
Research on the Construction of Typhoon Disaster Chain Based on Chinese Web Corpus


Abstract
1. Introduction
2. Methods
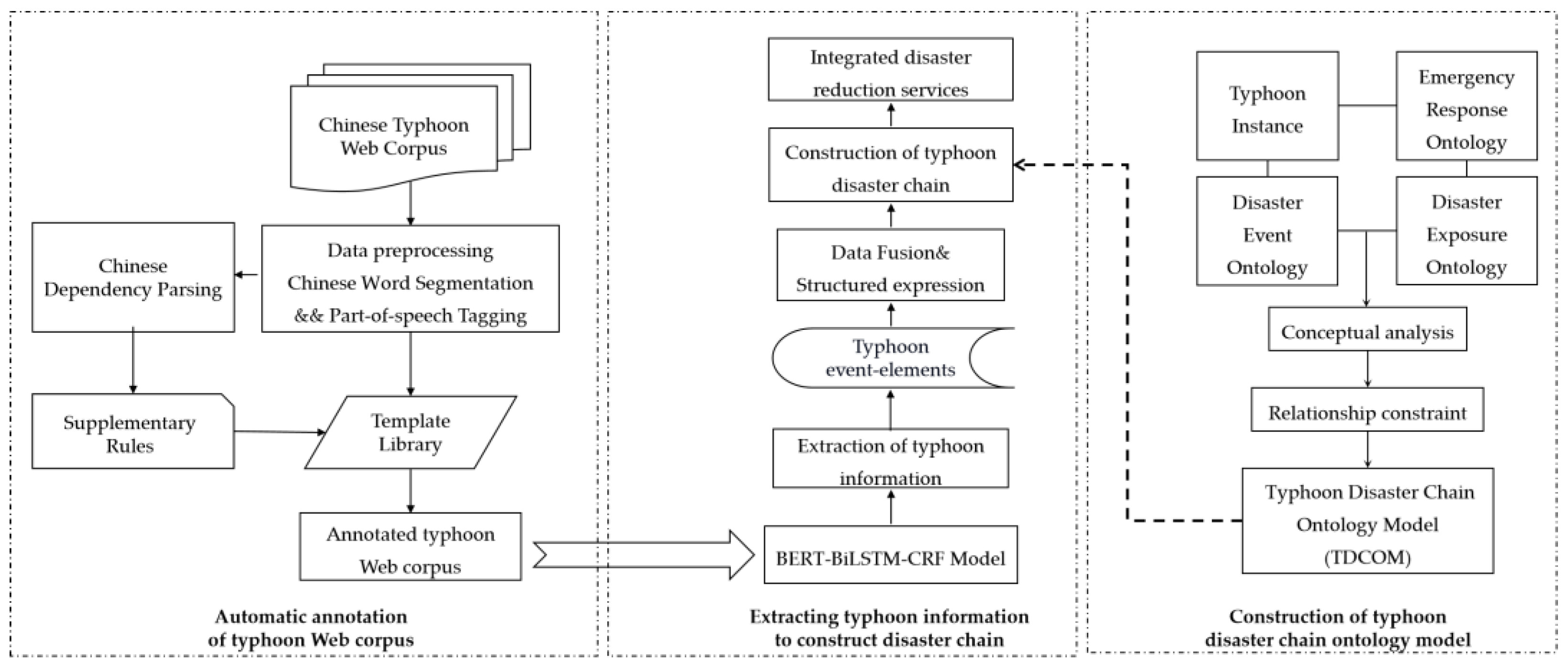
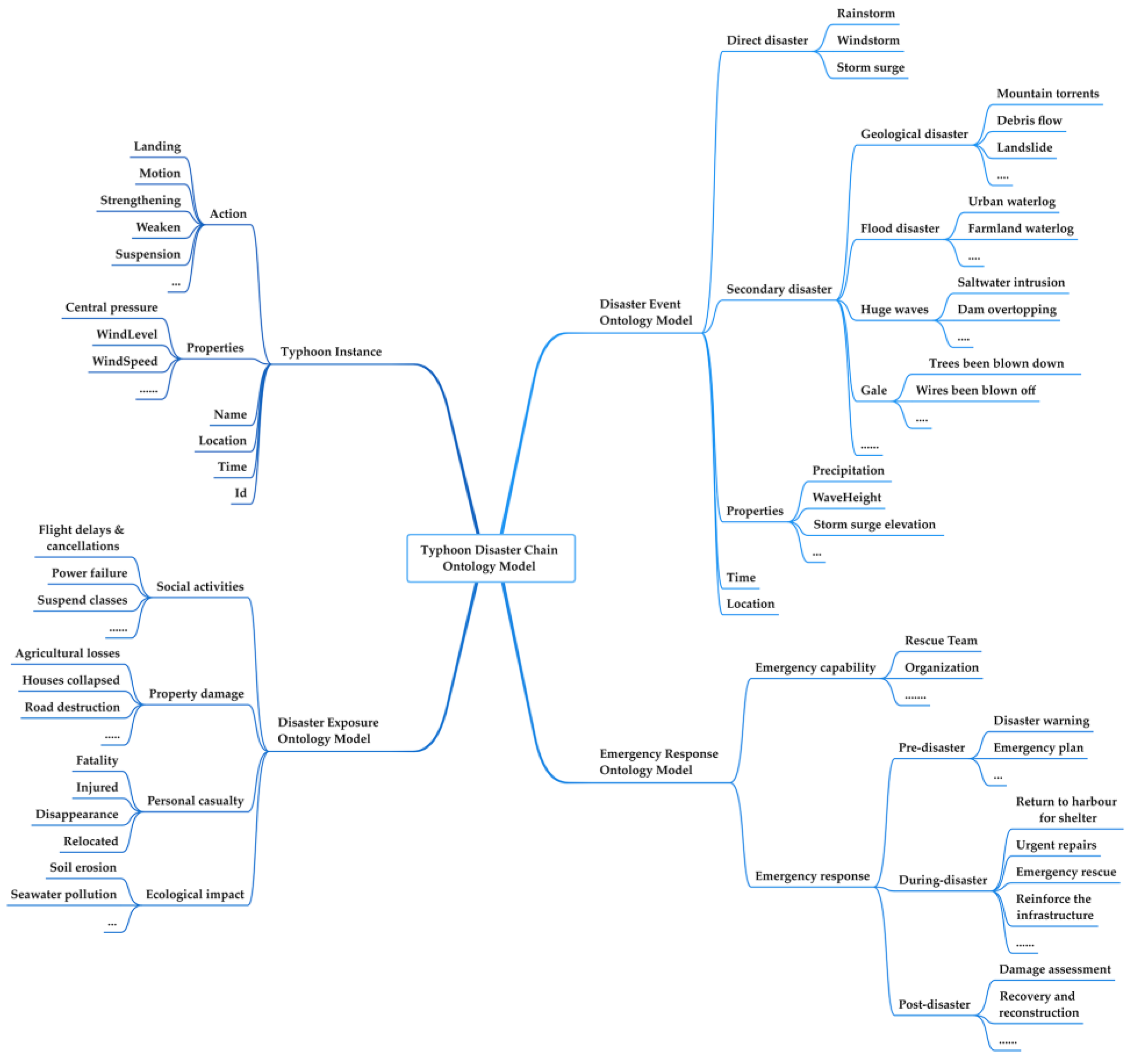
2.1. Construction of Typhoon Disaster Chain Ontology Model
2.2. Extraction of Typhoon Disaster Information Based on Chinese Web Corpus
- The pattern-matching algorithm requires manual construction of a knowledge base and statement expression so as to extract typhoon information. For example, Madhyastha presented a scheme for extracting semantic information from the syntactic structure given by the link grammar system and identifying instances of events. Information is derived by using a set of rules [15]. This method is simple with high recognition accuracy, yet it is time-consuming, less portable, and costly to maintain.
