
A Channel-Aware AUV-Aided Data Collection Scheme Based on Deep Reinforcement Learning


 ,
,
Abstract
1. Introduction
- This study pioneers a channel-aware node traversal algorithm for AUVs, optimizing energy efficiency and data collection rates by integrating asymmetric acoustic propagation characteristics with signal strength analysis, moving beyond traditional distance-only metrics.
- In response to the challenges of underwater data collection, we propose an AUV-aided path planning algorithm based on DRL. This algorithm takes into account key factors such as underwater propagation loss, underwater obstacles, and ocean currents to achieve efficient data collection rates and energy consumption optimization.
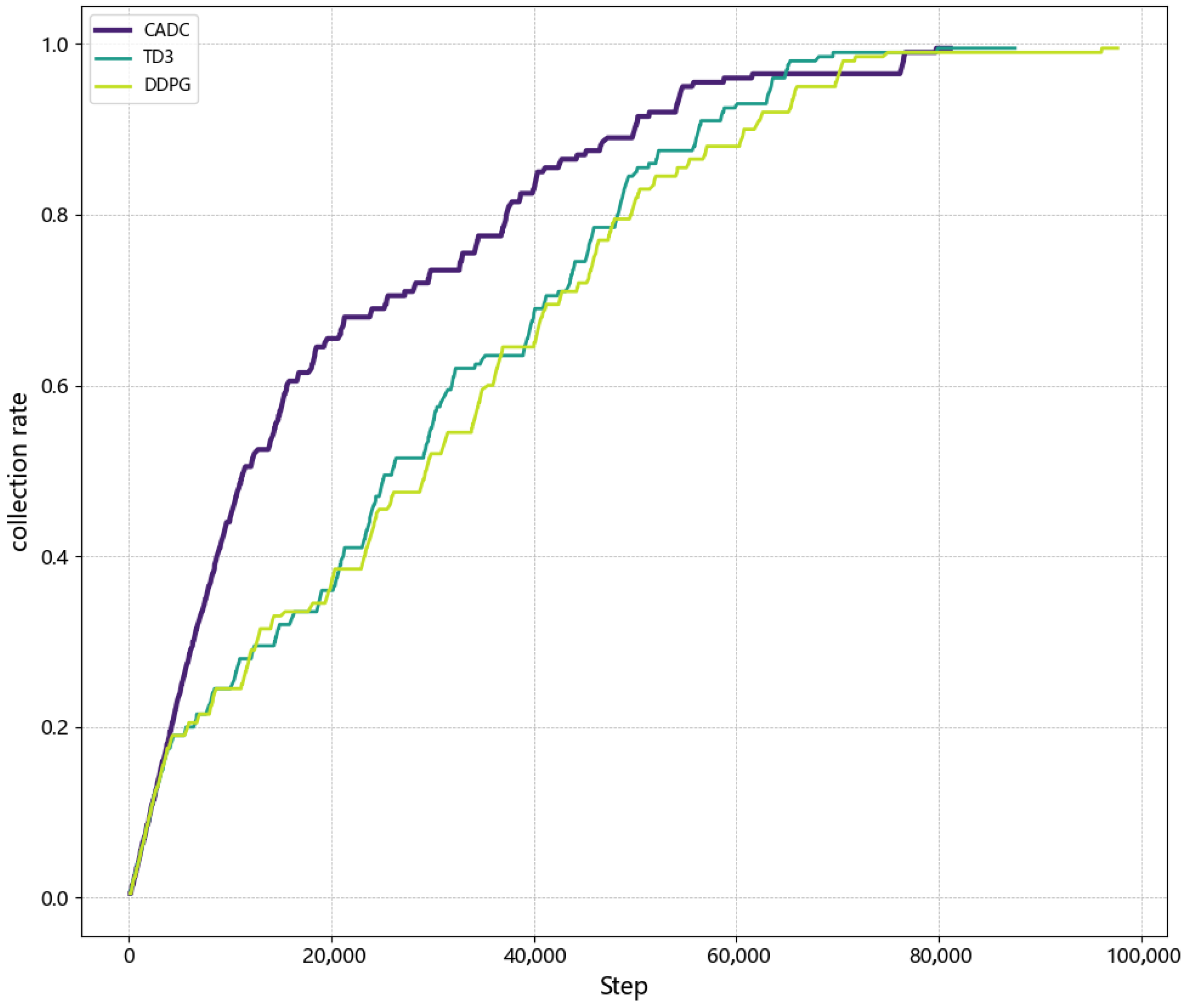
- Extensive simulations demonstrate that the proposed algorithm achieves a 71.2% improvement in energy efficiency compared to clustering-based methods and a 2.3% faster convergence than TD3, validating its capability to optimize AUV paths through asymmetric channel-aware trajectory planning while minimizing network energy consumption.
