1. Introduction
The digitalization and intelligence of the maritime transportation industry are steadily progressing, with Maritime Autonomous Surface Ships (MASS) at the forefront of modern shipping innovation, garnering global attention. MASS offers a significant advantage in enhancing the safety and efficiency of shipping operations, particularly by reducing human errors and optimizing navigation decisions. However, in complex maritime environments, MASS continues to face several challenges, especially in collision avoidance decision-making tasks under real-world conditions. Existing research often suffers from overly simplistic environmental designs and lacks sufficient algorithmic robustness, failing to address issues such as the long-tail effect. This paper tackles challenges such as environmental uncertainty, high-dimensional state space, and inadequate decision robustness that autonomous vessels encounter in complex maritime navigation. It proposes an adaptive temporal reinforcement learning method, utilizing a simulation environment that closely mirrors real-world maritime conditions. This method simulates ship dynamics equations and introduces an adaptive temporal decision-making model. It integrates dynamic ship parameters (e.g., position, velocity, heading), environmental factors (e.g., wind speed, current velocity, wave height), and the motion trajectories of other vessels, while ensuring adherence to the COLREGs to achieve safe and efficient autonomous navigation and collision avoidance decision-making.
The ship navigation decision-making model incorporates various methods, including rule-based systems, game theory, expert systems, fuzzy logic, model predictive control, and deep reinforcement learning. The rule-based approach, the most fundamental decision-making method, relies on established navigation rules and logical reasoning, and is widely used in autonomous collision avoidance decision-making for ships. Zhang, Ruolan, and others proposed a decision-making method that combines rule-based and neural network approaches. Their results demonstrate strong robustness and collision avoidance capabilities, and the method can be extended to incorporate various sensor data, thereby enhancing the feasibility of unmanned navigation [
1]. Perera, Lokukaluge P., and others addressed the issue of Mamdani inference failure in fuzzy logic-based collision avoidance decision-making by introducing smooth transition areas, optimizing the size of transition zones, and proposing a multi-level decision-making scheme. They developed a fuzzy inference system (FIS) based on IF-THEN rules [
2]. Koch, Paul proposed a rule set based on electronic charts to enhance collision avoidance decision-making for unmanned vessels navigating narrow channels and operating under separation traffic schemes, thus, improving both autonomous navigation and compliance [
3]. While rule-based methods can address autonomous decision-making challenges for unmanned vessels in localized areas, their poor generalization ability and over-reliance on predefined rules limit their broader applicability.
Fuzzy logic, which emulates human-like reasoning to handle uncertainty, is widely applied in autonomous collision avoidance and decision support systems. Perera, L.P. proposed an intelligent decision-making system based on fuzzy logic. This study analyzed the collision avoidance relationship between the own vessel and the target ship, developed a fuzzy inference system, and implemented it on the MATLAB platform [
4]. Wu, Bing introduced a fuzzy logic-based ship-bridge collision warning method that comprehensively integrates ship characteristics, bridge parameters, and environmental factors. The study assessed collision risk through fuzzy inference and validated its effectiveness in ensuring safe navigation in bridge areas [
5]. Wu, Bing also proposed a fuzzy logic-based decision-making method for selecting navigation strategies under inland waterway separation traffic schemes, analyzing dynamic factors such as free navigation, following, and overtaking vessels [
6]. Liu, Wenwen presented a fuzzy logic-based multi-sensor data fusion algorithm, combining AIS and radar data to improve target vessel detection accuracy and optimizing computational efficiency with Kalman filtering [
7]. Shi, Ziqiang developed a fuzzy logic-based method for regional multi-ship collision risk assessment, considering factors such as crossing angles, navigation environment, DCPA, and TCPA, and calculating risk weights using the Analytic Hierarchy Process (AHP) [
8]. Fuzzy logic provides intuitive and efficient decision-making mechanisms for simple and well-defined tasks and environments. However, it faces challenges in high-dimensional problems, leading to excessive computational costs in more complex tasks.
Expert systems utilize knowledge bases and inference mechanisms to simulate human expert decision-making processes, with applications in rule-based reasoning, fault diagnosis, and intelligent decision support. Hanninen assessed the impact of enhanced navigation support information services—based on expert knowledge—on the risks of ship collisions and groundings in the Gulf of Finland, analyzing the results using a Bayesian network model. The findings indicate that this service can reduce accident probabilities [
9]. Rudzki developed a decision support system based on expert systems to optimize ship propulsion system parameters, reducing fuel consumption and navigation costs. The system integrates a bi-objective optimization model to assist operators in making informed decisions under the manual control mode of controllable-pitch propellers [
10]. A.Lazarowska proposed a decision support system based on expert systems for collision avoidance and path planning, employing a trajectory-based algorithm to calculate the optimal safe route [
11]. Huang proposed an expert knowledge graph framework based on social network analysis (SNA), analyzing the functionality of knowledge graphs and quantifying network structure to identify factors that hinder knowledge dissemination and innovation. The results indicate that SNA can enhance the effectiveness of knowledge navigation and sharing [
12]. S.Srivastava proposed a rule-based expert system approach for the automatic reconfiguration of U.S. Navy ship power systems to restore power to undamaged loads after battle damage or failure [
13]. Expert systems offer strong interpretability and stability; however, they lack adaptive capabilities, and the construction of their knowledge base is time-consuming and labor-intensive.
Model Predictive Control (MPC) uses a system model to predict future states over a specified time horizon and optimizes control actions based on these predictions. Oh, So-Ryeok introduced an MPC method for waypoint tracking underactuated surface vessels with constrained inputs. This method incorporates an MPC scheme with Line-of-Sight (LOS) path generation capability [
14]. Li Zhen et al. proposed a novel disturbance compensation MPC (DC-MPC) algorithm designed to satisfy state constraints in the presence of environmental disturbances. The proposed controller performs effectively in reducing heading errors, meeting yaw rate constraints, and managing actuator saturation constraints [
15]. Yan Zheng et al. introduced an MPC algorithm for trajectory tracking control of underactuated vessels, which only have two available control inputs: longitudinal thrust and yaw torque [
16]. Johansen et al. developed an MPC-based collision avoidance system for ships, which generates various control behaviors by adjusting heading offsets and propulsion commands. The system evaluates the compliance and collision risks of these behaviors by simulating and predicting the trajectories of obstacles and ships, ultimately selecting the optimal behavior [
17]. While MPC can directly handle constraints and perform multi-objective optimization, it suffers from high computational complexity and struggles with high-dimensional nonlinear problems.
Reinforcement learning optimizes strategies through interaction with the environment and has been widely applied in autonomous ship decision-making. Li, Xiulai investigates the application of artificial intelligence, particularly the Q-learning algorithm, in unmanned vessel technology, aiming to improve autonomous decision-making capabilities and navigation accuracy [
18]. Wang, Yuanhui introduces an enhanced Q-learning algorithm (NSFQ) for unmanned vessel path planning and obstacle avoidance, integrating a Radial Basis Function (RBF) neural network to accelerate convergence [
19]. Chen, Chen presents a Q-learning-based path planning and control method, utilizing the Nomoto model to simulate the channel environment. This approach converts distance, obstacles, and no-go zones into reward or penalty signals, guiding the vessel to learn the optimal path and control strategy [
20]. Yuan, Junfeng proposes a second-order ship path planning model that combines global static planning with local dynamic obstacle avoidance. The model employs Dyna-Sarsa (2) for global path planning, and bidirectional GRU is used to predict trajectory switching to local planning. Collision risk is ultimately mitigated through the FCC-A* algorithm [
21]. Li, Wei suggests a risk-based approach for selecting remote-controlled ship navigation modes, combining System-Theoretic Process Analysis (STPA) to identify key risk factors and employing a Hidden Markov Model (HMM) to assess the risk levels of various control modes [
22]. Biferale, L. applies reinforcement learning to solve the Zermelo problem, achieving the shortest-time navigation of ships in two-dimensional turbulent seas [
23].
Deep reinforcement learning integrates the strengths of both deep learning and reinforcement learning, offering powerful autonomous learning capabilities. It continuously refines decision-making strategies through interaction with the environment. Wang Ning et al. proposed an optimal tracking control (RLOTC) scheme utilizing reinforcement learning [
24]. Woo Joohyun developed a collision avoidance method for unmanned surface vehicles (USVs) based on deep reinforcement learning, designed to assess the need for collision avoidance and, if necessary, determine the direction of the avoidance action [
25]. Li Lingyu et al. introduced a strategy that combines path planning and collision avoidance functions using deep reinforcement learning, with the enhanced algorithm effectively enabling autonomous collision avoidance path planning [
26]. Zhao Luman et al. proposed an efficient multi-vessel collision avoidance method leveraging deep reinforcement learning, wherein the state of encountering vessels is directly mapped to the rudder angle command of the own vessel through deep neural networks (DNN) [
27]. Wang Ning et al. employed a neural network-based actor-critic reinforcement learning framework to directly optimize controller synthesis derived from the Bellman error formula, transforming the tracking error into a data-driven optimal controller [
28]. Guo Siyu utilized the DDPG algorithm combined with the artificial potential field method to optimize collision avoidance. The model was trained using AIS data and integrated into an electronic chart platform for experimentation [
29]. Xu Xinli optimized collision avoidance timing by integrating a risk assessment model and applied the DDPG algorithm to design continuous control strategies, thereby improving the algorithm’s generalization capability. An accumulated priority sampling mechanism was introduced to enhance training efficiency [
30]. Xu Xinli developed a USV navigation situation model, incorporating collision cones and COLREGs to quantify encounter scenarios, and formulated corresponding collision avoidance strategies [
31]. Du Yiquan proposed a ship path planning method based on the improved DDPG and Douglas-Peucker (DP) algorithms, integrating LSTM to process historical state information and enhance decision accuracy [
32]. Zheng, Yuemin designed a heading and forward velocity controller using linear active disturbance rejection control (LADRC) and optimized control parameters with the DDPG algorithm to improve robustness [
33]. Cui, Zhewen et al. introduced an intelligent planning and decision-making method for MASS based on the Rapidly-exploring Random Tree Star (RRT-star) and an improved PPO algorithm [
34]. While deep reinforcement learning eliminates the need for manual feature design and excels at handling complex decision-making tasks, it is hindered by long training times and a significant reliance on environmental models.
