1. Introduction
In the era of Agriculture 4.0, precision orchard production achieves intelligent and refined management through smart technologies and decision support systems. The Internet of Things (IoT), drones, sensors, and satellite remote sensing technologies can monitor soil moisture, climate changes, pests and diseases, and fruit growth well, providing accurate data collection in real time. Big data analytics and cloud computing platforms efficiently process these data, assisting farmers in production dynamic analyses and trend forecasting. Control systems, such as smart irrigation, automated fertilization, and precision spraying, perform refined operations based on real-time data, significantly improving the resource utilization efficiency and crop yields. Furthermore, decision support systems based on big data and artificial intelligence help farmers optimize resource allocation, reduce costs, and enhance sustainability by analyzing historical data, weather forecasts, and crop growth models. Precision orchard production not only enhances productivity but also promotes agricultural ecological protection, driving the development of efficient, green, and intelligent agriculture. Rural revitalization has been vigorously promoted and small agriculture has been rapidly developing, and against such a backdrop, precise yield estimation during the fruit tree growth cycle and the intelligent management of orchards have become key research topics. Apple, as a common fruit with an extremely large growth area and sales, is a significant focus. As reported by the United Nations Food and Agriculture Organization, China is the largest apple producer worldwide, with a planting area of 2,088,080 hectares and an annual output of 45.97 million tons in 2021, accounting for over 50% of the global apple production. However, China’s apple industry faces challenges, such as labor shortages, high labor intensity, and low picking efficiency, necessitating the automation and intelligent transformation of the industry. The use of flying inspection robots and artificial intelligence for the regular visual inspections of apple orchards is becoming increasingly important, with machine-vision-based apple detection, tracking, and counting methods emerging as key technologies. As machine vision, robotics, and artificial intelligence technologies continue to evolve, related research has gradually been applied to apple pruning, yield estimation, and harvesting, and research into intelligent fruit-picking technologies is gaining momentum [
1,
2,
3,
4]. However, a high fruit growth density in apple orchards, particularly in non-structured environments with low-stem-density planting [
5], results in fruit often being obscured by branches and leaves, leading to significant overlapping and occlusion. This complicates the target detection and recognition, reduces the accuracy, and presents a challenge that must be addressed in intelligent management.
To address the challenges in fruit detection, researchers put forward various solutions by combining traditional image processing and machine learning algorithms. Traditional techniques for fruit detection typically focus on feature extraction, using color, shape, and texture, which, however, exhibit a low detection accuracy and poor generalization in complex scenarios, such as lighting variations, fruit occlusion [
6], and environmental changes. For instance, Gongal et al. [
7] used RGB-to-HIS conversion, histogram equalization, and threshold segmentation for apple recognition. Wang et al. [
8] applied wavelet transforms to reduce lighting effects in fruit images with complex backgrounds. Chaivivatrakul et al. [
9] introduced a texture analysis for detecting green fruits affected by lighting. Bulanon et al. [
10] enhanced the red channel to improve apple target extraction. Some researchers also incorporated human observation or wind-blown leaves to reduce occlusion [
11], and others focused on color features [
12] or local textures [
13] using support vector machines for detection [
14]. Mai et al. [
15] used the Log-Hough transform to extract apple shape features. Lin et al. [
16] developed a detection algorithm that combines color, depth, and shape but struggles with occlusion. Lv et al. [
17] utilized R-G color features for segmentation, while Luo et al. [
18] applied k-means clustering for grape cluster detection. Si et al. [
19] introduced apple segmentation using the red–green difference and template matching. Moallem et al. [
20] combined morphological methods with a Mahalanobis distance classifier for stem detection. Despite progress, these traditional methods face limitations in handling challenges, including lighting changes, complex backgrounds, and occlusion, often resulting in a low recognition accuracy and poor boundary localization. These issues highlight the need for improvements in robustness and adaptability in fruit detection systems.
Traditional fruit image detection techniques and machine learning algorithms face limitations in complex environments, making them unsuitable for practical applications. Deep convolutional neural networks (CNNs) have become the dominant approach in fruit target detection due to their robustness and generalization capabilities [
21]. CNN-based detection algorithms are typically categorized into two-stage and single-stage models. Two-stage algorithms classify the generated candidate regions using a CNN to detect targets, with notable examples being Fast R-CNN and Faster R-CNN. For instance, Häni et al. [
22] combined deep learning with a semi-supervised Gaussian mixture model for high-precision apple detection in natural environments. In the study by Xiong et al. [
23], Faster R-CNN was employed for the detection of citrus fruits under various conditions, where it achieved detection accuracies of 77.45%, 73.53%, and 82.58% for different lighting conditions, sizes, and quantities. Peng et al. [
24] improved fruit detection using SSD based on ResNet-101, while Juntao et al. [
23] achieved a mean average precision (mAP) of 85.49% for citrus fruit detection using Faster R-CNN. Sun et al. [
25] applied ResNet50 for Faster R-CNN to detect tomatoes. However, while two-stage algorithms perform well in unobstructed scenarios, they struggle with dense fruit and occlusion, exhibiting lower robustness and generalization in such settings. Additionally, their high computational complexity and slower detection speed limit their practicality. Thus, improving the detection accuracy under occluded conditions and enhancing real-time performance remain significant challenges for practical applications.
