
Wave Run-Up Distance Prediction Combined Data-Driven Method and Physical Experiments

 , ,
, ,
Abstract
1. Introduction
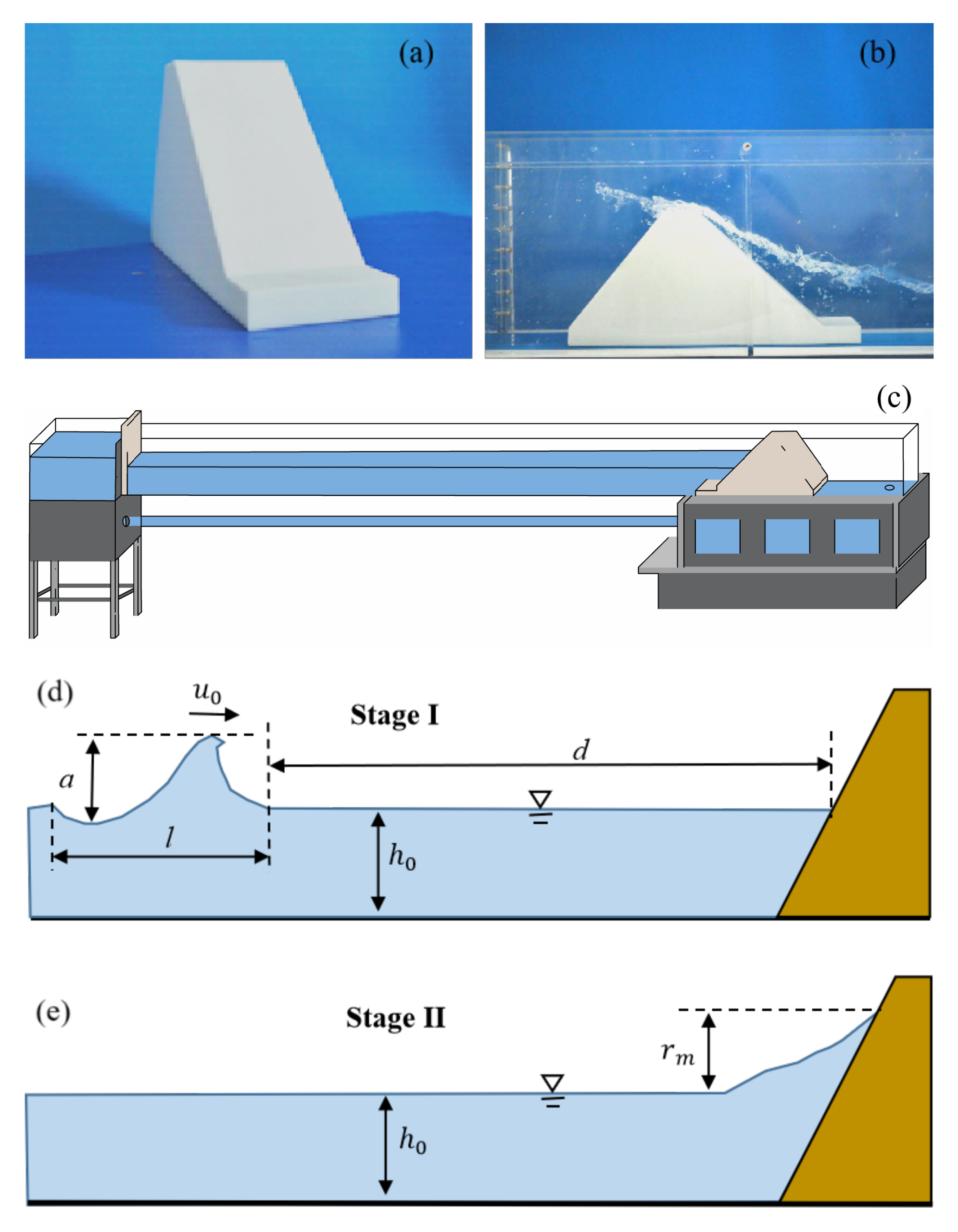
2. Physical Model Experiments
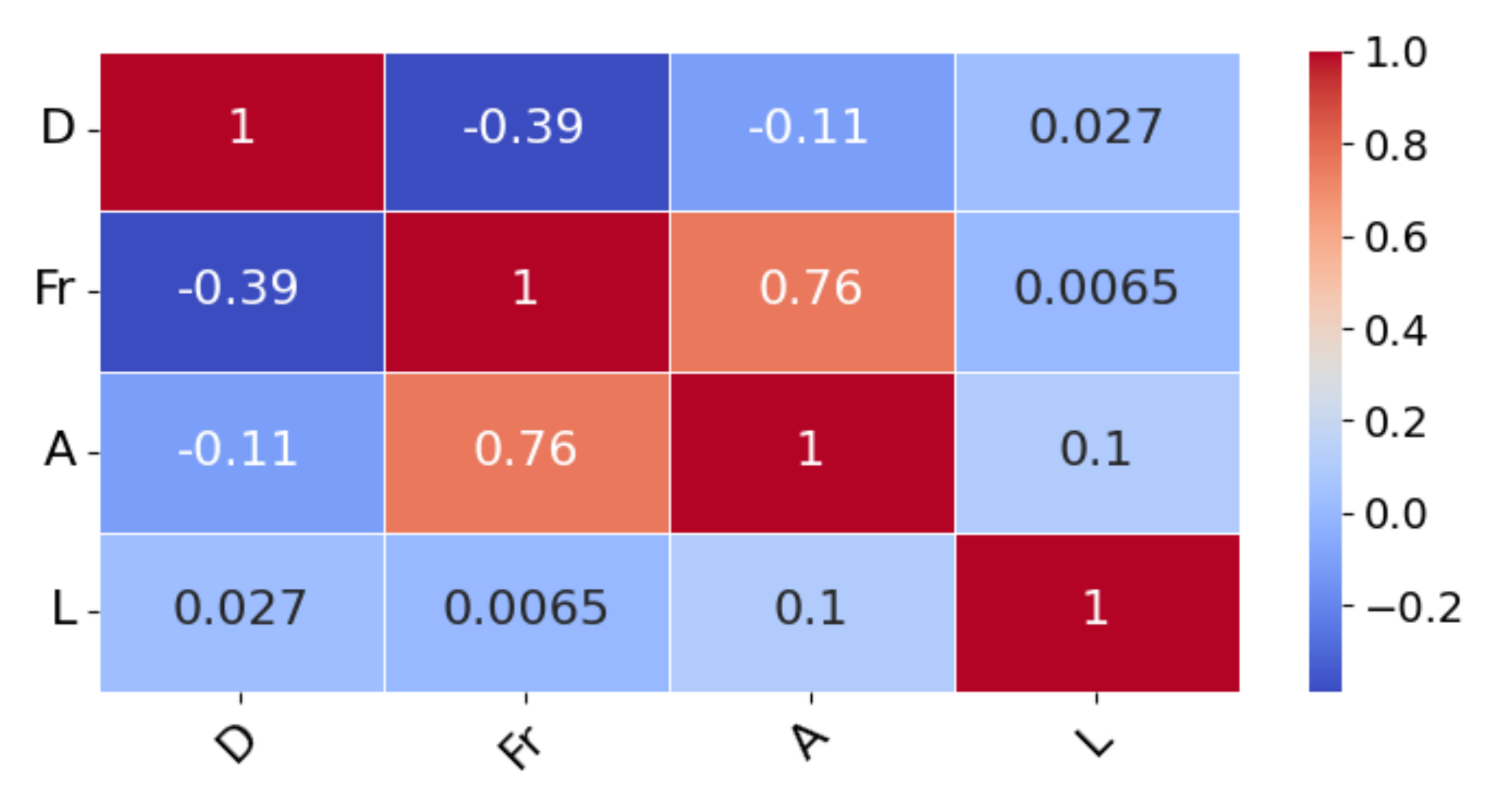
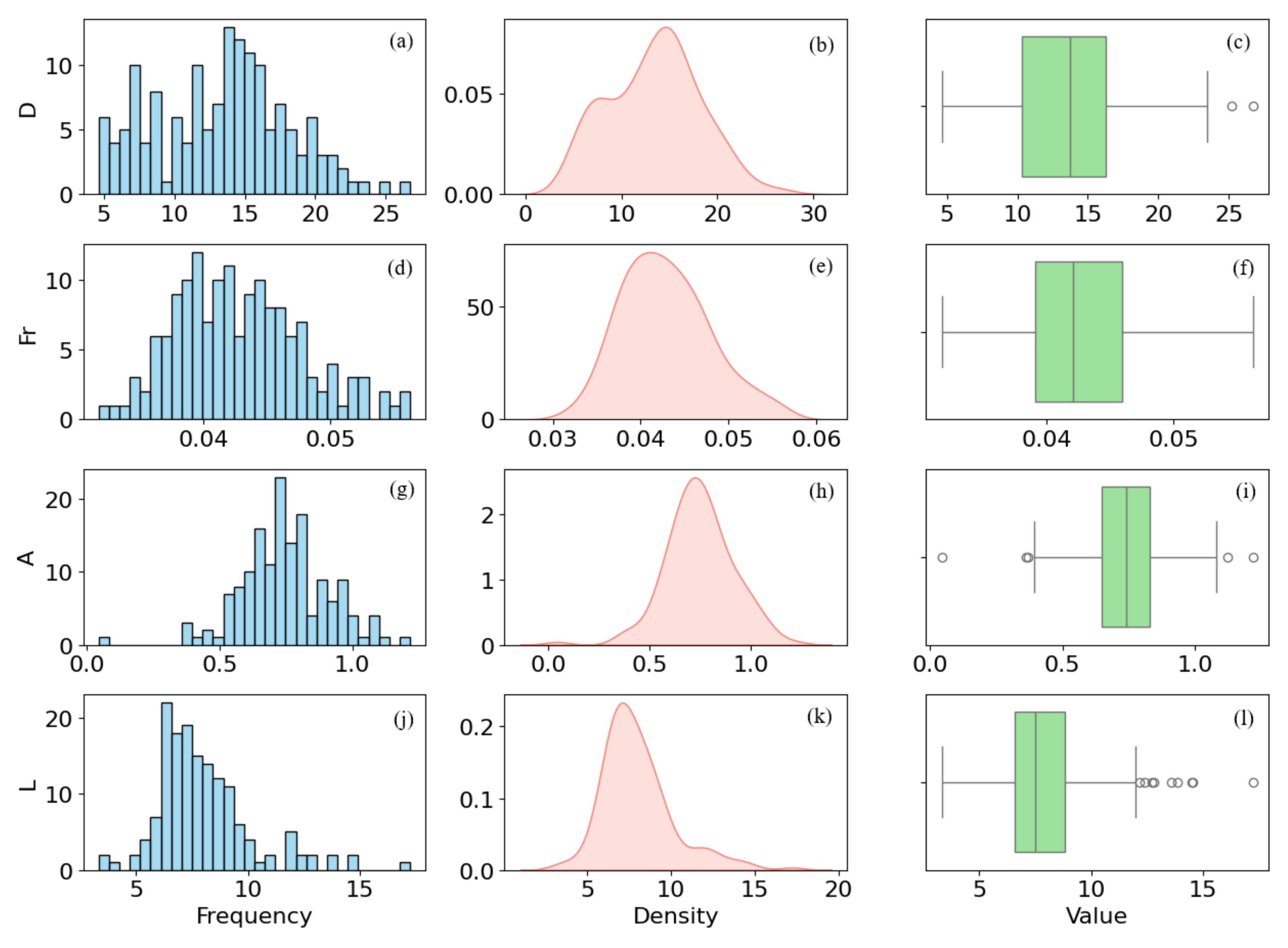
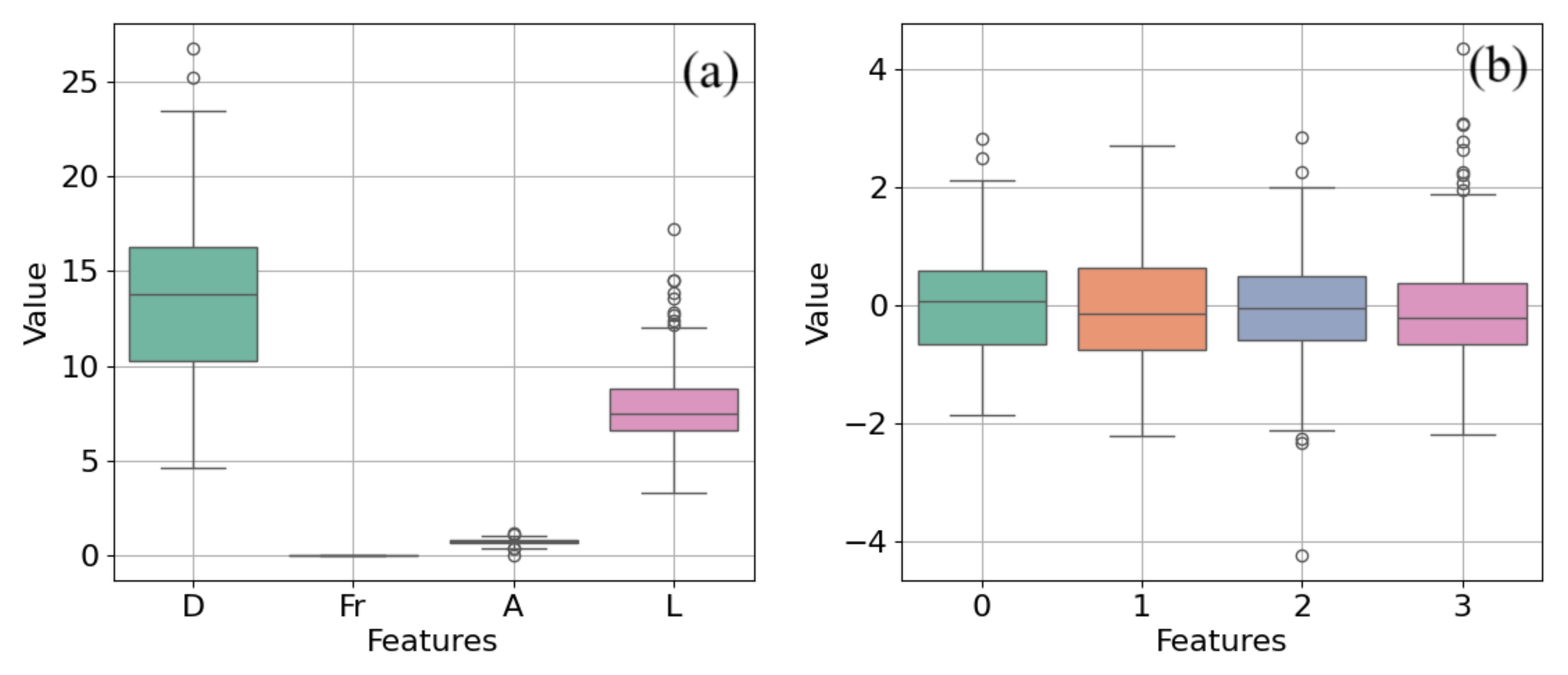
3. Dimensionless Analysis
4. Mathematical Principles of the GBR-GMM Combined Model
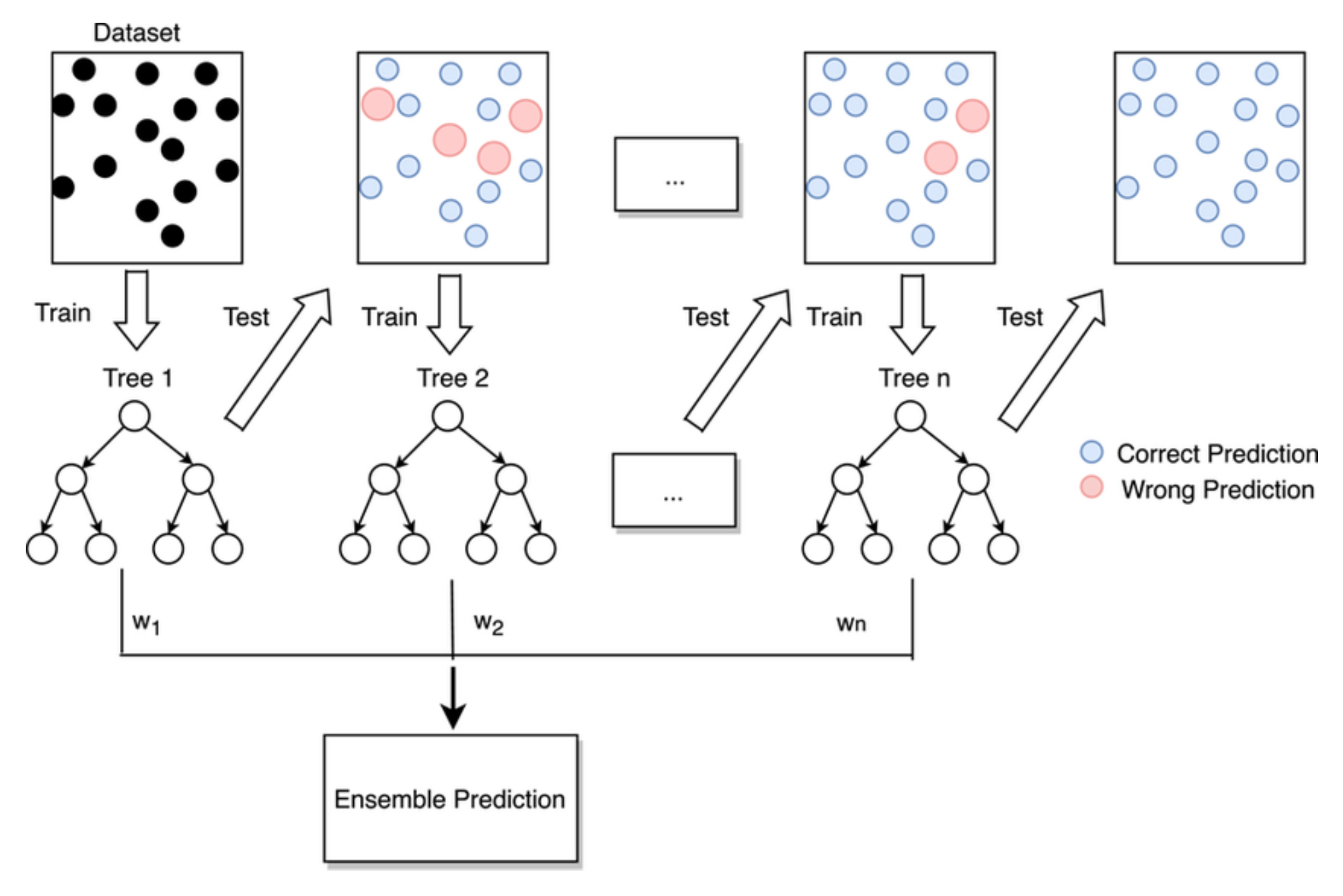
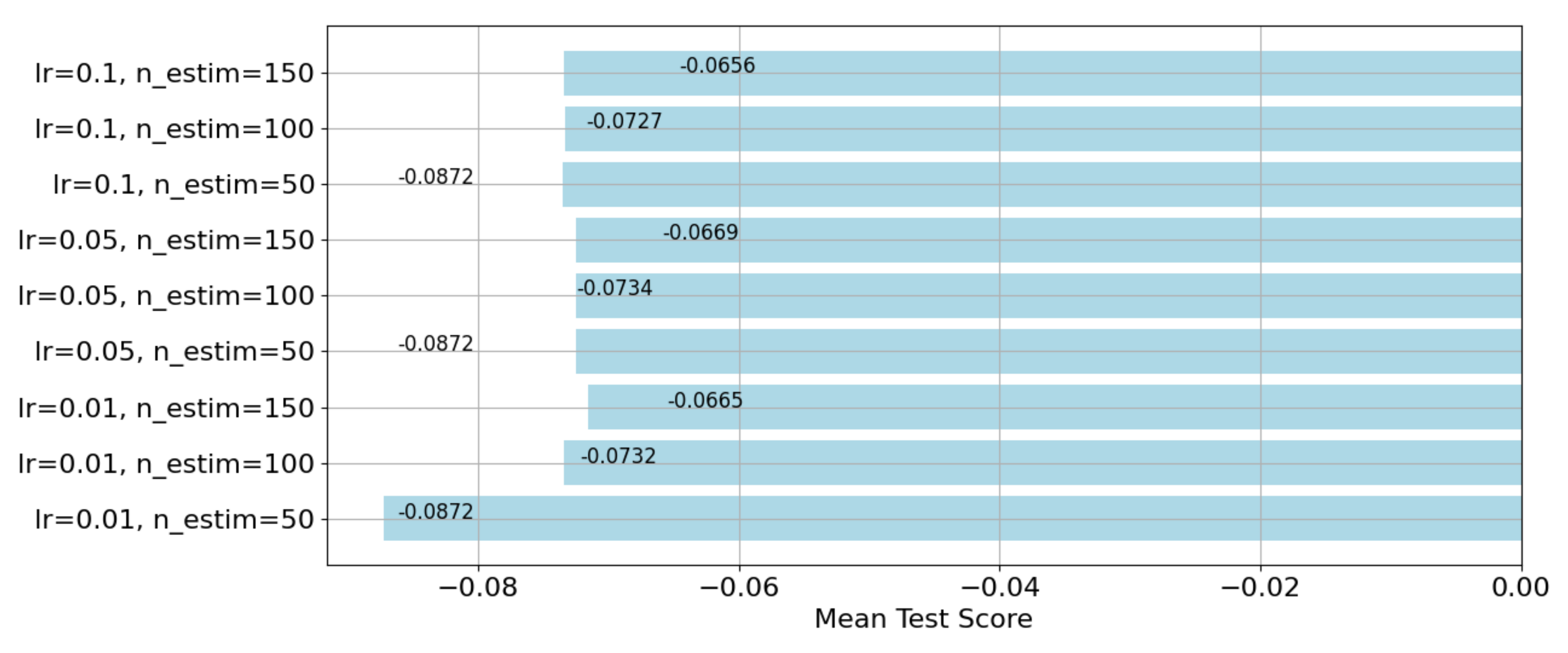
4.1. Run-Up Distance Prediction Based on Gradient Boosting Regression (GBR)
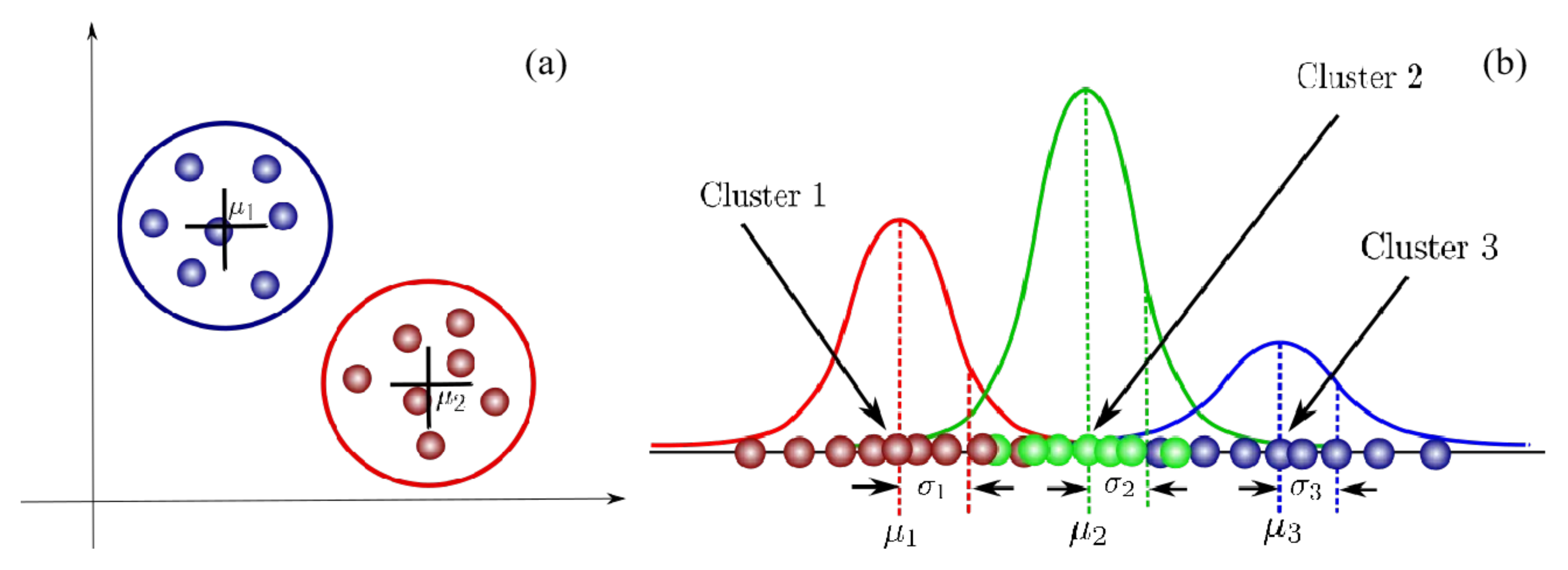
4.2. Data Clustering Using Gaussian Mixture Model (GMM)
5. Results
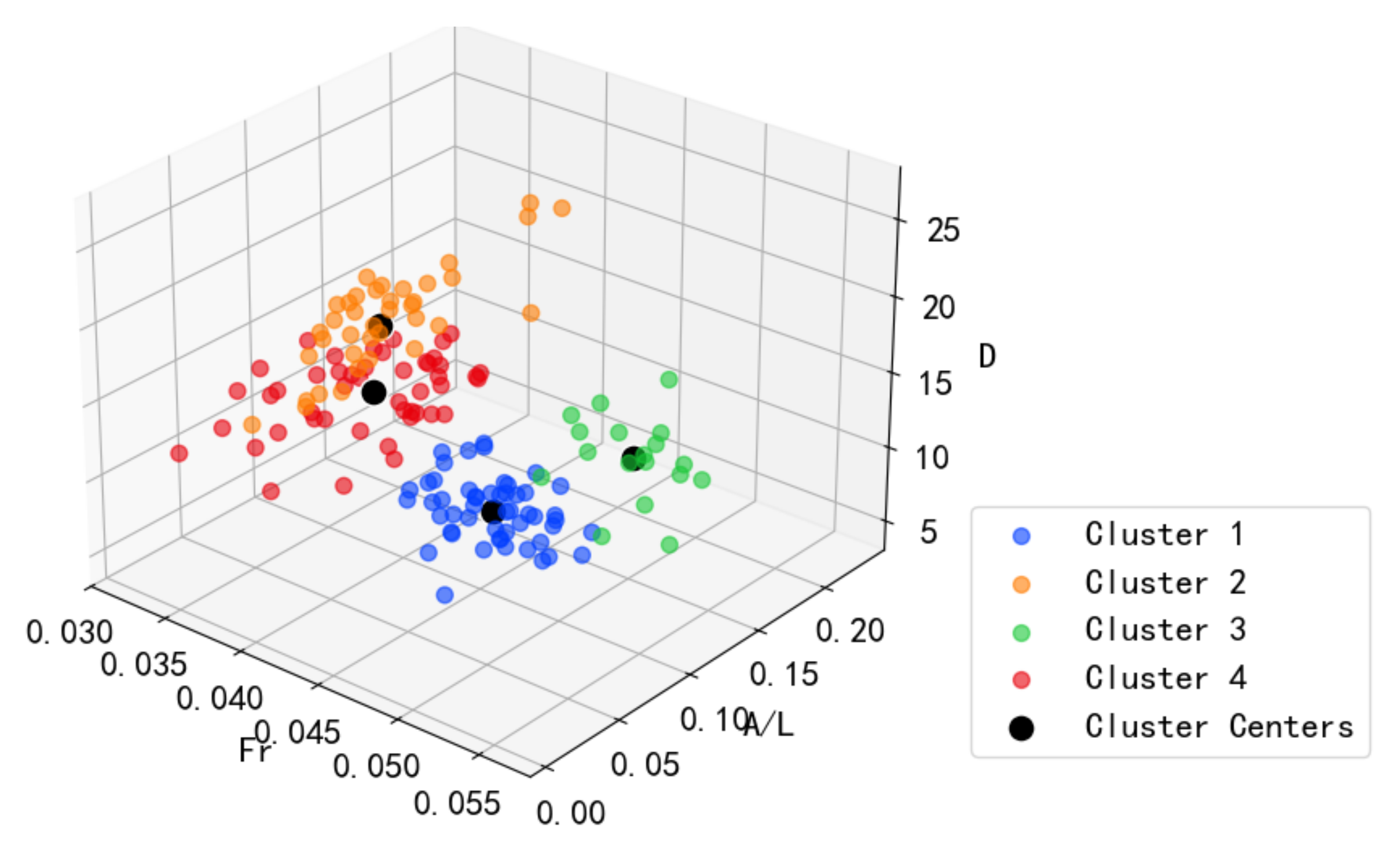
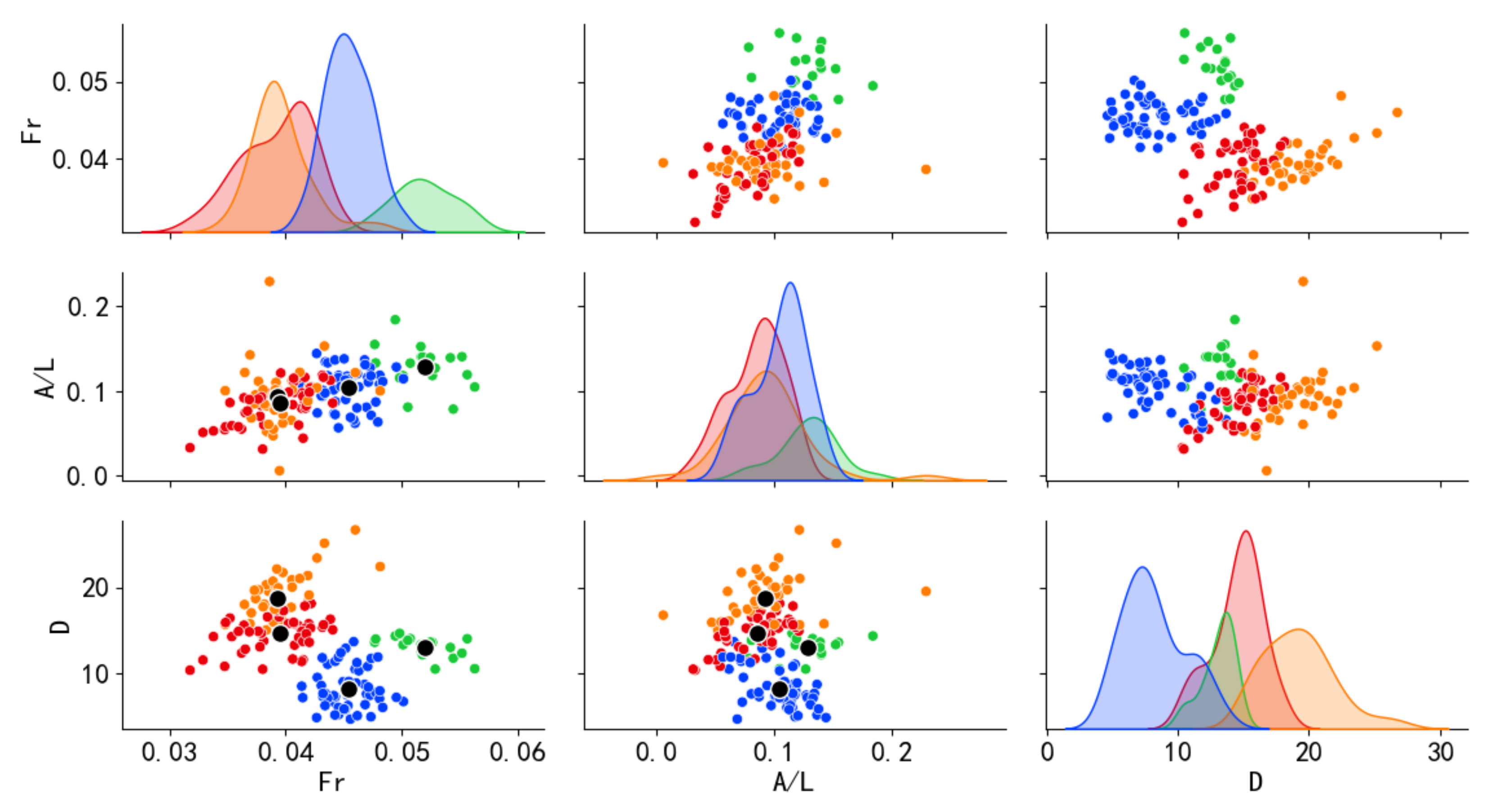
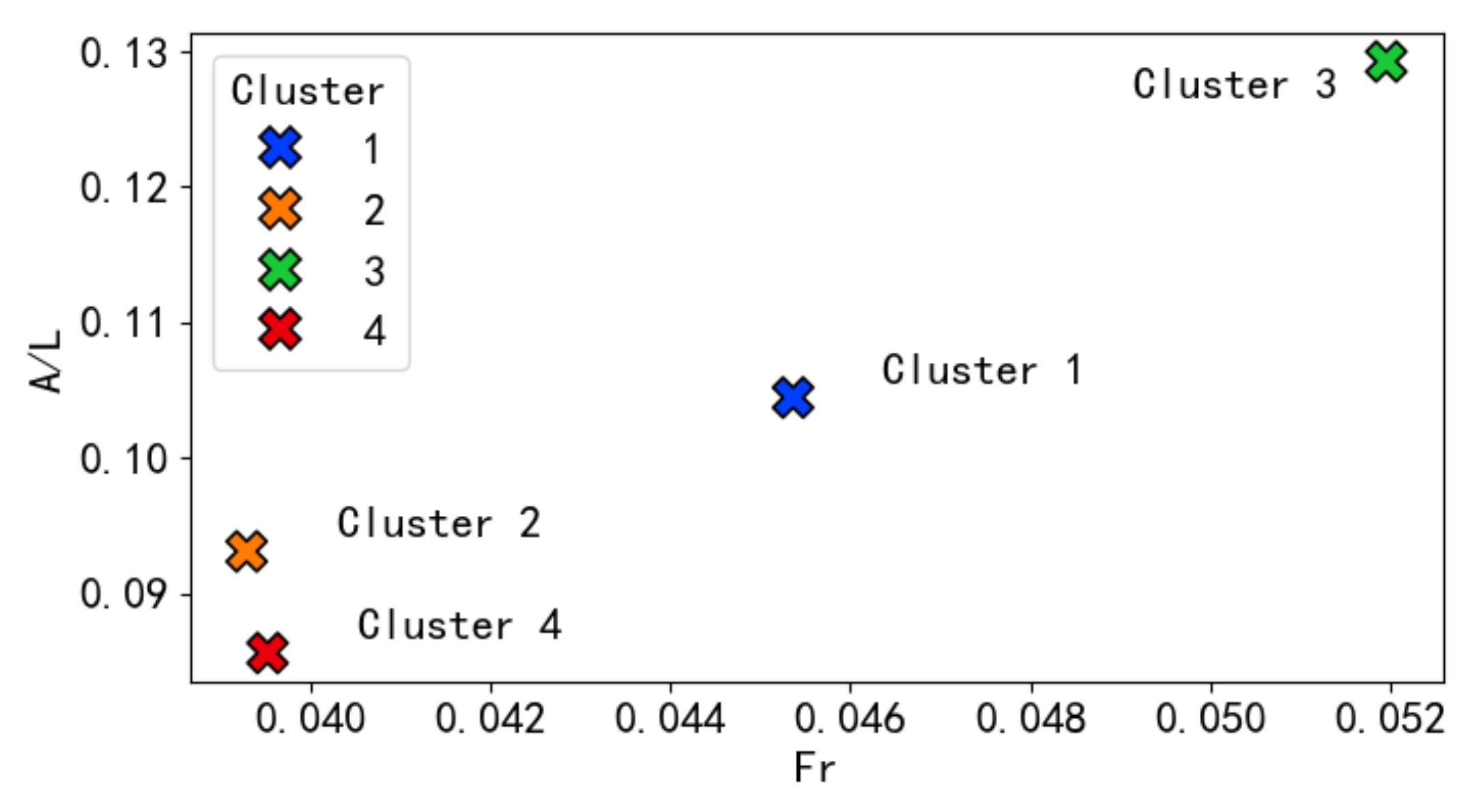
5.1. Clustering Results Using GMM
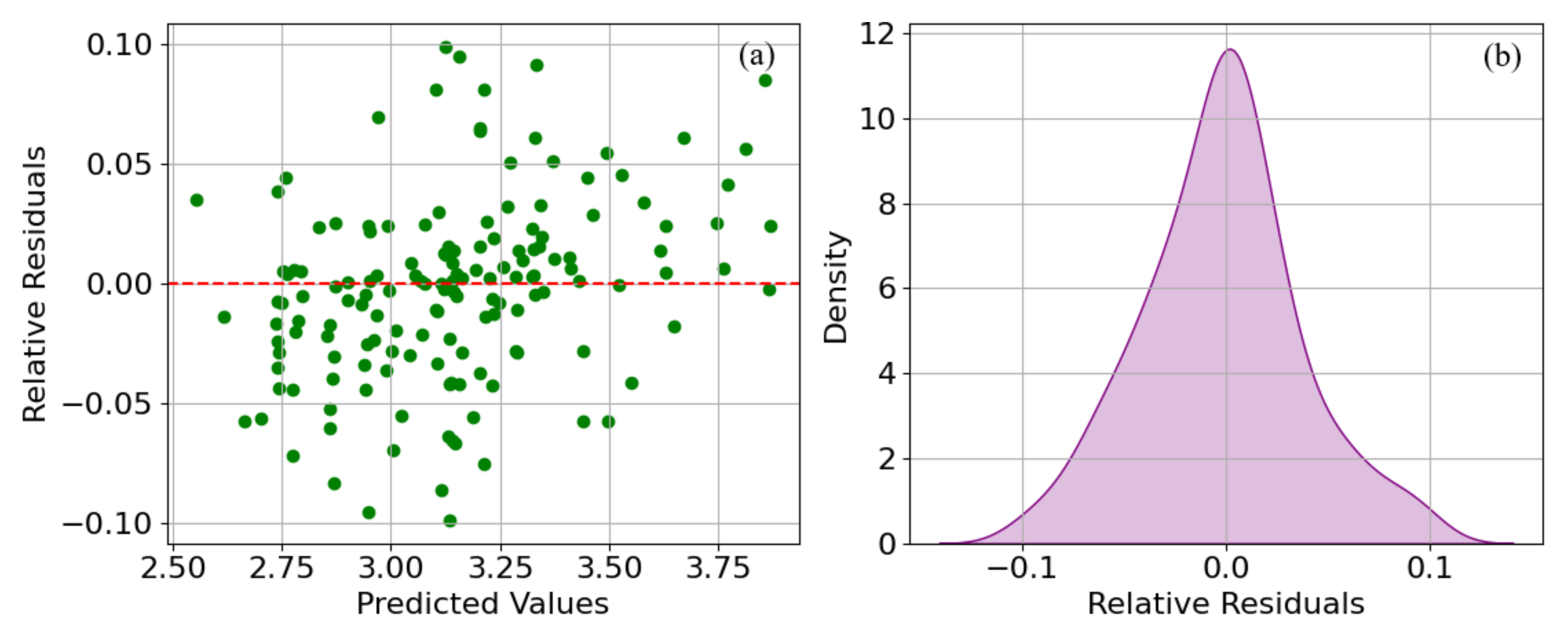
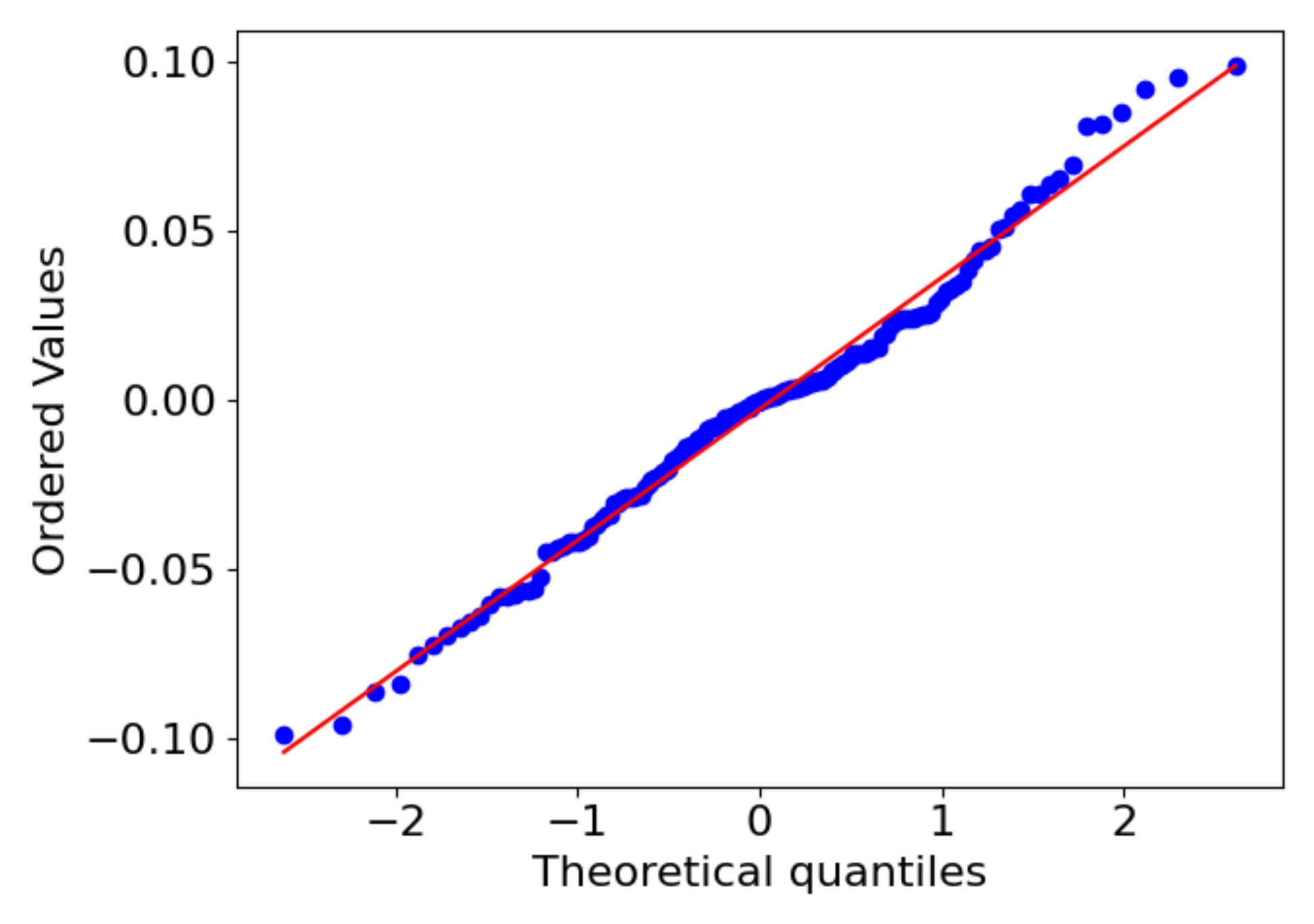
5.2. Predicting Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Koraim, A.; Heikal, E.; Zaid, A.A. Hydrodynamic characteristics of porous seawall protected by submerged breakwater. Appl. Ocean Res. 2014, 46, 1–14. [Google Scholar] [CrossRef]
- Mase, H.; Miyahira, A.; Hedges, T.S. Random wave runup on seawalls near shorelines with and without artificial reefs. Coast. Eng. J. 2004, 46, 247–268. [Google Scholar] [CrossRef]
