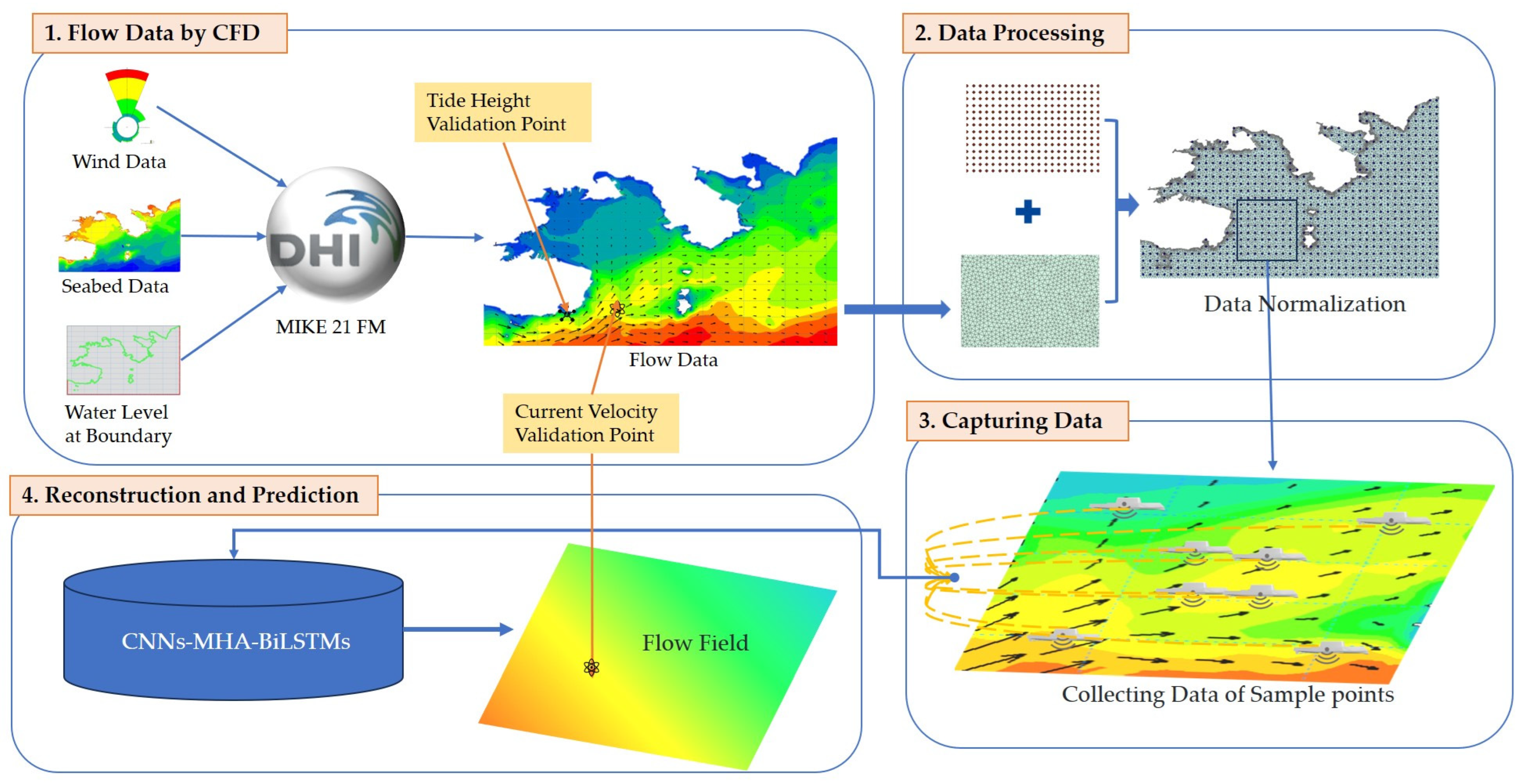
First, the MIKE21 flow model (FM) commercial coast and marine modelling software, released 2014, were used to solve the entire flow field, thereby generating a comprehensive database by solving the hydrodynamic equations on a two-dimensional unstructured mesh. The database provided reliable data for subsequent analysis and modelling by capturing information over the entire area.
Second, the numerical solutions corresponding to the measured points were extracted from the database and compared with the measured values to verify the accuracy and reliability of the numerical solutions.
Third, the original unstructured mesh data were transformed into regular data by sampling the data at fixed intervals (e.g., 0.01°) within the selected area.
Fourth, the CNNs–MHA–BiLSTMs model was employed to predict the velocities of points in the flow based on the input data, including wind velocity components, tide height, and previous flow velocities, in order to forecast them.
Finally, the application of the CNNs–MHA–BiLSTMs model combined with the flow velocities in the current moment for these points as the inputs enabled the prediction of flow velocities over an extended surface or a larger area in the next moment. The purpose of this step is to structure the points into surface data by leveraging the spatiotemporal prediction capability of the model.
3.1. Development of the Flow Field Database
In our study, one of the significant challenges we face is the scarcity of measured data. Such data are crucial for training and validating AI models aimed at predicting complex fluid environments. Given the time-consuming and costly nature of field measurements, CFD methods become an invaluable tool for obtaining alternative data; CFD simulations can mimic fluid motion under various conditions, generating detailed and diverse time-series flow field data.
To ensure that CFD-generated data closely resemble real-world data, we implemented a series of precise settings during simulations. Although CFD data may not perfectly match real-world fluid fields, it provides a valuable training foundation, especially in the absence of direct observation data. This approach based on CFD simulation data aids in progressively achieving more precise prediction and higher efficiency in engineering applications and lays a foundation for adopting precise measurement data to replace simulated data for algorithm training in the future.
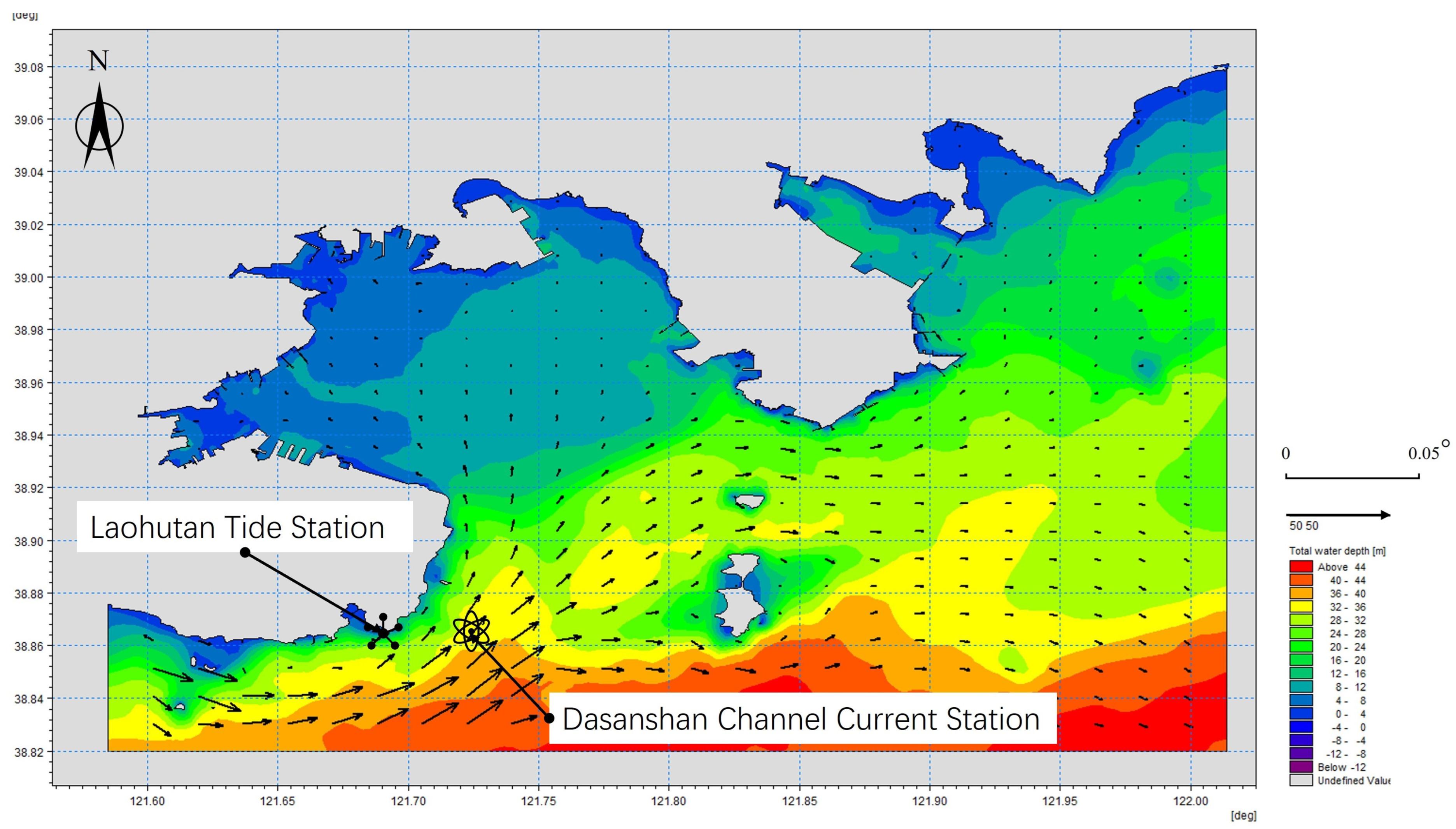
The MIKE21 FM software, which is based on the finite volume method using unstructured meshes, takes the ocean areas around Dalian Port, China, as a case study for numerical simulations. The objective was to obtain data for the entire two-dimensional ocean surface domain and subsequently validate the data. The topographic and bathymetric data used for the simulation area were obtained from CN412301, CN412312, and CN412333 electronic nautical charts. The computational field is delineated by the red square in
Figure 3, with the blue marks indicating the locations of the depth sampling points, as listed in
Table 1.
Grid independence, a pivotal aspect of numerical simulations, ensures that results remain consistent and convergent as the computational grid is refined. Employing various element resolutions (
Table 2) verifies how numerical solutions accurately reflect physical phenomena, free from grid-related artefacts, thereby enhancing the reliability and validity of our findings. In this study, rigorous grid independence tests were conducted to validate our result.
