1. Introduction
Modeling morphological evolution remains a challenging task primarily owing to the difficulty in fully resolving the distribution and transport of sediment grains with different shapes and sizes [
1,
2,
3,
4]. Specifically, the availability of sediment data is essential in determining the morphological responses of wave-dominated embayed sand beaches. Therefore, numerical models that simulate morphological changes incorporate parameters to account for sediment information. Kalligeris et al. [
4], along with Do and Yoo [
5], reported the improvements in predictability for beach profile changes during storm events. They achieved this by optimizing site-calibrated parameters related to sediment, including the spatial distribution of sand layer thickness and sediment grain size, using process-based numerical models such as CShore [
6] and XBeach [
7]. Additionally, the characteristics of grain size in coastal beach and dune environments are assumed to be influenced by the intensity of eolian processes, timing, and sediment sources. However, this assumption is mainly based on relatively limited empirical studies rather than extensive observations. Furthermore, in recent years, deep learning (DL)-based data-driven approaches have been actively applied to modeling morphological evolution and predicting its changes [
8,
9,
10]. Specifically, de Melo et al. [
11] quantitatively demonstrated the accuracy of predicted beach profile changes based on the inclusion or exclusion of sediment data.
To effectively use sediment information while minimizing errors from assumptions or constants, it is essential to characterize grain size distribution using parameters such as average grain size, the variation in sizes around the average (standard deviation), the symmetry or preferential distribution relative to the average (skewness), and the concentration of the grains in relation to the average (kurtosis) [
12].
There are two main approaches to quantifying grain size distribution: direct measurement through sediment sampling and indirect estimation via sediment imaging. Direct measurements can be performed using techniques such as sieve/hydrometer analysis, X-ray attenuation, scanning electron microscopy, and laser diffraction [
13,
14]. While direct physical measurements are the most accurate methods, they tend to be intrusive and only sample grains that are exposed to flow, making them susceptible to transport or winnowing. Additionally, these methods are labor-intensive, costly, time-consuming, and provide limited spatial coverage. To address these drawbacks, digital image processing techniques using edge detection, image segmentation principles, and statistical methods that analyze pixel intensity variations have been used to estimate grain size distribution. The digital image processing method relies on intensity contrasts between grains and the gaps between them, allowing for the establishment of thresholds that can be used to distinguish individual grains from the background intensity levels [
15]. Rubin [
16] developed a comprehensive sedimentary look-up-catalog by proposing an autocorrelation algorithm to determine grain size from digital sediment images. Buscombe and Masselink [
17] progressively degraded sediment images and used the loss of detail to calculate the fractal dimension of the images. However, these imaging approaches depend on calibration or on advanced sequences of image processing techniques to isolate and measure each individual grain, or on both, which often makes them specific to particular sediment population populations. Additionally, conventional image processing approaches are susceptible to various optical artifacts caused by reflections of ambient and flash lighting (resulting in grain shading problems) and from grain structures (such as imbrication or intragranular marks and scratches). These methods also face procedural biases that can lead to over- or under-segmentation of particles in the image. Recently, DL techniques have been increasingly used to address these challenges. In this study, we propose a method for estimating grain size distribution through spatial feature representation learning based on optical images of sediment. The proposed method is applied to 41 littoral systems, encompassing 102 sand beaches in Gangwon Province, South Korea. In particular, data augmentation techniques are used to improve the accuracy of grain size estimation and to ensure robustness against environmental factors, such as external light sources, which pose challenges in imaging sediment. The performance of the method is evaluated by comparing it with DL-based approaches.
The remainder of this paper is structured as follows.
Section 2 provides an overview of related studies that have focused on DL-based approaches.
Section 3 describes the study area and sediment datasets, including grain size distribution measurements obtained through sieve analysis and optimal sediment imagery.
Section 4 introduces the proposed spatial encoder network designed for spatial representation learning to estimate grain size distribution from optical sediment images using data augmentation techniques.
Section 5 details the experimental setup, implementation specifics, and evaluation metrics.
Section 6 evaluates the performance of the proposed methodology by assessing the accuracy of the estimated grain size distribution. Finally,
Section 7 presents a summary of the paper, highlights the strengths and limitations of the proposed method, and outlines potential directions for future research.
2. Related Work
The key previous studies on image-based sediment information estimation using DL techniques are summarized as follows. Buscombe [
18] introduced SediNet, a DL-based optical granulometry system that classifies sedimentological properties using two-dimensional (2D) convolutional neural networks (CNNs). This study used a total of 409 labeled images obtained from coastal and riverine environments for supervised learning, with labels manually verified and categorized into six sediment categories and four shape/size categories. When tested with 200 and 205 images, respectively, the classification accuracy exceeded 85%, while the mean error based on the nine percentiles of the cumulative grain size distribution ranged from 24% to 45%.