- Liu, X.; Li, X.; Ma, G.; Rezania, M. Characterization of spatially varying soil properties using an innovative constraint seed method. Comput. Geotech. 2025, 183, 107184. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, X.; Li, H.; Fan, Y.; Meng, Z.; Liu, D.; Pan, S. Optimization of Water Quantity Allocation in Multi-Source Urban Water Supply Systems Using Graph Theory. Water 2025, 17, 61. [Google Scholar] [CrossRef]
- Gao, J.; Ma, X.; Zang, J.; Dong, G.; Ma, X.; Zhu, Y.; Zhou, L. Numerical investigation of harbor oscillations induced by focused transient wave groups. Coast. Eng. 2020, 158, 103670. [Google Scholar] [CrossRef]
- Meng, Z.; Zhang, J.; Hu, Y.; Ancey, C. Temporal Prediction of Landslide-Generated Waves Using a Theoretical-Statistical Combined Method. J. Mar. Sci. Eng. 2023, 11, 1151. [Google Scholar] [CrossRef]
- Ebrahimi, A.; Askar, M.B.; Pour, S.H.; Chegini, V. Investigation of various random wave run-up amounts under the influence of different slopes and roughnesses. Environ. Conserv. J. 2015, 16, 301–308. [Google Scholar] [CrossRef]
- Gao, J.; Hou, L.; Liu, Y.; Shi, H. Influences of bragg reflection on harbor resonance triggered by irregular wave groups. Ocean Eng. 2024, 305, 117941. [Google Scholar] [CrossRef]
- Meng, Z.; Wang, Y.; Zheng, S.; Wang, X.; Liu, D.; Zhang, J.; Shao, Y. Abnormal Monitoring Data Detection Based on Matrix Manipulation and the Cuckoo Search Algorithm. Mathematics 2024, 12, 1345. [Google Scholar] [CrossRef]
- Sujantoko, S.; Fuad, H.F.; Azzarine, S.; Raehana, D.R. Experimental Study of Wave Run-Up for Porous Concrete on Seawall Structures. E3S Web Conf. 2024, 576, 02004. [Google Scholar] [CrossRef]
