Abstract
Precise identification and quantification of fish movement states are of significant importance for conducting fish behavior research and guiding aquaculture production, with object tracking serving as a key technical approach for achieving behavioral quantification. The traditional DeepSORT algorithm has been widely applied to object tracking tasks; however, in practical aquaculture environments, high-density cultured fish exhibit visual characteristics such as similar textural features and frequent occlusions, leading to high misidentification rates and frequent ID switching during the tracking process. This study proposes an underwater fish object tracking method based on the improved DeepSORT algorithm, utilizing ResNet as the backbone network, embedding Deformable Convolutional Networks v2 to enhance adaptive receptive field capabilities, introducing Triplet Loss function to improve discrimination ability among similar fish, and integrating Convolutional Block Attention Module to enhance key feature learning. Finally, by combining the aforementioned improvement modules, the ReID feature extraction network was redesigned and optimized. Experimental results demonstrate that the improved algorithm significantly enhances tracking performance under frequent occlusion conditions, with the MOTA metric improving from 64.26% to 66.93% and the IDF1 metric improving from 53.73% to 63.70% compared to the baseline algorithm, providing more reliable technical support for underwater fish behavior analysis.
1. Introduction
As global marine fishery resources become increasingly strained, aquaculture has emerged as a crucial pathway for ensuring global food security. China stands out as the only major fishing nation where aquaculture production surpasses that of capture fisheries, playing a key role in alleviating pressure on global fishery resources [1]. Aquaculture products play a prominent role in improving residents’ dietary structure and providing high-quality protein [2], making significant contributions to ensuring national food security. With the expansion of aquaculture scale and continuous technological advancement, aquaculture vessels have emerged as an important cultivation mode for deep-sea and offshore aquaculture operations. When aquaculture vessels navigate between different sea areas or water layers, they encounter variations in seawater temperature, including temperature differences between water layers and fluctuations in ocean currents, which result in excessively high or low water temperatures in certain regions [3,4]. The leopard coral grouper (Plectropomus leopardus) is a high-value tropical marine fish species that is sensitive to water temperature and environmental changes, making it susceptible to low temperature stress and resulting in abnormal behaviors. These abnormal behaviors initially manifest as surface breathing and swimming imbalance. If these precursory behaviors are not detected promptly, they tend to trigger mass mortality of fish, thereby severely affecting aquaculture efficiency and production stability [5,6].
Therefore, accurate identification of abnormal fish behaviors is of significant im-portance. Current primary technological approaches for detecting fish behavior include optical [7], acoustic [8], and sensor technologies [9]. Acoustic sensors are extensively uti-lized in large-scale offshore aquaculture scenarios; however, due to their acoustic propa-gation characteristics, they cannot meet the requirements for precise observation of indi-vidual fish at close range. Flexible sensors [10] can monitor individual behaviors, but ma-terial limitations prevent them from satisfying long-term monitoring needs, thus restrict-ing their application scope. Computer vision technology has been widely adopted in ab-normal behavior detection for aquaculture due to its noninvasive nature, real-time capa-bility, extensive monitoring capacity, and relatively low hardware costs [11]. However, behavior detection alone has apparent limitations, as it cannot track the behavioral changes in individuals across temporal sequences and struggles to distinguish individual differences within populations [12]. These challenges have prompted us to expand our research focus from static abnormal behavior detection to the dynamic field of abnormal behavior tracking, thereby achieving more comprehensive and continuous monitoring and analysis of fish abnormal behaviors [13,14,15].
Behavior tracking technology, as a natural extension of detection technology, inte-grates target detection, target association, and motion prediction to continuously track the identity and behavioral patterns of each fish in sequential video frames. Traditional be-havior tracking research has primarily focused on Correlation Filter (CF) technology, exemplified by filtering algorithms such as MOSSE [16], CSK [17], KCF [18], and BACF [19]. Although these methods are computationally efficient, their applications are limited. Their core Kalman filtering mechanism can only perform linear motion prediction based on coordinate information of target bounding boxes, lacking the capability to model and update target appearance features. This limitation results in drastically degraded tracking performance under conditions of rapid fish deformation or occlusion, failing to meet the requirements for group behavior analysis in practical aquaculture scenarios. Furthermore, due to the textural similarity among fish, feature engineering-based representation meth-ods exhibit insufficient robustness in complex aquatic environments, leading to signifi-cant deviations in overall behavior analysis and tracking. This prevents effective macro-scopic description of fish behavioral states and makes it difficult to handle complex inter-active behaviors in multi-fish scenarios [20].
