1. Introduction
With rising temperatures, global extreme weather events have increased, causing an upsurge in natural disasters worldwide. Natural disaster outbreaks are generally complex, unpredictable and frequent and have a serious impact on social and economic development [
1,
2,
3]. One of the most serious marine natural disasters in the world is a storm surge disaster, which causes serious damage to the sea, nearshore and inland [
4,
5,
6]. Storm surge disasters are transient, high-risk, complex and frequent, resulting in serious damage in a short time [
7,
8,
9]. After the occurrence of sudden natural disasters, people need to respond promptly for an immediate analysis and handling, by comparing with historical natural disaster information. Furthermore, they need to make a qualitative damage determination in real time based on the actual situation of sudden natural disasters, so as to facilitate the subsequent adjustment and decision-making for effective rescue measures [
10,
11].
An important empirical resource for natural disaster emergency managers is the relevant historical disaster cases [
6,
12], but historical case information is widely recorded in texts and people need to obtain historical natural disaster information and knowledge from these texts to manage and analyze disasters [
13]. As reference knowledge, historical natural disaster cases can provide a scientific basis and support for emergency decision-making to achieve an orderly and effective response over a short time. In recent years, scenario construction techniques have been proposed in the field of emergency management from home and abroad [
14,
15]. They can generate solutions to new problems by using source cases through case-based reasoning (CBR) techniques, and they complete the mapping of similar elements between source and target cases via reasoning [
16,
17]. Existing studies have carried out a large number of case similarity calculations for scenario building in the areas of business [
18,
19,
20], medical health [
21,
22,
23] and disaster incidents [
24,
25]. However, the existing studies provide very limited help for emergency decisions during sudden natural disasters [
2,
26].
The paper [
27] in the field of emergency management of sudden natural disasters proposed an ontology-based semantic similarity calculation model to calculate the similarity by quantifying the semantic similarity between concepts. The paper [
28] proposed a case inference based on a differential evolution algorithm, which obtained a new differential evolution algorithm through a hybrid mutation operator and improved the adaptiveness of the model. The paper [
29] proposed a modeling and analysis of disaster chains based on stochastic Petri nets, established the model elements of disaster chains and analyzed their control flow relations. The paper [
30] proposed an emergency risk decision-making method based on fault tree analysis; they constructed fault trees by analyzing the evolution process of emergencies and described the logical relations between the conditions and factors leading to the evolution of emergencies.
The following problems and challenges are found when calculating the similarity between cases in the natural disaster field: (1) natural disaster information is usually recorded in unstructured texts, which generally contain a lot of noisy data (texts that are irrelevant to disaster descriptions); (2) texts contain a variety of information, such as text information, data information, geographic information, etc., which makes it difficult to calculate the similarity between cases by processing the corpus uniformly; (3) natural disaster cases contain many disaster events, and the values of the disaster-bearing body and damage information in disaster are not unified, which makes it more difficult to judge the similarity between disaster cases; (4) the temporal information between disaster events is not obvious as many natural disasters are transient in nature, resulting in a lack of temporal information in the text; (5) the spatial distribution of disaster events in natural disaster cases is wide and disasters are generally scattered in different locations.
It can be found that most of the existing studies focus on disaster analysis, numerical simulation, prediction and warning, damage assessment and emergency decision-making in the field of sudden natural disasters [
31], while the comprehensive problems caused by sudden natural disasters are not considered globally. The distribution of disaster “dynamics” in the field of sudden natural disasters is widely varied, resulting in a large number of influencing factors. In this paper, we focus on the geographic distribution and the damage of natural disasters and build a multifactor, multiaspect and multihierarchy model to calculate the similarity between natural disaster cases. The main contributions of the study can be summarized as follows:
We transform the case similarity calculation into a similarity calculation of the case structure and case node labels by using the “vertex-edge-label” case structure;
We propose the similarity calculation of sudden natural disaster cases with a fused case hierarchy and we calculate the similarity in “case scenario”, “disaster damage” and “case structure” in a multihierarchy, multiaspect and multifactor way;
The experimental results of the storm surge disaster cases show that the results of aggregating the three similarities of “case scenario”, “disaster damage” and “case structure” in this paper are better than other comparison methods.
2. Related Work
The intercase similarity calculations in traditional methods are mainly based on a case’s textual content [
32,
33,
34] and case hierarchy [
35,
36].
In the similarity calculation method based on a case’s textual content, an ontology mapping is generally an effective means of multisource data fusion and an ontology enables the sharing, common understanding and reuse of the domain knowledge [
27,
37]. An ontology mapping obtains the source ontology that is similar to the target ontology by a similarity calculation method. It forms a mapping relationship, obtains a unified global representation and realizes the effective fusion of multisource data. The ontology-based similarity calculation methods can be broadly classified into five categories: semantic-distance-based similarity calculation methods [
38], information-content-based similarity calculation methods [
33,
39], concept-attribute-based similarity calculation methods [
40], hybrid semantic similarity calculation methods [
41] and deep-learning-based similarity calculation methods [
42,
43]. Among them, the calculation methods based on semantic distance have a low computational complexity, but the single consideration makes the results less accurate and unstable. For the calculation methods based on information content, the results are more accurate for a corpus with a high completeness and the algorithm does not have robustness. The calculation method based on concept attributes shows more accurate results but ignores the location and content information between concept nodes. Furthermore, the hybrid semantic similarity calculation method has more objective and accurate results but has a high computational complexity. Furthermore, the calculation method based on deep learning has accurate results but poor convergence. In this paper, we build a domain ontology for the domain of storm surge natural disasters and use the similarity calculation method of information content to calculate the similarity of the cases’ textual content.
The graph structure is flexible and widely used in terms of similarity calculation methods for case hierarchies, and the graphs are available in the form of a Petri net model [
44,
45], BPMN network model [
46], Bayesian network model [
47], etc. A graph structure is used for the similarity measure of sudden natural disaster case hierarchies by methods such as the graph edit distance [
48], maximum common subgraph [
49] and graph isomorphism [
50] for the similarity search and graph matching on the graph structure. With the development of neural networks, many studies have recently turned similarity estimation into a learning problem, and a graph neural network is a powerful tool for learning various structural graph representations [
51,
52]. However, since the extracted sudden natural disaster case structures have fewer graph structure nodes, shallower layers and smaller sizes, which makes the neural network [
53] unable to learn effective features, we used the unsupervised graph edit distance method to learn the similarity between sudden natural disaster case hierarchies.
For the main problems of the similarity calculations between sudden natural disasters cases, to deal with sudden natural disaster cases timely and intelligently and to overcome the one-sidedness and limitations of the existing cases’ text content and hierarchy, we propose a case similarity calculation with a fused case hierarchy.
3. Disaster Case Analysis
The current “scenario–response” model is the trend in the study of emergency natural disaster response, and managers need to study the “situation” of the occurrence and the development of that current emergency natural disaster [
54]. The characteristics of the storm surge disaster “situation” are that the “situation” is spatially dispersed and temporally short-lived.
