1. Introduction
Water covers about 71% of the Earth’s surface, and humans have engaged in a wide range of production and research activities across various aquatic environments, including rivers, lakes and oceans. Due to inherent physiological limitations, underwater operations present greater challenges compared to activities conducted on the water’s surface. As the foundation for subsequent operations, underwater object detection has garnered increasing attention from researchers in recent years. It aims to utilize various advanced technological methods to automatically recognize and locate objects in underwater environments. These objects may include aquatic organisms, sunken ships, underwater personnel and seabed equipment, and the ability to detect them is of significant importance for underwater resource exploration, water resource monitoring, aquaculture and marine biodiversity conservation. With the advancements in image acquisition hardware and improvements in computational capabilities, computer vision-based object detection has emerged as a major research direction and has made substantial progress, and has been widely applied across various industries on both land and water, including autonomous driving, intelligent video surveillance, ship detection, and so on. However, there are still many difficulties to be solved in underwater object detection. Firstly, poor lighting conditions have a serious impact on underwater optical imaging, and factors such as water quality and flow can also affect the clarity and quality of images. Secondly, underwater targets such as marine life and corroded shipwrecks exhibit diverse scales, shapes and appearances. Therefore, underwater object detection is a challenging yet promising research direction. With ongoing technological advancements and innovations, it is anticipated that more efficient and accurate underwater object detection systems will be developed in the future, providing robust support for marine resource development and research.
2. Related Work
Object detection is a challenging task in the field of computer vision, aiming to extract target feature information from images or videos and achieve target localization. Over the past few decades, it is generally believed that object detection has undergone the following two periods: the traditional algorithms and the deep learning-based algorithms.
Traditional object detection algorithms primarily rely on manually extracted features, and the entire algorithmic process can be summarized into three steps. First, select the regions of interest, choosing areas that may contain objects. Second, extract features from the regions that may contain objects. Finally, perform detection and classification on the extracted features. P. Viola et al. [
1] proposed the Viola–Jones (VJ) detector, which uses a sliding window approach to check if a target exists within the window. However, due to its massive computational demands, this detector has very high time complexity. To address this issue, the VJ detector significantly improved the detection speed by combining the following three key techniques: integral image, feature selection and detection cascade. N. Dalal et al. [
2] proposed the Histogram of Oriented Gradients (HOG) detector. This method improves the detection accuracy by calculating overlapping local contrast normalization on a dense grid of uniformly spaced cells. Thus, the HOG detector is an algorithm that extracts feature histograms based on local pixel blocks, showing good stability under local deformations and lighting variations. P. Felzenszwalb et al. [
3] proposed an object detection method based on a multi-scale, deformable parts model called the Deformable Parts Model (DPM), which can be seen as an extension of the HOG method, consisting of a root filter and several part filters. It improves the detection accuracy through techniques such as hard negative mining, bounding box regression and context initialization.
Deep learning-based object detection methods are mainly divided into single-stage and two-stage categories. Single-stage methods directly produce the final prediction results through a single forward propagation process. First, the input image is preprocessed and then target features are extracted through operations such as convolution and attention mechanisms. These features are fed into the object detection head, which performs target localization and classification and ultimately outputs the prediction results. Single-stage object detection algorithms focus more on speed and real-time performance. Two-stage methods, on the other hand, process in phases. The first stage generates candidate boxes, extracts regions that may contain objects by using a region proposal network and performs pooling operations to map the features to a fixed size. In the second stage, it extracts target feature information from the candidate regions by using a feature extraction network, and then performs target classification and localization. Finally, non-maximum suppression is used to remove redundant candidate boxes, and the final results are obtained. Currently, single-stage methods mainly include the SSD [
4] and the YOLO series algorithms [
5], while RCNN [
6], Fast RCNN [
7], Faster RCNN [
8] and Mask RCNN [
9] belong to the two-stage methods.
With the development of object detection technology, researchers are committed to exploring how to improve the accuracy of object detection in complex environments. Typically, attention mechanisms are used within networks to improve the extraction of target features, enhance semantic information and increase the precision of detection tasks. Woo et al. [
10] designed a CBAM module combining channel and spatial attention mechanisms, effectively addressing some issues in attention mechanisms. The channel attention module weights channel features and the spatial attention module weights spatial features, enabling the network to more accurately extract important features and improve the detection accuracy. Cao et al. [
11] proposed GCNet, which combines the long-range dependency modeling of NLNet [
12] and the channel attention adjustment of SENet [
13], enhancing the network’s overall ability to model global context information. Lee et al. [
14] improved the SENet channel attention module and proposed the EffectiveSE attention module, effectively avoiding the loss of channel information and helping to enhance the representation of feature information. Misra et al. [
15] introduced TripletAttention, which captures cross-dimensional interactions to calculate attention weights using a three-branch structure. This method processes input features through rotation and residual transformations, effectively establishes cross-dimensional dependencies, encodes channel and spatial features and maintains a low computational overhead. Chen et al. [
16] proposed a new hybrid attention transformer, HAT, which combines channel attention and self-attention methods and leverages the complementary advantages of both in global statistics and local fitting capabilities. Ouyang et al. [
17] proposed a novel attention module, EMA, which reshapes feature information on partial channel dimensions and groups them into multiple sub-features, preserving channel features and reducing computational resource waste. This method recalibrates the channel weights of each parallel branch by encoding global feature information and captures pixel-level relationships through cross-dimensional interactions. Wan et al. [
18] introduced the MLCA attention module, which integrates local and global levels of spatial and channel feature information through mixed local channel attention, enhancing the network’s expressive capability. Yu et al. [
19] proposed an attention module called the MCA, which reduces the model size and improves the network accuracy through a three-branch structure of multi-dimensional collaboration. In the MCA module, dual cross-dimensional feature responses are merged through an adaptive combination mechanism and a gating mechanism is designed to extract local feature information interaction during excitation transformation.
