
Construction and Optimization of Integrated Yield Prediction Model Based on Phenotypic Characteristics of Rice Grown in Small–Scale Plantations

 ,
,
Abstract
:1. Introduction
2. Research Region and Data Processing
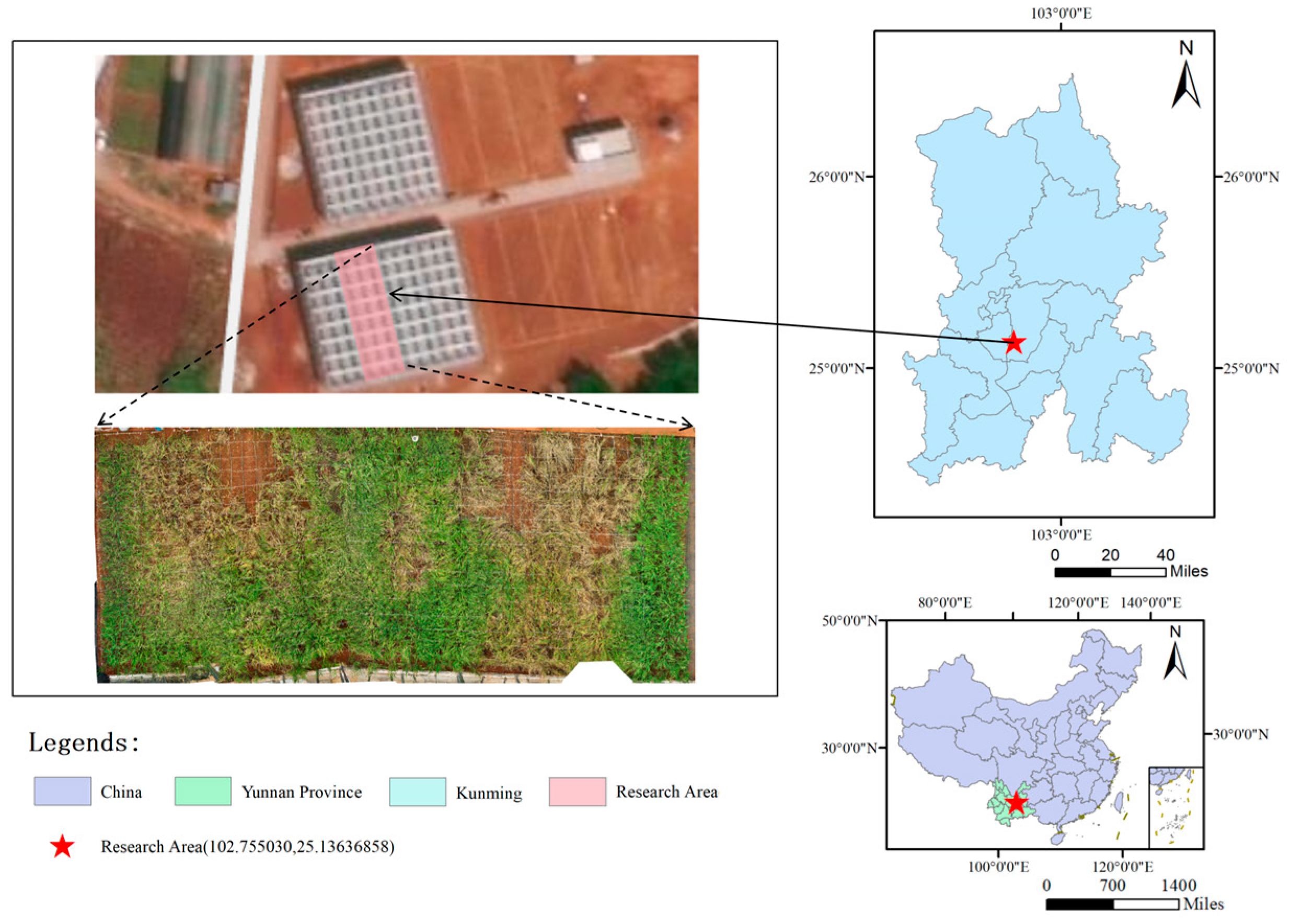
2.1. Study Area
2.2. Data Collection and Processing
2.2.1. Dataset
2.2.2. Data Analysis and Processing
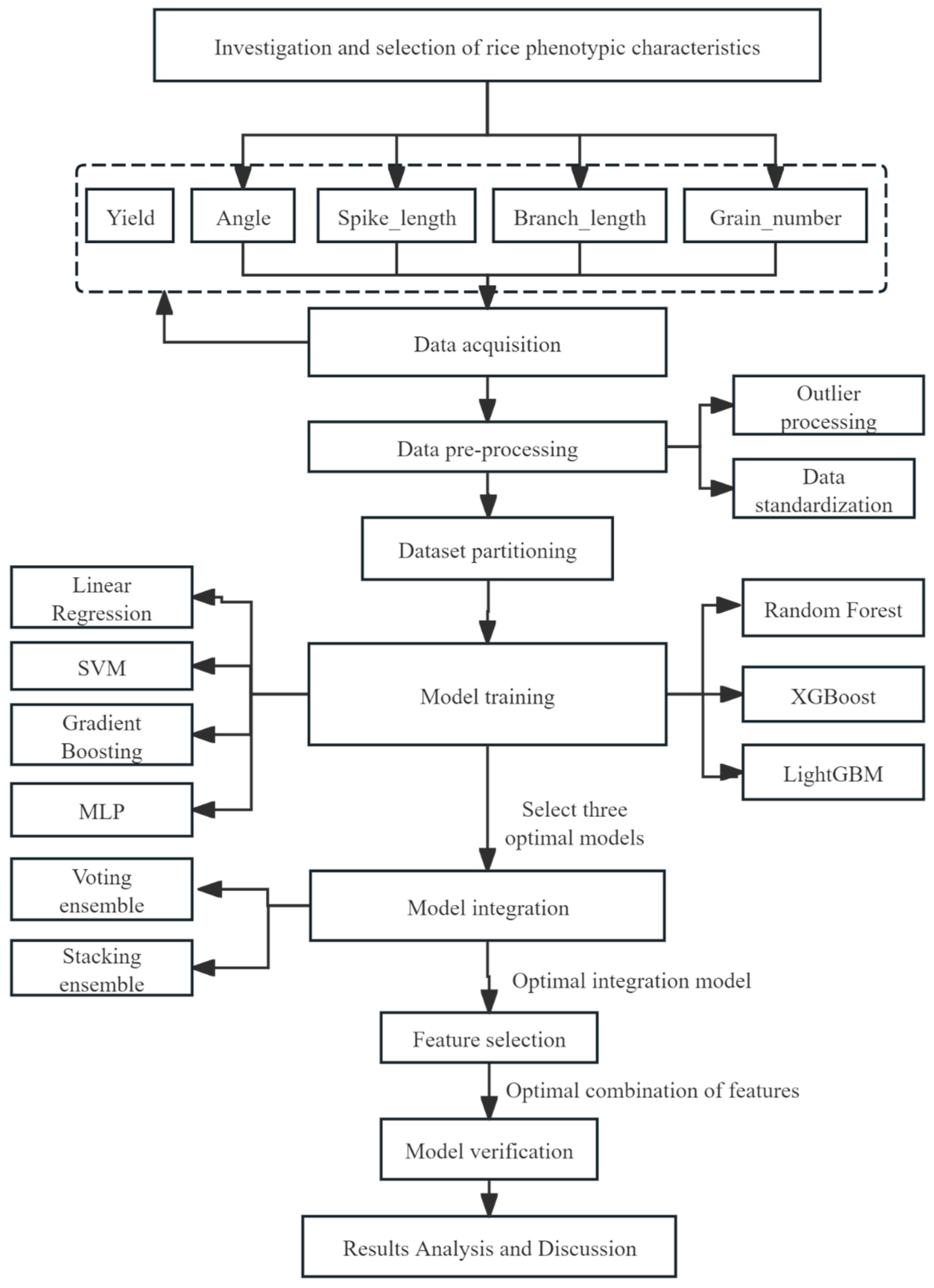
3. Methodology
3.1. Handling of Anomalous Data
3.2. Algorithm Selection
- Multiple Linear Regression (LR)
- 2.
- Support Vector Machine (SVM)
- 3.
- Multilayer Perceptron (MLP)
- 4.
- Random Forest (RF)
- 5.
- Gradient Boosting Regression (GBR)
- 6.
- XGBoost
- 7.
- LightGBM
3.3. Dataset Partitioning
