
Dynamic Target Hunting Under Autonomous Underwater Vehicle (AUV) Motion Planning Based on Improved Dynamic Window Approach (DWA)

Abstract
1. Introduction
- Assumption 1: Obstacles and AUVs are on the same horizontal plane.
- Assumption 2: AUVs can obtain environmental information using sonar and other sensor equipment, including the positions of obstacles and the size and speed of dynamic obstacles.
- Assumption 3: AUVs navigate along the planned path, and their motion parameters are consistent with the planned parameters.
- Assumption 4: The motion state information of AUVs, including position, heading angle, and speed, can be shared within the cluster.
- A motion planning algorithm based on improved DWA is proposed to enhance the collision avoidance performance of AUVs in complex static obstacle environments and dynamic obstacle environments.
- Setting up multi-AUV-distributed collision avoidance rules and integrating them into the evaluation system of DWA, quantifying the collision avoidance rules, and establishing the corresponding rule evaluation function so as to optimize the motion trajectories conforming to the collision avoidance rules among the predicted set of trajectories.
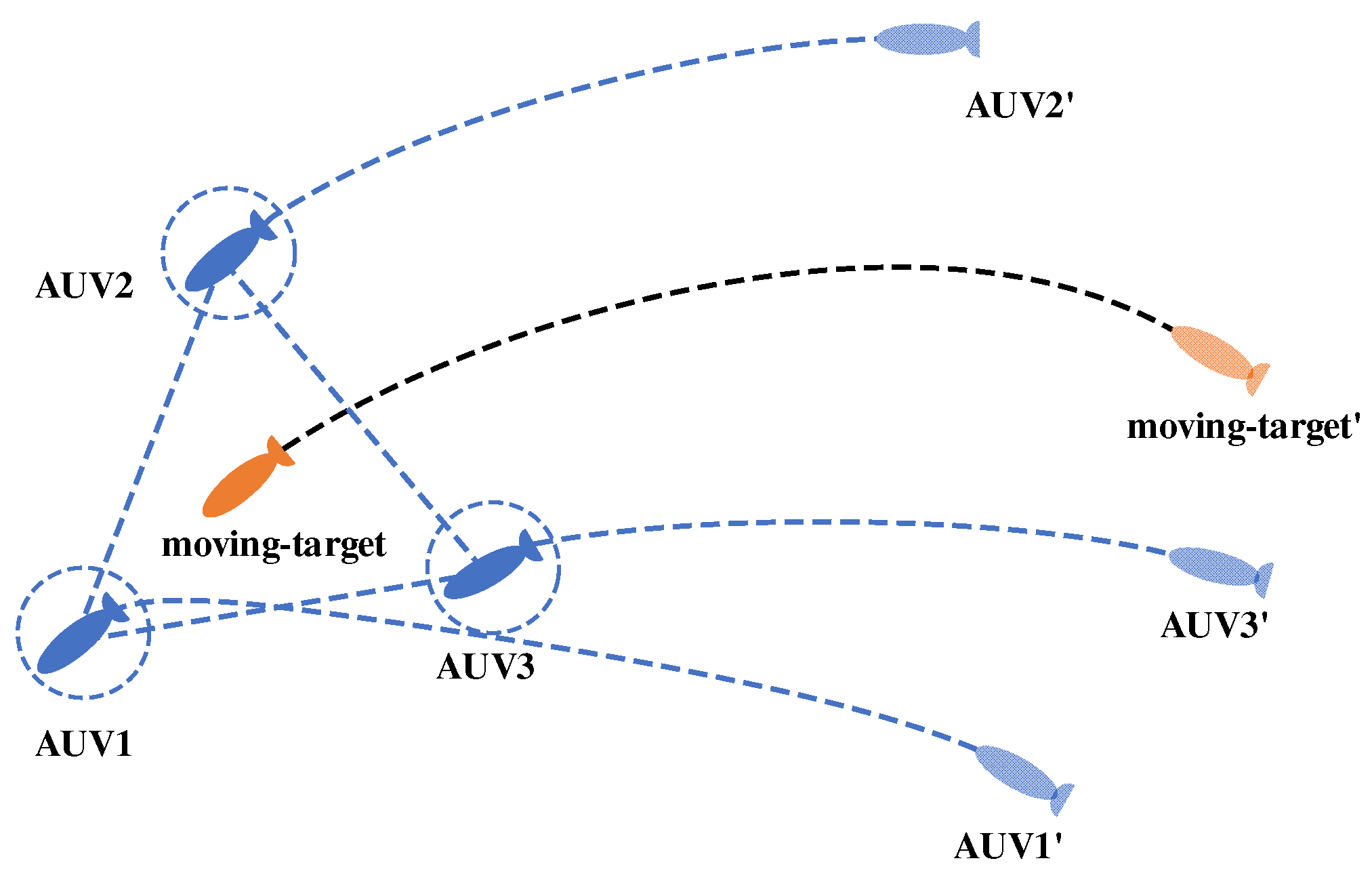
- A consistency algorithm is introduced to ensure the consistency of multi-AUV information and mission continuity in the case of leader failure. Dynamic target trajectories are predicted by polynomial regression, and hunting potential points are dynamically assigned according to the polygonal hunting formation, which is formed by combining the distributed motion planning of each AUV.
2. Task Element Modeling
