
Individual Recognition of a Group Beef Cattle Based on Improved YOLO v5



Abstract
1. Introduction
- (1)
- The MSR-ATT (MCA-SimAM-Resnet Attention Module) is introduced into the baseline YOLO v5 model to enhance feature extraction by capturing spatial and channel-wise information in feature maps simultaneously, thereby improving the model’s detection accuracy.
- (2)
- The loss function is improved to use an optimized loss function, which enhances the model’s positioning precision and adapts it better to real farming environments.
- (3)
- Structural pruning is applied to the model to reduce parameter count and memory usage, improve model inference speed, and facilitate deployment on edge devices with limited computing power.
2. Materials and Methods
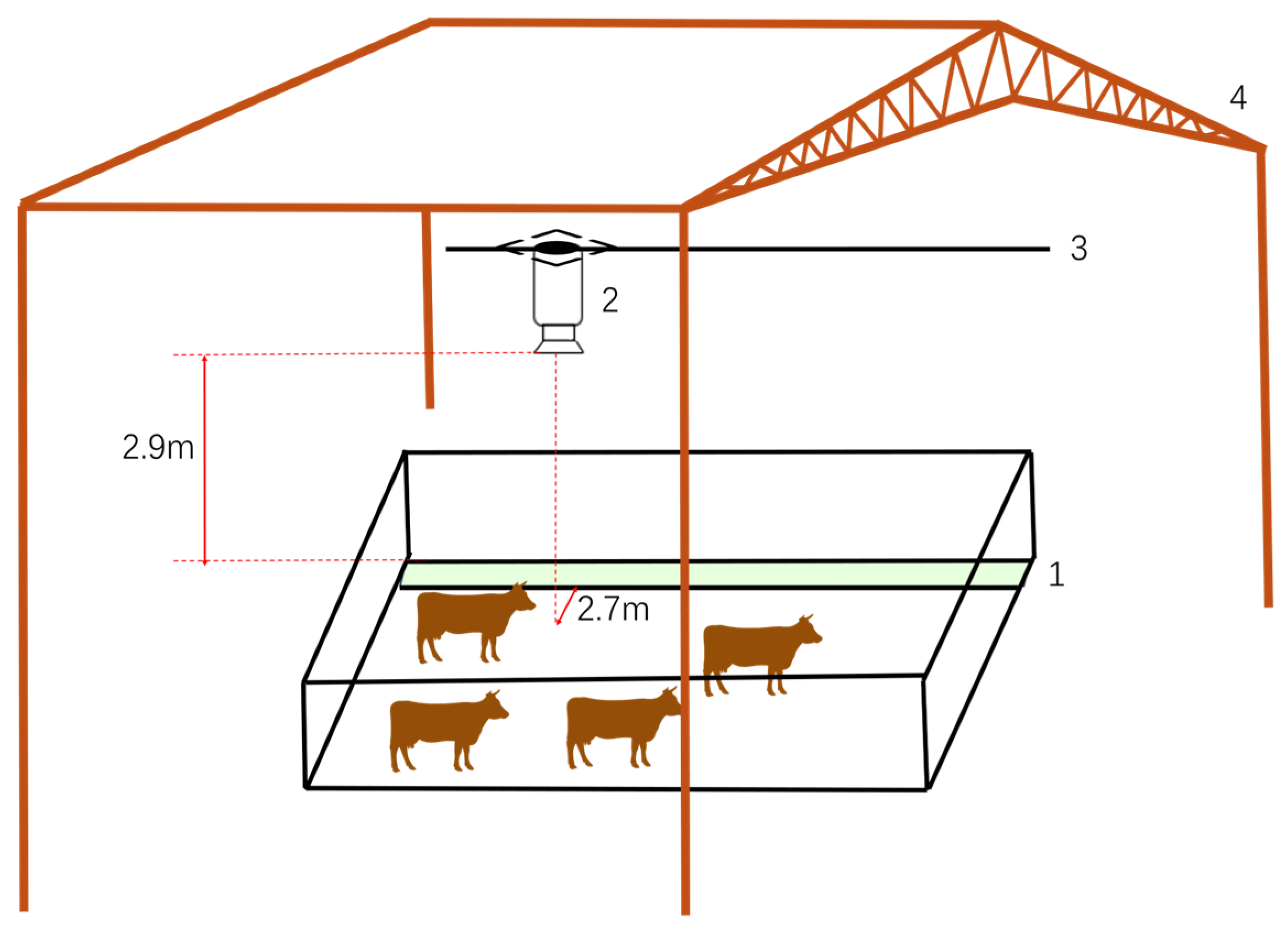
2.1. Data Collection
