1. Introduction
In the face of rapidly dwindling natural resources, the search for clean, renewable energy has gained urgency. The crucial requirement to pinpoint sustainable substitutes for fossil fuels and conceive of innovative strategies for energy development is more apparent than ever. Consequently, the research and application of renewable energy sources have become of prime interest. In current renewable energy alternatives, offshore wind energy is known for its reliability, consistency, and energy yield, making it a promising candidate [
1,
2]. As a measure against climate change, China’s 14th Five-Year Plan aims to achieve carbon neutrality prior to 2060. Key strategies within the plan involve the rapid advancement of non-fossil fuel energy resources, a substantial amplification in the deployment of wind and photovoltaic power technologies, and the systematic exploration and development of offshore wind energy capacities.
Estimating the wind energy potential of a specific site or area is crucial to determine the amount of electricity that can be produced. This aids in identifying the optimum wind turbine technology suitable for a given promising location. Therefore, the assessment of wind resources is vital in planning wind power projections. It establishes the framework for evaluating feasibility and estimating revenue, which are essential components for attracting the necessary investment. For conducting a thorough and accurate examination, it is typically recommended, where possible, to utilize a dataset spanning a decade or more [
3]. For managing data of such extensive scale, a statistical distribution model is recommended. This model can elucidate the probability distribution of wind speeds and provide predictions for the generation of wind energy [
4].
However, the presence of multiple concurrent weather systems indicates that accurately estimating wind resources might not be straightforward. Prior to initiating in-depth analysis, it is important to categorize wind data based on their originating wind-generating weather systems. This is due to the potential for winds produced by different weather systems to display unique probabilistic characteristics [
5]. This notion is especially prevalent when it comes to the estimation of extreme wind velocities. Gomes and Vickery [
6] introduced a technique to compute probability estimates for extreme wind velocities in mixed climatic conditions. This method requires an exhaustive investigation of each significant meteorological incident responsible for wind generation. The evaluation of wind speeds follows a three-step process. First, various wind phenomena, including extra-tropical depressions, thunderstorms, and gust fronts, are distinctly identified. Subsequently, the respective distribution of wind speed for each event is determined. The final phase combines these distributions into a unified mixed distribution representing the wind speed. Cook et al. [
7] further improved this method by incorporating recent advancements in extreme value analysis.
The practice of categorizing based on weather patterns is also employed in simulating wave fields within mixed climate scenarios [
8,
9]. The process initiates with the collecting and preprocessing of historical predictor and predictand data. Next, weather types associated with synoptic circulation conditions are classified and identified. A probability distribution model is then fine-tuned to align with the predictand pertinent to each weather type. The final step involves the computation of return periods, factoring in the occurrence likelihoods affiliated with each distinct weather category. Assuming the homogeneity of extreme wave height data originating from a distinct meteorological pattern, Solari and Alonso [
10] employed clustering algorithms to categorize weather formations. This enabled the identification of homogenous populations allied with each pattern. Consequently, the traditional extreme value distribution could be applied to each homogenous subset. The overall distribution was then configured using the multivariate Poisson model. This technique was then applied by De Leo et al. [
11] to examine severe sea storms across Italy’s coastal areas.
The essential task in executing this methodology lies in categorizing wind data in the context of weather systems. To facilitate this, a range of classification algorithms have been put forward. Lombardo et al. [
12] proposed an approach for the automated classification of winds, distinguishing between thunderstorm and non-thunderstorm origins. This method utilizes meteorological data, along with the initiation and cessation timings of thunderstorms. De Gaetano et al. [
13] proposed a semi-automated technique for the discernment and categorization of extreme wind phenomena using a blend of systematic quantitative measures alongside specific qualitative decisions.
It is worth noting that a unified standard for the classifying meteorological patterns is still lacking. The utilization of diverse classification standards often leads to significantly divergent outcomes. The effectiveness of classifying wind events into disparate groups to facilitate comprehensive analysis can be challenged if the preliminary segregation process lacks equivalent precision [
14,
15]. For instance, despite the customary division of wind events in the scholarly literature into extra-tropical depressions and thunderstorms, Kasperski [
16] underscored the existence of an intermediate third class of occurrences. Adding to this perspective, Choi and Tanurdjaja [
17] suggested that categorizing the mixed weather systems based on their scale, namely into large-scale and small-scale categories, would be a more suitable approach. In addition, measuring wind speeds from typhoons is very difficult due to their relatively scarcity compared to other events. A given site may confront a mere one or two typhoons in a season, which inevitably leads to insufficient data required for a precise quantification of extreme wind speeds [
6].