2.1. AUV Kinematic Modeling
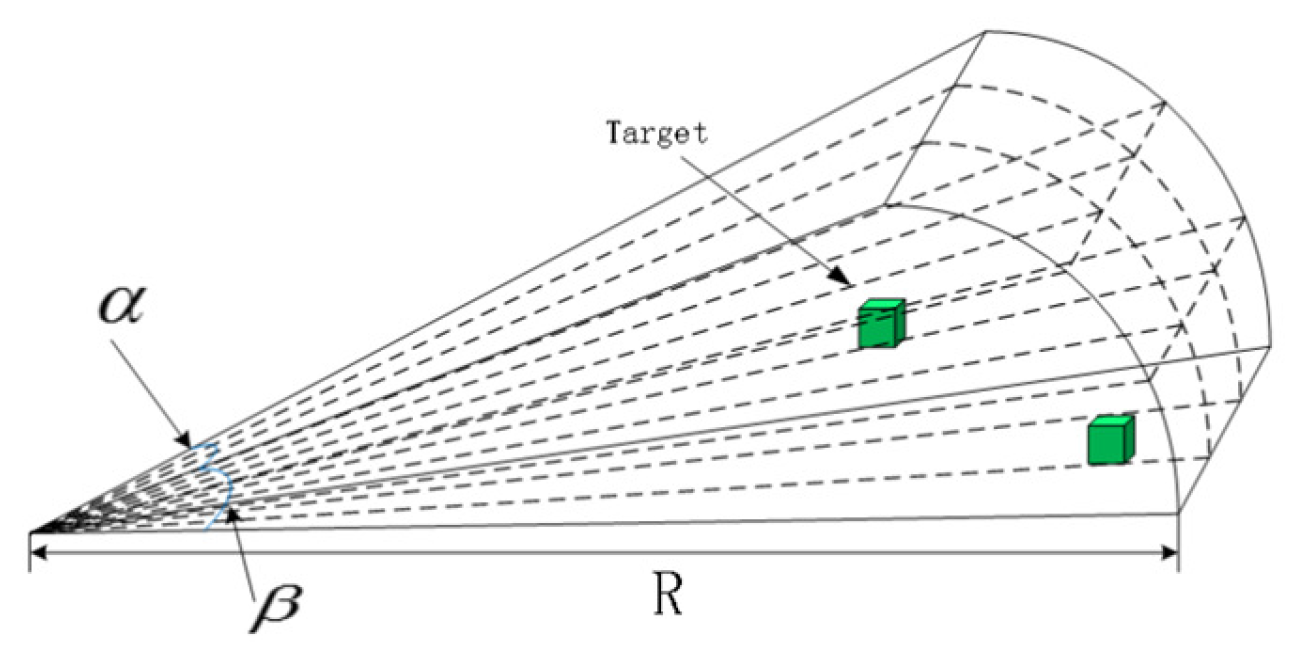
2.2. Forward-Looking Sonar Detection Model
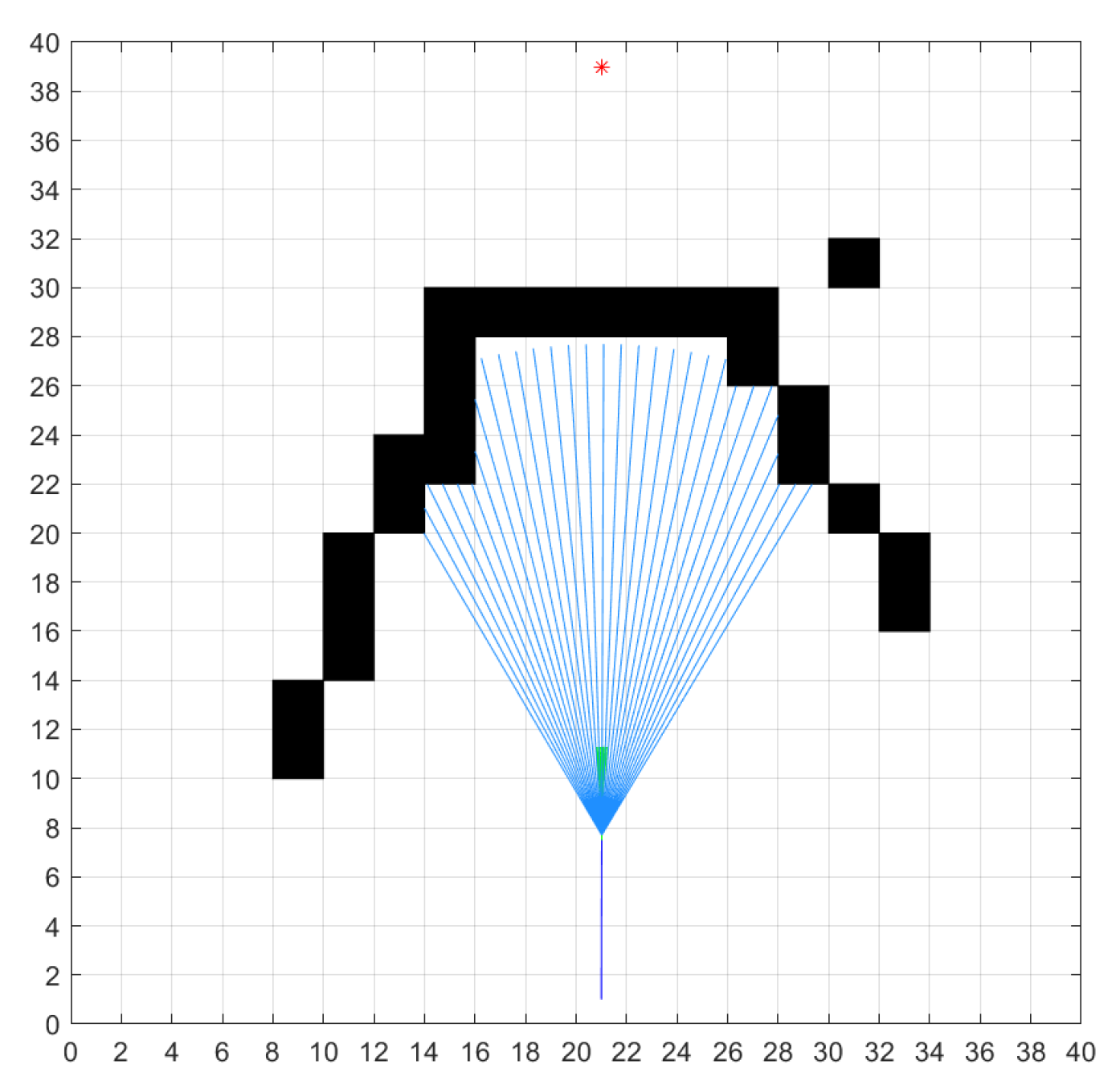
2.3. Static Obstacle Modeling
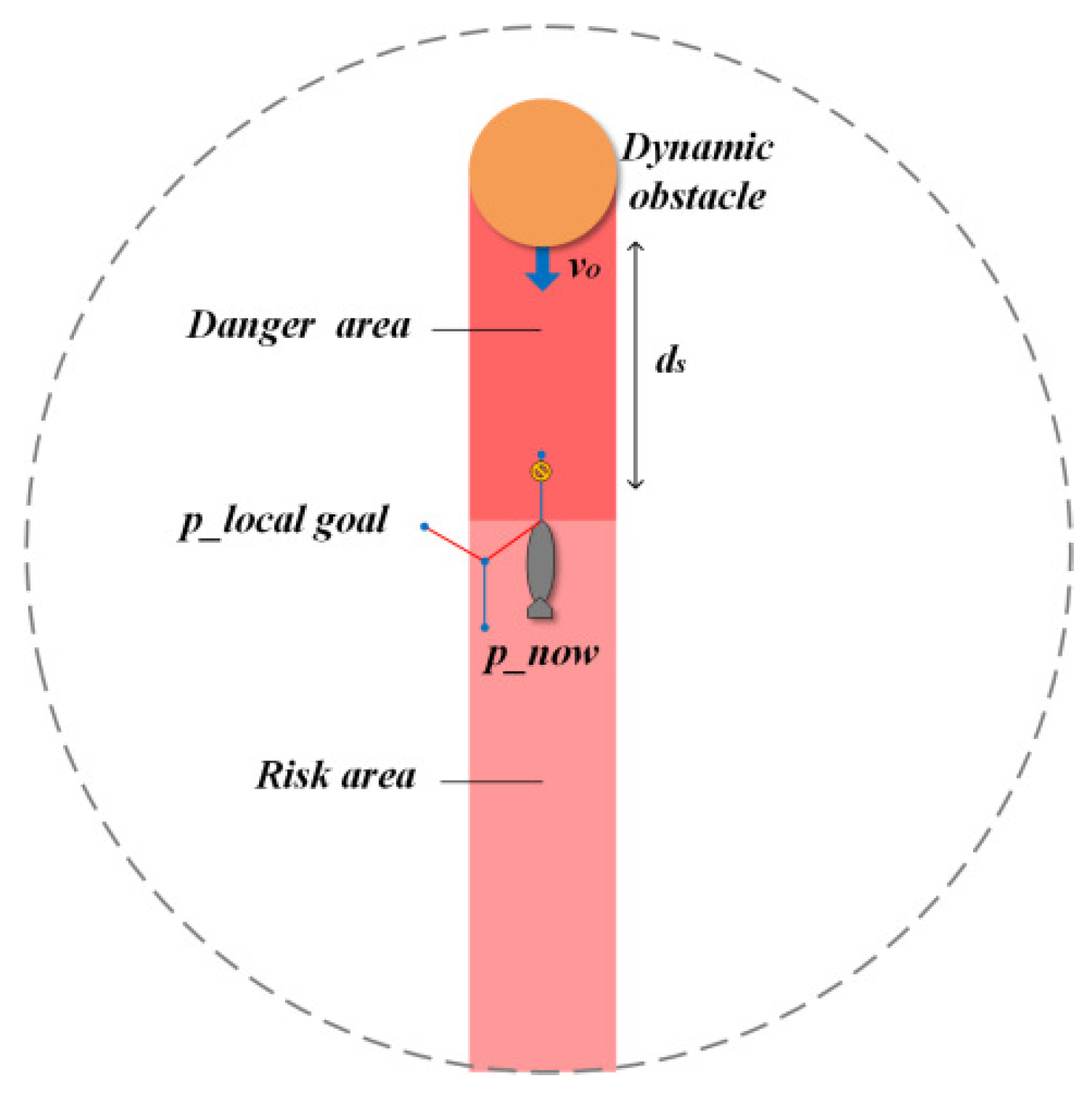
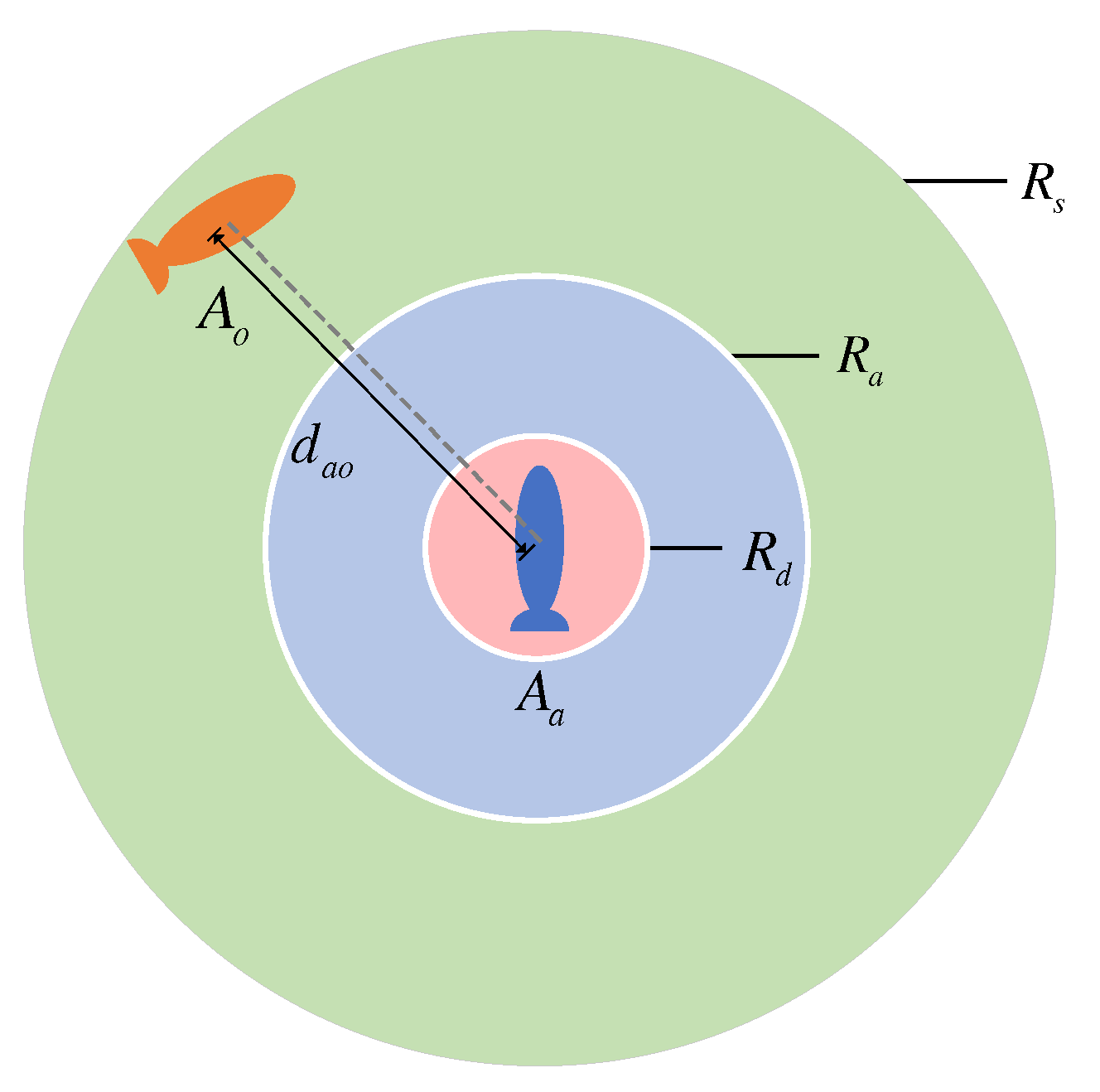
2.4. Dynamic Obstacle Modeling
3. Obstacle Avoidance Motion Planning for AUV Based on DWA and RRT
3.1. Basic DWA Algorithm
| Algorithm 1 Dynamic Window Approach |
| Input: current position robotPose, target point robotGoa, model parameter robotModel Output: motion trajectory dataset robotTrajectory |
| 1: BEGIN 2: desiredV = calculateV(robotPose,robotGoal) 3: laserscan = readScanner() 4: allowable_v = generateWindow(robotV, robotModel) 5: allowable_w = generateWindow(robotW, robotModel) 6: for each v in allowable_v 7: for each w in allowable_w 8: dist = find_dist(v,w,laserscan,robotModel) 9: breakDist = calculateBreakingDistance(v) 10: if (dist > breakDist) 11: heading = hDiff(robotPose,goalPose, v,w) 12: clearance = (dist − breakDist)/(dmax − breakDist) 13: cost = costFunction(heading,clearance, abs(desired_v −v)) 14: if (cost > optimal) 15: best_v = v 16: best_w = w 17: optimal = cost 18: set robotTrajectory to best_v, best_w 19:END |
3.2. Improvement of Velocity Space
3.3. Obstacle Sampling Window
3.4. Complex Static Obstacle Avoidance Incorporating SAGRRT
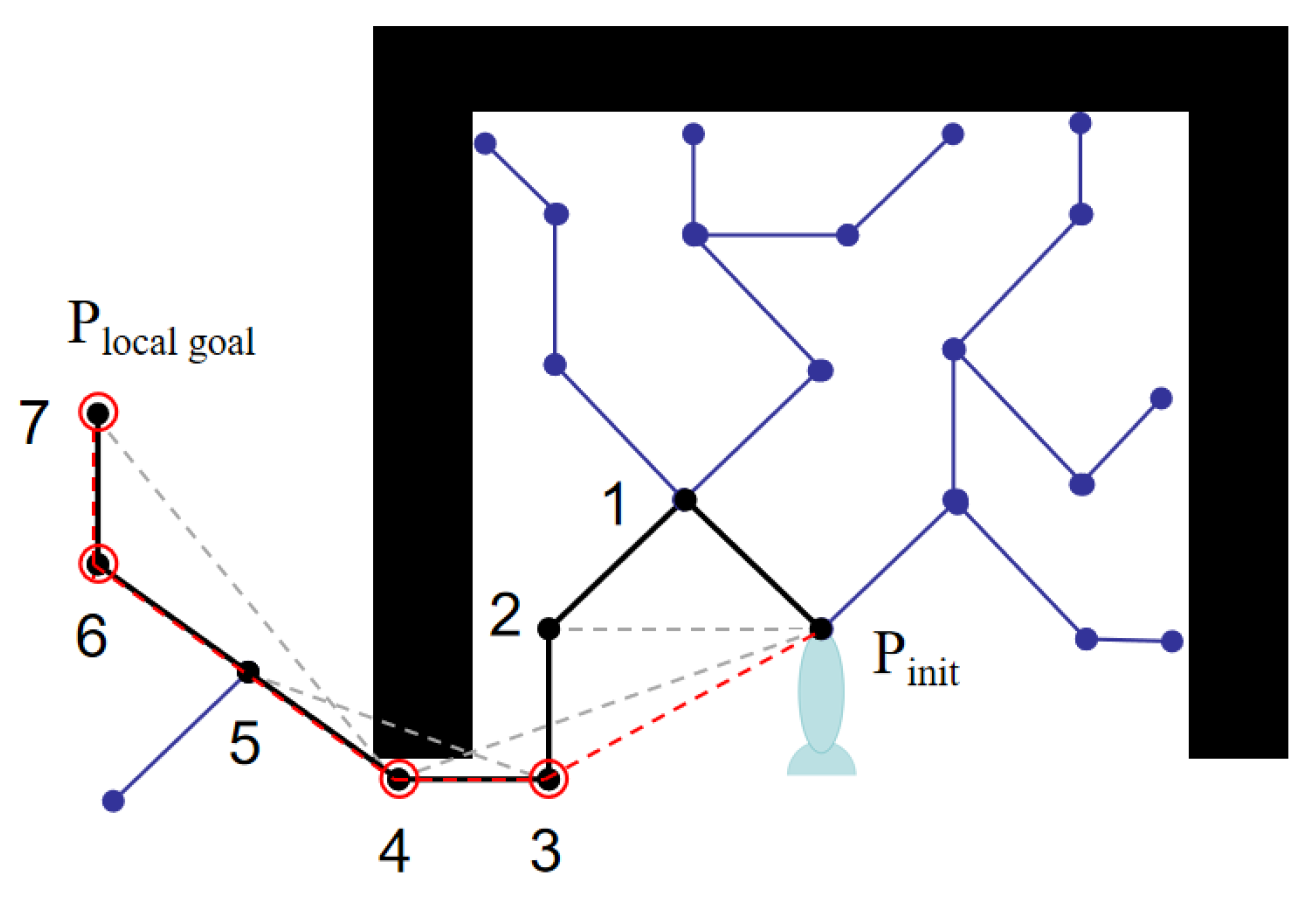
3.4.1. SAGRRT Static Obstacle Avoidance Guidepost Planning
3.4.2. Extraction Rules for Key Guiding Points
3.5. Dynamic Obstacle Avoidance Incorporating DAGRRT
4. Introduction of DAGRRT Dynamic Obstacle Avoidance
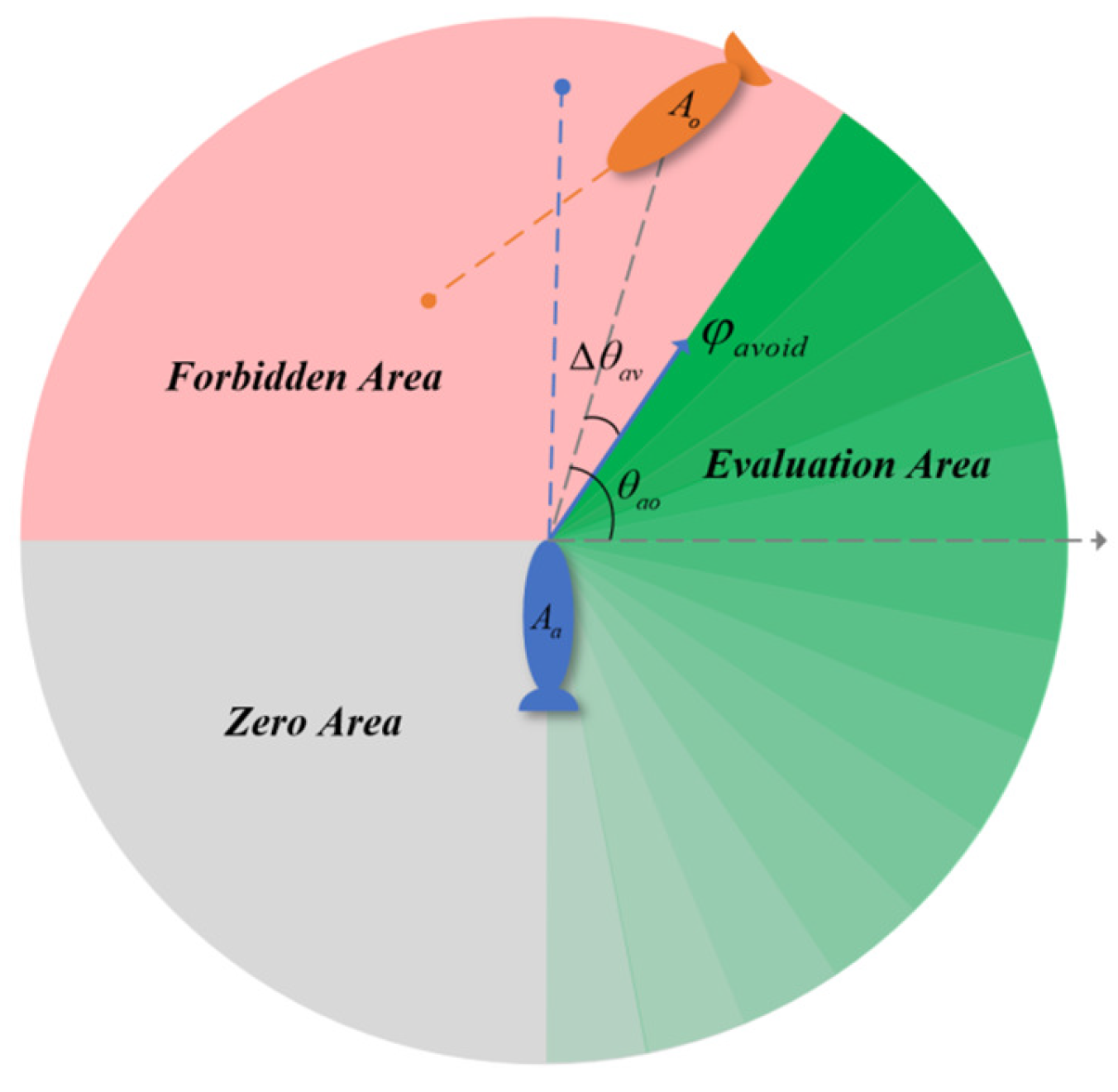
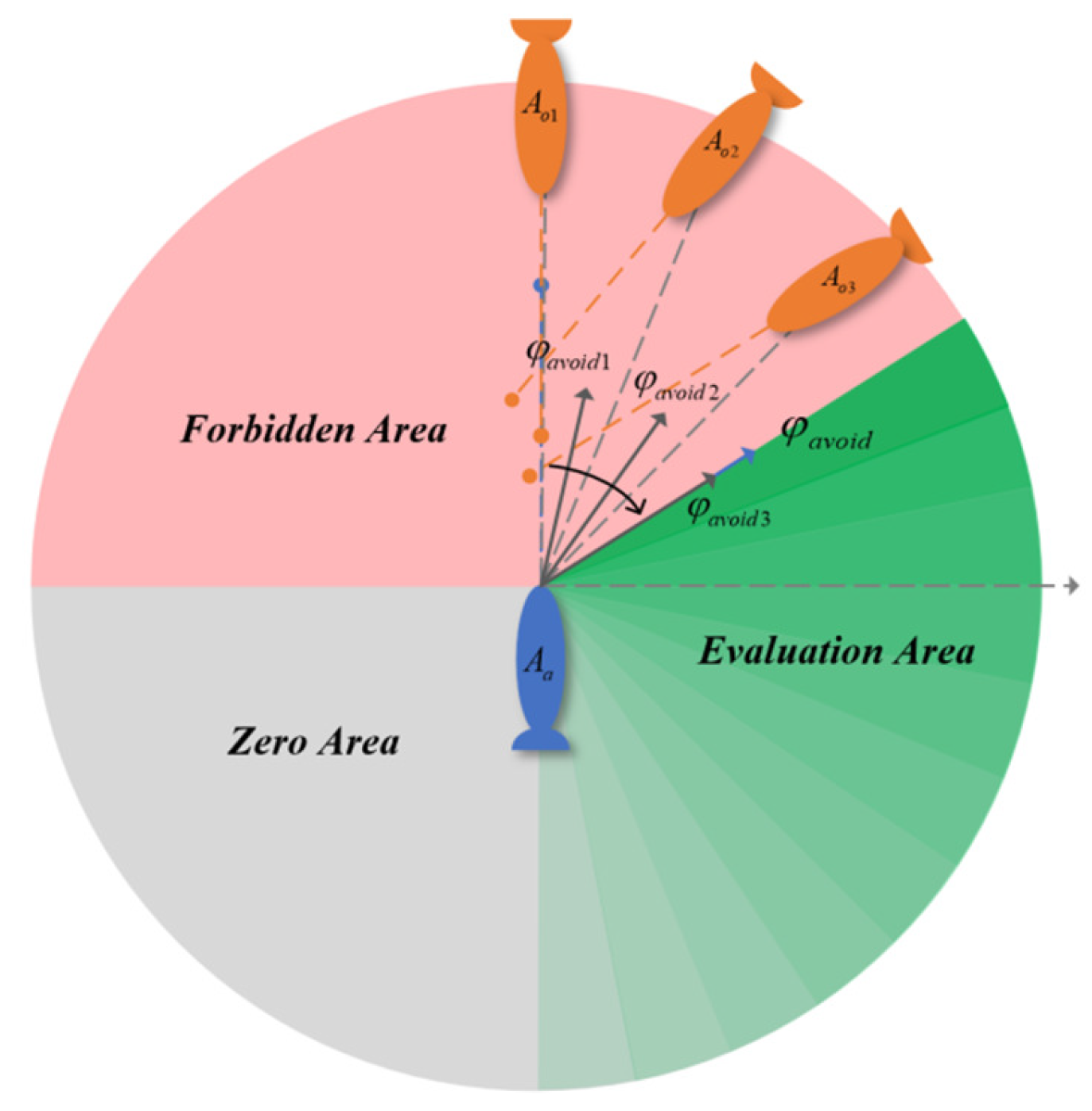
