1. Introduction
As wind power expands globally, aging turbines are failing more often [
1]. Gearboxes, as wind turbines’ critical transmission component, not only account for the most significant downtime (exceeding 20% of total failure-related outages [
2]) but also require high maintenance costs [
3,
4]. The health status of the gearbox directly affects the overall system reliability and power generation efficiency. Among all gearbox components, the gearbox high-speed shaft (GHSS) is especially vulnerable. Common failure modes of wind turbine gearbox high-speed shafts include fatigue fracture (often initiating at stress concentrators like shoulders or keyways due to cyclic bending/torsional loads), shaft damage induced by bearing failure (causing wear, bending, or micro-fretting at bearing seats), various wear mechanisms (abrasive, adhesive, or fretting wear from contamination or lubrication issues), overload fracture/bending from extreme transient events, and corrosion or corrosion-fatigue accelerated by moisture ingress [
5]. The temperature anomaly of the GHSS is a critical early indicator of these potential failures [
6].
The supervisory control and data acquisition (SCADA) system, widely used for wind turbine monitoring, tracks multiple variables, including the gearbox high-speed shaft temperature (GHSST). When the GHSST surpasses a set threshold, the SCADA system triggers alarms and shutdowns. However, the GHSST fluctuates significantly due to complex factors like environmental conditions and operational states. Fixed thresholds alone cannot reliably detect GHSS anomalies. For example, a gearbox fault under low ambient temperatures may delay the GHSST from reaching the threshold. During this delay, the turbine keeps operating with undetected faults, risking further structural damage. Thus, developing a method for timely GHSS fault detection and early warnings across diverse conditions is critical.
The structural analysis and failure investigations of GHSS can be performed using various approaches. Typical offline methods include computational fluid dynamics simulations [
7], finite element analysis [
8], and thermal network modeling [
9]. These offline methods are especially critical during the wind turbine design phases. Once the turbines are deployed, monitoring data becomes an essential tool for failure detection and fault warnings. Fault diagnosis based on monitoring signals generally falls into two categories: traditional signal analysis and data-driven approaches. Traditional signal analysis has evolved over decades, yielding various fault detection and warning methods [
10]. However, these methods typically rely on one or several following assumptions: well-defined physical mechanisms, relatively stable boundary conditions, low stochasticity, and low-dimensional data spaces [
11]. In this study, gearbox damages result from multiple factors with ambiguous physical mechanisms. The SCADA system’s long sampling periods (usually over 5 min) are inadequate for capturing transient damage processes. Furthermore, wind turbines operate under continuously varying environmental conditions and dynamic states, causing unstable boundary conditions and significant stochasticity. Additionally, the GHSST is correlated with multiple variables from the SCADA system. Multi-dimensional data are necessary for a comprehensive diagnosis. Given these constraints, it is worth investigating data-driven methods for advancing GHSS fault diagnosis and early warning.
Machine learning methods excel at extracting latent patterns from high-dimensional SCADA data [
12,
13,
14]. The current research predominantly focuses on fault diagnosis (i.e., fault classification and localization), while fault prediction and early warning are relatively limited [
15,
16,
17]. Traditional machine learning methods perform well in fault classification. However, these methods rely heavily on manual feature engineering, making them less adaptable to dynamic operating conditions. Deep learning, leveraging hierarchical nonlinear transformations, significantly enhances detection accuracy [
18]. Shao et al. proposed a novel deep-autoencoder-based fault diagnosis method [
19]. It integrates the maximum correntropy criterion for robust feature learning under noisy conditions and the artificial fish swarm algorithm for adaptive parameter optimization. Experimental validation demonstrated its superior effectiveness in gearbox and bearing fault detection. Other fault diagnosis models include convolutional neural networks (CNNs) [
20], long short-term memory networks (LSTM) [
21], extreme gradient boosting (XGBoost) [
22], gated recurrent units [
23], and stacked models [
24]. Nonetheless, these approaches primarily focus on classification tasks, with limited research on fault prediction.
Fault prediction infers the future state evolution from historical data, offering greater engineering value than passive diagnostics [
25]. Model-based methods rely on a residual analysis against normal operational baselines to generate early alerts [
26,
27]. Model selection is critical, determining generalization capabilities from historical to future states. Common approaches include artificial neural networks (ANNs) [
28] and principal component analysis (PCA) [
29]—ANN achieves a 44.4% cost reduction in wind farm maintenance, while PCA attains sub-1% false alarm rates in sensor networks. However, their limitations persist: ANN overlooks mechanical interdependencies and environmental dynamics, while PCA struggles with nonlinear sensor responses and real-time demands. Rezamand et al. reviewed the adaptive-network-based fuzzy inference system (ANFIS), recurrent neural network (RNN) variants, and extreme learning machines for the remaining useful life prediction [
30], finding hybrid methods (e.g., ANFIS with particle filtering or Bayesian algorithms) superior for accuracy under variable conditions. Time-series regression models of temperature parameters effectively assess turbine health [
31]. XGBoost and LightGBM are two emerging fault detection methods. Studies demonstrate their superiority over traditional deep learning approaches due to their robustness and computational efficiency as well as their abilities to work with real-time data [
32,
33].
Selecting appropriate indicators proves critical for fault prediction under constantly shifting boundary conditions. For example, fixed-threshold temperature methods lack adaptability to operational variability and require repeated calibration across turbine fleets, hindering generalizability [
34]. Similarly, RMSE-based warnings rely solely on monolithic metrics that overlook data dependencies, triggering false alarms or missed detections [
35]. Bangalore et al. [
36] demonstrate the use of the Mahalanobis distance as a dynamic threshold alternative that outperforms traditional methods. Nevertheless, this approach assumes multivariate normality—an invalid premise for gearbox temperature data during sudden operational shifts where bimodal distributions cause erroneous anomaly probabilities. Its static covariance matrix also fails to track the system evolution over time.
The challenges for GHSS fault prediction in engineering applications can be summarized as follows:
Noise sensitivity: Raw SCADA data contains multi-source noise, such as shutdown periods and power-limiting operations. Existing data-cleaning methods lack the adaptability to heterogeneous noise, adversely affecting model performance [
37,
38].
Insufficient spatio-temporal coupling modeling: The low-frequency nature of SCADA data results in the inadequate extraction of cross-variable interactions and long-term dependencies. Additionally, determining optimal network hyperparameters remains challenging, and some studies fail to model normal operating conditions effectively.
Lack of dynamic adaptability in alarm indicators: The fixed-threshold alarm mechanism in the SCADA system struggles to detect early-stage temperature accumulation leading to faults. Moreover, most existing fault-warning methods rely on single statistical error metrics as thresholds, neglecting dynamic data correlations. This results in poor adaptability and limited generalization across different operational scenarios.
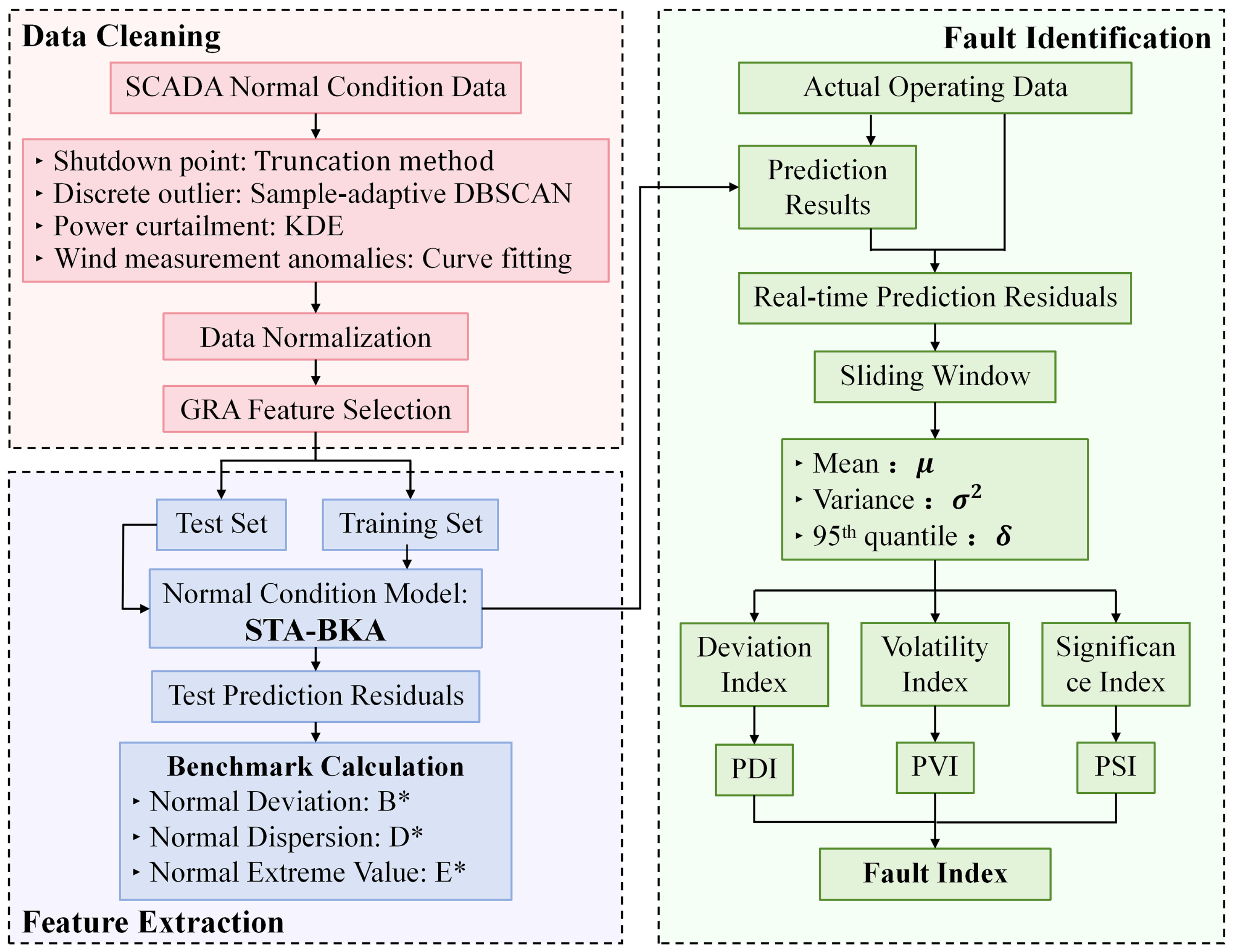
To overcome the aforementioned challenges and enhance wind farms’ maintenance, a comprehensive architecture is proposed, including data preprocessing, multi-dimensional spatial feature extraction, temporal dependency modeling, global relationship learning, and hyperparameter optimization. The remainder of the paper is organized as follows:
Section 2 introduces the proposed method, including methods for multidimensional data cleaning, the composition of the improved hybrid deep learning model, and the principles of fault early warning.
