
Underwater Image Enhancement via Triple-Branch Dense Block and Generative Adversarial Network



Abstract
1. Introduction
- (1)
- We propose a TDGAN for underwater image enhancement. Extensive experiments demonstrate that TDGAN can improve the quality of underwater images and has potential applications in the fields of image denoising, object detection, image segmentation, and so on;
- (2)
- We design a dual-branch discriminator to reconstruct underwater images. The discriminator can guide the generator to exploit global semantics and local details fully;
- (3)
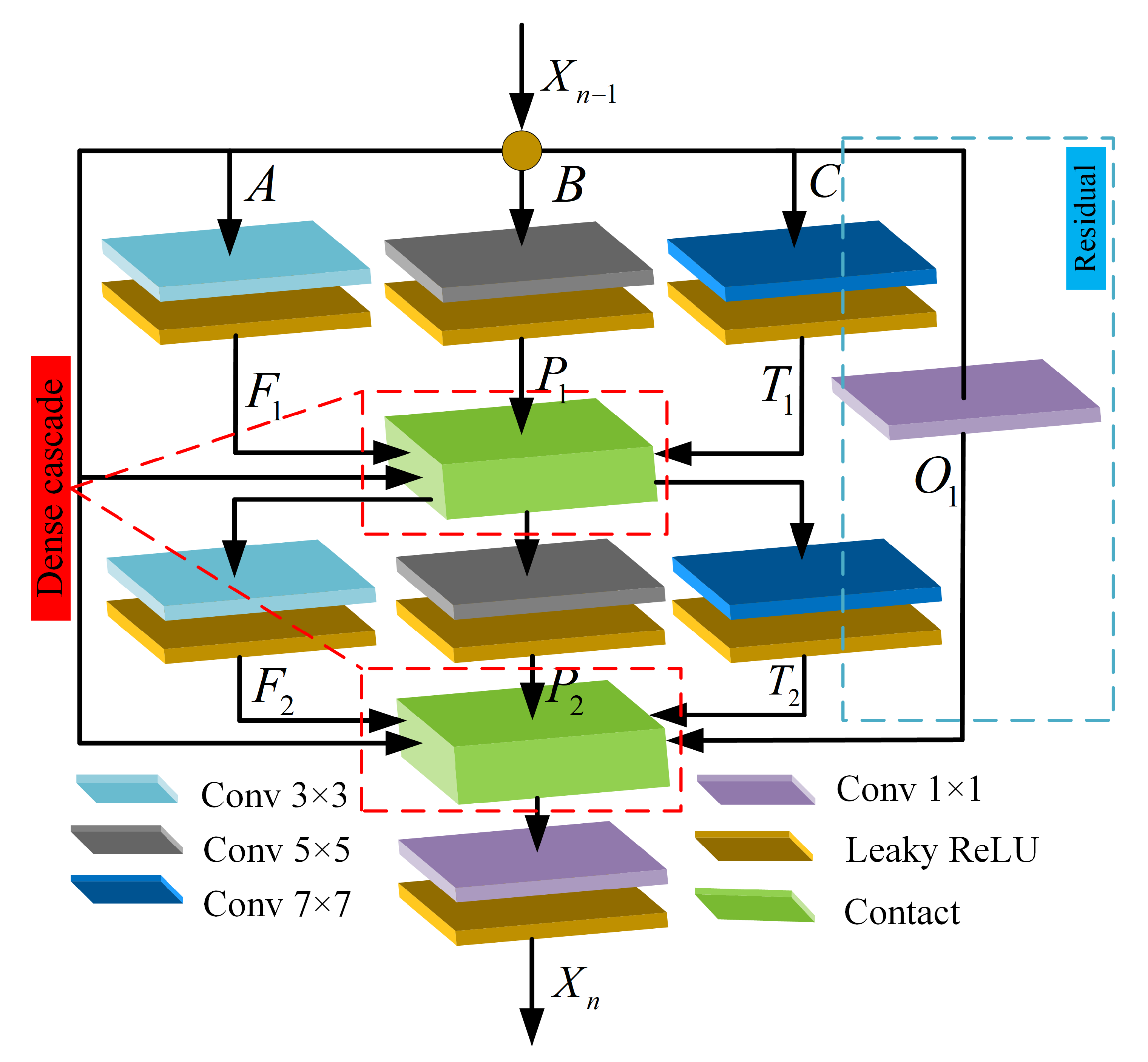
- We develop a TBDB that can significantly improve the feature mining ability of the network and make full use of the underlying semantic information. Compared with the dual-scale channel MSDB in UWGAN [18], the TBDB adopts three channels with different scales, which can obtain different levels of detailed information and is more sensitive to detail changes.