With the advancement of parallel computing capabilities and the development of deep learning technologies [21], efficient computation of complex models has become feasible, driving the rapid development of Multi-Object Tracking (MOT) technology. Multi-object tracking technology can provide more comprehensive, accurate, and real-time monitoring in fish behavioral anomaly detection, adapting to dynamic and complex aquaculture environments [22]. Deep learning-based target tracking algorithms are primarily classified into one-stage [23] and two-stage [24] approaches. Among these, one-stage target tracking algorithms integrate detection and appearance feature extraction branches into a single backbone, utilizing weight-sharing networks to simultaneously perform detection and feature extraction, then complete the tracking process through correlation filtering and data association, thereby enhancing the real-time performance of the algorithm. Examples include FairMOT and CenterTrack [25,26,27], which employ anchor-free detection strategies to collect embedding data required for tracking and transform it into classification information for assignment. However, due to insufficient ReID feature learning, these algorithms are prone to target loss and mismatching, resulting in lower tracking accuracy and difficulties in effectively handling complex morphological changes during fish swimming. Two-stage tracking methods are divided into two independent stages: target detection and target association. In the target detection stage, deep learning models such as RCNN [28] or YOLO [29] are employed to identify targets. In the association stage, cross-frame target recovery is accomplished based on appearance or motion cues of detected targets. Classic two-stage tracking algorithms include ByteTrack and DeepSORT. DeepSORT first utilizes target detection algorithms to identify objects and additionally trains convolutional neural networks to obtain appearance features of objects for feature matching. Du et al. [30] upgraded DeepSORT by adopting YOLOX-X and ResNeSt50 as the detection module and ReID module, respectively, effectively improving the model’s tracking accuracy. ByteTrack simplifies the ReID dependency and achieves data association optimization through a dual-threshold detection box processing strategy, improving computational efficiency. However, the aforementioned two-stage tracking methods primarily focus on optimizing target detection and data association, and most existing re-search concentrates on scenarios such as human subjects and street vehicles, with insufficient consideration for the special requirements of fish behavior tracking in aquaculture. When fish exhibit abnormal physiological activities, they display nonlinear swimming patterns and severe mutual occlusion, and the similar appearance of fish bodies can easily cause similarity matching-based cross-frame detection methods to fail, resulting in frequent ID switching and inability to meet continuous tracking requirements, which con-strains the further application of underwater fish tracking technology.
This study proposes an improved DeepSORT strategy based on enhanced appearance feature matching. Experimental validation demonstrates that the proposed method achieves accurate tracking and identification of fish targets in complex underwater environments, with recognition performance significantly superior to other comparative models. In summary, our main contributions are as follows:
- (1)
- ResNet is adopted as the backbone network to reconstruct the ReID feature extraction network for enhancing underwater fish multi-object tracking performance. Deformable Convolutional Networks v2 (DCNv2) [31] is embedded into residual blocks to achieve adaptive receptive field adjustment, thereby accurately capturing the nonlinear morphological changes of fish during the swimming motion.
- (2)
- Triplet Loss function [32] is introduced as a training strategy to improve the robustness and discriminative capability of the ReID module among similar fish individuals.
- (3)
- The Convolutional Block Attention Module (CBAM) [33] is incorporated to enhance feature learning of key fish body parts, effectively suppressing interference factors in complex underwater environments and further improving feature recognition accuracy.
- (4)
- The effectiveness of the proposed method is comprehensively validated through ablation experiments and comparative analysis, providing a complete technical solution for underwater fish multi-object tracking.
The remainder of this paper is organized as follows: Section 2 briefly introduces the experimental methodology, data collection and processing procedures, and provides a detailed exposition of the proposed method; Section 3 conducts ablation experiments on real datasets and performs comparative analysis with existing state-of-the-art methods; Section 4 discusses and analyzes the experimental results, including the discussion of fish trajectory visualization results; Section 5 summarizes the work presented in this paper, analyzes the limitations of existing methods, and proposes future research directions.
2. Materials and Methods
2.1. Experimental Setup
The experiment was conducted at the laboratory of Sanya Marine Research Institute, Ocean University of China. The experimental subjects were leopard coral grouper with a body weight of (8.9 ± 2) g and body length of (9.6 ± 2) cm. The experiment utilized a recirculating aquaculture tank with a diameter of 1.5 m and depth of 0.8 m, equipped with a comprehensive recirculating water system, cooling water system, and real-time environmental monitoring system. Before the experiment, the coral trout were acclimated in the tank for 1–2 days to ensure no stress response. Natural seawater was used for cultivation, with initial water temperature maintained at (26 ± 1) °C and dissolved oxygen concentration controlled at (6.2 ± 0.2) mg/L. Fish were fed three times daily at regular intervals to meet their normal feeding requirements.
The low temperature stress experiment began at 26 °C with temperature reduction controlled by an intelligent temperature regulation system, decreasing by 1 °C every 2 h on average. Video recording was conducted throughout the entire process to document the transition of fish behavior from normal state to abnormal behaviors. The video acquisition system consisted of a digital video recorder and underwater cameras, as shown in Figure 1. A Boles UW-46S2-3LCTX10 camera (2 megapixels, 2 mm fixed focal length lens, focusing distance 0.6 m) made in Shenzhen, China, was mounted on a retractable bracket and positioned vertically in the center of the tank with horizontal placement and no elevation angle. The captured video resolution was 1920 × 2560 with a frame rate of 20 fps. The data analysis platform operated on a 64-bit Windows 10 system, equipped with an Intel(R) Xeon(R) CPU processor (from Intel Corporation, Santa Clara, CA, USA) and NVIDIA Quadro M4000 GPU (24GB VRAM, from NVIDIA Corporation, Santa Clara, CA, USA). The algorithm was based on the PyTorch 3.7 framework and developed using Python 3.9 programming language.
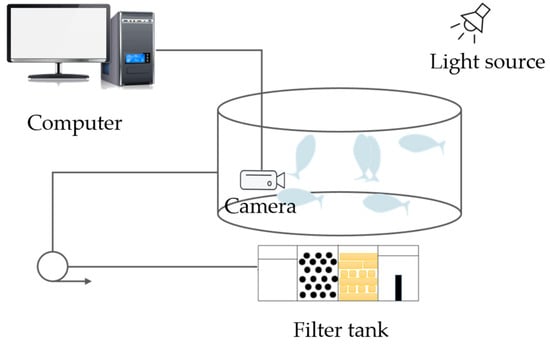
Figure 1.