These meshes of different cases are shown as (a), (b), and (c) in
Figure 4, where the green data markers denote the land boundaries and the red data markers denote the open boundaries. The selection of triangular meshes was a result of the complex coastline of our study area, where triangular meshes perform better than rectangular meshes in dealing with intricate shoreline structures. Triangular meshes can flexibly adapt to irregular boundaries, automatically adjusting the positions of mesh nodes to fit the curves and protrusions of complex coastlines and capture small geographical features to achieve higher precision.
Ocean currents are driven by various forces, and the wind pressure on the ocean surface is one of the key factors. The input parameter for this study was the wind velocity at a height of 10 m above the ocean surface, which was used to compute the average wind velocity over the area [
22]. Meteorological data were obtained from the Xihe Energy Big Data Platform [
23].
The temperature and salt level were set by a positive pressure equation; Manning’s M was 30 m
1/3/s, the time step was calculated to be 30s, and the CFL number was set to 0.8 to avoid model divergence. The influence of Coriolis force and tidal potential was not considered since the simulation area was small. Wave radiation stress was considered negligible because its influence was overshadowed by the stronger and more consistent forces created by tidal movements [
24,
25]. For more detailed parameter settings, refer to [
26]. Closed boundaries were assigned to coastal areas, whereas open boundaries with Flather boundary conditions were applied to open areas outside the coast. The water level at the open boundaries was set as the tidal water level, which varied with time. The water depth data were obtained by sampling depth points marked on electronic nautical charts and interpolating them to achieve a more continuous and accurate distribution of the water depth.
Figure 5 illustrates both the water depth distribution and flow velocity vectors at a scale magnified 50 times.
To verify and validate the accuracy of the MIKE21 FM numerical model, validation was performed during spring tides. The numerical simulations were conducted from 8th January 2024 (08:00) to 22nd January 2024 (08:00), with the results outputted every 30 s. The simulation period for the spring tides was selected from 15th January 2024 (08:00) to 16th January 2024 (08:00). The results were compared with the observed tide height data from the Laohutan tide station in Dalian city and the observed current speed and direction data from the Dasanshan Channel current station in Dalian city, provided by the National Ocean Data and Information Service, which is a government-funded public institution under the State Oceanic Administration of China [
27]. The station coordinates are presented in
Table 3.
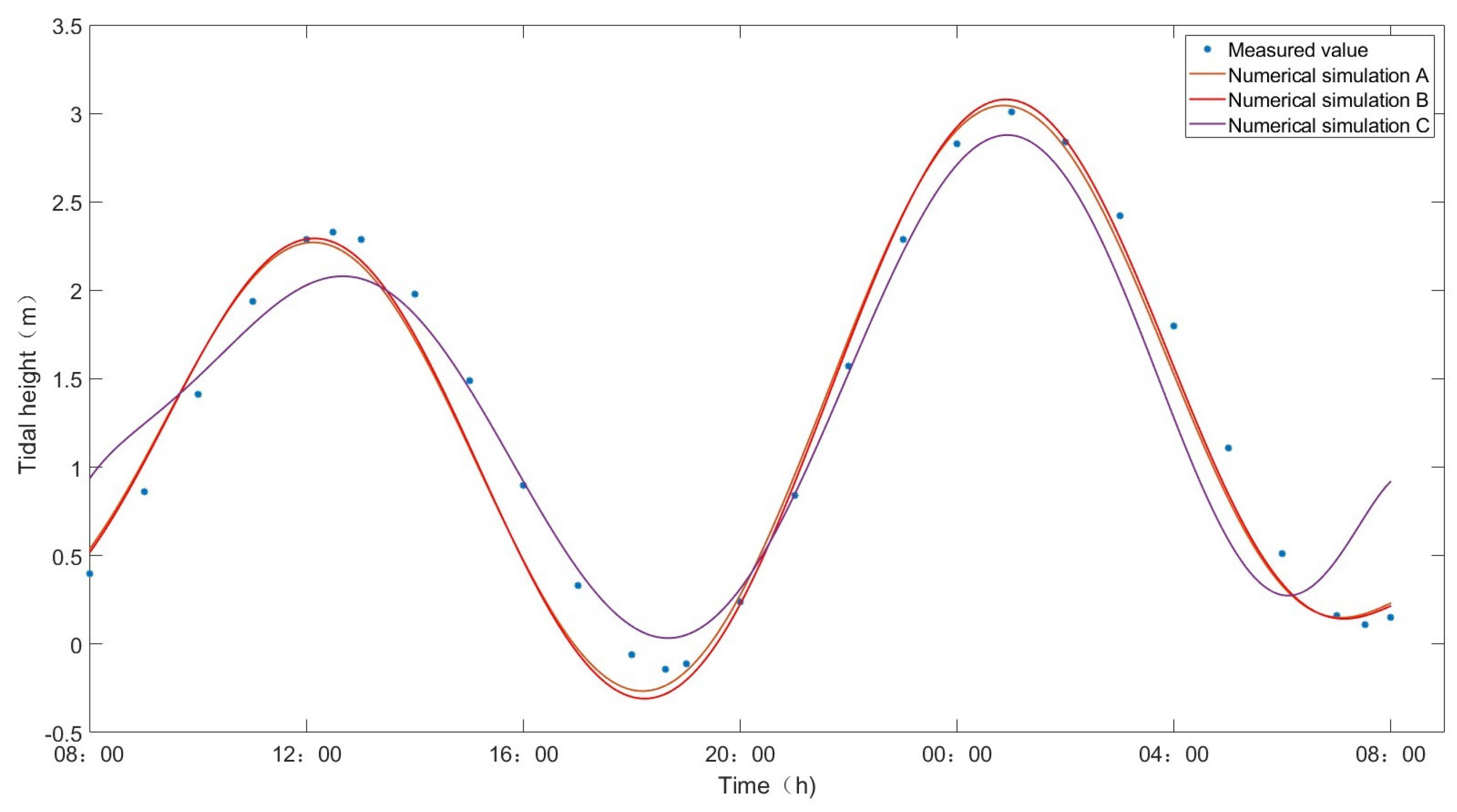
The tide height validation results for Laohutan are shown in
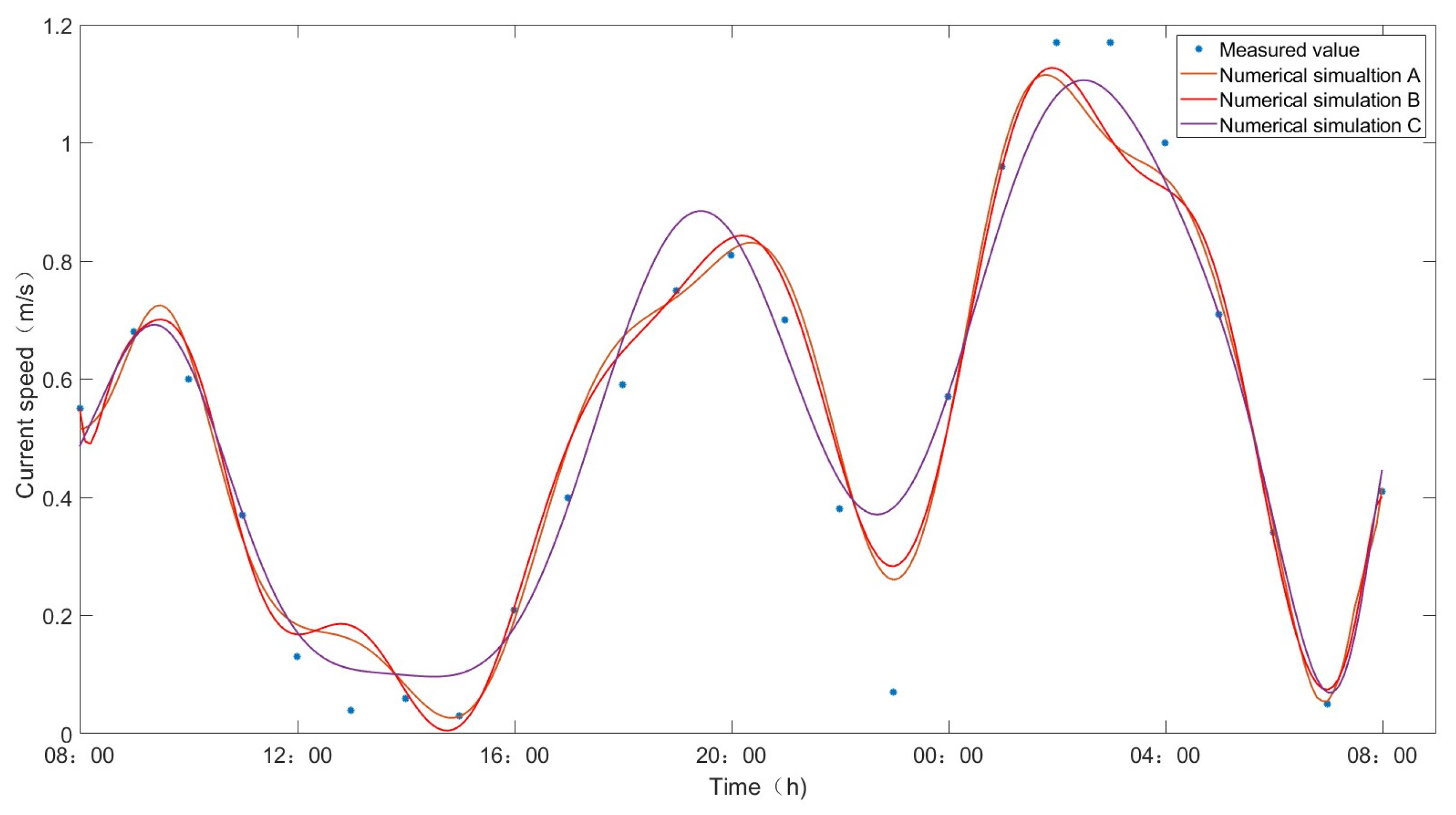
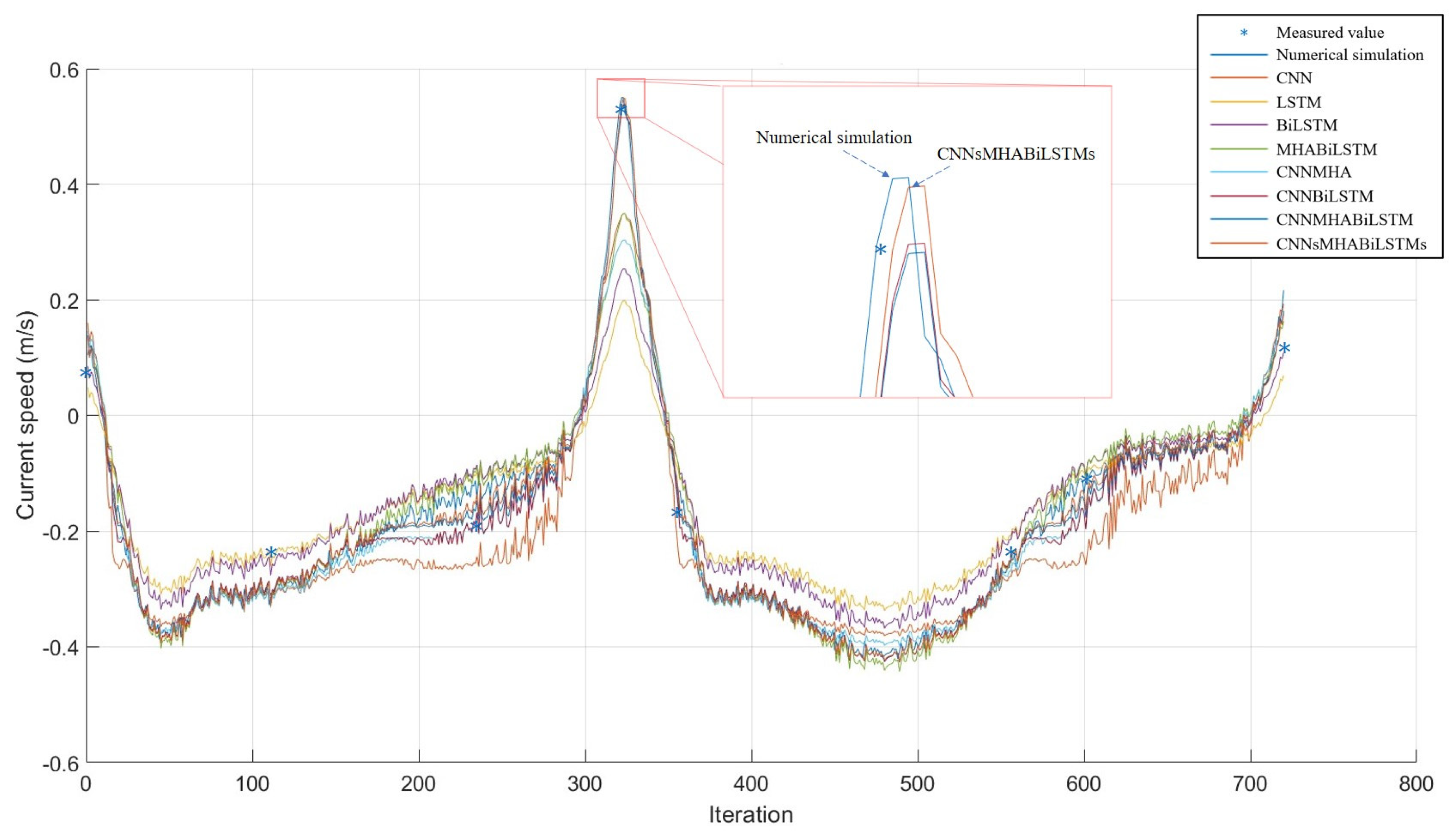
Figure 6. The current speed validation results for the Dasanshan Channel are shown in
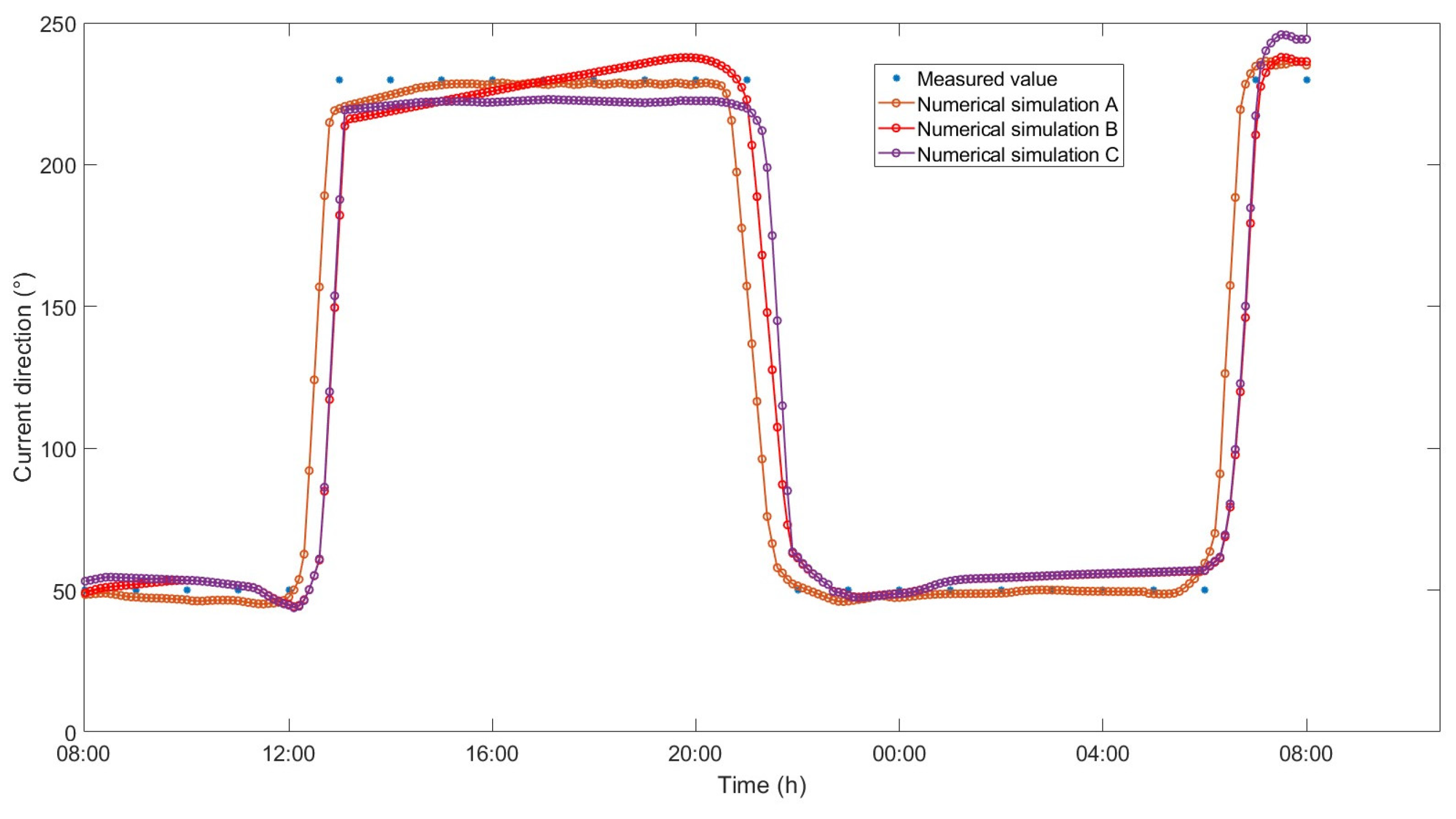
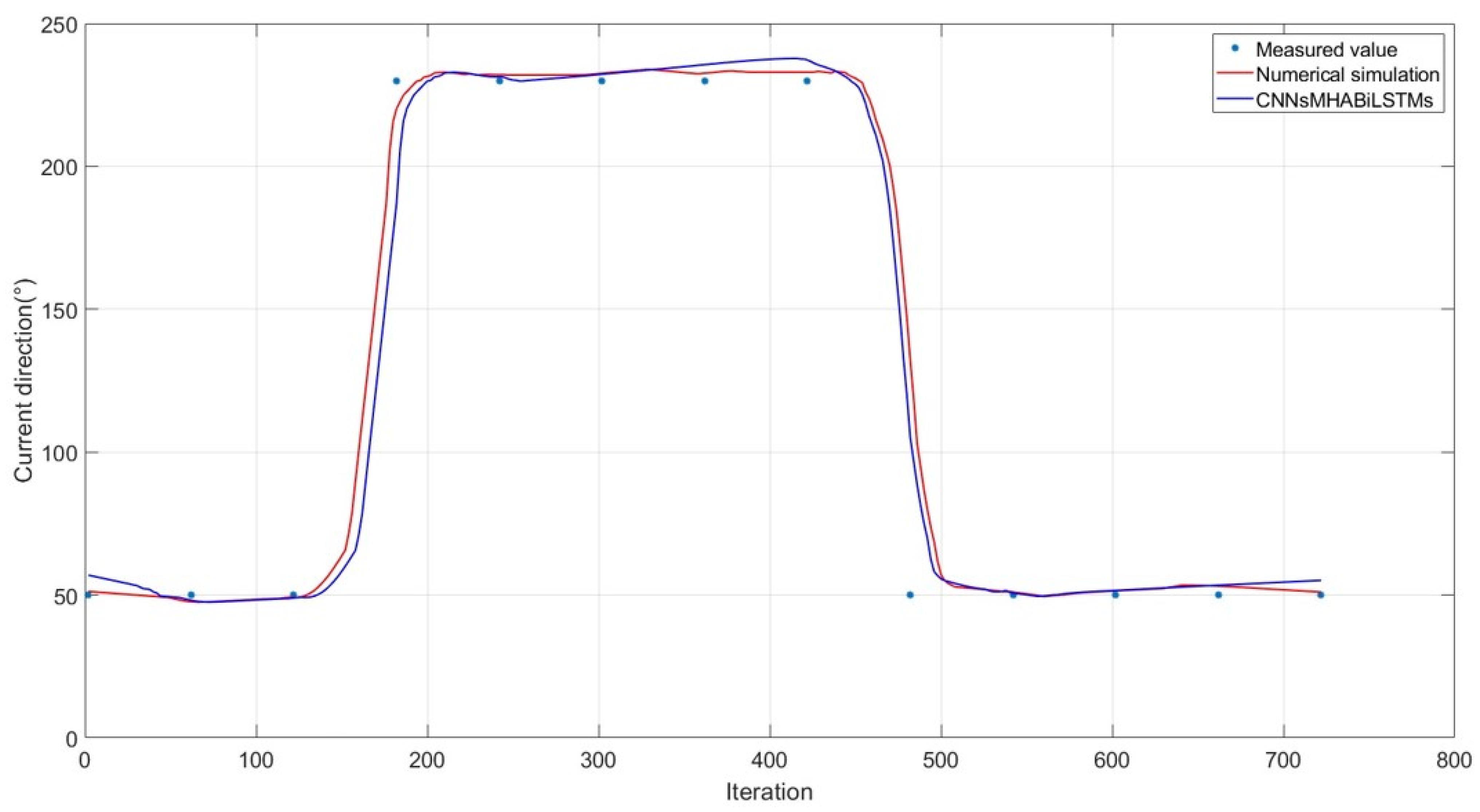
Figure 7, whereas the current direction validation results for the Dasanshan Channel are shown in
Figure 8.