2.2. Data Preprocessing
2.2.1. Data Filtering
2.2.2. Dataset
2.2.3. Image Resizing
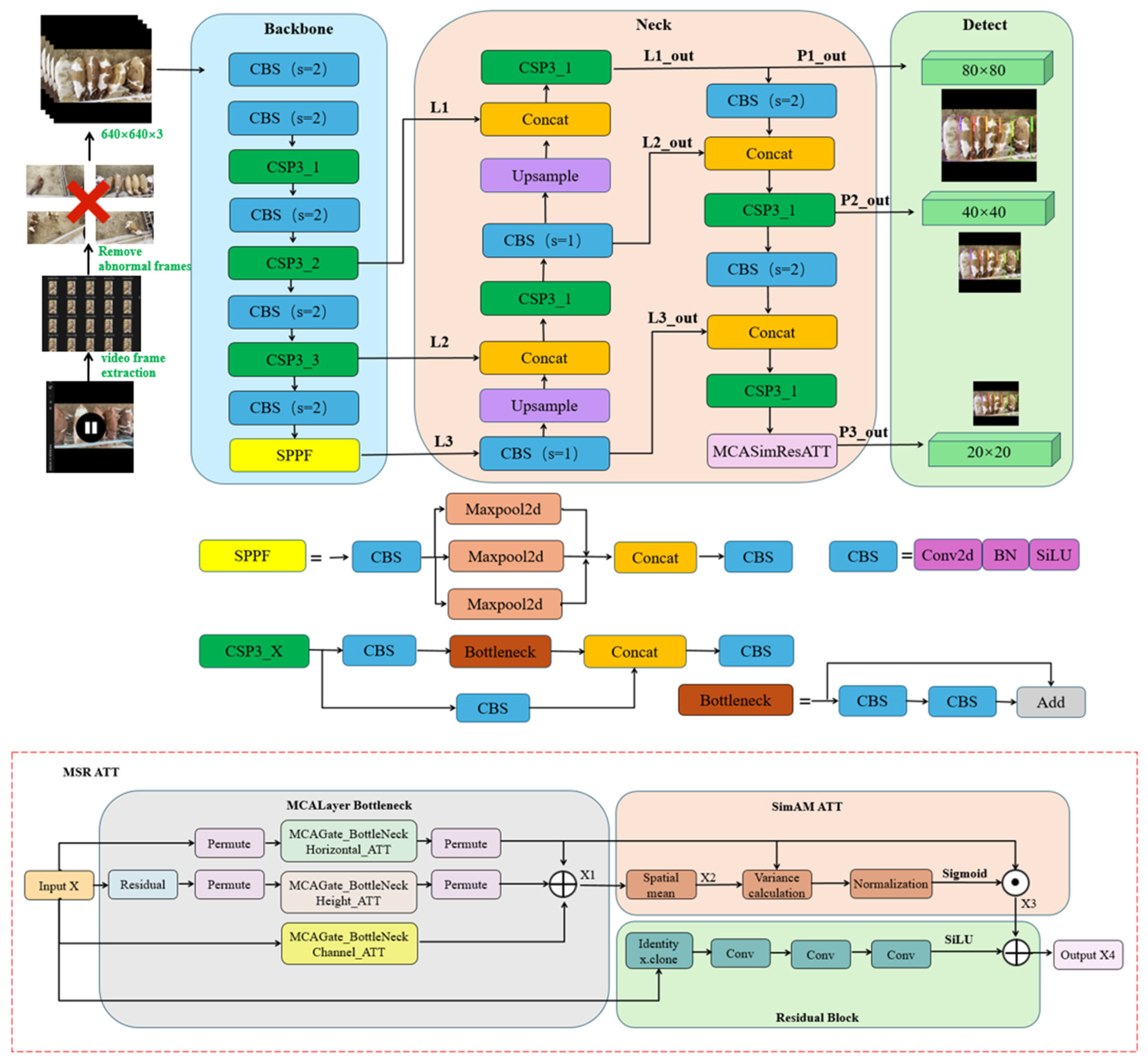
2.3. Improved YOLO v5 Network Structure
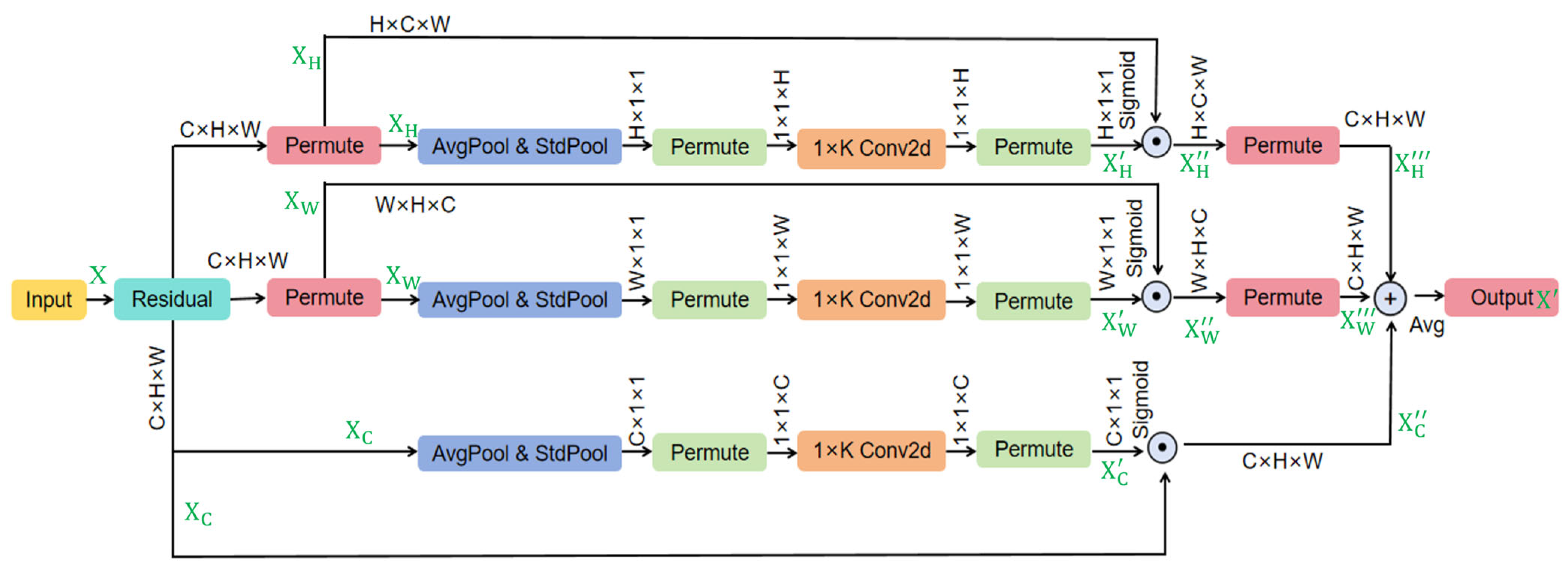
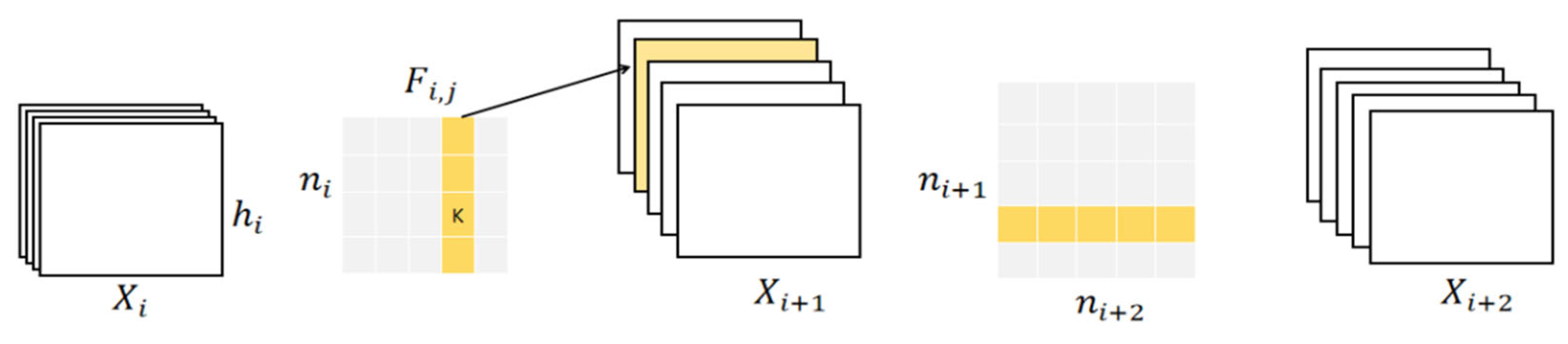
2.3.1. MCA Attention Mechanism
- (1)
- Branch structure captures feature dependencies
- (2)
- Squeeze transformation
- (3)
- Excitation transformation