Section 3 presents the preprocessing of SCADA data from actual wind turbine operations, including data cleaning algorithms, normalization, and steps for feature extraction.
Section 4 details the mathematical formulation of the proposed hybrid deep learning architecture.
Section 5 applies the model to predict the GHSST in real wind turbine operation cases, comparing the operational data preceding failures with fault logs to generate warnings via fault indices. Finally,
Section 6 concludes the paper.
3. Data Description and Preprocessing
3.1. Data Sources
This study utilizes operational data from a wind farm located along the coast of China to conduct a detailed analysis of gearbox-type wind turbines. The wind farm has an installed capacity of 49,500 kW, comprising 33 wind turbines, each with a hub height of 70 m and a stand-alone capacity of 1500 kW. The operational data analyzed in this study spans from 1 December 2022, to 15 February 2023, and was collected through the SCADA system at 5 min intervals. The key data categories include wind-related metrics, such as wind speed, wind direction, and nacelle-wind angle. Temperature variables include ambient temperature and internal component temperatures. Electrical variables encompass active and reactive power. Operational parameters include nacelle orientation, with a northerly offset, and wind turbine speed. These data collectively provide a comprehensive overview of the turbines’ performance under various operational conditions.
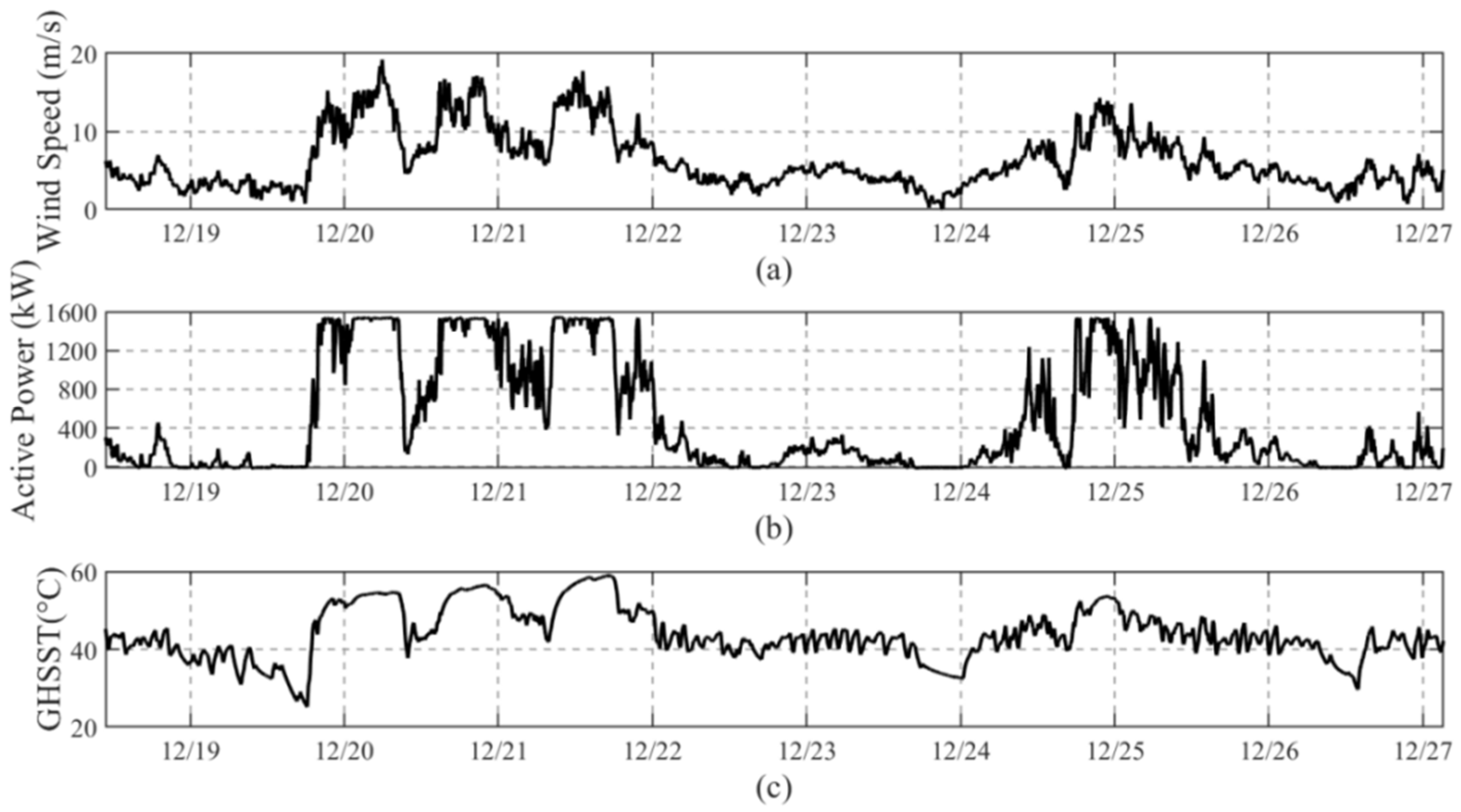
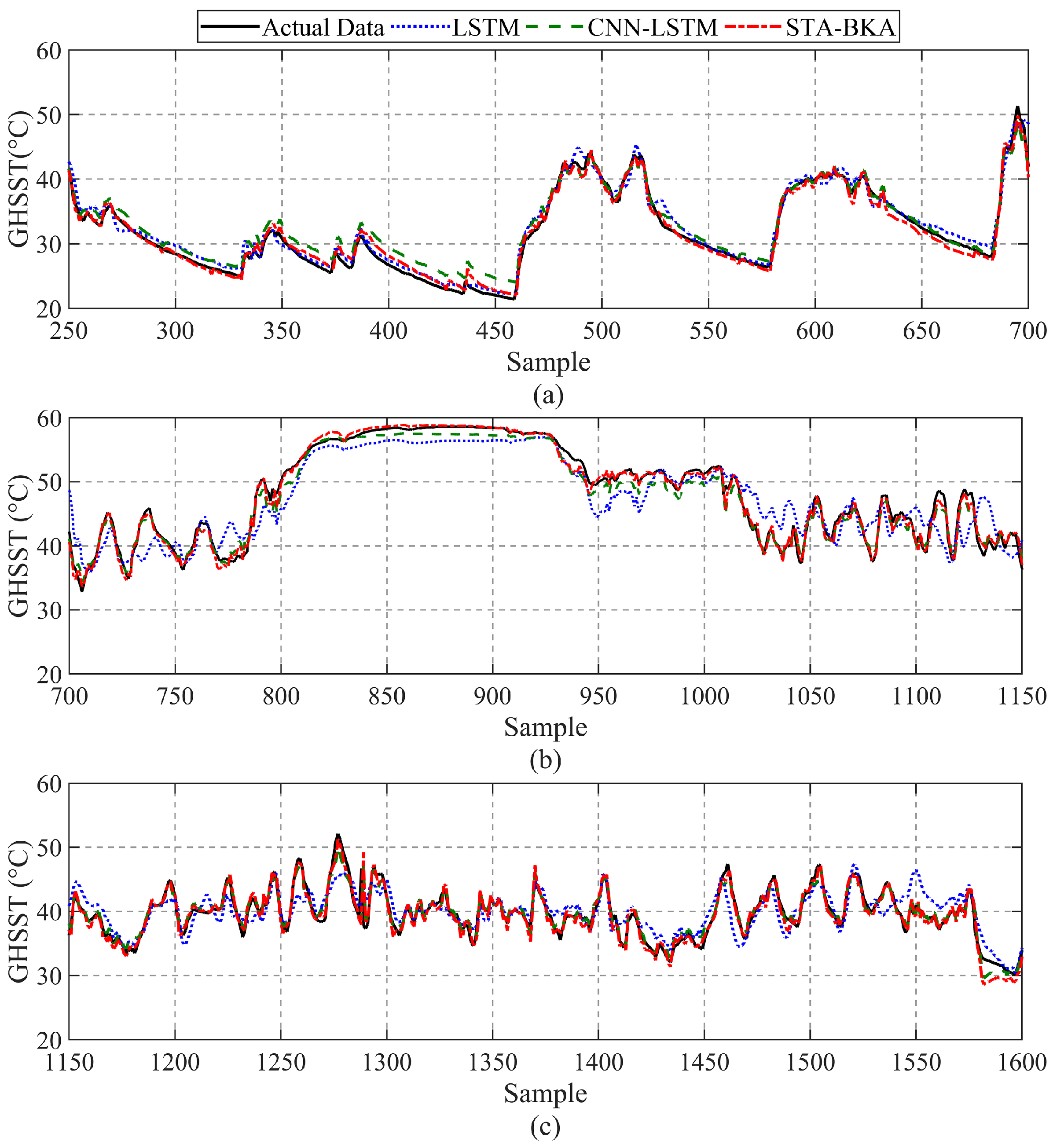
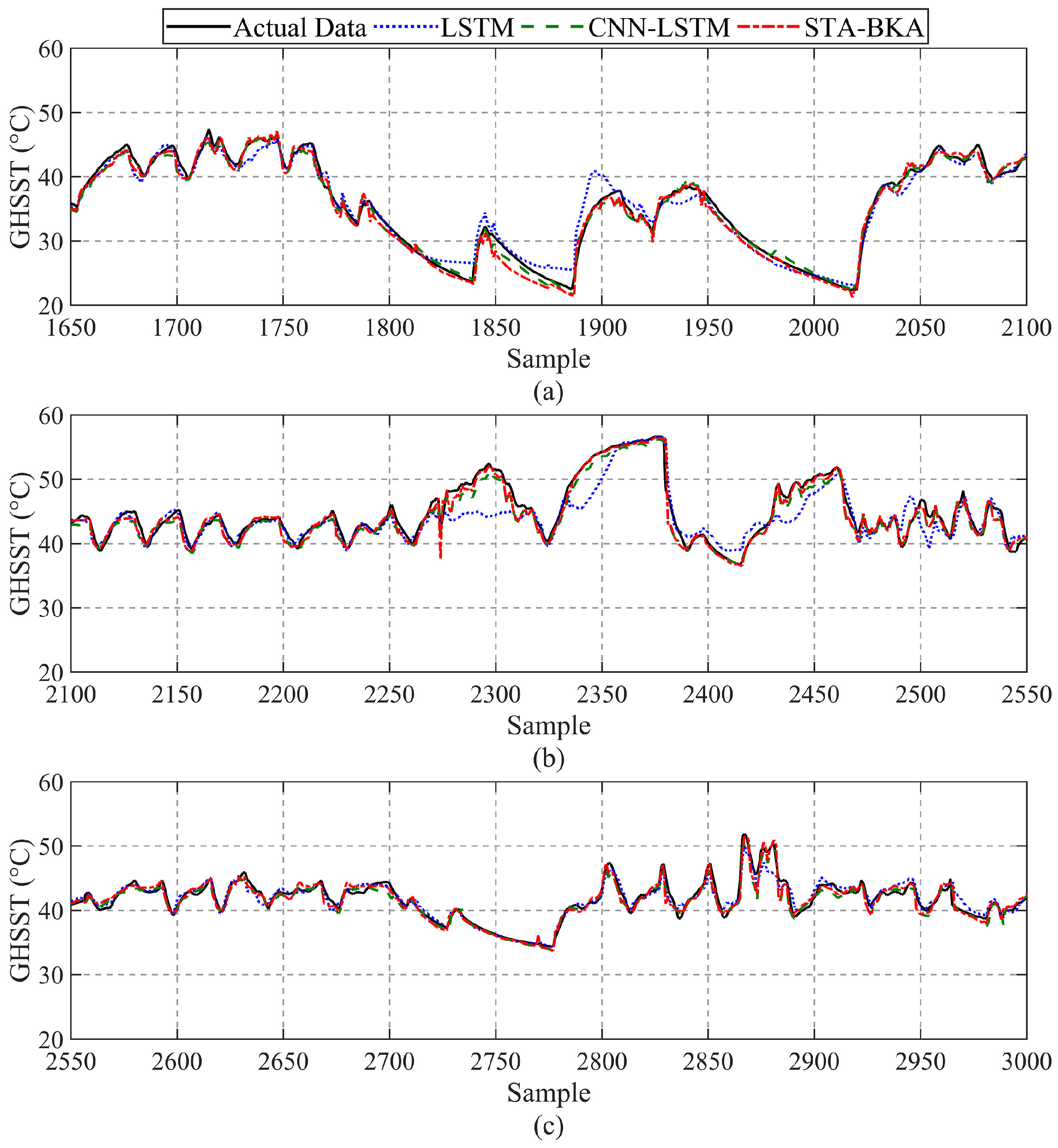
Traditional fault detection methods using SCADA data focus on the secondary effects of faults, with abnormal conditions often detected through heat generation in gearbox components. While the SCADA system monitors hundreds of different signals, this study concentrates on high-temperature fault-related signals to construct the normal behavior model. A subset of the monitored data is presented in
Figure 5. The figure depicts the time histories of wind speed, active power, and GHSST from 18 December to 25 December. These variables exhibit similar trends; however, the active power responds almost instantaneously to changes in the wind speed, while GHSST demonstrates a delayed response to active power. Specifically, wind speed varies between 0 m/s and 20 m/s, exceeding the rated wind speed of 11 m/s during