
Agent-Guided Non-Local Network for Underwater Image Enhancement and Super-Resolution Using Multi-Color Space


Abstract
1. Introduction
- An agent-guided non-local attention network using the multi-color space is proposed for underwater image enhancement and super-resolution. The network extracts feature maps with different receptive fields and captures long-range dependency in the RGB, Lab, and HSI color spaces simultaneously, then the adaptive fusion of outputs from different color spaces is achieved with learned weight coefficients. Finally, enhanced images and high-resolution underwater images are generated by the reconstruction block.
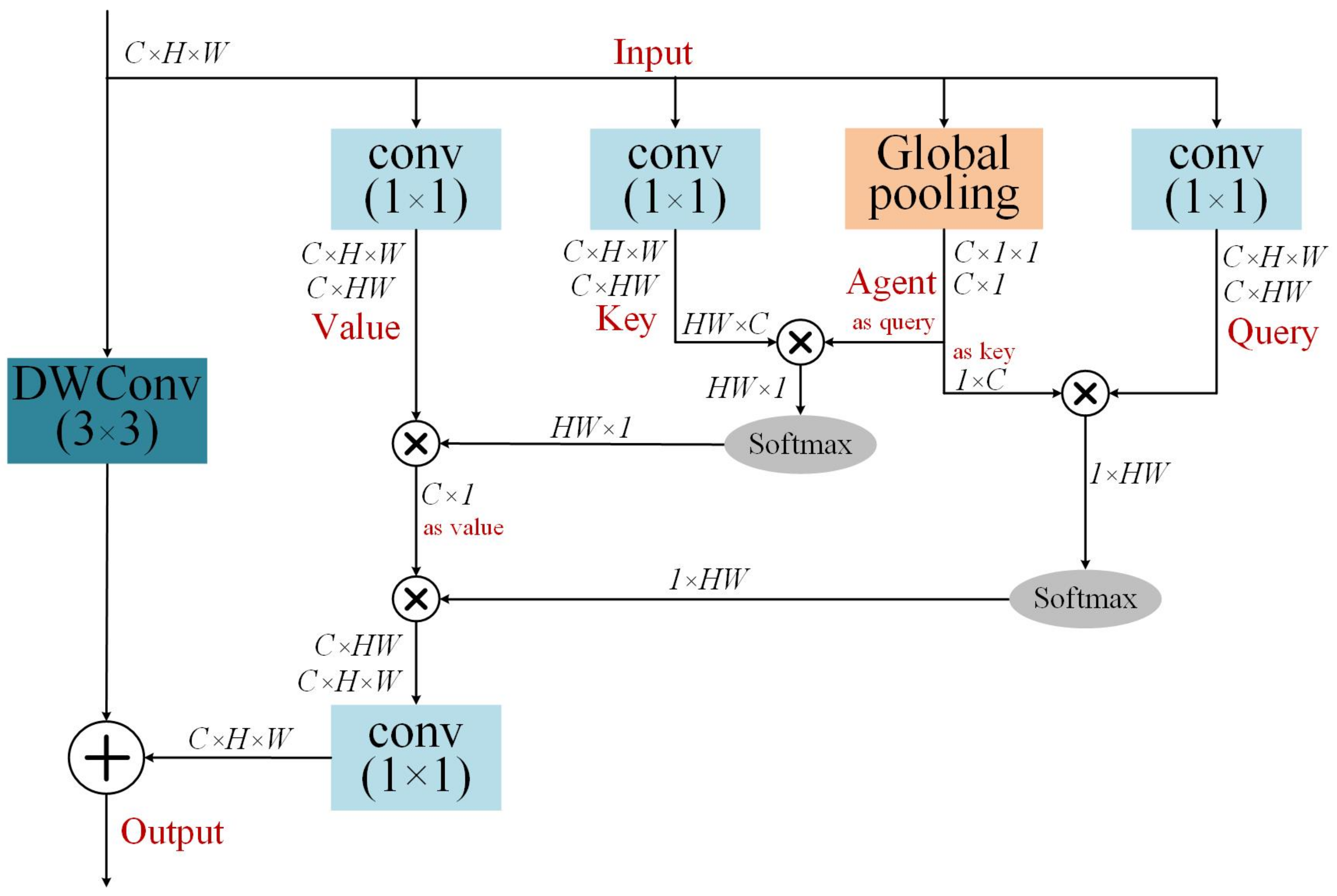
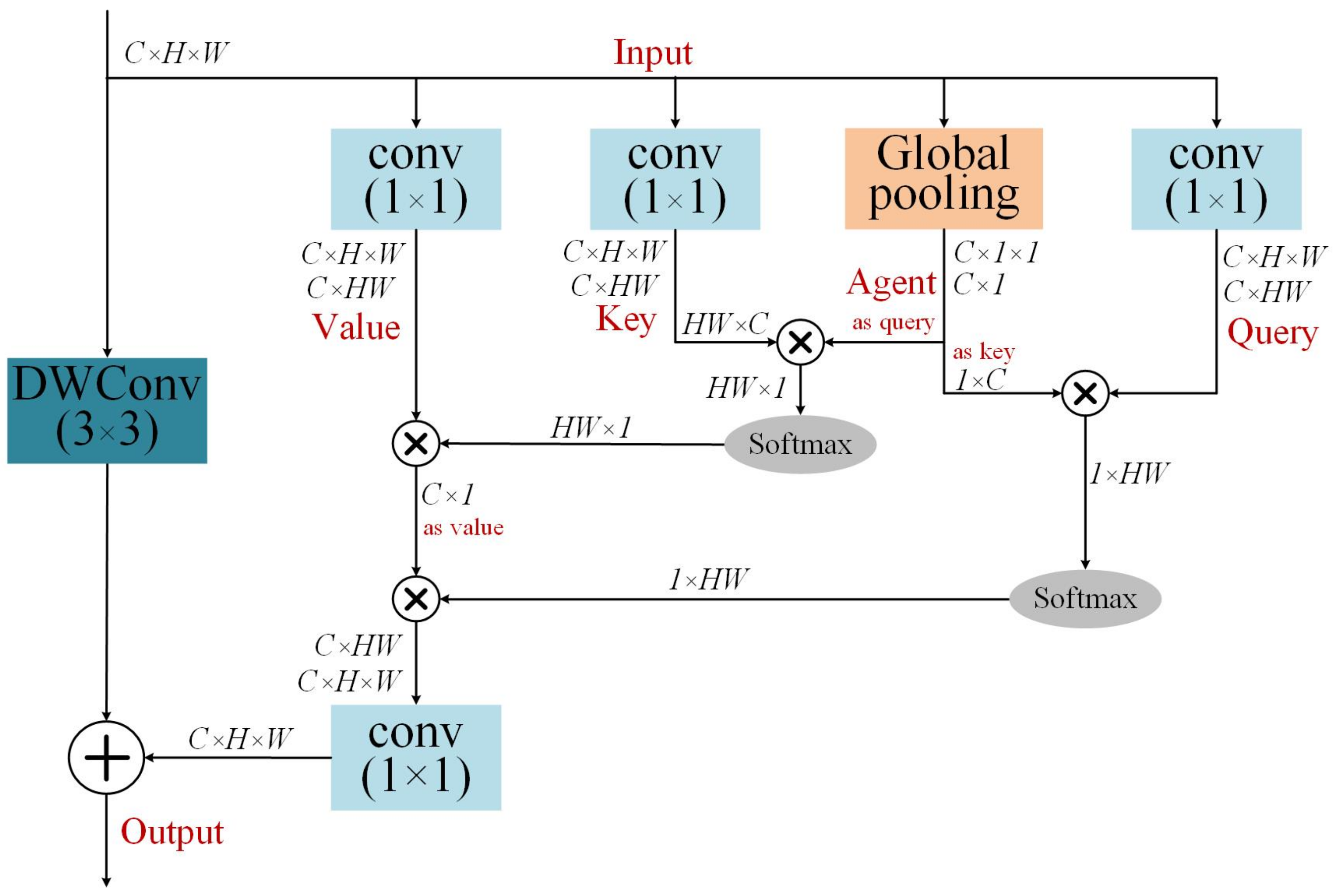
- An agent-guided non-local attention module is designed to capture long-range dependency in underwater images, enhancing the understanding of the global structure and contextual information. The module performs two non-local attention computations, demonstrating high expressive power while maintaining significantly lower computational complexity compared to the typical non-local block.
