1. Introduction
Ship target detection, as an indispensable real-time monitoring technology in the marine environment, has shown high application value and practical significance in multiple key fields. Specifically, this technology plays a crucial role in improving the safety and efficiency of port operations, optimizing the response speed of maritime emergency rescue, ensuring absolute safety of ship navigation, and promoting sustainable management of fishery resources. Early ship detection methods mainly relied on manual observation and radar technology. The former mainly depended on crew members to identify the position and motion status of ships through naked eyes or optical equipment, while the latter detected the position and motion status of ships by emitting electromagnetic waves and receiving reflected waves. These methods relied on subjective human judgment and were influenced by factors such as lighting and weather. Since computer vision technology has advanced, cameras and image manipulation techniques have also begun to be applied to ship monitoring. Methods based on feature extraction and pattern recognition have gradually emerged, but their accuracy and robustness in complex marine environments are very limited. In recent years, significant progress has been made in ship detection methods based on deep learning, especially those based on convolutional neural network models, which greatly improve the accuracy and effectiveness of ship detection and make significant contributions to the cause of maritime traffic safety.
Deep learning-based detection methods reduce reliance on manual labor and automatically achieve end-to-end detection. Two categories can be distinguished between deep learning-based algorithms: two-stage algorithms and single-stage algorithms. The two-stage algorithm mainly consists of two main stages: candidate region generation and candidate region classification. Its common algorithms include R-CNN, Fast R-CNN, Faster R-CNN [
1,
2,
3], etc. Although two-stage algorithms have great advantages in accuracy and reliability, their algorithm speed is slow and cannot achieve real-time monitoring purposes. In addition, they also have high requirements for computing resources and pose certain challenges for detecting small or dense targets. The single-stage algorithm directly predicts the position and category of targets in the image without the need for candidate region generation and classification, with high real-time performance and simple network structure. The common algorithms mainly include SSD [
4], YOLO [
5,
6,
7,
8,
9,
10,
11] series, etc. Although single-stage algorithms have lower computational complexity than two-stage algorithms, they are still not lightweight enough for mobile devices with limited marine resources.
To solve the problem of a lack of lightweight many lightweight CNN network models have been proposed one after another, such as MobileNetV1, V2, V3 [
12,
13,
14] ShuffleNetV1, V2 [
15,
16], etc. MobileNetV3 mainly achieves lightweighting by combining a depthwise separable convolution and neural structure search, while ShuffleNetV2 enables the network lightweighting through shuffling operations and equalization of channel width. These networks can effectively make the model lightweight, while their lightweighting are commonly achieved at the expense of model detection accuracy. Moreover, the marine environments are generally complicated, such as obstructed ships or complex backgrounds, so their detection results still cannot meet monitoring requirements.
In addition, the clarity of images captured by maritime surveillance systems is often affected by factors such as occlusion, lighting, and shooting angles. This low-quality image poses a huge challenge to the monitoring of maritime traffic safety. It becomes particularly difficult to accurately identify ships under poor visual conditions. Also, the complex and ever-changing marine environment requires extremely high equipment requirements for monitoring systems. Large equipment cannot work continuously and stably in edge operations, and the real-time performance of systematic data transmission is poor, which cannot meet the needs of maritime traffic safety. In order to meet this demand, some common practices sacrifice detection performance to achieve lightweight requirements, but this process weakens the detection accuracy of ships due to the loss of feature details.
To ensure its detection speed and accuracy, improvements and optimizations are made on the basis of YOLOv8. Firstly, deformable convolution is used, which can adaptively adjust the shape and sampling position of the convolution kernel. Secondly, attention mechanism-based feature fusion is introduced to enhance feature fusion. Then, in terms of lightweight, GhostConv [
17] convolution was used to reduce computational costs and parameter count through low-cost linear transformation. Finally, the SIOU [
18] loss function was introduced to improve the convergence speed of the model. This model ensures its detection accuracy while achieving lightweight, making it suitable for resource limited offshore monitoring systems. And a large number of experiments were conducted on the optical image ocean ship dataset SeaShips7000 [
19] to demonstrate the effectiveness of the proposed model. The main contributions of this article are as follows:
We propose a lightweight network for maritime vessel detection by combining lightweight convolutional GhostConv with iterative attention feature fusion iAFF and DCNv2 convolution, which not only meets the requirements of detection accuracy but also reserves expected lightweight nature;
The SIOU loss function is introduced in the model to ensure the convergence speed and detection accuracy of the model;
Compared with other models, this model achieves a better balance between detection accuracy and model lightweight.
The rest of the work in this article is arranged as follows: In
Section 2, the development history of YOLO series algorithms is reviewed;
Section 3 elaborates on the proposed lightweight ship detection model based on feature fusion;
Section 4 presents the experimental results on the SeaShips dataset;
Section 5 provides a summary of this work.
3. Proposed Ship Detection Model
The challenges of ship inspection at sea mainly include improving inspection accuracy to meet the stringent requirements of marine environments, optimizing model design to achieve lightweightness, thereby reducing the demand for computing resources and enhancing the feasibility of practical applications. We suggest a YOLOv8-based lightweight vessel detecting network, called AFF-LightNet.
Figure 1 shows the exploration trajectory from YOLOv8 to AFF-LightNet. When the following modules are added one by one to the base model, their impact on the model is observed to evaluate whether they have a positive effect on the proposed model, including the loss function, feature fusion module, and lightweight module with mAP0.5:0.95 for the model. A comparison of data between 0.95 and GFLOPs and the model framework is as seen in
Figure 2. To guarantee the model’s minimal weight while also enhancing its detection precision, we have made the following changes to YOLOv8:
In order to extract the desired features more accurately, we changed the regular convolution in the Backbone network with DCNv2 for abstract of crucial characteristics;
So as to better fuse the extracted features, we added an iAFF module to the C2f of the head network to better fuse shallow and deep information;
Replacing GhostConv with the convolution module used in the Head network for faster processing speed and lower resource consumption;
Replacing the bounding box loss function CIOU with SIOU for more accurate localization, increased precision of detection, and accelerated convergence speed.
Figure 1.
The exploration process of model.
![Jmse 13 00044 i001]()
the method used in this article;
![Jmse 13 00044 i002]()
the comparative method used in this article;
![Jmse 13 00044 i003]()
the original model.
Figure 1.
The exploration process of model.
![Jmse 13 00044 i001]()
the method used in this article;
![Jmse 13 00044 i002]()
the comparative method used in this article;
![Jmse 13 00044 i003]()
the original model.
