
A Ship Underwater Radiated Noise Prediction Method Based on Semi-Supervised Ensemble Learning


Abstract
1. Introduction
- (1)
- A genetic algorithm-based adaptive weighted ensemble (AWE) model is proposed. By constructing an anti-perturbation regularization term using unlabeled data, this framework optimizes base learner weights to enhance pseudo-label quality while improving ensemble robustness.
- (2)
- An ensemble semi-supervised regression (ESSR) model integrating dynamic pseudo-label screening and uncertainty bias correction (UBC) is established. Pseudo-labels are dynamically filtered based on local prediction performance improvement. Ensemble prediction variance quantifies pseudo-label uncertainty, with sample weights assigned via uncertainty-aware adjustment to minimize bias in training.
- (3)
- The UBC-AWESSR method proposed in this study is validated by cabin model experiments and sea trials of the vessel. Results confirm its superior performance in static and dynamic scenarios, outperforming traditional supervised regression (SR) and semi-supervised regression (SSR) models with maximum error reductions of 65.5% and 62.1%, respectively.
2. Related Work
2.1. Consistency Regularization
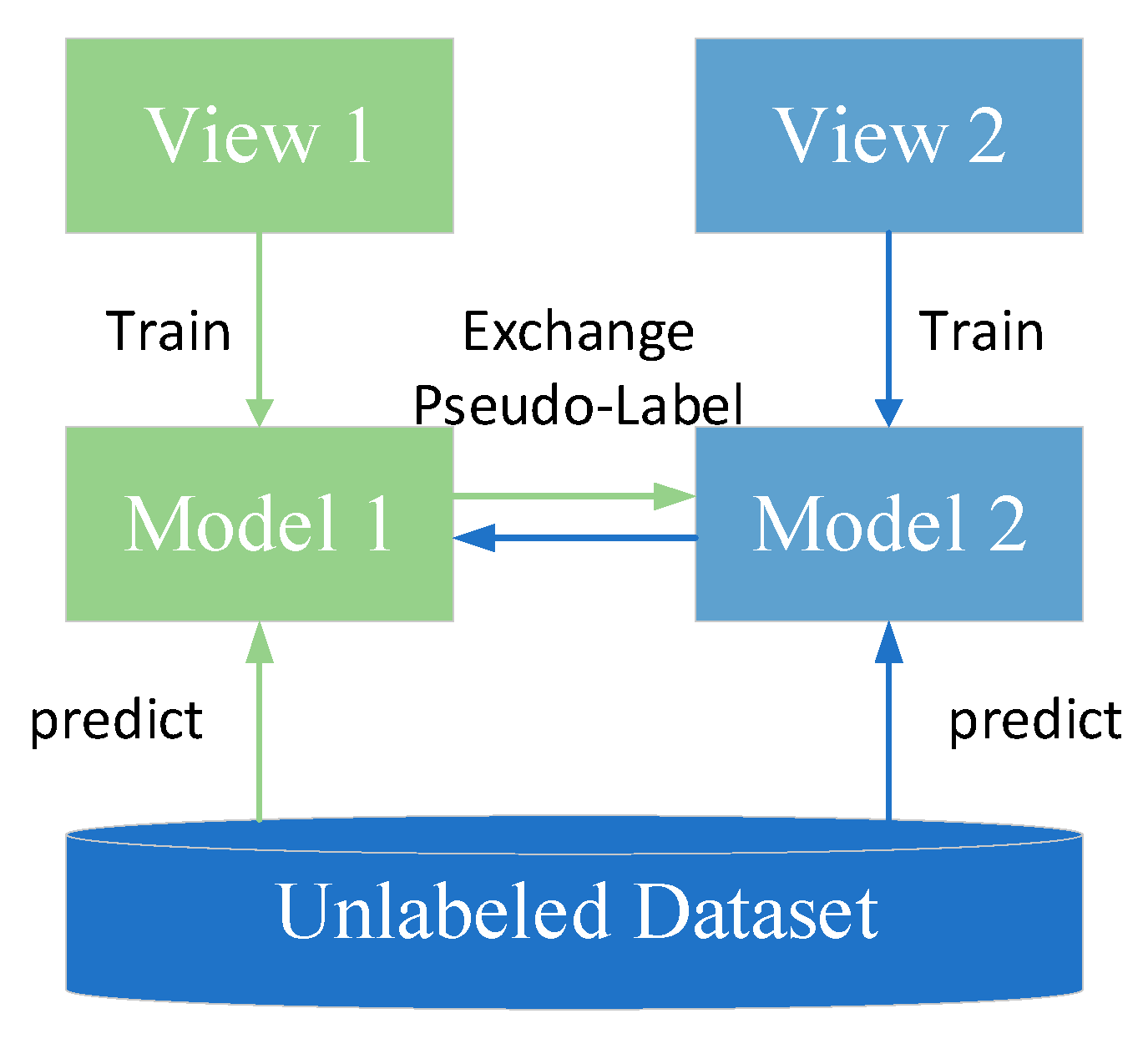
2.2. Semi-Supervised Co-Training Based on Disagreement
2.3. Ensemble Semi-Supervised Learning
3. Methodology
3.1. Symbol Setting
3.2. Adaptive Weighted Ensemble (AWE) Learning Based on Genetic Algorithm
3.2.1. Objective Function Optimization
3.2.2. Adaptive Weighting
3.3. ESS Based on Pseudo-Label Dynamic Screening and Uncertainty Bias Correction
3.3.1. Dynamic Screening of Pseudo-Labels
3.3.2. Uncertainty Bias Correction
| Algorithm 1. Pseudo-code of UBC-AWESSR model pseudo-label screening |
| Input: Labeled dataset: 𝓛; Unlabeled dataset: 𝓤; Trained ensemble models (EMs): {f1, f2, ..., fM} Maximum number of learning iterations: T |
| Output: Get pseudo-label dataset 𝓤_pseudo: {(xu, ŷu, Wu)} |
