1. Introduction
With the aging of the global population and the increasing shortage of agricultural labor, modern agriculture is facing unprecedented challenges [
1]. Against this backdrop, the rapid development of smart agricultural technology becomes an important driving force for promoting agricultural transformation. As a popular fruit, cherry tomatoes play an important role in global agricultural production due to their appeasing taste and richness in lycopene [
2]. However, due to the small size and uneven distribution, their harvesting faces significant challenges. Existing mechanical picking equipment often misses fruits or mistakenly picks leaves because it is difficult to accurately identify the location of the fruit, making it difficult to effectively improve robotic harvesting efficiency and quality. Therefore, developing efficient and intelligent identification and position detection for cherry tomatoes is the key to improving production efficiency and fruit quality.
Fruit detection is one of the core components of fruit-harvesting robots [
3]. In recent years, Deep Neural Networks (DNNs) have made significant progress in fruit detection. These algorithms no longer rely on manually designed features and can automatically learn complex patterns in images, effectively overcoming the limitations of traditional fruit detection methods when facing complex lighting and background interference. Object detection methods based on deep learning are mainly divided into single-stage detection and two-stage detection. The single-stage detection directly regresses and predicts the bounding box of the target. Its advantages are a fast detection speed and high efficiency, and it is one of the most widely used methods. Typical single-stage detection methods include the YOLO series and the SSD network [
4,
5,
6]. For example, Lyu et al. improved the backbone network and loss function of YOLOv5 in YOLOv5-CS for the detection and counting of green citrus in orchard environment [
7]. Wang et al. used ShuffleNet v2 as an improved backbone and introduced the CBAM attention mechanism to improve detection accuracy and reduce the model size [
8]. Gai et al. improved YOLOv4 by combining it with DenseNet for the maturity detection of small tomatoes [
9]. Zhao et al. achieved an accurate detection of grapes and picking points by improving YOLOv4, where the average precision of grape detection reached 93.27% [
10]. Another popular single-stage detection method is the SSD model by Yuan et al. [
11], who verified its performance on cherry tomatoes using different backbone networks (VGG16, MobileNet, Inception V2). In addition, Fuentes-Peñailillo et al. proposed a seedling counting model that combines traditional image processing with MobileNet-SSD, achieving a maximal precision of 96% [
12]. In contrast, two-stage detection processes candidate region extraction and classification in two steps. Although the detection speed is slower, it performs better in precision. Typical two-stage detection methods include the RCNN series [
13,
14,
15] and SPPNet [
16]. For example, Hu et al. used Faster R-CNN combined with color space conversion and fuzzy set method to realize bounding box detection and the segmentation of tomatoes [
17]. It performed well in cases where the fruit edges were blurred or overlapped. Song et al. built a Faster R-CNN model based on VGG16 and achieved kiwifruit detection under different lighting conditions [
18]. The average detection accuracy reached 87.61%. Gao et al. used Faster R-CNN to detect and classify apples under four different growth conditions, with an average precision of 87.9% [
19].
Although single-modal visual data processing based on deep learning has made significant progress in fruit detection, they still face many challenges in complex environments. First, single-modal methods (e.g., RGB only detection) are highly susceptible to illumination changes, occlusion, and background clutter, leading to insufficient detection accuracy and robustness. For instance, in low-light conditions or when fruits are partially occluded by leaves, the performance of these methods degrades significantly. Second, most existing models rely heavily on large-scale annotated datasets, which are labor-intensive and time-consuming to acquire, especially for small and densely distributed fruits like cherry tomatoes. Third, while some studies have attempted to improve detection accuracy by increasing model complexity, this usually comes at the cost of increased computational cost, making them unsuitable for real-time applications, such as robotic harvesting. To address these issues, multimodal fusion has gradually become an important research direction to meet these challenges. Especially when picking, robots are usually equipped with multiple sensors, such as color and depth cameras. Fusing information from different modalities can not only improve the precision of fruit detection but also enhance the system’s ability to adapt to environmental changes. In recent years, multimodal methods combining color (RGB) and depth images have been widely used in fruit detection and made remarkable progress. Tu et al. developed a fruit and maturity detection model using RGB-D images [
20]. Their ablation experiment showed that the introduction of depth improved the detection accuracy by 3.03%. Cui et al. proposed a single cherry tomato detection method that combines RGB-D inputs. The RGB image is converted into the LAB color space and then fused with the depth map and normal vector map obtained from the point cloud as the inputs of an improved YOLOv7 to detect cherry tomatoes [
21,
22]. Similarly, Rong et al. optimized YOLOv5 by fusing RGB and depth images to improve the detection performance of cherry tomato clusters/bunches [
23]. In addition, Kaukab et al. used multimodal data as the input of YOLOv5 and effectively reduced the impact of depth image noise via a deep fusion method of non-targeted background removal and achieved an precision of 96.4% for apple detection [
24].
The fusion methods of multimodal images can be divided into three types, early fusion, mid-term fusion, and late fusion, according to its introduction at different processing stages. In early-fusion methods, images from different modalities are directly integrated at the image level before being fed into the network. For example, Liu et al. significantly improved the average precision of kiwifruit detection to 90.7% by superimposing RGB and near-infrared images to form a four-dimensional tensor as the input of the VGG16 [
25]. However, this method is prone to pixel misalignment due to offset between images of different modalities. In contrast, late fusion linearly combines independent predictions at the decision stage. Sa et al. combined the detection results of RGB and NIR images in the last step of the shared feature extraction network Faster R-CNN and improved the detection accuracy from 81.6% to 83.8% [
26], especially effective for fruits with similar colors, such as green peppers and melons. However, in late fusion, different modality features cannot learn from each other, resulting in poor interactions between different network branches. As a feature-level fusion method, mid-term fusion combines multimodal feature maps and can effectively balance the depth and efficiency of feature integration. For example, Wei et al. designed a multi-branch backbone network that includes color, infrared, and polarization image inputs [
27]. By using operations such as feature connection, dimensionality reduction, and activation, they achieved higher target-recognition precision in complex environments. However, it also significantly reduces the inference speed.
