
RTDETR-MARD: A Multi-Scale Adaptive Real-Time Framework for Floating Waste Detection in Aquatic Environments


Abstract
1. Introduction
- •
- We leverage the gather-and-distribute (GD) mechanism to enhance multi-scale feature aggregation and cross-layer information interaction, improving fine-grained spatial representation.
- •
- Inspired by GD, we develop a feature fusion framework integrating the Feature Alignment Module (FAM), Information Fusion Module (IFM), Information Injection Module (IIM), and Scale Sequence Feature Fusion Module (S2F2M), which jointly refine multi-scale representations and enhance both spatial and semantic consistency. To further improve localization, we adopt the Wise-IoU (WIoU) loss for better anchor supervision.
- •
- Extensive experiments on the FloW and our custom water surface waste datasets demonstrate that RTDETR-MARD achieves 86.6% mAP@0.5 at 96.8 FPS on FloW and 49.2% mAP@0.5 at 97.5 FPS on our dataset, surpassing the RT-DETR baseline in both accuracy and efficiency.
2. Related Work
2.1. Floating Waste Detection
- •
- DatasetsRecent advancements in deep learning have significantly propelled research in aquatic surface waste detection. To support this research, several benchmark datasets have been developed, providing annotated image collections that facilitate the training and evaluation of detection algorithms. The FloW dataset [5] is a specialized dataset focusing on a single category of floating waste, making it useful for fundamental research on waterborne waste detection. The WSODD dataset [6], on the other hand, provides a more diverse set of annotated images, including both floating waste and other objects commonly found in aquatic environments. Additionally, datasets such as Trash-ICRA19 [7] and AquaTrash [8] have contributed to the field, particularly in the context of underwater object detection. To further advance research in this area, we introduce our dataset, which contains a diverse collection of annotated images for floating waste detection. A summary of these datasets is presented in Table 1.
- •
- MethodsIn the field of object detection models, researchers have explored various deep learning architectures for aquatic surface waste detection, including the YOLO series [9,10,11,12,13,14], Faster R-CNN [15], and SSD [16]. These models have been rigorously validated across multiple datasets to evaluate their efficacy in identifying floating waste. For example, Yang et al. [17] introduced an improved version of YOLOv7 specifically adapted to the Chengdu Sha River environment by refining the network aggregation and downsampling modules, which led to notable gains in both detection accuracy and inference speed. Ma et al. [18] further advanced the field by integrating YOLOv5s with UNet segmentation and dark channel prior denoising, effectively enhancing detection accuracy by mitigating wave and lighting interference. Additionally, Chen et al. [19] implemented a lightweight YOLOv5 variant to address computational constraints in unmanned surface vessel deployments.Deep learning-based object detection has also demonstrated its versatility across other domains, such as the automated identification of urban exterior materials from street view images [20], highlighting its adaptability to diverse visual recognition tasks.
- •
- ApplicationRecent advancements in sensing platforms have significantly improved operational capabilities for aquatic waste detection. Notable developments include the work by Luo et al. [21], who developed drone-mounted hyperspectral sensors enabling airborne pollutant mapping through spectral analysis. In parallel, Chang et al. [22] demonstrated an integrated USV system incorporating multi-sensor arrays and robotic manipulators, achieving simultaneous waste identification and automated collection in aquatic environments. Similarly, the UAV- and deep learning-based rebar detection method for concrete columns [23] demonstrates the relevance of UAV-based object detection in construction and aquatic waste applications. The study highlights the growing utility of UAVs in precise object identification, which is crucial for applications in various fields, including waste detection and environmental monitoring.
