
Explaining a Deep Reinforcement Learning Docking Agent Using Linear Model Trees with User Adapted Visualization




Abstract
:1. Introduction
- Whether all the details of an explanation should be provided, or if it is preferable to highlight only the most relevant parts, with respect to the specific end-user, of the explanation;
- Whether the end-user need to process the explanations in real-time or not;
- In what way the explanation will be presented to the end-user.
- An overview of the background knowledge, skills, needs, and requirements the different end-users of the docking agents have;
- Two different visualizations of the explanations based on the characteristics of each end-user.
2. Preliminaries
2.1. The ASV Docking Problem
- The approach phase;
- The berthing phase;
- The mooring phase.
2.2. The Docking Agent
- Avoiding any obstacles, specifically keeping ;
- Reaching and staying at the berthing point, specifically achieve a stable situation with .
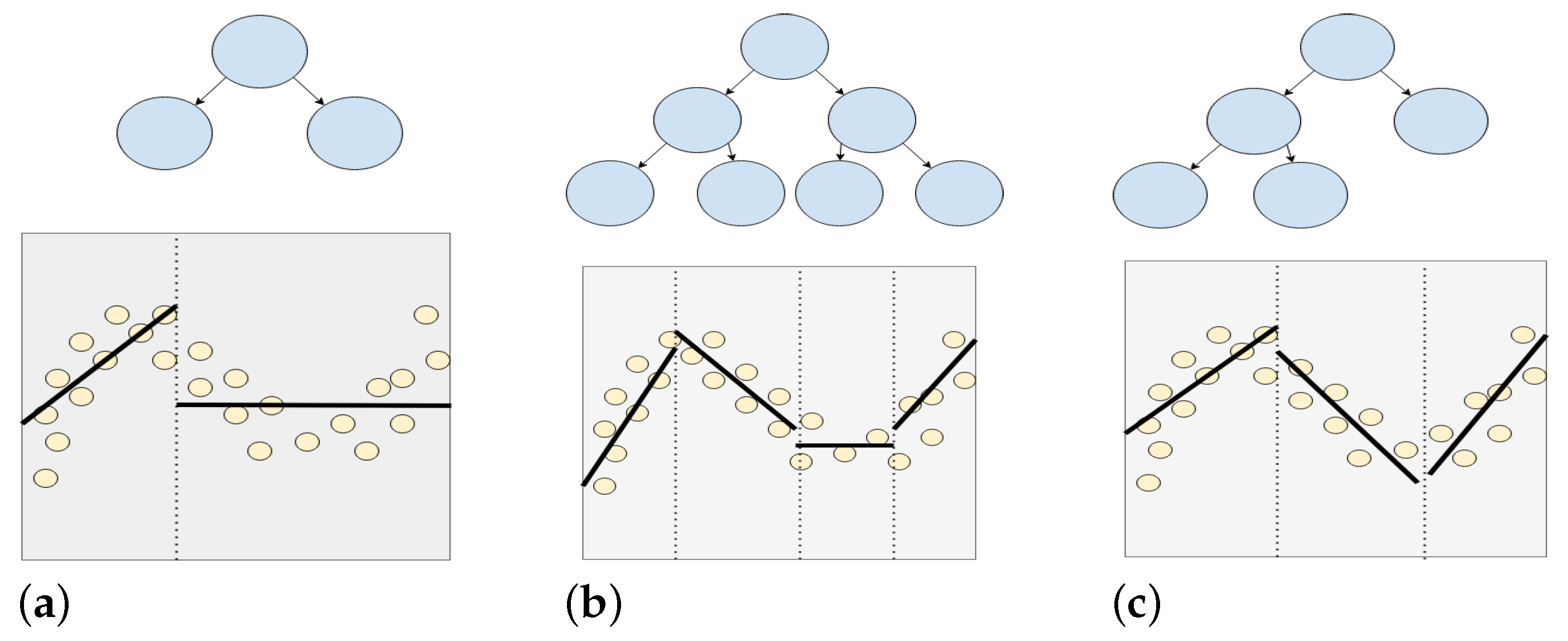
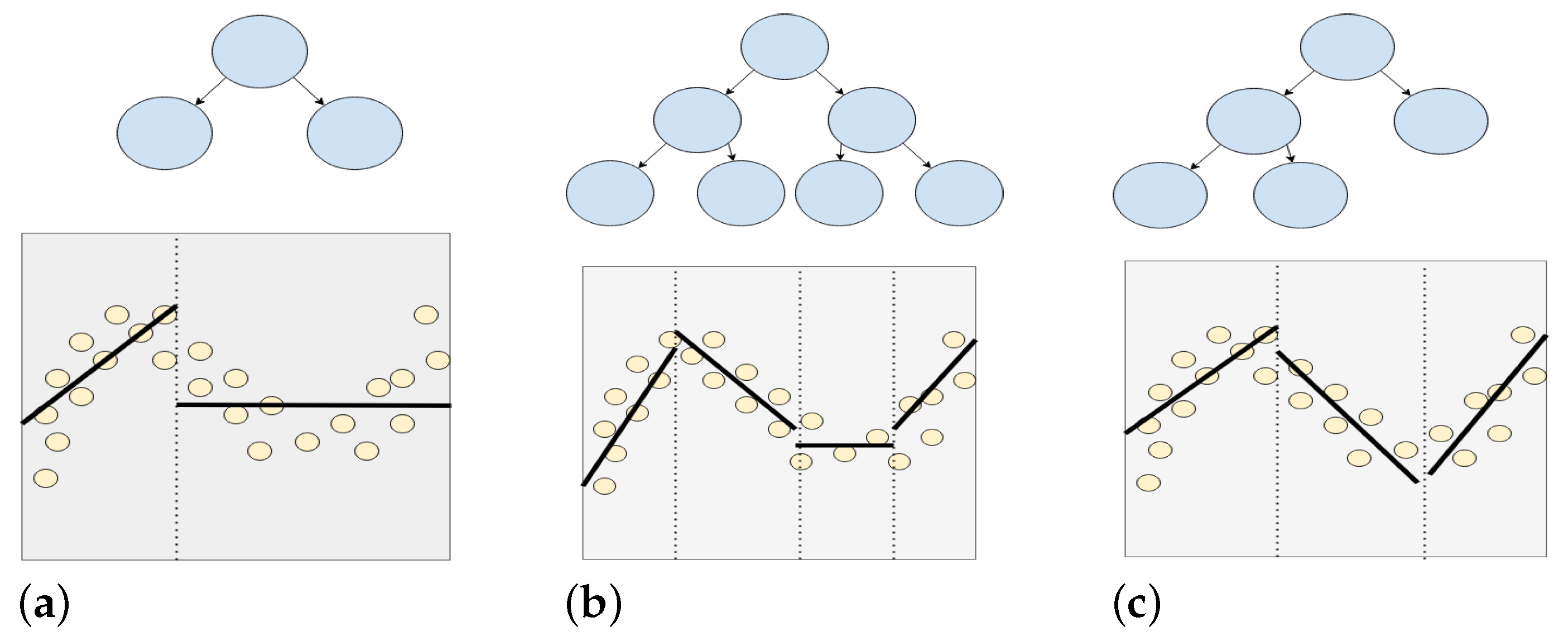
3. Linear Model Trees
3.1. Heuristic Tree Building
| Algorithm 1: The LMT algorithm from [27]. |
| Require: Training data Maximum number of leaf nodesN Minimum number of data samples for leaf nodesM  |