four distinct periods. During these intervals, the power output reached its rated power of 1500 kW. Conversely, when wind speed was below the cut-in speed of 3 m/s, the turbine generated no power. When the turbine operated at low power, the GHSST fluctuated around 40 °C. During turbine shutdown, the GHSST gradually decreased, occasionally falling below 30 °C, depending primarily on the ambient temperature. When the turbine resumed operation at rated power, the GHSST rapidly increased, reaching 50 °C, after which the temperature rise rate slowed and gradually stabilized within the range of 55 °C to 60 °C. The correlation among these variables supports the feasibility of diagnosing and predicting turbine performance based on SCADA monitoring signals.
In this study, the operational data from two wind turbines, WT#106 and WT#122, within the wind farm were selected as the primary dataset due to their diverse anomalies and GHSS fault occurrences. The dataset covers a period from 00:00:00 on 1 December 2022, to 07:00:00 on 15 February 2023. Data were sampled with high frequency but recorded at five-minute intervals, yielding a total of 21,876 data points. After applying a comprehensive data cleaning process to WT#106, 18,940 data points were retained, indicating that approximately 13.4% of the recorded data were identified as noise and subsequently removed. For WT#122, a total of 18,695 data points remained post-cleaning, with about 14.5% deemed noise and extracted
3.2. Data Cleaning Algorithm and Verification
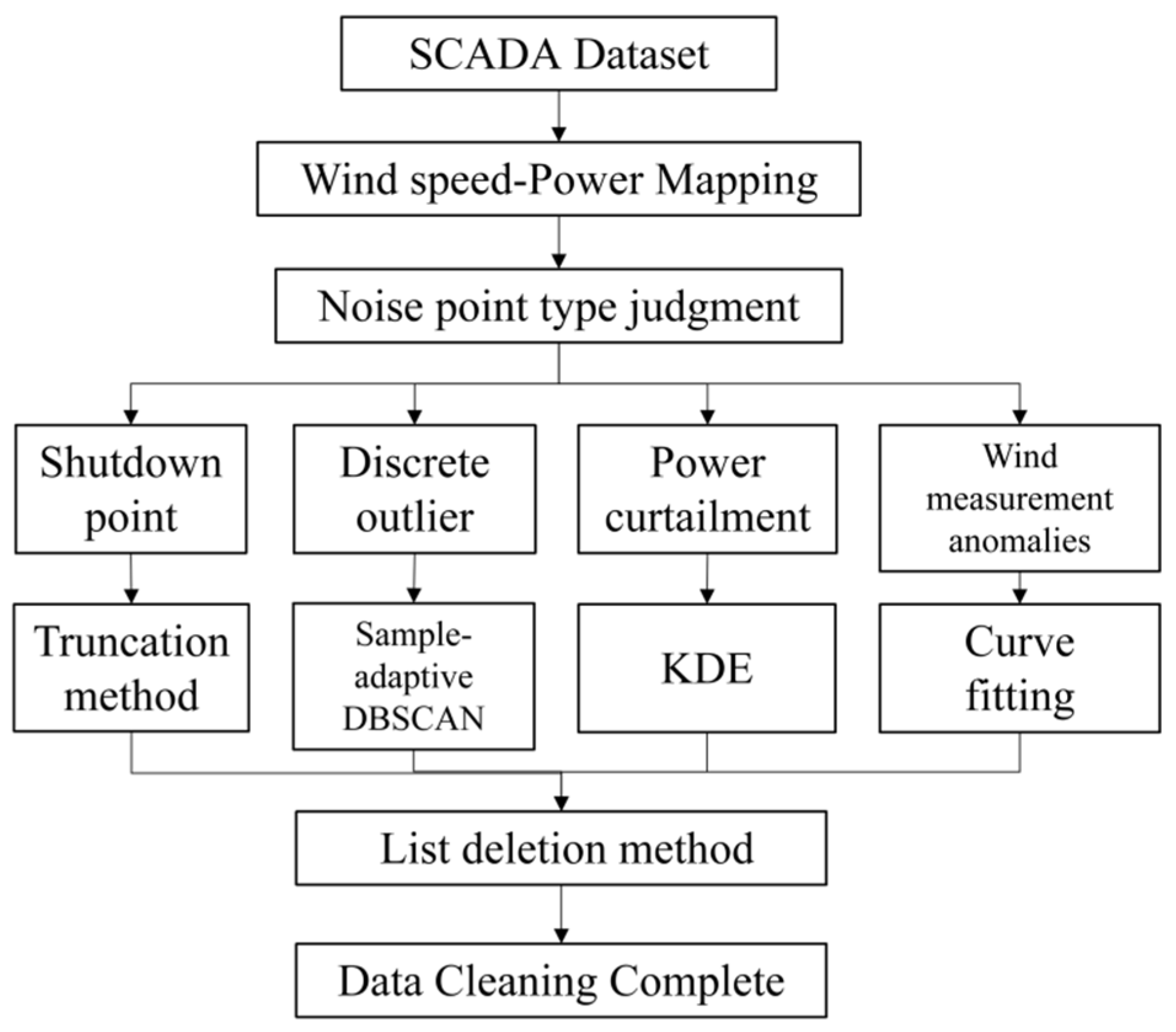
3.2.1. Anomalous Data Identification
Anomalous data can be effectively cleaned based on their spatial distribution characteristics on the WSP curve, ensuring a robust approach applicable to various types of anomalies. The anomalous data can be categorized into four types, based on the operational status and distribution characteristics, as illustrated in
Figure 6.
Shutdown point: The turbine is shut down due to faults, sensor failures, or scheduled maintenance, leading to zero power output irrespective of wind speed. In the WSP graph, the output power remains at 0 even when the wind speed exceeds the cut-in threshold.
Discrete outliers: These abnormal data points exhibit irregular dispersion, typically arising from random events such as sensor malfunctions or sudden climatic changes. In the WSP graph, they appear as irregularly scattered data points.