In this study, three metrics were used to evaluate the performance of the MIKE21 FM, namely, the mean absolute percentage error (MAPE), root mean squared error (RMSE), and coefficient of determination (R
2). These metrics place different emphasis on the prediction results of deep learning models. The RMSE, MAPE, and R
2 were calculated using Equation (11), Equation (12), and Equation (13), respectively.
In these equations,
N is the maximum number of iterations,
is the actual value,
is the predicted value, and
is the mean of the actual values. According to the validation results for the tide height, current velocity, and current direction, the numerical simulation results at the monitoring sites were generally consistent with the measured values. The evaluation metrics of the MIKE21 FM of various element resolutions used to predict the single-point flow field characteristics are presented in
Table 4.
Through the analysis of three numerical simulations (Case I, II, and III) using error metrics such as RMSE, MAPE, and R2, several important conclusions regarding grid independence can be drawn. First, Case I demonstrates the best performance in capturing THE water level, flow speed, and flow direction, exhibiting remarkable stability and high accuracy, indicating that the simulation results are relatively insensitive to grid variations at the defined resolution. In contrast, Case II, while showing slightly reduced performance, still maintains a high level of accuracy, suggesting that a moderate reduction in the number of nodes and elements does not significantly impact THE results. Conversely, Case III presents a contrasting scenario, with marked increases in RMSE and MAPE, as well as a decline in R2, indicating a strong grid dependence. This is particularly evident with only 13,580 nodes and 22,047 elements, leading to a substantial reduction in the accuracy of the simulation results. This indicates that an overly coarse grid can lead to the loss of critical details, resulting in larger errors. Considering the overall computational power, the analysis of the three cases must balance grid refinement with the efficient use of computational resources. Case I excels in accuracy and stability; however, its high number of nodes and elements (45,437 nodes and 82,660 elements) implies greater computational resource and time consumption, which might lead to inefficiency or resource exhaustion. Case II maintains high precision while slightly reducing the number of nodes and elements, indicating that a reasonable grid resolution can achieve a balance between accuracy and computational power consumption, resulting in a satisfactory outcome. Based on these results, it can be deduced that the MIKE21 FM can accurately predict the flow field characteristics within the area of interest.
3.2. Supplementary Validation
Due to the scarcity of publicly available data points on currents, velocity, and tide height in the waters near Dalian, to ensure the reliability of the CFD data, we conducted detailed numerical simulations for another coastal area (Lianyungang). Lianyungang is located in the central region of China’s coastline, adjacent to the Yellow Sea. These simulations were rigorously validated using tidal and current station data that are publicly available for that region. By meticulously comparing the model outputs with actual field measurement data, we achieved a high level of consistency, significantly enhancing the accuracy and reliability of the initial data input for the AI model.
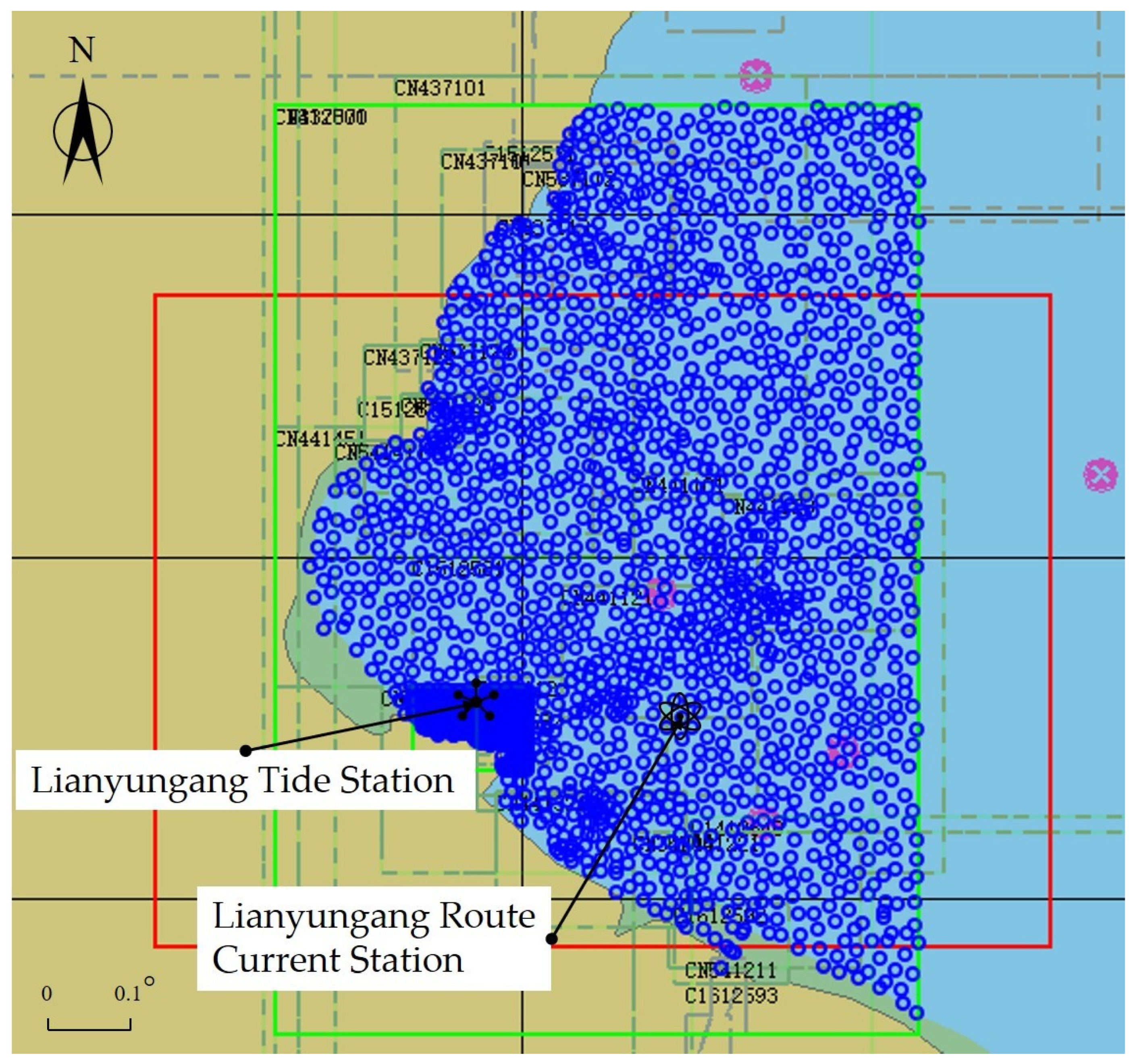
The topographic and bathymetric data used for the simulation area were obtained from CN337001 and CN541112 electronic nautical charts. The computational field is delineated by the green square in
Figure 9, with the blue marks indicating the locations of the depth-sampling points.
A two-dimensional unstructured grid was used for discretization, consisting of 36,067 computational nodes and 67,125 triangular elements within the computational domain, as shown in
Figure 10. The green markers denote the land boundaries, while the red markers indicate the open boundaries.
The meteorological data are also sourced from the Xihe Energy Big Data Platform. Aside from changing Manning’s M to 28 m
1/3/s, this approach and other parameters remain the same as those used in the previous CFD model setup for the waters near Dalian.
Figure 11 illustrates both the water depth distribution and flow velocity vectors, magnified 50 times.
To verify and validate the accuracy of the MIKE21 FM, results were outputted every 30 s. The simulation period for the spring tides was chosen from 9 April 2024 (00:00) to 10 April 2024 (00:00). The results were then compared with the observed tide height data from the Lianyungang tide station and the observed current speed and direction data from the Lianyungang Route current station, both located in Lianyungang city. These data were provided by the National Ocean Data and Information Service, which is a government-funded public institution under the State Oceanic Administration of China [
27]. The station coordinates are listed in
Table 5.