An alternative approach for data clustering involves using the mixture distribution model. This approach affords adaptability in managing clusters with diverse sizes and internal correlation architectures, rendering it a potentially superior choice over methods like k-means clustering for certain applications [
18,
19,
20]. The premise of the mixture distribution methodology is that the larger population is divided into multiple subgroups, each following its own unique probability distribution. Following this, data clustering is accomplished by associating each data point with the component exhibiting the highest computed posterior likelihood of membership for that specific data point. This turns clustering into an endeavor to estimate parameters within the mixture model [
21,
22]. Mixture distribution models have gained widespread acceptance in the analysis of wind and wave data due to their flexibility [
23,
24,
25,
26,
27]. Research has indicated that these models, comprising a blend of individual probability distributions, offer a robust approach to analyzing data with complex structures, that surpass the capabilities of a single distribution. Their adaptability proves advantageous in addressing the patterns in wind and wave data, making them well-suited for predictive analysis. This remarkable versatility is of utmost significance in applications such as wind power generation, where precise wind speed forecasts are indispensable for optimizing energy production efficiency [
28,
29]. Consequently, mixture distribution models have emerged as a potent method in the pursuit of accurate and efficient utilization of renewable energy sources.
Although mixture distribution models offer a degree of flexibility and adaptability, they are accompanied by computational complexities that introduce significant challenges, especially in parameter estimation. Conceptually, the direct maximization of a mixture model’s likelihood function to estimate its parameters might appear viable. However, the complexity of doing so often becomes a limiting factor due to the computational challenges in these models. In addressing mixture distribution problems, the expectation–maximization (EM) algorithm is often chosen. This preference can be primarily ascribed to its advantageous characteristics, such as numerical robustness, guaranteed global convergence, and straightforward implementation [
30]. In many simple scenarios, the EM algorithm is commonly relied upon for its capacity to yield practical solutions. Nevertheless, it might not always identify the global optimum in a mixture distribution context. Additionally, the computational demands of such a process can be very complex and the pace of convergence could prove to be unsatisfactorily slow [
31].
Usually, wind energy resources can be assessed using variables such as wind power density (
WPD). This often involves parameters like wind speed and air density. Please note that although air density is often assumed to remain constant in many previous studies, the value of this variable could be affected by many factors, such as altitude, temperature, pressure, and humidity. Research indicates that it is not reasonable to assume air density as constant when forecasting wind energy resources [
29]. Therefore, this study aims to evaluate wind energy resources by establishing a bivariate probability distribution for wind speed and air density. However, the co-existence of different meteorological systems presents considerable challenges for wind energy assessment. Current methods, proposed by Gomes and Vickery [
6], require a thorough examination of individual meteorological events, and the lack of standardized classification meteorological patterns often yields inconsistent results. Additionally, although mixture distribution models provide adaptability and flexibility for mixed data clustering, significant computational challenges can be introduced in parameter estimation. Even established approaches, such as the EM algorithm, often encounter difficulties when handling complex probability distributions. In light of these challenges, this research aims to apply the principles of cluster analysis with the primary goal of partitioning a mixed dataset into distinct groups or classes. Each of these groups or classes is characterized by a homogeneous pattern of probabilistic statistical properties. By transforming the challenge of mixture distribution models into dealing with multiple single-mode probability distributions, the problem of solving the complex likelihood function can be averted. This approach enables a more precise wind resource assessment using the mixture distribution model. The rest of the paper is structured as follows.
Section 2 details the unsupervised classification approach and the implementation of the EM algorithm for mixture distribution. In
Section 3, experiments are presented to validate the efficacy of the proposed algorithm in clustering data with diverse statistical characteristics into uniformly distributed groups. Moving on to
Section 4, the proposed classification approach is applied to model the mixture bivariate distribution of wind speed and air density, subsequently enabling the assessment of wind power potential based on the constructed joint distribution.