4.1. Bump Avoidance Space Division
4.2. DWA Collision Avoidance Rule Evaluation Function
5. Distributed Dynamic Target Hunting by AUVs Based on CPPPEA
5.1. AUV Swarm Consistency Algorithm
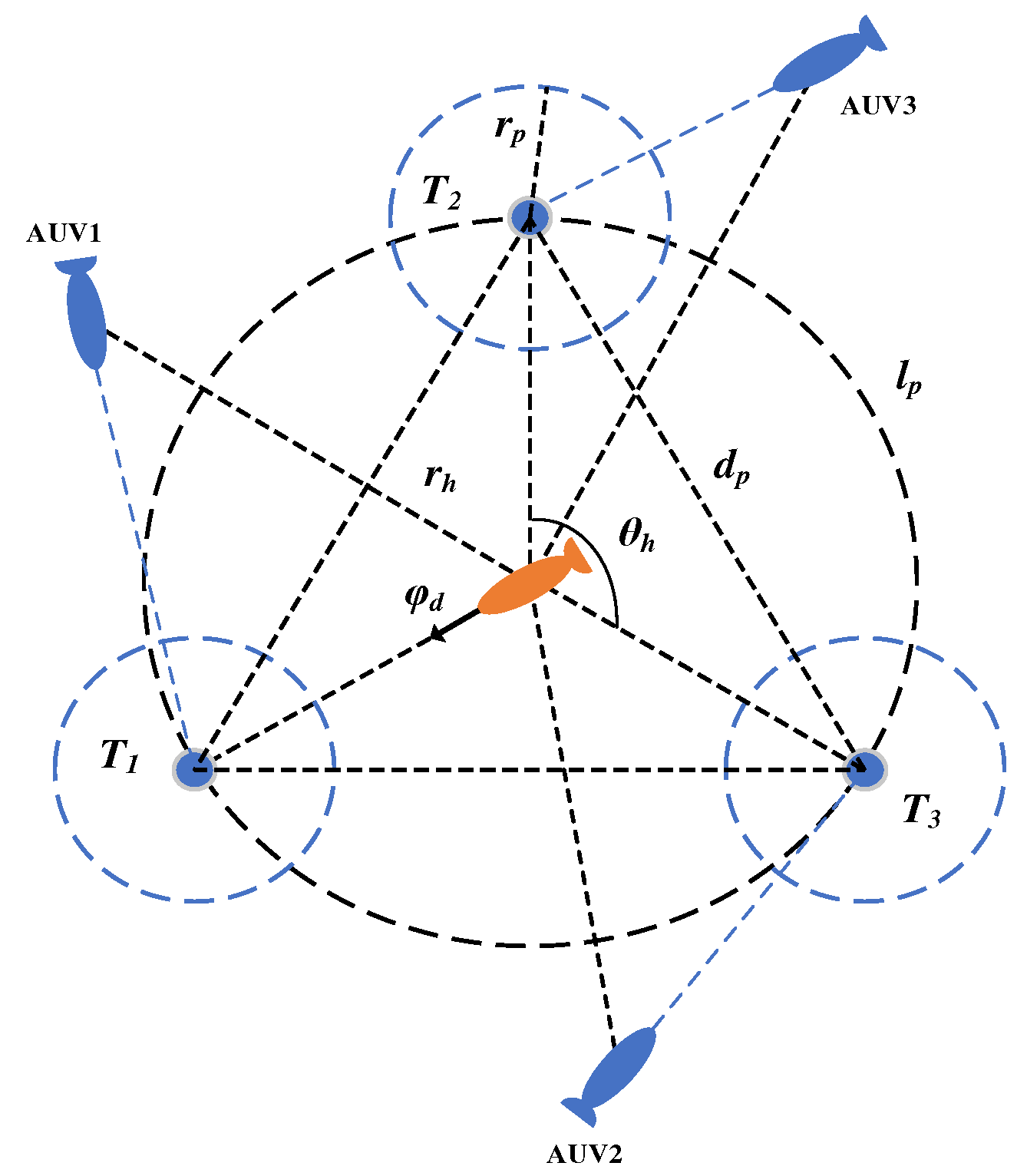
5.2. Formation Method of the Hunting Formation
5.2.1. Nonlinear Regression Fitting of Moving Target Trajectories
5.2.2. Calculation Method for Hunting Base Point
5.2.3. Moving Target Hunting Formation Method
6. Simulation Results
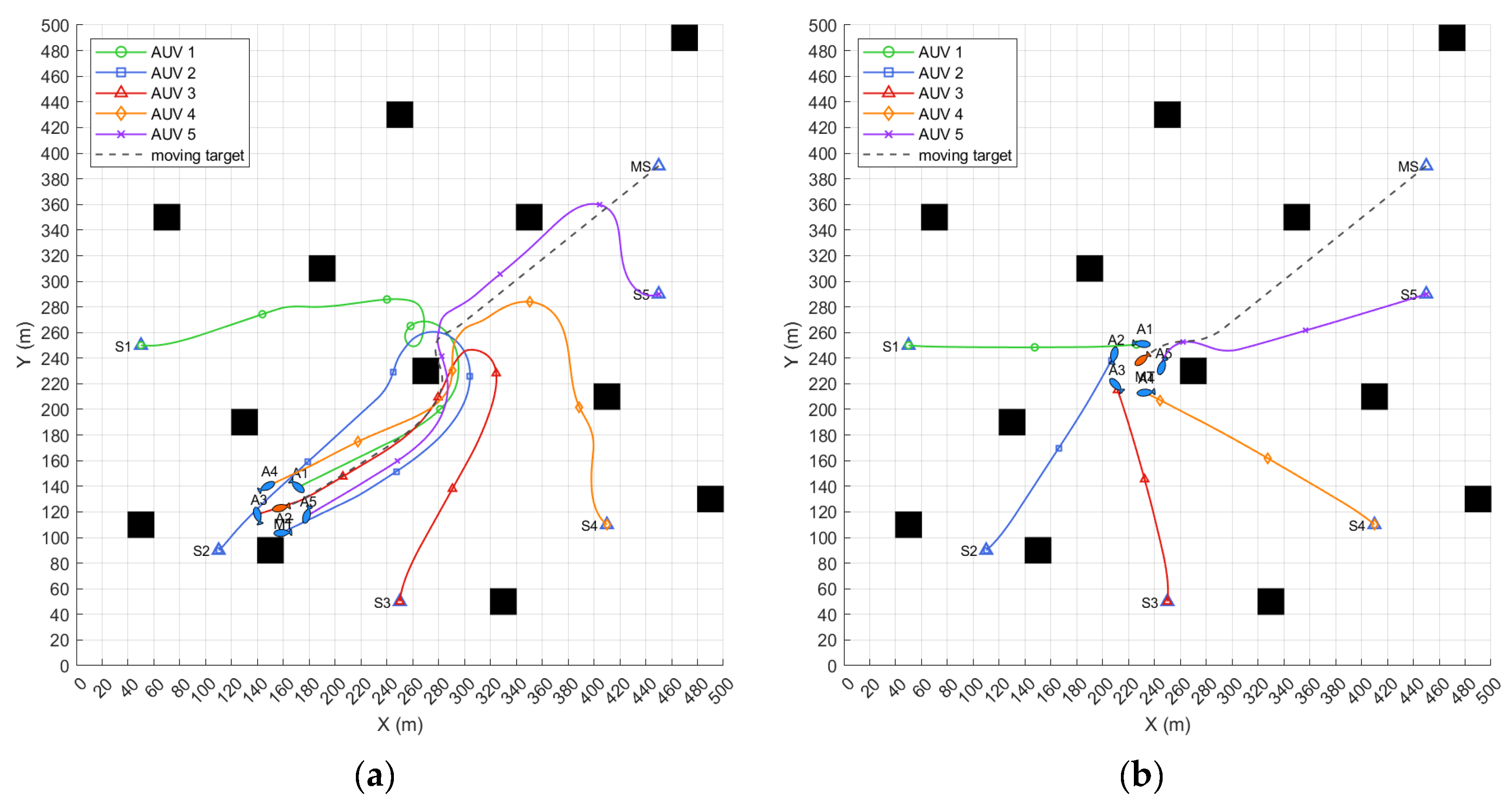
6.1. Simulation of Target Hunting Task When the Moving Target’s Speed Is Less than the AUV’s
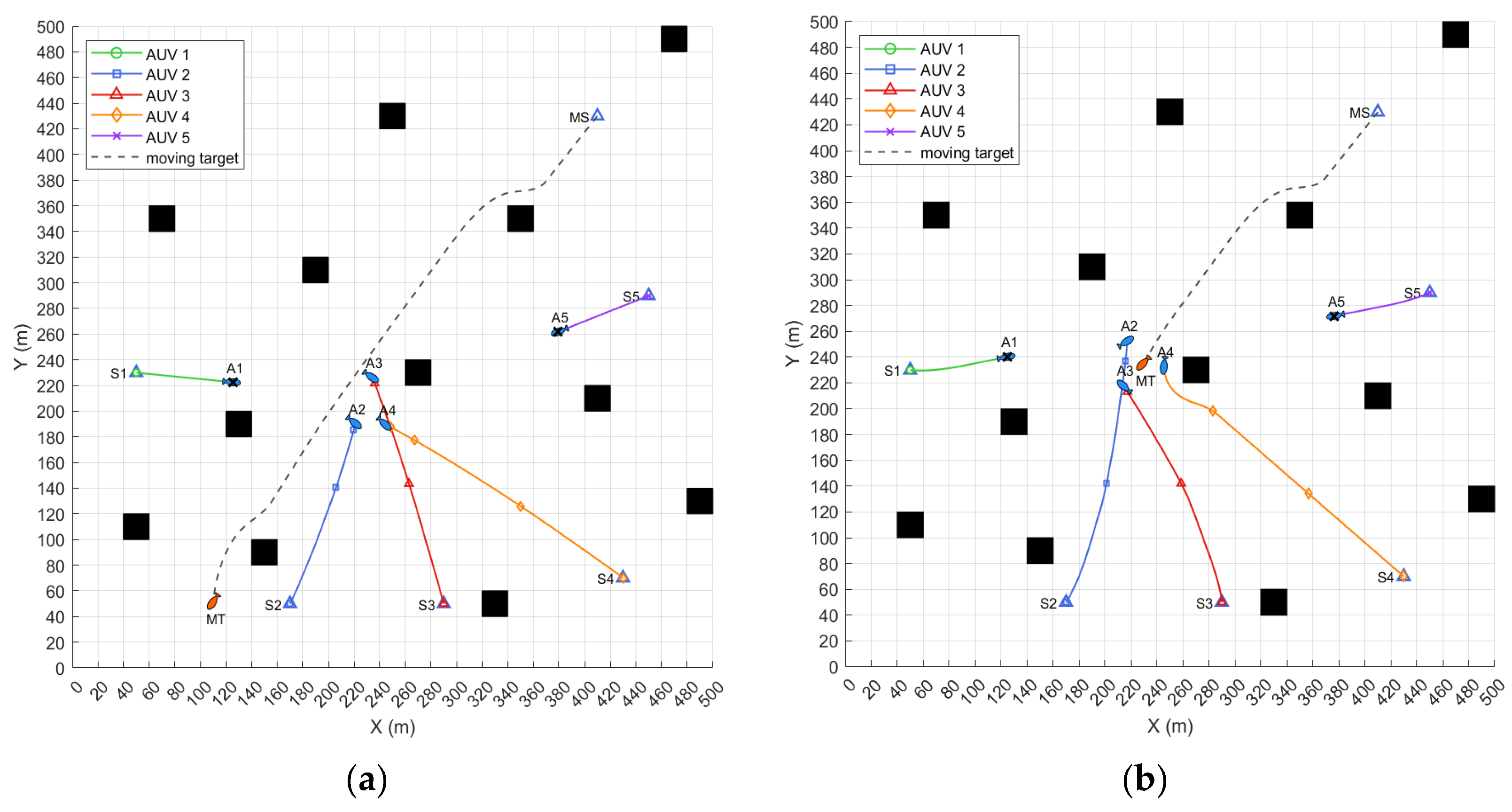
6.2. Simulation of the Hunting Task When the Moving Target’s Speed Equals the AUV’s
6.3. Simulation of Hunting Task When the Leader Fails
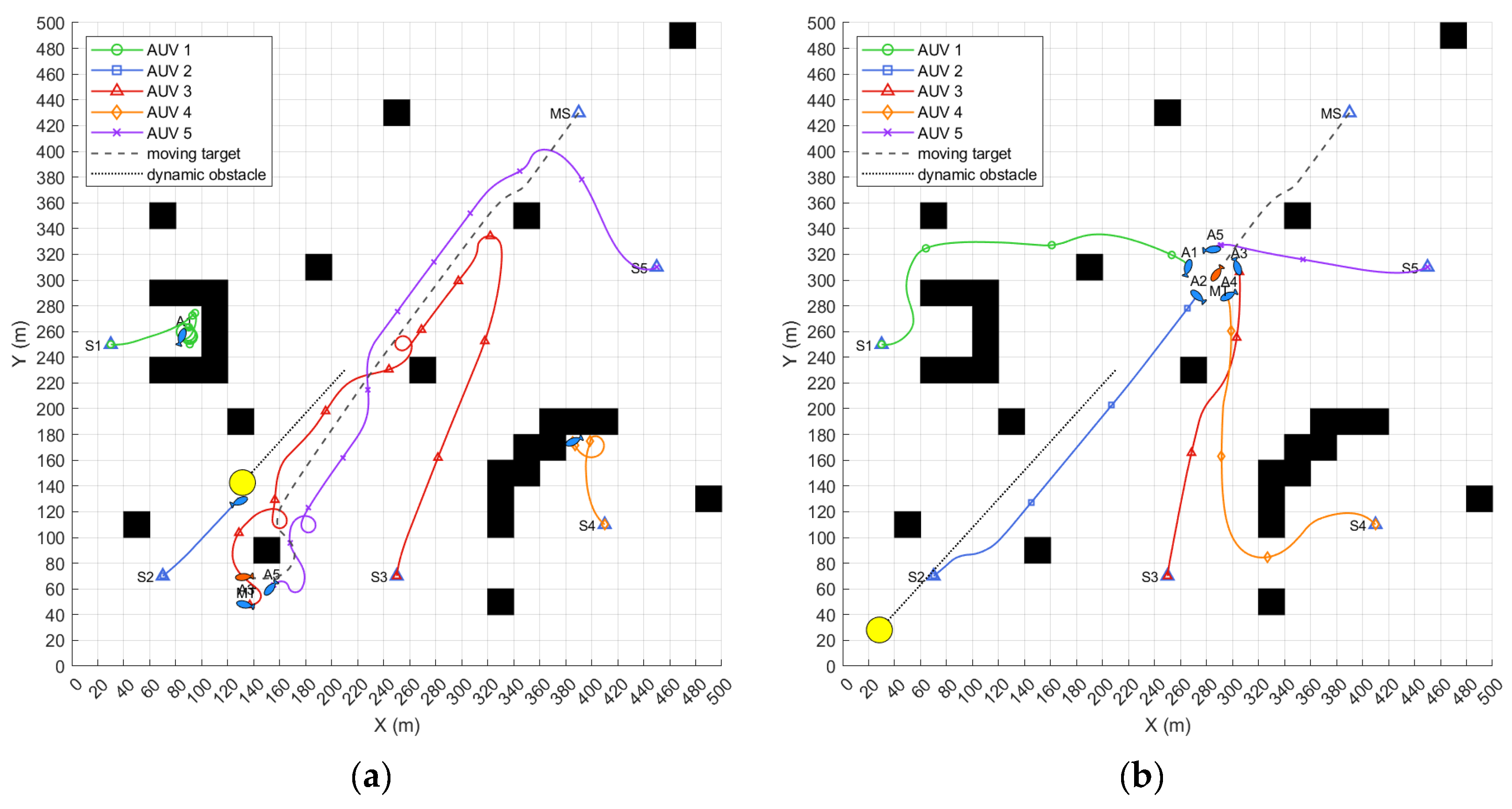
6.4. Simulation of Hunting Task in a Complex Obstacle Environment
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, L.; Zhu, D.; Pang, W.; Zhang, Y. A survey of underwater search for multi-target using Multi-AUV: Task allocation, path planning, and formation control. Ocean. Eng. 2023, 278, 114393. [Google Scholar] [CrossRef]
- Cheng, C.; Sha, Q.; He, B.; Li, G. Path planning and obstacle avoidance for AUV: A review. Ocean. Eng. 2021, 235, 109355. [Google Scholar] [CrossRef]
- Hao, K.; Zhao, J.; Li, Z.; Liu, Y.; Zhao, L. Dynamic path planning of a three-dimensional underwater AUV based on an adaptive genetic algorithm. Ocean. Eng. 2022, 263, 112421. [Google Scholar] [CrossRef]