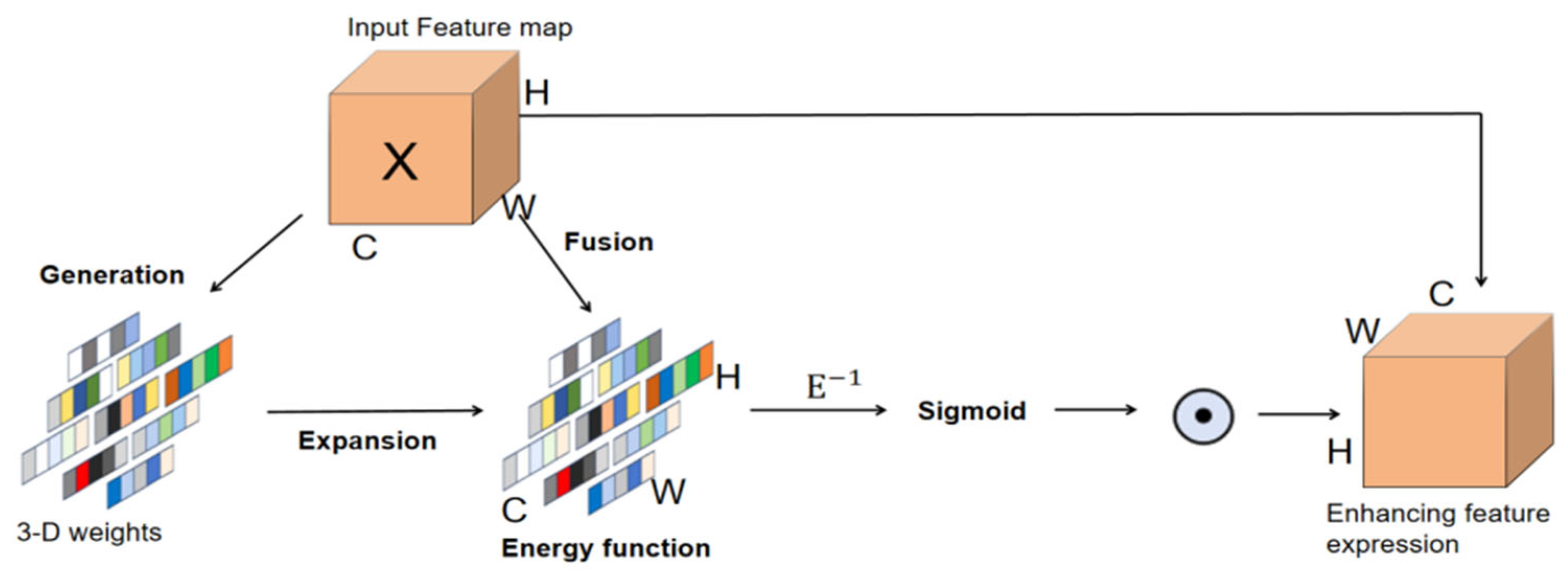
2.3.2. SimAM Attention Module
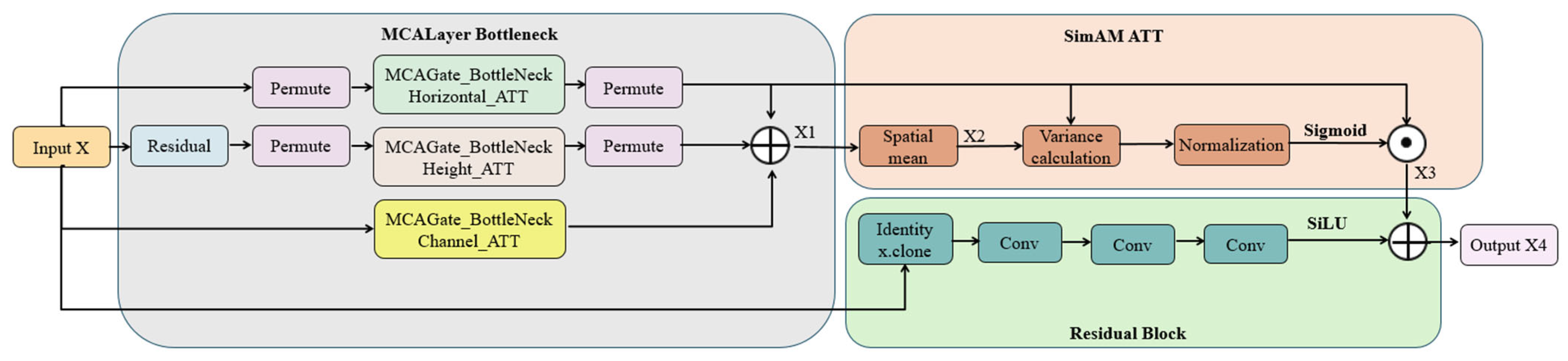
2.3.3. MSR ATT Model
2.3.4. Improve the Loss Function
- (1)
- For A and B, represents the coordinates of the top-left corner of A, and represents the coordinates of the bottom-right corner of A; represents the coordinates of the top-left corner of B, and represents the coordinates of the bottom-right corner of B.
