
LatentResNet: An Optimized Underwater Fish Classification Model with a Low Computational Cost


Abstract
1. Introduction
- Proposing a lightweight autoencoder named LiteAE and lightweight feature extraction and refining blocks called DeepResNet blocks, inspired by the well-known ResNet block: the computational cost of DeepResNet blocks is lower than ResNet blocks, and their presence in the model architecture improves the underwater image classification accuracy.
- Efficiency of using the encoder part of LiteAE model as a suitable tool for extracting discriminative features from underwater imagery while compressing the input data: this approach leads to classification models with lower computational costs while reducing the computational load, making it more suitable for marine applications in remote applications.
- Proposing the LatentResNet model, which integrates the encoder part of LiteAE with DeepResNet blocks for underwater image classification: LatentResNet is available in three scaled versions: small, medium, and large, achieved by modifying the number of DeepResNet blocks or number of units inside DeepResNet blocks; these variations are designed to accommodate a range of devices with different computational capacities. The source code has also been made available at https://github.com/MuhabHariri/LatentResNet (accessed on 20 May 2025)
2. Related Work
3. Materials and Methods
3.1. Fish4Knowledge Dataset
3.2. Autoencoder Design
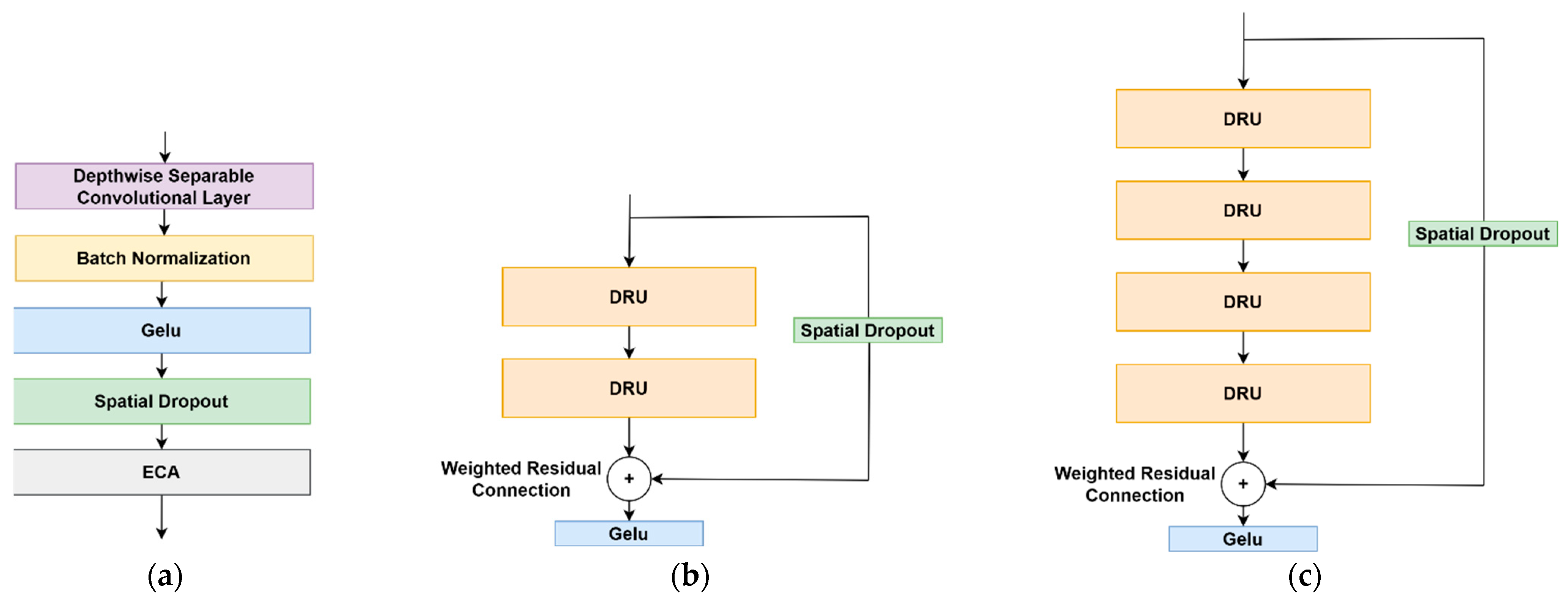
3.3. DeepResNet Block (DRB) Architecture
| Listing 1. Weighted residual connection in DRB. |
| Input: Residual path: = F() Trainable scalar: #Learned during training Output: = + · |
3.4. The LatentResNet Model
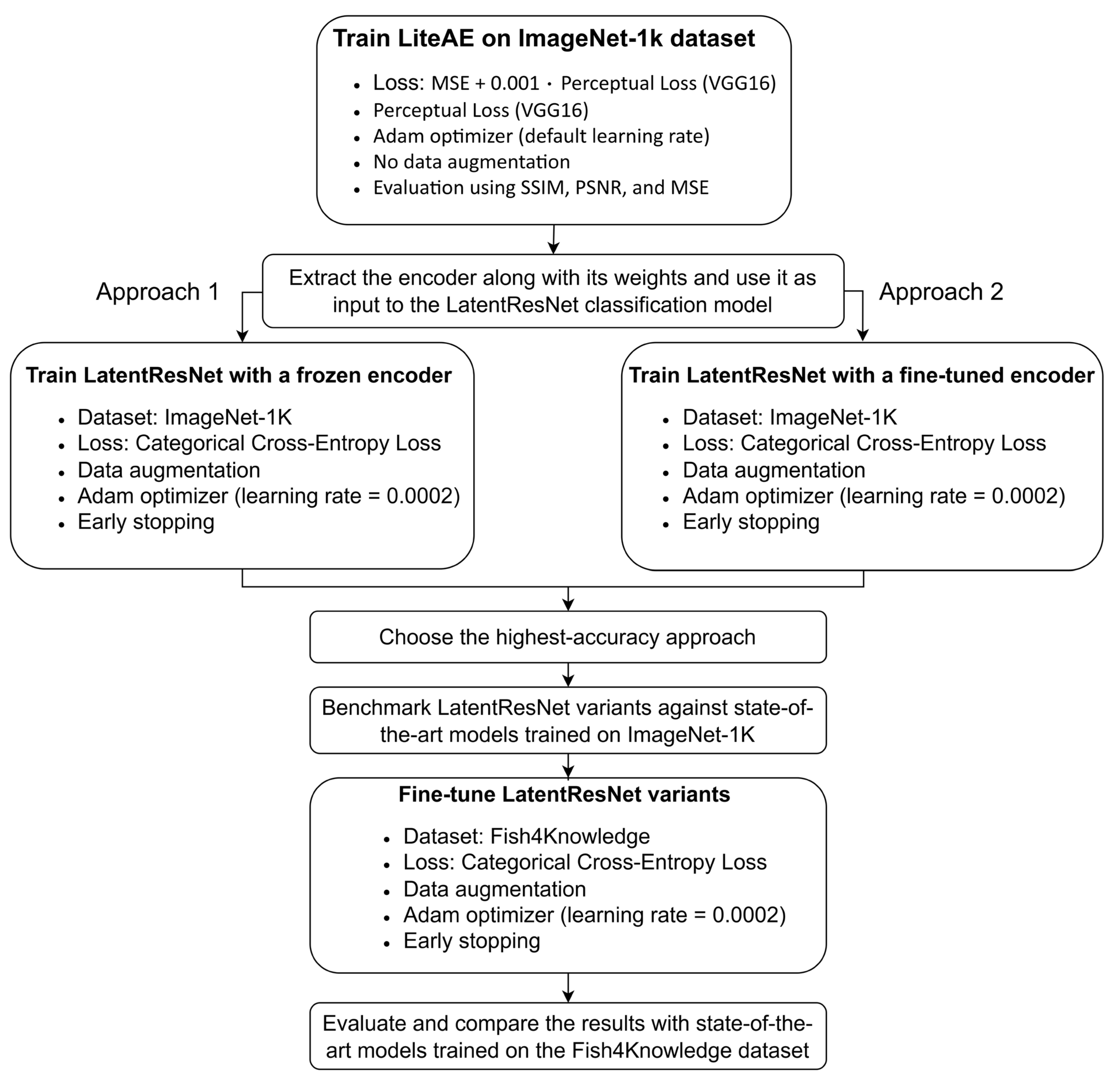
3.5. Training Strategy and Implementation Details
4. Results and Discussion
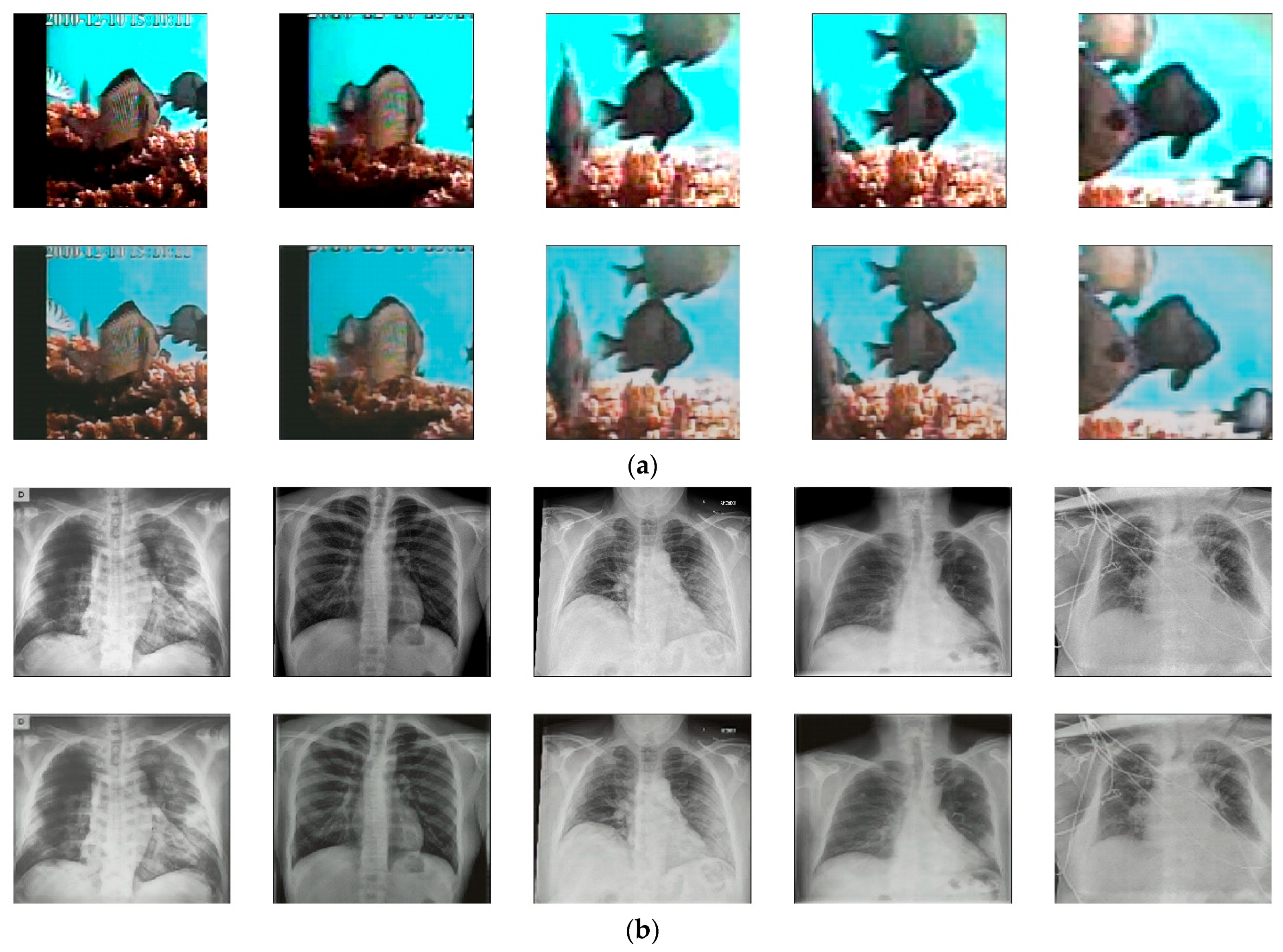
4.1. Experiments on Autoencoder (LiteAE)