- Machine learning methods are widely used, such as the Maximum Entropy model (ME), Hidden Markov Model (HMM), Support Vector Machine (SVM), Conditional Random Field (CRF), and, etc., which do not require complex matching rules. However, a large number of the manually annotated corpus is necessary and the quality of which influences the method significantly. For example, in order to detect location estimation for events, Sagcan proposed a hybrid system, in which regular expressions are used to define some of the toponym recognition patterns and conditional random fields (CRF) are conducted to extract toponyms from tweets [16].
- The method based on deep learning can obtain the semantic features of the corpus. Especially in recent years, the sequence labeling model based on the neural network can better mine the contextual information and reduce the tedious artificial features, such as long short-term memory networks (LSTM), bidirectional long short-term memory networks (BiLSTM), and various neural network models, that are combined or improved on this basis [17,18,19,20,21]. For example, Xu proposed a deep neural network-based framework to jointly detect and extract events from Twitter by defining a joint loss function, a BiLSTM based common representation layer, and a control gate. A CRF layer is further employed to capture the strong dependencies among output labels [21]. These information extraction models with different network structures have strong generalization ability and perform well in tasks, such as Named Entity Recognition and Relationship Extraction. However, these methods cannot resolve the problem of polysemy. Furthermore, the amount of training corpus is relatively small to tackle the problem of specific domain tasks.
2.2.1. Automatic Annotation of Typhoon Web Corpus
- Data preprocessing. Since the Web corpus contains various redundant information, it is necessary to use Chinese word segmentation and part-of-speech (POS) tagging technology to convert unstructured text data into a lexical combination, which is the basis for information extraction, information aggregation, and text categorization. A large number of irrelevant words and unknown words in the text will introduce a lot of noise to the corpus dataset. Therefore, in this research, a user-defined stop words list, and a typhoon disaster domain dictionary were constructed based on the ontology model of the typhoon to filter phrases and to reduce the impact of noise.
- Construction of template library based on POS tagging and regular expressions. Since similar rules are shared by event description, analyzing which can obtain the linguistic characteristics of event expression. Based on these characteristics, regular expressions and POS tagging are used to establish the rule templates for the temporal, spatial, and attribute information of typhoon events, respectively. For example, the text which translated into English is “central pressure/995/pha” can be matched with the POS combination of “stf + m + q” or the rule template of “N (Disaster attribute) + X (Attribute value) + Q (Unit noun)”.
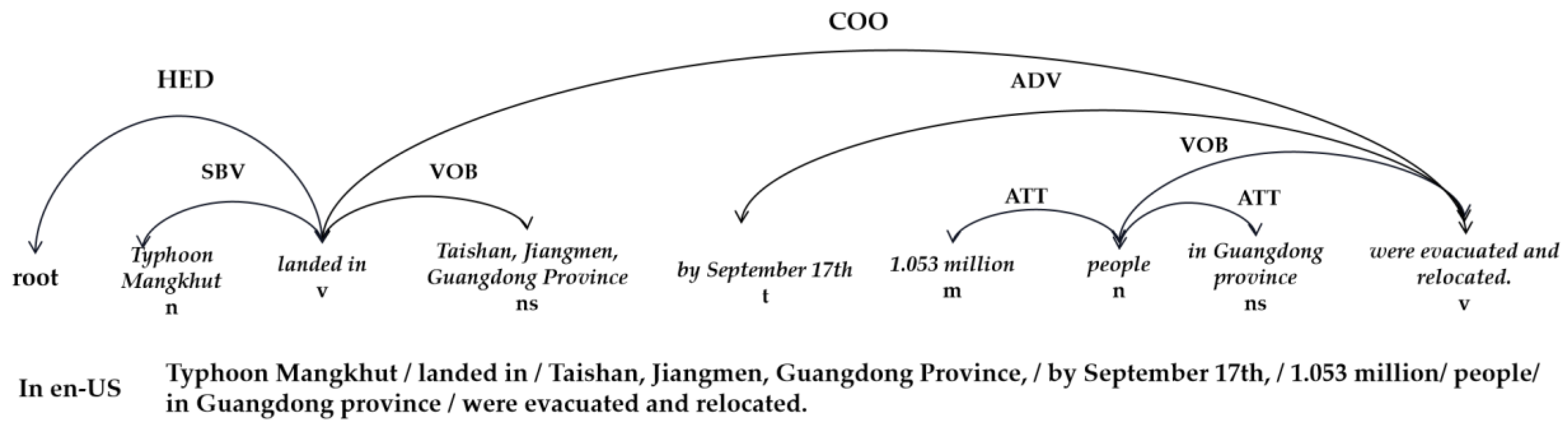
- Supplements templates with Chinese dependency parsing. The same meaning can be phrased by different expressions in typhoon events description, which imposes a limit on information extracting by using the single rule template. Dependency parser can analyze both the semantic associations and dependencies between the constituent units in a sentence, and it can supplement the rule templates effectively to improve the effect of information extraction [25]. For typhoon events, the syntactic relations that this research mainly focuses on are “Subject–Verb” (SVB), “Verb–Object” (VOB), and “Attribute” (ATT). For example, as shown in Figure 3, the sentence translated into English is “Typhoon Mangkhut landed in Taishan, Jiangmen, Guangdong Province, by September 17th, 1.053 million people in Guangdong province were evacuated and relocated”. To make it easier to understand, the Chinese syntactic structure has been transformed into the corresponding English expression. Among them, “Typhoon Mangkhut” is the Subject of “landed”, “Taishan, Jiangmen, Guangdong Province” is the Object of “landed”, “17th September” is the temporal adverbial, “people” is the Object of “evacuated and relocated”, “Guangdong Province” and “1.053 million” are the attributive complement of “people”. Through the traversal of the nodes and dependencies on the syntactic tree, event-elements can be obtained, and the rule templates can be supplemented effectively.