2.2. Transformer for Object Detection
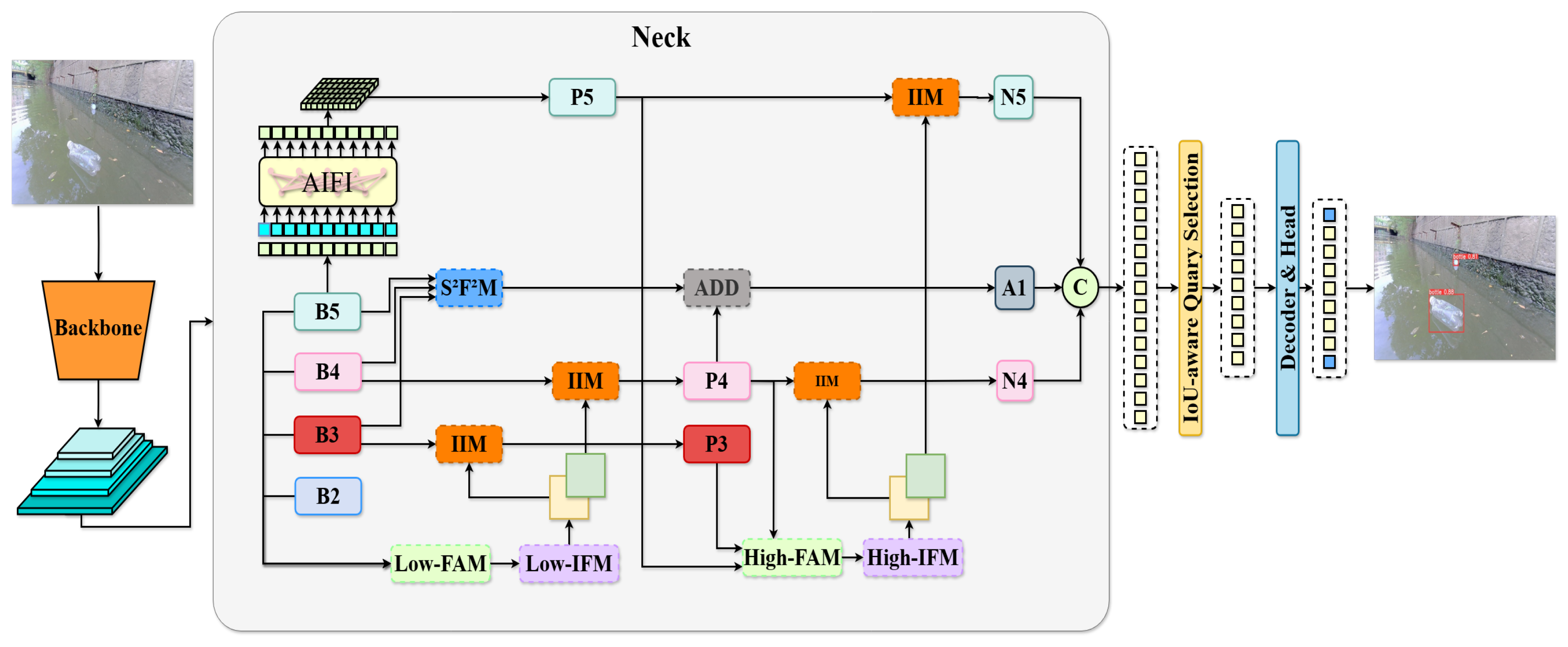
3. Methods
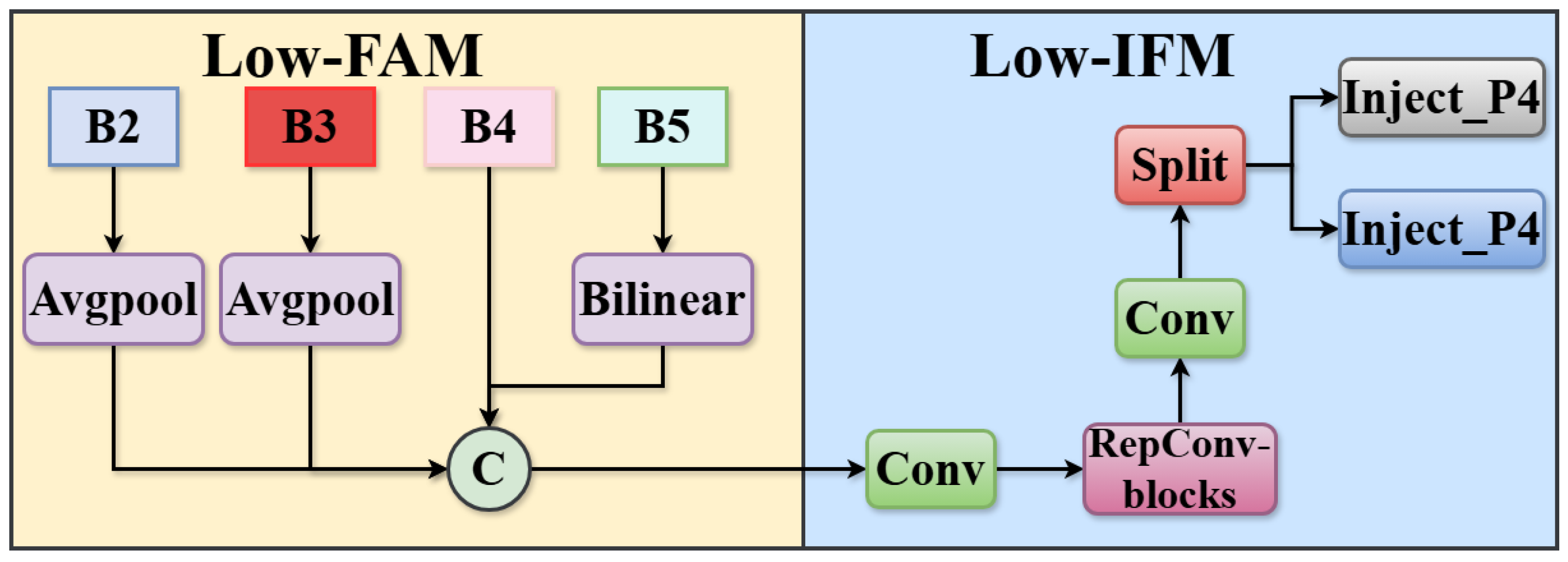
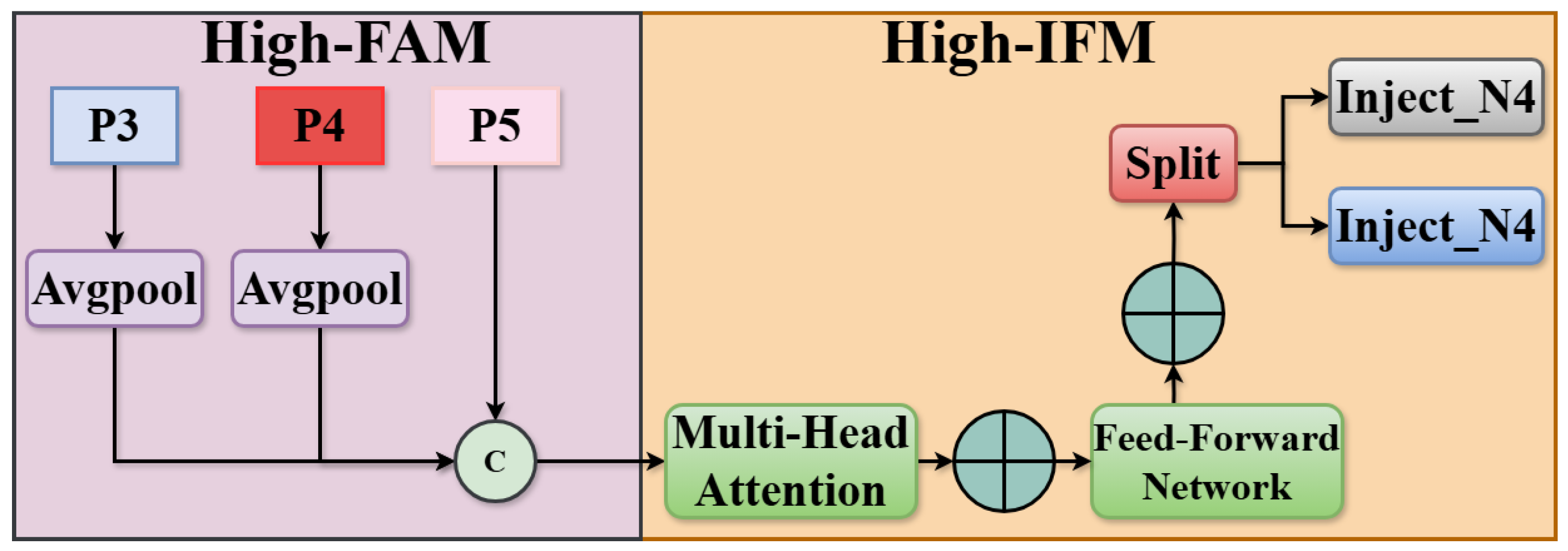
3.1. Feature Aggregation Module
3.2. Information Fusion Module
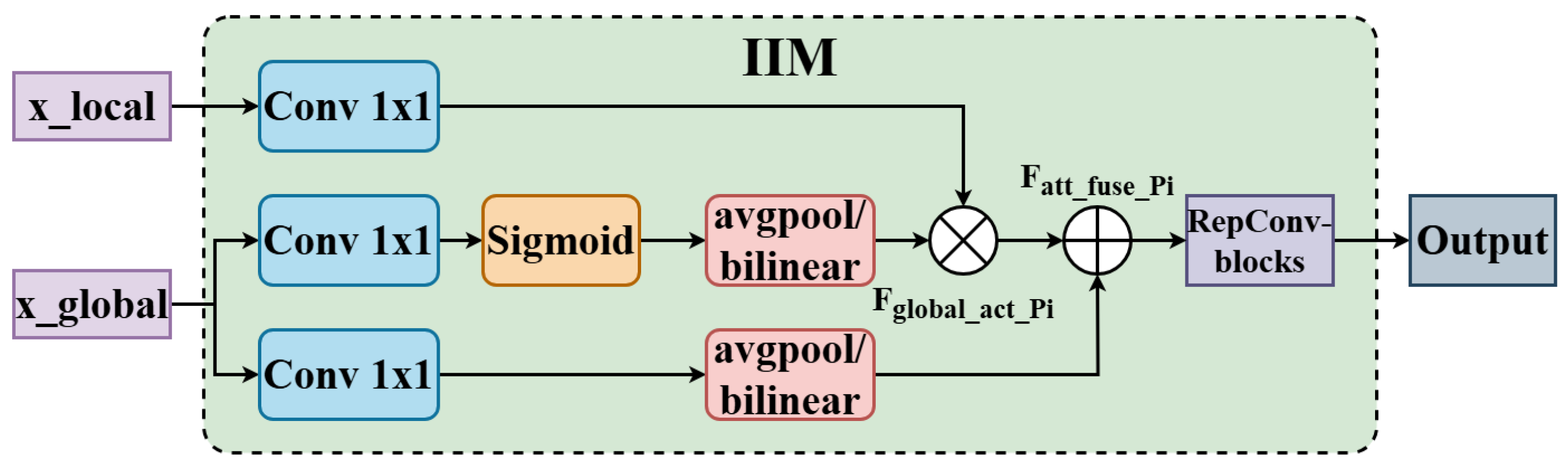
3.3. Information Injection Module
3.4. Scale Sequence Feature Fusion
3.5. Loss Function
4. Experiments and Results
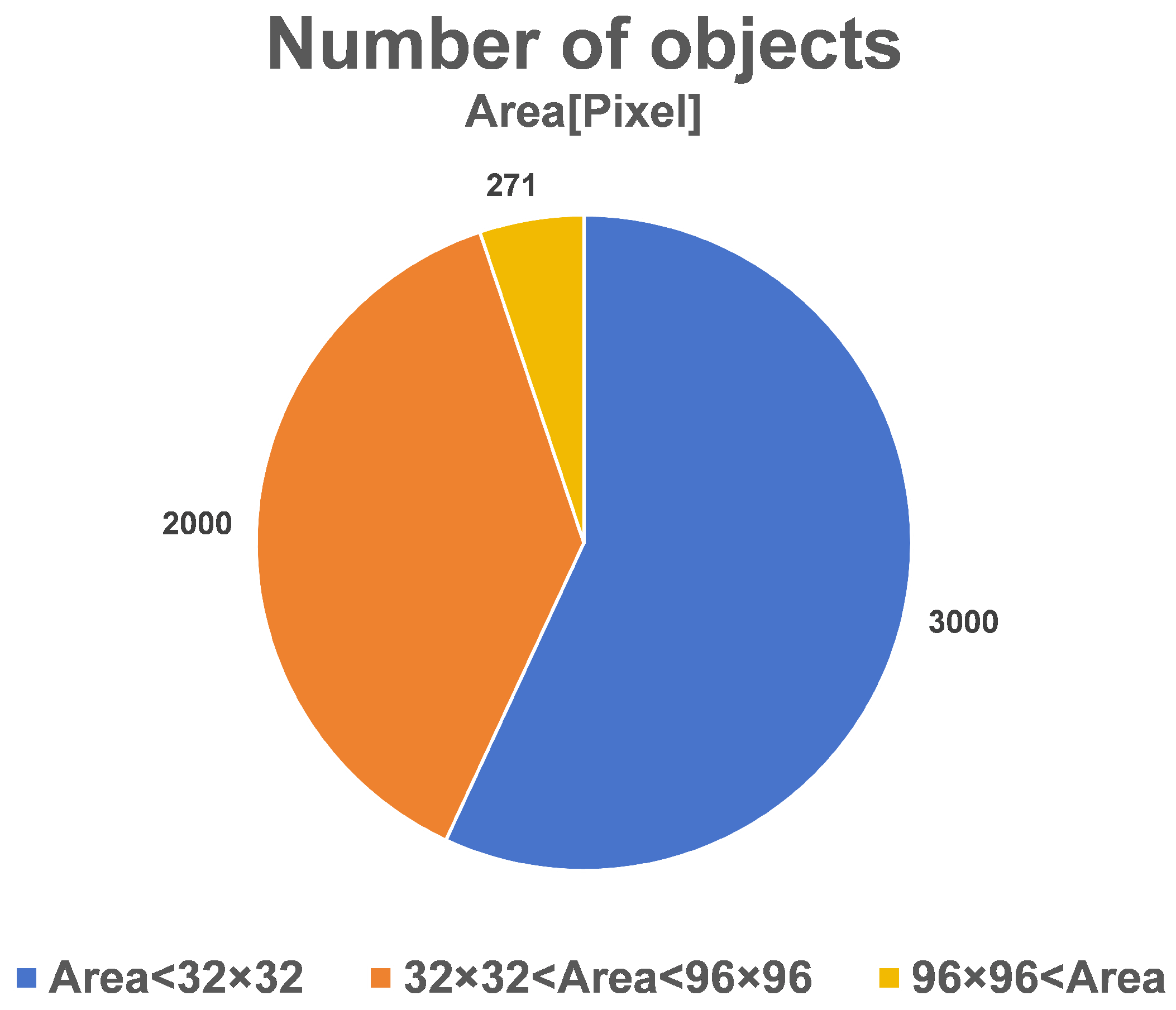
4.1. Dataset
4.2. Implementation
4.3. Evaluation Metrics
4.3.1. Precision
4.3.2. Recall
4.3.3. mAP