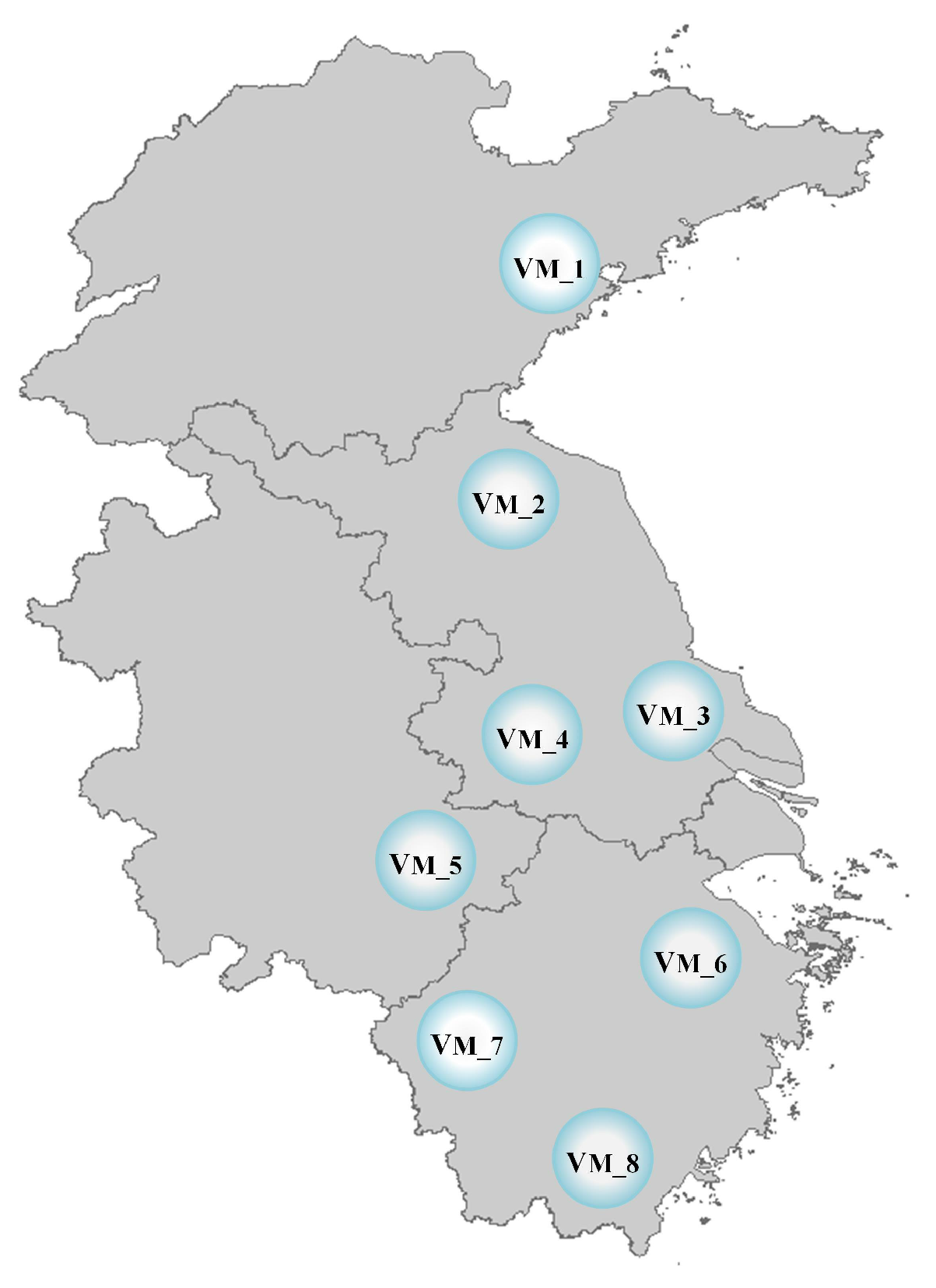
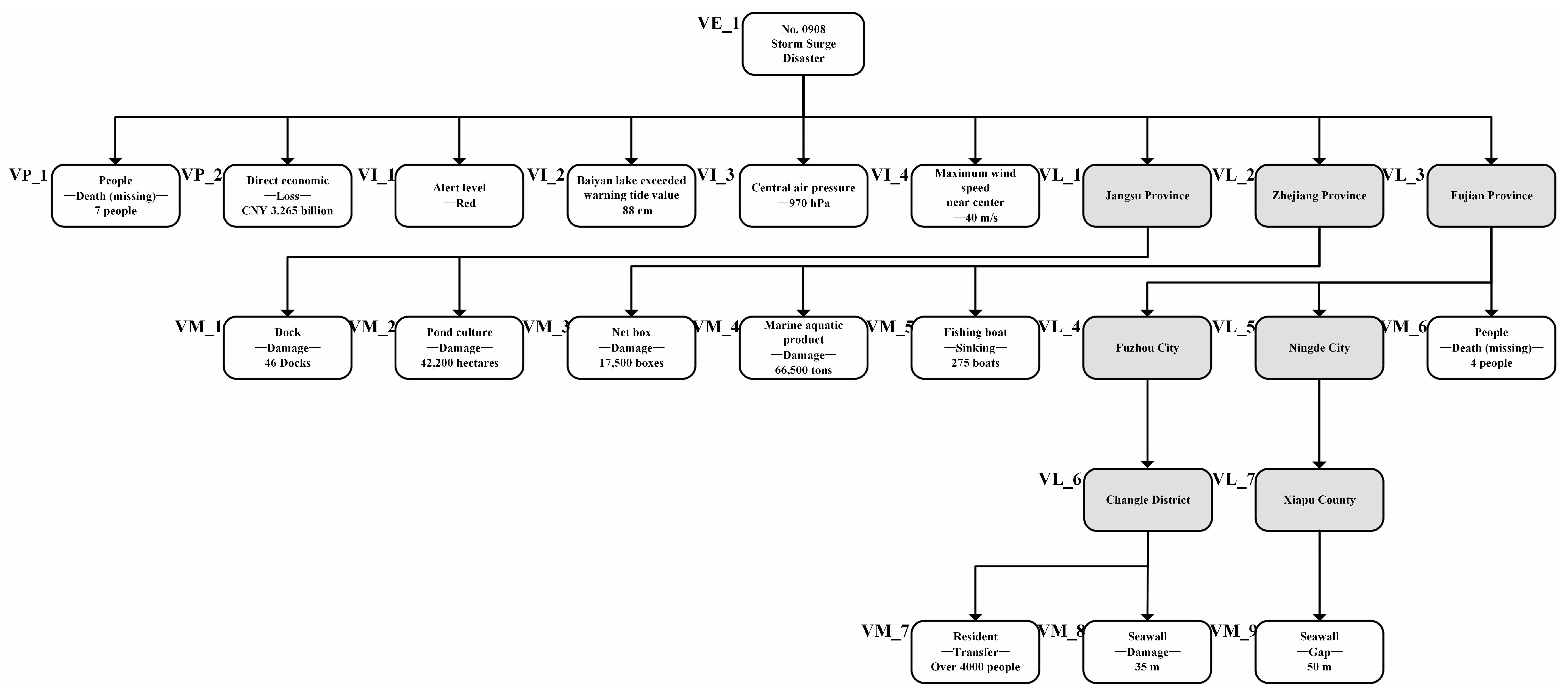
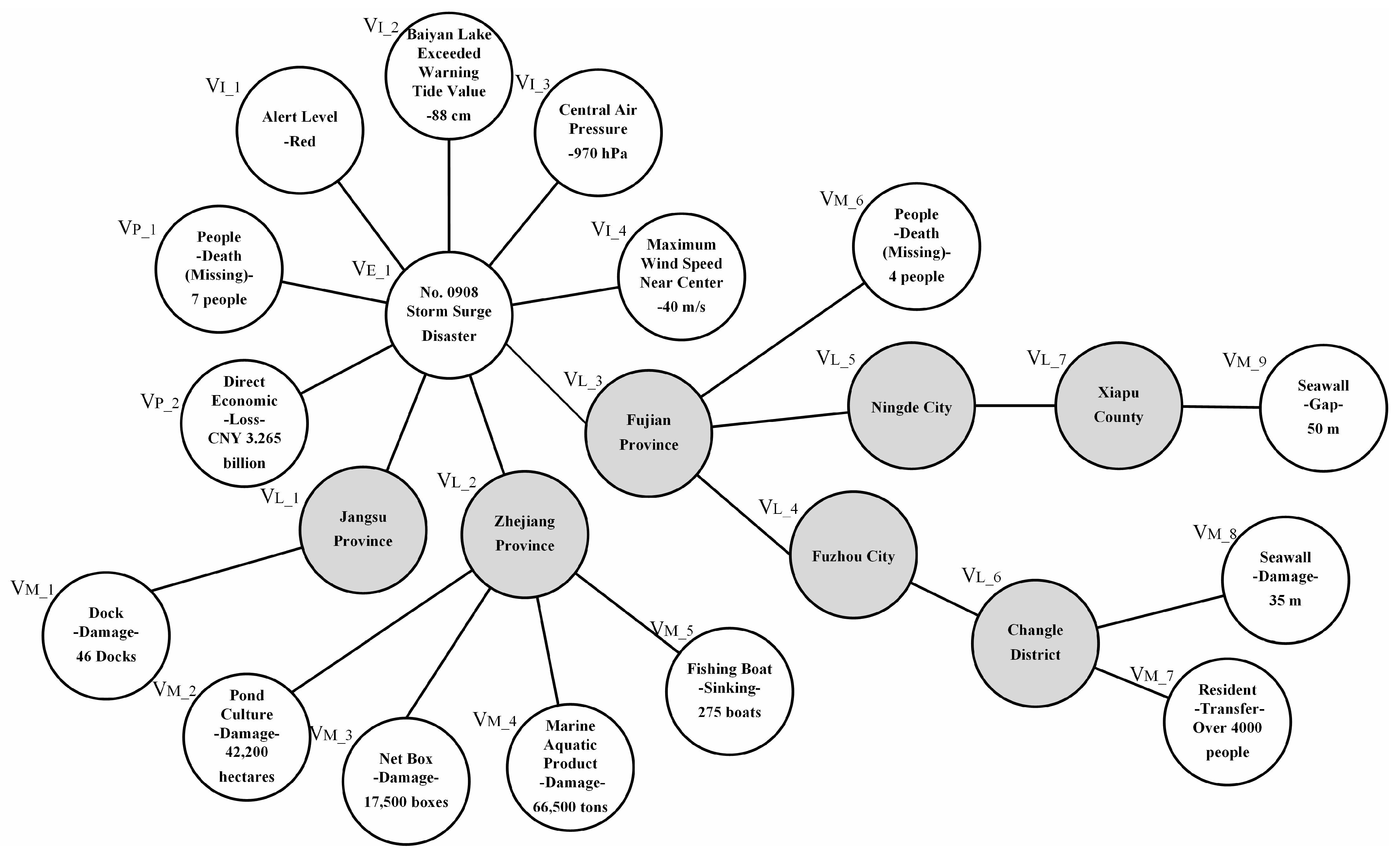
Figure 1 shows the decomposition of multiple events in the spatial dimension of a storm surge disaster case, which shows the spatial distribution of the disaster conditions after the storm surge disaster
. The distribution of the disaster is generally expressed as the information and distribution of the storm-surge-disaster-bearing body, which is a manifestation of the set of “states”.
