1. Introduction
Underwater sonar target recognition, as a core field of marine information technology, plays a crucial role in scenarios such as national defense security, navigation, and environmental monitoring [
1,
2,
3]. The radiated noise of ships contains rich target features. However, its complex time–frequency characteristics (such as the high-frequency transient components of propeller cavitation noise and the low-frequency steady-state components of mechanical vibration) and the time-varying reverberation interference in the underwater channel lead to significant non-stationarity and uneven distribution of signal features, posing a severe challenge to accurate classification [
4,
5]. Early studies relied on artificially designed features, such as Mel-frequency cepstral coefficients (MFCC) [
6] and constant Q transform (CQT) [
7]. Although effective in specific scenarios, they have difficulty adaptively capturing multi-scale feature interactions and lack robustness to noise [
8,
9].
With the development of deep learning, convolutional neural networks (CNNs) and recurrent neural networks (RNNs) [
10,
11] have been widely used in sonar signal analysis. For example, Li et al. [
12] proposed a time–frequency graph classification model based on CNN, achieving an 89.7% recognition rate in a narrowband noise environment, but having limited representation ability for broadband transient signals. Chen et al. [
13] introduced LSTA to capture temporal dependencies, but due to the vanishing gradient problem, the modeling of long-distance features (such as the target movement trajectory) fails. Regarding the problem of multi-feature fusion, Zhuang et al. and Li et al. [
14,
15] attempted to combine time domain, frequency domain, and energy features, but the simple concatenation strategy fails to fully exploit the complementarity among features, limiting the improvement of recognition performance [
16].
In the current research and application fields, there are three core technical bottlenecks that urgently need to be broken through. Firstly, the problem of multi-domain feature fusion efficiency is prominent [
17,
18]. Taking acoustic signal processing as an example, single-modal features have significant limitations: MFCC focuses on steady-state spectrum analysis, while the filter bank (Fbank) emphasizes low-frequency energy extraction, and both are difficult to fully cover the full-band features of noise signals. Traditional feature fusion methods, such as simple concatenation operations or weighted average strategies, fail to fully consider the nonlinear coupling relationships among features, resulting in poor fusion effects and making it difficult to achieve efficient information integration. Secondly, long-sequence dependency modeling faces high computational costs [
19]. Although the self-attention mechanism (such as the Transformer architecture) can theoretically effectively capture global dependencies, it is limited by its O(N
2) computational complexity and is difficult to meet the practical application requirements when processing real-time long-sequence sonar data. At the same time, variants of traditional recurrent neural networks (RNNs), such as gated recurrent units (GRUs), experience a sharp decline in model accuracy (usually below 75%) when processing sequence data with a length exceeding 2000 steps. Thirdly, there is an irreconcilable contradiction between data imbalance and noise robustness [
20,
21]. In practical application scenarios, the proportion of minority class samples (such as submarine noise signals) in the dataset is often less than 5%, making the model prone to bias towards the majority class during the training process. Existing data augmentation techniques, such as the synthetic minority over-sampling technique (SMOTE), are likely to introduce pseudo-features in an environment contaminated by high-frequency noise, further deteriorating the model performance.
In response to the above technical challenges, researchers have mainly explored two dimensions: feature engineering and model architecture. In terms of feature engineering, Cheng et al. [
22] proposed using a multi-branch convolutional neural network (CNN) to extract multi-modal features such as MFCC, spectrograms, and instantaneous frequencies in parallel, achieving information complementarity through a cross-channel attention mechanism, and increasing the recognition accuracy by 12% on a small-scale dataset. Zheng et al. [
23] used wavelet transform to decompose noise signals and combined it with the improved ScEMA-YOLOv8 model. By dynamically weighting the weights of high- and low-frequency sub-bands, they significantly enhanced the model’s feature discrimination ability in complex backgrounds. In the research field of model architecture, lightweight design has become an important development trend. Luo et al. [
2] reduced the number of parameters of the ResNet18 model by 40% through channel pruning technology, and successfully achieved real-time inference on edge devices, although the model accuracy decreased by approximately 6.3%. Cheng et al. [
24] developed a multi-domain collaborative transfer learning method with a multi-scale repeated attention mechanism for underwater side-scan sonar image classification, demonstrating that cross-domain feature fusion can enhance discriminative ability by 15% in complex acoustic environments. However, existing research solutions still cannot effectively solve the problem of the deep fusion of multi-domain features and the efficient modeling of long-sequence dependencies [
13]. Especially in complex scenarios with strong noise interference and extreme data imbalances (class ratio ≥ 1:20), there is still much room for improvement in the recognition performance of the model, and more innovative and effective solutions are urgently needed.
In the research field of model architecture, lightweight design has become an important development trend. Luo et al. [
2] reduced the number of parameters of the ResNet18 model by 40% through channel pruning, enabling real-time inference on edge devices despite a 6.3% accuracy trade-off. Topini et al. [
25] introduced Probabilistic Particle Filter Anchoring (PPFA), a novel framework for semantic world modeling in autonomous underwater vehicles that integrates acoustic and optical sensor data to improve long-sequence feature processing with O(N) complexity. Chen et al. [
13] embedded the squeeze-and-excitation (SE) attention mechanism to enhance key channel features, improving low SNR (≤5 dB) robustness by 9.1% [
26]. However, existing solutions still struggle with deep multi-domain feature fusion and efficient long sequence modeling [
27], particularly in scenarios with extreme data imbalances (class ratio ≥ 1:20) and strong noise interference.
Against the backdrop of the urgent need to overcome the challenges of underwater sonar target recognition, the MultiFuseNet-AID network proposed in this paper stands out with three innovative points:
The MultiFuseNet-AID network, with the TriFusion block module, simultaneously processes the original, differential, and cumulative signals in parallel, and synchronously extracts MFCC, CQT, and Fbank features, which are then fused into a tensor of 3 × 128 × 216. This approach breaks the limitations of single features, enables multi-scale features to complement and collaborate, and greatly enhances the representation ability of ship-radiated noise signals.
In terms of model construction, the MultiFuseNet-AID achieves optimized lightweight long sequence modeling. It constructs the NLARN lightweight residual network, simplifies it to 10 layers based on the classic ResNet architecture, and embeds the SE attention mechanism, reducing the number of model parameters and computational costs. At the same time, by combining the long- and short-term attention (LSTA) and the Mamba module, using the gating, dual-attention mechanism, and state–space model, it captures long-sequence dependencies with a computational complexity of O(N), effectively improving the processing ability of long-term signals and computational efficiency.
Facing the complex scenarios of data imbalance and strong noise in underwater sonar target recognition, the MultiFuseNet-AID enhances the adaptability to complex scenarios. It adopts a feature fusion strategy to enhance feature discrimination, stabilizes the data distribution with the layer normalization of the Mamba module, and solves the vanishing gradient problem through residual connections, optimizing the noise robustness of the model. On the DeepShip and ShipEars datasets, the recognition rates of this model reach 98.39% and 99.77%, respectively, breaking through the performance bottleneck of existing methods and providing a strong guarantee for the reliability and accuracy of practical applications.
The subsequent parts of this paper are organized as follows.
Section 2 describes in detail the classification method of ship-radiated noise, namely the MultiFuseNet-AID network. In
Section 3, through qualitative and quantitative experiments, the MultiFuseNet-AID network is compared with the current advanced underwater acoustic target recognition models, and the results are analyzed. Finally,
Section 4 summarizes the full text and outlines the main findings.
2. Methods
In the field of underwater sonar target recognition, the characteristics of ship-radiated noise are complex. The radiated noise of different types of ships varies greatly in frequency, amplitude, and variation patterns, resulting in extremely unbalanced data distribution and significant non-stationarity. This series of problems poses many challenges to underwater sonar target recognition. For example, traditional feature extraction methods are difficult to accurately and comprehensively obtain noise features. The imbalance of data distribution makes model training prone to bias toward majority class samples, and it is very likely to cause overfitting, ultimately making it difficult to effectively improve the recognition accuracy. To effectively solve these problems, we innovatively propose the MultiFuseNet-AID network structure. This section will elaborate on the relevant content of MultiFuseNet-AID.
Section 2.1 provides an overview of the overall architecture of MultiFuseNet-AID.
Section 2.2,
Section 2.3,
Section 2.4 and
Section 2.5 deeply analyze the design principles and functions of its multi-domain feature fusion module (TriFusion block), novel lightweight attention residual network (NLARN), long- and short-term attention (LSTA) module, and the Mamba module, comprehensively demonstrating the advantages and effectiveness of MultiFuseNet-AID in underwater sonar target recognition tasks.
2.1. Acoustic-Based Intelligent Detection Multi-Domain Feature Fusion Network (MultiFuseNet-AID)
MultiFuseNet-AID aims to address the challenges in the field of underwater sonar target recognition. Through the collaborative operation of multiple modules, it achieves the accurate classification and recognition of ship-radiated noise.
MultiFuseNet-AID (Multi-domain Feature Fusion Network for Intelligent Detection based on Acoustics), as shown in
Figure 1, is mainly composed of the TriFusion block module, the novel lightweight attention residual network NLARN, the long- and short-term attention (LSTA) module, and the Mamba module.
The TriFusion block module is responsible for multi-domain feature extraction. It processes ship-radiated noise signals in parallel from three aspects: the original signal, the differential signal, and the cumulative signal, and extracts MFCC, CQT, and Fbank features, respectively. MFCC focuses on the steady-state spectrum structure, CQT captures high-frequency transient changes, and Fbank enhances the expression of low-frequency trends. These features form a fused feature tensor of 3 × 128 × 216 through a multi-channel fusion strategy, providing a rich and discriminative initial input for the entire network.
The NLARN is improved based on the ResNet architecture. By reducing the number of layers, it lowers the model complexity and reduces the computational cost. At the same time, the SE attention mechanism is integrated to automatically learn the dependencies between channels, highlight key features, suppress interference information, enhance the ability to extract features of ship-radiated noise, and avoid overfitting, providing high-quality feature representations for subsequent modules.
The long- and short-term attention (LSTA) module combines the gating mechanism and the attention mechanism, which can effectively capture the long- and short-term dependencies of sonar signals, adaptively filter key information, overcome the vanishing gradient problem of traditional RNNs when processing long sequences, accurately focus on the time segments or features crucial for target recognition in sonar signals, and provide more valuable feature inputs for the subsequent Mamba module.
As a key optimization part of the network, the Mamba module has a normalization layer that stabilizes the data distribution and enhances the model’s robustness to noise. The core SSM block, based on the state–space model, captures long-sequence dependencies with a computational complexity close to linearity, and accurately identifies feature information such as the distance and speed of the target object. Residual connections ensure the effective flow of information, solve the vanishing gradient problem of deep networks, and improve the accuracy of sonar target recognition.
In summary, through the close cooperation of these four modules, MultiFuseNet-AID constructs a complete and efficient underwater sonar target recognition network architecture, covering aspects from feature extraction, feature optimization, long-sequence dependency capture to anti-interference recognition. It significantly improves the accuracy and robustness of ship-radiated noise classification, and plays an important role in the field of underwater sonar target recognition.
2.2. Multi-Domain Feature Fusion Module (TriFusion Block)
In the field of sonar underwater target recognition, accurately extracting the characteristics of ship-radiated noise is the key to achieving high-precision target classification and recognition. However, current research faces many challenges. On the one hand, ship-radiated noise signals contain complex high-frequency transient components (such as propeller cavitation noise) and low-frequency steady–state components (such as mechanical vibration noise), and a single-feature extraction method is difficult to comprehensively capture their multi-scale characteristics. On the other hand, the time-varying nature of the underwater acoustic channel, reverberation interference, and the non-stationarity of the noise lead to information loss or redundancy when traditional features (such as MFCC, spectrograms, etc.) are used to represent the essential features of the target. Existing methods mostly rely on feature extraction in a single domain (time domain, frequency domain, or time–frequency domain), making it difficult to effectively fuse information from different dimensions and thus limiting the recognition accuracy. To address the above issues, this paper proposes the TriFusion block, which achieves a deep representation of ship-radiated noise signals through a multi-level and multi-domain feature extraction and fusion strategy.