Section 5 delves into a comprehensive discussion of the clustering algorithm. Finally,
Section 6 offers concluding remarks summarizing the study’s major findings.
3. Experimental Validation of the Clustering Algorithm
The precise segmentation of mixed datasets into well-defined and separate clusters necessitates the development of a flexible algorithmic approach. The clustering algorithm introduced herein, as described in
Section 2, aims to meet this demand by employing the maximum likelihood function and dynamic data point classification. The primary focus of the algorithm is the accurate separation of data, comprising varied statistical characteristics, into uniformly distributed groups. In the context of this section, the efficacy of the proposed algorithm will be put to the test through a series of carefully designed experiments.
To validate the applicability of the proposed algorithm across different dimensions and under varying statistical characteristics, four specific cases are constructed, each representing different statistical characteristics. These cases are selected on the basis of established models from the scholarly literature and allow the testing of the algorithm’s performance across different dimensions. In the following descriptions, we will employ x as the variable denoting one-dimensional mixture distributions, while x and y will represent the two variables in two-dimensional mixture distributions. These notations will be utilized across the different cases to describe various mixture distribution models. The detailed specifications for each model are as follows:
Case I: Mixture lognormal distribution
This case implements a mixture lognormal distribution with parameters aligned to those presented by Huang and Dong [
47], given by
where
μj and
σj constitute the location and scale parameters of the
j-th sub-model. A histogram representation of the generated random numbers is shown in
Figure 2.
Case II: Mixture Weibull distribution
Case II utilizes a mixture Weibull distribution, with parameters also adopted from Huang and Dong [
47], as described by
where
αj and
βj are the scale and shape parameters of the
j-th sub-model.
Figure 2 provides a histogram depiction of the generated random numbers.
Case III: Mixture bivariate lognormal distribution
Incorporating a mixture bivariate lognormal distribution, Case III’s parameters derived from Huang and Dong [
25], expressed as:
Within the
j-th sub-model, (
μx j,
σx j) and (
μy j,
σy j) denote the location and scale parameters of the marginal distributions for
X and
Y, respectively, while
ηj is the dependence parameter.
Figure 3 illustrates the scatter plot and histograms of the generated random numbers.
Case IV: Mixture Gaussian copula distribution
The final scenario, Case IV, features a mixture Gaussian copula distribution with lognormal and Weibull marginal distributions, consistent with the parameters described in Huang and Dong [
26], given by:
For the
j-th sub-model,
fX j (
x) and
fY j (
y) correspond to the probability density function of the lognormal distribution and Weibull distribution, respectively.
FX j (
x) and
FY j (
y) symbolize the respective cumulative probability functions, and
cj (
FX j (
x),
FY j (
y)) denotes the copula density for the
j-th component, expressed as:
Φ
−1 signifies the inverse of the cumulative distribution of a standard Gaussian distribution, and Φ
B is the cumulative distribution of a bivariate Gaussian distribution with mean vector (0, 0)
T and covariance matrix:
where
γj is the dependence parameter for the
j-th sub-model. The scatter plot and histograms of the generated random numbers is depicted in
Figure 3.
A comprehensive summary of these chosen models, including their specific parameters, is provided in
Table 1, serving as a clear reference for the experimental configuration. All random numbers were generated using inverse transform sampling [
48], implemented in MATLAB, producing 10,000 data points for each case. These carefully selected cases serve as a robust foundation for evaluating the proposed clustering algorithm under diverse conditions, illustrating its potential applicability across varied contexts.
Following the generation of random numbers, the proposed clustering algorithm was applied to rigorously estimate the parameters of the mixture model. Traditionally, this area has been predominantly governed by the EM algorithm. The parameters calculated by the EM algorithm are presented in
Table 2, whereas those estimated by the clustering algorithm are detailed in
Table 3. Our investigation reveals a remarkable alignment between the introduced clustering algorithm and the established EM algorithm. Despite their distinct methodologies, both approaches converge towards the close proximity of the results to the original parameters delineated in
Table 1. This precision in estimation, consistently observed across different cases and dimensions, underscores not just the reliability but also the robustness of the clustering algorithm.