We performed the analysis from the perspective of the disposal model of emergency decision-making in sudden natural disasters, assuming that the fundamental goal of emergency decision-making is to control, reduce and eliminate the impact of the disaster around different disaster-bearing bodies. Based on the fundamental goal of emergency decision-making, we combined the definition and spatial analysis of sudden natural disaster texts. We believe that the damage of the disaster-bearing body (disaster damage) and the disaster scenario constitute the core of sudden natural disaster cases. Furthermore, we propose the concept of “sudden natural disaster cases”.
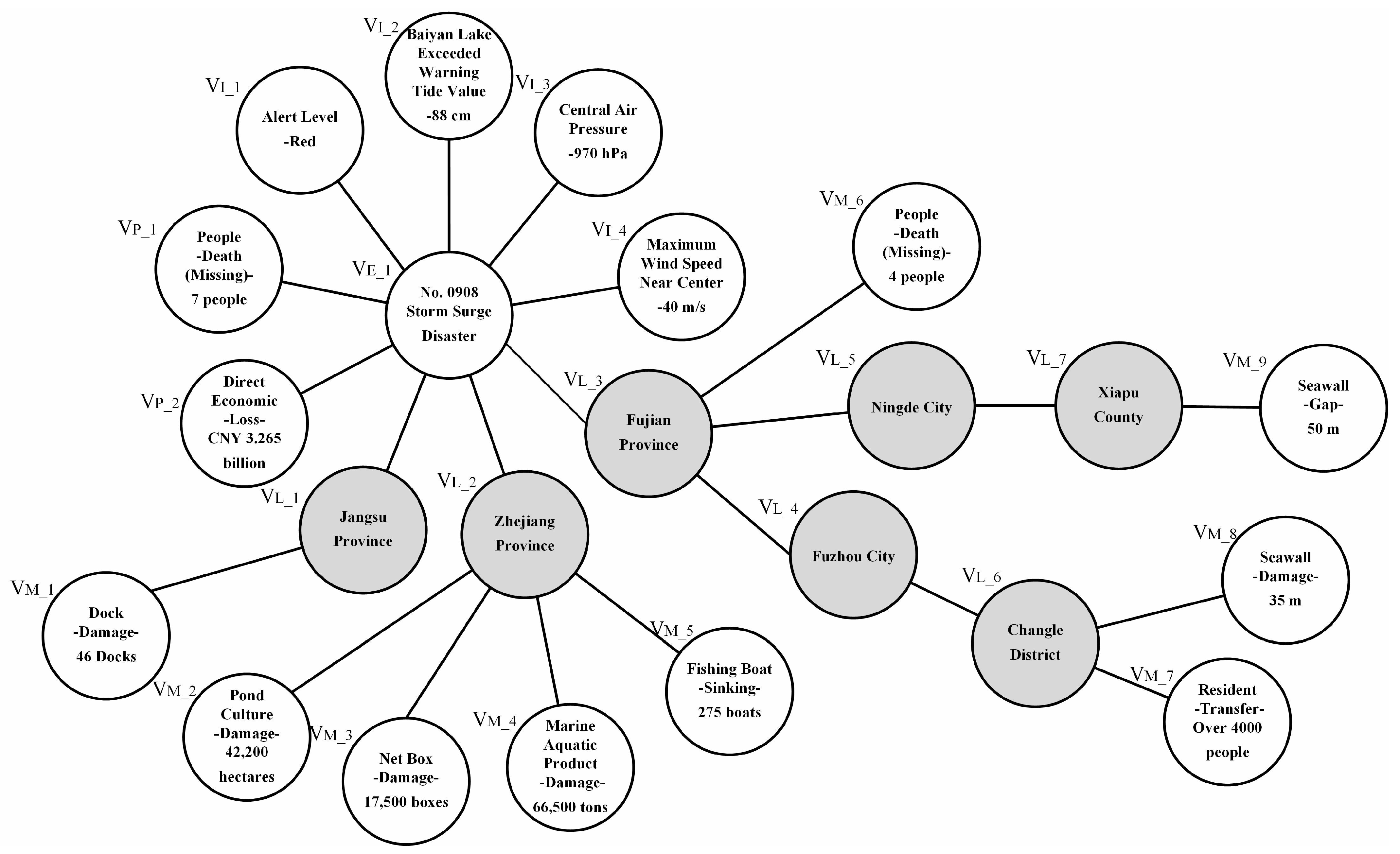
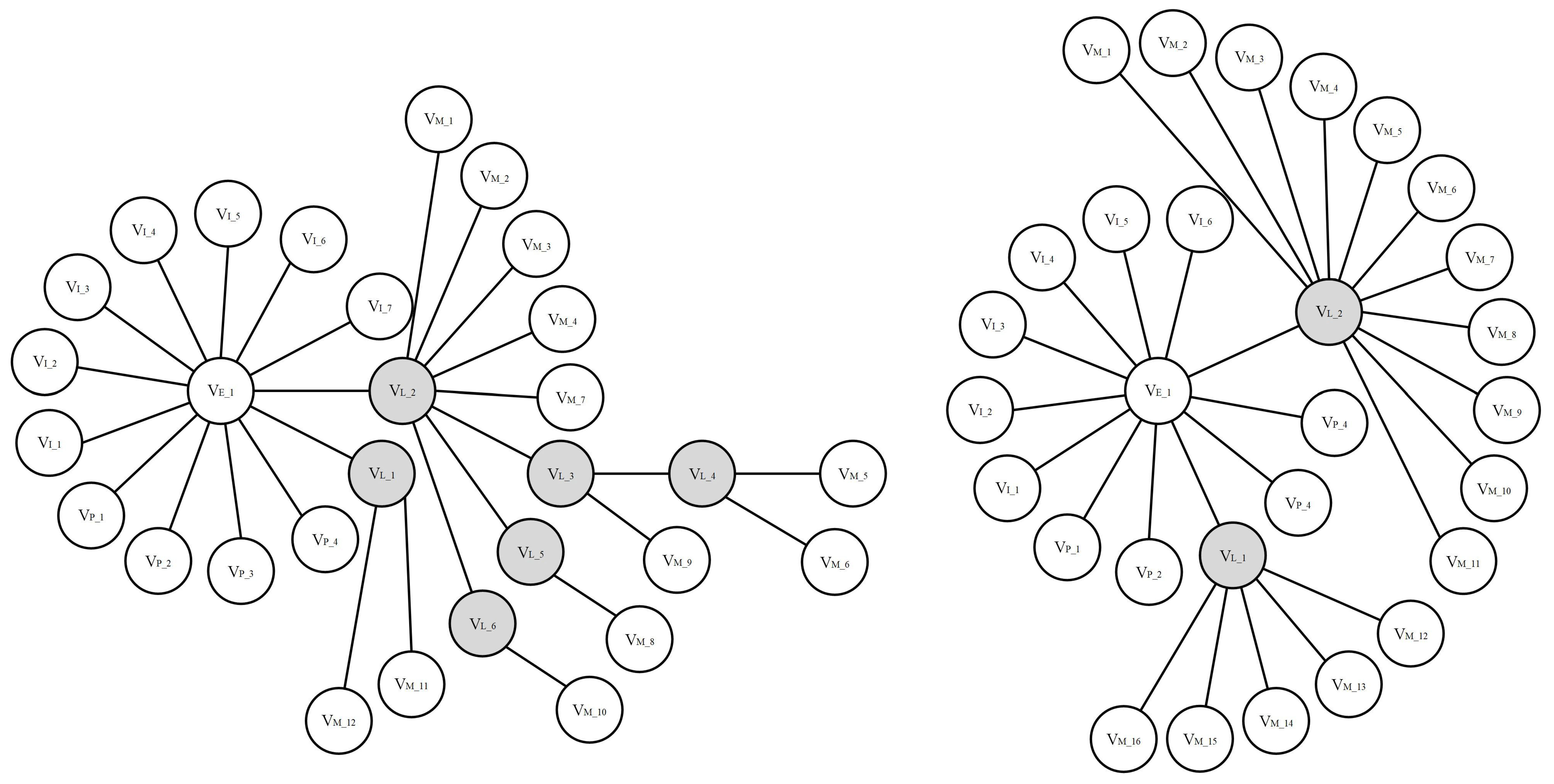
This paper used 281 cases of storm surge disasters in China from 1949 to 2019. We analyzed the text of sudden natural disaster cases and found that they contained many case scenarios and disaster damage information. Therefore, in response to the spatial and temporal distribution characteristics of natural disasters, we constructed “sudden natural disaster cases” by converting case scenarios and disaster damage into case structure hierarchies according to the geographical location of natural disasters. We defined a case as a collection of information, which combined the disaster information suffered by a disaster-bearing body and the disaster-generating environment in a sudden natural disaster. A sample of sudden natural disasters from storm surges is shown in
Figure 2.