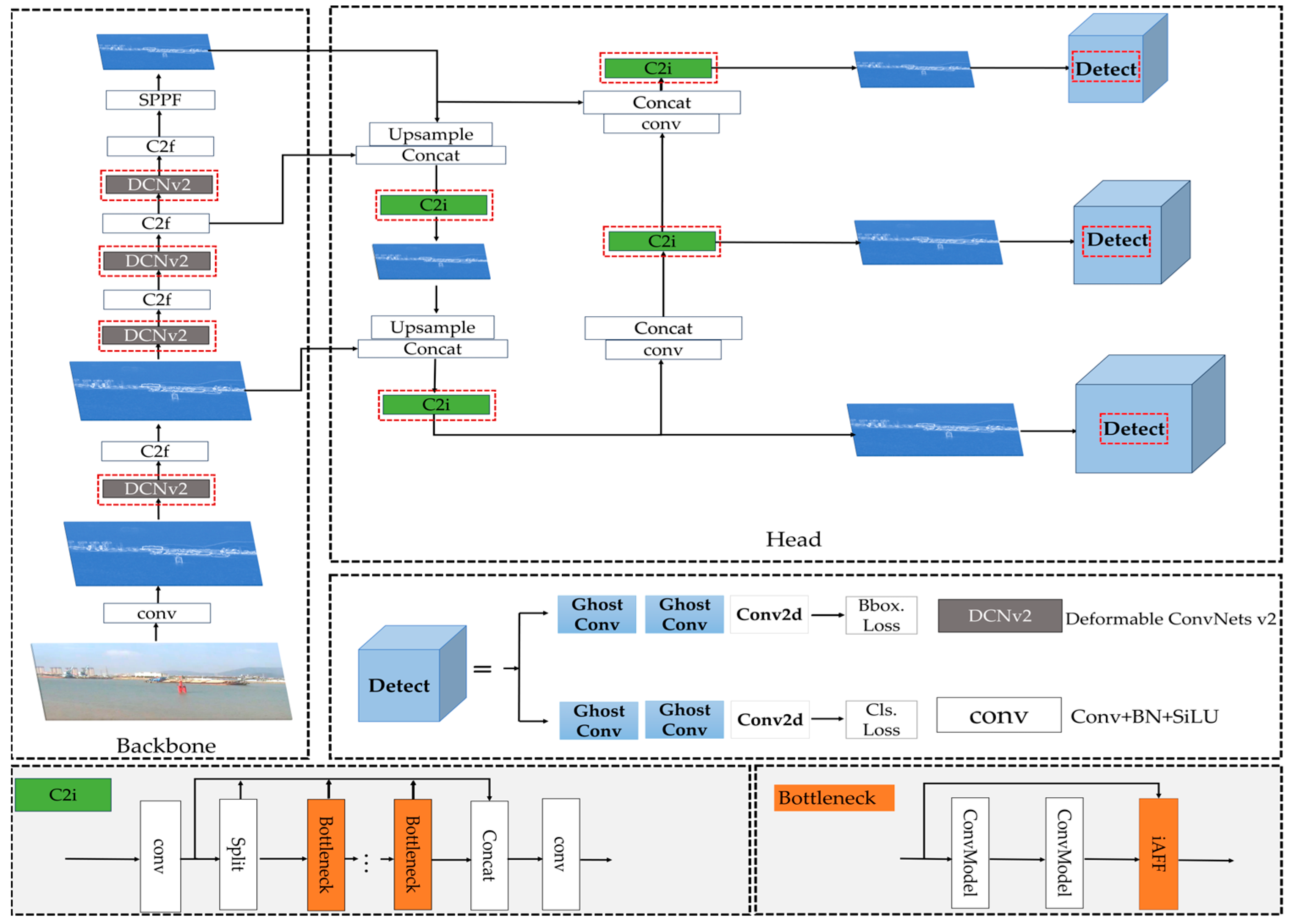
Figure 2.
AFF-LightNet model structure diagram. The red box in the figure mainly represents the improved modules of this model. AFF-LightNet mainly consists of two parts. The backbone network is mainly used for feature extraction, while the head network is mainly used for feature fusion and object detection of the features extracted from the backbone network.
Figure 2.
AFF-LightNet model structure diagram. The red box in the figure mainly represents the improved modules of this model. AFF-LightNet mainly consists of two parts. The backbone network is mainly used for feature extraction, while the head network is mainly used for feature fusion and object detection of the features extracted from the backbone network.
3.1. DCNv2 Convolution
Although traditional convolution has been widely applied in object detection tasks and has achieved significant success, it can encounter limitations in receptive fields and local connectivity issues when processing large-scale images and complex tasks. These problems stem from the fixed convolution kernel used in traditional convolution, which poses a huge challenge for targets of different scales, rotations, and deformations.
To settle the aforementioned issues, DCN (Deformable Convolutional Networks) [
38] was proposed by Zhu Junyan. et al. at the 2017 Computer Vision Conference. It adds offsets on the basis of CNN, which means that in deformable convolution, it is no longer limited to regular networks but is freely sampled on the input feature map according to requirements. The added offset is an additional parameter learned by the network, allowing the convolutional kernel to adapt more flexibly to items with varying scales, rotations, or deformations, consequently advancing the model’s learning ability for complex scenes. DCNv1 [
38] is its first version, which enhances CNN’s adaptability to target deformation and position changes in object detection tasks by introducing deformable convolutional layers. It has good effects on feature extraction and enhancing receptive fields. The operation process of it is as follows: first, use a regular grid
R with added offset
on the input feature map x, and then sum the sampling values weighted by w, which is represented as:
after undergoing deformable convolution, for each position
on the output feature map
y, it is:
among them,
represents the nth position, and
represents the offset at the
nth position.
The sample of DCNv1 activation unit is more inclined to the objects around it, but its target coverage is not comprehensive, and the sample distribution has exceeded the region of interest. To solve these problems, Microsoft Research Asia proposed DCNv2 [
39] in 2019, which mainly proposed the Deformable Roll Pooling operation and modulation mechanism. The location is shown as on the output feature map
y:
among them,
represents the modulation scalar at the nth position. In order to enhance the sensitivity of deformable convolution to spatial positions, DCNv2 introduces a modulation mechanism, it has the ability to modify both the amplitude and offset of input features at several spatial locations. Under extreme conditions, the module can control the signal that the model does not accept by setting its amplitude to zero, which can reduce the spatial position input response. This modulation mechanism allows the module to freely adjust the spatial support domain for its input data.
3.2. Introducing Iterative Attention Feature Fusion (iAFF)
Attention feature fusion is receiving increasing attention in object detection. AFF is a common method in neural networks that solves the problem of combining features from several tiers by introducing a multi-scale channel attention module (MS-CAM). Its emergence proves the existence of bottleneck problems in initial feature fusion. Based on this, it is proposed to introduce iterative operations into AFF to form iAFF, mainly optimizing the process of feature fusion through iteration.