2. Related Works
2.1. Data Collection Methods Relying on UWSN
2.2. AUV-Based Data Collection Methods
2.2.1. Clustering-Based Data Collection Schemes
2.2.2. Data Collection Schemes Based on the Information Value of the Data
2.2.3. Reinforcement Learning-Based Data Collection Schemes
2.3. Combined UWSN and AUV-Assisted Methods
3. System Model
3.1. Network Architecture
3.2. Underwater Acoustic Channel Model
- (1)
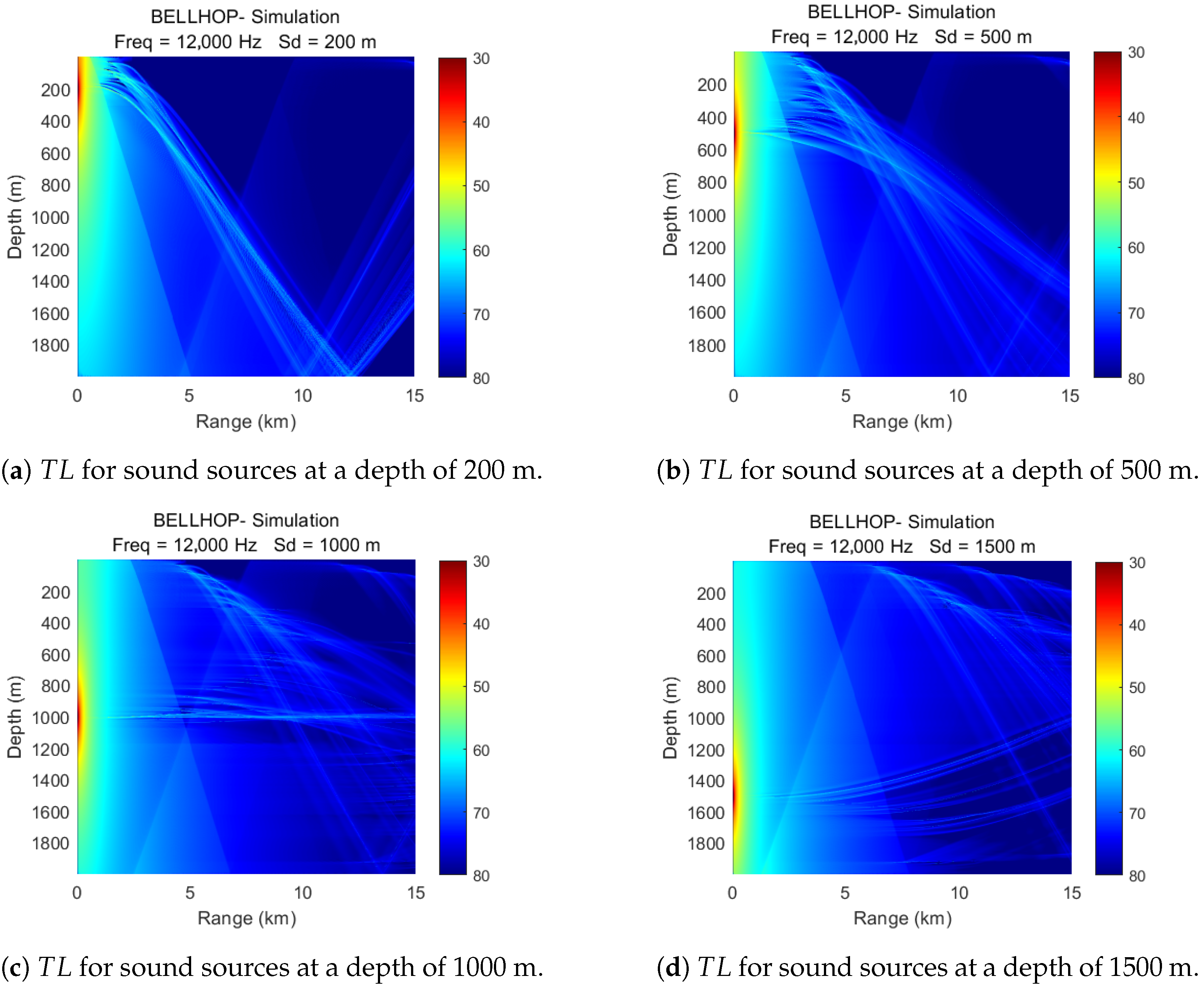
- In Figure 2a, it is clearly observed that there are large shaded areas in the propagation loss and when the AUV is located in these areas, communication with the nodes will become difficult. At the same time, the clear and bright curves show that communication is still possible despite the longer distance between the AUV and the node.
- (2)
- Source node located at 500 m in Figure 2b shows similar characteristics in terms of as at 200 m, although the shaded area is reduced and the clear and bright curves in the figure cover a wider area. As a result, the active area available for AUV selection increases accordingly.
- (3)
- As the depth of the node drops to 1000 m as in Figure 2c, a distinct acoustic channel axis develops, which is the most significant difference from the propagation loss characteristics of shallower depth source nodes. An AUV at a water depth of approximately 1000 m still has a high probability of communicating with the source node even if it is far away from it.
- (4)
- As shown in Figure 2d, when the node is located at a water depth of 1500 m, the shadow zone is mainly concentrated in the area that is deeper and farther away from the source node. At the same time, the sound reflection phenomenon near the water surface is quite obvious.
