
Dynamic Target Tracking of Autonomous Underwater Vehicle Based on Deep Reinforcement Learning


Abstract
:1. Introduction
- (1).
- We design reward function for multiple control objectives and formulate MDP for the AUV target tracking task.
- (2).
- The use of the experience replay technique for training leads to low sample utilization. In order to improve the training efficiency, combined with the temporal difference error, an adaptive experience replay rule is proposed.
- (3).
- Based on the actor–critic algorithm, a reinforcement learning training framework is built, and the target tracking of AUV is realized combined with the experience replay technique.
2. Problem Formulation
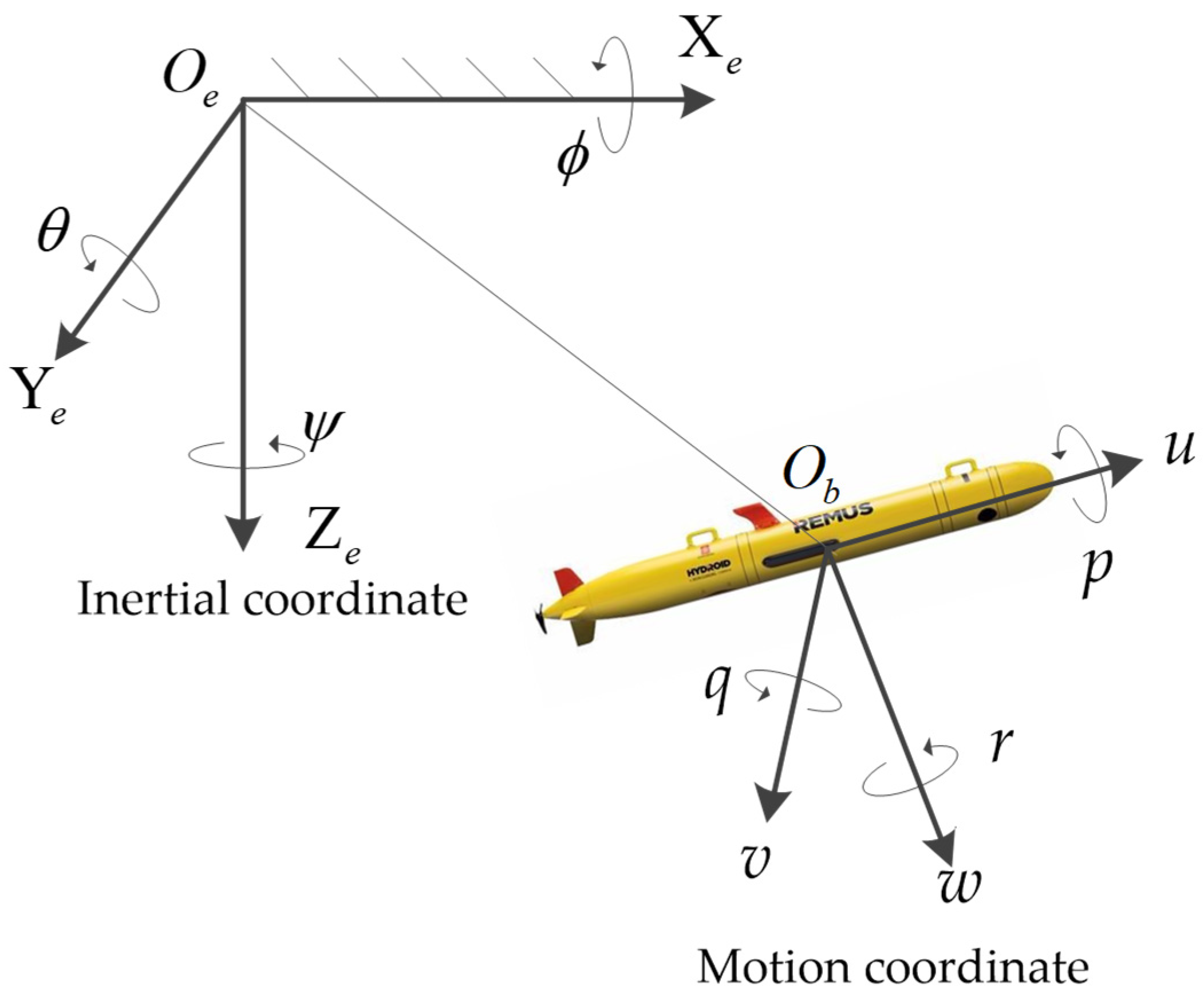
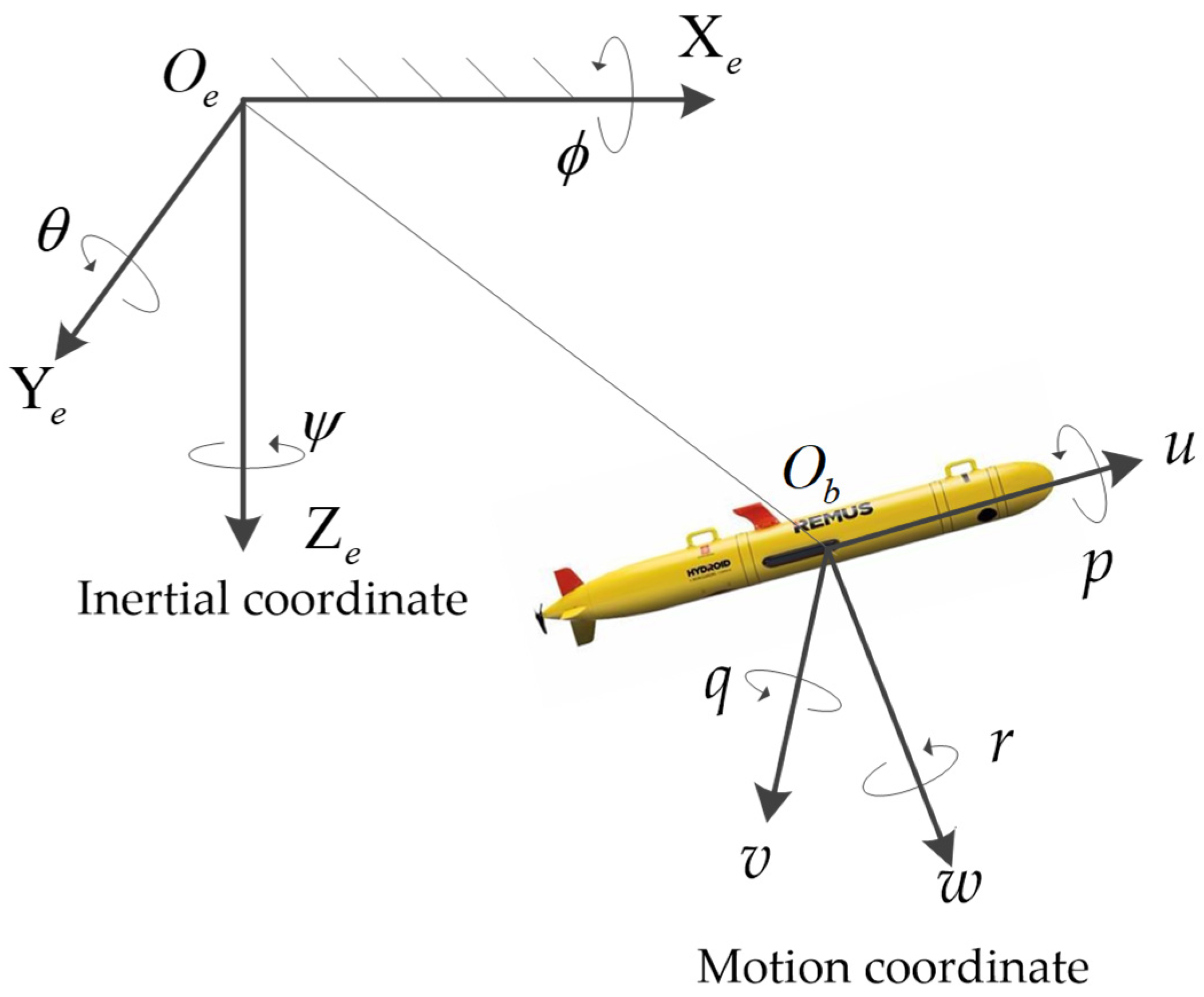
2.1. Coordinate Systems of AUVs
2.2. Dynamic Model of AUVs
- (1).