3.2. Building Linear Model Trees Utilizing Ordered Feature Splitting
- , , ;
- , ;
- u, v, r.
| Algorithm 2: The data sampling process from [27]. |
| Require: Maximum number of iterationsMax_it Maximum number of leaf nodesN Minimum number of data samples for leaf nodesM it = 0  |
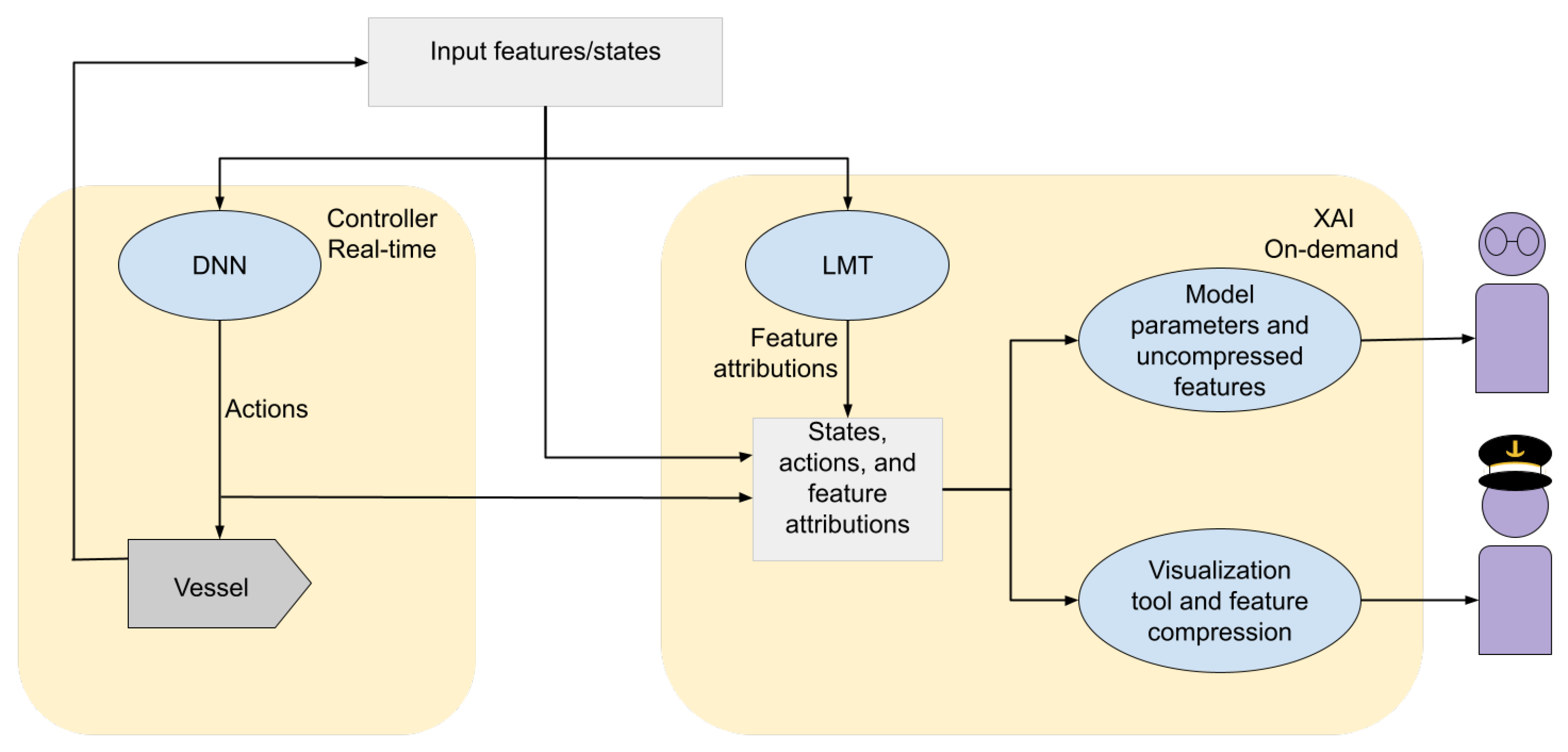
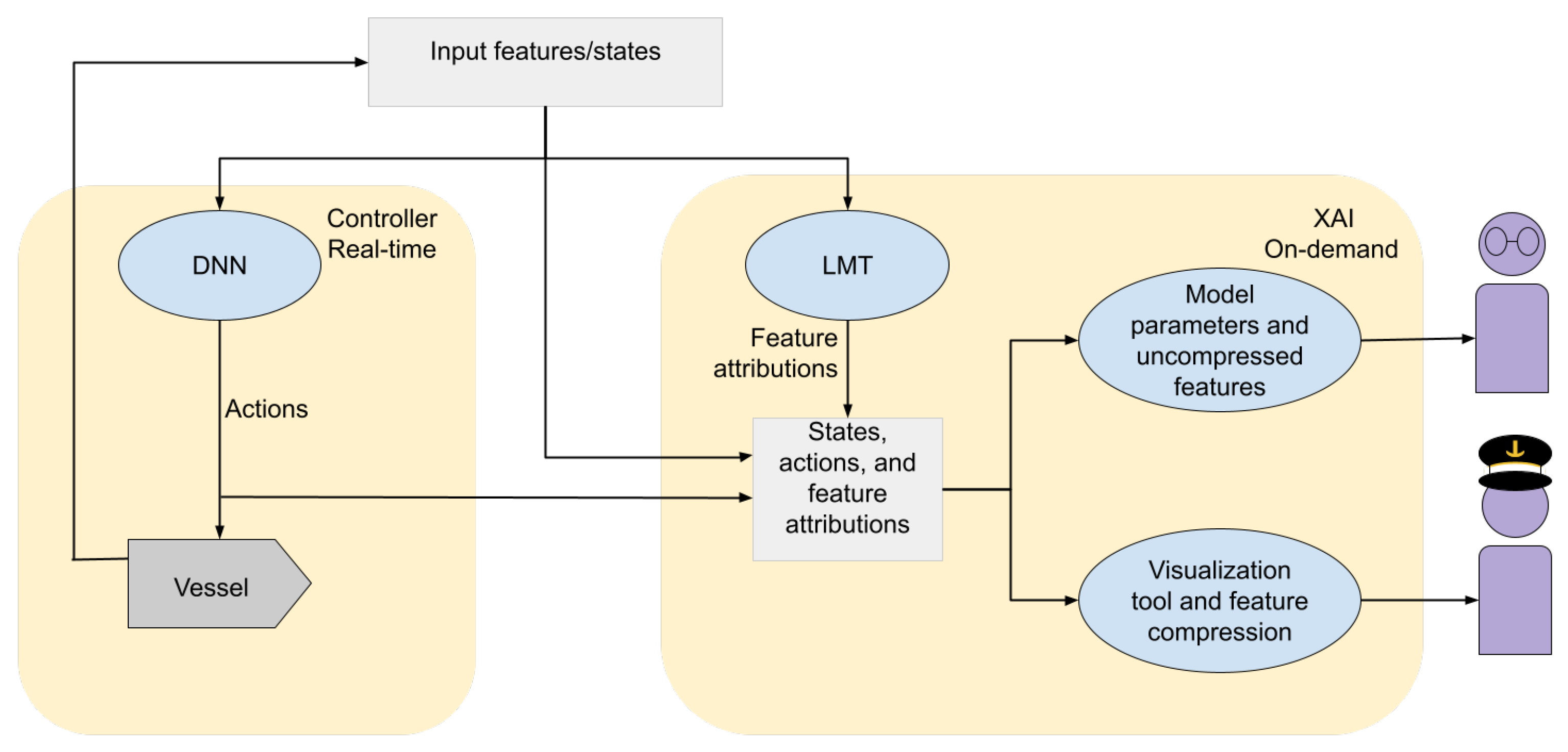
4. Increasing Model Interpretability Using Linear Model Trees
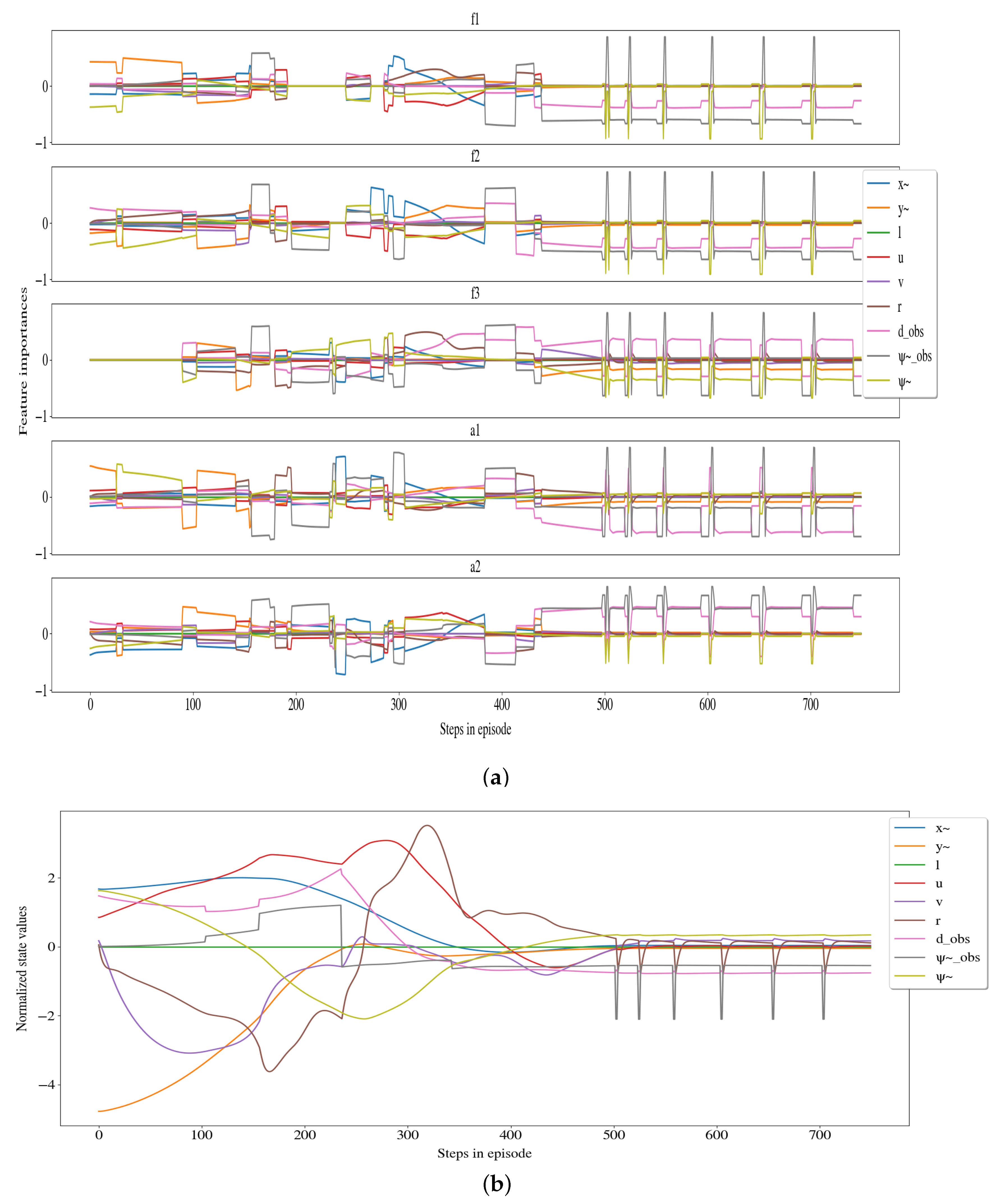
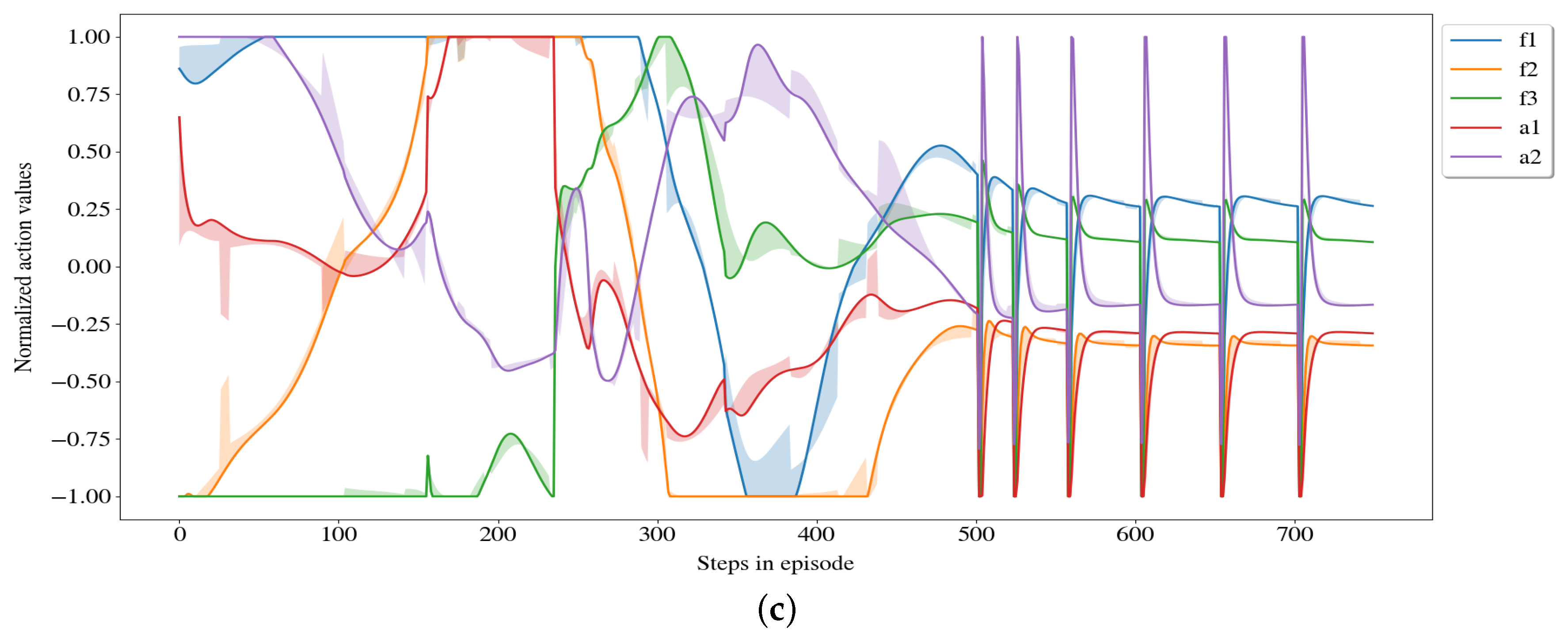
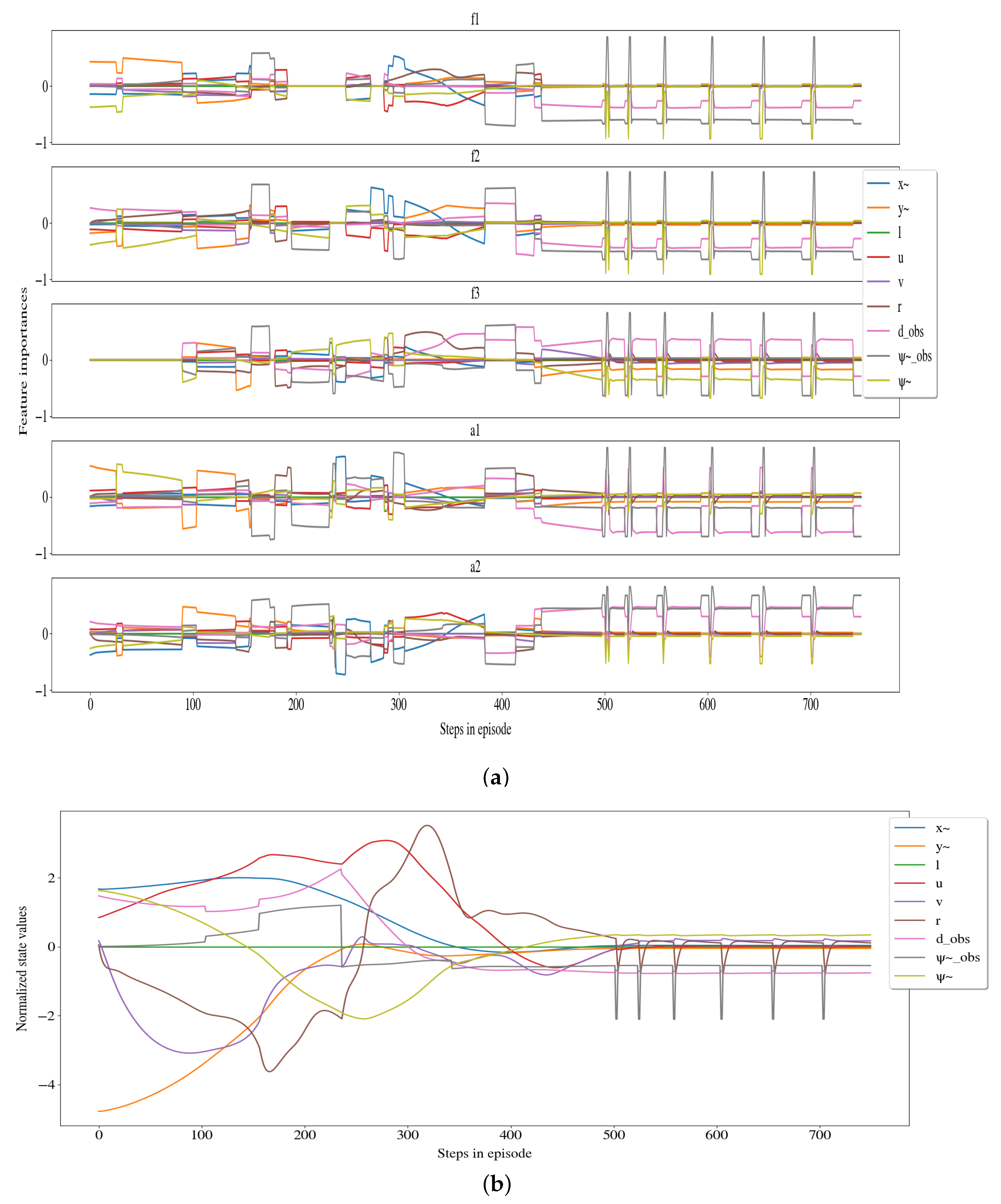
4.1. Extracting Feature Attributions from the Leaf Nodes
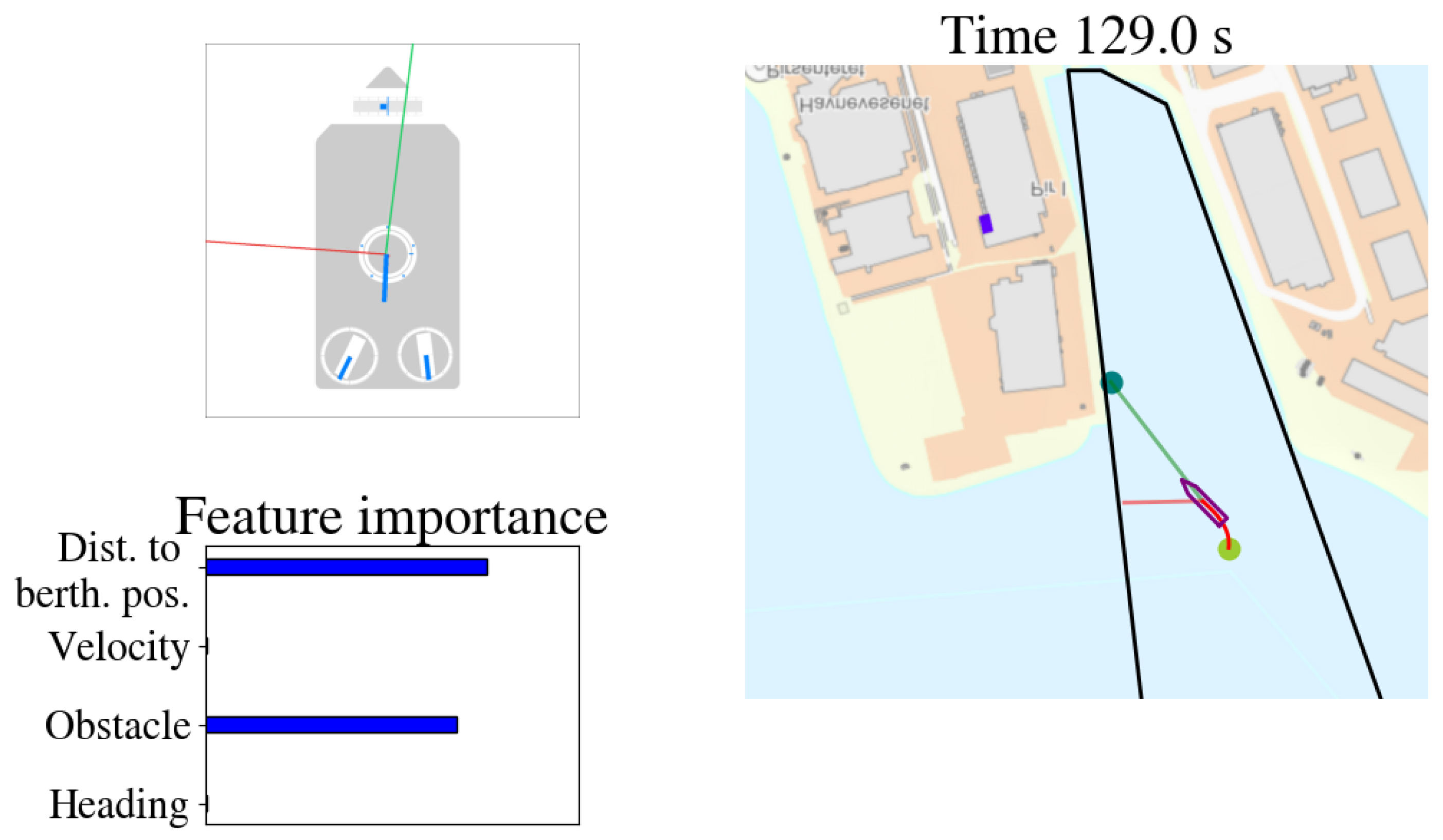
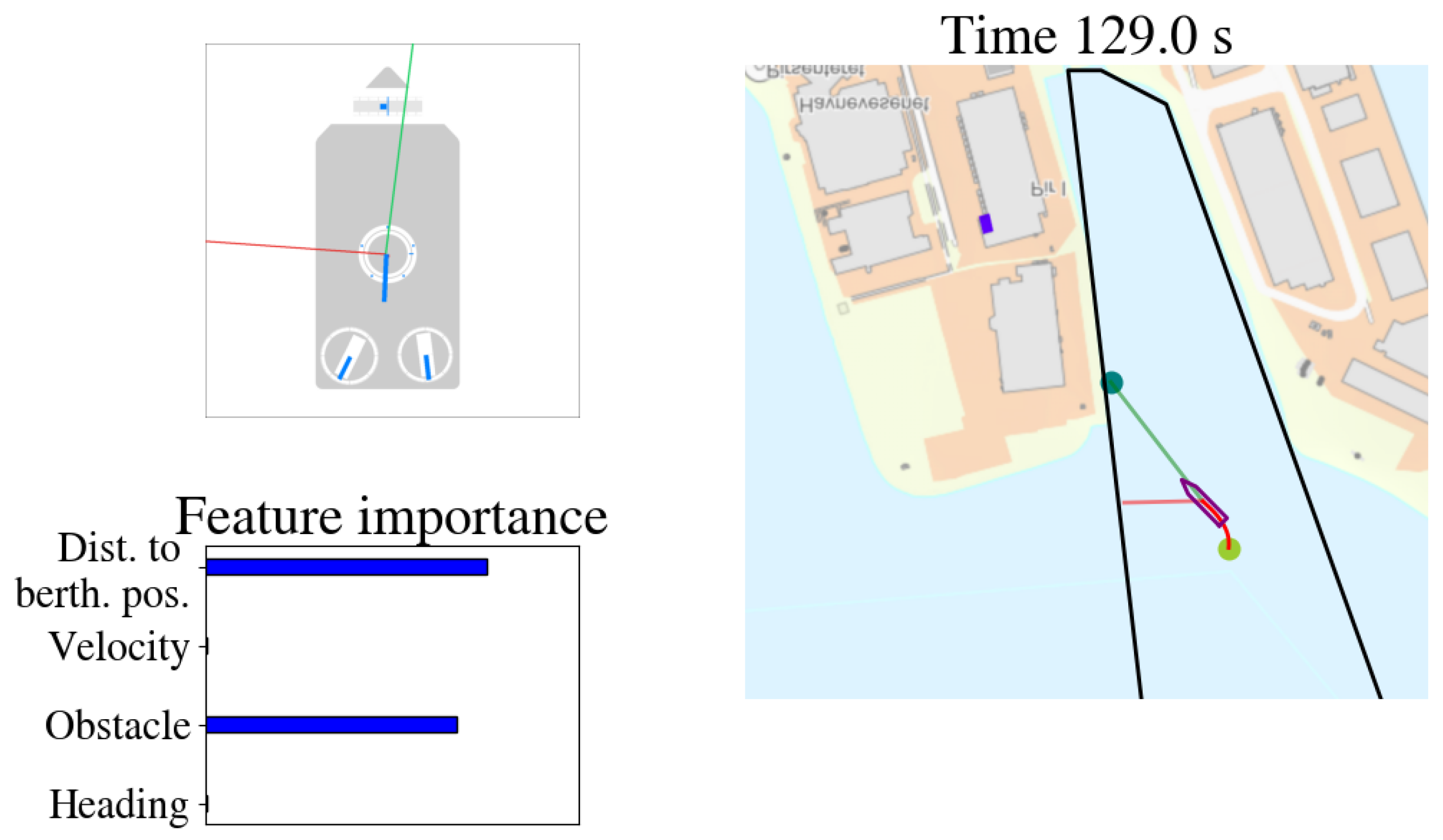
4.2. Visualization of Feature Attributions
5. Results
5.1. Structure of Linear Model Trees
5.2. Computational Complexity
5.3. Evaluating the Fidelity
- The average error between the DRL-agent’s output and the tree’s output given the same input state as presented in Section 5.3.1;
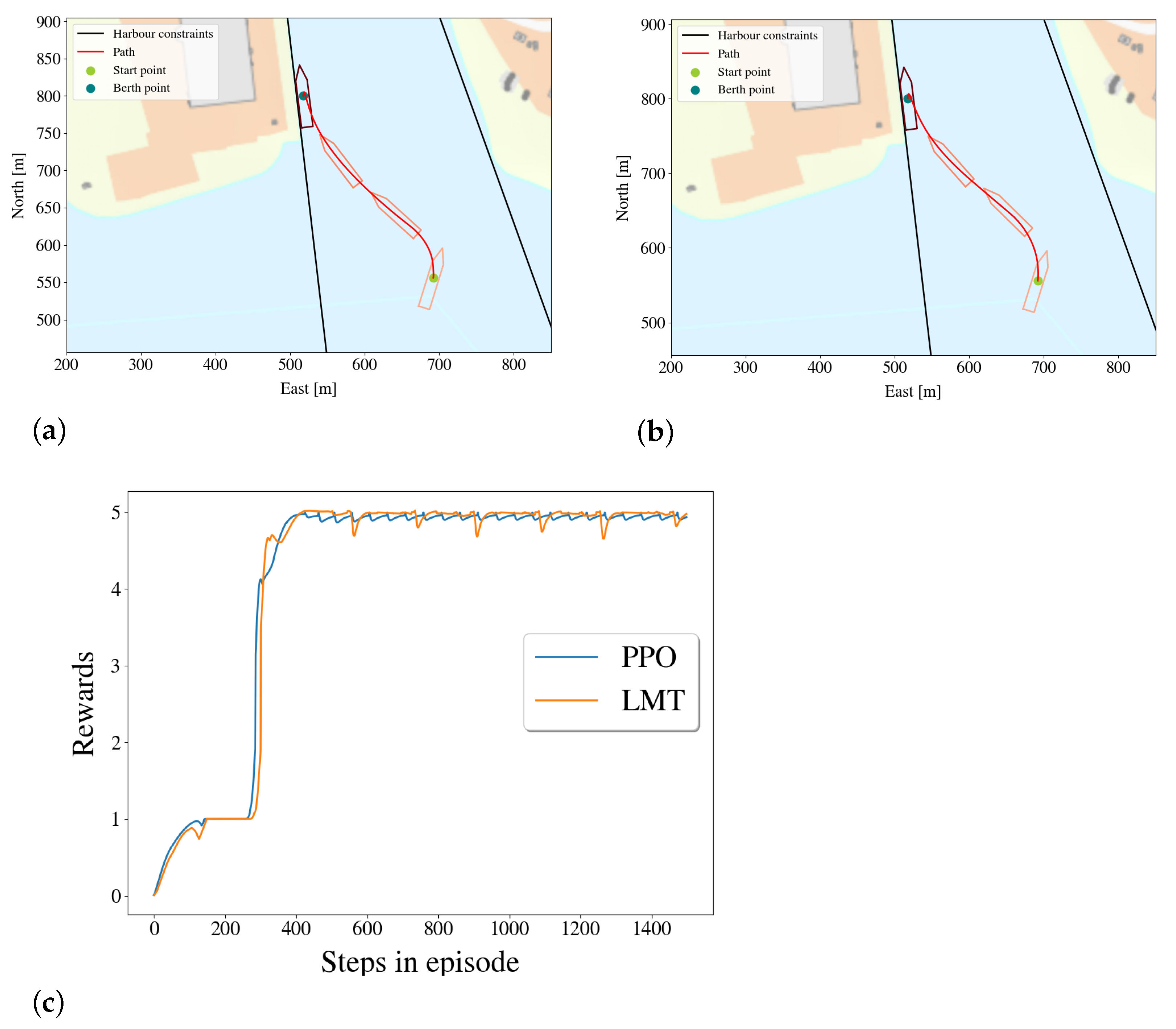
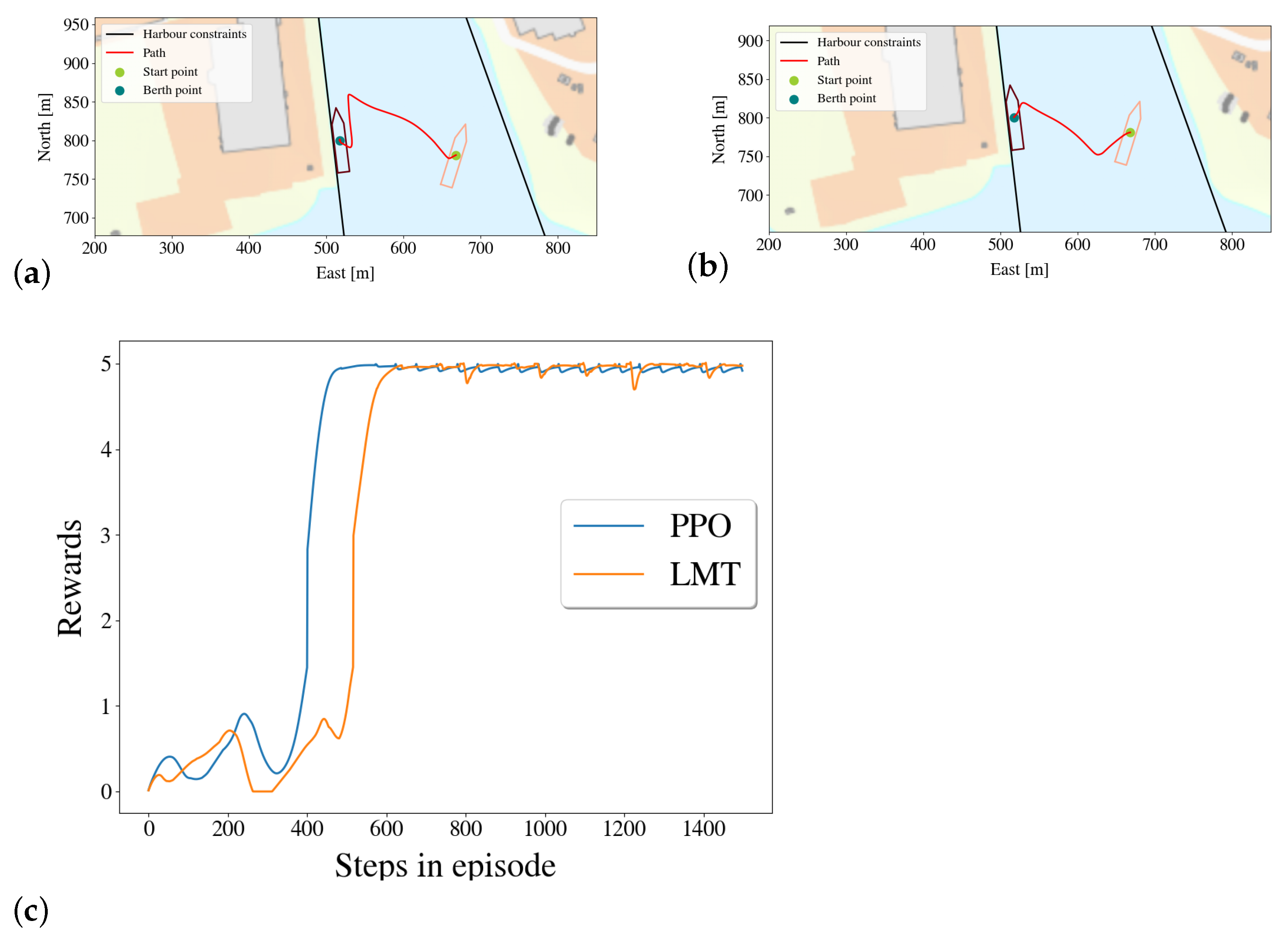
- The trees’ path when running the vessel in the simulator compared to the path taken by the DRL-agent as presented in Section 5.3.2;
