4.1. Datasets and Evaluation Metrics
To comprehensively evaluate and compare with other UIE methods, several well-known datasets are utilized. The Underwater Image Enhancement Benchmark (UIEB) and Large-Scale Underwater Image (LSUI) datasets are widely used paired datasets for training and testing our model. The UIEB and LSUI datasets have paired degraded underwater images and ground truth maps, which can be well used for supervised training and quantitative evaluation of the model. Additionally, we utilize the unpaired datasets U45 and C60 to verify the model’s generality and adaptability. These underwater image datasets comprise a diverse range of real underwater scenes and are well-suited for evaluation and comparison with other methods.
UIEB [
33]. The UIEB dataset consists of manually collected underwater images and the corresponding GT images selected by manual voting. The UIEB dataset includes 890 paired underwater images. We randomly divide the dataset into 800 and 90 paired images (U_90) for training and validation, respectively.
LSUI [
18]. The LSUI dataset currently contains 4279 degraded images and their corresponding reference images. This dataset comprises a substantial collection of underwater images, featuring diverse subjects such as deep-sea creatures, deep-sea rocks, and cave formations. We randomly select 3800 and 479 paired underwater images (L_479) for training and validation, respectively.
C60 [
33]. The UIEB dataset contains 60 challenging underwater images (C60) without suitable reference images. In this paper, we use C60 for verification.
U45 [
34]. The U45 dataset consists of 45 typical underwater images. This dataset contains common color attenuation, lack of contrast, and fogging phenomena in underwater environments.
Evaluation Metrics. Peak signal-to-noise ratio (PSNR) [
35] and structural similarity index (SSIM) [
36] are classic indicators for measuring image reconstruction quality. PSNR quantifies the enhancement algorithm’s performance at the pixel level by comparing the pixel intensity differences with those of a reference image. At the same time, SSIM evaluates brightness, contrast, and structural similarity to better reflect the structural-level enhancement. Fréchet Inception Distance (FID) [
37] and Learned Perceptual Image Patch Similarity (LPIPS) [
38] measure the difference in feature space distribution and perceptual similarity between generated images and real images, respectively. FID is a metric for evaluating the difference between the distribution of generated and real images. LPIPS is a similarity metric for evaluating the perceptual differences of images based on deep learning models, which quantifies the similarity of two images by analyzing the differences in their perceptual features. In the unpaired C60 and U45 datasets, we use two pairs of no-reference metrics for evaluation: Underwater Color Image Quality Evaluation (UCIQE) [
39] and Underwater Image Quality Measurement (UIQM) [
40]. UCIQE and UIQM conduct a comprehensive assessment of underwater image quality based on image characteristics, including color distribution, contrast, and clarity.
4.3. Comparison with Other UIE Methods
We compare the performance of various UIE methods on the U_90 and L_479 datasets. The compared methods include physics-based methods, non-physical methods, and deep learning-based methods. Among them, UDCP [
8] is a physics-based method that mainly relies on the physical laws of imaging to enhance the image. WWPE [
15] is a non-physical method, which is usually processed by designing prior rules or image statistical characteristics. The remaining methods are all deep learning-based methods, including UWCNN [
17], UIEC
2-Net [
23], U-Shape [
18], FA
+Net [
16], UVZ [
19], DM [
20], and DATDM [
21], which use deep neural networks to learn mapping relationships from large-scale data to improve image quality. To ensure reproducibility and fairness in comparison, we used the official MATLAB (The implemented version is MATLAB R2023a.) implementations for UDCP and WWPE, applying them directly to the input images without any further modification. For the deep learning-based methods, including UWCNN, UIEC
2-Net, U-Shape, FA
+Net, UVZ, DM, and DATDM, we adopted the authors’ publicly available PyTorch-based implementations. All methods were evaluated using their default settings, and we selected the best-performing pre-trained weights for validation, as provided by the original authors or trained according to their recommended protocols. We use 256 × 256-sized images for training and validation for all methods.
