
Marine Mammal Call Classification Using a Multi-Scale Two-Channel Fusion Network (MT-Resformer)

 , , and
, , and
Abstract
1. Introduction
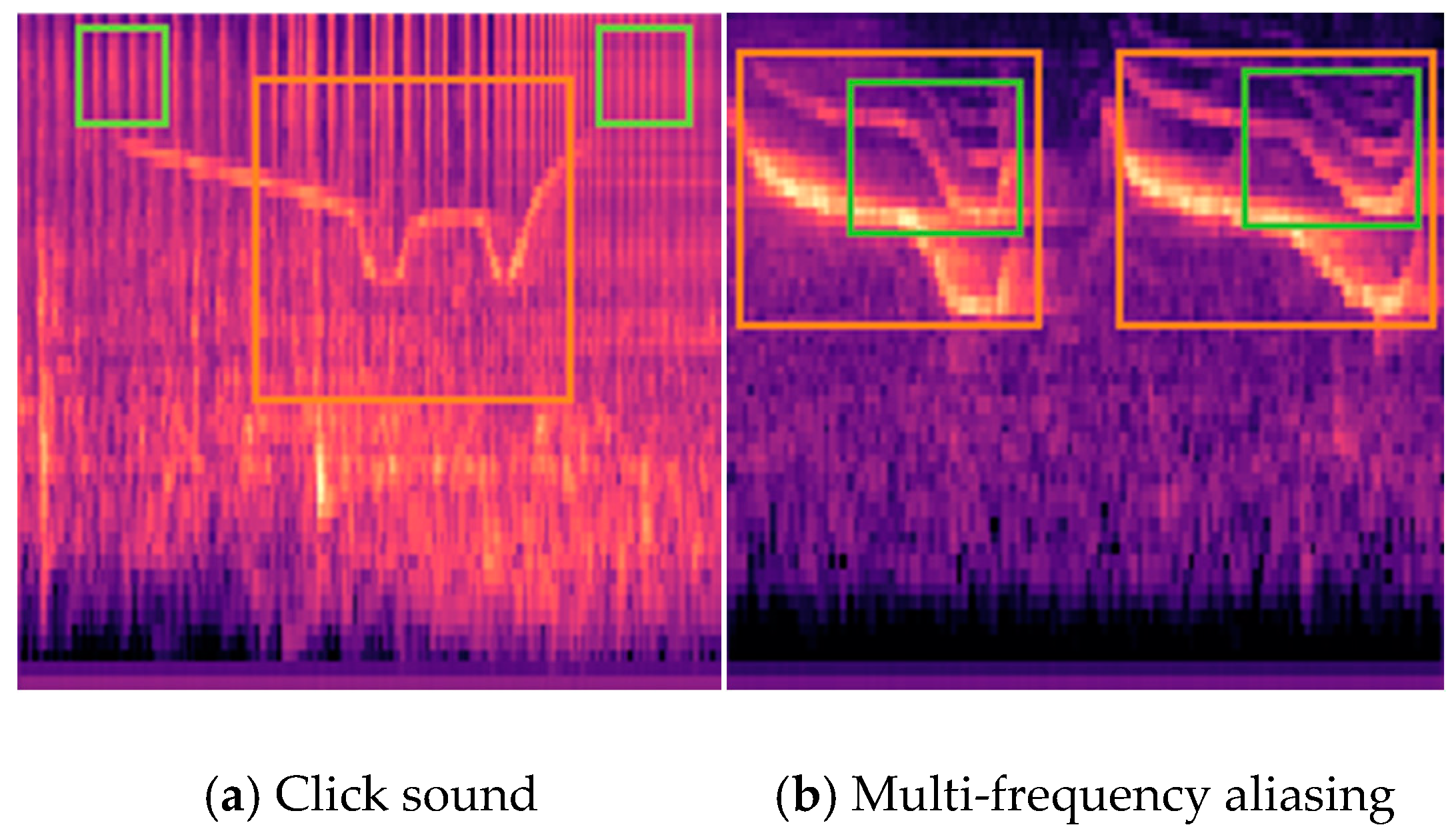
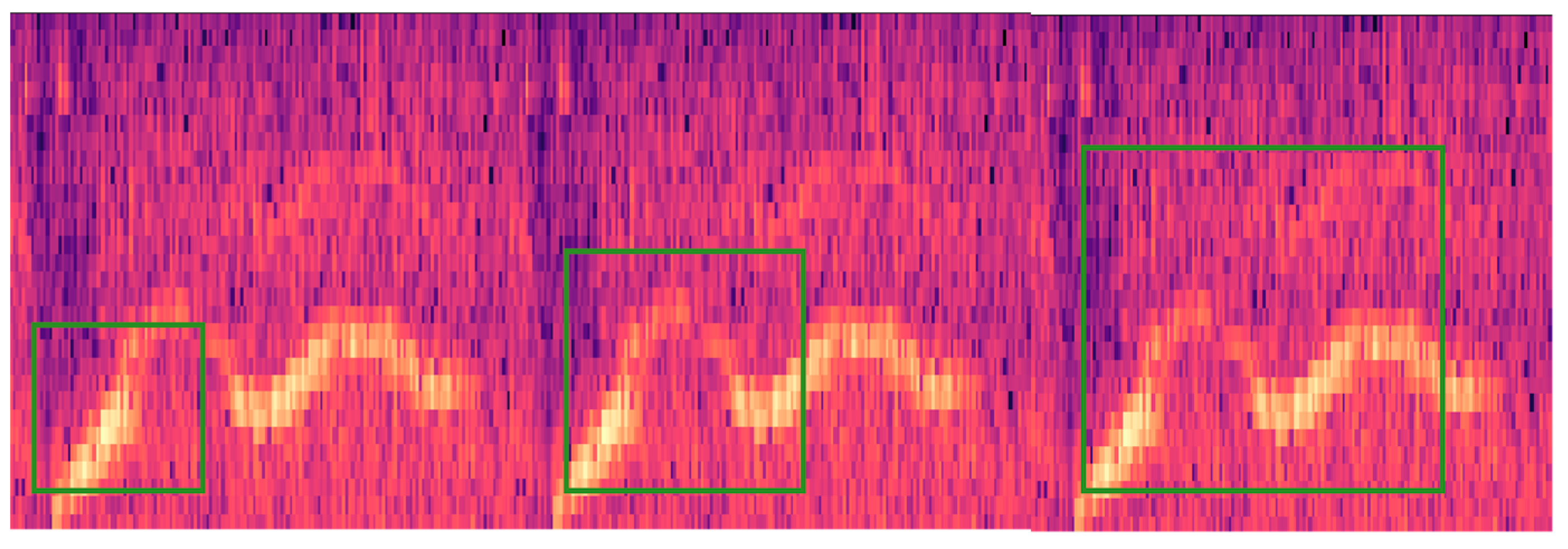
- In the feature extraction process, this study combines Mel features with Constant-Q Transform (CQT) features, effectively addressing the limitations of single Mel features in capturing high-frequency information of marine mammal calls.
- The ResNet architecture is further enhanced by incorporating a multi-scale parallel computation structure and integrating it with a Transformer network in a dual-channel design. This improves the model’s accuracy, adaptability, and robustness in classifying various marine mammal vocalizations.