3.4. Construction of a Yield Prediction Model Group for Rice Cultivation in Small Areas Based on the Integration of Multiple Machine Learning Techniques
3.5. Rice Yield Prediction Model Based on Stacking Ensemble Learning
3.6. Establishment of Evaluation Metrics
- Root Mean Square Error (RMSE)
- 2.
- Coefficient of Determination (R-Square)
- 3.
- Mean Absolute Percentage Error (MAPE)
4. Results
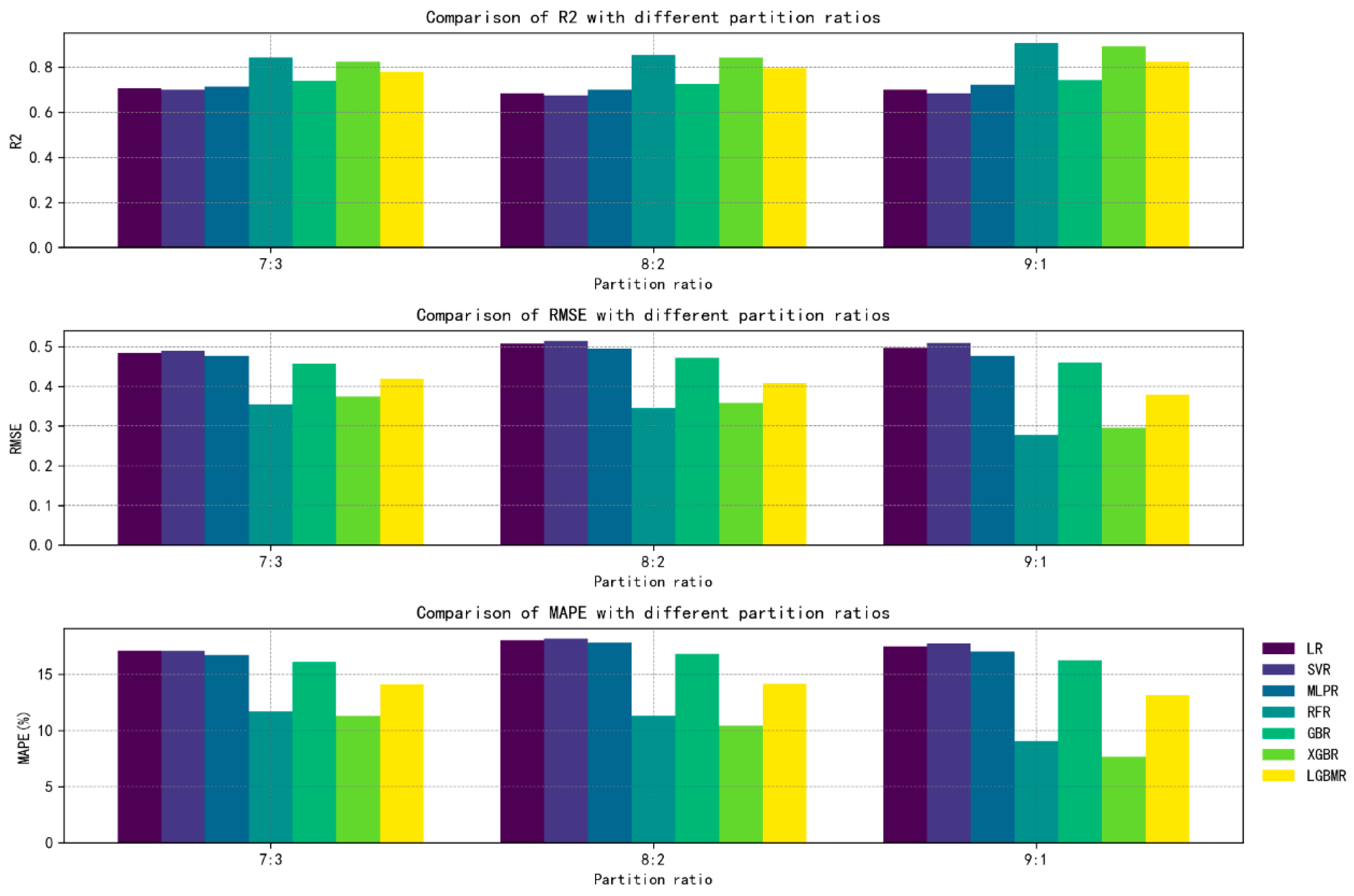
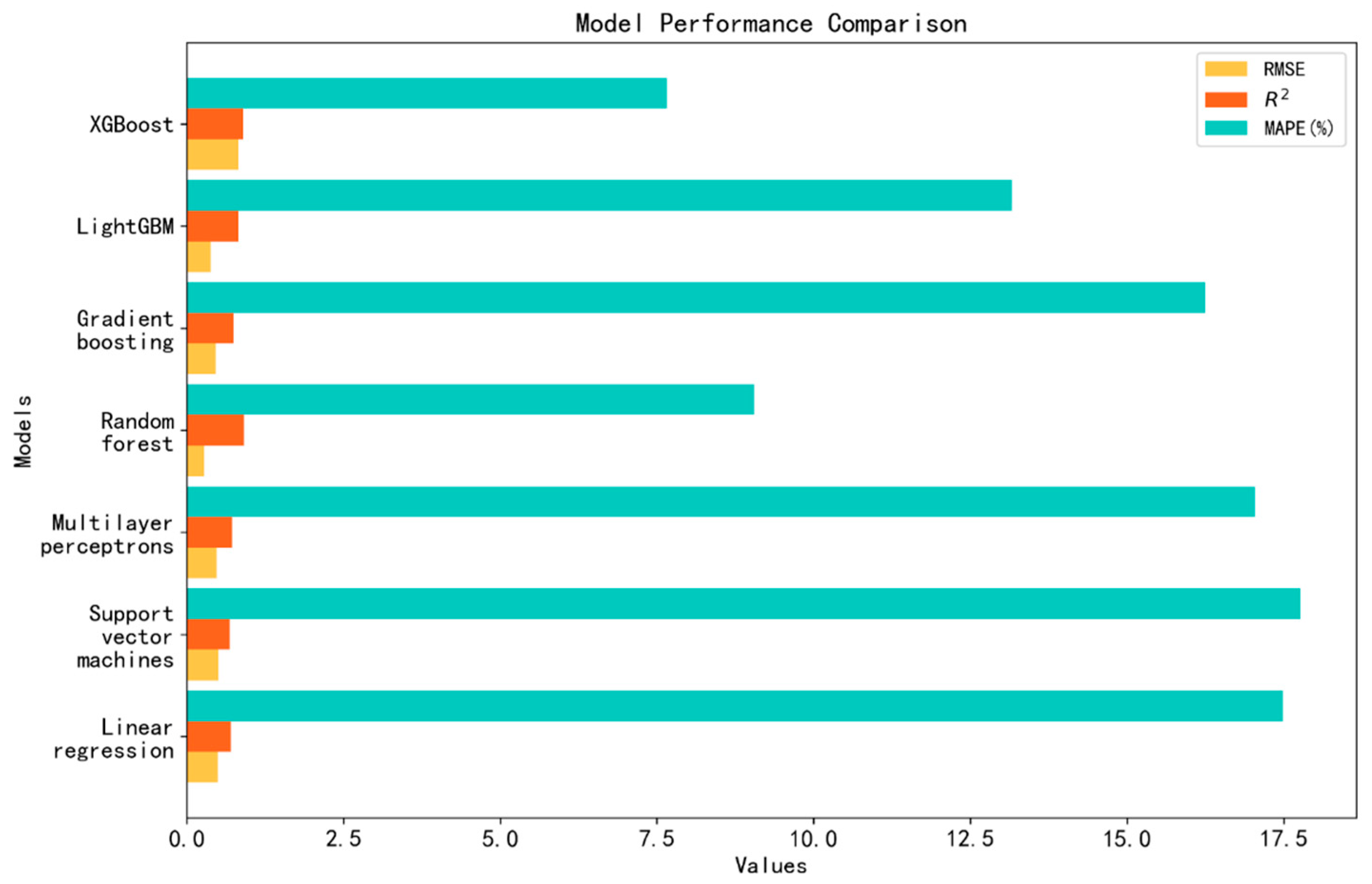
4.1. Analysis of the Results Obtained by Constructing a Rice Yield Prediction Model Using Various Machine Learning Algorithms
4.2. Performance Analysis of Rice Yield Prediction Model Based on Ensemble Learning in a Small Area
4.3. Comparative Analysis of Rice Yield Prediction Models Based on Ensemble Learning Versus Non–Ensemble Learning Approaches