- The proposed network outperforms state-of-the-art methods in several objective quality assessment metrics on multiple datasets, both for underwater image enhancement and underwater image super-resolution. Qualitative comparisons also demonstrate that our network produces visually pleasing results.
2. Related Works
2.1. Underwater Image Enhancement
2.2. Underwater Image Super-Resolution
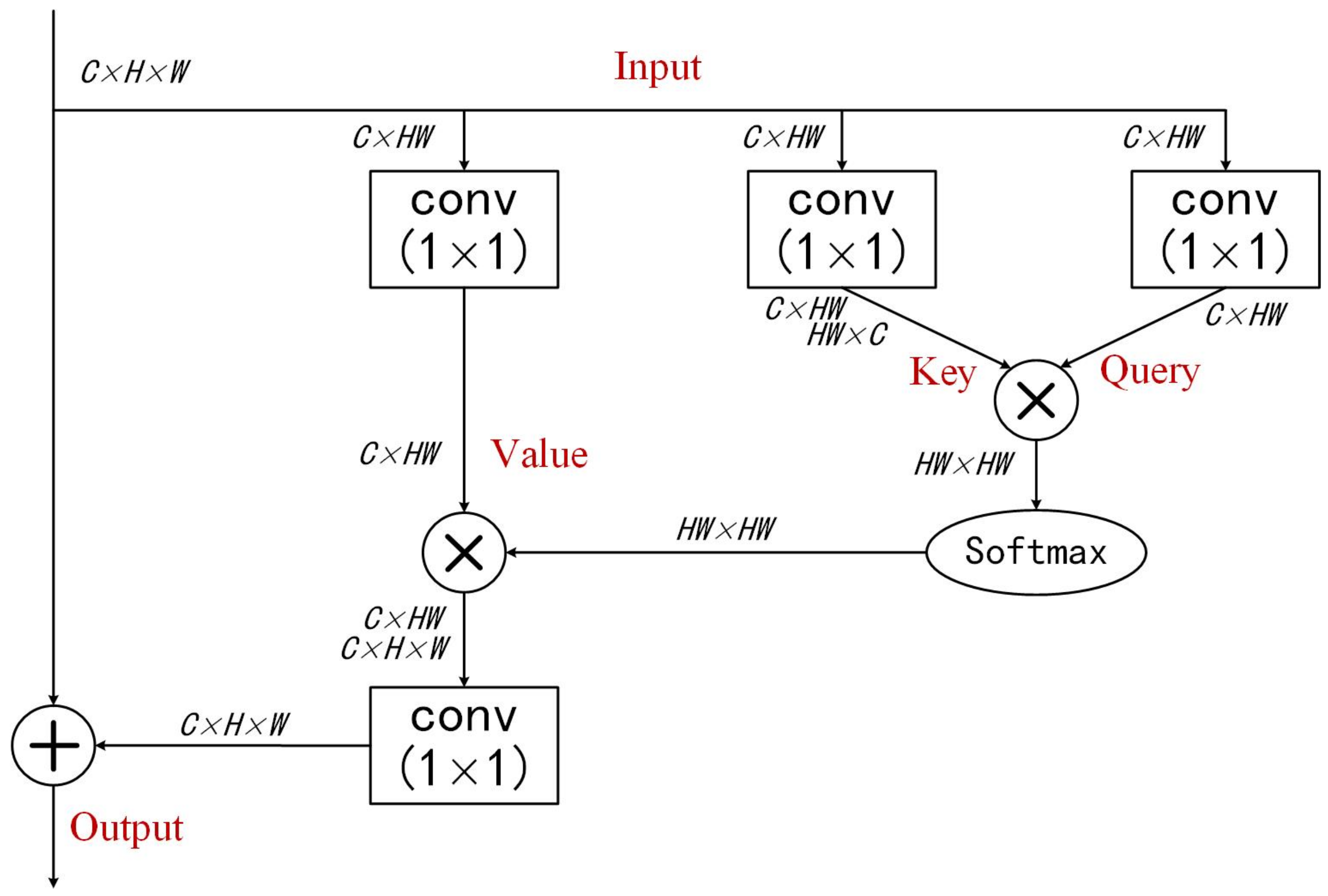
2.3. Non-Local Block
3. Proposed Method
3.1. Network Architecture
3.2. Agent-Guided Non-Local Attention Module
3.3. Loss Function
4. Experimental Results and Analysis
4.1. Datasets and Implementation Details
4.2. Evaluation Metrics
4.3. Underwater Image Enhancement Results
4.4. Underwater Image Super-Resolution Results
4.5. Analysis and Discussion
4.6. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Anwar, S.; Li, C. Diving deeper into underwater image enhancement: A survey. Signal Process. Image Commun. 2020, 89, 115978. [Google Scholar] [CrossRef]
- Zhou, J.; Yang, T.; Zhang, W. Underwater vision enhancement technologies: A comprehensive review, challenges, and recent trends. Appl. Intell. 2023, 53, 3594–3621. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar]
- Drews, P.L.J.; Nascimento, E.R.; Botelho, S.S.C.; Campos, M. Underwater depth estimation and image restoration based on single images. IEEE Comput. Graph. Appl. 2016, 36, 24–35. [Google Scholar] [CrossRef]
- Song, W.; Wang, Y.; Huang, D.; Tjondronegoro, D. A rapid scene depth estimation model based on underwater light attenuation prior for underwater image restoration. In Proceedings of the Advances in Multimedia Information Processing–PCM 2018: 19th Pacific-Rim Conference on Multimedia, Hefei, China, 21–22 September 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 678–688. [Google Scholar]
- Song, W.; Wang, Y.; Huang, D.; Liotta, A.; Perra, C. Enhancement of underwater images with statistical model of background light and optimization of transmission map. IEEE Trans. Broadcast. 2020, 66, 153–169. [Google Scholar] [CrossRef]
- Liang, Z.; Ding, X.; Wang, Y.; Yan, X.; Fu, X. GUDCP: Generalization of underwater dark channel prior for underwater image restoration. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4879–4884. [Google Scholar] [CrossRef]