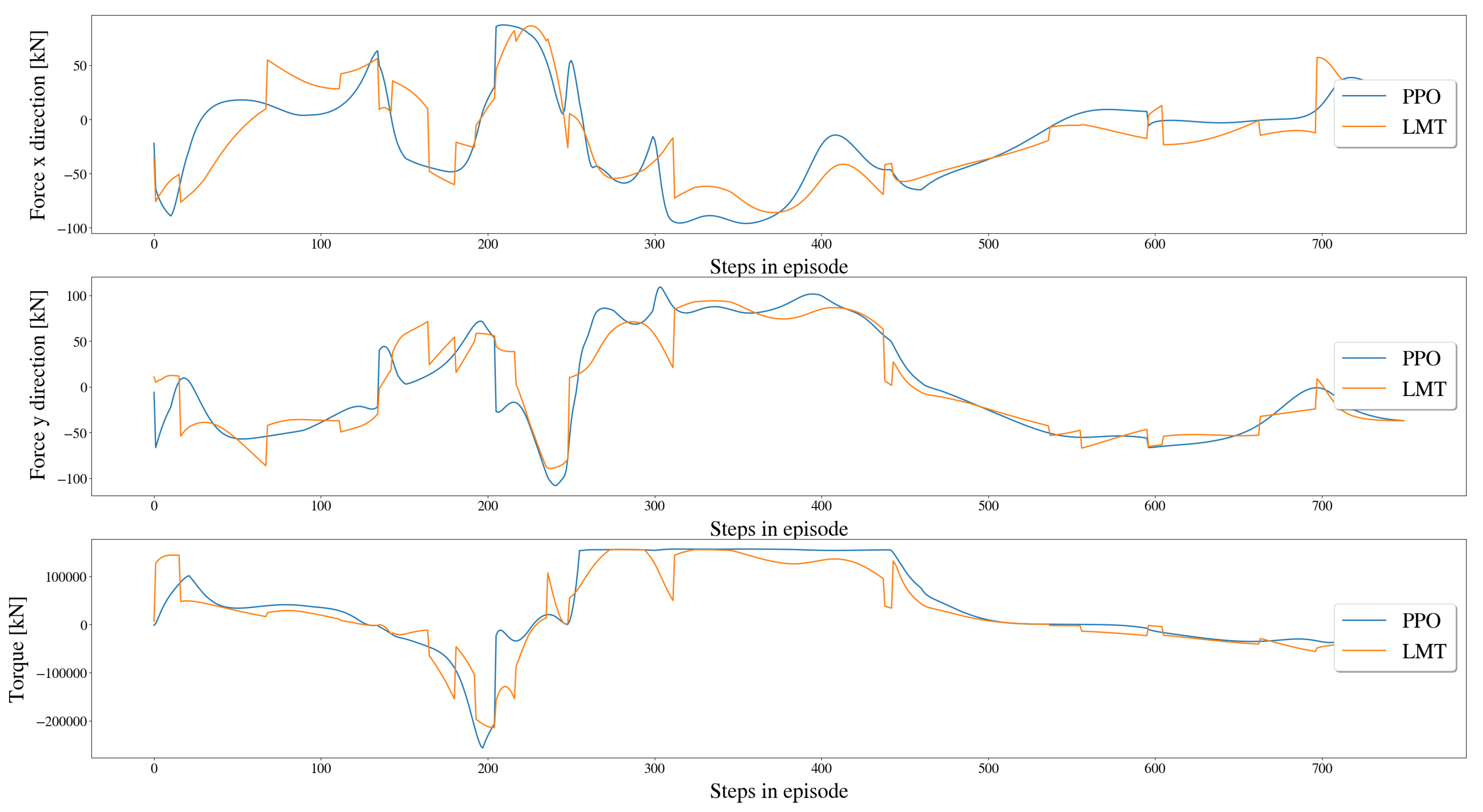
- The error between the resulting forces and moment based on the predicted actions as presented in Section 5.3.3;
- The rewards of the PPO-policy’s and the LMT OFS 312’s given the same starting points are compared in Section 5.4.
5.3.1. Output Error
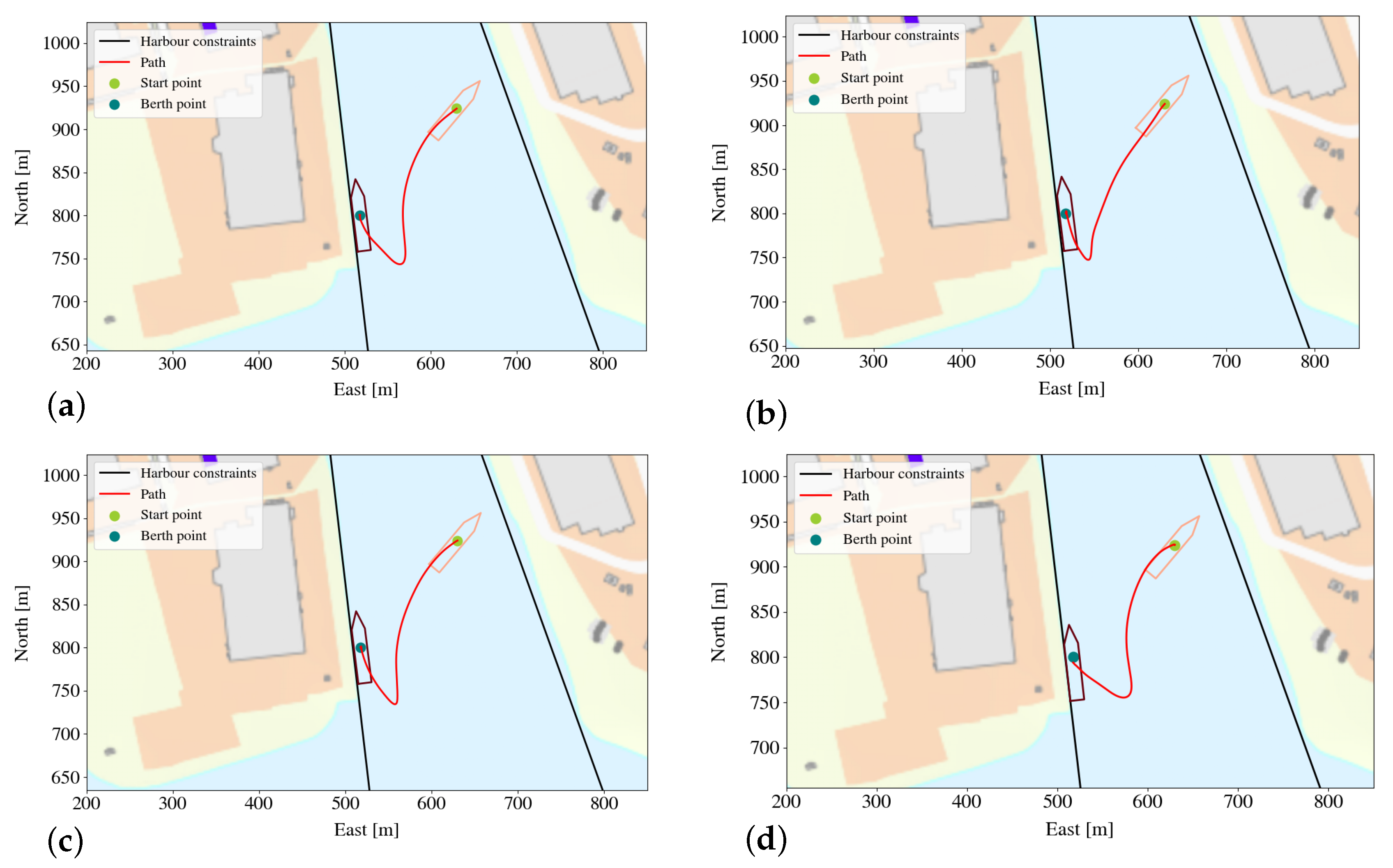
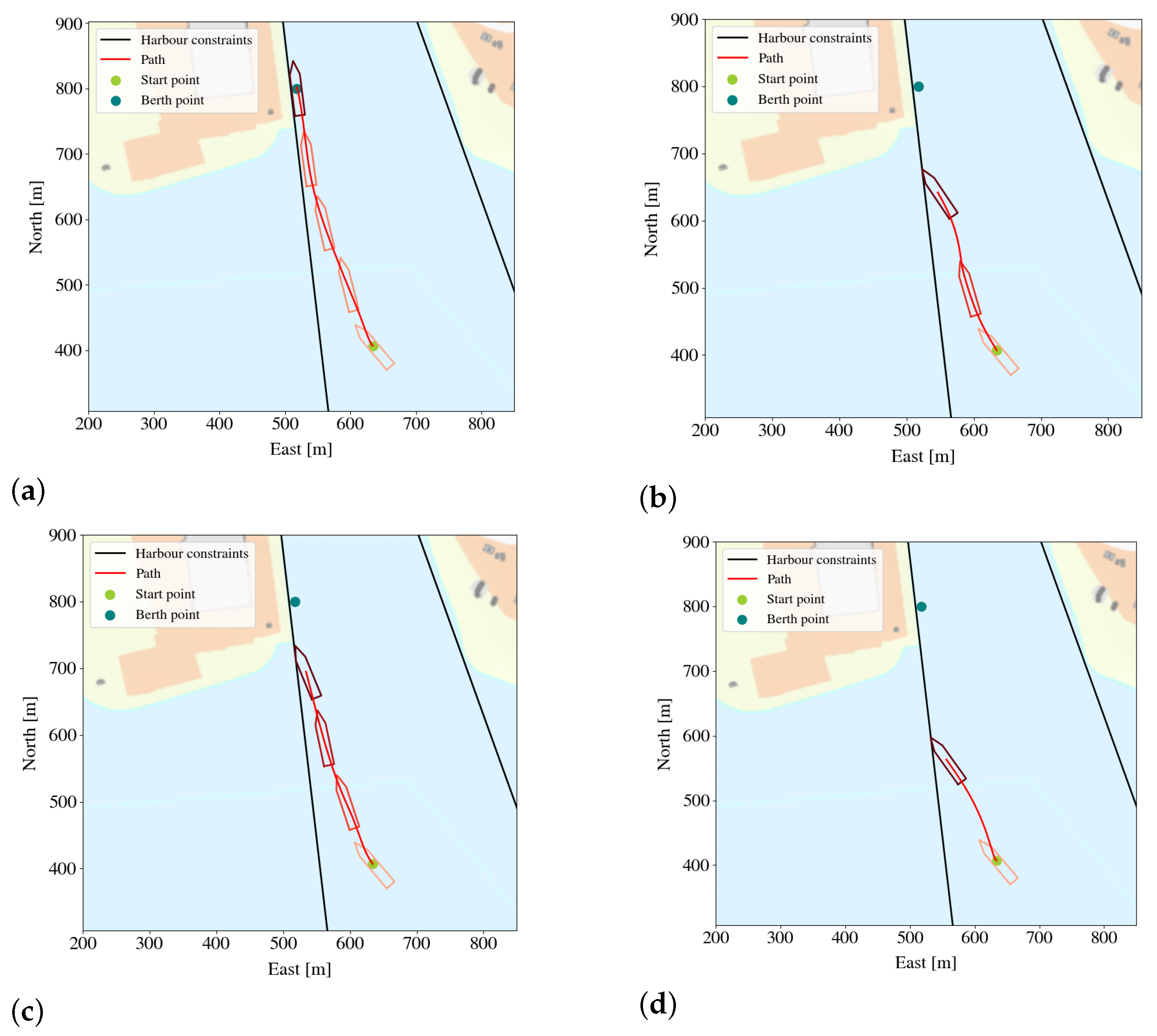
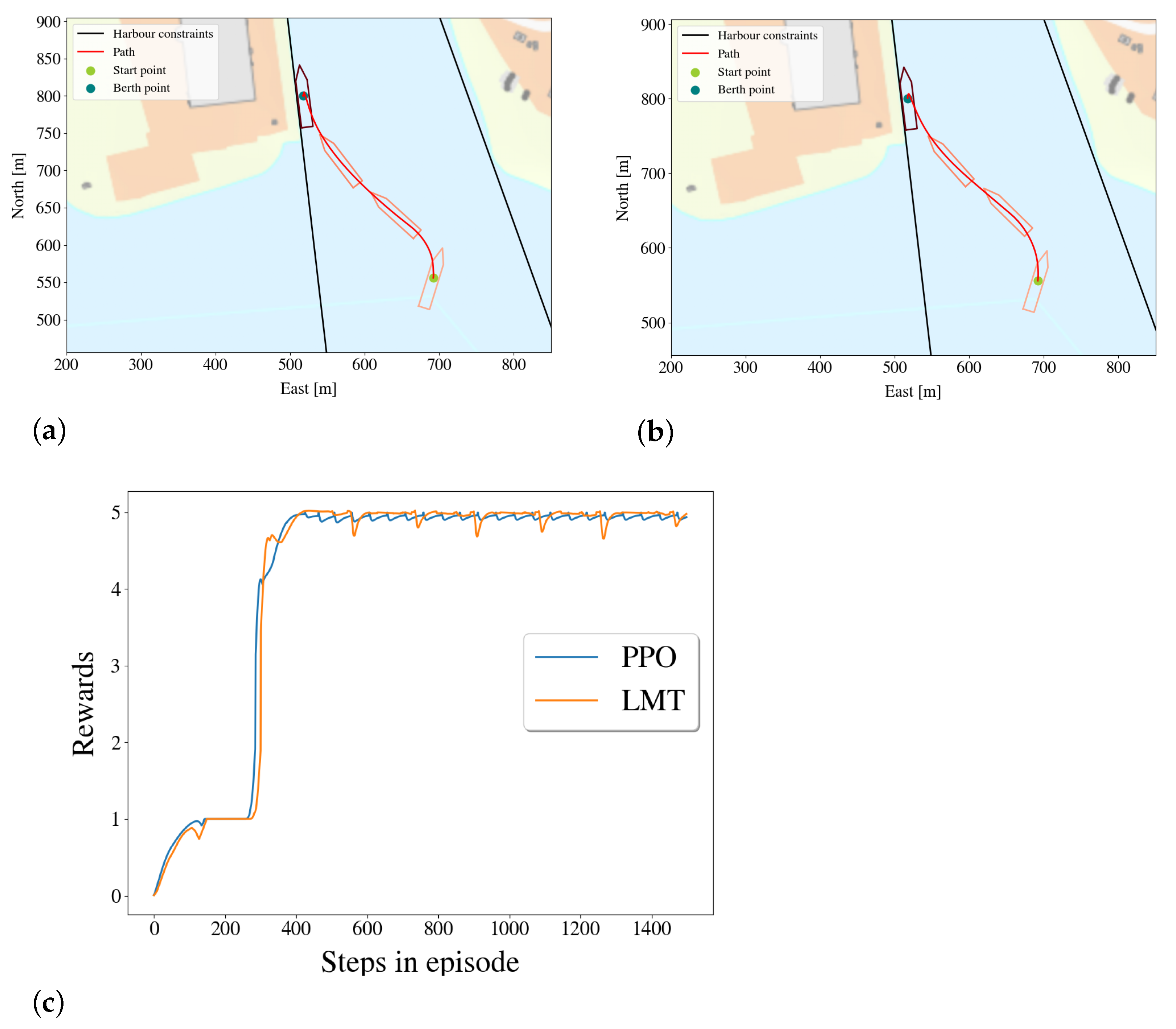
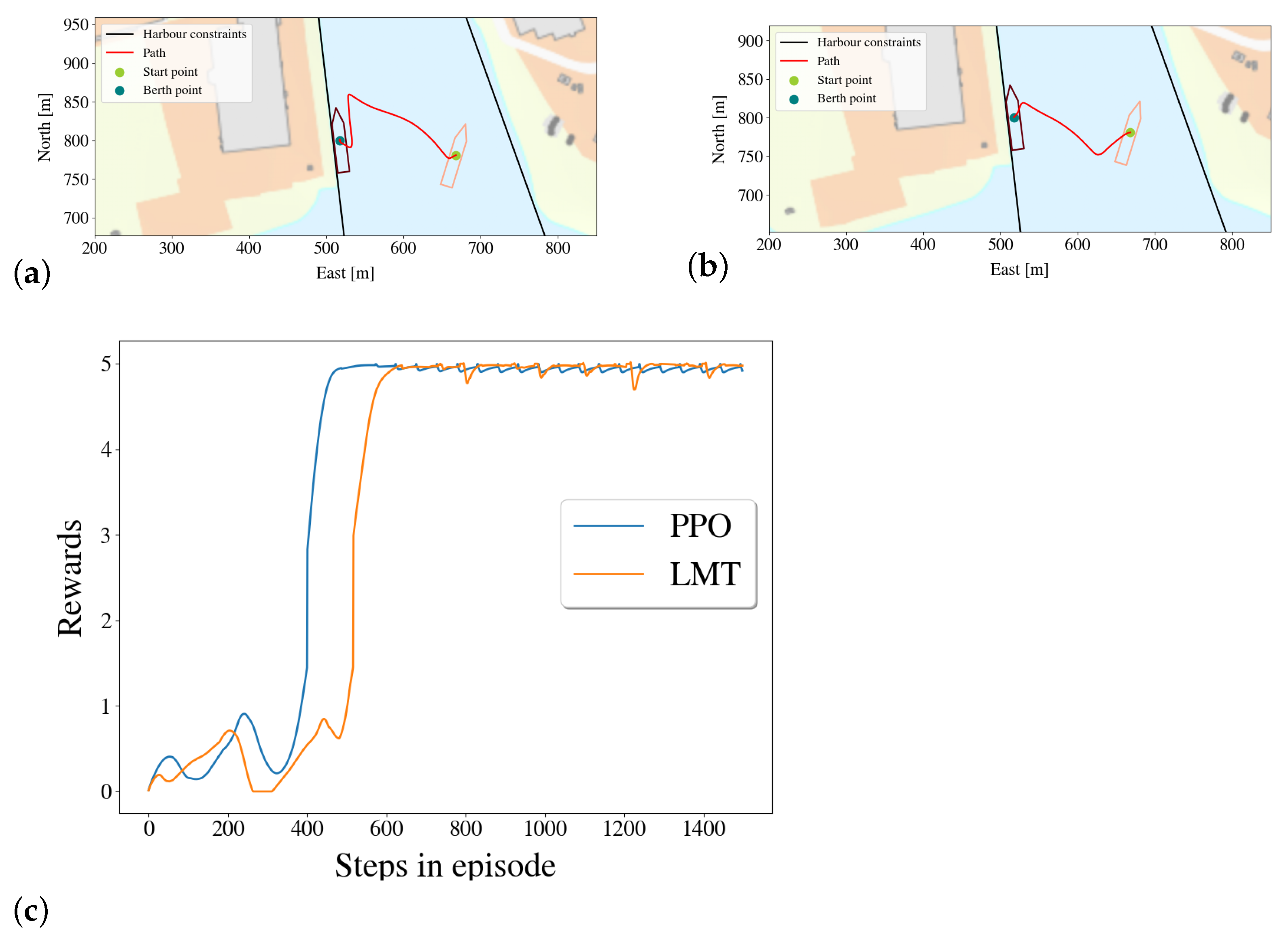
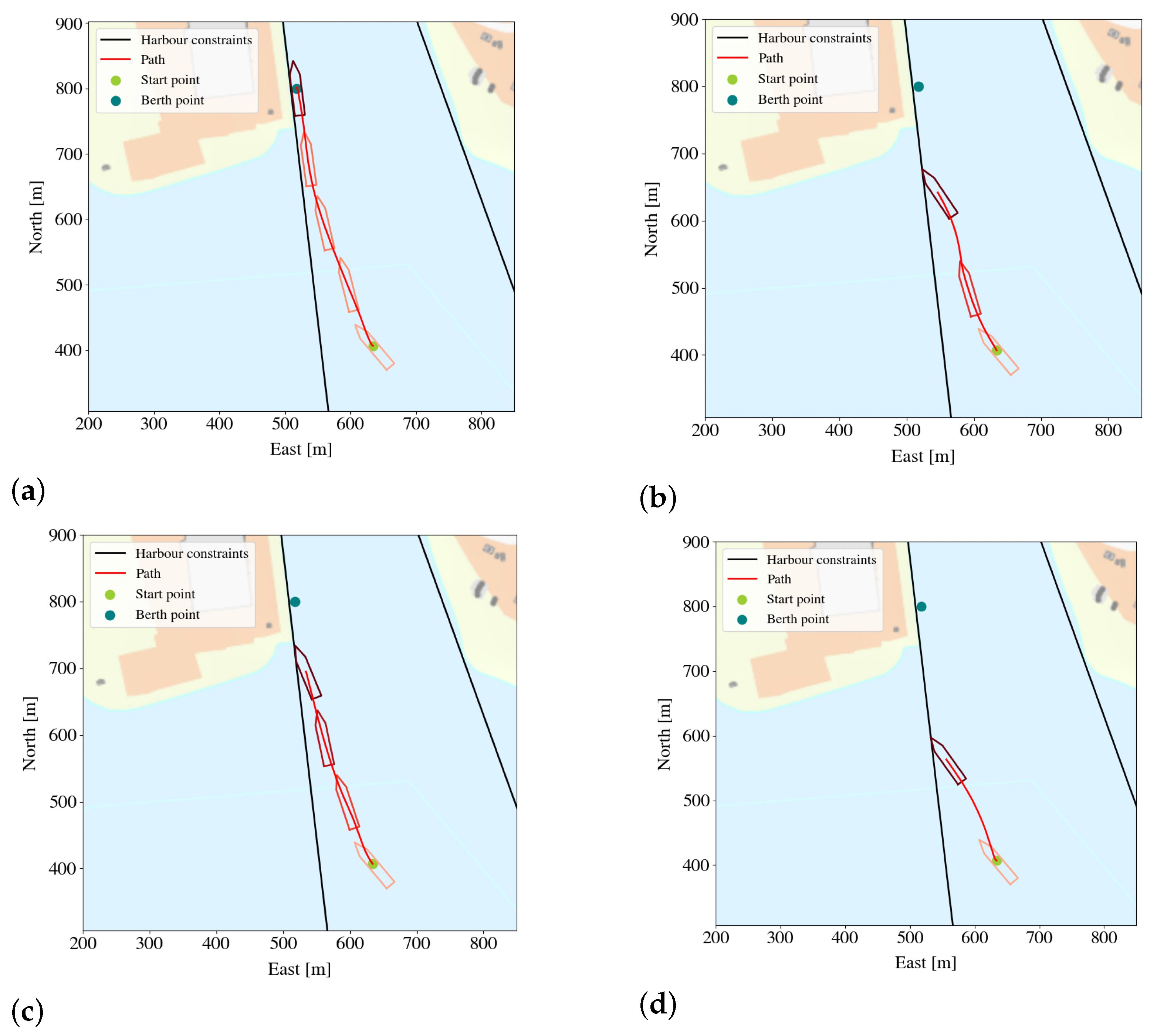
5.3.2. Comparing the Paths of the Agent and of the Linear Model Trees
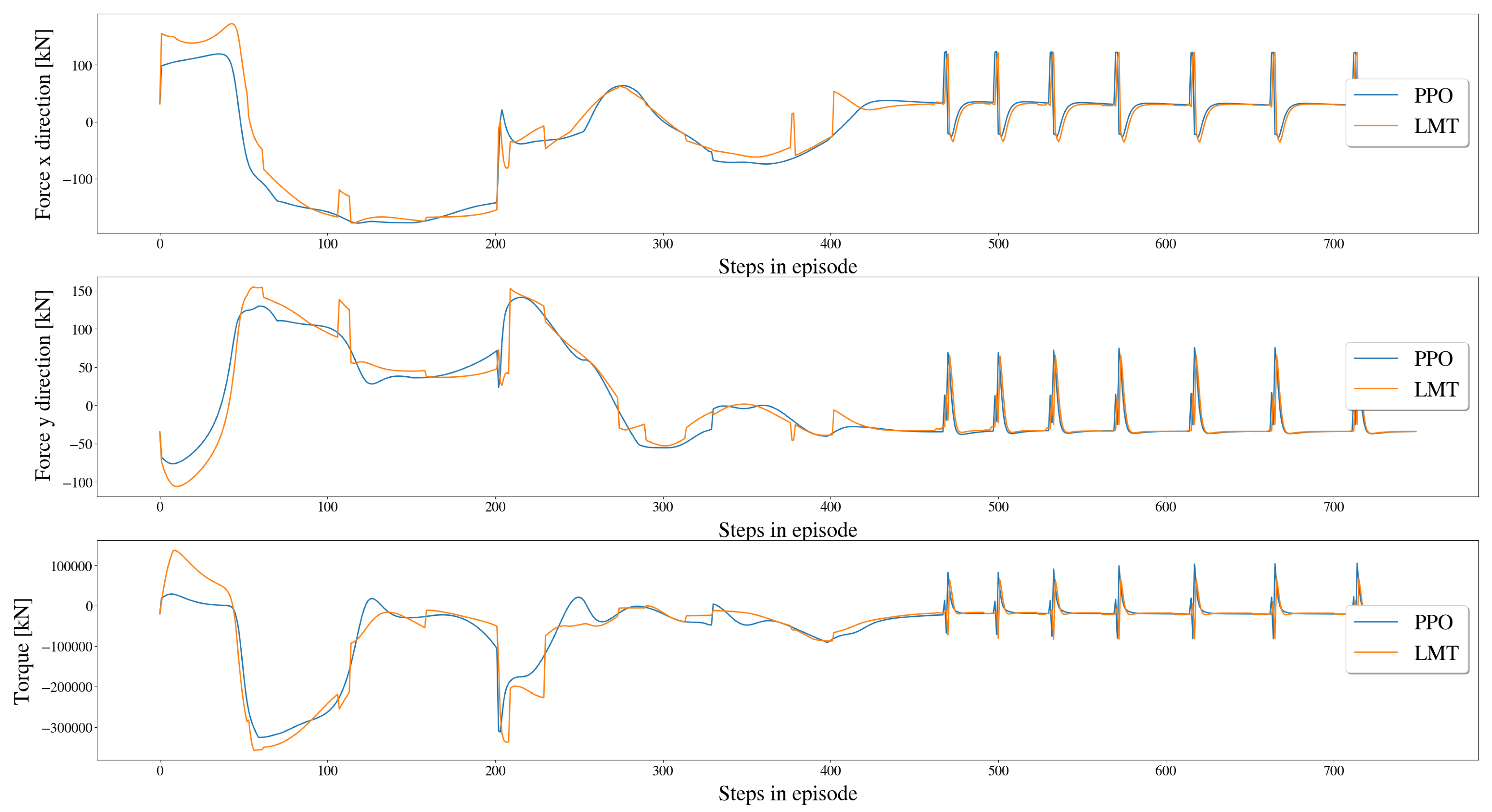
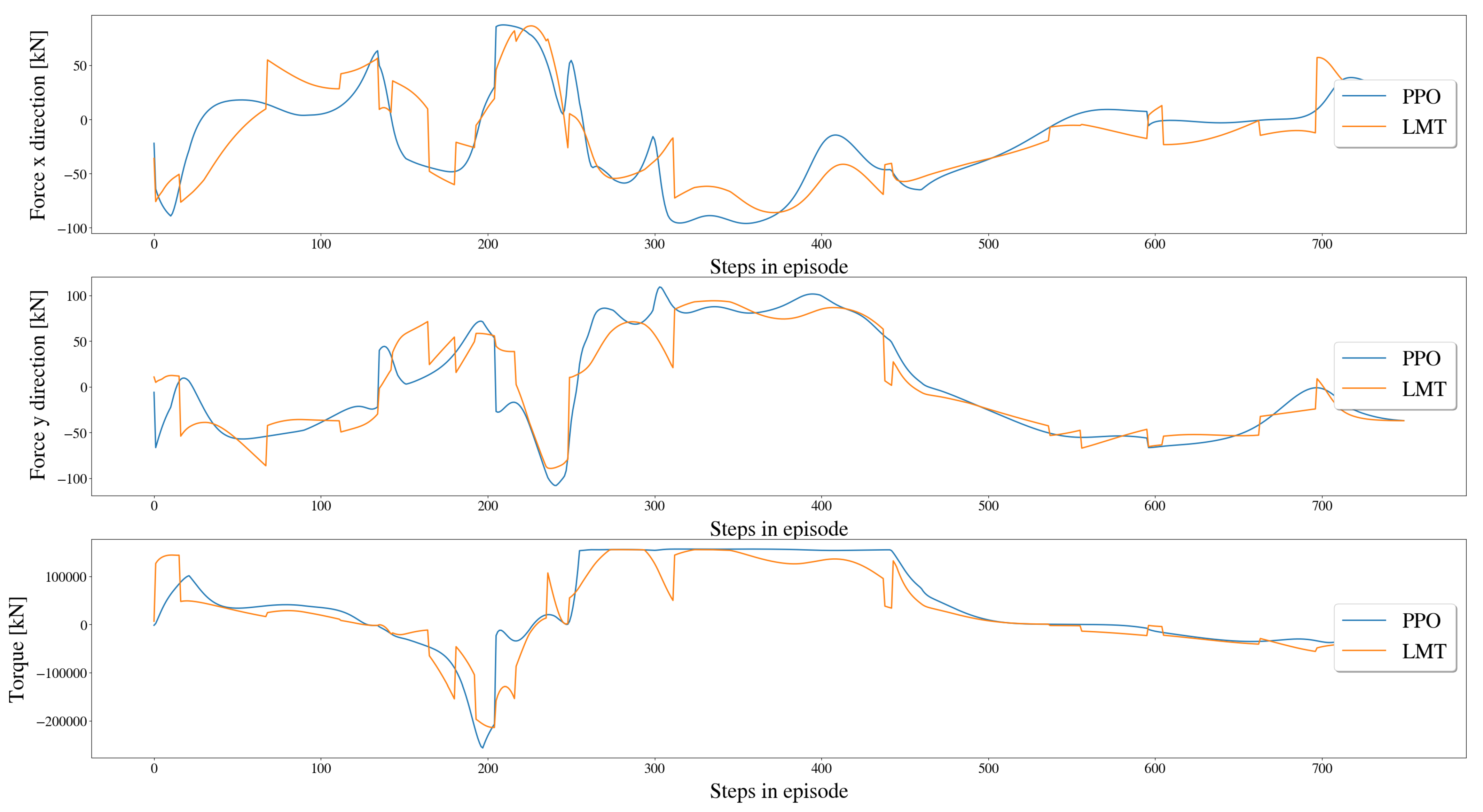
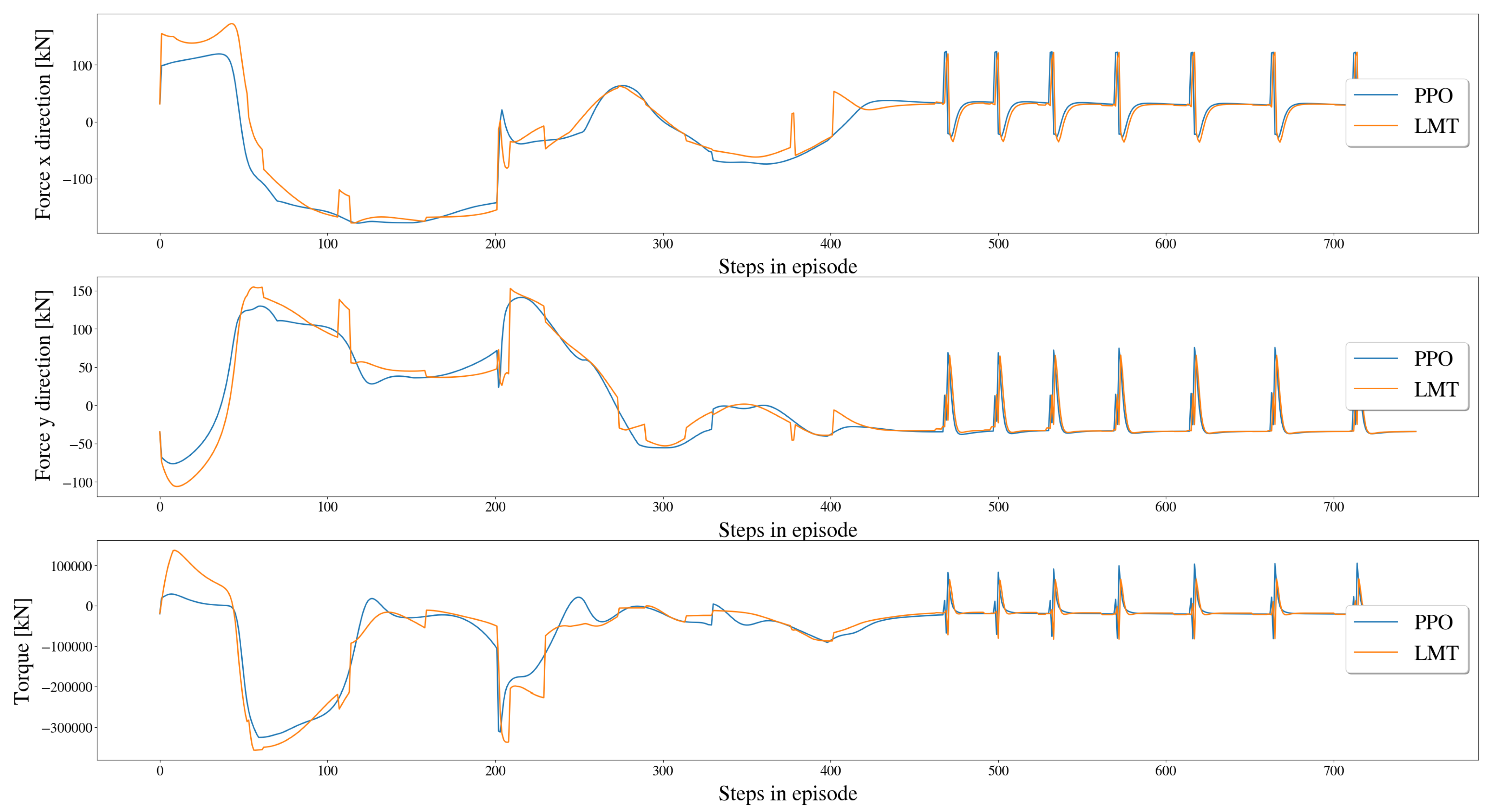
5.3.3. Comparison of Resulting Forces and Moment on Vessel
5.4. Comparison of Rewards
6. Discussion
- There are no guarantees for optimality;
- The LMTs are not small enough to be simulatable transparent;
- The splits in the trees are not used when forming the explanations, even though they are of importance;
- In regions where the LMT makes a constant prediction, no explanations can be made;