Simple feature fusion can no longer meet the needs of cross level fusion in object detection. In order to better achieve cross level feature fusion, we propose an improved C2f module, abbreviated as C2i.
Figure 3 shows the overall structure of C2i. The original feature fusion is just a simple addition operation, which requires the input feature maps to have the same size and number of channels. Direct addition can lead to information loss and low detection accuracy. However, iAFF can overcome the limitations of addition operations in processing features of different scales, optimize the process of feature fusion through iteration, gradually improve the fusion results, and enhance the performance of the model.
Compared with traditional feature fusion, the features of small ships in images are not obvious and are easily affected by complex backgrounds. Due to the introduction of the MS-CAM module in iAFF, it can integrate features from different scales and semantic inconsistencies, which can better capture the features of small targets. iAFF can also use contextual information to assist in detection. When detecting occluded ships, iAFF can infer the position and information of the occluded part based on the characteristics of the surrounding environment and prior knowledge of the known ships. In addition, the attention weights of iAFF are dynamically adjusted based on input features, and different attention weights are assigned to different input features to highlight important features and suppress irrelevant features, in order to cope with complex and changing detection scenarios.
IAFF as a swift implementation module, can be integrated into any location in the network. Integrate it into the bottleneck of the C2f module in our model.
Figure 4 shows the embedding of iAFF at various points within the head network.
3.3. Lightweight Convolution
An essential assurance of the dependability and safety of maritime commerce is ship inspection. Though existing methods are too cumbersome for marine vessel detection and are not suitable for resource limited marine vessel detection equipment. For sorting out this problem, Google first proposed the MobileNet [
12] lightweight convolutional network in 2017, and Face++ also raised ShuffleNet [
15] in the same year. Moreover, model compression methods include pruning [
39], knowledge distillation [
40], etc. Although these methods can effectively abate the model’s computational complexity and quantity of arguments, there are still some problems such as high computational density and increased network complexity. Relatively speaking, the GhostNet [
17] model can better overcome these problems, mainly using grouped convolution and depthwise separable convolution to reduce model computation and complexity.
In this study, we replaced the ordinary convolution in the head network with GhostConv, aiming to decline the number of model parameters and computational complexity while ensuring that detection accuracy is not affected. It achieves the generation of feature layers through two parts: the main convolution kernel and the auxiliary convolution kernel. The former contains more parameters, while the latter generates more “Ghost” feature maps from the original feature map through low-cost linear transformation. The implementation process is as seen in
Figure 5, which includes three main steps: first, the input image is convolved to obtain an intrinsic feature map; then, an operation of linear transformation is performed to generate a Ghost feature map; finally, the intrinsic feature map is concatenated with the obtained Ghost feature map through identity concatenation to obtain the final output. This greatly lessens the computational complexity and parameter count of the model without affecting its performance, making it more suitable for mobile or embedded devices in resource constrained environments.
3.4. Optimizing the Bounding Box Loss Function
The training effect in the object detection task is directly impacted by the loss function selection, convergence speed, and functioning of the model. An excellent bounding box loss function can bring breakthrough performance to the model. However, existing regression loss functions only consider the ratio of intersection and union between the predicted box and the true box, without considering additional geometric factors, which can lead to the problem of gradient vanishing and affect the training effectiveness of the model. SIOU [
18] not only considers the overlapping area of bounding boxes but also introduces geometric characteristics such as center point distance, aspect ratio, and angle, which enables SIOU to more accurately describe the differences between predicted boxes and real boxes, thereby improving detection accuracy and robustness.
The SIOU loss function specifically includes four parts: angle cost, distance cost, shape cost, and IOU [
34] loss. Angle loss describes the minimum angle between the center point of the predicted box and the true box when connected to the horizontal and vertical distances. The distance loss describes the distance between the predicted box and the center point of the true box, and its penalty cost is proportional to the angle cost; The shape loss mainly considers the aspect ratio between the predicted box and the actual box. It is defined by calculating the difference in width between the two boxes and the maximum width ratio and converges on both sides of the length and width to achieve overall convergence. The definition of the SIOU loss function is:
among them:
where ∆ indicates distance loss, Ω indicates form loss,
represents the horizontal distance amid the actual box’s center and the anticipated box’s center,
represents the vertical separation between the actual box’s center and the box’s anticipated center, and w represents the weight. The degree of attention to shape loss is controlled by
θ, and the range of
θ parameter is specified as [
2,
6].
4. Experimental Results and Analysis
In order to comprehensively verify the effectiveness of our proposed network, we conducted a large number of experiments on the dataset SeaShips7000 [
19]. Through qualitative analysis and quantitative evaluation, with different networks, we contrasted the presented network. The following is a detailed explanation of the specific execution process of the experiment and the comparison results.
4.1. Experimental Details
4.1.1. Experimental Environment and Parameter Settings
The experiment of the network model we proposed is based on the Python (1.12.1) software library installed in Ubuntu 22.04, with a programming language of Python 3.9 and an integrated development environment of CUDA 11.8. The CPU model is the 12th generation Intel (R) Core (TM) i5-12490F, running at 3 GHz, and the GPU is NVIDIA GeForce GTX 1080Ti-11G. During the training process, set the learning rate to 0.01, momentum to 0.937, and optimizer weight decay to 0.0005. All input images used in the experiment were adjusted to a pixel size of 640 * 640, the training process epoch was set to 200, the batch size was set to 16, and all other parameters followed the default parameter settings of the YOLOv8 model.