Table 1 presents a quantitative comparison of various UIE methods on the paired datasets U_90 and L_479. Our proposed method, LITM, achieves state-of-the-art performance across all metrics on both datasets. On the U_90 dataset, LITM achieves the lowest FID (28.68) and LPIPS (0.0989) while also obtaining the highest SSIM (0.9044) and the top PSNR score (23.73). Similarly, on the L_479 dataset, LITM again achieves the best results in all four metrics: FID (29.02), LPIPS (0.1092), PSNR (26.71), and SSIM (0.9410). These results demonstrate the superior perceptual and structural enhancement capabilities of LITM. While the diffusion-based DATDM method achieves competitive performance, LITM consistently outperforms it on all metrics. Traditional physics-based methods (e.g., UDCP) and non-physical methods (e.g., WWPE) suffer from significant performance degradation due to their limited generalization capabilities in diverse underwater scenes. Among the deep learning-based methods, FA
+Net and UVZ achieved relatively good performance on structural metrics (PSNR and SSIM), but their perceptual metrics (e.g., FID and LPIPS) performed poorly. UIEC
2-Net also demonstrates strong overall performance, achieving the second-best SSIM and PSNR on both datasets, as well as competitive FID and LPIPS scores. UWCNN falls short in all metrics and performs poorly in terms of perceptual and structural quality. U-Shape achieves competitive PSNR on the L_479 dataset, but its FID and LPIPS scores are relatively poor, indicating poor perceptual restoration. DM performs worse than other deep learning methods on most metrics.
Additionally, we compared the visual effects of different UIE methods on the paired datasets U_90 and L_479. As shown in
Figure 3, the images generated by physics-based and non-physical methods (such as UDCP and WWPE) generally exhibit severe color distortion. The enhancement effect of UWCNN is generally average, and the U-shape is slightly better than that of UWCNN. FA+Net and UVZ have positive effects in some images, but they struggle to adapt to all underwater scenes, and their generalization ability is limited. The images generated by the DM method are generally blue and have an unbalanced color palette. Although the enhancement effect of DATDM is ideal, it is lower than our proposed LITM method in all performance indicators. We also use red boxes to highlight key areas and zoom in on them for enhanced visibility.
To further validate the statistical significance and robustness of the performance improvements, we calculate 95% confidence intervals (CI) for PSNR and SSIM scores on the U_90 and L_479 datasets, as shown in
Table 2. The results demonstrate that our proposed LITM achieves the best mean performance with consistently tight confidence bounds across both datasets. For instance, on the L_479 dataset, our method achieves a PSNR CI of [26.30, 27.11] and an SSIM CI of [0.9356, 0.9454], which not only exceed those of all baseline methods but also show lower variance. These intervals indicate that LITM produces more stable and reliable enhancement outcomes, further supporting the statistical significance of the reported improvements.
To verify the generality and adaptability of LITM, we conducted further validation experiments on the unpaired datasets C60 and U45.
Table 3 shows a quantitative comparison of various UIE methods, which were evaluated using the UCIQE and UIQM metrics. The top three results for each metric are marked in red, blue, and green, respectively. On the C60 dataset, our proposed method achieves the second-highest UCIQE score (0.5914) and the third-highest UIQM score (0.5845), indicating excellent performance in both colorimetry and perceptual quality. While DATDM slightly surpasses our method in UIQM (0.6072), its UCIQE score (0.5700) is inferior. On the U45 dataset, our method performs well in both metrics, achieving the highest UCIQE (0.6148) and the third highest UIQM (0.8060). These results confirm the robustness and excellent perceptual quality of our method under various underwater conditions.
Although WWPE achieves promising results on UCIQE (0.5948 and 0.5999) and UIQM (0.9597 and 1.2948), the abnormally high UIQM value suggests potential over-enhancement or color distortion. This reflects the limitation of UIQM, which may favor high saturation and contrast, even when the perceptual quality is degraded. In
Figure 4, the images generated by WWPE tend to generate over-saturated or unnatural tones. Other deep learning-based methods, such as UWCNN and U-Shape, performed mediocre in terms of metrics and visual quality. As shown in
Figure 4, UWCNN often produces blurry textures and washed-out colors, while U-Shape slightly improves contrast. FA+Net achieved the third-best UCIQE score (0.5774) on the C60 dataset but performed poorly on UIQM. UIEC
2-Net also shows competitive performance, achieving the third-highest UCIQE score (0.5898) on the C60 dataset and the third-highest (0.6009) on U45. DATDM performs reasonably well in both metrics and visual appearance, producing relatively natural color restoration. However, our proposed LITM generates more transparent textures and more balanced tones in various scenes, outperforming DATDM in both quantitative scores and visual fidelity. Meanwhile, the performance indicators in paired datasets are superior to those in DATDM. We also use red boxes to highlight key areas and zoom in on them for enhanced visibility.