Despite the progress in multimodal fusion, several challenges remain unresolved. First, early-fusion methods often suffer from pixel misalignment due to the spatial offset between RGB and depth images, leading to inaccurate feature extraction. Second, late-fusion methods lack effective interaction between modalities, as they process each modality independently until the final decision stage, which limits their ability to leverage complementary information. Third, mid-term-fusion methods, while achieving better feature integration, often introduce high computational complexity, making them unsuitable for real-time applications such as robotic harvesting. Additionally, most existing multimodal fusion methods do not fully exploit the potential of attention mechanisms to enhance the saliency of critical features and suppress irrelevant information, which is crucial for improving detection accuracy in complex environments. These limitations underscore the need for a more efficient and robust multimodal fusion approach that can address these challenges while maintaining real-time performance.
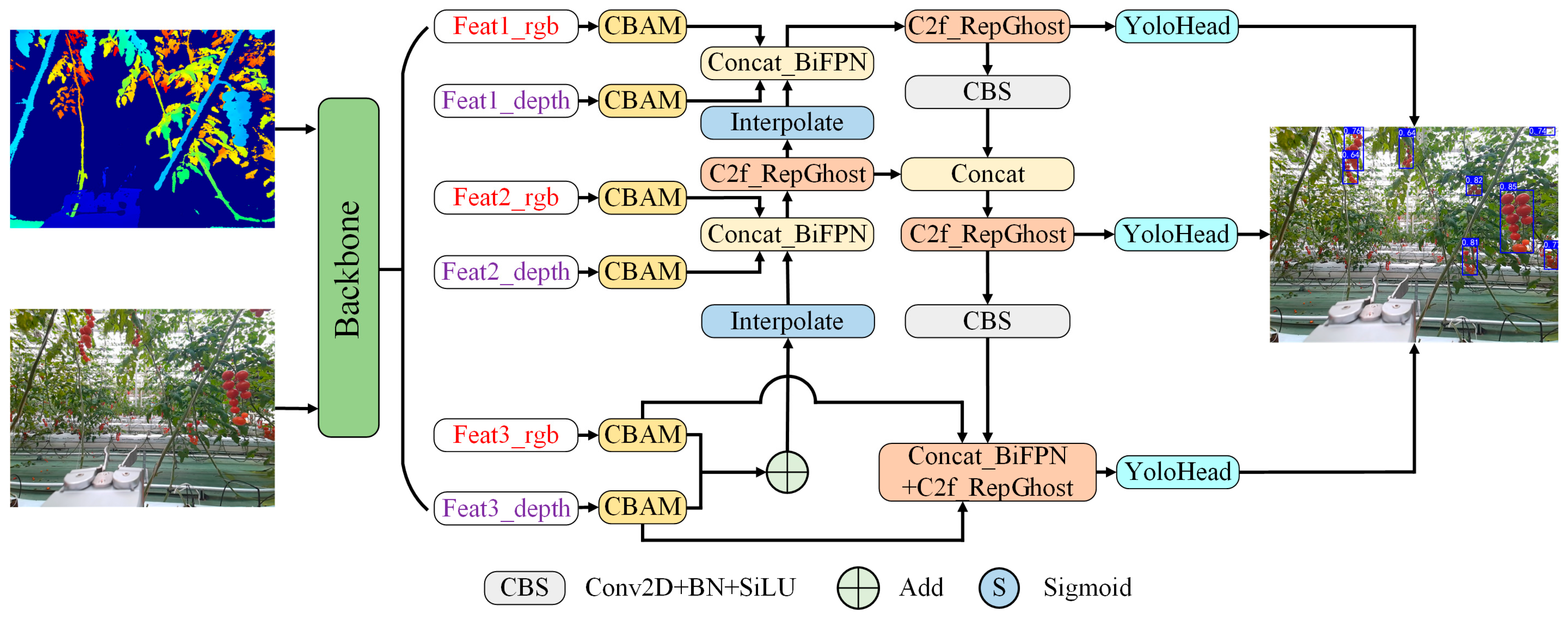
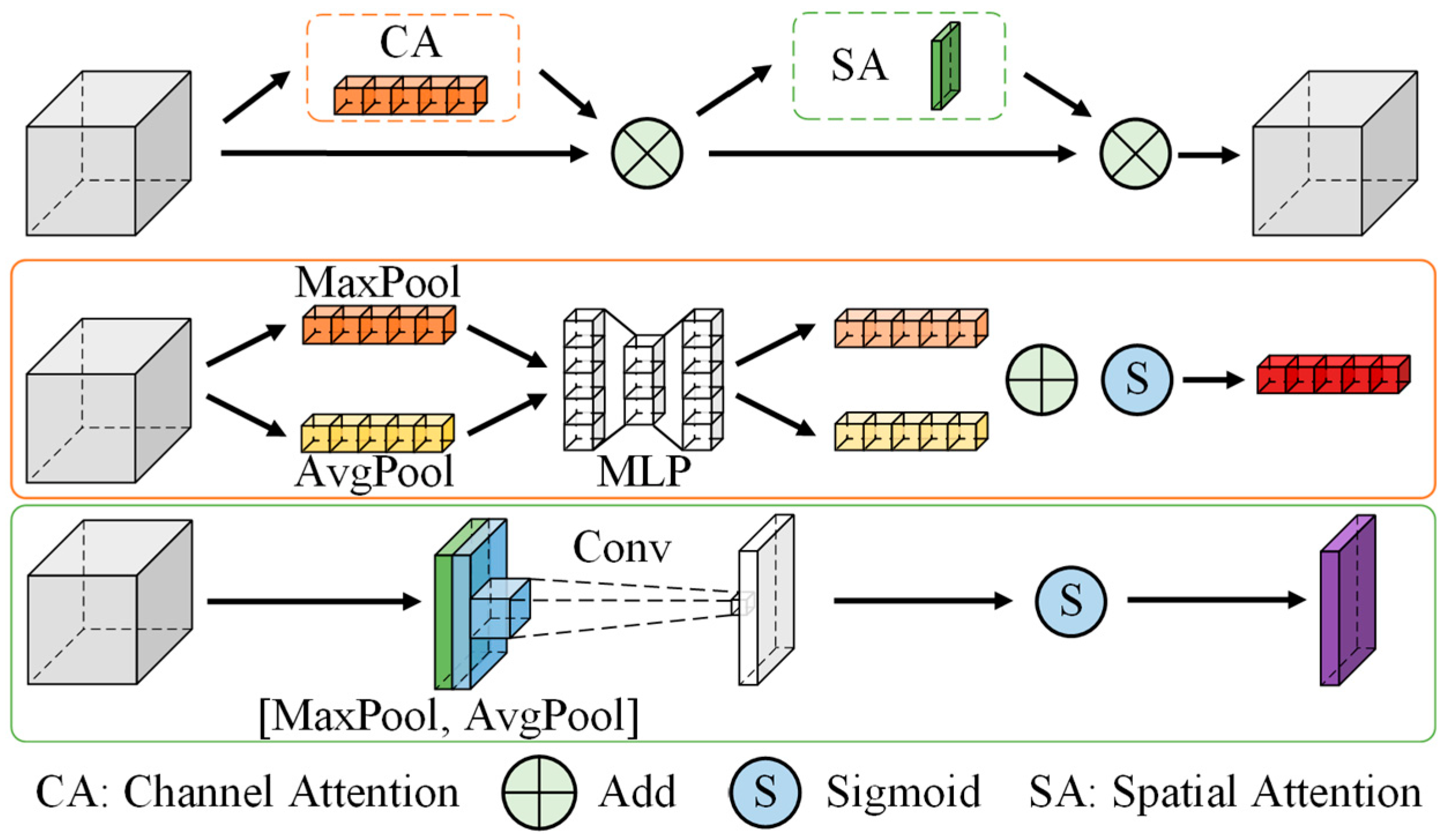
In order to further optimize the performance of multimodal fusion, in recent years, researchers began to introduce attention mechanisms to highlight critical information and reduce the interference of irrelevant features. Woo et al. introduced self-learning weight parameters in the CBAM module, which effectively improves the weight of the region of interest and suppresses invalid features [
28]. Li et al. proposed a solution using DenseBlock combined with the attention mechanism to achieve image denoising when fusing RGB and NIR images for multimodal segmentation tasks [
29]. Inspired by their work, this paper proposes a dual-channel cross-fusion attention YOLO (DCFA-YOLO) network to meet the needs of accurate and fast multimodal cherry tomato bunch detection. Specifically, we introduce a parallel attention mechanism in the mid-term-fusion stage. By enhancing the learning ability and saliency of the region of interest, it overcomes the interference introduced by pixel offset in early fusion and the high independence of each modality feature in late fusion. DCFA-YOLO integrates multimodal data of color and depth images and uses dual-channel cross-fusion and attention mechanisms to effectively extract and fuse features of different modalities. At the same time, the model is designed with the goal of being lightweight for real-time applications. Even when multimodal fusion is used, the size of its model parameters remains similar to that of the single-modal method, ensuring its high efficiency and ease of deployment. The design of this model not only enhances the ability to understand and process multimodal data but also takes into account the conservation of computing resources. It provides a reliable and efficient solution for precision agriculture and intelligent fruit harvesting. The contributions of this paper can be summarized as follows:
A new feature fusion method is developed to combine different modal features effectively. It integrates a dual-channel cross-fusion attention mechanism into YOLO to enhance the fusion of color and depth images in a balanced way, significantly improving fruit detection accuracy and robustness.