The YOLO (You Only Look Once) algorithm exhibits excellent real-time performance and accuracy, making it commonly used for fruit target detection and widely applied in fruit detection, yield estimation, and plant trait research. To address challenges such as occlusion in complex environments, various improvements were proposed to enhance the detection performance. For example, Chu et al. [
26] developed a region-based detection model to handle severe occlusion and a high amount of overlap. In their study [
27], YOLOv7 added with a small-object detection layer and lightweight convolutions presented improved citrus fruit detection accuracy. Praveen et al. [
28] optimized YOLOv5 by integrating adaptive pooling and attribute enhancement, particularly enhancing apple detection in complex scenes. Li et al. [
29] obtained an improved YOLOv4-Tiny-based model by combining attention mechanisms with multi-scale predictions to enhance the way occluded and small targets were recognized. Lai et al. [
30] developed a YOLOv7 model for pineapple recognition, incorporating the SimAM attention module and replacing NMS with soft-NMS to boost the accuracy. Tian et al. [
31] proposed YOLOv3-dense, which improved the detection accuracy for overlapping and occluded apples. Zhou et al. [
32] introduced a fusion method integrating visual perception and image processing, ensuring that YOLOv7 bounding boxes for oil tea fruits matched extracted centroid points. Ji et al. [
33] improved YOLOX by integrating the Shufflenetv2 attention mechanism and CBAM, enhancing apple detection. Wu et al. [
34] combined YOLOv7 with an enhanced dataset, constructing the DA-YOLOv7 model for tea fruit recognition, achieving over 96% accuracy. Liu et al. [
35] used CA attention and BiFPN to improve YOLOv5 with a zoom loss function. Wang et al. [
36] applied variant convolutions and SE attention in YOLOv7-Tiny to improve the detection accuracy for chili peppers at different maturity stages. Zhao et al. [
37] combined CSPNet and residual modules in YOLOv3 to enhance the apple detection in complex environments. Yang et al. [
38] adopted an enhanced CenterNet network for the enhancement of the detection speed and accuracy for multi-apple detection in dense scenes.
Researchers developed various methods for object tracking and counting in recent years. Kuhn et al. introduced the SORT algorithm, which uses the intersection over unit (IOU) and the Hungarian algorithm to associate targets across frames in real time [
39]. Henriques et al. proposed the KCF algorithm, which tracks targets by extracting features from the initial frame and applying regression methods in subsequent frames [
40]. Xu Liu et al. used semantic segmentation to determine apple center positions, combined with 3D reconstruction for matching and counting; however, this method is time-consuming [