4.1.2. Dataset
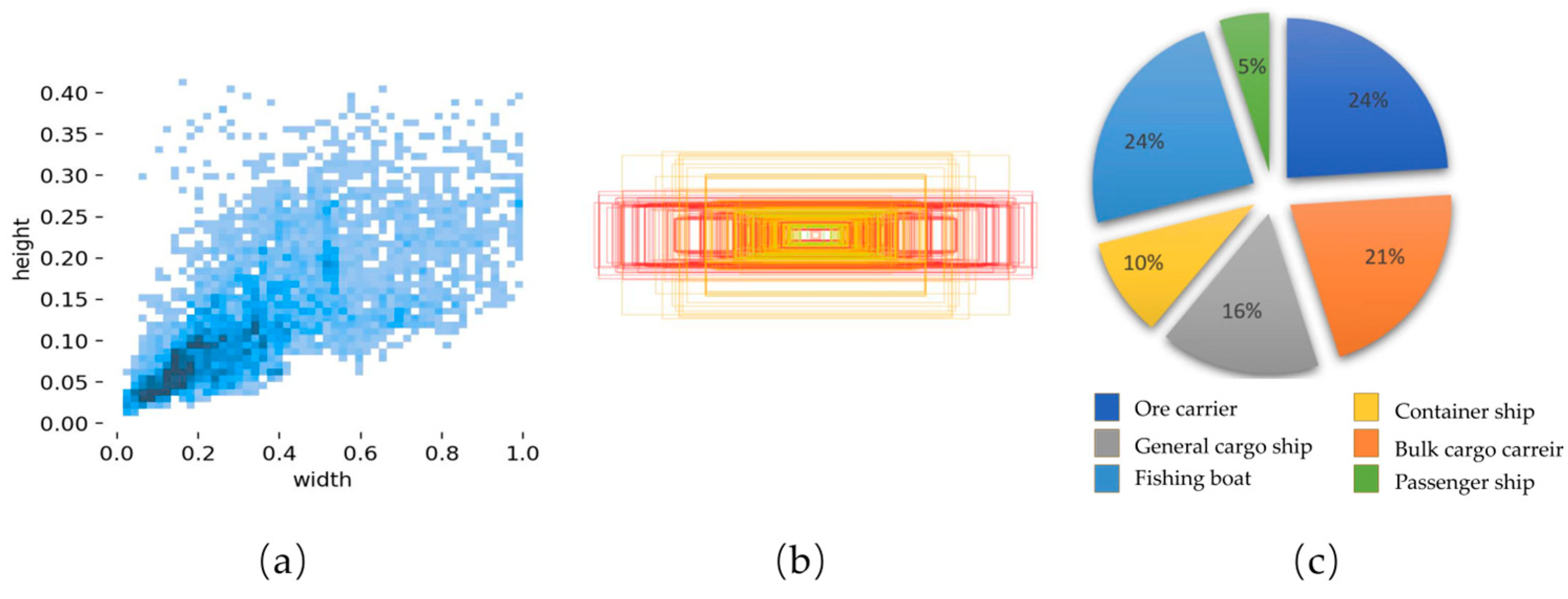
This experiment used the publicly available and free SeaShips7000 dataset, images collected by Wuhan University. It was mainly derived from mobile phones and collation of the monitoring videos of Hengqin Island, Zhuhai, and it comprises six different types of ships, namely: ore ships, bulk carriers, conventional container ships, container ships, fishing ships, and passenger ships. These images have different scales, hull parts, lighting, viewpoints, and occlusion. In this experiment, they were separated into a training set, validation set, and test set in a 3:1:1 ratio. As shown in
Figure 6, the figure shows the number of samples contained in each type of ship, the dimensions and corresponding number of bounding boxes in the training set, the distribution of the center point of the bounding box in the image, and the distribution of the target aspect ratio in the training set.
Figure 7 shows the six categories of ships in the dataset. The limitations of the offshore filming equipment result in errors in monitoring small targets when monitoring offshore ships, and there is also a certain degree of ambiguity in monitoring distant ships. Ships on the shore are also susceptible to interference from the shore background, which can lead to inadequate monitoring.
4.2. Evaluation Indicators
In our experiments, we primarily employ the objective measurements such as accuracy, recall, F1 score, mAP@0.5, mAP@0.5:0.95, Params, FLOPs, and Traintime to evaluate the availability and efficiency of the proposed model.
Accuracy is the evaluation of the accuracy of a model in object detection tasks, representing the percentage of accurately detected masculine specimen that are truly positive; recall rate is the ability of a model to successfully identify the proportion of positive samples to all true positive samples; the F1 score is the average of accuracy and recall, which comprehensively measures the performance of the model. The larger the F1 score, the better the performance of the model; mAP@0.5 is the average accuracy when the IOU threshold is set to 0.5, which is used to measure the detection accuracy of the model; mAP@0.5:0.95 not only measures the accurateness of the model but also reflects its robustness; Params and FLOPs reflect the model’s quantity of parameters and computational complexity, and the lower they are, the lighter the model is; the training time mainly reflects the efficiency and cost of model training. The shorter the training time, the faster the iteration speed of the model.
4.3. Train Results and Analysis
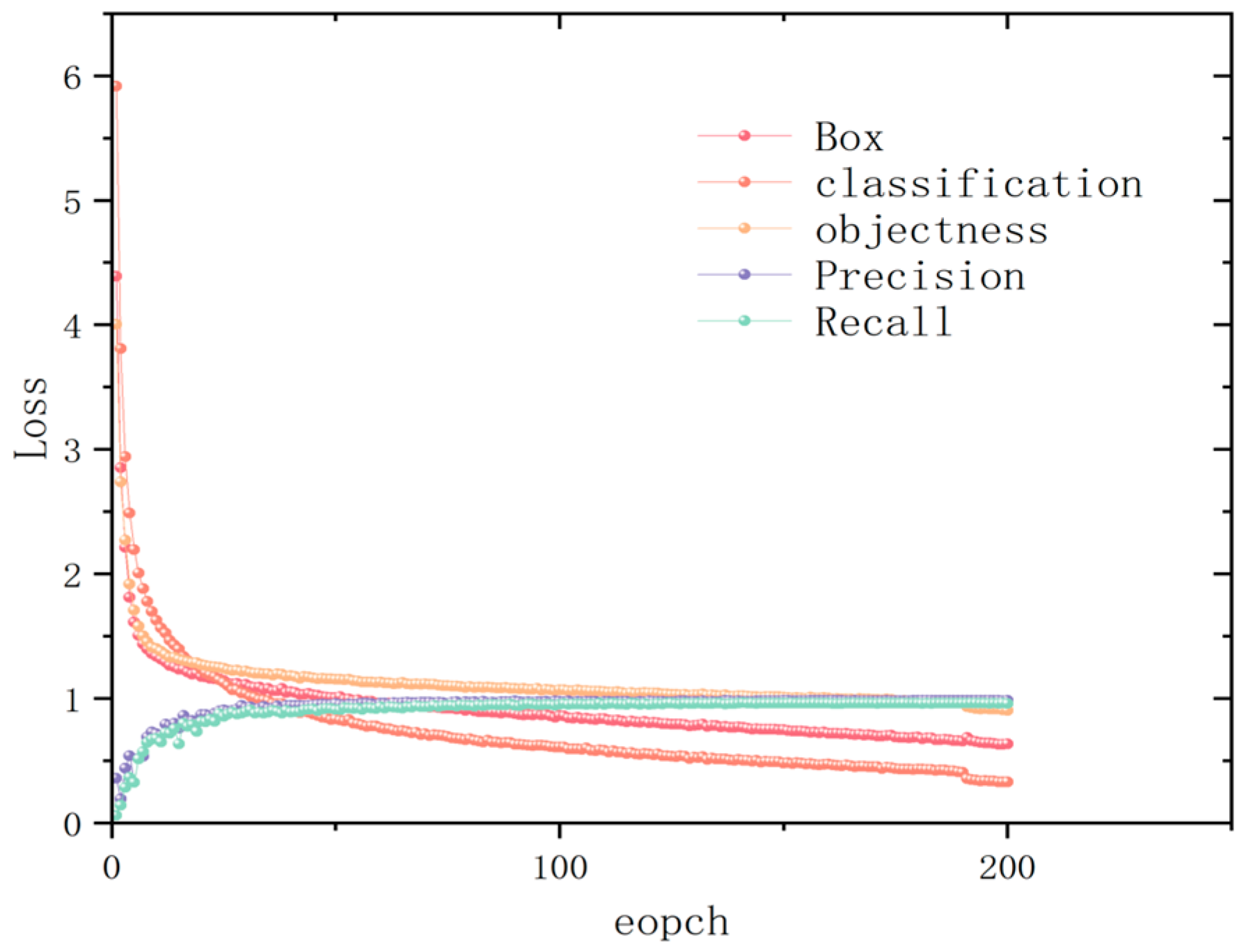
To validate the performance advantage of this method in object detection, we evaluated it on the SeaShips dataset and analyzed its training results. In the experiment, the epoch was set to 200 and the batch size to 16. After 200 rounds of training, the loss curve of AFF-LightNet is shown in
Figure 8. From the graph, we can understand that after training, the loss value is continuously decreasing and the convergence speed is also faster, indicating that the model is not overfitting.