Image Acquisition System.
2.2. Dataset
During the data processing phase, we extracted image sequences from continuously recorded videos at a sampling rate of 15 frames per second to ensure continuous capturing of behavioral changes over time. Using the LabelImg tool, we performed fine-grained annotation on 3000 collected images of leopard coral grouper, focusing on marking typical patterns such as behavioral abnormalities and swimming anomalies, thereby constructing a complete abnormal behavior recognition dataset. To evaluate the performance of the multi-object tracking model, we additionally selected a representative group interaction behavior video segment containing 600 frames and performed frame-by-frame annotation following the MOTChallenge standard format, recording the bounding box coordinates and identity ID for each target.
This study employed the YOLOv12 model to construct an object detector for identifying surface-floating abnormal behavior in leopard coral grouper and trained it on the constructed abnormal behavior dataset. The dataset was randomly divided into training, validation, and test sets with a 7:2:1 ratio, consisting of 2100 training images, 600 validation images, and 300 test images, respectively. All datasets were validated through cross-validation to ensure balanced distribution, where the validation set was used for hyperparameter tuning, while the test set was strictly reserved for the final evaluation phase to ensure the reliability and accuracy of experimental results. To enhance model generalization and effectively mitigate overfitting, this study employs ImageNet pre-trained weights for model initialization and comprehensively applies multiple anti-overfitting techniques including data augmentation strategies and training optimization. During training, the Adam optimizer is utilized with β1 = 0.9 and β2 = 0.999, with an initial learning rate of 0.001 and a StepLR scheduler that reduces the learning rate by a factor of 0.1 every 30 epochs. The training epochs were set to 1000 to ensure sufficient model convergence, with a batch size of 16.
2.3. Research Methodology
2.3.1. Deformable Convolutional Networks
Fish targets exhibit morphological diversity and postural variation challenges. Due to the influence of water flow disturbances and swimming behaviors, individual fish specimens present irregular geometric deformations and postural differences at different temporal instances. Traditional standard convolution operations employ fixed rectangular receptive fields for feature extraction, making it difficult to effectively adapt to such dynamic morphological changes. This results in extracted feature representations lacking geometric adaptability, thereby affecting the accuracy of ReID.
To address the aforementioned geometric deformation adaptation problem, this study introduces DCNv2. As illustrated in Figure 2, DCNv2 enables convolution operations to flexibly adapt to geometric variations in images through dynamic adjustment of convolutional kernel sampling positions, thereby capturing more discriminative morphological features. Standard convolution operations employ fixed sampling patterns on input feature maps, with their output computation formula as follows:
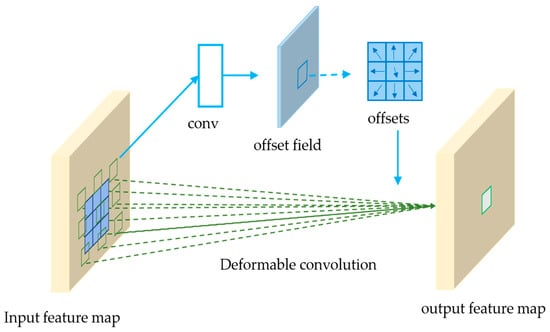
Figure 2.
Deformable Convolutional Networks v2.
In this formula, represents the k-th predefined fixed offset relative to position b in the convolutional kernel, ω_k denotes the convolutional weight at the k-th position, and K is the kernel size.
DCNv2 introduces a learnable offset and modulation factor mechanism based on ordinary convolution, with the output equation:
where is the learnable offset of the k-th sampling point, and is the modulation factor, which is generated by independent branching via the sigmoid function and is used to control the feature weights of each sampling point.
2.3.2. Improved Residual Structure
As illustrated in Figure 3, residual blocks effectively mitigate the vanishing gradient problem in deep neural networks through the introduction of skip connections, enabling direct information propagation from shallow to deep layers and ensuring that networks maintain effective training performance while increasing depth. To address the flexible deformation characteristics of moving fish targets in underwater environments and their dynamic feature matching requirements, this paper presents improvements to the traditional residual structure. We integrate DCNv2 into residual blocks, replacing the original standard convolutional layers to enhance the network’s capacity for modeling geometric transformations. Unlike standard convolution with fixed receptive fields, DCNv2 can learn additional spatial offset parameters and dynamically adjust the sampling positions of convolutional kernels, making it more suitable for capturing non-rigid deformation features of fish.