In underwater image detection tasks, methods such as feature fusion and attention mechanisms are commonly used to improve the extraction of target feature information. Additionally, image enhancement techniques can address issues of insufficient lighting and poor image quality in underwater images, thereby enhancing the accuracy of detection tasks. Song et al. [
20] proposed Boosting R-CNN, a two-stage detection method. This method employs a new region proposal network called RetinaRPN, which has strong capabilities to detect blurry and low-contrast underwater images. Moreover, the method introduces a probabilistic reasoning pipeline and Boosting reweighting, helping the detector to make more accurate predictions based on uncertainties when dealing with blurry objects in underwater images. Guo et al. [
21] improved YOLOv8 [
22] by introducing the FasterNet [
23] module, combining a fast feature pyramid network with a lightweight C2f structure. This enhances the ability to extract target features from underwater images while reducing the network complexity. Lin et al. [
24] proposed a network based on DETR [
25], designing a learnable query recall mechanism to improve the network’s convergence speed by adding supervision signals to the queries, thereby enhancing the underwater detection accuracy. Additionally, a lightweight adapter was introduced to extract target feature information, improving the detection capability for small and irregular underwater targets. Wang et al. [
26] proposed DJL-Net, an end-to-end model, which uses a dual-branch joint learning network, combining underwater image enhancement and underwater object detection through multitask joint learning. DJL-Net uses enhanced images produced by the image processing module to supplement features lost due to the degradation of the original underwater images, thereby improving the detection accuracy. Liang et al. [
27] proposed RoIAttn to improve the accuracy of general detectors in underwater environments. RoIAttn aims to effectively capture relationships at the region of interest (RoI) level, achieving the decoupling of regression and classification tasks through a dual-head structure. Considering the difficulty of convolution in accurately regressing coordinate information, RoIAttn introduces positional encoding in the regression branch to provide more precise regression box position information. Dai et al. [
28] observed that the edges of underwater objects are distinctive and can be differentiated from low-contrast environments based on their edges. Therefore, they proposed an edge-guided representation learning network called ERL-Net, aiming to achieve distinctive representation learning and aggregation under the guidance of edge cues.
The current underwater object detection algorithms do not perform well in complex underwater environments, which is usually due to the network’s insufficient feature extraction capability and the pervasive noise information within the network. Therefore, improving the accuracy and robustness of underwater object detection algorithms is a research direction worth exploring.
The proposed YOLO-GE in this study effectively enhances the network’s feature extraction capability by introducing image enhancement techniques, high-resolution feature layers, an attention fusion enhancement module and an adaptive fusion detection head. This approach increases the focus on small objects, suppresses the propagation of noise information within the network and improves the detection accuracy of object detection algorithms in complex underwater environments.
3. Methodology
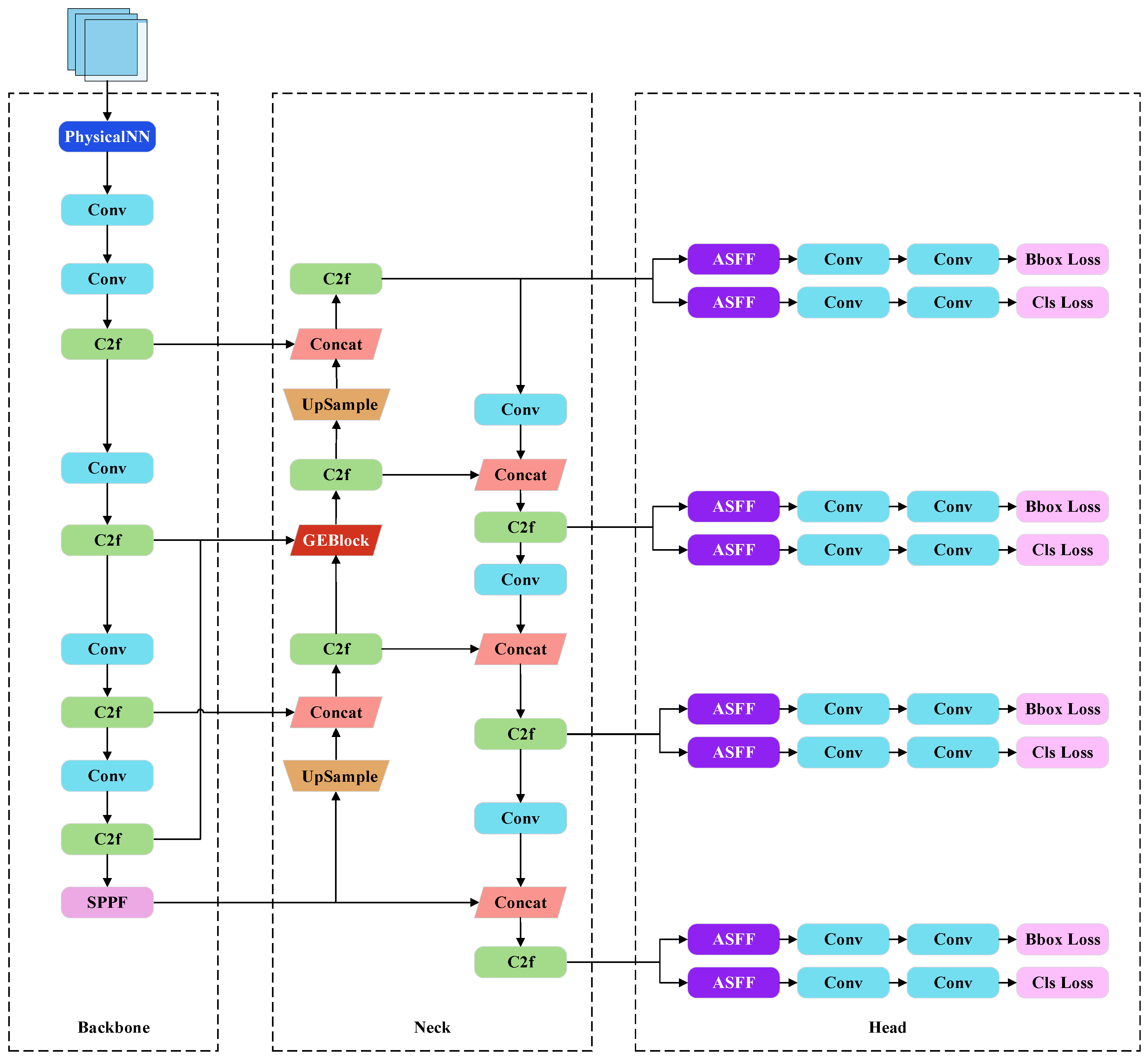
To address the issue of low detection accuracy caused by poor underwater image quality and the presence of many small aquatic organisms, an attention fusion enhancement model based on YOLOv8s, called YOLO-GE (GCNet-EMA), is proposed, as shown in
Figure 1.