- Ordering feature splitting significantly improved both the accuracy and build time of the LMTs because the search process for each split becomes faster, in addition to that the iterative data sampling process becomes unnecessary;
- The two user-adapted visualizations of the explanations should be evaluated by the said end-users.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
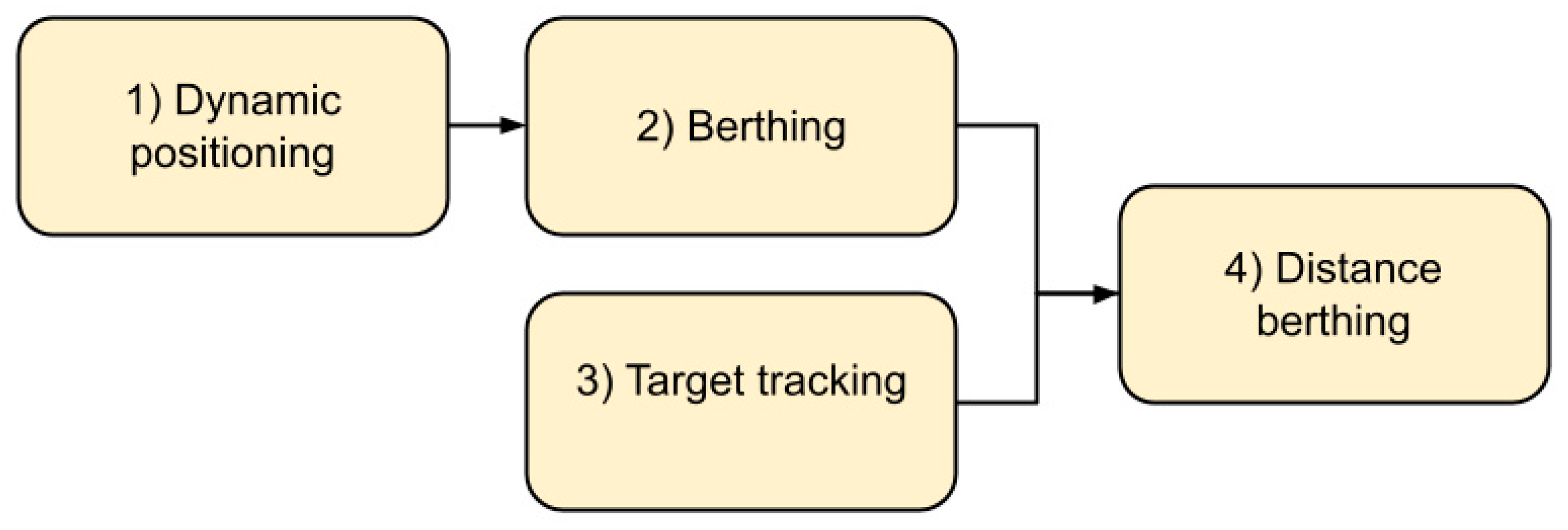
Appendix A. The Docking Agent
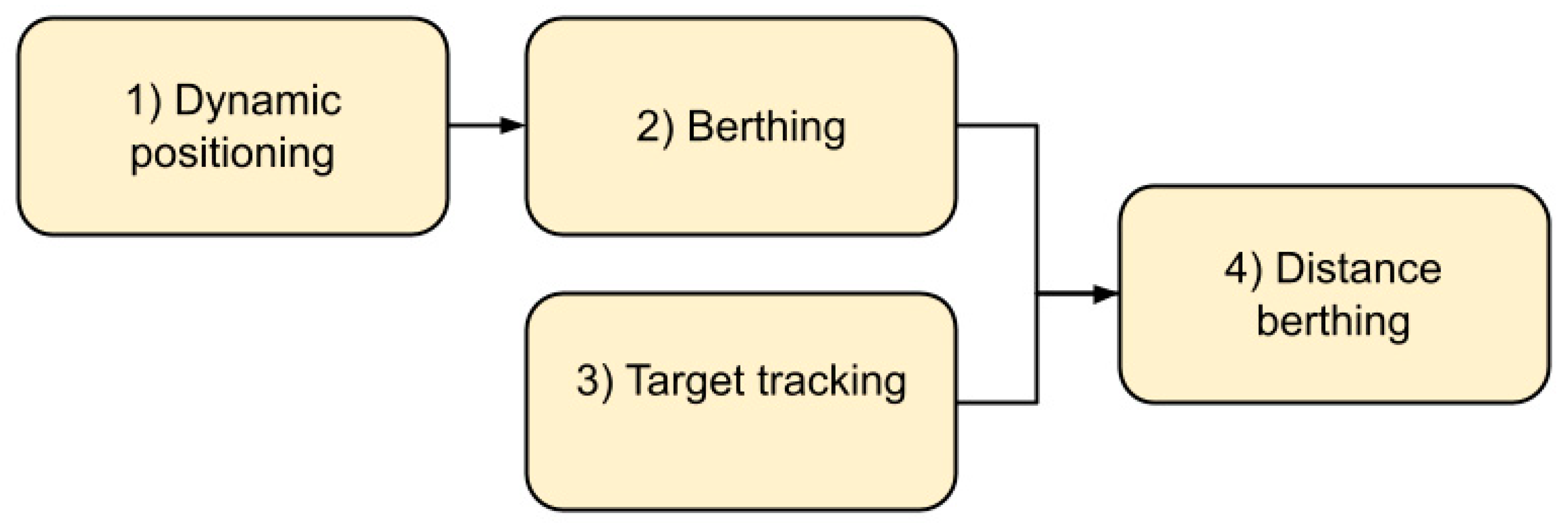
- Dynamic positioning involves getting the vessel to a specific point and keeping the vessel there. Here the vessel started in close proximity to the point;
- Berthing involves getting the vessel to the berthing point and keeping it there, starting in close proximity to the berthing point;
- Target tracking involves getting the vessel in the vicinity of the berthing point and keeping it there, starting from the outside of the harbor;
- Distance berthing involves performing berthing from larger distances.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| −600 | −2.5 | 2.5 | 2.5 | 1 | 1 | 10 | 0.17 |
| Mini batch size | 20,000 |
| Replay buffer size | |
| Actor learning rate | |
| Critic learning rate | |
| Discount rate | 0.99 |
| Number of epoch updates with minibatch | maximum 8 |
| GAE parameter | 0.96 |