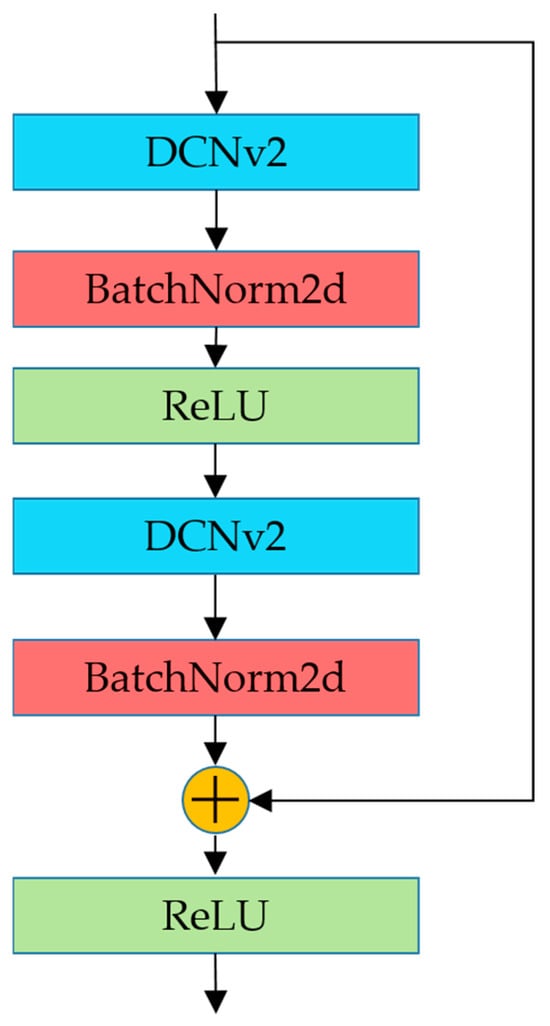
Figure 3.
The residual block structure integrated with deformable convolution.
2.3.3. Triplet Loss Function
During fish target tracking, frequent ID switching occurs due to the high similarity in fish appearance. Triplet Loss optimizes feature space distribution by constructing triplet-based loss, as shown in Figure 4. The triplet consists of three components: the anchor feature vector (Anchor), a positive sample feature vector from the same category as the Anchor (Positive), and a negative sample feature vector from a different category than the Anchor (Negative). Through this approach, the network learns to generate a discriminative embedding space where each input is mapped to a unique, distinguishable feature vector. By training the network to maximize the distance between feature vectors of similar targets and minimize the distance between dissimilar targets, ID switching caused by similar target appearances is effectively reduced. The formula for Triplet Loss is as follows:
where d(a,p) represents the distance between the Anchor and Positive samples, d(a,n) represents the distance between the Anchor and Negative samples, and α is a hyperparameter used to control the distance requirement for negative samples. Triplet Loss prevents the embedding vectors of positive and negative samples from being trained too closely together by setting a margin constant hyperparameter, which is set to 0.5 in this study.
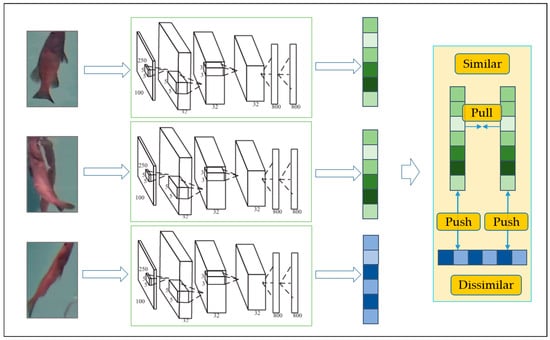
Figure 4.
Triplet Loss Training Framework.
2.3.4. Enhanced ReID Feature Extraction Network
The DeepSORT algorithm introduces a ReID model based on the SORT framework, enhancing the matching effectiveness of the Hungarian algorithm by combining appearance information with motion information [34]. The original ReID network is primarily designed for pedestrian detection scenarios, with network architecture and input image dimensions (64 × 128) optimized for human characteristics [35]. However, when applied to underwater fish target detection, significant differences exist compared to human and vehicle tracking due to the nonlinear motion, variable morphology, and highly similar appearance characteristics of underwater fish. Relying solely on color and texture recognition yields poor results, leading to suboptimal performance of traditional ReID networks in underwater fish target association. To address these issues, this paper proposes an improved ReID feature extraction network strategy based on appearance feature optimization, aimed at enhancing feature matching efficiency and constraining the excessive growth of underwater target IDs. Figure 5 illustrates the improved feature extraction network architecture.
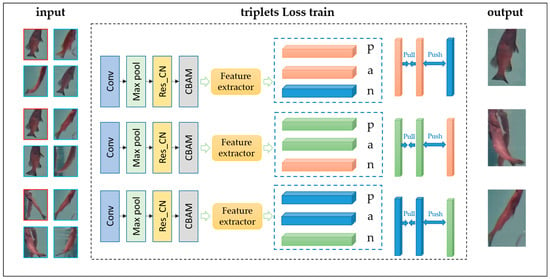
Figure 5.
Enhanced Feature Extraction Network Architecture for ReID.
Residual networks effectively mitigate the gradient vanishing problem in deep networks through skip connections. In this study, DCNv2 is introduced to replace the original structure in the first 3 × 3 convolutional layer of the third residual block within the feature extraction network. The incorporation of DCNv2 further enhances the network’s adaptability to complex spatial structures, enabling the model to more flexibly capture structural information in images, which is particularly suitable for processing underwater fish targets with non-rigid deformation characteristics.
The CBAM is introduced after the improved residual block. The CBAM employs a cascaded design of channel attention and spatial attention, capable of adaptively recalibrating feature responses. Through the channel attention mechanism, the network focuses on the most important feature channels for the current task, effectively suppressing redundant information interference. The spatial attention mechanism concentrates on the most discriminative spatial locations in feature maps, highlighting key regional features of targets.
