
Netting Damage Detection for Marine Aquaculture Facilities Based on Improved Mask R-CNN


Abstract
1. Introduction
2. Materials and Methods
2.1. Damaged Netting Images Dataset
2.1.1. Netting Images Acquisition
2.1.2. Image Processing
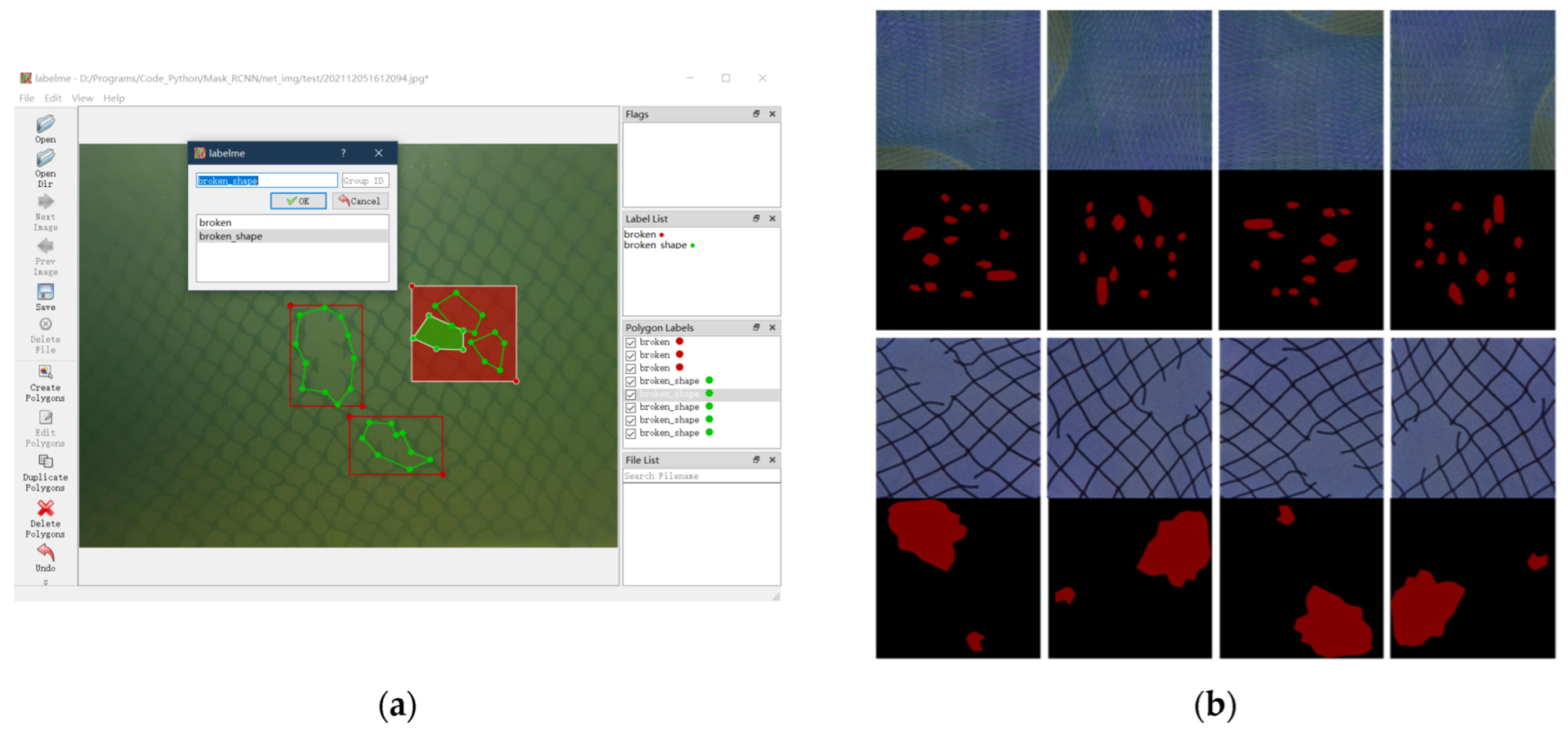
2.1.3. Dataset Annotation
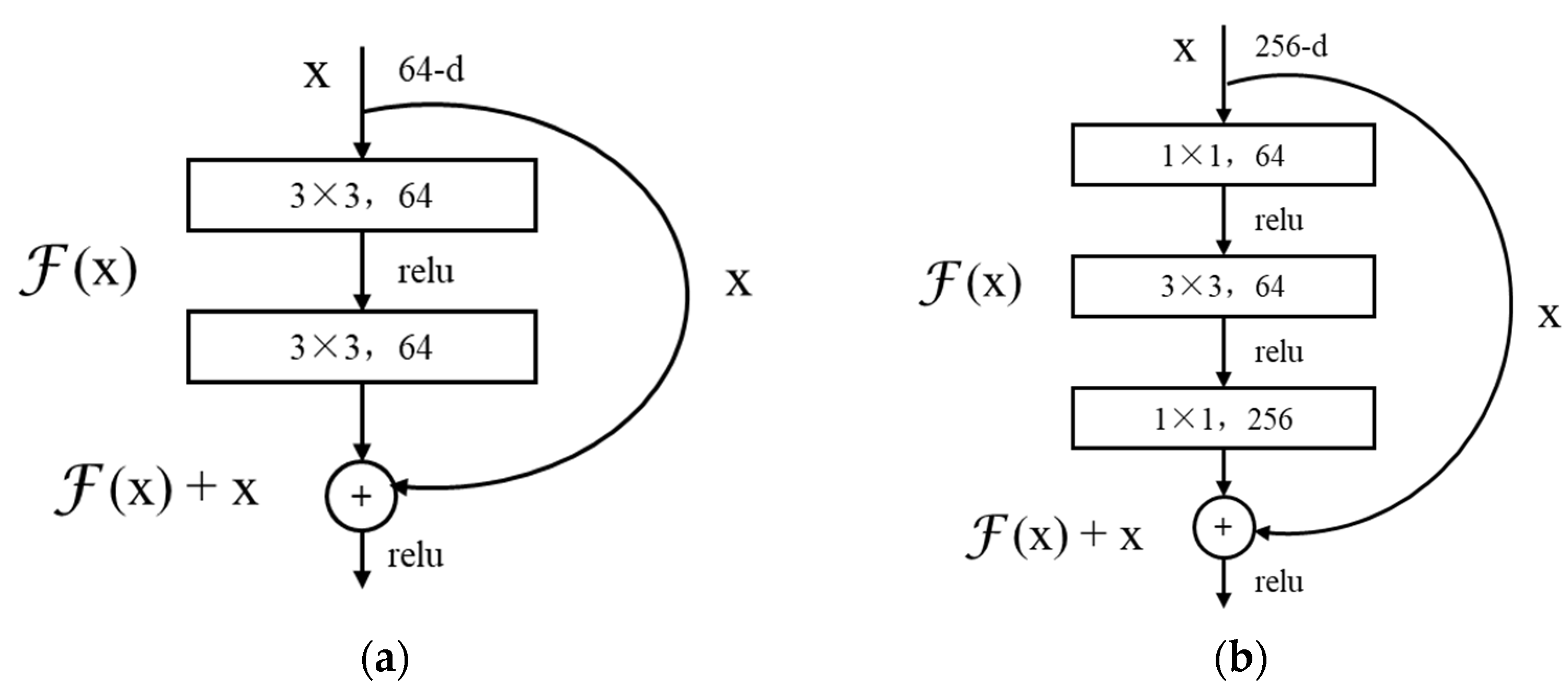
2.2. Basic Network Selection
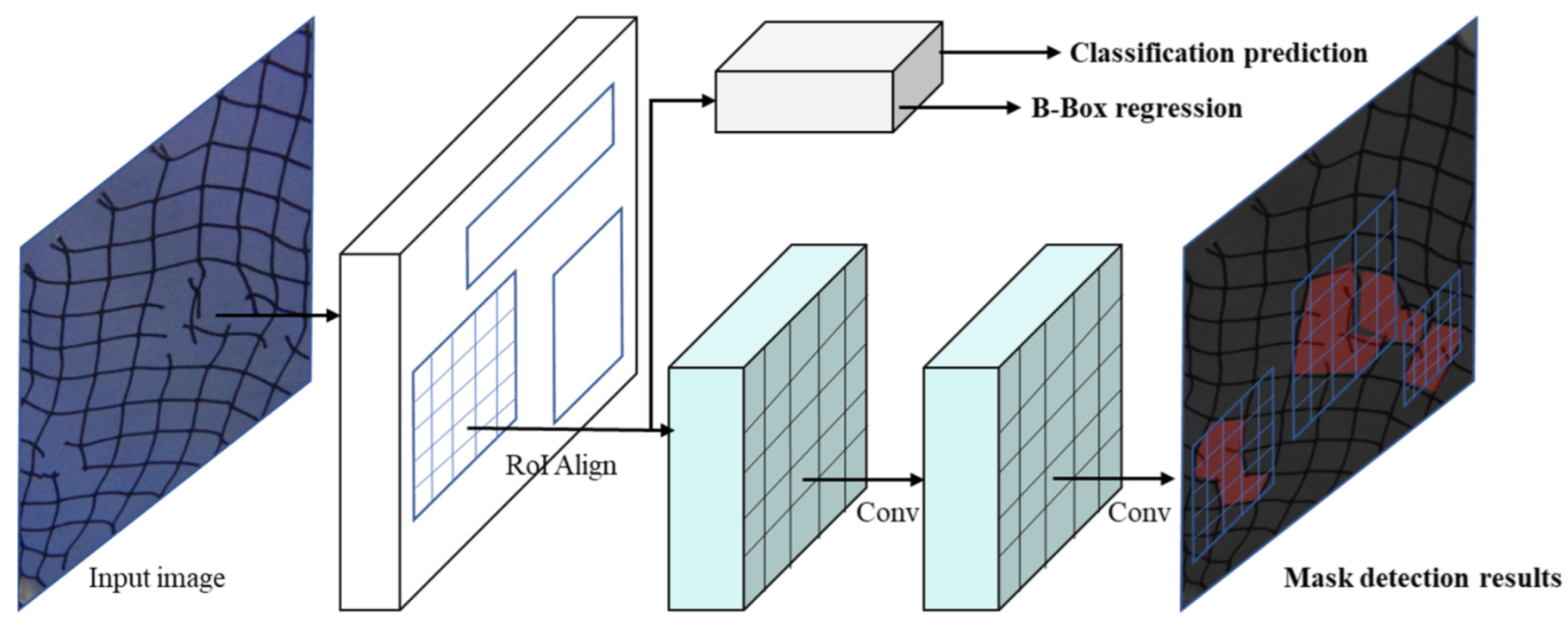
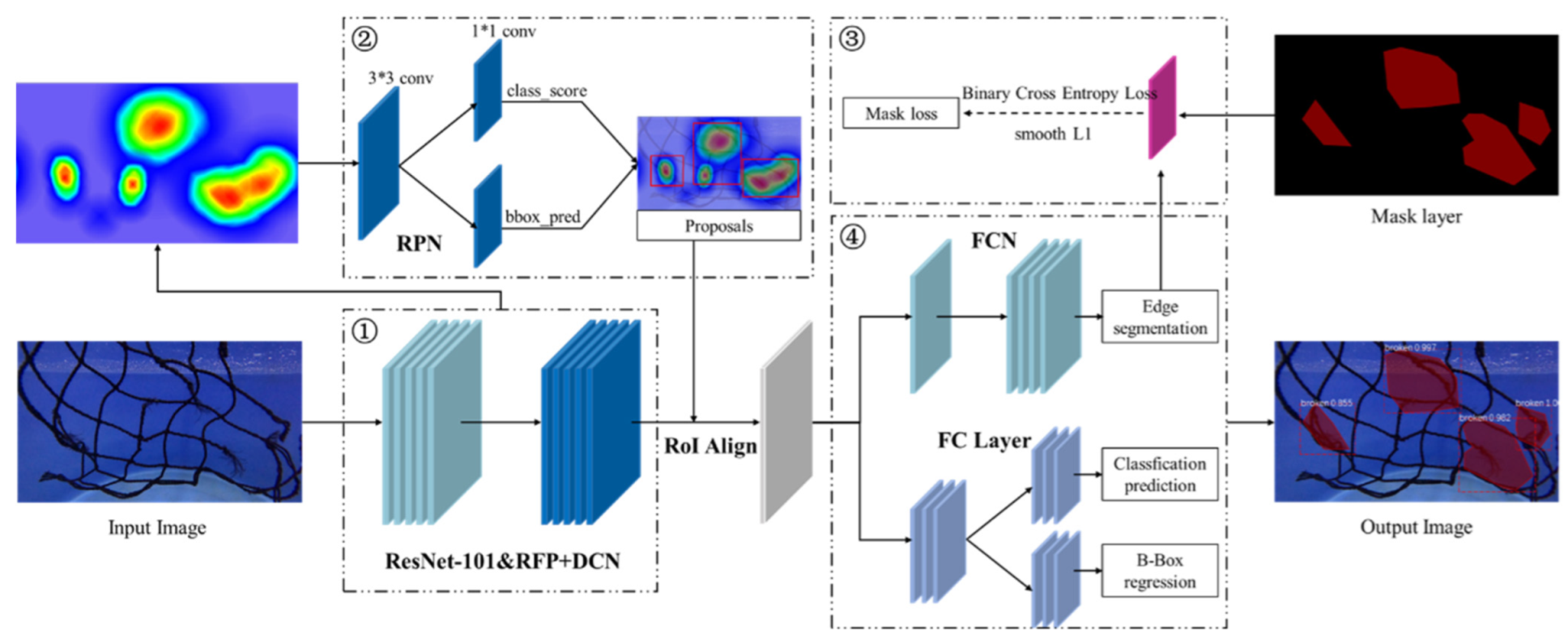