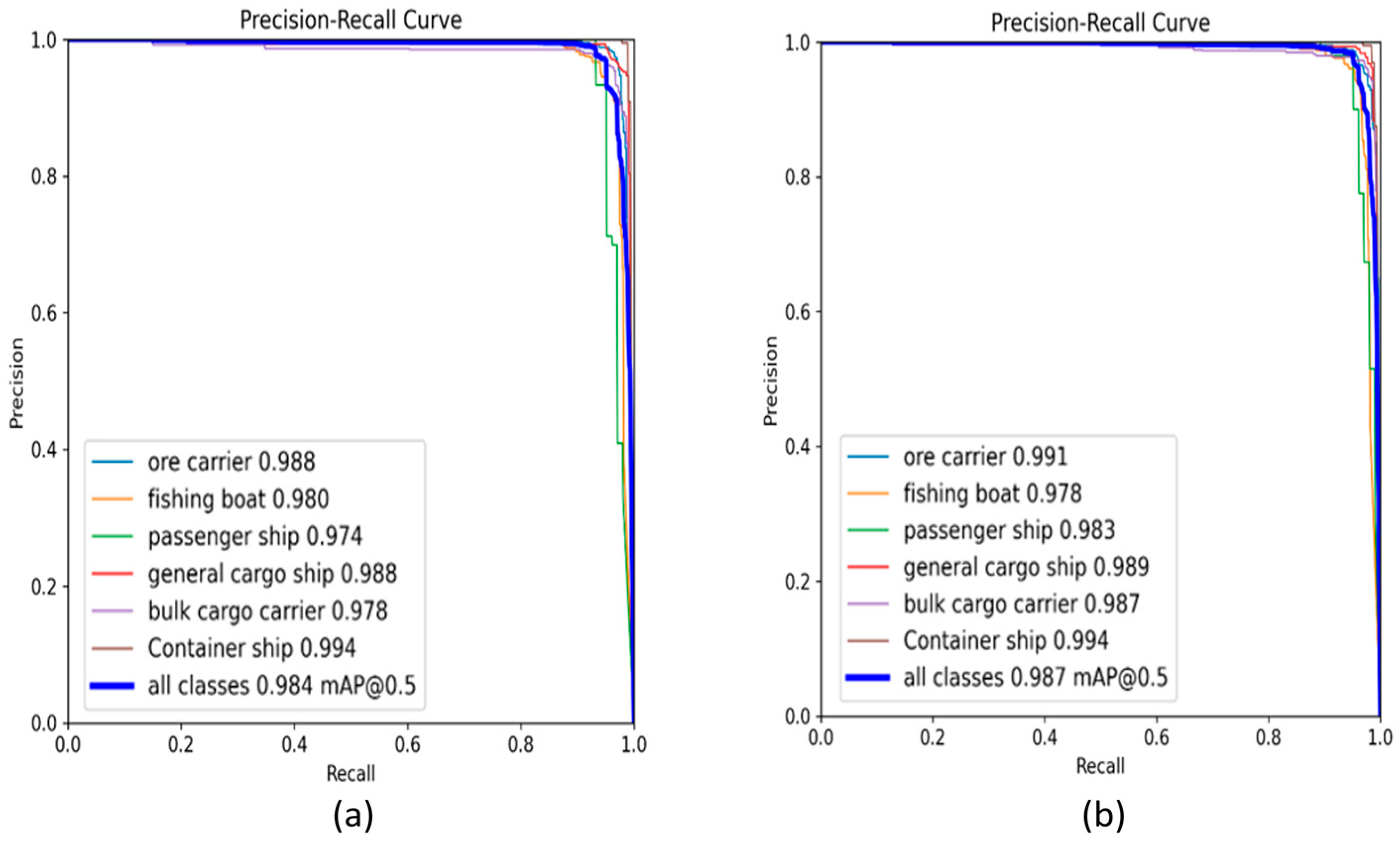
Figure 9 shows the P-R (Precision Recall) curve after training. From the graph, we are able to understand that compared with the original YOLOv8 model, our proposed model has an overall mAP better than the original model, indicating that our proposed model has more advantages in performance.
Figure 10 shows the F1 score curve. The F1 score curve is a comprehensive indicator of model performance, with higher values indicating better model performance. From
Figure 10, we may be aware that our model’s score is higher than that of the original model, which indicates that our model has a better performance advantage compared to the original model.