Specifically, a sudden natural disaster case can be represented formally as a triplet , where V is the set of all nodes of the graph, E is the set of all edges of the graph and N is the set of all node labels in the graph.
The set is the set of case nodes, is the set of case ID nodes, is the set of case damage nodes, is the set of case attribute nodes, is the set of disaster damage nodes and is the set of disaster geographic location nodes. The set of case edges is the set of directed edges, which is used to represent the order relation between the case nodes of sudden natural disasters.
The set of case node labels is , where is the set of case damage information and the statistical information on dead population, affected population, house loss, economic loss, crop damage and overalert tide value in sudden natural events, consisting of the set of case disaster-bearing bodies , the set of attributes of the case disaster-bearing body and the set of data of the case disaster-bearing body ; is the set of case attribute information, the meteorological attributes and time attributes, etc., at the landing of sudden natural cases, composed of the set of case attribute types and the set of case attribute data ; is a disaster damage information set and the basic information of a sudden natural disaster event element, composed of a disaster-damage-bearing body set , the set of attributes of the damage-bearing body and the data set of disaster-damage-bearing body ; is a disaster geographic location information collection, which is the specific location of the event caused by sudden natural disasters and it consists of the set of geographic locations . The sets , , are numerical information and the other nodes are textual information.
4. Similarity Calculation between Cases
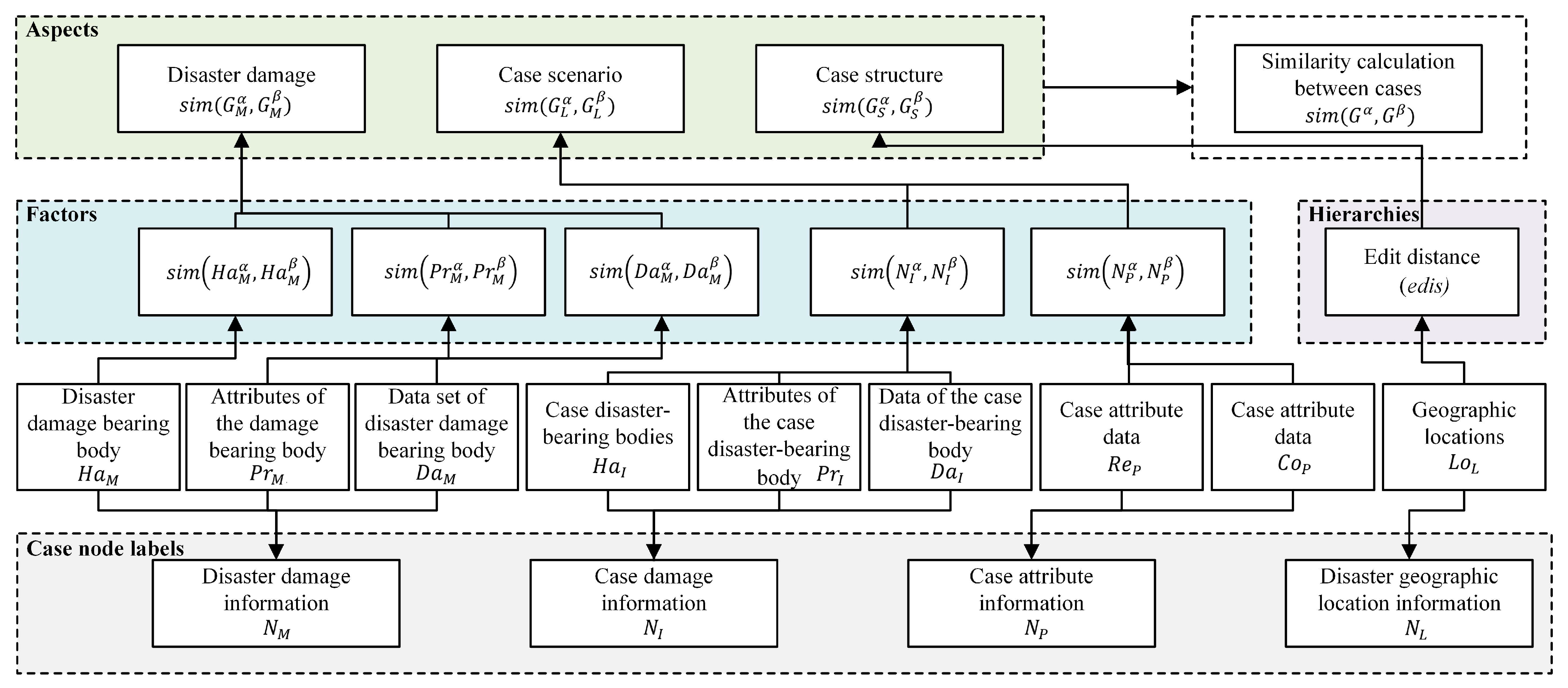
The similarity between cases was obtained by combining the similarity in “case scenario”, “disaster damage” and “case structure” between two cases. The similarity in “case scenario” in the case of sudden natural disasters was calculated from the label data between the case loss node and the case attribute node. The similarity in “disaster damage” was calculated from the textual information and data information in the label data. Furthermore, the “case structure” was the geographic location information of the event, which was transformed into a case hierarchy for the similarity calculation. In other words, the similarity in the label text and the case structure were calculated and analyzed in a multihierarchy, multiaspect and multifactor way for the label text and structure of the cases that constituted sudden natural disasters. The architecture of the similarity model between natural disaster cases is shown in
Figure 3.
4.1. Similarity between Case Scenarios
The “case scenario” mainly contains the natural and disaster-forming attributes of the disaster [
55]. The natural attributes of the storm surge disaster were mainly the statistical information about the disaster level, landfall time, landfall location, landfall wind speed, central air pressure and coastal water increase in the case; the disaster-forming attributes of the storm surge disaster were mainly the statistical information about the dead population, affected population, housing damage, economic loss, crop damage and excess tide value. The natural attributes and disaster-forming attributes corresponded to the case loss node
and the case attribute node
in the case, respectively.
Specifically, we used the disaster level (), landfall wind speed (), central air pressure () and coastal water increase () information for the natural attributes’ similarity calculation. For disaster-forming attributes followed the Statistical System of Natural Disaster Situation (Minfa [2016] No. 23) and Natural Disaster Statistics (Part 1): Basic Indicators (GB/T24438.1-2009), and for case damage we used the death population (), affected population (), house damage (), economic loss (), crop damage () and exceeded warning tide values () for the similarity calculation.