2. Related Work
2.1. Traditional Underwater Image Enhancement Methods
2.2. Underwater Image Enhancement Method Based on Deep Learning
2.3. Underwater Image Evaluation Metrics
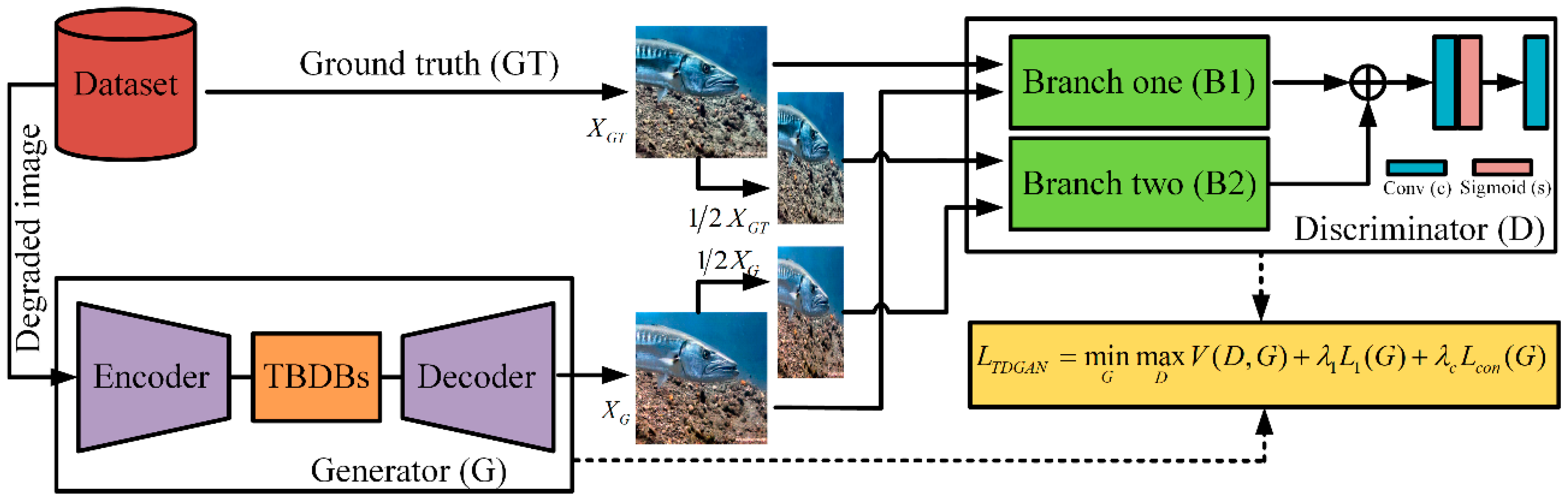
3. Method
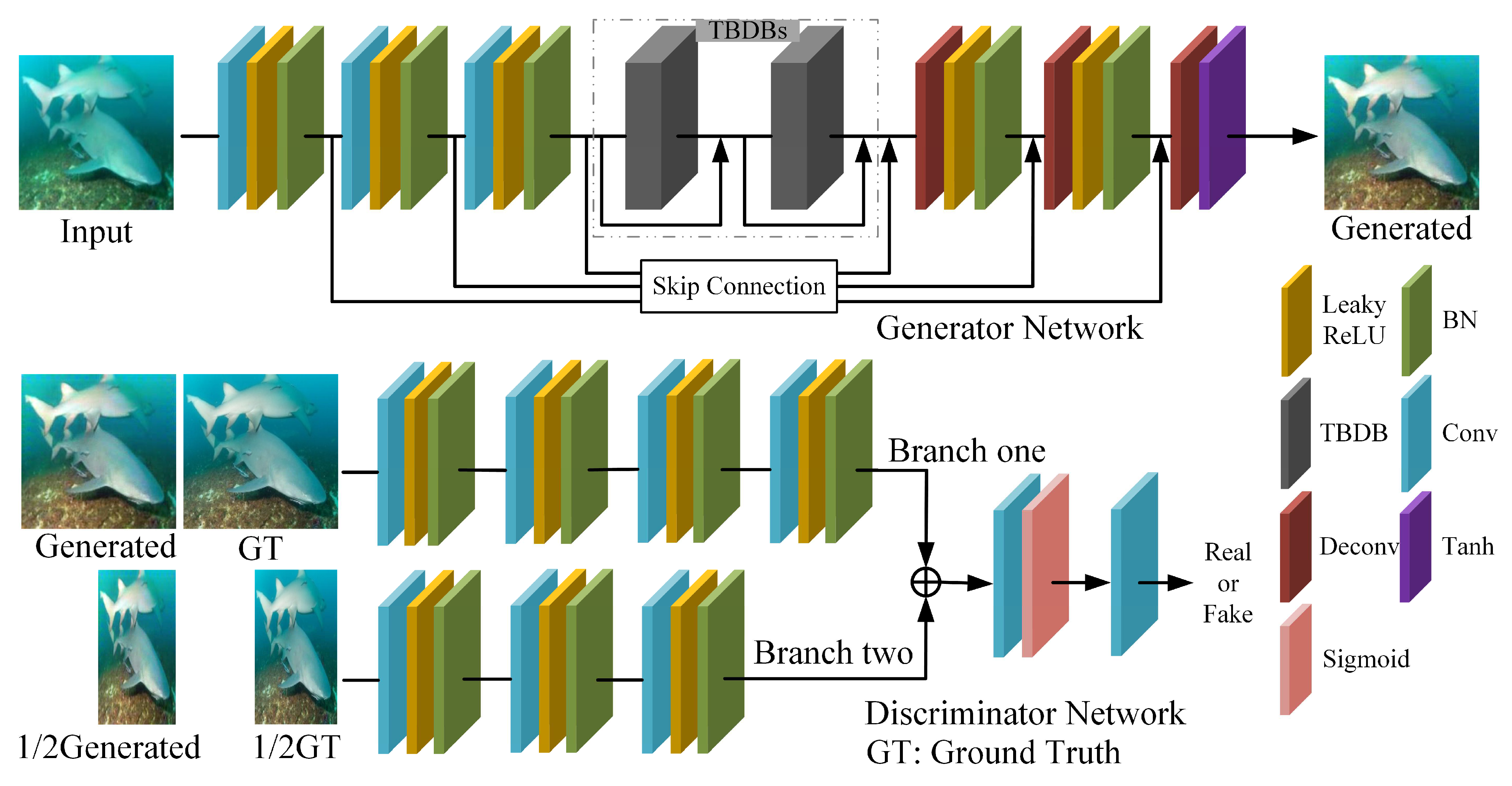
3.1. Generator Network
3.2. Discriminator Network
3.3. Loss Function
4. Experiments
4.1. Experiment Settings
4.2. Qualitative Analysis
4.3. Quantitative Analysis
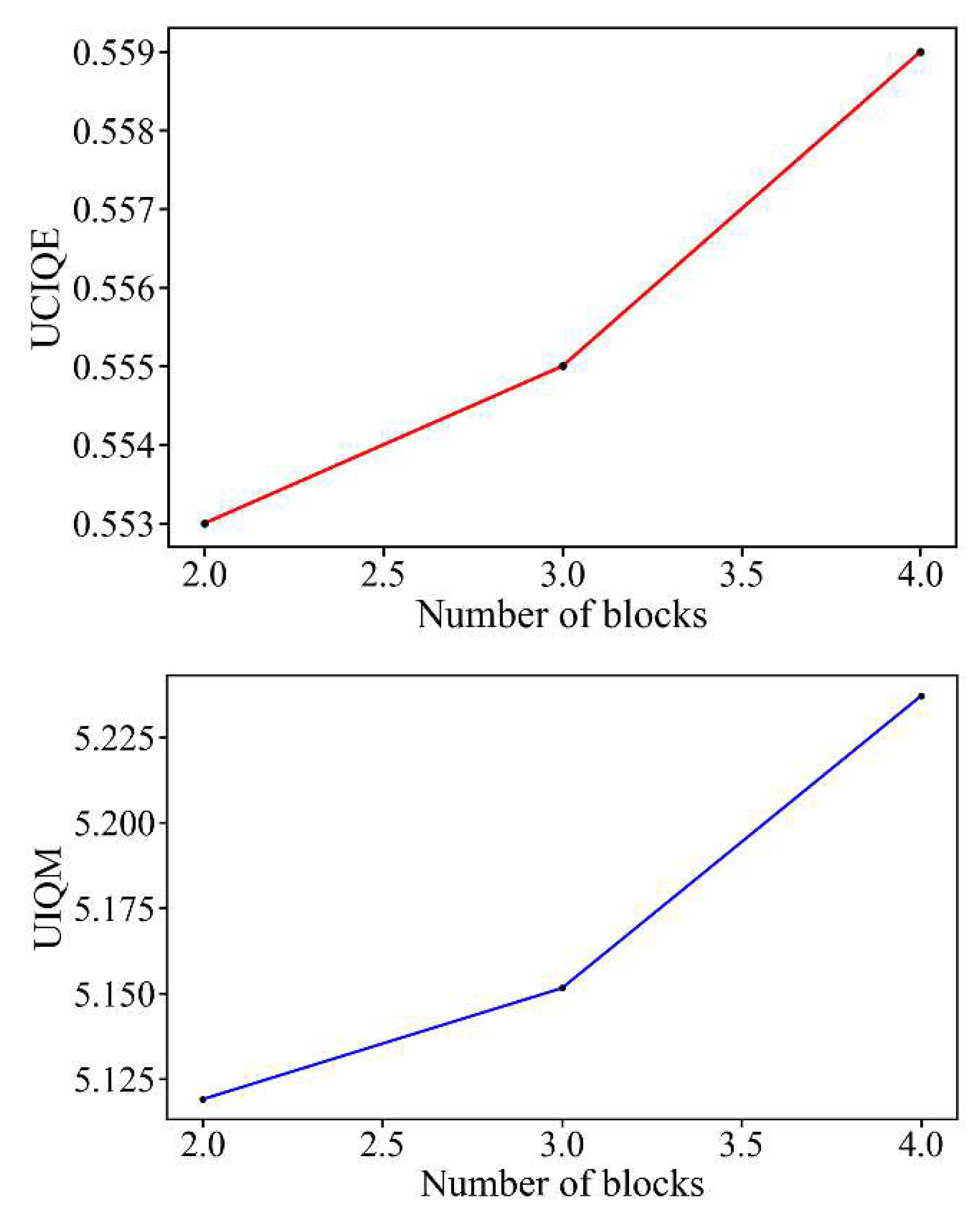
4.4. Ablation Study
4.5. Application Test
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kocak, D.M.; Dalgleish, F.R.; Caimi, F.M.; Schechner, Y.Y. A focus on recent developments and trends in underwater imaging. Mar. Technol. Soc. J. 2008, 42, 52. [Google Scholar] [CrossRef]
- Ghani, A.S.A.; Isa, N.A.M. Underwater image quality enhancement through integrated color model with Rayleigh distribution. Appl. Soft Comput. 2015, 27, 219–230. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Abd-Alhamid, F.; Kent, M.; Bennett, C.; Calautit, J.; Wu, Y. Developing an innovative method for visual perception evaluation in a physical-based virtual environment. Build. Environ. 2019, 162, 106278. [Google Scholar] [CrossRef]
- Li, C.; Guo, J.; Cong, R.; Pang, Y.; Wang, B. Underwater image enhancement by dehazing with minimum information loss and histogram distribution prior. IEEE Trans. Image Process. 2016, 25, 5664–5677. [Google Scholar] [CrossRef]
- Chang, H.; Cheng, C.; Sung, C. Single underwater image restoration based on depth estimation and transmission compensation. IEEE J. Oceanic Eng. 2018, 44, 1130–1149. [Google Scholar] [CrossRef]
- Kar, A.; Dhara, S.K.; Sen, D.; Biswas, P.K. Zero-Shot Single Image Restoration Through Controlled Perturbation of Koschmieder’s Model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2021, Nashville, TN, USA, 20–25 June 2021; pp. 16205–16215. [Google Scholar]
- Marques, T.P.; Albu, A.B. L2uwe: A framework for the efficient enhancement of low-light underwater images using local contrast and multi-scale fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops 2020, Seattle, WA, USA, 14–19 June 2020; pp. 538–539. [Google Scholar]