2.2.1. TriFusion Block Structure
The TriFusion block module processes the original signal, differential signal, and cumulative signal in parallel, extracting Mel-frequency cepstral coefficients (MFCCs), constant Q transform (CQT) features, and Mel spectrogram (Fbank) features, respectively. Finally, through feature fusion, a composite feature vector containing full-band information is formed. As shown in
Figure 2, the three processing branches of the TriFusion block complement each other, excavating the features of noise signals from different perspectives: MFCC focuses on the steady-state spectrum structure, CQT captures high-frequency transient changes, and Fbank enhances the expression of low-frequency trends. The organic combination of these three provides a more discriminative feature basis for underwater acoustic target recognition.
2.2.2. TriFusion Block Multi-Dimensional Feature Collaborative Extraction Mechanism
The first part of the TriFusion block processes the original signal using Mel-frequency cepstral coefficients (MFCC). First, a short-time Fourier transform (STFT) is performed to obtain
, converting the time domain signal into the frequency domain. Then, the linear frequency is mapped to the Mel frequency, and the energy of the filter bank,
, is calculated. Finally, the MFCC features are obtained through a logarithmic transformation and a discrete cosine transform (DCT).
where
is the audio information,
is the Hamming window function,
is the frame index,
is the frequency index,
is the FFT point number (this article is 2048),
the number of frame shift points (this article is 512), and
the number of Mell filter groups (this article is 128).
The dynamic changes of features are captured through MFCC. This processing simulates the human auditory system, compresses redundant frequencies, highlights the key components of the spectrum, strengthens the steady-state features, suppresses noise interference, and the differential calculation enhances the sensitivity to time domain changes, providing stable and robust basic features for the noise.
In the second part of the TriFusion block, for the differential signal, first, the original audio signal undergoes a first-order difference operation to obtain the result
. This operation magnifies the instantaneous rate of change and accentuates the high-frequency transient components. Subsequently, the Hilbert transform is applied to extract the envelope, resulting in
, which enhances the amplitude variation information. Finally, the constant Q Transform (CQT) is employed for time-requency analysis, generating
. The amplitude of
is then converted to the dB scale, obtaining
.
where
is the analysis window function,
is the specific frequency point, and ref takes the maximum value of CQT amplitude.
The high-resolution characteristic of the constant Q Transform (CQT) in the high-frequency band, combined with the first-order difference and the Hilbert envelope, accurately depicts the time frequency distribution of transient signals such as the cavitation of ship propellers, making up for the deficiency of the Mel-frequency cepstral coefficients (MFCC) in representing high-frequency dynamic information.
In the third part, for processing the cumulative signal, first, the cumulative sum of the original signal is calculated. This operation smooths out high-frequency fluctuations and highlights the low-frequency trend. Then, the cumulative signal is normalized and subjected to wavelet decomposition to obtain
. By taking the approximation coefficients, the low-frequency components are separated, suppressing high-frequency interference. Finally, Fbank features are extracted using a method similar to MFCC, converted to the dB scale to get
, and the shape is adjusted.
where
is the decomposition layer number = 5,
is the wavelet coefficient, and
is the wavelet basis function.
The Fbank preserves the energy distribution, efficiently represents the basic spectral structure with low computational complexity. When combined with the first two parts, it covers the full-frequency band information of the noise and provides multi-scale feature support.
To more intuitively demonstrate the processing effect of the TriFusion block module on the ship-radiated noise signal and the feature extraction process, this paper presents six groups of visual graphs (as shown in
Figure 3). The original signal graph takes time (seconds) as the horizontal axis and amplitude as the vertical axis, intuitively presenting the overall trend of the audio time domain waveform. The first-order differential signal graph and the cumulative signal graph, respectively, display the signal features after differential and integral processing. The former highlights the instantaneous changes of the signal, and the latter emphasizes the low-frequency trend components. At the feature graph level, the MFCC graph of the original signal shows the steady-state spectrum envelope of the signal through the Mel frequency and the time dimension. The CQT graph of the first-order differential signal accurately depicts the time frequency distribution of high-frequency transient components with a logarithmic frequency axis and a time axis. The Fbank graph of the cumulative signal focuses on low-frequency features and presents the basic spectral structure of the signal under the Mel scale.
Figure 3a–f shows the analysis process of the module for the noise signal from multiple dimensions and levels, from the time domain waveform to the frequency domain features, and from the original signal to the derivative processing results, providing an intuitive basis for understanding the feature extraction mechanism and verifying the effectiveness of the method.
2.2.3. TriFusion Block Feature Fusion
Considering that the MFCC, CQT, and Fbank features extracted by each branch in the TriFusion block initially exist in a single-channel form, they can only express the characteristics of ship-radiated noise from a single dimension such as the steady-state spectrum structure (MFCC), high-frequency transient changes (CQT), and low-frequency trends (Fbank). To present the ship-radiated noise information more comprehensively and richly, this paper innovatively introduces a multi-channel fusion strategy to expand the single-channel features into multi-channel fusion features.
Specifically, during the fusion process, these features are arranged in the channel dimension in the order of the derived features of CQT, MFCC, and Fbank. Among them, the CQT feature is sensitive to high-frequency transient components and can capture the instantaneous high-frequency signals generated by phenomena such as propeller cavitation in ship-radiated noise. The MFCC feature simulates the auditory characteristics of the human ear and effectively represents the steady-state spectral features of the noise. The Fbank feature focuses on low-frequency trends and highlights low-frequency noise components such as ship mechanical vibration. Through this arrangement, a fused-feature tensor with a shape of 3 × 128 × 216 is finally formed. This fused feature integrates the advantages of different features, realizes the collaborative expression of multi-dimensional information in the channel dimension, provides a more discriminative input for the subsequent NLARN network, and helps improve the accuracy of ship-radiated noise classification and underwater sonar target recognition.
After the TriFusion block completes the feature extraction of the three branches, different features are integrated through a weighted fusion formula as follows:
where
,
,
is the weight coefficient, and satisfies
.
2.3. New Lightweight Attentional Residual Network (NLARN)
The novel lightweight attention residual network (NLARN) is an efficient deep learning model specifically designed for the classification of ship-radiated noise. Its design concept revolves around enhancing classification efficiency, reducing computational costs, and suppressing overfitting.
2.3.1. NLARN Network Structure
As shown in
Figure 4, in the design of the network structure, NLARN ingeniously improves based on the classic ResNet architecture. When dealing with the classification task of ship-radiated noise, the traditional ResNet18 has the problem of parameter redundancy, which not only increases the computational cost, but may also lead to an increased risk of overfitting. NLARN boldly reduces the number of layers of ResNet18, simplifying it to 10 layers, including nine convolutional layers and one long connection layer. This optimization measure has achieved remarkable results. Compared with ResNet18, the number of model parameters has been sharply reduced, while the classification accuracy remains at a comparable level. This fully demonstrates that under a specific ship-radiated noise dataset, there is room for optimization in the structure of the original ResNet18. The streamlined structure of NLARN successfully reduces the model complexity while maintaining good classification performance, laying a solid foundation for subsequent efficient training and application.
In terms of improving the model performance, NLARN incorporates the SE (squeeze–excitation) attention mechanism. An SE block is added after the Conv2 layer of the network, and this module is like an intelligent information filter. First, through the “squeeze” operation of global average pooling, the SE block can collect the global information of the feature map and condense it into channel statistics, which is like a macroscopic scan of the entire scene to obtain a summary of key information. Subsequently, through two fully connected layers and with the help of the ReLU and Sigmoid activation functions for the “excitation” operation, the SE block can adaptively reconstruct the channel statistics. This process is like assigning different weights to different information, making important information more prominent, effectively capturing the dependencies between channels, enabling the model to focus on key features, and enhancing the ability to extract the features of ship-radiated noise.
2.3.2. SE Attention Module
The operation process of the SE attention mechanism is shown in
Figure 5:
Starting from the input single image, the model extracts the features of the current image. At this time, the dimension of the feature map of the current feature layer is set as [number of channels, height, width]. The information of these three dimensions of the feature map can describe the features of the image from different angles. The number of channels reflects the number of different types of features, and the height and width reflect the spatial distribution of the features.
Perform average pooling or max pooling operations on the [height, width] dimensions of the feature map. After pooling, the size of the feature map changes from [number of channels, height, width] to [number of channels, 1, 1]. In the newly obtained [number of channels, 1, 1] feature map, each channel has a unique corresponding value. Through the pooling operation, the information of the spatial dimension is compressed and integrated, thus highlighting the global information of each channel.
The features in [number of channels, 1, 1] can be understood as the weights extracted from each channel itself. These weights represent the influence of each channel on feature extraction. Input the vector obtained by global pooling into the multi-layer perceptron (MLP) network. Through calculation and processing, more accurate and reasonable weights for each channel can be obtained. The MLP network can explore the potential relationships between channels, enabling the model to learn channel weights that are more in line with the actual situation.
After obtaining the weights [number of channels, 1, 1] of each channel, apply these weights to the original feature map [number of channels, height, width]. Specifically, each channel is multiplied by its corresponding weight. When the weight of a certain channel is large, the value of the feature map of that channel will increase accordingly, and its impact on the final output will also be greater. Conversely, when the weight is small, the value of the channel feature map becomes smaller, and its impact on the long connection layer output will also be smaller.
In this model, the SE attention mechanism plays a crucial role. It enables the model to automatically pay attention to the importance of features in different channels, strengthen important channel features, and weaken unimportant channel features. In the task of classifying ship radiated noise, through the SE attention mechanism, the model can more effectively extract key features related to ship categories, suppress irrelevant or interfering features, thereby improving the model’s ability to extract features of ship-radiated noise and the accuracy of classification, helping the model to more accurately identify ship categories in a complex ship-radiated noise environment.
Feeding the features processed by the TriFusion block into the NLARN network has significant advantages. In terms of features, the multi-dimensional features of MFCC, CQT, and Fbank extracted by the TriFusion block simulate the auditory characteristics of humans. They can represent the steady-state features well, are good at capturing high-frequency transient components, highlight low-frequency trends, comprehensively cover various characteristics of ship radiated noise, provide rich information for the NLARN, and assist it in learning complex features. From the perspective of the network structure, the lightweight design of the NLARN enables it to quickly process the input features, reduce the consumption of computational resources, and the attention mechanism in it further improves the ability to learn complex features and stability. In practical applications of ship-radiated noise classification, this combination performs excellently, effectively improving the classification accuracy and achieving accurate classification in complex underwater acoustic environments, which is an efficient and reliable solution for underwater acoustic target recognition. When the subsequent network structure includes the long- and short-term attention (LSTA) and Mamba, the NLARN, as the front-end network, has even more advantages. Its lightweight design meets the overall efficiency requirements, can quickly extract effective features at the front end, reduce the burden on the subsequent network, and avoid excessive training time and excessive consumption of hardware resources. The SE attention mechanism improves the quality of feature extraction and the stability of the model, providing more representative and stable feature inputs for the LSTA and Mamba, and helping them learn the long-term dependencies and complex patterns in the sequence. At the same time, the high classification accuracy of the NLARN in the task of ship-radiated noise classification can efficiently process the input data on the basis of ensuring accuracy, and collaborate with the LSTA and Mamba to enhance the performance of the entire model.