Rapidly Exploring Random Trees (RRT) is a randomized method that efficiently explores the entire search space by constructing a random tree. D. Jang et al. enhanced traditional sampling-based path-planning algorithms by incorporating oceanic conditions and the perspective of ship operators, proposing an optimized path-planning approach that yields shorter routes [
35]. S.W. Ohn et al. considered open seas, restricted waters, and both two-ship and multi-ship interactions, integrating maritime practices and COLREGs. They proposed optimization requirements for local path planning of autonomous vessels and applied these to typical path planning algorithms [
36]. Namgung H et al., based on a fuzzy inference system (FIS-NC), ship domain (SD), and velocity obstacle (VO) models, introduced a local path planning algorithm. This algorithm ensures that the autonomous vessel maintains a safe distance from the target vessel (TS) during passage, avoiding near-collision incidents, and optimizing heading deviation and collision avoidance efficiency [
37]. Vagale A et al. conducted a comparative study of 45 relevant papers to evaluate the performance of current path planning and collision avoidance algorithms for autonomous surface vehicles. They focused particularly on the performance of these algorithms in ship operations and environmental contexts, with an emphasis on safety and risk [
38]. Vagale A et al. also discussed ship autonomy, regulatory frameworks, guidance, navigation and control components, industry progress, and prior reviews in the field, highlighting the potential need for new regulations governing autonomous surface vehicles [
39]. While RTT can effectively handle high-dimensional space problems, the paths it generates may not always be optimal.
The autonomous decision-making model for ships based on deep reinforcement learning has the capacity to adapt to various complex navigation environments by mapping the real-world navigation conditions to the state space that interacts with the deep reinforcement learning model, without compressing the spatial representation. This capability has become a key issue in autonomous ship decision-making research. It involves dealing with uncertainty factors in complex marine environments, such as the random variations in wind, waves, and currents, which affect ship stability. Additionally, the model must account for the nonlinear characteristics of the ship’s motion, allowing it to better adapt to real-world navigation scenarios. Moreover, COLREGs will serve as a fundamental constraint for collision avoidance decisions in unmanned vessels, ensuring that autonomous ships remain compliant and acceptable when interacting with manned vessels. Therefore, constructing a high-fidelity simulation environment that accurately reflects both the physical characteristics and the complexities of real-world navigation is crucial for advancing intelligent decision-making in autonomous ships. As shown in
Table 1, we have summarized the parameters for deep reinforcement learning state space mapping, including the configuration of the state space, whether the action space is discrete, and whether the reward function incorporates COLREGs.
The research presented in
Table 1 primarily focuses on the development of a ship’s hydrodynamic model and the perception of external obstacles. However, limited attention has been given to the incorporation of hydrometeorological factors, resulting in simulation environments that fail to account for their impact on ship maneuverability. In contrast, real-world environmental factors, such as meteorological conditions, wave fluctuations, and currents, play a crucial role in determining the ship’s operational trajectory and decision-making. For example, container vessels, with their large wind-exposed areas, are significantly affected by wind direction and force, which influence their motion. Similarly, fishing vessels are more susceptible to water currents due to the underwater trawls used during fishing operations. To ensure the practical applicability of the strategies derived from MASS training, it is essential to incorporate comprehensive hydrometeorological factors into the simulation environment. While some studies use discrete action spaces to reduce computational complexity and accelerate convergence, the resulting ship trajectories are often overly simplistic and do not accurately reflect real-world navigational paths. Furthermore, in the design of reward functions, certain studies have neglected to include COLREG-related rewards, which diminishes the practical applicability of the resulting models.
The primary issues in current research on MASS-assisted collision avoidance decision-making are as follows:
In the design of MASS-assisted collision avoidance models, a significant discrepancy exists between the simulated and real-world environments during MASS navigation. In some studies, ships are represented as rigid bodies or particles, with motion inputs limited to basic actions such as turning or stopping, neglecting the maneuverability differences among ship types. Moreover, the simulation environment lacks realistic obstacles and inter-ship interactions, preventing it from accurately replicating the motion states of MASS in maritime navigation. As a result, while the collision avoidance models perform well during training, they lack practical applicability. Additionally, some fixed simulation settings contribute to model overfitting. Lastly, several studies fail to integrate the learning of COLREGs into the reward functions, which hinders the generalization ability of the resulting models.
The construction of complex state spaces faces the challenge of dimensional explosion. In maritime environments, which involve data on ship navigation and environmental factors, the state space mapping leads to a rapid increase in dimensionality. This, in turn, raises the computational and resource demands during training, making it more difficult for models to converge. Additionally, the excessively large state space may cause overfitting to specific local regions. Therefore, ensuring both the authenticity of the state space and the prevention of dimensional explosion is a critical issue requiring immediate attention.
To address the limitations in existing research, this study aims to develop an intelligent decision-making model that accurately reflects real-world navigation data, thereby enhancing the autonomous navigation and collision avoidance capabilities of unmanned ships in complex marine environments. As shown in
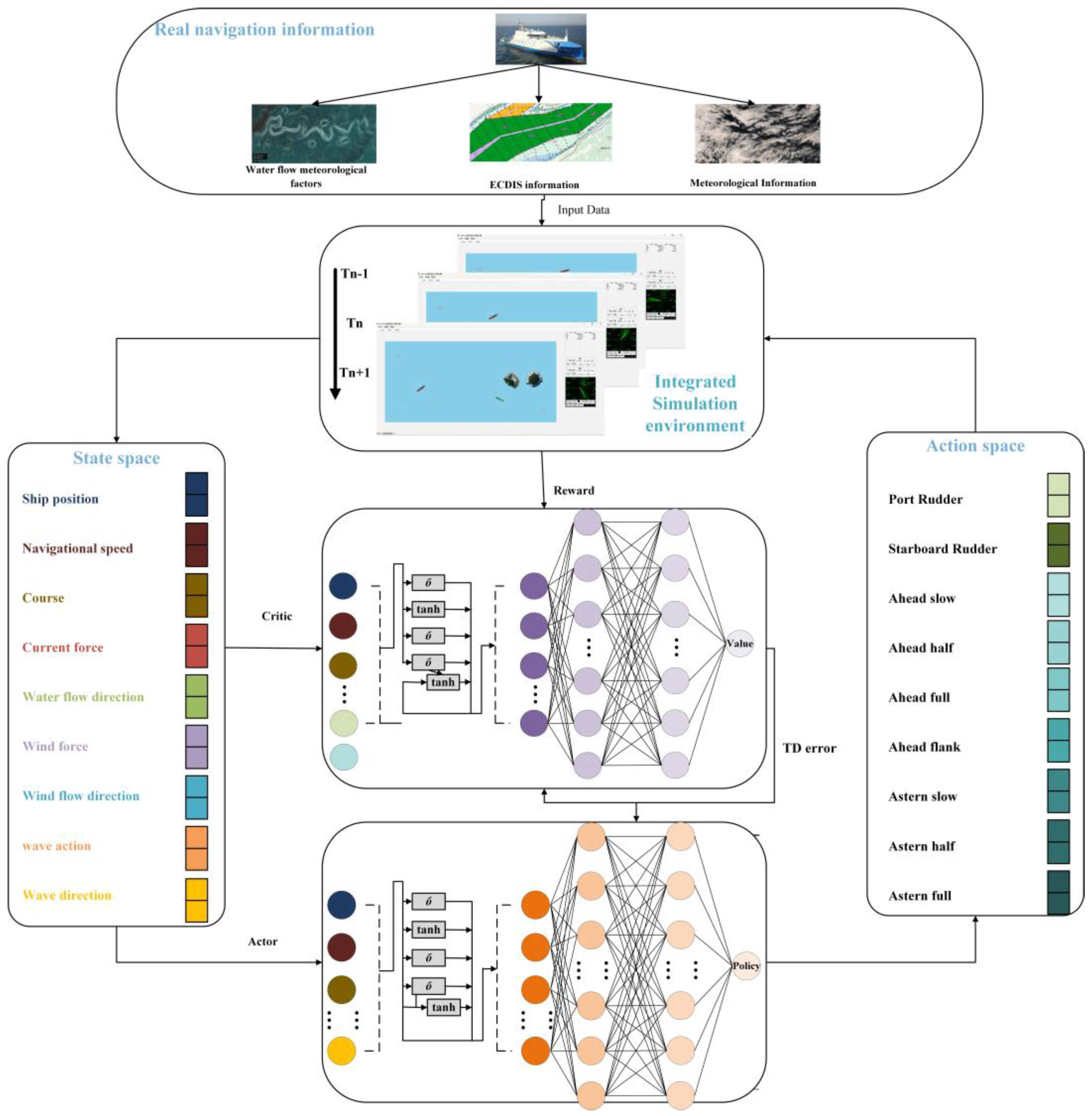
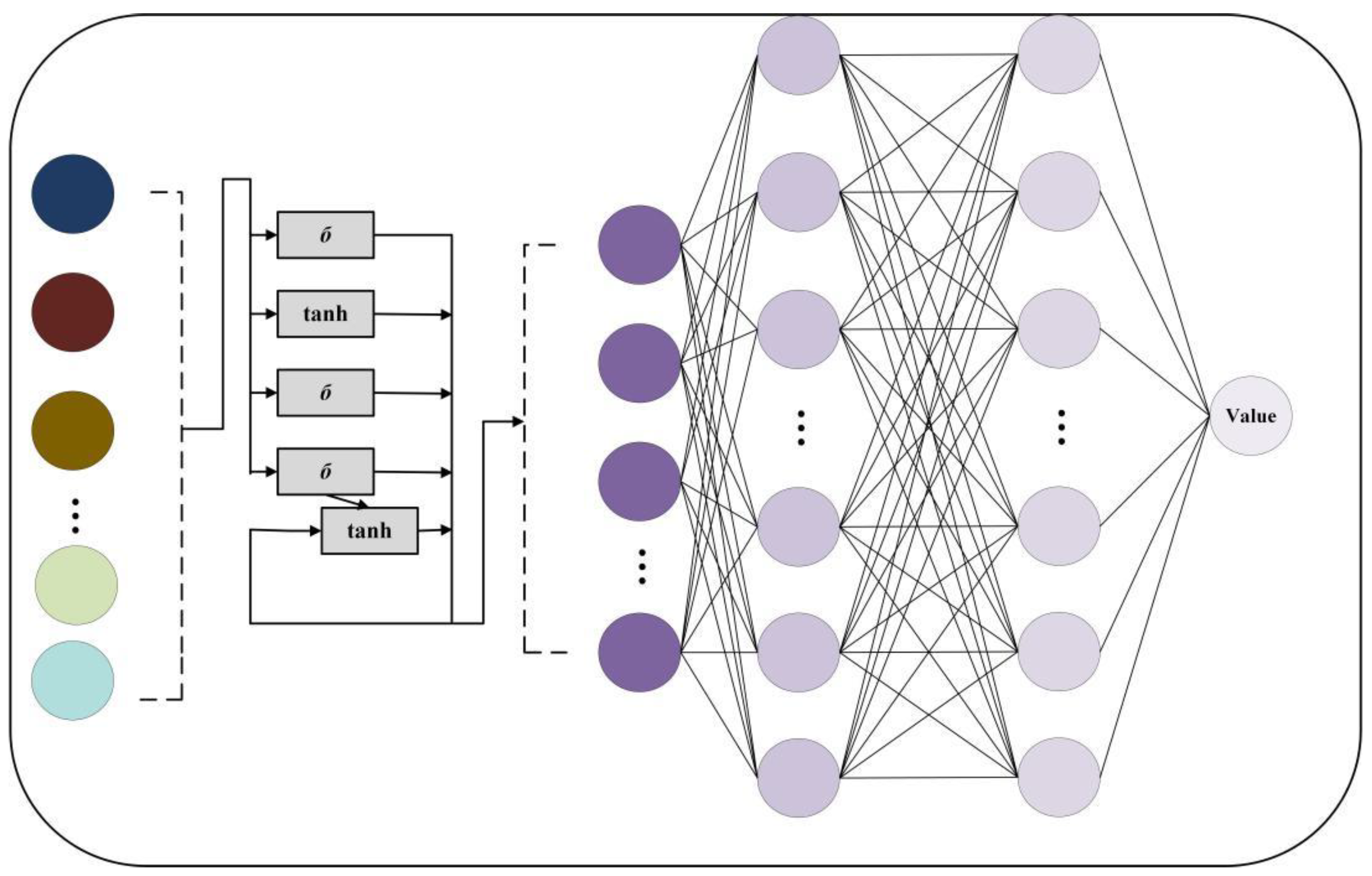
Figure 1, the system simulates real-world environmental factors, such as water currents, meteorological conditions, and electronic chart data (ECDIS), among others, to create a high-fidelity simulation environment. This enables the agent to train under dynamic conditions that closely resemble actual navigation scenarios. Within a reinforcement learning framework, the state space includes key environmental variables, such as ship position, speed, heading, flow fields, and wind/waves, allowing the agent to fully perceive the complexity of the external environment and optimize its decisions under varying meteorological and hydrodynamic conditions. The reinforcement learning architecture incorporates an Actor-Critic structure, where the Critic evaluates decision values and the Actor generates specific control commands (e.g., steering and engine control) through a policy network. This ensures the ship operates safely and efficiently while adhering to COLREGs. Reinforcement learning optimizes strategy through TD error, enhancing the agent’s collision avoidance and path planning abilities through continuous interactions. Ultimately, the system uses an end-to-end learning approach, enabling the unmanned ship to autonomously perceive, decide, and execute navigation tasks, thereby improving its adaptability and reliability in complex environments.