41]. Stein et al. and Bargoti and Underwood adopted multi-view imaging and the Hungarian algorithm for fruit tracking [
42,
43]. Wojke improved the DeepSort algorithm to enhance the tracking accuracy in occluded environments and reduce the frequency of ID switching [
44]. Halstead et al. applied IOU to track chili pepper fruit counting [
45]. Bhattarai et al. designed a VGG16-based method to estimate apple counts from single images [
46]. Nicolai Hani et al. tended to simplify the problem to apple cluster detection and classification based on the number of apples within the clusters [
47]. These studies provide various methods for accurate fruit tracking and counting; however, there is still potential for improvements in real-time processing and accuracy.
The YOLO model is characterized by strong accuracy, fast recognition, and ease of deployment in object detection. However, in complex natural environments, such as those with a high density of apple fruit, leaf occlusion, and fruit overlap, existing object detection and tracking algorithms still face challenges. Specific issues include the following: (1) In complex scenarios, such as occlusion, the target detection network suffers from significant parameter redundancy and computational load. (2) In unstructured apple orchard environments, the model is incapable of extracting features of targets at varying scales well, leading to missed or misidentified target fruits and a low accuracy when dealing with occlusion, overlap, or small objects. (3) In complex scenes, the model’s convergence speed is slow, and its optimization capability is inadequate. (4) There are also issues with tracking prediction mismatches across video frames due to fruit occlusion by leaves or surface changes. On these accounts, existing algorithms exhibit poor effectiveness in practical, complex environments.
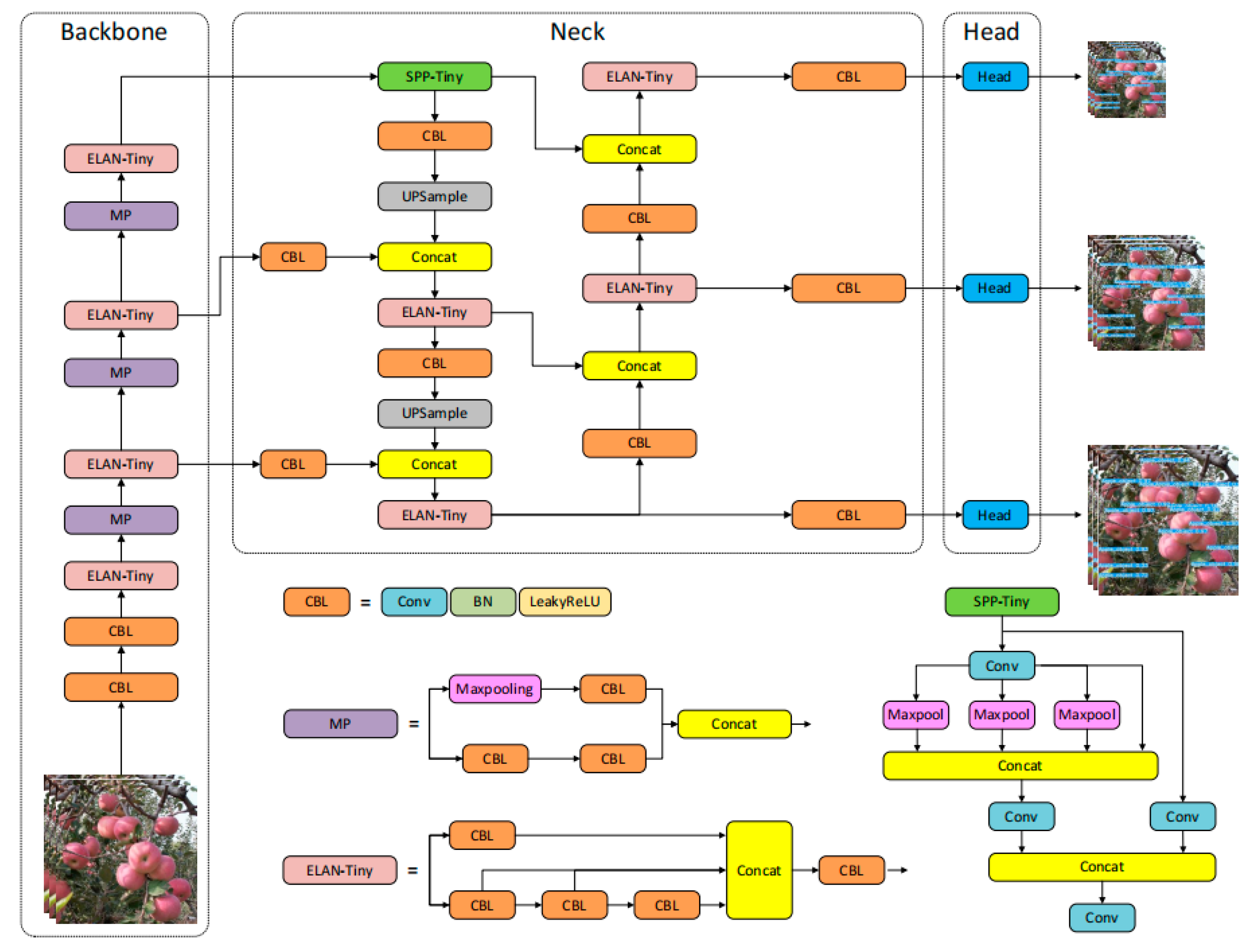
To ensure that apple fruit detection performs better in complex scenes and satisfies the requirements of lightweight edge devices, the existing model framework shall be optimized. Therefore, with the aim of achieving the accurate and fast recognition and counting of apples in complex environments, this study developed an improved YOLOv7-Tiny-PDE method based on the YOLOv7-Tiny model to handle apple fruit detection and tracking.
This study made contributions primarily from four perspectives:
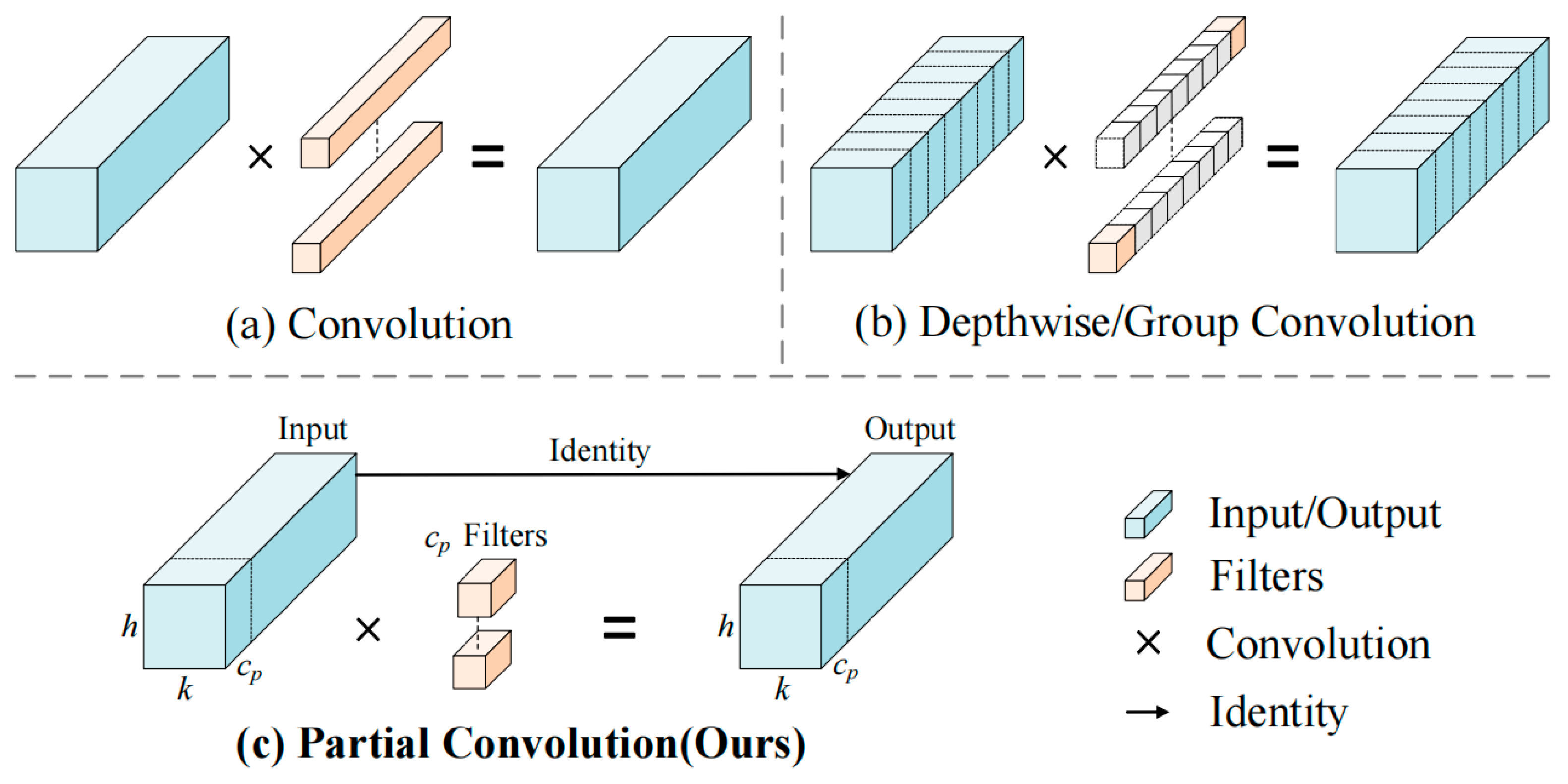
(1) Partial convolution (PConv) was used to replace the simplified efficient layer aggregation network (ELAN) in the backbone network, effectively reducing the network parameters and redundant computations while maintaining the detection accuracy.