2. Materials and Methods
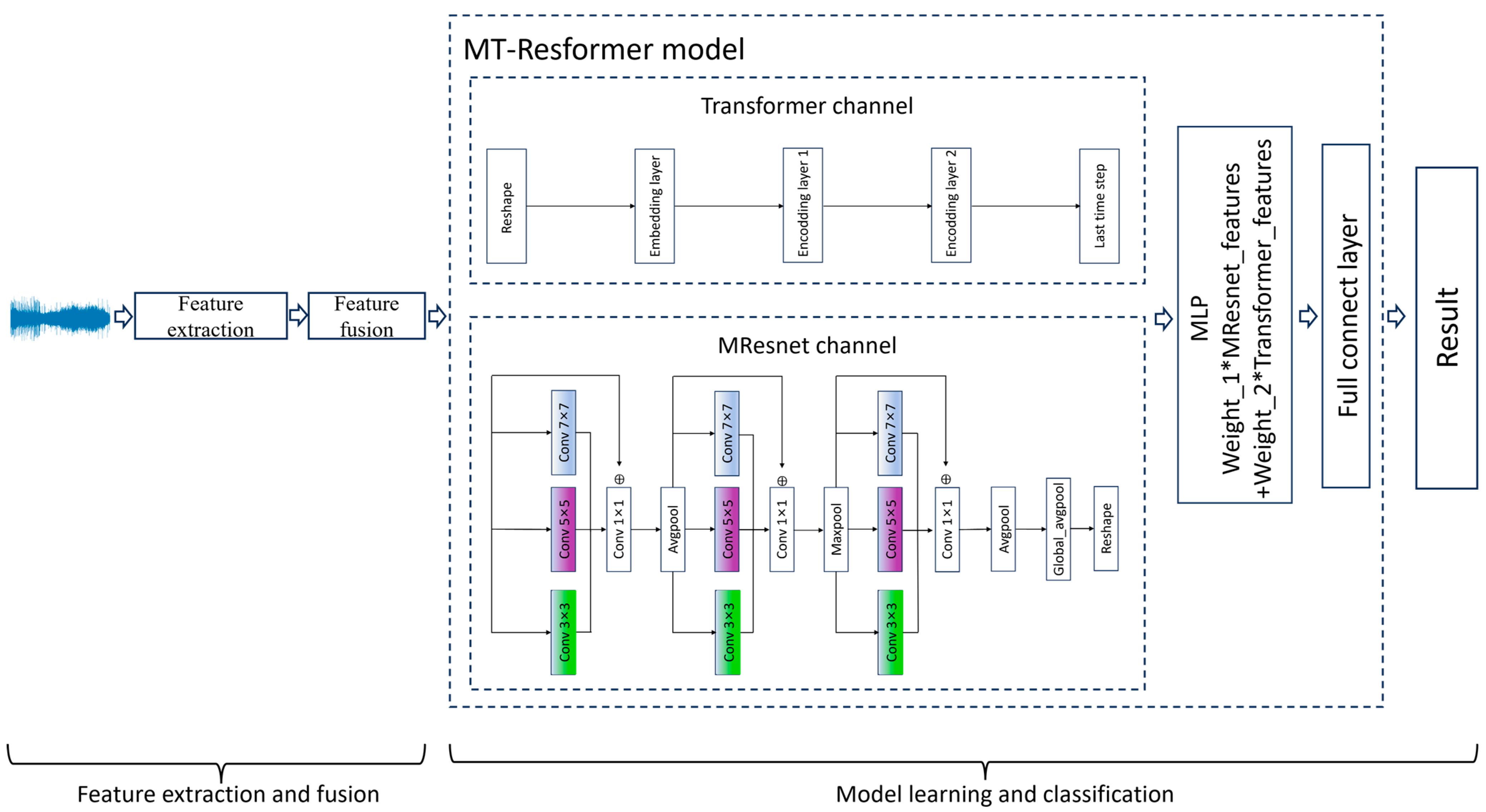
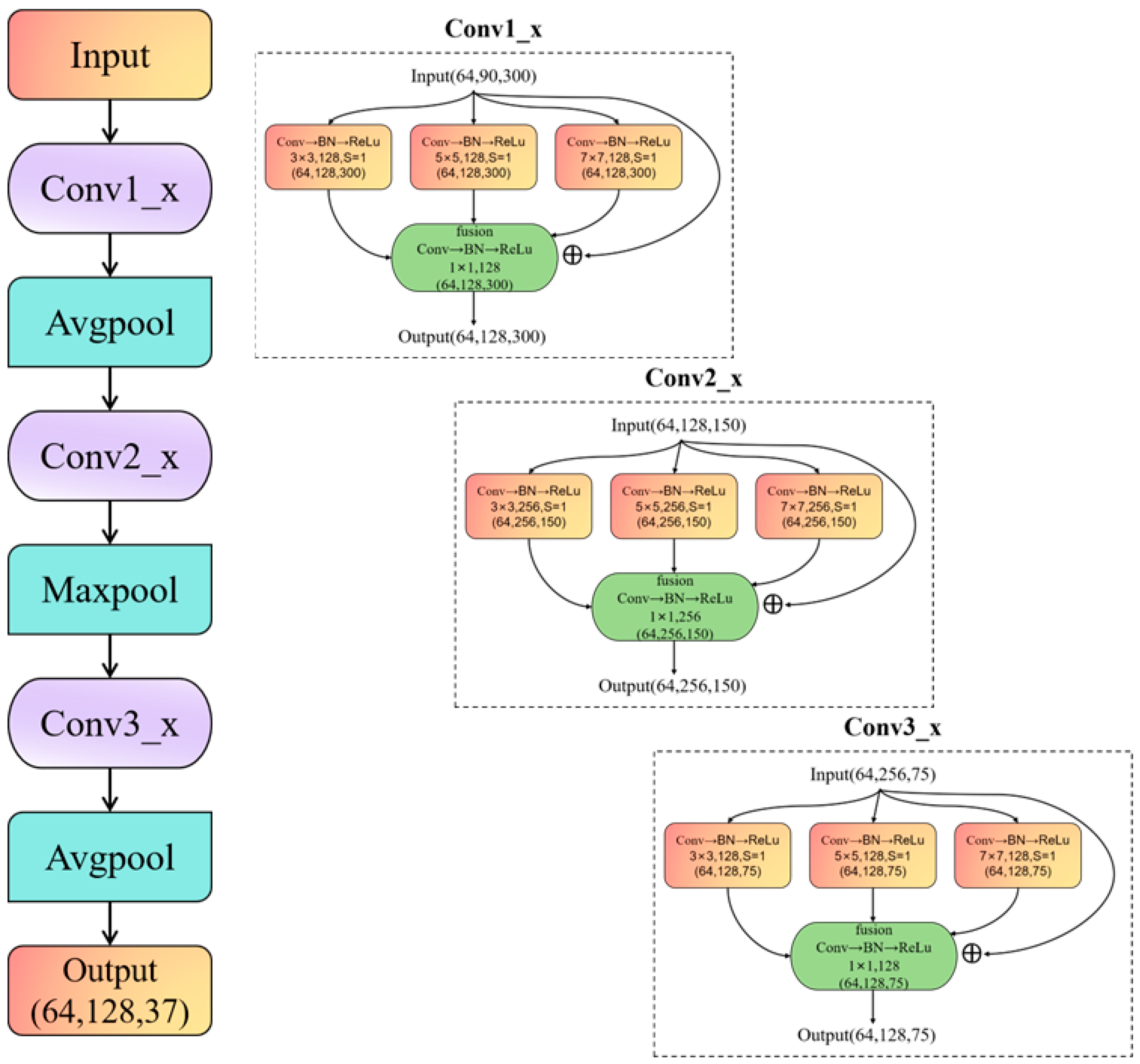
2.1. System Overview
- Data pre-processing: The long audio recordings captured by the audio acquisition devices were segmented into 2 s intervals. Silent segments were removed using a silence detection algorithm, and the audio clips were organized into separate folders based on their respective categories.