| Initialize 𝓤_pseudo = [ ] Repeat for T rounds: 𝓤’ is randomly selected from 𝓤, the size of 𝓤’ is s, the remaining part of 𝓤 is 𝓤0 |
| for xu ∈ 𝓤’ do |
| Φ ← KNN(xu, 𝓛) h ← EMs(𝓛, 𝓤0) |
| end If exist 𝓤_pseudo ← |
| h ← EMs(𝓛 ∪ 𝓤_pseudo, 𝓤0)
𝓤’← 𝓤’ remove 𝓤 ← 𝓤’ Else 𝓤_pseudo ← End End the repeat |
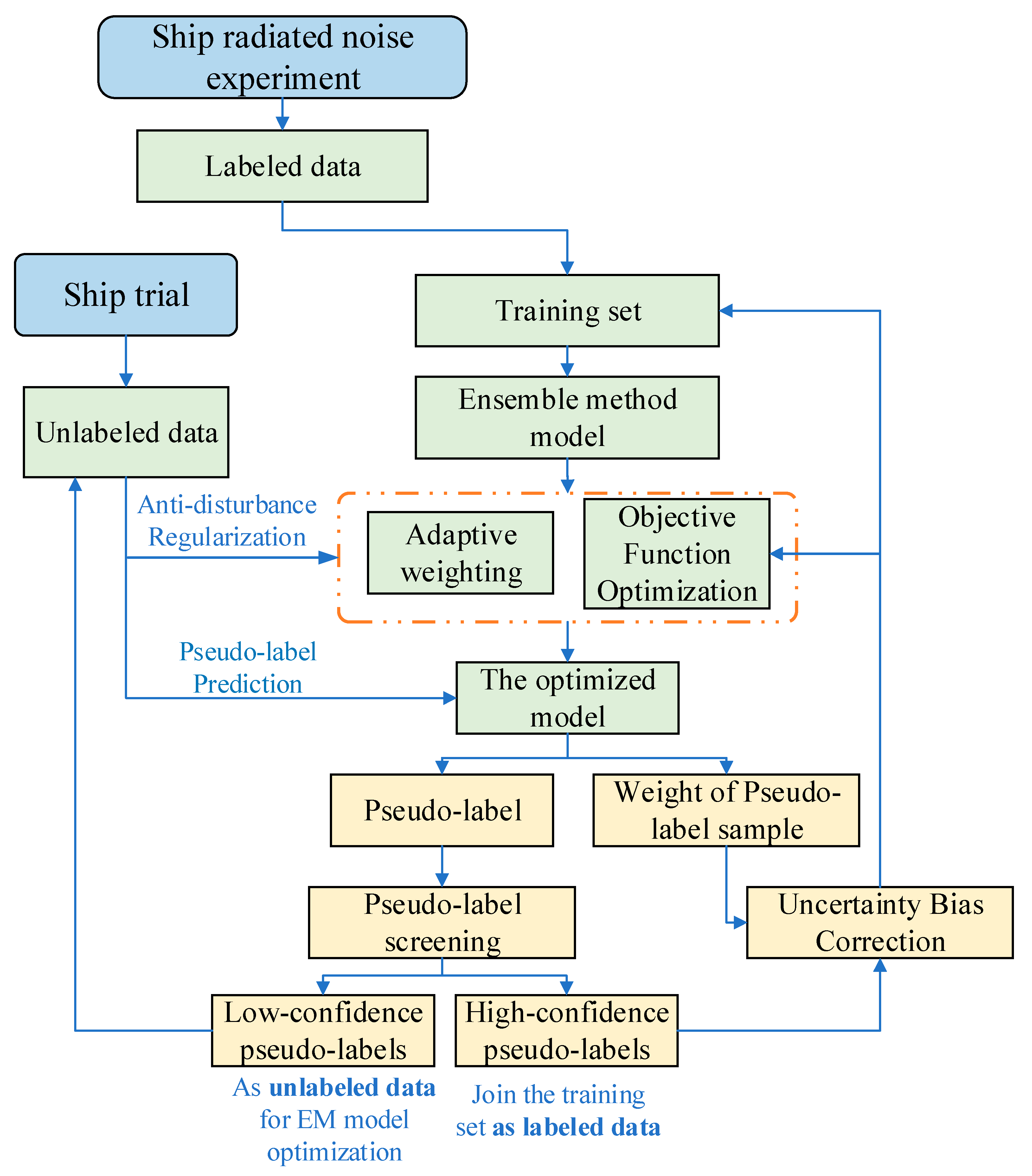
3.4. The Overall Framework of the Ship URN Prediction Model
- (1)
- Multi-source data acquisition and preprocessing
- (2)
- EL model optimization training
- (3)
- Pseudo-label screening and application
4. Experiment
4.1. Introduction of the Dataset
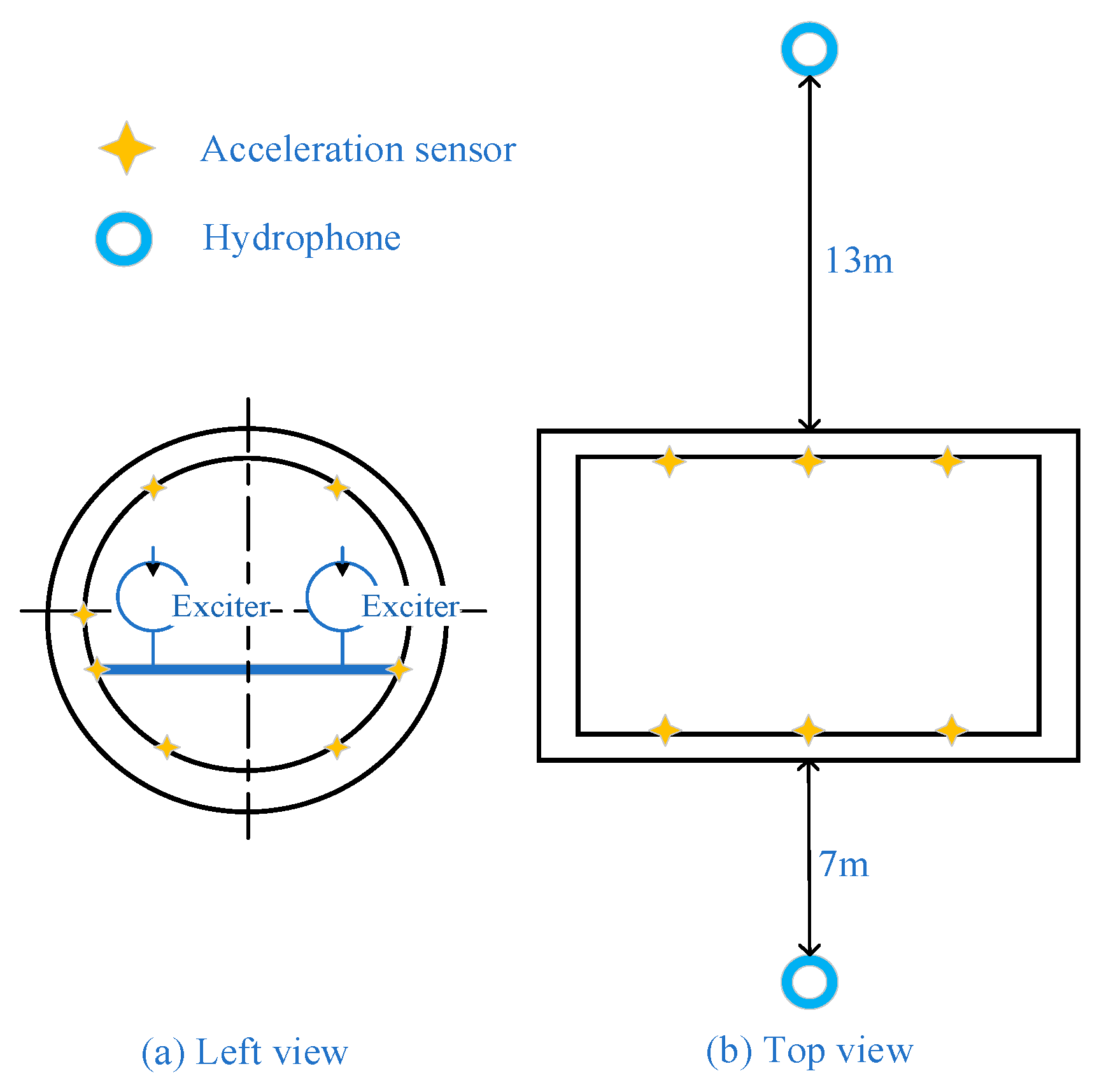
4.1.1. Experiment of the Cabin Model
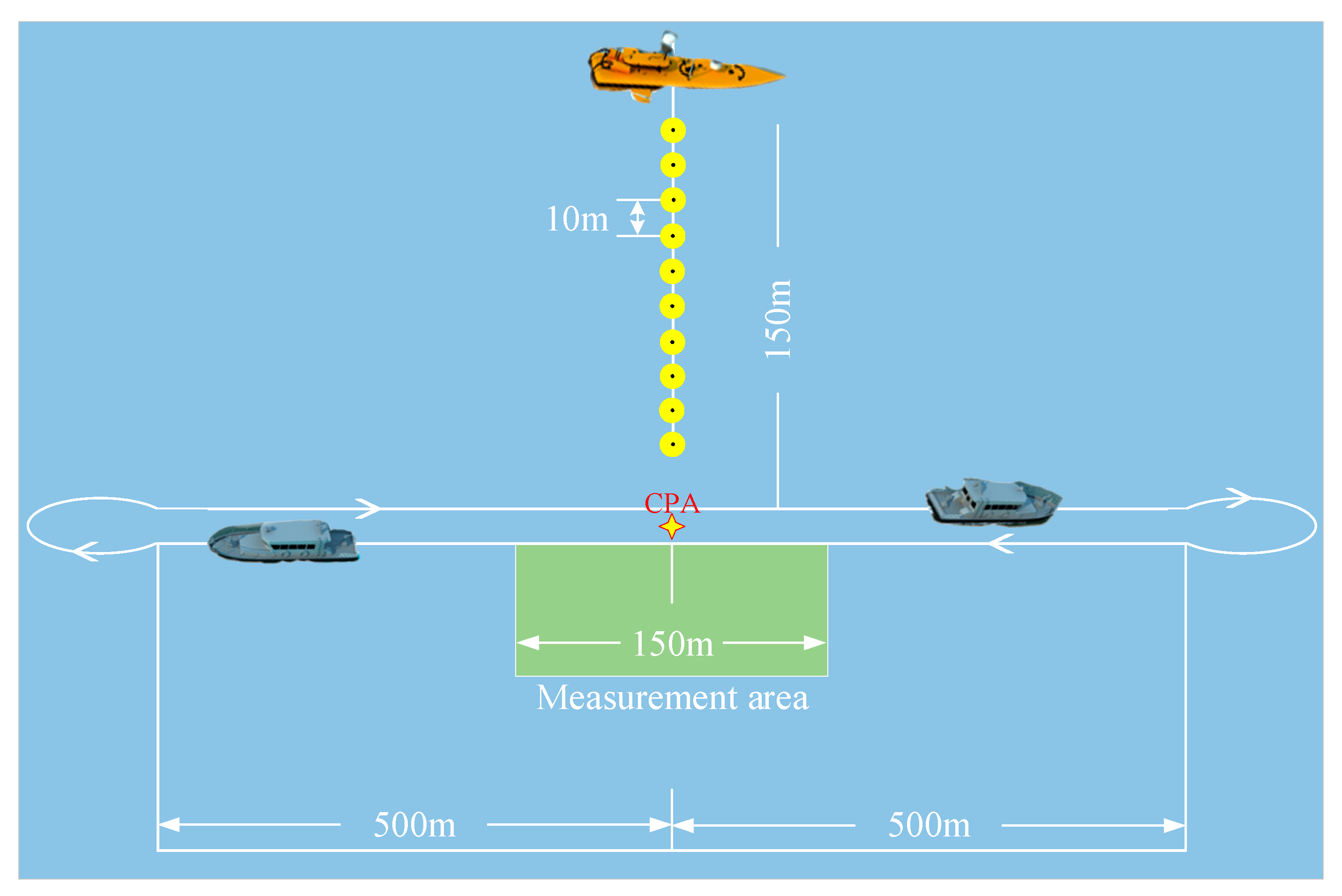
4.1.2. Experiment of the Scientific Research Vessel at Sea
4.2. Model Evaluation Index
4.3. Model Parameter Setting
4.4. Experiment Result
4.4.1. Experiment on the Cabin Model
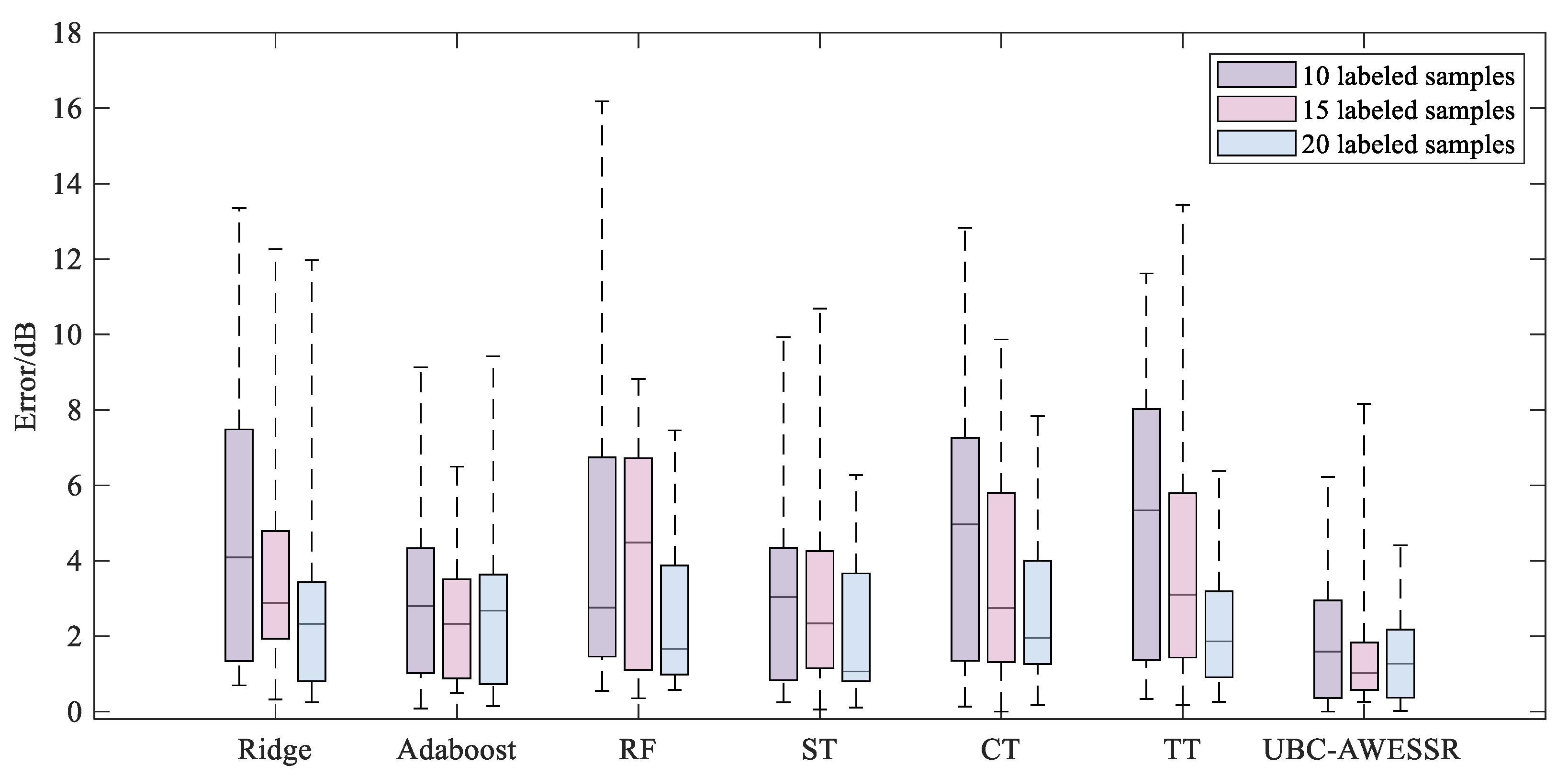
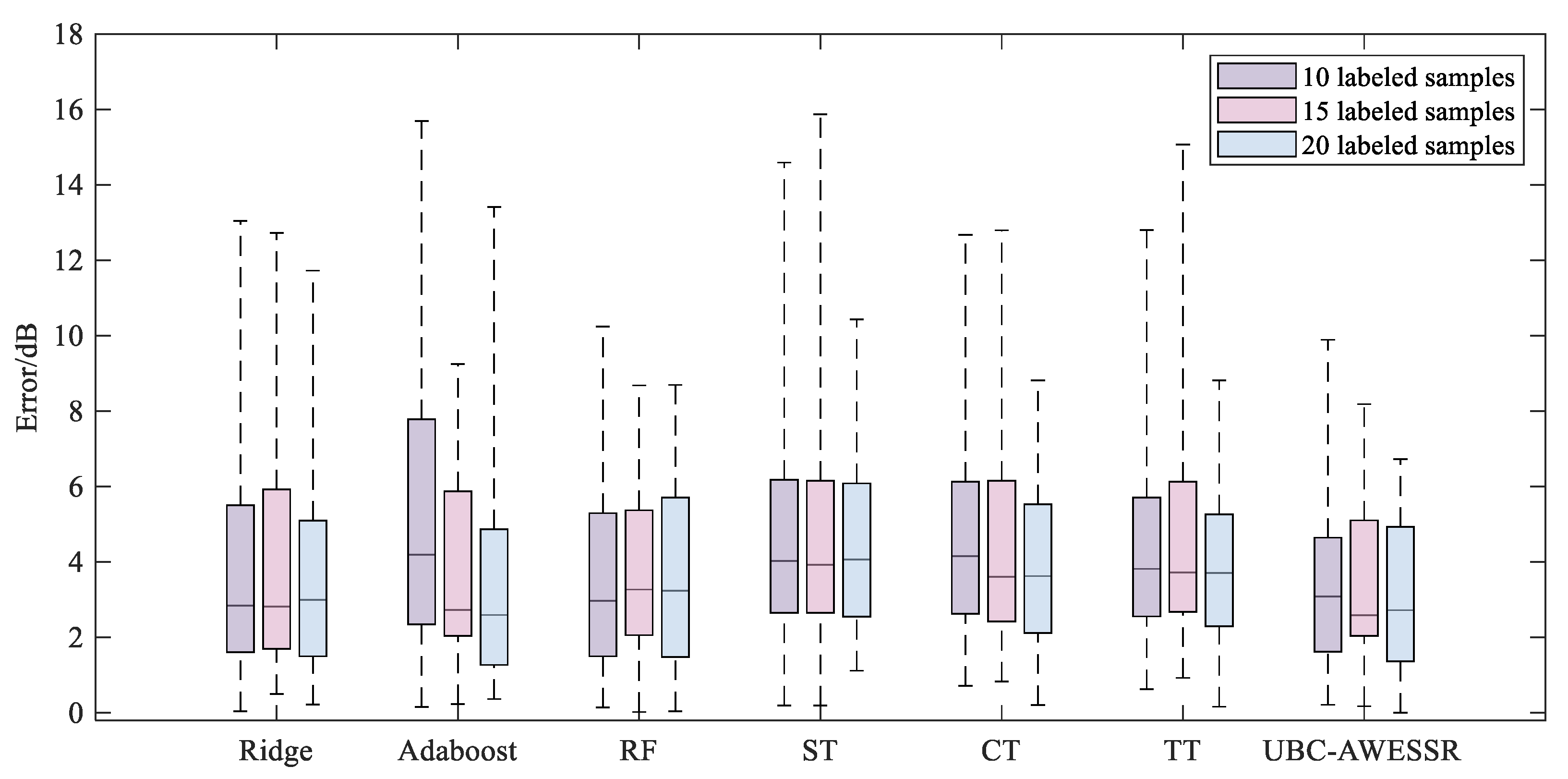
- Comparison of prediction results from different models
- b.