The similarity between the “case scenarios” was calculated by combining the information of natural attributes and disaster attributes, which was transferred to the similarity calculation of the label information in the and nodes of the disaster case. The formulas for the natural attributes in the “case scenario” were given by the similarity between disaster levels, similarity between landfall wind speeds and central air pressures and similarity between coastal water increases, respectively, and the formulas for the disaster attributes were for the similarity between case damages.
(1) Calculation of disaster level similarity: a storm surge disaster level
is generally divided into four levels: red, orange, yellow and blue, corresponding to level I, level II, level III and level IV and corresponding to values 1∼4. Thus, the disaster level similarity between case A and case B is calculated by the formula shown in Equation (
1).
(2) Landing wind speed and central pressure similarity calculation: landing wind speed
and central pressure
are both storm surge disaster environments; the more similar the landing wind speed and central pressure of cases A and B are to the environment, the higher their similarity is. The calculation formula is shown in Equations (
2) and (
3).
(3) Coastal water increase similarity calculation: the maximum water increase value
in the storm surge disaster process was divided into five levels: extralarge, large, relatively large, medium and general, corresponding to level I, level II, level III, level IV and level V. The specific classification criteria for the levels are shown in
Table 1. Coastal water increase counting in storm surge disasters involves multiple tide gauge sites. We first counted the number of tide gauge sites and tide gauge site water increase values in cases A and B; then, according to the corresponding values 1∼5 of the grade, we averaged the site water increase values and calculated the similarity between coastal water increases in cases A and B. The calculation formula is shown in Equation (
4).
In conclusion, we combined these four calculations results of the disaster level, landfall wind speed, central air pressure and coastal water increase to derive the case attribute similarity
, and the formula is shown in Equation (
5).
(4) Case damage similarity calculation: death (missing) people
, affected population
, house collapse
, direct economic loss
, crop damage area
and exceeded warning tide value
were divided into four grades (extralarge, large, relatively large, general) and the specific classification criteria are shown in
Table 2. The case damage similarity between cases A and B was calculated according to the values 1∼4 corresponding to their rank, where the formula for calculating the number of fatalities is shown in Equation (
6) and
,
,
,
and
also can be calculated by the same formula.
In conclusion, the six calculation results of death (missing) people, affected population, collapsed houses, direct economic loss, crop damage area and exceeded warning tide value were combined to derive the case damage similarity
, and the formula is shown in Equation (
7).
4.2. Similarity in Disaster Damage