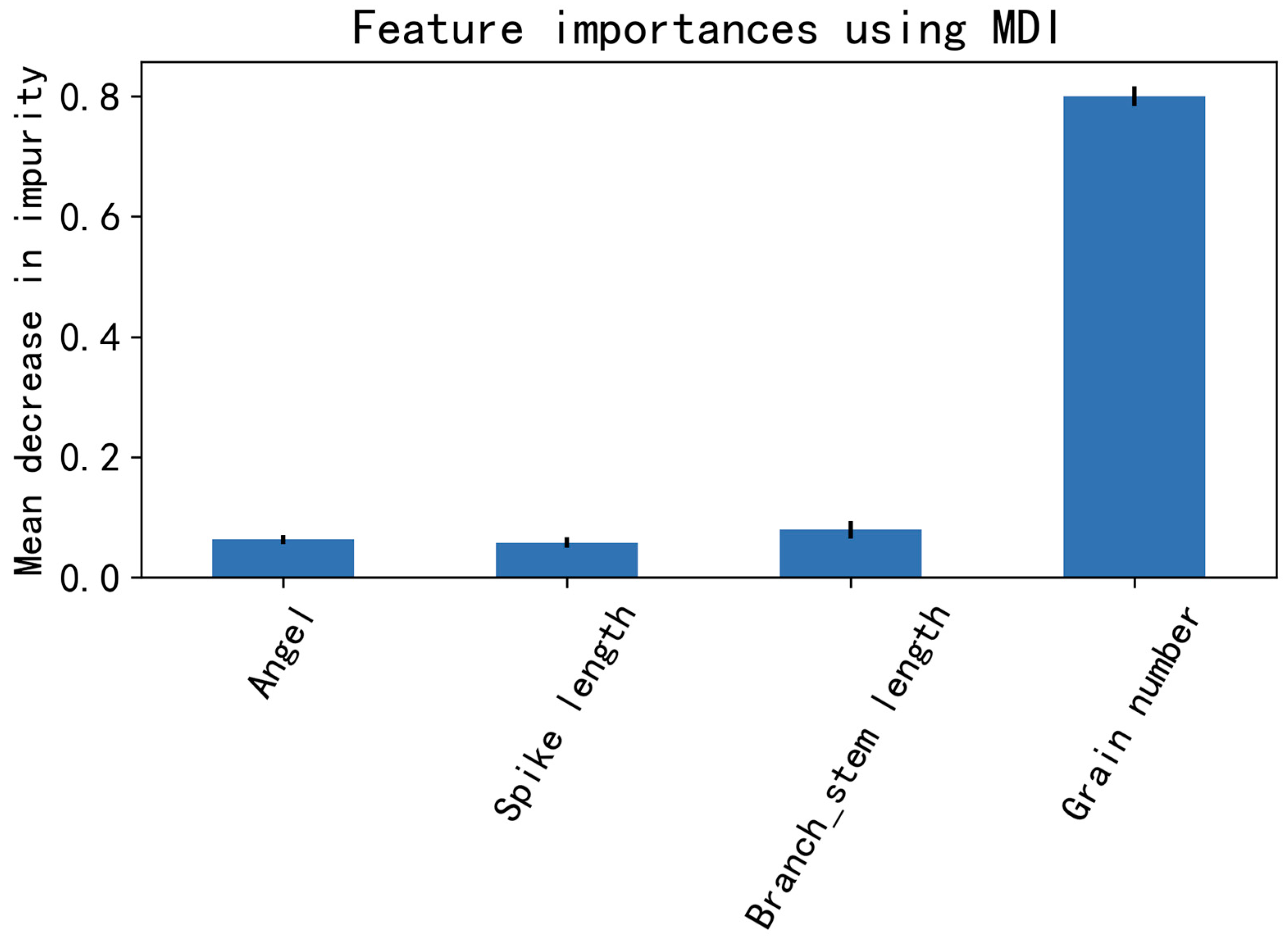
4.4. The Impact of Important Phenotypic Characteristics on the Performance of Integrated Models
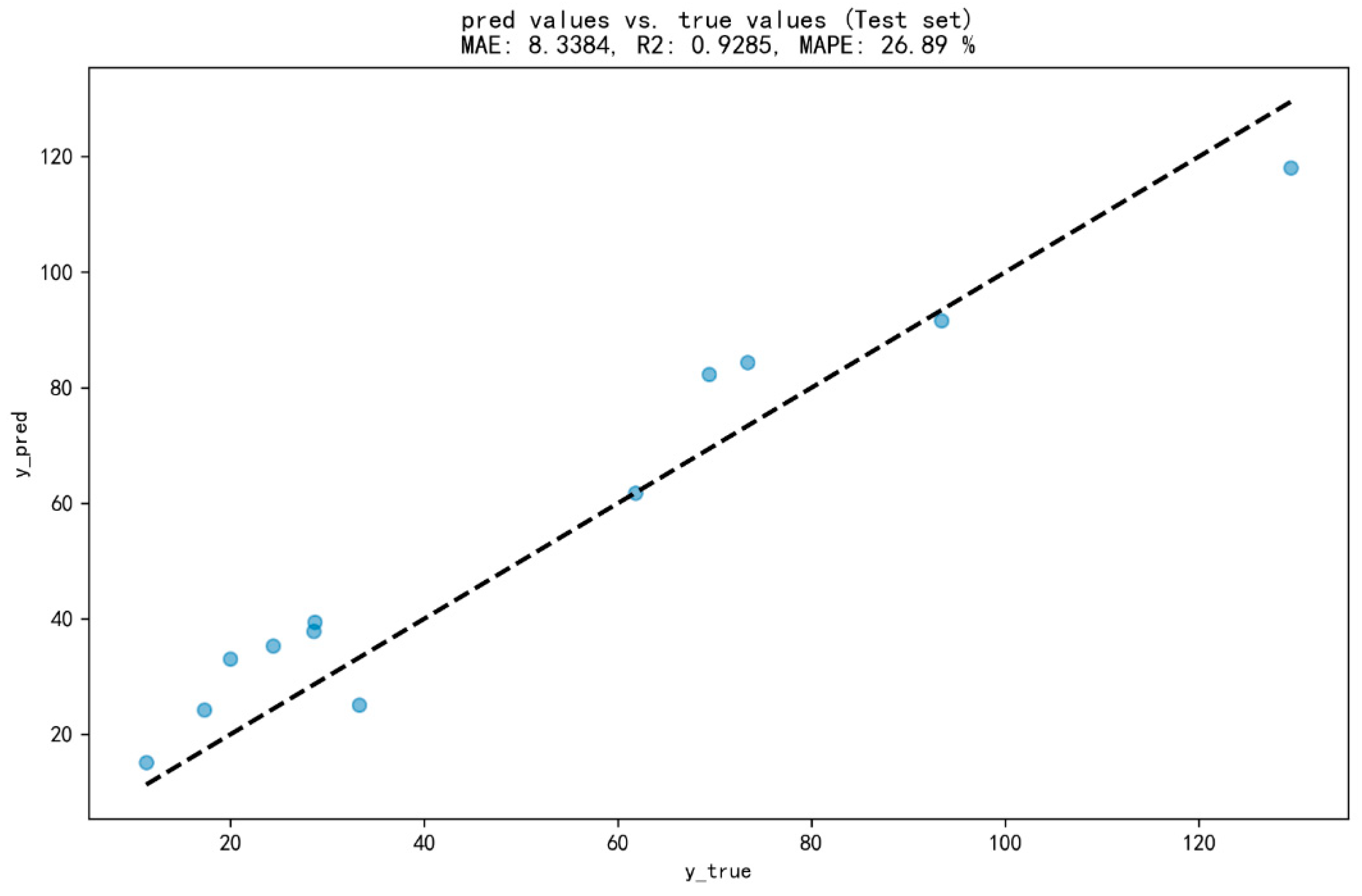
4.5. Validation of Yield Prediction Model Based on Phenotypic Characteristics of Rice Grown in Small–Scale Plantations
5. Discussion
5.1. Comparative Analysis of the Performance of Different Machine Learning Algorithms
5.2. Propose a Method for Constructing a Precise Prediction Model of Rice Yield Based on Various Influencing Factors
5.3. A Low–Cost and High–Efficiency Method for Predicting Rice Yield Has Been Proposed
5.4. Limitations and Future Research Directions of Integrated Yield Prediction Model Based on Rice Phenotypic Characteristics
6. Conclusions
- The performance of the Stacking–3m integrated model surpasses that of individual models. In the ensemble learning experiment, optimal results were achieved when selecting the three models with the highest determination coefficients based on the stacking method. The RMSE, R2, and MAPE of the best integrated model, Stacking–3m, reached 0.2483, 0.9250, and 6.90%, respectively. Compared to individual models, the root mean square error decreased by 10.58%, the determination coefficient increased by 1.88%, and the mean absolute percentage error decreased by 0.76%, indicating a significant improvement in model performance. This suggests that the stacking method can effectively combine the strengths of different models and further enhance predictive performance through linear regression meta–models.