- The AUV center of buoyancy coincides with its center of gravity.
- (2).
- The yaw, pitch, and roll motions can be neglected.
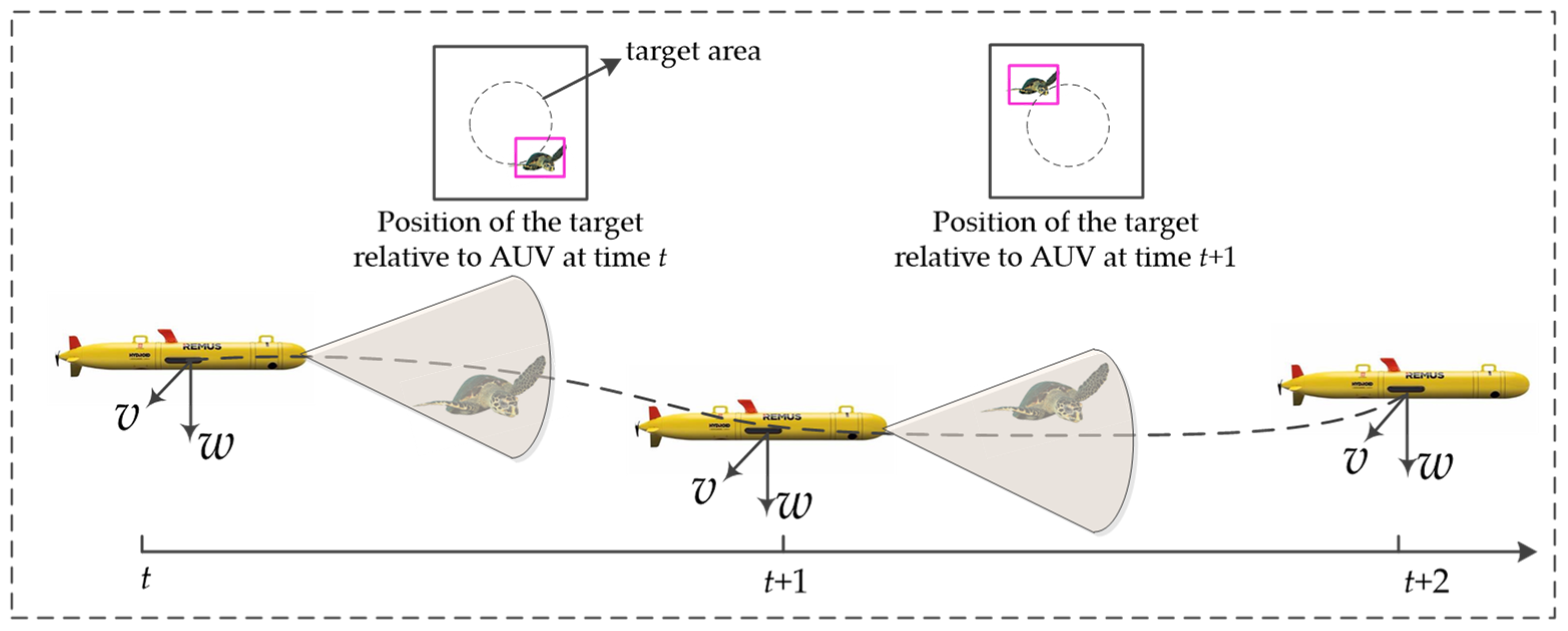
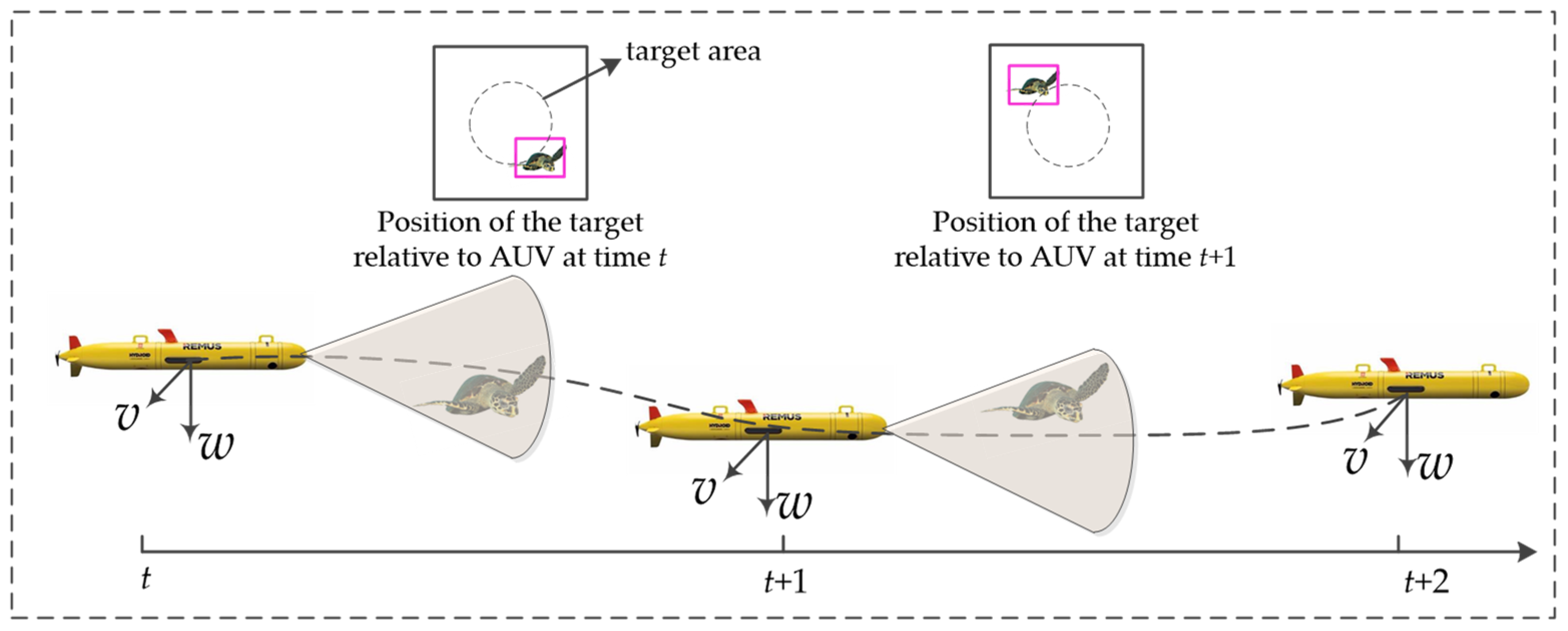
2.3. Target Tracking Tasks
3. MDP of Target Tracking Problem
4. The AERDPG Algorithm
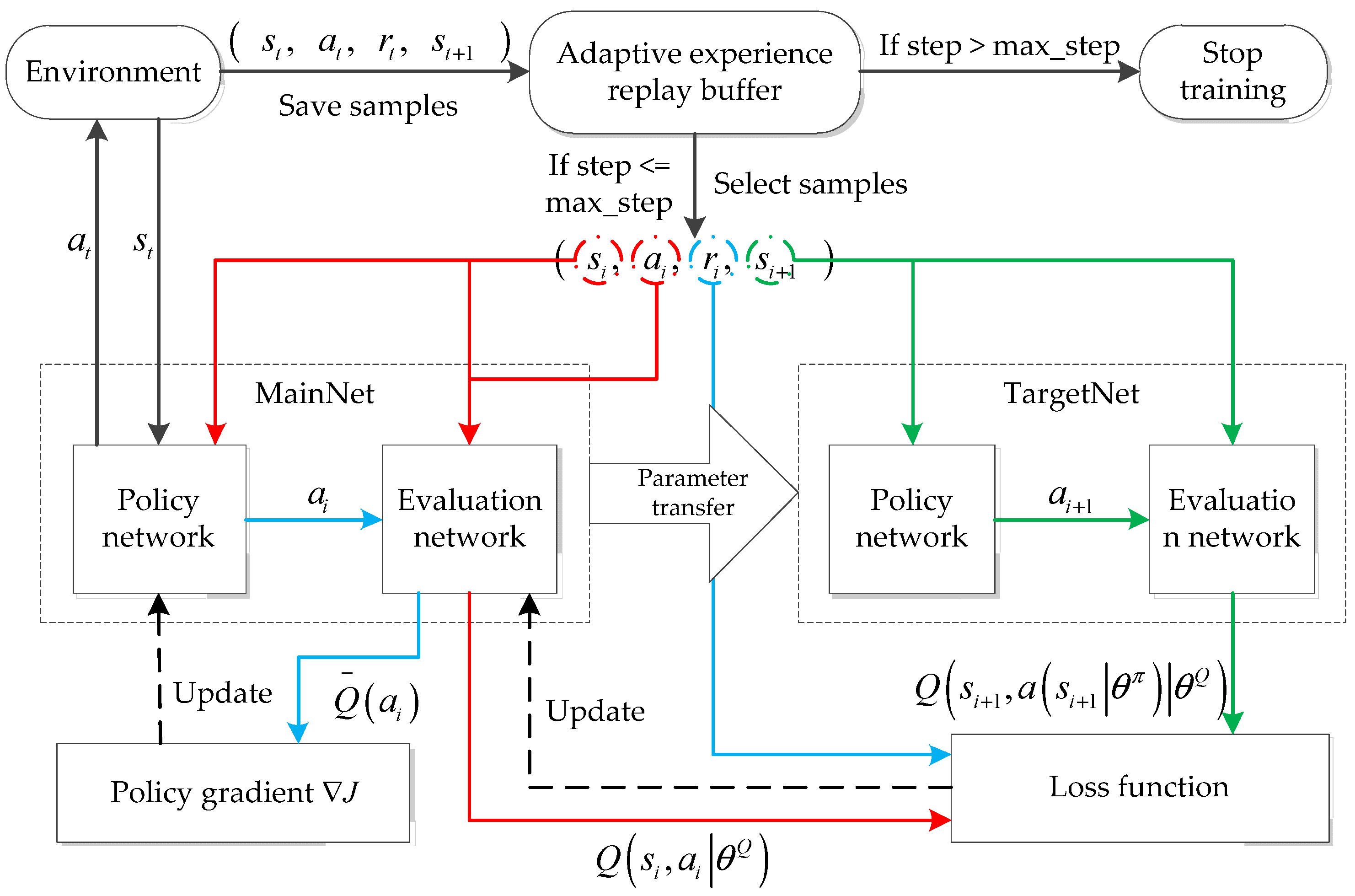
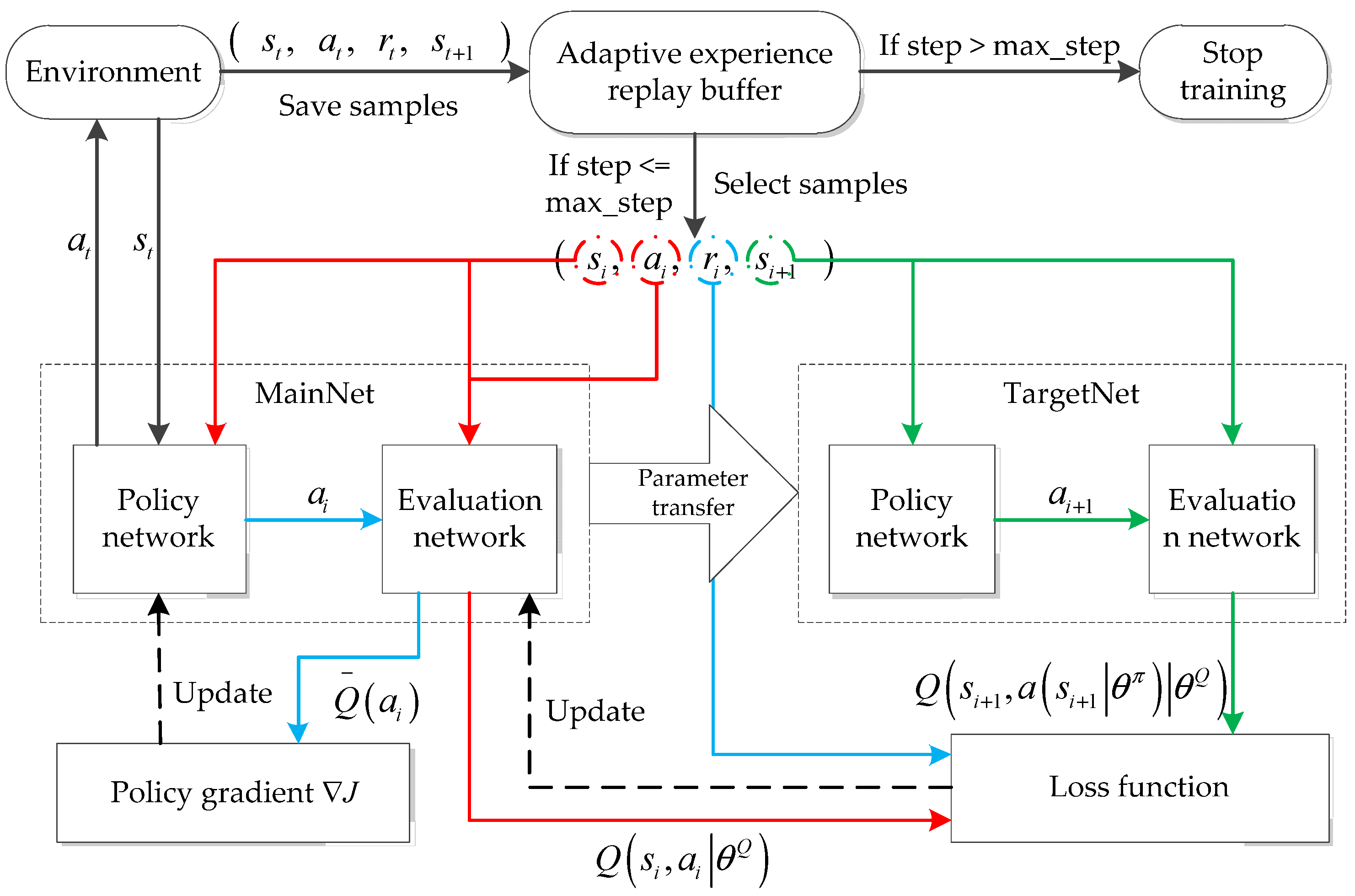
4.1. Algorithm Structure
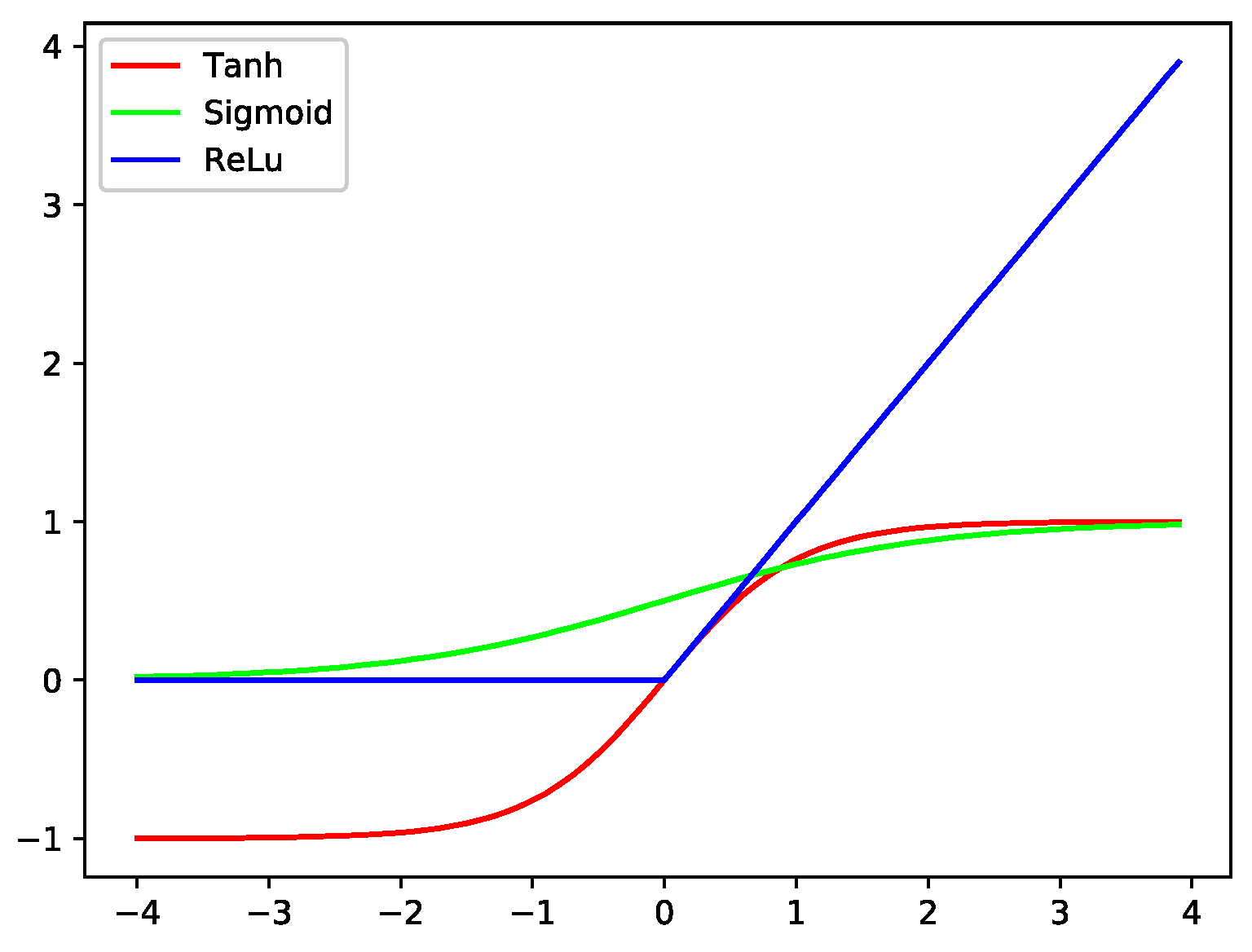
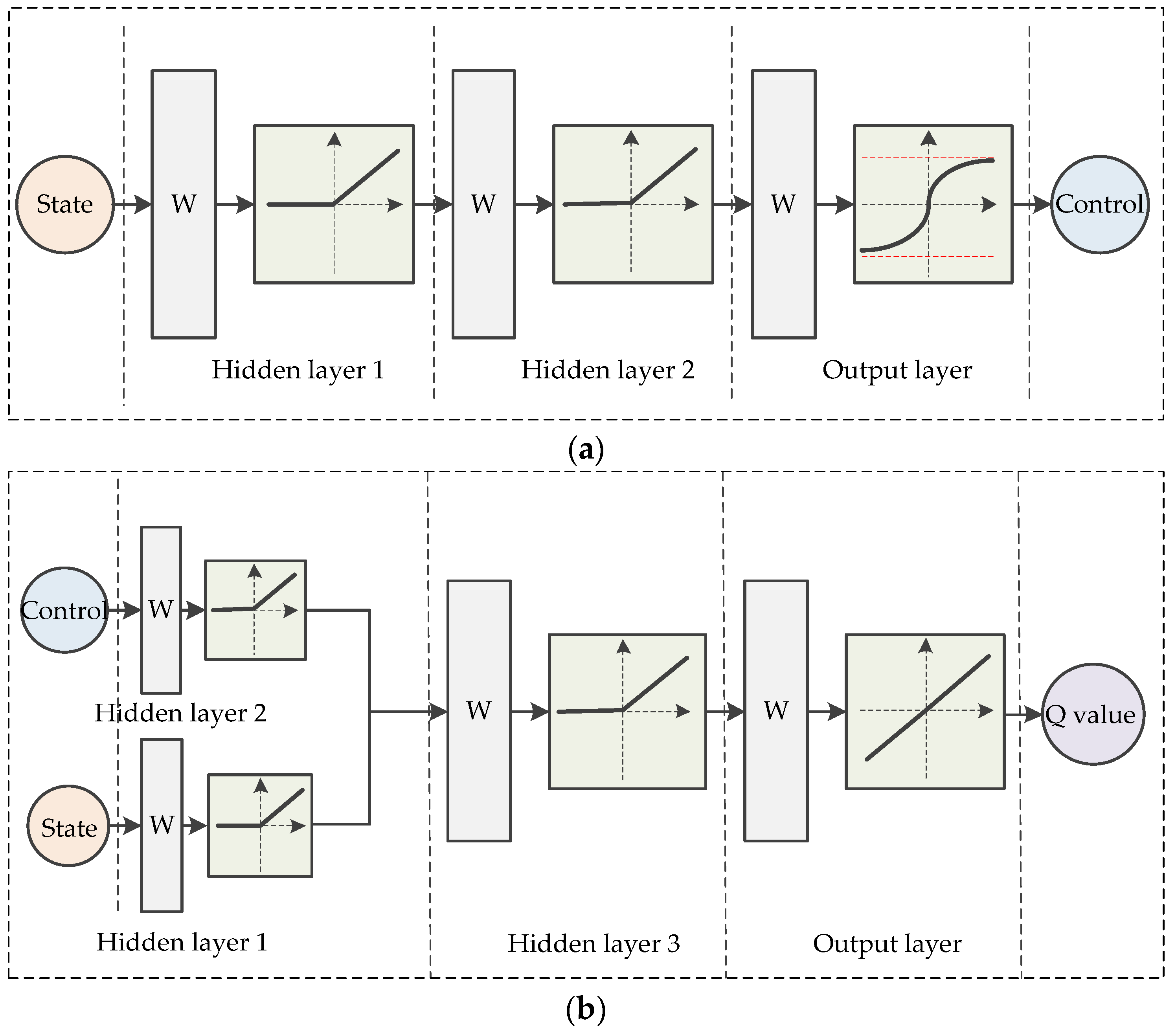
4.2. Neural Network Structure
4.3. Adaptive Experience Replay Technique
4.4. Algorithm Process
| Algorithm 1. AERDPG for the target tracking of the AUV |
| Input: number of episodes , number of steps for each episode , batch size , learning rates for evaluation and policy networks and , respectively, discount factor , experience replay buffer capacity , target motion change probability , and current number of samples in experience replay buffer . Output: Target tracking strategy . 1 Initialize the evaluation network and the policy network . Initialize the current number of samples in the experience replay buffer . 2 for do: 3 Reset the initial state ; 4 for do: 5 if : 6 Generate a control strategy with additional exploration noise obtained from the current policy network; 7 Reward and next state are obtained from the current state and action ; 8 Store quadruples into experience replay buffer; 9 end for; 10 else: 11 The priority of each sample is calculated by Equation (17); 12 Select group from the experience replay buffer based on ; 13 Update the current evaluation network by Equation (14); 14 Update the current policy network by Equation (15); 15 Transfer the current network parameters to the target network after a pre-defined time step; 16 end for; 17 end for; 18 end for. |