- Ablation test results
- (1)
- The influence of AW based on the genetic algorithm on model performance
- (2)
- The influence of the pseudo-label screening method based on UBC on model performance
4.4.2. Experiment on the Research Vessel
- Comparison of prediction results from different models
- b.
- Ablation test results
- (1)
- The influence of AW based on the genetic algorithm on model performance
- (2)
- The influence of the pseudo-label screening method based on UBC on model performance
5. Conclusions
- (1)
- We designed cabin model experiment and vessel experiment to verify the effectiveness of UBC-AWESSR model, and the results showed that UBC-AWESSR can reduce MAE and RMSE by up to 65.5% and 69.4% compared with the traditional SR and SSR models.
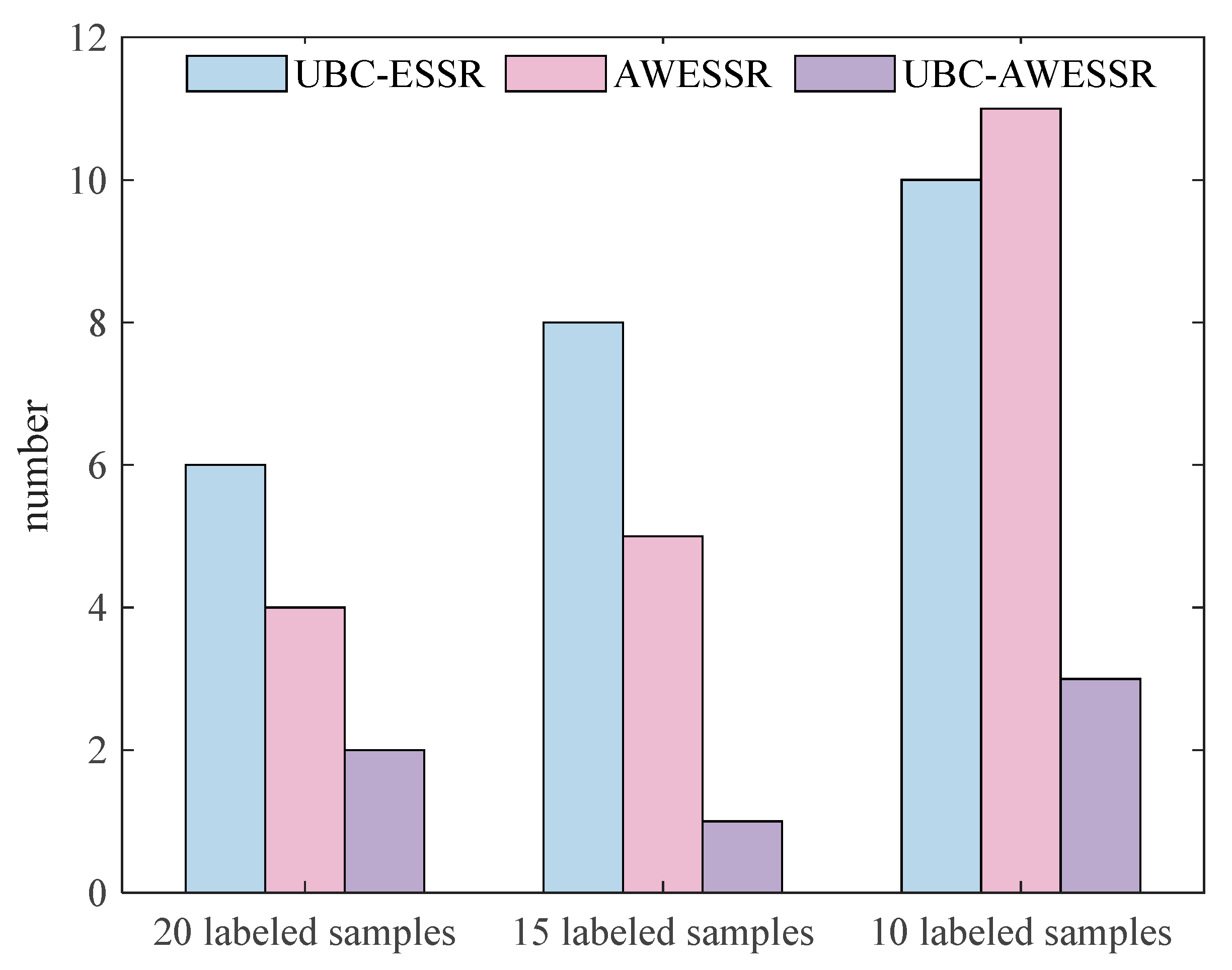
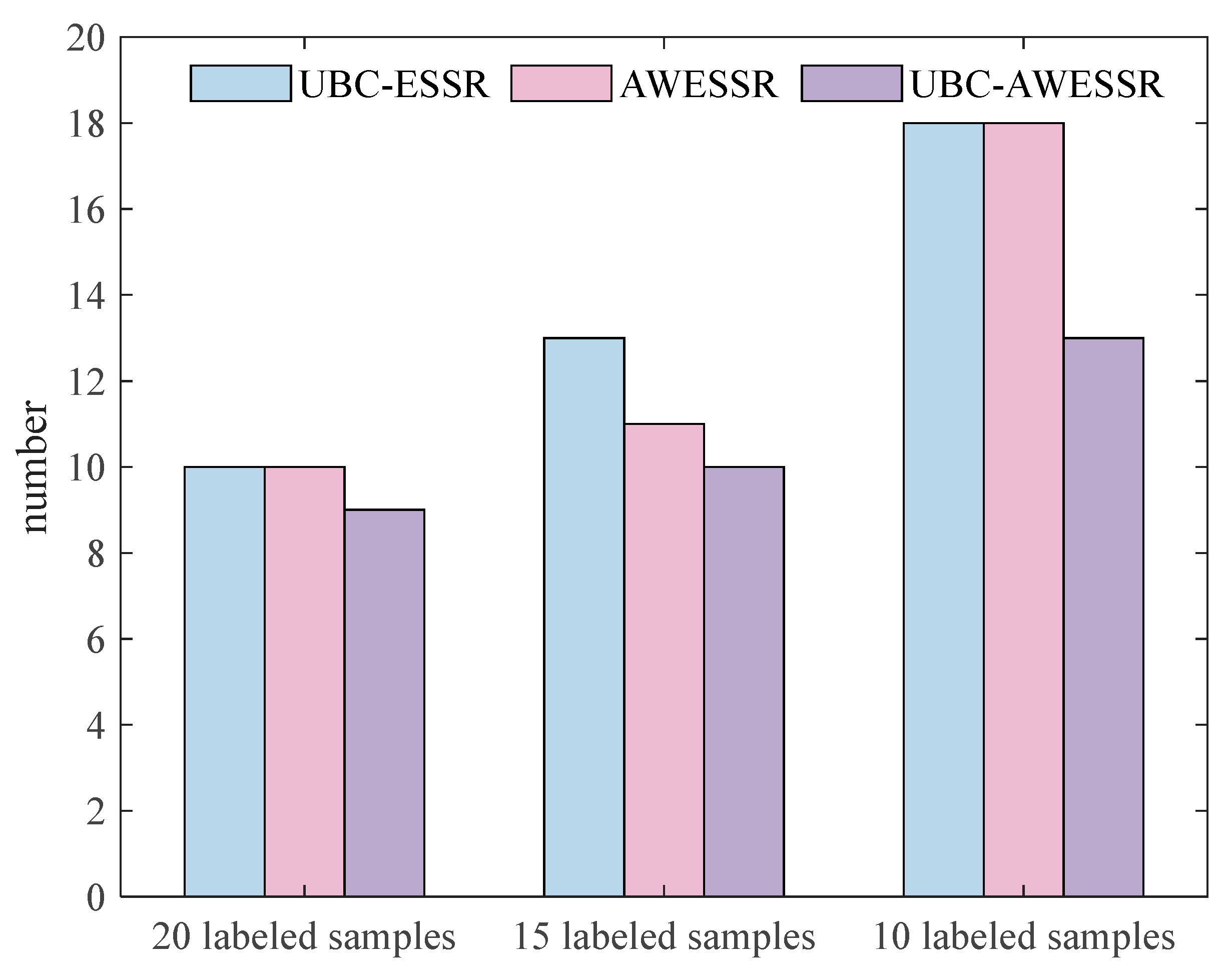
- (2)
- The predictive performances of different models under different numbers of labeled samples were compared. The results show that the fewer the number of labeled samples, the more obvious the advantages of UBC-AWESSR model become.