At the start of the backbone network, an image enhancement module (PhysicalNN) is introduced. In the neck network, an attention fusion enhancement module (GEBlock) is designed to incorporate high-resolution feature layers. In the detection head, an Adaptive Spatial Feature Fusion (ASFF) module is added. The number of trainable parameters of YOLO-GE is as follows: the backbone network has 5.1 M trainable parameters; the neck network has 4.3 M parameters; since the detection head integrates ASFF, the number of trainable parameters is relatively large, reaching 6.9 M.
3.1. Image Enhancement Module
Due to the lack of lighting in underwater images, the images become blurry and have a blue–green color cast, which reduces the image contrast and decreases the accuracy of the detection tasks. To address this issue, we introduce the image enhancement module PhysicalNN [
29], as shown in
Figure 2. First, the input image is passed through the Backscatter Estimation module to estimate the environmental illumination. Then, using the estimated environmental illumination and the input image, the Direct-transmission Estimation module estimates the direct transmission map. Finally, a reconstruction operation is performed on the estimation results. This module effectively mitigates the effects of the underwater environment, enriches the colors and enhances the image contrast, thereby significantly improving the detection accuracy. The visual effects of image enhancement using PhysicalNN are shown in
Figure 3.
3.2. High-Resolution Feature Layer
During the process of extracting object features in the network, the target feature information gradually weakens after several downsampling operations. For small objects, the feature information in the image is inherently weak and this information further diminishes, or even disappears, after multiple downsampling steps, resulting in poor detection performance for small targets. For example, if the input image size is
pixels, after 4 downsampling operations, the image size becomes
pixels. A target that originally measures
pixels in the input image would be reduced to