- Galdran, A.; Pardo, D.; Picón, A.; Alvarez-Gila, A. Automatic red-channel underwater image restoration. J. Vis. Commun. Image Represent. 2015, 26, 132–145. [Google Scholar] [CrossRef]
- Li, J.; Skinner, K.A.; Eustice, R.M.; Johnson-Roberson, M. WaterGAN: Unsupervised generative network to enable real-time color correction of monocular underwater images. IEEE Robot. Autom. Lett. 2017, 3, 387–394. [Google Scholar] [CrossRef]
- Naik, A.; Swarnakar, A.; Mittal, K. Shallow-UWnet: Compressed model for underwater image enhancement. arXiv 2021, arXiv:2101.02073. [Google Scholar]
- Ye, X.; Li, Z.; Sun, B.; Wang, Z.; Xu, R.; Li, H.; Fan, X. Deep joint depth estimation and color correction from monocular underwater images based on unsupervised adaptation networks. IEEE Trans. Circ. Syst. Vid. 2019, 30, 3995–4008. [Google Scholar] [CrossRef]
- Yang, H.; Huang, K.; Chen, W. Laffnet: A lightweight adaptive feature fusion network for underwater image enhancement. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 685–692. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Fabbri, C.; Islam, M.J.; Sattar, J. Enhancing underwater imagery using generative adversarial networks. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 7159–7165. [Google Scholar]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast Underwater Image Enhancement for Improved Visual Perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Guo, Y.; Li, H.; Zhuang, P. Underwater image enhancement using a multiscale dense generative adversarial network. IEEE J. Ocean. Eng. 2019, 45, 862–870. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; Romeny, B.T.H.; Zimmerman, J.B.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vis. Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Pisano, E.D.; Zong, S.; Hemminger, B.M.; DeLuca, M.; Johnston, R.E.; Muller, K.; Braeuning, M.P.; Pizer, S.M. Contrast limited adaptive histogram equalization image processing to improve the detection of simulated spiculations in dense mammograms. J. Digit. Imaging 1998, 11, 193–200. [Google Scholar] [CrossRef] [PubMed]