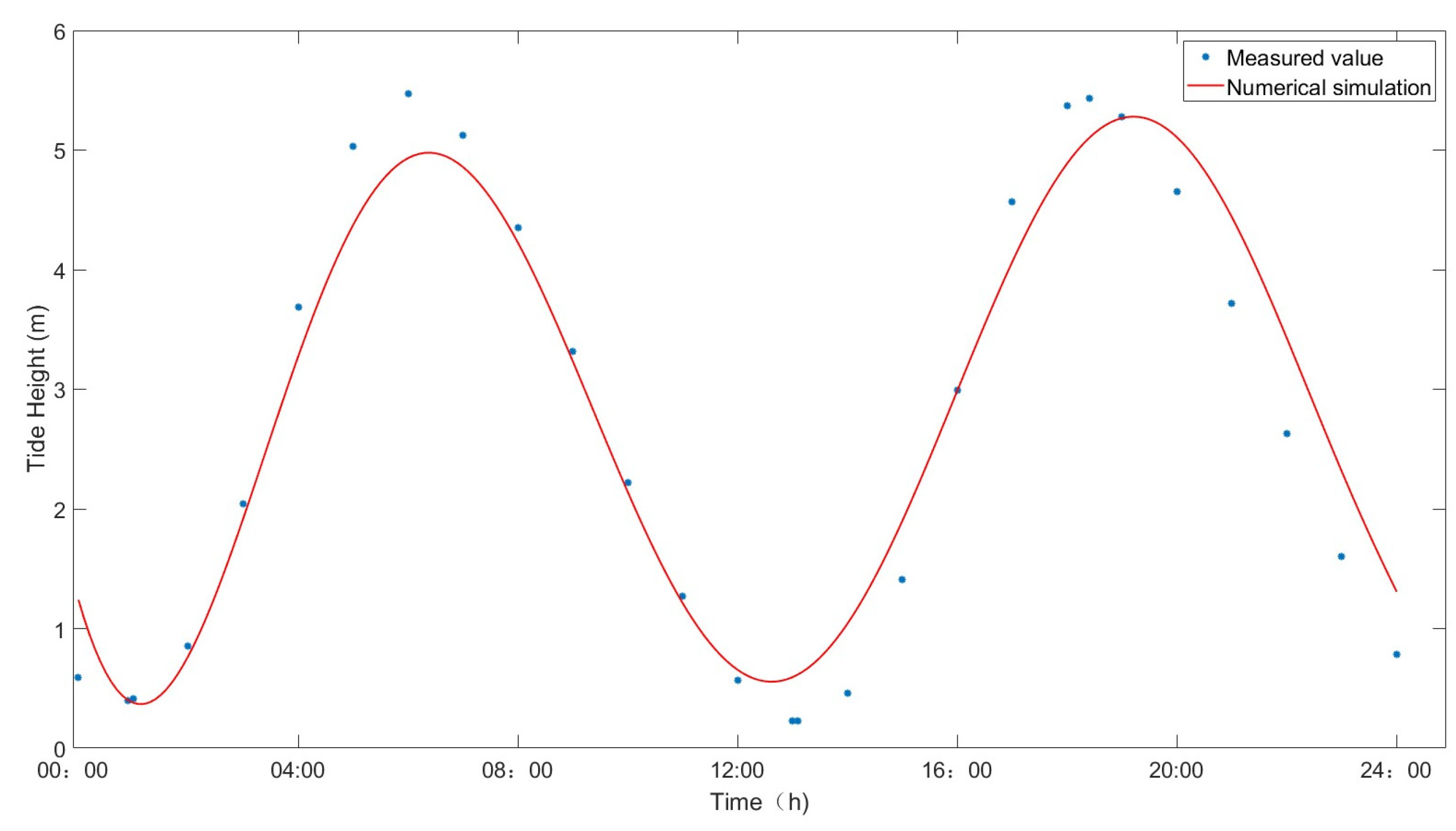
The verification result of tide height is presented in
Figure 12, while the verification results of current speed and direction are displayed in
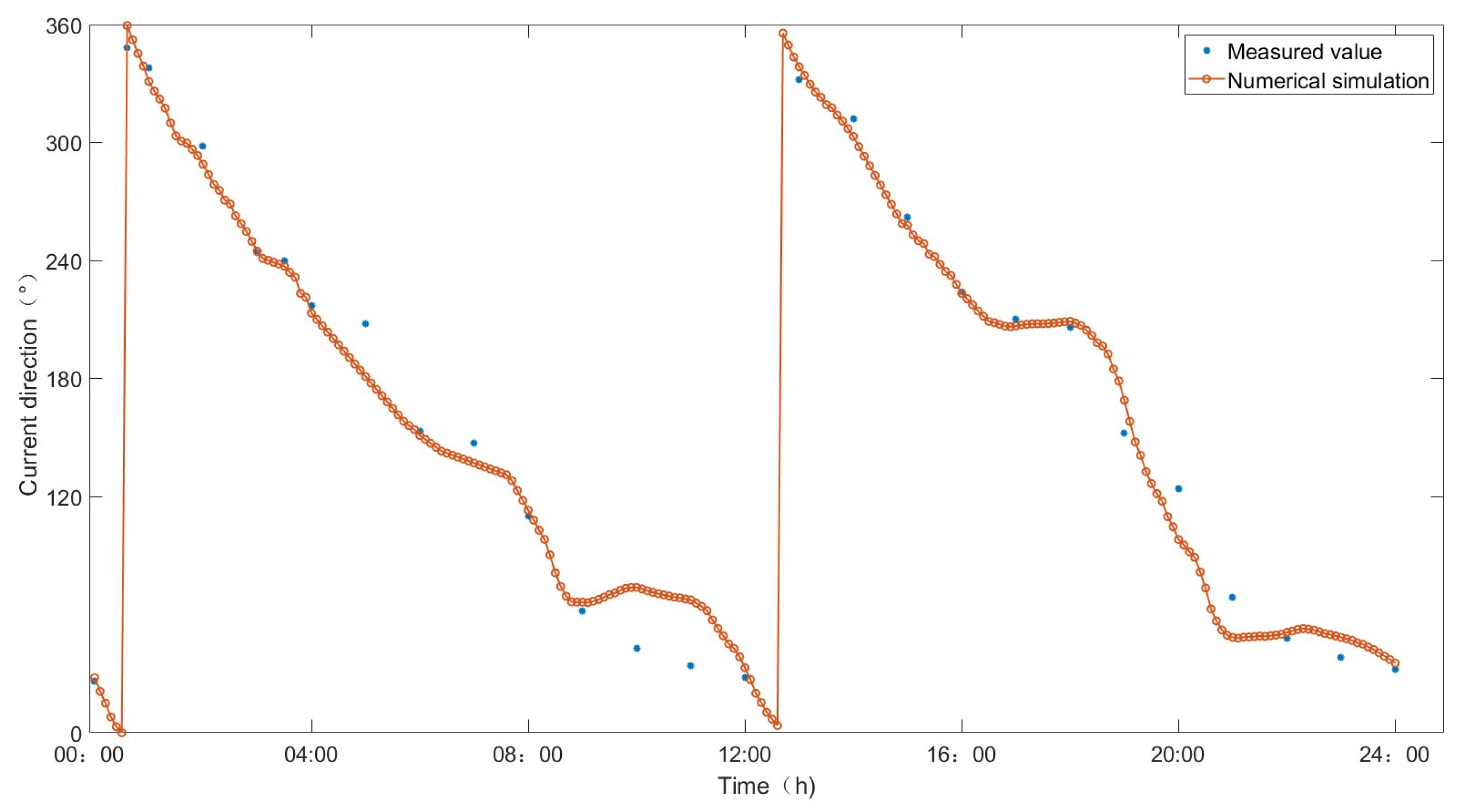
Figure 13 and
Figure 14, respectively.
The evaluation indicators for CFD simulations are shown in
Table 6.
The approach taken to conduct CFD simulations and validations in the sea area adjacent to Lianyungang, through the selection of an additional computational domain for verification purposes, addressed the limitation of having a restricted number of validation points within our initial domain. The finding that the data accuracy across multiple domains at validation points is comparatively high further underscores the dependability and trustworthiness of the CFD data referenced in our earlier content.