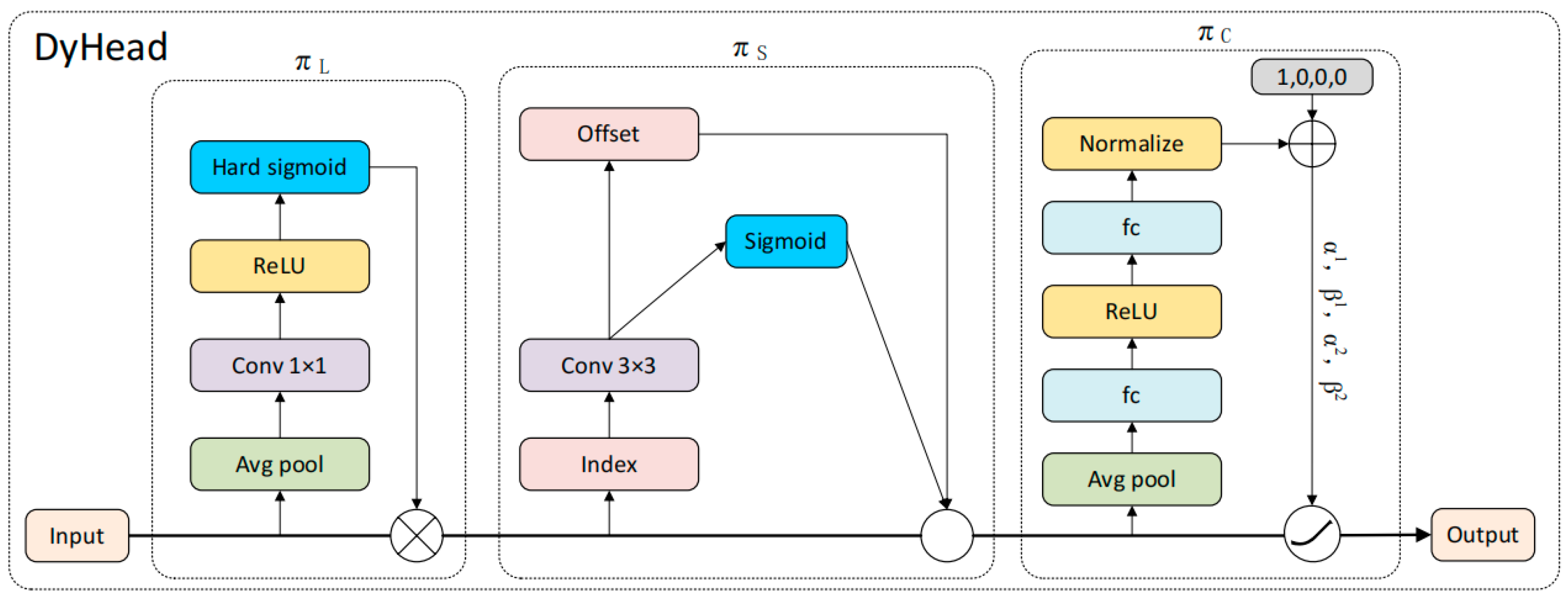
(2) The original detection head was replaced with a dynamic detection head (DyHead), which effectively suppresses background interference and captures background features more comprehensively, thereby improving the detection accuracy of occluded targets at different scales and enhancing the ability to extract fruit features.
(3) The boundary box loss function complete intersection over union (CIOU) loss was replaced with efficiency intersection over union (EIOU) loss, which minimizes the differences in width and height between the predicted and ground truth boxes, thereby accelerating the model’s convergence speed and effectively improving the optimization performance.
