
Recognition and Depth Estimation of Ships Based on Binocular Stereo Vision

 ,
, 
Abstract
:1. Introduction
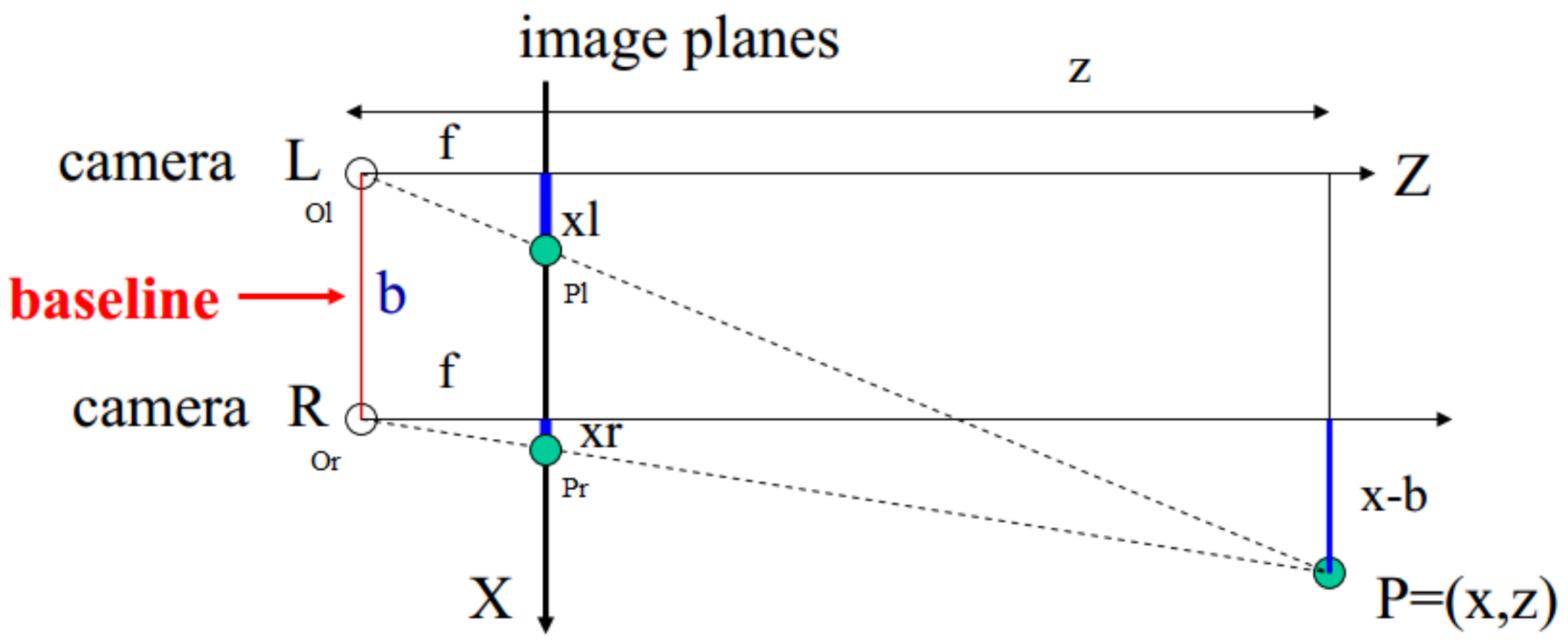
2. BSV Depth Estimation Model
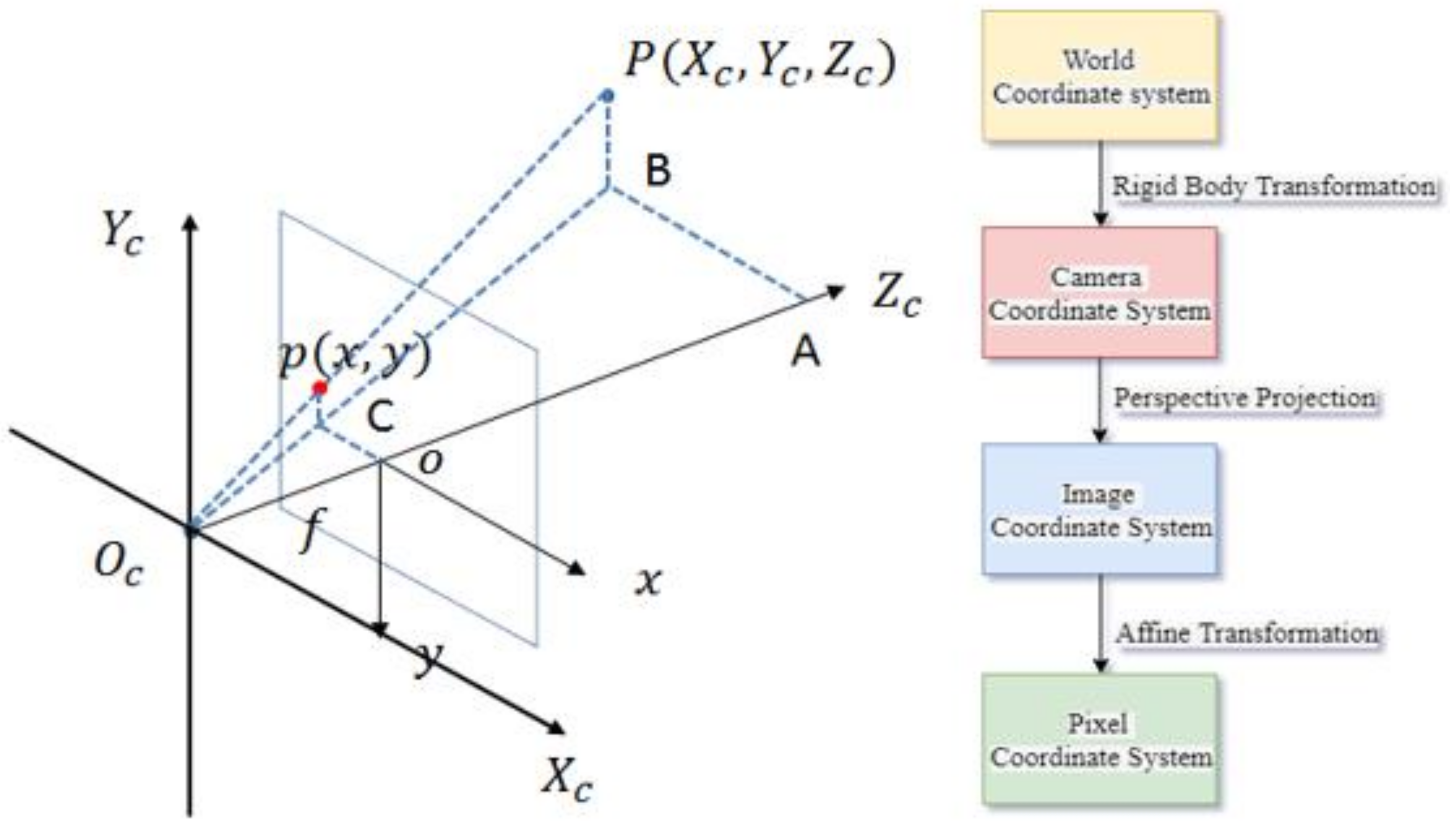
3. Camera Calibration Model
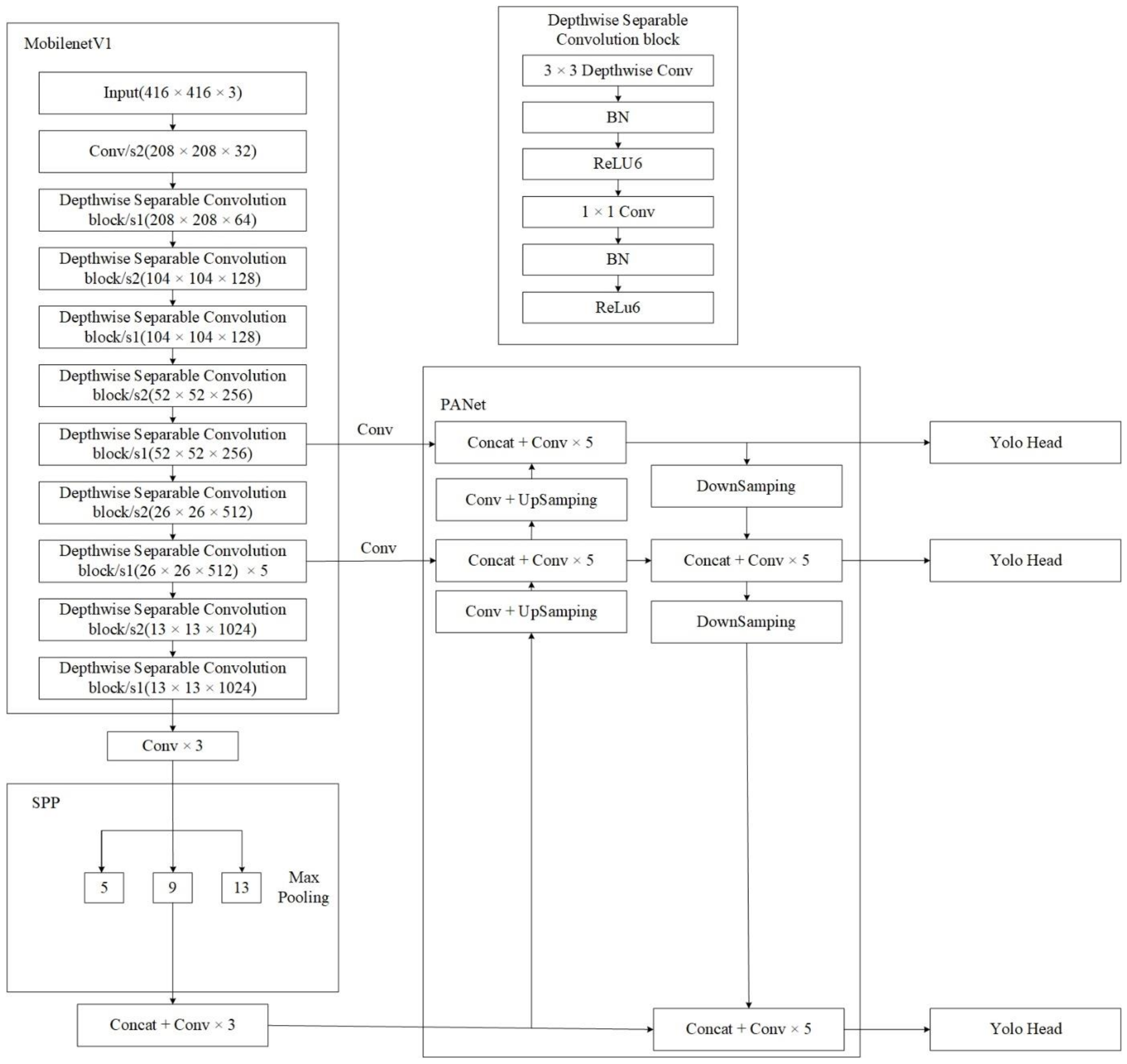
4. MobileNetV1-YOLOv4 Model
4.1. YOLOv4 Model
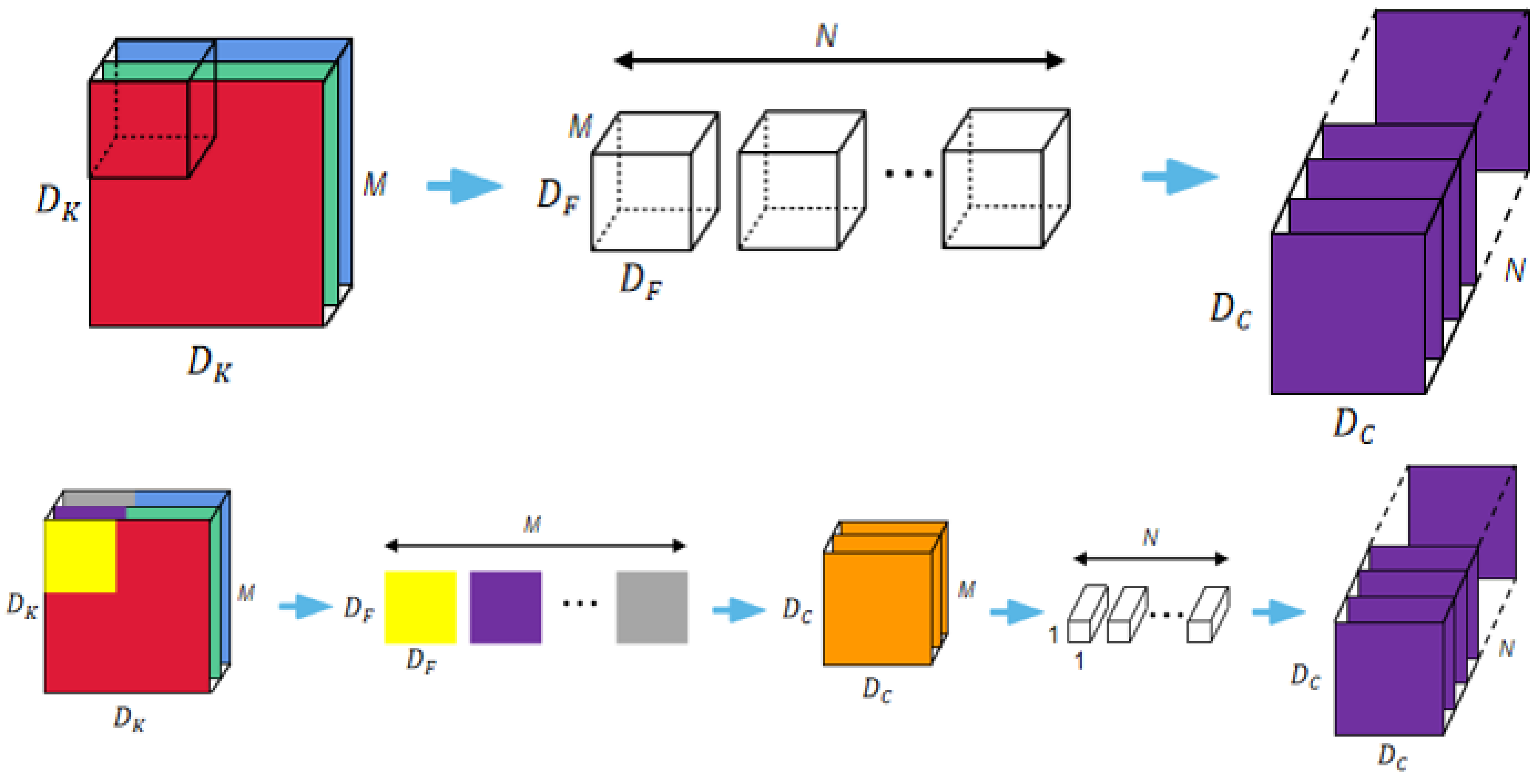
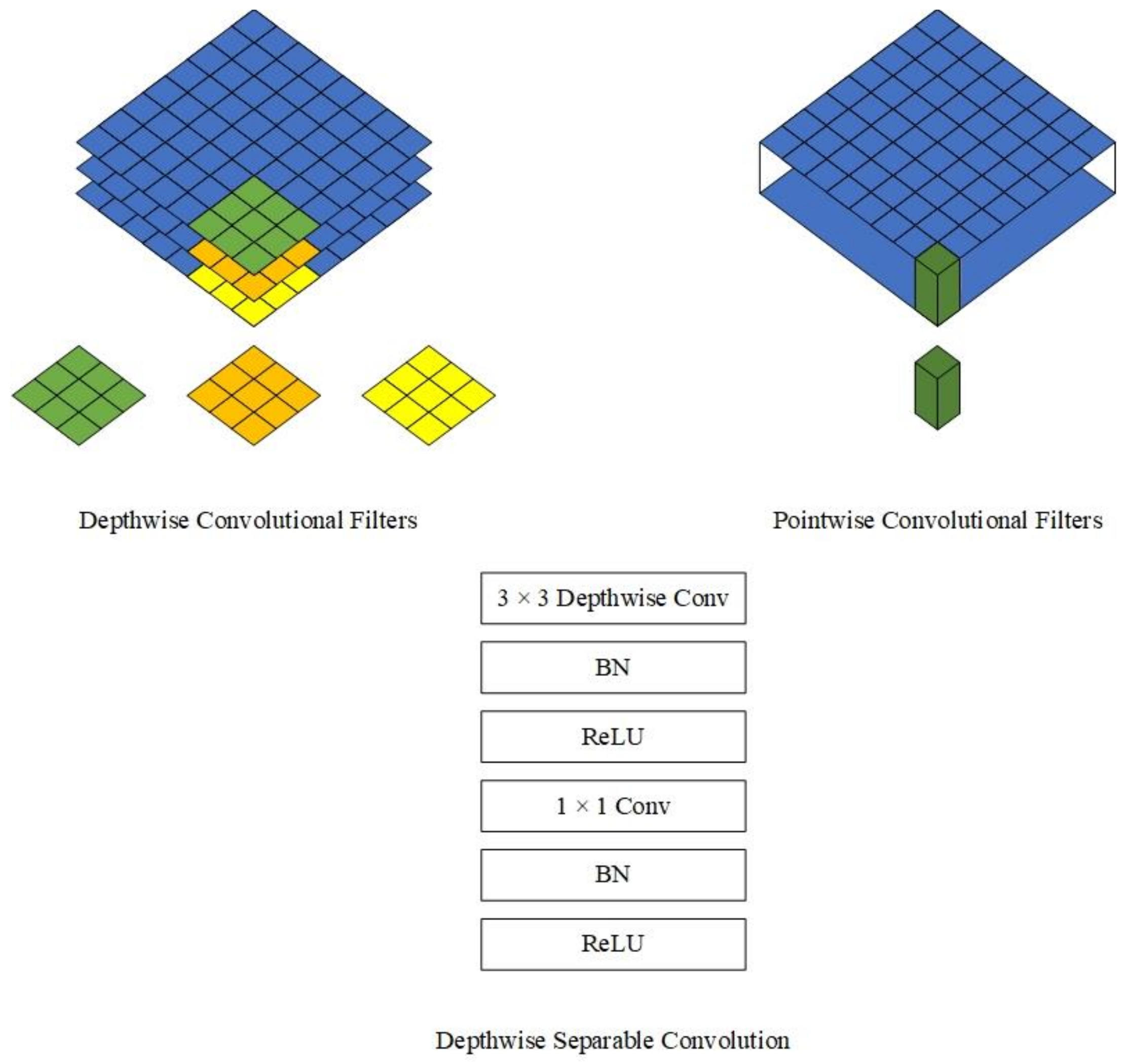
4.2. MobileNetV1 Model
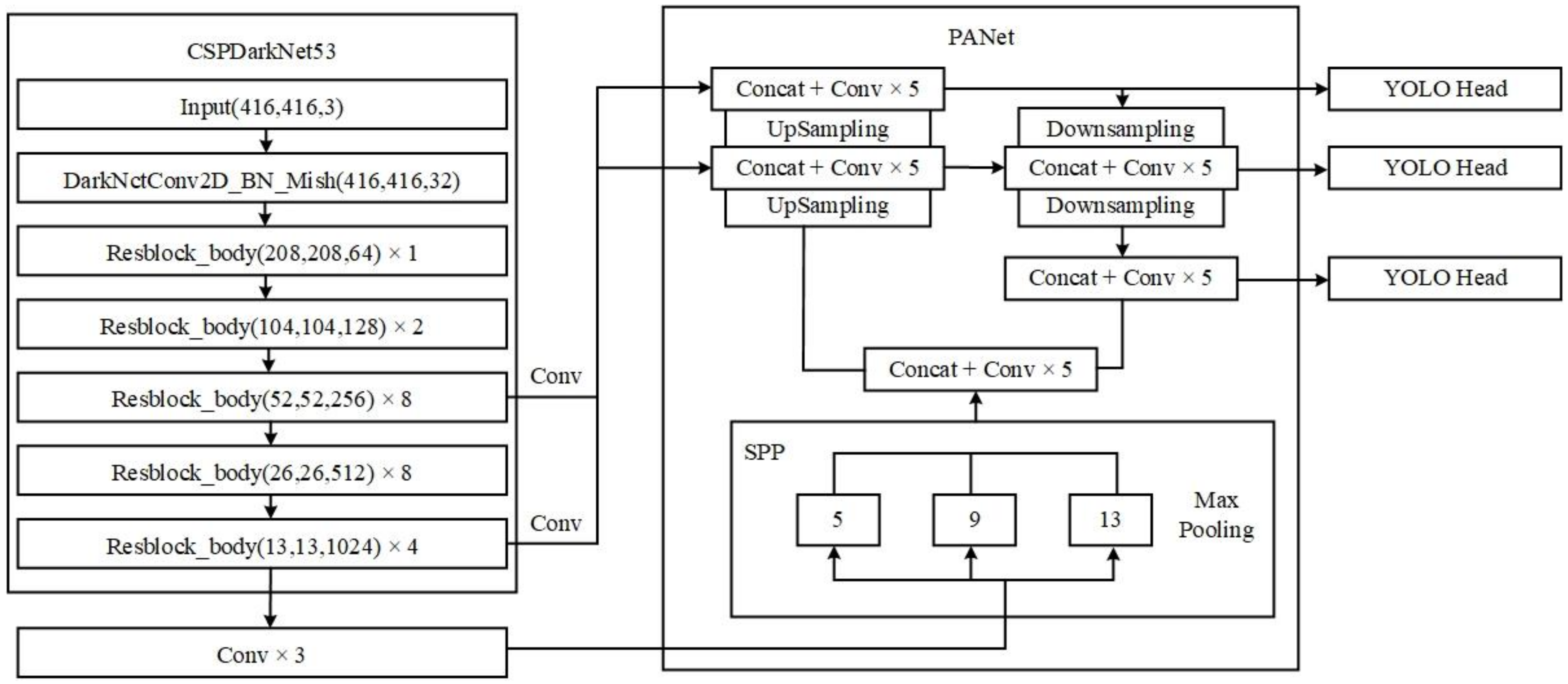
4.3. MobileNetV1-YOLOv4 Model Structure
5. Ship Feature Detection and Matching
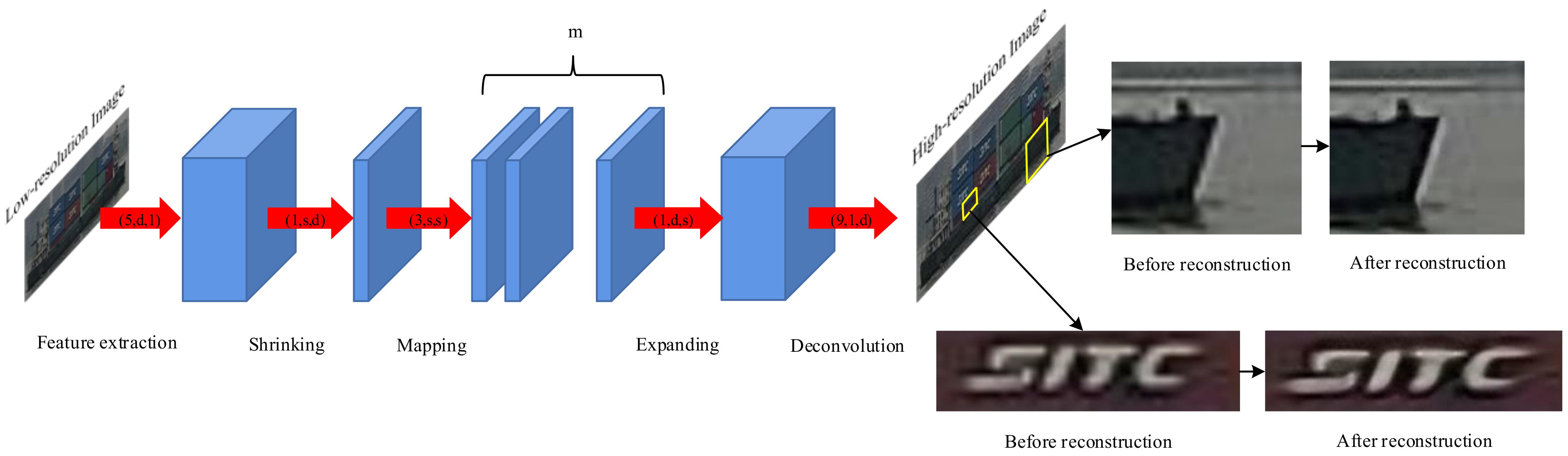
5.1. FSRCNN Network
5.2. ORB Algorithm
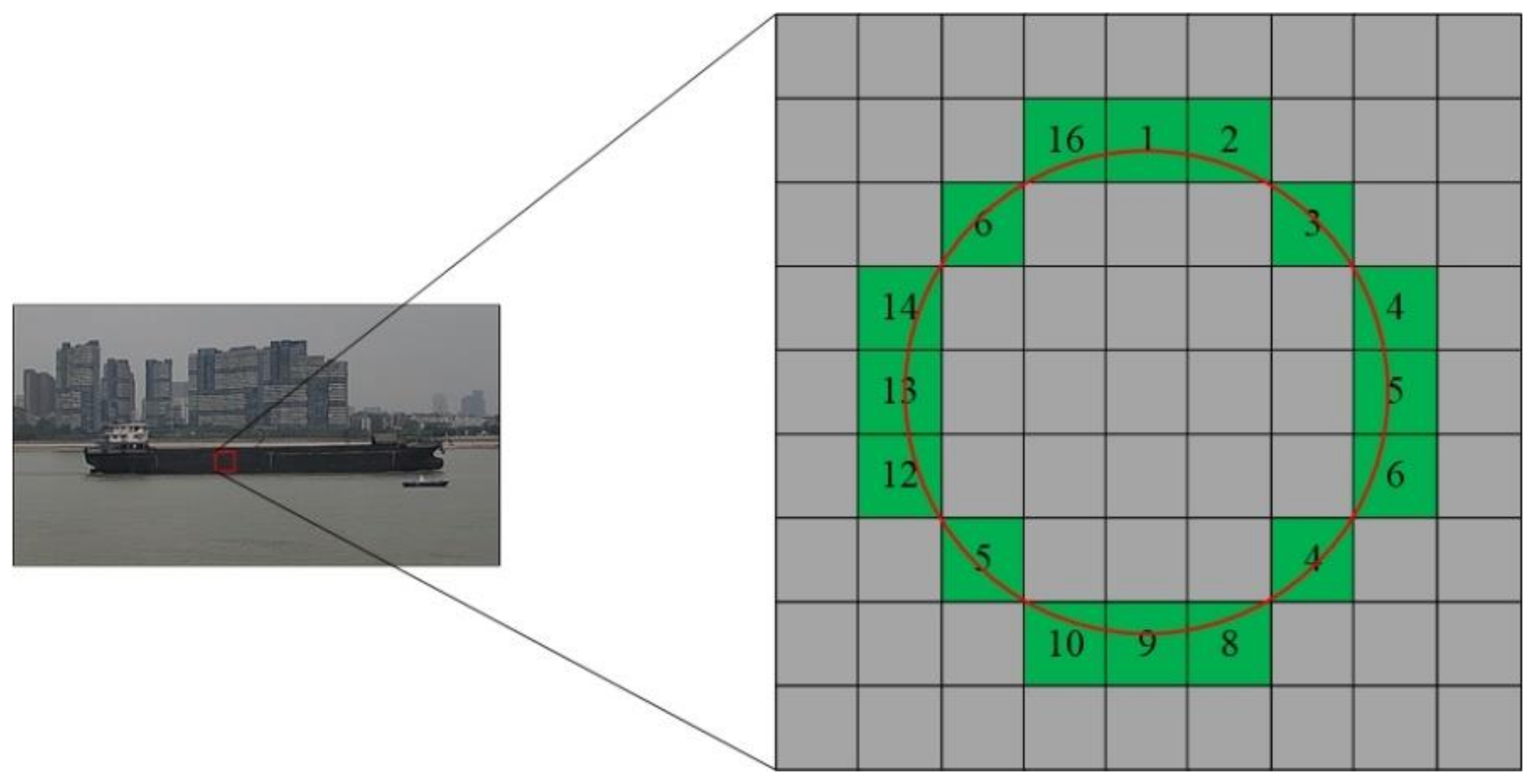
5.2.1. Feature Points Extraction
- Determine a threshold:
- Calculate the difference between all pixel values on the determined circle and the pixel value of point . If there are consecutive points that satisfy Equation (10), then this point could be taken as a candidate point, where represents a certain point of 16 pixels on the circle, according to experience, generally set . Generally, in order to reduce the amount of calculation and speed up the efficiency of feature points search, the pixel points 1, 9, 5, and 13 are detected for each pixel point. If at least three of the four points satisfy the Formula (10), then the point is a candidate detection point.
5.2.2. Build BRIEF Feature Descriptors
- In order to further reduce the sensitivity of feature points to noise, Gaussian filtering is first performed on the detected image.
- BRIEF takes the candidate feature point as the center point, selects a region with size , randomly selects two points and in this region, then compares the pixel sizes of the two points, and performs the following assignments:where, and are the pixel values of random points and in the region, respectively.