4.2. Experiments on LatentResNet Model
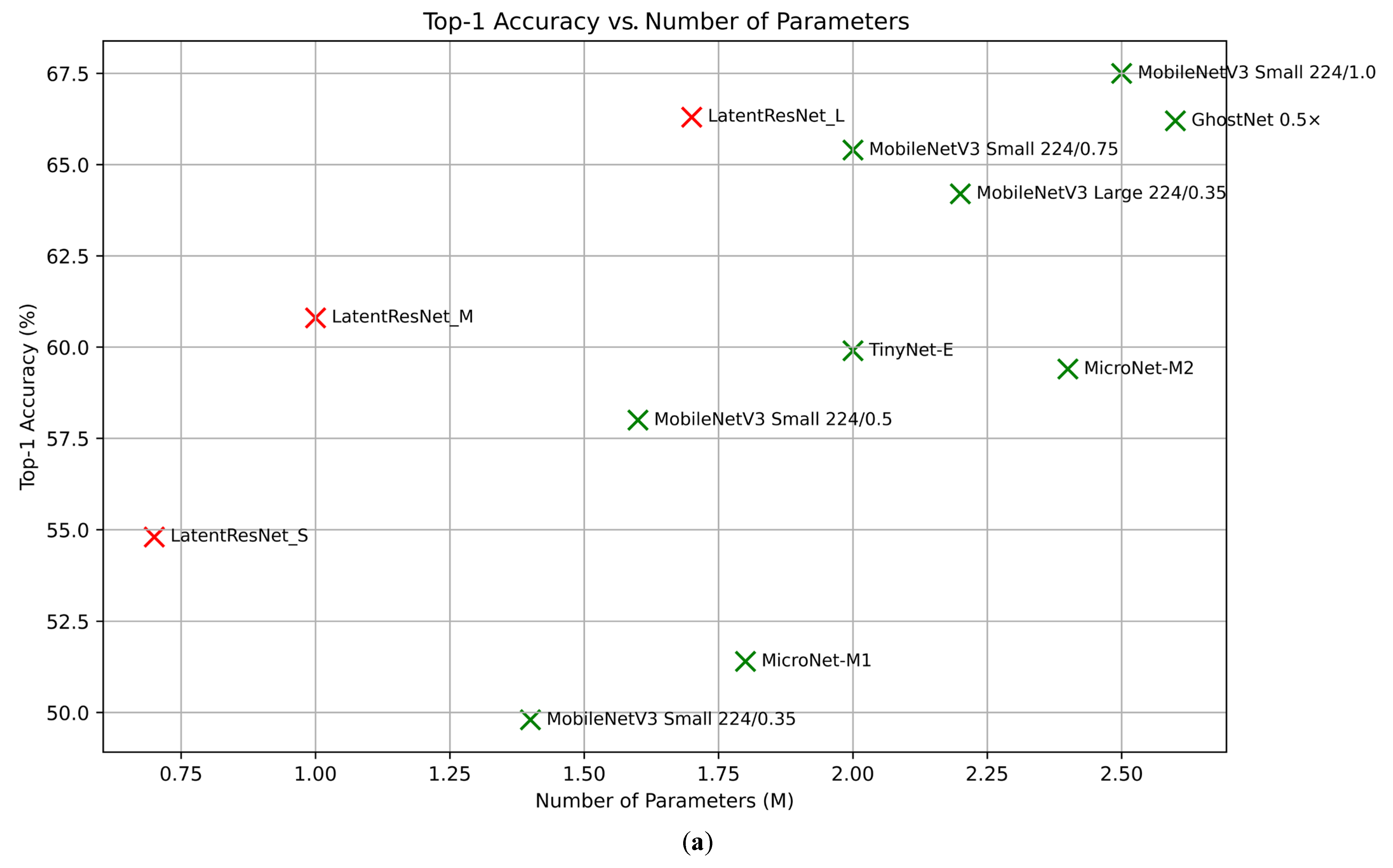
4.2.1. Pretraining and Performance Evaluation on ImageNet-1K Dataset
4.2.2. Fish Species Classification in Underwater Images
4.3. Evaluation of LiteAE and LatentResNet Models’ Performance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I.S.; Xie, S. Convnext v2: Co-designing and scaling convnets with masked autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16133–16142. [Google Scholar]
- Park, S.; Byun, H. Fair-VPT: Fair Visual Prompt Tuning for Image Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 12268–12278. [Google Scholar]
- Hariri, M.; Aydın, A.; Sıbıç, O.; Somuncu, E.; Yılmaz, S.; Sönmez, S.; Avşar, E. LesionScanNet: Dual-path convolutional neural network for acute appendicitis diagnosis. Health Inf. Sci. Syst. 2025, 13, 3. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y. A YOLO-NL object detector for real-time detection. Expert Syst. Appl. 2024, 238, 122256. [Google Scholar] [CrossRef]
- Chen, S.; Sun, P.; Song, Y.; Luo, P. Diffusiondet: Diffusion model for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 19830–19843. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Xiong, Y.; Varadarajan, B.; Wu, L.; Xiang, X.; Xiao, F.; Zhu, C.; Dai, X.; Wang, D.; Sun, F.; Iandola, F. Efficientsam: Leveraged masked image pretraining for efficient segment anything. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16111–16121. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 4015–4026. [Google Scholar]
- Zou, X.; Yang, J.; Zhang, H.; Li, F.; Li, L.; Wang, J.; Wang, L.; Gao, J.; Lee, Y.J. Segment everything everywhere all at once. Adv. Neural Inf. Process. Syst. 2023, 36, 19769–19782. [Google Scholar]
- Weinbach, B.C.; Akerkar, R.; Nilsen, M.; Arghandeh, R. Hierarchical deep learning framework for automated marine vegetation and fauna analysis using ROV video data. Ecol. Inform. 2025, 85, 102966. [Google Scholar] [CrossRef]