- (2)
- Calculate
- (3)
- Calculate
- (4)
- Calculate
2.3.5. Improved YOLO v5 Network Framework
- (1)
- Input: Group beef cattle back morphology videos are captured and frame-by-frame using OpenCV, resulting in image data of group beef cattle back morphology. Manual removal of duplicate frames, blurry frames, etc., yields filtered image data. OpenCV is then used to resize images to 640 × 360 resolution.
- (2)
- Backbone: Group beef cattle back morphology images with a resolution of 640 × 360 are padded with gray to obtain input images of 640 × 640 resolution. The backbone network uses CSP3_X, CBS, and SPPF modules to extract beef cattle back features from the images. Three effective feature layers are extracted: L1 (80 × 80 × 256), L2 (40 × 40 × 512), and L3 (20 × 20 × 1024).
- (3)
- Neck: The Neck network adopts the Feature Pyramid Network (PAFPN) architecture, enhancing the extraction of back morphology features of group beef cattle through CSP3_X, CBS, and MSR-ATT modules. The PAFPN structure utilizes a top-down path to transfer high-level semantic features (L3) to lower layers via upsampling operations, fusing them with corresponding scale feature layers L2 and L1. Meanwhile, through lateral connections, after adjusting the number of channels with 1 × 1 convolution, the feature layers L1, L2, and L3 output by the backbone network are added to the upsampled features to retain more scale details. The MSR-ATT modules are integrated into each level of the PAFPN, generating attention weights for each channel through their unique three-branch structure and fusing them into an enhanced back morphology feature map of group beef cattle to improve feature representation capability. The Neck network processes the beef cattle back morphology feature layers L1, L2, and L3, producing three enhanced feature layers: P1_out (80 × 80 × 256), P2_out (40 × 40 × 512), and P3_out (20 × 20 × 1024).
- (4)
- Prediction: The three enhanced features P1_out, P2_out, and P3_out from the Neck network are fed into the head network for accurate individual identification of group beef cattle. For each feature layer, convolutional layers in the YOLO head adjust the number of channels and store four spatial position information (predicted center point offset in x and y coordinates, predicted bounding box width and height), the confidence of the predicted bounding box, and the type of detected target. By modifying the loss function, a minimum point distance-based loss function is used to calculate the loss value between the prediction box and the ground truth box. For the coordinate regression branch, it adjusts the convolutional layer parameters via backpropagation to improve the localization accuracy of prediction boxes, compensating for the defects of traditional loss functions. This complements the feature enhancement model in the Neck network, jointly addressing the scenario requirements of dense targets and high similarity in the detection of closely clustered group beef cattle, thereby improving the accuracy of group beef cattle individual recognition.