- McCabe, M.; Stansby, P.K.; Apsley, D.D. Random wave runup and overtopping a steep sea wall: Shallow-water and Boussinesq modelling with generalised breaking and wall impact algorithms validated against laboratory and field measurements. Coast. Eng. 2013, 74, 33–49. [Google Scholar] [CrossRef]
- Ting-Chieh, L.; Hwang, K.S.; Hsiao, S.C.; Ray-Yeng, Y. An experimental observation of a solitary wave impingement, run-up and overtopping on a seawall. J. Hydrodyn. Ser. B 2012, 24, 76–85. [Google Scholar]
- Gao, J.; Ma, X.; Dong, G.; Chen, H.; Liu, Q.; Zang, J. Investigation on the effects of Bragg reflection on harbor oscillations. Coast. Eng. 2021, 170, 103977. [Google Scholar] [CrossRef]
- Neelamani, S.; Sandhya, N. Surface roughness effect of vertical and sloped seawalls in incident random wave fields. Ocean Eng. 2005, 32, 395–416. [Google Scholar] [CrossRef]
- Neelamani, S.; Schüttrumpf, H.; Muttray, M.; Oumeraci, H. Prediction of wave pressures on smooth impermeable seawalls. Ocean Eng. 1999, 26, 739–765. [Google Scholar] [CrossRef]
- Larson, M.; Erikson, L.; Hanson, H. An analytical model to predict dune erosion due to wave impact. Coast. Eng. 2004, 51, 675–696. [Google Scholar] [CrossRef]
- Gao, J.; Shi, H.; Zang, J.; Liu, Y. Mechanism analysis on the mitigation of harbor resonance by periodic undulating topography. Ocean Eng. 2023, 281, 114923. [Google Scholar] [CrossRef]