- Different influencing factors exert a significant impact on model performance. In this study, we employed a method of gradually reducing the number of influencing factors to adjust the various combinations among them, ultimately forming 14 distinct combinations. Based on these 14 different combinations, when the influencing factors were selected as “1,0,2,3”, the RMSE, R2, and MAPE reached 0.2483, 0.9250, and 6.90%, respectively, representing the optimal performance model; when the influencing factor was selected as “0”, the RMSE, R2, and MAPE were 0.8546, 0.0576, and 35.41%, respectively, indicating the worst performing model; when the influencing factors were selected as “0,2,3”, the R2 value reached 0.9291, representing the optimal value. The above experimental data led to the following conclusions: when constructing an integrated model for predicting rice yield based on phenotypic traits, selecting different influencing factors for modeling results in significant variations in model performance. Therefore, choosing appropriate influencing factors becomes one of the most critical aspects in building predictive models using machine learning.
- A method for the precise prediction of rice yield within a small-scale planting area was developed. This study addresses the challenge of the precise prediction of rice yield within a small-scale planting area under the unique geographical conditions of the Yunnan Plateau. Initially, based on seven machine learning algorithms, multiple rice yield prediction models utilizing intelligent algorithms were constructed. The three models with the best performance were selected, and two ensemble methods, namely voting and stacking, were employed to build an integrated model group for rice yield prediction. After comparative analysis, the optimal integrated model, Stacking–3m, was determined. Subsequently, by adjusting various influencing factors, a new integrated model for rice yield prediction was constructed and compared with Stacking–3m. The resulting model, based on rice phenotypic traits within a small-scale planting area, is designated as Stacking–3m.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Son, N.; Chen, C.; Chen, C.; Minh, V.; Trung, N. A comparative analysis of multitemporal MODIS EVI and NDVI data for large-scale rice yield estimation. Agric. For. Meteorol. 2014, 197, 52–64. [Google Scholar] [CrossRef]
- Wang, L.; Tian, Y.; Yao, X.; Zhu, Y.; Cao, W. Predicting grain yield and protein content in wheat by fusing multi-sensor and multi-temporal remote-sensing images. Field Crop. Res. 2014, 164, 178–188. [Google Scholar] [CrossRef]
- Chou, J.; Dong, W.; Xu, G.; Tu, G. New Ideas for Research on the Impact of Climate Change on China’s Food Security. Clim. Environ. Res. 2022, 27, 206–216. (In Chinese) [Google Scholar]
- Li, P.; Chang, T.; Chang, S.; Ouyang, X.; Qu, M.; Song, Q.; Xiao, L.; Xia, S.; Deng, Q.; Zhu, X.G. Systems model-guided rice yield improvements based on genes controlling source, sink, and flow. J. Integr. Plant Biol. 2018, 60, 1154–1180. [Google Scholar] [CrossRef] [PubMed]
- Cao, J.; Zhang, Z.; Tao, F.; Zhang, L.; Luo, Y.; Zhang, J.; Han, J.; Xie, J. Integrating multi-source data for rice yield prediction across China using machine learning and deep learning approaches. Agric. For. Meteorol. 2021, 297, 108275. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Lobell, D.; Potgieter, A.B.; Wang, S.; Peng, J.; Xu, T.; Asseng, S.; Zhang, Y.; You, L. Integrating satellite and climate data to predict wheat yield in Australia using machine learning approaches. Agric. For. Meteorol. 2019, 274, 144–159. [Google Scholar] [CrossRef]
- Sun, S.; Zhang, L.; Chen, Z.; Sun, J. Advances in AquaCrop Model Research and Application. Sci. Agric. Sin. 2017, 50, 3286–3299. [Google Scholar]
- Noureldin, N.; Aboelghar, M.; Saudy, H.; Ali, A. Rice yield forecasting models using satellite imagery in Egypt. Egypt J. Remote Sens. Space Sci. 2013, 16, 125–131. [Google Scholar] [CrossRef]
- Peng, D.; Huang, J.; Li, C.; Liu, L.; Huang, W.; Wang, F.; Yang, X. Modelling paddy rice yield using MODIS data. Agric. For. Meteorol. 2014, 184, 107–116. [Google Scholar] [CrossRef]
- Wang, F.; Yi, Q.; Hu, J.; Xie, L.; Yao, X.; Xu, T.; Zheng, J. Combining spectral and textural information in UAV hyperspectral images to estimate rice grain yield. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102397. [Google Scholar] [CrossRef]
- Zhou, X.; Zheng, H.; Xu, X.; He, J.; Ge, X.; Yao, X.; Cheng, T.; Zhu, Y.; Cao, W.; Tian, Y. Predicting grain yield in rice using multi-temporal vegetation indices from UAV-based multispectral and digital imagery. ISPRS J. Photogramm. Remote Sens. 2017, 130, 246–255. [Google Scholar] [CrossRef]