pixels after 4 downsampling steps, making feature extraction very challenging. Although high-level feature maps have a larger receptive field and rich semantic information, their lower resolution makes them less suitable for detecting small objects. On the other hand, shallow feature maps, which have a higher resolution, are more favorable for extracting and detecting small object features. In underwater object detection tasks, there are many small aquatic organisms in the underwater environment. In the UTDAC2020 dataset, the target size distribution is shown in
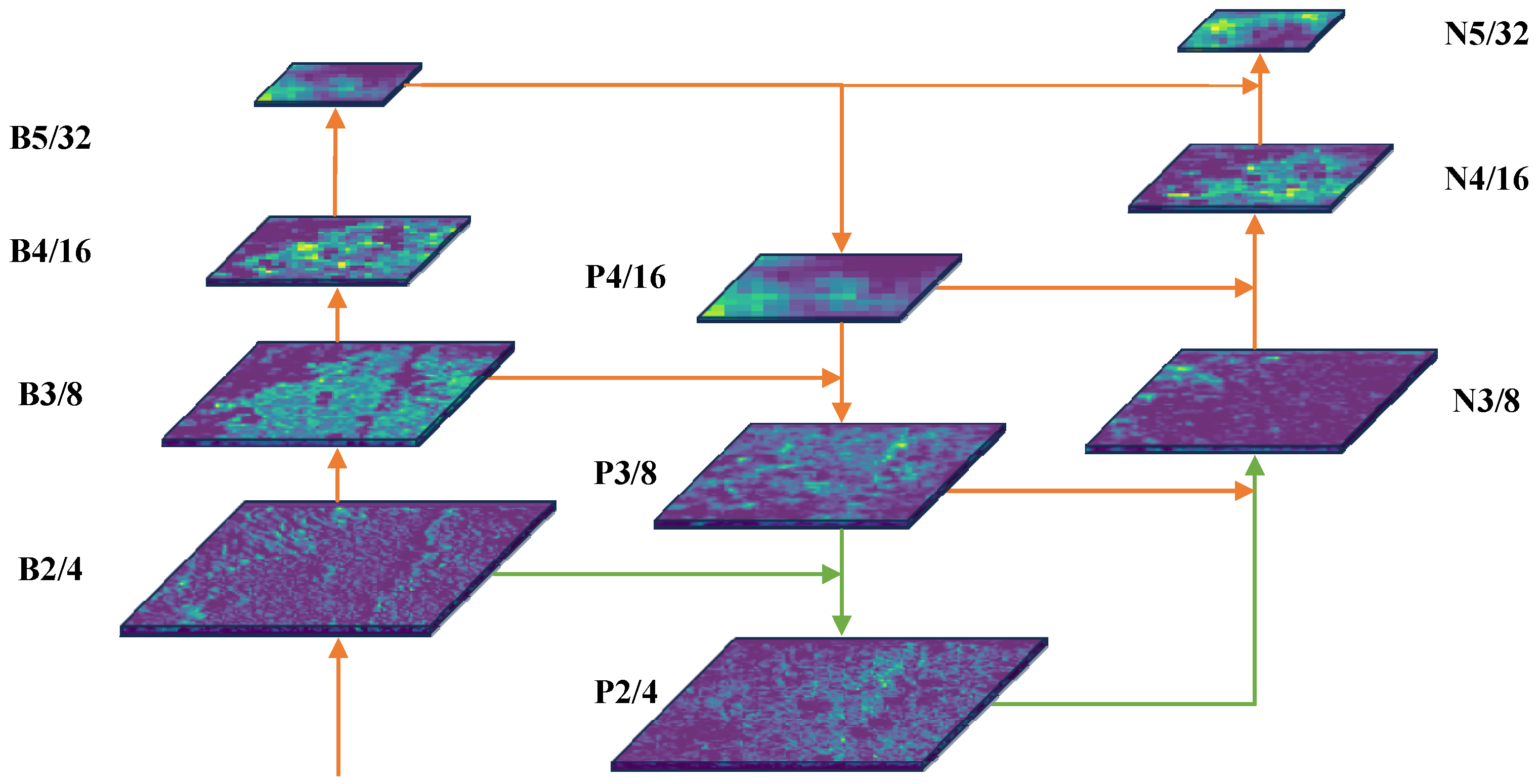
Table 1, where the smallest target in the Echinus category occupies only 2 pixels and the smallest target in the Scallop category occupies only 12 pixels. Small targets are mainly concentrated in the Echinus category. Therefore, adding high-resolution feature layers helps capture the features of small objects and improves the overall performance of the network. We introduced a high-resolution feature layer, P2, with a resolution of
pixels into the network, as shown in
Figure 4. The feature information from the B2 layer of the feature extraction network is fused with the feature information from the P3 layer of the neck to obtain the P2 layer, and then the feature information from the P2 layer is fed into the detection head for object localization and classification.
3.3. Attention Fusion Enhancement
YOLOv8 [
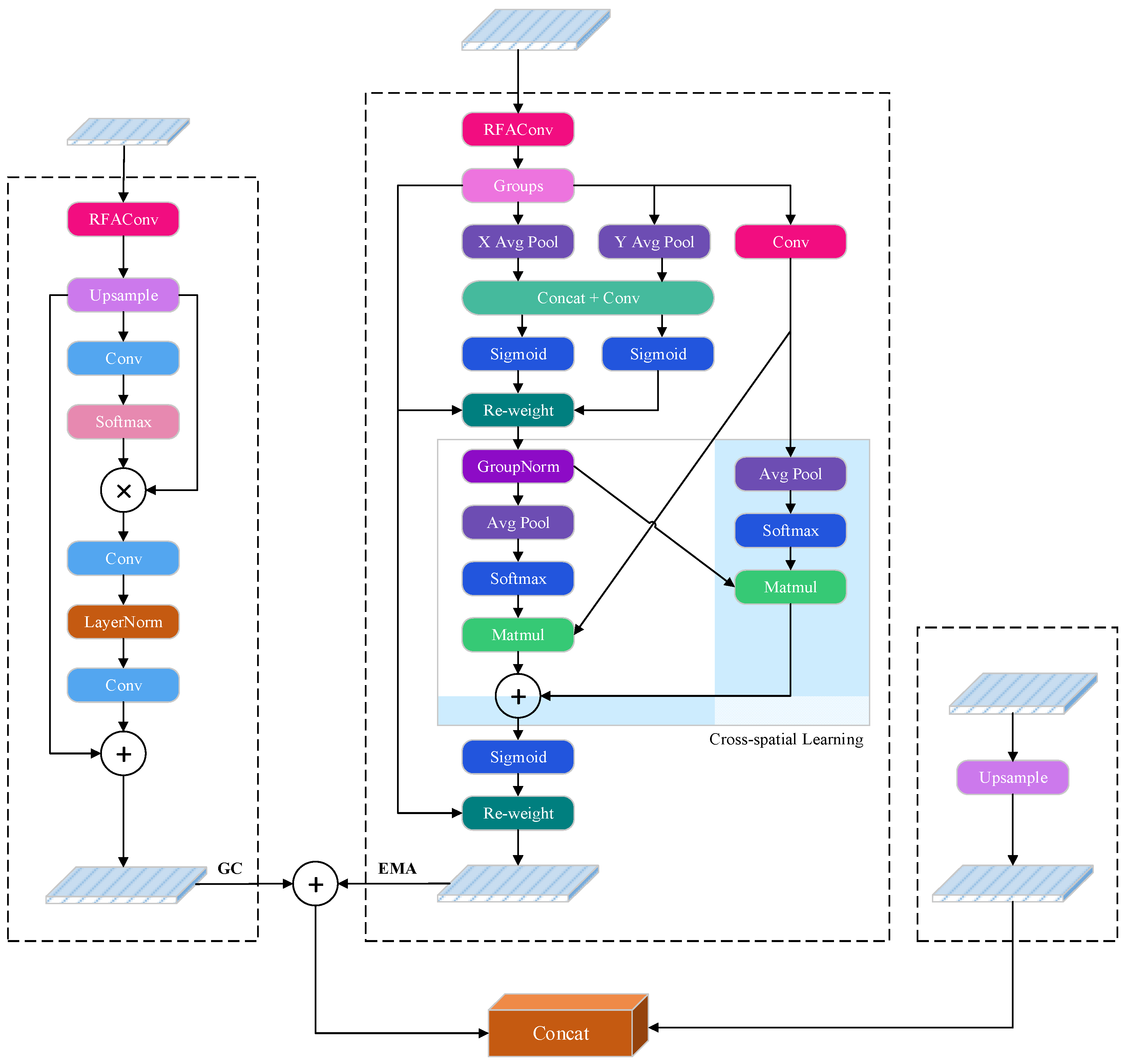
22] uses a PAN-FPN structure, which simply fuses feature information from different scales. However, this simple fusion has obvious issues: it cannot effectively differentiate the importance of feature information from different scales, resulting in fused feature information that does not highlight the important information at each level. Additionally, the fusion of high-level and low-level features may introduce more noise, reducing the network performance. To address this problem, we designed an attention fusion enhancement module (GEBlock), and
Figure 5 shows the overall structure of this module. The GE module integrates the GCNet [
11] and EMA [