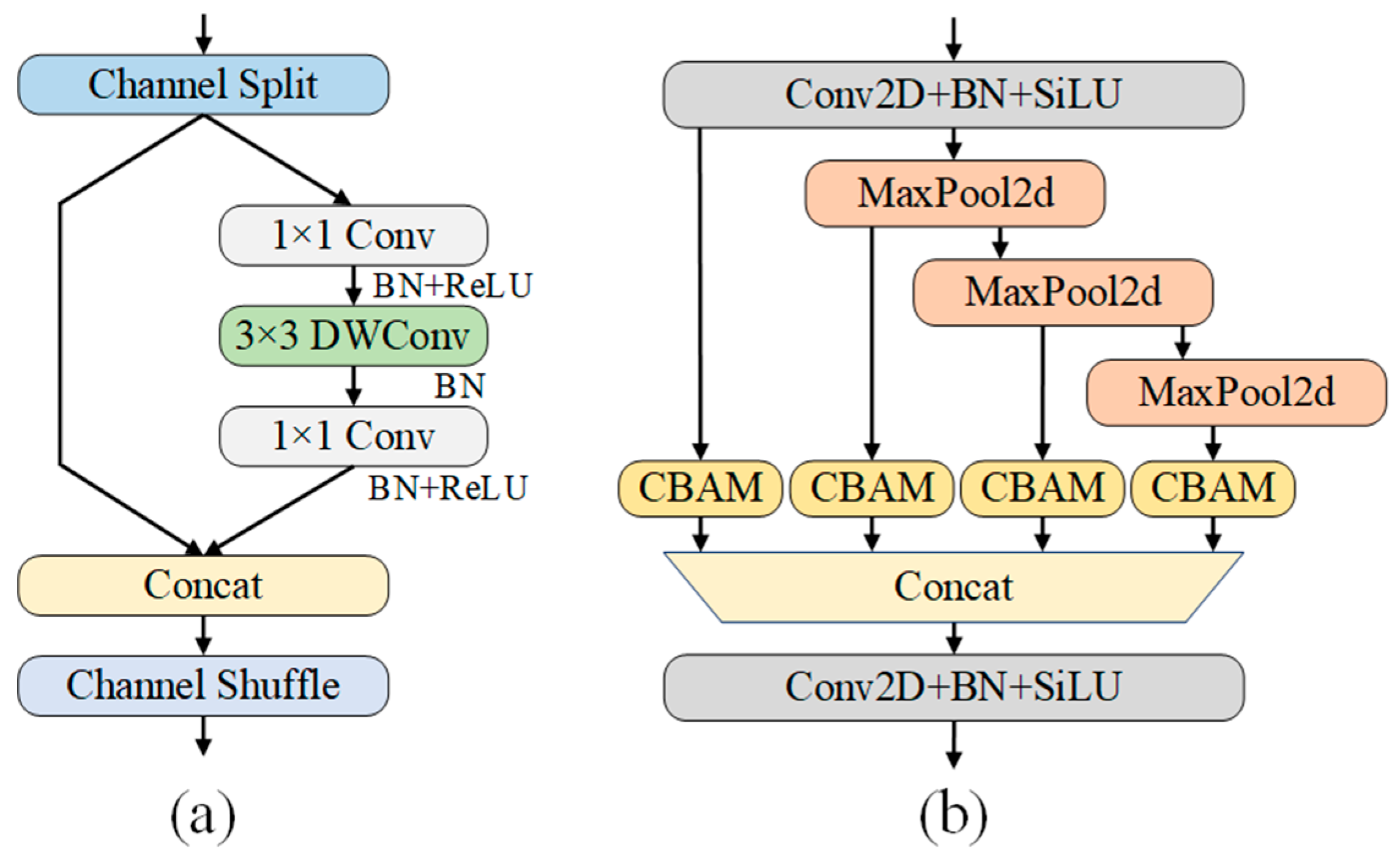
An efficient lightweight design is proposed by replacing the C2f module with the ShuffleNetV2 unit, optimizing the backbone network for faster and more efficient early feature extraction, while reducing computational complexity.
The attention mechanism is enhanced by introducing a SPPF_CBAM unit to the early feature extraction stage, improving the model’s ability to focus on key features through dynamic channel and spatial attention.
The proposed DCFA-YOLO has been evaluated for cherry tomato bunch detection using a dataset obtained from a commercial greenhouse, achieving an mAP50 of 96.5%, outperforming multiple YOLO models while being relatively lightweight.
The paper is organized as follows:
Section 1 provides an overview of related work and existing challenges in fruit detection as well as multimodal object detection.
Section 2 describes the proposed DCFA-YOLO method in detail.
Section 3 experimentally verifies and analyzes the effectiveness of DCFA-YOLO.
Section 4 discusses the results and implications and potential directions for future research, while
Section 5 concludes the work.
3. Experiments and Results
To verify the effectiveness and performance of the proposed DCFA-YOLO, a series of ablation and comparative experiments were designed and implemented. Through ablation experiments, the impact of each component on model performance is analyzed. At the same time, the full DCFA-YOLO is compared with a few state-of-the-art YOLO networks to comprehensively evaluate its performance in terms of detection accuracy, recall, computational complexity, and model parameter quantity.
3.1. Experimental Setup and Dataset
The cherry tomato images were acquired at a greenhouse in a plant science and technology park in Dongguan, China (
Figure 7). A Microsoft Azure Kinect DK (Microsoft, Redmond, WA, USA) or Litemaze TOF camera (Litemaze Technology, Shenzhen, China) installed at the end of the robotic arm collected 843 RGB-D image pairs, including RGB and corresponding depth images. The purpose was to simulate the posture and distance of the robotic arm during the picking process. More detailed descriptions of the image acquisition environment and procedures have been reported in a previous study on single cherry tomato detection [
22]. The original data were expanded using data augmentation methods such as cropping, flipping, and random brightness enhancement, and finally, 3372 images were obtained. Cherry tomato bunches within 1 m of the camera were labeled using LabelImg (version 1.8.1). Finally, the dataset was divided into the training set (2700 images), the validation set (336 images), and the test set (336 images).