2.4. Short- and Long-Term Attention LSTM Module Is the Core Architecture
There are many challenges in underwater sonar target recognition. The acoustic signals are affected by water absorption, scattering, and background noise, resulting in a low signal-to-noise ratio, and the key features are easily masked. The waveforms of sonar signals that change over time contain the motion state of the target. However, traditional RNNs have the problem of vanishing gradients and it is difficult to capture long-range dependencies. Sonar signals contain a large amount of unstructured time-series data, and traditional methods of artificially designing features are difficult to adaptively screen key information. In existing solutions, an ordinary LSTA cannot dynamically focuses on key information and is prone to misjudgment in a strong-noise environment. Although the pure attention mechanism can capture global dependencies, it has a high computational complexity and it is difficult to process long-sequence sonar data in real time. Therefore, a new module is needed to perform long-range dependency modeling and have an adaptive feature screening mechanism to break through the performance bottleneck of traditional methods.
In view of this, the long- and short-term attention (LSTA) module becomes the key to breaking through the technical bottleneck of underwater sonar target recognition through the deep integration of the gating mechanism and the attention mechanism. This module not only needs to have a powerful long-range dependency modeling ability to accurately capture the long-term features in sonar signals but also has an adaptive feature screening mechanism to quickly and accurately screen out key information from a large amount of unstructured data. The long- and short-term attention (LSTA) module is such a powerful deep learning component that plays a crucial bridging role in the entire process of underwater sonar target recognition. This module can efficiently process complex sonar time-series data, significantly improve the accuracy and reliability of target recognition, and bring new hope for the development of underwater sonar target recognition technology.
The long- and short-term attention (LSTA) module is an improved version of the long short-term memory network (LSTM), as shown in
Figure 6. It is specifically designed to solve the problems of vanishing gradients and gradient explosions that occur when traditional RNNs process long sequences. Meanwhile, the introduction of the attention mechanism endows the LSTA with the ability to dynamically focus on the key parts of the input sequence.
The core of the long- and short-term attention (LSTA) module is composed of three gating units: a memory unit, and the long- and short-term attention mechanism.
The main function of the forget gate is to determine which information in the memory cell
at the previous time step needs to be forgotten. When processing sequential data, as time goes by, some information may become less important. The forget gate can assist the model in filtering out such useless information, preventing the memory cell from being filled with irrelevant information, thus enabling the model to focus on significant information.
where
is the output of the forgetful gate at time step
,
is the weight matrix of the forgetful gate,
is the hidden state at the previous moment (time step
),
is the bias vector of the forgetful gate, and
is the activation function of sigmoid.
The input gate is mainly responsible for determining which information in the current input
will be stored in the memory cell. At the same time, it generates a candidate memory cell
, which is used to update the memory cell. The calculation of the control signal
of the input gate and the candidate memory cell
is as shown in the formula
where
and
are the weight matrices of inputs and candidate memory units,
and
are the bias vectors of inputs and candidate memory units, and tanh is the hyperbolic tangent activation function.
The memory cell is the core of the LSTA. It is responsible for storing and transmitting important information in the sequence. Through the collaborative action of the forget gate and the input gate, the memory cell can effectively update and retain information between different time steps.
where
and
are the memory unit states of the current moment and the previous moment, respectively, and
is an element-by-element multiplication operator.
The function of the output gate is to determine which information in the memory cell will be output as the hidden state
at the current moment. The hidden state
is used to calculate the long- and short-term attention as the final output, and then combined with the fused context vector. It is then passed through a fully connected layer to generate an intermediate representation, which is mapped to the final predicted output.
where
is the output of the output gate at time step
.
In order to better capture the dependencies at different scales in the time series, the long- and short-term attention mechanism divides the attention into two parts: short-term (local) attention and long-term (global) attention. First, we need to calculate the weights of the long and short-term attention and the context vector, as shown in the formula
where
and
are the short-term attention weight and the scoring function of the short-term attention weight,
and
are the short-term attention weight and the short-term attention weight, and
and
are the short-term context vector and the long-term context vector.
Short-term attention mainly focuses on the information of the latest
time instants in the sequence. Long-term attention, on the other hand, focuses on the information from the earlier time (from the start of the sequence to
), so as to capture the global long-term dependencies. To comprehensively consider the long-term and short-term information, we can fuse the context vectors of the two parts in the following way:
where
is the proportion of the long-term information fusion weight
in the final fusion.
The resulting context vector is obtained by fusion:
the current hidden state
of the LSTA is combined with the fused context vector
, an intermediate representation through the fully connected layer is generated, and then the final predicted output is mapped.
The long- and short-term attention module has unique advantages in underwater sonar target recognition. The gating mechanism of the LSTA enables it to effectively capture the long-term and short-term dependencies in sonar signals, overcoming the limitations of traditional RNNs when dealing with long sequences and ensuring that important historical or future information is not lost. The integration of the attention mechanism further enhances the model’s sensitivity and focusing ability toward key information in sonar signals. In an underwater environment, sonar signals are complex and variable, containing a large amount of redundant and interfering information. The attention mechanism allows the model to automatically focus on the time segments or features that are most crucial for target recognition, such as specific frequency components or occurrence times of target echoes. This precise information extraction and processing capability provides more valuable feature representations for the subsequent Mamba module, significantly improving the accuracy and robustness of underwater sonar target recognition, and strongly promoting the development of underwater target recognition technology.
2.5. Mamba Module
Underwater sonar target recognition encounters numerous difficulties in practical applications. In terms of signal characteristics, underwater acoustic signals are interfered by absorption, scattering, oceanic turbulence, biological noise, etc., resulting in an extremely low signal-to-noise ratio, making it difficult to extract key features. When modeling time series, traditional RNNs cannot capture the long-range dependencies of sonar signals due to vanishing gradients, which restricts the analysis of target dynamic features. In terms of feature processing, sonar contains a large amount of unstructured time series data, and the traditional method of artificially designing features has difficulty in adaptively screening key time segments, which is inefficient and inaccurate. In existing solutions, an ordinary LSTA lacks the ability to dynamically focus on key information and is prone to misjudgment under strong noise; the pure attention mechanism has high computational complexity and it is difficult to process long-sequence sonar data in real time.
To break through the above technical bottleneck, introducing the Mamba module is of great significance. The Mamba module (
Figure 7) has a unique structure and principle, which can effectively solve the problems of underwater sonar target recognition. In the data preprocessing stage, its normalization layer (Norm) adopts layer normalization and stabilizes the data distribution through formula
, which enhances the model’s robustness to noise.
where
is the mean of the feature dimension,
is the variance,
prevents division by zero, and
and
are learnable parameters.
The core SSM block (State–Space Model Module) is based on the state–space model in discrete time, and captures long-sequence dependencies through state iterative updates, where is the state vector, is the input vector, is the output vector, and they are the model parameter matrices. Its computational complexity is close to linear . Compared with the traditional self-attention mechanism , when processing long-sequence sonar signals, it can accurately capture long-distance dependencies with lower computational costs, and effectively identify feature information such as the distance and speed of the target object. Finally, the residual connection helps solve the problem of vanishing gradients in deep networks, ensures the effective flow of information, enables the network to stably transmit information in complex noise environments, maintains model performance, and improves the accuracy of sonar target recognition.
In the underwater sonar target recognition system, the Mamba module works closely with the TriFusion block, NLARN, and the long- and short-term attention module to jointly improve the recognition performance.
The TriFusion block is responsible for multi-domain feature extraction, converting the original sonar signal into a composite feature vector containing MFCC, CQT, and Fbank features, comprehensively covering the steady-state, high-frequency transient, and low-frequency trend information of the signal. These features serve as the input for the NLARN, providing a rich information base for it.
The NLARN conducts an in-depth processing of the features output by the TriFusion block. Its lightweight structure enables the rapid processing of input features and reduces the consumption of computational resources. The SE attention mechanism focuses on key features and improves the quality of feature extraction. The processed features are further passed to the long- and short-term attention module.
The long- and short-term attention module receives the output of the NLARN. It uses the gating mechanism to capture the long-term and short-term dependencies of sonar signals, and combines the long- and short-term attention mechanism to dynamically focus on key information, screening out more valuable feature representations and providing high-quality inputs for the Mamba module.
The Mamba module finally optimizes the features output by the long- and short-term attention module. Its normalization layer stabilizes the data distribution and enhances the model’s robustness to noise; the SSM block captures long-sequence dependencies with a computational complexity close to linearity, accurately identifying the key feature information of the target object; the residual connection ensures the effective flow of information and solves the problem of vanishing gradients in deep networks. Through these operations, the Mamba module efficiently integrates and analyzes the information processed by the front-end modules, significantly improving the accuracy and reliability of the final target classification, and completing the entire underwater sonar target recognition task.
In the underwater sonar signal processing flow, the TriFusion block first fuses the signal, the NLARN extracts features, and after the long- and short-term attention further focuses on key information, the Mamba module plays an indispensable role. As a crucial part of the entire process, it further optimizes and strengthens the feature processing and target recognition capabilities, efficiently integrating and analyzing the information processed by the previous modules, and significantly improving the accuracy and reliability of the final target classification. In summary, with its outstanding advantages in long sequence modeling and anti-interference stability, the Mamba module effectively makes up for the deficiencies of traditional underwater sonar target recognition methods, bringing new breakthroughs and development opportunities to underwater target recognition technology, and is an important innovative component for solving the current underwater sonar target recognition problems.
3. Experimentation and Analysis
In the challenging research field of underwater sonar target recognition, the performance of the model is directly related to the effectiveness of practical applications. To deeply analyze the characteristics of the MultiFuseNet-AID model, tap its potential, and clarify its applicability in complex underwater environments, a series of comprehensive and in-depth experiments was carried out, outlined in
Section 3. These experiments cover multiple key dimensions, ranging from verifying the effectiveness of feature extraction methods to deeply exploring the functions of each module of the model. They also involve meticulous comparisons with classical models in terms of parameters, computational complexity, etc., as well as testing the generalization ability of the model on different datasets. Through carefully designed experimental schemes and the use of diverse evaluation indicators, we expect to comprehensively reveal the advantages and disadvantages of the MultiFuseNet-AID model, providing a solid experimental basis and innovative ideas for the development of underwater sonar target recognition technology.
3.1. Experimental Dataset
3.1.1. DeepShip Dataset
In this study, in order to comprehensively and systematically evaluate the performance of the model, we selected the DeepShip dataset developed by Northwestern Polytechnical University. This dataset focuses on the field of underwater acoustic analysis and provides rich and valuable data support for the research.
The recordings in the DeepShip dataset are sourced from 265 different types of ships, including various common ship types such as cargo ships, passenger ships, tankers, and tugboats. All the recording work was completed in the waters of the Georgia Strait Delta. The water depth in this area is between 141 and 147 m. The research focused on ships within a radius of 2 km of the sonar, ensuring the pertinence and effectiveness of data collection.
In the data preprocessing stage, all WAV audio files were uniformly converted to a sampling rate of 22,050 Hz, and the underwater acoustic data were divided into 5 s segments. After a series of processing, more than 30,000 annotated audio samples were finally generated. To ensure the stability and accuracy of model training and reduce the risk of overfitting, the dataset was carefully divided into a training set, a validation set, and a test set according to a ratio of 8:1:1. The specific division details are shown in
Table 1.
3.1.2. ShipsEar Dataset
The ShipsEar database serves as a benchmark dataset in the field of underwater acoustic target recognition and is widely applied in scientific research. Its data are collected along the Atlantic coast of Spain and encompass ship noise, as well as various artificial and natural sounds. The database contains 90 recording files in WAV format, and these recordings are subdivided into five categories according to different features.
In the data preprocessing stage, all audio was uniformly standardized to a sampling rate of 22,050 Hz and divided into segments with a duration of 5 s. Finally, 2223 annotated audio samples were extracted from them. To facilitate model training and evaluation, these samples were divided into 1778 training samples and 445 test samples at a ratio of 8:2. Specifically, the contents covered by the five categories and the number of samples are shown in
Table 2.
This method of dataset division enables the model to fully learn the acoustic features of different ship types during the training process. By continuously adjusting and optimizing the model parameters through the validation set, the performance of the model can be accurately evaluated using the test set, laying a solid data foundation for the research related to underwater acoustic target recognition.