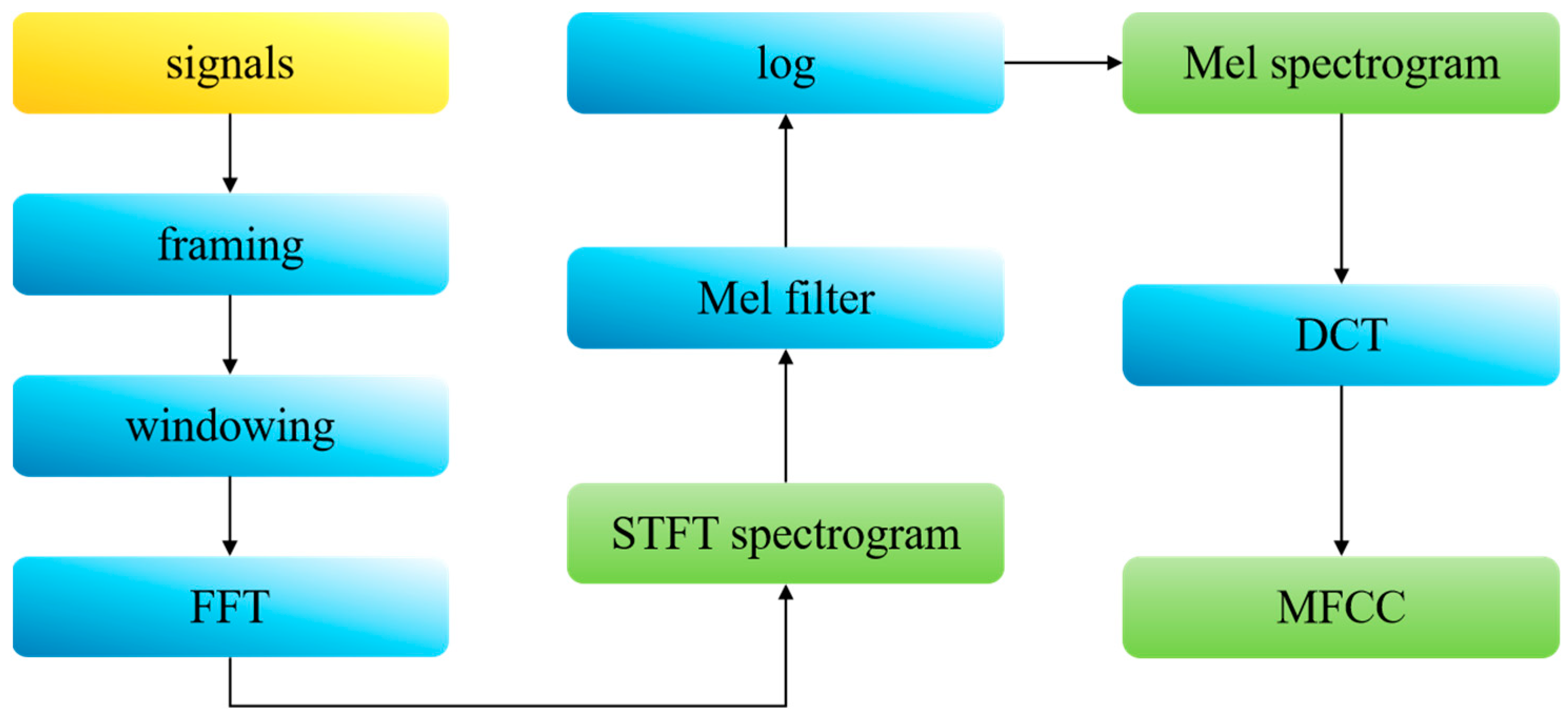
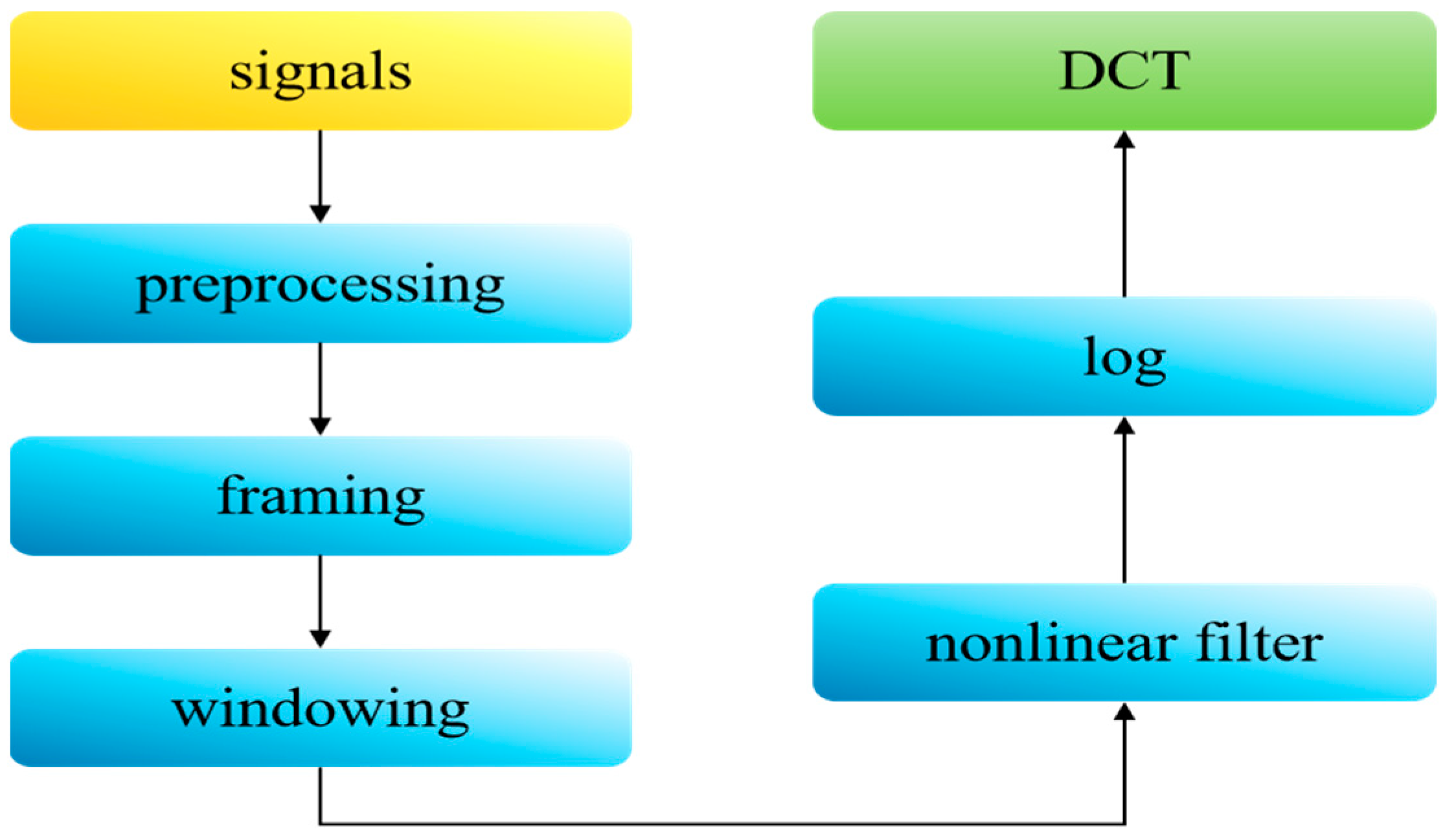
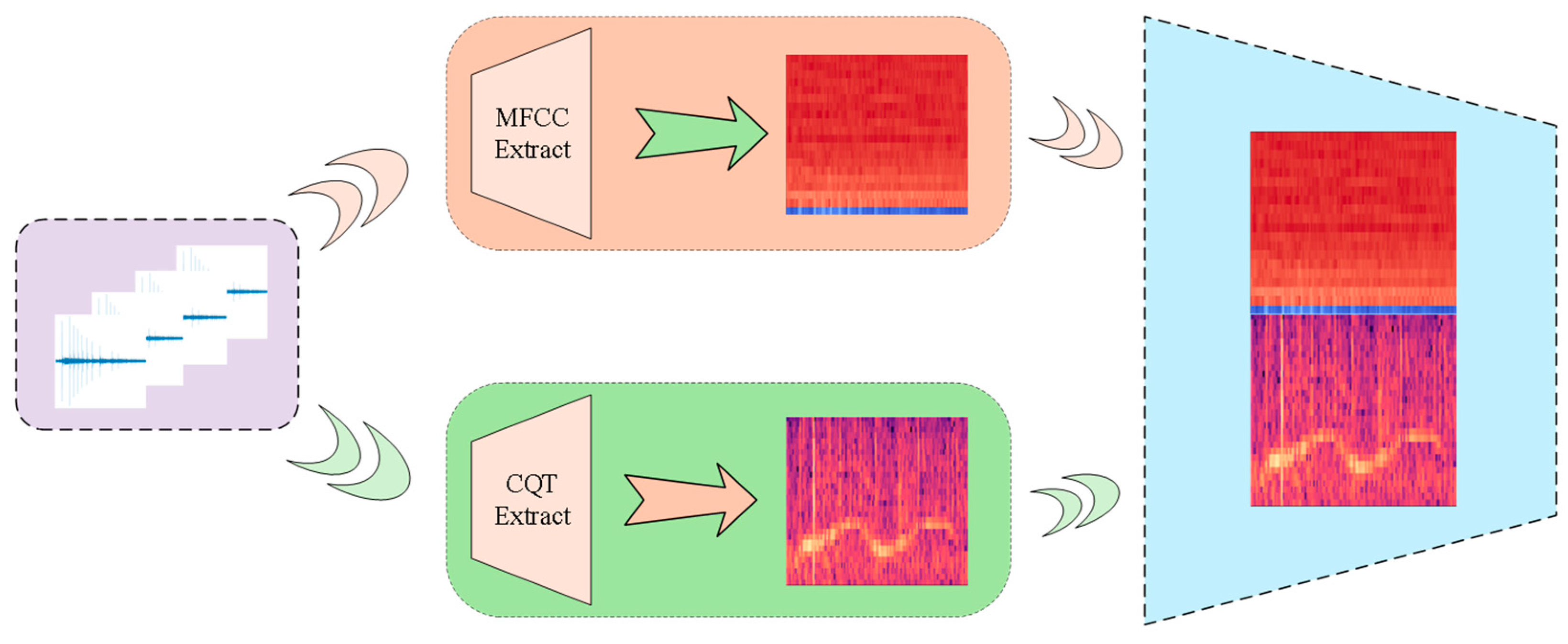
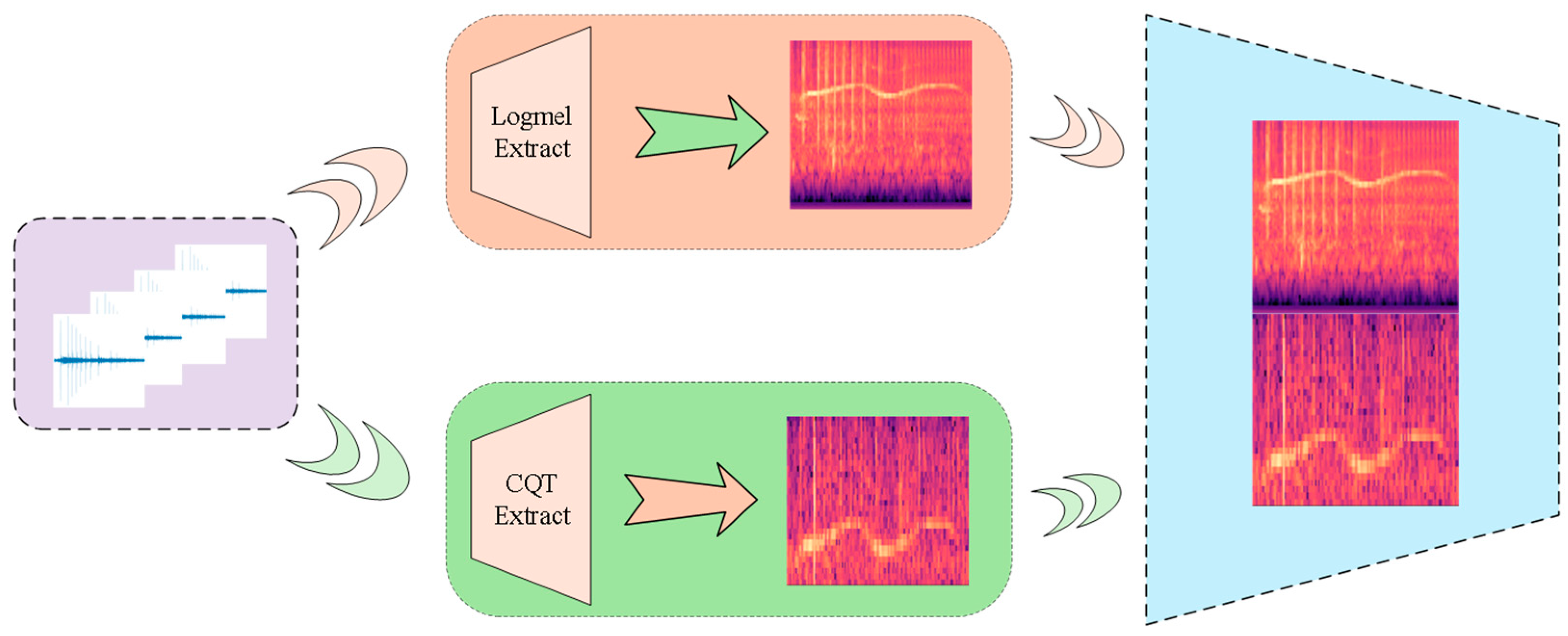
- Feature extraction and fusion: we simultaneously extracted Log-Mel spectrograms and MFCCs, and then individually fused each with Constant-Q Transform spectrograms.
