
DCE-Net: An Improved Method for Sonar Small-Target Detection Based on YOLOv8


Abstract

1. Introduction
- (1)
- A distinctive end-to-end DCE-Net framework is devised to tackle the challenge of small-target detection in sonar images. Unlike previous methods, the proposed DCE-Net simultaneously enhances sonar image quality and aggregates global contextual features, thereby strengthening the feature relevance of small sonar targets.
- (2)
- For the first time, a strategy combining sonar image defogging (DEAB) with spatial perception localization optimization (CoordGate) is proposed for underwater small-target detection. This approach efficiently extracts small-target detail feature information while suppressing background interference.
- (3)
- A new efficient multi-scale attention module (MH-EMA) is designed. By introducing a multi-head AM, the feature fusion process is further optimized, significantly improving the model’s precision and recall for small-target detection in complex backgrounds.
- (4)
- Finally, extensive experiments validate the effectiveness and superiority of DCE-Net in the task of small-target detection in sonar images, offering a novel solution for the field of underwater target detection.
2. Related Work
2.1. Image Processing
2.2. YOLO Series Algorithms
2.3. Feature Fusion Technology
3. Method
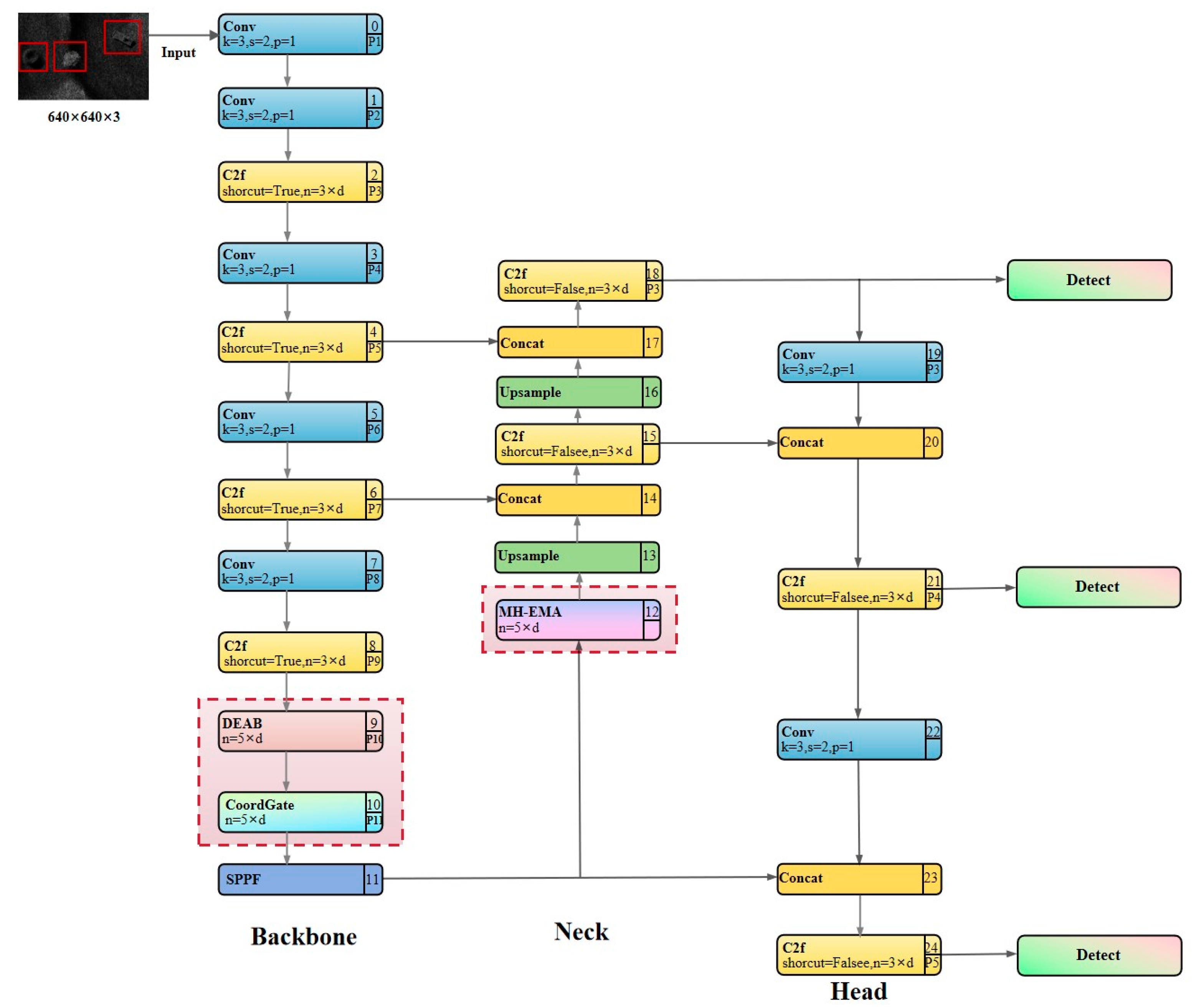
3.1. Overall Network Architecture
3.2. Core Modules
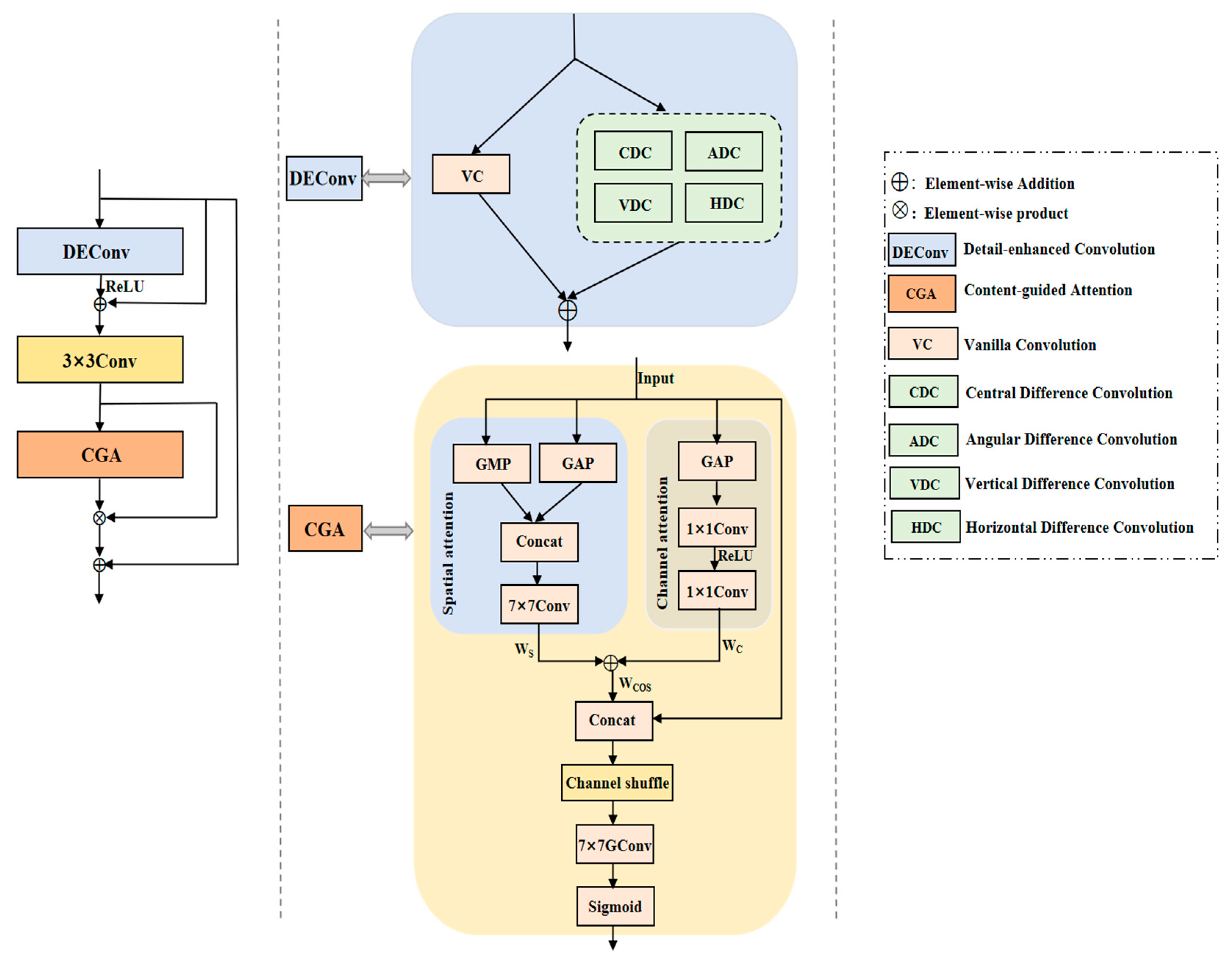
3.2.1. DEAB Module
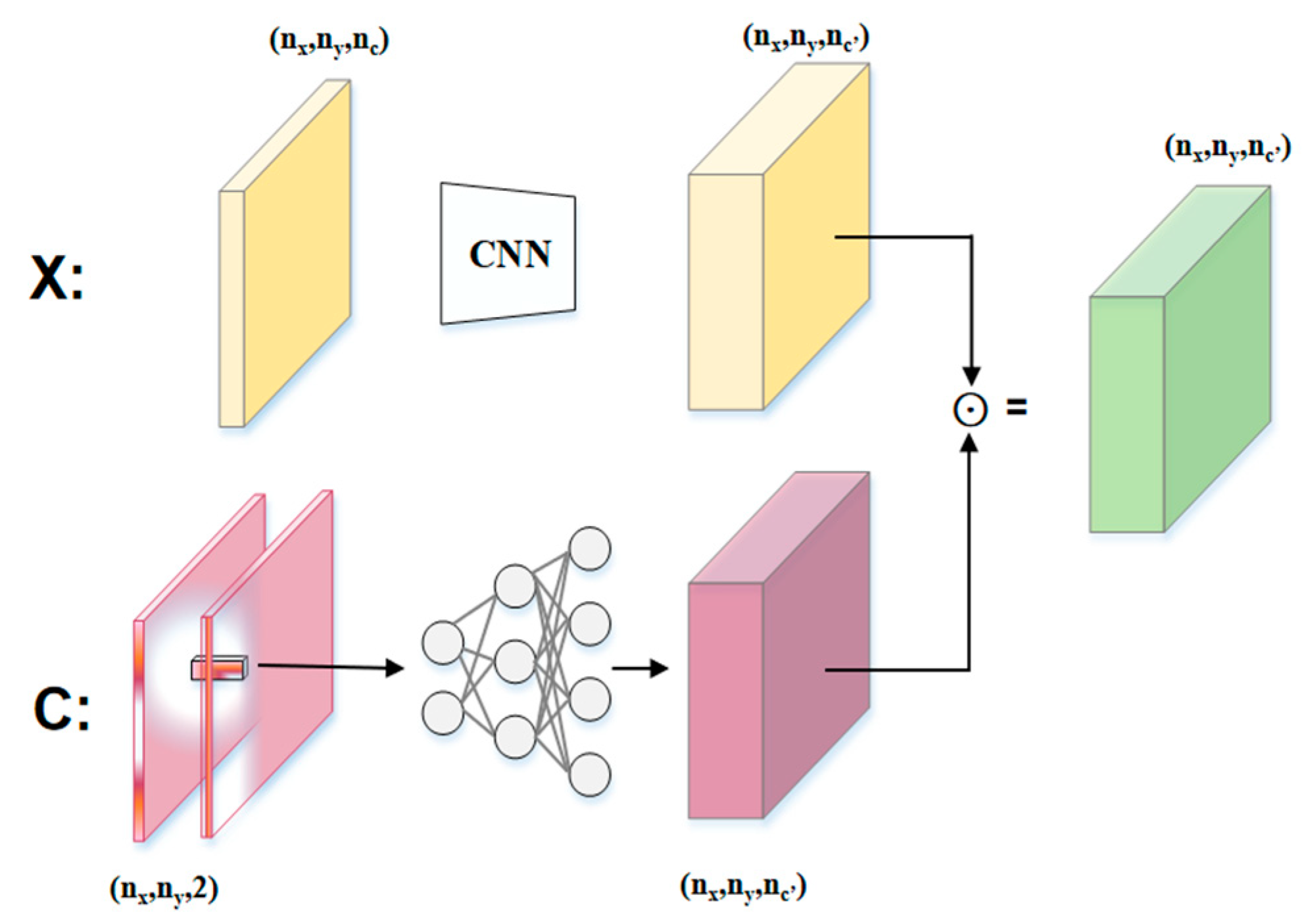
3.2.2. CoordGate Module
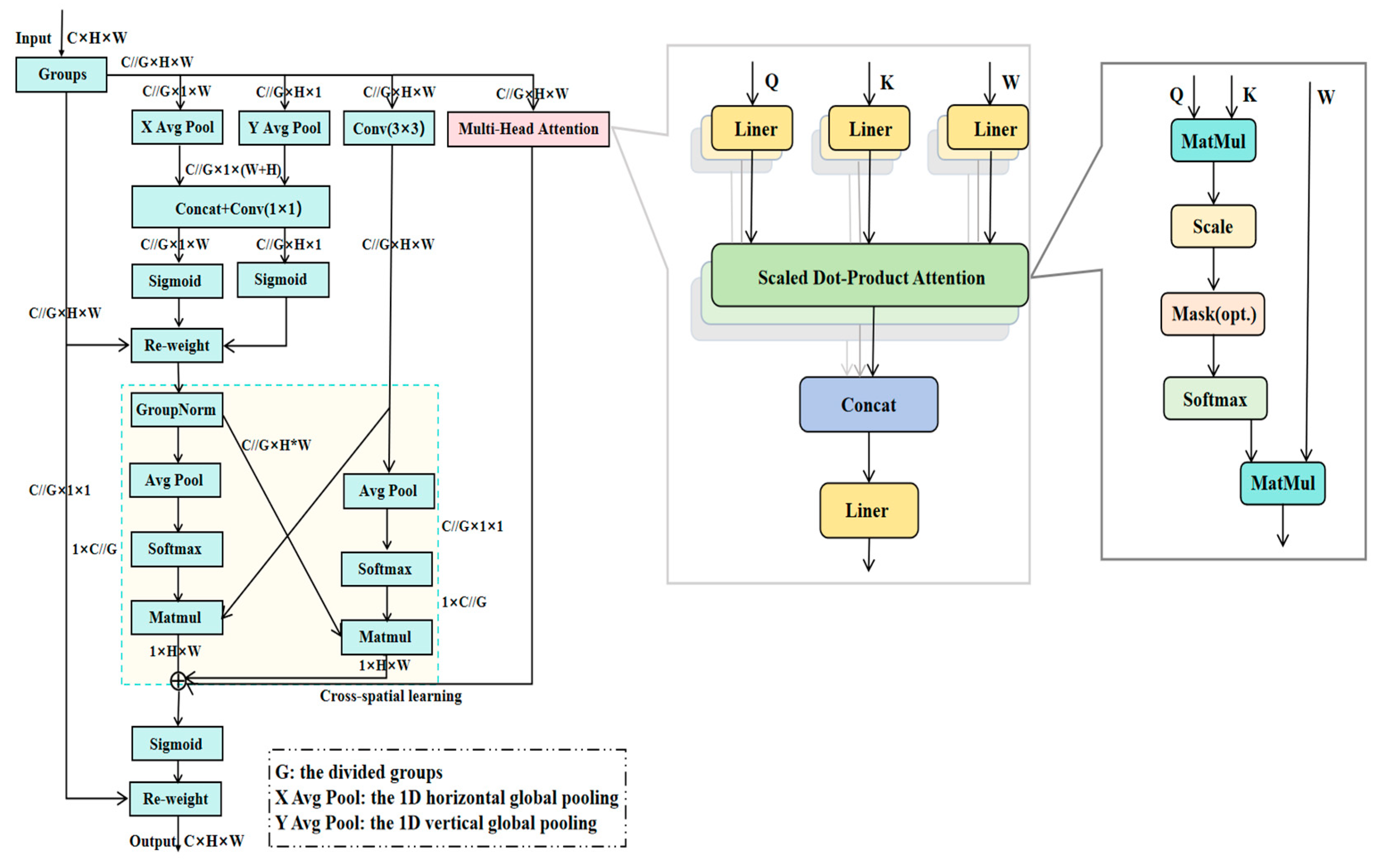
3.2.3. MH-EMA Module
4. Experiments and Results
4.1. Design of Experiments
4.2. Ablation Studies
4.3. Visual Analytics
4.4. Comparative Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rioblanc, M. High productivity multi-sensor seabed Mapping Sonar for Marine Mineral Resources Exploration. In Proceedings of the 2013 IEEE International Underwater Technology Symposium (UT), Tokyo, Japan, 5–8 March 2013. [Google Scholar]
- Character, L.; Ortiz JR, A.; Beach, T.; Luzzadder-Beach, S. Archaeologic Machine Learning for Shipwreck Detection Using Lidar and Sonar. Remote Sens. 2021, 13, 1759. [Google Scholar] [CrossRef]