This synergistic effect of dual attention and deformable convolution enables the network to extract fish key features more precisely, effectively filtering background noise in complex underwater environments, and providing high-quality feature representations for subsequent triplet loss optimization. To further address the high inter-similarity problem among underwater targets, this study employs a triplet loss function to perform deep optimization on the outputs of the aforementioned feature extraction module. The triplet loss forms an end-to-end optimization framework with the DCNv2-CBAM feature extraction module, where the feature extraction module provides rich and discriminative feature representations, while the triplet loss further refines the discriminative boundaries in the feature space by simultaneously optimizing positive sample pair similarity and negative sample pair dissimilarity. This training mechanism fully exploits the refined features extracted by the DCNv2-CBAM, controlling the relative distances between positive and negative sample pairs in the embedding space through the margin parameter, thereby preventing excessive clustering of feature vectors that would compromise discriminative capability. The introduction of triplet loss enables the entire network to learn more robust and highly discriminative deep feature representations, significantly improving the accuracy and reliability of ReID.
3. Results
3.1. Evaluation Metrics
To evaluate the results, the model is applied to the CLEAR metrics used on the MOT Challenge to assess model performance [36,37]. The following are some typical evaluation metrics: Multiple Object Tracking Accuracy (MOTA) [38] is one of the most important metrics in multi-object tracking. Identity switches (IDsw) are the only tracking related component in MOTA; thus, it only considers the accuracy of instance matching. The calculation formula is as follows:
In the formula, FNt, FPt, IDSt, and GTt represent the number of false negatives, false positives, identity switches, and ground truth targets in frame t, respectively.
The IDF1 [39] identification score (IDF1) comprehensively considers identification precision (IDP) and identification recall (IDR). In IDF1, the involved true positives (TP), false positives (FP), and false negatives (FN) all take into account the ID information, making this metric more sensitive to the accuracy of ID information. The calculation formula is as follows:
Multiple Object Tracking Precision (MOTP) represents the localization accuracy of the detector, and its calculation formula is as follows:
where denotes the number of correctly matched objects at frame t, and represents the bounding box overlap between target i and its assigned ground truth object. A smaller MOTP indicates lower tracking localization error.
3.2. Ablation Experiment
The ablation experiments in this section demonstrate that the Res-ReID network effectively addresses the gradient problem inherent in the original ReID feature extraction network. The Triplet Loss enhances fish individual identification capability, DCN improves adaptability to deformed targets, and CBAM strengthens key feature extraction. Through the synergistic effects of multiple modules, the system achieves a 4.15% improvement in MOTA metrics and an 18.55% improvement in IDF1 metrics compared to the original DeepSORT, thereby validating the effectiveness of the proposed improvement scheme. Figure 6 illustrates the tracking performance of the system in practical applications.
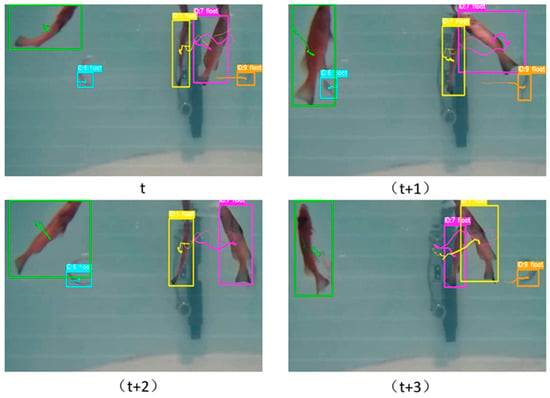
Figure 6.
Multi-object tracking trajectories of the improved model across consecutive frames t, t + 1, t + 2, and t + 3, with different colors representing different tracked objects.
In the original ReID network, the individual incorporation of Triplet Loss resulted in an improvement of IDF1 from the baseline value of 53.73% to 61.73%, while simultaneously enhancing IDP from 51.98% to 62.73% and IDR from 54.36% to 61.26%. Under the Res-ReID network architecture, the introduction of Triplet Loss improved IDF1 from 53.73% to 62.90%. When Triplet Loss was combined with DCN, the effects were more pronounced. In the original network structure, IDF1 improved from 61.73% to 62.47%, with IDP and IDR increasing from 62.71% and 61.26% to 63.90% and 61.73%, respectively. Under the improved ReID network architecture, the combined application of these two techniques enhanced IDP and IDR from 63.24% and 62.50% to 64.67% and 62.91%, respectively.
When DCN was applied independently, the MOTA of the original network improved from 64.26% to 64.98%, while in the Res-ReID network, MOTA increased from 64.57% to 65.10%. When DCN was combined with Triplet Loss, a favorable synergistic effect was observed. In the original network structure, this combination enhanced MOTA from 64.26% to 64.96% and improved IDF1 from 53.73% to 62.47%. In the Res-ReID network structure, compared to individual application, MOTA increased from 65.10% to 66.56%, and IDF1 also improved from 60.00% to 62.85%.
Following the introduction of CBAM into the baseline ReID model, as shown in Table 1, MOTA, IDF1, and IDP increased by 0.56%, 1.35%, and 1.44%, respectively. In the Res-ReID network structure, CBAM similarly enhanced all performance metrics, with MOTA, IDF1, and IDR improving by 0.63%, 0.58%, and 0.92%, respectively. These results validate the effectiveness of the CBAM attention mechanism in multi-object tracking tasks.

Table 1.
Comparison of Ablation Experiment Results.