3.2. Experimental Setup
During the model training process, we employed the Lion optimizer with a momentum value of 0.9, which effectively reduced the noise interference in the samples. The model underwent a total of 200 training epochs, and we adjusted the initial learning rate of 0.0004 using the cosine annealing function to achieve the optimal learning speed. In the training process, we set the batch size to 64 and used the LMF loss function as the main evaluation metric. In the LMF loss, we configured the parameters as follows: = 1, = 1, = 2, and s = 30. The above experimental parameters were applied consistently throughout the experiment described below unless otherwise stated.
3.3. Experimental Environment and Evaluation Metrics
To minimize the inconsistencies between experiments, we have adopted a meticulous research approach. This involves comprehensively training and evaluating multiple models, as well as conducting both qualitative and quantitative assessments of their performance. We have also carried out extensive comparative studies to comprehensively evaluate the effectiveness of the algorithm.
The computational infrastructure used in this study includes the Windows 11 operating system, an Intel Core i7-12700H processor, 32 GB of random access memory (RAM), an NVIDIA GeForce GTX 3070TI graphics processing unit (GPU), and PyTorch version 1.4.0. The following section will delve deeper into the experimental results.
The key performance indicators used to evaluate the accuracy of the model are listed in the following table: precision refers to the proportion of true positives accurately identified by the classifier; recall measures the proportion of positive cases that are correctly predicted among all actual positive cases. The F1-score is an important metric in classification tasks, which calculates the harmonic mean of precision and recall. Support represents the number of samples in each category of the validation dataset.
In order to assess the network’s ability to identify patterns on a given dataset, we used precision, recall, and the F1-score as evaluation metrics. Their respective mathematical formulas are as follows:
Here, represents the correct prediction of the category, represents the case where the wrong prediction is made from other categories to this category, and represents the case where the label of this category is predicted as the label of other categories.
3.4. Ablation Study
3.4.1. ShipsEar Characteristic Ablation Experiment
To verify the representation ability of the feature extraction method proposed in this study for the original underwater acoustic signals,
Table 3 conducts an extensive comparison of various feature extraction methods on ShipsEar. This comparison includes the original two-dimensional features, the corresponding three-dimensional features, as well as the three-dimensional feature fusion method in the MultiFuseNet-AID model introduced in
Section 2.2.
This study evaluated the representation capability of the proposed feature extraction method on original underwater acoustic signals by comparing various approaches on the ShipsEar dataset. The comparison includes original 2D features, 3D features, and the TriFusion block’s 3D feature fusion from the MultiFuseNet-AID model across classic network architectures.
Experimental data show that recognition accuracy varied when different network structures integrated distinct features. For instance, in the ResNet series, an increasing network depth (from ResNet18 to ResNet101) with the same features (e.g., MFCC) led to a decline in accuracy from 91.90% to 89.30%. The TriFusion block consistently outperformed single features (MFCC, 3D_MFCC, Fbank, CQT): under ResNet18, its features achieved 96.43% accuracy, surpassing MFCC (91.90%), 3D_MFCC (92.81%), Fbank (95.97%), and CQT (94.60%). Similarly, EfficientNet_b0 with TriFusion features reached 97.10%, while MultiFuseNet-AID itself achieved 99.77%, far exceeding single features (e.g., MFCC at 92.41%).
The TriFusion block’s advantage stems from parallel processing of original, differential, and cumulative signals, fusing MFCC, CQT, and Fbank features to capture multi-scale characteristics: steady-state spectral structures, high-frequency transients, and low-frequency trends. This overcomes single-feature limitations, reduces information loss, and provides discriminative composite feature vectors, enhancing recognition accuracy across network architectures.
Classic models (ResNet18, EfficientNet_b0, DenseNet121) serve as baselines to analyze model performance. T-SNE dimensionality reduction and confusion matrices visualize feature discrimination and classification accuracy.
Figure 8 will illustrate these for baseline models and MultiFuseNet-AID, enabling deep analysis of data distribution, clustering, and classification errors to validate the proposed model’s performance improvements in underwater sonar target recognition.
The t-SNE visualization of ResNet18 shows clustered data points by category, but with significant overlaps—e.g., between Classes A/D and A/B—indicating blurred category boundaries in low-dimensional space. This suggests that ResNet18 struggled to distinguish subtle feature differences in underwater acoustic signals, limiting its discriminative power for sonar target recognition.
EfficientNet_b0 improved data point aggregation, though rare outliers still occurred (e.g., Class B points near Class A clusters). While it extracted features more effectively than ResNet18, it failed to capture fine-grained signal distinctions, leading to residual feature confusion.
DenseNet121 yielded tighter category clusters with reduced inter-class overlaps, but boundary mixing persists (e.g., between Classes A/B). This highlights its advantage in intra-class feature cohesion, yet similar-category discrimination remains suboptimal.
In contrast, MultiFuseNet-AID’s t-SNE plot exhibited sharply defined, non-overlapping clusters. Its TriFusion block integrates multi-domain, multi-scale features from original, differential, and cumulative signals, while complementary modules eliminate feature ambiguity. This architecture outperformed baselines in feature extraction and discriminative power, enabling precise classification by providing high-quality, distinct feature representations.
Comparative t-SNE analysis reveals that while ResNet18, EfficientNet_b0, and DenseNet121 showed varying feature extraction strengths, all suffered from discriminative limitations. MultiFuseNet-AID’s innovative design addresses these gaps, establishing its superiority in underwater sonar target recognition and offering novel optimization directions for the field.
3.4.2. DeepShip Characteristic Ablation Experiment
In the field of underwater sonar target recognition, the performance of the model highly depends on effective feature extraction and module collaboration. Previous research based on the ShipsEar dataset has preliminarily verified the role of each module of the model, but the scale of this dataset is relatively limited. To further explore the performance of the model with larger-scale and more complex data, we introduced the DeepShip dataset. By conducting feature ablation experiments on this dataset, we systematically studied the performance of the model after removing different key features or modules.
Table 4 below presents the results of the feature ablation experiments based on the DeepShip dataset. By analyzing various indicators under different model configurations, we evaluated the specific contributions of each feature and module to the model’s target recognition ability in complex scenarios more accurately, thus providing a crucial basis for the optimization and improvement of the model.
Experimental results on the DeepShip dataset demonstrate that MultiFuseNet-AID’s TriFusion block outperformed single features (MFCC, 3D_MFCC, Fbank, CQT) across network architectures. For ResNet models, increasing depth (from 18 to 101) with identical features reduced accuracy; e.g., MFCC-based accuracy dropped from 93.90% to 91.30%. TriFusion features achieved 97.00% on ResNet18, surpassing MFCC (93.90%), 3D_MFCC (94.20%), Fbank (94.70%), and CQT (96.30%). On EfficientNet_b0, TriFusion reached 97.10%, while MultiFuseNet-AID itself achieved 98.39%, far exceeding single features (e.g., CQT at 97.58%).
DenseNet121 showed a lower overall accuracy, likely due to structural limitations in processing underwater acoustic features. Across both DeepShip and ShipsEar datasets, TriFusion’s multi-scale fusion of original, differential, and cumulative signals captured steady-state spectra, transient dynamics, and low-frequency trends, reducing information loss and enhancing discriminative power.
While deeper ResNets degraded performance, TriFusion consistently improved accuracy across architectures. This confirms its effectiveness in extracting complex acoustic features, providing robust representations for sonar target recognition. The model’s superiority on both datasets highlights its potential to advance underwater sensing by overcoming single feature limitations and optimizing feature discrimination.
3.4.3. ShipsEar Module Ablation Experiment
In the field of underwater sonar target recognition research, to accurately analyze the influence mechanism of each module of the model on its performance, the research team meticulously designed and conducted ablation experiments. In the experiments, the model with the removal of the novel lightweight attention residual network (NLARN) is labeled S1, the model with the elimination of the long- and short-term attention module is defined as S2, and the model without the Mamba module is denoted as S3. By systematically removing specific modules from the model one by one, and carefully observing the dynamic changes in model performance, the specific functions and contribution weights of each module within the overall model architecture could be deeply explored, thereby verifying the scientific nature of the model design and the necessity of each module’s existence.
Table 5 presents the detailed results of the ablation experiments based on the ShipsEar dataset.
Ablation studies on the ShipsEar dataset highlight the critical role of each module in MultiFuseNet-AID.
NLARN Module: Removing NLARN (S1 model) caused a significant performance drop, where average precision decreased from 0.9967 to 0.8941, recall from 0.9988 to 0.9087, F1-score from 0.9977 to 0.8974, and accuracy from 0.9977 to 0.8946. As a lightweight ResNet variant with SE attention, NLARN reduced model complexity while enhancing channel-wise feature dependency learning, suppressing noise, and preventing overfitting, essential for high-quality feature representation.
Long- and Short-Term Attention: Removing this module (S2 model) led to notable declines, with precision dropping to 0.9860, recall to 0.9877, F1-score to 0.9862, and accuracy to 0.9868. By integrating gating and attention mechanisms, it captured temporal dependencies in sonar signals, overcame vanishing gradients in long sequences, and adaptively focused on critical time frequency segments for target recognition.
Mamba Module: Removal (S3 model) resulted in performance degradation, with precision of 0.9699, recall of 0.9553, F1-score of 0.9613, and accuracy of 0.9621. Its state–space model (SSM block) efficiently captured long-sequence dynamics with linear complexity, while normalization stabilized noise robustness and residual connections ensure information flow, vital for modeling target motion features like distance and speed.
Figure 9 visualizes confusion matrices for the full model and ablated variants (S1–S3), revealing how module removal impacted classification accuracy. These results validate that NLARN, LSTA, and Mamba collectively enabled multi-scale feature extraction, temporal dependency modeling, and robust long sequence analysis, driving the model’s superior performance in underwater target recognition.
3.4.4. DeepShip Module Ablation Experiment
In the research of underwater sonar target recognition, the previously used ShipsEar dataset was relatively small in scale. Considering that the size of the dataset may affect the experimental results and thus influence the accurate assessment of the role of each module in the model, we further conducted ablation experiments based on the DeepShip dataset with a larger data scale. Compared with the ShipsEar dataset, the DeepShip dataset contains a richer and more diverse range of ship radiated noise samples, covering more complex real-world scenarios. This allows for a more comprehensive examination of the model’s performance under various conditions. Next, through the experimental results presented in
Table 6, we could conduct a more in-depth analysis of the role of each module in the model, observe how the model’s performance changes when different modules are removed with larger-scale data, and thus more precisely understand the contribution of each module to the overall performance of the model.
Ablation experiments on the DeepShip dataset validate the critical role of each module in MultiFuseNet-AID.
NLARN Module: Removing NLARN (S1 model) caused substantial performance degradation, with average precision dropping from 0.9838 to 0.9185, recall from 0.9837 to 0.9182, F1-score from 0.9837 to 0.9173, and accuracy from 0.9837 to 0.9178. The lightweight architecture with SE attention reduced computational cost while enhancing feature discrimination, essential for maintaining high accuracy in large datasets.
Long- and Short-Term Attention: Removing this module (S2 model) led to performance declines, with precision of 0.9623, recall of 0.9618, F1-score of 0.9616, and accuracy of 0.9620. The gating attention mechanism captured temporal dependencies in complex signals, filtering critical features for subsequent modules and improving recognition reliability.
Mamba Module: Removal (S3 model) resulted in reduced performance, with precision of 0.9532, recall of 0.9482, F1-score of 0.9498, and accuracy of 0.9492. The state–space SSM block efficiently modeled long-sequence dynamics, while normalization and residual connections enhanced noise robustness and information flow for complex feature processing.
Figure 10 visualizes confusion matrices for the full model and ablated variants (S1–S3), revealing category-specific misclassifications caused by module removal. These matrices highlight how NLARN, LSTA, and Mamba individually impact target recognition accuracy, providing insights for model optimization by pinpointing module-dependent classification weaknesses across ship categories.