Normally, a disaster case contains multiple “disaster damage” pieces of information. For example, a storm surge disaster case may contain events such as “46 docks destroyed in Jiangsu Province”, “275 fishing boats sunk in Zhejiang Province”, etc., where the “disaster damage” corresponds to the node in the case of a sudden natural disaster, and the label information of the node is “46 docks destroyed” and “275 fishing boats sunk”; the label information contains the disaster’s textual information “docks” and “fishing boats” as the “disaster damage”-bearing body ; “destroyed” and “sunk” are the “disaster damage”-bearing body attributes ; “46 docks” and “275 boats” are the “disaster damage”-bearing body data .
All the “disaster damage” elements in cases A and B contributed to the similarity calculated by the textual information of , and the data information of .
4.2.1. Similarity in Textual Information
Both disaster-bearing body information
and disaster-bearing body attribute information
in the “disaster damage” information are concepts of the mentioned disaster domain ontology. The similarity calculation of
and
can be transformed into the similarity calculation between concepts of the ontology. In our previous work, we constructed the storm surge disaster domain ontology by comprehensively referring to the existing domain ontologies for sudden natural disasters and the National General Emergency Response Plan for Public Emergencies issued by the State Council and other emergency management departments [
56,
57].
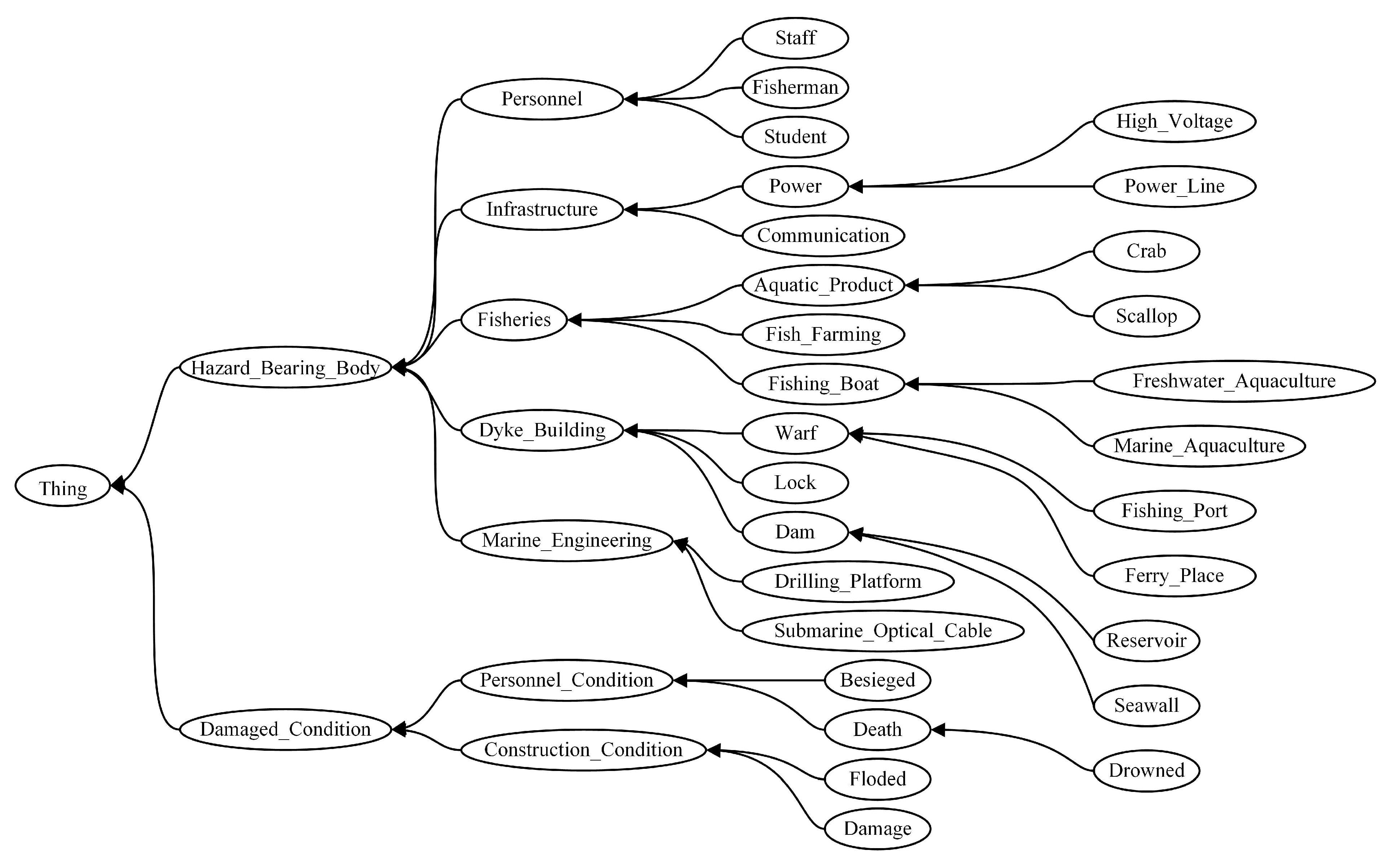
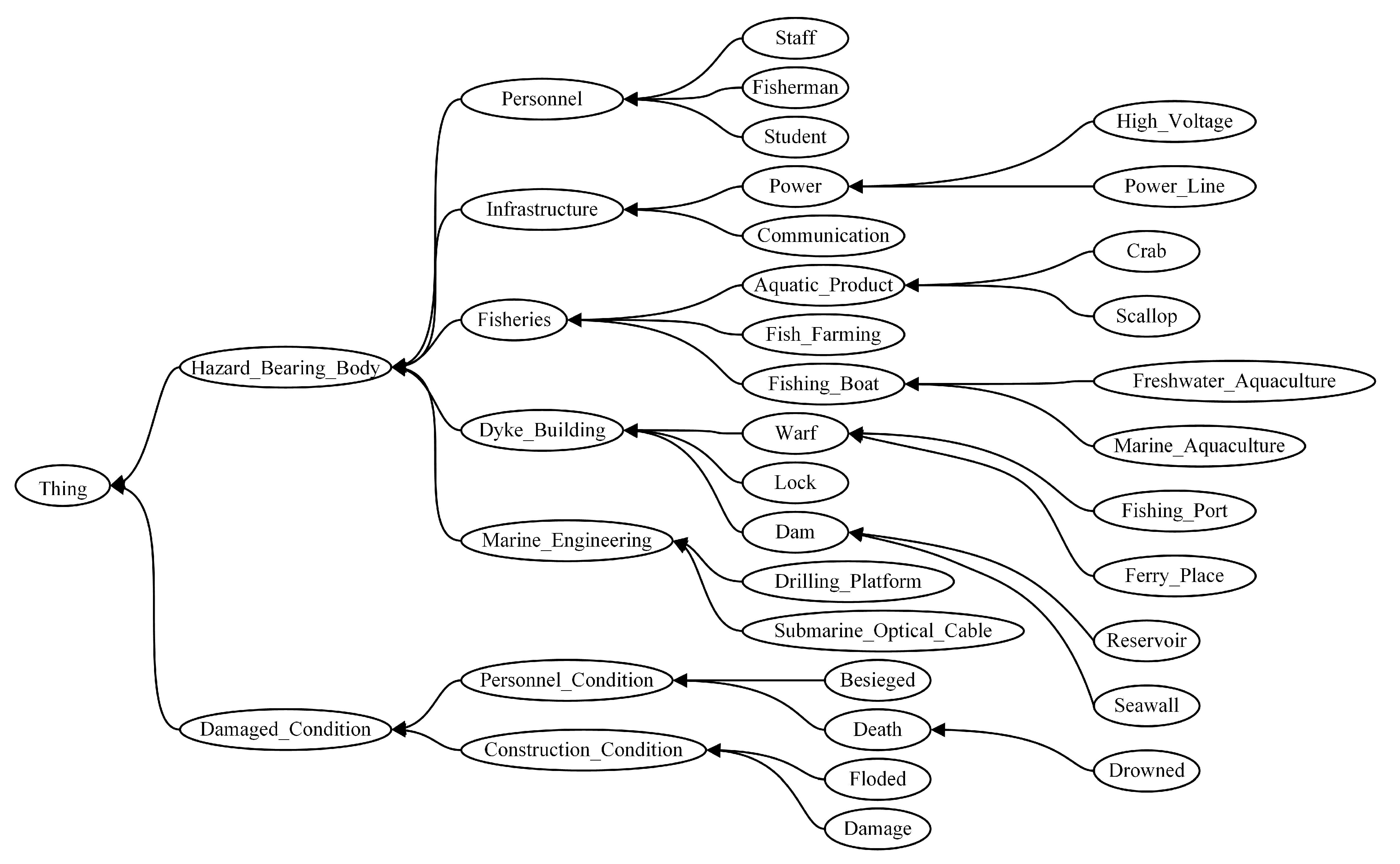
Figure 4 shows the hierarchy among some concepts in the storm surge disaster domain ontology.
In this paper, the similarity between the disaster-bearing body of storm surge disaster case A and the of case B was taken as an example for the calculation of textual information similarity, which mainly contained the following three steps.
(1) Construct the disaster similarity matrix:: the sets of
of the two cases are
,
and
,
. Then, the following
disaster-bearing body similarity matrix
can be established based on the two
sets, and the calculation formula is shown in Equation (
8).
where
is the similarity between the disaster-bearing body
in the set
and
in the set
.
(2) Calculate the value of each element in the similarity matrix: each element of the matrix
represents the similarity between two concepts, and they can be calculated by any concept hierarchy method in the domain ontology. The similarity calculation method based on the domain ontology concept was used to calculate the concept similarity matrix
for the content based on the amount of concept information within the ontology. The elements in the matrix
were calculated by the formula shown in Equation (
9).
where
is the commonality between two words, which is expressed as the nearest neighbor common ancestor concept of concepts
and
in the ontology structure tree, and
and
denote the information quantity of concepts
and
, respectively.
The
value illustrates the amount of information provided by a concept when it appears in context [
58], and the
value of the function used the method reported in [
59] to calculate the information content of a concept. The value of the function increases incrementally with the depth of the ontology, which means a more abstract concept has a smaller
value and a more concrete concept has a larger
value. This approach ensures that the value of the concept decreases as it moves from the leaf node to the root node of the hierarchy, and the calculated value is greater for the more concrete concept. To calculate the concept information content (