3.3. Data Processing
The use of a two-dimensional unstructured mesh for horizontal space discretization of the MIKE21 FM can lead to nonuniform element sizes, irregular node arrangements, and varying inter-node distances, posing a challenge for deep learning models that aim to extract spatial features. To address these issues effectively, a sparse regularization data-processing method was adopted.
Initially, transforming original unstructured mesh data into a regularly spaced format with a point spacing of 0.01° yielded a sparser representation; this transformation enabled our deep learning model to better capture the spatial characteristics of current variations. Subsequently, we reduced the number of computational nodes from 24,207 to just 593, limiting each cell data point to one and extending the time intervals from 30 s to 120 s. This not only diminished the volume of the dataset but also standardized the data format, thereby enhancing regularity and optimizing subsequent analytical and modelling processes.
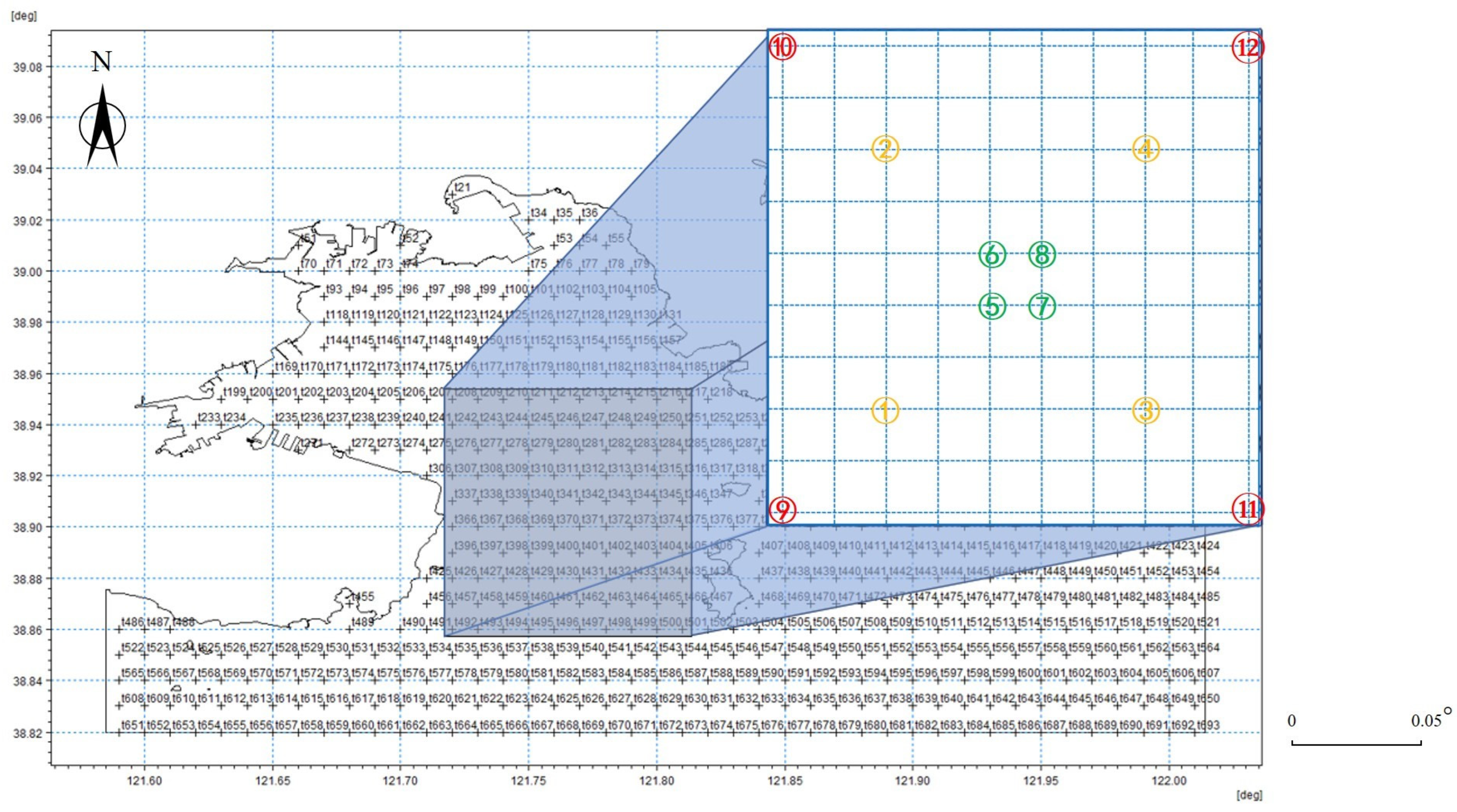
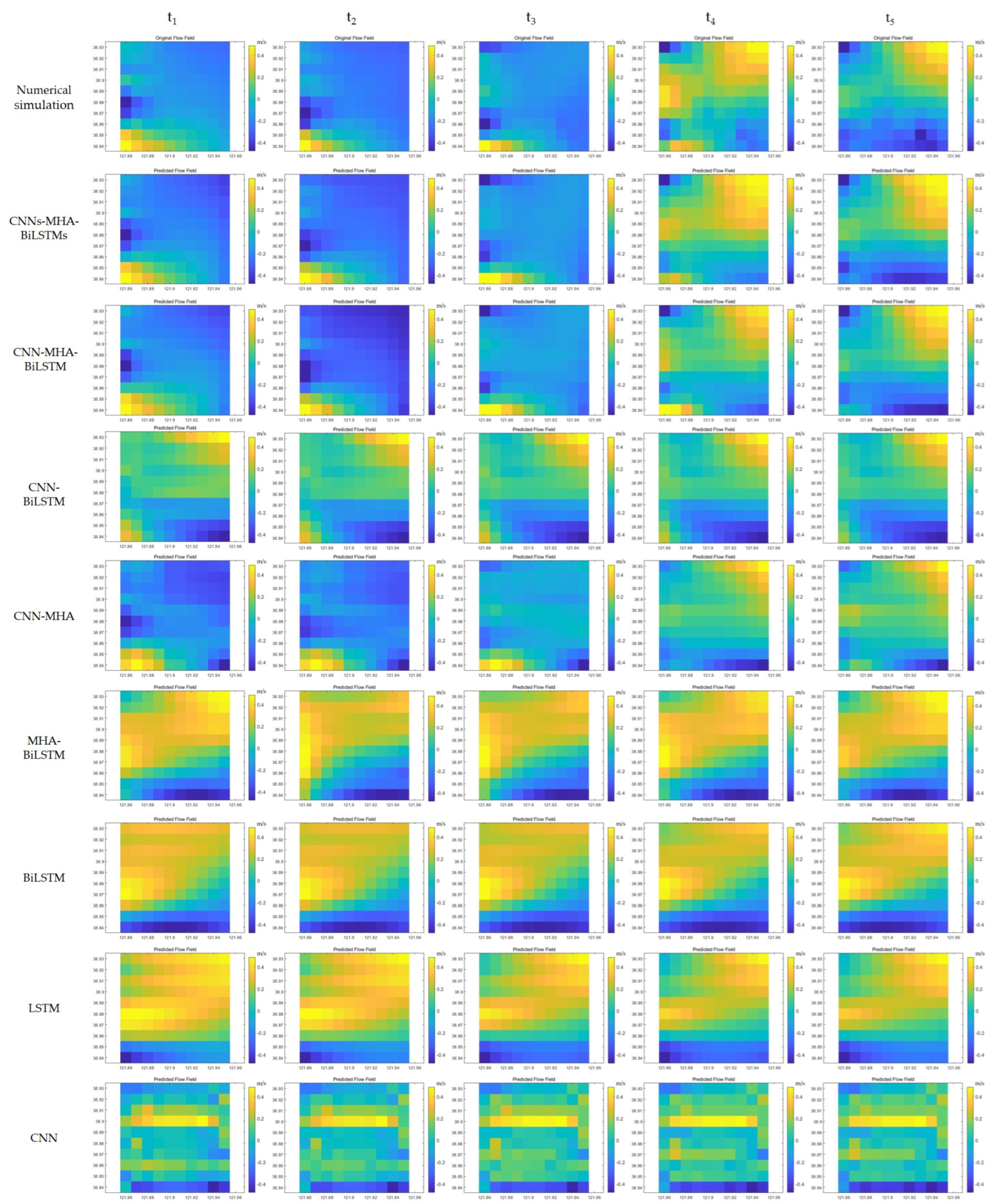
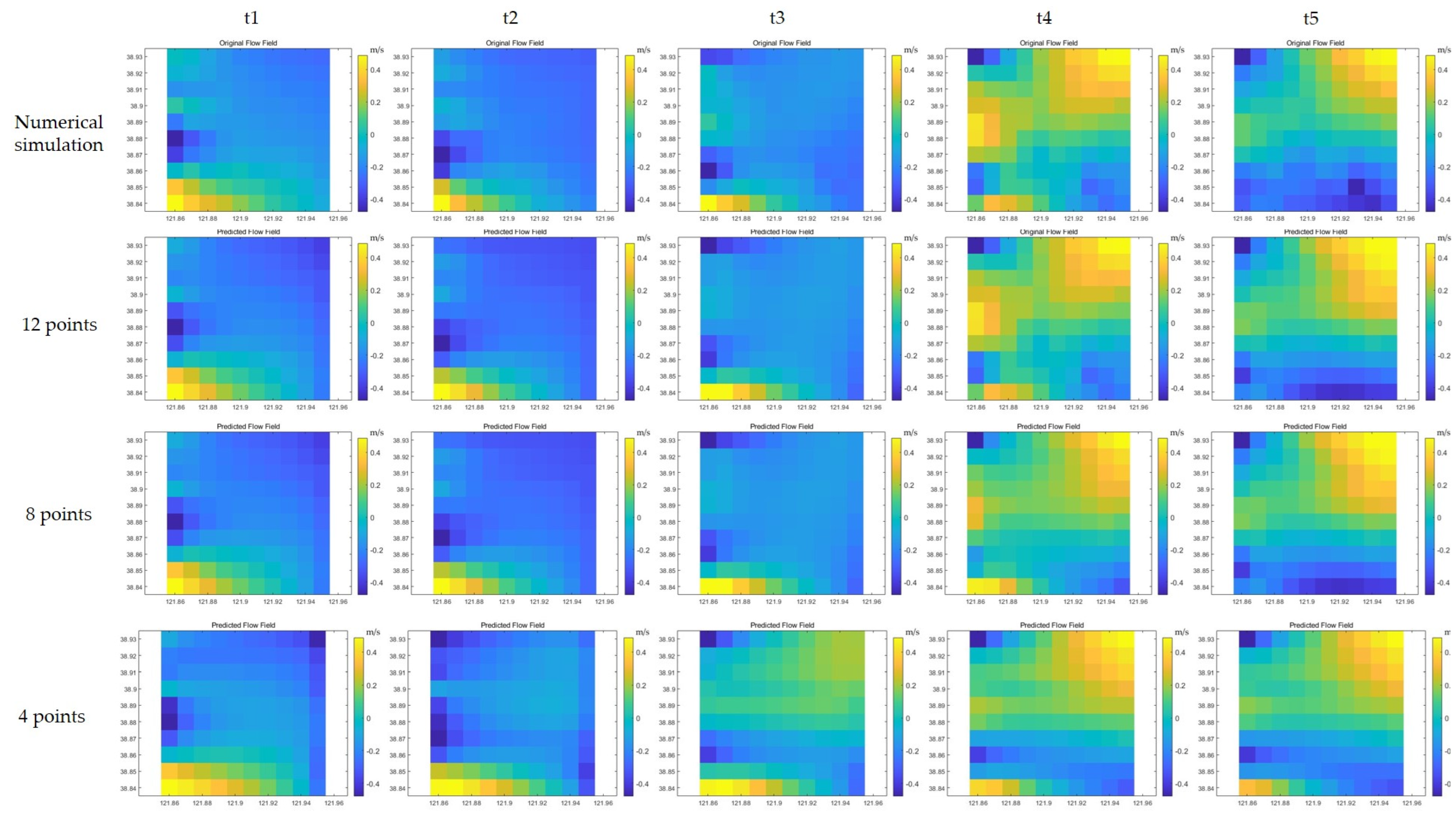
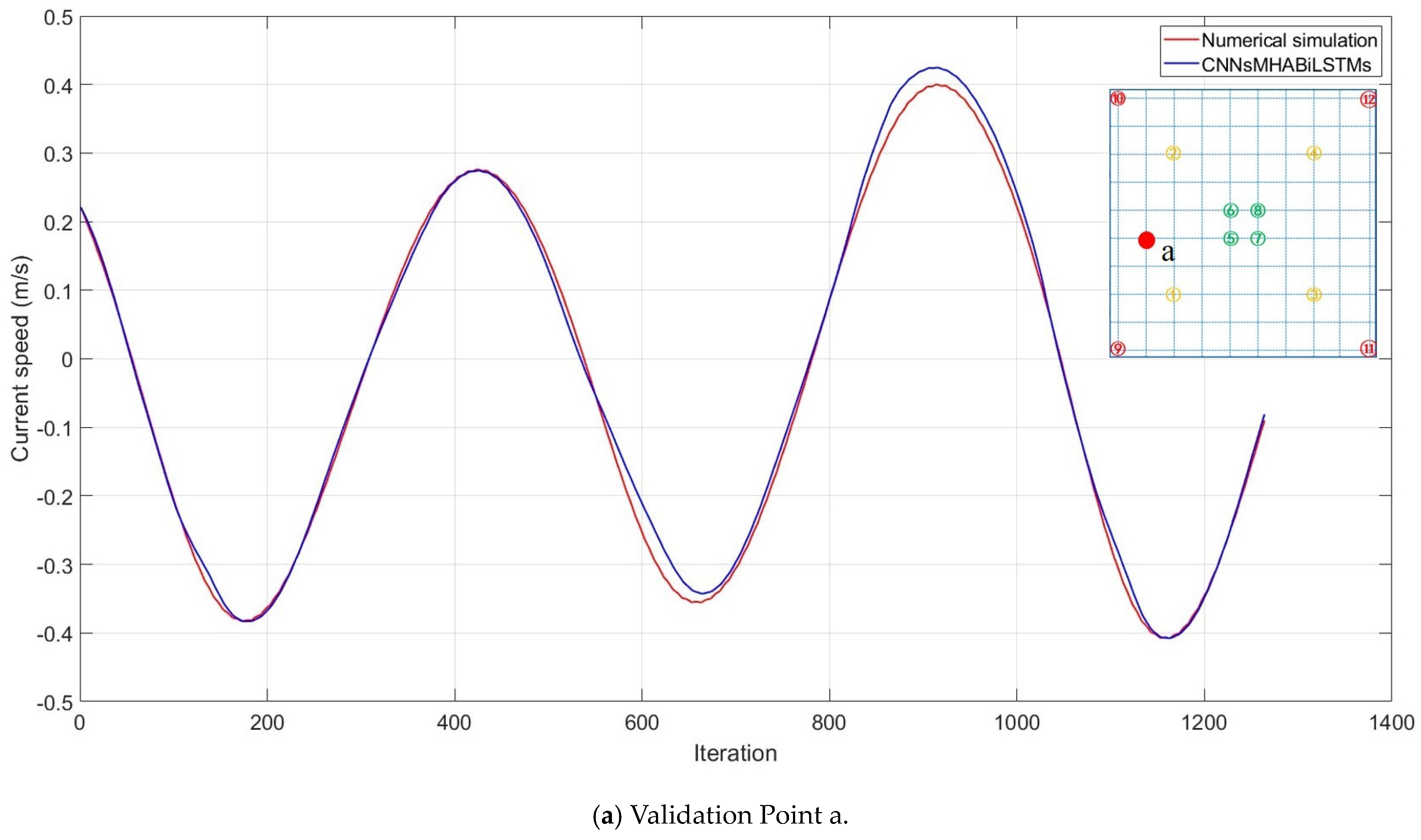
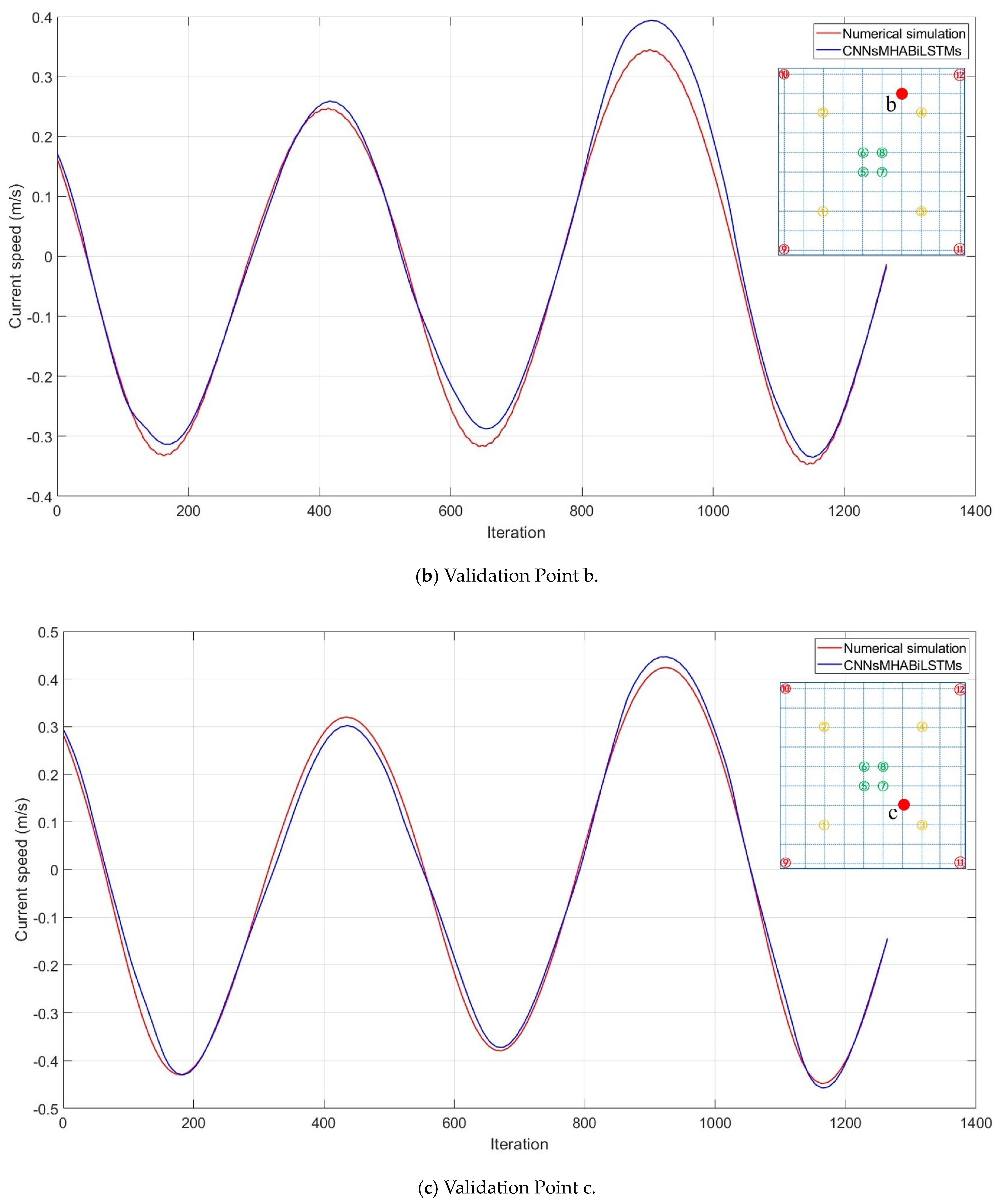
Following this transformation process, a specific area measuring 10 km × 10 km was selected for subsequent model training and testing purposes, as shown in
Figure 15. Here, the first experiment was sampled by four points (as indicated by the green circles), the second experiment was sampled by eight points (as indicated by the green and yellow circles), and the third experiment was sampled by 12 