- Corpus Annotation. Rule templates are used for customized annotation of the dataset. The BIO text annotation system is adopted in this research. The annotation specifications of event-elements, such as time, location, disaster, and emergency attributes, in the Web corpus are shown in Table 1. There are 8 types of event-elements that need to be obtained.
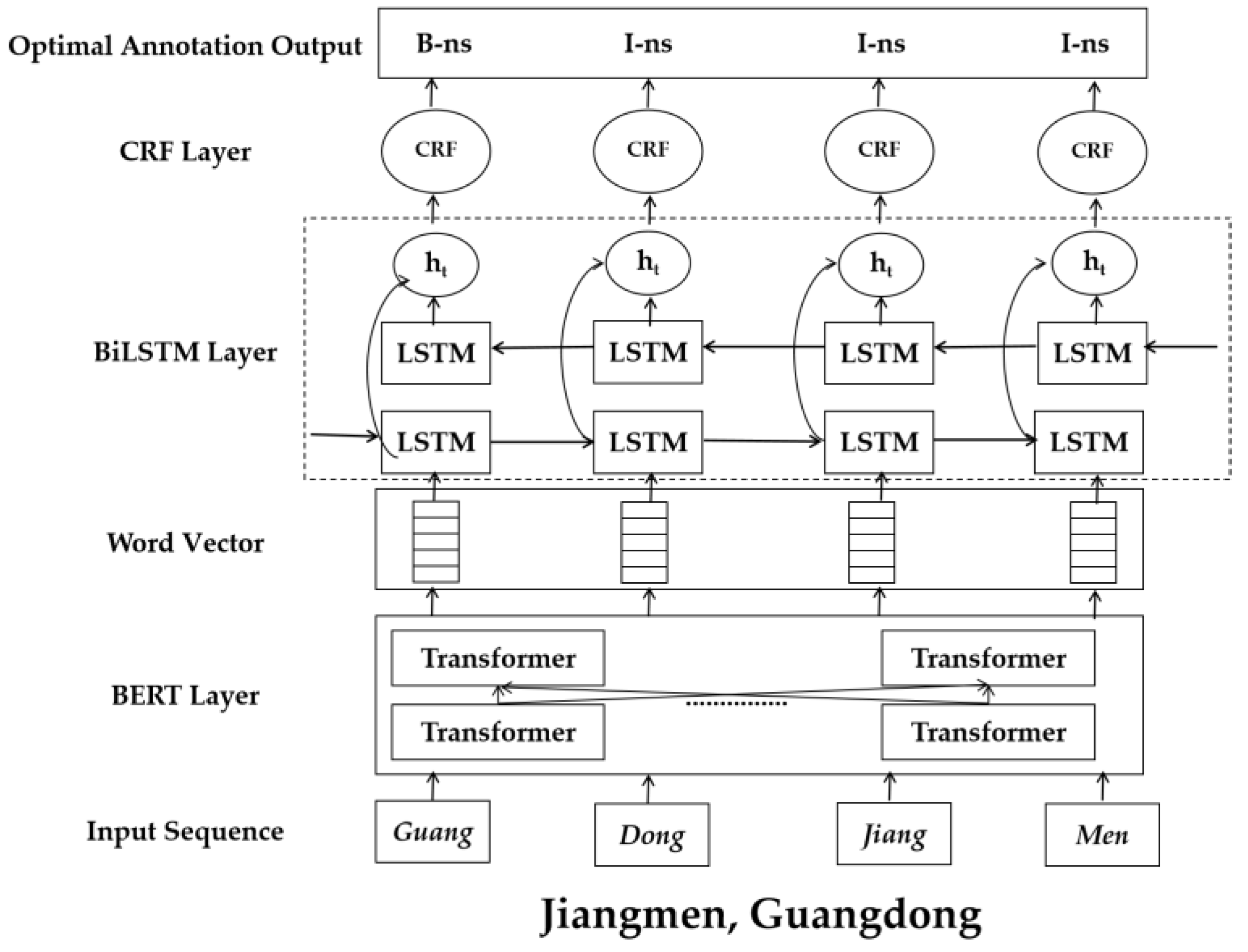
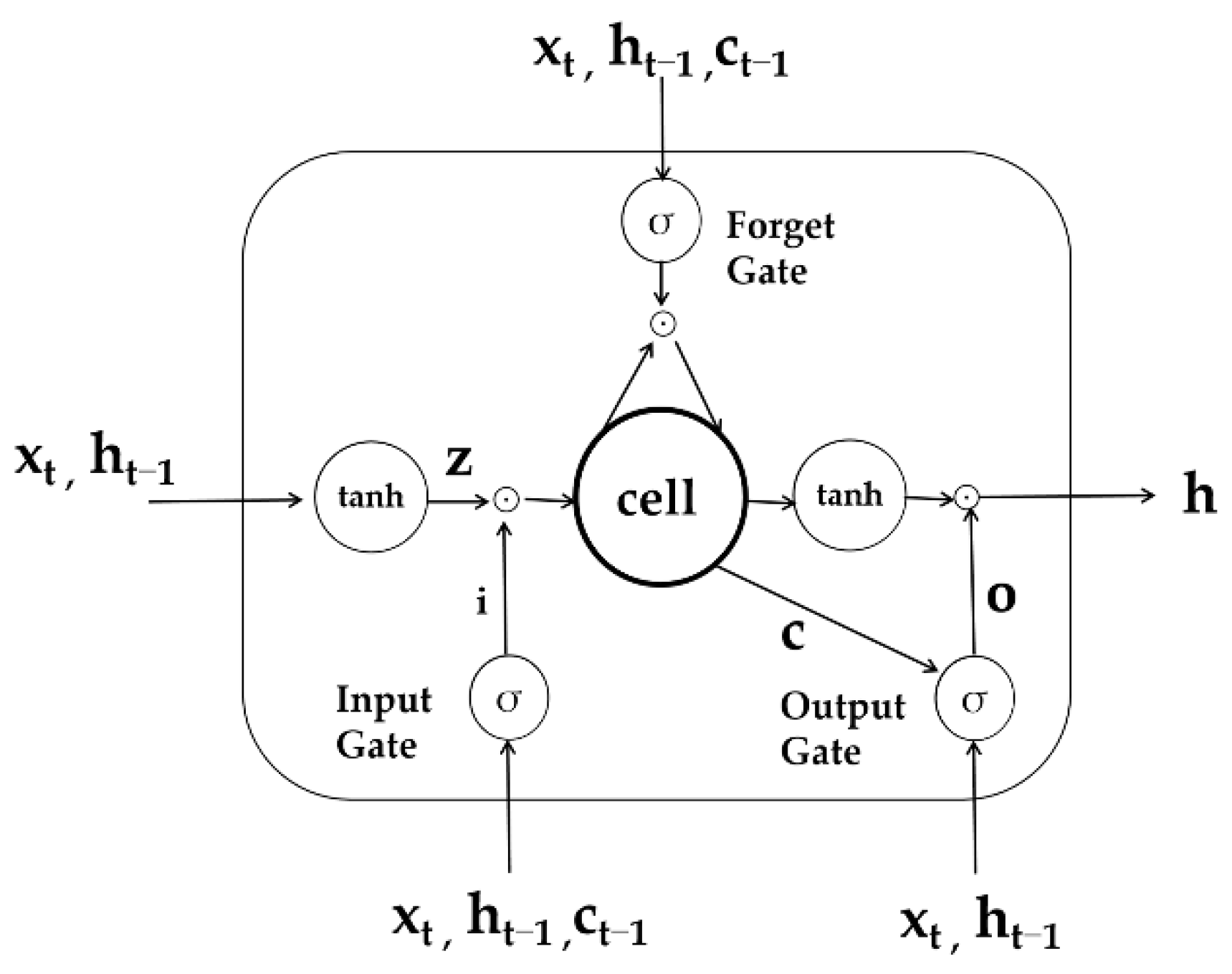
2.2.2. Typhoon Information Extraction Model Based on BERT-BiLSTM-CRF
- Model training. Based on large-scale unlabeled corpus and deep Bidirectional Transformers, BERT performs unsupervised training to obtain corpus features. Meanwhile, a small-scale typhoon corpus was introduced to fine-tune the model.
- Character vectorized representation. The typhoon text sequence is input into the BERT model to obtain the real-valued vector corresponding to the character sequence, and the results are spliced to obtain the typhoon corpus word vector matrix incorporating semantic features.
2.3. Data Fusion
3. Results
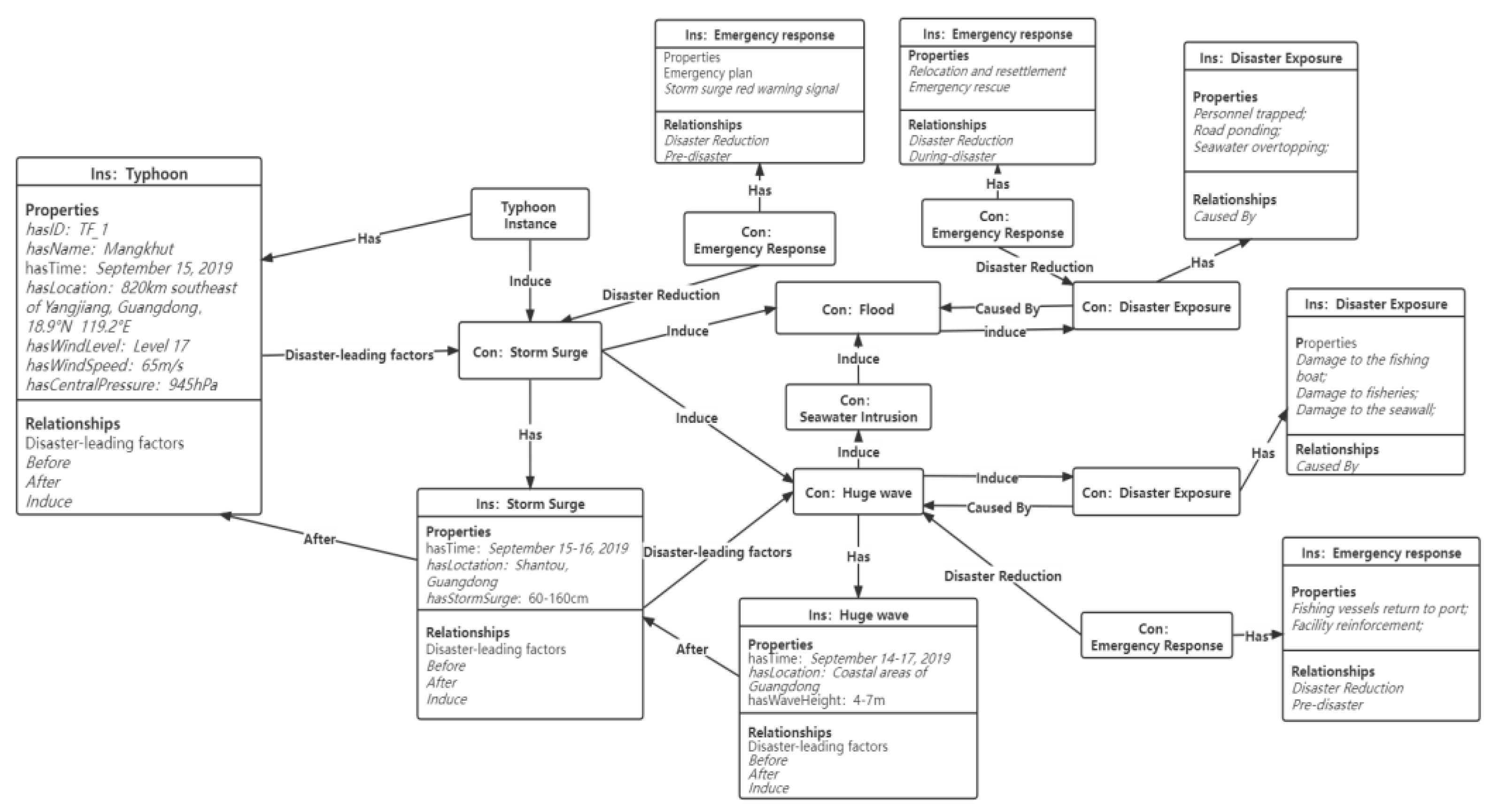
3.1. The Typhoon Disaster Chain Ontology Model
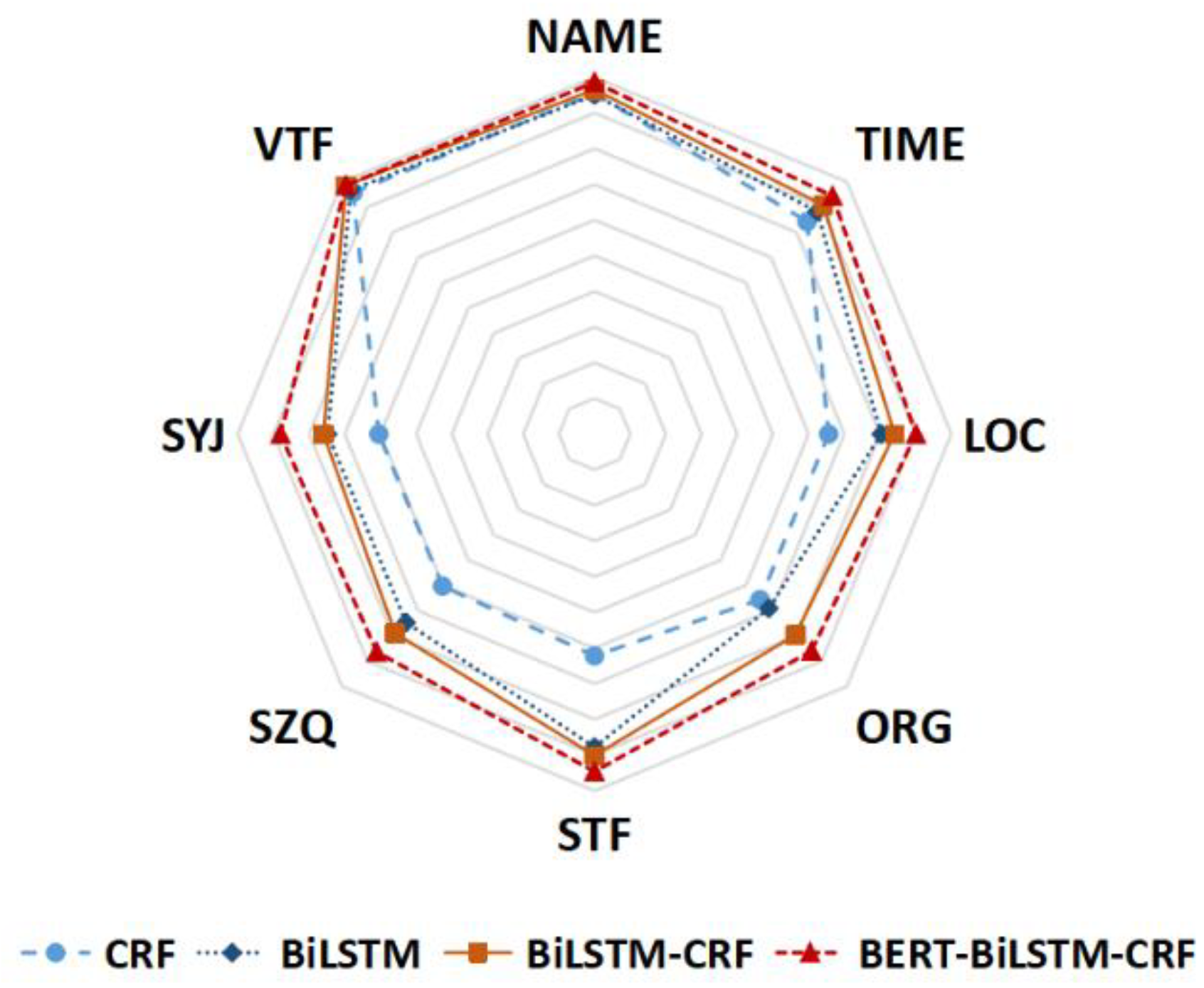
3.2. Extraction Results of Typhoon Disaster Information
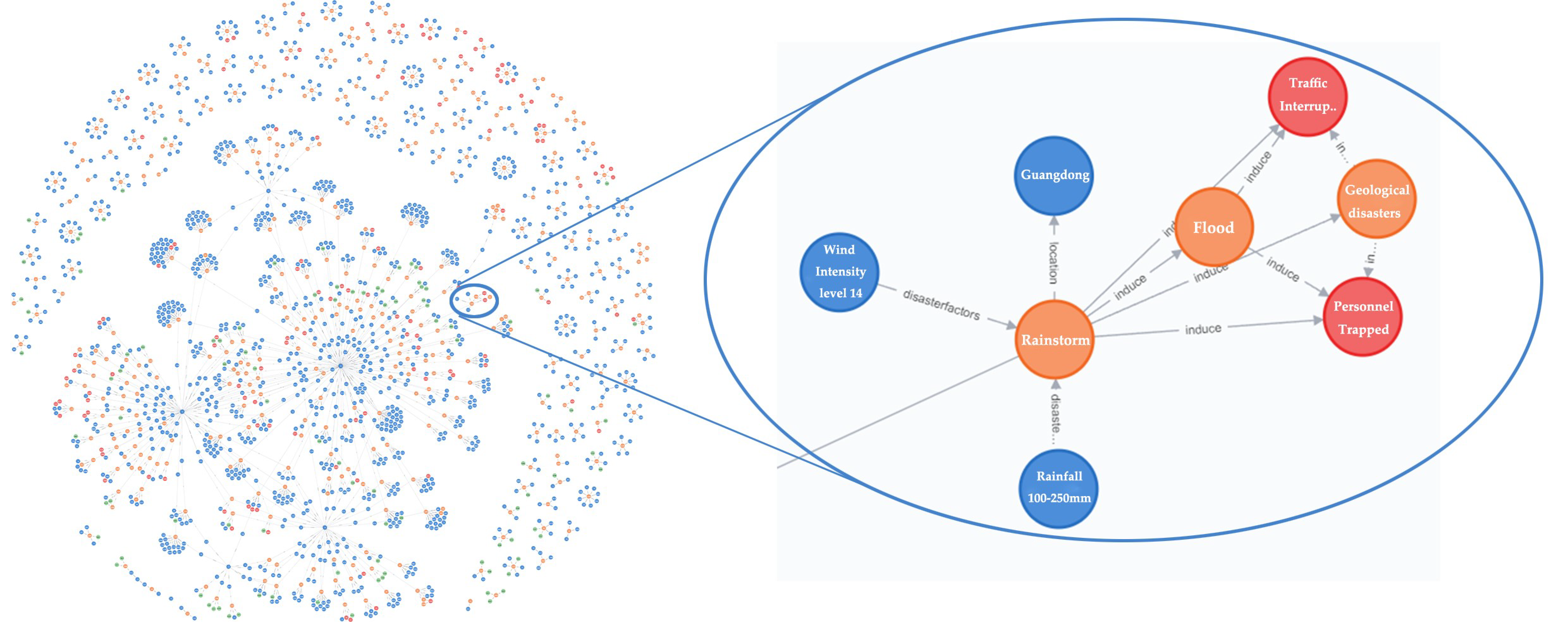
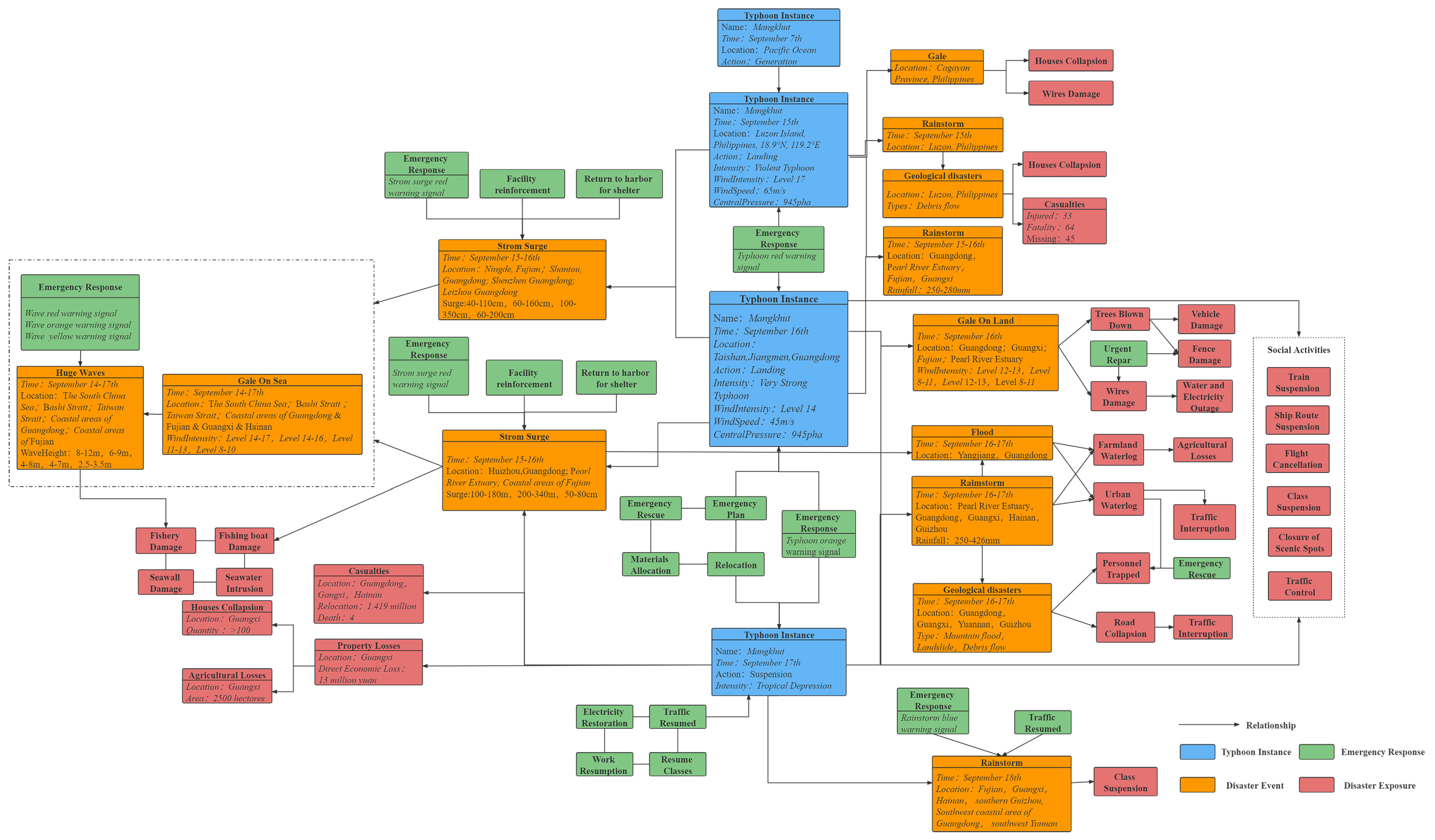
3.3. Construction of the Disaster Chain for Typhoon Mangkhut
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, W.; Xiao, S.; Sui, Y.; Zhou, J.; Gao, H. Analysis of natural disaster chain and chain-cutting disaster mitigation mode. Chin. J. Rock Mech. Eng. 2006, 25, 2675–2681. [Google Scholar]
- Ye, J.Y.; Lin, G.F.; Zhang, M.F. Spatial Characteristics of Typhoon Disaster Chains in Fujian Province. J. Fujian Norm. Univ. Nat. Sci. Ed. 2014, 30, 99–106. [Google Scholar]
- Hua, J.; Hu, H.F.; Chen, X.L.; Hou, Q.Q. Analysis of typhoon disaster chain and risk management in northward typhoon effecting Hebei. In Proceedings of the Fourth Symposium on Disaster Risk Analysis and Management in Chinese Littoral Regions (DRAMCLR 2019), Qingdao, China, 7 June 2019. [Google Scholar]