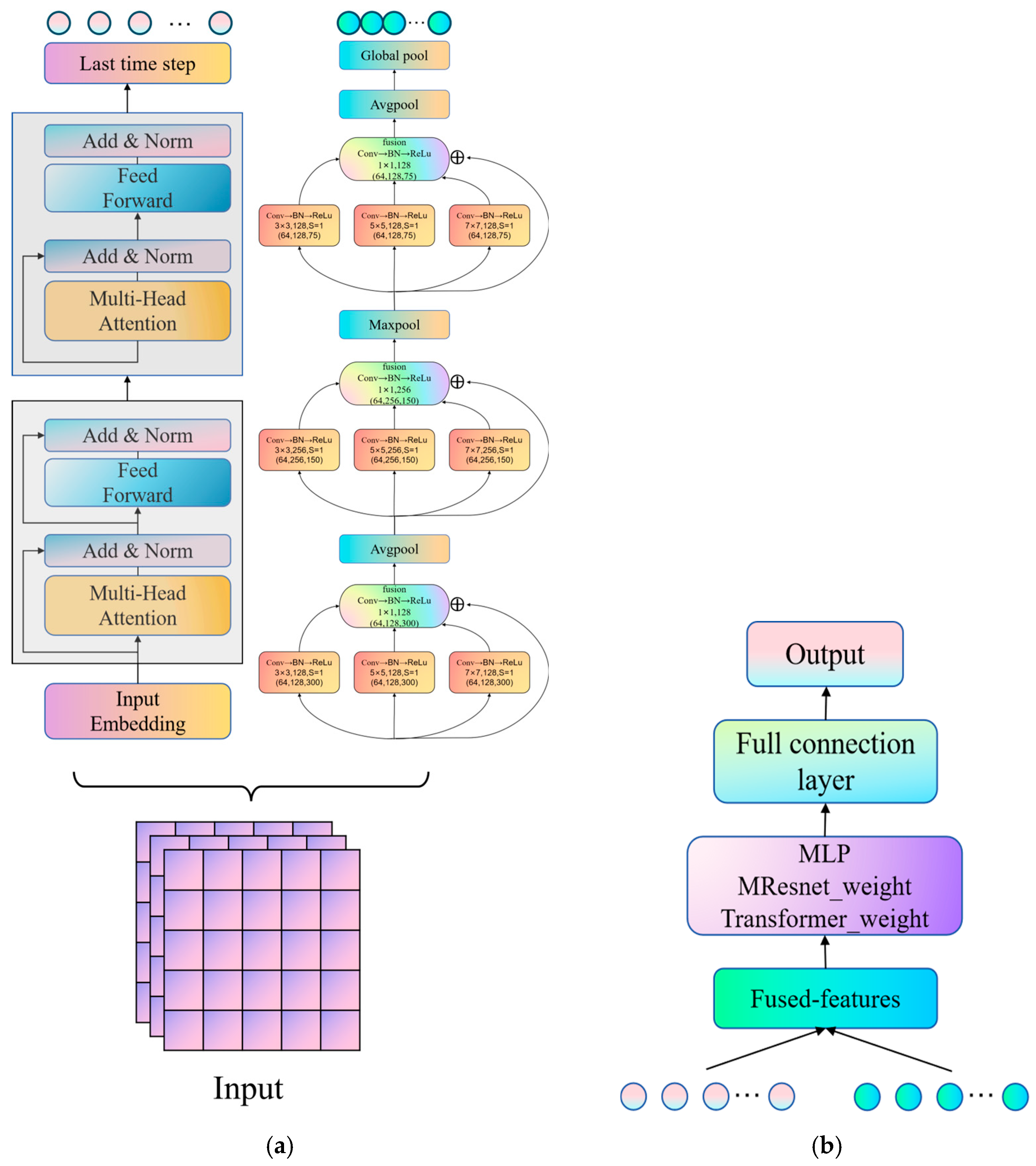
- Model learning and classification: The fused features are fed into the MT-Resformer model. The MResnet channel employs a multi-scale parallel computation architecture to extract local information at different scales, while the Transformer channel captures global information from the features. A multi-layer perceptron (MLP) is utilized to adaptively adjust the weights of the two channels. Finally, the output passes through a fully connected layer to generate the predicted class labels.
2.2. Feature Preparing
2.3. MT-Resformer Model
2.3.1. Multi-Scale Parallel Feature Extraction Framework
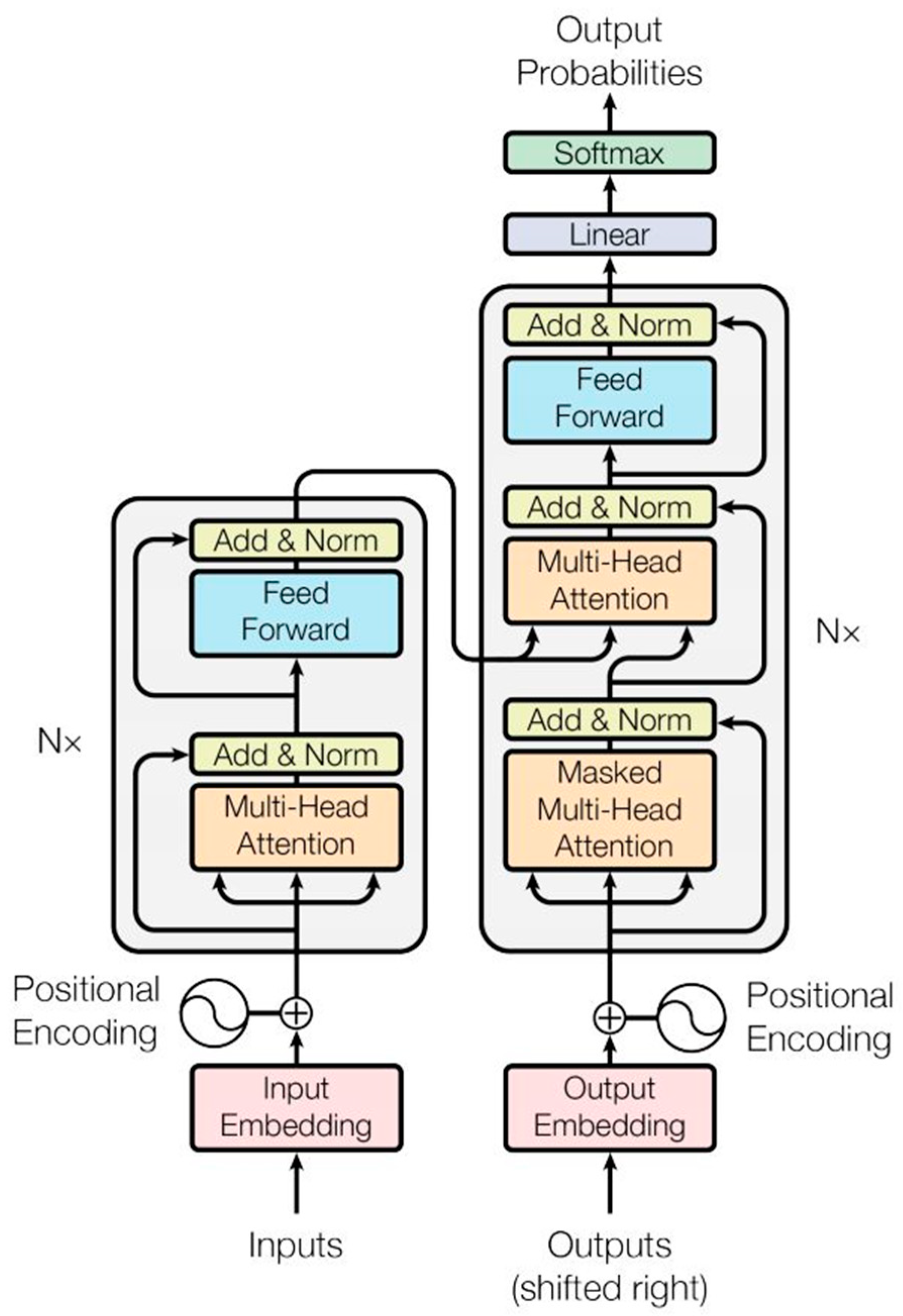
2.3.2. Architecture and Fusion of the Dual-Channel Model
3. Experiments
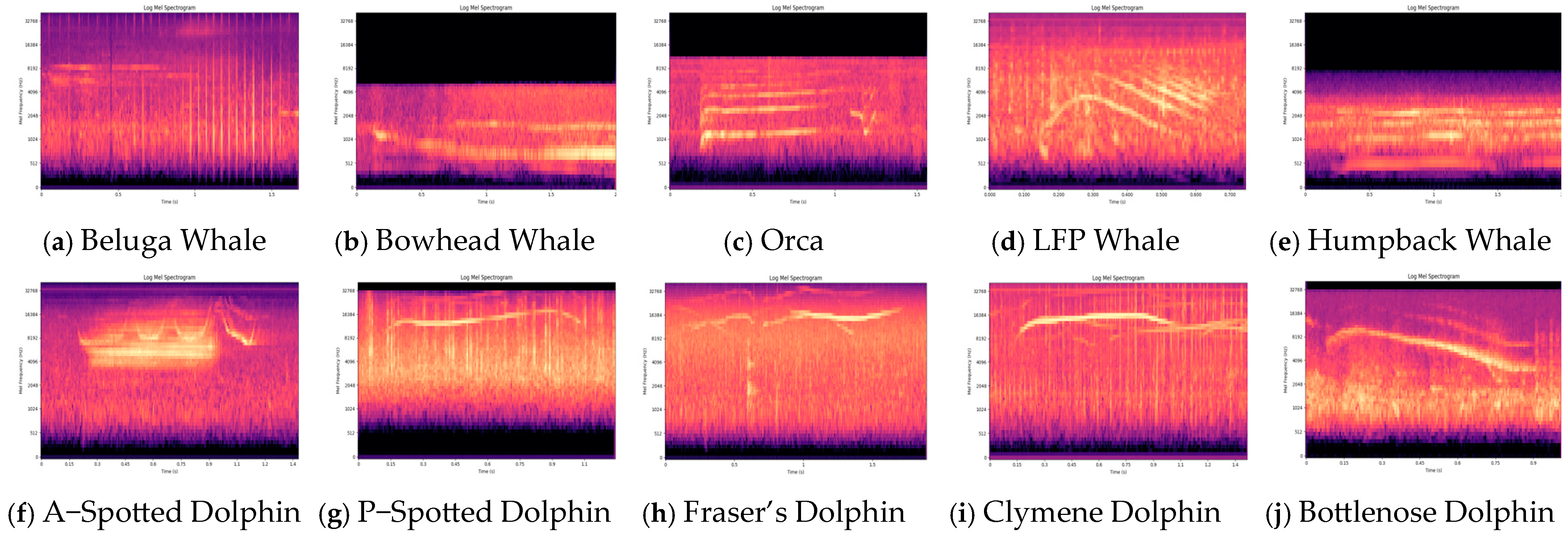
3.1. Dataset
3.2. Dataset Preprocessing
3.3. Network Training Parameter Setting
- ♦
- 12th Gen Intel(R) Core(TM) i5-12400F (manufactor: Intel; city: Guangzhou; country: China);
- ♦
- RAM: 96GB DDR5 4000MHz (manufactor: Corsair Gaming, Inc.; city: Guangzhou; country: China);
- ♦
- CUDA Version: 12.6;
- ♦
- NVIDIA GeForce RTX 4070 (manufactor: ASUS; city: Guangzhou; country: China).