- Iqbal, K.; Odetayo, M.; James, A.; Salam, R.A.; Talib, A.Z.H. Enhancing the low quality images using unsupervised colour correction method. In Proceedings of the 2010 IEEE International Conference on Systems, Man and Cybernetics, Istanbul, Turkey, 10–13 October 2010; pp. 1703–1709. [Google Scholar]
- Song, W.; Wang, Y.; Huang, D.; Tjondronegoro, D. A rapid scene depth estimation model based on underwater light attenuation prior for underwater image restoration. In Advances in Multimedia Information Processing–PCM 2018: Proceedings of the 19th Pacific-Rim Conference on Multimedia, Hefei, China, 21–22 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 678–688. [Google Scholar]
- Deng, X.; Wang, H.; Liu, X. Underwater image enhancement based on removing light source color and dehazing. IEEE Access 2019, 7, 114297–114309. [Google Scholar] [CrossRef]
- Tao, Y.; Dong, L.; Xu, W. A novel two-step strategy based on white-balancing and fusion for underwater image enhancement. IEEE Access 2020, 8, 217651–217670. [Google Scholar] [CrossRef]
- Zhang, W.; Zhuang, P.; Sun, H.; Li, G.; Kwong, S.; Li, C. Underwater image enhancement via minimal color loss and locally adaptive contrast enhancement. IEEE Trans. Image Process. 2022, 31, 3997–4010. [Google Scholar] [CrossRef]
- Ke, K.; Zhang, C.; Wang, Y.; Zhang, Y.; Yao, B. Single underwater image restoration based on color correction and optimized transmission map estimation. Meas. Sci. Technol. 2023, 34, 55408. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, Y.; Li, C. Underwater image enhancement by attenuated color channel correction and detail preserved contrast enhancement. IEEE J. Ocean. Eng. 2022, 47, 718–735. [Google Scholar] [CrossRef]
- Li, J.; Fang, F.; Mei, K.; Zhang, G. Multi-scale residual network for image super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 517–532. [Google Scholar]