In summary, comprehensive experiments on both paired (U_90 and L_479) and unpaired (C60 and U45) datasets demonstrate the strong overall performance and robustness of the proposed LITM method. On the paired dataset, LITM achieves the best results on all key metrics, including FID, LPIPS, PSNR, and SSIM, significantly outperforming existing physical-based, non-physical, and deep learning-based UIE methods. On the unpaired dataset, although LITM does not achieve the highest scores on all UCIQE and UIQM metrics, it consistently ranks among the top, demonstrating highly competitive performance and balanced enhancement quality. LITM produces sharper textures, natural colors, and better perceptual consistency in a variety of underwater scenes. Compared to recent diffusion-based methods, such as DM and DATDM, LITM exhibits a stronger generalization ability and superior visual quality. These results confirm the generality and adaptability of LITM for underwater image enhancement tasks.
4.4. Computational Complexity Comparison
To comprehensively evaluate the computational efficiency of the proposed LITM framework, we compare its model complexity and runtime with those of several representative UIE methods in terms of the number of parameters (Params), inference time (Infertime), and floating-point operations (FLOPs), as shown in
Table 4.
Our LITM model achieves a good balance between lightweight design and computational performance. Specifically, it contains only 0.42 M parameters, which is significantly smaller than U-Shape (31.62 M), UVZ (5.39 M), DM (10.2 M), and DATDM (18.34 M). Despite being more compact than UIEC2-Net (0.54 M), our method maintains a strong enhancement capability while reducing inference time to 0.0317 s, making it more suitable for real-time or low-latency applications. In terms of FLOPs, LITM reaches 28.04 GFLOPs, which is notably lower than UVZ (124.88 G), DM (62.3 G), and DATDM (66.89 G), and comparable to UIEC2-Net (26.06 G) and U-Shape (26.09 G). Although UWCNN (2.61 G) and FA+Net (0.5852 G) exhibit very low computational complexity, their enhancement performance and perceptual quality remain limited. These results demonstrate that LITM not only reduces the computational burden but also offers superior inference efficiency. Overall, compared to both traditional deep models and recent diffusion-based methods, LITM offers an efficient solution with minimal computational cost, making it well-suited for deployment in resource-constrained environments.
4.5. Methodological Comparison and Analysis of Existing UIE Methods
In
Table 5, we present a methodological analysis of various representative UIE methods and summarize their main theoretical foundations as well as their advantages and disadvantages. Traditional physics-based methods (e.g., UDCP) offer good interpretability and are easy to implement. However, they often exhibit poor generalization and limited enhancement performance in complex underwater environments. Non-physical methods, such as WWPE, typically enable fast inference and effectively enhance image contrast, but they often suffer from over-enhancement and noticeable color distortion.
Deep learning-based methods, including UWCNN, U-Shape, FA+Net, and UVZ, generally offer improved structural reconstruction and computational efficiency. However, they exhibit notable differences in perceptual quality and generalization ability. Specifically, UIEC2-Net demonstrates strong generalization with balanced structural and color preservation, though there remains room for improvement in perceptual realism. Meanwhile, recent diffusion-based approaches (DM and DATDM) possess strong theoretical foundations and promising generative capabilities. However, their computational complexity and inference time are significantly higher, restricting their practical application scenarios.
In comparison, our proposed LITM method leverages a transformer-based architecture combined with RGB-HSV fusion, achieving an optimal balance between perceptual quality, structural fidelity, and computational efficiency. Although LITM has slightly higher computational overhead than simpler CNN-based methods, it still demonstrates excellent overall performance, adaptability, and generalization capabilities under a variety of underwater imaging conditions.This comprehensive methodological analysis further validates the advantages and novelty of our proposed approach.