- Malik, H.; Naeem, A.; Hassan, S.; Ali, F.; Naqvi, R.A.; Yon, D.K. Multi-classification deep neural networks for identification of fish species using camera captured images. PLoS ONE 2023, 18, e0284992. [Google Scholar] [CrossRef]
- Lowe, S.C.; Misiuk, B.; Xu, I.; Abdulazizov, S.; Baroi, A.R.; Bastos, A.C.; Best, M.; Ferrini, V.; Friedman, A.; Hart, D. BenthicNet: A global compilation of seafloor images for deep learning applications. Sci. Data 2025, 12, 230. [Google Scholar] [CrossRef]
- Wang, B.; Hua, L.; Mei, H.; Kang, Y.; Zhao, N. Monitoring marine pollution for carbon neutrality through a deep learning method with multi-source data fusion. Front. Ecol. Evol. 2023, 11, 1257542. [Google Scholar] [CrossRef]
- Li, Y.; Liu, J.; Kusy, B.; Marchant, R.; Do, B.; Merz, T.; Crosswell, J.; Steven, A.; Tychsen-Smith, L.; Ahmedt-Aristizabal, D. A real-time edge-AI system for reef surveys. In Proceedings of the 28th Annual International Conference on Mobile Computing And Networking, Sydney, NSW, Australia, 17–21 October 2022; pp. 903–906. [Google Scholar]
- Avsar, E.; Feekings, J.P.; Krag, L.A. Edge computing based real-time Nephrops (Nephrops norvegicus) catch estimation in demersal trawls using object detection models. Sci. Rep. 2024, 14, 9481. [Google Scholar] [CrossRef]
- Lu, Z.; Liao, L.; Xie, X.; Yuan, H. SCoralDet: Efficient real-time underwater soft coral detection with YOLO. Ecol. Inform. 2025, 85, 102937. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Hi, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Hi, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Pham, H.; Guan, M.; Zoph, B.; Le, Q.; Dean, J. Efficient neural architecture search via parameters sharing. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4095–4104. [Google Scholar]