5. Experiments
5.1. Experiment Settings
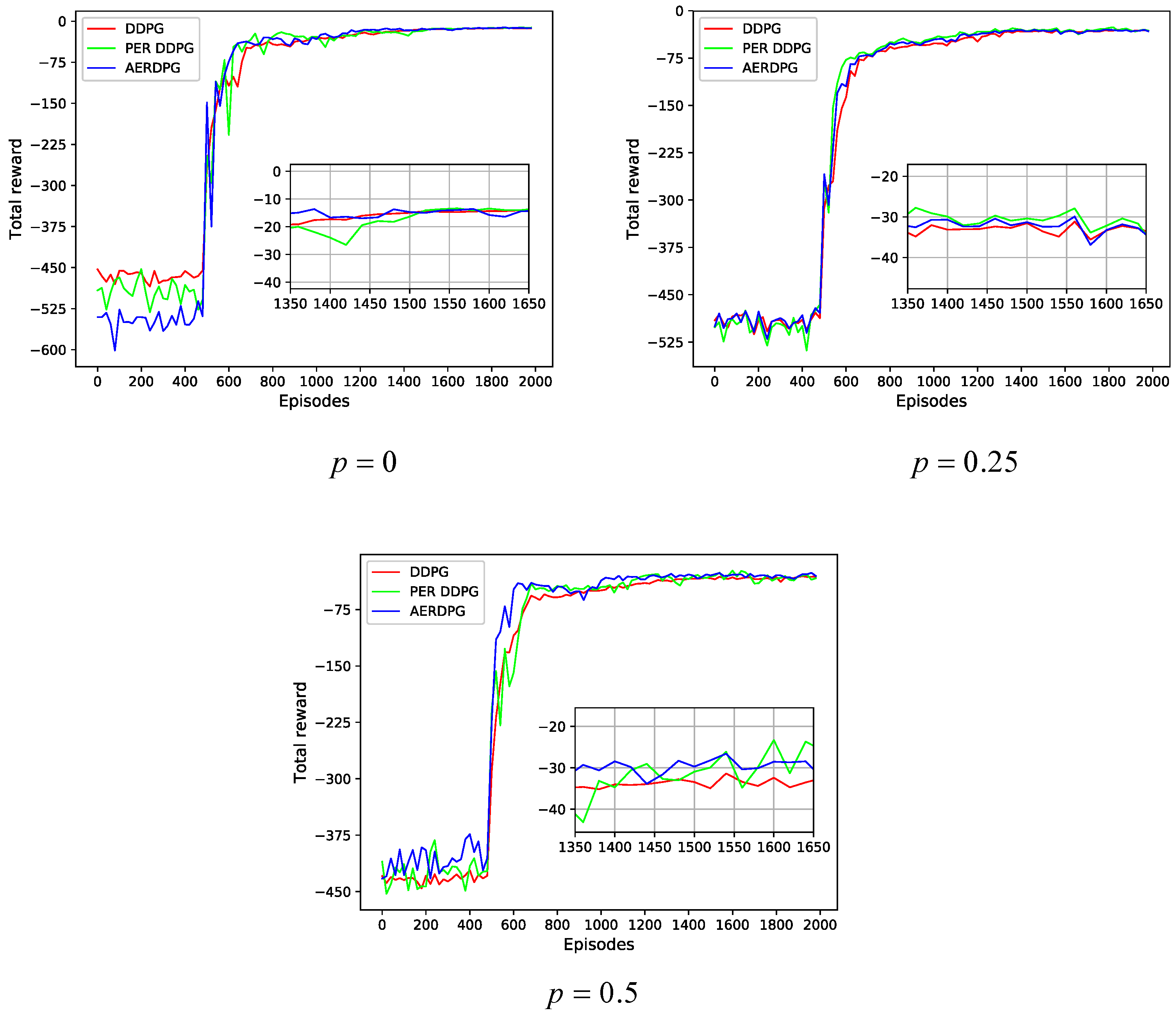
5.2. Training Process Comparison
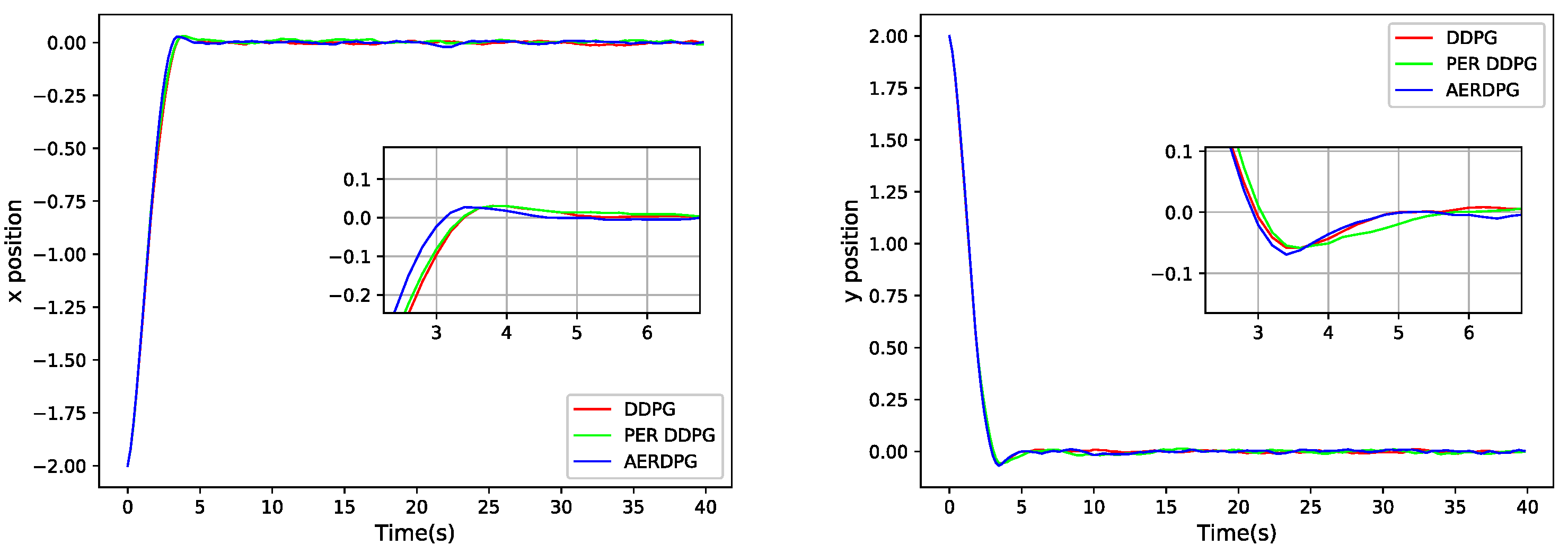
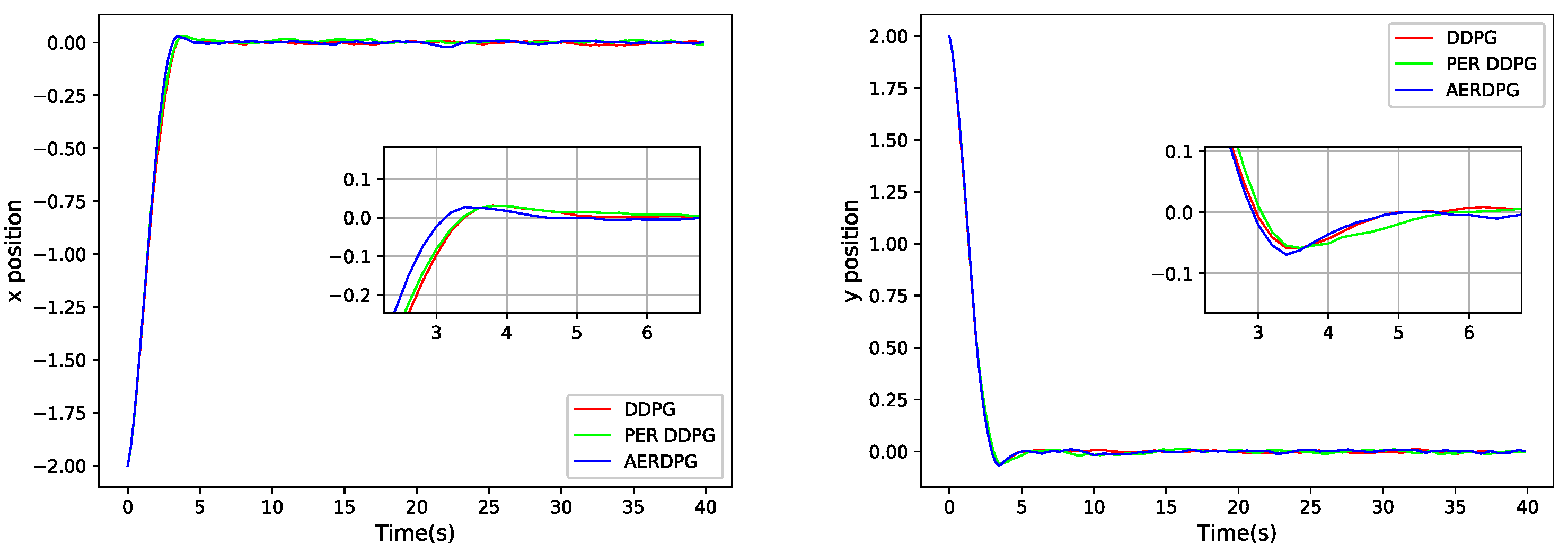
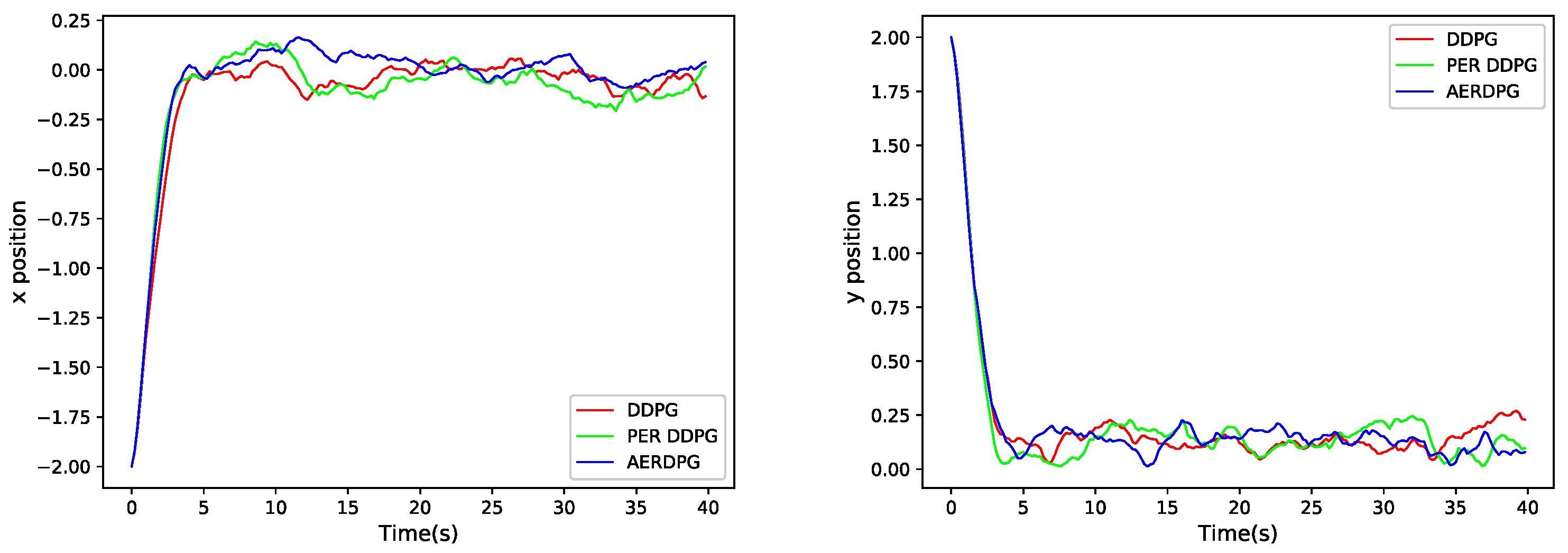
5.3. Controller Performance Comparison
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, Y.; Wang, P.; Sun, P. Review on research of control technology of autonomous underwater vehicle. World Sci.-Tech. R & D 2021, 43, 14–26. [Google Scholar]
- Zhang, Q.; Lin, J.; Sha, Q.; He, B.; Li, G. Deep interactive reinforcement learning for path following of autonomous underwater vehicle. IEEE Access 2020, 8, 24258–24268. [Google Scholar] [CrossRef]
- Guo, Y.; Qin, H.; Xu, B.; Han, Y.; Fan, Q.-Y.; Zhang, P. Composite learning adaptive sliding mode control for AUV target tracking. Neurocomputing 2019, 351, 180–186. [Google Scholar] [CrossRef]
- Mintchev, S.; Ranzani, R.; Fabiani, F.; Stefanini, C. Towards docking for small scale underwater robots. Auton. Robot. 2015, 38, 283–299. [Google Scholar] [CrossRef]
- Li, J.; Li, C.; Chen, T.; Zhang, Y. Improved RRT algorithm for AUV target search in unknown 3D environment. J. Mar. Sci. Eng. 2022, 10, 826. [Google Scholar] [CrossRef]
- Li, L.; Li, Y.; Zhang, Y.; Xu, G.; Zeng, J.; Feng, X. Formation Control of Multiple Autonomous Underwater Vehicles under Communication Delay, Packet Discreteness and Dropout. J. Mar. Sci. Eng. 2022, 10, 920. [Google Scholar] [CrossRef]
- Sun, Y.; Ran, X.; Zhang, G.; Wang, X.; Xu, H. AUV path following controlled by modified deep deterministic policy gradient. Ocean. Eng. 2020, 210, 107360. [Google Scholar] [CrossRef]