Figure 1 illustrates the overall architecture of the Adaptive Temporal Reinforcement Navigation Model (ATRNM) designed in this study for intelligent navigation decision-making in MASS. The model is built around an integrated simulation environment that replicates real-world navigation data, including water currents, meteorological conditions, ECDIS, and weather information. It interacts dynamically across multiple time steps (Tn − 1, Tn, Tn + 1). The state space incorporates external environmental variables, such as ship position, speed, heading, and wind/wave conditions. These data are processed by an Actor-Critic network, where the Critic evaluates the state value function and computes the TD error, while the Actor generates the optimal navigation strategy. Through the integration of LSTM networks, the model effectively captures temporal dependencies, improving its adaptability to complex and dynamic marine environments. The action space controls the ship’s rudder and propulsion system, adjusting the left and right rudders and varying forward and backward speeds to optimize the navigation path and ensure the effectiveness of the collision avoidance strategy. The overall architecture optimizes the strategy through a reinforcement learning framework (PPO), enabling the model to enhance its collision avoidance capabilities and navigation stability in dynamic environments, thereby providing efficient decision support for intelligent navigation in MASS.
The main contributions of this study are as follows:
First, the real-world ship navigation environment is accurately mapped into a reinforcement learning simulation environment through mathematical modeling. In this simulation, the unmanned ship is no longer modeled as a particle; instead, the forces exerted by the rudder and engine are applied to the ship’s stern. Furthermore, hydrometeorological factors are integrated into the environmental design. All relevant environmental information is incorporated into the state space, enabling the proposed PPO-LSTM model to gain a better understanding of the ship’s current navigation state. The LSTM’s processing of temporal information allows the unmanned ship to more effectively capture trends in the dynamic environment. This also helps mitigate potential issues of dimensionality explosion in the state space. Finally, incorporating the COLREGs into the reward function design ensures the practicality of the trained model.
The remainder of this study is organized as follows:
Section 2 presents the preliminary work for the intelligent collision avoidance model, including the design of the simulation environment and the COLREG regulations.
Section 3 describes the design of the unmanned ship’s intelligent decision-making model, which is trained using the policy gradient update method to develop a collision avoidance decision model. The model is trained with the improved PPO algorithm, and the designs of the state space, action space, and reward function are also detailed.
Section 4 discusses the improved decision-making model, including algorithm enhancements and the construction of the temporal information network.
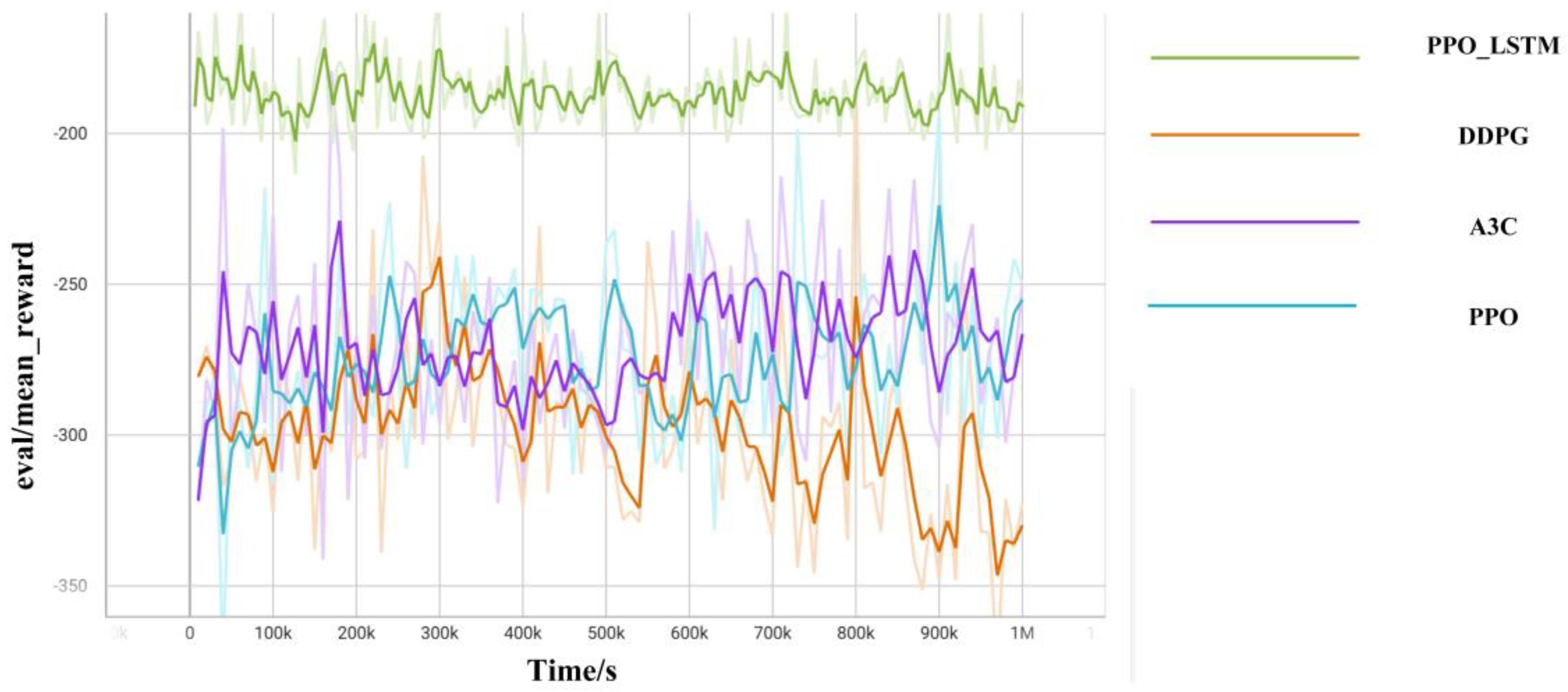
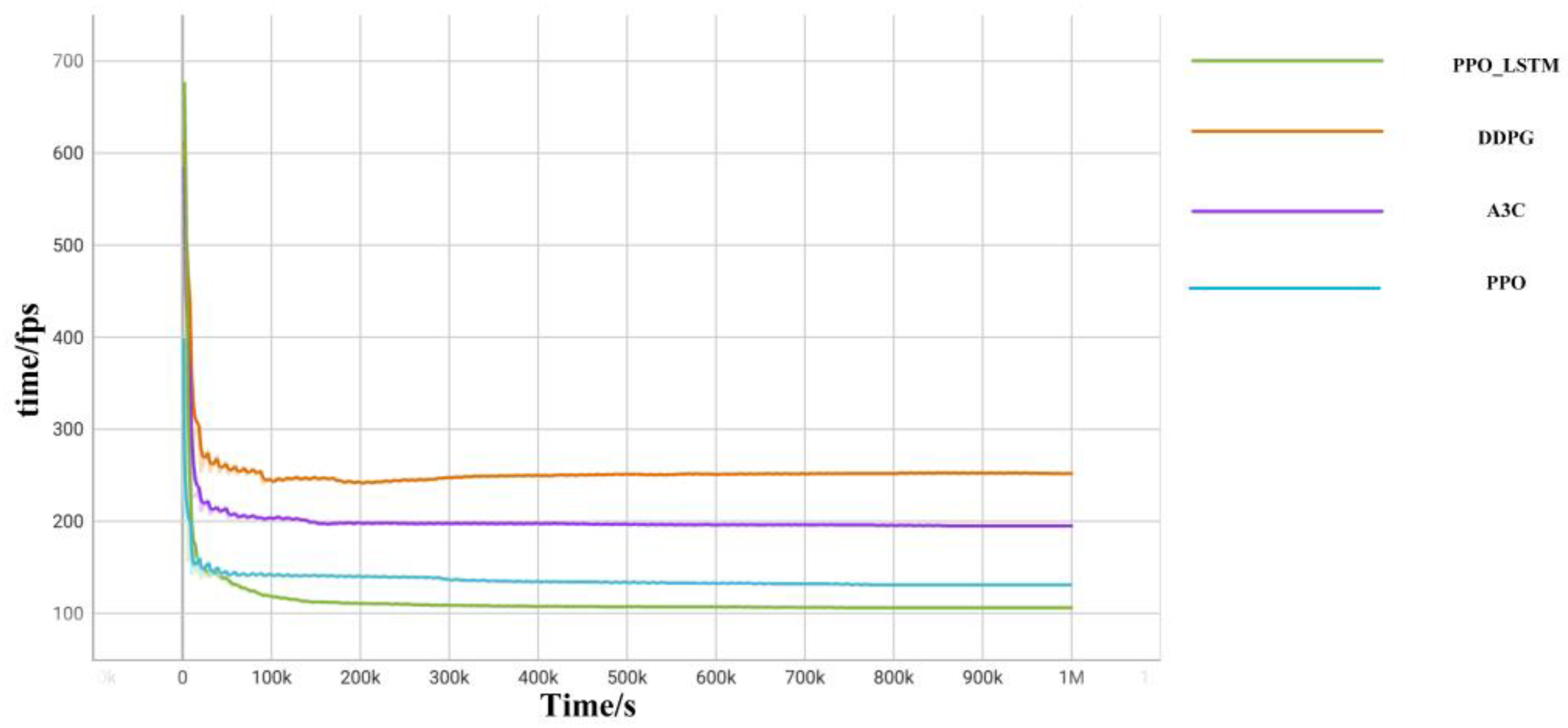
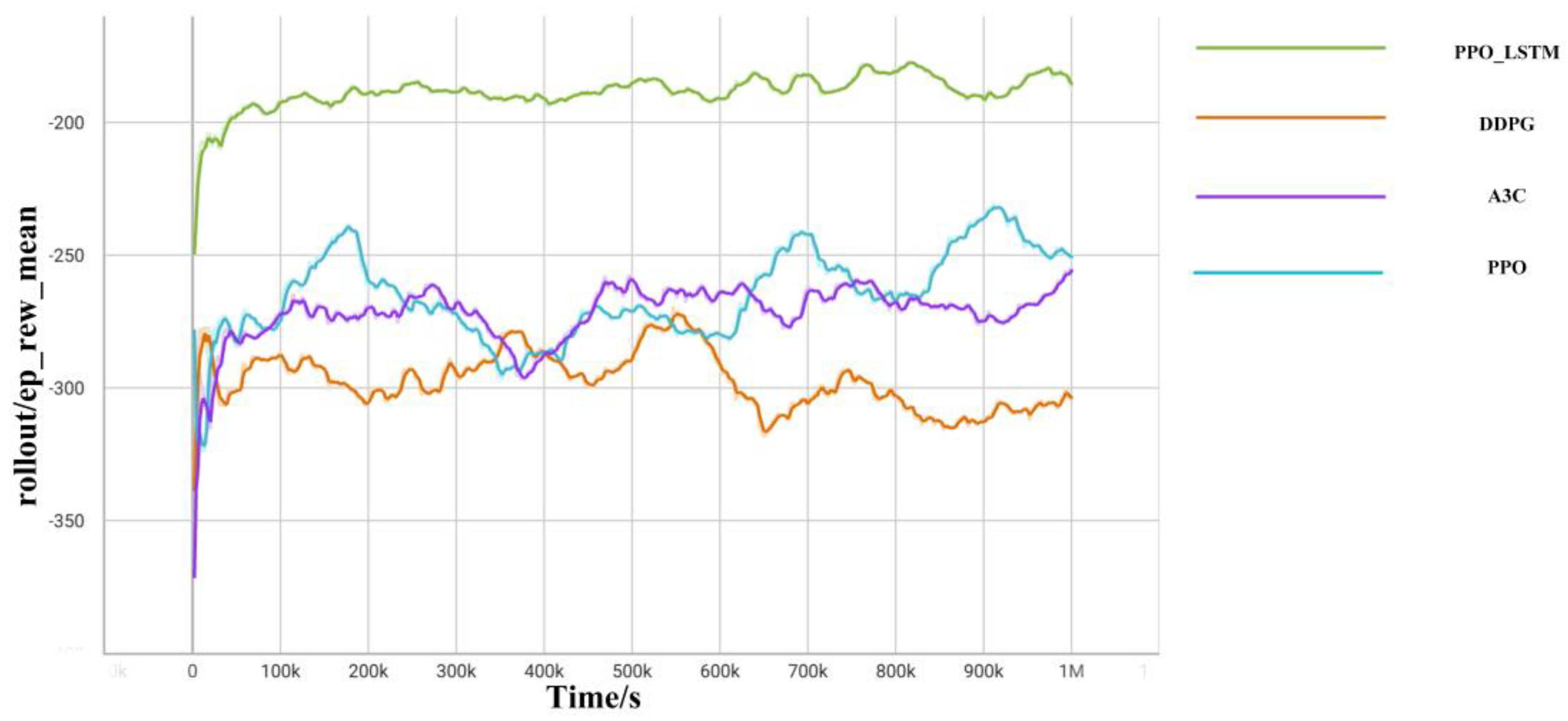
Section 5 compares the model’s training performance in simulation experiments and presents the results of the trained strategy in the simulation environment. Finally,
Section 6 provides conclusions and outlines future research directions.
2. Preliminary Preparations
This chapter introduces the design of the simulation environment and the regulations of COLREG. To accurately replicate the real-world navigation environment of ships in the reinforcement learning simulation, mathematical models of the ship and hydrometeorological factors are required. In the simulation environment, the forces exerted by hydrometeorological factors interact with the ship’s physical characteristics (e.g., propulsion, resistance), influencing its trajectory. Furthermore, COLREG requirements must be considered to ensure that the agent’s behavior adheres to legal regulations and safety standards in both simulated and real-world scenarios.
2.1. Modeling Real-World Complex Environments
During a ship’s voyage, hydrometeorological factors significantly influence its maneuverability. To effectively simulate these environmental effects, numerical methods based on physical models and stochastic processes are utilized. This section discusses the modeling of wind, waves, and currents, simplifying higher-order small quantities to reduce computational complexity, while retaining the influence of hydrometeorological factors on the ship’s maneuverability.
- (1)
Simulation of wind