- Kamath, V.; Renuka, A. Deep learning based object detection for resource constrained devices: Systematic review, future trends and challenges ahead. Neurocomputing 2023, 531, 34–60. [Google Scholar] [CrossRef]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.; He, K.; Dollár, P. Designing network design spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10428–10436. [Google Scholar]
- Maaz, M.; Shaker, A.; Cholakkal, H.; Khan, S.; Zamir, S.W.; Anwer, R.M.; Shahbaz Khan, F. Edgenext: Efficiently amalgamated cnn-transformer architecture for mobile vision applications. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 3–20. [Google Scholar]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Chen, Y.; Wang, Z. An effective information theoretic framework for channel pruning. arXiv 2024, arXiv:2408.16772. [Google Scholar]
- Liu, J.; Tang, D.; Huang, Y.; Zhang, L.; Zeng, X.; Li, D.; Lu, M.; Peng, J.; Wang, Y.; Jiang, F. Updp: A unified progressive depth pruner for cnn and vision transformer. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; pp. 13891–13899. [Google Scholar]
- Xu, K.; Wang, Z.; Chen, C.; Geng, X.; Lin, J.; Yang, X.; Wu, M.; Li, X.; Lin, W. Lpvit: Low-power semi-structured pruning for vision transformers. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 269–287. [Google Scholar]
- Choi, K.; Lee, H.Y.; Kwon, D.; Park, S.; Kim, K.; Park, N.; Lee, J. MimiQ: Low-Bit Data-Free Quantization of Vision Transformers. arXiv 2024, arXiv:2407.20021. [Google Scholar]
- Shi, H.; Cheng, X.; Mao, W.; Wang, Z. P $^ 2$-ViT: Power-of-Two Post-Training Quantization and Acceleration for Fully Quantized Vision Transformer. IEEE Trans. Very Large Scale Integr. VLSI Syst. 2024, 32, 1704–1717. [Google Scholar] [CrossRef]
- Ding, R.; Yong, L.; Zhao, S.; Nie, J.; Chen, L.; Liu, H.; Zhou, X. Progressive Fine-to-Coarse Reconstruction for Accurate Low-Bit Post-Training Quantization in Vision Transformers. arXiv 2024, arXiv:2412.14633. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Chen, Y.; Zheng, Z.; Li, X.; Cheng, M.-M.; Hou, Q. CrossKD: Cross-head knowledge distillation for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16520–16530. [Google Scholar]