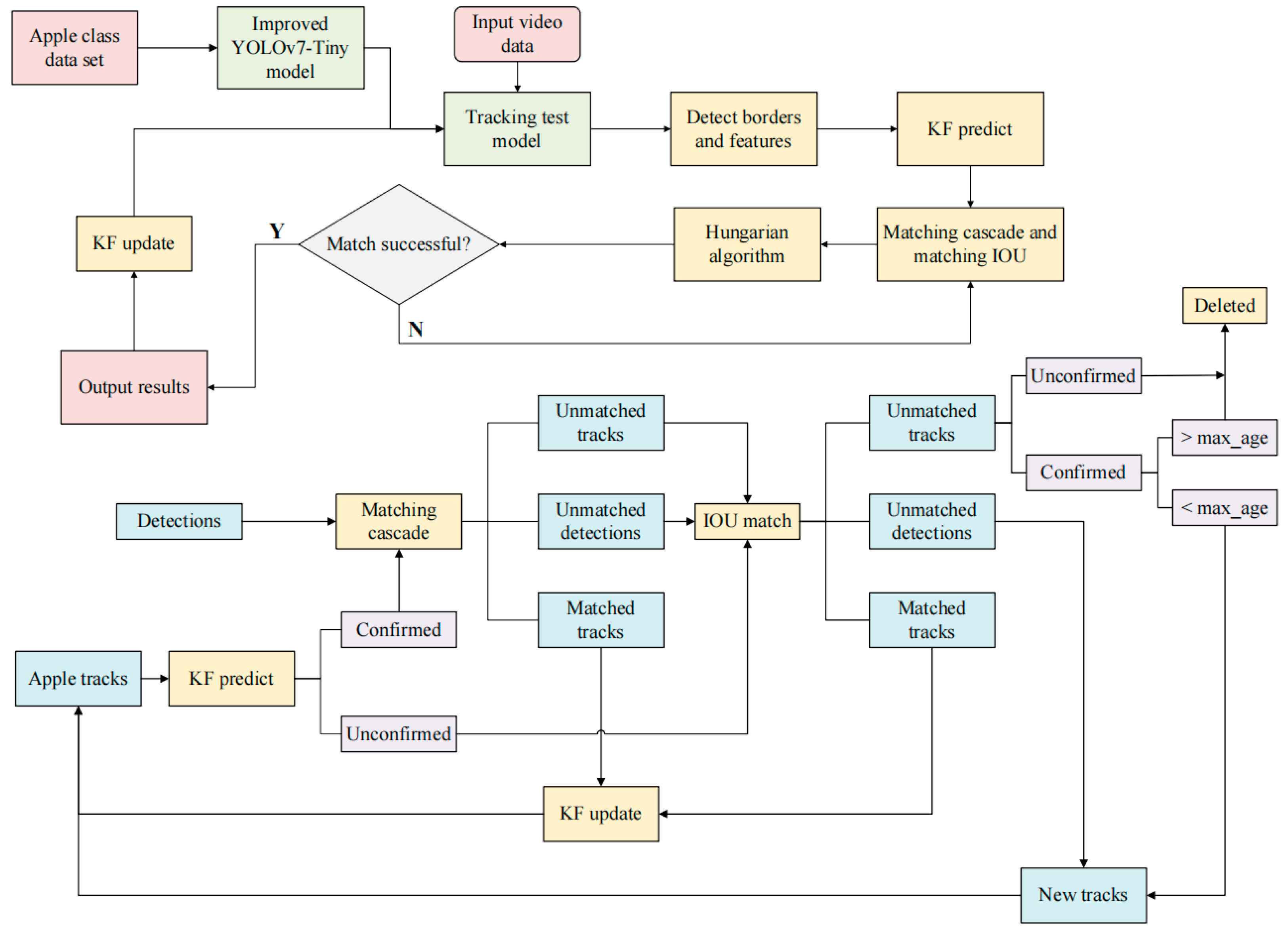
(4) The improved model was combined with the DeepSort algorithm and further integrated with the Kalman filter (KF) state prediction algorithm, the motion-based cascade matching algorithm, and the Hungarian algorithm to achieve the precise tracking and counting of fruit.
3. Results and Analysis
3.1. Comparison of Detection and Counting Results of Varying Detection Models
In natural apple orchards, apple fruit are often partially obscured due to mutual overlapping or occlusion by leaves and branches, leading to the loss of some contour information, making it more difficult to achieve fruit detection. As the degree of occlusion intensifies, much more fruit contour information will be lost, and the size information of the occluded regions will be reduced, which further complicates the detection task. Therefore, analyzing the model’s detection accuracy under varying occlusion conditions is crucial. With the purpose of enhancing the model’s performance in apple fruit detection, we selected several lightweight models, namely, MobileNetv2; ShuffleNetv2; and the YOLO series models YOLOv8n, YOLOv8s, YOLOv9s, YOLOv10s, and YOLOv11n. We also used mainstream object detection networks from the YOLOv7 series, namely, YOLOv7, YOLOv7x, and YOLOv7-Tiny. Additionally, we included the newly improved YOLOv7-Tiny-PDE, for a total of 11 models for comparative testing. During the training, all models used the same training dataset and maintained consistent hyperparameters. After the training, the best-performing network weights were selected for testing and evaluated on the same test set. The test set consisted of 420 apple images that covered various complex scenarios, and the comprehensive evaluation results are shown in
Table 1.
According to the experimental results, the YOLOv7-Tiny-PDE model could balance the lightweight design and detection performance well. Specifically, the model had a low parameter count (4.68M) and computational complexity (10.7 GFLOPs), ranking just behind the lightweight models, such as MobileNetv2, ShuffleNetv2, and YOLOv8n. At the same time, these values were significantly lower than those of the high-performance models, such as YOLOv9s and YOLOv10s, demonstrating its advantages in computational and storage resources. While maintaining a low computational complexity, YOLOv7-Tiny-PDE exhibited an mAP@0.5 of 97.90%, ranking first among all the compared models, as well as significantly outperforming the other models, such as ShuffleNetv2 (95.60%) and YOLOv7x (94.20%), thereby proving its superior detection capability. Additionally, YOLOv7-Tiny-PDE achieved the highest values for the recall rate (R = 96.60%) and F1 score (0.969), indicating that it maintained a high detection accuracy while also achieving a low false-negative rate. Although YOLOv9s and YOLOv10s slightly outperformed in the two mAP metrics, their GFLOP values were 26.7 and 24.4, respectively, which were significantly higher than the computational complexity of YOLOv7-Tiny-PDE. Compared with the original YOLOv7-Tiny model, the improved model demonstrated a 22.2% reduction in the total parameter count, a 18.3% reduction in computational complexity, an 0.5% increase in the p-value, a 2.7% increase in the recall rate, a 4% increase in the mAP@0.5 score, and 1.7% increase in the F1 score.