Figure 4,
Figure 5,
Figure 6 and
Figure 7 visually represent the efficacy of both the EM and clustering algorithms in matching the individual sub-models as well as the complete mixture model, illustrating a noteworthy degree of congruency. In
Figure 4 and
Figure 5, an examination of the probability density curves for Cases I and II reveals a pronounced similarity between the curves deduced by both the EM and clustering algorithms, compared with the preset models. Such a level of alignment underscores the robust capability of the algorithms to identify the distinct features inherent within the mixed data with remarkable accuracy.
Similarly,
Figure 6 and
Figure 7 demonstrate a clear alignment between the preset probability density contours and those estimated by both algorithms for Cases III and IV. This precision highlights the clustering algorithm’s superior effectiveness in capturing the multi-modal characteristics within the probability structure of the mixed data, in concert with the EM algorithm.
A rigorous quantitative analysis provides additional insight into the performance of both the EM and clustering algorithms. For the one-dimensional probability models (Case I and II), established metrics such as Euclidean squared distance (
D2):
Kolmogorov–Smirnov distance (
Dn):
and Anderson–Darling distance (
An2):
Serve as benchmarks for algorithmic assessment. The subscript ‘
o’ and ‘
p’ are indicative of observed and predicted data, respectively. For the two-dimensional models (Case III and IV), the initial step involves generating two-dimensional data points from the formulated probabilistic models through inverse transform sampling. To ensure a more robust and comprehensive comparison, the number of simulated data points is intentionally set to be tenfold the quantity of the original data. Upon preparing these simulated sets, they are then compared against the original data sets. The principal metric for this evaluative analysis is the root mean square error (
RMSE). For a thorough examination of the two-dimensional models’ performance, the domain is segmented into specific cells. Each cell is distinctly represented by Indices
g and
h, adhering to the conditions
xg <
x ≤
xg +
l (for
g = 1, 2, …,
l) and
yh <
y ≤
yh +
m (for
h = 1, 2, …,
m). With this partitioning, the
RMSE emerges as a reliable tool, offering detailed insights into the precision of the models over each discrete region of the two-dimensional space:
where
π denotes the data density within a cell, indicating the relative concentration of data points compared to the entirety of the space. For each specific cell, this density is determined by the proportion of data points within the cell, relative to the total count of the entire dataset. Additionally, to assess how closely simulations approximate the original data, the coefficient of determination (
R2) was also invoked for two-dimensional models [
49]:
Numerical evaluations of the discussed metrics, as detailed in
Table 4 and
Table 5, further validate the efficacy of the clustering algorithm. Across both one-dimensional and two-dimensional models, the proposed algorithm demonstrates close agreement with the EM algorithm. The consistent performance observed across varied scenarios establishes the clustering algorithm as a robust alternative for parameter estimation in mixture models, ensuring both accuracy and efficiency.
4. Application of the Clustering Algorithm for Wind Energy Assessment in Coastal China
In the current section, the proposed clustering algorithm, designed for constructing the joint distribution of wind speed and air density, has been introduced and validated. Having corroborated its effectiveness through synthetic data and simulated scenarios, we proceed to apply this approach to the assessment of wind energy potential in China’s coastal regions. This study focuses on six emerging offshore wind farm projects along the coastlines of Fujian and Guangdong Provinces, as depicted in
Figure 8 and summarized in
Table 6 [
50]. The selection of these provinces has been informed by their demonstrably abundant wind energy potential, largely influenced by monsoon patterns, making them particularly rich in wind resources, compared to other maritime regions in China [
51,
52]. The projects are diversely situated across a range of latitudinal and longitudinal coordinates, spanning from 25.59° N, 120.19° E to 20.88° N, 112.14° E, thereby capturing the spatial heterogeneity in wind characteristics. By incorporating such diversity in project locations, along with variations in project depths and capacities, this study aims to offer a detailed and comprehensive examination of the wind energy potential along China’s southeastern coastal region. This closely aligns with the strategic objectives outlined in China’s 14th Five-Year Plan, which advocates for the establishment of offshore wind energy infrastructure within these geographically specified regions.