17] attention modules, effectively enhancing the ability to capture long-range dependencies and utilizing cross-dimensional interactions to extract pixel-level relationships. After introducing the GE module into the network, it effectively suppresses the noise information from the lower-level feature layers during feature fusion, thereby improving the overall detection performance. The feature information for this module comes from high-level feature information in the backbone network, low-level feature information and the previous layer’s feature information from the GE module.
Figure 1 shows the position of the GE module in the network and the sources of its feature information inputs.
Equations (1)–(3) provide the mathematical representation of the GE module, where
represents the high-level feature layer information,
represents the low-level feature layer information and
represents the feature information from the previous layer of the GE module.
and
are intermediate variables and
is the final output.
RFAConv represents receptive field attention convolution operations,
GCNet represents global context attention operations and
EMA represents multi-scale attention operations.
Concat denotes the concatenation of feature maps,
ADD denotes the addition of feature maps and
UpSample denotes the upsampling operation.
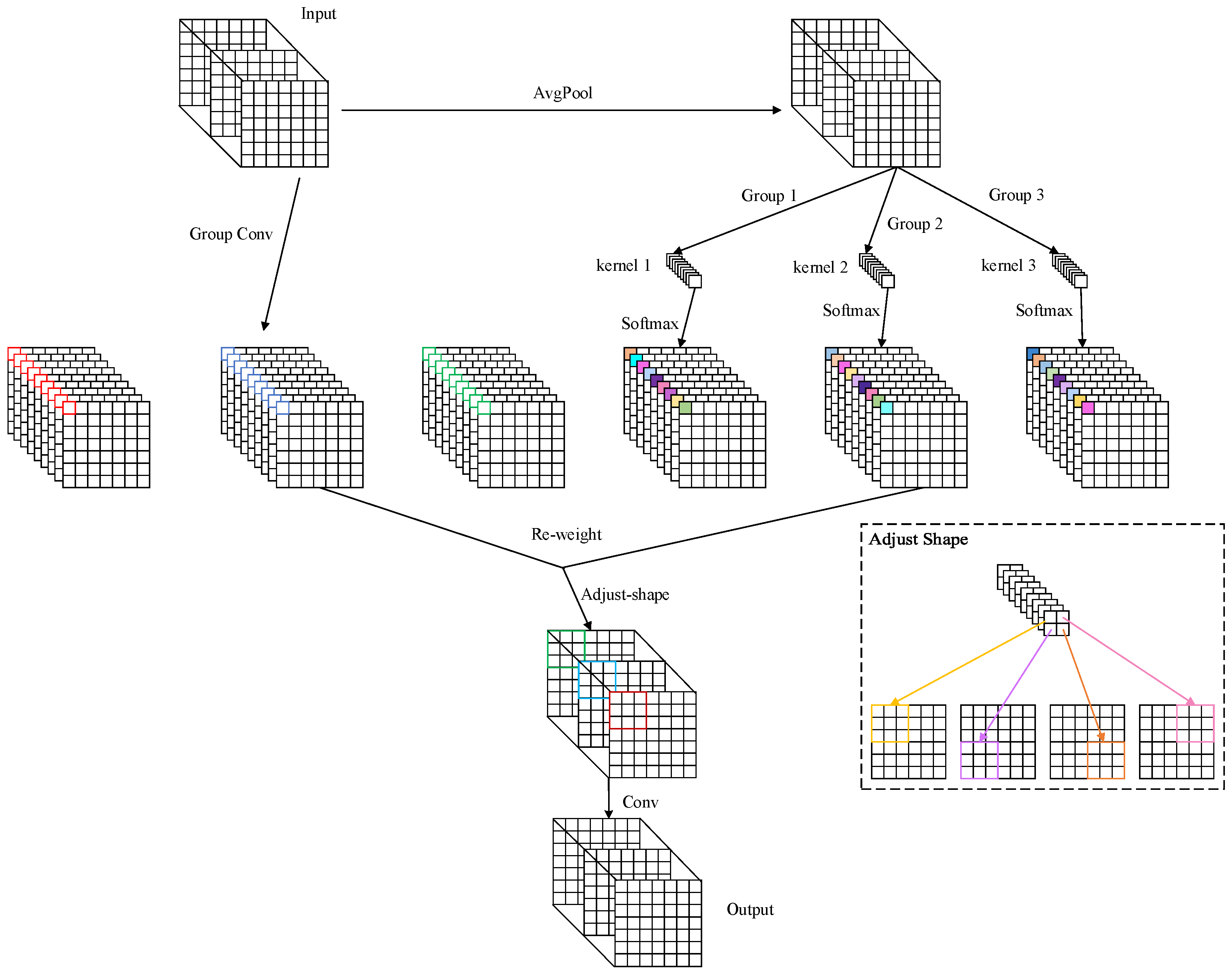
In the GE module, the receptive field attention convolution (RFAConv) [
30] is also introduced, which considers long-range information through global pooling and solves the problem of convolution kernel parameter sharing in traditional convolutions. This helps to highlight feature information at different locations in the image. The structure of RFAConv is shown in
Figure 6. First, the input feature map is passed through average pooling to reduce the spatial dimensions. Then, the pooled feature map is processed through three different group convolutions and a Softmax activation function to generate three attention maps. Next, these attention maps are used to reweight the feature map that has been processed through group convolution, allowing different parts of the feature map to be adjusted based on the importance indicated by the attention maps. After reweighting, the feature map is reshaped and then subjected to a convolution operation to obtain the final output.