- Köhntopp, D.; Lehmann, B.; Kraus, D.; Birk, A. Classification and Localization of Naval Mines With Superellipse Active Contours. IEEE J. Ocean. Eng. 2019, 44, 767–782. [Google Scholar] [CrossRef]
- Grothues, T.M.; Newhall, A.E.; Lynch, J.F.; Vogel, K.S.; Gawarkiewicz, G.G. High-frequency side-scan sonar fish reconnaissance by autonomous underwater vehicles. Can. J. Fish. Aquat. Sci. 2017, 74, 240–255. [Google Scholar] [CrossRef]
- Wu, Q.; Liu, Y.; Li, Q.; Jin, S.; Li, F. The application of deep learning in computer vision. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017. [Google Scholar]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6999–7019. [Google Scholar] [CrossRef] [PubMed]
- Reddy, G.P.O. Digital Image Processing: Principles and Applications. In Geospatial Technologies in Land Resources Mapping, Monitoring and Management; Reddy, G.P.O., Singh, S.K., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 101–126. [Google Scholar]
- Yin, J.-L.; Huang, Y.-C.; Chen, B.-H.; Ye, S.-Z. Color Transferred Convolutional Neural Networks for Image Dehazing. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3957–3967. [Google Scholar] [CrossRef]
- Su, J.; Xu, B.; Yin, H. A survey of deep learning approaches to image restoration. Neurocomputing 2022, 487, 46–65. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E.H. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed]
- Liu, R.; Monfort, M.A.S.; Huang, J.Y.; Berg, A.S.; Hays, J. An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution. arXiv 2018, arXiv:1807.03247v2. [Google Scholar]
- Li, Z.; Xie, Z.; Duan, P.; Kang, X.; Li, S. Dual Spatial Attention Network for Underwater Object Detection with Sonar Imagery. IEEE Sens. J. 2024, 24, 6998–7008. [Google Scholar] [CrossRef]
- Chen, Y.; Yuan, X.; Wang, J.; Wu, R.; Li, X.; Hou, Q.; Cheng, M.M. YOLO-MS: Rethinking Multi-Scale Representation Learning for Real-time Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 4240–4252. [Google Scholar] [CrossRef]