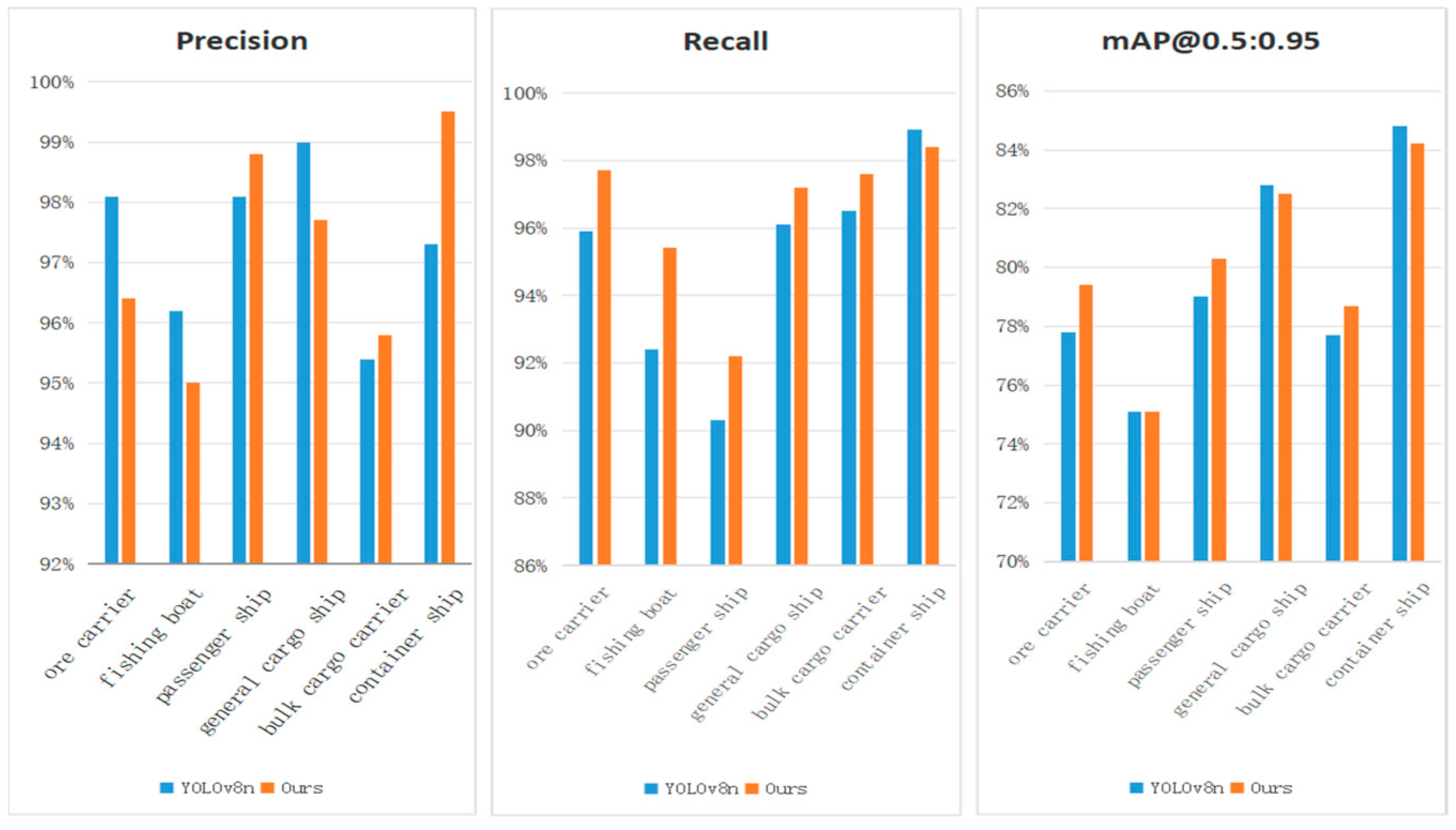
In the bargain, to better demonstrate the detection of different types of ships using our proposed model, we calculated the accuracy, recall, and mAP@0.5:0.95, represented by a bar chart for a more intuitive observation. The experimental outcomes are displayed in
Figure 11. We can see that the proposed model has good detection performance for bulk cargo ships, container ships, and passenger ships, but its detection accuracy for fishing boats, mineral sand ships, and general cargo ships is lower than YOLOv8n. This is because the loss function SIOU introduced by the proposed model is more conducive to the localization and regression of large targets, and inappropriate adjustment of category weights affect the detection of small targets. In addition, the introduced variability convolution increases the model’s receptive field, which can lead to a decrease in detection accuracy for some targets if the receptive field is too large.
4.4. Qualitative Evaluation
In an effort to better evaluate the performance of our proposed model, in this section we will evaluate our model from a visual perspective. Firstly, we visually compare our model with the original model, and the outcomes are displayed in
Figure 12. It displays the comparison outcomes between our model and the original model under different lighting conditions. The first column is the unprocessed image, the second column is the detection result of the original model, and the third column is the detection result of the newly proposed model. The three images were taken in the morning, noon, and evening, respectively. The proposed model introduces a module with attention mechanism, which dynamically assigns weights based on the input image, making the model more focused on task-related information, reducing the interference of redundant information and, thus, improving detection accuracy. From the figure, we can see that our model has higher accuracy in ship detection than the original model under weak and strong light conditions. In addition, we will visually compare our model with other models for different scale targets (small, medium, and large targets). The experimental results are shown in
Figure 13. It can be observed that the features extracted by our model are relatively inadequate for the detection of large targets, due to their long distance and low resolution, so the detection accuracy of the proposed model is the second best. By contrast, the comparative models have the best results, as they provide adequate features and can learn more information. Moreover, the detection of small targets is the most challenging, as they have fewer discriminative features, resulting in the lowest detection accuracy. The proposed model also presents similar challenges, but it has the best detection accuracy for different scales.
Finally, we also visually compared our model with other models under different types of ships, and the experimental results are shown in
Figure 14. Due to the large overlap area when multiple ships appear simultaneously, obstructed ships are difficult to identify and locate, making it difficult for ships to be detected, resulting in unreliable maritime traffic monitoring. We can see that when multiple ships appear simultaneously, YOLOv5 and YOLOv6 experience missed or false detections. They are unable to distinguish the obstructed container ships and also detect the general cargo ships as container ships. For the detection of small targets, YOLOv8 cannot detect fishing boats since the features of small targets may be interfered with by other target information during the fusion process, which makes it difficult for the model to recognize their features. However, iAFF embedded in the MS-CAM module can integrate features from different scales, so it performs well in feature fusion. The angle loss introduced by SIOU finds the direction of the bounding box from different directions, making the model more accurate in detecting occluded and small targets.
4.5. Quantitative Evaluation
In order to evaluate the performance of the AFF-LightNet model from multiple perspectives, this section will compare it quantitatively. We conducted quantitative evaluations on other YOLO series. The YOLO series includes YOLOv3-tiny, YOLOv5n, YOLOv6n, and YOLOV8. The experimental results are shown in
Figure 15 and
Table 1.