3.3. Comparison with Other Models
To systematically evaluate the effectiveness of the proposed method, this study selected four classical algorithms—SORT [40], DeepSORT [41], ByteTrack [42], and FairMOT [43]—for comparative analysis, covering both one-stage and two-stage tracking. All methods were tested on a unified dataset to ensure fair evaluation of their detection and ReID performance. As shown in Table 2, ByteTrack, using the same detector as our model, achieved a MOTA of 64.56%, but with an IDF1 of only 36.52%. The proposed method demonstrates improvements in MOTA of 72.64%, 3.67%, and 5.07% compared to SORT, ByteTrack, and FairMOT, respectively. For IDF1, our method shows improvements of 79.94%, 74.48%, and 37.52% compared to SORT, ByteTrack, and FairMOT, respectively. Both IDP and IDR metrics exhibit improvements of over 35% across all comparisons.
Table 2.
Comparison of the Method in This Study with Other Methods. Note: In the table, ↑ indicates that higher values are better, and ↓ indicates that lower values are better.
4. Discussion
As demonstrated in Table 1, the incorporation of Triplet Loss resulted in improvements across IDF1, IDP, and IDR metrics, with a particularly notable enhancement of 17.04% in IDF1 under the Res-ReID network architecture. These findings indicate that Triplet Loss enhances the model’s identity discrimination capability. However, while identity recognition-related metrics showed improvement, the MOTA metric remained unchanged. This phenomenon can be attributed to the fact that MOTA evaluates the overall accuracy of multi-object tracking, encompassing factors such as missed detections, false positives, and identity switches, whereas Triplet Loss may exhibit excessive focus on identity features in scenarios involving frequent interactions, potentially neglecting localization accuracy or detection completeness. As illustrated in Figure 7, when applied to the Res-ReID network, the advantages of Triplet Loss are further amplified, resulting in comprehensive tracking performance enhancement. As shown in Table 1, when DCN is applied individually to both the original network and the Res-ReID network, improvements in MOTA are observed. This enhancement stems from DCN’s capability to dynamically adjust the receptive field according to target deformation, thereby effectively strengthening the model’s ability to handle flexible motion in fish targets. However, when DCN is employed independently, the improvement in identity recognition-related metrics such as IDF1, IDP, and IDR is not significant. As depicted in Figure 7, although DCN enhances the model’s feature extraction capability, certain limitations persist in terms of feature discrimination and maintaining identity consistency. When Triplet Loss is combined with DCN, both the original ReID model and Res-ReID demonstrate more substantial improvements, particularly in IDP and IDR metrics. This improvement occurs because DCN enhances the model’s adaptability to target deformation, while Triplet Loss provides superior feature discrimination capability, creating a favorable complementary effect between these two components. The CBAM attention mechanism filters the most discriminative features to provide more precise input for Triplet Loss, while simultaneously collaborating with DCN to handle target deformation and complex motion trajectories.

Figure 7.
Visualization of tracking results in ablation study. From left to right: DeepSort, DeepSort + DCNv2, DeepSort + Triplet Loss, and Triplet Loss + DCNv2. Each method shows tracking results across four consecutive frames (t, t + 1, t + 2, t + 3) with unique ID numbers for each fish, demonstrating tracking continuity.
As demonstrated in Table 2, ByteTrack achieved a MOTA of 64.56% using the same detector as our model but obtained an IDF1 of only 36.52%. This indicates that while the algorithm exhibits satisfactory tracking accuracy, the absence of a dedicated ReID module causes the association mechanism to fail when handling similar targets, resulting in relatively low IDF1 performance. Consequently, ByteTrack is more suitable for relatively simple multi-object tracking tasks. FairMOT employs a joint training paradigm attempting to balance detection and tracking tasks; however, its model lacks a specialized tracking branch and relies solely on Kalman filtering for motion modeling. In the specific task of fish tracking, it struggles to effectively distinguish between fish targets with similar appearances. Figure 8 illustrates the fish movement trajectories across different multi-object tracking models. In the experimental scenario, the fish 1 and fish 4 exhibit relatively simple lateral swimming patterns with minimal occlusion interference. The fish 2 and fish 3 demonstrate high-frequency interaction states, continuously performing rotational movements with frequent mutual occlusion. This complex interactive behavior results in highly nonlinear and irregular motion trajectory characteristics. Through comparative analysis of the tracking trajectory patterns across different algorithms, it is evident that the traditional SORT model suffers from insufficient detection accuracy and target ReID capability in complex underwater environments, making it difficult to maintain target identity continuity. Although FairMOT and ByteTrack show improvements in overall performance compared to SORT, they still exhibit technical limitations when confronted with the complex scenarios in our experiments. Both methods demonstrate frequent ID switching phenomena, with trajectory fragmentation issues remaining prominent. In contrast, the improved algorithm proposed in this paper generates more continuous and complete motion trajectories for the fish 1 and fish 2 tracking, with significantly reduced ID switching frequency compared to baseline methods, demonstrating superior stability and robustness. However, for the fish 3 under conditions of prolonged, high-frequency mutual occlusion, the performance remains suboptimal.
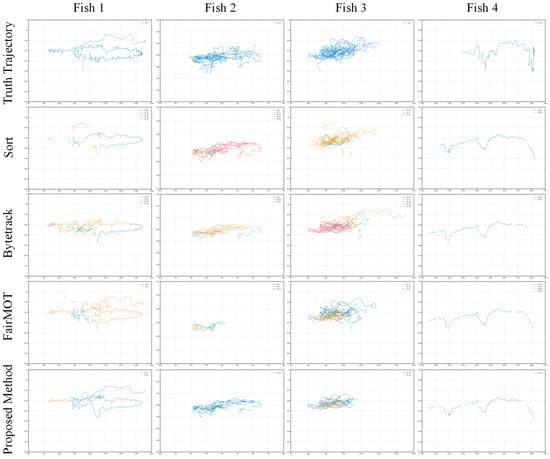
Figure 8.
