
Multi-View and Multi-Type Feature Fusion Rotor Biofouling Recognition Method for Tidal Stream Turbine




Abstract
1. Introduction
- A semantic segmentation method based on MVTFF is proposed for TST biofouling recognition, aiming to improve the accuracy of TST biofouling recognition in turbid environments.
- The rotor contour features are extracted by explicit shape priors, which is conducive to more accurate positioning and recognition of targets.
- We enhance semantic information by integrating and interacting different perspectives and different types of features to improve semantic segmentation effects.
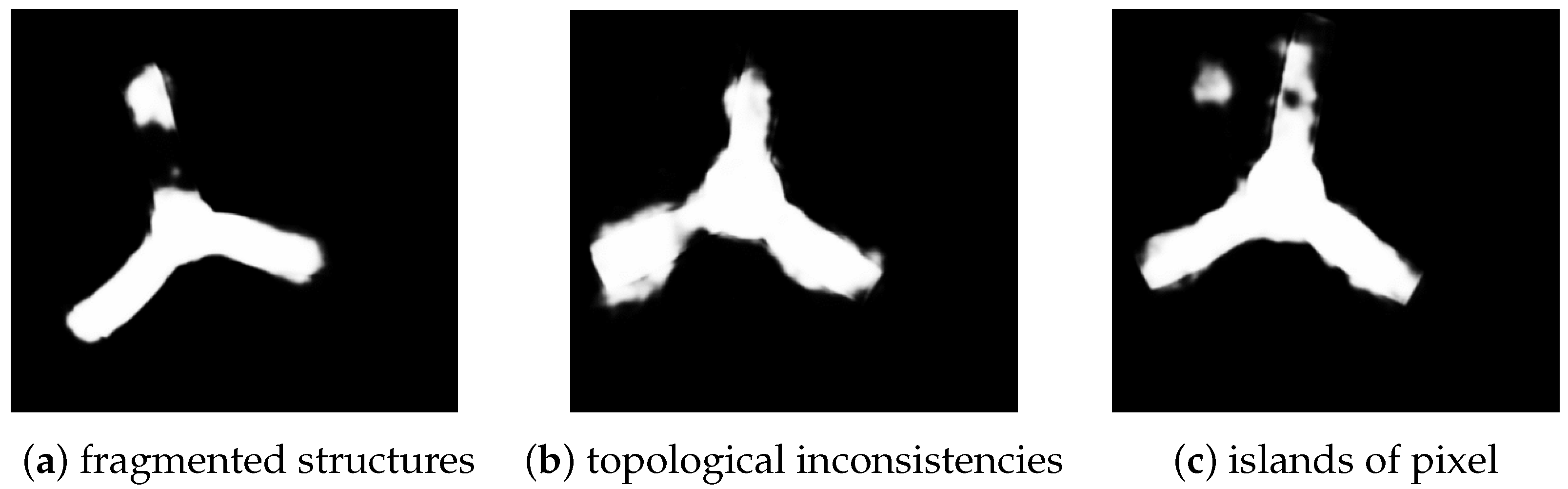
2. Problem Description
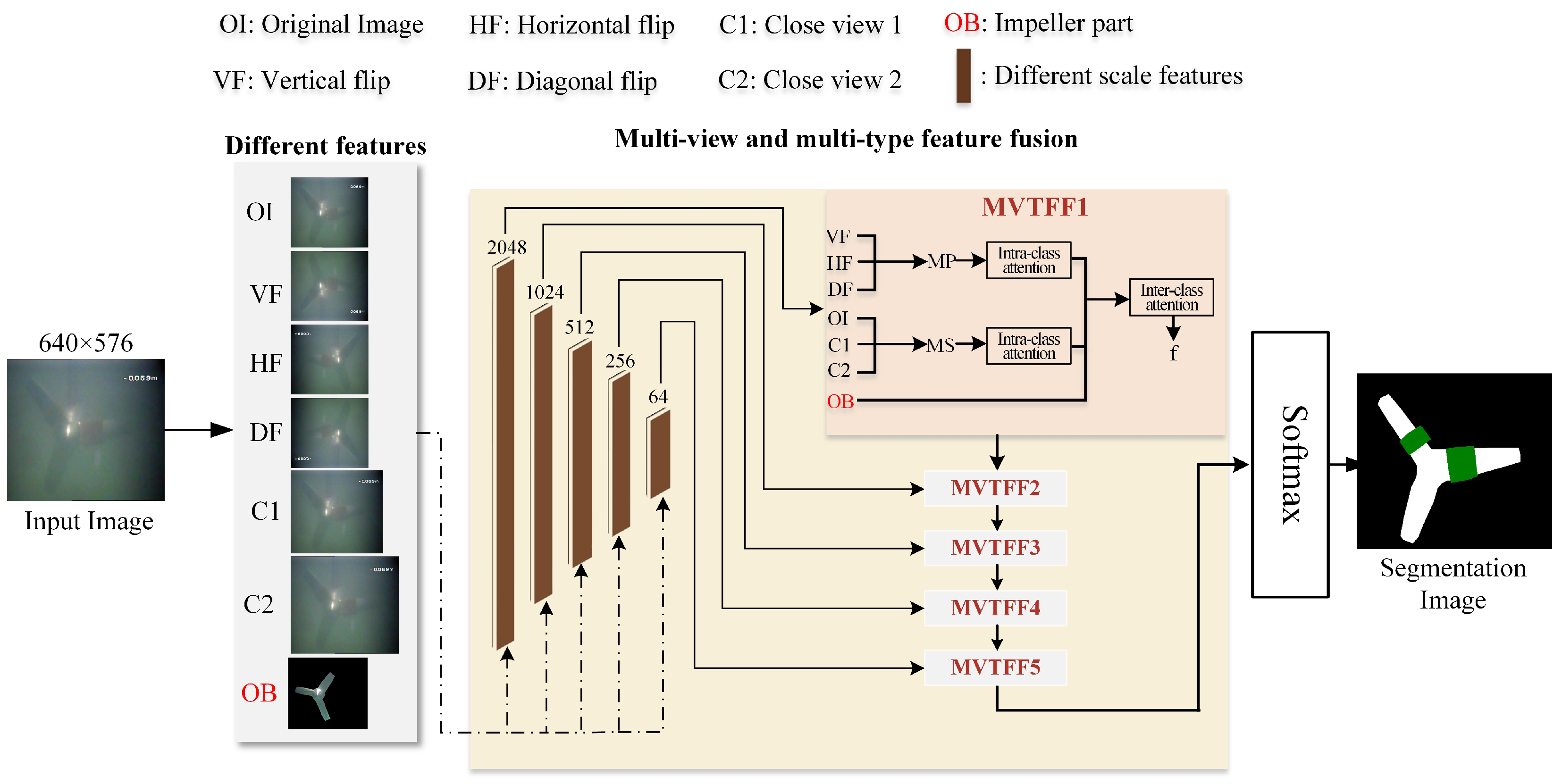
3. MVTFF-Based Biofouling Recognition for TST Rotor
3.1. Basic Process of MVTFF
3.2. Explicit Shape Prior for Training Process
3.3. Multi-View and Multi-Type Feature Fusion
3.4. Parameter Transfer for Pretrained
4. Results and Discussion
4.1. Image Dataset of TST
4.2. Implement Details of the MVTFF
4.3. Ablation Study on TST Dataset
4.4. Comparison with State-of-the-Art Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| TST | tidal stream turbine |
| MVTFF | multi-view and multi-type feature fusion |
| mIoU | mean intersection over union |
| mPA | mean pixel accuracy |
References
- Wang, S.; Yuan, P.; Li, D.; Jiao, Y. An overview of ocean renewable energy in China. Renew. Sustain. Energy Rev. 2011, 15, 91–111. [Google Scholar] [CrossRef]
- Segura, E.; Morales, R.; Somolinos, J. A strategic analysis of tidal current energy conversion systems in the European Union. Appl. Energy 2018, 212, 527–551. [Google Scholar] [CrossRef]
- Myers, L.; Bahaj, A. Simulated electrical power potential harnessed by marine current turbine arrays in the Alderney Race. Renew. Energy 2005, 30, 1713–1731. [Google Scholar] [CrossRef]
- Goundar, J.N.; Ahmed, M.R. Marine current energy resource assessment and design of a marine current turbine for Fiji. Renew. Energy 2014, 65, 14–22. [Google Scholar] [CrossRef]
- Xie, T.; Wang, T.; He, Q.; Diallo, D.; Claramunt, C. A review of current issues of marine current turbine blade fault detection. Ocean Eng. 2020, 218, 108194. [Google Scholar] [CrossRef]
- Farkas, A.; Degiuli, N.; Martić, I.; Barbarić, M.; Guzović, Z. The impact of biofilm on marine current turbine performance. Renew. Energy 2022, 190, 584–595. [Google Scholar] [CrossRef]