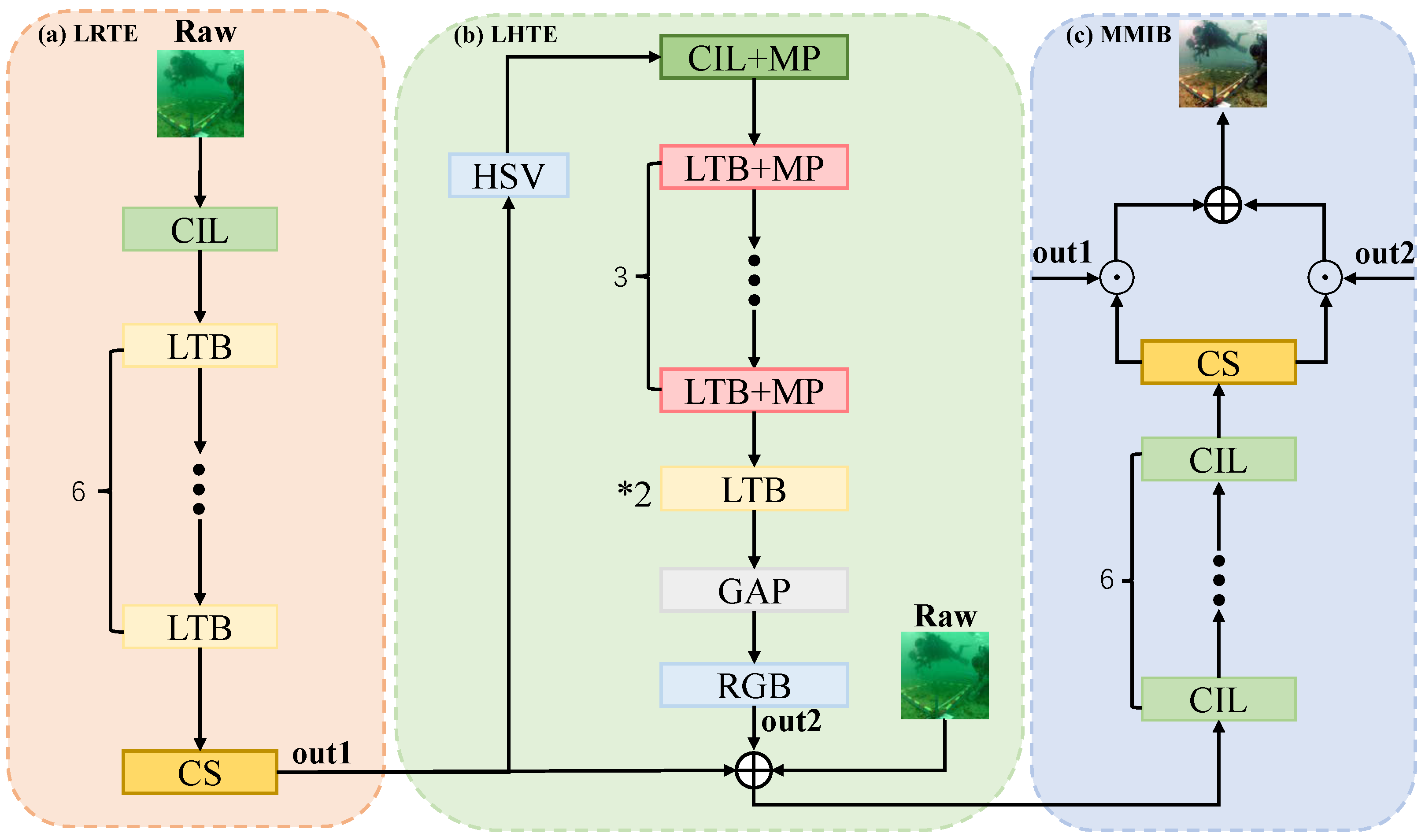
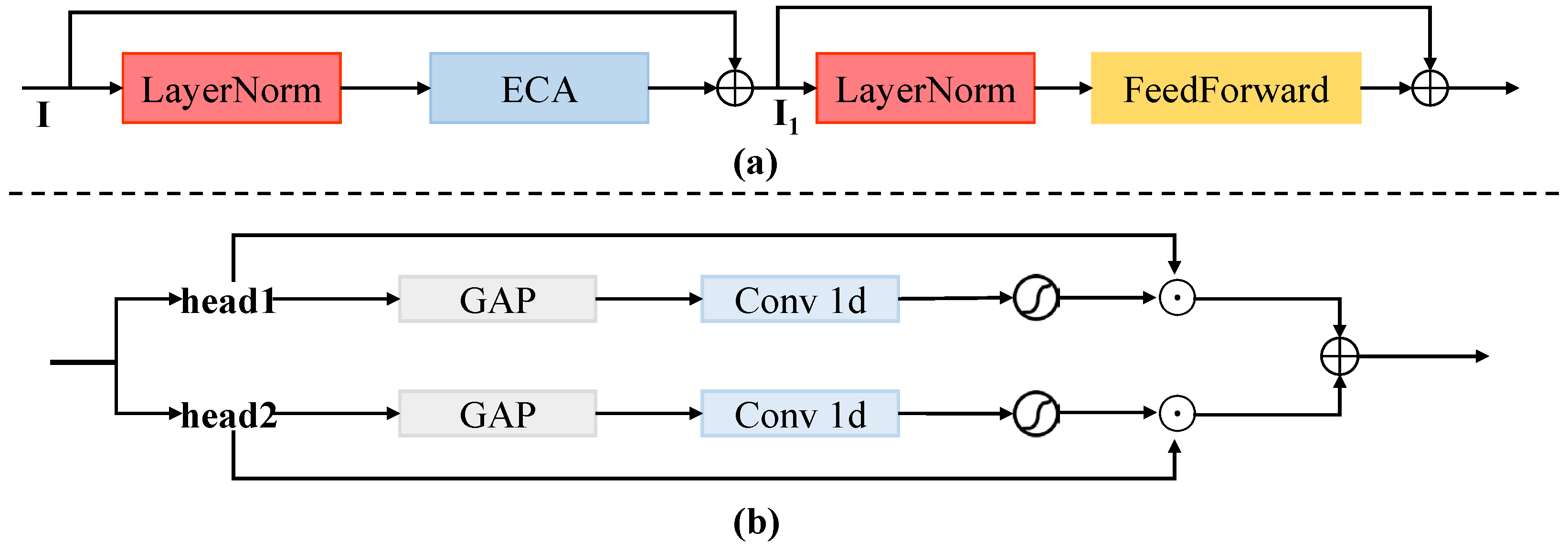
4.6. Ablation Studies
To demonstrate the effectiveness of our proposed LRTE, LHTE, and MMIB modules, we design ablation experiments to compare LITM with a model containing only LRTE (denoted as Model-A) and a model containing both LRTE and LHTE (denoted as Model-B). As shown in
Table 6, Model-B outperforms Model-A in FID, PSNR, SSIM, and UCIQE, indicating that the introduction of the LHTE module enhances structural restoration and color balance. The LPIPS scores of both models are nearly identical (0.1167 vs. 0.1168), suggesting comparable perceptual similarity. However, the lack of effective integration of the global features introduced by LHTE resulted in a slight decrease in the UIQM score of Model-B compared with Model-A. We introduce the MMIB module into the LITM model, which effectively addresses this limitation and achieves significant improvements in all indicators. LITM achieves the best FID (28.68), LPIPS (0.0989), PSNR (23.70), SSIM (0.9048), UCIQE (0.6227), and UIQM (0.8250). These results verify the effectiveness of each module and confirm the advantages of their joint design within the LITM framework.
As shown in
Figure 5, we show the original input, model-A (only LRTE), model-B (LRTE and LHTE), and the enhanced results generated by the LITM model, and make visual comparisons with the ground truth (GT). In the first row of results, the enhanced results generated by model-A have relatively weak color restoration and noticeable artifacts in the background. Model-B improves color saturation and detail preservation, but its enhanced images have