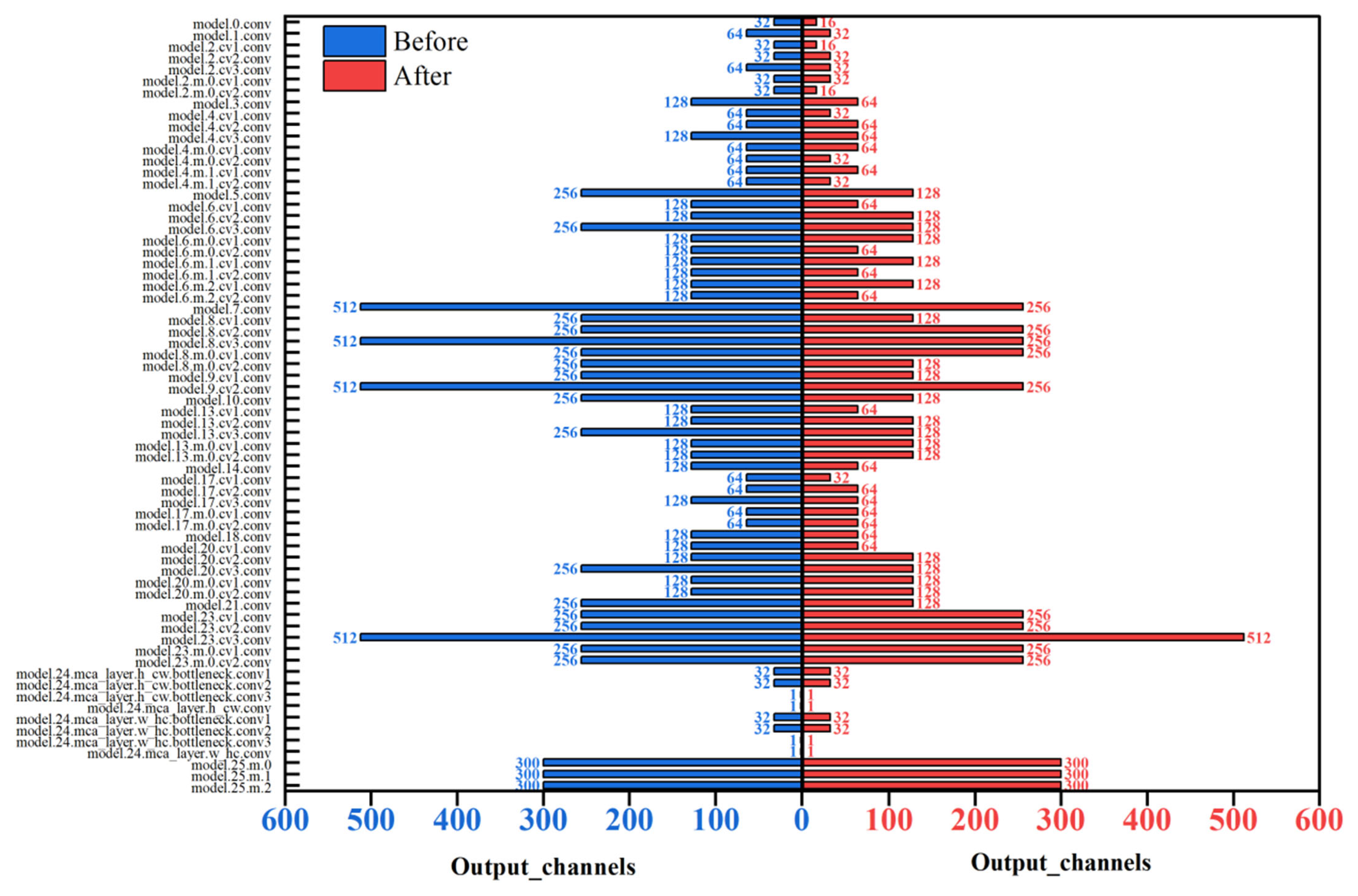
2.3.6. Structured Pruning
3. Results
3.1. Test Platform
3.2. Improved YOLO v5 Precise Individual Identification Detection Results for Group Beef Cattle
3.3. Improved YOLO v5 Ablation Experiments and Analysis
3.4. Analysis of Improvements in Loss Functions
3.5. Pruning Effect of the Model
3.6. Improved YOLO v5 Results for Individual Identification of Beef Cattle with Different Coat Patterns
4. Discussion
4.1. Advantages of the Improved YOLO v5
4.2. Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Menezes, G.L.; Alves, A.A.C.; Negreiro, A.; Ferreira, R.E.P.; Higaki, S.; Casella, E.; Rosa, G.J.M.; Dorea, J.R.R. Color-independent cattle identification using keypoint detection and siamese neural networks in closed- and open-set scenarios. J. Dairy Sci. 2025, 108, 1234–1245. [Google Scholar] [CrossRef] [PubMed]
- Meng, Y.; Yoon, S.; Han, S.; Fuentes, A.; Park, J.; Jeong, Y.; Park, D.S. Improving known–unknown cattle’s face recognition for smart livestock farm management. Animals 2023, 13, 3588. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Zhang, Y.; Niu, K.; He, Z. Neural network-based method for contactless estimation of carcass weight from live beef images. Comput. Electron. Agric. 2025, 229, 109830. [Google Scholar] [CrossRef]
- Tong, L.; Fang, J.; Wang, X.; Zhao, Y. Research on cattle behavior recognition and multi-object tracking algorithm based on yolo-bot. Animals 2024, 14, 2993. [Google Scholar] [CrossRef]
- Awad, A.I. From classical methods to animal biometrics: A review on cattle identification and tracking. Comput. Electron. Agric. 2016, 123, 423–435. [Google Scholar] [CrossRef]
- Williams, L.R.; Fox, D.R.; Bishop-Hurley, G.J.; Swain, D.L. Use of radio frequency identification (rfid) technology to record grazing beef cattle water point use. Comput. Electron. Agric. 2019, 156, 193–202. [Google Scholar] [CrossRef]
- Li, J.; Yang, Y.; Liu, G.; Ning, Y.; Song, P. Open-set sheep face recognition in multi-view based on li-sheepfacenet. Agriculture 2024, 14, 1112. [Google Scholar] [CrossRef]
- Kumar, S.; Singh, S.K.; Abidi, A.I.; Datta, D.; Sangaiah, A.K. Group sparse representation approach for recognition of cattle on muzzle point images. Int. J. Parallel. Program 2018, 46, 812–837. [Google Scholar] [CrossRef]
- Barry, B. Using muzzle pattern recognition as a biometric approach for cattle identification. Trans ASABE 2007, 50, 1073–1080. [Google Scholar] [CrossRef]
- Li, G.; Erickson, G.E.; Xiong, Y. Individual beef cattle identification using muzzle images and deep learning techniques. Animals 2022, 12, 1453. [Google Scholar] [CrossRef]
- Zhao, K.; Wang, J.; Chen, Y.; Sun, J.; Zhang, R. Individual identification of holstein cows from top-view rgb and depth images based on improved pointnet++ and convnext. Agriculture 2025, 15, 710. [Google Scholar] [CrossRef]
- He, D.; Liu, J.; Xiong, H.; Lu, Z. Individual Identification of Dairy Cows Based on Improved YOLO v3. Trans. Chin. Soc. Agric. Mach. 2020, 51, 250–260. [Google Scholar] [CrossRef]