- Cao, Y.; Cui, X.D.; Gan, M.Y.; Wang, Y.X.; Yang, F.L.; Huang, Y. MAL-YOLO: A lightweight algorithm for target detection in side-scan sonar images based on multi-scale feature fusion and attention mechanism. Int. J. Digit. Earth 2024, 17, 2398050. [Google Scholar] [CrossRef]
- Chen, Z.; He, Z.; Lu, Z.M. DEA-Net: Single Image Dehazing Based on Detail-Enhanced Convolution and Content-Guided Attention. IEEE Trans. Image Process. 2024, 33, 1002–1015. [Google Scholar] [CrossRef]
- Howard, S.; Norreys, P.; Döpp, A. CoordGate: Efficiently Computing Spatially-Varying Convolutions in Convolutional Neural Networks. arXiv 2024, arXiv:2401.04680. [Google Scholar] [CrossRef]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. arXiv 2023, arXiv:2305.13563v2. [Google Scholar]
- Celik, T.; Tjahjadi, T. A Novel Method for Sidescan Sonar Image Segmentation. IEEE J. Ocean. Eng. 2011, 36, 186–194. [Google Scholar] [CrossRef]
- Saad, N.H.; Isa, N.A.M.; Saleh, H.M. Nonlinear Exposure Intensity Based Modification Histogram Equalization for Non-Uniform Illumination Image Enhancement. IEEE Access 2021, 9, 93033–93061. [Google Scholar] [CrossRef]
- Yin, M.; Yang, J. ILR-Net: Low-light image enhancement network based on the combination of iterative learning mechanism and Retinex theory. PLoS ONE 2025, 20, e0314541. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Xu, K. Innovative adaptive edge detection for noisy images using wavelet and Gaussian method. Sci. Rep. 2025, 15, 5838. [Google Scholar] [CrossRef] [PubMed]
- Choudhary, R.R.; Jisnu, K.K.; Meena, G. Image DeHazing Using Deep Learning Techniques. Procedia Comput. Sci. 2020, 167, 1110–1119. [Google Scholar] [CrossRef]
- Fu, H.; Ling, Z.; Sun, G.; Ren, J.; Zhang, A.; Zhang, L.; Jia, X. HyperDehazing: A hyperspectral image dehazing benchmark dataset and a deep learning model for haze removal. ISPRS J. Photogramm. Remote Sens. 2024, 218, 663–677. [Google Scholar] [CrossRef]
- Wang, D.; Wang, Z. Research and Implementation of Image Dehazing Based on Deep Learning. In Proceedings of the 2022 International Conference on Computer Network, Electronic and Automation (ICCNEA), Xi’an, China, 23–25 September 2022. [Google Scholar]