- Singhai, J.; Rawat, P. Image enhancement method for underwater, ground and satellite images using brightness preserving histogram equalization with maximum entropy. In Proceedings of the International Conference on Computational Intelligence and Multimedia Applications (ICCIMA 2007), Sivakasi, India, 13–15 December 2007; IEEE: Piscataway, NJ, USA, 2007; Volume 3, pp. 507–512. [Google Scholar]
- Fu, X.; Zhuang, P.; Huang, Y.; Liao, Y.; Zhang, X.; Ding, X. A retinex-based enhancing approach for single underwater image. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 4572–4576. [Google Scholar]
- Ancuti, C.; Ancuti, C.O.; Haber, T.; Bekaert, P. Enhancing underwater images and videos by fusion. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 81–88. [Google Scholar]
- Ancuti, C.O.; Ancuti, C.; Vleeschouwer, C.D.; Bekaert, P. Color balance and fusion for underwater image enhancement. IEEE Trans. Image Process. 2018, 27, 379–393. [Google Scholar] [CrossRef]
- Li, C.; Anwar, S.; Porikli, F. Underwater scene prior inspired deep underwater image and video enhancement. Pattern Recognit. 2020, 98, 107038. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef]
- Hu, J.; Jiang, Q.; Cong, R.; Gao, W.; Shao, F. Two-branch deep neural network for underwater image enhancement in HSV color space. IEEE Signal Process. Lett. 2021, 28, 2152–2156. [Google Scholar] [CrossRef]
- Li, C.; Anwar, S.; Hou, J.; Cong, C.; Guo, C.; Ren, W. Underwater image enhancement via medium transmission-guided multi-color space embedding. IEEE Trans. Image Process. 2021, 30, 4985–5000. [Google Scholar] [CrossRef]
- Chen, Y.; Li, H.; Yuan, Q.; Wang, Z.; Hu, C.; Ke, W. Underwater Image Enhancement based on Improved Water-Net. In Proceedings of the 2022 IEEE International Conference on Cyborg and Bionic Systems (CBS), Wuhan, China, 24–26 March 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 450–454. [Google Scholar]
- Yan, J.; Wang, Y.; Fan, H.; Huang, J.; Grau, A.; Wang, C. LEPF-Net: Light Enhancement Pixel Fusion Network for Underwater Image Enhancement. J. Mar. Sci. Eng. 2023, 11, 1195. [Google Scholar] [CrossRef]
- Fabbri, C.; Islam, M.J.; Sattar, J. Enhancing underwater imagery using generative adversarial networks. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 7159–7165. [Google Scholar]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast underwater image enhancement for improved visual perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Hambarde, P.; Murala, S.; Dhall, A. UW-GAN: Single-image depth estimation and image enhancement for underwater images. IEEE Trans. Instrum. Meas. 2021, 70, 1–12. [Google Scholar] [CrossRef]