Power curtailment: These data points primarily stem from the curtailment of wind power. Although the turbines function normally, factors such as grid constraints, instability in wind power generation, or mismatched construction schedules prevent full power operation. The characteristic feature of such data is a constant active power, represented as a horizontal straight line in the graph. This phenomenon does not occur in all turbines.
Wind measurement anomalies: These anomalies occur due to anemometer measurement errors, resulting in a shape similar to the probability power curve. They appear either above or below the expected probability power curve.
3.2.2. Anomalous Data Cleaning
Shutdown point: When the wind speed is between the cut-in and cut-out wind speeds, the generator operates and the output power is non-zero. Therefore, the SCADA data should be truncated according to Equation (8).
In this equation, Pi represents the output power at time i, Vi is the corresponding wind speed, and Vin and Vout denote the cut-in and cut-out wind speeds, respectively.
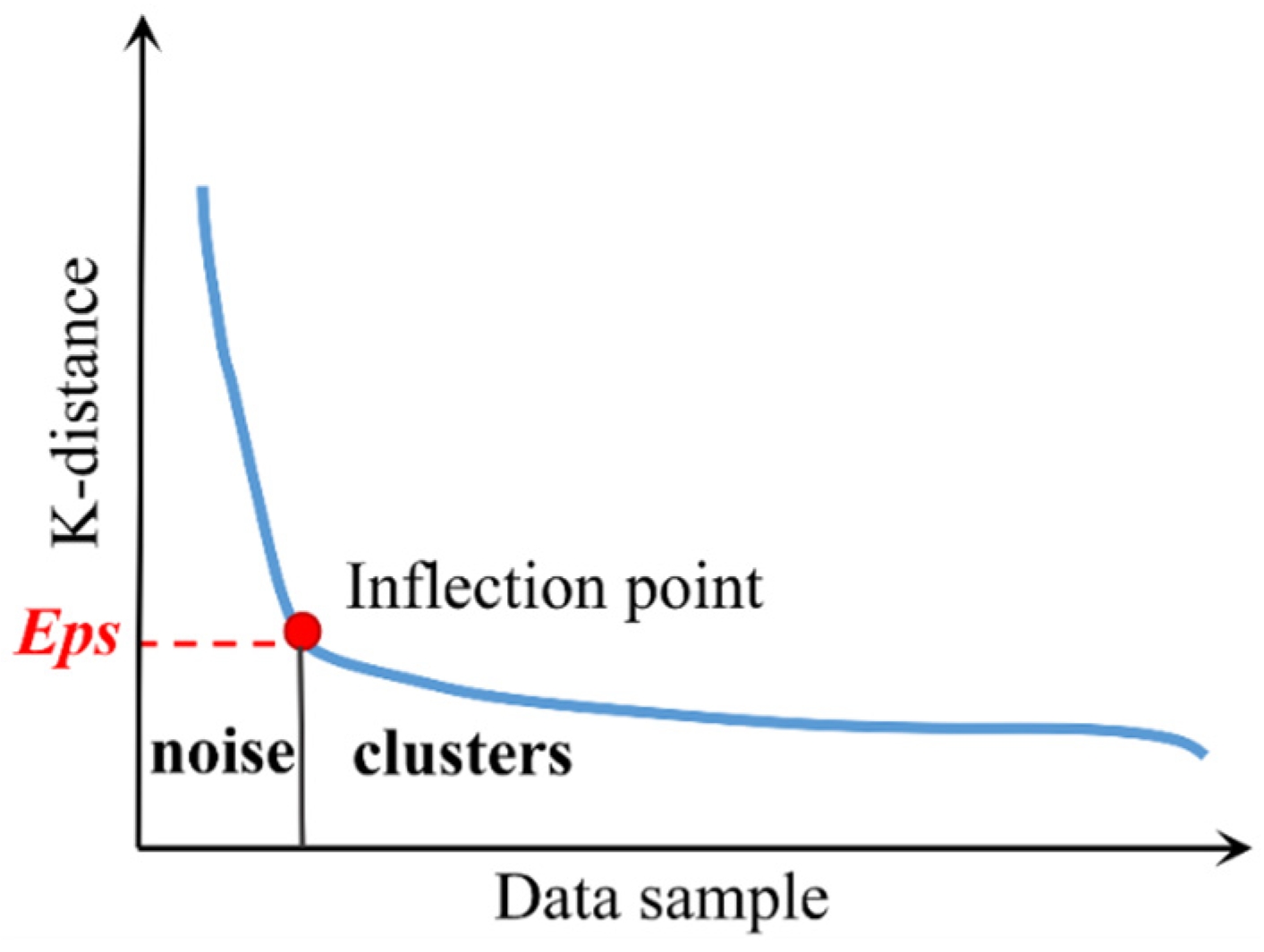
The key characteristic of discrete noise data is its random and scattered distribution, making it difficult to describe using a mathematical model. We adopt DBSCAN for identifying the discrete points [
41]. The DBSCAN method has two parameters to be determined, the domain radius
Eps and the minimum number of points within the domain radius
MinPts. K-distance curves are drawn, and the value at the inflection point is set as the domain radius
Eps, as shown in
Figure 7, where the K-distance is the distance between each data point and the
k-th nearest point.
The substantial volume of the SCADA data from wind turbines in this study necessitated an optimized parameter selection methodology. We developed an adaptive sample-size-based approach, where the key parameter
k is determined by the heuristic relationship
k = ln(
Ntotal), with
Ntotal denoting the total number of data. The conventional determination of
MinPts typically relies on the mathematical expectation of sample counts within
Eps-neighborhoods. However, the SCADA data from wind turbines presents two critical challenges: (1) massive normal dataset scales and (2) high-density distributions within
Eps-neighborhoods. The direct application of statistical expectations would yield excessively large
MinPts values, thereby compromising clustering efficacy. Given that the DBSCAN clustering objective focuses on detecting sparsely distributed anomalies that deviate from normal operational clusters, which typically constitute approximately 10% of the dataset, this work proposes the following empirically validated formula to determine
MinPts:
where
represents the amount of data within the
i-th
Eps-neighborhood, and these values are arranged in ascending order. A smaller number of data points within the neighborhood indicates a more discrete data distribution, suggesting a higher likelihood of the presence of discrete abnormal points. In this paper, the values of
are sorted in ascending order, which shows that the earlier a neighborhood is in the sequence, the fewer data points it contains, while the data points become denser as the sequence progresses. By calculating the mean value of the top 10% of
values, a more suitable
MinPts value can be identified among discrete abnormal points more effectively.
KDE is a non-parametric method employed to estimate the probability density function (PDF). KDE applies a smooth kernel function to fit the observed data points, thereby approximating the underlying probability distribution. The presence of stacked anomalous data can result in bimodal or multimodal distributions in the PDF. To address this issue, the PDF curves of power scatter points across various wind speed intervals are adjusted by peak-shaving to eliminate anomalies associated with low-density peaks. This process transforms multimodal distributions into unimodal ones, effectively cleaning the stacked power limitation data.
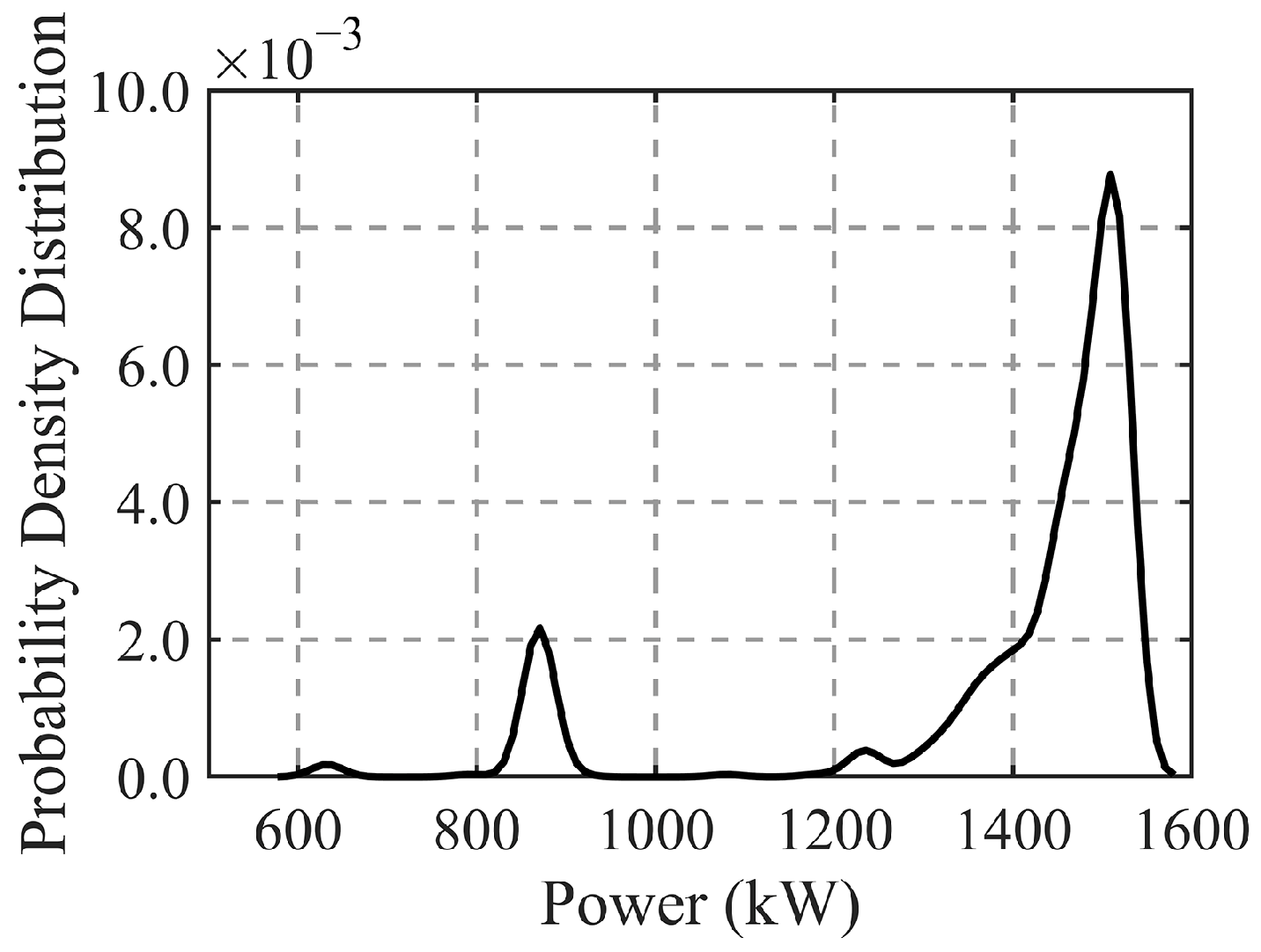
Take WT#106 with a wind speed range of 10–13 m/s as an example, as shown in
Figure 8. Under normal operating conditions, the active power should be approximately 1500 kW. However, due to the presence of a power limitation, the power in this wind speed range occasionally drops to around 870 kW. The peak-shaving process can remove outputs below 1000 kW in this interval. The figure also shows small peaks at 630 kW and 1230 kW, indicating power-limiting points that require cleaning.