The complexity of the model is an important evaluation metric. In terms of the parameters, YOLOv7-Tiny-PDE had a parameter count of 4.68M, which is considered to be at a medium–low level; it is slightly higher than that of YOLOv8n and YOLOv11n, but obviously lower than that of MobileNetv2; ShuffleNetv2; and most other YOLO series models, such as YOLOv8s with 11.17M, YOLOv9s with 7.17M, and YOLOv10s with 8.04M, indicating that its parameter scale was relatively manageable. In terms of the GFLOPs, YOLOv7-Tiny-PDE had a value of 10.7, which was slightly higher than that of YOLOv8n and YOLOv11n and just behind that of the lightweight MobileNetv2 (10.2) and ShuffleNetv2 (10.6). It was significantly lower than that of YOLOv7 (103.2) and YOLOv7x (188.0), demonstrating its reliability in computational resource requirements.
Clearly, the improved YOLOv7-Tiny-PDE model exhibited a lower computational complexity and smaller model size while achieving a detection accuracy comparable to or even surpassing that of some high-performance models, demonstrating a balance between lightweight design and high precision. Furthermore, we randomly selected 10 apple images for fruit counting.
Table 2 lists the detection-counting results of different models.
3.2. Comparative Experiments of Different Detection Models in Various Environments
In unstructured orchards, the scene complexity is significantly higher. Considering the inherent growth characteristics of fruit trees, the fruits can usually be obscured by branches and leaves or partially damaged. Additionally, fruits of varying sizes and shapes tend to overlap, causing incomplete contour information for some fruits. During the feature extraction process, information from the occluded regions is further reduced, which undoubtedly increases the difficulty of detection. Furthermore, variations in field lighting conditions, such as direct sunlight and backlighting, introduce additional interference, making fruit recognition and counting even more challenging. Against such a backdrop, this study compared the performance of the YOLOv7x model, which is known for its superior detection accuracy; the lightweight YOLOv7-Tiny model; and the improved YOLOv7-Tiny-PDE model.
Figure 11,
Figure 12,
Figure 13 and
Figure 14 highlight the detection failure regions in different environments using green and red bounding boxes.
3.2.1. Comparison of Detection Results Under Varying Occlusion Conditions
We analyzed the accuracy of the models in recognizing apples with different levels of occlusion, aiming at assessing the detection performance of apples under various occlusion conditions. The lightly occluded test set A and the heavily occluded test set B were selected as the occlusion test datasets.
Table 3 lists the detection results of the three models.
As shown in
Figure 11, in scenarios with slight occlusion, both YOLOv7x and YOLOv7-Tiny could identify relatively prominent targets. However, due to the occlusion, the networks exhibited limited capabilities in extracting the contour features of the fruit, which resulted in some missed detections. In contrast, the improved YOLOv7-Tiny-PDE, enhanced with the DyHead module, demonstrated significantly improved sensitivity and representation abilities for target region features. This enhancement allowed the network to more accurately extract fruit boundary features from complex backgrounds, which effectively increased the detection accuracy of the apple positions.
As shown in
Figure 12, occlusion leads to the loss of certain target features, and both YOLOv7-Tiny and YOLOv7x still exhibited missed detections under the same occlusion conditions. When the occlusion area exceeded 80%, the models struggled to effectively locate the fruit’s boundaries and contours. In contrast, the improved YOLOv7-Tiny-PDE excelled at accurately detecting the occluded fruit, demonstrating a superior feature extraction capability. In summary, the proposed YOLOv7-Tiny-PDE network exhibited strong detection performance under varying degrees of occlusion.
3.2.2. Detection Result Comparison Under Varying Lighting Conditions
To assess whether the model was robust under varying lighting conditions, we selected 100 images that faced the light and 100 images that faced away from the light from the original dataset to form test sets C and D. During the field validation, we observed that the lighting conditions also affected the recognition and counting of the fruit.
Table 4 lists the detection results. Under frontlit conditions, all three models exhibited a good detection performance. However, under backlit conditions, the insufficient lighting severely impacted the fruit’s color and texture features; hence, all three models exhibited a weaker detection performance.
As shown in
Figure 13, under well-lit conditions, when there was mutual occlusion between the leaves and fruit, the detection results of YOLOv7x and YOLOv7-Tiny still exhibited missed detection issues. In contrast, the improved YOLOv7-Tiny-PDE did not show any missed detections, which could be attributed to its better capture of the semantic color information of the fruit.
As shown in
Figure 14, under backlit conditions, YOLOv7-Tiny presented an obviously worse recognition performance versus the other two networks, with two apple targets being missed. YOLOv7x also failed to detect one fruit. In contrast, the improved YOLOv7-Tiny-PDE demonstrated better overall detection performance in this scenario, with no missed detections.
The above findings indicate that under low-light conditions, the network could not extract effective texture information of the fruit well due to their less pronounced color features. Furthermore, overlap and occlusion between the leaves and fruit exacerbated the detection challenge, which led to some fruit not being accurately recognized. Hence, the YOLOv7-Tiny-PDE network demonstrated superior detection performance under complex lighting conditions and exhibited higher recognition rates and lower missed detection rates in various lighting scenarios; hence, it applies better to fruit detection tasks in complicated orchard environments.
