4.1. Datasets
The SeaShips (SS) dataset [
37] is a widely used resource for maritime object detection. It contains 7000 high-resolution images (1920 × 1080 pixels) across six vessel categories: general cargo ships, bulk cargo carriers, ore carriers, fishing boats, container ships, and passenger ships. This dataset is divided into a training set of 5500 images and a test set of 750 images.
The Singapore Maritime Dataset (SMD) [
20] serves as a benchmark for various maritime vision tasks, featuring ten categories of typical static and dynamic objects on the water’s surface. The images in this dataset are captured using visible light (VIS) and near-infrared (NIR) sensors from both aerial and terrestrial video footage, which is essential for tracking and detecting maritime vessels. The categories in SMD include ferry, buoy, vessel/ship, speed boat, boat, kayak, sail boat, flying bird/plane, other, and swimming person. However, the swimming person category is absent from the dataset, leaving a total of nine categories. The training set contains 5455 images, while the test set includes 1346 images.
By default, we randomly sampled 10% of the training images as labeled data, treating the remaining images as unlabeled data with annotations removed in our experiments. Additionally, we evaluated our method under varying labeled data sampling ratios, i.e., 5%, 10%, 20%, and 50%.
4.2. Evaluation Metrics
We evaluated our methods on the SeaShips dataset and the Singapore Maritime Dataset, and report the results using the mean average precision (mAP) metric. mAP quantifies network performance by measuring the area under the precision–recall curves, integrating both precision (P) and recall (R). A higher mAP value indicates better detection accuracy. The definitions of precision and recall are given by
The average precision (AP) is calculated as
For multiple categories, mAP is defined as
where
n is the number of categories and
denotes the average precision for each category. mAP can be measured at different IoU thresholds, such as mAP
50 and mAP
75. It can also be classified into mAP
s, mAP
M, and mAP
L for small, medium, and large objects, respectively, following the COCO dataset [
19]. In this paper, we utilized all these forms for a comprehensive evaluation.
4.3. Implementation Details
For the experiments on the two datasets, all models were trained using four NVIDIA RTX 3090 GPUs, with a batch size of six images per GPU (two labeled and four unlabeled images). The software environment was based on Python 3.8.0 and PyTorch 1.12.1, running on Linux with CUDA 11.3 for efficient GPU acceleration. Training was performed for 50K iterations, taking approximately 12 h for each dataset. The model was optimized using the stochastic gradient descent (SGD) optimizer with a constant learning rate of 0.01, momentum of 0.9, and weight decay of 0.0001. The Gaussian mixture model (GMM) was fitted using the standard ’GaussianMixture’ from the sklearn library. The threshold parameter
c was set to 2, while the dynamic mixup parameters were set as
and
. For a fair comparison, we followed the same data processing and model training pipeline described in [
16]. All models adopted the focal loss for the classification loss
and the generalized IoU (GIoU) loss for the regression loss
. Other parameters, such as the EMA decay rate and loss weights, followed the settings reported in [
16,
18].
4.4. Comparative Experiments
In this section, we compare our method with several SOTA semi-supervised learning methods, including Soft Teacher [
32], PseCo [
28], Polish Teacher [
38], Dense Teacher [
26], ARSL [
15], Consistent Teacher [
18], and Mixpl [
16], on two maritime datasets. All methods were implemented using the code released in the corresponding literature.
Table 1 presents the results on the SeaShips dataset. Our proposed method achieved the highest mAP values among all evaluated methods, establishing a new state-of-the-art record for semi-supervised object detection on SeaShips. Notably, our method surpassed Mixpl [
16] by a substantial margin of 3.4% in the mAP, underscoring the effectiveness of the proposed DAPF module.
We also report the results on the SMD dataset in
Table 2. Once again, our method outperformed all other methods, demonstrating its superiority on this more challenging dataset with diverse objects. Our method showed an improvement of 0.9% in absolute mAP compared to Consistent Teacher. It is worth noting that our method ranked first in four metrics and second in the remaining two, highlighting its robust performance.