- Xiang, X.; Yu, C.; Zhang, Q. On intelligent risk analysis and critical decision of underwater robotic vehicle. Ocean. Eng. 2017, 140, 453–465. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, N.; Wu, W. A hybrid path planning algorithm considering AUV dynamic constraints based on improved A* algorithm and APF algorithm. Ocean. Eng. 2023, 285, 115333. [Google Scholar] [CrossRef]
- Liu, T.; Zhao, J.; Huang, J.; Li, Z. A hybrid RVO-MPPI approach for efficient collision avoidance for multiple autonomous underwater vehicles. Ocean. Eng. 2024, 312, 119205. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, Z.; Xue, Y.; Deng, Z.; Qin, H. Local path planning of under-actuated AUV based on VADWA considering dynamic model. Ocean. Eng. 2024, 310, 118705. [Google Scholar] [CrossRef]
- Rösmann, C.; Feiten, W.; Wösch, T.; Hoffmann, F.; Bertram, T. Trajectory modification considering dynamic constraints of autonomous robots. In Proceedings of the ROBOTIK 2012—7th German Conference on Robotics, Munich, Germany, 22–25 May 2012; pp. 74–79. [Google Scholar]
- Guo, Y.; Liu, H.; Fan, X.; Lyu, W. Research progress of path planning methods for autonomous underwater vehicle. Math. Probl. Eng. 2021, 2021, 8847863. [Google Scholar] [CrossRef]
- Molinos, E.J.; Llamazares, A.; Ocaña, M. Dynamic window based approaches for avoiding obstacles in moving. Robot. Auton. Syst. 2019, 118, 112–130. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, C.; Wu, H.; Wei, Y. Mobile Robot Path Planning Based on Kinematically Constrained A-Star Algorithm and DWA Fusion Algorithm. Mathematics 2023, 11, 4552. [Google Scholar] [CrossRef]
- Song, B.; Tang, S.; Li, Y. A new path planning strategy integrating improved ACO and DWA algorithms for mobile robots in dynamic environments. Math. Biosci. Eng. MBE 2024, 21, 2189–2211. [Google Scholar] [CrossRef] [PubMed]