- Randomly select pixel pairs in the region , and binary assignment is performed by the formula (12). This encoding process is the description of the feature points in the image, that is, the feature descriptor. The value of is usually 128, 258, or 512. while the image features can be described by n-bit binary vectors, namely:
5.2.3. Match the Feature Points
6. Experiments and Analysis
6.1. Experiments Environment and Equipment
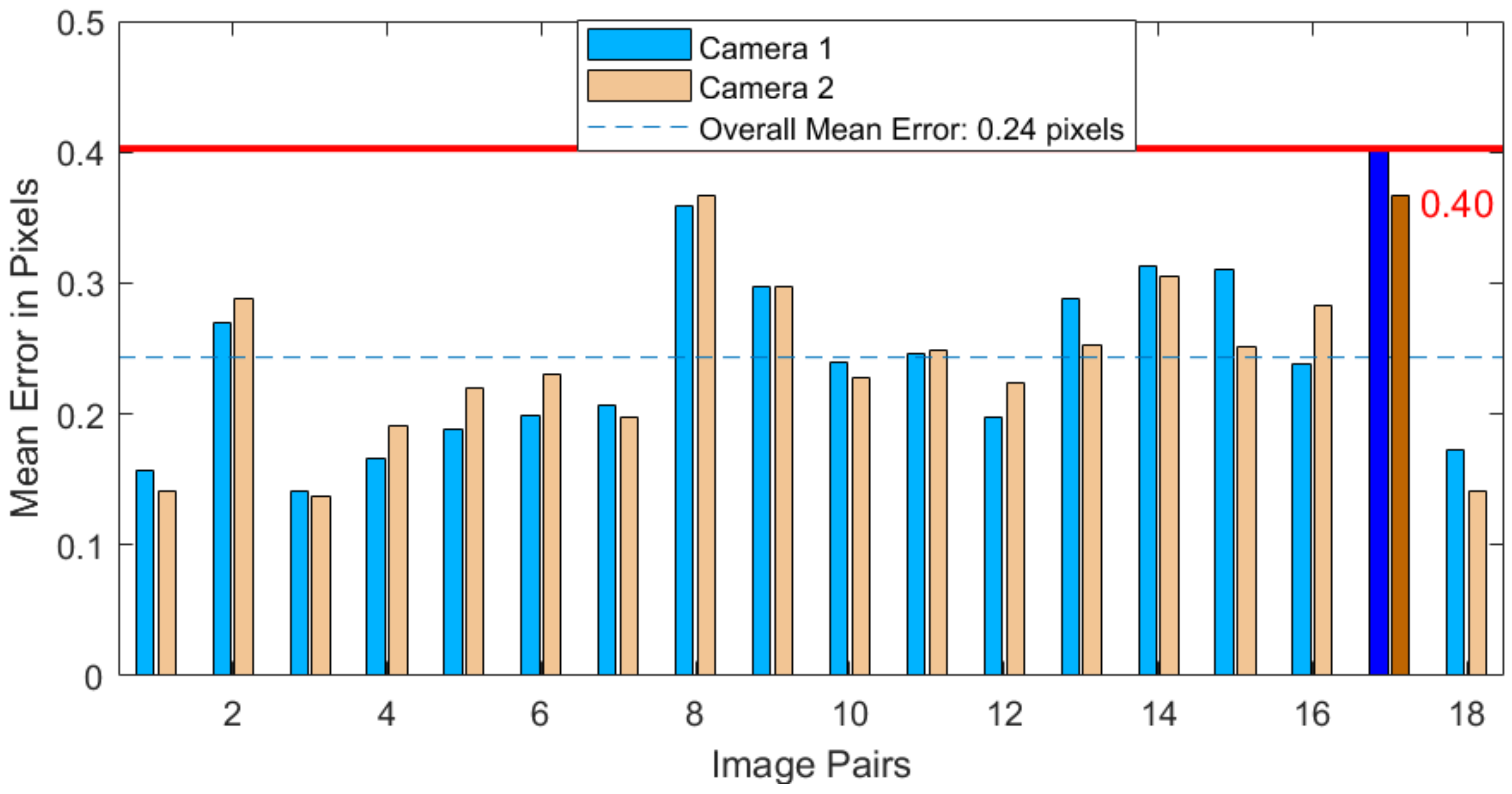
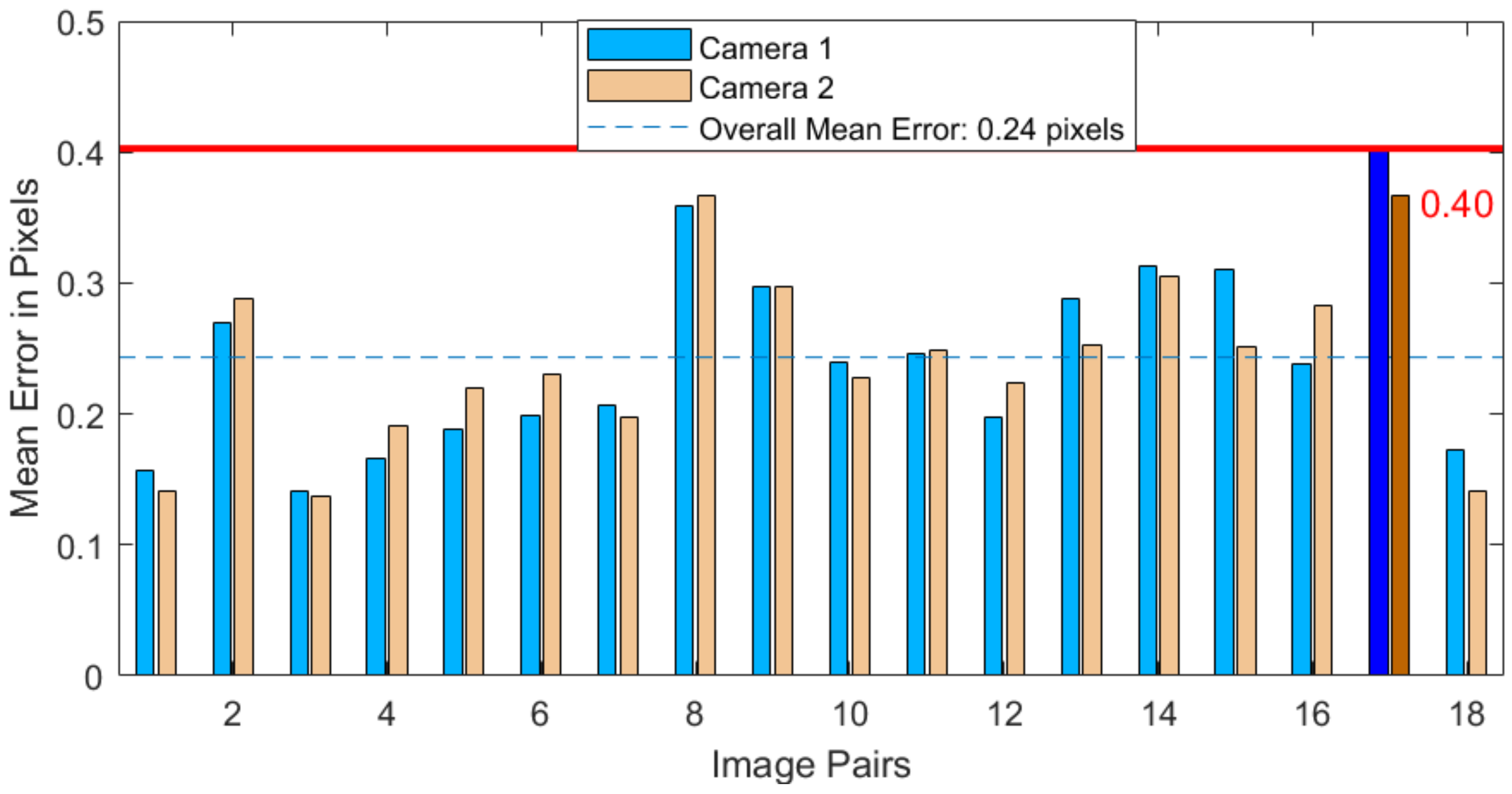
6.2. Camera Calibration Analysis
6.3. Ship Target Recognition Analysis
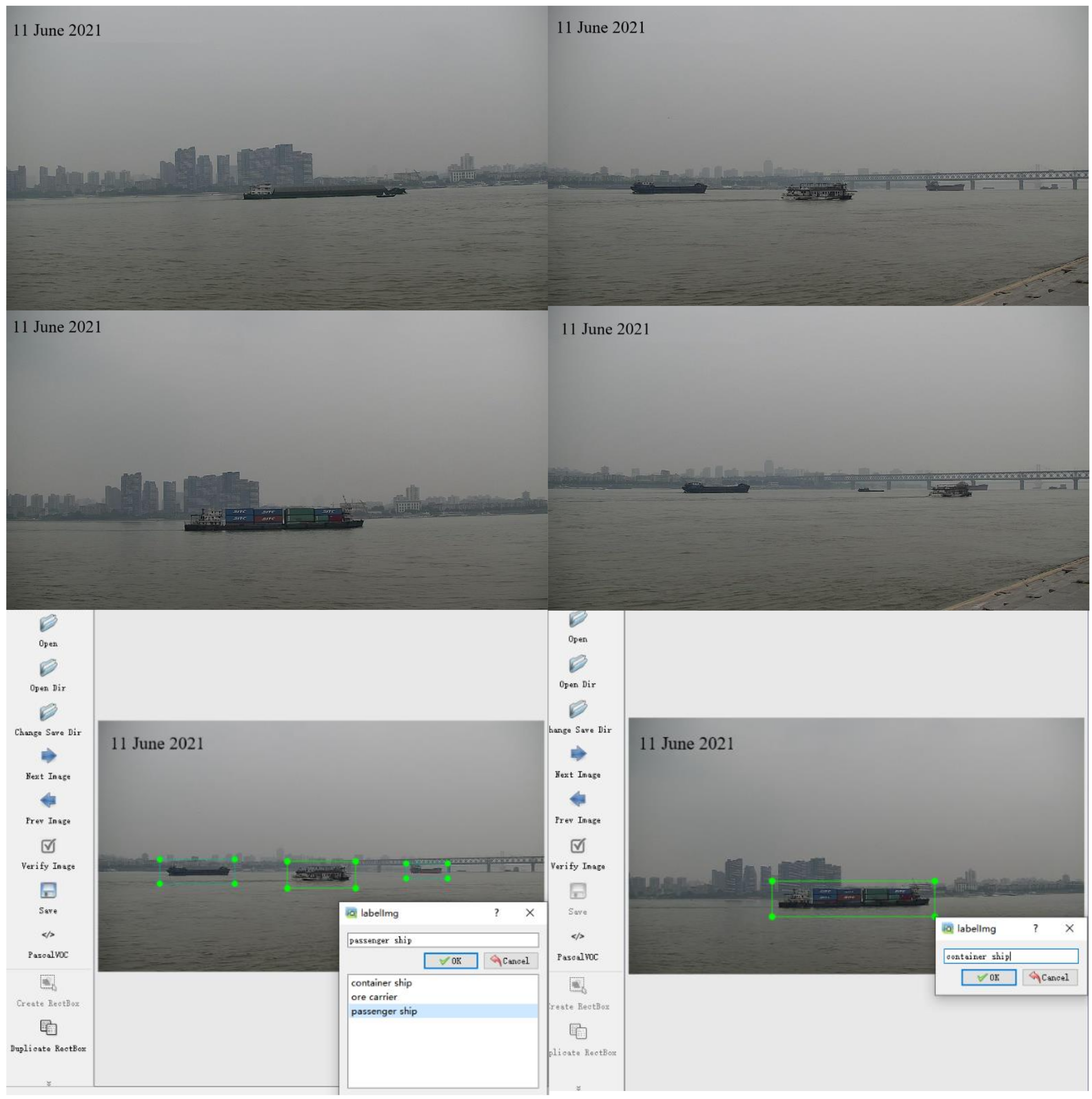
6.3.1. Ship Images Collection and Labeling
6.3.2. Model Evaluation Index
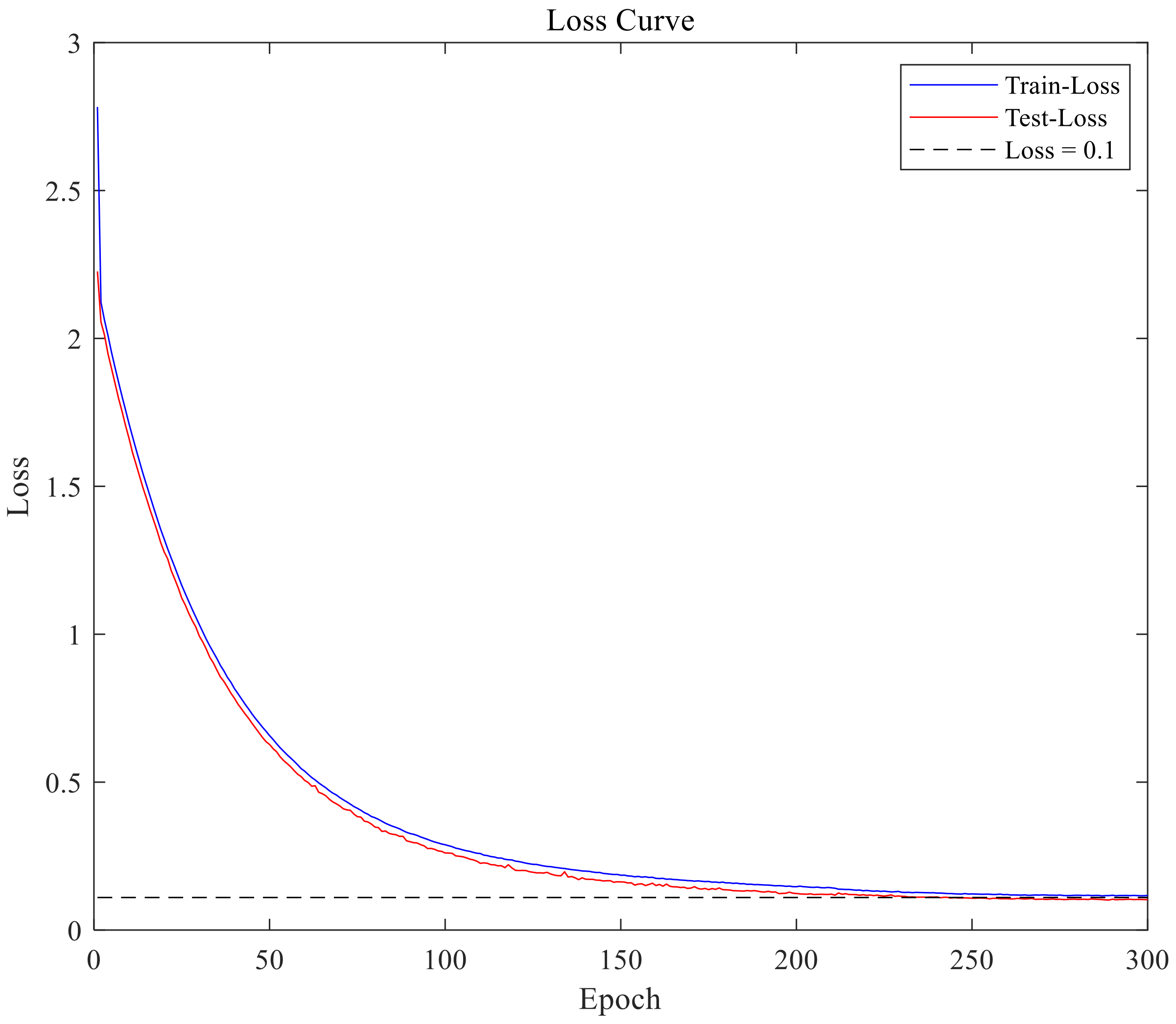
6.3.3. Ship Target Recognition
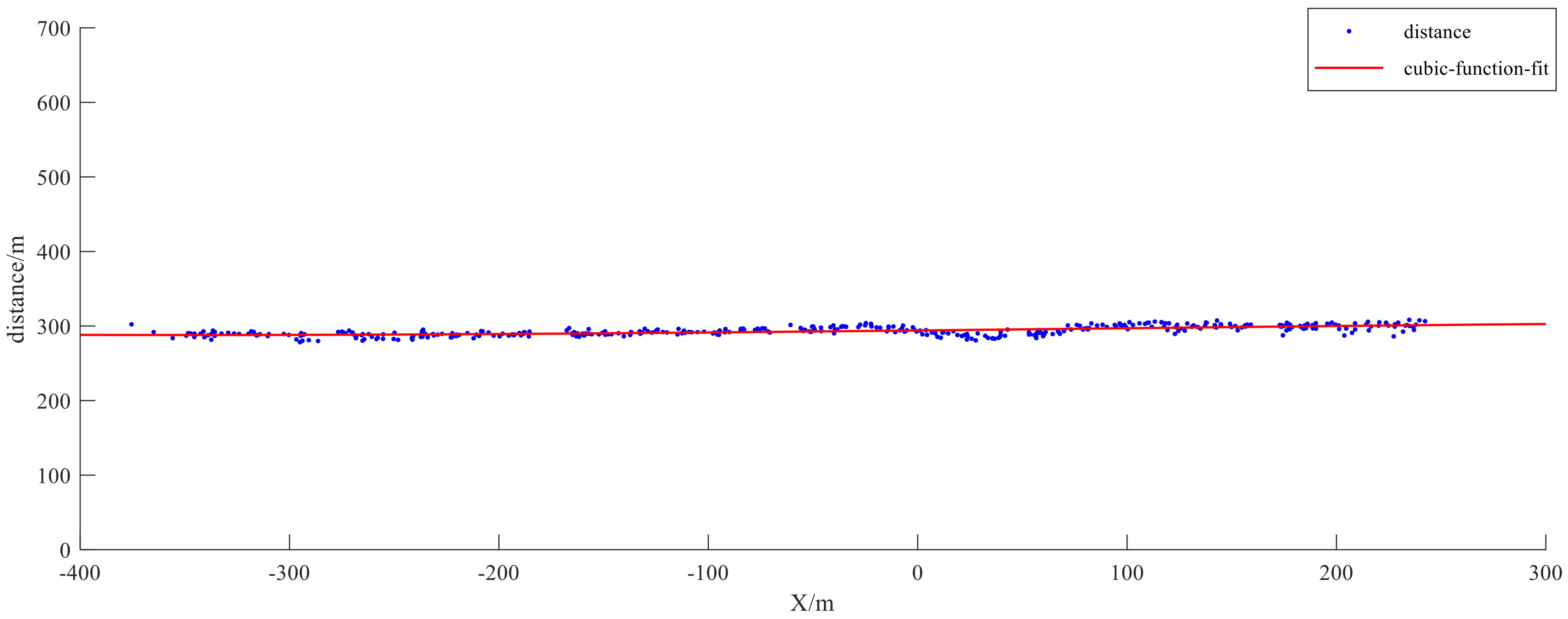
6.4. Ship Target Depth Estimation Analysis
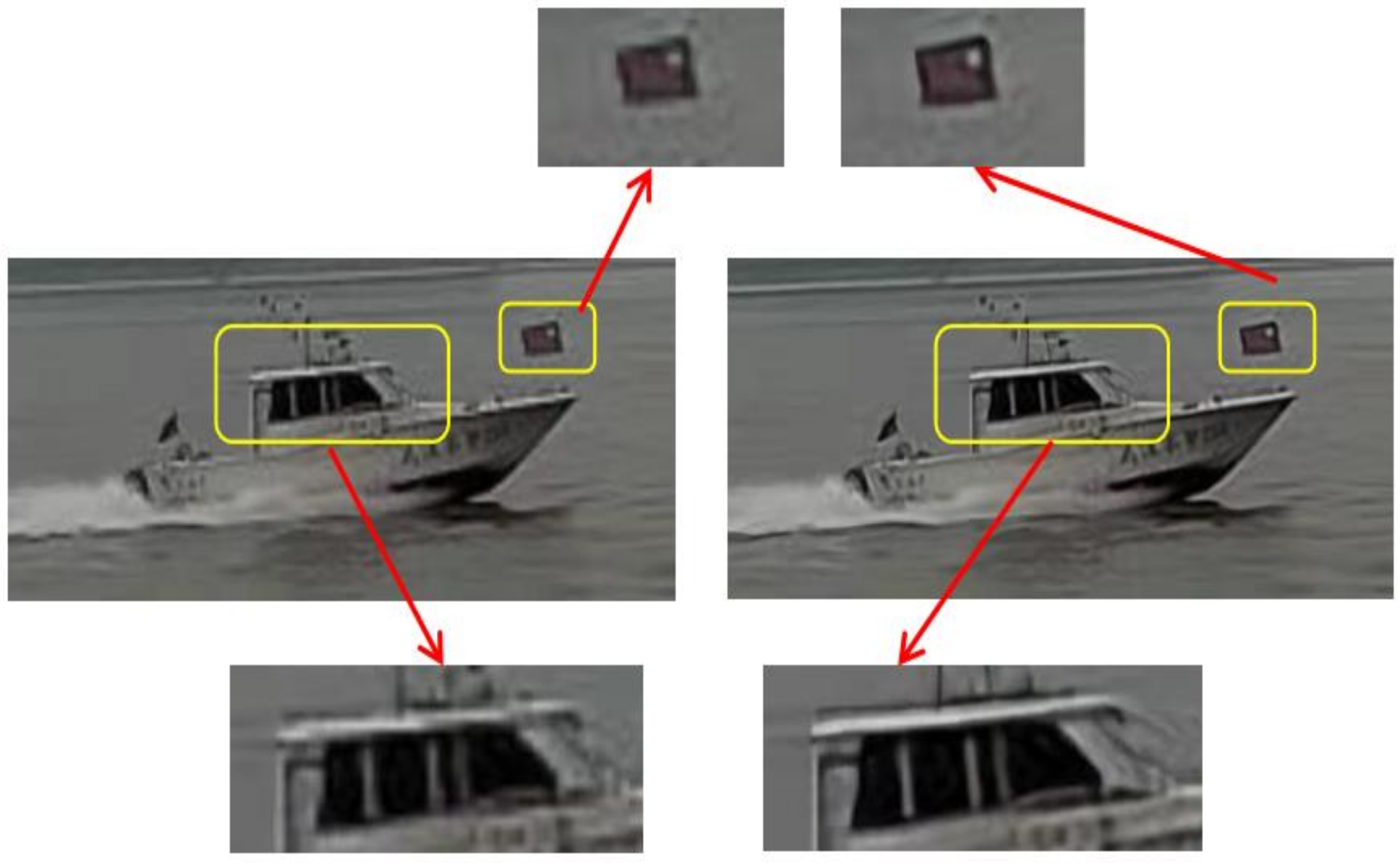
6.4.1. Ship Features Detection and Matching
6.4.2. Ship Target Depth Estimation
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, D.X.; Luo, M.F.; Yang, Z.Z. Manufacturing relocation and port/shipping development along the Maritime Silk Road. Int. J. Shipp. Transp. Logist. 2018, 10, 316–334. [Google Scholar] [CrossRef]
- Lehtola, V.; Montewka, J.; Goerlandt, F.; Guinness, R.; Lensu, M. Finding safe and efficient shipping routes in ice-covered waters: A framework and a model. Cold Reg. Sci. Technol. 2019, 165, 102795. [Google Scholar] [CrossRef]
- Liu, R.W.; Guo, Y.; Lu, Y.X.; Chui, K.T.; Gupta, B.B. Deep Network-Enabled Haze Visibility Enhancement for Visual IoT-Driven Intelligent Transportation Systems. IEEE Trans. Ind. Inform. 2022. [Google Scholar] [CrossRef]