All experimental were carried out on a desktop workstation with Intel(R) Core (TM) i7-14700K CPU (Intel, Santa Clara, CA, USA), 20 cores and 28 threads, 64G memory, and Nvidia GeForce RTX 4070 Ti SUPER GPU (Nvidia, Santa Clara, CA, USA), and the Ubuntu 22.04 operating system. All deep learning algorithms were executed in the same environment of Windows 11, Cuda 12.6, Python 3.8, Pytorch-2.4.1, and Torchvision-0.19.1. All experiments set the image size to 640 × 640, batch_size to 8, and epochs to 200.
The initial learning rate was set to 0.01, with the minimal learning rate reduced to 1% of the initial value. The optimization utilized the Stochastic Gradient Descent (SGD) optimizer, configured with a momentum of 0.937 and a weight decay factor of 0.0005 to regularize the model parameters. The learning rate scheduling followed a cosine decay strategy, dynamically adjusting the learning rate throughout the training process to enhance convergence and performance.
3.2. Evaluation Metrics
We used precision, recall, F1-score, and mAP as the basic detection performance evaluation metrics. The mean average precision (mAP) is an important indicator to measure the global detection performance of the model. AP is defined as the area under the precision–recall curve, which represents the comprehensive evaluation of single-category detection performance [
33]. mAP50 represents the average precision value calculated when the Intersection over Union (IoU) threshold is 0.5 and is a commonly used evaluation criterion in object detection tasks. mAP75 is the average precision calculated under a higher IoU threshold (0.75), which requires the model to predict the target position more accurately and can reflect the positioning ability of the model. mAP50-95 represents the average mAP at different IoU thresholds (from 0.5 to 0.95, with an interval of 0.05), which can more comprehensively evaluate the detection performance of the model under different precision requirements. The precision (
), recall (
), and F1-score (
) are calculated as
where
,
, and
represent the true positives, false positives, and false negatives. The
and
are calculated as follows:
where
is the number of recall levels;
and
are consecutive recall levels;
is the the precision at recall level;
and
is the number of classes.
In addition, we also considered GFLOPs to measure the computational complexity of the model and parameters to reflect the size and complexity of the model. Together, these metrics provided us with a comprehensive perspective to evaluate the precision, robustness, efficiency, and resource consumption of models in object detection tasks.
3.3. Ablation Experiments
The baseline model is the YOLOv8_n implemented by a third party. Compared with the official YOLOv8_n, this version of the model is easier to integrate multimodal feature extraction branches and lightweight improvements. All ablation experiments were conducted based on this model to incrementally verify the effectiveness of each additional module.
The design of the ablation experiment is shown in
Table 1. First, the single-modal RGB input was used as the baseline to build the initial detection framework (Single-RGB). Then, by adding a depth channel, a basic model of dual-modal input (Base_DM) was constructed to verify the performance improvement of multimodal input. On this basis, several improved modules were introduced, including the interpolation module (+Interpolate), the multimodal cross-fusion module (+Concat_BiFPN), the lightweight structure C2f_repghost module (+C2f_repghost), the ShuffleNetV2 lightweight module (+ShuffleNetV2), the channel and spatial attention module CBAM (+CBAM), and the fusion module combining the SPPF and CBAM (+SPPF_CBAM). The last case was the full DCFA-YOLO model.
The baseline model achieved a basic performance of 0.938 precision, 0.886 recall, and 0.911 F1-score in single mode. With multimodal input, the precision and F1-score increased to 0.947 and 0.917, confirming the positive impact of multimodal input. Adding the interpolation module (+Interpolate) further improved the precision and F1-score to 0.949 and 0.923. The addition of the multimodal cross-fusion module (+Concat_BiFPN) further improved the precision to 0.959, F1-score to 0.924, and mAP50 to 0.957. After further replacing it with the lightweight C2f_repghost module, although GFLOPs dropped to 10.765 and the model complexity was reduced, various metrics only decreased slightly. After adding the ShuffleNetV2 module, GFLOPs further dropped to 7.218, while the precision was 0.949 and F1-score remained at 0.924. The introduction of the CBAM module increased the recall to 0.906 and F1-score to 0.928. Finally, the introduction of the SPPF_CBAM module resulted in the best performance. These results confirm that the improved model achieves a good balance between improving performance and maintaining a lightweight design.
It should be noted that after adding the CBAM module to the backbone’s six feature outputs, the performance improves notably with better feature extraction. However, when we further replace the final layer’s SPPF module with the SPPF_CBAM module, this small adjustment leads to the best overall performance in terms of precision, recall, F1-score, and mAP50 while still maintaining a lightweight model. This improvement is primarily due to the effective combination of spatial and channel attention from CBAM with the spatial pyramid pooling (SPPF) module, which enhances multi-scale feature extraction, ensuring better performance without a significant increase in computational cost.