- Ji, Z.; Pan, Y.; Zhu, X.; Zhang, D.; Wang, J. A generalized model to predict large-scale crop yields integrating satellite-based vegetation index time series and phenology metrics. Ecol. Indic. 2022, 137, 108759. [Google Scholar] [CrossRef]
- Meng, L.; Liu, H.; Zhang, X.; Ren, C.; Ustin, S.; Qiu, Z.; Xu, M.; Guo, D. Assessment of the effectiveness of spatiotemporal fusion of multi-source satellite images for cotton yield estimation. Comput. Electron. Agric. 2019, 162, 44–52. [Google Scholar] [CrossRef]
- Wu, G.; De Leeuw, J.; Skidmore, A.K.; Prins, H.H.; Liu, Y. Exploring the Possibility of Estimating the Aboveground Biomass of Vallisneria spiralis L. In Using Landsat TM Image in Dahuchi, Jiangxi Province, China, Proceedings of the MIPPR 2005: Geospatial Information, Data Mining, and Applications, Wuhan, China, 2 December 2005; SPIE: Bellingham, WA, USA, 2005; pp. 800–810. [Google Scholar]
- Wang, Z.; Ma, Y.; Chen, P.; Yang, Y.; Fu, H.; Yang, F.; Raza, M.A.; Guo, C.; Shu, C.; Sun, Y. Estimation of rice aboveground biomass by combining canopy spectral reflectance and unmanned aerial vehicle-based red green blue imagery data. Front. Plant Sci. 2022, 13, 903643. [Google Scholar] [CrossRef] [PubMed]
- Hosoi, F.; Umeyama, S.; Kuo, K. Estimating 3D chlorophyll content distribution of trees using an image fusion method between 2D camera and 3D portable scanning lidar. Remote Sens. 2019, 11, 2134. [Google Scholar] [CrossRef]
- Su, W.; Sun, Z.; Chen, W.-h.; Zhang, X.; Yao, C.; Wu, J.; Huang, J.; Zhu, D. Joint retrieval of growing season corn canopy LAI and leaf chlorophyll content by fusing Sentinel–2 and MODIS images. Remote Sens. 2019, 11, 2409. [Google Scholar] [CrossRef]
- Zhang, H.; Ge, Y.; Xie, X.; Atefi, A.; Wijewardane, N.K.; Thapa, S. High throughput analysis of leaf chlorophyll content in sorghum using RGB, hyperspectral, and fluorescence imaging and sensor fusion. Plant Methods 2022, 18, 60. [Google Scholar] [CrossRef]
- Wan, L.; Cen, H.; Zhu, J.; Zhang, J.; Zhu, Y.; Sun, D.; Du, X.; Zhai, L.; Weng, H.; Li, Y. Grain yield prediction of rice using multi-temporal UAV-based RGB and multispectral images and model transfer—A case study of small farmlands in the South of China. Agric. For. Meteorol. 2020, 291, 108096. [Google Scholar] [CrossRef]
- Wang, J.; He, P.; Liu, Z.; Jing, Y.; Bi, R. Yield estimation of summer maize based on multi-source remote-sensing data. Agron. J. 2022, 114, 3389–3406. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, J.; Zhang, J.; Fan, Y.; Cheng, Y.; Wang, B.; Wu, X.; Tan, X.; Tan, T.; Li, S. Predicting grain yield and protein content using canopy reflectance in maize grown under different water and nitrogen levels. Field Crop. Res. 2021, 260, 107988. [Google Scholar] [CrossRef]
- Cao, J.; Wang, H.; Li, J.; Tian, Q.; Niyogi, D. Improving the forecasting of winter wheat yields in Northern China with machine learning-dynamical hybrid subseasonal-to-seasonal ensemble prediction. Remote Sens. 2022, 14, 1707. [Google Scholar] [CrossRef]
- Sharma, A.; Jain, A.; Gupta, P.; Chowdary, V. Machine learning applications for precision agriculture: A comprehensive review. IEEE Access 2020, 9, 4843–4873. [Google Scholar] [CrossRef]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, C.; Park, D.S.; Yoon, S. Machine Learning and Artificial Intelligence for Smart Agriculture; Frontiers Media SA: Lausanne, Switzerland, 2023; Volume 14, p. 1166209. [Google Scholar]
- González Sánchez, A.; Frausto Solís, J.; Ojeda Bustamante, W. Predictive ability of machine learning methods for massive crop yield prediction. Span. J. Agric. Res. 2014, 12, 313–328. [Google Scholar] [CrossRef]
- Van Klompenburg, T.; Kassahun, A.; Catal, C. Crop yield prediction using machine learning: A systematic literature review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
- Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine learning approaches for crop yield prediction and nitrogen status estimation in precision agriculture: A review. Comput. Electron. Agric. 2018, 151, 61–69. [Google Scholar] [CrossRef]
- Yamparla, R.; Shaik, H.S.; Guntaka, N.S.P.; Marri, P.; Nallamothu, S. Crop Yield Prediction Using Random Forest Algorithm. In Proceedings of the 2022 7th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 22–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 1538–1543. [Google Scholar]
- Paudel, D.; Boogaard, H.; de Wit, A.; van der Velde, M.; Claverie, M.; Nisini, L.; Janssen, S.; Osinga, S.; Athanasiadis, I.N. Machine learning for regional crop yield forecasting in Europe. Field Crop. Res. 2022, 276, 108377. [Google Scholar] [CrossRef]
- Drummond, S.T.; Sudduth, K.A.; Joshi, A.; Birrell, S.J.; Kitchen, N.R. Statistical and neural methods for site-specific yield prediction. Trans. ASAE 2003, 46, 5. [Google Scholar] [CrossRef]