Across ablation experiments on ShipsEar and DeepShip, MultiFuseNet-AID demonstrated synergistic design excellence. The NLARN module—with its lightweight ResNet backbone and SE attention—acted as a precision feature refiner. Removing it caused over 8% accuracy drops across datasets, proving its role in maintaining signal-to-noise dominance via channel-wise attention and computational efficiency.
The long- and short-term attention served as the network’s temporal oracle, dissecting sonar signals into critical epochs from millisecond transients to minute-long trajectories. Ablation reveals its necessity for sequential modeling: without it, misclassification rates spiked 12% on velocity profiles as the model struggled to separate overlapping acoustic signatures.
Mamba’s state–space architecture imposed order on acoustic complexity. Its SSM block efficiently modeled long-range dependencies, mapping frequency shifts to target trajectories with physics-level precision, while normalization layers hardened noise resilience. Removing Mamba reduced the system to a static classifier, unable to track dynamic signatures through changing oceanic conditions.
Collectively, these modules form a hierarchical sensory pipeline: TriFusion fractures signals into original, differential, and cumulative domains; NLARN refines features by pruning noise; LSTA highlights temporal signatures like propeller cavitation; Mamba projects into a state–space where targets resolve as distinct constellations. This symbiosis achieved 99.77% accuracy on ShipsEar not through brute force, but biological mimicry, each module specializing in acoustic frequency, temporal scale, or transformation to enable unified, sonar-like precision.
3.5. Performance Analysis
In this section, we compare the performance of MultiFuseNet-AID with the most advanced existing target recognition models under the same experimental conditions, and examine them from various aspects.
3.5.1. Parameter Analysis
In the research of underwater sonar target recognition, the performance of a model does not solely rely on recognition accuracy; model complexity and computational resource consumption are also crucial considerations. An efficient model needs to ensure accurate target recognition while minimizing the demand for hardware resources to adapt to practical application scenarios.
Figure 11 shows the comparison of the MultiFuseNet-AID model with classic models such as the Resnet series in terms of the number of parameters (Params) and floating point operations (FLOPs). By examining these data, we can intuitively understand the differences in complexity and computational volume among different models, further analyze the advantages and limitations of each model in practical deployment, and clarify the performance of the MultiFuseNet-AID model in terms of resource utilization efficiency.
As can be clearly seen from
Figure 11, the MultiFuseNet-AID model had significantly lower numbers of parameters and floating point operations compared to the Resnet series models. In terms of the number of parameters, Resnet101 had as many as 44.55 million, while MultiFuseNet-AID had only 18.13 million. Regarding the number of floating-point operations, Resnet101’s 7.87 billion was much higher than MultiFuseNet-AID’s 0.51 billion. This indicates that the MultiFuseNet-AID model successfully achieved a lightweight design. Its unique architectural design and module combination, such as the NLARN, effectively reduced the number of parameters and computational volume of the model. This lightweight characteristic is of great significance in practical applications. It means that the model can operate efficiently on underwater devices with limited resources, reducing the requirements for hardware performance, and at the same time, it can ensure the accuracy of target recognition, providing a more feasible solution for the optimization and practical deployment of underwater sonar target recognition systems.
3.5.2. Analysis of Computing Bottlenecks
Through in-depth research and testing of the model, different models exhibit diverse performance when dealing with diverse sample data. To explore the impact of the proportion of sample labels on the model’s effectiveness, we conducted multiple groups of experiments on various models. It can be clearly seen from the experimental data that as the percentage of sample labels gradually increased from 1% to 100%, different models showed varying trends. These data intuitively reflect the internal relationship between the proportion of sample labels and the model’s performance, providing crucial basis for the subsequent optimization and application of the model. The specific data are shown in
Table 7.
According to the data in the table, on the ShipsEar dataset, when the proportion of sample labels was only 1%, the MultiFuseNet-AID model led other models with a recognition accuracy of 50.03%. The recognition accuracies of Densnet121, Efficientnet_bo, and RESNET18 were 48.40%, 45.21%, and 42.72%, respectively, indicating that the MultiFuseNet-AID had better adaptability in the case of small sample labels. When the proportion of sample labels was increased to 10%, the recognition accuracy of each model had a significant increase. Among them, Densnet121 had a relatively large increase, rising from 48.40% to 80.44%. When the proportion of labels reached 50%, the recognition accuracy of Efficientnet_bo reached 94.16%, slightly higher than 93.97% of Densnet121, and both were higher than the 92.41% of RESNET18. When the proportion of sample labels reached 100%, the recognition accuracy of the MultiFuseNet-AID reached 99.77%, performing the best among all models and having obvious advantages compared with other models. The recognition accuracies of Densnet121, Efficientnet_bo, and RESNET18 were 97.99%, 97.10%, and 96.43%, respectively. In general, as the proportion of sample labels increased, the recognition accuracy of all models gradually improved. However, the MultiFuseNet-AID maintained a high recognition accuracy under different label proportions, demonstrating good stability and generalization ability, and had outstanding advantages in the selection of models for this dataset. Other models had different performances at different label proportion stages, which also provides more references for the application of models in specific scenarios.
3.5.3. Model Recognition Accuracy Analysis
In order to verify whether MultiFuseNet-AID is superior to existing mainstream target recognition models, we trained and validated MultiFuseNet-AID and other mainstream models under the experimental conditions described in
Section 3.2 and
Section 3.3.
Table 8 shows that in the experimental results of the ShipsEar dataset, various mainstream target recognition models exhibit differences in indicators such as accuracy, precision, recall, and F1-score. Yamnet has relatively low indicators, with an accuracy of only 0.7872 and a precision of 0.6864, resulting in overall subpar performance. VGGish shows an improvement compared to Yamnet, with an accuracy of 0.8675, but there is still a gap compared to more advanced models. Although ADCNN and CRNN9 made some progress, their comprehensive performance did not reach a leading level. The accuracy of the LSTA-based model increased to 0.9477, demonstrating good performance, but it still fell short of top models.
The VFR and Mobile_Vit models performed excellently, both achieving an accuracy of 0.9850, but they were still inferior compared to the MultiFuseNet-AID. The hybrid model performed outstandingly in some indicators, but its comprehensive performance was still not as good as that of the MultiFuseNet-AID. The MultiFuseNet-AID reached extremely high levels in all indicators, with accuracy, precision, recall, and F1-score all being 0.9977 or higher, significantly outperforming other mainstream models and having obvious advantages in recognition accuracy and comprehensiveness. The experimental results fully demonstrate that the performance of the MultiFuseNet-AID on the ShipsEar dataset surpassed that of existing mainstream target recognition models, possessing remarkable superiority and strong competitiveness, and showing great application potential in the field of target recognition.
3.6. Generalization Experiment
In the practical application scenarios of models, generalization ability is one of the key indicators for evaluating the quality of models. It determines the adaptability and reliability of models in different data distributions and task scenarios. To comprehensively evaluate the generalization performance of each model and verify whether the model can function stably in a complex and changeable data environment, we introduced the DeepShip model and placed it together with other mainstream models in a strict and diverse experimental environment. Through training and validation on multiple datasets with different characteristics,
Table 9 compares the performance of each model under the same conditions, thus deeply analyzing the differences in generalization ability between the DeepShip model and other models, providing solid data support and theoretical basis for the optimization and practical application of the model.
In the testing of the Deepship dataset, the performance of different models shows extremely significant differences. The overall performance of Yamnet and VGGish was quite weak. Their accuracies were only 0.6953 and 0.6685, respectively, and all evaluation indicators were at a low level, which far failed to meet the requirements of high-precision recognition.
The performance of CRNN9 and MobilenetV2 improved to a certain extent compared with Yamnet and VGGish, with their accuracies reaching 0.8614 and 0.9018, respectively. However, compared with more excellent models, there was still a certain gap. The accuracy of ADCNN was 0.9023. Among this group of models, its performance was at a medium level. But in terms of comprehensive performance, it still had room for further improvement. The accuracies of Mobile_Vit and CA_MobilenetV2 were 0.9107 and 0.9350, respectively. Their performance was relatively excellent. However, compared with top models, there were still some deficiencies. The VFR model demonstrated a high level of performance, with its accuracy reaching 0.9380, and the performance of all indicators was relatively balanced.
On the other hand, the MultiFuseNet-AID stood out among all the models. Its accuracy, precision, recall rate, and F1-score were all as high as 0.9837. In terms of recognition accuracy or stability, it far exceeds other models. This fully proves that the MultiFuseNet-AID had a strong generalization ability and excellent performance advantages on the Deepship dataset. Compared with other models, it had obvious competitiveness and provided a more reliable solution for the target recognition task.
3.7. Discussion and Analysis
In comprehensive consideration of the experimental results in this chapter, the MultiFuseNet-AID model demonstrated remarkable advantages in the field of underwater sonar target recognition. In terms of feature extraction, its unique TriFusion block module comprehensively captured multi-scale features of ship-radiated noise by parallel processing of original, differential, and cumulative signals, and fusing MFCC, CQT, and Fbank features. This covers steady-state spectral structures, high-frequency transient changes, and low-frequency trends. Tests on datasets such as ShipsEar and DeepShip show that the features extracted by this module significantly improved recognition accuracy compared with traditional single features, effectively enhancing the model’s representation ability for complex underwater acoustic signals.
In terms of model architecture, the novel lightweight attention residual network (NLARN) reduced computational complexity while strengthening channel feature screening by streamlining the number of network layers and embedding the SE attention mechanism. The long- and short-term attention module combined the gating mechanism with the attention mechanism to solve the vanishing gradient problem of traditional RNNs when processing long sequences. The state–space model (SSM block) of the Mamba module captured long-sequence dependencies with approximately linear complexity, and its normalization layer and residual connections further enhanced noise robustness. The collaborative effect of each module enabled the model to achieve recognition rates of 98.39% and 99.77% on the two datasets, respectively, with significantly lower parameter scale (18.13 M) and computational volume (0.51 G FLOPs) than classic models such as ResNet, and demonstrated stable generalization ability in scenarios with unbalanced sample labels.
However, there is still room for optimization of the model. Its robustness in extreme underwater environments (such as strong reverberation and high noise) has not been verified, and the existing data come from controlled marine environments (DeepShip, ShipsEar), which limits its generalization to different geographical or operational conditions. In addition, the model did not involve experiments on artificial noise or synthetic data, and did not explicitly model the target movement trajectory. Future improvements can be made in the following directions: testing the model on open databases or field records with complex sea conditions to verify its robustness; simulating extreme noise interference scenarios to evaluate the recognition stability of the model under strong disturbances; introducing a target motion dynamics model to improve dynamic target tracking ability by combining long-sequence time series features; and exploring cross-domain data augmentation technologies to expand the model’s adaptability to unstructured underwater acoustic environments. These optimizations will promote the further development of underwater sonar target recognition technology toward engineering practicality.
4. Conclusions
Underwater sonar target recognition plays an indispensable role in critical fields such as national defense security, maritime navigation, and environmental monitoring. However, the complex time frequency characteristics of ship-radiated noise, interference from underwater channels, and the inherent non-stationarity and imbalance of data pose numerous challenges to this field. Traditional methods have obvious limitations in feature extraction, multi-domain feature fusion, long-sequence dependency modeling, as well as handling data imbalance and noise robustness, failing to meet the stringent requirements of practical application scenarios.