- Qian, L.; Zheng, Y.Z.; Li, L.; Ma, Y.; Zhou, C.H.; Zhang, D.F. A New Method of Inland Water Ship Trajectory Prediction Based on Long Short-Term Memory Network Optimized by Genetic Algorithm. Appl. Sci. 2022, 12, 4073. [Google Scholar] [CrossRef]
- Krzyszof, J.; Łukasz, M.; Andrzej, F.; Marcin, J.; Mariusz, S. Automatic Identification System (AIS) Dynamic Data Integrity Monitoring and Trajectory Tracking Based on the Simultaneous Localization and Mapping (SLAM) Process Model. Sensors 2021, 21, 8430–8448. [Google Scholar]
- Ervin, H. Navigating the Smart Shipping Era. Mar. Log. 2019, 124, 2. [Google Scholar]
- Liu, R.W.; Guo, Y.; Nie, J.; Hu, Q.; Xiong, Z.; Yu, H.; Guizani, M. Intelligent Edge-Enabled Efficient Multi-Source Data Fusion for Autonomous Surface Vehicles in Maritime Internet of Things. IEEE Trans. Green Commun. Netw. 2022. [Google Scholar] [CrossRef]
- Łosiewicz, Z.; Nikończuk, P.; Pielka, D. Application of artificial intelligence in the process of supporting the ship owner’s decision in the management of ship machinery crew in the aspect of shipping safety. Procedia Comput. Sci. 2019, 159, 2197–2205. [Google Scholar] [CrossRef]
- Liu, R.W.; Yuan, W.Q.; Chen, X.Q.; Lu, Y.X. An enhanced CNN-enabled learning method for promoting ship detection in maritime surveillance system. Ocean. Eng. 2021, 235, 109435. [Google Scholar] [CrossRef]
- Pourya, S.; Salvador, G.; Huiyu, Z.; Emre, C.M. Advances in domain adaptation for computer vision. Image Vis. Comput. 2021, 114, 104268. [Google Scholar]
- Wang, T.B.; Liu, B.Q.; Wang, Y.; Chen, Y.C. Research situation and development trend of the binocular stereo vision system. In Proceedings of the Materials Science, Energy Technology, and Power Engineering, Hangzhou, China, 15–16 April 2017. [Google Scholar]