The distribution of these anomalies in the WSP scatter plot resembles the main shape under normal operation. A sigmoid curve is applied to fit the wind speed–power scatter plot, and points beyond the quartile distance from the fitted curve are removed to complete the cleaning of the anemometer noise data. The mathematical expression of the sigmoid curve is shown in Equation (11).
Since the number of noisy data points is small and appears randomly, direct deletion has minimal impact on the overall data distribution. Therefore, deleting the entire timestamp containing noise points preserves the spatiotemporal relationships of each variable and ensures high-quality data for subsequent analyses.
3.2.3. Data Cleaning Case
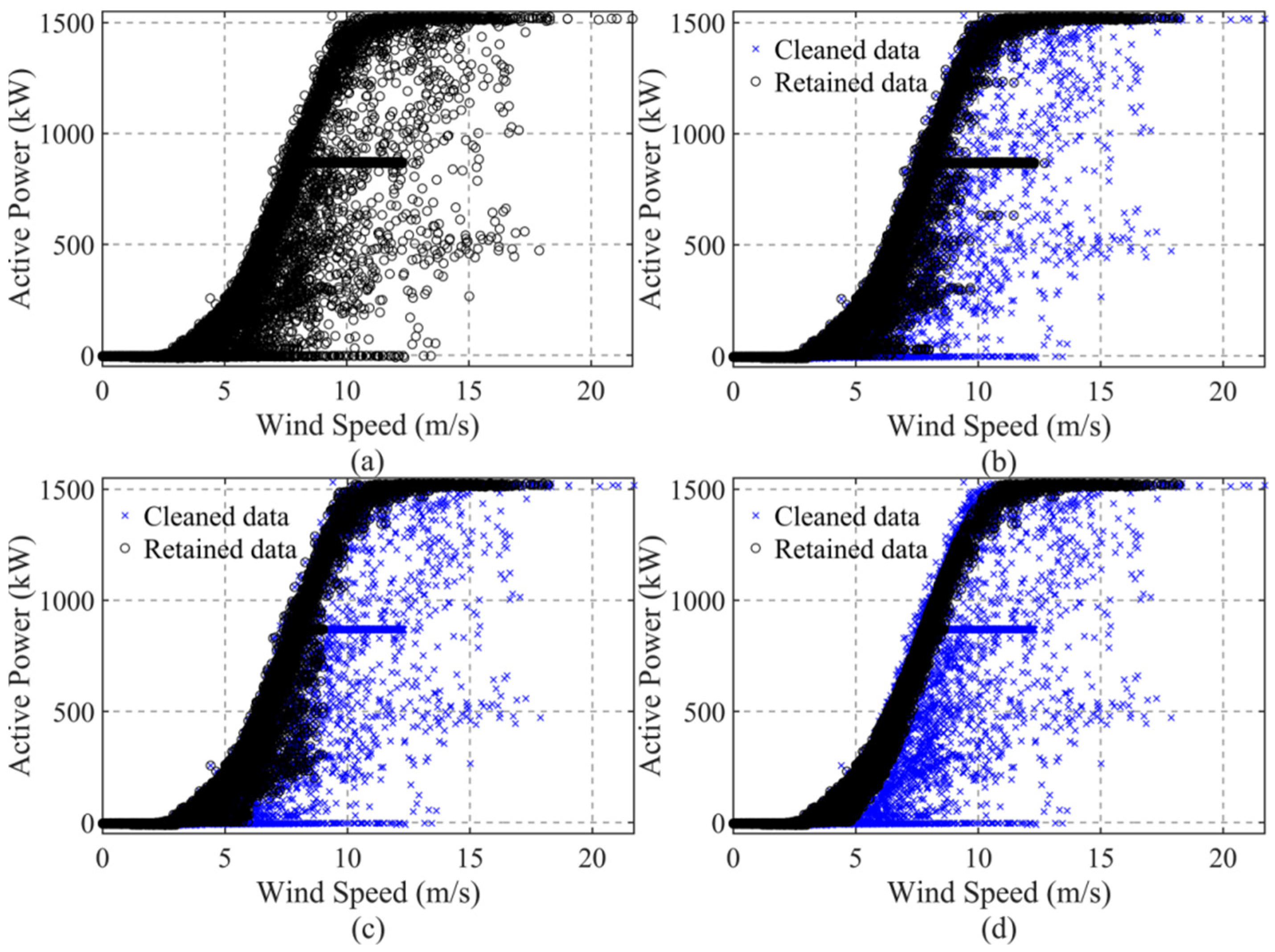
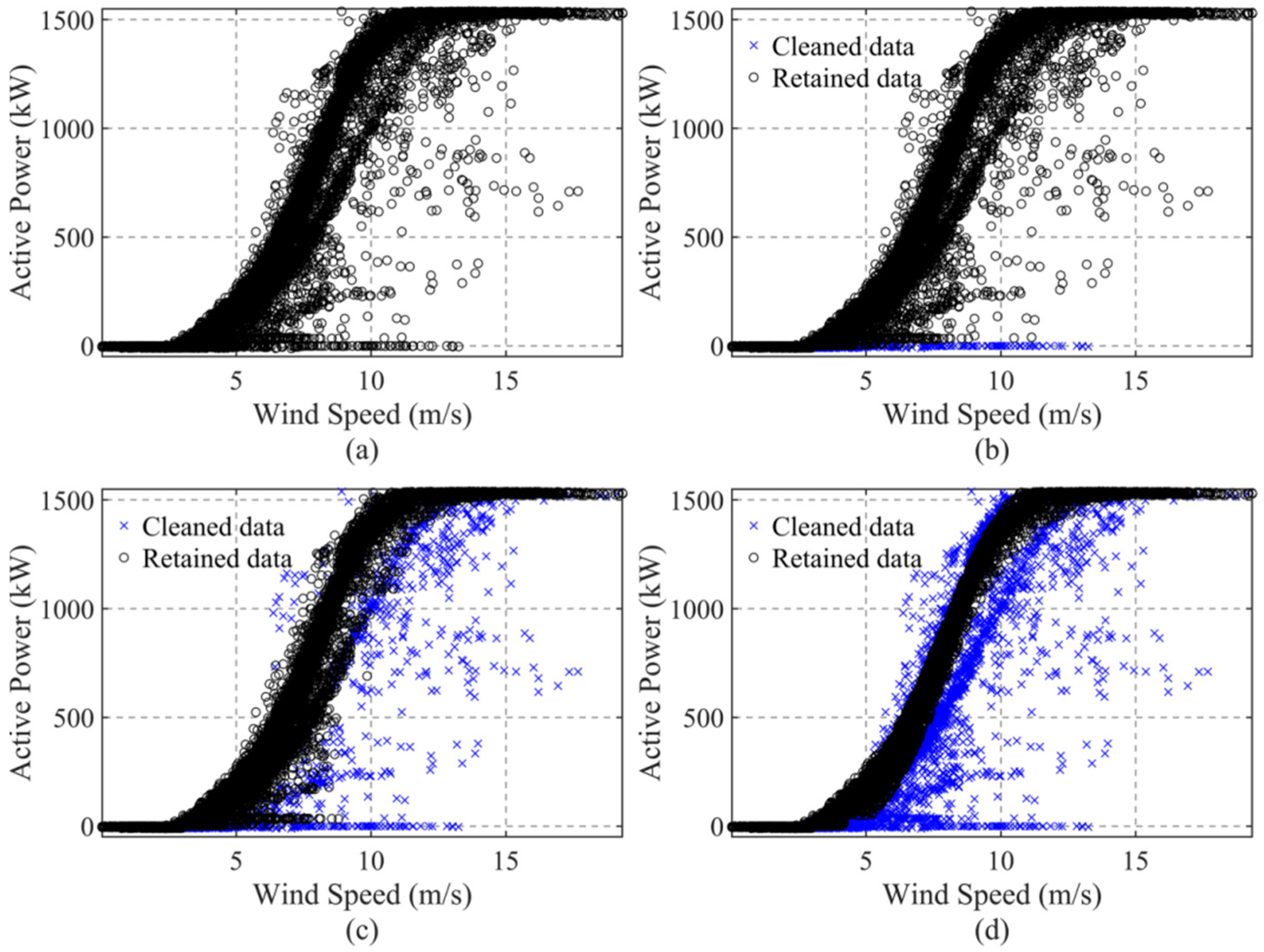
Before data cleaning, it is essential that we analyze the distribution characteristics of the original WSP curve to identify the types of anomalies. The cleaning process should then be customized according to each specific anomaly type. To comprehensively demonstrate the effectiveness of the proposed data cleaning algorithm, the operational monitoring data from WT#106, which contains all types of noise data, was selected for cleaning. According to the original power curve as shown in
Figure 9a, the data contains shutdown points, discrete noise points, power curtailment points, and stacked anomalies below the normal power curve. The stacked noise points below the curve exhibit an upward trend similar to that of the original curve, indicating wind measurement anomalies. The results of the targeted and step-by-step cleaning process, as described in
Section 2.2, are shown in
Figure 9b–d.