), the formula shown in Equation (
10) was used:
where
is the information content of the concept
, and
refers to a specific concept.
is the number of the set composed of all leaf concepts under
,
is the number of the set composed of all leaf concepts and all their parent concepts
, and sum_leaves is the number of all leaf concepts in the storm surge disaster domain ontology.
(3) Calculate the similarity of textual information: after calculating the value of each element in
, we selected the element with the largest value
and added it to the set
. Then, we removed all the elements in row
i and column
j from
. Repeating the above procedure until the number of elements in the set
gets to
, assuming that the set
, the similarity between the set of disaster-bearing bodies can be calculated by the sum of all elements of the normalized set
. The corresponding formula is shown in Equation (
11).
In the same way, we can calculate the similarity between the set of attributes in cases A and B.
4.2.2. Similarity in Data Information
Considering the different data types in the data set of the disaster-bearing body, we classified the data information into three types of cases, namely, exact values, definite intervals and fuzzy intervals, for the calculation of the similarity.
(1) Similarity between exact values: the data of exact value type can be continuous or discrete, and we used the evolution formula based on the Hamming distance formula [
60] to calculate the similarity of value attributes in this paper. The formula is shown in Equation (
12), where
a,
b are the specific data information values of concepts
,
and
S denotes the range of these data information values.
(2) Similarity between definite intervals: a definite interval is a set of real numbers in a closed interval with definite upper and lower bounds and the data information interval value of the concept
is
and for the concept
, it is
. The formula for calculating the similarity between them is shown in Equation (
13).
(3) Similarity between fuzzy intervals: fuzzy intervals have no definite upper and lower bounds, the values of such data information are usually sets and the elements in the sets are fuzzy concepts corresponding to the concept variables
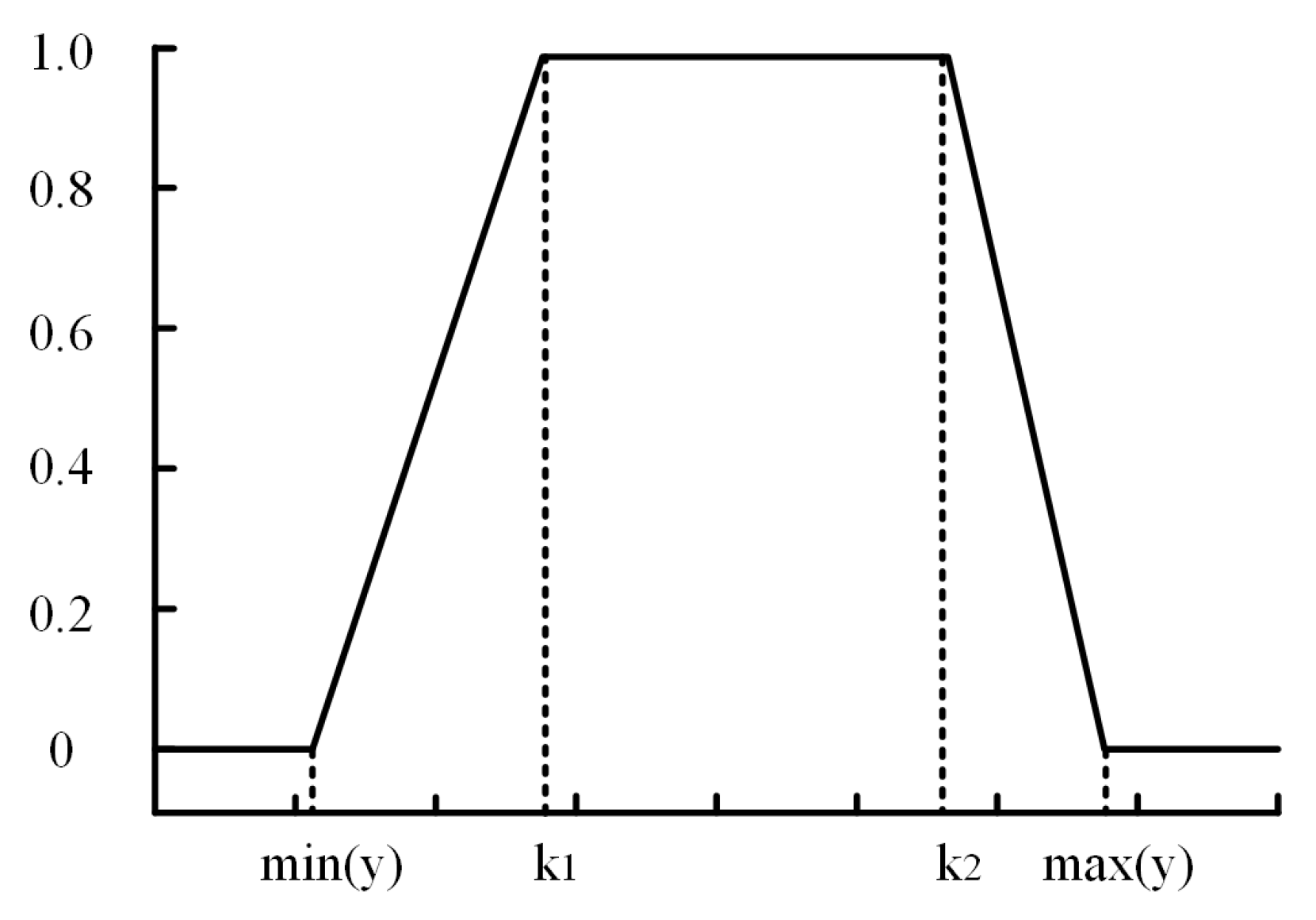
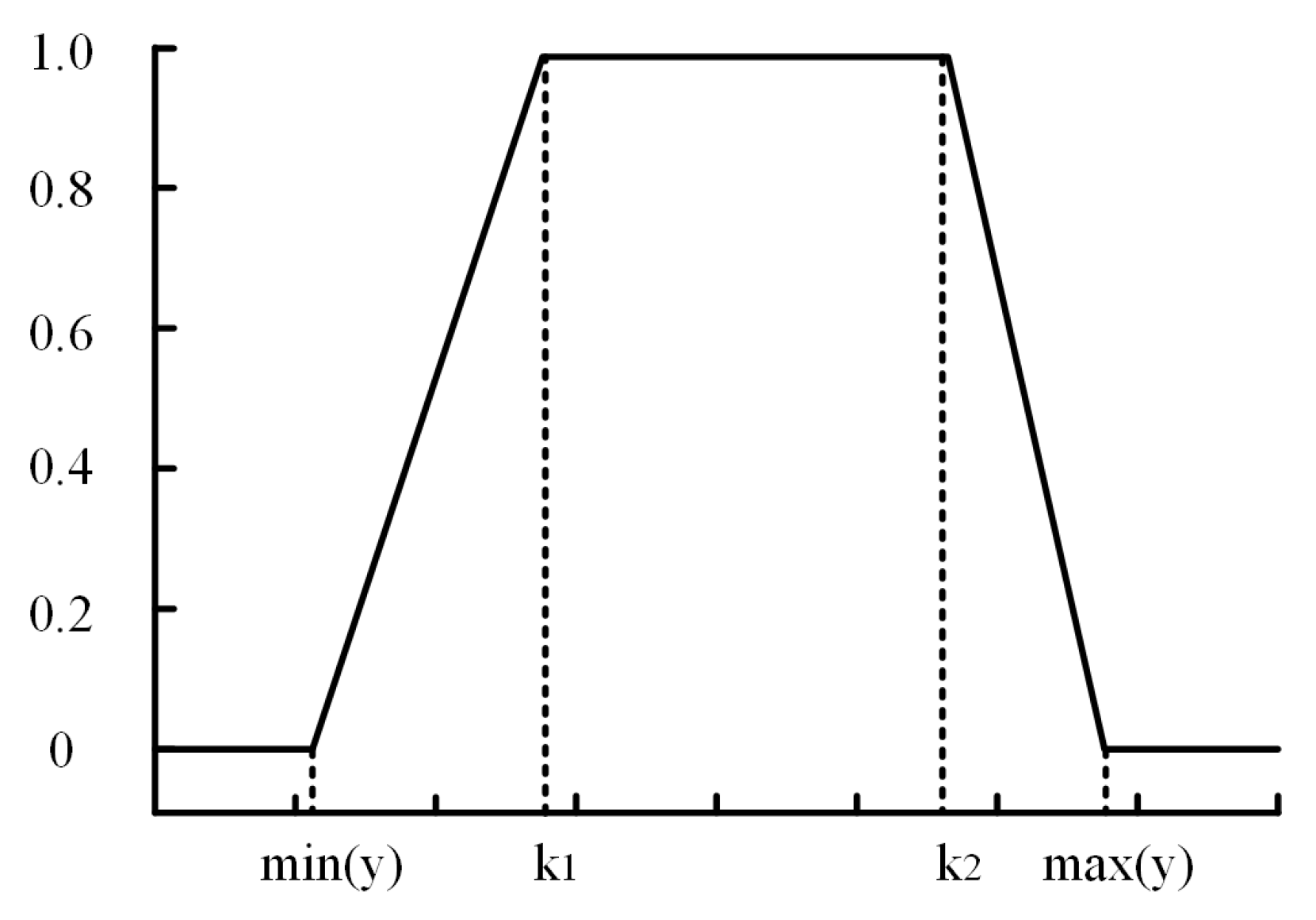
x. In this paper, the intervals were divided by the trapezoidal affiliation function [
61], and the affiliation function was as in Equation (
14), shown in
Figure 5. The similarity between the concepts
and
was set to one in the optimal value interval, and the other intervals were expressed by the affiliation function relation. The two fuzzy intervals and their overlapping interval areas were calculated according to the responding affiliation function, and the rate of area overlapping was the similarity between the fuzzy intervals. The formula is shown in Equation (
15), where
g,
k are the fuzzy intervals of concepts
and
.
The steps to calculate the similarity matrix of the data information were the same as those of the text information and took the calculation of the similarity
of the set
as an example. We needed to calculate the value of each element in
at first and select the element with the largest value to add to the set
. Then, we standardized the sum of all elements of the set
to obtain the final “disaster damage” set
of cases A and B, and the formula is shown in Equation (
16).