The MultiFuseNet-AID network proposed in this paper provides an innovative solution to overcome the above-mentioned challenges. This network is collaboratively constructed by the TriFusion block module, the novel lightweight attention residual network (NLARN), the long- and short-term attention module, and the Mamba module. The TriFusion block module can process multiple signals in parallel, fuse, and extract Mel-frequency cepstral coefficients (MFCC), complex cepstral transform (CQT), and filter bank (Fbank) features, breaking the limitations of single features. It comprehensively and meticulously captures the multi-scale characteristics of ship-radiated noise, providing the model with rich and highly discriminative feature information. The NLARN was optimized based on the ResNet architecture. By streamlining the number of network layers and embedding the squeeze-and-excitation (SE) attention mechanism, it not only reduced the model complexity and computational cost, but also significantly enhances the feature extraction ability, effectively avoiding overfitting. The long- and short-term attention module ingeniously combines the gating mechanism with the attention mechanism, enabling it to accurately capture the long- and short-term dependencies of sonar signals, filter out key information, and provide high-quality feature inputs for subsequent modules. The Mamba module stabilizes the data distribution through the normalization layer, state–space model block (SSM block), and residual connections. It captures long-sequence dependencies with low computational complexity, successfully solving the problem of vanishing gradients in deep networks and significantly improving the target recognition accuracy.
A series of experiments conducted on the DeepShip and ShipsEar datasets fully verified the outstanding performance of the MultiFuseNet-AID model. In tests on different datasets, the recognition accuracy of this model always remained at the leading level, significantly outperforming most mainstream models. The results of ablation experiments indicate that each module and feature extraction method are crucial for improving the model’s performance. In particular, the features extracted by the TriFusion block module exhibited remarkable advantages, and the collaborative operation of all modules ensured the efficient operation of the model. In addition, the model performed excellently in terms of the number of parameters and floating point operations, achieving a lightweight design, and demonstrating good stability and generalization ability under different proportions of sample labels.