3.3. Ocean Currents Model
3.4. Energy Optimization Model and Problem Formulation
4. A Channel-Aware AUV-Aided Data Collection Scheme (CADC) Based on Deep Reinforcement Learning
4.1. Channel-Aware Task Allocation
| Algorithm 1 Task allocation for AUV. |
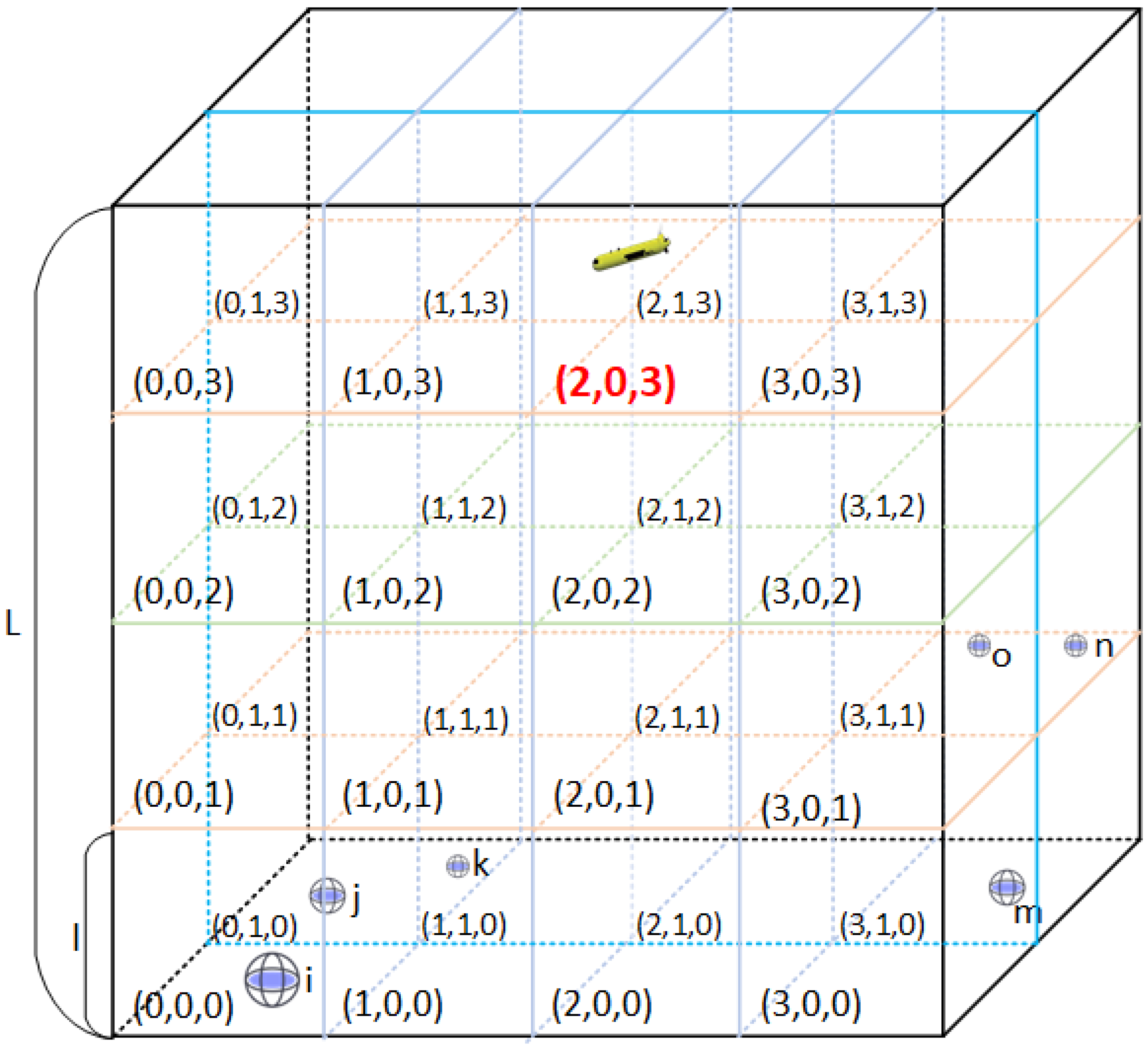
| 1. Sub-areas’ division |
| Define the edge length of cubes as L |
| Initialize an empty task list TsubArea to hold the sub-areas |
| for i in range (0,M,1): |
| for j in range (0,N,1): |
| for k in range (0,O,1): |
| for nodei in range (0, MAX_NODE,1): |
| if : |
| Add nodei to the task list |
| 2. Sub-area Selection and the optimal order to visit nodes |
| While node data collection not completed: |
| Obtaining the optimal task through Equation (17) |
| Obtaining the order of traversing these nodes with the ACO algorithm. |
| Inform AUV of the node traversal order. |
4.2. AUV-Aided Path Planning Based on Deep Reinforcement Learning
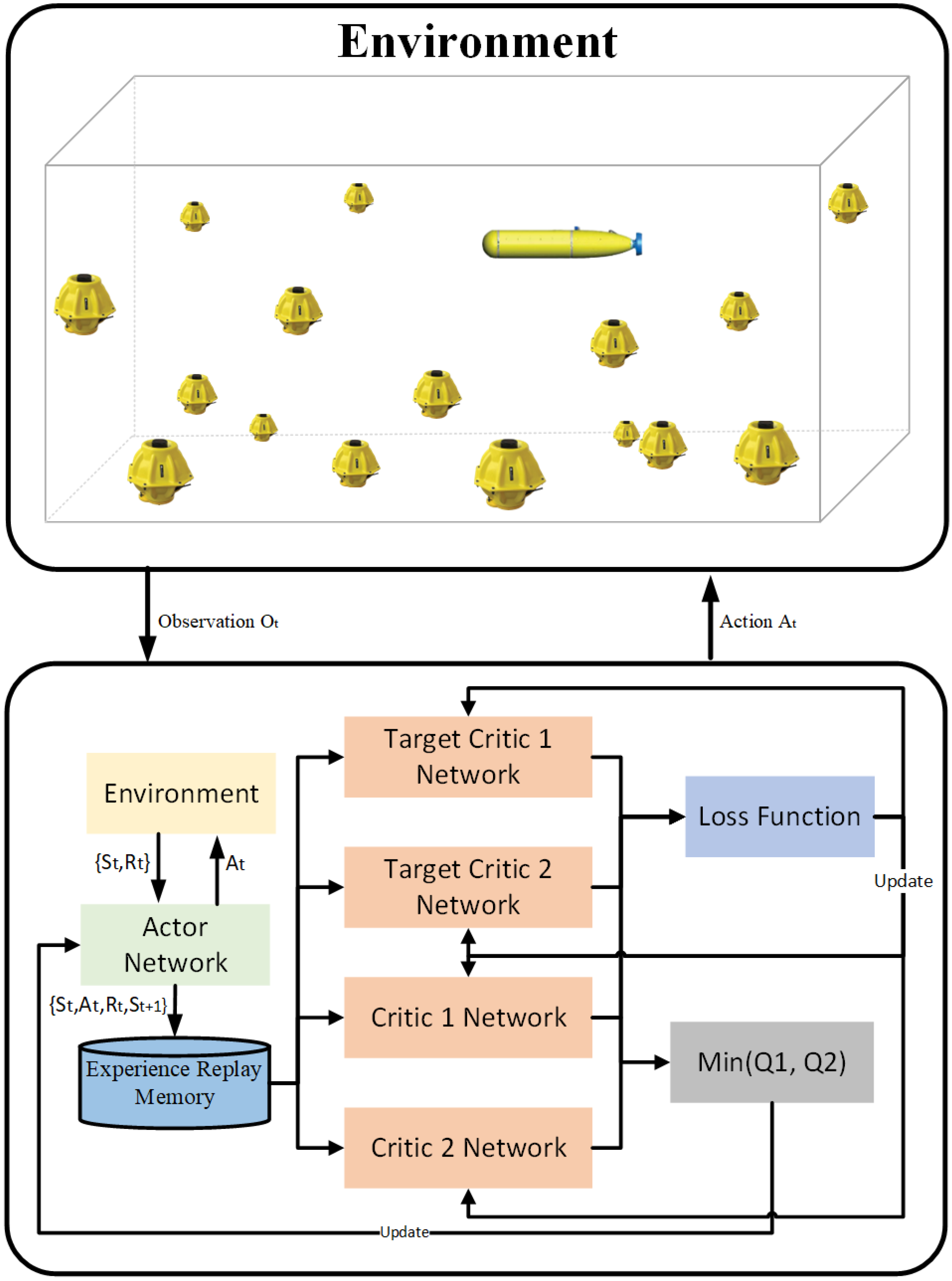
| Algorithm 2 Training for AUV. |