- Liu, X.; Jiang, S.H.; Xie, J.; Li, X. Bayesian inverse analysis with field observation for slope failure mechanism and reliability assessment under rainfall accounting for nonstationary characteristics of soil properties. Soils Found. 2025, 65, 101568. [Google Scholar] [CrossRef]
- Di Leo, A.; Dentale, F.; Buccino, M.; Tuozzo, S.; Pugliese Carratelli, E. Numerical analysis of wind effect on wave overtopping on a vertical seawall. Water 2022, 14, 3891. [Google Scholar] [CrossRef]
- Schwab, D.J.; Bennett, J.R.; Liu, P.C.; Donelan, M.A. Application of a simple numerical wave prediction model to Lake Erie. J. Geophys. Res. Ocean. 1984, 89, 3586–3592. [Google Scholar] [CrossRef]
- Wu, G.K.; Li, R.Y.; Li, D.W. Research on numerical modeling of two-dimensional freak waves and prediction of freak wave heights based on LSTM deep learning networks. Ocean Eng. 2024, 311, 119032. [Google Scholar] [CrossRef]
- Huang, C.J.; Chang, Y.C.; Tai, S.C.; Lin, C.Y.; Lin, Y.P.; Fan, Y.M.; Chiu, C.M.; Wu, L.C. Operational monitoring and forecasting of wave run-up on seawalls. Coast. Eng. 2020, 161, 103750. [Google Scholar] [CrossRef]
- Buccino, M.; Di Leo, A.; Tuozzo, S.; Lopez, L.F.C.; Calabrese, M.; Dentale, F. Wave overtopping of a vertical seawall in a surf zone: A joint analysis of numerical and laboratory data. Ocean Eng. 2023, 288, 116144. [Google Scholar] [CrossRef]
- Amini, E.; Marsooli, R.; Ayyub, B.M. Assessing Beach–Seawall Hybrid Systems: A Novel Metric-Based Approach for Robustness and Serviceability. Asce-Asme J. Risk Uncertain. Eng. Syst. Part Civ. Eng. 2024, 10, 04023062. [Google Scholar] [CrossRef]
