of the model. The results in
Figure 6 show that the accuracy has dropped. This is because BN only learns the patterns from training samples (2005–2019) while the rules of new testing samples (2001–2005) are not captured. The new testing samples are different from training samples in statistical rules, so the assessment accuracy decreases. However, it is up to 80.56%, still better than BPNN (73.34%) and ELM (76.67%), indicating that the assessment model has the characteristic of general use.
5. Conclusions
There are two challenges in the studies about the comprehensive hazard assessment of marine disasters. On the one hand, interactions between each two indicators are non-linear, and the impact mechanism between indicators and disaster hazard is fuzzy. On the other hand, time series of disaster data are not long enough, and the continuity is poor, especially in the lack of associated information between disaster losses and environmental conditions. To solve the two problems, we combine the information diffusion algorithm and BN to put forward a novel assessment model, coming with two advantages:
(1) Sample expansion. The information diffusion algorithm is used to expand associated samples between disaster losses and environmental conditions so that sufficient disaster data can be obtained for model construction.
(2) Uncertainty expression and reasoning. BN is capable of mining influence relationships among the marine hazard and environmental factors through structural learning and parameter learning. Based on the probability theory, BN achieves the expression and reasoning of uncertain relationships.
Experimental comparison results show that our proposed model is able to deal with the uncertainty relations and achieve more accuracy risk assessment under the small sample condition. However, in the practical application to some coastal areas, there may be a serious lack of data on some indicators. Extreme data loss may affect the efficiency and feasibility of information diffusion algorithm. In addition, BN learning is the core of the proposed assessment model. The richness of training data sets can affect the application range of the model. Besides this, the BN structure is established based only on objective data in our research. However, studies show expert knowledge can also improve BN learning [
35]. Therefore, we will focus on improving the structural learning and parameter learning of BN in the next step.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}