- Mannarini, G.; Subramani, D.N.; Lermusiaux, P.F.; Pinardi, N. Graph-search and differential equations for time-optimal vessel route planning in dynamic ocean waves. IEEE Trans. Intell. Transp. Syst. 2019, 21, 3581–3593. [Google Scholar] [CrossRef] [Green Version]
- Shi, W.; Song, S.; Wu, C.; Chen, C.P. Multi pseudo Q-learning-based deterministic policy gradient for tracking control of autonomous underwater vehicles. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 3534–3546. [Google Scholar] [CrossRef] [Green Version]
- Carlucho, I.; De Paula, M.; Wang, S.; Petillot, Y.; Acosta, G.G. Adaptive low-level control of autonomous underwater vehicles using deep reinforcement learning. Robot. Auton. Syst. 2018, 107, 71–86. [Google Scholar] [CrossRef] [Green Version]
- Prestero, T. Development of a six-degree of freedom simulation model for the REMUS autonomous underwater vehicle. In Proceedings of the MTS/IEEE Oceans 2001 An Ocean Odyssey. Conference Proceedings (IEEE Cat. No.01CH37295), Honolulu, HI, USA, 5–8 November 2001; Volume 1, pp. 450–455. [Google Scholar]
- Refsnes, J.E.; Sorensen, A.J.; Pettersen, K.Y. Model-based output feedback control of slender-body underactuated AUVs: Theory and experiments. IEEE Trans. Control. Syst. Technol. 2008, 16, 930–946. [Google Scholar] [CrossRef]
- Li, D.; Du, L. Auv trajectory tracking models and control strategies: A review. J. Mar. Sci. Eng. 2021, 9, 1020. [Google Scholar] [CrossRef]
- Carlucho, I.; De Paula, M.; Wang, S.; Menna, B.V.; Petillot, Y.R.; Acosta, G.G. AUV position tracking control using end-to-end deep reinforcement learning. In Proceedings of the OCEANS 2018 MTS/IEEE Charleston, Charleston, SC, USA, 22–25 October 2018; pp. 1–8. [Google Scholar]