- Babu, G.H.; Odugu, V.K.; Venkatram, N.; Satish, B.; Revathi, K.; Rao, B.J. Development and performance evaluation of enhanced image dehazing method using deep learning networks. J. Vis. Commun. Image Represent. 2023, 97, 103976. [Google Scholar] [CrossRef]
- Li, Z.; Zheng, C.; Shu, H.; Wu, S. Single Image Dehazing via Model-Based Deep-Learning. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022. [Google Scholar]
- Vishnoi, R.; Goswami, P.K. A Comprehensive Review on Deep Learning based Image Dehazing Techniques. In Proceedings of the 2022 11th International Conference on System Modeling & Advancement in Research Trends (SMART), Moradabad, India, 16–17 December 2022. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar] [CrossRef]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. DehazeNet: An End-to-End System for Single Image Haze Removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef]
- Lin, K.; Wang, G.; Li, T.; Wu, Y.; Li, C.; Yang, Y.; Shen, H.T. Toward Generalized and Realistic Unpaired Image Dehazing via Region-Aware Physical Constraints. IEEE Trans. Circuits Syst. Video Technol. 2024, 35, 2753–2767. [Google Scholar] [CrossRef]
- Wang, Y.; Yan, X.; Wang, F.L.; Xie, H.; Yang, W.; Zhang, X.-P.; Qin, J.; Wei, M. UCL-Dehaze: Toward Real-World Image Dehazing via Unsupervised Contrastive Learning. IEEE Trans. Image Process. 2024, 33, 1361–1374. [Google Scholar] [CrossRef]
- Zheng, Y.; Su, J.; Zhang, S.; Tao, M.; Wang, L. Dehaze-TGGAN: Transformer-Guide Generative Adversarial Networks With Spatial-Spectrum Attention for Unpaired Remote Sensing Dehazing. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5634320. [Google Scholar] [CrossRef]
- Engin, D.; Genç, A.; Kemal Ekenel, H. Cycle-Dehaze: Enhanced CycleGAN for Single Image Dehazing. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Sahu, G.; Seal, A.; Yazidi, A.; Krejcar, O. A Dual-Channel Dehaze-Net for Single Image Dehazing in Visual Internet of Things Using PYNQ-Z2 Board. IEEE Trans. Autom. Sci. Eng. 2024, 21, 305–319. [Google Scholar] [CrossRef]
- Wang, Y.K.; Fan, C.T. Single Image Defogging by Multiscale Depth Fusion. IEEE Trans. Image Process. 2014, 23, 4826–4837. [Google Scholar] [CrossRef] [PubMed]