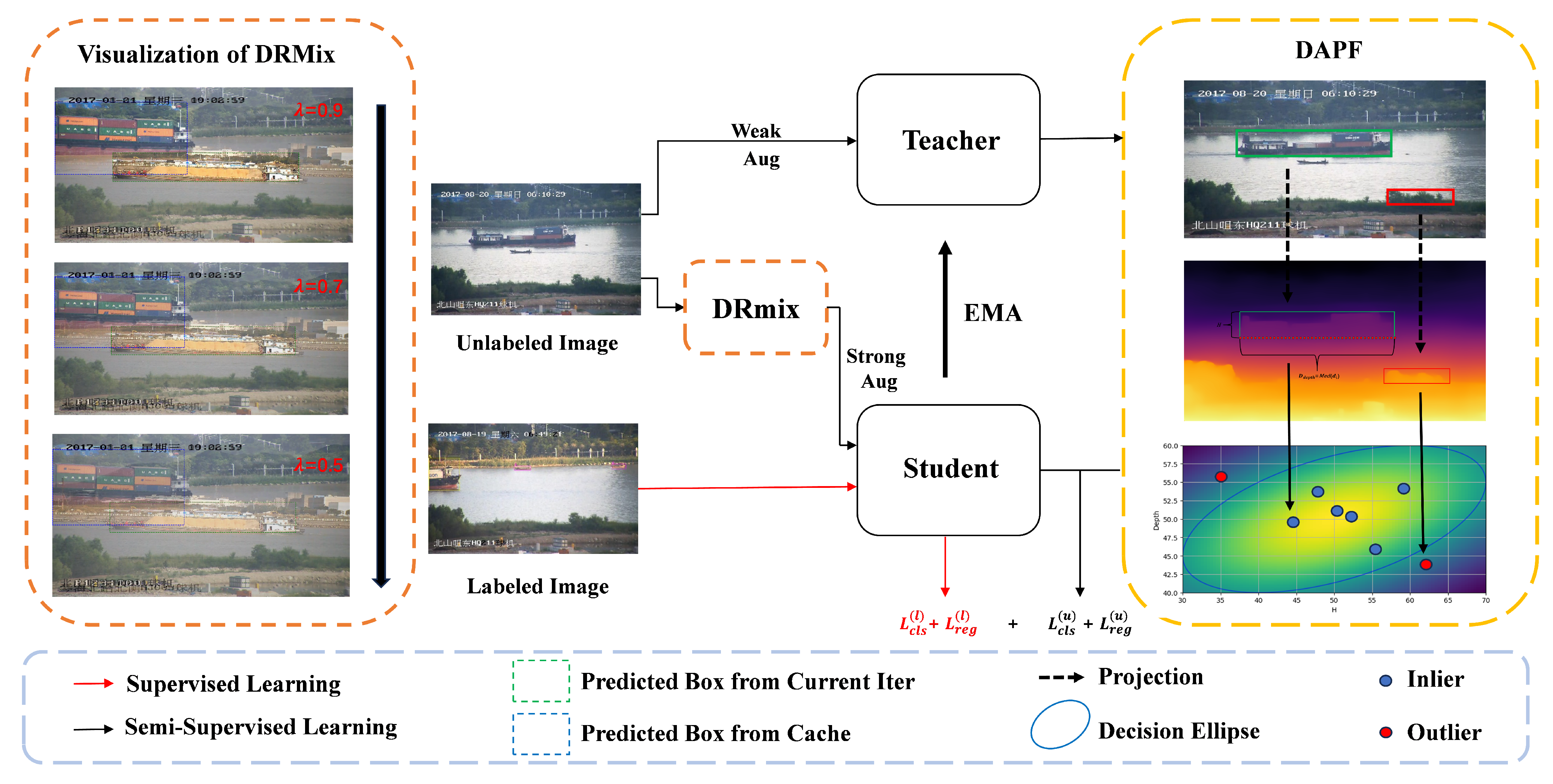
Figure 4 showcases the qualitative performance of our method on the SeaShips [
37] and SMD [
20] datasets, in comparison with other SSOD models. The other models exhibited various issues such as false detections in the background, overlapping or imprecise bounding boxes, and lower confidence scores. In contrast, our approach consistently delivered superior performance, generating more accurate bounding boxes with higher confidence while effectively reducing false detections. These results indicate that our method not only improves localization precision but also effectively suppresses erroneous detections.