GRAINet, developed by Lang et al. [
19], is a regression model based on 2D CNNs that uses supervised learning to estimate the grain size distribution of gravel and the slope curve of gravel sandbars from drone imagery. A dataset comprising 1491 labeled instances was created by extracting mean diameters and grading curves for entire gravel bars through digital line sampling performed by human annotators across 25 sandbars along six rivers in Switzerland. The entire dataset was divided into 10 disjoint subsets, with 1 subset reserved for testing to assess the model’s performance. The root mean square error (RMSE) for estimating the mean grain diameter, excluding labeling uncertainty, was found to be 1.7 cm.
Furthermore, Ghanbari and Antoniades [
20] introduce a DL-based encoder network that uses one-dimensional (1D) CNNs to map particle sizes in lake sediment cores using hyperspectral remote sensing images. Hyperspectral images were captured for half-core samples collected with the Aquatic Research Instruments gravity or universal corer, and the mean grain size distribution was determined using the Folk and Ward method in GRADISTAT [
21] through grain size measurements taken with a Horiba laser granulometer (model LA950v2). The model’s performance was assessed using 20% of the test data, encompassing a total of 703 hyperspectral image and particle size datasets, resulting in an RMSE of 8.53
m, which showed a performance improvement of approximately 45% in RMSE compared to the random forest machine learning model.
Liu et al. [
22] introduced a DL-based framework aimed at reducing the methodological uncertainty associated with the parameter selection process in universal decomposition models for sediment grain-size analysis. The framework used grain size data from three sedimentary-type losses and fluvial and lake delta deposits comprising approximately 73,370 samples collected from 18 sites using the Malvern Mastersizer 2000 laser diffraction instrument. These data were combined with information generated by generative adversarial networks and used as training data for the decomposition classifier. The performance of the decomposition classifier was evaluated using approximately 14,650 samples, representing 20% of the total dataset and achieved average accuracy of 97% across 100 grain-size classes in the 0.02–2000
m range.
3. Study Area and Data
The study area shown in
Figure 1, located on the east coast of Gangwon Province, has a unique geography where mountains and coastal regions are in close proximity. The average distance between the coastal area and the mountains, which have an average of approximately elevation levels (+) 800 m ranges from approximately 10 to 25 km. Thus, the river channels in the area are short, and the flow velocity possesses high characteristics typical of steep-slope basins. In the past, sandy sediments along the east coast were primarily provided by rivers; however, the construction of numerous dams and reservoirs for water resource management since the 1970s has considerably decreased the sediment supply to the coast. Urban development in this region has manifested as narrow, elongated coastal settlements, and recent coastal development has led to considerable degradation of coastal dune systems. The eastern coast of Gangwon Province directly faces the East Sea, creating a high-energy wave environment that is greatly influenced by seasonal winds and typhoons. During winter, waves predominantly originate from the northeast, while in summer, southeast waves are dominant, highlighting distinct seasonal variability in wave conditions. In particular, high waves driven by the northeast monsoon frequently occur during the winter season, with an average significant wave height (Hs) of approximately 5.0 m and a significant wave period (Ts) ranging from 6 to 9 s. In contrast, during summer, long-period high waves produced by typhoons reach the coastline, with average Hs around 7 m and Ts ranging from 8 to 12 s. In spring and autumn, wave energy is relatively low, with Hs between 0.8 and 1.2 m and Ts from 6 to 10 s, leading to more stable wave conditions. Additionally, crescentic bars are well established in the nearshore area. During high wave events, cross-shore sediment transport becomes dominant. The pattern of littoral sediment transport exhibits seasonal variations: erosional beach characteristics are prominent in the winter, while depositional features are more pronounced in the summer.
The east coast of Gangwon Province is divided into 41 littoral systems (GW01–GW41) based on the main fluvial sediment sources and the characteristics of the ocean hydrodynamic environment, as depicted in
Figure 1. These systems are managed by the Ministry of Oceans and Fisheries and exhibit the hydrodynamic characteristics typical of a wave-dominant environment. This area is greatly affected by strong waves and micro-tidal currents, with an average tidal range of approximately 0.2 m. Between 2010 and 2024, an average of 45 sediment surveys were performed at 473 sites across the 41 littoral systems. To analyze the sediments, seabed samples were collected at intervals of 300–600 m in both the surf/swash zone and the seabed area for each littoral cell. Each littoral system has, on average, approximately 12 cross-shore transect lines defined. However, due to variations in coastline length among systems, the number of transects may vary by approximately ±6 to 8. Sand samples were collected at four locations along each transect, corresponding to E.L 0, 3, 6, and 8 m. The sample at E.L 0 m (swash zone) was collected manually by field personnel, while samples at depths of 3 m and beyond were collected using a catamaran-type survey vessel. In the study area along the eastern coast of Gangwon Province, the closure depth is approximately 8 to 10 m. These samples were then analyzed to determine the characteristics of grain size and distribution.