- Mao, Y.; Gao, F.; Zhang, Q.; Yang, Z. An AUV target-tracking method combining imitation learning and deep reinforcement learning. J. Mar. Sci. Eng. 2022, 10, 383. [Google Scholar] [CrossRef]
- Chowdhury, R.; Subramani, D.N. Physics-driven machine learning for time-optimal path planning in stochastic dynamic flows. In Proceedings of the International Conference on Dynamic Data Driven Application Systems, Boston, MA, USA, 2–4 October 2020; pp. 293–301. [Google Scholar]
- Bhopale, P.; Kazi, F.; Singh, N. Reinforcement learning based obstacle avoidance for autonomous underwater vehicle. J. Mar. Sci. Appl. 2019, 18, 228–238. [Google Scholar] [CrossRef]
- El-Fakdi, A.; Carreras, M. Two-step gradient-based reinforcement learning for underwater robotics behavior learning. Robot. Auton. Syst. 2013, 61, 271–282. [Google Scholar] [CrossRef]
- Sun, T.; He, B.; Nian, R.; Yan, T. Target following for an autonomous underwater vehicle using regularized ELM-based reinforcement learning. In Proceedings of the OCEANS 2015-MTS/IEEE Washington, Washington, DC, USA, 19–22 October 2015; pp. 1–5. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Zhao, Y.; Gao, F.; Yu, J.; Yu, X.; Yang, Z. Underwater image mosaic algorithm based on improved image registration. Appl. Sci. 2021, 11, 5986. [Google Scholar] [CrossRef]
- Hu, K.; Weng, C.; Zhang, Y.; Jin, J.; Xia, Q. An Overview of Underwater Vision Enhancement: From Traditional Methods to Recent Deep Learning. J. Mar. Sci. Eng. 2022, 10, 241. [Google Scholar] [CrossRef]
- Gao, F.; Wang, K.; Yang, Z.; Wang, Y.; Zhang, Q. Underwater image enhancement based on local contrast correction and multi-scale fusion. J. Mar. Sci. Eng. 2021, 9, 225. [Google Scholar] [CrossRef]