| Clipping range | 0.2 |
Appendix B. The Simulated Environment
Appendix B.1. Vessel Dynamics
Appendix B.2. Vessel’s Shape
Appendix B.3. Docking Area
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: London, UK, 2016. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: London, UK, 1998. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Baker, B.; Kanitscheider, I.; Markov, T.; Wu, Y.; Powell, G.; McGrew, B.; Mordatch, I. Emergent Tool Use From Multi-Agent Autocurricula. arXiv 2020, arXiv:1909.07528. [Google Scholar]
- Lillicrap, T.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2016, arXiv:1509.02971. [Google Scholar]
- Singh, L.Y.; Hartikainen, C.F.K.; Levine, S. End-to-end robotic reinforcement learning without reward engineering. Robot. Sci. Syst. 2019. [Google Scholar] [CrossRef]
- Haarnoja, T.; Ha, S.; Zhou, A.; Tan, J.; Tucker, G.; Levine, S. Learning to walk via deep reinforcement learning. Robot. Sci. Syst. (RSS) 2019. [Google Scholar] [CrossRef]
- Rolls-Royce. Marine RRC. Rolls-Royce and Finferries Demonstrate World’s First Fully Autonomous Ferry. 2018. Available online: https://www.rolls-royce.com/media/press-releases/2018/03-12-2018-rr-and-finferries-demonstrate-worlds-first-fully-autonomous-ferry.aspx (accessed on 18 May 2021).