- Sun, B.; Mei, Y.; Yan, N.; Chen, Y. UMGAN: Underwater Image Enhancement Network for Unpaired Image-to-Image Translation. J. Mar. Sci. Eng. 2023, 11, 447. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Cai, X.; Jiang, N.; Chen, W.; Hu, J.; Zhao, T. CURE-Net: A Cascaded Deep Network for Underwater Image Enhancement. IEEE J. Ocean. Eng. 2023. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Laurens, V.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Yang, M.; Sowmya, A. An underwater color image quality evaluation metric. IEEE Trans. Image Process. 2015, 24, 6062–6071. [Google Scholar] [CrossRef]
- Panetta, K.; Gao, C.; Agaian, S. Human-Visual-System-Inspired Underwater Image Quality Measures. IEEE J. Ocean. Eng. 2016, 41, 541–551. [Google Scholar] [CrossRef]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Ioffe, S.; Normalization, C.S.B. Accelerating deep network training by reducing internal covariate shift. arXiv 2014, arXiv:1502.03167. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 2849–2857. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Computer Vision–ECCV 2016: Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Liu, R.; Fan, X.; Zhu, M.; Hou, M.; Luo, Z. Real-world underwater enhancement: Challenges, benchmarks, and solutions under natural light. IEEE Trans. Circ. Syst. Vid. 2020, 30, 4861–4875. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Wang, W. A fusion adversarial underwater image enhancement network with a public test dataset. arXiv 2019, arXiv:1906.06819. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Drews, P.L.; Nascimento, E.R.; Botelho, S.S.; Campos, M.F.M. Underwater depth estimation and image restoration based on single images. IEEE Comput. Graph. 2016, 36, 24–35. [Google Scholar] [CrossRef]
- Peng, Y.; Cosman, P.C. Underwater image restoration based on image blurriness and light absorption. IEEE Trans. Image Process. 2017, 26, 1579–1594. [Google Scholar] [CrossRef]
- Li, C.; Guo, J.; Guo, C. Emerging from water: Underwater image color correction based on weakly supervised color transfer. IEEE Signal Process. Lett. 2018, 25, 323–327. [Google Scholar] [CrossRef]
- Zhuang, P.; Wu, J.; Porikli, F.; Li, C. Underwater image enhancement with hyper-laplacian reflectance priors. IEEE Trans. Image Process. 2022, 31, 5442–5455. [Google Scholar] [CrossRef]