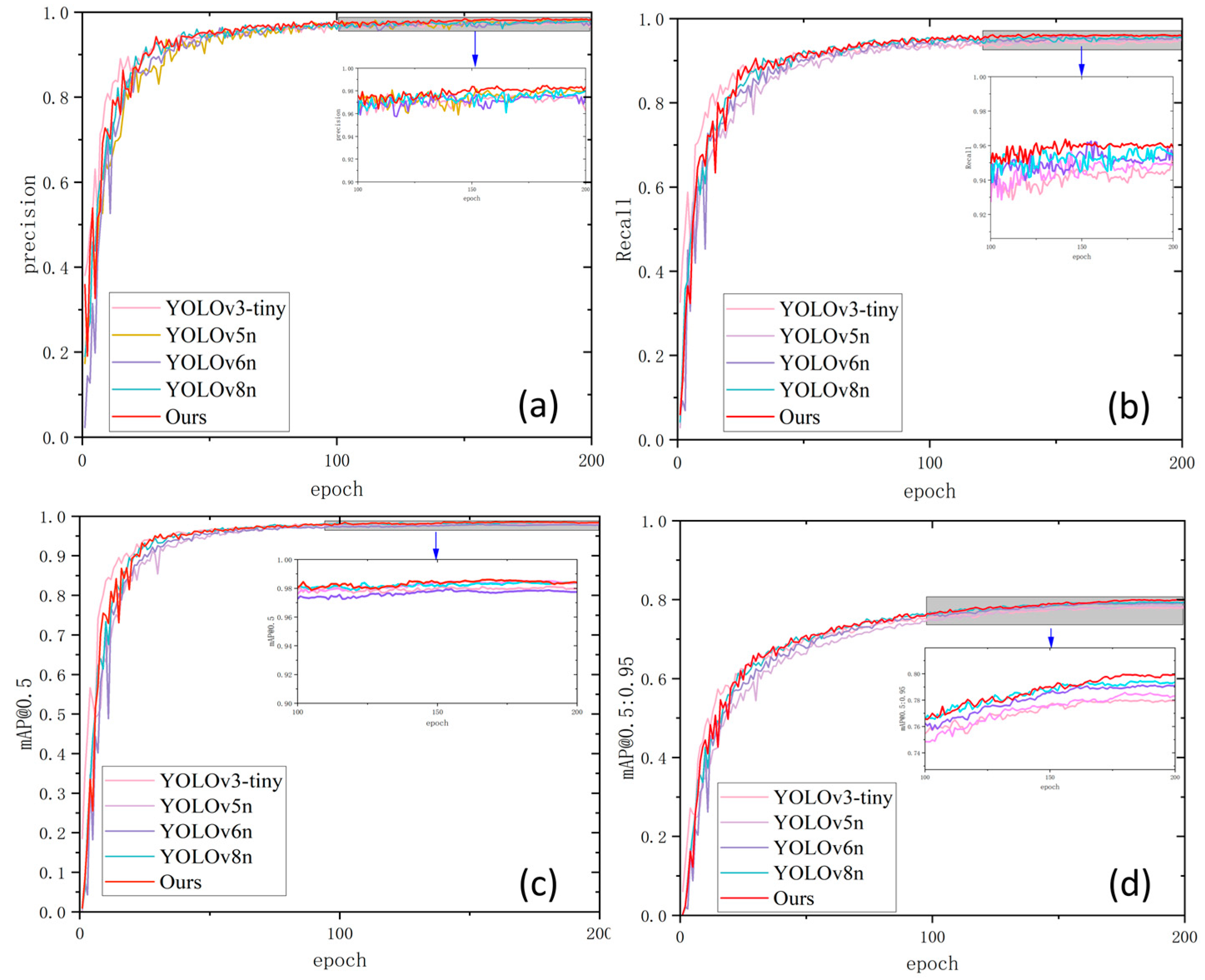
Figure 15 shows the accuracy, recall, mAP@0.5, and mAP@0.5:0.95 within 200 model training cycles; it is 0.95. The figure shows that as the number of training iterations increases, the parameters of the model are better optimized, and more features can be learned. The feature extraction ability is constantly improving. Meanwhile, the addition of lightweight and attention mechanism modules in the model reduces the computational resources and improves detection accuracy. As a result, the model gradually learns how to generalize to unknown data with the increase in epochs. Thus, our model performs better than other competitors, with a slow curve rise and fast convergence speed, indicating that our model does not overfit. From
Table 1, it can be seen that the YOLOv5n model uses MobileNetV3 and anchor-free detection methods, significantly reducing its parameter count, but its detection accuracy is not as good as other comparative YOLO models. The proposed model leverages lightweight modules and feature fusion modules, which can better capture significant features in the image while reducing computational resources. Therefore, our model performs the best.
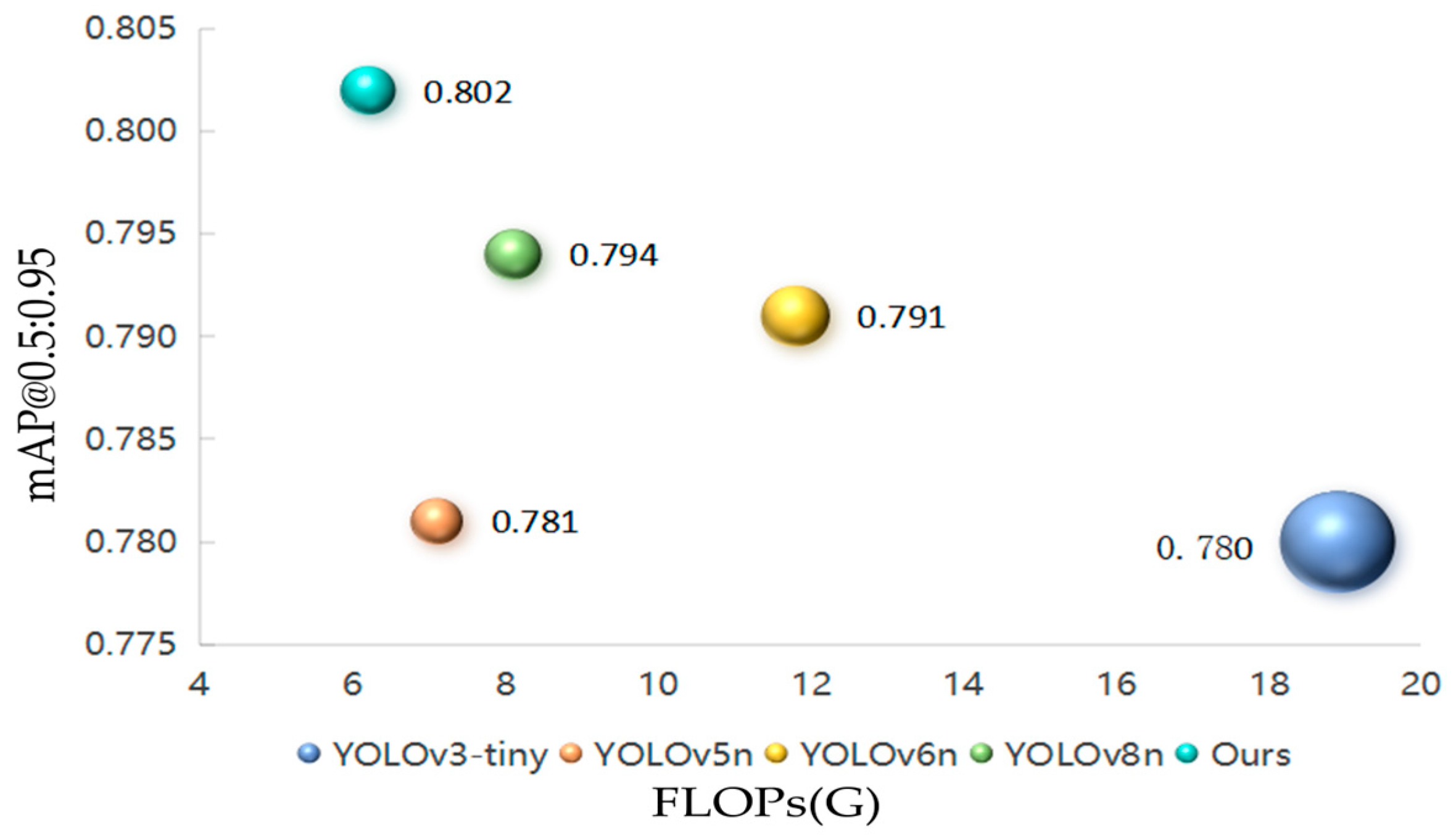
Figure 16 shows the performance of AFF-LightNet and other models in terms of FLOP, parameter count, and mAP@0.5 as well as mAP@0.5:0.95. The size of each ball area represents the sum of parameters. As shown in the figure, our model achieves higher detection accuracy with fewer parameters and lower complexity. Compared with other models, the model proposed in this paper achieves a better balance between model size and detection accuracy.