Owing to the limited publicly accessible long-term wind data, this study necessitates the utilization of reanalysis products, as corroborated by the extant literature [
53,
54,
55]. Among the various reanalysis datasets, the European Centre for Medium-Range Weather Forecasts (ECMWF) ERA5 was selected, given its robust alignment with in situ measurements along China’s coastlines [
56,
57]. An extensive analysis was conducted using a 30-year span of ERA5 data, from 1993 to 2022, to investigate the features of wind energy.
Variations in wind energy characteristics with differing hub heights are well-established. In this study, a hub height of 120 m was selected as representative of standard offshore wind turbine configurations [
58]. Algorithms previously outlined in Yang et al. [
29] were applied to derive hourly wind speeds and air densities at the designated hub height using ERA5 dataset. To attenuate the effect of short-term dependencies in the time-series data, daily mean wind speeds and air densities were incorporated into subsequent analyses.
To provide a thorough analysis of wind energy characteristics across the selected six locations, statistical analyses of both wind speed and air density were conducted.
Table 7 presents statistical parameters including mean, standard deviation, skewness, and kurtosis for each location. With respect to wind speed, L1 exhibits the highest mean value of 10.2208 m/s, highlighting its superior wind energy potential. Conversely, L5 presents the lowest mean wind speed of 7.2685 m/s, yet is characterized by a higher kurtosis, indicative of a higher frequency of extreme values compared to other locations. A minimal kurtosis value of 2.3512 is exhibited by L2, suggesting a distribution that is less subject to tail extremities and outliers. Skewness metrics reveal that the distribution of wind speed for L1 approximates symmetry, as corroborated by a skewness value of −0.0248. For L2 through L6, however, it exhibits slight positive skewness, spanning a range from 0.2639 to 0.4857, suggestive of a modestly elongated tail on the right side of the distribution, thus indicating an increased likelihood for wind speeds exceeding the mean at these locations.
While the mean air density remains relatively consistent, ranging from 1.1614 kg/m3 at L6 to 1.1781 kg/m3 at L1, greater variances are observed in the kurtosis values, underscoring disparate tail behaviors or outlier frequencies in the distributions of air density across these locations. Skewness parameters, fluctuating between 0.2488 at L1 and 0.5656 at L6, illuminate dissimilarities in the distributional geometries of air density. Locations L1 to L4 exhibit relatively symmetric air density distributions, as reflected by their lower skewness values, whereas L5 and L6 are marked by higher skewness, signifying a tendency toward lower air density values.
To yield a more rigorous examination of the complex interrelationships between wind speed and air density, a mixture Gaussian copula model, as defined in Equation (12) and recommended by Yang et al. [
29], was adopted to characterize the bivariate structure. Specifically, the marginal distributions incorporate a mixture Weibull distribution for wind speed and a mixture lognormal distribution for air density. A clustering algorithm, developed within the framework of the current research, was deployed for parameter estimation in the mixture models. This algorithm served as an alternative to conventional estimation techniques and was evaluated in comparison to results obtained through the EM algorithm.
To comprehensively analyze the joint distribution of wind speed and air density derived by both algorithms, the inverse transform sampling technique was utilized to generate random samples that follow the mixture distributions deduced from each algorithm. Specifically, the size of these synthetic samples was determined to be ten times the size of the original dataset, thus facilitating a thorough representation for comparison.
Figure 9 presents the scatter plot of the original dataset, with each data point color-coded according to its probability density. In contrast,
Figure 10 depicts the data simulated using the EM algorithm, and
Figure 11 shows the data generated by the clustering algorithm, both with consistent color-coding to maintain uniformity in interpretation. The probability structures shown in
Figure 9 are quite similar with those illustrated in
Figure 10 and
Figure 11, indicating that the mixture Gaussian copula distribution model can provide a satisfactory approximation to mixed wind data. The bivariate probability density scatter plots of the original data across the six selected locations distinctly feature multiple peaks. When derived through both the clustering and EM algorithms, this multimodal structure is accurately reproduced, underscoring the efficacy of these two algorithms in modeling the empirical patterns.