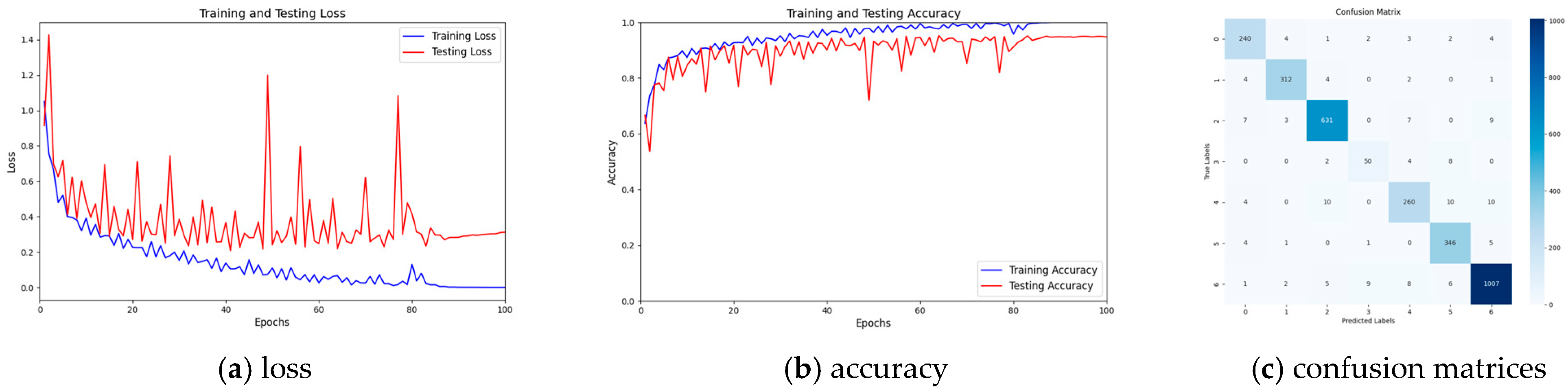
4. Experimental Results and Analysis
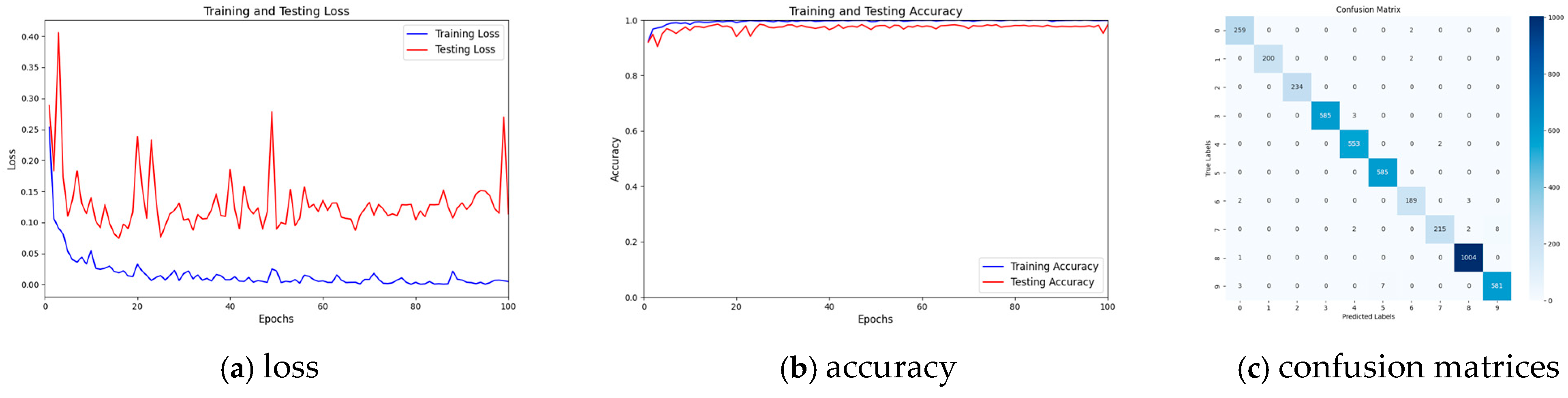
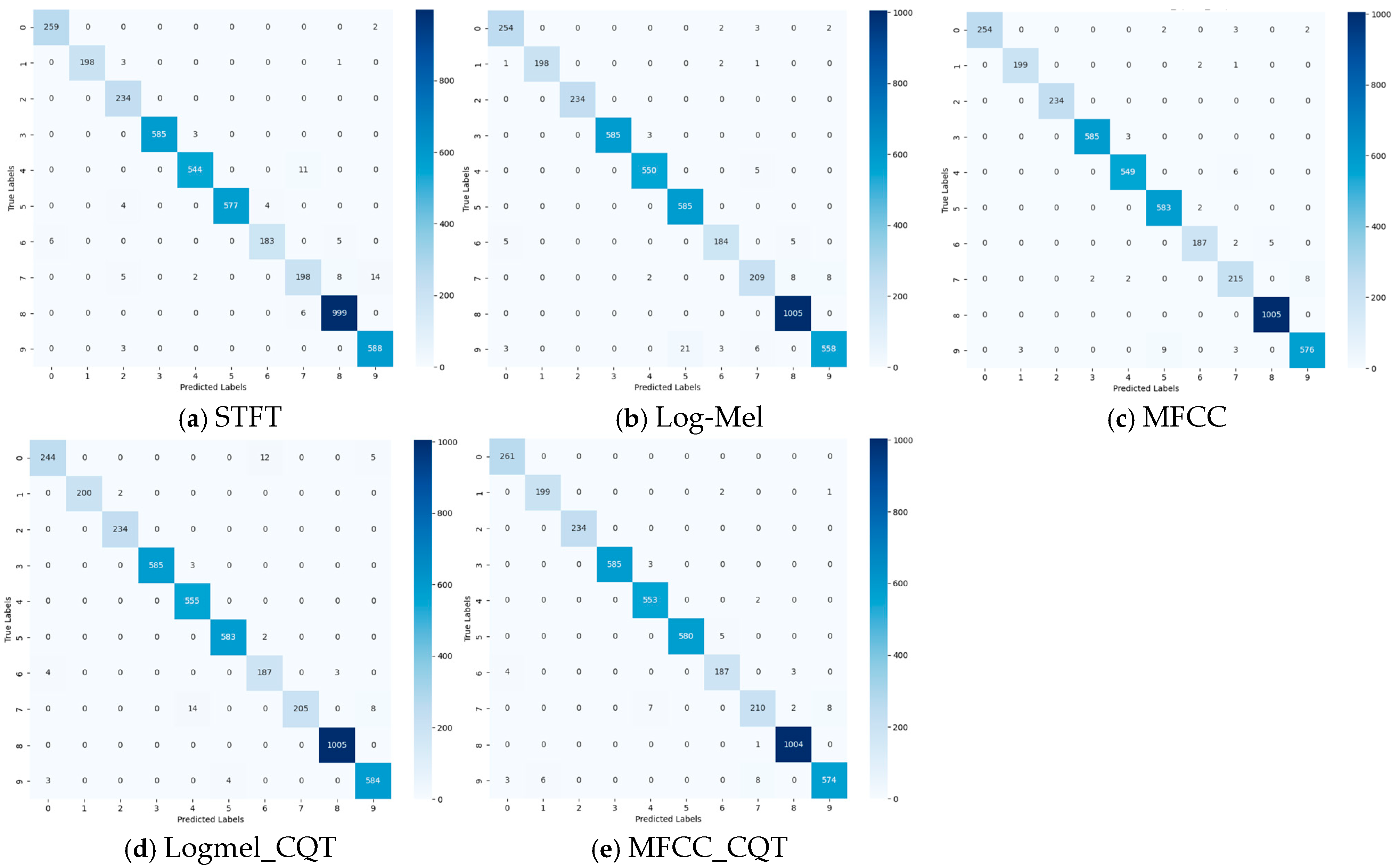
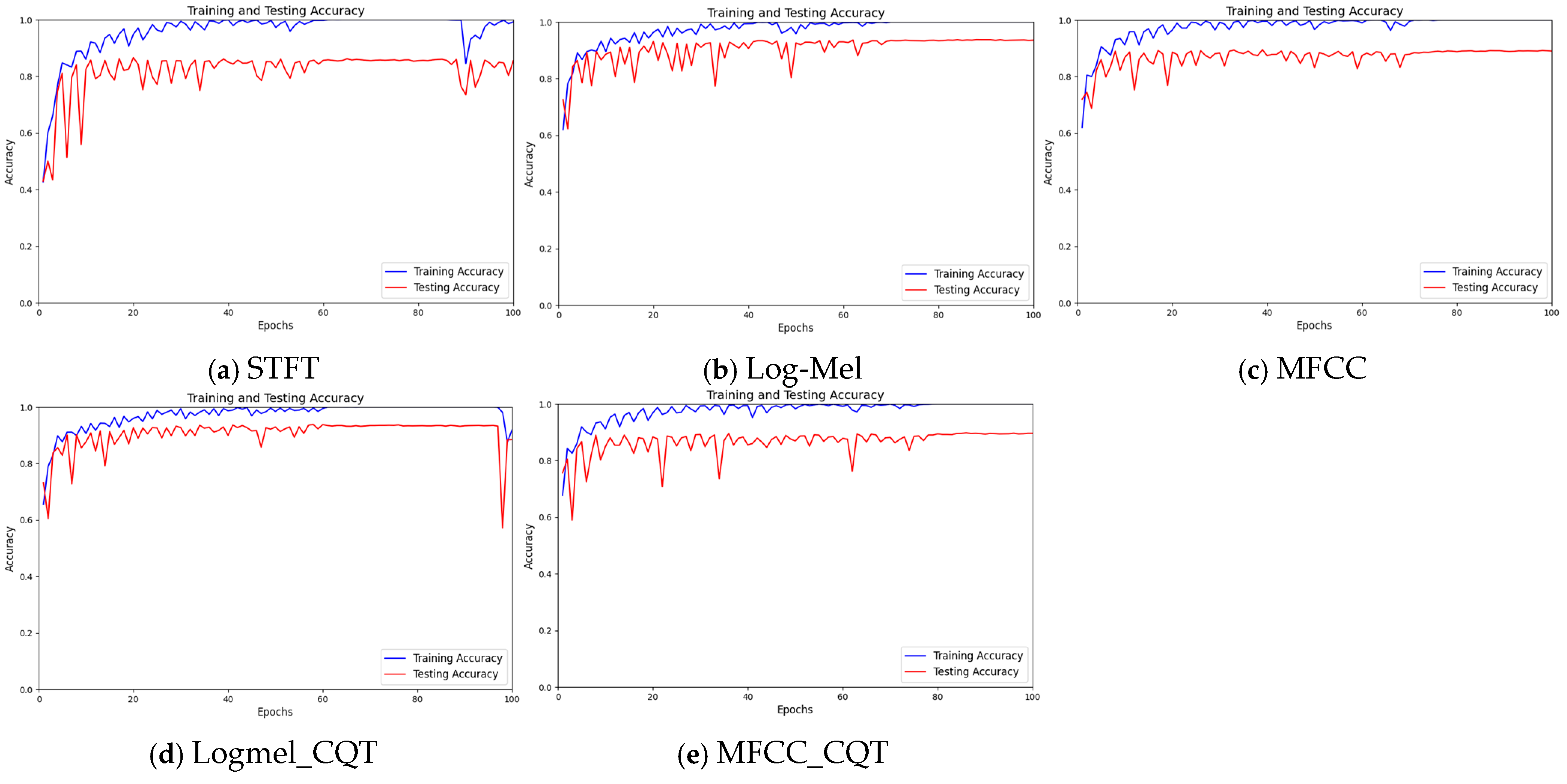
4.1. Comparison of Recognition Accuracy Across Various Feature Extraction Methods
- Comparison of classification accuracy for the Watkins dataset