- Hu, H.; Dai, B.; Shen, W.; Wei, X.; Sun, J.; Li, R.; Zhang, Y. Cow identification based on fusion of deep parts features. Biosyst. Eng. 2020, 192, 245–256. [Google Scholar] [CrossRef]
- Achour, B.; Belkadi, M.; Filali, I.; Laghrouche, M.; Lahdir, M. Image analysis for individual identification and feeding behaviour monitoring of dairy cows based on convolutional neural networks (cnn). Biosyst. Eng. 2020, 198, 31–49. [Google Scholar] [CrossRef]
- Paudel, S.; Brown-Brandl, T.; Rohrer, G.; Sharma, S.R. Deep learning algorithms to identify individual finishing pigs using 3d data. Biosyst. Eng. 2025, 255, 104143. [Google Scholar] [CrossRef]
- Zhang, H.; Zheng, L.; Tan, L.; Gao, J.; Luo, Y. Yolox-s-tkecb: A holstein cow identification detection algorithm. Agriculture 2024, 14, 1982. [Google Scholar] [CrossRef]
- Song, H.; Li, R.; Wang, Y.; Jiao, Y.; Hua, Z. Recognition Method of Heavily Occluded Beef Cattle Targets Based on ECA-YOLO v5s. Trans. Chin. Soc. Agric. Mach. 2023, 54, 274–281. [Google Scholar] [CrossRef]
- Wu, D.; Yin, X.; Jiang, B.; Jiang, M.; Li, Z.; Song, H. Detection of the respiratory rate of standing cows by combining the deeplab v3+ semantic segmentation model with the phase-based video magnification algorithm. Biosyst. Eng. 2020, 192, 72–89. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, R.; Dong, P.; Sun, H.; Li, S.; Wang, H. Beef Cattle Multi-target Tracking Based on DeepSORT Algorithm. Trans. Chin. Soc. Agric. Mach. 2021, 52, 248–256. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Wei, L.; Dragomir, A.; Dumitru, E.; Christan, S.; Scott, R.; Cheng, Y. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Yu, Y.; Zhang, Y.; Cheng, Z.; Song, Z.; Tang, C. Mca: Multidimensional collaborative attention in deep convolutional neural networks for image recognition. Eng. Appl. Artif. Intell. 2023, 126, 107079. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, R.; Li, L. SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks. In Proceedings of the 38th International Conference on Machine Learning (ICML 2021), Vienna, Austria, 18–24 July 2021. [Google Scholar] [CrossRef]
- Siliang, M.; Yong, X. MPDIoU: A Loss for Efficient and Accurate Bounding Box Regression. arXiv 2023, arXiv:2307.07662. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Hao, L.; Asim, K.; Igor, D.; Hanan, S.; Hans, P. Pruning Filters for Efficient ConvNets. In Proceedings of the IEEE International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Back Pattern | Images | Cattle Number | Images Number | Description | |
|---|---|---|---|---|---|
| Train | Test | ||||
| Dark solid patterns |  | 8 | 362 | 17 | The back of a beef cattle is mostly dark in color, usually brown or dark brown, and the color is single without extra patterns. |
| Light solid patterns |  | 7 | 317 | 13 | The back of most beef cattle is light in color, mostly white or off-white, with a single uniform color and no extra patterns. |
| Dark patterns |  | 27 | 1987 | 164 | The base color of the patterns on the back of beef cattle is dark, with mostly a small amount of light-colored patterns on top. |