3.3. Ablation Study
This study employed a controlled variable method for comparatively examining the baseline model, with the objective of verifying whether the proposed model could effectively detect apple fruit. In this ablation study, a detection speed comparison metric was introduced, which included the total time for image preprocessing, non-maximum suppression (NMS), and inference. A lower value for this metric indicates better overall model performance. The five models were compared, with the results listed in
Table 5. Based on the YOLOv7-Tiny network, we progressively set up ablation experiments. Specifically, Model 1 served as the baseline, while Models 2–4 introduced PConv, DyHead, and the EIoU loss function into the YOLOv7-Tiny architecture, respectively. Models 5–7 integrated two of the proposed improvements into the YOLOv7-Tiny baseline model, and Model 8 represented the YOLOv7-Tiny-PDE model.
According to
Table 5, replacing the original backbone’s ELAN with a Fasternet-based PConv increased the average precision by 0.5%. This improvement was due to PConv’s focus on shallow features, enabling the better extraction of texture and edge information for small-scale targets. By enhancing local feature weighting, the model better emphasized visible regions (e.g., unobstructed apple stems or edges), which led to a 0.2% recall increase, indicating effective spatial information retention and the mitigation of feature loss from occlusion. Despite balancing lightweight design and accuracy, PConv’s detection of extremely small targets (diameter < 50 pixels) remained limited. Additionally, the total parameters decreased by 21.3%, the GFLOPs decreased by 18.3%, and the detection speed improved by 3.5%. Since the original detection head in the neck network was replaced by DyHead, due to the correlation between precision and recall, the precision increased by 1.1%, while the recall decreased by 3.6%. However, the mAP rose by 3.3%, and the detection speed rose by 14.1%. This improvement intensified the model’s detection accuracy, as well as maintained the computational efficiency, and it provided better feature enhancement for multi-scale targets in complicated scenes. Finally, with the original CIoU loss function being replaced by the EIoU loss function, both the precision and accuracy improved a lot, with a significant 21.2% increase in the detection speed and a notably optimized convergence speed for target localization. The model parameters for all three combinations of the two improvement schemes were significantly reduced. In the PConv+DyHead scheme, the accuracy increased by 1.3%, the mAP improved by 2.9%, and the detection speed was enhanced by 4.7%. In the PConv+EIoU scheme, the mAP increased by 2.2%, and the detection speed improved by 9.5%, but the accuracy slightly decreased. In the EIoU+DyHead scheme, the accuracy, mAP, and detection speed all showed significant improvements.
After introducing the three improvement methods, the recall increased by 2.7%, the precision improved by 0.5%, the mAP rose by 4.0%, the F1 score rose by 1.6%, and the detection time decreased by 11.6%. The combination of these three modifications effectively leveraged their corresponding advantages, which resulted in an overall performance enhancement. This outcome confirms that the improved model, YOLOv7-Tiny-PDE, demonstrated efficiency and stability in handling complex scenes, particularly in the recognition and localization of occluded, dense, and multi-scale targets. The model shows advantages in being more lightweight, accurate, and easier to deploy.
3.4. Comparison Experiment of Detection Head Attention Mechanism
Compared with single-level attention modules, such as CBAM, DyHead dynamically adapts to the detection requirements of multi-scale targets in complex scenarios by jointly optimizing the scale, spatial, and task-aware features. According to
Table 6, the F1 score of DyHead (0.972) significantly outperformed those of CBAM (0.948) and SE (0.932). Its multi-level attention mechanism was more effective at extracting local salient features of occluded apples (e.g., stems or edge textures).
The experiments demonstrated that DyHead, while maintaining a lightweight design, significantly outperformed the traditional attention modules at dynamic feature aggregation. For example, under similar parameter counts, although DyHead’s computational complexity was slightly higher than that of CBAM and SE, its mAP@0.5 improved by 2.6% and 3.9% compared with that of CBAM and SE, respectively, which validated its overall advantages in complex orchard scenarios.
3.5. Improved Network Model Combined with DeepSort for Counting Performance
The improved YOLOv7-Tiny and YOLOv7-Tiny-PDE models were combined with the DeepSort algorithm to track and count apple fruit.
Figure 15 illustrates the counting results.
To validate the performance of the combined algorithm, the pre- and post-improvement model weights were integrated into the DeepSort algorithm and applied to video detection tasks for the evaluation of the tracking and counting effectiveness. In this study, the MOTA metric was used to assess the tracking performance on five selected apple fruit video segments as test inputs.
The
MAE (mean absolute error) was used to test the difference in the average absolute error between the predicted and true values. By taking the absolute value, this disregards the direction of the error (positive or negative), ensuring that all differences are non-negative. A smaller MAE value indicates a higher prediction accuracy.
In this equation, x_test(i) represents the ground truth count obtained through manual annotation in the video sequence, while y_test(i) denotes the predicted count generated by the multi-object tracking algorithm. The variable m indicates the total number of videos being evaluated, and i is the index of the current video. This metric directly assesses the overall performance of the model and serves as an effective measure of the detection and counting accuracy.
Table 7 presents the MOTA of the detection results after combining the pre- and post-improvement models with the DeepSort tracking algorithm, as well as the MAE between the improved overall algorithm and the manual counting results. Here, target number A and target number B represent the number of targets before and after the improvement, respectively, while MAE-A and MAE-B denote the average error values of the models before and after the improvement when combined with DeepSort.