2.3. Construction of the Netting Damage Detection Model
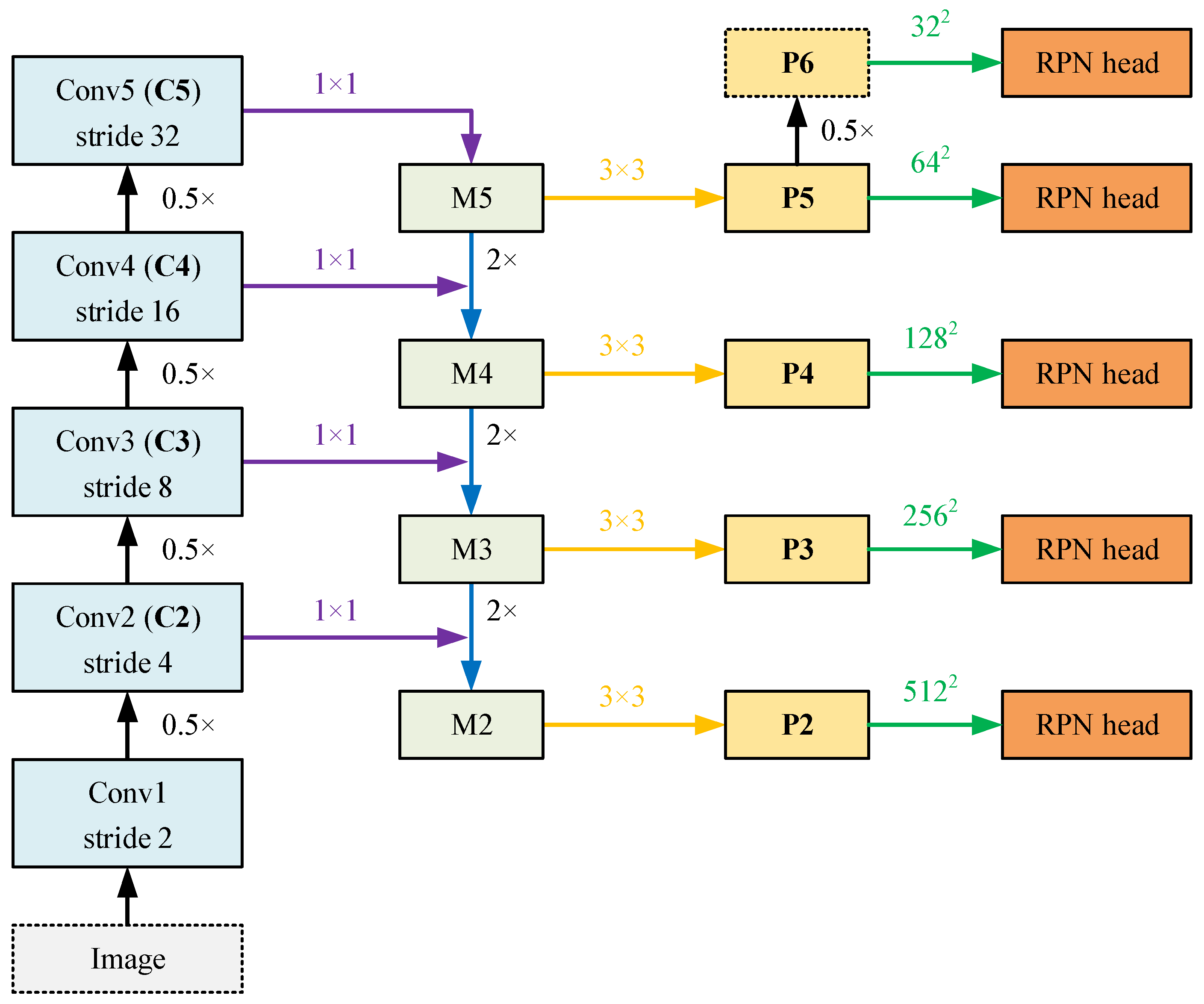
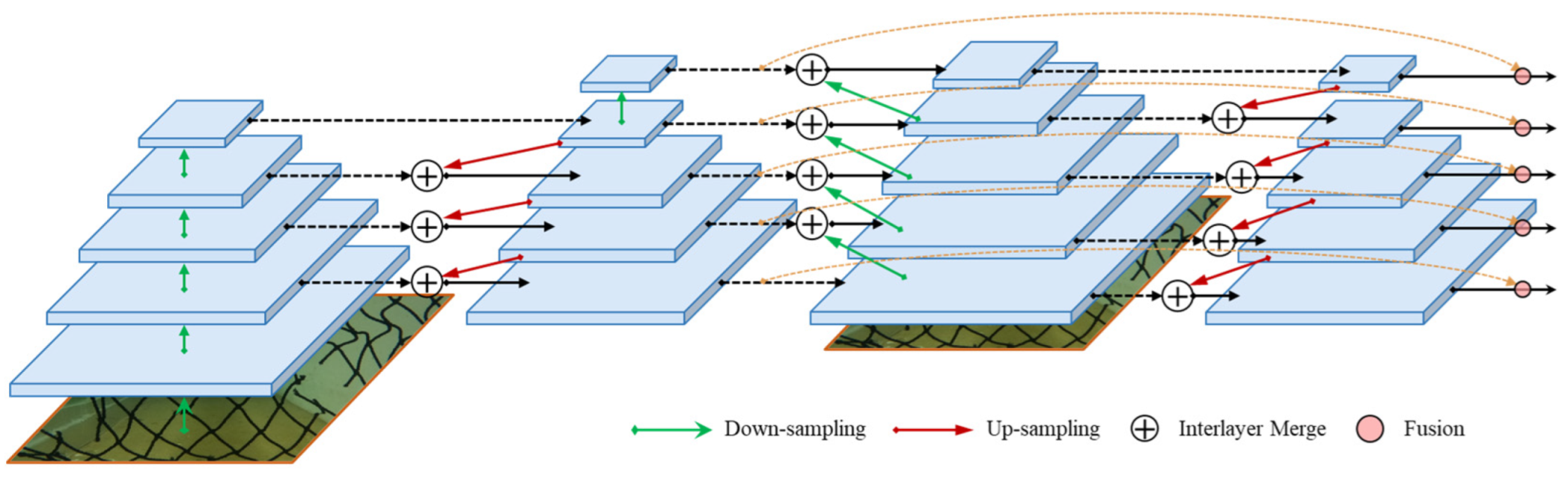
2.3.1. Recursive Feature Pyramid (RFP)
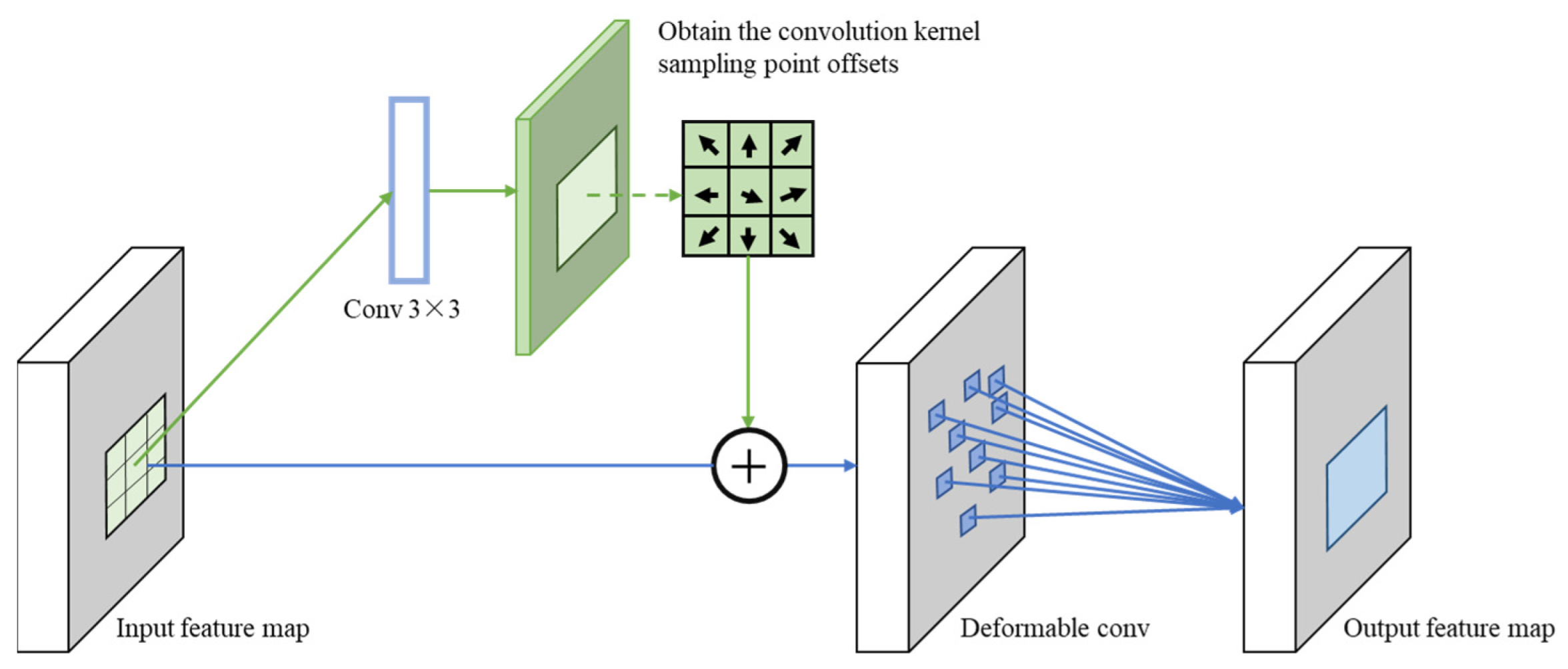
2.3.2. Deformable Convolution Network (DCN)