First, the truncation method and DBSCAN clustering are applied to clean the downtime points and discrete noise points. The results are shown in
Figure 9b. At this stage, the power-limited points become more intuitively visible, and the probability density characteristics are more apparent. In
Figure 9c, KDE is used to clean the power-limiting points. The lower part of the curve contains stacked noise points with a trend similar to that of the main body of the normal data points. The fitting method is then employed to remove points that deviate more than the 95th percentile from the fitted curve.
Figure 9d displays the final cleaning results, where noise data is thoroughly removed while maximizing the retention of normal operational data.
The wind measurement anomalies in WT#122 are more pronounced. An examination of the original power scatters in
Figure 10a reveals stacked shutdown points, discretely distributed anomalous data, and side wind anomalies with a trend similar to the normal wind speed–power curve. First, the truncation method is applied to remove downtime data points, with the results shown in
Figure 10b. DBSCAN clustering is then used to eliminate discrete noise points, as shown in
Figure 10c. The characteristics of wind measurement anomalies are clearly visible, along with power-limiting points at the bottom of the curve. These anomalies are cleaned using the fitting method, with the final results displayed in
Figure 10d.
3.3. Data Normalization
In deep learning models, normalization ensures that the value ranges of different features are comparable, preventing certain features from disproportionately influencing the loss function during training. This accelerates model convergence, improves training efficiency, and mitigates issues such as gradient explosion and vanishing gradients. Furthermore, normalization enhances the model’s performance and generalization ability, ensuring stability and robustness when handling features with different units and scales. Therefore, normalization is a crucial step in ensuring an efficient and robust model operation.
For preprocessing SCADA monitoring variables, this study employs z-score normalization to standardize features with different scales into a standard normal distribution (mean of 0, and standard deviation of 1). This process eliminates disparities in feature scales and ensures that each feature contributes equally during model training. The z-score is calculated according to Equation (12):
where
Z represents the normalized matrix,
I denotes the input matrix,
mu is the vector of the means of each variable, and
sig is the vector of the standard deviations of each variable.
3.4. Feature Selection
The SCADA system is a comprehensive data monitoring and acquisition platform that tracks dozens, or even hundreds, of parameter variables. Directly using all these variables for data modeling may introduce redundant information. Therefore, it is essential that we select the most relevant variables. The GHSST is chosen as the model’s target variable. The grey relational analysis (GRA) method is employed to identify the key factors influencing this temperature. GRA assesses the strength of relationships between the target temperature and other operational state variables, even in cases of incomplete data. By quantifying the similarity between data series, GRA identifies variables with higher grey correlation coefficients, which are then selected as input features for the training model.
The grey relational degree is calculated as shown in Equation (13):
where
x0 represents the temperature of the high-speed shaft of the gearbox (the parent sequence),
xi denotes other variables monitored by the SCADA system (the subsequences),
i represents different monitored variables,
l is the length of the monitoring sequence over the selected time period, and
ρ is the resolution coefficient, set to 0.5 in this study, balancing outlier suppression and relational discrimination for SCADA data. Once the correlation coefficient matrix is derived from this equation, the correlation coefficients for each variable are averaged. This average quantifies the grey correlation between any SCADA-monitored variable and the GHSS temperature.
SCADA-monitored parameters can be divided into two categories based on their correlation with wind speed. The first category includes parameters significantly affected by wind speed, such as the component temperature, generator speed, and power. The second category comprises parameters primarily influenced by environmental factors and factory performance, such as the yaw position and lubricating oil pressure. Since wind turbine faults are typically caused by environmental factors in the absence of performance degradation, this study focuses on the first category of parameters. The model extracts features strongly correlated with abnormal operating states for in-depth fault diagnosis.
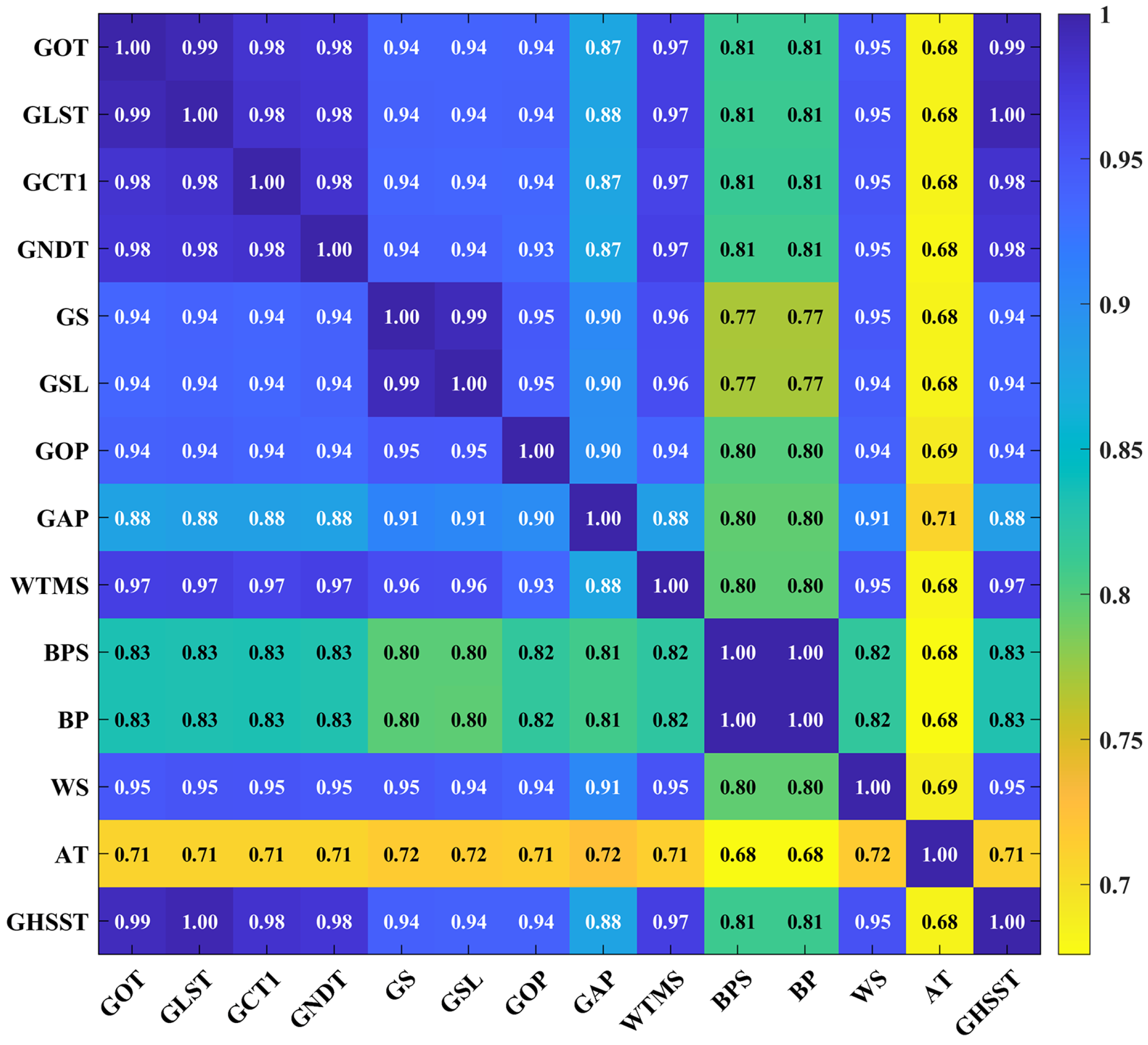
Taking the data of WT#106 as an example, the GHSST is designated as the target variable for feature selection. Fourteen variables were used for the GRA calculation, with the data input into Equation (13). The computational results, as illustrated in
Figure 11, demonstrate that the majority of variables maintain high grey relational coefficients with the target parameter. Only three variables—blade pitch setpoint, BPS, blade position, BP, and ambient temperature, AT—exhibited relatively weaker correlations. Based on the GRA outcomes, the top ten variables with the highest grey relational coefficients were selected as candidate inputs for the multi-source input prediction model. Note that the generator speed limit (GSL) exhibits a high correlation coefficient with the target variable. However, it was excluded as an input due to its inherent operational constraints. Specifically, the GSL is confined within a predefined safe range during normal operation. When the GSL approaches either its upper or lower boundary limits, it loses its capability to effectively reflect the variations in the GHSST. This limitation in dynamic responsiveness makes the GSL unsuitable as a predictive input parameter for the model. Therefore, the final selection of input features for multivariate prediction consists of nine variables, as shown in
Table 1.