- Xu, T. Recent advances in Rapidly-exploring random tree: A review. Heliyon 2024, 10, e32451. [Google Scholar] [CrossRef] [PubMed]
- Hu, W.; Chen, S.; Liu, Z.; Luo, X.; Xu, J. HA-RRT: A heuristic and adaptive RRT algorithm for ship path planning. Ocean. Eng. 2024, 316, 119906. [Google Scholar] [CrossRef]
- Li, J.; Zhang, Z. AUV Local Path Planning Based on Fusion of Improved DWA and RRT Algorithms. In Proceedings of the ICMA 2023—2023 IEEE International Conference on Mechatronics and Automation, Harbin, China, 6–9 August 2023; pp. 935–941. [Google Scholar]
- Zhu, Y.; Liu, J.; Guo, C.; Song, P.; Zhang, J.; Zhu, J. Prediction of Battlefield Target Trajectory Based on LSTM. In Proceedings of the ICCA 2020 IEEE International Conference on Control and Automation, Singapore, 9–11 October 2020; pp. 725–730. [Google Scholar]
- Wang, H.; Wang, X.; Yu, L.; Zhong, F. Design of Mean Shift Tracking Algorithm Based on Target Position Prediction. In Proceedings of the ICMA 2019—2019 IEEE International Conference on Mechatronics and Automation, Tianjin, China, 4–7 August 2019; pp. 1114–1119. [Google Scholar]
- Zhang, R.; Wang, Y.; Wan, X.; Ming, Y.; Yang, S. Position prediction of underwater gliders based on a new heterogeneous model ensemble method. Ocean. Eng. 2024, 309, 118312. [Google Scholar] [CrossRef]
- Meng, X.; Sun, B.; Zhu, D. Harbour protection: Moving invasion target interception for multi-AUV based on prediction planning interception method. Ocean. Eng. 2021, 219, 108268. [Google Scholar] [CrossRef]
- Lan, Y. Multiple mobile robot cooperative target intercept with local coordination. In Proceedings of the CCDC 2012—2012 24th Chinese Control and Decision Conference, Taiyuan, China, 23–25 May 2012; pp. 145–151. [Google Scholar]