- Walker, J.; Green, R.; Gillies, E.; Phillips, C. The effect of a barnacle-shaped excrescence on the hydrodynamic performance of a tidal turbine blade section. Ocean Eng. 2020, 217, 107849. [Google Scholar] [CrossRef]
- Song, S.; Demirel, Y.K.; Atlar, M.; Shi, W. Prediction of the fouling penalty on the tidal turbine performance and development of its mitigation measures. Appl. Energy 2020, 276, 115498. [Google Scholar] [CrossRef]
- Grosvenor, R.I.; Prickett, P.W.; He, J. An assessment of structure-based sensors in the condition monitoring of tidal stream turbines. In Proceedings of the 2017 Twelfth International Conference on Ecological Vehicles and Renewable Energies (EVER), Monte-Carlo, Monaco, 11–13 April 2017; pp. 1–11. [Google Scholar]
- Chen, H.; Ait-Ahmed, N.; Zaim, E.; Machmoum, M. Marine tidal current systems: State of the art. In Proceedings of the 2012 IEEE International Symposium on Industrial Electronics, Hangzhou, China, 28-31 May 2012; pp. 1431–1437. [Google Scholar]
- Zheng, Y.; Wang, T.; Xin, B.; Xie, T.; Wang, Y. A sparse autoencoder and softmax regression based diagnosis method for the attachment on the blades of marine current turbine. Sensors 2019, 19, 826. [Google Scholar] [CrossRef]
- Xin, B.; Zheng, Y.; Wang, T.; Chen, L.; Wang, Y. A diagnosis method based on depthwise separable convolutional neural network for the attachment on the blade of marine current turbine. Proc. Inst. Mech. Eng. Part I J. Syst. Control Eng. 2021, 235, 1916–1926. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Peng, H.; Yang, D.; Wang, T.; Pandey, S.; Chen, L.; Shi, M.; Diallo, D. An adaptive coarse-fine semantic segmentation method for the attachment recognition on marine current turbines. Comput. Electr. Eng. 2021, 93, 107182. [Google Scholar] [CrossRef]
- Qi, F.; Wang, T. A semantic segmentation method based on image entropy weighted spatio-temporal fusion for blade attachment recognition of marine current turbines. J. Mar. Sci. Eng. 2023, 11, 691. [Google Scholar] [CrossRef]
- Yang, D.; Gao, Y.; Wang, X.; Wang, T. A rotor attachment detection method based on ADC-CBAM for tidal stream turbine. Ocean Eng. 2024, 302, 116923. [Google Scholar] [CrossRef]
- Chen, L.; Peng, H.; Yang, D.; Wang, T. An attachment recognition method based on semi-supervised video segmentation for tidal stream turbines. Ocean Eng. 2024, 293, 116466. [Google Scholar] [CrossRef]