- Salie, D.; Brown, D.; Chieza, K. Deep Neural Network Compression for Lightweight and Accurate Fish Classification. In Proceedings of the Southern African Conference for Artificial Intelligence Research, Bloemfontein, South Africa, 2–6 December 2024; pp. 300–318. [Google Scholar]
- Sun, S.; Ren, W.; Li, J.; Wang, R.; Cao, X. Logit standardization in knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 15731–15740. [Google Scholar]
- Wu, B.; Dai, X.; Zhang, P.; Wang, Y.; Sun, F.; Wu, Y.; Tian, Y.; Vajda, P.; Jia, Y.; Keutzer, K. Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 10734–10742. [Google Scholar]
- Tan, M.; Le, Q. Efficientnetv2: Smaller models and faster training. arXiv 2021, arXiv:2104.00298. [Google Scholar]
- Sharma, K.; Gupta, S.; Rameshan, R. Learning optimally separated class-specific subspace representations using convolutional autoencoder. arXiv 2021, arXiv:2105.08865. [Google Scholar]
- Gogna, A.; Majumdar, A. Discriminative autoencoder for feature extraction: Application to character recognition. Neural Process. Lett. 2019, 49, 1723–1735. [Google Scholar] [CrossRef]
- Kong, Q.; Chiang, A.; Aguiar, A.C.; Fernández-Godino, M.G.; Myers, S.C.; Lucas, D.D. Deep convolutional autoencoders as generic feature extractors in seismological applications. Artif. Intell. Geosci. 2021, 2, 96–106. [Google Scholar] [CrossRef]
- Fisher, R.B.; Chen-Burger, Y.-H.; Giordano, D.; Hardman, L.; Lin, F.-P. Fish4Knowledge: Collecting and Analyzing Massive Coral Reef Fish Video Data; Springer: Berlin/Heidelberg, Germany, 2016; Volume 104. [Google Scholar]
- Hinton, G.E.; Zemel, R. Autoencoders, minimum description length and Helmholtz free energy. Adv. Neural Inf. Process. Syst. 1993, 6, 3–10. [Google Scholar]