- Zhong, S.; Su, G.; Wang, F.; Chen, J.; Zhang, F.; Huang, C.; Huang, Q.; Yuan, H. A preliminary research on incident chain modeling and analysis. Commun. Comput. Inf. Sci. 2013, 399, 171–180. [Google Scholar]
- Liang, Z.; Fei, W.; Zheng, X. Complex network construction method to extract the nature disaster chain based on data mining. In Proceedings of the 2017 7th IEEE International Conference on Electronics Information and Emergency Communication (ICEIEC), Macau, China, 21–23 July 2017. [Google Scholar]
- Dunbar, P.K. Increasing public awareness of natural hazards via the Internet. Nat. Hazards 2007, 42, 529–536. [Google Scholar] [CrossRef]
- Peduzzi, P.; Herold, H. Mapping Disastrous Natural Hazards Using Global Datasets. Nat. Hazards 2005, 35, 265–289. [Google Scholar] [CrossRef]
- Kuzey, E.; Vreeken, J.; Weikum, G. A Fresh Look on Knowledge Bases: Distilling Named Events from News. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 1689–1698. [Google Scholar]
- Trivedi, R.; Dai, H.; Wang, Y.; Son, L. Know-Evolve: Deep Temporal Reasoning for Dynamic Knowledge Graphs. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 3462–3471. [Google Scholar]
- Gruber, T.R. Toward principles for the design of ontologies used for knowledge sharing? Int. J. Hum.-Comput. Stud. 1995, 43, 907–928. [Google Scholar] [CrossRef]
- Studer, R.; Benjamins, V.R.; Fensel, D. Knowledge Engineering: Principles and methods. Data Knowl. Eng. 1998, 25, 161–197. [Google Scholar] [CrossRef]
- Shi, G.; Barker, K. Extraction of geospatial information on the Web for GIS applications. In Proceedings of the IEEE 10th International Conference on Cognitive Informatics and Cognitive Computing (ICCI-CC’11), Banff, AB, Canada, 18–20 August 2011; pp. 41–48. [Google Scholar]
- Li, B.; Liu, J.; Shi, L.; Wang, Z. A method of constructing geo-object ontology in disaster system for prevention and decrease. In Proceedings of the International Symposium on Spatial Analysis, Spatial-Temporal Data Modeling, and Data Mining, Wuhan, China, 13–14 October 2009. [Google Scholar]
- Lu, H.; Xian-gang, L.; Hong-qi, C.; Jing, P.; Yi, C. A Visualization Model of Geological Disaster Emergency Scheme Based on Ontology. Open Cybern. Syst. J. 2014, 8, 393–398. [Google Scholar] [CrossRef][Green Version]