- Zhang, J.; Benoit, M.; Kimmoun, O.; Chabchoub, A.; Hsu, H.C. Statistics of extreme waves in coastal waters: Large scale experiments and advanced numerical simulations. Fluids 2019, 4, 99. [Google Scholar] [CrossRef]
- Rasmeemasmuang, T.; Rattanapitikon, W. Predictions of run-up scale on coastal seawalls using a statistical formula. J. Ocean Eng. Mar. Energy 2021, 7, 173–187. [Google Scholar] [CrossRef]
- Cao, D.; Yuan, J.; Chen, H.; Zhao, K.; Liu, P.L.F. Wave overtopping flow striking a human body on the crest of an impermeable sloped seawall. Part I: Physical modeling. Coast. Eng. 2021, 167, 103891. [Google Scholar] [CrossRef]
- Salauddin, M.; Shaffrey, D.; Habib, M. Data-driven approaches in predicting scour depths at a vertical seawall on a permeable shingle foreshore. J. Coast. Conserv. 2023, 27, 18. [Google Scholar] [CrossRef]
- Chen, H.; Huang, S.; Xu, Y.P.; Teegavarapu, R.S.; Guo, Y.; Nie, H.; Xie, H. Using baseflow ensembles for hydrologic hysteresis characterization in humid basins of Southeastern China. Water Resour. Res. 2024, 60, e2023WR036195. [Google Scholar] [CrossRef]
- Beuzen, T.; Goldstein, E.B.; Splinter, K.D. Ensemble models from machine learning: An example of wave runup and coastal dune erosion. Nat. Hazards Earth Syst. Sci. 2019, 19, 2295–2309. [Google Scholar] [CrossRef]
- Berbić, J.; Ocvirk, E.; Carević, D.; Lončar, G. Application of neural networks and support vector machine for significant wave height prediction. Oceanologia 2017, 59, 331–349. [Google Scholar] [CrossRef]