- Zheng, Y.; Peng, S.L. A Practical Roadside Camera Calibration Method Based on Least Squares Optimization. IEEE Trans. Intell. Transp. Syst. 2014, 15, 831–843. [Google Scholar] [CrossRef]
- Nguyen, P.H.; Ahn, C.W. Stereo Matching Methods for Imperfectly Rectified Stereo Images. Symmetry 2019, 11, 570–590. [Google Scholar]
- Wang, C.L.; Zou, X.J.; Tang, Y.C.; Luo, L.F.; Feng, W.X. Localisation of litchi in an unstructured environment using binocular stereo vision. Biosyst. Eng. 2016, 145, 39–51. [Google Scholar] [CrossRef]
- Gai, Q.Y. Optimization of Stereo Matching in 3D Reconstruction Based on Binocular Vision. J. Phys. Conf. Ser. 2018, 960, 12029–12036. [Google Scholar] [CrossRef]
- Duan, S.L.; Li, Y.F.; Chen, S.Y.; Chen, L.P.; Min, J.J.; Zou, L.; Ma, Z.H.; Ding, J. Research on Obstacle Avoidance for Mobile Robot Based on Binocular Stereo Vision and Infrared Ranging. In Proceedings of the 2011 9th World Congress on Intelligent Control and Automation (Wcica), Taipei, Taiwan, 21–25 June 2011; pp. 1024–1028. [Google Scholar]
- Ma, Y.Z.; Tao, L.Y.; Wang, X.H. Application of Computer Vision Technology. Test Technol. Test. Mach. 2006, 26, 60–65. [Google Scholar]
- Ma, Y.P.; Li, Q.W.; Chu, L.L.; Zhou, Y.Q.; Xu, C. Real-Time Detection and Spatial Localization of Insulators for UAV Inspection Based on Binocular Stereo Vision. Remote Sens. 2021, 13, 230. [Google Scholar] [CrossRef]
- Zhang, J.X.; Hu, S.L.; Shi, H.Q. Deep Learning based Object Distance Measurement Method for Binocular Stereo Vision Blind Area. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 606–613. [Google Scholar] [CrossRef]