- Liu, R.; Jiang, Z.; Yang, S.; Fan, X. Twin adversarial contrastive learning for underwater image enhancement and beyond. IEEE Trans. Image Process. 2022, 31, 4922–4936. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhuang, P.; Li, C.; Wu, J. Bayesian retinex underwater image enhancement. Eng. Appl. Artif. Intell. 2021, 101, 104171. [Google Scholar] [CrossRef]
- Lei, T.; Jia, X.; Zhang, Y.; Liu, S.; Meng, H.; Nandi, A.K. Superpixel-based fast fuzzy C-means clustering for color image segmentation. IEEE Trans. Fuzzy Syst. 2018, 27, 1753–1766. [Google Scholar] [CrossRef]
- Hou, X.; Zhang, L. Saliency detection: A spectral residual approach. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Generator Network | Discriminator Network | |||||||
|---|---|---|---|---|---|---|---|---|
| Layer | Kernel Size | Output Shape | Branch One | Branch Two | ||||
| Conv, Leaky_ReLU, BN | [7,7,2] | h/2 × w/2 × 64 | Layer | Kernel size | Output shape | Layer | Kernel size | Output shape |
| Conv, Leaky_ReLU, BN | [5,5,2] | h/4 × w/4 × 128 | Conv, Leaky_ReLU, BN | [3,3,2] | h/2 × w/2 × 32 | Conv, Leaky_ReLU, BN | [3,3,2] | h/4 × w/4 × 64 |
| Conv, Leaky_ReLU, BN | [3,3,2] | h/8 × w/8 × 256 | Conv, Leaky_ReLU, BN | [3,3,2] | h/4 × w/4 × 64 | Conv, Leaky_ReLU, BN | [3,3,2] | h/8 × w/8 × 128 |
| TBDBs | —— | h/8 × w/8 × 256 | Conv, Leaky_ReLU, BN | [3,3,2] | h/8 × w/8 × 128 | Conv, Leaky_ReLU, BN | [3,3,2] | h/16 × w/16 × 256 |
| Deconv, Leaky_ReLU, BN | [3,3,2] | h/4 × w/4 × 128 | Conv, Leaky_ReLU, BN | [3,3,2] | h/16 × w/16 × 256 | |||
| Deconv, Leaky_ReLU, BN | [5,5,2] | h/2 × w/2 × 64 | Conv, Sigmoid | [3,3,2] | h/16 × w/16 × 1 | |||
| Method | UIEB and U45 (500 Images) (Non-Reference) | EUVP (500 Images) (Full-Reference) | |||||
|---|---|---|---|---|---|---|---|
| UICM | UIConM | UISM | UIQM | UCIQE | PSNR | SSIM | |
| Raws | −14.913 | 0.629 | 7.058 | 4.017 | 0.501 | 19.017 | 0.704 |
| UDCP | −64.298 | 0.827 | 7.027 | 3.220 | 0.543 | 19.401 | 0.891 |
| UIBLA | −28.646 | 0.871 | 7.289 | 4.459 | 0.522 | 19.825 | 0.874 |
| WSCT | −33.678 | 0.896 | 7.231 | 4.389 | 0.474 | 21.613 | 0.806 |
| CycleGAN | −2.011 | 0.893 | 7.051 | 5.219 | 0.554 | 21.654 | 0.776 |
| Water-net | −55.209 | 0.894 | 7.177 | 3.759 | 0.507 | 20.107 | 0.725 |