- Skredderberget, A.Y.I.A. The First Ever Zero Emission, Autonomous Ship. 2018. Available online: https://www.yara.com/knowledge-grows/game-changer-for-the-environment/ (accessed on 18 May 2021).
- Shen, H.; Guo, C. Path-following control of underactuated ships using actor-critic reinforcement learning with mlp neural networks. In Proceedings of the Sixth International Conference on Information Science and Technology (ICIST), Dalian, China, 6–8 May 2016; pp. 317–321. [Google Scholar] [CrossRef]
- Martinsen, A.; Lekkas, A. Curved-path following with deep reinforcement learning: Results from three vessel models. OCEANS MTS/IEEE 2018. [Google Scholar] [CrossRef]
- Martinsen, A.; Lekkas, A. Straight-Path Following for Underactuated Marine Vessels using Deep Reinforcement Learning. IFAC-PapersOnLine 2018, 329–334. [Google Scholar] [CrossRef]
- Meyer, E.; Heiberg, A.; Rasheed, A.; San, O. COLREG-compliant collision avoidance for unmanned surface vehicle using deep reinforcement learning. IEEE Access 2020, 8, 165344–165364. [Google Scholar] [CrossRef]
- Zhao, L.; Roh, M.I. COLREGs-compliant multiship collision avoidance based on deep reinforcement learning. Ocean Eng. 2019, 191, 106436. [Google Scholar] [CrossRef]
- Anderlini, E.; Parker, G.; Thomas, G. Docking Control of an Autonomous Underwater Vehicle Using Reinforcement Learning. Appl. Sci. 2019, 9, 3456. [Google Scholar] [CrossRef] [Green Version]
- Rørvik, E.L.H. Automatic Docking of an Autonomous Surface Vessel: Developed Using Deep Reinforcement Learning and Analysed with Explainable AI. Master’s Thesis, Norwegian University of Science and Technology (NTNU), Trondheim, Norway, 2020. [Google Scholar]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A Survey of Methods for Explaining Black Box Models. ACM Comput. Surv. 2018. [Google Scholar] [CrossRef] [Green Version]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Jing, Q.; Wang, H.; Hu, B.; Liu, X.; Yin, Y. A Universal Simulation Framework of Shipborne Inertial Sensors Based on the Ship Motion Model and Robot Operating System. J. Mar. Sci. Eng. 2021, 9, 900. [Google Scholar] [CrossRef]
- Glomsrud, J.; Ødegårdstuen, A.; Clair, A.; Smogeli, O. Trustworthy versus Explainable AI in Autonomous Vessels. Available online: https://sciendo.com/chapter/9788395669606/10.2478/9788395669606-004 (accessed on 10 October 2021).