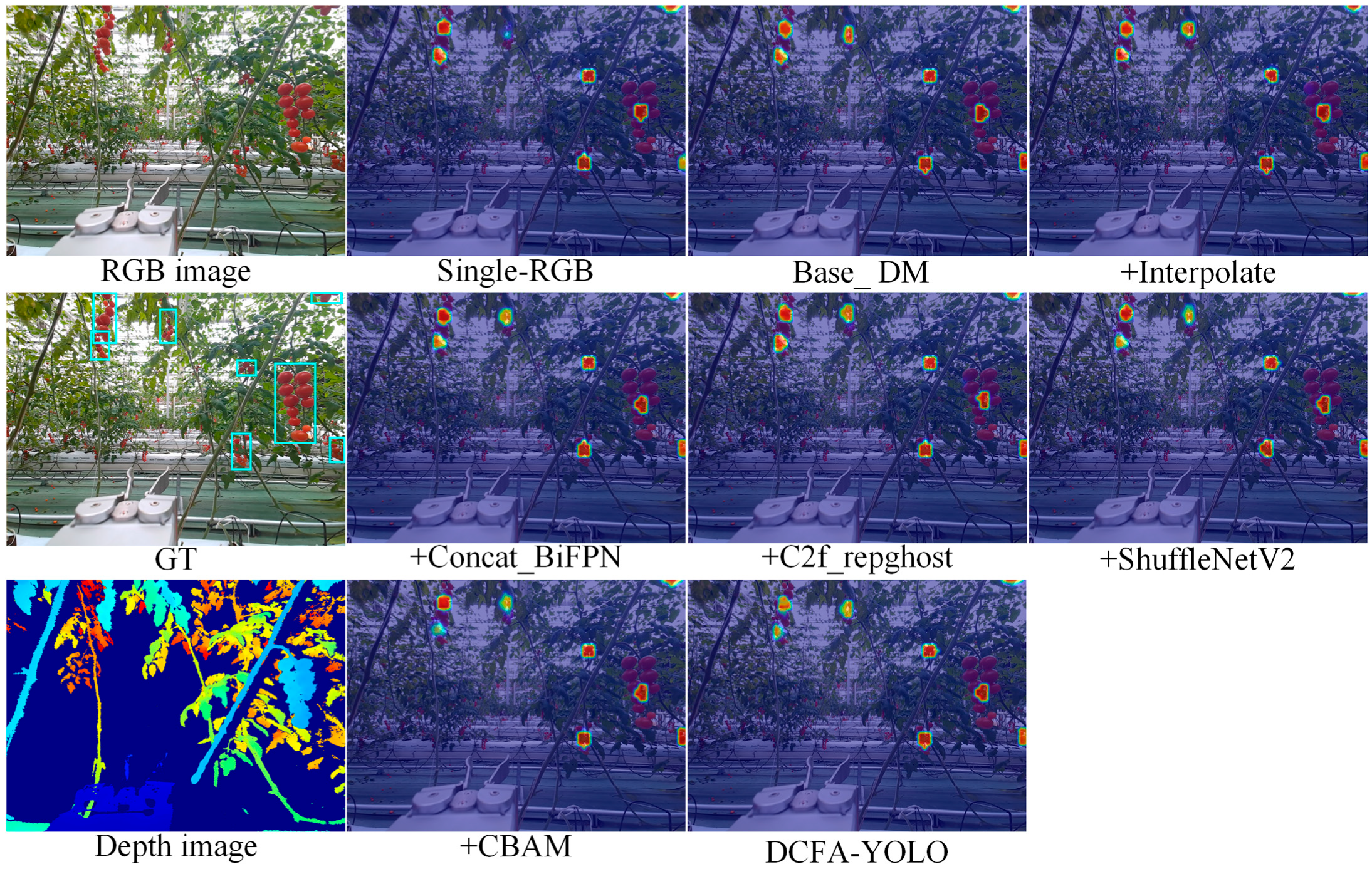
Figure 8 shows the heat map comparison for the ablation experiments. The baseline Single-RGB model exhibits focused attention on most targets but struggles with partially occluded cherry tomato clusters. The multimodal Base_DM model improves attention on these targets. Subsequent modules, such as +Interpolate, +Concat_BiFPN, and +C2f_repghost, show increasingly accurate and concentrated attention across all cherry tomato bunches. The +ShuffleNetV2 and +CBAM modules enhance the attention distribution, with +SPPF_CBAM achieving the best focus across all targets, particularly improving the detection of partially occluded clusters.
3.4. Comparison of Different Detection Algorithms
To compare the detection performance of DCFA-YOLO to other DNN models, we selected state-of-the-art YOLO models, YOLOv5_n [
34], YOLOv8_n [
30], YOLOv9_t [
35], YOLOv10_n [
36], YOLO11_n [
37], EfficientDet [
31], SSD [
6], and CenterNet [
38], for quantitative and qualitative comparison in terms of evaluation metrics and visual effects. The quantitative results are summarized in
Table 2.
DCFA-YOLO shows significant improvements in almost all key metrics. Compared with YOLOv5_n, YOLOv8_n, and YOLOv9_t, DCFA-YOLO achieves a notable increase in precision, recall, F1-score, and mAP50. Specifically, its precision improves from 0.871 (YOLOv8_n) to 0.949, and its F1-score rises from 0.865 to 0.931. Even compared with the higher-performance YOLOv9_t, DCFA-YOLO also shows obvious advantages, especially in F1-score and mAP50, with notable improvement in both. Though YOLOv10_n and YOLO11_n have lower GFLOPs and parameters, DCFA-YOLO outperforms them in key metrics like precision and mAP50. Moreover, it surpasses models such as EfficientDet and CenterNet. This further shows that DCFA-YOLO has achieved a good balance between performance and being lightweight, making it an excellent model for both accuracy and computational efficiency.