6. Discussion
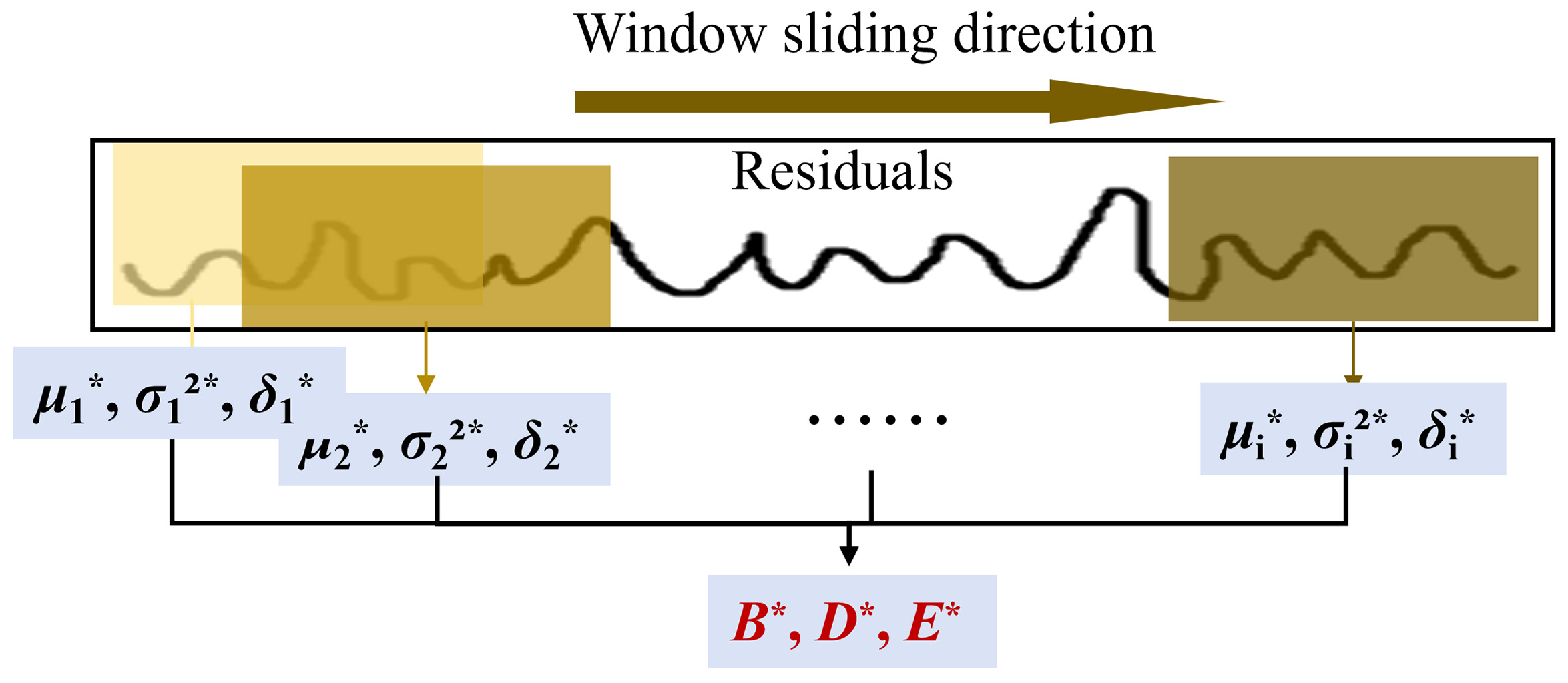
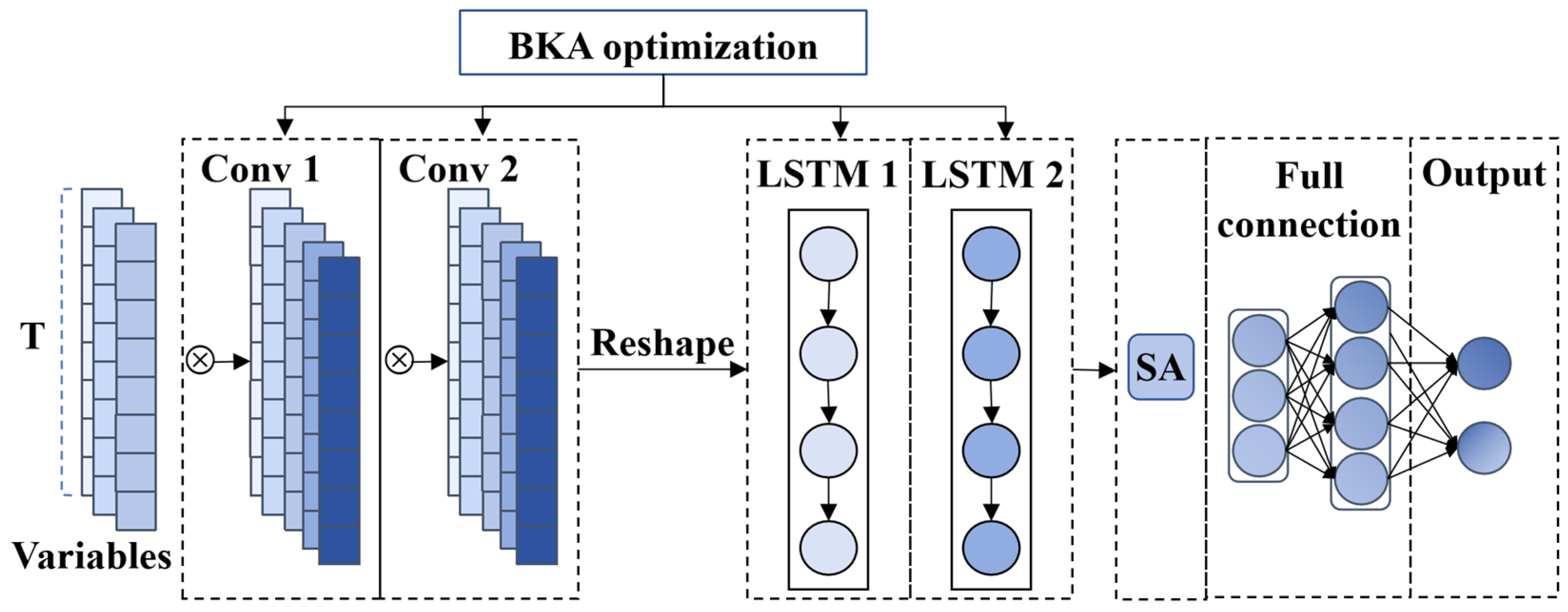
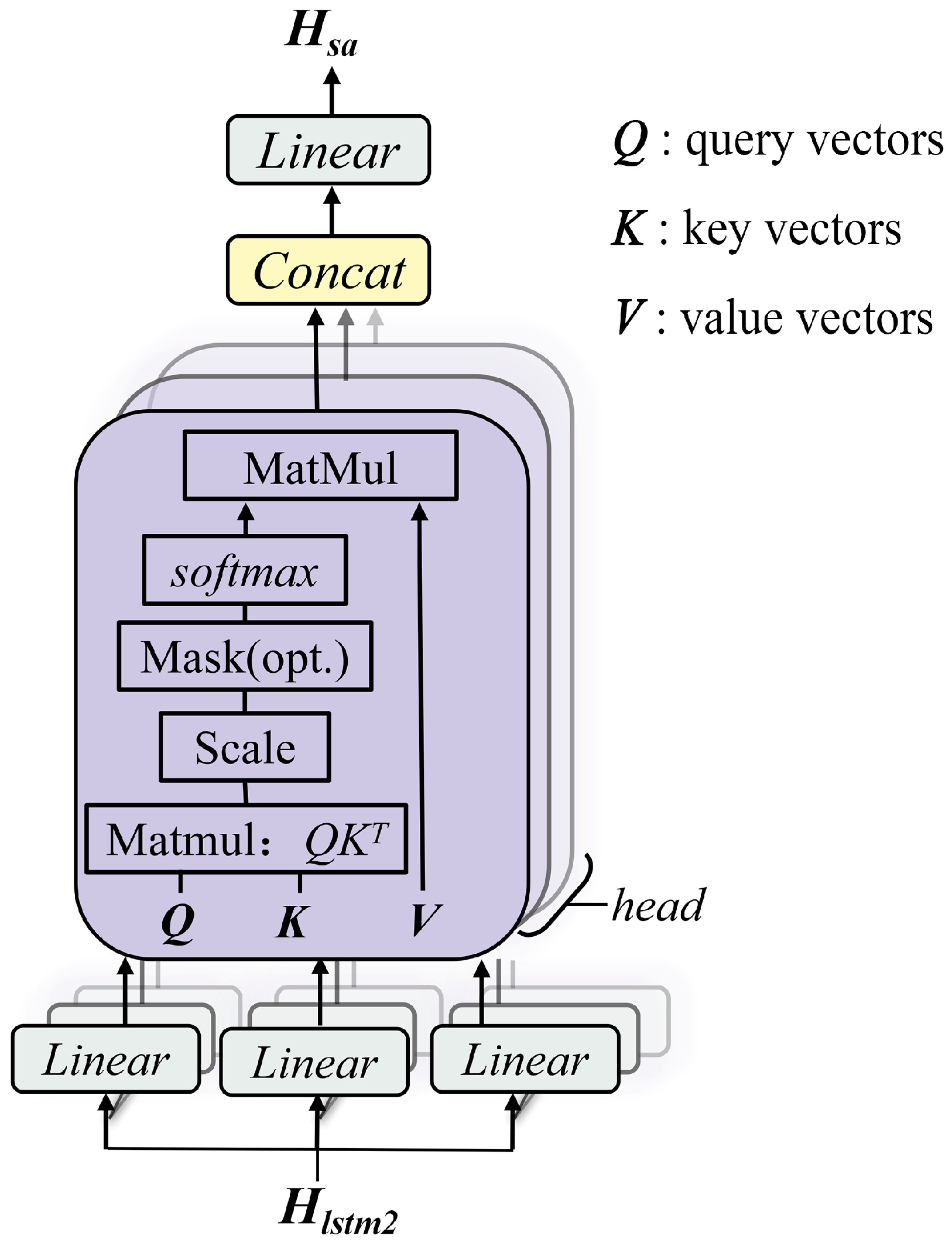
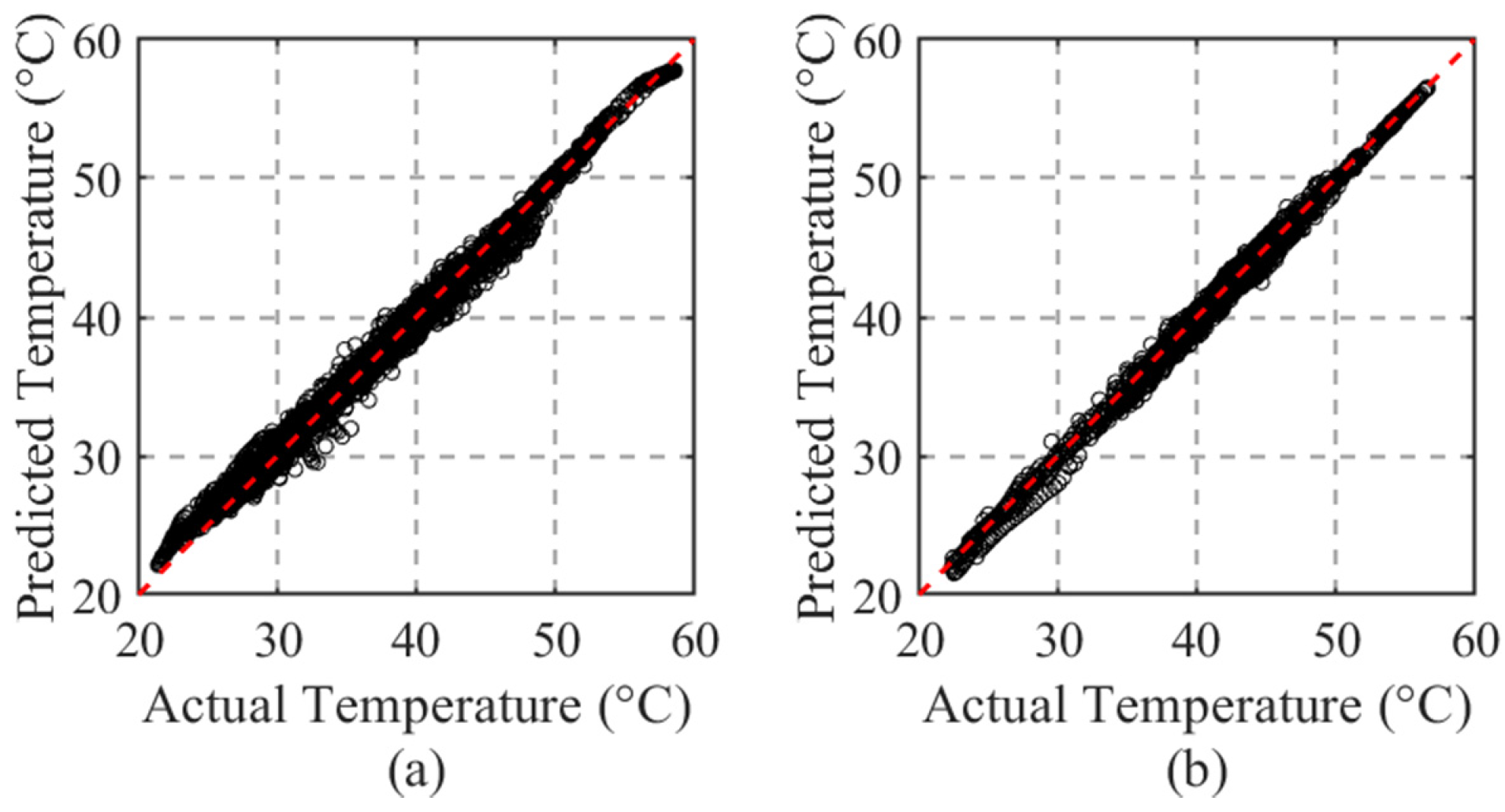
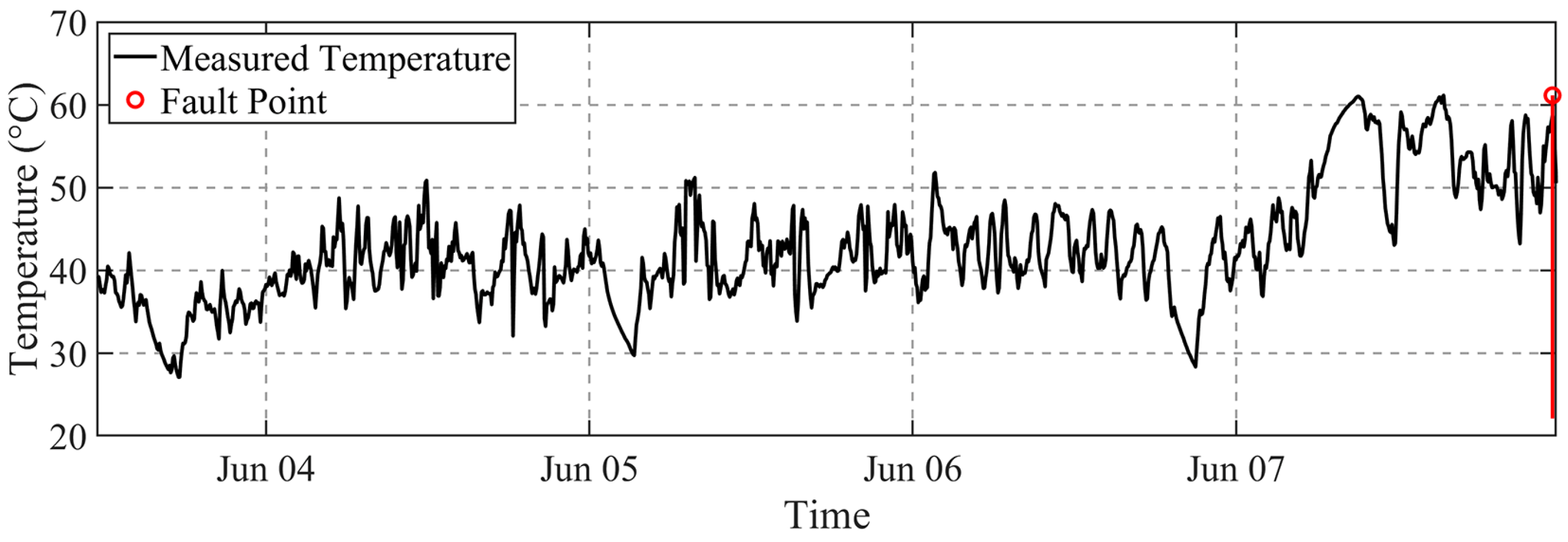
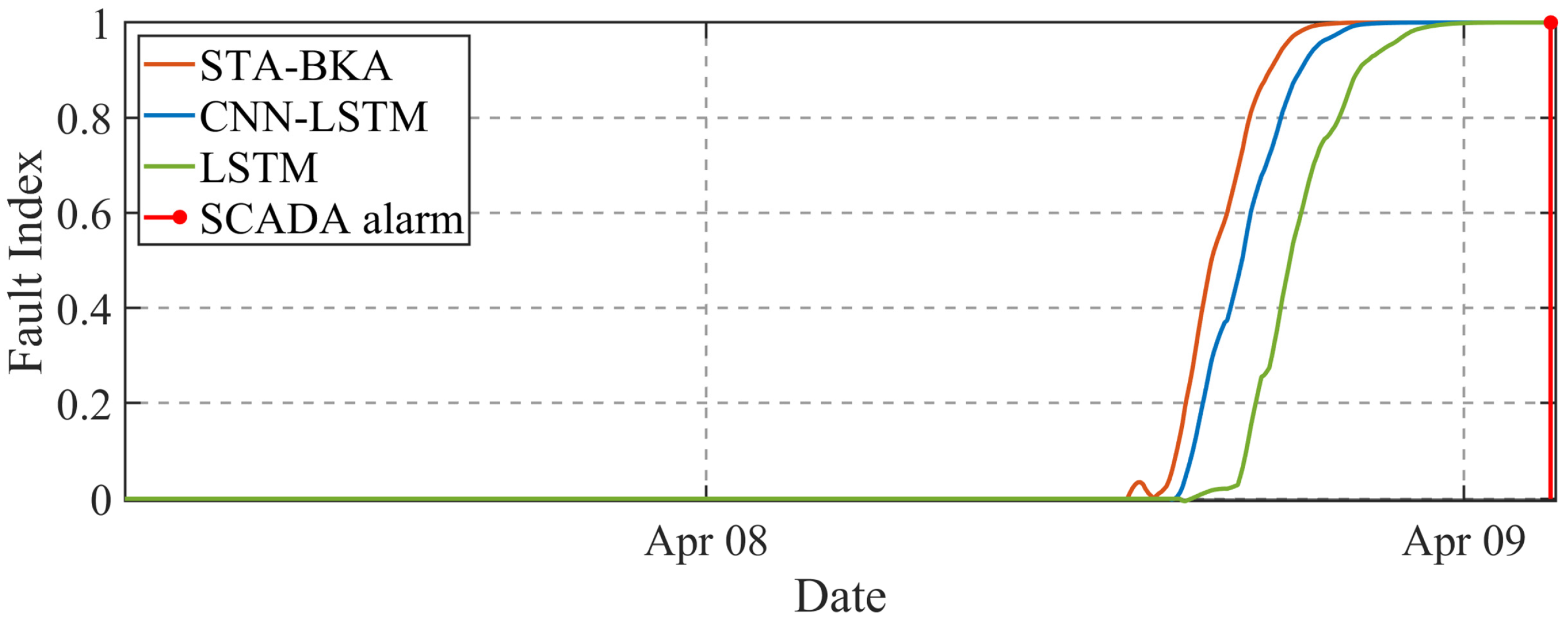
The STA-BKA model’s significant performance is anchored in its targeted resolution of three core SCADA prognostics challenges. First, its hybrid architecture overcomes the limitations in spatio-temporal modeling: convolutional layers capture multi-scale interactions among the. monitored variables, while attention-augmented LSTMs preserve long-term dependencies in low-frequency data. Second, BKA optimization prevents overfitting by balancing global–local hyperparameter tuning, enhancing noise robustness. Critically, the FI dynamically validates deviations via residual statistics in sliding windows, avoiding false alarms from fixed thresholds. This synergy explains the model’s reliable early warnings under environmental noise.
This work bridges a critical gap in wind turbine prognostics. The proposed architecture enables the accurate prediction of the GHSST and forthcoming failures, which were previously unattainable via SCADA threshold systems. By unifying spatio-temporal modeling with SA and BKA optimization, it offers a hardware-free solution scalable to existing wind farms.
It is worth noting that the model’s performance under extreme weather events (e.g., blizzards or cold waves) remains unverified. Since the SCADA dataset from operational wind farms lacks sufficient samples of such rare events, due to the limited monitoring duration and geographical coverage, further validation is needed for these scenarios. Future work will employ transfer learning to fine-tune the pretrained model when extreme-condition data becomes available, enhancing its generalization capability. When dealing with larger-scale dataset, the proposed architecture will need to be upgraded with additional enhancements, such as more systematic parameter initialization methods.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}