- Zhang, S.; Zhao, S.; An, D.; Li, D.; Zhao, R. MDNet: A Fusion Generative Adversarial Network for Underwater Image Enhancement. J. Mar. Sci. Eng. 2023, 11, 1183. [Google Scholar] [CrossRef]
- Cong, R.; Yang, W.; Zhang, W.; Li, C.; Guo, C.; Huang, Q.; Kwong, S. PUGAN: Physical Model-Guided Underwater Image Enhancement Using GAN with Dual-Discriminators. IEEE Trans. Image Process. 2023, 32, 4472–4485. [Google Scholar] [CrossRef]
- Ren, T.; Xu, H.; Jiang, G.; Yu, M.; Zhang, X.; Wang, B.; Luo, T. Reinforced swin-convs transformer for simultaneous underwater sensing scene image enhancement and super-resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Peng, L.; Zhu, C.; Bian, L. U-shape transformer for underwater image enhancement. IEEE Trans. Image Process. 2023, 32, 3066–3079. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef]
- Mao, X.J.; Shen, C.; Yang, Y.B. Image restoration using convolutional auto-encoders with symmetric skip connections. arXiv 2016, arXiv:1606.08921. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Cunningham, J.C.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; Shi, W. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Choi, H.; Lee, J.; Yang, J. N-gram in swin transformers for efficient lightweight image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2071–2081. [Google Scholar]
- Islam, M.J.; Enan, S.S.; Luo, P.; Sattar, J. Underwater image super-resolution using deep residual multipliers. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 900–906. [Google Scholar]
- Chen, X.; Wei, S.; Yi, C.; Quan, L.; Lu, C. Progressive attentional learning for underwater image super-resolution. In Intelligent Robotics and Applications: Proceedings of the 13th International Conference, ICIRA 2020, Kuala Lumpur, Malaysia, 5–7 November 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 233–243. [Google Scholar]
- Islam, M.J.; Luo, P.; Sattar, J. Simultaneous Enhancement and Super-Resolution of Underwater Imagery for Improved Visual Perception. In 16th Robotics: Science and Systems, RSS 2020; MIT Press Journals: Cambridge, MA, USA, 2020. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–4. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Berman, D.; Levy, D.; Avidan, S.; Treibitz, T. Underwater single image color restoration using haze-lines and a new quantitative dataset. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 4, 2822–2837. [Google Scholar] [CrossRef]