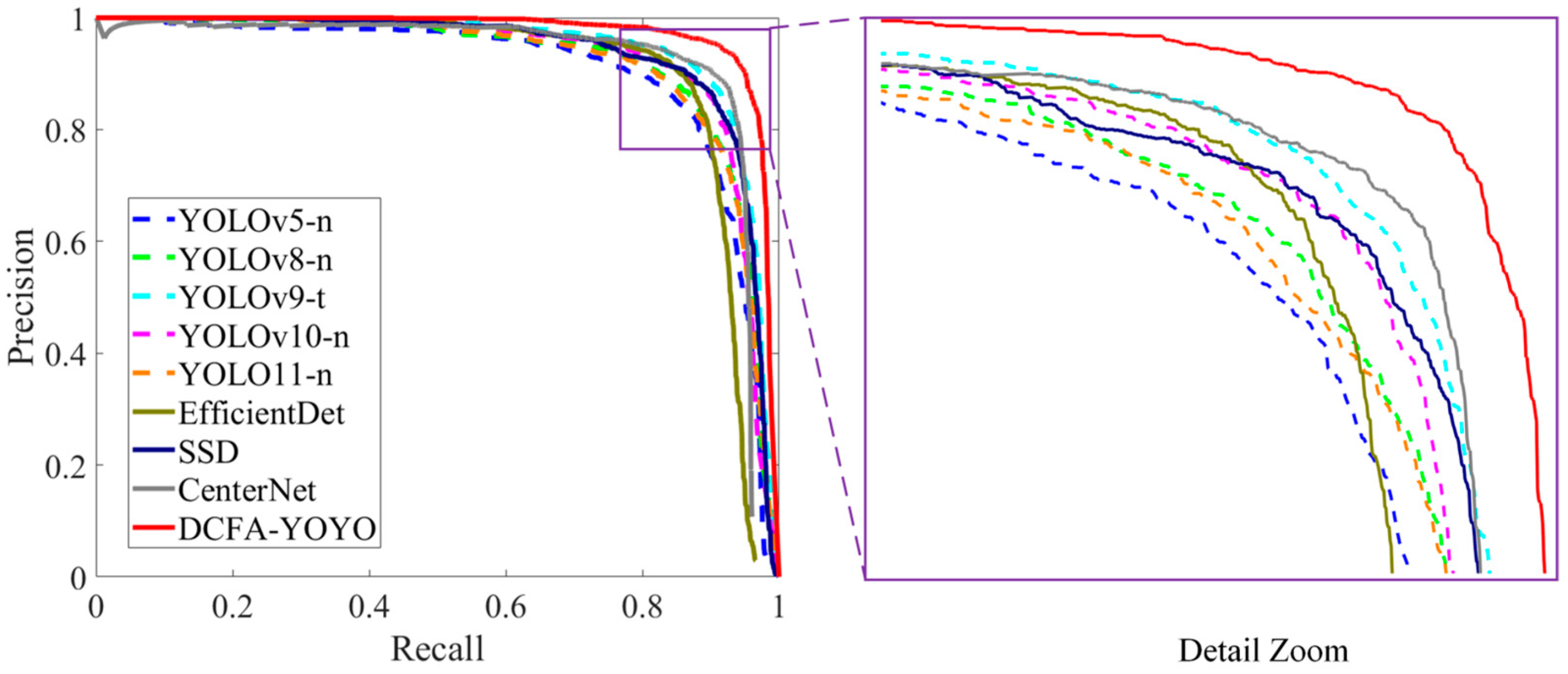
Figure 9 compares precision–recall curves across various detection models, showing that DCFA-YOLO consistently outperforms other models in terms of both precision and recall. By closely inspecting the PR curve, it is clear that the performance improvements noted in
Table 2, especially in precision, recall, and F1-score, are visually reflected, demonstrating the model’s strong overall detection capabilities.
Figure 10,
Figure 11 and
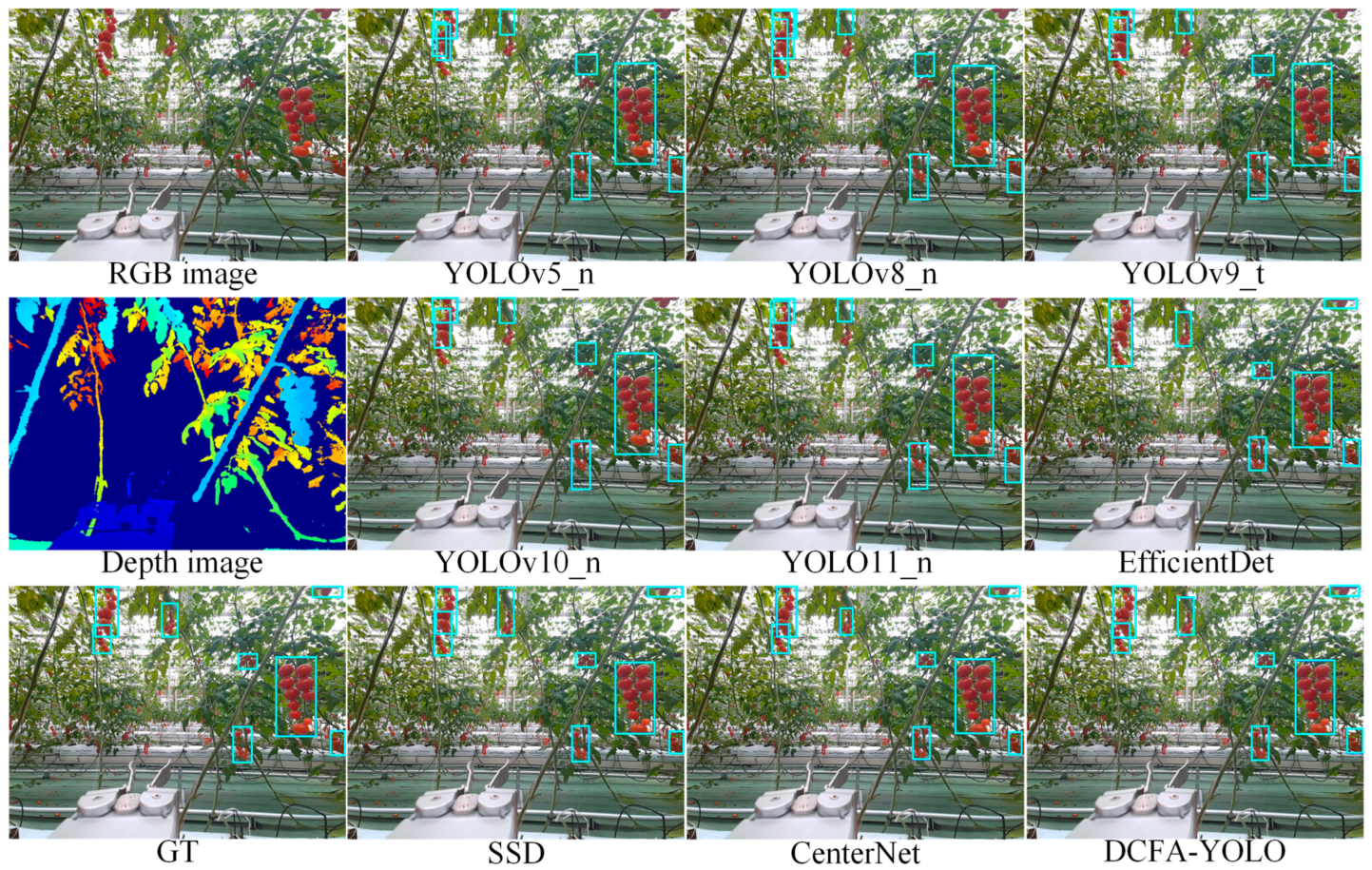
Figure 12 present the visualization of detection results under normal lighting, high-light, and low-light scenarios, respectively. Under normal lighting (
Figure 10), the compared models exhibit varying degrees of incomplete detection, frequently missing small, or overlapping objects and displaying suboptimal boundary precision. In contrast, DCFA-YOLO can detect cherry tomato bunches more accurately, significantly reducing missed and false detections.
Figure 11 and
Figure 12 illustrate detection results under challenging lighting conditions. In the high-light case (
Figure 11), excessive brightness causes the image to appear washed out, leading to increased missed detections in most YOLO-based models and over-detection in CenterNet. In the low-light scenario (
Figure 12), the darkness of the image exacerbates missed detections for YOLO-based models, while CenterNet again suffers from over-detection. Despite these challenges, DCFA-YOLO demonstrates superior adaptability in both scenarios, maintaining high detection accuracy with minimal false positives or missed targets.
4. Discussion
The proposed DCFA-YOLO method for multimodal cherry tomato bunch detection achieves the best results in six evaluation metrics (precision, recall, F1-score, mAP50, mAP75, and mAP50–95) among nine compared DNNs. It ranks the 5th among the nine models in terms of parameter size, and its GFLOPs rank the 4th lowest. For robotic fruit harvesting, the detection algorithm typically runs on edge computing devices, so the accuracy and computational cost of detection are both important, and we believe DCFA-YOLO strikes an excellent balance between the two. The computing platform in the current study is essentially a regular PC, and DCFA-YOLO runs cherry tomato bunch detection at a frame rate of 52.93 fps, which is sufficient for practical real-time robotic harvesting. By achieving high accuracy with lower computational costs, DCFA-YOLO reduces the burden on hardware, which could lead to lower energy consumption and operational costs in real-world applications. It can be integrated into agricultural systems like robotic harvesters or drones, enhancing their perception for precise and efficient fruit picking and measurement.