2.4. Loss Function
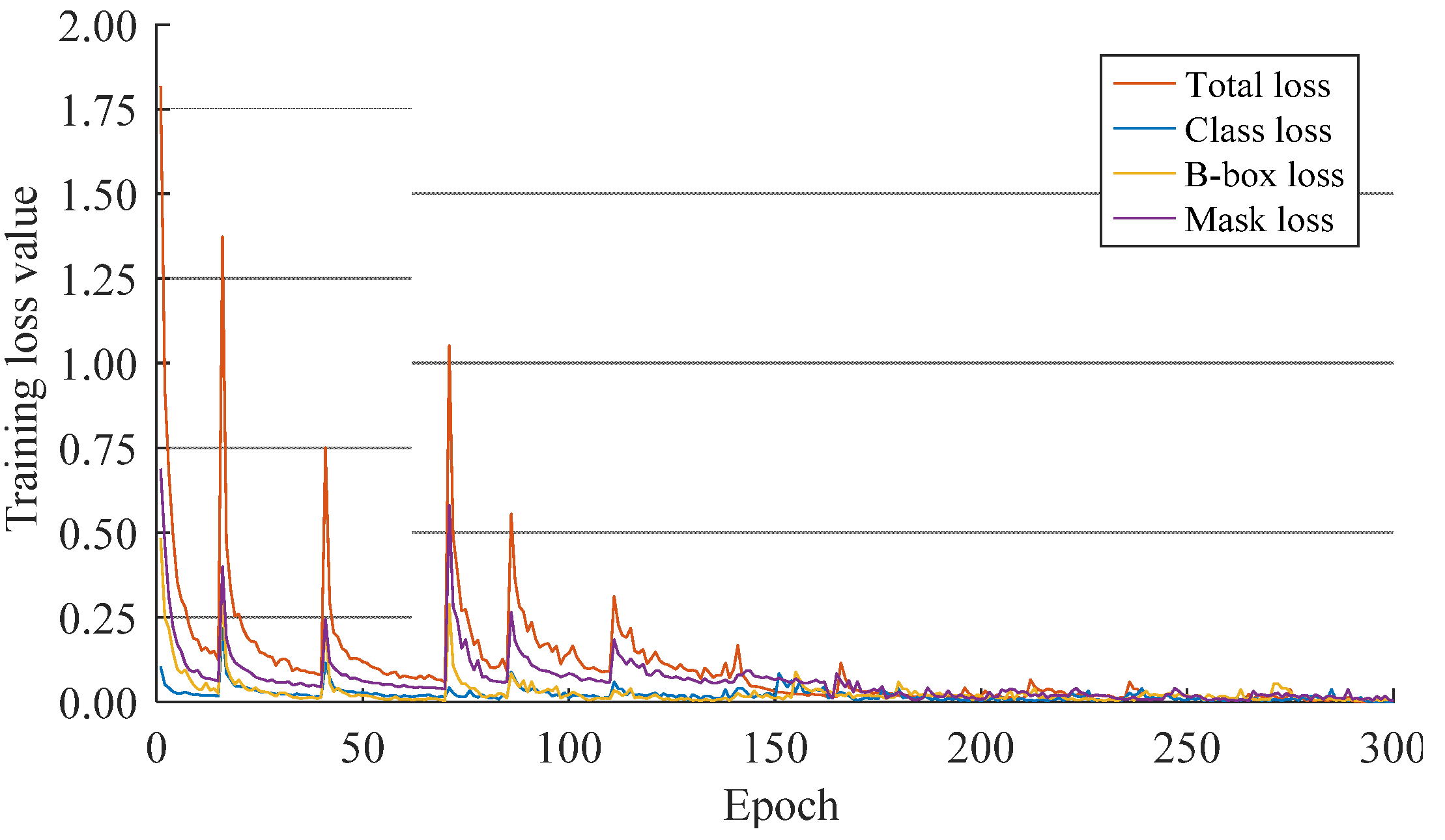
2.5. Training
2.5.1. Runtime Environment
2.5.2. Model Parameters
2.6. Evaluation Metrics
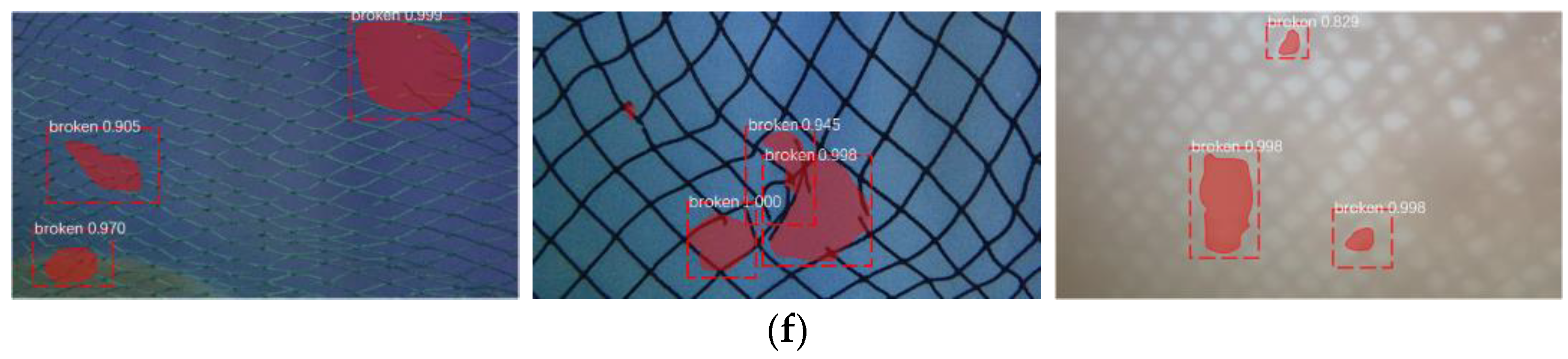
3. Results and Discussion
3.1. Ablation Experiment Result
3.2. Model Performance Comparison
4. Conclusions
- (1)
- Our proposed model combining Mask R-CNN, RFP, and DCN detects netting damage in both laboratory and actual marine environments. The missing detection rate of the final model is 7.12%, with an accuracy of 94.48%. The detection processes around 4.74 FPS while using about 231.8 MB of RAM, which satisfies actual application requirements and facilitates the deployment of this method in embedded equipment.