Samples were collected using a grab channel yielding more than 600 g of seabed sediment per sample and were then analyzed using the sieve/hydrometer method as part of the direct sediment measurement process with the FRITSCH ANALYSETTE 3 PRO Vibratory Sieve Shaker (Germany, Idar-Oberstein) (
https://www.fritsch-international.com/, accessed on 8 May 2025). The mean diameter, standard deviation, skewness, and kurtosis were calculated using the Folk and Ward method [
23] in conjunction with GRADISTAT [
21], allowing for the determination of a central grain size distribution. The mean diameter
of the grain size presents the average of all sieve analysis values, with results ranging from 1 to 0, indicating gravel or coarse sand.
Figure 2a–c show the grain size distribution over the survey period for the 41 littoral cells, represented by the average diameters
of
(the grain diameter below which 10% of the sample falls),
(50%), and
(90%), respectively. According to Folk and Ward [
23], the mean grain size
is calculated as:
where
,
, and
correspond to the particle sizes at the 16%, 50%, and 84% cumulative percentage points, respectively. Additionally,
, where
D is the grain diameter in millimeters and it is dimensionless.
Table 1 provides the geographic locations, sample counts, and statistical summaries of grain size distribution for each of the 41 littoral systems. Moreover, for the development of data-driven models, the number of sample images collected for each littoral system (# of samples) has been included as well.
The littoral systems along the east coast of Gangwon Province are characterized by sandy coasts composed predominantly of sand-dominated sediments, with particle diameters ranging from 0.25 to 2 mm. Sand thickness is classified into four levels based on grain size: coarse sand (≥0.5), medium sand (0.5–0.35 mm), fine sand (0.35–0.25 mm), and very fine sand (<0.25 mm). The average mean grain diameter is 0.43 mm, corresponding to coarse sand, with an average standard deviation of 0.67, indicating a moderately well-sorted distribution. The average skewness is slightly negative at −0.06, reflecting a nearly symmetrical distribution, while the kurtosis indicates a platykurtic profile.
After sieve and hydrometer measurements, the samples were stored in transparent containers of uniform size, and top view images were captured using digital camera under consistent ambient lightning conditions. A total of 6337 sediment images were collected across all littoral systems, with representative sample for each system shown in
Figure 3. Each image is mapped one to one with the corresponding sand size distribution obtained from sieve analysis, forming a dataset for supervised learning in a deep neural network model designed to estimate sand size distribution from optical images.
5. Experiments
The input image to the model has dimensions of 2560 (width) × 1792 (height) with three channels, as shown in
Figure 3. The model output is a 1D vector with seven channels, representing seven variables: mean grain size, standard deviation, skewness, kurtosis, and
,
, and
, which describe the grain size distribution. For model training, 70% of the total data is randomly selected while maintaining sample balance across the 41 littoral systems, with the remaining 30% used for performance evaluation of the trained model. A total of 4290 samples, consisting of 70% of the 6337 original data and augmented data, were used to train the final proposed model.
Let
M be a model that estimates seven variables
describing grain size distribution from an input image
x. Let
be the probability distribution of the ground-truth variables
y corresponding to
x. The model is trained to minimize the difference between the estimated variables
and the ground-truth variable
y, where
x is randomly sampled from the training data. For model training, the mean squared error between the variables
y and
is used as the loss function
L, as shown in Equation (
1).
denotes the expected value, written as for random variable X. Here, D represents the dimensionality of the model output (seven variables: mean grain size, standard deviation, skewness, kurtosis, , , and ).
The model was trained using the Adam optimizer with a learning rate () of 0.00001, of 0.9, of 0.999, and regularization of 0.00001 minimizing mean squared error loss. The dataset used for training consists of 4290 samples, with a batch size of twelve, 27.97 epochs, and a total of 10,000 iterations.
Model batch and experiments were performed on two NVIDIA RTX A6000 GPUs (48 GB each), an Intel(R) Xeon(R) Gold 6130 CPU @ 2.10 GHz, and 192 GB of system memory. The network and algorithms were implemented using Python 3.6.9 and PyTorch 1.8.1.