- Ullah, H.; Muhammad, K.; Irfan, M.; Anwar, S.; Sajjad, M.; Imran, A.S.; de Albuquerque, V.H.C. Light-DehazeNet: A Novel Lightweight CNN Architecture for Single Image Dehazing. IEEE Trans. Image Process. 2021, 30, 8968–8982. [Google Scholar] [CrossRef]
- Sahu, G.; Seal, A.; Jaworek-Korjakowska, J.; Krejcar, O. Single Image Dehazing via Fusion of Multilevel Attention Network for Vision-Based Measurement Applications. IEEE Trans. Instrum. Meas. 2023, 72, 4503415. [Google Scholar] [CrossRef]
- Nie, J.; Wei, W.; Zhang, L.; Yuan, J.; Wang, Z.; Li, H. Contrastive Haze-Aware Learning for Dynamic Remote Sensing Image Dehazing. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5634311. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767v1. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934v1. [Google Scholar]
- Cao, X.; Ren, L.; Sun, C.Y. Dynamic Target Tracking Control of Autonomous Underwater Vehicle Based on Trajectory Prediction. IEEE Trans. Cybern. 2023, 53, 1968–1981. [Google Scholar] [CrossRef] [PubMed]
- Lu, Y.; Zhang, L.; Xie, W. YOLO-compact: An Efficient YOLO Network for Single Category Real-time Object Detection. In Proceedings of the 2020 Chinese Control And Decision Conference (CCDC), Hefei, China, 22–24 August 2020. [Google Scholar]
- Li, X.; Cai, K. Method research on ship detection in remote sensing image based on Yolo algorithm. In Proceedings of the 2020 International Conference on Information Science, Parallel and Distributed Systems (ISPDS), Xi’an, China, 14–16 August 2020. [Google Scholar]
- Yang, N.; Li, G.; Wang, S.; Wei, Z.; Ren, H.; Zhang, X.; Pei, Y. SS-YOLO: A Lightweight Deep Learning Model Focused on Side-Scan Sonar Target Detection. J. Mar. Sci. Eng. 2025, 13, 66. [Google Scholar] [CrossRef]
- Ge, J.; Zhang, B.; Wang, C.; Xu, C.; Tian, Z.; Xu, L. Azimuth-Sensitive Object Detection in Sar Images Using Improved Yolo V5 Model. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022. [Google Scholar]
- Liu, C.; Tao, Y.; Liang, J.; Li, K.; Chen, Y. Object Detection Based on YOLO Network. In Proceedings of the 2018 IEEE 4th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 14–16 December 2018. [Google Scholar]