| Input: State |
| Output: Action |
| 1: Initialize actor network and critic network |
| 2: Copy target actor network and target critic network, respectively. |
| 3: Initialize environment and receive initial observations |
| 4: for episode = 1, 2 …M do |
| 5: for do |
| 6: AUV takes action , and gets reward |
| 7: The AUV updates to a new state |
| 8: Store in experience replay buffer |
| 9: Set |
| 10: Select N samples from experience replay buffer randomly |
| 11: Update critic network and actor network |
| 12: Update target critic network and target actor network |
| 13: end for |
| 14: end for |
| 15: return action |
5. Simulation Results
5.1. Experiment Settings
Environment Parameters
5.2. Algorithm Parameters
5.3. Simulation Results and Analysis
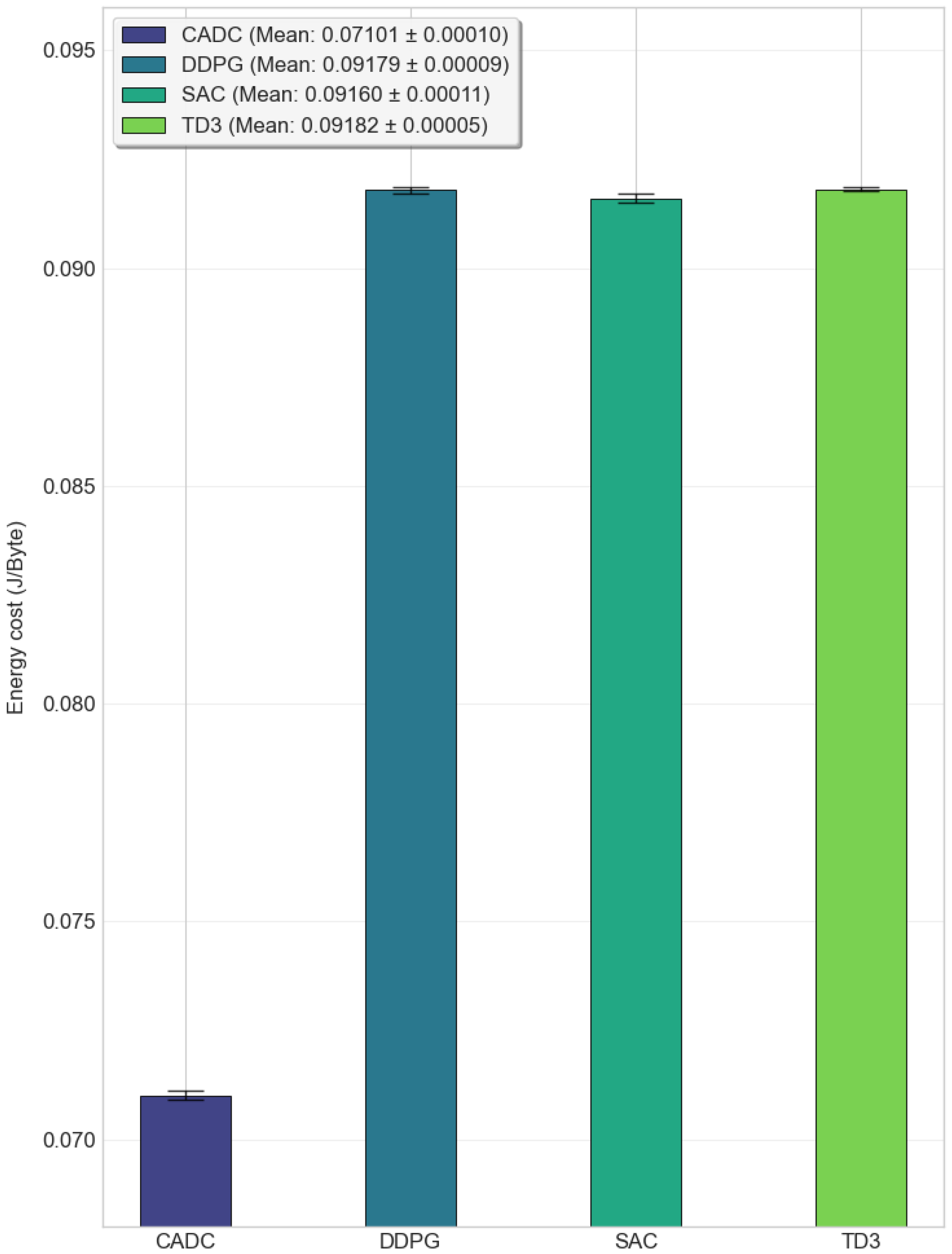
5.3.1. Comparison of Energy-Saving Performance
5.3.2. Comparison with Proximity-Based TSP Data Collection Methods
5.3.3. Accumulated Reward and Algorithm Stability
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AUV | Autonomous Underwater Vehicle |
| AWGN | Additive White Gaussian Noise |
| BPSK | Binary Phase Shift Keying |
| UWSN | Underwater Wireless Sensor Network |
| DRL | Deep Reinforcement Learning |
| Signal-to-Noise Ratio | |
| PER | Packet Error Rate |
| BER | Bit Error Rate |
| PDR | Packet Delivery Rate |
| CADC | Channel-Aware AUV-Aided Data Collection Scheme |
| ACO | Ant Colony Optimization |
| SAC | Soft Actor-Critic |
| DDPG | Deep Deterministic Policy Gradient |
| TD3 | Twin Delayed Deep Deterministic Policy Gradient |
| VoI | Value of Information |
| TSP | Traveling Salesman Problem |
| Transmission Loss | |
| Energy Cost | |
| OFDM | Orthogonal Frequency Division Multiplexing |
| SN | sensor node |
References
- Martin, C.; Weilgart, L.; Amon, D.; Müller, J. Deep-Sea Mining: A Noisy Affair—Overview and Recommendations. 2021. Available online: https://www.oceancare.org/wp-content/uploads/2021/12/Deep-Sea-Mining_A-noisy-affair_Report-OceanCare_2021.pdf (accessed on 19 March 2025).