- Madhyastha, H.V.; Balakrishnan, N.; Ramakrishnan, K.R. Event information extraction using link grammar. In Proceedings of the Seventeenth Workshop on Parallel and Distributed Simulation 2003, San Diego, CA, USA, 10–13 June 2003; pp. 16–22. [Google Scholar]
- Sagcan, M.; Karagoz, P. Toponym Recognition in Social Media for Estimating the Location of Events. In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015; pp. 33–39. [Google Scholar] [CrossRef]
- Sagcan, M.; Karagoz, P. Neural Architectures for Named Entity Recognition. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 260–270. [Google Scholar]
- Chiu, J.; Nichols, E. Named Entity Recognition with Bidirectional LSTM-CNNs. Trans. Assoc. Comput. Linguist. 2016, 4, 357–370. [Google Scholar] [CrossRef]
- Huang, Z.; Wei, X.; Kai, Y. Bidirectional LSTM-CRF Models for Sequence Tagging. Comput. Sci. 2015, 3, 56–69. [Google Scholar]
- Ma, X.; Hovy, E. End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1064–1074. [Google Scholar]
- Xu, M.; Zhang, X.; Guo, L. Jointly Detecting and Extracting Social Events from Twitter Using Gated BiLSTM-CRF. IEEE Access 2019, 7, 148462–148471. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies 2019, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Zhang, W.; Jiang, S.; Zhao, S.; Hou, K.; Liu, Y.; Zhang, L. A BERT-BiLSTM-CRF Model for Chinese Electronic Medical Records Named Entity Recognition. In Proceedings of the 2019 12th International Conference on Intelligent Computation Technology and Automation (ICICTA), Xiangtan, China, 26–27 October 2019; pp. 166–169. [Google Scholar]
- Hou, J.; Li, X.; Yao, H.; Sun, H.; Mai, T.; Zhu, R. BERT-Based Chinese Relation Extraction for Public Security. IEEE Access 2020, 8, 132367–132375. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, M.; Che, W.; Liu, T.; Chen, W.; Li, H. Joint models for Chinese POS tagging and dependency parsing. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, EMNLP 2011, Edinburgh, UK, 27–31 July 2011; pp. 274–286. [Google Scholar]