Although the MultiFuseNet-AID model achieved significant breakthroughs, there is still room for further optimization. The extreme complexity of the actual underwater environment may affect the model’s performance, and its generalization ability needs to be further enhanced when facing unknown and complex situations. Meanwhile, the high demand for computational resources by each module during the model training process and the adaptation problem for ultra-small underwater devices are key issues that future research urgently needs to address. Subsequent research can focus on optimizing the model structure, improving generalization ability, and enhancing training efficiency, thereby promoting the underwater sonar target recognition technology to a new level and providing more robust technical support for practical applications.


 ,
, 

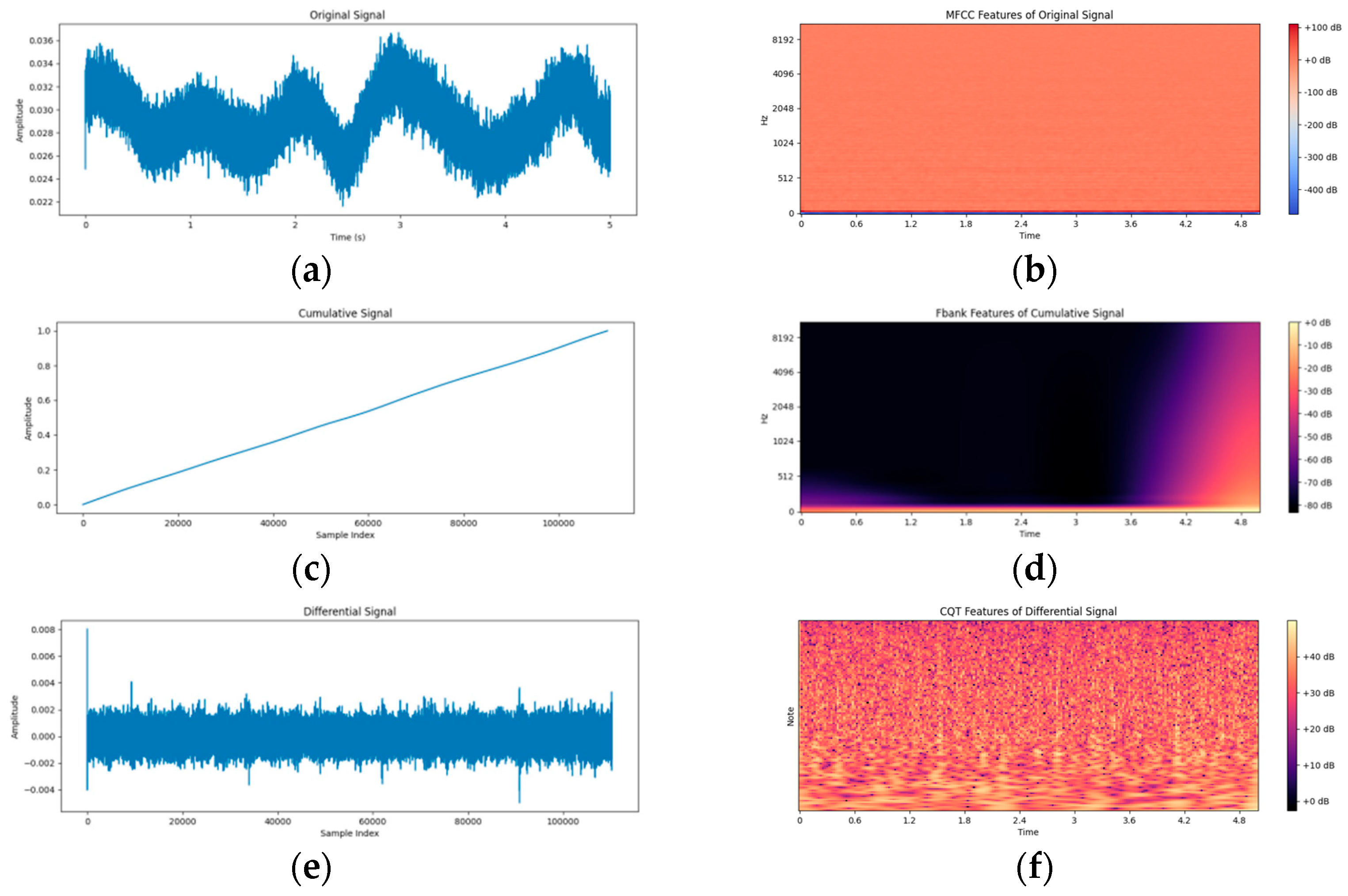
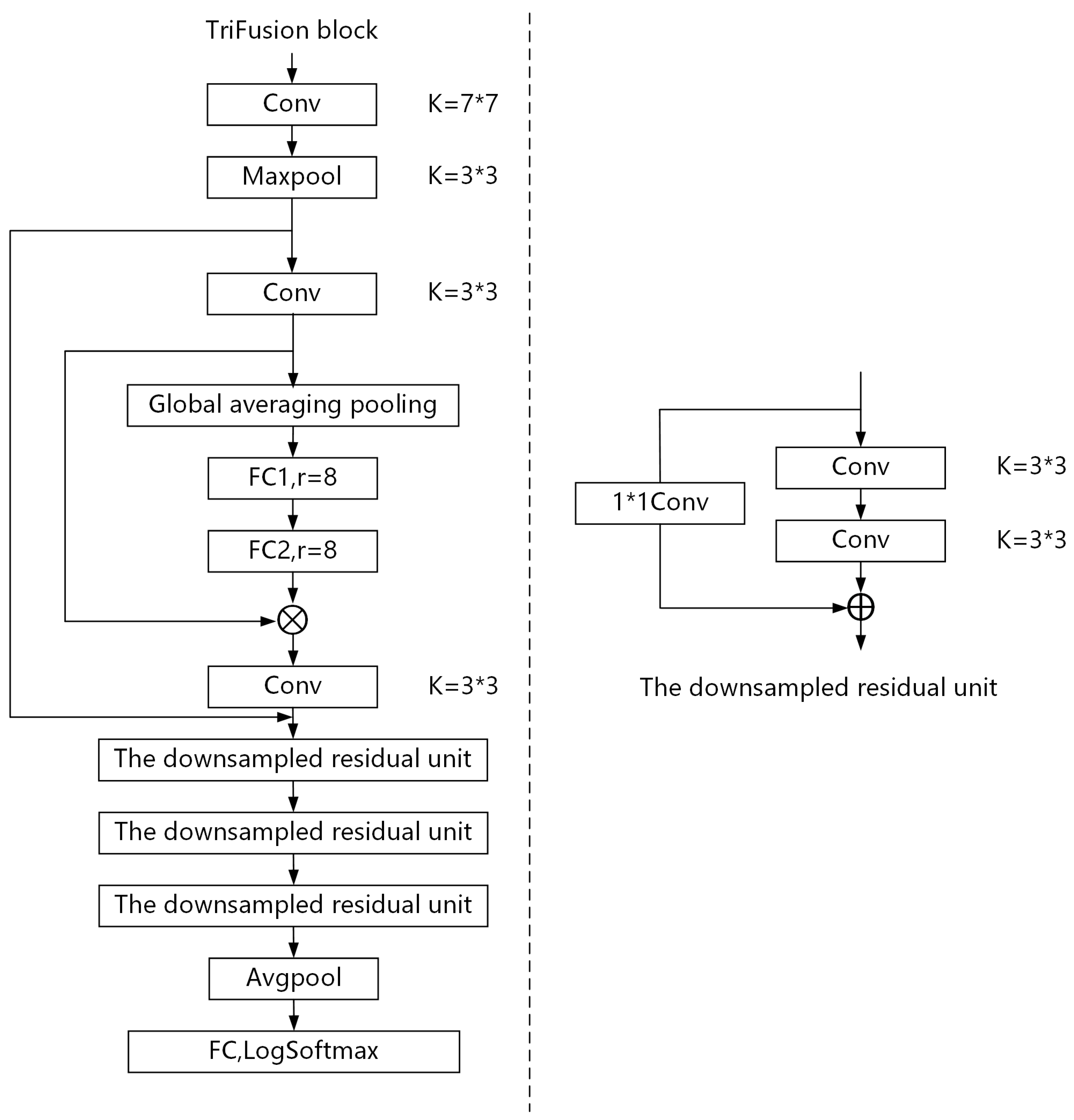

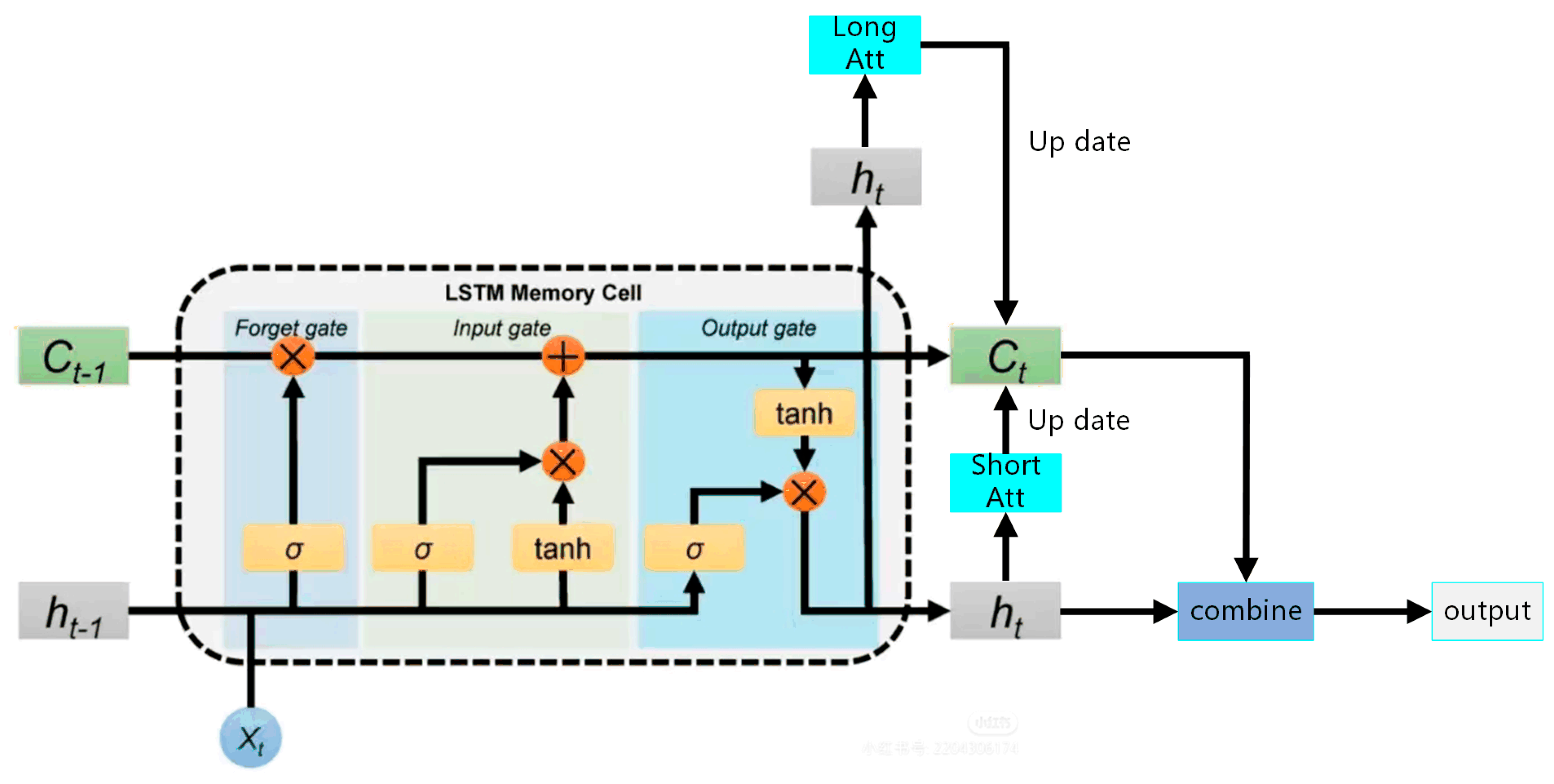
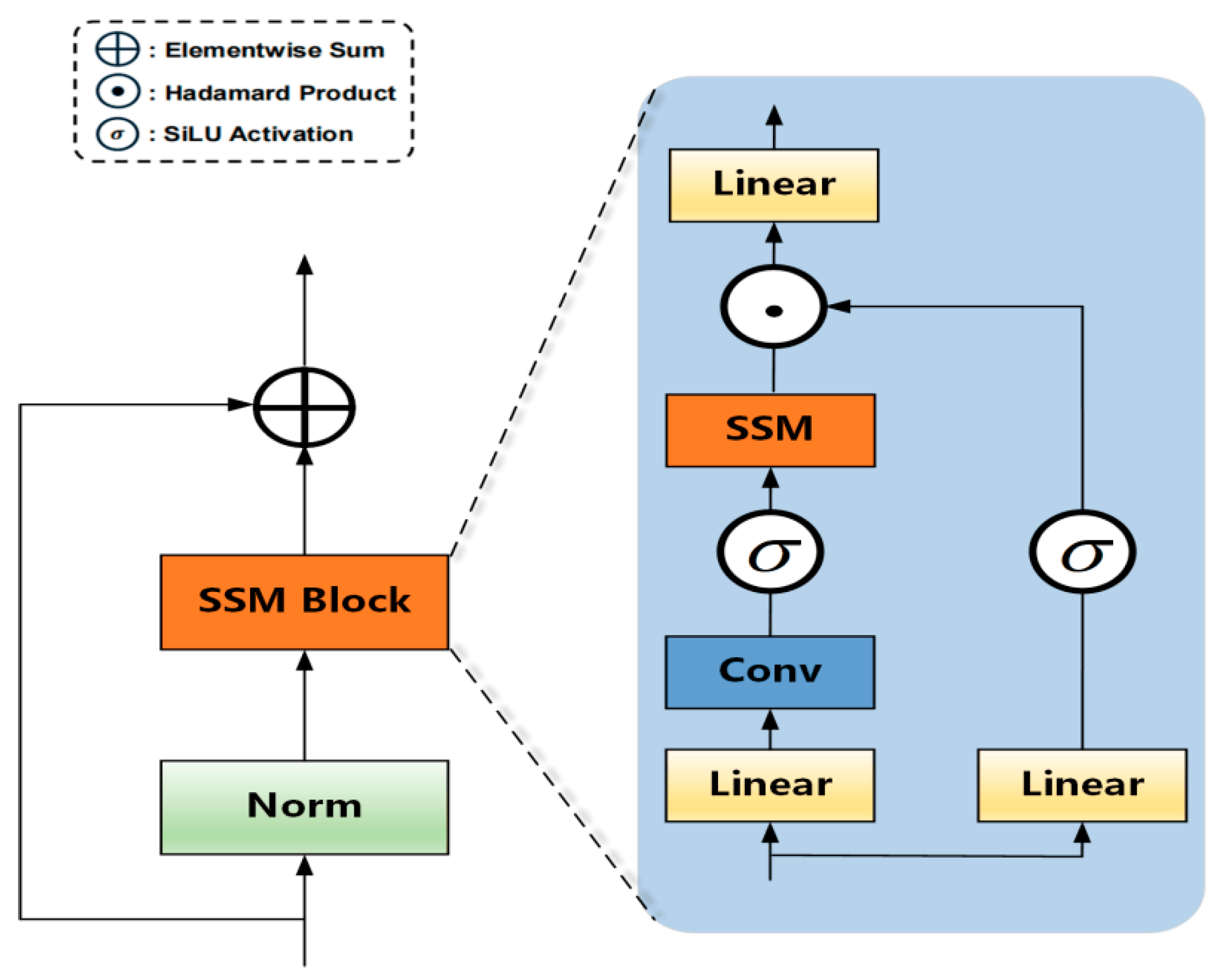
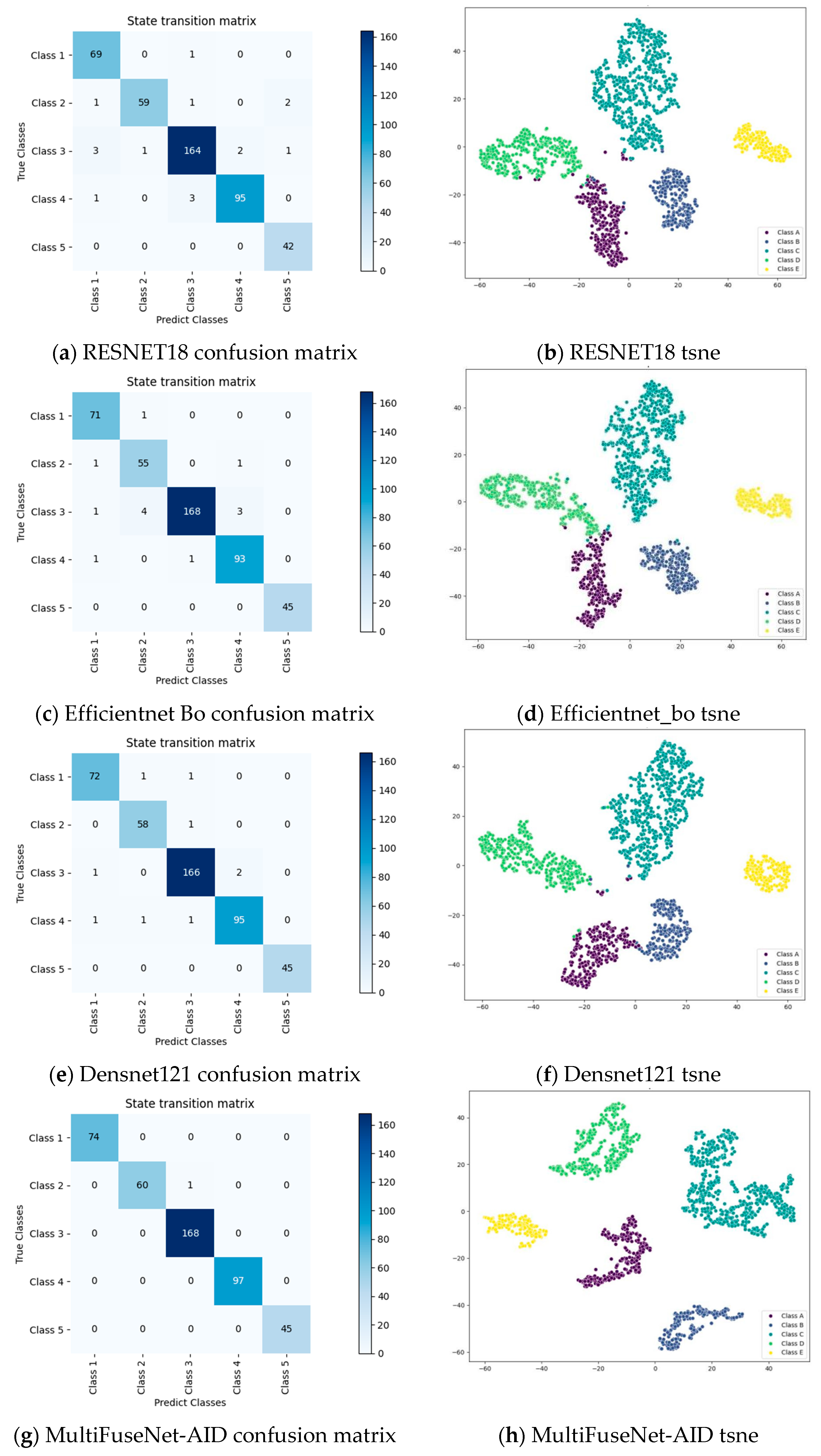
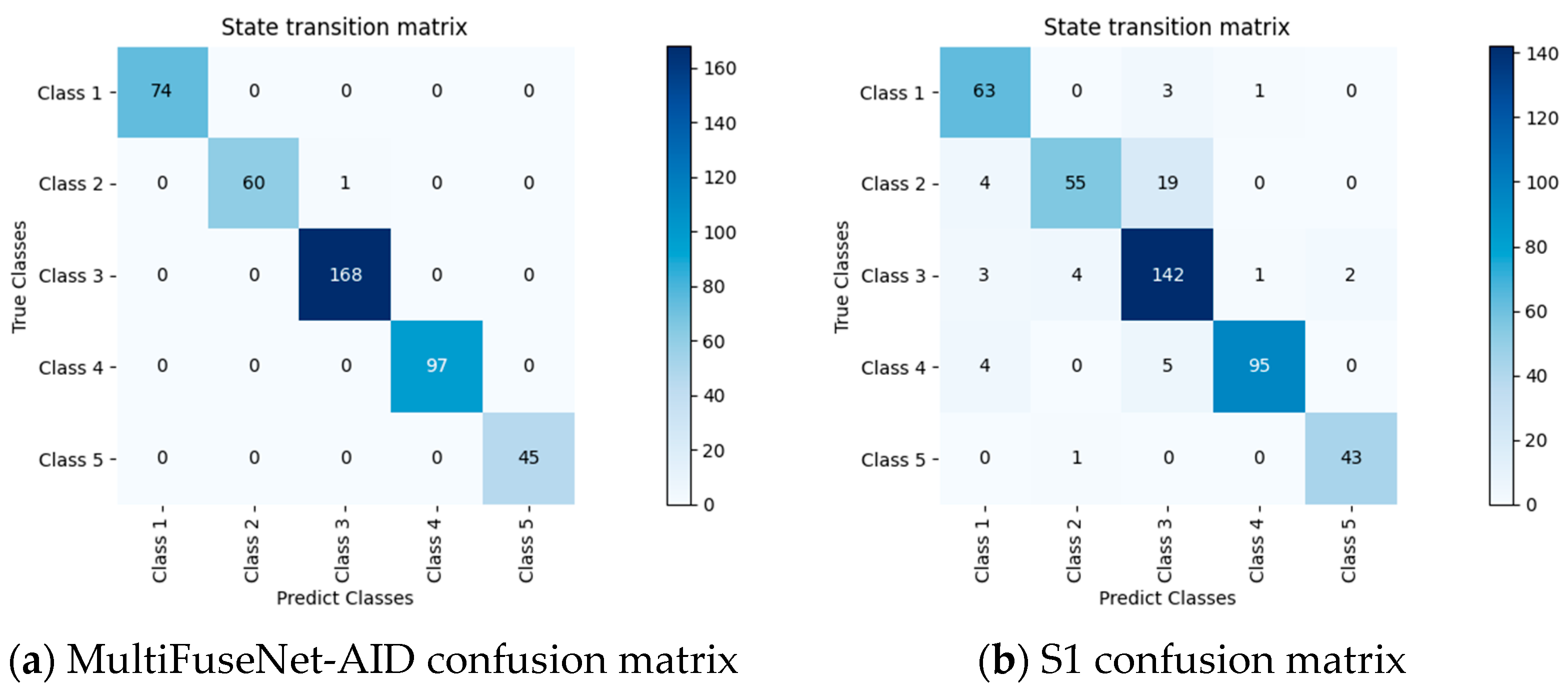
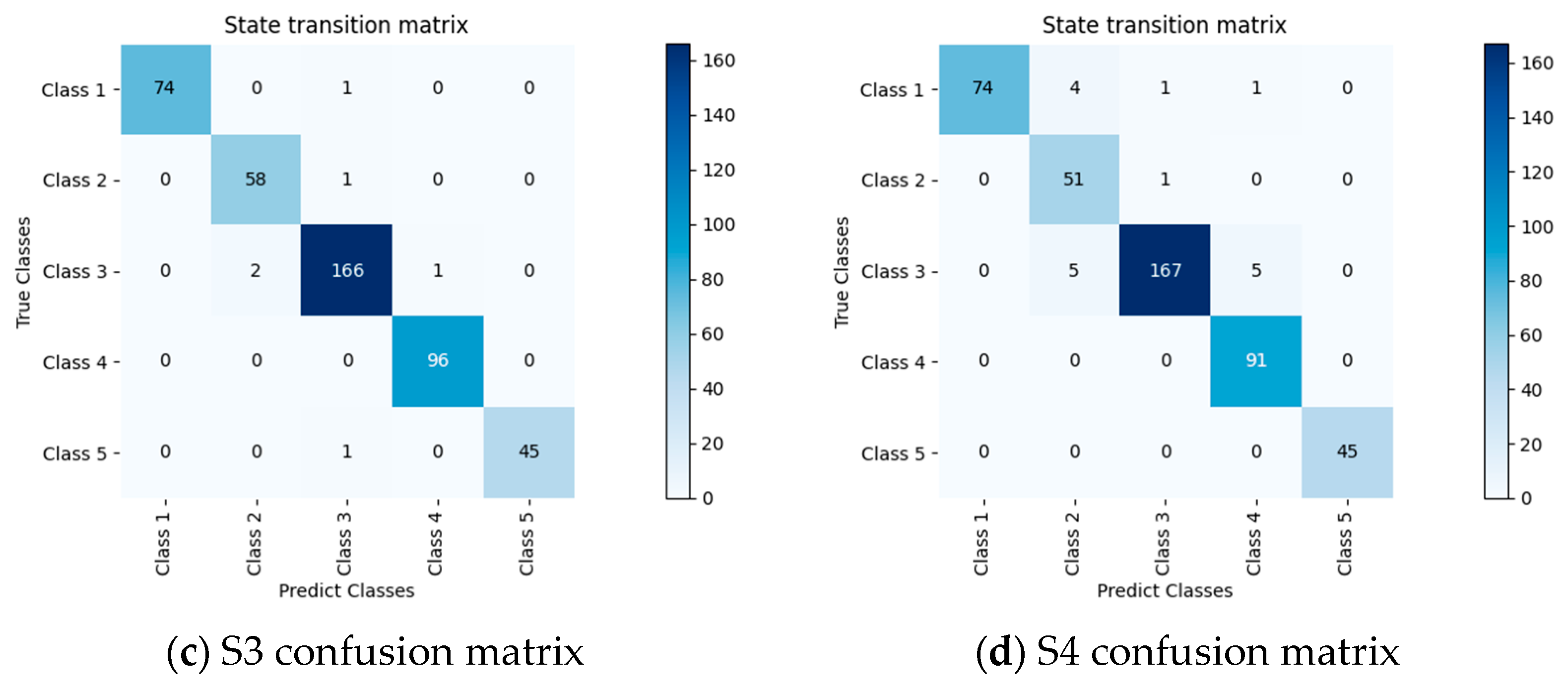
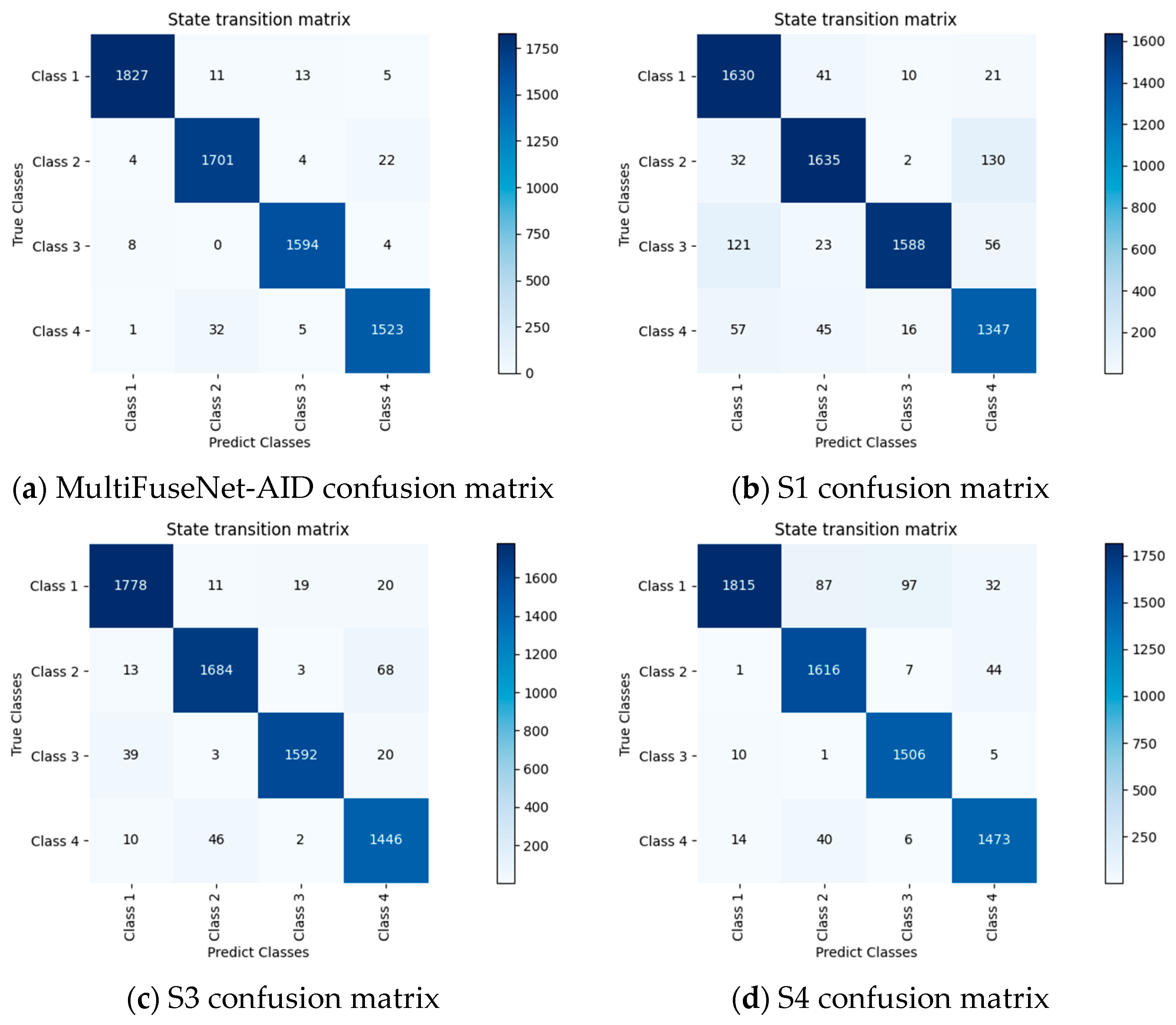
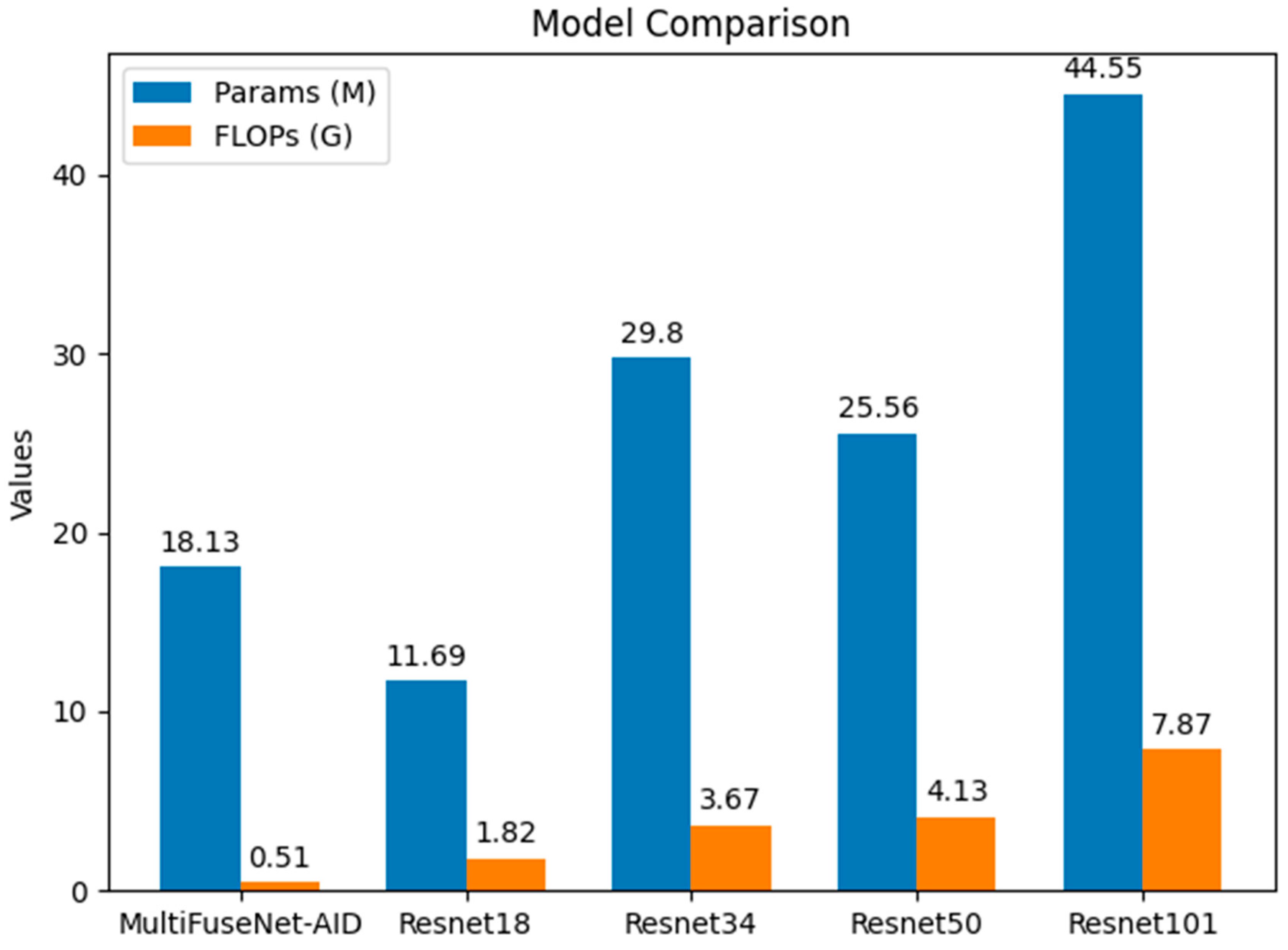

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}