- Panetta, K.; Gao, C.; Agaian, S. Human-visual-system-inspired underwater image quality measures. IEEE J. Ocean. Eng. 2015, 41, 541–551. [Google Scholar] [CrossRef]
- Yang, M.; Sowmya, A. An underwater color image quality evaluation metric. IEEE Trans. Image Process. 2015, 24, 6062–6071. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Params (M) | T-U90 | Test-C60 | SQUID | ||||
|---|---|---|---|---|---|---|---|---|
| MSE | PSNR (dB) | SSIM | UIQM | UCIQE | UIQM | UCIQE | ||
| UDCP [4] | - | 4542.44 | 12.09 | 0.59 | 1.45 | 0.53 | 0.94 | 0.55 |
| ULAP [5] | - | 2254.50 | 16.27 | 0.76 | 1.66 | 0.53 | 0.87 | 0.46 |
| UWCNN [12] | 0.04 | 3260.72 | 13.92 | 0.67 | 2.38 | 0.47 | 2.12 | 0.44 |
| Water-Net [13] | 1.09 | 848.16 | 20.05 | 0.85 | 2.67 | 0.56 | 2.34 | 0.54 |
| FUnIE-GAN [19] | 7.02 | 1448.76 | 17.75 | 0.75 | 2.64 | 0.52 | 2.12 | 0.48 |
| Ucolor [15] | 149 | 433.06 | 22.65 | 0.89 | 2.61 | 0.53 | 2.13 | 0.50 |
| URSCT-SESR [23] | 11.19 | 2097.75 | 16.18 | 0.78 | 1.51 | 0.54 | 1.37 | 0.49 |
| U-Trans [24] | 31.59 | 595.95 | 21.32 | 0.78 | 2.59 | 0.53 | 2.13 | 0.51 |
| Ours | 1.36 | 432.14 | 22.99 | 0.91 | 2.64 | 0.55 | 2.25 | 0.50 |
| Method | MSE | PSNR (dB) | SSIM | UIQM |
|---|---|---|---|---|
| HE [8] | 3433.87 | 13.52 | 0.55 | 2.44 |
| UDCP [4] | 3020.50 | 14.47 | 0.50 | 1.95 |
| ULAP [5] | 1017.88 | 18.77 | 0.65 | 2.22 |
| UWCNN [12] | 1984.30 | 16.41 | 0.59 | 2.88 |
| Water-Net [13] | 819.03 | 19.70 | 0.69 | 3.02 |
| Ucolor [15] | 821.32 | 19.56 | 0.69 | 3.10 |
| Deep SESR [33] | 332.26 | 23.76 | 0.75 | 3.12 |
| Ours | 268.20 | 24.54 | 0.78 | 2.90 |
| Methods | Params (M) | PSNR | SSIM | UIQM | ||||
|---|---|---|---|---|---|---|---|---|
| SRCNN [25] | 0.06 | 0.06 | 26.81 | 23.38 | 0.76 | 0.67 | 2.74 | 2.38 |
| DSRCNN [26] | 1.11 | 1.11 | 27.14 | 23.61 | 0.77 | 0.67 | 2.71 | 2.36 |
| EDSRGAN [27] | 1.38 | 1.97 | 27.12 | 21.65 | 0.77 | 0.65 | 2.67 | 2.40 |
| SRGAN [28] | 5.95 | 5.95 | 28.05 | 24.76 | 0.78 | 0.69 | 2.74 | 2.42 |
| SRDRM [31] | 0.83 | 1.90 | 28.36 | 24.64 | 0.80 | 0.68 | 2.78 | 2.46 |
| SRDRM-GAN [31] | 11.31 | 12.38 | 28.55 | 24.62 | 0.81 | 0.69 | 2.77 | 2.48 |
| PAL [32] | 0.83 | 1.92 | 28.41 | 24.89 | 0.80 | 0.69 | – | – |