- Rashid, H.; Benbouzid, M.; Amirat, Y.; Berghout, T.; Titah-Benbouzid, H.; Mamoune, A. Biofouling detection and classification in tidal stream turbines through soft voting ensemble transfer learning of video images. Eng. Appl. Artif. Intell. 2024, 138, 109316. [Google Scholar] [CrossRef]
- Xu, S.; Zhang, M.; Song, W.; Mei, H.; He, Q.; Liotta, A. A systematic review and analysis of deep learning-based underwater object detection. Neurocomputing 2023, 527, 204–232. [Google Scholar] [CrossRef]
- Schettini, R.; Corchs, S. Underwater image processing: State of the art of restoration and image enhancement methods. EURASIP J. Adv. Signal Process. 2010, 2010, 1–14. [Google Scholar] [CrossRef]
- Hou, G.; Pan, Z.; Wang, G.; Yang, H.; Duan, J. An efficient nonlocal variational method with application to underwater image restoration. Neurocomputing 2019, 369, 106–121. [Google Scholar] [CrossRef]
- Jian, M.; Liu, X.; Luo, H.; Lu, X.; Yu, H.; Dong, J. Underwater image processing and analysis: A review. Signal Process. Image Commun. 2021, 91, 116088. [Google Scholar] [CrossRef]
- Muniraj, M.; Dhandapani, V. Underwater image enhancement by combining color constancy and dehazing based on depth estimation. Neurocomputing 2021, 460, 211–230. [Google Scholar] [CrossRef]
- Aguirre-Castro, O.A.; García-Guerrero, E.E.; López-Bonilla, O.R.; Tlelo-Cuautle, E.; López-Mancilla, D.; Cárdenas-Valdez, J.R.; Olguín-Tiznado, J.E.; Inzunza-González, E. Evaluation of underwater image enhancement algorithms based on Retinex and its implementation on embedded systems. Neurocomputing 2022, 494, 148–159. [Google Scholar] [CrossRef]
- Yang, S.; Chen, Z.; Wu, J.; Feng, Z. Underwater imaging in turbid environments: Generation model, analysis, and verification. J. Mod. Opt. 2022, 69, 750–768. [Google Scholar] [CrossRef]
- Akkaynak, D.; Treibitz, T.; Shlesinger, T.; Loya, Y.; Tamir, R.; Iluz, D. What is the space of attenuation coefficients in underwater computer vision? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4931–4940. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Bohlender, S.; Oksuz, I.; Mukhopadhyay, A. A survey on shape-constraint deep learning for medical image segmentation. IEEE Rev. Biomed. Eng. 2021, 16, 225–240. [Google Scholar] [CrossRef] [PubMed]
- You, X.; He, J.; Yang, J.; Gu, Y. Learning with explicit shape priors for medical image segmentation. IEEE Trans. Med. Imaging 2024, 44, 927–940. [Google Scholar] [CrossRef] [PubMed]