- Liu, Y.; Swaminathan, A.; Agarwal, A.; Brunskill, E. Provably good batch off-policy reinforcement learning without great exploration. Adv. Neural Inf. Process. Syst. 2020, 33, 1264–1274. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Yan, C.; Xiang, X.; Wang, C. Fixed-Wing UAVs flocking in continuous spaces: A deep reinforcement learning approach. Robot. Auton. Syst. 2020, 131, 103594. [Google Scholar] [CrossRef]
- Devo, A.; Dionigi, A.; Costante, G. Enhancing continuous control of mobile robots for end-to-end visual active tracking. Robot. Auton. Syst. 2021, 142, 103799. [Google Scholar] [CrossRef]
- Konda, V.R.; Tsitsiklis, J.N. Actor-critic algorithms. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 29 November–4 December 1999; pp. 1008–1014. [Google Scholar]
- Qin, Z.; Li, N.; Liu, X.; Liu, X.; Tong, Q.; Liu, X. Overview of research on model-free reinforcement learning. Comput. Sci. 2021, 48, 180–187. [Google Scholar]
- Fechert, R.; Lorenz, A.; Liessner, R.; Bäker, B. Using deep reinforcement learning for hybrid electric vehicle energy management under consideration of dynamic emission models. In Proceedings of the SAE Powertrains, Fuels & Lubricants Meeting, Virtual, Online, Poland, 22–24 September 2020; pp. 2506–2518. [Google Scholar]
- Chowdhury, R.; Subramani, D. Optimal Path Planning of Autonomous Marine Vehicles in Stochastic Dynamic Ocean Flows using a GPU-Accelerated Algorithm. IEEE J. Ocean. Eng. 2022, 48, 1–16. [Google Scholar] [CrossRef]
- Chowdhury, R.; Navsalkar, A.; Subramani, D. GPU-Accelerated Multi-Objective Optimal Planning in Stochastic Dynamic Environments. J. Mar. Sci. Eng. 2022, 10, 533. [Google Scholar] [CrossRef]