- 2.
- Evaluation of Accuracy, Precision, Recall, and F1-Score for the Watkins Dataset
- 3.
- Comparison of Confusion Matrices for the Watkins Dataset
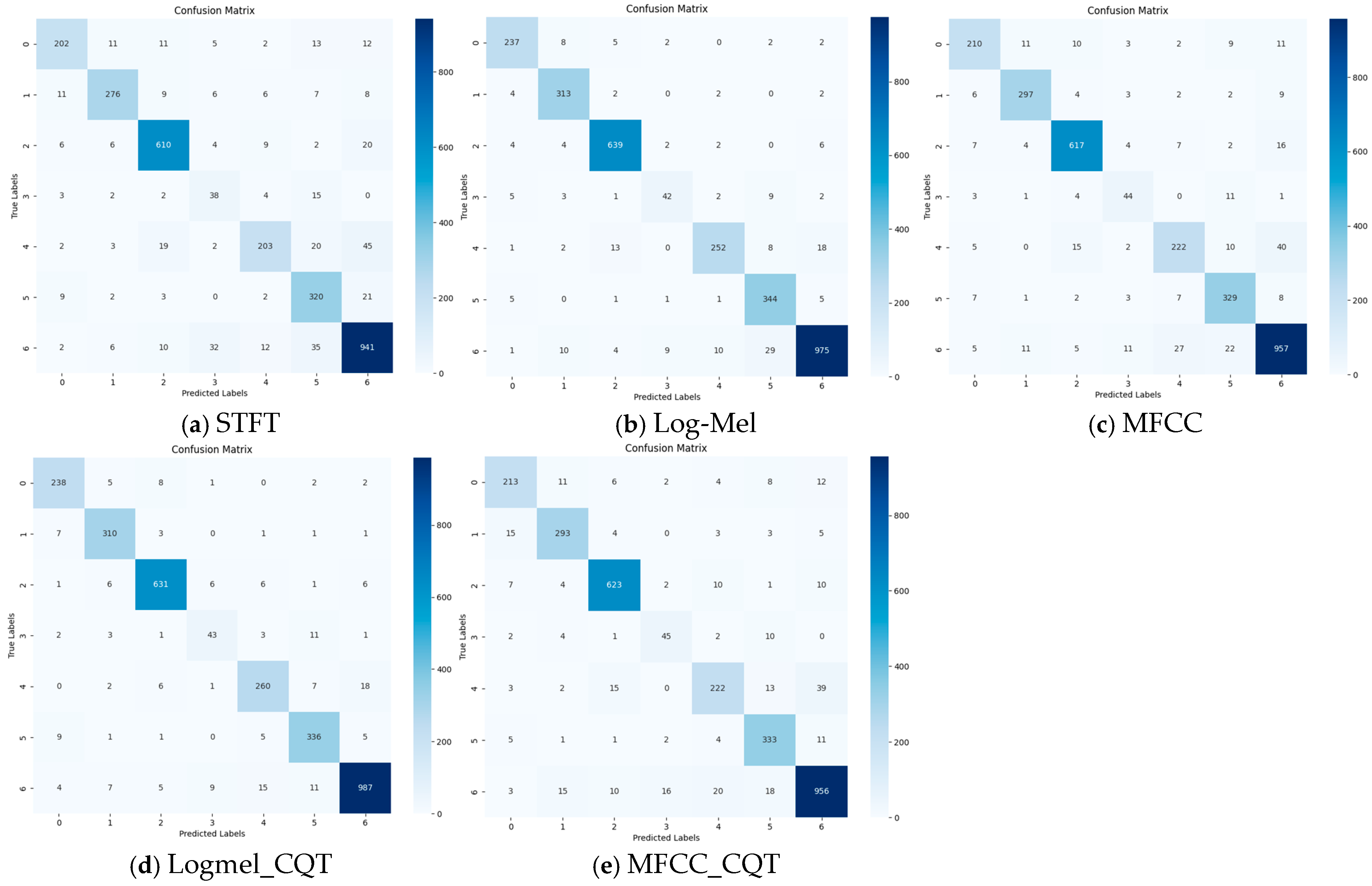
- Comparison of Accuracy for the ChangLong Dataset
- 2.
- Comparison of the accuracy, precision, recall, and F1-score metrics for the ChangLong dataset
- 3.