- Ding, J.; Yan, Z.G.; We, X.C. High-Accuracy recognition and 1oca1ization of moving targets in an indoor environment using binocu1ar stereo vision. Int. J. Geo-Inf. 2021, 10, 234. [Google Scholar] [CrossRef]
- Haizhen, L.; Baojun, Z. Application of integrated binocular stereo vision measurement and wireless sensor system in athlete displacement test. Alex. Eng. J. 2021, 60, 4325–4335. [Google Scholar]
- Liu, Z.; Yin, Y.; Wu, Q.; Li, X.J.; Zhang, G.J. On-site calibration method for outdoor binocular stereo vision sensors. Opt. Lasers Eng. 2016, 86, 75–82. [Google Scholar] [CrossRef]
- Xu, B.P.; Zhao, S.Y.; Sui, X.; Hua, C.S. High-speed Stereo Matching Algorithm for Ultra-high Resolution Binocular Image. In Proceedings of the 2018 IEEE International Conference on Aytomation, Electronics and Electrical Engineering (AUTEEE), Shenyang, China, 16–18 November 2018; pp. 87–90. [Google Scholar]
- Yin, Z.Y.; Ren, X.Y.; Du, Y.F.; Yuan, F.; He, X.Y.; Yan, F.J. Binocular camera calibration based on timing correction. Appl. Opt. 2022, 61, 1475–1481. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhad, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Wang, Y.F.; Hua, C.C.; Ding, W.L.; Wu, R.N. Real-time detection of flame and smoke using an improved YOLOv4 network. Signal Image Video Processing 2022, 16, 1109–1116. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW 2020), Electr Neywork, Seattle, DC, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. In Proceedings of the Computer Vision-ECCV 2014 IEEE Transactions on Pattern Analysis and Machine Intelligence, Zurich, Switzerland, 6–12 September 2014; Volume 37, pp. 1904–1916. [Google Scholar]