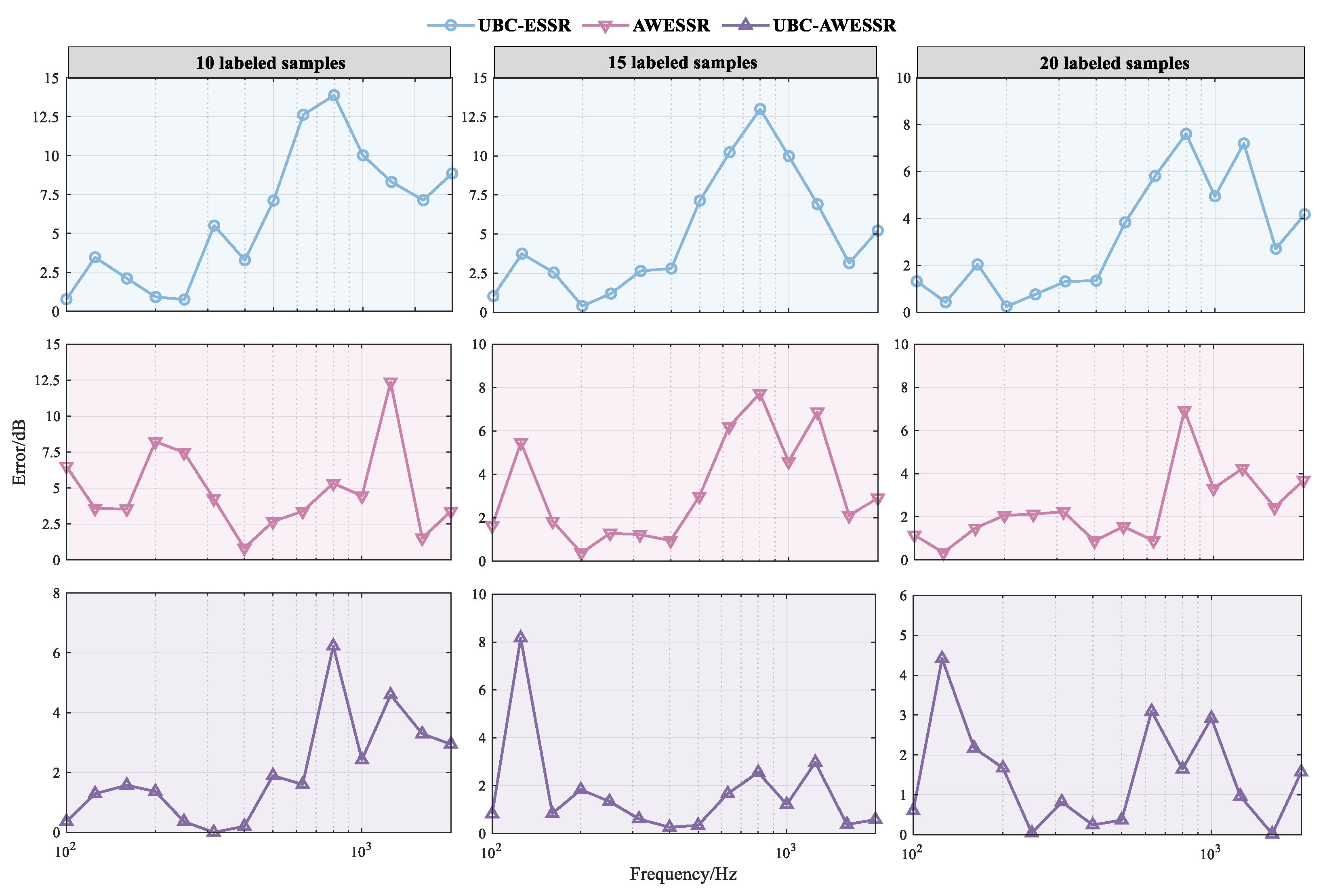
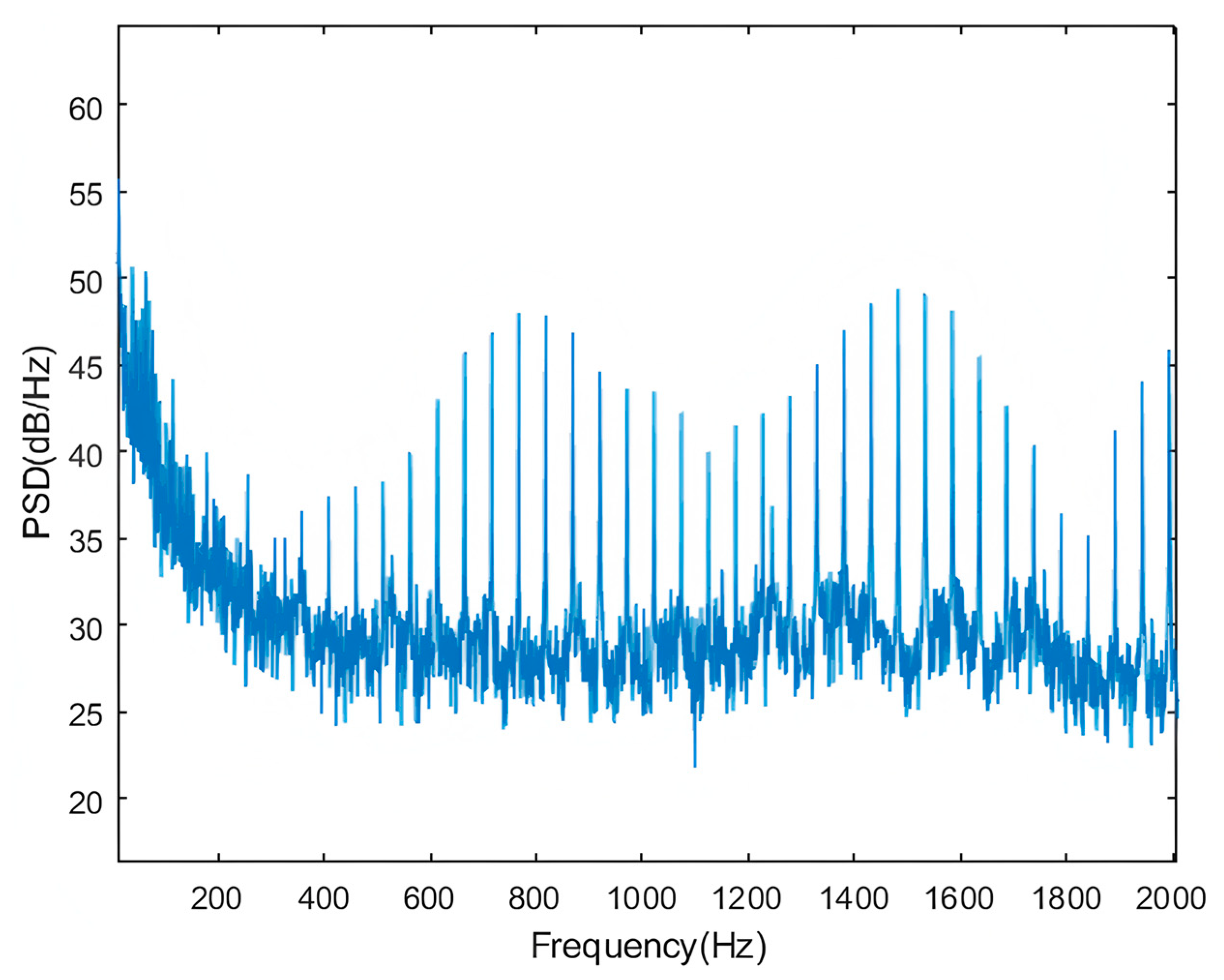
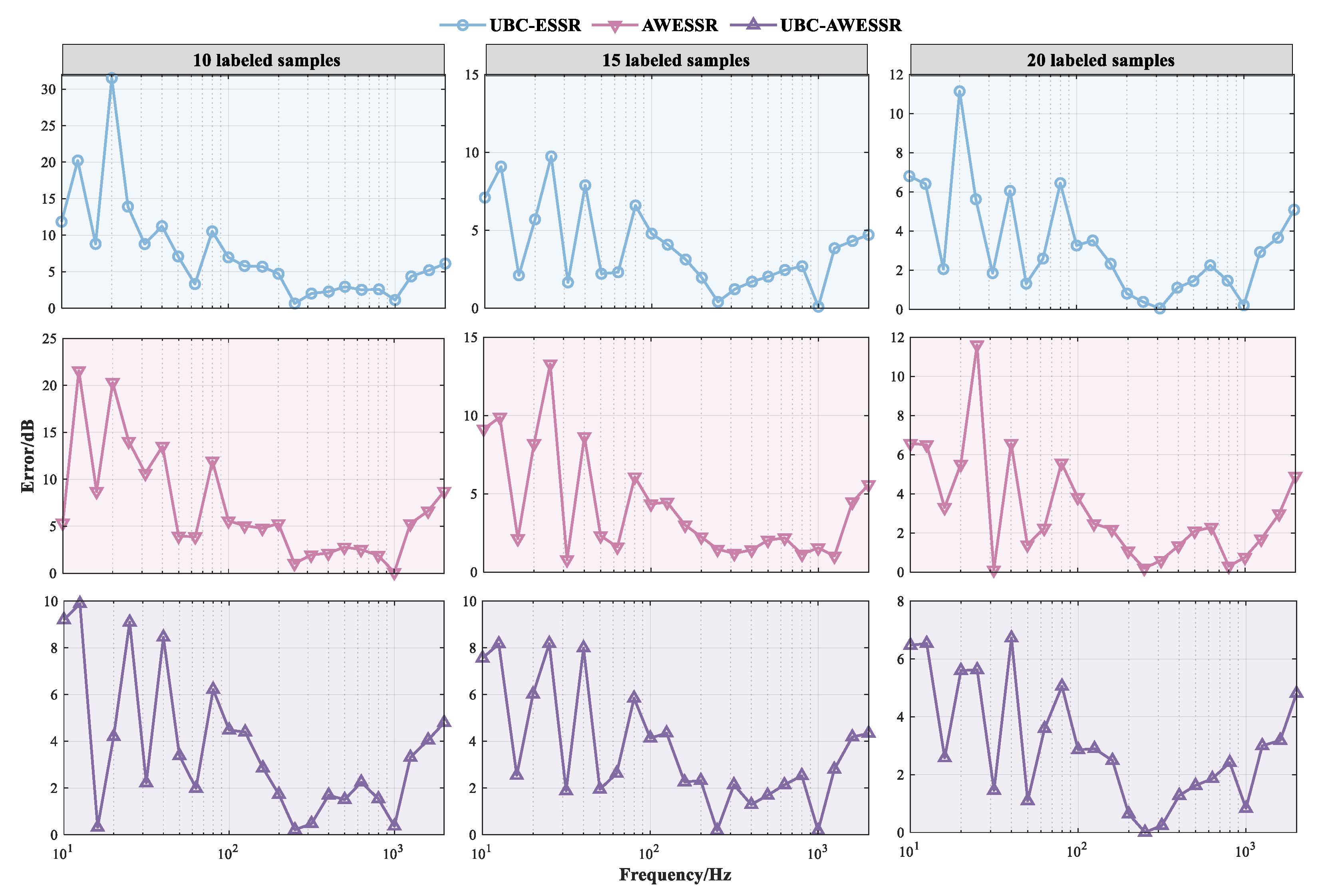
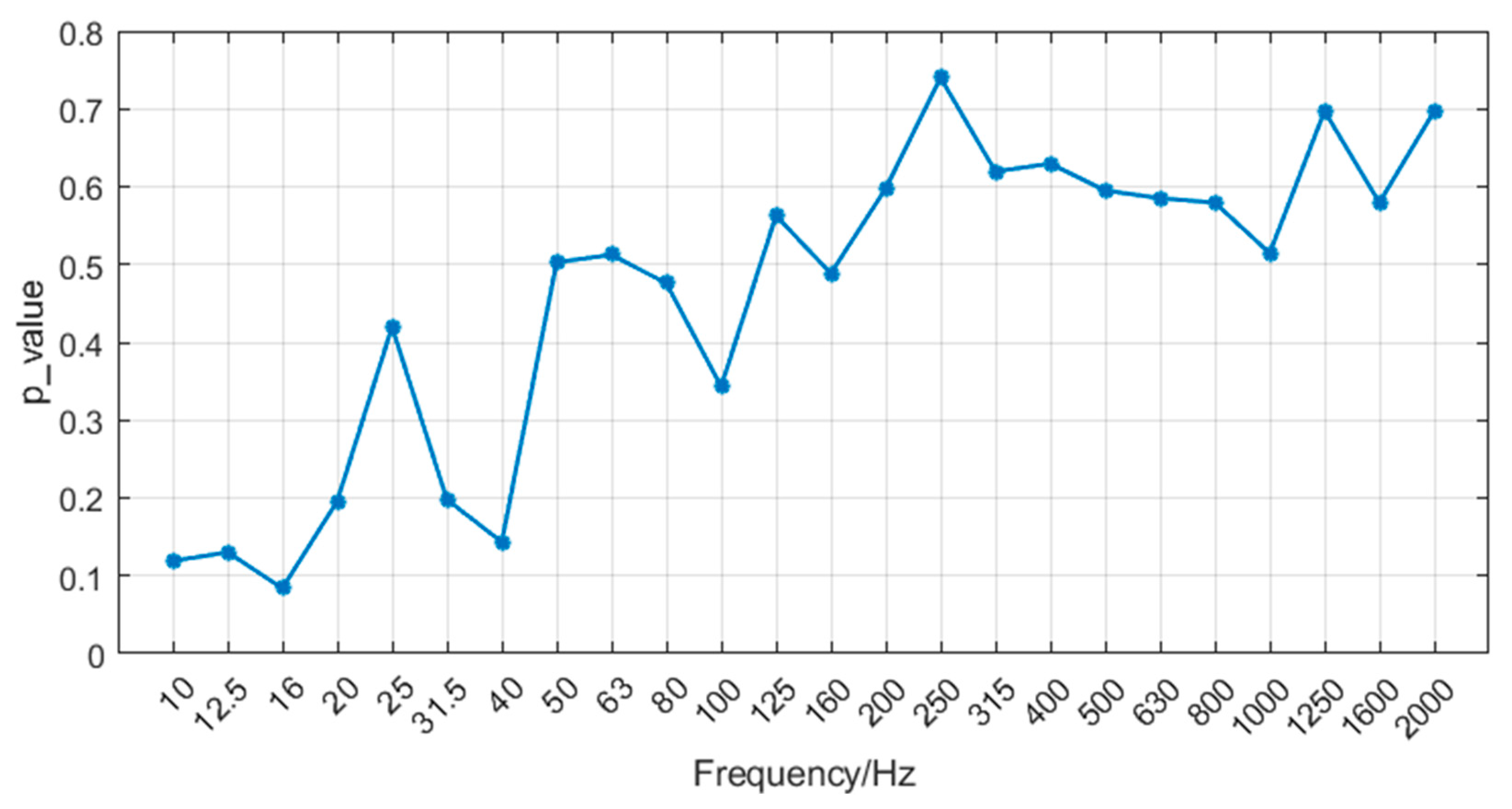
- (3)
- The experimental data collected during the sea trial contained single-frequency interference signals. However, even when the data quality was poor, UBC-AWESSR model still exhibited a relatively good predictive effect.