Wind affects the ship’s navigation path, speed, and stability. Under strong wind conditions, the lateral force exerted by the wind increases significantly, causing a deviation in the ship’s heading. In this model, both wind strength and direction are represented by a two-dimensional vector. The wind speed is controlled by a random number generator, with its magnitude fluctuating within a specified maximum wind speed range. Each time the simulation is updated, the wind direction is randomly selected within a range from 0 to 2π. This method of variation reflects the high degree of variability and randomness of wind in real-world conditions.
The mathematical expression for wind force is:
Here, Fwind represents the wind force magnitude; vmax denotes the maximum wind speed, which can be set during system initialization to account for severe sea conditions during model training. Random (−vmax, vmax) generates a random value within the specified wind speed range for simulating wind force.
The mathematical expression for wind direction is as follows:
Here, W represents the wind direction, and θ denotes the wind direction angle, measured in radians and randomly distributed within the range (0, 2π).
In the system, wind force updates follow a time-step process, where new values for wind speed and direction are randomly generated to simulate the continuous variation of wind.
- (2)
Simulation of Currents
Ocean currents significantly affect the ship’s navigation path. In contrast to wind, the influence of currents is typically persistent and directional, meaning ocean currents generally change more gradually, though they may also cause long-term offset effects. In this system, the current is represented as a two-dimensional vector that describes its speed and direction.
The mathematical expression for the current force is as follows:
Here, Fcurrent represents the magnitude of the current force; vcurrent,x and vcurrent,y represent the components of the current in the x-axis and y-axis directions, respectively. The principle is analogous to that of wind force.
The direction of the current is expressed as an angle. The initial direction is randomly generated within a specified range, and during each update, the direction is adjusted based on a given variance. This process allows for a change in the current’s direction, though not randomly; instead, the direction retains a certain degree of correlation.
The mathematical expression for the current direction is as follows:
Here, Fcurrent(t+1) represents the current direction at the next time step, while Fcurrent(t) indicates the current direction at the present time step. δFcurrent denotes the adjustment, which is dependent on the current direction.
- (3)
Wave Model
The influence of waves on maritime navigation is particularly pronounced, especially under adverse weather conditions, where wave forces can significantly affect vessel stability. The oscillatory effect of waves may induce vibrations during navigation, and in extreme cases, it can result in the vessel losing control or sustaining damage. Therefore, wave impacts must be carefully considered in the design of MASS.
The mathematical expression for wave force is as follows:
Here, Fwave represents the wave force, while Vwave,x and Vwave,y denote the magnitudes of the wave force in the x-axis and y-axis directions, respectively.
The wave magnitude fluctuates periodically at a fixed frequency during each update, and the wave direction is random. The wave update formula is as follows:
Here, ϵ is the threshold used to determine whether the wave’s influence is updated at the current time step.
2.2. Modeling for Realistic Ship Maneuvering
This section explores the process of developing ship maneuvering models, with a particular emphasis on hydrodynamic modeling and the mathematical representation of maneuvering dynamics. We begin by analyzing the six degrees of freedom in ship motion and then focus on key maneuvers involved in collision avoidance, such as forward motion, yaw, and heave. By constructing a ship motion diagram in a still-water coordinate system, we introduce key parameters of maneuverability, including rudder angle input, yaw response, and the maneuverability index. Additionally, this section discusses how hydrometeorological factors are incorporated into the ship’s dynamic model.
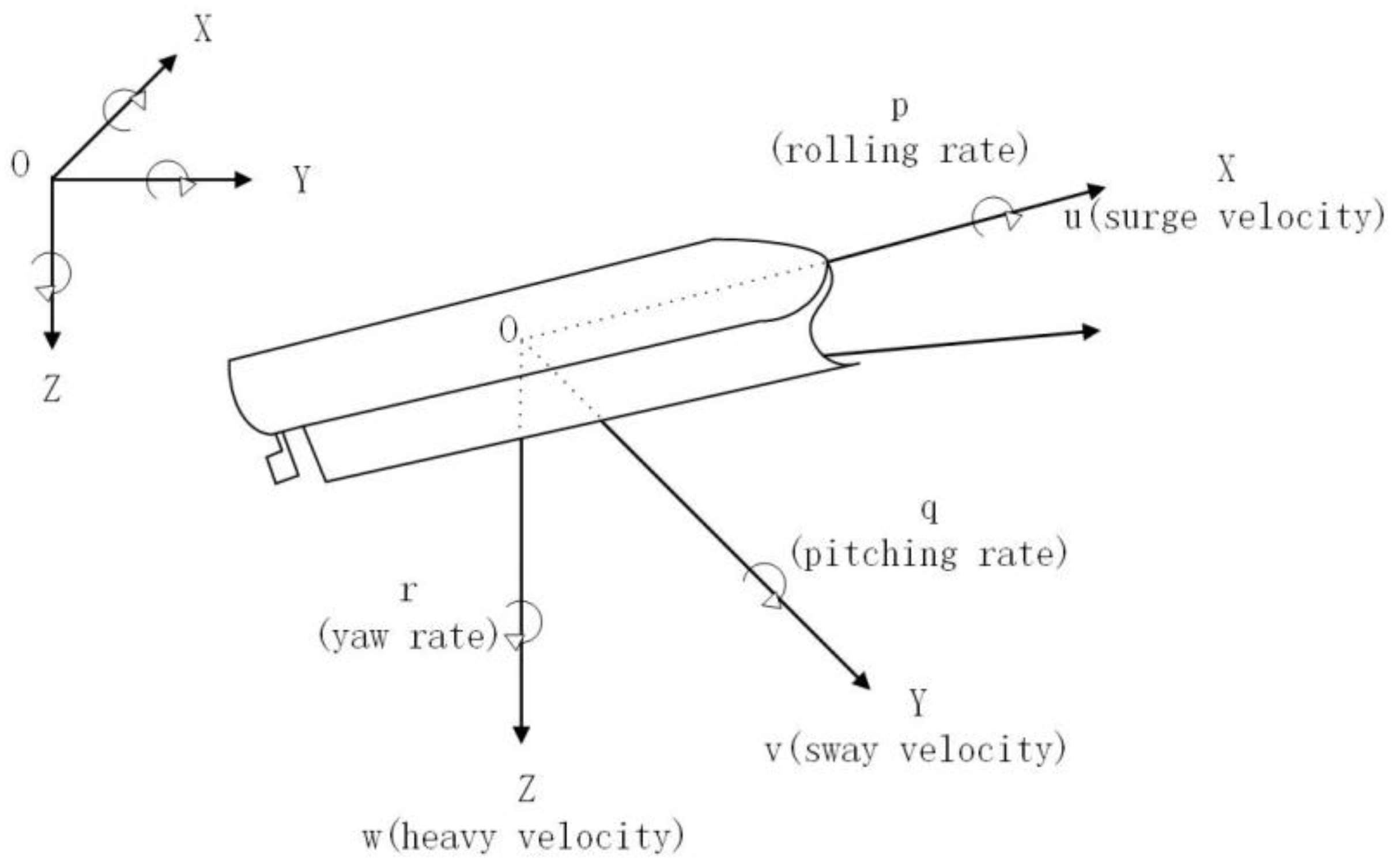
The motion of a ship is inherently complex and typically exhibits six degrees of freedom. As shown in
Figure 2, these motions consist of three translational movements along the body-fixed coordinate axes and three rotational movements around these axes. The translational motions include forward speed along the X-axis, lateral speed along the Y-axis, and heaving speed along the Z-axis. The rotational motions include pitch angular velocity along the X-axis, roll angular velocity along the Y-axis, and yaw angular velocity along the Z-axis. During collision avoidance, the primary focus is on the ship’s forward motion, drift, and pitch. In contrast, heaving, yawing, and rolling motions have relatively minor effects.