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient object localization using convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 648–656. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Shen, F.; Gan, R.; Zeng, G. Weighted residuals for very deep networks. In Proceedings of the 2016 3rd International Conference on Systems and Informatics (ICSAI), Shanghai, China, 19–21 November 2016; pp. 936–941. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- DTU Computing Center. DTU Computing Center Resources; DTU Computing Center: Lyngby, Denmark, 2024. [Google Scholar]
- Sait, U.; Lal, K.; Prajapati, S.; Bhaumik, R.; Kumar, T.; Sanjana, S.; Bhalla, K. Curated dataset for COVID-19 posterior-anterior chest radiography images (X-Rays). Mendeley Data 2020, 1. [Google Scholar] [CrossRef]
- Hariri, M.; Avşar, E. Tipburn disorder detection in strawberry leaves using convolutional neural networks and particle swarm optimization. Multimed. Tools Appl. 2022, 81, 11795–11822. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Zhang, Q.; Zhang, W.; Xu, C.; Zhang, T. Model Rubik’s cube: Twisting resolution, depth and width for tinynets. Adv. Neural Inf. Process. Syst. 2020, 33, 19353–19364. [Google Scholar]
- Li, Y.; Chen, Y.; Dai, X.; Chen, D.; Liu, M.; Yuan, L.; Liu, Z.; Zhang, L.; Vasconcelos, N. Micronet: Improving image recognition with extremely low flops. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 468–477. [Google Scholar]
- Sun, S.; Pang, J.; Shi, J.; Yi, S.; Ouyang, W. Fishnet: A versatile backbone for image, region, and pixel level prediction. Adv. Neural Inf. Process. Syst. 2018, 31, 1–11. [Google Scholar]
- Knausgård, K.M.; Wiklund, A.; Sørdalen, T.K.; Halvorsen, K.T.; Kleiven, A.R.; Jiao, L.; Goodwin, M. Temperate fish detection and classification: A deep learning based approach. Appl. Intell. 2022, 52, 6988–7001. [Google Scholar] [CrossRef]