- Cheng, M.; Guan, Q.; Ji, F.; Cheng, J.; Chen, Y. Dynamic-detection-based trajectory planning for autonomous underwater vehicle to collect data from underwater sensors. IEEE Internet Things J. 2022, 9, 13168–13178. [Google Scholar] [CrossRef]
- Koschinsky, A.; Heinrich, L.; Boehnke, K.; Cohrs, J.C.; Markus, T.; Shani, M.; Singh, P.; Smith Stegen, K.; Werner, W. Deep-sea mining: Interdisciplinary research on potential environmental, legal, economic, and societal implications. Integr. Environ. Assess. Manag. 2018, 14, 672–691. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J.; Tian, W.; Han, G.; Zhang, F. A Medium Access Control Protocol Based on Parity Group-Graph Coloring for Underwater AUV-Aided Data Collection. IEEE Internet Things J. 2024, 11, 5967–5979. [Google Scholar] [CrossRef]
- Porter, M.B. The Bellhop Manual and User’s Guide: Preliminary Draft; Tech. Rep. Heat, Light, and Sound Research, Inc.: La Jolla, CA, USA, 2011; Volume 260. [Google Scholar]
- Chen, M.; Zhu, D. Data collection from underwater acoustic sensor networks based on optimization algorithms. Computing 2020, 102, 83–104. [Google Scholar] [CrossRef]
- Che, S.; Song, S.; Xu, C.; Liu, J.; Cui, J.H. ACARP: An Adaptive Channel-Aware Routing Protocol for Underwater Wireless Sensor Networks. In Proceedings of the 2023 IEEE/CIC International Conference on Communications in China (ICCC), Dalian, China, 10–12 August 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Jiang, Q.; Zhu, R.; Boukerche, A.; Yang, Q. An AUV-Assisted Data Collection Approach for UASNs Based on Hybrid Clustering and Matrix Completion. In Proceedings of the 2024 IEEE Wireless Communications and Networking Conference (WCNC), Dubai, United Arab Emirates, 21–24 April 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Guo, Z.; Colombi, G.; Wang, B.; Cui, J.H.; Maggiorini, D.; Rossi, G.P. Adaptive Routing in Underwater Delay/Disruption Tolerant Sensor Networks. In Proceedings of the 2008 Fifth Annual Conference on Wireless on Demand Network Systems and Services, Garmisch-Partenkirchen, Germany, 23–25 January 2008; pp. 31–39. [Google Scholar] [CrossRef]
- Di Valerio, V.; Lo Presti, F.; Petrioli, C.; Picari, L.; Spaccini, D.; Basagni, S. CARMA: Channel-Aware Reinforcement Learning-Based Multi-Path Adaptive Routing for Underwater Wireless Sensor Networks. IEEE J. Sel. Areas Commun. 2019, 37, 2634–2647. [Google Scholar] [CrossRef]
- Wang, J.; Liu, S.; Shi, W.; Han, G.; Yan, S. A Multi-AUV Collaborative Ocean Data Collection Method Based on LG-DQN and Data Value. IEEE Internet Things J. 2024, 11, 9086–9106. [Google Scholar] [CrossRef]
- Hao, Z.; Li, W.; Zhang, Q. Efficient Clustering Data Collection in AUV-Aided Underwater Sensor Network. In Proceedings of the OCEANS 2023—MTS/IEEE U.S. Gulf Coast, Biloxi, MS, USA, 25–28 September 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Li, Y.; Huang, H.; Zhuang, Y.; Chen, Z.; Wang, X.; Xu, X. Multi-AUV Collaborative Data Collection Scheme to Clustering and Routing for Heterogeneous UWSNs. IEEE Sens. J. 2024, 24, 42289–42301. [Google Scholar] [CrossRef]
- Liu, Z.; Liang, Z.; Yuan, Y.; Chan, K.Y.; Guan, X. Energy-Efficient Data Collection Scheme Based on Value of Information in Underwater Acoustic Sensor Networks. IEEE Internet Things J. 2024, 11, 18255–18265. [Google Scholar] [CrossRef]
- Liu, Z.; Meng, X.; Liu, Y.; Yang, Y.; Wang, Y. AUV-Aided Hybrid Data Collection Scheme Based on Value of Information for Internet of Underwater Things. IEEE Internet Things J. 2022, 9, 6944–6955. [Google Scholar] [CrossRef]
- Yan, J.; Yang, X.; Luo, X.; Chen, C. Energy-Efficient Data Collection Over AUV-Assisted Underwater Acoustic Sensor Network. IEEE Syst. J. 2018, 12, 3519–3530. [Google Scholar] [CrossRef]
- Ding, Y.; Wang, X.; Xu, J.; Xie, G.; Liu, W.; Li, Y. Multi-Objective-Optimization Multi-AUV Assisted Data Collection Framework for IoUT Based on Offline Reinforcement Learning. arXiv 2024. [Google Scholar] [CrossRef]
- Jiang, B.; Du, J.; Ren, K.; Jiang, C.; Han, Z. Multi-Agent Reinforcement Learning based Secure Searching and Data Collection in AUV Swarms. In Proceedings of the ICC 2023—IEEE International Conference on Communications, Rome, Italy, 28 May–1 June 2023; pp. 5085–5090. [Google Scholar] [CrossRef]