Table 1 shows the comparison between our model and the YOLO series models. As can be observed from the data, our model achieved the best performance among them due to its accuracy, F1 score, mAP@0.5, and mAP@0.5:0.95, which are the highest, and although our model is not the lightest, it is also in second place. The lightest size is 2.50 MB, while our model size is 2.81 MB. To verify that our network is more lightweight, we compared our model with other lightweight networks, currently popular lightweight networks that include MobileNetV3 and ShuffleNetV2. The experimental results are shown in
Table 2. The chart indicates that although our network’s detection accuracy is not the best, its computational complexity and parameter quantity are both optimal, achieving the desired detection effect. Furthermore, the test velocity of the presented network model reaches a high standard among similar detection models, which demonstrates the powerful ability of our network to achieve real-time and latency-free detection, that is, to achieve real-time detection.
Furthermore, we also compared our model with some models from recent years, and the comparison results are shown in
Table 3. From the table, our model does better than other models in terms of mAP@0.5, mAP@0.5:0.95, and parameter quantity. Although its computational complexity is not the lowest, it is among the lowest.
4.6. Ablation Experiment
To validate the effectiveness and efficiency of the proposed model, we conducted a sequence of ablation tests on the components of the AFF-LightNet model (on the SeaShips dataset). The architecture and experimental details of AFF-LightNet are shown in
Table 4 (√ indicates the introduction of improved modules). The visual representation reveals that when adding iAFF, although its parameter counts increase, mAP@0.5:0.95 significantly increased. When GhostConv and iAFF were added, their number of parameters and computational complexity were significantly reduced, but their accuracy was still not high enough. Therefore, DCNv2 and SIOU were added, and the results clearly showed that their computational complexity and detection accuracy improved after addition.
It is obviously visible from
Table 4 that the proposed AFF-LightNet attains both lightweight and more elevated detection accuracy than the original model, indicating that our proposed AFF-LightNet model achieves a better balance between lightweight and improved accuracy. On top of that, we also conducted ablation experiments on the effects of various components of the AFF-LightNet model architecture on various types of ships. The specific experimental results are shown in
Table 5. It is observable in the table that compared with the original YOLOv8n, the introduction of iAFF and DCNv2 can significantly improve detection accuracy, while the loss function can improve detection accuracy. Although GhostConv does not significantly improve detection accuracy, it greatly reduces computational complexity.
To verify the reliability of the proposed method, we compared the detection of different feature fusion modules in the model, and the results are shown in
Table 6. From the table, it can be seen that when our model is mAP@0.5 and mAP@0.5:0.95, it performs the best. Although it has a higher number of parameters than other modules, our training time is the least and our top inference speed illustrates how well our model number of iAFFs added is also one of the factors affecting the accuracy of the hard model. In this model, we introduced different numbers of iAFFs into C2f, and the experimental results are shown in
Table 7. The experimental results show that introducing iAFF into each C2f module in the head network has the best effect. As the number of iAFFs increases, the model can further explore and utilize the correlation and complementarity between these characteristics, hence increasing feature fusion’s efficacy; through an iterative attention mechanism, the model can gradually emphasize on the crucial specifics of the entering image, ignore irrelevant information and, thus, ameliorate the sensitivity and accuracy of the model to target features. To verify the good performance of the loss function SIOU on our model, we conducted experiments on the SeaShips dataset, and the experimental results are shown in
Table 8. From the table, we can see that SIOU provides a more comprehensive and accurate loss metric by considering more geometric characteristics of bounding boxes, thereby helping the model optimize bounding box prediction better during training. Compared to other loss functions, SIOU performs better in this model.
5. Conclusions
In this paper, a lightweight network architecture is presented for efficient detection of ships in ocean monitoring systems, bringing improved technological solutions to the field of ocean monitoring. The proposed model introduces iAFF and GhostConv based on YOLOv8n, ensuring detection accuracy while achieving lightweight, making it more suitable. For resource-limited offshore mobile improvement of the model’s target localization and robustness, we substituted CIOU with SIOU, which helps the model converge more stably during the training process. Finally, we conducted extensive experiments on the dataset SeaShips7000, and the experimental results showed that the model has good performance in both lightweight and detection accuracy. Compared with other ship detection methods, our method not only demonstrates high efficiency in computational complexity but also achieves satisfactory levels of detection accuracy. However, faulty sensors can still result in significant differences or missing data in the collected data, thereby affecting the measurement of differences between the actual box and the predicted box. Different noises can lead to incorrect gradient information, affecting the adjustment of model parameters, resulting in a decrease in training rate and, thus, limiting the performance of the model. Looking ahead, in order to further enhance the overall performance of this method, we can explore and optimize it in the following directions:
The dataset used in the proposed model consists entirely of static ship images, and the model is too simplistic. Therefore, in future research, our goal is to incorporate videos into the model, while maintaining a balance between lightweighting and detection accuracy.
Maritime monitoring systems take photos from a two-dimensional perspective. When ships are obstructed or overlapping, it can lead to missed or false detections. Therefore, optical images can be combined with remote sensing images to effectively avoid missed or false detections and improve the performance of the model.



 the method used in this article;
the method used in this article;  the comparative method used in this article;
the comparative method used in this article;  the original model.
the original model.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}