- Qu, H.; Wang, G.-G.; Li, Y.; Qi, X.; Zhang, M. ConvFishNet: An efficient backbone for fish classification from composited underwater images. Inf. Sci. 2024, 679, 121078. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GFLOPs | Number of Parameters (Millions) | |
|---|---|---|
| Encoder | 0.01 | 0.006 |
| Decoder | 0.37 | 0.088 |
| Augmentation Name | Range/Parameters (Random) |
|---|---|
| Shear | Shear angle: [−0.25, 0.25] (radians) |
| Translate | Width: [0%, 25%]; height: [0%, 25%] of image size |
| Zoom | Zoom factor: [0.75, 1.25] |
| Flip (horizontal) | - |
| Rotate | Rotation angle: [−0.35, 0.35] radians |
| Brightness adjustment | Δ ∈ [0.06, 0.14] to pixel values |
| Channel shift | Shift: [−0.196, 0.196] (normalized from pixel range [−50, 50]) |
| Random crop + pad | Crop: 160 × 160, then pad to 224 × 224 |
| Random black rectangle | Height: [45, 60]; width: [80, 100]; position: random |
| Number of Filters | Spatial Dropout Rate | Classic Dropout Rate | |||
|---|---|---|---|---|---|
| 1st Pair of DeepResNet Blocks | 2nd Pair of DeepResNet Blocks | 3rd Pair of DeepResNet Blocks | |||
| LatentResNet-L | 110 | 180 | 340 | 0.02 | 0.1 |
| LatentResNet-M | 0.01 | 0.05 | |||
| LatentResNet-S | 0.005 | 0.05 | |||
| Dataset | SSIM | PSNR (dB) | MSE |
|---|---|---|---|
| Imagnet1k test data | 0.7508 | 23.15 | 0.0067 |
| Fish4Knowledge dataset | 0.8436 | 22.98 | 0.0053 |
| X-ray dataset | 0.7200 | 21.83 | 0.0049 |
| Strawberry dataset | 0.7193 | 23.40 | 0.0069 |
| Model | LatentResNet | LatentResNet (Frozen Encoder) |
|---|---|---|
| Top-1 accuracy | 66.3% | 65.1% |
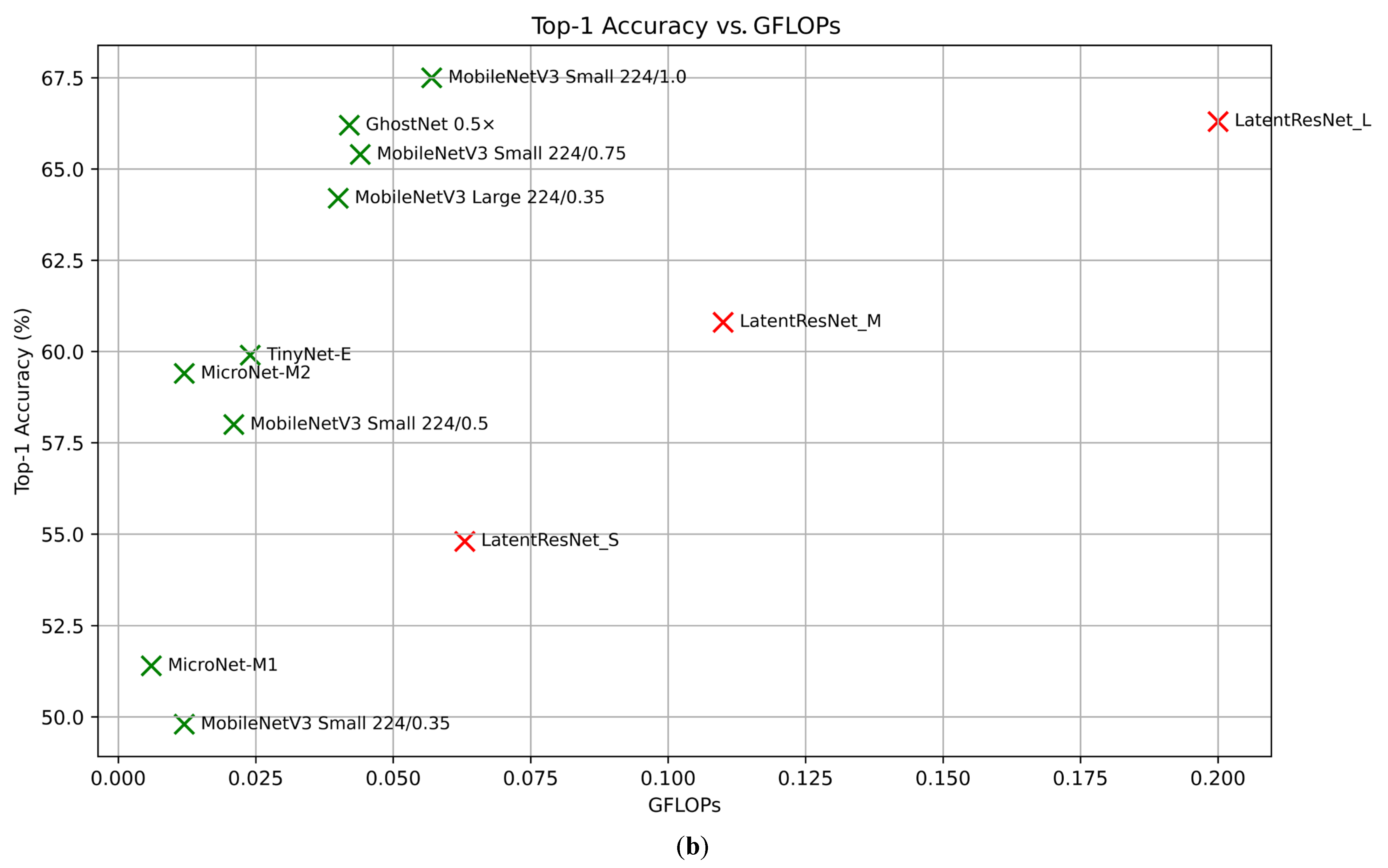
| Model | Top-1 Accuracy | GFLOPs | Number of Parameters (M) |
|---|---|---|---|
| MobileNetV3 Large 224/0.35 [24] | 64.2% | 0.040 | 2.2 |
| MobileNetV3 Small 224/1.0 [24] | 67.5% | 0.057 | 2.5 |
| MobileNetV3 Small 224/0.75 [24] | 65.4% | 0.044 | 2.0 |
| GhostNet 0.5× [26] | 66.2% | 0.042 | 2.6 |