- Wu, J.; Wang, R.; Li, R.; Zhang, H.; Hu, X. Multi-critic DDPG method and double experience replay. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Miyazaki, Japan, 7–10 October 2018; pp. 165–171. [Google Scholar]
- Ye, Y.; Qiu, D.; Sun, M.; Papadaskalopoulos, D.; Strbac, G. Deep reinforcement learning for strategic bidding in electricity markets. IEEE Trans. Smart Grid 2019, 11, 1343–1355. [Google Scholar] [CrossRef]
- Hou, Y.; Liu, L.; Wei, Q.; Xu, X.; Chen, C. A novel DDPG method with prioritized experience replay. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Banff, AB, Canada, 5–8 October 2017; pp. 316–321. [Google Scholar]
- McCue, L. Handbook of marine craft hydrodynamics and motion control. IEEE Control Syst. Mag. 2016, 36, 78–79. [Google Scholar]
- Bao, H.; Zhu, H. Modeling and trajectory tracking model predictive control novel method of AUV based on CFD data. Sensors 2022, 22, 4234. [Google Scholar] [CrossRef]
- Khodayari, M.H.; Balochian, S. Modeling and control of autonomous underwater vehicle (AUV) in heading and depth attitude via self-adaptive fuzzy PID controller. J. Mar. Sci. Technol. 2015, 20, 559–578. [Google Scholar] [CrossRef]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 387–395. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Coefficient | Value | Coefficient | Value |
|---|---|---|---|
| 30.51 | −131.00 | ||
| −1.62 | −35.50 | ||
| −0.93 | −28.60 |
| Algorithm | DDPG | PER DDPG | AERDPG | |
| Average reward | −18.4416 | −18.7932 | −16.2437 | |
| Reward variance | 41.3573 | 65.8884 | 30.8670 | |
| Episodes | 732.0000 | 627.0000 | 647.0000 | |
| Average reward | −36.6492 | −32.6332 | −34.7070 | |
| Reward variance | 63.3247 | 72.3156 | 53.2815 | |