As shown in
Table 8, for the selected video segments, the improved algorithm’s MOTA increased by 2.2% compared with the baseline model. The number of identity switches (IDSWs) was significantly reduced, and the IDF1 score improved by 10.9%, demonstrating the enhanced target association consistency provided by the DyHead and EIoU loss function. However, tracking failures still occurred when the fruit was occluded by dense branches and leaves at a rate of over 90% and when there were sudden motion changes between consecutive frames. In such cases, the tracking algorithm may experience identity switches due to the loss of appearance features.
3.6. Algorithm Performance Evaluation in Field Scenarios
In practical orchard deployment, the algorithm’s energy consumption directly affects the device’s endurance and usability. The YOLOv7-Tiny-PDE algorithm was deployed on a drone platform (P230) during the field validation in this study, with the aim of assessing the improved model’s energy efficiency. The drone was equipped with a powerful Graphics Processing Unit (GPU) and applied the NVIDIA Jetson AGX Xavier embedded platform to the processing of the algorithm [
51]. The testing scenarios covered various lighting conditions (frontlit and backlit) and occlusion environments (mild occlusion and dense occlusion). The system was run for a continuous 10 min video stream detection task, recording both the average and peak power consumptions.
The test results indicate that YOLOv7-Tiny-PDE exhibited significant energy consumption advantages while maintaining a high detection accuracy. According to
Table 9, the average power consumption of the improved model was 8.3 W, 17.8% lower than that of the baseline YOLOv7-Tiny (10.1 W). In dense occlusion scenarios, the collaborative optimization of the DyHead and EIoU loss function improved the model inference efficiency, where it reduced the peak power consumption from 12.5 W to 10.9 W, a decrease of 12.8%. Additionally, a comparison of different hardware load states (GPU utilization) shows that the PConv module effectively reduced the memory access frequency, which led to a decrease in the GPU utilization from 78% to 65%, and thus, further reduced the energy consumption fluctuations.
This result confirms that the lightweight design of the improved model significantly reduced the computational redundancy while also lowering the energy consumption in the field deployments. It provides feasible support for the long-term operation of resource-constrained devices, such as drones and mobile robots.
4. Conclusions
This study integrated PDE into the original YOLOv7-Tiny model to obtain the improved YOLOv7-Tiny-PDE algorithm, combined with the DeepSort algorithm. “PDE” stands for partial convolution (PConv), dynamic detection head (DyHead), and loss function (EIOU). The algorithm uses regular convolutions to replace an efficient layer aggregation network in the backbone, substitutes the CIoU loss function, and replaces the original detection head in the neck network to enable apple detection and counting.
In complex scenarios with occlusion, object detection networks often struggle with parameter redundancy and a high computational load. PConv reduces parameters and unnecessary computations while maintaining detection accuracy. In unstructured apple orchards, particularly in complex scenes and multi-scale target situations, feature extraction is often insufficient, resulting in missed or incorrect detections. Introducing the DyHead effectively suppressed the background interference and captured features more comprehensively, which improved the detection accuracy for various scales and occlusions. The EIOU loss function accelerated the model convergence by minimizing the difference between the predicted and practical truth boxes in terms of the width and height, and thereby enhanced the optimization performance.
The improved model excelled at apple recognition and localization, where it enabled precise detection and tracking in complex environments while it enhanced the model’s lightweightness, accuracy, and counting performance. The experimental results show that the improved YOLOv7-Tiny-PDE algorithm performed better than the custom apple dataset: the parameters were reduced by 22.2%; the GFLOPs were reduced by 18.3%; the P and R values increased by 0.5% and 2.7%, respectively; the mAP@0.5 and F1 scores were increased by 4% and 1.7%; and MOTA was increased by 2%. These improvements will assist orchard managers in achieving more efficient orchard management, reducing labor costs, and accurately and intelligently estimating the fruit yield in complex natural environments.
Based on the existing research status in the fields of object detection and fruit yield estimation, future research directions can be envisioned in the following aspects:
(1) Small fruit targets and growth cycle patterns: The performance of current algorithm in detecting small targets shall be further improved. Further optimization is required, as the existing dataset lacks sufficient differentiation in color and maturity for apples at different growth stages, particularly for light-colored, immature, or yellow-green apples, which are underrepresented in the detection samples. Variations in apple varieties at the same maturity stage may also lead to estimation biases, indicating significant potential for improving the accuracy of actual fruit yield estimation.
(2) Generalization and real-time deployment: The current data collection is limited in time and location, making it difficult to fully represent diverse orchard environments and potentially affecting the model’s generalization ability. Future research will explore model compression and channel pruning techniques to accurately trim redundant channels without compromising the detection accuracy, thereby reducing the model size and improving the efficiency. Additionally, the model will be adapted to hardware devices used in practical agricultural environments in order to ensure efficient operation on such devices.
(3) Stability between video frames: Future work will explore the integration of time-series models, such as long short-term memory (LSTM) networks or gated recurrent units (GRUs), to effectively integrate temporal information between video frames. By learning feature variations in the time dimension, this approach improves the model’s prediction accuracy of fruit movement trajectories, thereby enhancing the tracking stability.
Future work will explore advanced improvement methods and evaluation criteria, along with multi-object tracking models, to balance the lightweight design, detection accuracy, and speed. Techniques such as model compression and channel pruning will enhance the efficiency. Data collection will expand to cover diverse times, regions, and growth stages. The focus will also be on deploying lightweight networks on embedded and resource-constrained edge devices, minimizing the accuracy loss and enhancing the practical applicability.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}