Upon examination of the scatter plots, it is observed that, while the marginal distribution of wind speed predominantly displays a single peak, the distribution for air density consistently presents multimodal characteristics. This observation is further corroborated by the univariate probability density histograms for wind speed (
Figure 12) and air density (
Figure 13). The mixture Weibull distribution, as inferred from both computational techniques, is adeptly matched to the univariate probability density of wind speed. Similarly, the mixture lognormal distribution, derived from both algorithms, demonstrates a notable capability in capturing the multimodal characteristic inherent in the distribution of air density.
For a refined quantitative evaluation, both the root mean square error and the coefficient of determination were computed and presented in
Table 8. Notably, the clustering algorithm consistently yields marginally better
RMSE values across all locations when compared to the EM algorithm. Additionally, the
R2 values remains remarkably high for both algorithms, indicative of an excellent fit to the data. Notwithstanding, the clustering algorithm is found to slightly outperform the EM algorithm in
R2 values, particularly at locations L1, L3, and L6.
The scatter plots and quantitative metrics suggest that both the EM and clustering algorithms are capable of capturing the multimodal patterns of wind speed and air density data. This alignment between
Figure 10,
Figure 11,
Figure 12 and
Figure 13 and
Table 8 further underscores their capability in representing the inherent characteristics of the joint distribution for mixed datasets.
The joint probability distributions of wind speed and air density, derived from both the EM algorithm and the clustering algorithm, were then employed to analyze wind energy potential. Conventionally, wind energy resource evaluations predominantly emphasize metrics such as wind power density and the power output of wind turbines [
29,
51]. Notably, these metrics are intrinsically associated with the specific wind turbine model under consideration. Within the context of this study, the Aerodyne SCD 8.0/168 (ASCD-8) model, accessible via [
http://en.wind-turbine-models.com/, accessed on 28 August 2023], was selected as the reference for computing energy evaluation indices. Detailed specifications for this wind turbine can be found in
Table 9, with its power curve illustrated in
Figure 14.
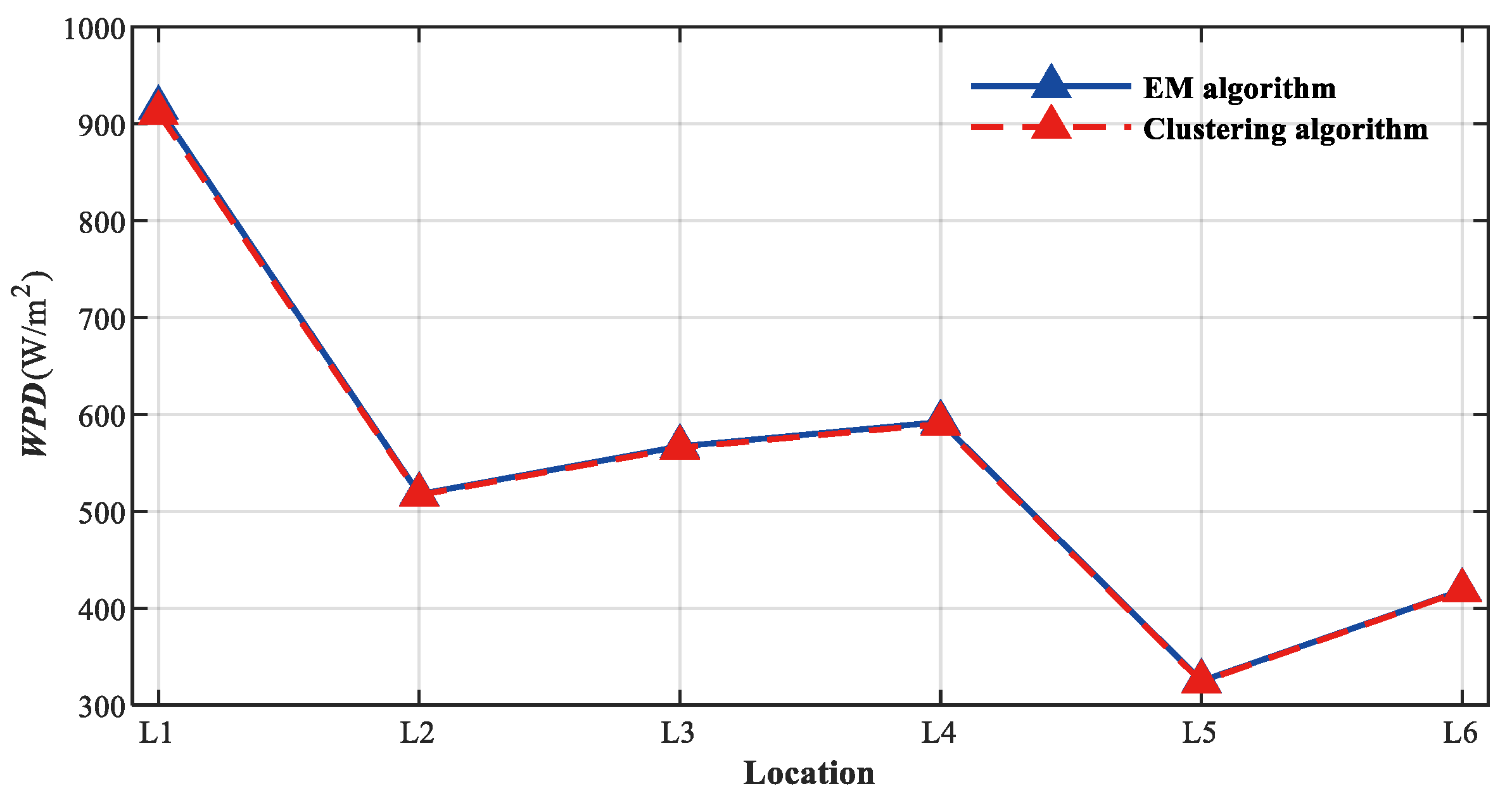
Both
Table 10 and
Table 11 reveal that the
WPD and
AEP values determined by the clustering algorithm are in close proximity to those derived from the traditional EM algorithm.
This consistency, clearly depicted in
Figure 15 and
Figure 16, underscores the reliability and robustness of the proposed clustering algorithm in capturing and modeling wind energy characteristics. Specifically, discrepancies in