- (4)
- The results of the ablation tests show that the AWE integrating anti-perturbation regularization has the most significant impact on the model prediction, and the model performance degrades severely after removal, which provides supporting evidence for conclusion (3) from a different perspective.
- (5)
- To obtain more useful information to assist model training and increase the interpretability of the model, the data-driven integrating physical knowledge is the future research direction and the next focus of this paper.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Meng, X.Y.; Xiao, G.L.; Chen, H. Review of Current Status and Development of Submarine Acoustic Stealth Technology Abroad. J. Ship Sci. Technol. 2011, 33, 135–139. [Google Scholar]
- Jiang, L.G. 21st-Century Naval Vessels; National Defense Industry Press: Beijing, China, 1988. [Google Scholar]
- Sun, X.R.; Zhu, X. Survey and Tendency of Study on the Underwater Noise of Ship Structure. J. Vib. Shock 2005, 1, 108–115. [Google Scholar]
- Cui, W.C.; Liu, S.G.; Gu, J.H.; Li, Z.Y. Some New Trends on Submarine Design and Performance Studies Abroad. J. Ship Mech. 2000, 2, 65–80. [Google Scholar]
- Guo, W.J.; Li, T.Y.; Zhu, X.; Miao, Y.Y. Acoustic analysis of a finite cylindrical shell in an acoustic half-space based on Fourier transform technique. J. Vib. Eng. Technol. 2019, 7, 611–627. [Google Scholar] [CrossRef]
- Guo, W.J.; Li, T.Y.; Zhu, X.; Miao, Y.Y. Vibro-acoustic analysis of the thin laminated rectangular plate-cavity coupling system. Compos. Struct. 2018, 189, 570–585. [Google Scholar]
- Zhang, L.; Duan, J.-X.; Da, L.-L.; Xu, G.-J.; Sun, X.-H. Vibroacoustic radiation and propagation properties of slender cylindrical shell in uniform shallow sea. Ocean Eng. 2020, 195, 106659. [Google Scholar] [CrossRef]
- Kim, S.M.; Brennan, M.J. A compact matrix formulation using the impedance and mobility approach for the analysis of structural-acoustic systems. J. Sound Vib. 1999, 223, 97–113. [Google Scholar] [CrossRef]
- Zhang, B.; Xiang, Y.; He, P.; Zhang, G.-J. Study on prediction methods and characteristics of ship underwater radiated noise within full frequency. Ocean Eng. 2019, 174, 61–70. [Google Scholar] [CrossRef]
- Li, D.-Q.; Hallander, J.; Johansson, T. Predicting underwater radiated noise of a full scale ship with model testing and numerical methods. Ocean Eng. 2018, 161, 121–135. [Google Scholar] [CrossRef]
- Viitanen, V.; Hynninen, A.; Sipilä, T. Computational fluid dynamics and hydroacoustics analyses of underwater radiated noise of an ice breaker ship. Ocean Eng. 2023, 279, 114264. [Google Scholar] [CrossRef]
- Kim, S.; Kinnas, S.A. Numerical prediction of propeller-induced noise in open water and ship behind conditions. Ocean Eng. 2022, 261, 112122. [Google Scholar] [CrossRef]
- Özden, M.C.; Gürkan, A.Y.; Ozden, M.C.; Canyurt, T.G.; Korkut, E. Underwater radiated noise prediction for a submarine propeller in different flow conditions. Ocean Eng. 2016, 126, 488–500. [Google Scholar] [CrossRef]
- Wang, B. Research on Prediction of Noise Radiated by Large Underwater Structure Via Surface Vibration Monitoring. Ph.D. Thesis, Shanghai Jiao Tong University, Shanghai, China, 2008. [Google Scholar]
- Cintosun, E. Derivations of transfer functions for estimating ship underwater radiated noise from onboard vibrations. Ocean Eng. 2024, 311, 118792. [Google Scholar] [CrossRef]
- Ye, L.; Shen, J.; Tong, Z.; Liu, Y. Research on acoustic reconstruction methods of the hull vibration based on the limited vibration monitor data. Ocean Eng. 2022, 266, 112886. [Google Scholar] [CrossRef]
- Park, U.; Kang, Y.J. Operational transfer path analysis based on neural network. J. Sound Vib. 2024, 579, 118364. [Google Scholar] [CrossRef]
- Zhang, X.Z.; Yang, H.C. To Predict the Radiation Noise of Ship Based on RBF Neural Network. Value Eng. 2011, 30, 62–63. [Google Scholar]
- Tang, Z.Y.; Li, G.H.; He, L. Acoustic stealth situation assessment of underwater vehicle based on fuzzy support vector machine. In Proceedings of the 2009 International Conference on Mechatronics and Automation, Changchun, China, 9–12 August 2009; pp. 2095–2100. [Google Scholar]
- Li, J.Y.; Pan, Y.; Wang, Q. Research on the Application of Deep Neural Network in Ship Radiated Noise Simulation. Acoust. Electron. Eng. 2022, 01, 10–15. [Google Scholar]
- Miglianti, L.; Cipollini, F.; Oneto, L.; Tani, G.; Gaggero, S.; Coraddu, A.; Viviani, M. Predicting the cavitating marine propeller noise at design stage: A deep learning based approach. Ocean Eng. 2020, 209, 107481. [Google Scholar] [CrossRef]
- Fan, B. Prediction of Cabin Noise for Offshore Platforms Based on Intelligent Algorithms. Master’s Thesis, Harbin Engineering University, Harbin, China, 2018. [Google Scholar]
- He, T.J. Research on Measurements of the Radiated Noise from Shipping in Shallow Water. Ph.D. Thesis, Harbin Engineering University, Harbin, China, 2022. [Google Scholar]
- Shahshahani, B.; Landgrebe, D. The effect of unlabeled samples in reducing the small sample size problem and mitigating the hughes phenomenon. IEEE Trans. Geosci. Remote Sens. 1994, 32, 1087–1095. [Google Scholar] [CrossRef]
- Liu, J.W.; Liu, Y.; Luo, X.L. Semi-supervised Learning Methods. Chin. J. Comput. 2015, 38, 1592–1617. [Google Scholar]
- Zhou, Z.H.; Li, M. Semisupervised regression with cotraining-style algorithms. IEEE Trans. Knowl. Data Eng. 2007, 19, 1479–1493. [Google Scholar] [CrossRef]
- Gan, H.T. Research on Semi-Supervised Clustering and Classification Algorithm. Ph.D. Thesis, Huazhong University of Science and Technology, Wuhan, China, 2014. [Google Scholar]
- Qin, Y.; Ding, S.; Wang, L.; Wang, Y. Research progress on semi-supervised clustering. Cogn. Comput. 2019, 11, 599–612. [Google Scholar] [CrossRef]
- Li, J.; Zhu, X.; Wang, H.; Zhang, Y.; Wang, J. Stacked co-training for semi-supervised multi-label learning. Inf. Sci. 2024, 677, 120906. [Google Scholar] [CrossRef]