- Wang, X.; Jiang, X.; Xia, Z.; Feng, X. Underwater Object Detection Based on Enhanced YOLO. In Proceedings of the 2022 International Conference on Image Processing and Media Computing (ICIPMC), Xi’an, China, 27–29 May 2022. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wang, Z.; Guo, J.; Zeng, L.; Zhang, C.; Wang, B. MLFFNet: Multilevel Feature Fusion Network for Object Detection in Sonar Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5119119. [Google Scholar] [CrossRef]
- Li, H.; Miao, S.; Feng, R. DG-FPN: Learning Dynamic Feature Fusion Based on Graph Convolution Network For Object Detection. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020. [Google Scholar]
- Tong, X.; Zuo, Z.; Sun, B.; Wei, J. Novel Feature Fusion for Infrared Small Target Detection Feature Pyramid Networks. In Proceedings of the 2021 IEEE 9th International Conference on Information, Communication and Networks (ICICN), Xi’an, China, 25–28 November 2021. [Google Scholar]
- Zhang, S.; Zhang, X.; Zhang, A.; Fu, H.; Cheng, J.; Huang, H.; Sun, G.; Zhang, L.; Yao, Y. Fusion Of Low-And High-Level Features For Uav Hyperspectral Image Classification. In Proceedings of the 2019 10th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), Amsterdam, The Netherlands, 24–26 September 2019. [Google Scholar]
- Chen, J.; Mai, H.; Luo, L.; Chen, X.; Wu, K. Effective Feature Fusion Network in BIFPN for Small Object Detection. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021. [Google Scholar]
- Zhang, Y.; Cheng, J.; Bai, H.; Wang, Q.; Liang, X. Multilevel Feature Fusion and Attention Network for High-Resolution Remote Sensing Image Semantic Labeling. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6512305. [Google Scholar] [CrossRef]
- Wang, J.; Ren, Y.; Wei, S. Synthetic Aperture Radar Images Target Detection and Recognition with Multiscale Feature Extraction and Fusion Based on Convolutional Neural Networks. In Proceedings of the 2019 IEEE International Conference on Signal, Information and Data Processing (ICSIDP), Chongqing, China, 11–13 December 2019. [Google Scholar]