WPD values across all six locations remain limited, with no variance surpassing 5.4 W/m
2. Similarly, the disparities in
AEP values are found to be less than 0.2 GWh. Such minimal variations highlight the comparable efficiency demonstrated by both algorithms in estimating the energy potential from the wind speed and air density data.
While the EM algorithm has long served as a foundational tool in such assessments, the alignment of results between the two methods indicates that the clustering algorithm, introduced in this study, not only matches the performance of established methods but also presents an alternative computational approach for future wind energy research.
5. Discussion
In the presented research, the introduced clustering algorithm demonstrates a precision comparable to the well-established EM algorithm. However, it further offers distinct advantages that emphasize its enhanced adaptability in situations where the EM algorithm may encounter limitations.
A critical characteristic of the EM algorithm is its dependency on
Q(
ξ) to solve for the parameters of mixture models, described as:
A pronounced challenge arises when dealing with complex probability density functions. As the complexity of these functions increases, the representation of
Q(
ξ) correspondingly intensifies, complicating the derivation of unknown parameters. The
Q(
ξ) of the distribution models presented in Equations (12)–(15) are given in
Appendix A. By examining the contrast between the
Q(
ξ) of the one-dimensional probability density functions presented in Equations (A1) and (A2), and those of the two-dimensional probability density functions presented in Equations (A3) and (A4), an enhanced complexity associated with increased dimensionality is clearly discernible. Such increased complexity is especially pronounced when formulating three-dimensional joint distributions, for instance, involving random variables
X,
Y, and
Z. When the vine copula is utilized to establish their joint probability density function, given by
the model incorporates three one-dimensional and three two-dimensional probability density functions. Given this complex structure, utilizing the EM algorithm for parameter estimation becomes significantly challenging.
Distinct from the EM algorithm, the clustering algorithm presented in this study offers a more direct approach. Instead of dealing with complex nonlinear equations, this technique transforms the challenge of mixture distribution models into multiple single-mode probability distributions. Consequently, when presented with an explicit form of the probability density function, the clustering algorithm effectively bypasses complexities associated with the likelihood function of mixture models. It utilizes data categorization to derive maximum likelihood estimates for individual data categories.