- Khaki, S.; Wang, L. Crop yield prediction using deep neural networks. Front. Plant Sci. 2019, 10, 621. [Google Scholar] [CrossRef]
- Mupangwa, W.; Chipindu, L.; Nyagumbo, I.; Mkuhlani, S.; Sisito, G. Evaluating machine learning algorithms for predicting maize yield under conservation agriculture in Eastern and Southern Africa. SN Appl. Sci. 2020, 2, 952. [Google Scholar] [CrossRef]
- Uyanık, G.K.; Güler, N. A study on multiple linear regression analysis. Procedia-Soc. Behav. Sci. 2013, 106, 234–240. [Google Scholar] [CrossRef]
- Tranmer, M.; Elliot, M. Multiple linear regression. Cathie Marsh Cent. Census Surv. Res. (CCSR) 2008, 5, 1–5. [Google Scholar]
- Jobson, J.; Jobson, J. Multiple linear regression. In Applied Multivariate Data Analysis: Regression and Experimental Design; Springer: New York, NY, USA, 1991; pp. 219–398. [Google Scholar]
- Suthaharan, S.; Suthaharan, S. Support vector machine. In Machine Learning Models and Algorithms for Big Data Classification: Thinking with Examples for Effective Learning; Springer: Boston, MA, USA, 2016; pp. 207–235. [Google Scholar]
- Popescu, M.-C.; Balas, V.E.; Perescu-Popescu, L.; Mastorakis, N. Multilayer perceptron and neural networks. WSEAS Trans. Circuits Syst. 2009, 8, 579–588. [Google Scholar]
- Delashmit, W.H.; Manry, M.T. Recent developments in multilayer perceptron neural networks. In Proceedings of the Seventh Annual Memphis Area Engineering and Science Conference, MAESC, Memphis, TN, USA, 11 May 2005; p. 33. [Google Scholar]
- Biau, G.; Scornet, E. A random forest guided tour. Test 2016, 25, 197–227. [Google Scholar] [CrossRef]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A Scalable Tree Boosting System. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4 December 2017; p. 30. [Google Scholar]
- Maimaitijiang, M.; Sagan, V.; Sidike, P.; Hartling, S.; Esposito, F.; Fritschi, F.B. Soybean yield prediction from UAV using multimodal data fusion and deep learning. Remote Sens. Environ. 2020, 237, 111599. [Google Scholar] [CrossRef]
- Vasit, S.; Maitiniyazi, M.; Sourav, B.; Matthew, M.; Brown, D.R.; Paheding, S.; Fritschi, F.B. Field-scale crop yield prediction using multi-temporal WorldView–3 and PlanetScope satellite data and deep learning. ISPRS J. Photogramm. Remote Sens. 2021, 174, 265–281. [Google Scholar]
- Jeong, S.; Ko, J.; Ban, J.-o.; Shin, T.; Yeom, J.-m. Deep learning-enhanced remote sensing-integrated crop modeling for rice yield prediction. Ecol. Inform. 2024, 84, 102886. [Google Scholar] [CrossRef]
- Zhou, H.; Huang, F.; Lou, W.; Gu, Q.; Ye, Z.; Hu, H.; Zhang, X. Yield prediction through UAV-based multispectral imaging and deep learning in rice breeding trials. Agric. Syst. 2025, 223, 104214. [Google Scholar] [CrossRef]
- Clercq, D.D.; Mahdi, A. Feasibility of machine learning-based rice yield prediction in India at the district level using climate reanalysis and remote sensing data. Agric. Syst. 2024, 220, 104099. [Google Scholar] [CrossRef]
- Rußwurm, M.; Courty, N.; Emonet, R.; Lefèvre, S.; Tuia, D.; Tavenard, R. End-to-end learned early classification of time series for in-season crop type mapping. ISPRS J. Photogramm. Remote Sens. 2023, 196, 445–456. [Google Scholar] [CrossRef]
- Weiguo, Y.; Gaoxiang, Y.; Dong, L.; Hengbiao, Z.; Xia, Y.; Yan, Z.; Weixing, C.; Lin, Q.; Tao, C. Improved prediction of rice yield at field and county levels by synergistic use of SAR, optical and meteorological data. Agric. For. Meteorol. 2023, 342, 109729. [Google Scholar]
- Nishu, B.; Anshu, S. Deep Learning Based Wheat Crop Yield Prediction Model in Punjab Region of North India. Appl. Artif. Intell. 2021, 35, 1304–1328. [Google Scholar]
- Debaditya, G.; Nihal, G.; Siddhartha, S.; Sudip, M. Role of existing and emerging technologies in advancing climate-smart agriculture through modeling: A review. Ecol. Inform. 2022, 71, 101805. [Google Scholar]
- Jeong, S.; Ko, J.; Yeom, J.-M. Predicting rice yield at pixel scale through synthetic use of crop and deep learning models with satellite data in South and North Korea. Sci. Total Environ. 2022, 802, 149726. [Google Scholar] [CrossRef]
- Yang, S.; Li, L.; Fei, S.; Yang, M.; Tao, Z.; Meng, Y.; Xiao, Y. Wheat Yield Prediction Using Machine Learning Method Based on UAV Remote Sensing Data. Drones 2024, 8, 284. [Google Scholar] [CrossRef]
- Seungtaek, J.; Jonghan, K.; Taehwan, S.; Min, Y.J. Incorporation of machine learning and deep neural network approaches into a remote sensing-integrated crop model for the simulation of rice growth. Sci. Rep. 2022, 12, 9030. [Google Scholar]