slight overexposure and imbalance in some areas. In contrast, the enhancement results generated by the proposed LITM are significantly closer to the real images. In the second and third rows, LITM not only restores more transparent object textures but also eliminates the residual color distortion in Model-A and Model-B. These qualitative results further demonstrate the effectiveness of integrating LRTE, LHTE, and MMIB modules in enhancing underwater images.
We conducted ablation experiments on the loss function to demonstrate the contribution of perceptual loss (
) and reconstruction loss (
) individually. As shown in
Table 7, using only
or only
results in substantially poorer performance on most metrics (FID, LPIPS, PSNR, and SSIM), compared to the combined loss function
. Notably, employing either loss alone severely reduces the perceptual quality and structural fidelity of enhanced underwater images, leading to significantly lower PSNR and SSIM values and notably higher FID and LPIPS scores. Although other image quality metrics degrade significantly, the UCIQE and UIQM scores of (
and
) are unexpectedly high. This contradictory result occurs because UCIQE and UIQM overemphasize contrast and color enhancement while ignoring perceptual realism and structural integrity. Therefore, severe distortion and unnatural enhancement not only damage visual realism but also inadvertently improve UCIQE and UIQM scores.
Overall, these results demonstrate that the combined achieves significantly superior performance and visually plausible enhancements compared to the individual loss components.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}