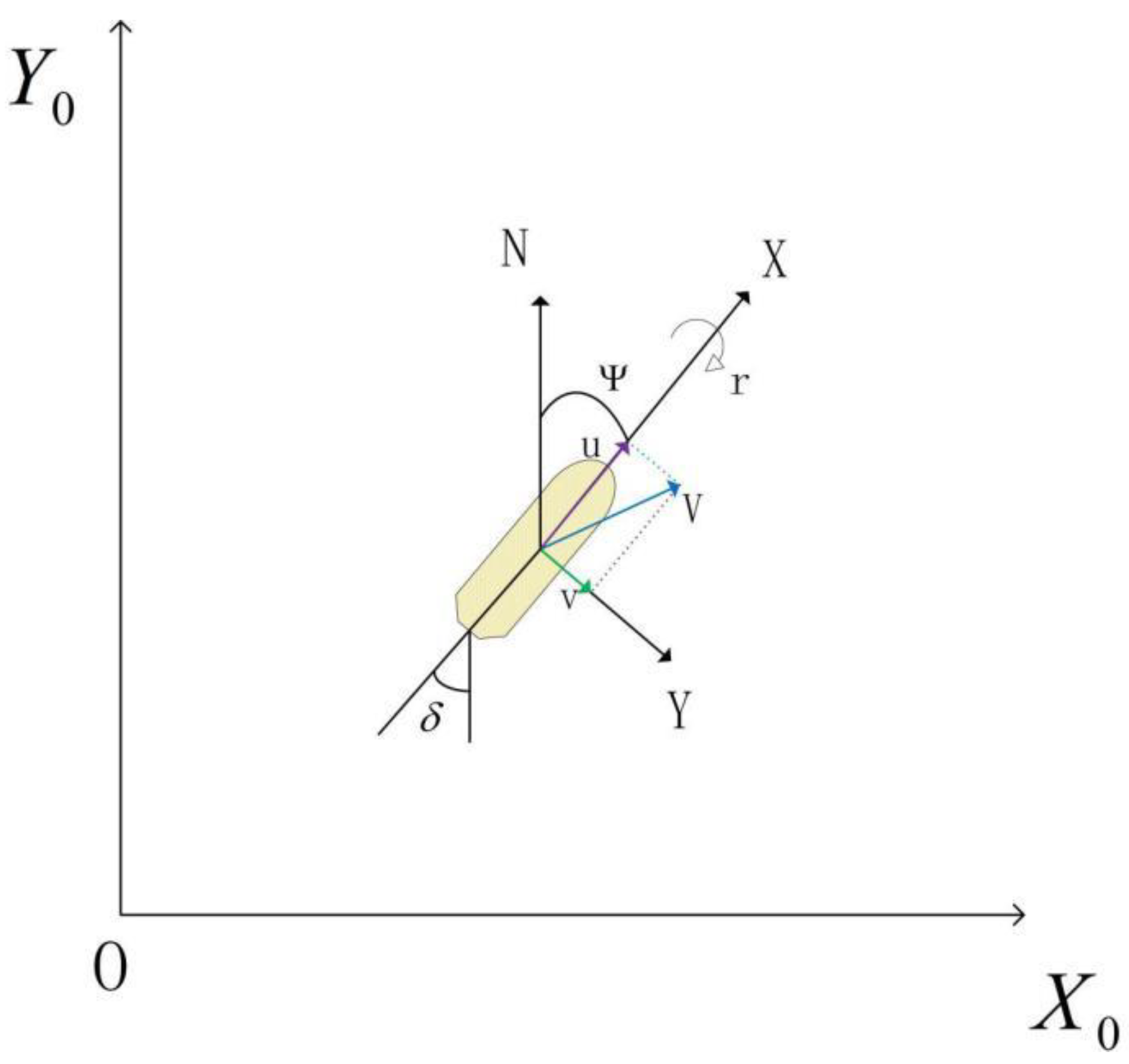
In
Figure 3, the coordinate system X
0OY
0 represents the still-water coordinate system, with the X-axis aligned along the ship’s length, the Y-axis perpendicular to the X-axis, and N denoting the true north direction. In the X-direction, the ship’s pitch velocity and forward motion are considered, while the Y-direction represents the ship’s drift motion. The variable V indicates the actual direction of the ship’s motion. Ψ represents the ship’s heading, and β denotes the rudder angle. Here, only the ship’s drift and pitch motions are considered, and the resulting mathematical model is as follows:
In Equation (7), δ represents the ship’s rudder angle input, and the coefficients a11, a12, a21, a22, b11, and b21 are determined by the ship’s basic parameters. The equation can be transformed into a simplified expression describing the effect of the rudder on the ship’s pitch response, as follows:
In Equation (8), K, T
1, T
2, and T
3 are maneuverability indices, which can be estimated using the ship’s basic parameters a11, a12, a21, a22, b11, and b21. Taking the Laplace transform of Equation (8) yields the transfer function, as expressed in Equation (9).
For a ship, which is a high-inertia vehicle, its dynamic characteristics are valid only in the low-frequency range. Therefore, we set s = jω→0, and after performing a series expansion while neglecting second and third order terms, we obtain the Nomoto model, as follows:
Based on the relationship
, we replace r in Equation (10) with the ship’s heading angle ψ, resulting in the corresponding equation:
Equation (12) represents the first-order K-T equation for ship maneuvering.
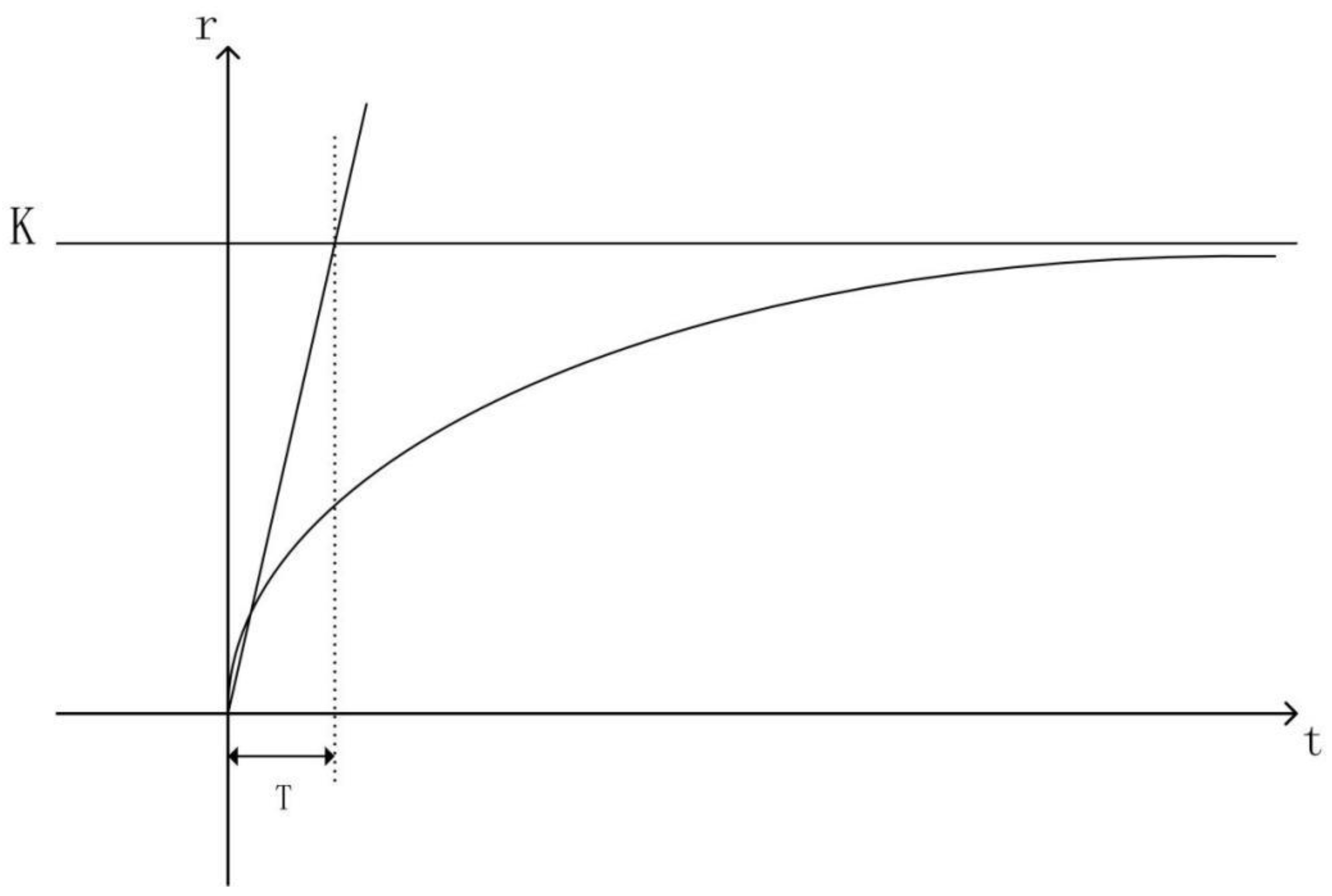
Figure 4 illustrates the output response of the first-order Nomoto model, clearly demonstrating the physical significance of the K and T indices. K represents the factor influencing the turning rate after the ship takes control; a larger K results in a higher turning rate, indicating better maneuverability. T denotes the key factor in determining the time required to reach the maximum turning rate, referred to as the time constant.