points (as indicated by the green, yellow, and red circles), providing the flow field characteristics across quadrants, including velocity variations along the diagonals. This study enhanced the adaptability and robustness through the addition of white noise variance (0.0001), which aligned with complex real-environment interferences.
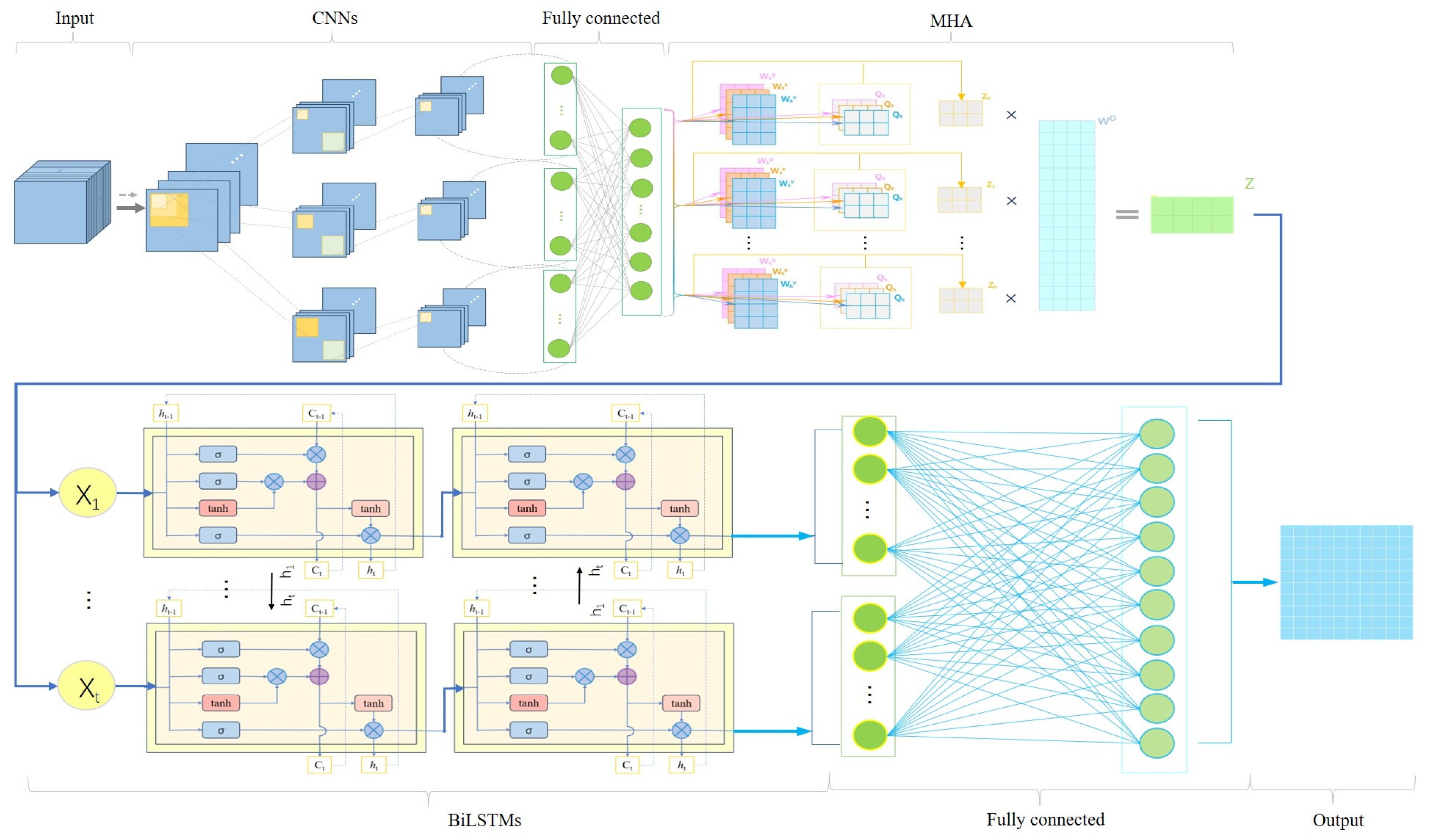
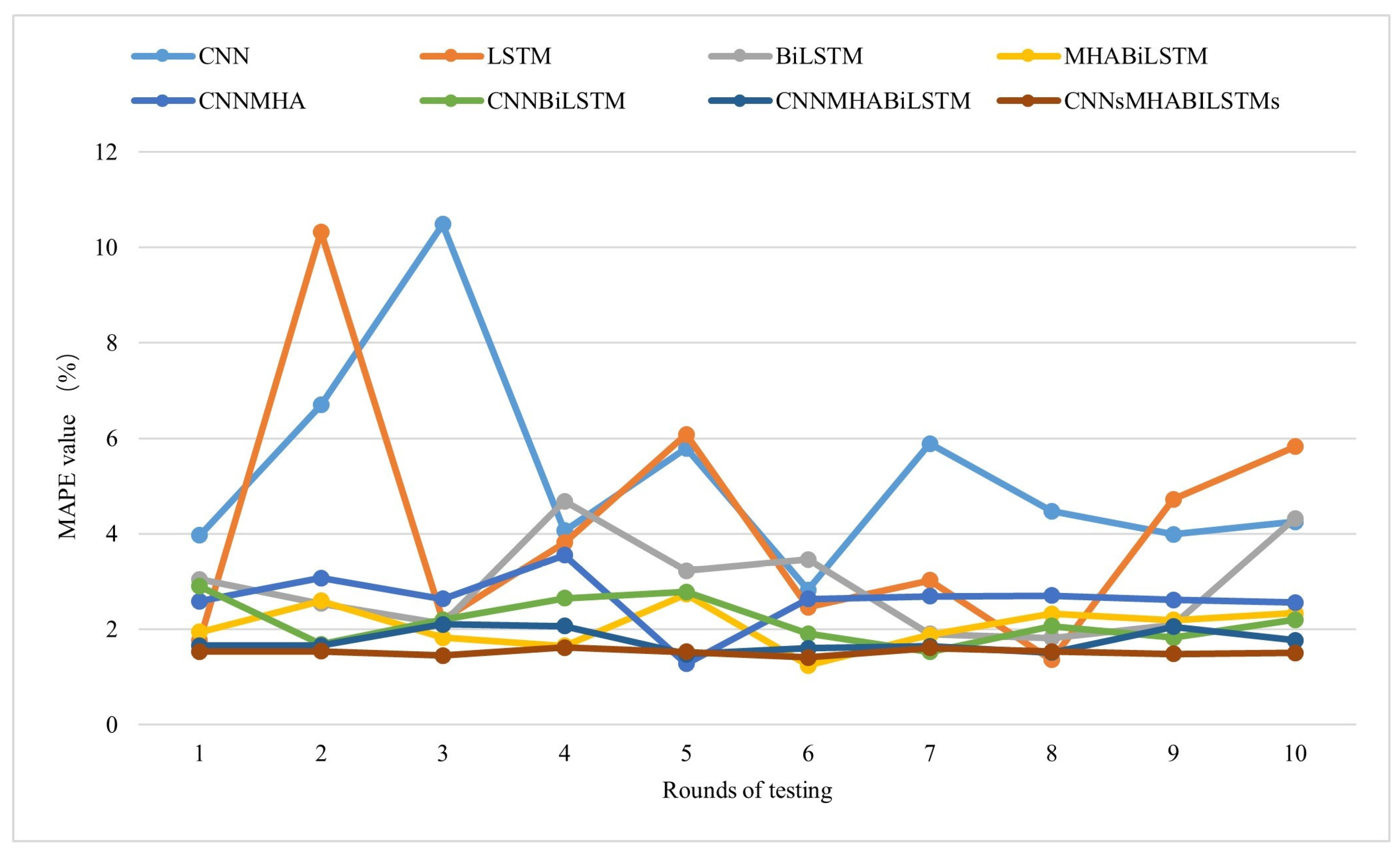
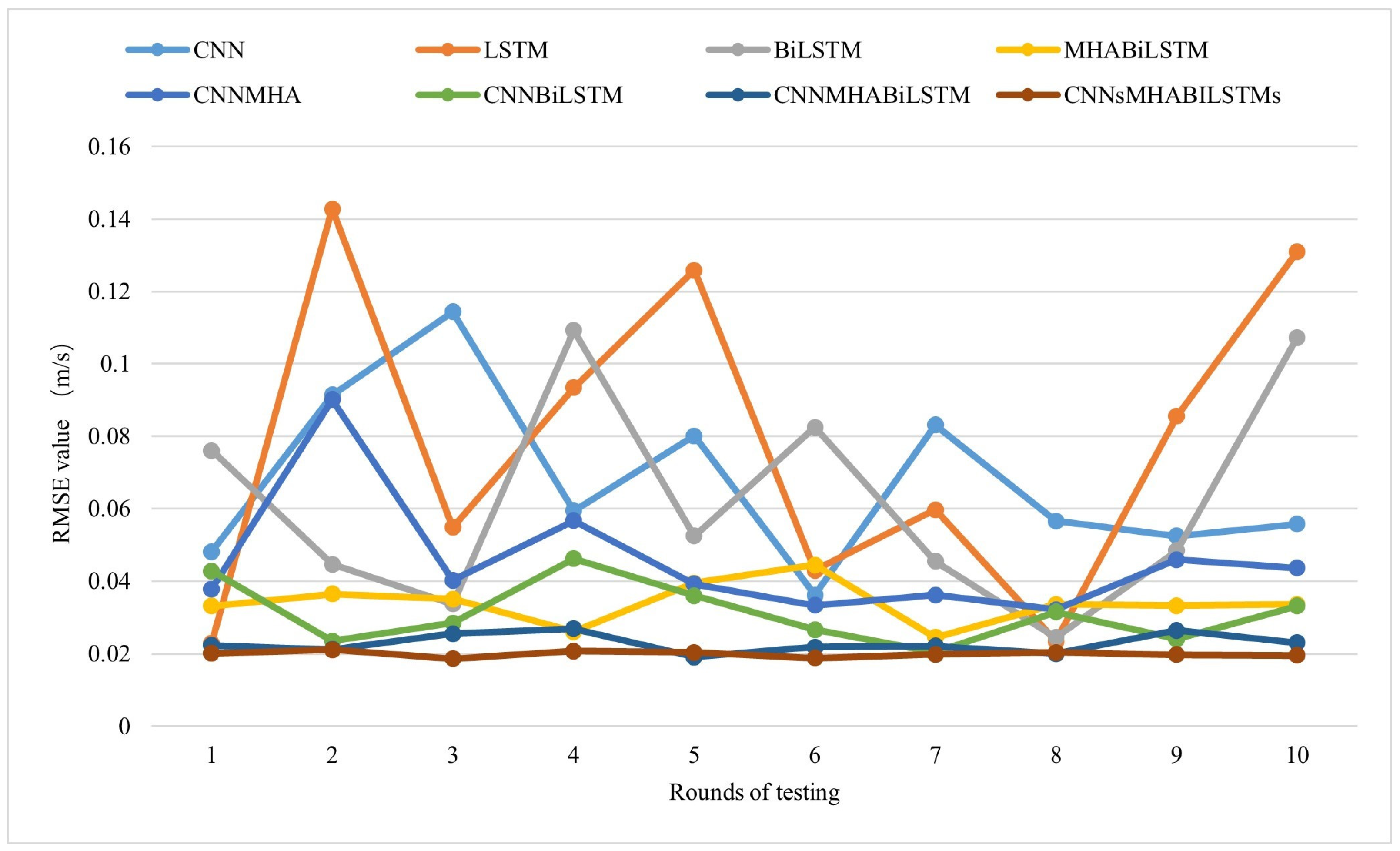
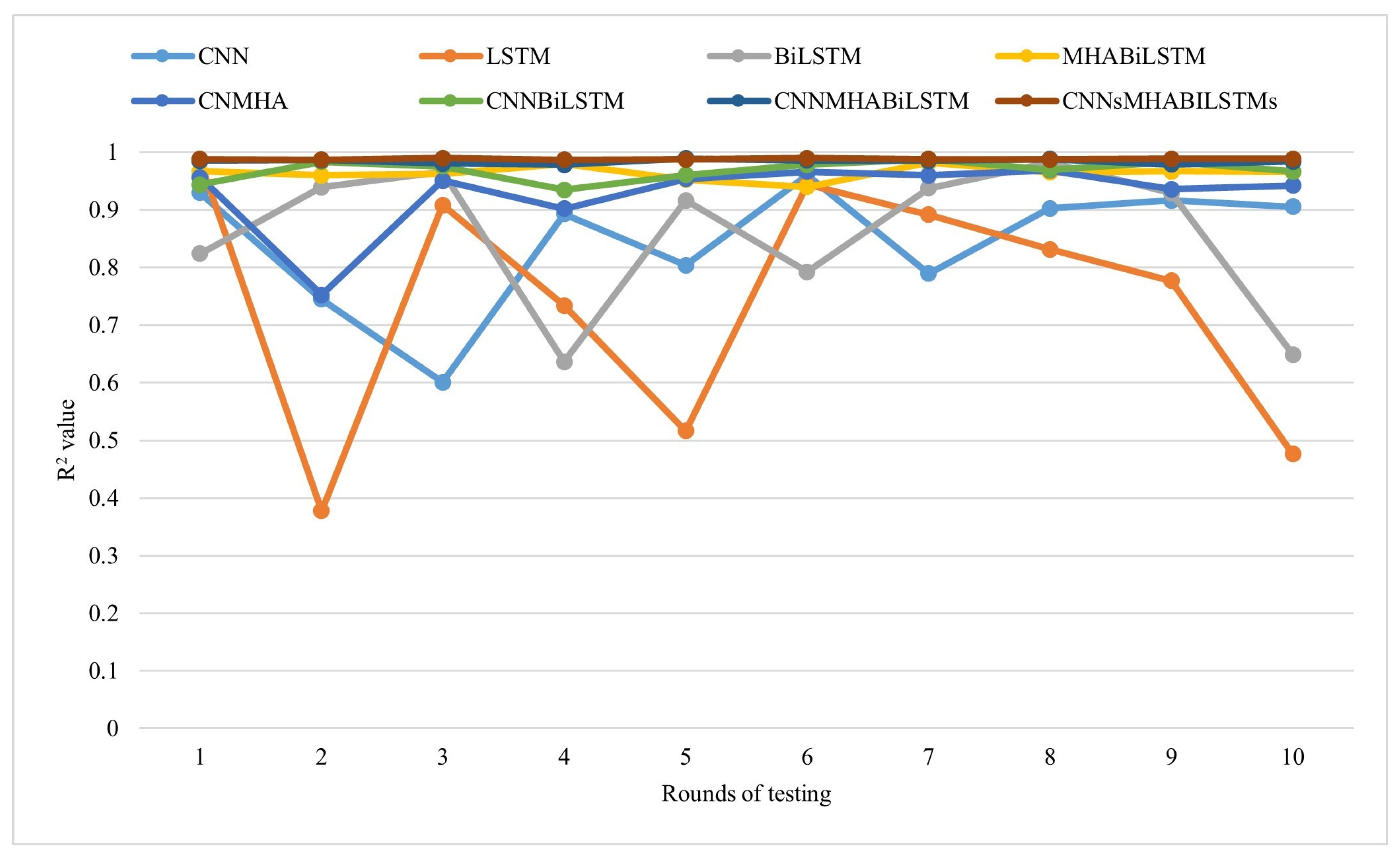
Various deep learning models (CNN, MHA, BiLSTM, and their hybrid models) were employed in this study, showing strong capabilities in processing spatiotemporal features, thereby effectively capturing the intricate patterns and characteristics present within the datasets.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}