- Wang, K.X.; Liew, J.H.; Zou, Y.T.; Zhou, D.Q.; Feng, J.S. PANet: Few-shot image semantic segmentation with prototype alignment. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV 2019), Seoul, Korea, 27 October–2 November 2019; pp. 9197–9206. [Google Scholar]
- Howard, A.G.; Zhu, M.L.; Chen, B.; Kalenichenko, D.; Wang, W.J.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X.O. Accelerating the Super-Resolution Convolutional Neural Network[C]/European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 391–407. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2011, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Bian, J.W.; Lin, W.Y.; Matsushita, Y.; Yeung, S.K.; Nguyen, T.D.; Cheng, M.M. GMS: Grid-Based Motion Statistics for Fast, Ultra-Robust Feature Correspondence. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR2017), Honolulu, HI, USA, 21–26 July 2017; pp. 2828–2837. [Google Scholar]
- Yu, S.B.; Jiang, Z.; Wang, M.H.; Li, Z.Z.; Xu, X.L. A fast robust template matching method based on feature points. Int. J. Model. Identif. Control. 2020, 35, 346–352. [Google Scholar] [CrossRef]
- Huan, Y.; Xing, T.W.; Jia, X. The Analysis of Measurement Accuracy of The Parallel Binocular Stereo Vision System; Institute of Optics and Electronics, The Hong Kong Polytechnic University: Hong Kong, China, 2016; pp. 1–10. [Google Scholar]
- Zhang, Z.Y. A Flexible New Technique for Camera Calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef] [Green Version]
- Heikkila, J.; Silvcn, O. A four-step camera calibration procedure with implicit image correction. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Santa Barbara, CA, USA, 17–19 June 1997; pp. 1106–1112. [Google Scholar]
- Shi, W.Z.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z.H. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Information |