Considering the ship as a rigid body, as shown in
Figure 4, when the ship steers with an arbitrary rudder angle
, the turning rate r is given by the formula above, which can be regarded as the ship’s steering motion equation. When the ship has a rudder angle input for steering, assuming its initial conditions are t = 0,
=
0, and r = 0, the yaw angle at any given time can be calculated using the KT formula in Equation (12):
The ship’s heading is the time derivative of the yaw angle, and its relationship is as follows:
The advantages of using the Nomoto model to develop the ship’s hydrodynamic model for simulation training are:
The Nomoto model simplifies higher-order infinitesimals, resulting in a lower-order ship motion control model, which enhances computational efficiency and simulation accuracy.
While the Nomoto model simplifies higher-order terms and the low-frequency range, the results from the low-frequency range in actual simulations closely align with those from higher-order models, ensuring the authenticity of the experiments.
Based on the previously introduced hydrodynamic model, a new ship motion model is proposed that integrates external environmental factors, including the ship’s rudder effect, propeller acceleration effect, and the influence of environmental factors such as wind speed, waves, and currents on ship motion.
- (1)
Ship Motion Model Design
The ship’s motion can be represented by a dynamic model, typically governed by Newton’s second law, while accounting for both linear and nonlinear responses. Based on this, we assume that the ship’s motion on the water surface is described by variables such as velocity, position, and heading angle. The equation of motion for the ship can be expressed as follows:
Here, r(t) represents the ship’s position vector in a two-dimensional space, which varies over time t; represent the velocity components along the x-axis and y-axis are denoted, while v(t) represents the ship’s current speed.
The rudder effect is a key factor influencing the ship’s steering. Equations (13) and (14) quantify the rudder effect on steering for different ship types, based on the ship’s KT index. We considered six ship types, including tankers, fishing vessels, and passenger ships, to comprehensively assess the impact of varying maneuverability on collision avoidance.
Additionally, the ship’s speed variation is influenced by the propeller’s rotational speed and the power system’s efficiency. Let n(t) represent the propeller speed, and the propeller’s acceleration a(t) can be calculated using the propeller’s efficiency, the ship’s current speed v(t), and environmental resistance.
Here, refers to the ship’s total resistance, which is typically influenced by factors such as the ship’s type and speed.
- (2)
Ship Resistance Model Design
The primary resistance model considered for the ship includes viscous resistance (D
viscous(v(t))), wave resistance (D
wave(v(t))), air resistance (D
air(v(t))), and additional resistance (D
extra(v(t))). The specific mathematical expressions are as follows:
Here, represents the total resistance; Cviscous is the viscous resistance coefficient related to the ship’s shape and the properties of the water body; Cwave is the coefficient associated with the ship’s speed, shape, and the wave characteristics of the water body; Cair is the coefficient related to air density and the ship’s surface characteristics; and Cextra is the coefficient linked to the ship’s design and dynamic characteristics.
- (3)
Interference from External Environmental Factors
We quantified the hydrometeorological factors discussed in
Section 2.1 and integrated them with the ship’s dynamic model to derive the expression for the interference from external environmental factors as follows:
The influence of wind on ship motion is primarily reflected in the applied torque and resistance. Wind speed (V
wind’) and wind direction (
) influence the ship’s speed and heading, especially as the ship’s hull near the water surface experiences considerable wind pressure. The mathematical expression for the effect of wind on the ship’s speed and heading is given as follows:
Here, Vwind’ represents the change in ship speed due to wind; Cwind is the wind influence coefficient on the ship, which depends on the ship’s type and the wind-exposed area of the hull; Vwind is the wind speed; wind is the wind direction (the angle between the wind direction and the ship’s heading); ship is the ship’s heading; is the wind torque influence coefficient.
The effect of the current is a significant external factor influencing the ship’s speed and heading. The current velocity (V
current) and direction (
current) combine to affect the ship’s motion by altering its velocity and direction. The mathematical expression for the impact of the current on the ship’s speed and heading is as follows:
Here, Vcurrent’ represents the change in ship speed due to the current; Ccurrent is the current influence coefficient; Vcurrent denotes the current speed; current and ship represent the directions of the current and the ship’s heading, respectively; and is the current torque influence factor.
The impact of waves primarily manifests in two ways: first, the wave height affects the ship’s pitch; second, the energy of the waves is transmitted through the hull, subsequently altering the ship’s heading and speed. Since the effect of pitch on collision avoidance is minimal, it can be disregarded. Therefore, we simplify the wave impact as the relationship between wave height, wavelength, and the ship’s speed and heading. The mathematical expression is as follows:
Here, Vwave represents the change in ship speed due to the waves; Cwave is the wave influence coefficient, which primarily depends on the ship’s shape and the wave frequency; Hwave denotes the wave height; wave and ship represent the wave direction and the ship’s heading, respectively; and is the wave torque influence factor.
2.3. COLREG Rules
The first step in collision risk assessment is to evaluate the potential for collision. According to the COLREGs, “every ship should use all available means to assess the risk of collision under the prevailing environmental conditions”. In practice, collision risks are often evaluated based on the Time to Closest Point of Approach (TCPA) and Closest Point of Approach (CPA) warnings displayed on electronic charts. In
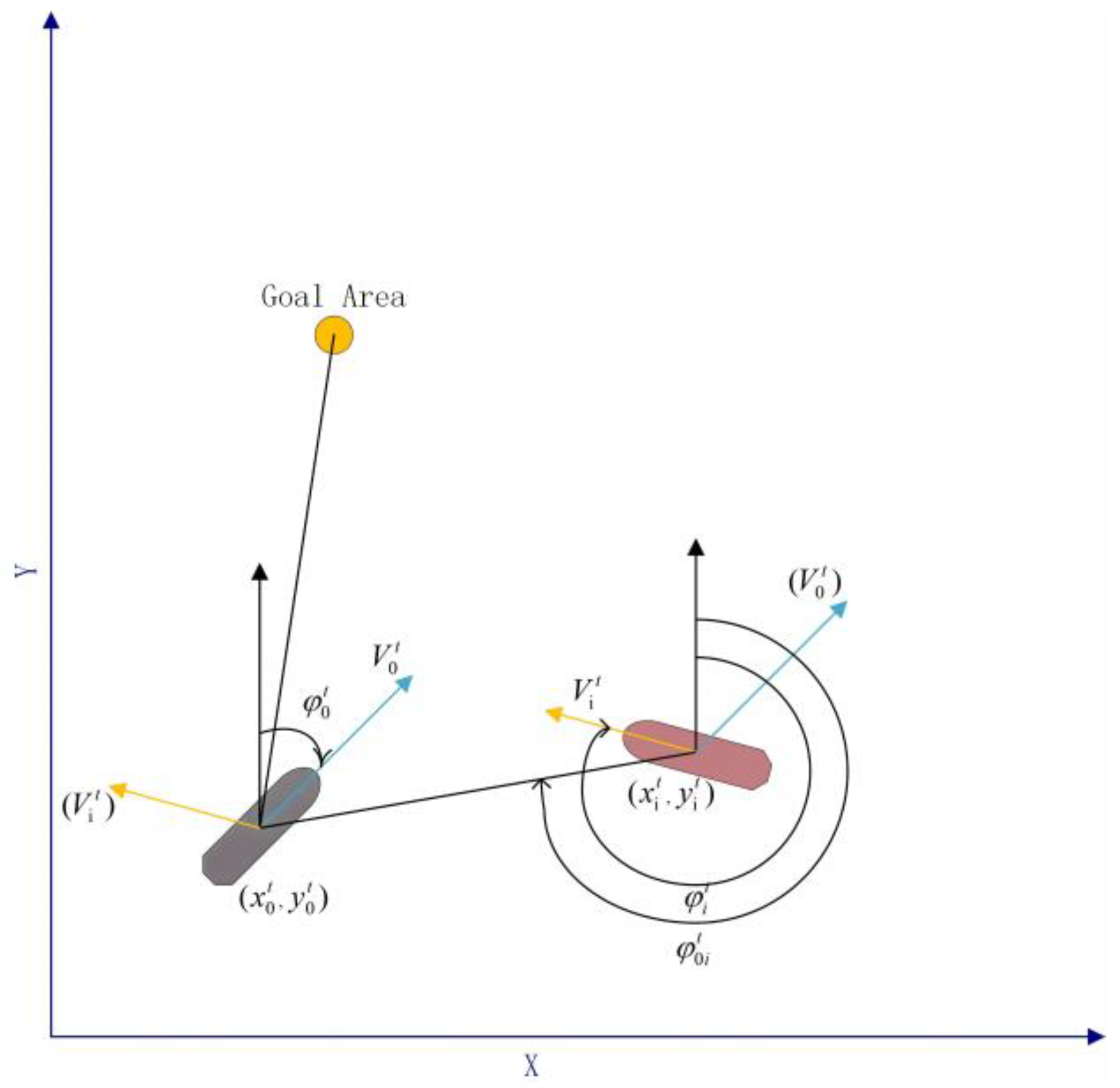
Figure 5, the two ships are identified as presenting a collision risk, which necessitates the calculation of TCPA and CPA to determine the likelihood of a collision.
Based on the relationships between DCPA and MINDCPA, as well as TCPA and MINTCPA, ships on the radar can be classified into three categories: (1) when DCPA > MINDCPA and TCPA > MINTCPA, the target ship is deemed safe and no collision risk exists; (2) when DCPA < MINDCPA and TCPA < MINTCPA, the target ship is considered dangerous but not immediately threatening, and evasive action should be considered; (3) when DCPA < MINDCPA and TCPA < MINTCPA, the target ship is highly dangerous, and immediate evasive action is required.