4.4. Analysis of Results
4.4.1. Comparison of Computed Parameter Quantities of RTDETR Model Versions
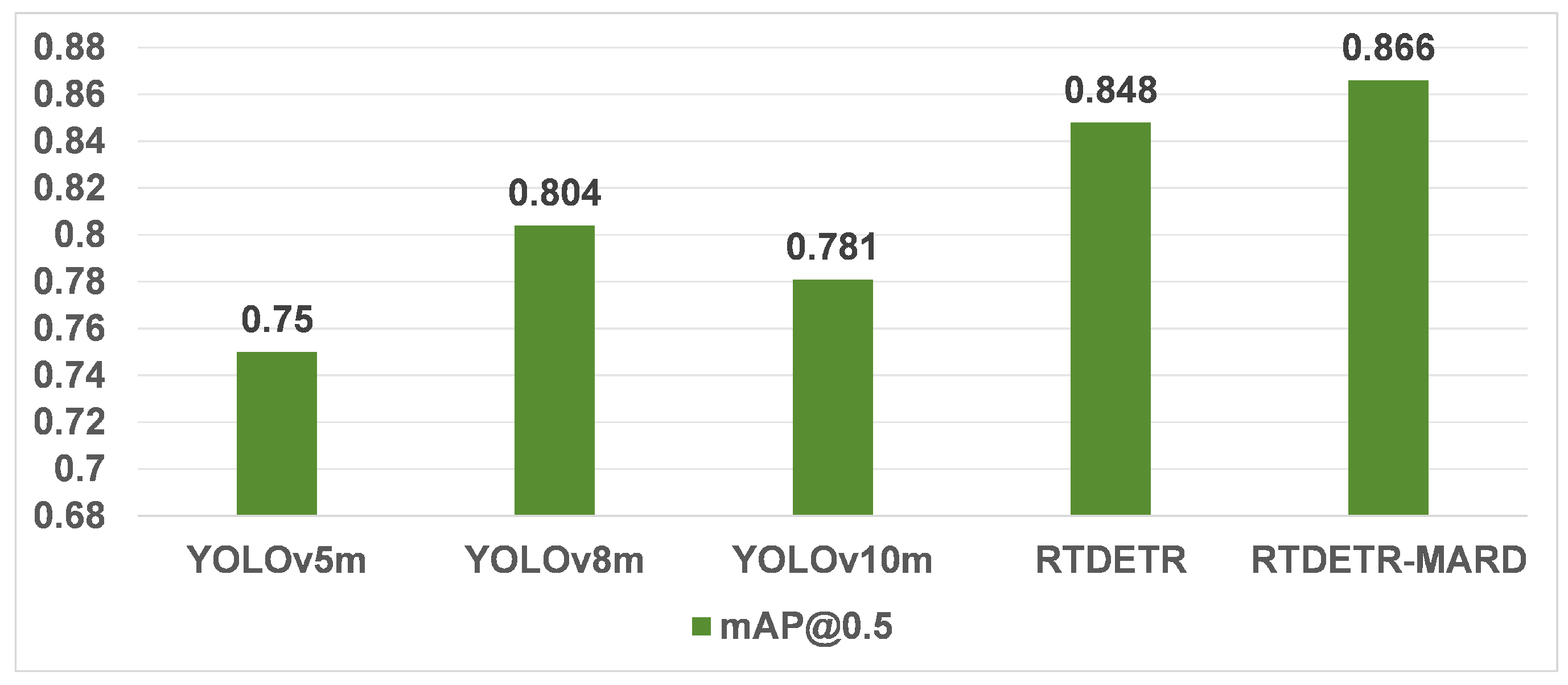
4.4.2. Comparison with Other Models
4.4.3. Comparison of Different IoU Loss Functions on Various Aspects of Performance
4.4.4. Ablation Experiment
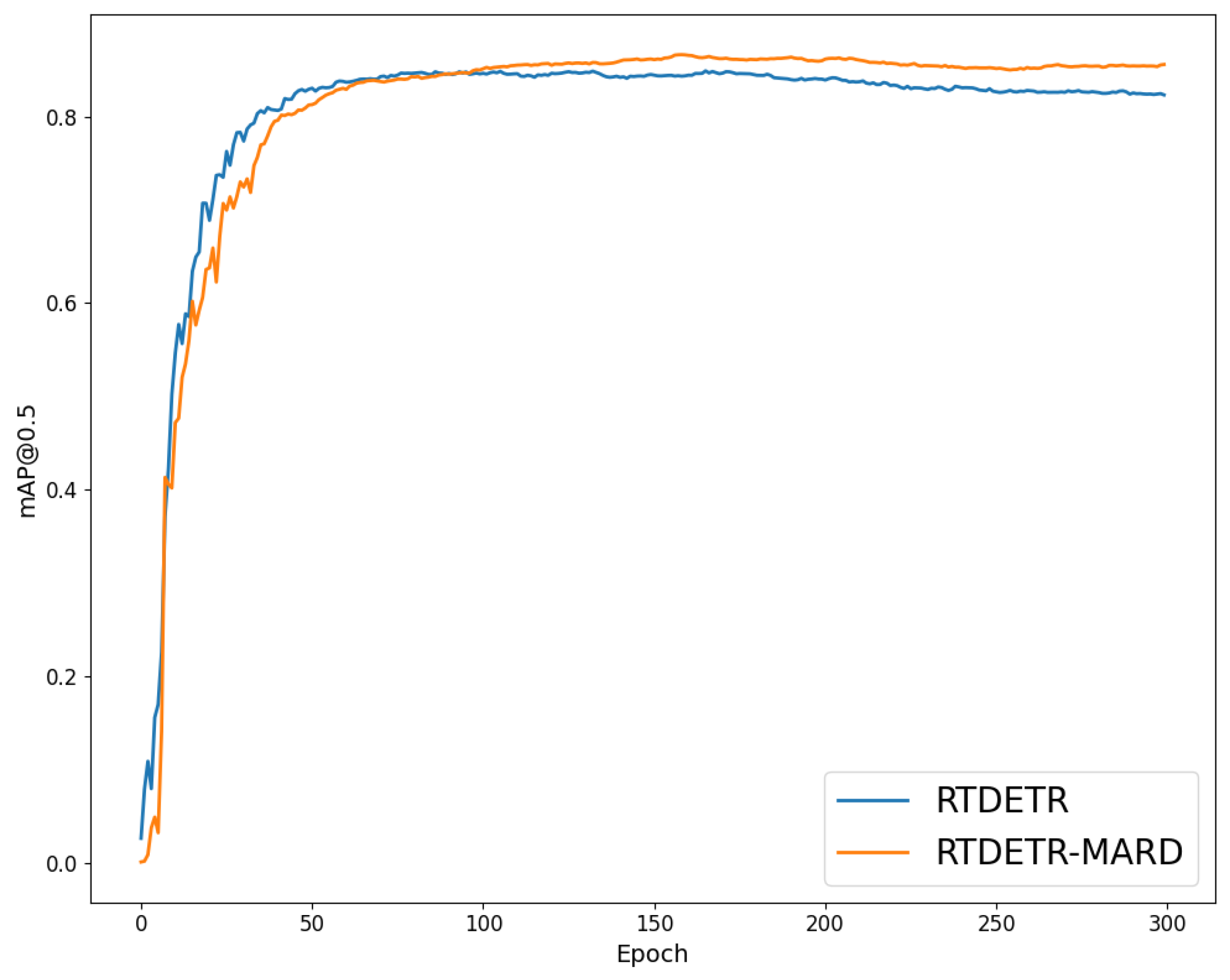
4.4.5. Experiment Results Visualization
4.4.6. Generalization Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, M.; Zheng, X.; Wang, J.; Pan, Z.; Che, W.; Wang, H. Trajectory Planning for