- Suleiman, D.; Awajan, A.A.; al Etaiwi, W. Arabic Text Keywords Extraction using Word2vec. In Proceedings of the 2019 2nd International Conference on new Trends in Computing Sciences (ICTCS), Amman, Jordan, 9–11 October 2019; pp. 1–7. [Google Scholar]
- Guo, W.; Zeng, Q.; Duan, H.; Ni, W.; Liu, C. Process-Extraction-Based Text Similarity Measure for Emergency Response Plans. Expert Syst. Appl. 2021, 1, 115301. [Google Scholar] [CrossRef]
- Partner, J.; Vukotic, A.; Watt, N. Neo4j in Action; Manning Publications Co.: Shelter Island, NY, USA, 2014. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Annotation | Illustration |
|---|---|
| B | The beginning of the event-element |
| I | Other parts of the event-element |
| O | Parts that are not event-element; |
| name | The Name of typhoon (Name) |
| t | Time information (Time): Time of generation, landing, occurrence, suspension, stop coding, etc. |
| ns | Location information (LOC): location of generation, landing, occurrence, suspension, typhoon center, etc., as well as affected area, longitude and latitude. |
| nt | Organization information (ORG): government departments, schools, airports, etc. |
| stf | Disaster information (STF): Typhoon intensity, wind intensity, wind speed, central pressure, the elevation of storm surge, etc.; secondary disasters, such as storm surge, flood, landslide. |
| szq | Disaster exposure information (SZQ): casualties, property losses, agricultural losses, fisheries loss, etc. |
| syj | Emergency response information (SYJ): level of emergency response, emergency plan, urgent repairs, emergency rescue, etc. |
| vtf | Action of typhoon (VTF): generation, landing, approaching, strengthen, weaken, suspension, stop coding, etc. |
| Properties of Typhoon Instance | Data Content | Instance (In en-US) |
|---|---|---|
| Location | … | hasLocation: Taishan, Jiangmen, Guangdong |
| Time | X (Year) X (Month) X (Date) | hasTime: 16 September 2018 |
| Central Pressure | X hpa | hasCentralPressure: 945 hpa |
| Wind Intensity | Level X | hasWindIntensity: 14 |
| Wind Speed | XX m/s | hasWindSpeed:45 m/s |
| … | … | … |