- Bu, F.; Luo, H.; Ma, S.; Li, X.; Ruby, R.; Han, G. AUV-Aided Optica-Acoustic Hybrid Data Collection Based on Deep Reinforcement Learning. Sensors 2023, 23, 578. [Google Scholar] [CrossRef] [PubMed]
- Busacca, F.; Galluccio, L.; Palazzo, S.; Panebianco, A.; Raftopoulos, R. AMUSE: A Multi-Armed Bandit Framework for Energy-Efficient Modulation Adaptation in Underwater Acoustic Networks. IEEE Open J. Commun. Soc. 2025, 6, 2766–2779. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, J.; Liu, Y.; Wang, B. Underwater Acoustic Adaptive Modulation with Reinforcement Learning and Channel Prediction. In Proceedings of the 15th International Conference on Underwater Networks & Systems, WUWNet ’21, Shenzhen, China, 22–24 November 2021; Association for Computing Machinery: New York, NY, USA, 2022. [Google Scholar] [CrossRef]
- Su, W.; Lin, J.; Chen, K.; Xiao, L.; En, C. Reinforcement Learning-Based Adaptive Modulation and Coding for Efficient Underwater Communications. IEEE Access 2019, 7, 67539–67550. [Google Scholar] [CrossRef]
- Cheng, C.F.; Li, L.H. Data gathering problem with the data importance consideration in Underwater Wireless Sensor Networks. J. Netw. Comput. Appl. 2017, 78, 300–312. [Google Scholar] [CrossRef]
- Shahapur, S.S.; Khanai, R. Localization, routing and its security in UWSN—A survey. In Proceedings of the 2016 International Conference on Electrical, Electronics, and Optimization Techniques (ICEEOT), Chennai, India, 3–5 March 2016; pp. 1001–1006. [Google Scholar] [CrossRef]
- Song, S.; Liu, J.; Guo, J.; Lin, B.; Ye, Q.; Cui, J. Efficient Data Collection Scheme for Multi-Modal Underwater Sensor Networks Based on Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2023, 72, 6558–6570. [Google Scholar] [CrossRef]
- Gul, S.; Zaidi, S.S.H.; Khan, R.; Wala, A.B. Underwater acoustic channel modeling using BELLHOP ray tracing method. In Proceedings of the 2017 14th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 10–14 January 2017; pp. 665–670. [Google Scholar] [CrossRef]
- Cheng, M.; Guan, Q.; Wang, Q.; Ji, F.; Quek, T.Q.S. FER-Restricted AUV-Relaying Data Collection in Underwater Acoustic Sensor Networks. IEEE Trans. Wirel. Commun. 2023, 22, 9131–9142. [Google Scholar] [CrossRef]
- Shehwar, D.E.; Gul, S.; Zafar, M.U.; Shaukat, U.; Syed, A.H.; Zaidi, S.S.H. Acoustic Wave Analysis In Deep Sea And Shallow Water Using Bellhop Tool. In Proceedings of the 2021 OES China Ocean Acoustics (COA), Harbin, China, 14–17 July 2021; pp. 331–334. [Google Scholar] [CrossRef]
- Awan, K.M.; Shah, P.A.; Iqbal, K.; Gillani, S.; Ahmad, W.; Nam, Y. Underwater Wireless Sensor Networks: A Review of Recent Issues and Challenges. Wirel. Commun. Mob. Comput. 2019, 2019, 6470359. [Google Scholar] [CrossRef]
- Felemban, E.; Shaikh, F.K.; Qureshi, U.M.; Sheikh, A.A.; Qaisar, S.B. Underwater Sensor Network Applications: A Comprehensive Survey. Int. J. Distrib. Sens. Netw. 2015, 11, 896832. [Google Scholar] [CrossRef]
- Urick, R.J. Principles of Underwater Sound, 3rd ed.; McGraw-Hill: New York, NY, USA, 1983. [Google Scholar]
- Wang, Y.; Liu, K.; Geng, L.; Zhang, S. Knowledge hierarchy-based dynamic multi-objective optimization method for AUV path planning in cooperative search missions. Ocean. Eng. 2024, 312, 119267. [Google Scholar] [CrossRef]
- Han, G.; Jiang, J.; Shu, L.; Guizani, M. An Attack-Resistant Trust Model Based on Multidimensional Trust Metrics in Underwater Acoustic Sensor Network. IEEE Trans. Mob. Comput. 2015, 14, 2447–2459. [Google Scholar] [CrossRef]
- Zhou, S.; Wang, Z. OFDM for Underwater Acoustic Communications, 1st ed.; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Garau, B.; Alvarez, A.; Oliver, G. AUV navigation through turbulent ocean environments supported by onboard H-ADCP. In Proceedings of the 2006 IEEE International Conference on Robotics and Automation, ICRA 2006, Orlando, FL, USA, 15–19 May 2006; pp. 3556–3561. [Google Scholar] [CrossRef]
- Zhang, T.; Gou, Y.; Liu, J.; Yang, T.; Cui, J.H. UDARMF: An Underwater Distributed and Adaptive Resource Management Framework. IEEE Internet Things J. 2022, 9, 7196–7210. [Google Scholar] [CrossRef]