Model performance was evaluated using bias, RMSE, and Pearson correlation coefficient (CC), as defined in Equations (
2)–(
4).
Here, represents the measured grain size distribution regarded as the ground truth, and denotes the estimated grain size distribution produced by the proposed model.
6. Results and Discussion
The performance of the proposed model in estimating the grain size distribution from input optical images on the test dataset is shown in
Table 2. The RMSE values recorded are 0.21, 0.12, 0.15, 0.19, 0.19, 0.22, and 0.36 for mean grain size, standard deviation, skewness, kurtosis,
,
, and
, respectively. Therefore, the experiment with the applied data augmentation technique (highlighted in gray as ‘with DA’ in
Table 2) is the final model proposed in this study.
Table 2 also presents the RMSE performance based on whether data augmentation was applied for training data inflation, as part of an ablation study. Additionally, the RMSE of SediNet, proposed by Buscombe [
18], is included as a baseline model for comparative analysis. When data augmentation was applied to the training data, improved performance was observed, with a decrease in RMSE for all seven estimated variables compared to when data augmentation was not used. Specifically, the RMSE values were reduced by 0.02, 0.02, 0.02, 0.03, 0.01, 0.01, and 0.03 for mean grain size, standard deviation, skewness, kurtosis,
,
, and
, respectively, when data augmentation was used. Additionally, when comparing the RMSE of the baseline model with that of the proposed model with data augmentation, the RMSE of the proposed model with data augmentation was considerably reduced. The RMSE differences for mean grain size, standard deviation, skewness, kurtosis,
,
, and
were 0.47, 0.08, 0.06, 0.04, 0.09, 0.25, and 0.61, respectively.
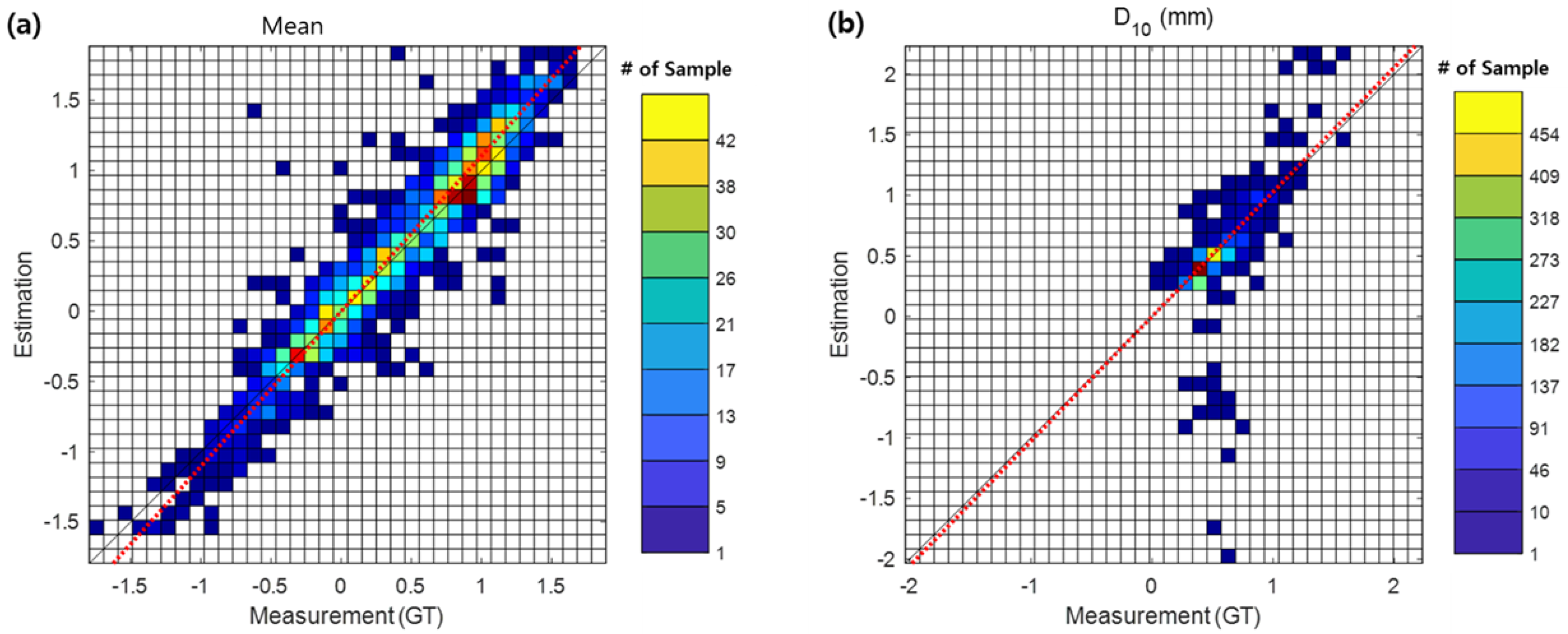
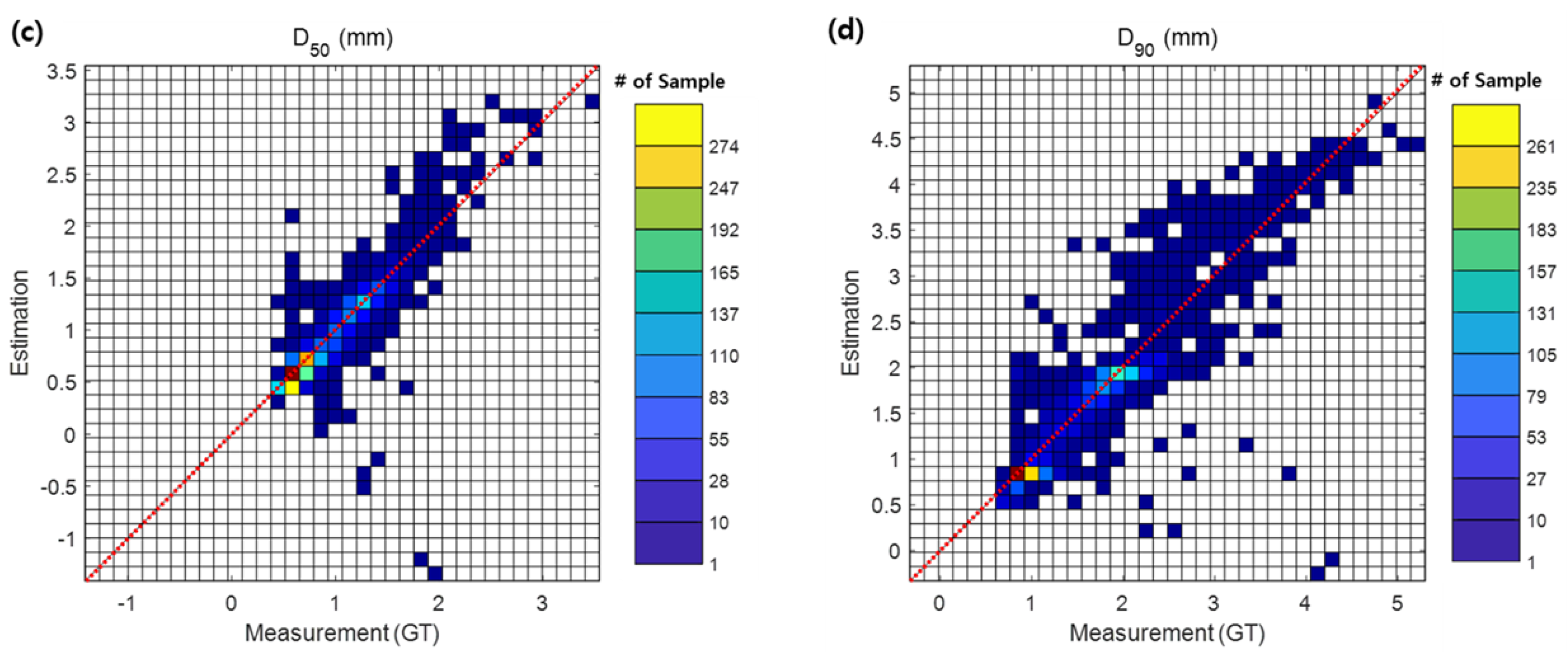
In particular,
Figure 5 shows a scatter plot comparing the ground-truth measurements with the estimated values of mean grain size,
,
, and
from the proposed model with data augmentation for the entire test dataset. The symmetric slopes
, indicated by the red dotted lines in
Figure 5, are 1.105, 1.028, 1.006, and 1.007 for mean grain size,
,
, and
, respectively. For the mean diameter, the estimated results show very good agreement with the measurements overall, with only a small number of samples showing discrepancies.