- Chen, H.; Xu, B.; Qiu, H.; Huang, S.; Teegavarapu, R.S.; Xu, Y.P.; Guo, Y.; Nie, H.; Xie, H. Adaptive assessment of reservoir scheduling to hydrometeorological comprehensive dry and wet condition evolution in a multi-reservoir region of southeastern China. J. Hydrol. 2025, 648, 132392. [Google Scholar] [CrossRef]
- Li, J.; Meng, Z.; Zhang, J.; Chen, Y.; Yao, J.; Li, X.; Qin, P.; Liu, X.; Cheng, C. Prediction of Seawater Intrusion Run-Up Distance Based on K-Means Clustering and ANN Model. J. Mar. Sci. Eng. 2025, 13, 377. [Google Scholar] [CrossRef]
- Habib, M.; O’Sullivan, J.; Abolfathi, S.; Salauddin, M. Enhanced wave overtopping simulation at vertical breakwaters using machine learning algorithms. PLoS ONE 2023, 18, e0289318. [Google Scholar] [CrossRef]
- Liu, Y.; Li, S.; Zhao, X.; Hu, C.; Fan, Z.; Chen, S. Artificial neural network prediction of overtopping rate for impermeable vertical seawalls on coral reefs. J. Waterw. Port Coast. Ocean Eng. 2020, 146, 04020015. [Google Scholar] [CrossRef]
- Vileti, V.L.; Ersdal, S. Wave Dynamics Run-Up Modelling: Machine Learning Approach. In Proceedings of the International Conference on Offshore Mechanics and Arctic Engineering. Am. Soc. Mech. Eng. 2024, 87837, V05BT06A072. [Google Scholar]
- Savitha, R.; Al Mamun, A. Regional ocean wave height prediction using sequential learning neural networks. Ocean Eng. 2017, 129, 605–612. [Google Scholar]