The experimental analysis and wind energy assessment conducted in China’s coastal region reveal the significant robustness and efficacy of the clustering algorithm. The results suggest that the performance of the clustering algorithm is not only comparable to that of the EM algorithm, but also consistently reliable across various data scenarios. In the experimental study, each subcategory’s data, obtained by the clustering algorithm for every case, can be well represented by a single probability distribution model, as depicted in
Figure 4,
Figure 5,
Figure 6 and
Figure 7. Additionally, the probability distribution parameters obtained for each subcategory in
Table 3 closely match the predetermined parameters in
Table 1. These findings suggest that the clustering algorithm introduced in this research, when classifying mixed data, ensures that the data of each subcategory satisfies homogeneity characteristics.
Figure 17,
Figure 18,
Figure 19,
Figure 20,
Figure 21 and
Figure 22 show the contour plots of the bivariate distribution for each subcategory of the mixed data from the coastal areas of China obtained through the clustering algorithm, while
Table 12 lists the statistical error analysis results for these subcategories. The results indicate that the value of
RMSE is small and the values of
R2 are all greater than 0.9, suggesting that each subcategory can be well fitted by a single-mode probability distribution model. Similar to the conclusions drawn from experimental research, studies on real data also demonstrate that the clustering algorithm proposed in this research not only has high accuracy but also ensures that each subcategory obtained from this classification satisfies homogeneity characteristics. Notably, in cases involving complex probability density functions, the clustering algorithm exhibits significant advantages, positioning itself as a compelling alternative to the EM algorithm.
While the proposed clustering algorithm presents promising accuracy and adaptability in wind energy research, it faces challenges related to computational demand, particularly with increasing sample sizes. Addressing this limitation is important for ensuring its scalability and wider applicability. One potential solution is the integration of parallel processing, utilizing the capabilities of modern multicore processors or specialized hardware such as graphics processing units. Given the divisibility of data clustering tasks, such an approach could significantly reduce computation times. Furthermore, the adoption of optimized data structures, such as trees or hash tables, can improve data efficiencies, thereby promoting quicker computations. In future research, these strategies will be thoroughly explored, with the aim of preserving the algorithmic accuracy while enhancing its computational efficiency, thus ensuring its viability in large-scale and real-time applications.
6. Conclusions
In the present study, a new clustering algorithm was proposed to estimate parameters in mixture distribution models. Carefully designed experiments were conducted to assess the algorithm’s performance in comparison to the established EM algorithm. Based on the experimental results, the precision of the suggested clustering algorithm was found to be comparable to the EM algorithm. Notably, when applied to wind energy assessment, a high degree of accuracy was exhibited by both algorithms, indicating their proficiency in predicting the probabilistic patterns for mixed data. Quantitative evaluations revealed the clustering algorithm’s robustness, with the root mean square error value being notably minimal and the coefficient of determination exceeding 0.9 for both experimental and real data analyses.
The EM algorithm often faces challenges with complex mixture multi-dimensional probability distributions, mainly due to its dependency on Q(ξ) to solve for the parameters. When dealing with complex probability density functions, the Q(ξ) can become exceedingly complex, making the EM algorithm less efficient. In contrast, the proposed clustering algorithm addresses these challenges by transforming mixture distributions into distinct single-mode probability distributions. This approach not only simplifies the estimation process but also broadens its applicability across various scenarios.
The investigation of wind resource assessment in China’s coastal regions highlighted the capabilities of the clustering algorithm. It accurately captures the multimodal structure of mixed wind data, enabling precise modeling of probabilistic distributions of wind speed and air density. The results further indicated that, for each subcategory derived from the clustering algorithm, the root mean square error values remained low and the coefficient of determination consistently exceeded 0.9. This suggests that each subcategory can be efficiently fitted by a single-mode probability distribution model, underscoring the algorithm’s ability to ensure subcategory obtained from classification homogeneity.
While the clustering algorithm demonstrates promising accuracy and adaptability in wind energy research, the computational demand, especially with larger datasets, is a challenge. To achieve scalability and wider application, future investigations should focus on addressing this limitation. One potential solution is applying parallel processing, utilizing modern multicore processors or specialized hardware like graphics processing units. Additionally, employing optimized data structures, like trees or hash tables, might improve data efficiency and speed up computations. Our future research will explore these optimization techniques, with the goal of enhancing both its efficiency and computational speed without compromising the precision of the results.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}