| Type of Disaster | Properties of Disaster Event | Data Content | Relationships of Disaster Event | Instance (In en-US) |
|---|---|---|---|---|
| Storm surge | Location | … | (Storm surge) -[r:Caused By]-> (Typhoon); (Storm surge) -[r:Induce]-> (Huge wave) | hasLocation: Ningde, Fujian |
| Time | X (Year) X (Month) X (Date) | hasTime: 15 September 2018 | ||
| Storm Surge Elevation | X cm | hasStormSurge: 40–110 cm | ||
| … | … | … | … | |
| Huge wave | Location | … | (Huge wave) -[r:Caused By]-> (Storm Surge); (Huge wave) -[r:Induce]-> (Fishery losses) | hasLocation: Coastal areas of Guangdong |
| Time | X (Year) X (Month) X (Date) | hasTime: 15 September 2018 | ||
| Wave Height | X m | hasWaveHeight: 4–7 m | ||
| … | … | … | … |
| Type of Disaster Exposure | Properties of Disaster Exposure | Data Content | Relationships of Disaster Event | Instance (In en-US) |
|---|---|---|---|---|
| Personal casualty | Location | … | (Personal casualty) -[r:Caused By]-> (Typhoon) | hasLocation: Guangdong, Guangxi, Hainan |
| Fatality | X (Number) | hasFatality: 4 | ||
| Relocation | X (Number) | hasRelocation: 1.419 million | ||
| … | … | … | … | |
| Property damage | Location | … | (Property damage) -[r:Caused By]-> (Typhoon); | hasLocation: Guangxi |
| Direct economic loss | X (Yuan) | hasEconomicLoss: 113 million yuan | ||
| Houses destroyed | X (Number) | hasHouseDestroyed: 100 | ||
| Agricultural losses | X (Hectares) | hasAgriculturalLosses: 2500 hectares | ||
| … | … | … | … |
| Emergency Phase | Aim of Emergency | Missions of Emergency |
|---|---|---|
| Pre-disaster | Disaster early warning, Disaster prevention | Risk monitoring, Disaster early warning, Emergency plan |
| During-disaster | Emergency response, Emergency disposal | Urgent repairs, Relocation and resettlement, Emergency rescue, Resource allocation |
| Post-disaster | Reconstruction and restoration, Loss assessment | Disaster assessment, Social activity restoration, Infrastructure reconstruction |
| Dataset | Number of Characters | Number of Characters with Labels |
|---|---|---|
| Training Set | 457,524 | 239,798 |
| Dev. Set | 154,001 | 84,627 |
| Test Set | 154,095 | 78,894 |