- Comparison of confusion matrices for the ChangLong dataset
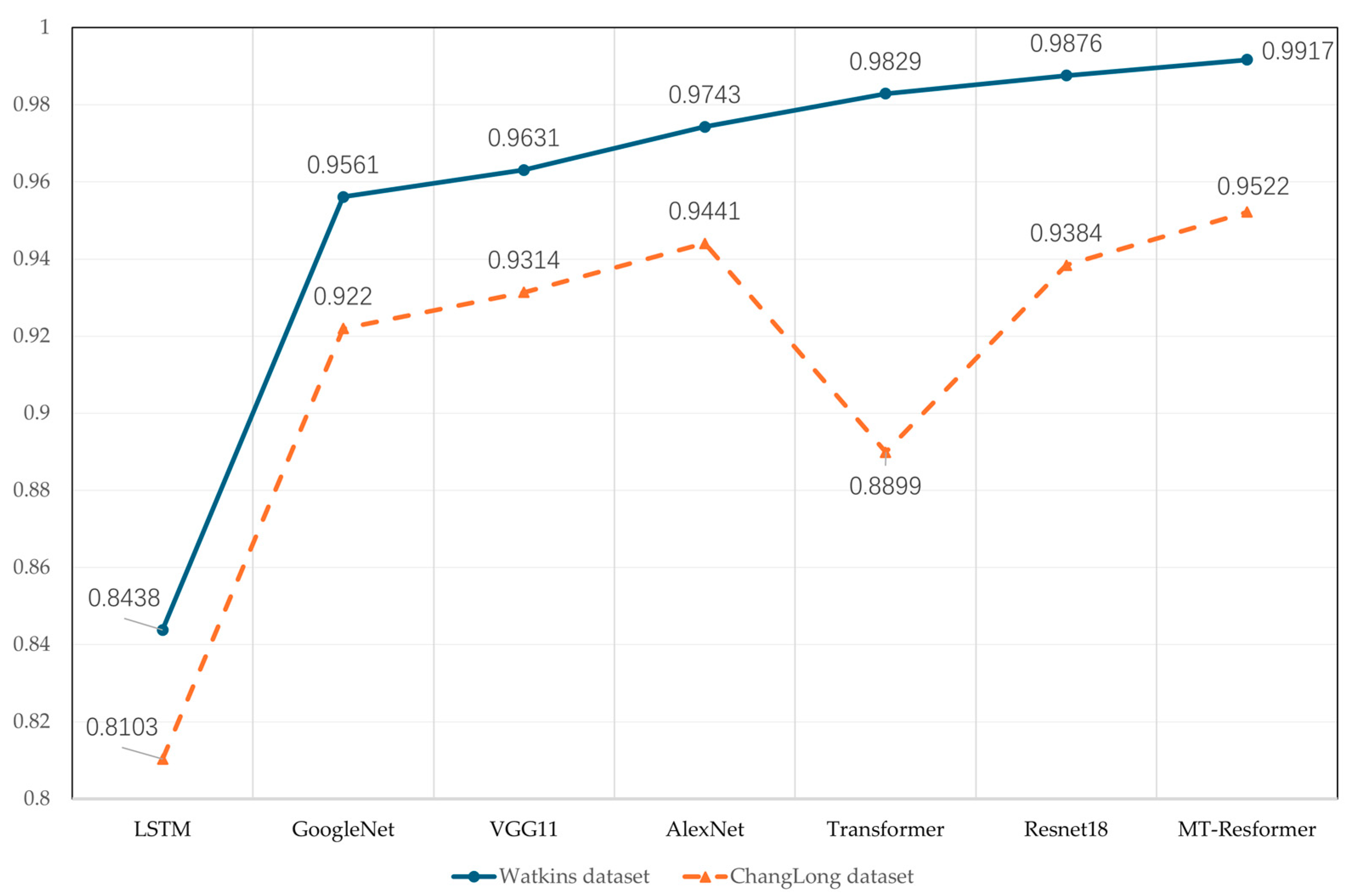
4.2. Comparison of Recognition Accuracy Across Various Neural Network Architectures
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- O’Hara, C.C.; Frazier, M.; Halpern, B.S. At-Risk Marine Biodiversity Faces Extensive, Expanding, and Intensifying Human Impacts. Science 2021, 372, 84–87. [Google Scholar] [CrossRef]
- Brando, S.; Broom, D.M.; Acasuso-Rivero, C.; Clark, F. Optimal Marine Mammal Welfare under Human Care: Current Efforts and Future Directions. Behav. Process. 2018, 156, 16–36. [Google Scholar] [CrossRef] [PubMed]
- Verfuss, U.K.; Gillespie, D.; Gordon, J.; Marques, T.A.; Miller, B.; Plunkett, R.; Theriault, J.A.; Tollit, D.J.; Zitterbart, D.P.; Hubert, P. Comparing Methods Suitable for Monitoring Marine Mammals in Low Visibility Conditions during Seismic Surveys. Mar. Pollut. Bull. 2018, 126, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Ramaiah, V.S.; Rao, R.R. Multi-Speaker Activity Detection Using Zero Crossing Rate. In Proceedings of the 2016 International Conference on Communication and Signal Processing (ICCSP), Melmaruvathur, India, 6–8 April 2016; pp. 23–26. [Google Scholar]
- Shannon, B.J.; Paliwal, K.K. Feature Extraction from Higher-Lag Autocorrelation Coefficients for Robust Speech Recognition. Speech Commun. 2006, 48, 1458–1485. [Google Scholar] [CrossRef]
- Caetano, M.; Rodet, X. Improved Estimation of the Amplitude Envelope of Time-Domain Signals Using True Envelope Cepstral Smoothing. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 4244–4247. [Google Scholar]
- Yang, S.; Jin, A.; Zeng, X.; Wang, H.; Hong, X.; Lei, M. Underwater Acoustic Target Recognition Based on Sub-Band Concatenated Mel Spectrogram and Multidomain Attention Mechanism. Eng. Appl. Artif. Intell. 2024, 133, 107983. [Google Scholar] [CrossRef]
- Ancilin, J.; Milton, A. Improved Speech Emotion Recognition with Mel Frequency Magnitude Coefficient. Appl. Acoust. 2021, 179, 108046. [Google Scholar] [CrossRef]
- Jeevan, M.; Dhingra, A.; Hanmandlu, M.; Panigrahi, B.K. Robust Speaker Verification Using GFCC Based I-Vectors. In Proceedings of the International Conference on Signal, Networks, Computing, and Systems; Lobiyal, D.K., Mohapatra, D.P., Nagar, A., Sahoo, M.N., Eds.; Lecture Notes in Electrical Engineering; Springer: New Delhi, India, 2017; Volume 395, pp. 85–91. ISBN 978-81-322-3590-3. [Google Scholar]
- Li, J.; Wang, B.; Cui, X.; Li, S.; Liu, J. Underwater Acoustic Target Recognition Based on Attention Residual Network. Entropy 2022, 24, 1657. [Google Scholar] [CrossRef]
- Aksenovich, T.V. Comparison of the Use of Wavelet Transform and Short-Time Fourier Transform for the Study of Geomagnetically Induced Current in the Autotransformer Neutral. In Proceedings of the 2020 International Multi-Conference on Industrial Engineering and Modern Technologies (FarEastCon), Vladivostok, Russky Island, 6–7 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Tohidypour, R.H.; Seyyedsalehi, S.A.; Behbood, H. Comparison between Wavelet Packet Transform, Bark Wavelet & MFCC for Robust Speech Recognition Tasks. In Proceedings of the 2010 The 2nd International Conference on Industrial Mechatronics and Automation, Wuhan, China, 30–31 May 2010; IEEE: Piscataway, NJ, USA, 2010; Volume 2, pp. 329–332. [Google Scholar]
- Esfahanian, M.; Erdol, N.; Gerstein, E.; Zhuang, H. Two-Stage Detection of North Atlantic Right Whale Upcalls Using Local Binary Patterns and Machine Learning Algorithms. Appl. Acoust. 2017, 120, 158–166. [Google Scholar] [CrossRef]
- Shen, W.; Tu, D.; Yin, Y.; Bao, J. A New Fusion Feature Based on Convolutional Neural Network for Pig Cough Recognition in Field Situations. Inf. Process. Agric. 2021, 8, 573–580. [Google Scholar] [CrossRef]
- Pentapati, H.; Vasamsetti, S.; Tenneti, M. MFCC for Voiced Part Using VAD and GMM Based Gender Recognition. Adv. Model. Anal. B 2017, 60, 581–592. [Google Scholar] [CrossRef]
- Ibrahim, A.K.; Zhuang, H.; Chérubin, L.M.; Schärer-Umpierre, M.T.; Erdol, N. Automatic Classification of Grouper Species by Their Sounds Using Deep Neural Networks. J. Acoust. Soc. Am. 2018, 144, EL196–EL202. [Google Scholar] [CrossRef] [PubMed]
- Trawicki, M.B. Multispecies Discrimination of Whales (Cetaceans) Using Hidden Markov Models (HMMS). Ecol. Inform. 2021, 61, 101223. [Google Scholar] [CrossRef]
- Mishachandar, B.; Vairamuthu, S. Diverse Ocean Noise Classification Using Deep Learning. Appl. Acoust. 2021, 181, 108141. [Google Scholar] [CrossRef]
- Lu, T.; Han, B.; Yu, F. Detection and Classification of Marine Mammal Sounds Using AlexNet with Transfer Learning. Ecol. Inform. 2021, 62, 101277. [Google Scholar] [CrossRef]
- Murphy, D.T.; Ioup, E.; Hoque, M.T.; Abdelguerfi, M. Residual Learning for Marine Mammal Classification. IEEE Access 2022, 10, 118409–118418. [Google Scholar] [CrossRef]
- Maldini, S.; Giovanni, S. Adaptative and Automatic Manatee Vocalization Detection Using Transformers. Master’s Thesis, Universidad de Chile, Santiago, Chile, 2024. [Google Scholar]
- Padovese, B.; Frazao, F.; Kirsebom, O.S.; Matwin, S. Data augmentation for the classification of North Atlantic right whales upcalls. J. Acoust. Soc. Am. 2021, 149, 2520–2530. [Google Scholar] [CrossRef]
- Duan, D.; Lü, L.; Jiang, Y.; Liu, Z.; Yang, C.; Guo, J.; Wang, X. Real-Time Identification of Marine Mammal Calls Based on Convolutional Neural Networks. Appl. Acoust. 2022, 192, 108755. [Google Scholar] [CrossRef]
- Luo, W.; Yang, W.; Zhang, Y. Convolutional neural network for detecting odontocete echolocation clicks. J. Acoust. Soc. Am. 2019, 145, EL7–EL12. [Google Scholar] [CrossRef]
- Luís, A.R.; May-Collado, L.J.; Rako-Gospić, N.; Gridley, T.; Papale, E.; Azevedo, A.; Silva, M.A.; Buscaino, G.; Herzing, D.; Dos Santos, M.E. Vocal Universals and Geographic Variations in the Acoustic Repertoire of the Common Bottlenose Dolphin. Sci. Rep. 2021, 11, 11847. [Google Scholar] [CrossRef]
- Scaradozzi, D.; De Marco, R.; Veli, D.L.; Lucchetti, A.; Screpanti, L.; Di Nardo, F. Convolutional Neural Networks for Enhancing Detection of Dolphin Whistles in a Dense Acoustic Environment. IEEE Access 2024, 12, 127141–127148. [Google Scholar] [CrossRef]
- Frainer, G.; Dufourq, E.; Fearey, J.; Dines, S.; Probert, R.; Elwen, S.; Gridley, T. Automatic Detection and Taxonomic Identification of Dolphin Vocalisations Using Convolutional Neural Networks for Passive Acoustic Monitoring. Ecol. Inform. 2023, 78, 102291. [Google Scholar] [CrossRef]
- Jensen, F.H.; Wolters, P.; Van Zeeland, L.; Morrison, E.; Ermi, G.; Smith, S.; Tyack, P.L.; Wells, R.S.; McKennoch, S.; Janik, V.M.; et al. Automatic Deep-Learning-Based Classification of Bottlenose Dolphin Signature Whistles. In The Effects of Noise on Aquatic Life; Popper, A.N., Sisneros, J.A., Hawkins, A.D., Thomsen, F., Eds.; Springer International Publishing: Cham, Switzerland, 2024; pp. 2059–2070. ISBN 978-3-031-50255-2. [Google Scholar]
- Liu, F.; Shen, T.; Luo, Z.; Zhao, D.; Guo, S. Underwater Target Recognition Using Convolutional Recurrent Neural Networks with 3-D Mel-Spectrogram and Data Augmentation. Appl. Acoust. 2021, 178, 107989. [Google Scholar] [CrossRef]
- Tiwari, V. MFCC and Its Applications in Speaker Recognition. Int. J. Emerg. Technol. 2010, 1, 19–22. [Google Scholar]