| Episodes | 1021.0000 | 838.0000 | 894.0000 | |
| Average reward | −36.3298 | −34.1015 | −30.8198 | |
| Reward variance | 42.4152 | 89.9896 | 70.1450 | |
| Episodes | 1032.0000 | 676.0000 | 663.0000 |
| Controller | DDPG | PER DDPG | AERDPG |
|---|---|---|---|
| Sway adjustment time (s) | 2.9840 | 2.9445 | 2.7473 |
| Sway steady-state error | 0.0017 | 0.0045 | 0.0026 |
| Sway overshoot | 0.0080 | 0.0171 | 0.0082 |
| Heave adjustment time (s) | 2.6433 | 2.7214 | 2.6189 |
| Heave steady-state error | 0.0015 | 0.0019 | 0.0016 |
| Heave overshoot | 0.0105 | 0.0140 | 0.0094 |
| Controller | DDPG | PER DDPG | AERDPG |
|---|---|---|---|
| Mean value of sway direction | 0.0415 | 0.0792 | 0.0399 |
| Mean square deviation of sway direction | 0.0013 | 0.0027 | 0.0012 |
| Mean value in heave direction | 0.1282 | 0.1415 | 0.1349 |
| Mean square deviation of heave direction | 0.0015 | 0.0026 | 0.0020 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, J.; Fang, J.; Zhang, Q.; Wu, Q.; Zhang, B.; Gao, F. Dynamic Target Tracking of Autonomous Underwater Vehicle Based on Deep Reinforcement Learning. J. Mar. Sci. Eng. 2022, 10, 1406. https://doi.org/10.3390/jmse10101406
Shi J, Fang J, Zhang Q, Wu Q, Zhang B, Gao F. Dynamic Target Tracking of Autonomous Underwater Vehicle Based on Deep Reinforcement Learning. Journal of Marine Science and Engineering. 2022; 10(10):1406. https://doi.org/10.3390/jmse10101406
Chicago/Turabian StyleShi, Jiaxiang, Jianer Fang, Qizhong Zhang, Qiuxuan Wu, Botao Zhang, and Farong Gao. 2022. "Dynamic Target Tracking of Autonomous Underwater Vehicle Based on Deep Reinforcement Learning" Journal of Marine Science and Engineering 10, no. 10: 1406. https://doi.org/10.3390/jmse10101406