Figure 5 visualizes the detection performance of our method under challenging conditions, including occlusions, complex backgrounds, and varying illumination. In the occlusion scenario (top row), our method accurately detected a heavily occluded target (left) and identified two overlapping vessels (right), which were frequently missed by other models. In the presence of complex backgrounds (middle row), it effectively localized vessels that blended into shorelines. Under diverse illumination conditions (bottom row), our method maintained consistent detection performance, showing robustness to lighting variations.
4.5. Ablation Study
To provide a deeper understanding of the proposed method, we evaluated the individual roles of each component on detection performance.
DAPF and DRMix. Table 3 presents different combinations with/without the two proposed strategies on the SeaShips dataset. The incorporation of depth-aware pseudo-label filtering (DAPF) resulted in remarkable increases of 2.8% in AP
50 and 3.2% in AP
50:95 over the baseline on the SeaShips dataset, thereby verifying its effectiveness. When replacing the mixup in Mixpl with our dynamic region mixup (DRMix) strategy, we observed performance increases of 1.7% in AP
50 and 2.2% in AP
50:95, indicating that our object-aware data augmentation strategy is better suited for object detection, especially in complex maritime scenarios. The full integration of both DAPF and DRMix yielded the best results, proving that the two components are complementary. Similarly, the same trends were also observed in the results on the SMD dataset, as shown in
Table 4, demonstrating both the effectiveness and generalization of our method across different datasets. To conclude, DAPF and DRMix are complementary and indispensable.
Besides the joint effect of DAPF and DRMix, we also examined the individual contribution of each component under different configurations on the SeaShips dataset.
Analysis of DAPF. To further investigate DAPF, we conducted a quantitative analysis of its pseudo-label purification process in comparison to the baseline. As illustrated in
Figure 6, which reports the number of false positives (FPs) and true positives (TPs) under varying classification confidence thresholds of the detector, DAPF significantly reduced the number of FPs by 36.5%, 16.9%, and 7.2% while retaining the majority of TPs. This indicates that DAPF can improve the quality of supervision, thereby contributing to enhanced detection performance.
We also performed an ablation study on the threshold parameter
c using the SeaShips dataset, as shown in
Table 5. Notably, an overly aggressive filtering threshold discarded valid pseudo-labels, resulting in degraded performance, which aligns with the observation shown in
Figure 3. Empirical results indicate that setting c = 2 yields favorable performance, supporting the effectiveness of this choice.
Analysis of DRMix. To examine the effect of DRMix, we employed Grad-CAM to visualize the results of the mixup technique in [
16] and our DRMix technique. For a fair comparison, identical model weights were adopted for inference. As shown in
Figure 7, DRMix effectively mitigated background interference with target object features by dynamically adjusting the mixing ratio between the target and background at the regional level. Consequently, DRMix produced a sharper and more focused heatmap that clearly highlights the relevant target regions. In contrast, the mixup strategy in [
16] exhibited missed detection.
To further investigate the impact of the mixing ratio schedule, we conducted experiments comparing fixed and dynamic mixing ratio strategies during training, as summarized in
Table 6. The first two rows correspond to the degenerate and standard cases described in Equation (
8), while the third row represents a curriculum-learning-inspired schedule. It is obvious that even a simple linear schedule exhibits clear advantages over fixed ratios.
Analysis of Labeled Data Sampling Ratio. To further verify the robustness and adaptability of our method under varying proportions of labeled data, we conducted experiments on the SeaShips and SMD datasets. Specifically, we assessed the model’s performance when trained with labeled data sampling ratios of 5%, 10%, 20%, and 50%. As shown in
Table 7, on both datasets, the performance of the proposed model steadily improved as the proportion of labeled data increased, indicating that additional annotations facilitate the model’s generalization capability, as expected. Notably, even with only 5% of the labeled data, the model maintained relatively high accuracy, demonstrating its robustness under limited supervision.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}