4.3. Similarity between the Case Structures
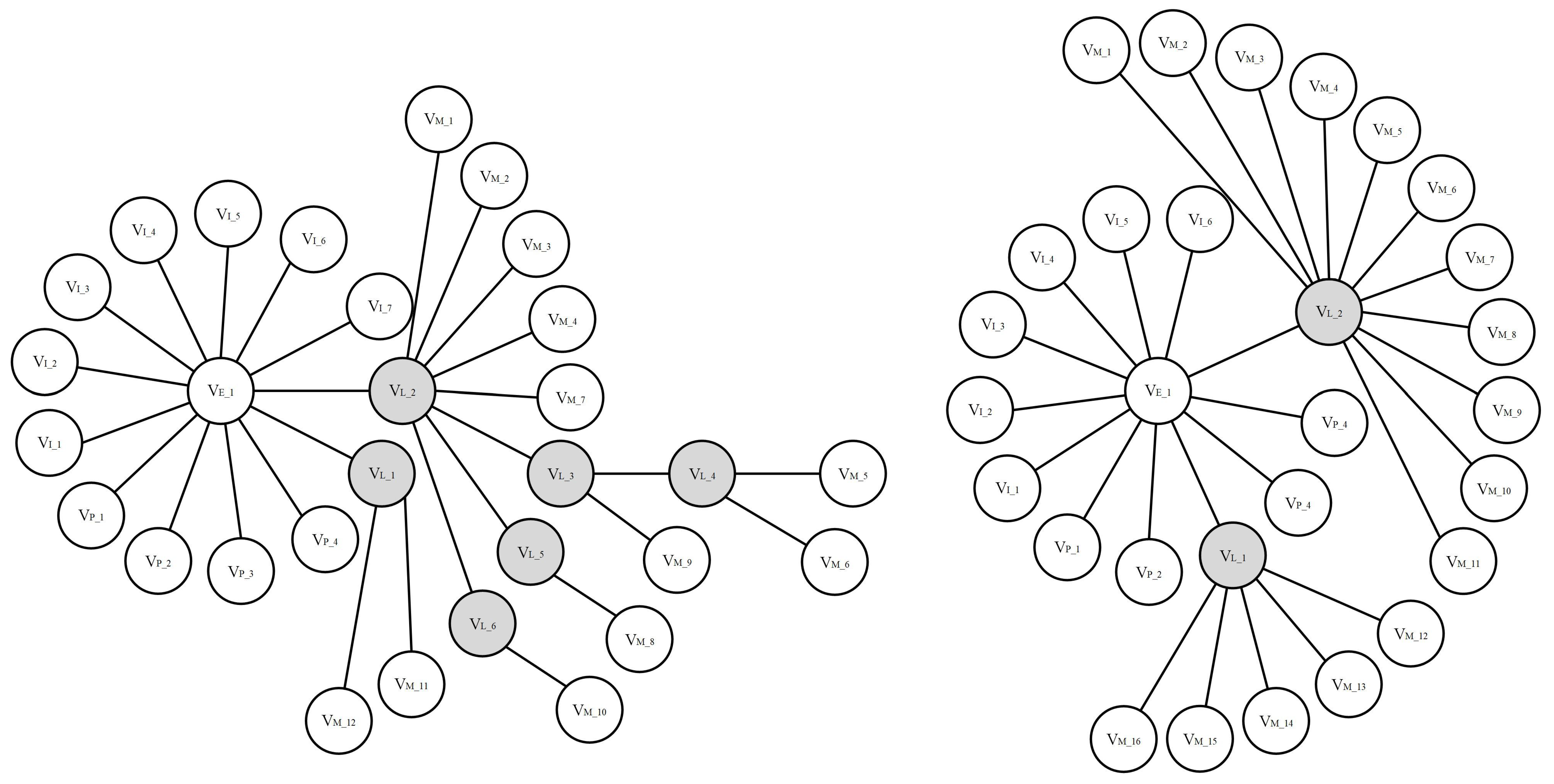
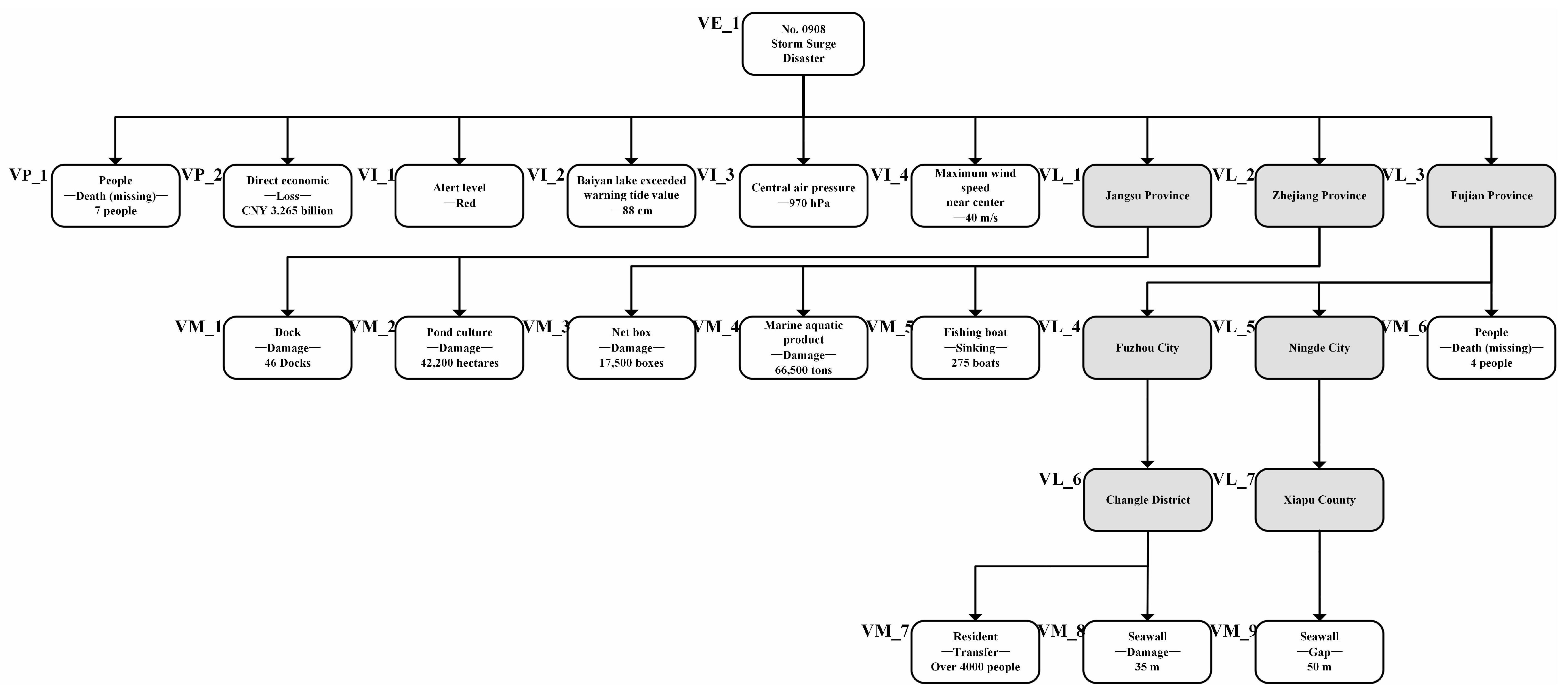
In this paper, we converted the geographic location in disaster cases into a hierarchy for a multihierarchy similarity calculation, and a case hierarchy sample is shown in
Figure 6. The difference in two cases’ structures was expressed as a sequence of editing operations, and the sequence of editing operations was the editing operations required when changing one case to another, such as deleting nodes, inserting nodes, deleting edges and inserting edges. Then, the case structure similarity between cases A and B was
, which was calculated as shown in Equation (
17).
In Equation (
18),
is the edit distance between graph
and graph
,
,
denotes the number of nodes in the graph
,
denotes the number of edges in the graph
,
denotes the set of all nodes to be replaced,
denotes the set of all nodes to be inserted or deleted,
denotes the set of all edges to be inserted or deleted,
denotes the cost weight assigned to the set of replacement nodes,
denotes the cost weight assigned to the set of nodes to be added or deleted and
denotes the cost weight assigned to the set of edges associated with the nodes to be added or deleted. For this group of parameters, we used the experimental best values
.
4.4. Similarity Calculation between Cases
The similarity between two cases can be obtained by aggregating the label and structure information of the cases in a multihierarchy, multiaspect and multifactor way. Specifically, we set the source case A as and the target case B as . The similarity between the two cases was calculated by the similarities of the “case scenario” , “disaster damage” and “case structure” .
The “case scenario” similarity
can be obtained by combining the multifactor case attribute similarity
and the case damage similarity
. The “disaster damage” similarity
can be obtained by combining the multifactor “disaster damage”-bearing body similarity
, “disaster damage”-bearing body attribute similarity
and “disaster damage”-bearing body data similarity
. Then, the similarity
between
and
was calculated as shown in Equation (
19).
where
is the overall similarity between the two cases,
,
and
are the weights of the aggregation method,
and
are the weights in the “case scenario”,
and
are the weights in the “disaster damage”, and they satisfy the conditions of
,
,
and
,
,
.
6. Example Analysis
Taking storm surge disasters no. 1 and no. 2 as examples, we show the process of similarity calculation between the two disasters. The relevant information in the two cases was extracted automatically from case text by the natural language processing technology, which included the label information of
,
,
,
and the structure information of the cases.
Figure 7 shows the case of storm surge disasters no. 1 and no. 2.
The label information
of the storm surge disaster cases is shown in
Table 5 and
Table 6, each node label
of a case attribute contains two attribute values of case attribute type
and case attribute data
. The label information
of the storm surge disaster cases is shown in
Table 7 and
Table 8, the label
of case damage node in each case contains three attribute values of case disaster-bearing body
, case disaster-bearing body attribute
and case disaster-bearing body data
. The label information
and
of the storm surge disaster cases are shown in
Table 9 and
Table 10, the label of disaster damage node
in each case contains three attribute values of disaster-damage-bearing body
, disaster-damage-bearing body attribute
and disaster-damage-bearing body data
, and the geographical location node label
contains the attribute value of geographical location
.
Based on the above results, the “case scenario” of storm surge disaster no. 1 contains 11 nodes of
and
, its “disaster damage” contains 12 nodes of
, and the “case structure” has four layers; the “case scenario” of storm surge disaster no. 2 contains 10 nodes of
and
, its “disaster damage” contains 16 nodes of
, and the “case structure” has three layers. The similarity in “case scenario”, “disaster damage” and “case structure” in both cases was calculated from the contents shown in
Table 5,
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10, and the aggregated similarity multifactor was 0.8922, using Equation (
23).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}