- Stansberg, C.T.; Baarholm, R.; Berget, K.; Phadke, A.C. Prediction of wave impact in extreme weather. In Proceedings of the Offshore Technology Conference. OTC, Houston, TX, USA, 3–6 May 2010; p. OTC-20573. [Google Scholar]
- Belmont, M.; Horwood, J.; Thurley, R.; Baker, J. Filters for linear sea-wave prediction. Ocean Eng. 2006, 33, 2332–2351. [Google Scholar] [CrossRef]
- Reynolds, D.A. Gaussian mixture models. Encycl. Biom. 2009, 741, 827–832. [Google Scholar]
- Biau, G.; Cadre, B.; Rouvìère, L. Accelerated gradient boosting. Mach. Learn. 2019, 108, 971–992. [Google Scholar] [CrossRef]
- Meng, Z.; Hu, Y.; Jiang, S.; Zheng, S.; Zhang, J.; Yuan, Z.; Yao, S. Slope Deformation Prediction Combining Particle Swarm Optimization-Based Fractional-Order Grey Model and K-Means Clustering. Fractal Fract. 2025, 9, 210. [Google Scholar] [CrossRef]
- Saha, S.; De, S.; Changdar, S. An application of machine learning algorithms on the prediction of the damage level of rubble-mound breakwaters. J. Offshore Mech. Arct. Eng. 2024, 146, 011202. [Google Scholar] [CrossRef]
- Scala, P.; Manno, G.; Ingrassia, E.; Ciraolo, G. Combining Conv-LSTM and wind-wave data for enhanced sea wave forecasting in the Mediterranean Sea. Ocean Eng. 2025, 326, 120917. [Google Scholar] [CrossRef]
- Kim, T.; Kwon, S.; Kwon, Y. Prediction of wave transmission characteristics of low-crested structures with comprehensive analysis of machine learning. Sensors 2021, 21, 8192. [Google Scholar] [CrossRef]