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Anchors: High-Precision Model-Agnostic Explanations. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic Attribution for Deep Networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, Sydney, NSW, Australia, 6–11 August 2017; pp. 3319–3328. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 4768–4777. [Google Scholar]
- Covert, I.; Lundberg, S.; Lee, S.I. Understanding Global Feature Contributions with Additive Importance Measures. arXiv 2020, arXiv:2004.00668. [Google Scholar]
- Gjærum, V.B.; Rørvik, E.L.H.; Lekkas, A.M. Approximating a deep reinforcement learning docking agent using linear model trees. Eur. Control. Conf. 2021. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Agarap, A.F. Deep Learning Using Rectified Linear Units (ReLU). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Herrera, F. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Hyafil, L.; Rivest, R.L. Constructing optimal binary decision trees is NP-complete. Inf. Process. Lett. 1976, 5, 15–17. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C. Classification and Regression Trees; Wadsworth: Belmont, CA, USA, 1984. [Google Scholar]
- Quinlan, R. Induction of Decision Trees. Mach. Lear 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers: San Mateo, CA, USA, 2014. [Google Scholar]
- Avellaneda, F. Efficient Inference of Optimal Decision Trees. AAAI Conf. Artif. Intell. (AAAI) 2020, 34, 3195–3202. [Google Scholar] [CrossRef]
- Izza, Y.; Ignatiev, A.; Marques-Silva, J. On Explaining Decision Trees. arXiv 2010, arXiv:2010.11034. [Google Scholar]
- Dinu, J.; Bigham, J.; Kolter, J.Z. Challenging common interpretability assumptions in feature attribution explanations. arXiv 2020, arXiv:2012.02748. [Google Scholar]

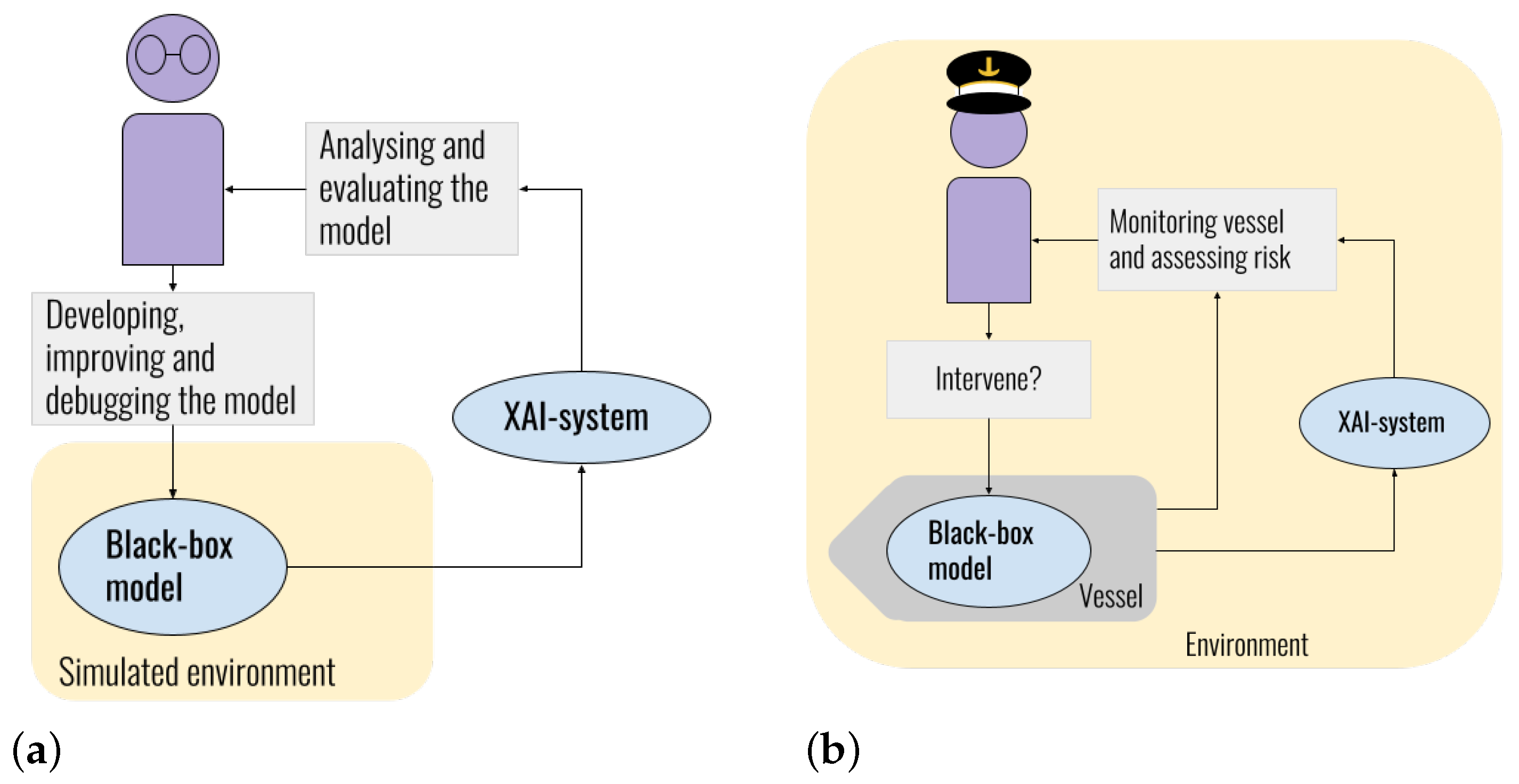


| Scope of explanation | Local/ Global | The scope of the explanations range from local explanations, where only one instance is explained, to global, where the entire model is explained. This is not a binary category, as groups of similar instances can be explained at the same time. |
| Complexity of model to be explained | Intrinsic/ Post-hoc | Models that are self-explanatory, such as simple linear regression, are called intrinsically explainable models. More complex methods, such as most DNNs or other models considered to be black-boxes however, cannot be easily understood by humans, so a post-hoc XAI-method must be applied to the model to aid with the understanding of it. |
| Applicability of XAI-method | Model-agnostic/ Model-specific | A model-agnostic XAI-method treats the model to be explained as a black-box, that is the XAI-method only cares about the inputs and outputs of the model to be explained. Thus, it can be applied to any model. A model-specific XAI-method, as the name implies, can only be applied to one specific model. |
| LMT | DRL | Description |
|---|---|---|
| Input features | States | The information that the model is trained and later used to predict on, in this case, a description of the environment as provided to the policy and the policy approximator, given in Equation (2). For this application, the states are describing how the vessel is situated in the harbor. |
| Predictions | Actions | The model output, given in Equation (1). For this application, the actions are directly controlling the force and angle of the vessel’s thrusters. |
| Policy approximator | Policy | The model itself, providing a mapping from input features to predictions or states to actions, respectively. The policy corresponds to the controller in robotics, while the LMT acts as the policy approximator and is only used to generate explanations. |
| Explainer | Agent | The application of the model. In the current setting, the agent comprises the policy and the vessel, while the explanations are formed using the LMT to generate feature attributions and visualizations. |
| Developer | Operator/Seafarer | |
|---|---|---|
| Background knowledge | Good analytical skills, but not necessarily domain knowledge | Domain knowledge, but not necessarily good analytical skills |
| Environment | Works in simulated environments or digital twins without risk of physical damage | Works with the physical vessel, with risks for material damage and potentially personnel injury |
| Risk | Works with a risk-free simulated environment | Works in a physical environment where errors can compromise safety of units involved |
| Urgency | Analyzes the model offline with no time pressure | Monitors the controller via the XAI module real-time under time pressure |
| Tools | Has access to analytical and mathematical tools | Has no analytical or mathematical tools available |
| Informationdesign | Prefers information enabling thorough and analytic investigation of the controller’s behavior | Prefers information suitable for fast processing, and related to the vessel |
| Level ofdetail | Desires high level of detail, has low risk of cognitive overload as information originates from one source only and the working environment is stress-free | Only interested in the necessary information, having several sources of information and a potentially stressful working environment, creating a risk for cognitive overload |
| Eventfrequency | Interested in examining the controller’s behavior over the entire state space | Not interested in experiencing states that might lead to undesired behavior or dangerous situations |
| Edgecases | Uses edge cases to detect undesirable or unexpected behavior | Does not wish to experience edge cases that involve higher risk of faulty controller behavior |
| Intervention | Does not intervene if undesirable or unexpected behavior is discovered | Intervenes if entering or experiencing state that lead to undesired behavior to avoid dangerous situations |
| Compressed Features | Features | Compressed Feature Importance |
|---|---|---|
| Distance to berthing point | ||
| Velocity | ||
| Obstacle | ||
| Heading |
| Name of LMT | Number of Leaf Nodes | Depth of Deepest Node(s) | Depth of Shallowest Node(s) |
|---|---|---|---|
| LMT 467 | 467 | 16 | 3 |
| LMT OFS 100 | 100 | 11 | 3 |
| LMT OFS 312 | 312 | 12 | 3 |
| Algorithm | Build Time for 10 Leaf Nodes | Build Time for 50 Leaf Nodes |
|---|---|---|
| LMT | 74.75 s | 171.45 s |
| LMT+ OFS | 52.748 s | 117.91 s |
| LMT OFS 100 | ||
| Output feature | Mean absolute error | Error standard deviation |
| (kN) | 4.57 (2.68%) | 9.31 (5.5%) |
| (kN) | 4.018 (2.36%) | 7.261 (4.2%) |
| (deg) | 3.43 (1.9%) | 7.66 (4.3%) |
| (deg) | 4.81 (2.67%) | 8.04 (4.4%) |
| (kN) | 1.77 (1.77%) | 4.049 (4.05%) |
| LMT OFS 312 | ||
| Output feature | Mean absolute error | Error standard deviation |
| (kN) | 3.55 (2.08%) (−7.22%) | 7.78 (4.57%) (−7.27%) |
| (kN) | 3.33 (1.95%) (−6.35%) | 7.085 (4.16%) (−5.675%) |
| (deg) | 2.463 (1.36%) (−7.84%) | 6.93 (3.85%) (−6.12%) |
| (deg) | 3.66 (2.15%) (−5,48%) | 8.03 (4.45%) (−3.42%) |
| (kN) | 1.302 (1.3%) (−7.78%) | 3.513 (3.51%) (−12.387%) |
| LMT 467 | ||
| Output feature | Mean absolute error | Error standard deviation |
| ( kN ) | 11.85 (6.97%) | 19.07 (11.22%) |
| ( kN ) | 9.039 (5.32%) | 17.38 (10.22%) |
| ( deg ) | 7.9 (4.3%) | 14.32 (7.96%) |
| ( deg ) | 14.09 (7.83%) | 18.91 (10.51%) |
| ( kN ) | 3.84 (3.84%) | 6.83 (6.83%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gjærum, V.B.; Strümke, I.; Alsos, O.A.; Lekkas, A.M. Explaining a Deep Reinforcement Learning Docking Agent Using Linear Model Trees with User Adapted Visualization. J. Mar. Sci. Eng. 2021, 9, 1178. https://doi.org/10.3390/jmse9111178
Gjærum VB, Strümke I, Alsos OA, Lekkas AM. Explaining a Deep Reinforcement Learning Docking Agent Using Linear Model Trees with User Adapted Visualization. Journal of Marine Science and Engineering. 2021; 9(11):1178. https://doi.org/10.3390/jmse9111178
Chicago/Turabian StyleGjærum, Vilde B., Inga Strümke, Ole Andreas Alsos, and Anastasios M. Lekkas. 2021. "Explaining a Deep Reinforcement Learning Docking Agent Using Linear Model Trees with User Adapted Visualization" Journal of Marine Science and Engineering 9, no. 11: 1178. https://doi.org/10.3390/jmse9111178
APA StyleGjærum, V. B., Strümke, I., Alsos, O. A., & Lekkas, A. M. (2021). Explaining a Deep Reinforcement Learning Docking Agent Using Linear Model Trees with User Adapted Visualization. Journal of Marine Science and Engineering, 9(11), 1178. https://doi.org/10.3390/jmse9111178