- Tahir, M.N.; Ren, Z. Maneuvering target interception using retrospective-cost-based adaptive input and state estimation. In Proceedings of the CGNCC 2016—2016 IEEE Chinese Guidance, Navigation and Control Conference, Nanjing, China, 12–14 August 2016; pp. 603–608. [Google Scholar]
- Refsnes, J.E.; Sorensen, A.J.; Pettersen, K.Y. Model-based output feedback control of slender-body underactuated AUVs: Theory and experiments. IEEE Trans. Control. Syst. Technol. 2008, 16, 930–946. [Google Scholar] [CrossRef]
- Cao, X.; Sun, H.; Jan, G.E. Multi-AUV cooperative target search and tracking in unknown underwater environment. Ocean. Eng. 2018, 150, 1–11. [Google Scholar] [CrossRef]
- Han, L.; Wu, X.; Sun, X. Hybrid path planning algorithm for mobile robot based on A* algorithm fused with DWA. In Proceedings of the ICIBA 2023—2023 IEEE 3rd International Conference on Information Technology, Big Data and Artificial Intelligence, Chongqing, China, 26–28 May 2023; pp. 1465–1469. [Google Scholar]
- Wu, B.; Chi, X.; Zhao, C.; Zhang, W.; Lu, Y.; Jiang, D. Dynamic Path Planning for Forklift AGV Based on Smoothing A* and Improved DWA Hybrid Algorithm. Sensors 2022, 22, 7079. [Google Scholar] [CrossRef] [PubMed]
- Zhong, X.; Tian, J.; Hu, H.; Peng, X. Hybrid Path Planning Based on Safe A* Algorithm and Adaptive Window Approach for Mobile Robot in Large-Scale Dynamic Environment. J. Intell. Robot. Syst. Theory Appl. 2020, 99, 65–77. [Google Scholar] [CrossRef]