- Kostopoulos, G.; Karlos, S.; Kotsiantis, S.; Ragos, O. Semi-supervised regression: A recent review. J. Intell. Fuzzy Syst. 2018, 35, 1483–1500. [Google Scholar] [CrossRef]
- Scudder, H.J. Probability of error of some adaptive pattern-recognition machines. IEEE Trans. Inf. Theory 1965, 11, 363–371. [Google Scholar] [CrossRef]
- Blum, A.; Mitchell, T. Combining labeled and unlabeled data with co-training. In Proceedings of the Eleventh Annual Conference on Cozmputational Learning Theory, Madison, WI, USA, 24–26 July 1998; pp. 92–100. [Google Scholar]
- Zhou, Z.H.; Li, M. Semi-supervised regression with co-training. In Proceedings of the 19th International Joint Conference on Artificial Intelligence (IJCAI), Edinburgh, UK, 30 July–5 August 2005; pp. 908–913. [Google Scholar]
- Zhou, Z.H. Tri-training: Exploiting unlabeled data using three classifiers. IEEE Trans. Knowl. Data Eng. 2005, 17, 1529–1541. [Google Scholar] [CrossRef]
- Li, M.; Zhou, Z.H. Improve computer-aided diagnosis with machine learning techniques using undiagnosed samples. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2007, 37, 1088–1098. [Google Scholar] [CrossRef]
- Zhou, Z.H. When semi-supervised learning meets ensemble learning. Front. Electr. Electron. Eng. China 2011, 6, 6–16. [Google Scholar] [CrossRef]
- Miyato, T.; Maeda, S.-I.; Koyama, M.; Ishii, S. Virtual adversarial training: A regularization method for supervised and semi-supervised learning. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1979–1993. [Google Scholar] [CrossRef]
- Meel, P.; Vishwakarma, D.K. A temporal ensembling based semi-supervised ConvNet for the detection of fake news articles. Expert Syst. Appl. 2021, 177, 115002. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Li, M. Semi-supervised learning by disagreement. Knowl. Inf. Syst. 2010, 24, 415–439. [Google Scholar] [CrossRef]
- Huang, X.; Xu, R.; Li, R. An Online Prediction Method for Ship Underwater Radiated Noise Based on Differential Evolution Feature Optimization and Ensemble Method. Ocean Eng. 2025, 333, 121517. [Google Scholar] [CrossRef]
- Montgomery, D.C.; Peck, E.A.; Vining, G.G. Introduction to Linear Regression Analysis; China Machine Press: Beijing, China, 2016; p. 35. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Parameter |
|---|---|
| Ridge | Alpha = 0.1 |
| MLP | hidden layers = 6; activation function= ReLU; learning_rate = 0.001 |
| Adaboost | n_estimators = 10; learning_rate = 0.01 |
| RF | n_estimators = 10; max_features = 5 |
| Self-Training | n_neighbors = 3; metric = ‘Euclidean’ |
| Co-Training | n_neighbors = {3, 5}; metric = {‘Euclidean’, ‘minkowski’} |
| Tri-Training | n_neighbors = {3, 5, 4}; metric = {‘Euclidean’, ‘minkowski’, ‘manhattan’} |
| UBC-AWESSR | n_base_models = 5; n_neighbors = {3, 5}; metric = {‘Euclidean’, ‘minkowski’} |
| MAE/dB | RMSE/dB | ||||||
|---|---|---|---|---|---|---|---|
| Number of Labeled Data | 10 | 15 | 20 | 10 | 15 | 20 | |
| SR | Ridge | 4.72 | 3.65 | 2.89 | 6.05 | 4.64 | 4.09 |
| MLP | 5.25 | 4.91 | 2.86 | 6.83 | 6.33 | 4.02 | |
| Adaboost | 3.13 | 2.51 | 2.92 | 3.90 | 3.09 | 3.79 | |
| RF | 5.83 | 3.65 | 2.59 | 8.63 | 4.86 | 3.23 | |
| SSR | ST | 3.74 | 3.14 | 1.96 | 4.99 | 4.29 | 2.66 |
| CT | 4.74 | 4.04 | 2.83 | 6.07 | 5.28 | 3.65 | |
| TT | 5.00 | 4.44 | 2.54 | 6.21 | 5.89 | 3.24 | |
| Proposed by us | UBC-AWESSR | 2.01 | 1.68 | 1.47 | 2.64 | 2.59 | 1.93 |
| MAE/dB | RMSE/dB | |||||
|---|---|---|---|---|---|---|
| Number of Labeled Data | 10 | 15 | 20 | 10 | 15 | 20 |
| UBC-ESSR | 6.05 | 5.00 | 3.13 | 7.36 | 6.25 | 3.94 |
| UBC-AWESSR | 2.01 | 1.68 | 1.47 | 2.64 | 2.59 | 1.93 |
| Error decreases | 66.8% | 66.4% | 53.0% | 64.1% | 58.6% | 51.0% |
| MAE/dB | RMSE/dB | |||||
|---|---|---|---|---|---|---|
| Number of Labeled Data | 10 | 15 | 20 | 10 | 15 | 20 |
| AWESSR | 4.83 | 3.29 | 2.38 | 5.63 | 4.04 | 2.91 |
| UBC-AWESSR | 2.01 | 1.68 | 1.47 | 2.64 | 2.59 | 1.93 |
| Error decreases | 58.4% | 48.9% | 38.2% | 53.1% | 35.9% | 33.7% |
| MAE/dB | RMSE/dB | ||||||
|---|---|---|---|---|---|---|---|
| Number of Labeled Data | 10 | 15 | 20 | 10 | 15 | 20 | |
| SR | Ridge | 3.90 | 4.08 | 3.68 | 5.02 | 5.08 | 4.61 |
| MLP | 4.68 | 4.54 | 3.40 | 6.75 | 5.98 | 4.17 | |
| Adaboost | 5.23 | 3.95 | 3.49 | 6.55 | 4.79 | 4.63 | |
| RF | 3.81 | 3.88 | 3.60 | 4.92 | 4.60 | 4.41 | |
| SSR | ST | 4.69 | 4.77 | 4.53 | 5.64 | 6.09 | 5.22 |
| CT | 4.73 | 4.54 | 3.84 | 5.63 | 5.50 | 4.42 | |
| TT | 4.57 | 4.69 | 3.92 | 5.56 | 5.70 | 4.49 | |
| Proposed by us | UBC-AWESSR | 3.69 | 3.63 | 3.04 | 4.69 | 4.36 | 3.66 |
| MAE/dB | RMSE/dB | |||||
|---|---|---|---|---|---|---|
| Number of Labeled Data | 10 | 15 | 20 | 10 | 15 | 20 |
| UBC-ESSR | 7.50 | 3.83 | 3.28 | 10.08 | 4.63 | 4.21 |
| UBC-AWESSR | 3.69 | 3.63 | 3.04 | 4.69 | 4.36 | 3.66 |
| Error decreases | 50.8% | 5.22% | 7.32% | 53.5% | 5.83% | 13.1% |
| MAE/dB | RMSE/dB | |||||
|---|---|---|---|---|---|---|
| Number of Labeled Data | 10 | 15 | 20 | 10 | 15 | 20 |
| AWESSR | 6.98 | 4.09 | 3.17 | 8.97 | 5.30 | 4.17 |
| UBC-AWESSR | 3.69 | 3.63 | 3.04 | 4.69 | 4.36 | 3.66 |
| Error decreases | 47.1% | 11.3% | 4.10% | 47.8% | 17.7% | 12.2% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Xu, R.; Li, R. A Ship Underwater Radiated Noise Prediction Method Based on Semi-Supervised Ensemble Learning. J. Mar. Sci. Eng. 2025, 13, 1303. https://doi.org/10.3390/jmse13071303
Huang X, Xu R, Li R. A Ship Underwater Radiated Noise Prediction Method Based on Semi-Supervised Ensemble Learning. Journal of Marine Science and Engineering. 2025; 13(7):1303. https://doi.org/10.3390/jmse13071303
Chicago/Turabian StyleHuang, Xin, Rongwu Xu, and Ruibiao Li. 2025. "A Ship Underwater Radiated Noise Prediction Method Based on Semi-Supervised Ensemble Learning" Journal of Marine Science and Engineering 13, no. 7: 1303. https://doi.org/10.3390/jmse13071303
APA StyleHuang, X., Xu, R., & Li, R. (2025). A Ship Underwater Radiated Noise Prediction Method Based on Semi-Supervised Ensemble Learning. Journal of Marine Science and Engineering, 13(7), 1303. https://doi.org/10.3390/jmse13071303