Table 3 shows a very high CC of 0.95. For
, overestimation occurs for samples above 1.2 mm, and underestimation occurs for samples below 0.8 mm. However, for most samples with values between 0.3 and 1.5 mm, the measurements and estimated results are in good agreement, with a CC of 0.88. For
, some samples between 1.3 and 2 mm are underestimated, while some samples above 2.5 mm are overestimated. Overall, the agreement is good, with a CC of 0.88. The results for
show a tendency to slightly overestimate overall, but they are in good agreement, with an overall CC of 0.91. However, some samples are underestimated in the range of 2.0–4.2 mm.
Table 3 shows error statistics for RMSE, bias, and correlation coefficient for mean grain size,
,
, and
. For the four estimation variables, the bias ranges from 0.02 to 0.04 mm, indicating a very small difference between the measurements and estimated values. RMSE values range from 0.19 to 0.36 mm. In terms of the CC, the mean diameter and
exhibit a high correlation of 91–95%, while
shows a correlation of 88%.
shows a somewhat lower correlation of 72% but still demonstrates a reasonable relationship.
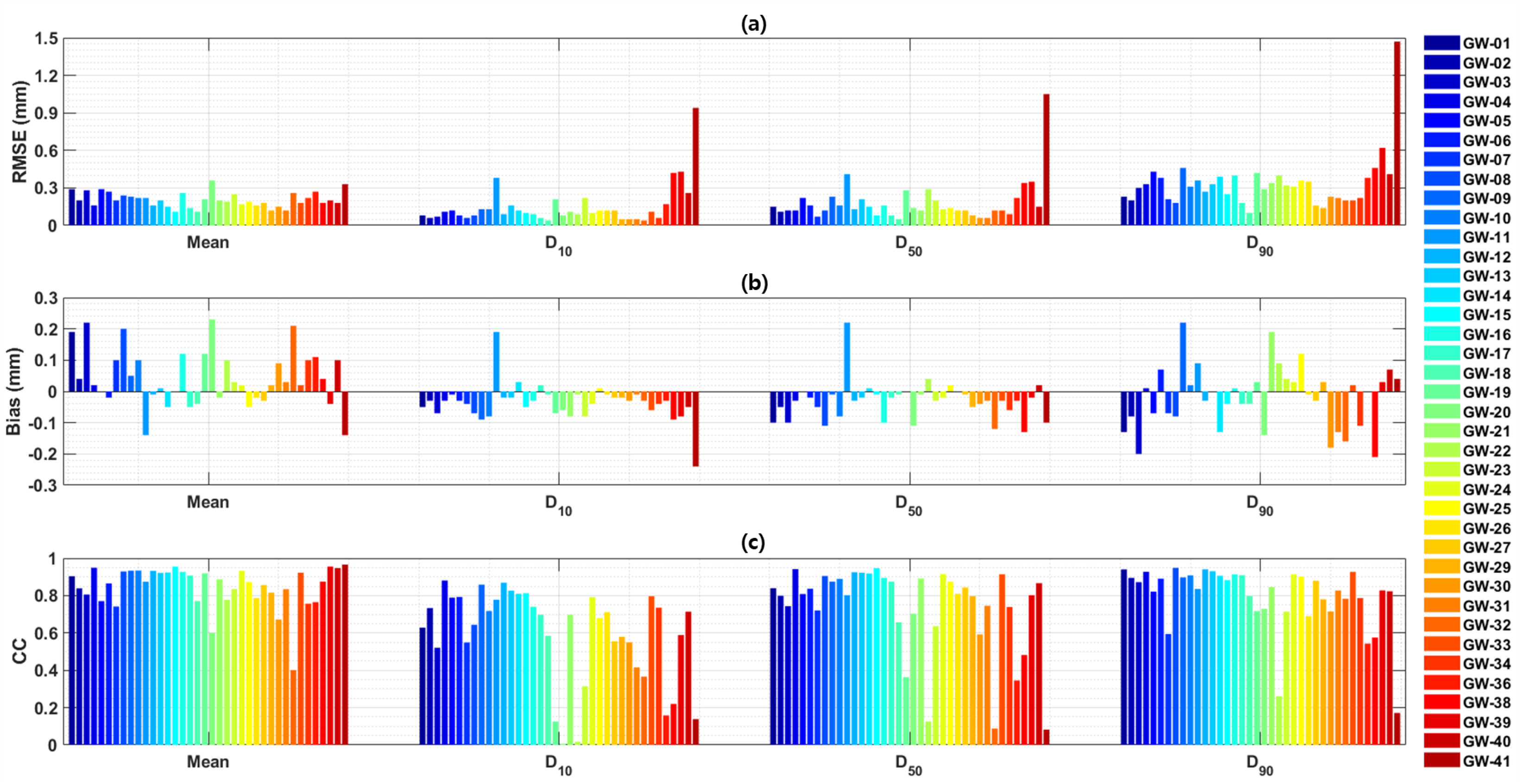
Figure 6 shows the RMSE, bias, and CC for mean grain size,
,
, and
for each littoral system. Overall, as the particle size increases (
), the estimation RMSE tends to increase, as can be seen in
Figure 6a. In
Table 1, the littoral system with the largest values for
,
, and
is GW11, with values of 1.15 mm, 2.06 mm, and 3.73 mm, respectively, which shows the lowest performance in terms of RMSE, bias, and CC, as shown in
Figure 6. In particular, GW41 has the highest RMSE for
,
, and
, indicating the lowest distribution estimation performance. The
,
, and
values for GW41 are 0.14 mm, 0.98 mm, and 2.56 mm, respectively. Although the values for
and
fall within a larger range compared to the surrounding littoral systems (see
Table 1), the reason for the high RMSE and low CC, despite not having the largest values, is likely due to the high variance in the distributed particle sizes, which is 0.90. Additionally, as shown in the bar graph for CC in
Figure 6c, the CC values for
are very low for GW20 and GW22, with values of 0.01 and 0.02, respectively. This is likely due to samples that are significantly overestimated or underestimated, as seen in
Figure 5b. Moreover, the mean grain diameters for these two systems are 1.33 and 1.16, which are higher than the average values (see
Table 1). The CC for
is also the lowest for GW30 and GW40, with values of 0.09 and 0.08, respectively. This is likely due to the significant underestimation observed in