- Yu, Q.; Lin, Q.; Zhu, Z.; Wong, K.C.; Coello, C.A. A dynamic multi-objective evolutionary algorithm based on polynomial regression and adaptive clustering. Swarm Evol. Comput. 2022, 71, 101075. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mission Elements | Initial Position/m | Bow Angle /rad | Initial Speed /kn | Maximum Speed/kn |
|---|---|---|---|---|
| AUV1 | 50,250 | −0.1 | 0 | 4 |
| AUV2 | 11,090 | 0.7 | 0 | 4 |
| AUV3 | 25,050 | 1.5 | 0 | 4 |
| AUV4 | 410,110 | 2.4 | 0 | 4 |
| AUV5 | 450,290 | −2.8 | 0 | 4 |
| Moving target | 450,390 | −2.5 | 0 | 2 |
| Hunting Method | Hunting Success | Travel Distance/m | Turning Cost/rad |
|---|---|---|---|
| Tracking hunting | Yes | 1692.3 | 126.7 |
| The proposed method | Yes | 1123.8 | 36.1 |
| Mission Elements | Initial Position/m | Bow Angle /rad | Initial Speed /kn | Maximum Speed/kn |
|---|---|---|---|---|
| AUV1 | 50,250 | −0.1 | 0 | 4 |
| AUV2 | 11,090 | 0.7 | 0 | 4 |
| AUV3 | 25,050 | 1.5 | 0 | 4 |
| AUV4 | 410,110 | 2.4 | 0 | 4 |
| AUV5 | 450,290 | −2.8 | 0 | 4 |
| Moving target | 450,390 | −2.5 | 0 | 4 |
| Hunting Method | Hunting Success | Travel Distance/m | Turning Cost/rad |
|---|---|---|---|
| Tracking hunting | No | 2088.5 | 63.9 |
| The proposed method | Yes | 976.6 | 44.7 |
| Mission Elements | Initial Position/m | Bow Angle /rad | Initial Speed /kn | Maximum Speed/kn |
|---|---|---|---|---|
| AUV1 | 50,230 | 0 | 0 | 4 |
| AUV2 | 17,050 | 1.1 | 0 | 4 |
| AUV3 | 29,050 | 1.7 | 0 | 4 |
| AUV4 | 43,070 | 2.4 | 0 | 4 |
| AUV5 | 450,290 | −2.8 | 0 | 4 |
| Moving target | 410,230 | −2.2 | 0 | 4 |
| Hunting Method | Hunting Success | Travel Distance/m | Turning Cost/rad |
|---|---|---|---|
| Tracking hunting | No | 707.6 | 20.5 |
| The proposed method | Yes | 796.6 | 22.8 |