| LatentResNet_L | 66.3% | 0.200 | 1.7 |
| MobileNetV3 Small 224/0.5 [24] | 58.0% | 0.021 | 1.6 |
| TinyNet-E [54] | 59.9% | 0.024 | 2.0 |
| MicroNet-M2 [55] | 59.4% | 0.012 | 2.4 |
| LatentResNet_M | 60.8% | 0.110 | 1.0 |
| MobileNetV3 Small 224/0.35 [24] | 49.8% | 0.012 | 1.4 |
| MicroNet-M1 [55] | 51.4% | 0.006 | 1.8 |
| LatentResNet_S | 54.8% | 0.063 | 0.7 |
| Model | Parameters (M) | GFLOPs | Macro-Averages | Accuracy (%) | ||
|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1 Score (%) | ||||
| FishNet [56] | 16.62 | 4.31 | 96.8 | 88.3 | 92.3 | - |
| CNN-SENet [57] | - | - | 97.4 | 95.3 | 96.0 | 99.3 |
| ConvFishNet [58] | 14.12 | 0.83 | 99.8 | 97.5 | 98.6 | - |
| MobileNetV2 (knowledge distillation) [37] | 2.29 | - | 97.7 | 82.7 | 89.6 | 96.6 |
| LatentResNet_L | 1.39 | 0.20 | 99.8 | 99.9 | 99.9 | 99.7 |
| LatentResNet_M | 0.71 | 0.11 | 98.8 | 99.4 | 99.0 | 99.8 |
| LatentResNet_S | 0.37 | 0.06 | 99.3 | 98.6 | 98.9 | 99.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hariri, M.; Avsar, E.; Aydın, A. LatentResNet: An Optimized Underwater Fish Classification Model with a Low Computational Cost. J. Mar. Sci. Eng. 2025, 13, 1019. https://doi.org/10.3390/jmse13061019
Hariri M, Avsar E, Aydın A. LatentResNet: An Optimized Underwater Fish Classification Model with a Low Computational Cost. Journal of Marine Science and Engineering. 2025; 13(6):1019. https://doi.org/10.3390/jmse13061019
Chicago/Turabian StyleHariri, Muhab, Ercan Avsar, and Ahmet Aydın. 2025. "LatentResNet: An Optimized Underwater Fish Classification Model with a Low Computational Cost" Journal of Marine Science and Engineering 13, no. 6: 1019. https://doi.org/10.3390/jmse13061019
APA StyleHariri, M., Avsar, E., & Aydın, A. (2025). LatentResNet: An Optimized Underwater Fish Classification Model with a Low Computational Cost. Journal of Marine Science and Engineering, 13(6), 1019. https://doi.org/10.3390/jmse13061019