For the high-level feature layer, the feature map size is pixels. In the GE module, the input feature information first passes through RFAConv, which not only reduces the dimensionality of the input features but also effectively highlights feature information from different positions in the image. Then, the downsampled feature information undergoes an upsampling operation, enlarging the image to pixels, which helps to improve the performance of small-object detection. The upsampled feature map is then processed by the global context attention mechanism, GCNet. In traditional self-attention models, each position can only interact with other positions in the sequence, whereas the global context attention mechanism allows each position to directly interact with the entire sequence, thus better capturing global semantic information. By introducing the global context attention mechanism, GCNet, the model can more effectively handle long-range dependencies, model global context information, enhance the understanding of global information and improve the performance of detection tasks.
For the low-level feature layer in the feature extraction network, the feature map size is 80 × 80 pixels. When input to the GE module, it first undergoes the RFAConv operation to reduce the feature dimensions and then is processed by the EMA. This effectively suppresses noise information from the low-level feature layer and enriches the semantic information. EMA is a high-performance multi-scale attention mechanism that, compared to traditional channel or spatial attention mechanisms, not only retains feature information of each channel but also reduces the computational burden. Its key lies in reshaping some channels into batch dimensions and grouping the channel dimensions into multiple sub-features, allowing spatial semantic features to be better distributed within each feature group. Specifically, the channel weights are recalibrated by global information in one parallel branch, while the output features from the two parallel branches are further aggregated through cross-dimensional interaction to capture pixel-level pairwise relationships.
After being processed by RFAConv and the attention mechanism, the low-level and high-level features from the backbone network have their feature maps merged through an addition operation within the GE module. This not only retains more detailed information from the low-level features but also effectively reduces the propagation of noise within the network. The input from the previous layer of the GE module contains richer semantic information. First, it undergoes an upsampling operation to enlarge the image to pixels and then it is concatenated with the feature map obtained from the addition operation, further enriching the semantic information.
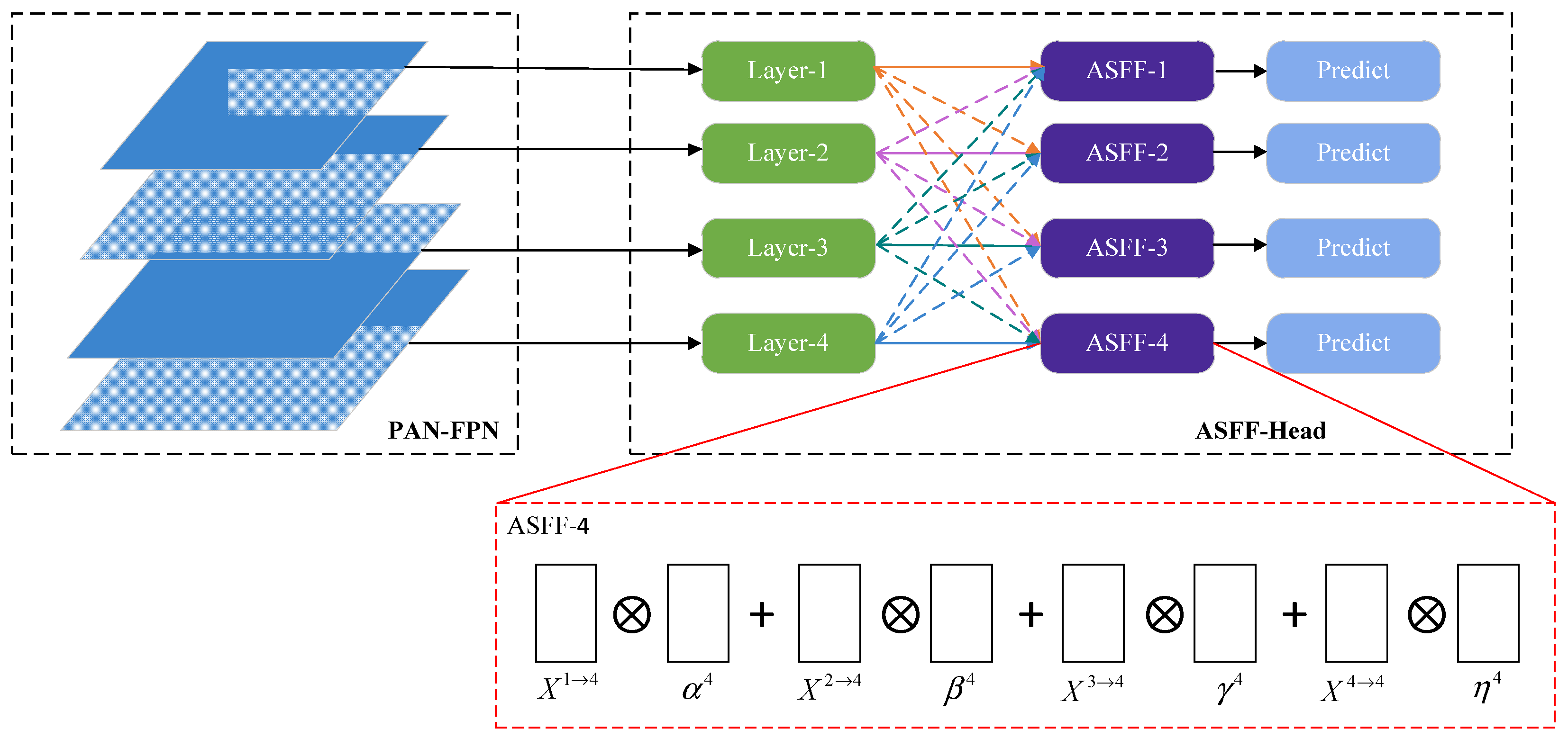
3.4. ASFFHead
In YOLO-GE, we use feature information from four different scales for object detection and localization. To handle potential conflicts between these four feature layers, we introduce ASFF [
31]. ASFF effectively filters out conflicting information and retains useful information for combination, thereby enhancing scale invariance. ASFF integrates and adjusts features from other levels to the same resolution at a specific level, then finds the optimal fusion method through training to achieve adaptive spatial fusion. This approach helps us to achieve more effective fusion among multi-scale features, improving the detection performance.
In YOLO-GE, we integrate ASFF into the detection head to form the ASFFHead, as shown in
Figure 7. During the detection task, the ASFFHead effectively reduces conflicts between feature information at different scales, enriching semantic information and thereby improving the accuracy of the object detection. The four different scale feature layers from PAN-FPN are used as detection layers and the red marked box in