Figure 5c. Additionally, as seen in
Table 1, the number of samples for GW40 is smaller compared to other littoral systems, which may also have an impact on the results. For
, the CC values for GW22 and GW41 are also low, at 0.26 and 0.17, respectively. This is considered to be due to the influence of underestimating samples, as seen in
Figure 5d. In particular, by examining the sample images for each system in
Figure 3, it can be visually observed that in GW26, GW30, and GW40, some particles exhibit outlier-like distributions within a single image. While this is not a characteristic of the entire test data and does not significantly affect the overall average performance, it is expected to cause some performance degradation in individual test results. However, for GW11 and GW41, this is not an anomaly but rather a clear indication of high variation in the grain size distribution of the sand in those regions, which can also be visually checked. For these two littoral systems, the performance of distribution estimation for grain size is somewhat lower compared to other littoral systems.
7. Conclusions
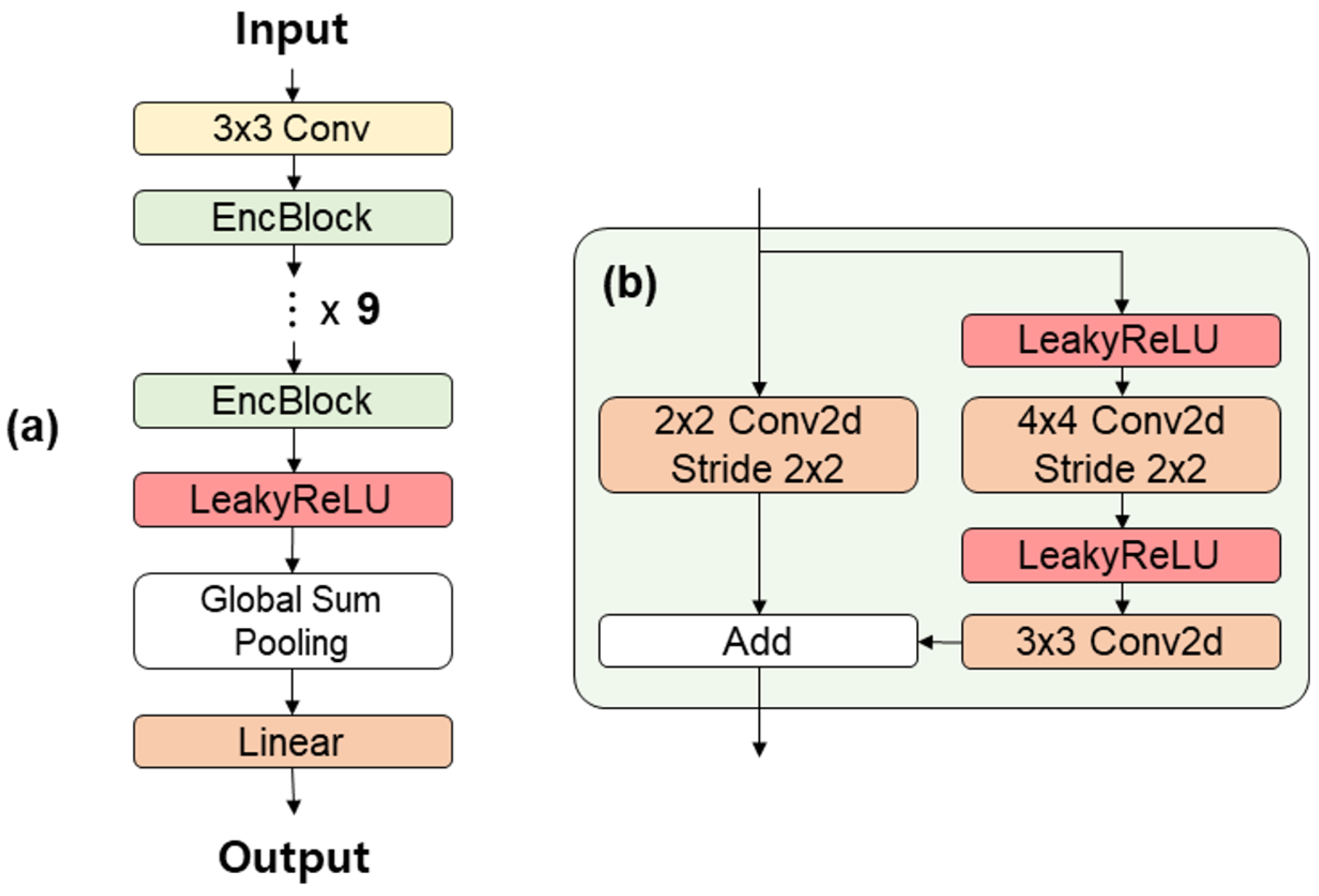
In this study, we propose a 2D CNN-based spatial encoder network for estimating grain size distribution from optical images of sediments using spatial feature representation learning and data augmentation. The proposed model was applied to 41 littoral systems along the east coast of Gangwon Province, Korea. Grain size distribution was measured through sieve analysis for sediments collected from these 41 littoral systems between 2010 to 2024. A total of 6337 optical images, each mapped to corresponding measurements, were acquired and used to develop the data-driven model. In total, seven variables are used to estimate the size distribution: mean grain size, standard deviation, skewness, kurtosis, , , and . In particular, when estimating grain size from sediment images, sufficient network capacity was achieved by deeply stacking multiple EncBlocks, enabling the model to understand and learn the spatial feature representation of the optical image. Additionally, to enhance the robustness and reliability of the model, data augmentation was applied using geometric transformations, including horizontal and vertical flipping methods for the training data.
For the grain size distribution estimated through the proposed model, we achieved improved performance for all output variables compared to the previous DL-based method. This improvement is attributed to the model’s ability to learn the spatial feature representation of images through the proposed network’s sufficient capacity. Additionally, we quantitatively evaluated the improved performance through data augmentation. In particular, the mean diameter for grain size estimated from sediment images demonstrated very high accuracy with a CC of 95%. For , , and , we also observed good correlations of 97%, 88%, and 91%, respectively.