- (2)
- A dataset of netting damage images was collected and labeled in the simulated laboratory environment and marine aquaculture environment. We performed comparison tests using OpenCV, SSD, YOLOv3, Mask R-CNN, Cascade R-CNN, and the proposed model. The results show that our proposed combination of Mask R-CNN, RFP, and DCN has better detection performance than the others.
- (3)
- Currently, the research on CNN-based damage detection of underwater netting in aquaculture facilities is scarce. We have constructed an underwater netting damage detection scheme based on computer vision and deep learning that not only detects ordinary netting damage but also accurately detects small-size and irregular damage. This method offers potential for use in actual aquaculture facilities to reduce aquaculture risk and maintenance costs by enabling early repairs to damaged netting.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, W.B.; Shi, J.G.; Yu, W.W.; Liu, F.L.; Song, W.H.; Gui, F.K. Current situation and development trend of marine seine culture in China. Fish. Inf. Strategy 2018, 33, 259–266. [Google Scholar]
- Gui, F.K.; Zhu, H.J.; Feng, D.J. Research progress on hydrodynamic characteristics of marine aquaculture netting. Fish. Mod. 2019, 46, 9–14+21. [Google Scholar]
- Yan, G.Q.; Ni, X.H.; Mo, J.S. Research status and development tendency of deepsea aquaculture equipments: A review. J. Dalian Ocean. Univ. 2018, 33, 123–129. [Google Scholar]
- Fish Farming Expert. Ocean Farm 1 escape total worked out at 16,000. Available online: https://www.fishfarmingexpert.com/article/ocean-farm-1-escape-total-worked-out-at-16000/ (accessed on 15 April 2021).
- Fish Farming Expert. Second escape from Ocean Farm 1. Available online: https://www.fishfarmingexpert.com/article/second-escape-from-ocean-farm-1/ (accessed on 15 April 2021).
- Wei, Y.G.; Wei, Q.; An, D. Intelligent monitoring and control technologies of open sea cage culture: A review. Comput. Electron. Agric. 2020, 169, 105119. [Google Scholar] [CrossRef]
- O’Mahony, N.; Campbell, S.; Carvalho, A.; Harapanahalli, S.; Hernandez, G.V. Deep Learning vs. Traditional Computer Vision. Advances in Computer Vision. In CVC 2019: Advances in Computer Vision; Springer: Cham, Switzerland, 2019; pp. 128–144. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- He, K.M.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Cai, Z.W.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar] [CrossRef]
- Lian, L.K.; Zhao, Y.P.; Bi, C.W.; Xu, Z.J.; Du, H. Research on the Damage Detection Method of the Plane Fishing Net Based on the Digital Twin Technology. Prog. Fish. Sci. 2022, 43, 1–8. [Google Scholar] [CrossRef]
- Wan, Y.L.; Qi, C.S.; Pan, H.J. Design of remote monitoring system for aquaculture cages based on 3G networks and ARM-Android embedded system. Procedia Eng. 2012, 29, 79–83. [Google Scholar] [CrossRef][Green Version]
- Peng, A.H.; Liu, C.W.; Lu, B. A deep-water fish cage with cleaning device and data acquisition system. South China Agric. 2016, 10, 169–171. [Google Scholar] [CrossRef]
- Chang, Z.Y.; Zhou, X.Y.; Chi, M.T.; Zheng, Z.Q. Fault Characteristics of Breakage on Net Sheet of Aquaculture Net Cage. In Proceedings of the 2019 Prognostics and System Health Management Conference, Qingdao, China, 25–27 October 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Lee, J.; Roh, M.; Kim, K.; Lee, D. Design of autonomous underwater vehicles for cage aquafarms. In Proceedings of the 2007 IEEE Intelligent Vehicles Symposium, Istanbul, Turkey, 13–15 June 2007; pp. 938–943. [Google Scholar] [CrossRef]
- Schellewald, C.; Stahl, A.; Kelasidi, E. Vision-based pose estimation for autonomous operations in aquacultural fish farms. IFAC-PapersOnLine 2021, 54, 438–443. [Google Scholar] [CrossRef]