Figure 7 shows the fusion method of the four different scale features in ASFF-4. These four scales of features are represented as
,
,
and
, and these features are multiplied by their corresponding weights and summed together. Finally, the output of ASFF-4 is obtained, with its mathematical representation shown in Equation (4), as follows:
where
represents the
vector of the output feature map
between channels. The weight parameters of the four different scale feature maps are given by
,
,
and
, respectively.
l denotes the level layer and, in YOLO-GE,
.
4. Experiments
We conducted a large number of experiments to validate the effectiveness of the proposed method, and no pre-trained weights were used in any of the experiments.
4.1. Dataset
The datasets used in this study include the following: the UTDAC2020 dataset, DUO dataset [
32] and RUOD dataset [
33]. The UTDAC2020 dataset consists of 6,461 images covering the following four categories: sea urchins, starfish, sea cucumbers and scallops. This dataset contains images of the following five different resolutions:
,
,
,
and
. The DUO dataset contains 7782 images covering the following four categories: sea urchin, starfish, sea cucumber and scallop. Most of the images in this dataset have a resolution of
pixels. The RUOD dataset consists of 14,000 images, with the majority of images having a resolution of
pixels. This dataset includes the following 10 common aquatic categories: sea cucumber, sea urchin, scallop, starfish, fish, coral, diver, squid, sea turtle and jellyfish. The quantity distributions of species categories in the three datasets are shown in
Figure 8.
4.2. Experimental Settings
The experimental environment is as follows: the operating system is Linux (Ubuntu 20.04), the processor is a seven-core Intel(R) Xeon(R) CPU E5-2680 v4, the graphics card is an NVIDIA RTX 3080 (20 GB) and the memory is 30 GB. We used Python 3.8 to implement the methods and conducted experiments in the PyTorch 2.0.0 and CUDA 11.8 environments. Due to GPU memory limitations, we set the batch size to eight and chose the SGD optimizer. To prevent overfitting, we conducted preliminary experiments to adjust the number of training epochs on different datasets. On the UTDAC2020 dataset, the loss function converged after 150 epochs, so we set the training epochs for this dataset to 150. On the DUO and RUOD datasets, the loss function converged after 300 epochs, so we set the epochs to 300. Additionally, we used Mosaic data augmentation, which further helped us to avoid overfitting. All other parameters were set to the default values of YOLOv8.
4.3. Evaluation Metrics
Because this research mainly focused on the improvement of the detection accuracy, we did not introduce the discussion of the computation amount and model complexity. The mean average precision (mAP) was used as the evaluation metric. This metric measures the average performance of the detection method across all categories. We evaluated the performance using the following three different Intersection over Union (IoU) thresholds for the
metric:
,
and
. The formula for the mean average precision (mAP) is as follows:
In this formula, represents the average precision (AP) for the -th category and denotes the number of categories in the dataset. The average precision measures the performance of the model for a specific category, while the mean average precision (mAP) is the average of average precisions across all categories, providing a single value for the overall performance of the model across all categories.
In Formula (5),
represents precision and
represents recall. Their mathematical representations are as follows:
In this context, (true positive) refers to the number of correctly predicted positive samples by the model. (false positive) indicates the number of negative samples that the model incorrectly predicted as positive.