Trajectory Comparison of Multiple Models. Note: The figure displays tracking results of five methods arranged by rows: Truth Trajectory, Sort, ByteTrack, FairMOT, and the Proposed Method; columns correspond to four tracking targets (Fish 1–4). In each subplot, continuous same-colored line segments represent stable identity tracking, while color transition points indicate identity switch errors.
This experiment was conducted under relatively ideal experimental conditions. While it successfully validates the fundamental effectiveness of the algorithm, it fails to adequately simulate the complex collective behavioral characteristics observed in high-density aquaculture environments. In real aquaculture scenarios, highly dense population structures and frequent complex interactive behaviors among individual fish result in inter-target occlusion levels and durations that far exceed those encountered in experimental settings. The model’s capability to handle complex occlusion scenarios requires further enhancement. As illustrated in Figure 8, the tracking performance for the fish 3 remains suboptimal under conditions of prolonged, high-frequency occlusion. The severe loss of target feature information presents a significant challenge: when fish targets are completely occluded by other individuals for extended periods, available visual features are substantially reduced, making it difficult for the ReID network to extract sufficient discriminative features. Therefore, how to further improve algorithm performance under extreme occlusion conditions represents a critical technical challenge that must be addressed in future research endeavors.
5. Conclusions
This study addresses the challenges of similar texture patterns and frequent occlusion-induced ID switching in high-density aquaculture fish tracking by proposing an improved DeepSORT tracking model that integrates deformable convolution and CBAM attention modules with triplet loss training. The proposed method effectively resolves occlusion and trajectory fragmentation issues in underwater fish tracking through occlusion detection and target ReID mechanisms. The effectiveness of this approach is validated through ablation experiments. Performance comparisons with other state-of-the-art models demonstrate that the optimized DeepSORT framework exhibits superior performance. However, tracking performance in scenarios involving frequent fish swarm interactions remains to be improved. How to further enhance the tracking stability and accuracy of the algorithm under extreme occlusion conditions represents a core technical challenge that requires focused breakthrough efforts in future research endeavors.
Author Contributions
Writing—original draft, S.L. (Shengnan Liu); data curation, J.Z. and S.L. (Shengnan Liu); formal analysis, H.Z.; software, S.L. (Shengnan Liu) and J.Z.; investigation, formal analysis, C.Q. and S.L. (Shijing Liu). All authors have read and agreed to the published version of the manuscript.
Funding
Supported by Hainan Seed Industry Laboratory B23H10004; Central Public-interest Scientific Institution Basal Research Fund, CAFS (NO. 2024XT0901); Central Public-interest Scientific Institution Basal Research Fund, ECSFRCAFS (NO. 2025YJ02).
Institutional Review Board Statement
This study complied with the regulations and guidelines established by the Animal Care and Use Committee of Fishery Machinery and Instrument Research Institute, Chinese Academy of Fishery Sciences (ethics committee approval code: FMIRI-AWE-2024-002, approval date: 7 August 2024).
Data Availability Statement
The datasets presented in this article are not readily available because the data are part of an ongoing study. Requests to access the datasets should be directed to liushijing@fmiri.ac.cn.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- FAO. The State of World Fisheries and Aquaculture 2024; Blue Transformation in Action; FAO: Rome, Italy, 2024. [Google Scholar]
- Ruan, W.; Wang, Y.; Ji, W.W.; Han, B.; Fang, H. Progress of sustainable development and management of aquaculture. Fish. Inf. Strat. 2013, 28, 267–272. [Google Scholar]
- Xu, H.; Jiang, T. Development strategy of offshore aquaculture engineering in China. Fish. Mod. 2012, 39, 1–7. [Google Scholar]
- Cui, M.; Jin, J.; Huang, W. Discussion about system construction and general technology of aquaculture platform. Fish. Mod. 2019, 46, 61–66. [Google Scholar]
- Mwaffo, V.; Vernerey, F. Analysis of group of fish response to startle reaction. J. Nonlinear Sci. 2022, 32, 96. [Google Scholar] [CrossRef]
- Barreiros, M.D.O.; Dantas, D.D.O.; Silva, L.C.D.O.; Ribeiro, S.; Barros, A.K. Zebrafish tracking using YOLOv2 and Kalman filter. Sci. Rep. 2021, 11, 3219. [Google Scholar] [CrossRef]
- Huang, Y.X.; Bao, X.T.; Xu, H. Research progress of fishery equipment science and technology in China. Fish. Mod. 2023, 50, 1–11. [Google Scholar]
- Li, D.L.; Wang, G.X.; Du, L.; Zheng, Y.; Wang, Z. Recent advances in intelligent recognition methods for fish stress behavior. Aquac. Eng. 2022, 96, 102222. [Google Scholar] [CrossRef]
- Liu, T.C.; Liu, J.; Wang, J.; Xu, J.; Sun, G. Optimization of the intelligent sensing model for environmental information in aquaculture waters based on the 5G smart sensor network. J. Sens. 2022, 2022, 6409046. [Google Scholar] [CrossRef]
- Makaras, T.; Razumienė, J.; Gurevičienė, V.; Šakinytė, I.; Stankevičiūtė, M.; Kazlauskienė, N. A new approach of stress evaluation in fish using β-D-Glucose measurement in fish holding-water. Ecol. Indic. 2020, 109, 105829. [Google Scholar] [CrossRef]