In a previous cherry tomato bunch detection study, precision, recall, and an F1-score of 98.9, 92.1, and 95.4 have been reported [
39], higher than the corresponding values of 0.949, 0.914, and 0.931 in the current study. However, the two studies were conducted with two very different datasets that were collected by different cameras (Intel RealSense structured light stereo vs. Microsoft Kinect TOF) at different plantations. The code and dataset are not available for apple-to-apple comparisons. To partly address this, we make the code publicly available on Github (see Data Availability Statement). Unfortunately, the dataset cannot be made fully public due to a non-disclosure agreement.
In this study, we only tested cherry tomato bunch detection. For clustered fruits like cherry tomatoes, whether harvesting by single fruits or by bunches depends on the production needs in a commercial setting, and both have been performed in previous studies [
22,
39,
40]. We believe DCFA-YOLO can be applicable to single fruit detection as well, which will be investigated in future work. However, it is important to note that the current model may face challenges in more complex scenarios, such as severe occlusions or highly dense clusters, where the accuracy of detection could be compromised. Future improvements could focus on enhancing the model’s robustness to these conditions, potentially through advanced attention mechanisms or multi-scale feature fusion techniques.
We would also like to explore applying DCFA-YOLO to other fruits; for example, it may be partially transferable to detecting other fruits in clusters/bunches, such as grape, longan, or lychee. It should be noted that for these fruits, even at maturity, the color features are less salient compared to cherry tomatoes. As such, we expect that the impact of adding depth information for these fruits is likely to have a more significant impact than for cherry tomatoes.
Moreover, when integrated with harvesting robots, DCFA-YOLO can contribute to agricultural sustainability by improving harvesting efficiency and reducing fruit waste. Its high detection accuracy minimizes missed or damaged fruits, while its real-time capabilities enable faster and more precise harvesting, ultimately supporting more sustainable and resource-efficient agricultural practices.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}