4.4. Results and Discussion
In order to validate the effectiveness of the improvements employed, we conducted ablation experiments on YOLO-GE. Additionally, we compared our method with the latest approaches on the UTDAC2020, DUO and RUOD datasets. Through extensive experiments, we demonstrated the superiority of the proposed method.
4.4.1. Ablation Experiment
We conducted ablation experiments on the UTDAC2020 dataset to validate the effectiveness of the proposed improvement methods. In
Table 2, Method A refers to the introduction of the image enhancement module, Method B refers to the inclusion of the high-resolution feature layer P2, Method C refers to the use of the attention fusion enhancement module and Method D refers to the use of ASFFHead.
Firstly, to address the issue of images appearing overall bluish-green due to factors such as inadequate lighting, we introduced an image enhancement module. Secondly, to improve the accuracy of small-object detection in underwater images, we incorporated the high-resolution feature layer P2. However, the inclusion of the high-resolution feature layer might cause low-level feature noise to propagate through the network. To address this issue, we introduced the Attention Fusion Enhancement GE module, which effectively prevents noise propagation and improves the network’s feature extraction capabilities. Finally, to eliminate potential feature information conflicts caused by the introduction of the high-resolution feature layer, we introduced ASFFHead, which effectively helps the network filter out conflicting information and further improves the detection accuracy. Compared to the baseline model YOLOv8s, our proposed method improves mAP50, mAP75 and mAP50:95 by 1.2%, 4.5% and 2.1%, respectively.
4.4.2. Comparison with the Benchmark Model
We compared our method with the baseline model YOLOv8s on the UTDAC2020, DUO and RUOD datasets, and partial qualitative comparison visualization results are shown in
Figure 9. It can be seen that, in terms of the detection accuracy, YOLO-GE is significantly superior to YOLOv8s, effectively improving the detection effect in complex environments.
In addition, to better demonstrate the improvement effects of the proposed method, we used the LayerCAM algorithm [
34] to visualize the results with heatmaps and compared the YOLO-GE method with the YOLOv8s method. The visualization results are shown in
Figure 10. It is evident that YOLO-GE highlights the important features of the target more effectively, leading to an optimal detection performance.
The quantitative comparison results are shown in
Table 3. It can be observed that YOLO-GE significantly outperforms YOLOv8s in detection accuracy, with particularly notable improvements in high-precision detection.
However, the improvements of YOLO-GE on the DUO and RUOD datasets are relatively smaller compared to the UTDAC dataset. This is because the DUO dataset has more pronounced class imbalance and more underwater object occlusions than the UTDAC dataset. As for the RUOD dataset, it contains more classes and includes many clearer underwater images with larger underwater objects. Since our proposed improvements are more focused on dealing with turbid underwater images and small objects, the enhancement on this dataset is not as significant.
4.4.3. Comparison with Other Methods
To comprehensively evaluate the performance of YOLO-GE and validate its generalization ability, we conducted comparative experiments with the latest methods on the UTDAC2020, DUO and RUOD datasets. It can be seen from
Table 4 that, on the three datasets, our proposed method achieves the best performance in mAP
50, mAP
75 and mAP
50:95, with particularly significant improvements in high-precision detection.
The outstanding performance of YOLO-GE on the UTDAC2020, DUO and RUOD datasets demonstrates its strong capability in handling various underwater scenarios, particularly in more challenging and diverse underwater environments. The results indicate that YOLO-GE is highly effective in dealing with turbid images and small objects, as evidenced by its performance on these datasets. Universal detectors like YOLOv8s and DetectoRS perform well across the datasets but generally lag behind YOLO-GE. This highlights YOLO-GE’s design advantages, especially for underwater detection in complex or challenging environments.
5. Conclusions
Underwater object detection research is significant for the development and protection of marine resources, as it helps scientists and engineers monitor marine life, underwater terrain and environmental changes more accurately. Additionally, this technology is crucial in the military field, where it can enhance the efficiency and safety of underwater combat and defense systems. Due to the lack of lighting in underwater environments, underwater images often suffer from blurriness and low contrast, increasing the difficulty of underwater object detection tasks. Additionally, the presence of numerous small aquatic organisms, combined with factors like water currents and poor water quality, weakens target features, leading to missed detections and false positives. To address these challenges and improve the detection accuracy, this paper proposes a YOLOv8-based Attention Fusion Enhancement underwater object detection model, named YOLO-GE. First, to improve the overall image quality and enhance the image contrast, an image enhancement module is introduced. Second, a high-resolution feature layer is incorporated to boost the detection capability for small targets. Third, an Attention Fusion Enhancement module is introduced to effectively prevent the propagation of noise from low-level feature layers through the network, and RFAConv is employed to further improve the target feature extraction. Finally, to resolve potential feature information conflicts among the four detection layers, the Adaptive Spatial Feature Fusion Detection Head is introduced, which further enhances the small-object detection capabilities and improves the network’s detection accuracy. The effectiveness of the proposed method is validated on the UTDAC2020, DUO and RUOD datasets, achieving optimal mAP performance across all three datasets.
However, the proposed method still has room for improvement. For instance, its detection performance is poor when there is occlusion between underwater objects or when the object surfaces are corroded. Additionally, when there is a class imbalance in the dataset, the improvement in the detection performance is not significant. In future work, we will continue to explore more effective algorithms and techniques to enhance the detection capabilities in more complex underwater environments.
The proposed model can help researchers in the field of marine science to monitor and study marine life and their habitats more accurately. Additionally, it can assist rescue personnel in the swift search and recovery of missing persons underwater. The development of this model is significant for fields such as aquaculture and underwater rescue operations.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}