|---|---|
| Sensor type | 1/2.8″ Progressive Scan CMOS |
| Electronic shutter | DC Drive |
| Focal length | 5.5–180mm |
| Aperture | F1.5–F4.0 |
| Horizontal field of view | 2.3–60.5° |
| Video compression standard | H.265/H.264/MJPEG |
| Main stream resolution | 50 HZ:25 fps (1920 × 1080, 1280 × 960, 1280 × 720) |
| Interface type | NIC interface |
| Parameter | Left Camera | Right Camera |
|---|---|---|
| Internal parameter matrix | ||
| Extrinsic parameter matrix | ||
| Distortion coefficient matrix |
| (17, 6) | (18, 8) | (19, 12) |
| (28, 10) | (29, 14) | (51, 9) |
| (44, 16) | (71, 19) | (118, 27) |
| Model | Classes | Input_size | Score_threhold | Precision/% | Recall/% | mAP/% | Backbone_weight/M | FPS | F1-Score |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv4 | Ore carrier | 416 × 416 | 0.5 | 91.23 | 86.21 | 90.70 | 244 | 26.11 | 0.89 |
| Container ship | 100.00 | 100.00 | 1 | ||||||
| Passenger ship | 87.10 | 75.00 | 0.81 | ||||||
| MobilevV1-YOLOv4 | Ore carrier | 416 × 416 | 0.5 | 87.95 | 84.91 | 89.25 | 47.6 | 66.23 | 0.86 |
| Container Ship | 100.00 | 100.00 | 1 | ||||||
| Passenger ship | 89.29 | 69.44 | 0.78 |
| Test_picture | Picture_size | Model | PSNR/dB | Time/s |
|---|---|---|---|---|
| Test_pic1 | 456 × 72 | FSRCNN | 35.945062 | 0.045590 |
| ESPCNN | 34.582875 | 0.027407 | ||
| Test_pic2 | 381 × 74 | FSRCNN | 35.562458 | 0.018695 |
| ESPCNN | 36.029904 | 0.016069 | ||
| Test_pic3 | 193 × 43 | FSRCNN | 35.875411 | 0.006879 |
| ESPCNN | 35.246397 | 0.007040 | ||
| Test_pic4 | 426 × 72 | FSRCNN | 38.673282 | 0.019900 |
| ESPCNN | 38.022336 | 0.016829 | ||
| Test_pic5 | 540 × 70 | FSRCNN | 38.444051 | 0.027066 |