- Sheng, L.; Huang, D.-Y.; Pavlovskiy, E.N. High-Quality Speech Synthesis Using Super-Resolution Mel-Spectrogram. arXiv 2019, arXiv:1912.01167. [Google Scholar]
- Singh, P.; Waldekar, S.; Sahidullah, M.; Saha, G. Analysis of Constant-Q Filterbank Based Representations for Speech Emotion Recognition. Digit. Signal Process. 2022, 130, 103712. [Google Scholar] [CrossRef]
- Huzaifah, M. Comparison of Time-Frequency Representations for Environmental Sound Classification Using Convolutional Neural Networks. arXiv 2017, arXiv:1706.07156. [Google Scholar]
- Yu, Y.; Zhu, W.; Ma, X.; Du, J.; Liu, Y.; Gan, L.; An, X.; Li, H.; Wang, B.; Fu, X. Recognition of Sheep Feeding Behavior in Sheepfolds Using Fusion Spectrogram Depth Features and Acoustic Features. Animals 2024, 14, 3267. [Google Scholar] [CrossRef]
- Trapanotto, M.; Nanni, L.; Brahnam, S.; Guo, X. Convolutional Neural Networks for the Identification of African Lions from Individual Vocalizations. J. Imaging 2022, 8, 96. [Google Scholar] [CrossRef]
- Du, Z.; Xu, X.; Bai, Z.; Liu, X.; Hu, Y.; Li, W.; Wang, C.; Li, D. Feature Fusion Strategy and Improved GhostNet for Accurate Recognition of Fish Feeding Behavior. Comput. Electron. Agric. 2023, 214, 108310. [Google Scholar] [CrossRef]
- Licciardi, A.; Carbone, D. WhaleNet: A Novel Deep Learning Architecture for Marine Mammals Vocalizations on Watkins Marine Mammal Sound Database. IEEE Access 2024, 12, 154182–154194. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Sayigh, L.; Daher, M.A.; Allen, J.; Gordon, H.; Joyce, K.; Stuhlmann, C.; Tyack, P. The Watkins Marine Mammal Sound Database: An Online, Freely Accessible Resource. Proc. Meet. Acoust. 2017, 27, 040013. [Google Scholar]
- Gallo, A.; De Moura Lima, A.; Böye, M.; Hausberger, M.; Lemasson, A. Study of Repertoire Use Reveals Unexpected Context-Dependent Vocalizations in Bottlenose Dolphins (Tursiops truncatus). Sci. Nat. 2023, 110, 56. [Google Scholar] [CrossRef] [PubMed]
- Jones, B.; Zapetis, M.; Samuelson, M.M.; Ridgway, S. Sounds Produced by Bottlenose Dolphins (Tursiops): A Review of the Defining Characteristics and Acoustic Criteria of the Dolphin Vocal Repertoire. Bioacoustics 2020, 29, 399–440. [Google Scholar] [CrossRef]
- Fripp, D.; Owen, C.; Quintana-Rizzo, E.; Shapiro, A.; Buckstaff, K.; Jankowski, K.; Wells, R.; Tyack, P. Bottlenose Dolphin (Tursiops truncatus) Calves Appear to Model Their Signature Whistles on the Signature Whistles of Community Members. Anim. Cogn. 2005, 8, 17. [Google Scholar] [CrossRef]
- Sayigh, L.S.; El Haddad, N.; Tyack, P.L.; Janik, V.M.; Wells, R.S.; Jensen, F.H. Bottlenose Dolphin Mothers Modify Signature Whistles in the Presence of Their Own Calves. Proc. Natl. Acad. Sci. USA 2023, 120, e2300262120. [Google Scholar] [CrossRef]
- Jones, B.; Sportelli, J.; Karnowski, J.; McClain, A.; Cardoso, D.; Du, M. Dolphin Health Classifications from Whistle Features. J. Mar. Sci. Eng. 2024, 12, 2158. [Google Scholar] [CrossRef]
- Díaz López, B. Context-Dependent and Seasonal Fluctuation in Bottlenose Dolphin (Tursiops truncatus) Vocalizations. Anim. Cogn. 2022, 25, 1381–1392. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Qi, P.; Yin, G.; Zhang, L. Underwater Acoustic Target Recognition Using RCRNN and Wavelet-Auditory Feature. Multimed. Tools Appl. 2024, 83, 47295–47317. [Google Scholar] [CrossRef]
- Li, D.; Liao, J.; Jiang, H.; Jiang, K.; Chen, M.; Zhou, B.; Pu, H.; Li, J. A Classification Method of Marine Mammal Calls Based on Two-Channel Fusion Network. Appl. Intell. 2024, 54, 3017–3039. [Google Scholar] [CrossRef]
- González-Hernández, F.R.; Sánchez-Fernández, L.P.; Suárez-Guerra, S.; Sánchez-Pérez, L.A. Marine Mammal Sound Classification Based on a Parallel Recognition Model and Octave Analysis. Appl. Acoust. 2017, 119, 17–28. [Google Scholar] [CrossRef]
- Ertam, F. An Effective Gender Recognition Approach Using Voice Data via Deeper LSTM Networks. Appl. Acoust. 2019, 156, 351–358. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Total Number | Train Set Size | Test Set Size |
|---|---|---|---|
| Beluga | 758 | 531 | 227 |
| Atlantic spotted dolphin | 676 | 474 | 202 |
| Pantropic spotted dolphin | 647 | 453 | 194 |
| Fraser dolphin | 1952 | 1367 | 585 |
| Bowhead whale | 1850 | 1295 | 555 |
| Killer whale | 3350 | 2345 | 1005 |
| Clemene dolphin | 872 | 611 | 261 |
| Bottlenose dolphin | 782 | 548 | 234 |
| Longfin pilot whale | 1970 | 1379 | 591 |
| Humpbackwhale | 1962 | 1374 | 588 |
| Category | Total Number | Train Set Size | Test Set Size |
|---|---|---|---|
| Concave | 854 | 598 | 256 |
| Double Concave | 1079 | 756 | 323 |
| Down Sweep | 2193 | 1536 | 657 |
| Constant | 215 | 151 | 64 |
| Sine | 983 | 689 | 294 |
| Up Sweep | 1193 | 836 | 357 |
| Convex | 3463 | 2425 | 1038 |
| Feature | Dimensionality | Feature | Dimensionality |
|---|---|---|---|
| MFCC | (20, 300) | Log-Mel | (60, 300) |
| CQT | (30, 300) | CQT | (30, 300) |
| MFCC_CQT | (50, 300) | Logmel_CQT | (90, 300) |
| MResnet | Layer | Output Shape |
|---|---|---|
| Input | (None, 50, 300) | |
| Conv_1 | (None, 128, 300) | |
| Avg_pool | (None, 128, 150) | |
| Conv_2 | (None, 256, 150) | |
| Max_pool | (None, 256, 75) | |
| Conv_3 | (None, 128, 75) | |
| Avg_pool | (None, 128, 37) | |
| Global_avg_pool | (None, 128, 1) | |
| Flatten | (None, 128) | |
| Transformer | Input | (None, 50, 300) |
| Transposition | (None, 300, 50) | |
| Embedded | (None, 300, 128) | |
| Encodded 1 | (None, 300, 128) | |
| Encodded 2 | (None, 300, 128) | |
| Last time step | (None, 128) | |
| Fusion | Concatenation | (None, 256) |
| Weighted fusion | (None, 128) | |
| Classification | Full connect 1 | (None, 128) |
| Full connect 2 | (None, 10) |
| Parameter Name | Parameter Setting |
|---|---|
| Epochs | 100 |
| Optimizer | Adam |
| Metric | Accuracy |
| Activation | ReLU |
| Batch size | 64 |
| Loss | Categorical_crossentropy |
| Study | Number of Classes | Accuracy |
|---|---|---|
| Danyang Li et al. [48] | 9 classes | 99.39% |
| Tao Lu et al. [19] | 3 classes | 97.42% |
| Dexin Duan et al. [23] | 3 classes | 91.28% |
| Fernando RubénGonzález-Hernández et al. [49] | 11 classes | 90.00% |
| Marek B. Trawicki. [17] | 9 classes | 82.72% |
| Our work | 10 classes | 99.17% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Dong, C.; Dong, G.; Cui, X.; Chen, Y.; Zhang, P.; Li, Z. Marine Mammal Call Classification Using a Multi-Scale Two-Channel Fusion Network (MT-Resformer). J. Mar. Sci. Eng. 2025, 13, 944. https://doi.org/10.3390/jmse13050944
Li X, Dong C, Dong G, Cui X, Chen Y, Zhang P, Li Z. Marine Mammal Call Classification Using a Multi-Scale Two-Channel Fusion Network (MT-Resformer). Journal of Marine Science and Engineering. 2025; 13(5):944. https://doi.org/10.3390/jmse13050944
Chicago/Turabian StyleLi, Xiang, Chao Dong, Guixin Dong, Xuerong Cui, Yankun Chen, Peng Zhang, and Zhanwei Li. 2025. "Marine Mammal Call Classification Using a Multi-Scale Two-Channel Fusion Network (MT-Resformer)" Journal of Marine Science and Engineering 13, no. 5: 944. https://doi.org/10.3390/jmse13050944
APA StyleLi, X., Dong, C., Dong, G., Cui, X., Chen, Y., Zhang, P., & Li, Z. (2025). Marine Mammal Call Classification Using a Multi-Scale Two-Channel Fusion Network (MT-Resformer). Journal of Marine Science and Engineering, 13(5), 944. https://doi.org/10.3390/jmse13050944