- Hu, Z.; Kong, Q.; Liao, Q. Multi-Level Adaptive Attention Fusion Network for Infrared and Visible Image Fusion. IEEE Signal Process. Lett. 2025, 32, 366–370. [Google Scholar] [CrossRef]
- Liang, M.; Jiao, L.; Yang, S.; Liu, F.; Hou, B.; Chen, H. Deep Multiscale Spectral-Spatial Feature Fusion for Hyperspectral Images Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2911–2924. [Google Scholar] [CrossRef]
- Yu, L.; Hu, H.; Zhong, Z.; Wu, H.; Deng, Q. GLF-Net: A Target Detection Method Based on Global and Local Multiscale Feature Fusion of Remote Sensing Aircraft Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4021505. [Google Scholar] [CrossRef]
- Cao, Z.; Chen, K.; Chen, J.; Chen, Z.; Zhang, M. CACS-YOLO: A Lightweight Model for Insulator Defect Detection Based on Improved YOLOv8m. IEEE Trans. Instrum. Meas. 2024, 73, 3530710. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
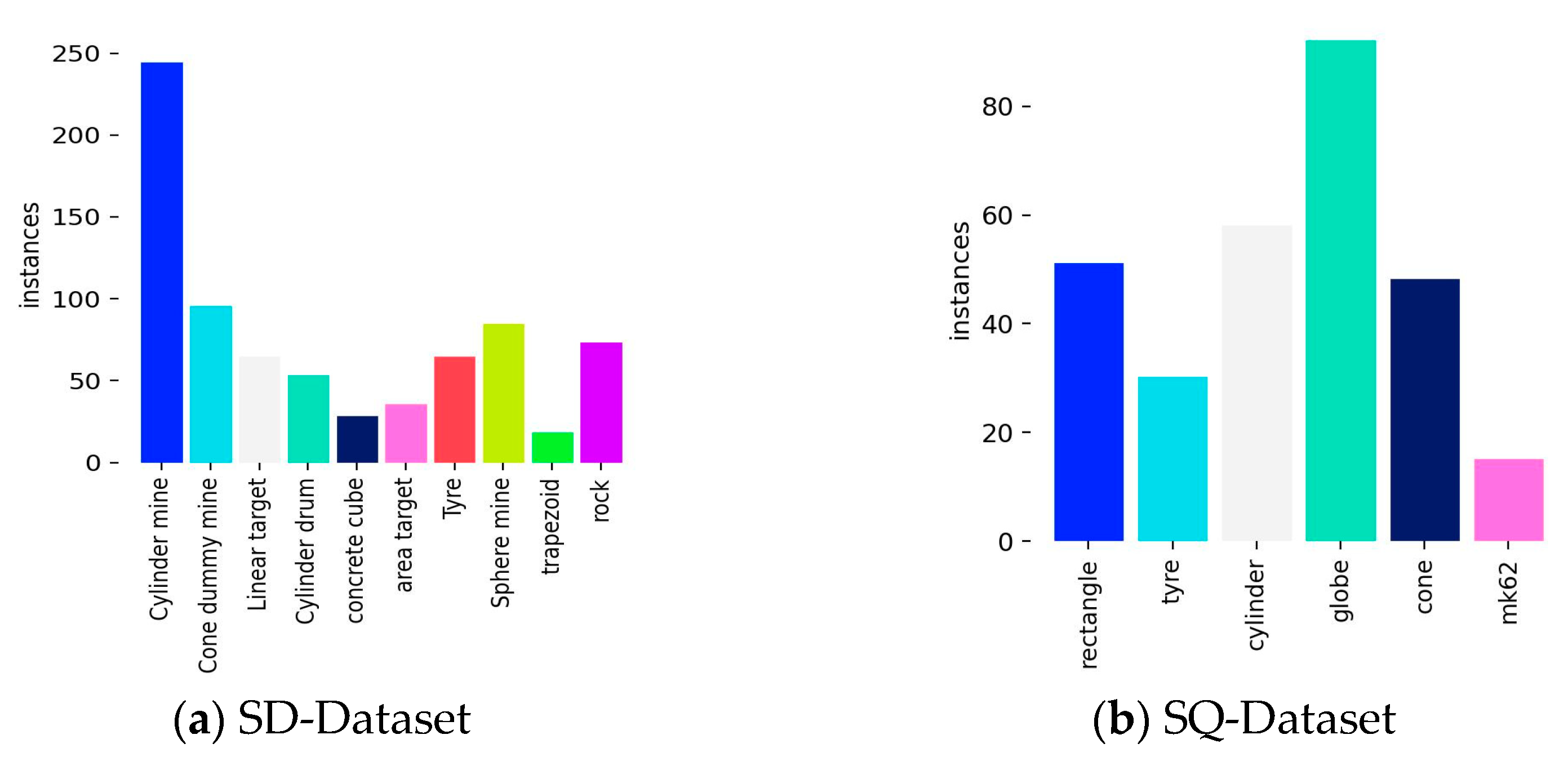

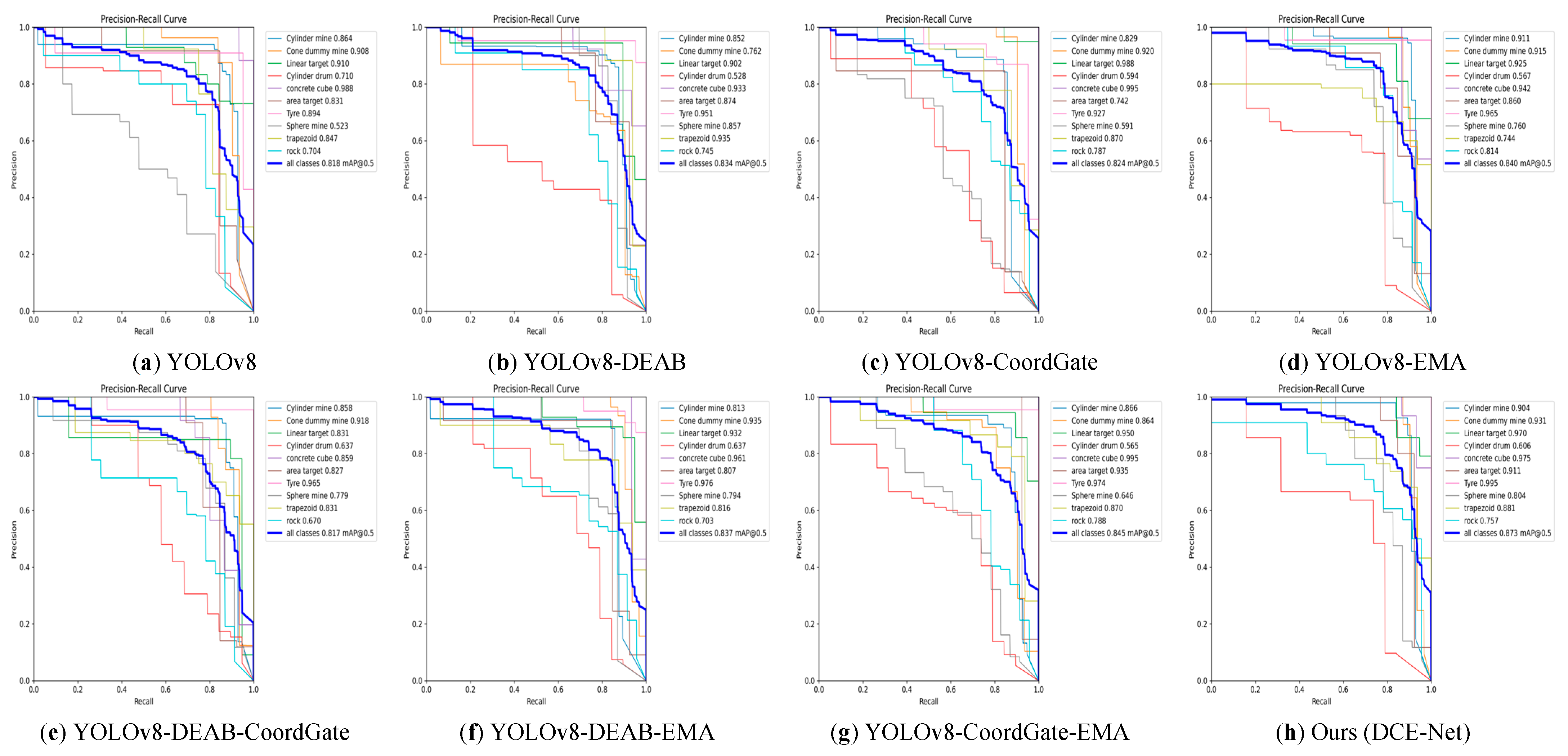

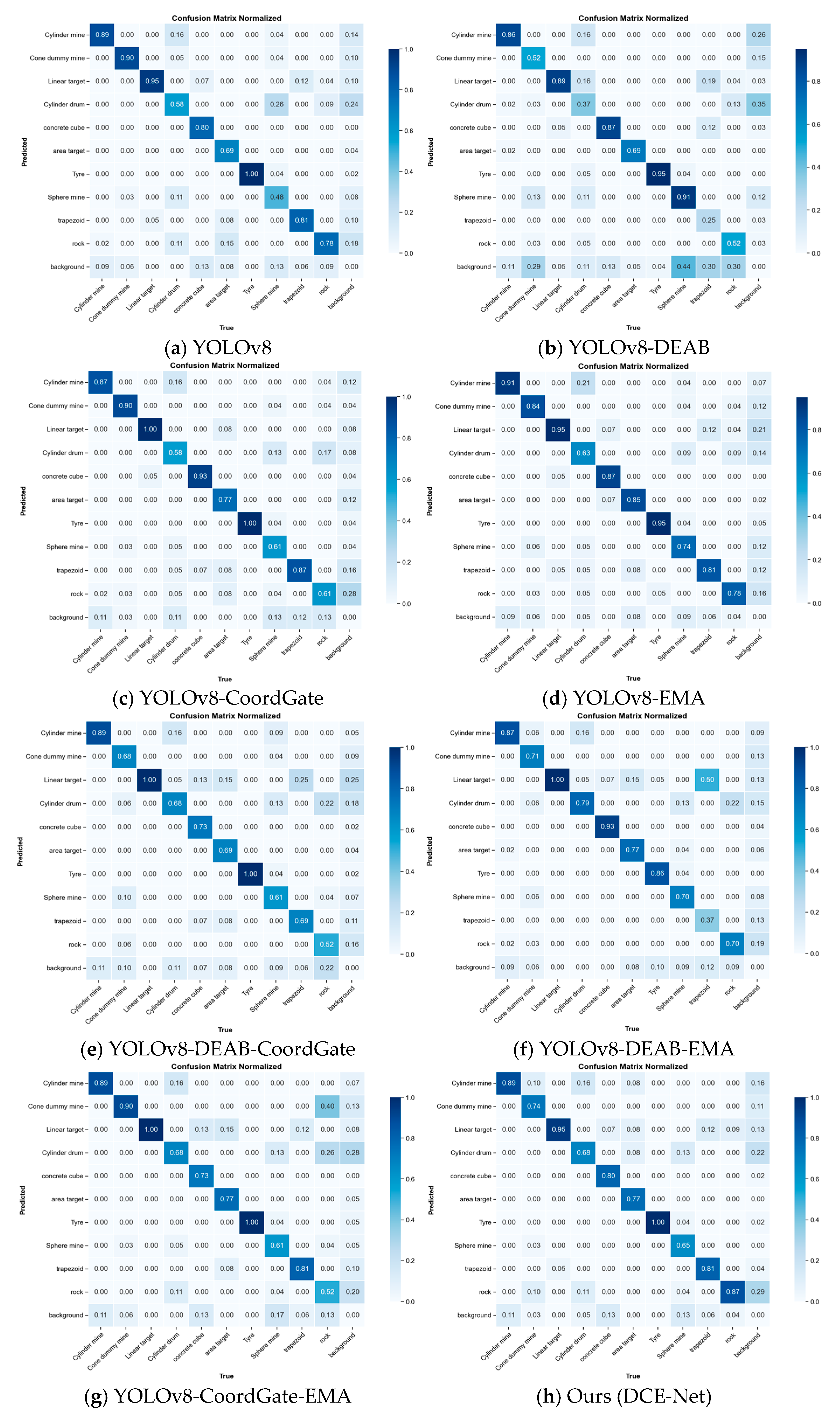


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | mAP@0.5:0.95 (%) | mAP@0.5 (%) | R (%) | F1 (%) | Params (M) | FLOPs (G) | FPS (f·s−1) |
|---|---|---|---|---|---|---|---|
| YOLOv8 | 33.9 | 81.8 | 81.2 | 80 | 3 | 8.1 | 277 |
| YOLOv8-DEAB | 36.6 (+2.7) | 83.4 (+1.6) | 76.8 | 74 | 3.35 | 8.3 | 263 |
| YOLOv8-CoordGate | 35.6 (+1.7) | 82.4 (+0.6) | 81.7 | 81 | 3.01 | 8.1 | 250 |
| YOLOv8-EMA | 36.7 (+2.8) | 84 (+2.2) | 84 | 82 | 3.01 | 8.1 | 277 |
| YOLOv8-DEAB-CoordGate | 38.7 (+4.8) | 83.8 (+2) | 78.2 | 78 | 3.35 | 8.3 | 200 |
| YOLOv8-DEAB-EMA | 38.5 (+4.6) | 83.3 (+1.5) | 76.9 | 76 | 3.35 | 8.4 | 217 |
| YOLOv8-CoordGate-EMA | 37.7 (+3.8) | 84.5 (+2.7) | 81.8 | 80 | 3 | 8.1 | 263 |
| YOLOv8-DEAB-CoordGate-EMA | 39.7 (+5.8) | 86.8 (+5) | 82 | 80 | 3.35 | 8.4 | 250 |
| Ours (DCE-Net) | 41.6 (+7.7) | 87.3 (+5.5) | 83.5 | 81 | 5.19 | 9.7 | 217 |
| Model | mAP@0.5:0.95 (%) | mAP@0.5 (%) | R (%) | F1 (%) | Params (M) | FLOPs (G) | FPS (f·s−1) |
|---|---|---|---|---|---|---|---|
| YOLOv8 | 43.9 | 87.3 | 77.1 | 80 | 3 | 8.1 | 143 |