| ESPCNN | 37.565404 | 0.029988 | ||
| Test_pic6 | 88 × 211 | FSRCNN | 36.462584 | 0.017341 |
| ESPCNN | 34.900440 | 0.012008 |
| Ship_num | BSV Depth Estimation/m | Laser Depth Estimation/m | Depth Estimation Error/m | Error Rate |
|---|---|---|---|---|
| Ship_1 | 105.10 | 103.80 | +1.30 | 1.25% |
| Ship_2 | 122.13 | 124.50 | −2.37 | −1.90% |
| Ship_3 | 168.31 | 166.30 | +2.01 | 1.21% |
| Ship_4 | 198.21 | 195.30 | +2.91 | 1.49% |
| Ship_5 | 220.92 | 224.60 | −3.68 | −1.63% |
| Ship_6 | 245.35 | 248.50 | −3.15 | −1.27% |
| Ship_7 | 279.02 | 275.40 | +3.62 | 1.31% |
| Ship_8 | 285.76 | 290.20 | −4.44 | −1.53% |
| Ship_9 | 311.26 | 305.80 | +5.46 | 1.97% |
| Ship_10 | 348.08 | 355.30 | −7.22 | −2.03% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Y.; Liu, P.; Qian, L.; Qin, S.; Liu, X.; Ma, Y.; Cheng, G. Recognition and Depth Estimation of Ships Based on Binocular Stereo Vision. J. Mar. Sci. Eng. 2022, 10, 1153. https://doi.org/10.3390/jmse10081153
Zheng Y, Liu P, Qian L, Qin S, Liu X, Ma Y, Cheng G. Recognition and Depth Estimation of Ships Based on Binocular Stereo Vision. Journal of Marine Science and Engineering. 2022; 10(8):1153. https://doi.org/10.3390/jmse10081153
Chicago/Turabian StyleZheng, Yuanzhou, Peng Liu, Long Qian, Shiquan Qin, Xinyu Liu, Yong Ma, and Ganjun Cheng. 2022. "Recognition and Depth Estimation of Ships Based on Binocular Stereo Vision" Journal of Marine Science and Engineering 10, no. 8: 1153. https://doi.org/10.3390/jmse10081153
APA StyleZheng, Y., Liu, P., Qian, L., Qin, S., Liu, X., Ma, Y., & Cheng, G. (2022). Recognition and Depth Estimation of Ships Based on Binocular Stereo Vision. Journal of Marine Science and Engineering, 10(8), 1153. https://doi.org/10.3390/jmse10081153