- Betancourt, J.; Coral, W.; Colorado, J. An integrated ROV solution for underwater net-cage inspection in fish farms using computer vision. SN Appl. Sci. 2020, 2, 1946. [Google Scholar] [CrossRef]
- Zhao, Y.P.; Niu, L.J.; Du, H.; Bi, C.W. An adaptive method of damage detection for fishing nets based on image processing technology. Aquac. Eng. 2020, 90, 102071. [Google Scholar] [CrossRef]
- Kagemoto, H. Forecasting a water-surface wave train with artificial intelligence- A case study. Ocean. Eng. 2020, 207, 107380. [Google Scholar] [CrossRef]
- Liao, W.X.; Zhang, S.B.; Wu, Y.H.; An, D.; Wei, Y.G. Research on intelligent damage detection of far-sea cage based on machine vision and deep learning. Aquac. Eng. 2022, 96, 102219. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–15 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, D.; Reed, S. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 24–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.M. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Dai, J.F.; Qi, H.Z.; Xiong, Y.W.; Li, Y.; Zhang, G.D. Deformable Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar] [CrossRef]
- Buslaev, A.; Parinov, A.; Khvedchenya, E.; Iglovikov, V.I. Albumentations: Fast and Flexible Image Augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Torralba, A.; Russell, B.C.; Yuen, J. LabelMe: Online image annotation and applications. Proc. IEEE 2010, 98, 1467–1484. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Qiao, S.Y.; Chen, L.C.; Yuille, A. DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10208–10219. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Height | 0.6-m |
| Width | 0.4-m |
| Twine diameter | 1.2 mm, 3.0 mm, 4.8 mm |
| Length of mesh bar | 1.5 cm, 3.0 cm |
| Material | Polyethylene |
| Parameter | Value |
|---|---|
| Batch size | 16 |
| Iteration | 675 |
| Epoch | 300 |
| Initial learning rate | 0.01 |
| Decay rate | 0.98 |
| Dropout rate | 0.4 |
| Prediction | |||
|---|---|---|---|
| Positive | Negative | ||
| Actual | True | True Positive (TP) | True Negative (TN) |
| False | False Positive (FP) | False Negative (FN) | |
| Model | Missing Rate | AP | F1 Score | FPS |
|---|---|---|---|---|
| Mask R-CNN | 28.56% | 86.62% | 85.81% | 4.46 |
| Mask R-CNN+RFP | 11.18% | 90.12% | 89.27% | 4.20 |
| Mask R-CNN+DCN | 21.83% | 91.90% | 90.11% | 4.82 |
| Mask R-CNN+RFP+DCN | 7.12% | 94.48% | 94.02% | 4.74 |
| Model | Missing Rate | AP | F1 Score | FPS |
|---|---|---|---|---|
| OpenCV | 56.92% | —— | — | 29.36 |
| SSD | 35.80% | 77.98% | 75.33% | 5.67 |
| YoloV3 | 29.21% | 81.27% | 78.79% | 9.77 |
| Mask R-CNN | 28.56% | 86.62% | 85.81% | 4.46 |
| Cascade R-CNN | 23.99% | 89.15% | 88.56% | 2.9 |
| Our model | 7.12% | 94.48% | 94.02% | 4.74 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Gui, F.; Qu, X.; Feng, D. Netting Damage Detection for Marine Aquaculture Facilities Based on Improved Mask R-CNN. J. Mar. Sci. Eng. 2022, 10, 996. https://doi.org/10.3390/jmse10070996
Zhang Z, Gui F, Qu X, Feng D. Netting Damage Detection for Marine Aquaculture Facilities Based on Improved Mask R-CNN. Journal of Marine Science and Engineering. 2022; 10(7):996. https://doi.org/10.3390/jmse10070996
Chicago/Turabian StyleZhang, Ziliang, Fukun Gui, Xiaoyu Qu, and Dejun Feng. 2022. "Netting Damage Detection for Marine Aquaculture Facilities Based on Improved Mask R-CNN" Journal of Marine Science and Engineering 10, no. 7: 996. https://doi.org/10.3390/jmse10070996
APA StyleZhang, Z., Gui, F., Qu, X., & Feng, D. (2022). Netting Damage Detection for Marine Aquaculture Facilities Based on Improved Mask R-CNN. Journal of Marine Science and Engineering, 10(7), 996. https://doi.org/10.3390/jmse10070996