| Mission Elements | Initial Position/m | Bow Angle /rad | Initial Speed /kn | Maximum Speed/kn |
|---|---|---|---|---|
| AUV1 | 30,250 | −0.1 | 0 | 4 |
| AUV2 | 7070 | 0.7 | 0 | 4 |
| AUV3 | 25,070 | 1.4 | 0 | 4 |
| AUV4 | 410,110 | 2.4 | 0 | 4 |
| AUV5 | 450,310 | −2.7 | 0 | 4 |
| Moving target | 390,430 | −2.2 | 0 | 2 |
| Dynamic obstacle | 210,230 | −2.3 | 11 | 11 |
| Hunting Method | Hunting Success | Travel Distance/m | Turning Cost/rad |
|---|---|---|---|
| DWA + tracking hunting | No | 1835.9 | 178.9 |
| The proposed method | Yes | 1346.2 | 44.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Lu, H.; Zhang, H.; Zhang, Z. Dynamic Target Hunting Under Autonomous Underwater Vehicle (AUV) Motion Planning Based on Improved Dynamic Window Approach (DWA). J. Mar. Sci. Eng. 2025, 13, 221. https://doi.org/10.3390/jmse13020221
Li J, Lu H, Zhang H, Zhang Z. Dynamic Target Hunting Under Autonomous Underwater Vehicle (AUV) Motion Planning Based on Improved Dynamic Window Approach (DWA). Journal of Marine Science and Engineering. 2025; 13(2):221. https://doi.org/10.3390/jmse13020221
Chicago/Turabian StyleLi, Juan, Houtong Lu, Honghan Zhang, and Zihao Zhang. 2025. "Dynamic Target Hunting Under Autonomous Underwater Vehicle (AUV) Motion Planning Based on Improved Dynamic Window Approach (DWA)" Journal of Marine Science and Engineering 13, no. 2: 221. https://doi.org/10.3390/jmse13020221
APA StyleLi, J., Lu, H., Zhang, H., & Zhang, Z. (2025). Dynamic Target Hunting Under Autonomous Underwater Vehicle (AUV) Motion Planning Based on Improved Dynamic Window Approach (DWA). Journal of Marine Science and Engineering, 13(2), 221. https://doi.org/10.3390/jmse13020221