- Maugis, C.; Celeux, G.; Martin-Magniette, M.L. Variable selection for clustering with Gaussian mixture models. Biometrics 2009, 65, 701–709. [Google Scholar] [CrossRef]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef]
- Huang, T.; Peng, H.; Zhang, K. Model selection for Gaussian mixture models. Stat. Sin. 2017, 27, 147–169. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GMM-GBR Model | GBR Model | |
|---|---|---|
| MAE | 0.07 | 0.09 |
| MSE | 0.012 | 0.015 |
| R2 | 0.91 | 0.86 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, P.; Zhu, H.; Jin, F.; Lu, W.; Meng, Z.; Ding, C.; Liu, X.; Cheng, C. Wave Run-Up Distance Prediction Combined Data-Driven Method and Physical Experiments. J. Mar. Sci. Eng. 2025, 13, 1298. https://doi.org/10.3390/jmse13071298
Qin P, Zhu H, Jin F, Lu W, Meng Z, Ding C, Liu X, Cheng C. Wave Run-Up Distance Prediction Combined Data-Driven Method and Physical Experiments. Journal of Marine Science and Engineering. 2025; 13(7):1298. https://doi.org/10.3390/jmse13071298
Chicago/Turabian StyleQin, Peng, Hangwei Zhu, Fan Jin, Wangtao Lu, Zhenzhu Meng, Chunmei Ding, Xian Liu, and Chunmei Cheng. 2025. "Wave Run-Up Distance Prediction Combined Data-Driven Method and Physical Experiments" Journal of Marine Science and Engineering 13, no. 7: 1298. https://doi.org/10.3390/jmse13071298
APA StyleQin, P., Zhu, H., Jin, F., Lu, W., Meng, Z., Ding, C., Liu, X., & Cheng, C. (2025). Wave Run-Up Distance Prediction Combined Data-Driven Method and Physical Experiments. Journal of Marine Science and Engineering, 13(7), 1298. https://doi.org/10.3390/jmse13071298