| Light patterns |  | 23 | 1894 | 139 | The base color of the patterns on the back of beef cattle is light, with most of them adorned with dark patterns as embellishments. |
| Complex patterns |  | 31 | 2012 | 168 | The back of beef cattle has interlaced dark and light patterns, which are relatively complex. |
| Name | Configuration |
|---|---|
| CPU | Intel(R) Core(TM) i7-14700F CPU @ 2.10 GHz, 3.19 GHz |
| Memory usage | 32 GB |
| GPU | NVIDIA GeForce RTX 4080SUPER |
| GPU-accelerated library | CUDA 12.6 cuDNN 8.0.5 |
| Operating system | Windows 11 (64 bits) |
| Environment | Python 3.8 Pytorch 11.7 |
| Models | Precision % | Recall % | mAP % | Params/M | FLOPs/G | Average Speed/s |
|---|---|---|---|---|---|---|
| YOLO v11 | 90.3 | 91.1 | 95.3 | 9.4 | 21.5 | 0.1617 |
| YOLO v8 | 88.4 | 94.6 | 93.9 | 11.2 | 28.6 | 0.1609 |
| YOLO v7 | 86.5 | 93.6 | 94.8 | 11.6 | 13.2 | 0.1284 |
| YOLO v5 | 87.8 | 95.5 | 95.8 | 7.2 | 16.75 | 0.1133 |
| YOLO v5n | 86.7 | 93.2 | 94.5 | 1.9 | 4.5 | 0.0645 |
| Improved YOLO v5 | 93.2 | 94.6 | 97.6 | 13.22 | 7.84 | 0.0746 |
| Models | Precision % | Recall % | mAP % | Params/M | Memory/MB | FLOPs | Average Speed/s |
|---|---|---|---|---|---|---|---|
| YOLO v5 | 86.5 | 93.6 | 94.8 | 28.3 | 14.1 | 16.75 | 0.1133 |
| YOLO v5 + MCA | 91.5 | 93.6 | 96.4 | 28.3 | 14.2 | 16.42 | 0.1132 |
| YOLO v5 + SimAM | 90.7 | 93.9 | 95.7 | 28.3 | 14.1 | 16.52 | 0.1133 |
| YOLO v5 + MSR-ATT | 93.4 | 93.7 | 96.9 | 28.4 | 14.2 | 16.73 | 0.1132 |
| Models | Precision % | Recall % | mAP % | Params/M | Memory/MB | FLOPs/G | Average Speed/s |
|---|---|---|---|---|---|---|---|
| Before pruning | 93.4 | 93.7 | 95.8 | 27.83 | 14.2 | 16.75 | 0.1133 |
| After pruning | 93.2 | 94.6 | 94.5 | 13.22 | 6.91 | 7.84 | 0.0746 |
| Models | Precision % | mAP % | ||||
|---|---|---|---|---|---|---|
| Dark Solid Patterns | Light Solid Patterns | Dark Patterns | Light Patterns | Complex Patterns | ||
| YOLO v11 | 78.3 | 75.9 | 88.7 | 87.4 | 90.1 | 91.8 |
| YOLO v8 | 73.4 | 82.6 | 89.4 | 90.1 | 92.5 | 93.7 |
| YOLO v7 | 65.5 | 73.1 | 90.6 | 88.3 | 91.3 | 91.4 |
| YOLO v5 | 84.8 | 81.6 | 94.3 | 91.4 | 92.5 | 95.2 |
| YOLO v5n | 65.5 | 73.4 | 88.7 | 90.7 | 94.1 | 94.1 |
| Improved YOLO v5 | 96.2 | 95.7 | 96.6 | 97.4 | 96.6 | 95.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Zhang, Y.; Kang, X.; Mao, T.; Li, Y.; Liu, G. Individual Recognition of a Group Beef Cattle Based on Improved YOLO v5. Agriculture 2025, 15, 1391. https://doi.org/10.3390/agriculture15131391
Li Z, Zhang Y, Kang X, Mao T, Li Y, Liu G. Individual Recognition of a Group Beef Cattle Based on Improved YOLO v5. Agriculture. 2025; 15(13):1391. https://doi.org/10.3390/agriculture15131391
Chicago/Turabian StyleLi, Ziruo, Yadan Zhang, Xi Kang, Tianci Mao, Yanbin Li, and Gang Liu. 2025. "Individual Recognition of a Group Beef Cattle Based on Improved YOLO v5" Agriculture 15, no. 13: 1391. https://doi.org/10.3390/agriculture15131391
APA StyleLi, Z., Zhang, Y., Kang, X., Mao, T., Li, Y., & Liu, G. (2025). Individual Recognition of a Group Beef Cattle Based on Improved YOLO v5. Agriculture, 15(13), 1391. https://doi.org/10.3390/agriculture15131391