Overall, the prediction performance is good; however, the model tends to show slightly deteriorated performance as the diversity of the grain size distribution increases or the particle size becomes larger. Some samples that are overestimated or underestimated contributed to the performance degradation. In cases where the number of samples per littoral system was relatively small, this also had some impact on the performance evaluation, but with the construction of a large number of data samples over a long-term period, it did not pose a significant issue when considering the overall average performance.
Understanding sediment transport is crucial across various disciplines because it plays a key role in geomorphology, hydrology and fluvial engineering, ecology, and environmental science, as well as in addressing climate change. In particular, understanding sediment transport in coastal management is essential for predicting coastal erosion, designing coastal structures and assessing their effectiveness, maintaining ports and shipping lanes, conserving coastal ecosystems, preserving beaches and the tourism industry, responding to climate change, and preventing disasters. However, collecting sediment samples and measuring grain size in the field can be challenging, and there are limitations in both the time and spatial resolution of measurement data. However, if grain size distribution can be accurately estimated using sediment images as in the proposed method, it would provide a considerable advancement over traditional, complex, and labor-intensive measurement techniques. The sediment images used in this study primarily consist of sand-dominated samples and can serve as a remote sensing-based observation method, offering sufficient accuracy for sites with similar sediment compositions to those found along the east coast of Gangwon Province, Korea. To increase the applicability of this approach in the future, data from a wider variety of sediments will be collected, and additional training will be performed. In addition to the characteristics of the grain size distribution, colorimetric information will also be estimated from the images. This is expected to be useful for applications such as determining sediment for sand nourishment in coastal management.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}