- Davidson, J.; Good, C.; Welsh, C.; Summerfelt, S.T. Abnormal swimming behavior and increased deformities in rainbow trout Oncorhynchus mykiss cultured in low exchange water recirculating aquaculture systems. Aquac. Eng. 2011, 45, 109–117. [Google Scholar] [CrossRef]
- Leon, F.; Gavrilescu, M. A review of tracking and trajectory prediction methods for autonomous driving. Mathematics 2021, 9, 660. [Google Scholar] [CrossRef]
- Shreesha, S.; Manohara, P.M.M.; Verma, U.; Pai, R.M. Computer vision based fish tracking and behaviour detection system. In Proceedings of the 2020 IEEE International Conference on Distributed Computing, VLSI, Electrical Circuits and Robotics (DISCOVER), Udupi, India, 30–31 October 2020; pp. 252–257. [Google Scholar] [CrossRef]
- Kumar, A.; Walia, G.S.; Sharma, K. Recent trends in multi-cue based visual tracking: A review. Expert Syst. Appl. 2020, 162, 113711. [Google Scholar] [CrossRef]
- Sun, S.; Akhtar, N.; Song, H.; Mian, A.; Shah, M. Deep affinity network for multiple object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 104–119. [Google Scholar] [CrossRef]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Rahmat, B.; Waluyo, M.; Rachmanto, T.A.; Afandi, M.I.; Widyantara, H.; Harianto. Video-based Tancho Koi Fish tracking system using CSK, DFT, and LOT. J. Phys. Conf. Ser. 2020, 1569, 022036. [Google Scholar] [CrossRef]
- Tang, M.; Yu, B.; Zhang, F.; Wang, J. High-speed tracking with multi-kernel correlation filters. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4874–4883. [Google Scholar] [CrossRef]
- Kiani Galoogahi, H.; Fagg, A.; Lucey, S. Learning background-aware correlation filters for visual tracking. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1135–1143. [Google Scholar] [CrossRef]
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Zhao, X.; Kim, T.-K. Multiple object tracking: A literature review. Artif. Intell. 2021, 293, 103448. [Google Scholar] [CrossRef]
- Li, D.L.; Liu, C. Recent advances and future outlook for artificial intelligence in aquaculture. Smart Agric. 2020, 2, 1–20. [Google Scholar]
- Stauffer, C.; Grimson, W.E.L. Adaptive background mixture models for real-time tracking. In Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (Cat. No PR00149), Fort Collins, CO, USA, 23–25 June 1999; Volume 2, pp. 246–252. [Google Scholar] [CrossRef]
- Emami, P.; Pardalos, P.M.; Elefteriadou, L.; Ranka, S. Machine learning methods for data association in multi-object tracking. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Wang, Z.; Zheng, L.; Liu, Y.; Wang, S. Towards real-time multi-object tracking. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 107–122. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. Fairmot: On the fairness of detection and re-identification in multiple object tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. Bytetrack: Multi-object tracking by associating every detection box. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2022; pp. 1–21. [Google Scholar]
- Zhou, X.; Koltun, V.; Krähenbühl, P. Tracking objects as points. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 474–490. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2004, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Du, Y.; Zhao, Z.; Song, Y.; Zhao, Y.; Su, F.; Gong, T.; Meng, H. Strongsort: Make deepsort great again. J. IEEE Trans. Multimed. 2023, 25, 8725–8737. [Google Scholar] [CrossRef]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Bayar, E.; Aker, C. When to extract ReID features: A selective approach for improved multiple object tracking. arXiv 2024, arXiv:2409.06617. [Google Scholar]
- Zhang, X.; Hao, X.; Liu, S.; Wang, J.; Xu, J.; Hu, J. Multi-target tracking of surveillance video with differential YOLO and DeepSort. In Proceedings of the Eleventh International Conference on Digital Image Processing (ICDIP 2019), Guangzhou, China, 10–13 May 2019; Volume 11179, pp. 701–710. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Dendorfer, P.; Rezatofighi, H.; Milan, A.; Shi, J.; Cremers, D.; Reid, I.; Roth, S.; Schindler, K.; Leal-Taixé, L. Mot20: A benchmark for multi object tracking in crowded scenes. arXiv 2020. [Google Scholar] [CrossRef]
- Bernardin, K.; Stiefelhagen, R. Evaluating multiple object tracking performance: The clear mot metrics. EURASIP J. Image Video Process. 2008, 2008, 1–10. [Google Scholar] [CrossRef]
- Wu, B.; Nevatia, R. Tracking of multiple, partially occluded humans based on static body part detection. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 1, pp. 951–958. [Google Scholar] [CrossRef]
- Shin, L.J.; Lo, J.C.; Chen, G.H.; Callis, J.; Fu, H.; Yeh, K.-C. IRT1 degradation factor1, a ring E3 ubiquitin ligase, regulates the degradation of iron-regulated transporter1 in Arabidopsis. Plant Cell. 2013, 25, 3039–3051. [Google Scholar] [CrossRef] [PubMed]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar] [CrossRef]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar] [CrossRef]
- Aharon, N.; Orfaig, R.; Bobrovsky, B.Z. BoT-SORT: Robust associations multi-pedestrian tracking. arXiv 2022. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, Z.; Zhang, Z.; Bian, S. AdapTrack: An adaptive FairMOT tracking method applicable to marine ship targets. J. AI Commun. 2023, 36, 127–145. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).