| Model | CRF | BiLSTM | BiLSTM-CRF | BERT-BiLSTM-CRF | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Typhoon Event-Element | P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 |
| NAME | 0.9432 | 0.9708 | 0.9553 | 0.9503 | 0.9509 | 0.9506 | 0.9587 | 0.9726 | 0.9656 | 0.9827 | 0.9904 | 0.9863 |
| TIME | 0.8653 | 0.8217 | 0.8423 | 0.8854 | 0.8788 | 0.8821 | 0.9149 | 0.8995 | 0.9071 | 0.9476 | 0.9394 | 0.9432 |
| LOC | 0.6798 | 0.6353 | 0.6562 | 0.8028 | 0.8046 | 0.8037 | 0.8331 | 0.8494 | 0.8412 | 0.8950 | 0.9076 | 0.9011 |
| ORG | 0.6974 | 0.6270 | 0.6560 | 0.6352 | 0.7570 | 0.6907 | 0.8073 | 0.7848 | 0.7959 | 0.8612 | 0.8651 | 0.8598 |
| STF | 0.6743 | 0.5778 | 0.6216 | 0.8619 | 0.8935 | 0.8774 | 0.8929 | 0.9092 | 0.9010 | 0.9458 | 0.9446 | 0.9459 |
| SZQ | 0.6369 | 0.5755 | 0.6025 | 0.7366 | 0.7578 | 0.7471 | 0.8046 | 0.7760 | 0.7900 | 0.8535 | 0.8752 | 0.8637 |
| SYJ | 0.6977 | 0.5743 | 0.6046 | 0.7594 | 0.7275 | 0.748 | 0.7416 | 0.7767 | 0.7599 | 0.8655 | 0.8861 | 0.8802 |
| VTF | 0.9462 | 0.9728 | 0.9571 | 0.9676 | 0.9659 | 0.9668 | 0.9805 | 0.9910 | 0.9857 | 0.9799 | 0.9924 | 0.9854 |
| Mean Value | 0.7676 | 0.7194 | 0.7370 | 0.8249 | 0.8420 | 0.8333 | 0.8667 | 0.8699 | 0.8683 | 0.9164 | 0.9251 | 0.9207 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Luo, N.; Zhao, Q. Research on the Construction of Typhoon Disaster Chain Based on Chinese Web Corpus. J. Mar. Sci. Eng. 2022, 10, 44. https://doi.org/10.3390/jmse10010044
Liu H, Luo N, Zhao Q. Research on the Construction of Typhoon Disaster Chain Based on Chinese Web Corpus. Journal of Marine Science and Engineering. 2022; 10(1):44. https://doi.org/10.3390/jmse10010044
Chicago/Turabian StyleLiu, Hongliang, Nianxue Luo, and Qiansheng Zhao. 2022. "Research on the Construction of Typhoon Disaster Chain Based on Chinese Web Corpus" Journal of Marine Science and Engineering 10, no. 1: 44. https://doi.org/10.3390/jmse10010044
APA StyleLiu, H., Luo, N., & Zhao, Q. (2022). Research on the Construction of Typhoon Disaster Chain Based on Chinese Web Corpus. Journal of Marine Science and Engineering, 10(1), 44. https://doi.org/10.3390/jmse10010044