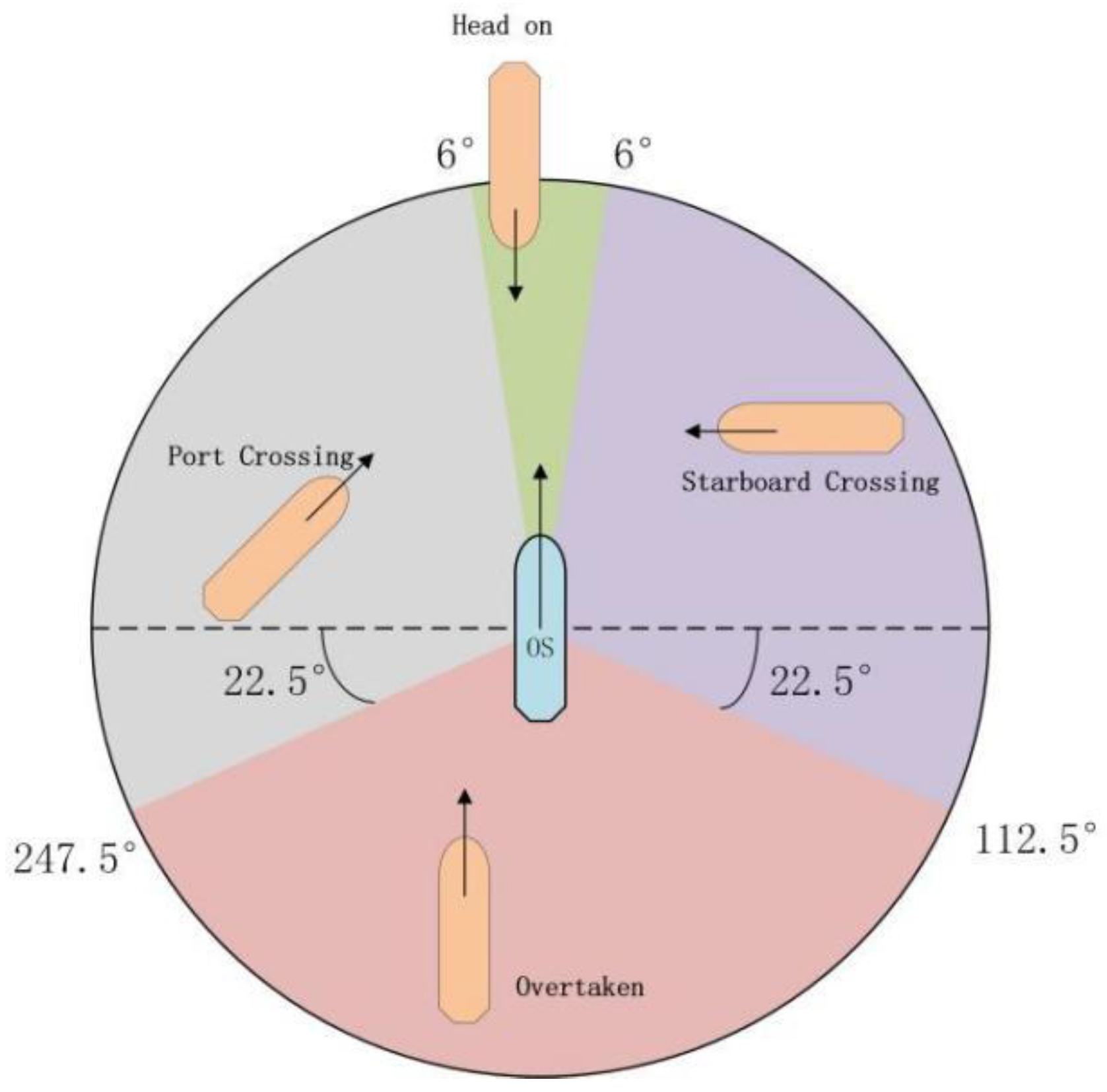
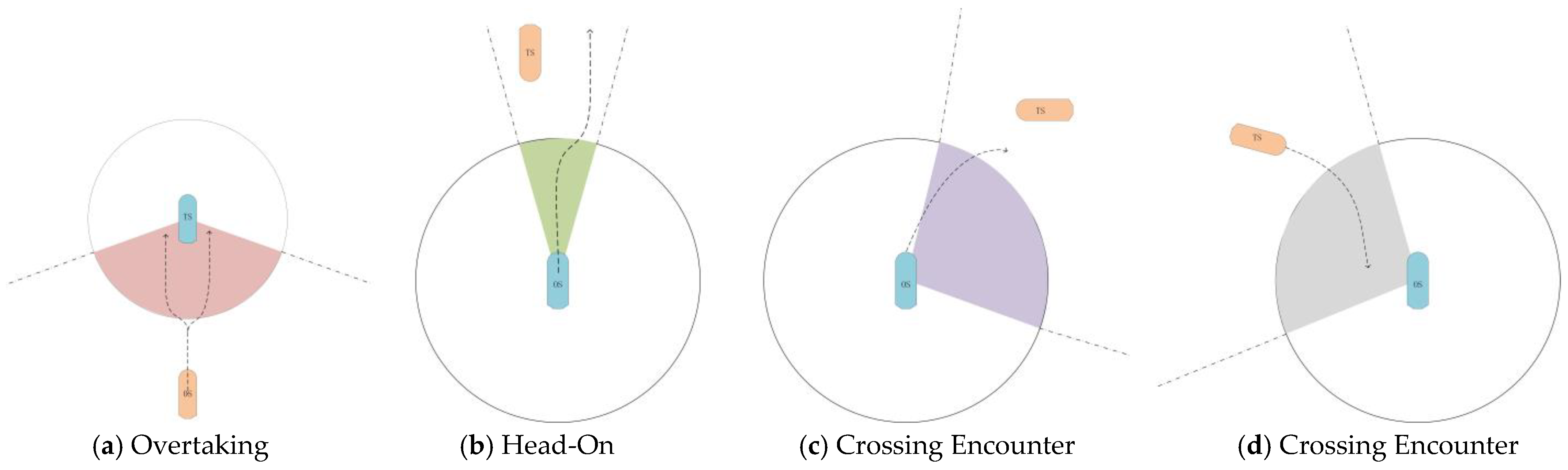
After assessing the collision risk between two ships, it is essential to evaluate their encounter situation, as shown in
Figure 6. Based on the relative positions of the target ship and the own ship, the encounter can be classified into four types. Depending on the specific encounter, the own ship must take appropriate collision avoidance measures in accordance with the rules. As shown in
Figure 7a, when a ship approaches another vessel from 22.5° to its stern, the ships are in an overtaking situation. The overtaking vessel must yield to the vessel ahead.
Figure 7b illustrates that when two motorized ships meet on opposite or nearly opposite courses, creating a collision risk, they must pass each other on the left side. In the case of a crossing collision risk between the two ships, the right-of-way and give-way relationship must first be determined. As shown in