| YOLOv8-DEAB | 45.6 (+1.7) | 87.1 (−0.2) | 80.7 | 83 | 3.35 | 8.3 | 113 |
| YOLOv8-CoordGate | 46.2 (+2.3) | 89.2 (+1.9) | 81.8 | 84 | 3.01 | 8.1 | 121 |
| YOLOv8-EMA | 46.3 (+2.4) | 87.1 (−0.2) | 83.5 | 82 | 3.01 | 8.1 | 111 |
| YOLOv8-DEAB-CoordGate | 47.7 (+3.8) | 87.8 (+0.5) | 79.6 | 82 | 3.35 | 8.3 | 108 |
| YOLOv8-DEAB-EMA | 47.6 (+3.7) | 89.9 (+2.6) | 82.3 | 85 | 3.35 | 8.4 | 135 |
| YOLOv8-CoordGate-EMA | 46.6 (+2.7) | 90.4 (+3.1) | 82 | 84 | 3 | 8.1 | 142 |
| YOLOv8-DEAB-CoordGate-EMA | 48.4 (+4.5) | 89.9 (+2.6) | 83.6 | 84 | 3.35 | 8.4 | 147 |
| Ours (DCE-Net) | 49.5 (+5.6) | 92.2 (+4.9) | 83.1 | 88 | 5.19 | 9.7 | 125 |
| Detection Method | mAP@0.5:0.95 (%) | mAP@0.5 (%) | R (%) | F1 (%) | Params (M) | FLOPs (G) | FPS (f·s−1) |
|---|---|---|---|---|---|---|---|
| Faster R-CNN | 36.2 | 83.05 | 85.08 | 68.7 | 137.1 | 370.2 | 6 |
| RetinaNet | 33.4 | 77.95 | 75.89 | 73.9 | 37.97 | 170.1 | 13 |
| YOLOv8m | 33.9 | 81.8 | 81.2 | 80 | 3 | 8.1 | 277 |
| YOLOv9m | 34.5 | 79.4 | 73.9 | 75 | 20.02 | 76.5 | 54 |
| YOLOv10m | 33.4 | 76.9 | 73.2 | 73 | 16.5 | 63.5 | 65 |
| YOLO11s | 37.7 | 85.3 | 80 | 79 | 2.58 | 6.3 | 294 |
| Ours (DCE-Net) | 41.6 | 87.3 | 83.5 | 81 | 5.19 | 9.7 | 217 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, L.; Ma, Z.; Hu, Q.; Xia, Z.; Zhao, M. DCE-Net: An Improved Method for Sonar Small-Target Detection Based on YOLOv8. J. Mar. Sci. Eng. 2025, 13, 1478. https://doi.org/10.3390/jmse13081478
Cao L, Ma Z, Hu Q, Xia Z, Zhao M. DCE-Net: An Improved Method for Sonar Small-Target Detection Based on YOLOv8. Journal of Marine Science and Engineering. 2025; 13(8):1478. https://doi.org/10.3390/jmse13081478
Chicago/Turabian StyleCao, Lijun, Zhiyuan Ma, Qiuyue Hu, Zhongya Xia, and Meng Zhao. 2025. "DCE-Net: An Improved Method for Sonar Small-Target Detection Based on YOLOv8" Journal of Marine Science and Engineering 13, no. 8: 1478. https://doi.org/10.3390/jmse13081478
APA StyleCao, L., Ma, Z., Hu, Q., Xia, Z., & Zhao, M. (2025). DCE-Net: An Improved Method for Sonar Small-Target Detection Based on YOLOv8. Journal of Marine Science and Engineering, 13(8), 1478. https://doi.org/10.3390/jmse13081478