- Joshi, A.; Pradhan, B.; Gite, S.; Chakraborty, S. Remote-sensing data and deep-learning techniques in crop mapping and yield prediction: A systematic review. Remote Sens. 2023, 15, 2014. [Google Scholar] [CrossRef]
- Shafi, U.; Mumtaz, R.; Anwar, Z.; Ajmal, M.M.; Khan, M.A.; Mahmood, Z.; Qamar, M.; Jhanzab, H.M. Tackling food insecurity using remote sensing and machine learning based crop yield prediction. IEEE Access 2023, 11, 108640–108657. [Google Scholar] [CrossRef]
- Alibabaei, K.; Gaspar, P.D.; Lima, T.M.; Campos, R.M.; Girão, I.; Monteiro, J.; Lopes, C.M. A review of the challenges of using deep learning algorithms to support decision-making in agricultural activities. Remote Sens. 2022, 14, 638. [Google Scholar] [CrossRef]
- Pandya, P.; Gontia, N.K. Early crop yield prediction for agricultural drought monitoring using drought indices, remote sensing, and machine learning techniques. J. Water Clim. Chang. 2023, 14, 4729–4746. [Google Scholar] [CrossRef]
- Sunitha, D.B.; Sandhya, N.; Shahu, C.K. Hybrid deep WaveNet–LSTM architecture for crop yield prediction. Multimed. Tools Appl. 2023, 83, 19161–19179. [Google Scholar]
- Alexandros, O.; Cagatay, C.; Ayalew, K. Hybrid Deep Learning-based Models for Crop Yield Prediction. Appl. Artif. Intell. 2022, 36, 2031822. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Plot | Number | Angle (°) | Spike Length (cm) | Branch Stem Length (cm) | Grain Number (Grain) | Yield (g) |
|---|---|---|---|---|---|---|
| 1 | 1 | 17.3 | 24.8 | 150.77 | 173 | 3.8 |
| 2 | 15.6 | 19.3 | 100.56 | 109 | 2.4 | |
| 3 | 7 | 19.9 | 105.06 | 120 | 3.3 | |
| 4 | 6 | 25.5 | 161.49 | 201 | 4.6 | |
| 2 | 5 | 5 | 23.2 | 150.07 | 170 | 4 |
| 6 | 5.1 | 21 | 92.71 | 95 | 2 | |
| 7 | 25.4 | 19.6 | 126.45 | 131 | 2.9 | |
| 8 | 9.7 | 15.5 | 114.73 | 148 | 3 | |
| … | … | … | … | … | … | … |
| 512 | 2045 | 8.4 | 13.5 | 46.99 | 42 | 0.6 |
| 2046 | 6 | 17.8 | 63.32 | 74 | 1.5 | |
| 2047 | 10.5 | 16.3 | 49.87 | 59 | 1 | |
| 2048 | 12.7 | 11.6 | 129.28 | 143 | 2.9 |
| Plot | Number | Angle (°) | Spike Length (cm) | Branch Stem Length (cm) | Grain Number (Grain) | Yield (g) |
|---|---|---|---|---|---|---|
| 1 | 1 | 11.475 | 22.375 | 129.47 | 151 | 3.525 |
| 2 | 2 | 11.3 | 19.825 | 120.99 | 136 | 2.975 |
| … | … | … | … | … | … | … |
| 512 | 512 | 9.4 | 14.8 | 72.365 | 80 | 9.4 |
| Plot | Number | Angle (°) | Spike Length (cm) | Branch Stem Length (cm) | Grain Number (Grain) | Yield (g) |
|---|---|---|---|---|---|---|
| 1 | 1 | 16.45 | 22.05 | 125.67 | 141 | 3.10 |
| 2 | 6.50 | 22.70 | 133.28 | 161 | 3.95 | |
| 3 | 5.05 | 22.10 | 121.39 | 133 | 2.98 | |
| 4 | 17.55 | 17.55 | 120.59 | 140 | 2.95 | |
| 2 | 5 | 19.00 | 19.20 | 79.85 | 96 | 2.00 |
| 6 | 13.25 | 15.15 | 72.84 | 77 | 1.30 | |
| 7 | 13.85 | 21.25 | 156.57 | 199 | 3.40 | |
| 8 | 11.45 | 19.50 | 109.78 | 127 | 1.52 | |
| … | … | … | … | … | … | … |
| 512 | 2045 | 11.75 | 17.35 | 109.31 | 133 | 3.25 |
| 2046 | 6.43 | 19.15 | 110.74 | 134 | 3.17 | |
| 2047 | 30.64 | 12.90 | 52.59 | 64 | 1.40 | |
| 2048 | 11.60 | 13.95 | 89.58 | 101 | 1.95 |
| Model | RMSE | R2 | MAPE (%) |
|---|---|---|---|
| LR | 0.4975 | 0.6989 | 17.49 |
| SVM | 0.5093 | 0.6844 | 17.77 |
| MLP | 0.4769 | 0.7233 | 17.04 |
| RF | 0.2777 | 0.9062 | 9.05 |
| GBR | 0.4599 | 0.7427 | 16.25 |
| LightGBM | 0.3798 | 0.8245 | 13.16 |
| XGBoost | 0.8245 | 0.8934 | 7.66 |
| Model | RMSE | R2 | MAPE (%) |
|---|---|---|---|
| Voting–2m | 0.2735 | 0.9090 | 8.12 |
| Stacking–2m | 0.2705 | 0.911 | 8.33 |
| Voting–3m | 0.2995 | 0.8909 | 9.69 |
| Stacking–3m | 0.2483 | 0.9250 | 6.90 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, J.; Tian, P.; Li, Z.; Wang, X.; Zhang, H.; Chen, J.; Qian, Y. Construction and Optimization of Integrated Yield Prediction Model Based on Phenotypic Characteristics of Rice Grown in Small–Scale Plantations. Agriculture 2025, 15, 181. https://doi.org/10.3390/agriculture15020181
Sun J, Tian P, Li Z, Wang X, Zhang H, Chen J, Qian Y. Construction and Optimization of Integrated Yield Prediction Model Based on Phenotypic Characteristics of Rice Grown in Small–Scale Plantations. Agriculture. 2025; 15(2):181. https://doi.org/10.3390/agriculture15020181
Chicago/Turabian StyleSun, Jihong, Peng Tian, Zhaowen Li, Xinrui Wang, Haokai Zhang, Jiangquan Chen, and Ye Qian. 2025. "Construction and Optimization of Integrated Yield Prediction Model Based on Phenotypic Characteristics of Rice Grown in Small–Scale Plantations" Agriculture 15, no. 2: 181. https://doi.org/10.3390/agriculture15020181
APA StyleSun, J., Tian, P., Li, Z., Wang, X., Zhang, H., Chen, J., & Qian, Y. (2025). Construction and Optimization of Integrated Yield Prediction Model Based on Phenotypic Characteristics of Rice Grown in Small–Scale Plantations. Agriculture, 15(2), 181. https://doi.org/10.3390/agriculture15020181