Cooperative Double Unmanned Surface Vehicles Connected with a Floating Rope for Floating Garbage Cleaning. J. Mar. Sci. Eng. 2024, 12, 739. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, P.; Lu, J.; Chen, Y.; Zhang, J. Hydrology Modulates the Microplastics Composition and Transport Flux Across the River–Sea Interface in Zhanjiang Bay, China. J. Mar. Sci. Eng. 2025, 13, 428. [Google Scholar] [CrossRef]
- Haward, M. Plastic Pollution of the World’s Seas and Oceans as a Contemporary Challenge in Ocean Governance. Nat. Commun. 2018, 9, 667. [Google Scholar] [CrossRef] [PubMed]
- Kong, S.; Tian, M.; Qiu, C.; Wu, Z.; Yu, J. IWSCR: An Intelligent Water Surface Cleaner Robot for Collecting Floating Garbage. IEEE Trans. Syst. Man Cybern. Syst. 2020, 51, 6358–6368. [Google Scholar] [CrossRef]
- Cheng, Y.; Zhu, J.; Jiang, M.; Fu, J.; Pang, C.; Wang, P.; Sankaran, K.; Onabola, O.; Liu, Y.; Liu, D.; et al. FloW: A Dataset and Benchmark for Floating Waste Detection in Inland Waters. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10953–10962. [Google Scholar]
- Zhou, Z.; Sun, J.; Yu, J.; Liu, K.; Duan, J.; Chen, L.; Chen, C.P. An Image-Based Benchmark Dataset and a Novel Object Detector for Water Surface Object Detection. Front. Neurorobot. 2021, 15, 723336. [Google Scholar] [CrossRef]
- Fulton, M.S.; Hong, J.; Sattar, J. Trash-ICRA19: A Bounding Box Labeled Dataset of Underwater Trash. The Data Repository for the University of Minnesota (DRUM). 2020. Available online: https://conservancy.umn.edu/items/c34b2945-4052-48fa-b7e7-ce0fba2fe649 (accessed on 1 March 2025).