Figure 7c, when the target ship is positioned on the right side of the own ship (6° to 112.5°), the own ship is the give-way vessel, and the target ship is the stand-on vessel. The own ship should actively steer to the right and pass the target ship on the left side.
Figure 7d shows that when the target ship is positioned on the left side of the own ship (247.5° to 354°), the own ship is the stand-on vessel, and the target ship is the give-way vessel. The target ship should actively steer to the right and pass the own ship on the left side.




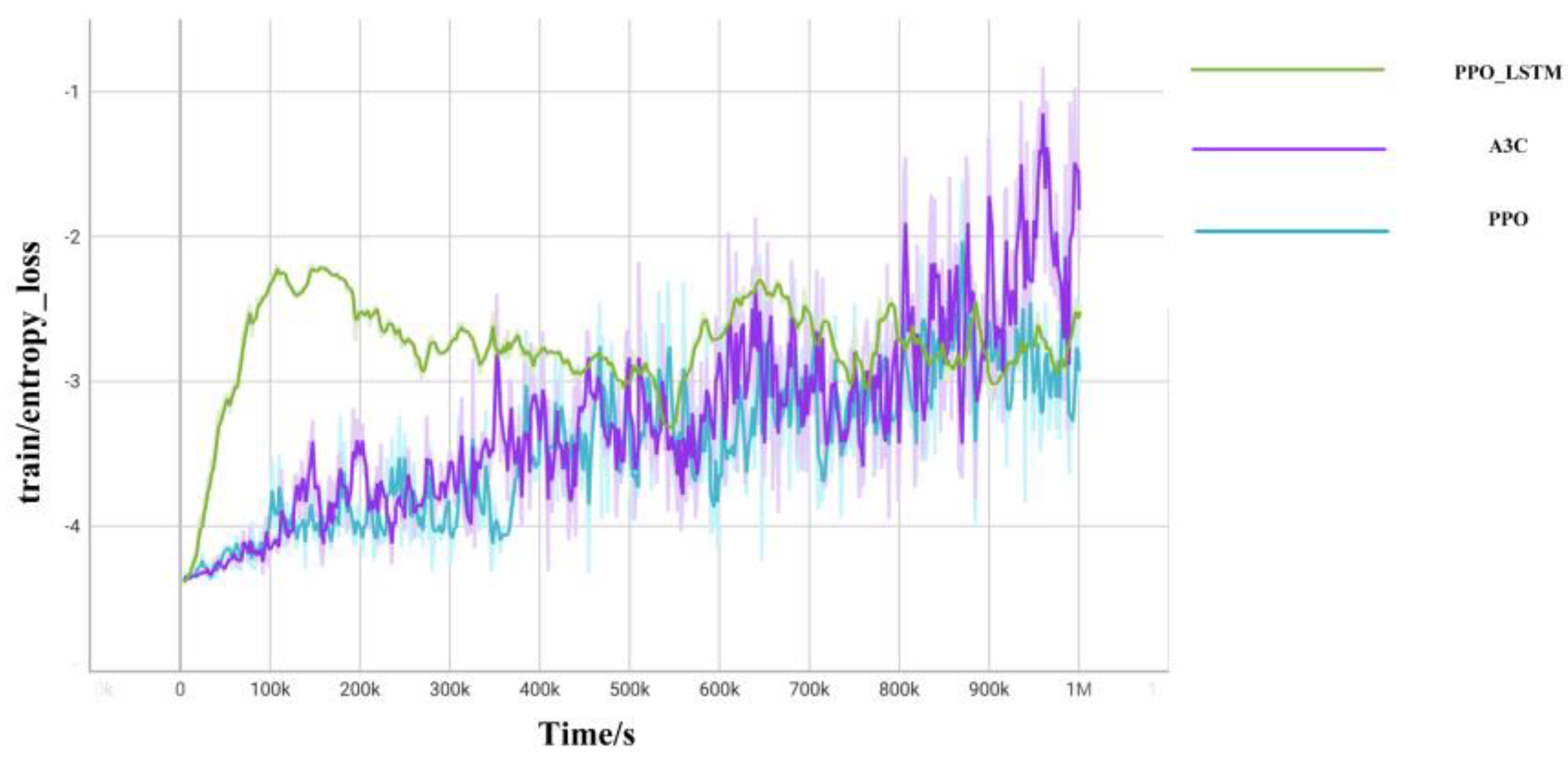
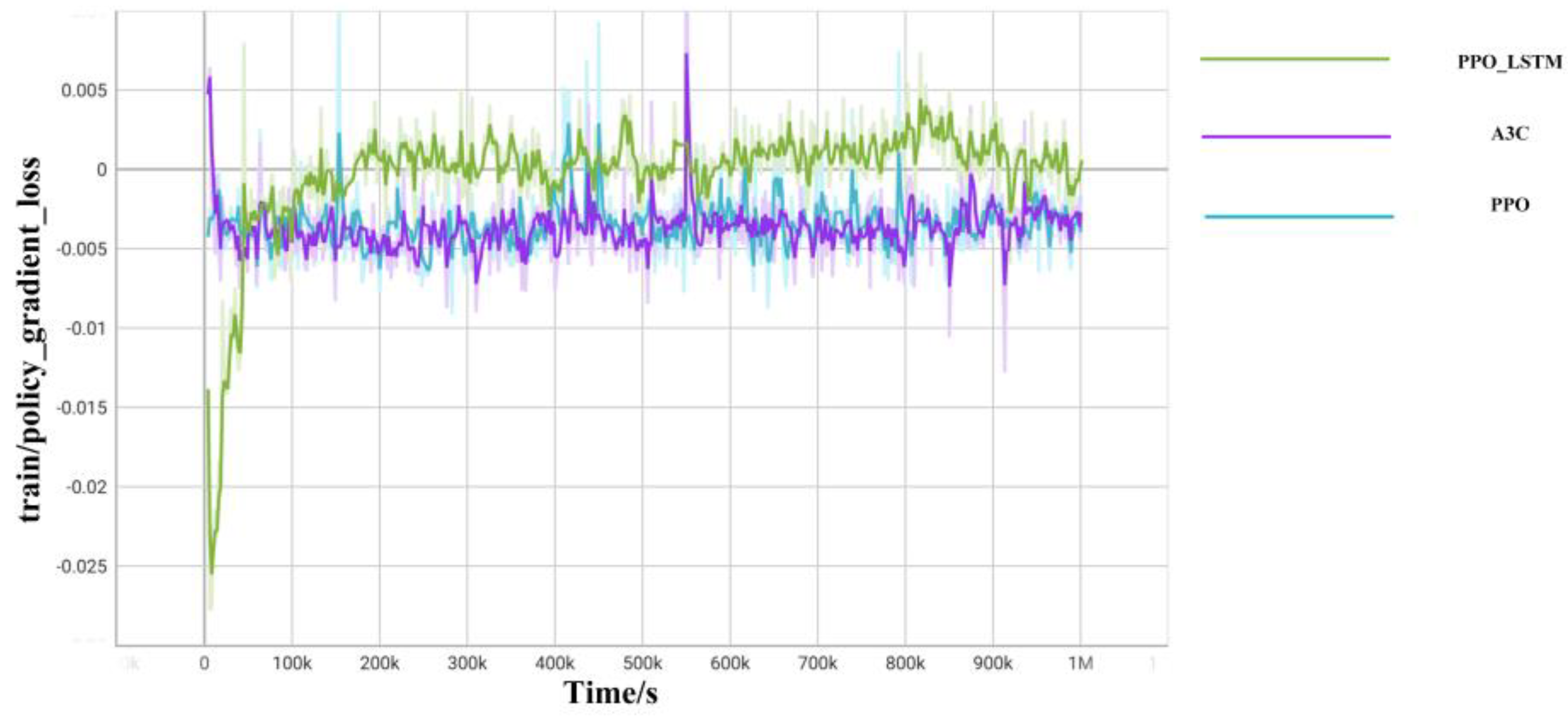
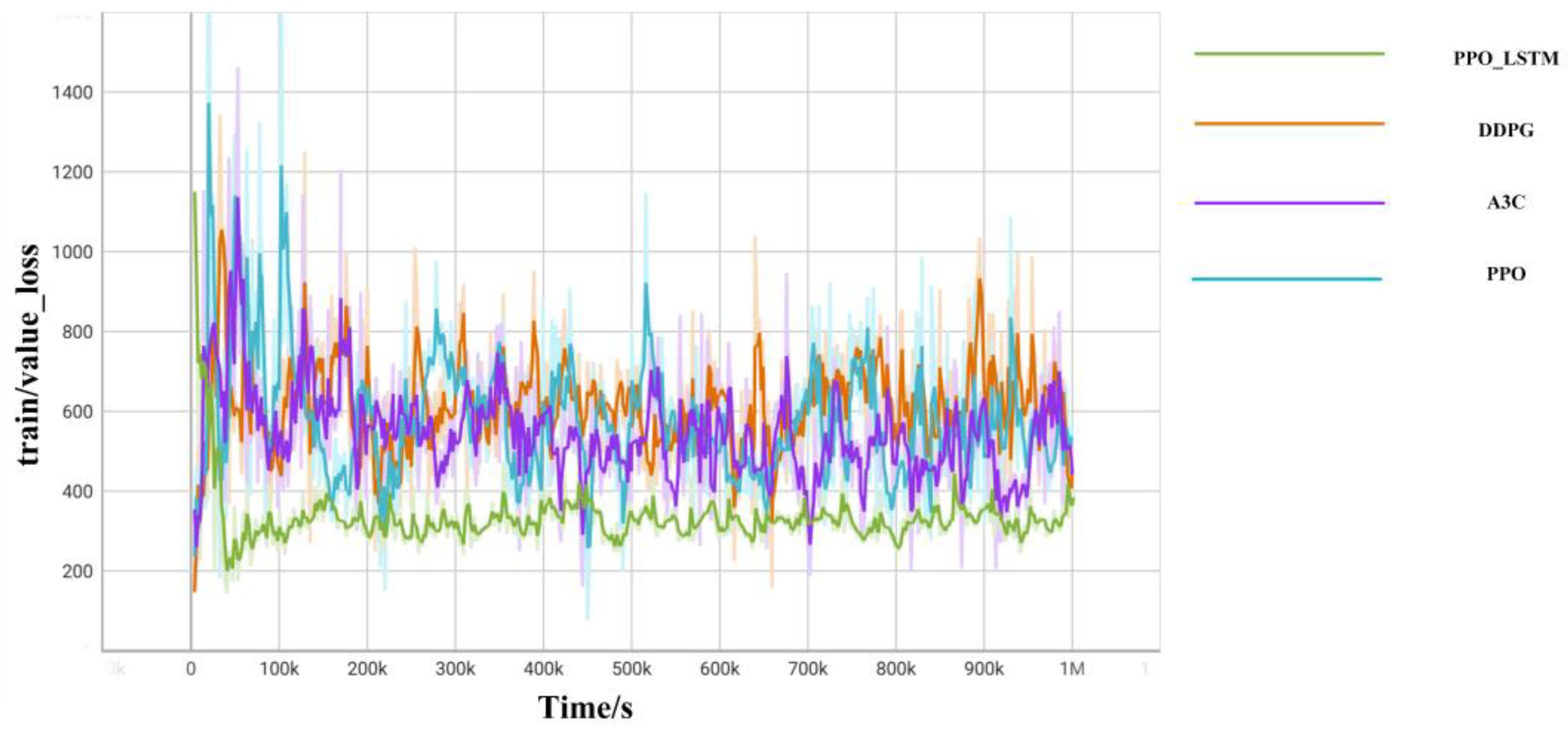
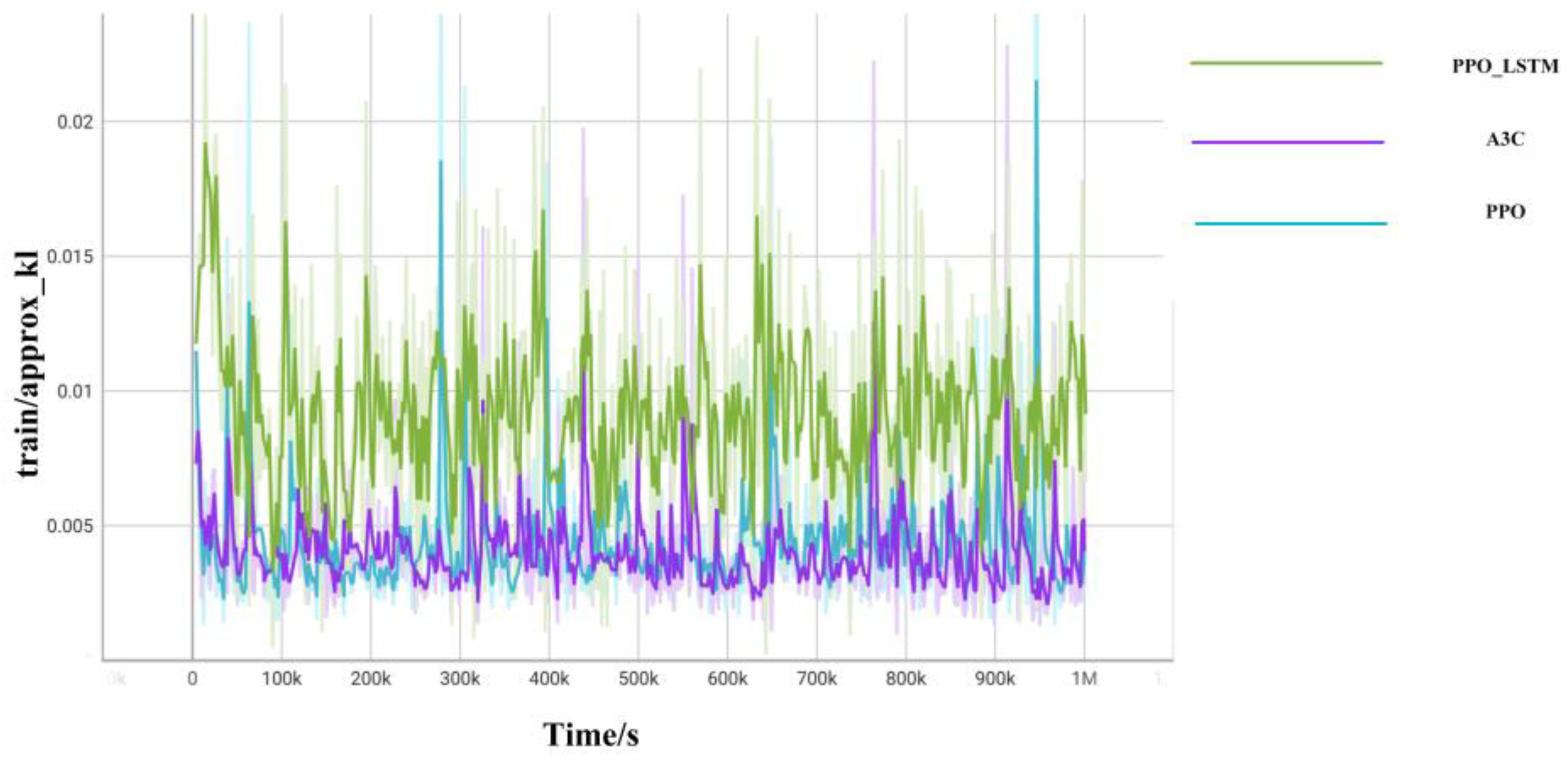





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}