| SwinIR-NG [30] | 1.18 | 1.20 | 29.03 | 25.66 | 0.79 | 0.68 | 2.65 | 2.54 |
| Ours | 1.36 | 1.39 | 29.10 | 25.76 | 0.80 | 0.67 | 2.71 | 2.60 |
| Method | PSNR | SSIM | UIQM | |||
|---|---|---|---|---|---|---|
| SRCNN [25] | 24.75 ± 3.7 | 19.05 ± 2.3 | 0.72 ± 0.07 | 0.56 ± 0.12 | 2.39 ± 0.35 | 2.02 ± 0.47 |
| SRResNet [28] | 25.23 ± 4.1 | 19.13 ± 2.4 | 0.74 ± 0.08 | 0.56 ± 0.05 | 2.42 ± 0.37 | 2.09 ± 0.30 |
| SRGAN [28] | 26.11 ± 3.9 | 21.08 ± 2.3 | 0.75 ± 0.06 | 0.58 ± 0.09 | 2.44 ± 0.28 | 2.26 ± 0.17 |
| SRDRM [31] | 24.62 ± 2.8 | 22.26 ± 2.5 | 0.72 ± 0.17 | 0.59 ± 0.05 | 2.59 ± 0.64 | 2.28 ± 0.35 |
| SRDRM-GAN [31] | 24.61 ± 2.8 | 22.21 ± 2.4 | 0.72 ± 0.17 | 0.58 ± 0.13 | 2.59 ± 0.64 | 2.27 ± 0.44 |
| Deep SESR [33] | 25.49 ± 3.3 | 24.75 ± 2.8 | 0.71 ± 0.19 | 0.66 ± 0.05 | 2.82 ± 0.47 | 2.55 ± 0.35 |
| Ours | 25.79 ± 3.0 | 24.97 ± 2.8 | 0.72 ± 0.16 | 0.71 ± 0.17 | 2.66 ± 0.56 | 2.62 ± 0.54 |
| Model | Params (M) | FLOPs (G) | T-U90 | Test-C60 | |||
|---|---|---|---|---|---|---|---|
| MSE | PSNR (dB) | SSIM | UIQM | UCIQE | |||
| with only RGB color space | 1.36 | 44.54 | 447.15 | 22.91 | 0.90 | 2.43 | 0.54 |
| with same receptive field (k = 5) | 1.25 | 40.96 | 453.41 | 22.84 | 0.91 | 2.45 | 0.55 |
| without Ag-NL module | 1.19 | 39.06 | 785.66 | 20.21 | 0.89 | 2.50 | 0.51 |
| ours | 1.36 | 44.54 | 432.14 | 22.99 | 0.91 | 2.64 | 0.55 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, R.; Zhang, Y.; Zhang, Y. Agent-Guided Non-Local Network for Underwater Image Enhancement and Super-Resolution Using Multi-Color Space. J. Mar. Sci. Eng. 2024, 12, 358. https://doi.org/10.3390/jmse12020358
Wang R, Zhang Y, Zhang Y. Agent-Guided Non-Local Network for Underwater Image Enhancement and Super-Resolution Using Multi-Color Space. Journal of Marine Science and Engineering. 2024; 12(2):358. https://doi.org/10.3390/jmse12020358
Chicago/Turabian StyleWang, Rong, Yonghui Zhang, and Yulu Zhang. 2024. "Agent-Guided Non-Local Network for Underwater Image Enhancement and Super-Resolution Using Multi-Color Space" Journal of Marine Science and Engineering 12, no. 2: 358. https://doi.org/10.3390/jmse12020358
APA StyleWang, R., Zhang, Y., & Zhang, Y. (2024). Agent-Guided Non-Local Network for Underwater Image Enhancement and Super-Resolution Using Multi-Color Space. Journal of Marine Science and Engineering, 12(2), 358. https://doi.org/10.3390/jmse12020358