- Panwar, H.; Gupta, P.K.; Siddiqui, M.K.; Morales-Menendez, R.; Bhardwaj, P.; Sharma, S.; Sarker, I.H. AquaVision: Automating the Detection of Waste in Water Bodies Using Deep Transfer Learning. Case Stud. Chem. Environ. Eng. 2020, 2, 100026. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Khokhar, S.; Kedia, D. Integrating YOLOv8 and CSPBottleneck Based CNN for Enhanced License Plate Character Recognition. J. Real-Time Image Process. 2024, 21, 168. [Google Scholar] [CrossRef]
- Luo, S.; Dong, C.; Dong, G.; Chen, R.; Zheng, B.; Xiang, M.; Zhang, P.; Li, Z. YOLO-DAFS: A Composite-Enhanced Underwater Object Detection Algorithm. J. Mar. Sci. Eng. 2025, 13, 947. [Google Scholar] [CrossRef]
- Zhu, J.; Li, H.; Liu, M.; Zhai, G.; Bian, S.; Peng, Y.; Liu, L. Underwater Side-Scan Sonar Target Detection: An Enhanced YOLOv11 Framework Integrating Attention Mechanisms and a Bi-Directional Feature Pyramid Network. J. Mar. Sci. Eng. 2025, 13, 926. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14 2016, Proceedings, Part I; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Yang, M.; Wang, H. Real-Time Water Surface Target Detection Based on Improved YOLOv7 for Chengdu Sand River. J. Real-Time Image Process. 2024, 21, 127. [Google Scholar] [CrossRef]
- Ma, L.; Wu, B.; Deng, J.; Lian, J. Small-Target Water-Floating Garbage Detection and Recognition Based on UNet-YOLOv5s. In Proceedings of the 2023 5th International Conference on Communications, Information System and Computer Engineering (CISCE), Guangzhou, China, 14–16 April 2023; pp. 391–395. [Google Scholar]
- Chen, L.; Zhu, J. Water Surface Garbage Detection Based on Lightweight YOLOv5. Sci. Rep. 2024, 14, 6133. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Han, J. Automated Detection of Exterior Cladding Material in Urban Area from Street View Images Using Deep Learning. J. Build. Eng. 2024, 96, 110466. [Google Scholar] [CrossRef]
- Luo, W.; Han, W.; Fu, P.; Wang, H.; Zhao, Y.; Liu, K.; Wei, G. A Water Surface Contaminants Monitoring Method Based on Airborne Depth Reasoning. Processes 2022, 10, 131. [Google Scholar] [CrossRef]
- Chang, H.C.; Hsu, Y.L.; Hung, S.S.; Ou, G.R.; Wu, J.R.; Hsu, C. Autonomous Water Quality Monitoring and Water Surface Cleaning for Unmanned Surface Vehicle. Sensors 2021, 21, 1102. [Google Scholar] [CrossRef]
- Wang, S.; Kim, M.; Hae, H.; Cao, M.; Kim, J. The Development of a Rebar-Counting Model for Reinforced Concrete Columns: Using an Unmanned Aerial Vehicle and Deep-Learning Approach. J. Constr. Eng. Manag. 2023, 149, 13. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Shum, H.Y. DINO: DETR with Improved Denoising Anchor Boxes for End-to-End Object Detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Liu, S.; Li, F.; Zhang, H.; Yang, X.; Qi, X.; Su, H.; Zhang, L. DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR. arXiv 2022, arXiv:2201.12329. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Chen, J. DETRs Beat YOLOs on Real-Time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Wang, S. Evaluation of Impact of Image Augmentation Techniques on Two Tasks: Window Detection and Window States Detection. Results Eng. 2024, 24, 103571. [Google Scholar] [CrossRef]
- Hwang, D.; Kim, J.-J.; Moon, S.; Wang, S. Image Augmentation Approaches for Building Dimension Estimation in Street View Images Using Object Detection and Instance Segmentation Based on Deep Learning. Appl. Sci. 2025, 15, 2525. [Google Scholar] [CrossRef]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Wang, Y.; Han, K. Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism. In Proceedings of the Advances in Neural Information Processing Systems 36 (NeurIPS 2023), New Orleans, LA, USA, 10–16 December 2023; pp. 51094–51112. [Google Scholar]