- Zheng, D.; Zheng, X.; Yang, L.T.; Gao, Y.; Zhu, C.; Ruan, Y. Mffn: Multi-view feature fusion network for camouflaged object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 6232–6242. [Google Scholar]
- Kolda, T.G.; Bader, B.W. Tensor decompositions and applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Components | Layer Type | Input Size | Parameter |
|---|---|---|---|
| Backbone Processing | Conv3x3 × 2 | (B, in_dim, H, W) | stride = 1, padding = 1 |
| Feature Fusion | Conv3x3 × 2 | (B, 192, H, W) | stride = 1, padding = 1 |
| Dataset Attribute | |
|---|---|
| Image size | 640 × 576 |
| Training set | 1100 |
| Testing set | 200 |
| mIoU | mPA | Precision | Recall | |
|---|---|---|---|---|
| different views | 68.84 | 83.87 | 79.32 | 83.87 |
| single view | 63.53 | 70.34 | 81.15 | 70.34 |
| mIoU | mPA | Precision | Recall | |
|---|---|---|---|---|
| shape priors | 68.84 | 83.87 | 79.32 | 83.87 |
| no shape priors | 58.98 | 69.16 | 74.78 | 69.16 |
| Method | MVTFF | Unet | Swin-Unet | DeeplabV3+ | SETR |
|---|---|---|---|---|---|
| mIoU | 68.84 | 54.22 | 66.92 | 59.79 | 40.21 |
| mPA | 83.87 | 75.25 | 82.84 | 73.50 | 57.26 |
| Precision | 79.32 | 81.36 | 83.90 | 75.50 | 58.79 |
| Recall | 83.87 | 75.25 | 82.84 | 73.50 | 57.26 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.; Yang, D.; Wang, T.; Benbouzid, M. Multi-View and Multi-Type Feature Fusion Rotor Biofouling Recognition Method for Tidal Stream Turbine. J. Mar. Sci. Eng. 2025, 13, 356. https://doi.org/10.3390/jmse13020356
Xu H, Yang D, Wang T, Benbouzid M. Multi-View and Multi-Type Feature Fusion Rotor Biofouling Recognition Method for Tidal Stream Turbine. Journal of Marine Science and Engineering. 2025; 13(2):356. https://doi.org/10.3390/jmse13020356
Chicago/Turabian StyleXu, Haoran, Dingding Yang, Tianzhen Wang, and Mohamed Benbouzid. 2025. "Multi-View and Multi-Type Feature Fusion Rotor Biofouling Recognition Method for Tidal Stream Turbine" Journal of Marine Science and Engineering 13, no. 2: 356. https://doi.org/10.3390/jmse13020356
APA StyleXu, H., Yang, D., Wang, T., & Benbouzid, M. (2025). Multi-View and Multi-Type Feature Fusion Rotor Biofouling Recognition Method for Tidal Stream Turbine. Journal of Marine Science and Engineering, 13(2), 356. https://doi.org/10.3390/jmse13020356