- Han, G.; Li, S.; Zhu, C.; Jiang, J.; Zhang, W. Probabilistic Neighborhood-Based Data Collection Algorithms for 3D Underwater Acoustic Sensor Networks. Sensors 2017, 17, 316. [Google Scholar] [CrossRef]
- Dorigo, M.; Birattari, M.; Stutzle, T. Ant colony optimization. IEEE Comput. Intell. Mag. 2006, 1, 28–39. [Google Scholar] [CrossRef]
- Cheng, C.; Sha, Q.; He, B.; Li, G. Path planning and obstacle avoidance for AUV: A review. Ocean. Eng. 2021, 235, 109355. [Google Scholar] [CrossRef]
- Lauri, M.; Hsu, D.; Pajarinen, J. Partially Observable Markov Decision Processes in Robotics: A Survey. IEEE Trans. Robot. 2023, 39, 21–40. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Dy, J., Krause, A., Eds.; Proceedings of Machine Learning Research (PMLR). Volume 80, pp. 1861–1870. [Google Scholar]
- Fujimoto, S.; van Hoof, H.; Meger, D. Addressing Function Approximation Error in Actor-Critic Methods. arXiv 2018. [Google Scholar] [CrossRef]
- Matheron, G.; Perrin, N.; Sigaud, O. The problem with DDPG: Understanding failures in deterministic environments with sparse rewards. arXiv 2019. [Google Scholar] [CrossRef]
- Martin, R.; Rajasekaran, S.; Peng, Z. Aqua-Sim Next Generation: An NS-3 Based Underwater Sensor Network Simulator. In Proceedings of the 12th International Conference on Underwater Networks & Systems, WUWNet ’17, Halifax, NS, Canada, 6–8 November 2017. [Google Scholar] [CrossRef]
- Riley, G.F.; Henderson, T.R. The ns-3 Network Simulator. In Modeling and Tools for Network Simulation; Wehrle, K., Güneş, M., Gross, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 15–34. [Google Scholar] [CrossRef]
- Gawlowicz, P.; Zubow, A. ns3-gym: Extending OpenAI Gym for Networking Research. arXiv 2018. [Google Scholar] [CrossRef]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016. [Google Scholar] [CrossRef]
- Chirdchoo, N.; Soh, W.S.; Chua, K.C. Aloha-Based MAC Protocols with Collision Avoidance for Underwater Acoustic Networks. In Proceedings of the IEEE INFOCOM 2007—26th IEEE International Conference on Computer Communications, Anchorage, AK, USA, 6–12 May 2007; pp. 2271–2275. [Google Scholar] [CrossRef]
- Padhye, V.; Lakshmanan, K. A deep actor critic reinforcement learning framework for learning to rank. Neurocomputing 2023, 547, 126314. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2019. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Execution Steps | Energy Efficiency (J/byte) | |
|---|---|---|
| DDPG | 99,737 | 0.03528 |
| TD3 | 83,092 | 0.035254 |
| CADC | 81,179 | 0.035254 |
| pre-specified | 555,620 | 0.05146 |
| clustering-based | 95,018 | 0.12210 |
| Number of Nodes | Execution Steps | Energy Efficiency |
|---|---|---|
| 50 | 58,577 | 0.0751 |
| 100 | 88,636 | 0.0589 |
| 150 | 94,026 | 0.046 |
| 200 | 81,179 | 0.0352 |
| DDPG | TD3 | CADC | Pre-Specified | Clustering-Based | |
|---|---|---|---|---|---|
| execution steps | 99,737 | 83,092 | 81,179 | 555,620 | 95,018 |
| PDR | 0.96538 | 0.96706 | 0.95288 | 1.0 | 0.94206 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, L.; Sun, M.; Peng, Z.; Guo, J.; Cui, J.; Qin, B.; Cui, J.-H. A Channel-Aware AUV-Aided Data Collection Scheme Based on Deep Reinforcement Learning. J. Mar. Sci. Eng. 2025, 13, 1460. https://doi.org/10.3390/jmse13081460
Wei L, Sun M, Peng Z, Guo J, Cui J, Qin B, Cui J-H. A Channel-Aware AUV-Aided Data Collection Scheme Based on Deep Reinforcement Learning. Journal of Marine Science and Engineering. 2025; 13(8):1460. https://doi.org/10.3390/jmse13081460
Chicago/Turabian StyleWei, Lizheng, Minghui Sun, Zheng Peng, Jingqian Guo, Jiankuo Cui, Bo Qin, and Jun-Hong Cui. 2025. "A Channel-Aware AUV-Aided Data Collection Scheme Based on Deep Reinforcement Learning" Journal of Marine Science and Engineering 13, no. 8: 1460. https://doi.org/10.3390/jmse13081460
APA StyleWei, L., Sun, M., Peng, Z., Guo, J., Cui, J., Qin, B., & Cui, J.-H. (2025). A Channel-Aware AUV-Aided Data Collection Scheme Based on Deep Reinforcement Learning. Journal of Marine Science and Engineering, 13(8), 1460. https://doi.org/10.3390/jmse13081460