- Kang, M.; Ting, C.M.; Ting, F.F.; Phan, R.C.W. ASF-YOLO: A Novel YOLO Model with Attentional Scale Sequence Fusion for Cell Instance Segmentation. Image Vis. Comput. 2024, 147, 105057. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 658–666. [Google Scholar]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Year | Number of Images | Categories | Application Domain |
|---|---|---|---|---|
| FloW [5] | 2021 | 2000 | 1 | Floating waste detection |
| WSODD [6] | 2021 | 7467 | 14 | Floating waste detection |
| Trash-ICRA19 [7] | 2020 | 5700 | 3 | Underwater waste detection |
| AquaTrash [8] | 2020 | 369 | 4 | Underwater waste detection |
| Ours | 2025 | 4000 | 11 | Floating waste detection |
| Parameters | Values |
|---|---|
| Epoch | 300 |
| Lr0 | 0.001 |
| Lrf | 1.0 |
| Image Size | 640 |
| Batch Size | 4 |
| Workers | 4 |
| Momentum | 0.9 |
| Weight Decay | 0.0001 |
| Method | P (%) | R (%) | mAP50 (%) | #Param (M) | FLOPs (G) |
|---|---|---|---|---|---|
| YOLOv5s | 82.3 | 69.2 | 75.1 | 7.0 | 15.8 |
| YOLOv5m | 82.2 | 68.7 | 75.0 | 20.9 | 47.9 |
| YOLOv5l | 82.2 | 71.6 | 74.4 | 46.1 | 107.6 |
| YOLOv5n | 78.7 | 66.8 | 70.8 | 1.8 | 4.1 |
| YOLOv8n | 80.7 | 69.2 | 75.0 | 3.0 | 8.1 |
| YOLOv8m | 82.7 | 74.5 | 80.4 | 25.9 | 78.7 |
| YOLOv8l | 83.1 | 75.1 | 81.1 | 43.6 | 164.8 |
| YOLOv8s | 82.6 | 71.8 | 77.7 | 11.1 | 28.4 |
| YOLOv10m | 81.6 | 70.1 | 78.1 | 16.4 | 63.4 |
| RTDETR-R18 | 85.1 | 81.0 | 84.8 | 19.9 | 56.9 |
| Our model | 85.3 | 83.2 | 86.6 | 22.5 | 63.2 |
| IoU Types | P | R | mAP50 (%) |
|---|---|---|---|
| GIoU | 0.855 | 0.817 | 86.0 |
| CIoU | 0.842 | 0.817 | 85.1 |
| SIoU | 0.864 | 0.797 | 85.5 |
| EIoU | 0.851 | 0.798 | 85.1 |
| DIoU | 0.852 | 0.807 | 85.2 |
| Wise-IoUv1 | 0.853 | 0.832 | 86.6 |
| Wise-IoUv2 | 0.841 | 0.825 | 85.5 |
| Wise-IoUv3 | 0.843 | 0.811 | 84.9 |
| FFM | S2F2M | WIoU | mAP50 (%) | Params (M) | FLOPs (G) | FPS |
|---|---|---|---|---|---|---|
| - | - | - | 84.8 | 19.9 | 56.9 | 123.7 |
| ✓ | - | - | 85.2 | 22.3 | 59.9 | 107.1 |
| - | - | ✓ | 85.1 | 19.9 | 56.9 | 137.9 |
| ✓ | - | ✓ | 85.1 | 22.3 | 59.9 | 106 |
| ✓ | ✓ | - | 86.0 | 22.5 | 63.2 | 98.7 |
| ✓ | ✓ | ✓ | 86.6 | 22.5 | 63.2 | 96.8 |
| Method | P (%) | R (%) | mAP50 (%) | Params (M) | FLOPs (G) |
|---|---|---|---|---|---|
| RTDETR-MARD | 61.0 | 48.9 | 49.2 | 22.5 | 63.2 |
| YOLOv8s | 59.9 | 43.3 | 47.7 | 11.1 | 28.5 |
| YOLOv5s | 58.8 | 46.1 | 47.3 | 9.1 | 24.1 |
| YOLOv8m | 59.4 | 47.3 | 47.3 | 25.8 | 78.7 |
| YOLOv8n | 48.1 | 45.7 | 46.8 | 3.0 | 8.1 |
| YOLOv5n | 51.9 | 47.0 | 46.8 | 11.1 | 28.5 |
| RTDETR-R18 | 52.3 | 48.8 | 46.3 | 19.9 | 57.0 |
| YOLOv5m | 52.0 | 48.2 | 46.2 | 25.1 | 64.4 |
| YOLOv11m | 57.9 | 42.9 | 45.8 | 20.1 | 68.2 |
| YOLOv10m | 56.4 | 41.0 | 44.0 | 16.5 | 63.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, B.; Tang, H.; Gao, L.; Bi, K.; Wen, J. RTDETR-MARD: A Multi-Scale Adaptive Real-Time Framework for Floating Waste Detection in Aquatic Environments. J. Mar. Sci. Eng. 2025, 13, 996. https://doi.org/10.3390/jmse13050996
Sun B, Tang H, Gao L, Bi K, Wen J. RTDETR-MARD: A Multi-Scale Adaptive Real-Time Framework for Floating Waste Detection in Aquatic Environments. Journal of Marine Science and Engineering. 2025; 13(5):996. https://doi.org/10.3390/jmse13050996
Chicago/Turabian StyleSun, Baoshan, Haolin Tang, Liqing Gao, Kaiyu Bi, and Jiabao Wen. 2025. "RTDETR-MARD: A Multi-Scale Adaptive Real-Time Framework for Floating Waste Detection in Aquatic Environments" Journal of Marine Science and Engineering 13, no. 5: 996. https://doi.org/10.3390/jmse13050996
APA StyleSun, B., Tang, H., Gao, L., Bi, K., & Wen, J. (2025). RTDETR-MARD: A Multi-Scale Adaptive Real-Time Framework for Floating Waste Detection in Aquatic Environments. Journal of Marine Science and Engineering, 13(5), 996. https://doi.org/10.3390/jmse13050996