| FGAN | 5.770 | 0.895 | 7.098 | 5.458 | 0.566 | 22.258 | 0.832 |
| HLRP | −2.265 | 0.867 | 7.443 | 5.225 | 0.585 | 21.563 | 0.796 |
| TACL | 0.259 | 0.916 | 6.962 | 5.337 | 0.528 | 21.737 | 0.837 |
| TDGAN | 5.501 | 0.925 | 7.203 | 5.588 | 0.571 | 25.434 | 0.911 |
| Models | Residual | Dense Cascade | TBDBs |
|---|---|---|---|
| −RL | ✗ | ✓ | ✓ |
| −DC | ✓ | ✗ | ✓ |
| −Ms | ✓ | ✓ | ✗ |
| TDGAN | ✓ | ✓ | ✓ |
| Method | UICM | UIConM | UISM | UIQM | UCIQE |
|---|---|---|---|---|---|
| −RL | −20.112 | 0.890 | 7.002 | 4.683 | 0.562 |
| −DC | −20.225 | 0.896 | 6.859 | 4.660 | 0.576 |
| −Ms | −11.857 | 0.870 | 6.753 | 4.770 | 0.566 |
| TDGAN | 5.484 | 0.887 | 6.823 | 5.341 | 0.580 |
| Models | Kernel 7 × 7 | Kernel 5 × 5 | Kernel 3 × 3 |
|---|---|---|---|
| −C | ✗ | ✓ | ✓ |
| −B | ✓ | ✗ | ✓ |
| −A | ✓ | ✓ | ✗ |
| TDGAN | ✓ | ✓ | ✓ |
| Method | UICM | UIConM | UISM | UIQM | UCIQE |
|---|---|---|---|---|---|
| −C | −95.251 | 0.635 | 6.466 | 1.495 | 0.551 |
| −B | −79.637 | 0.533 | 6.459 | 1.566 | 0.544 |
| −A | −97.816 | 0.639 | 6.674 | 1.500 | 0.527 |
| TDGAN | −91.796 | 0.636 | 6.605 | 1.634 | 0.551 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, P.; He, C.; Luo, S.; Wang, T.; Wu, H. Underwater Image Enhancement via Triple-Branch Dense Block and Generative Adversarial Network. J. Mar. Sci. Eng. 2023, 11, 1124. https://doi.org/10.3390/jmse11061124
Yang P, He C, Luo S, Wang T, Wu H. Underwater Image Enhancement via Triple-Branch Dense Block and Generative Adversarial Network. Journal of Marine Science and Engineering. 2023; 11(6):1124. https://doi.org/10.3390/jmse11061124
Chicago/Turabian StyleYang, Peng, Chunhua He, Shaojuan Luo, Tao Wang, and Heng Wu. 2023. "Underwater Image Enhancement via Triple-Branch Dense Block and Generative Adversarial Network" Journal of Marine Science and Engineering 11, no. 6: 1124. https://doi.org/10.3390/jmse11061124
APA StyleYang, P., He, C., Luo, S., Wang, T., & Wu, H. (2023). Underwater Image Enhancement via Triple-Branch Dense Block and Generative Adversarial Network. Journal of Marine Science and Engineering, 11(6), 1124. https://doi.org/10.3390/jmse11061124