1. Introduction
According to the latest data released by the Food and Agriculture Organization of the United Nations (FAO), as of 2024, global rice production ranks second among food crops, after wheat. This highlights the importance of rice in global agricultural production, especially in Asia, where rice is a major part of people’s daily diet. However, during processing, transportation, and storage of rice, foreign objects such as stones, metal fragments, other grains, and clods are often introduced. This not only affects the appearance and texture of rice but also poses a threat to consumer health [
1]. In addition, the varietal purity of rice seeds—which guarantees the genetic quality of the seed, ensuring that it belongs to a single rice variety—is also a critical concern in agricultural production. Accurate foreign object detection can contribute to identifying and preserving such purity during the seed selection and processing stages. Therefore, ensuring rice is free from harmful foreign objects is essential for safeguarding food safety and enhancing product quality [
2], and it plays an important role in identifying and maintaining the varietal purity of rice seeds during seed production. Traditional manual screening methods are inefficient and prone to human error, making them inadequate for modern large-scale production. With rising consumer concerns about food quality and safety, and increasingly stringent food safety requirements in international markets, producers are under pressure to ensure that their products meet quality standards and regulations. In this context, efficiently and accurately detecting and rejecting foreign matter in rice has become a key challenge in food safety.
In recent years, foreign object detection in agricultural products has become a critical research area in food safety and quality control. Various methods have been proposed to improve detection efficiency and accuracy, including hyperspectral imaging, terahertz spectroscopy, and image processing techniques. For instance, Saeidan et al. [
3] identified wood chips, plastics, stones, and plant debris in cocoa beans using hyperspectral imaging combined with principal component analysis (PCA) and support vector machines (SVM), achieving a test accuracy of 81.28%. Wang et al. [
4] applied terahertz spectral imaging for nondestructive detection of shell contaminants in walnuts, with classification accuracy exceeding 95%. Yang et al. [
5] enhanced the detection of foreign fibers in cotton using an improved image processing pipeline that integrates image enhancement, Otsu segmentation, and morphological post-processing.
Despite promising results in specific scenarios, foreign object detection in agricultural contexts still faces several challenges. First, foreign materials often closely resemble crops in color and shape, making traditional feature-based algorithms less robust and limiting their generalization capability. Second, small-sized foreign objects occupy minimal image area and are susceptible to noise, leading to frequent missed or false detections. Additionally, variations in illumination and background clutter in complex environments further degrade detection performance. Therefore, enhancing detection accuracy and robustness—particularly for small objects under challenging conditions—remains a key issue in the field.
With the rapid development of deep learning, convolutional neural networks (CNNs) have become the dominant technology in object detection, especially for automatic feature extraction from raw data. Using multiple convolutional and pooling layers, CNNs capture local image features and abstract complex patterns layer by layer. Like the YOLO series [
6] (including YOLO, YOLO9000, YOLOv3, YOLOv4, YOLOv5 [
7], YOLOX, YOLOv6 [
8], YOLOv7 [
9], etc.), faster deep learning methods such as Faster R-CNN [
10], Mask-RCNN [
11], and SSD have been widely used in real-time object detection and image classification tasks. Through end-to-end learning, these methods can automatically learn and identify key features in images without manual feature design, providing fast and accurate target location and recognition.
In particular, in the detection of foreign objects in rice, such as stones and metal fragments, traditional detection methods often struggle to meet the requirements for precise identification, thereby affecting quality control. Therefore, improving the detection accuracy of targets in complex backgrounds has become a hot topic in current research. Many researchers have significantly improved target detection accuracy by employing data augmentation, anchor box optimization, multi-scale feature fusion, and enhanced attention mechanisms. For example, Yang et al. [
12] proposed KPE-YOLOv5, which optimizes anchor box distribution using K-means++ clustering and integrates the scSE attention module with small target detection layers, significantly improving target localization and classification accuracy. Wang et al. [
13] proposed UAV-YOLOv8, which incorporates Wise-IoU v3 bounding box regression loss and the BiFormer attention mechanism to optimize localization accuracy and feature focus in object detection. Alhawsawi et al. [
14] proposed an improved YOLOv8-based framework that improves multi-scale contextual information capture by incorporating a context enrichment module (CEM). Meng et al. [
15] proposed the YOLOv7-MA model, which incorporates micro-scale detection layers and the convolutional block attention module (CBAM) to improve the detection accuracy of wheat spikes in complex backgrounds. Although these methods have achieved success in many applications, they still face challenges in detecting foreign objects in rice under complex backgrounds.
To address the aforementioned challenges, this paper proposes an innovative deep learning-based algorithm, YOLOv-MA, specifically designed for the efficient detection of foreign objects in rice. By incorporating the multi-scale dilated attention (MSDA) mechanism, the model enhances feature representation across different object scales, enabling adaptive handling of small, medium, and large foreign objects. Additionally, the adaptive spatial feature fusion (ASFF) module is employed to further optimize the multi-scale feature fusion process, significantly enhancing the model’s detection accuracy and robustness in complex backgrounds [
16]. The main contributions of this paper are listed as follows:
A YOLOv8-based model is proposed, in which the multi-scale dilated attention (MSDA) and adaptive spatial feature fusion (ASFF) modules are integrated. This represents the first attempt to combine both modules for rice foreign object detection, and the model’s ability to identify small and irregular contaminants in complex scenes is effectively enhanced.
A high-quality rice foreign object detection dataset was constructed with detailed annotations. A diverse range of contaminants, such as stones, metal fragments, and clods, is included, providing a reliable benchmark for future research.
Extensive experiments were conducted to evaluate the proposed method. The results demonstrate that the model is able to outperform several mainstream detection algorithms in terms of accuracy and robustness, proving its effectiveness in practical applications.
2. Materials and Methods
2.1. Data Acquisition and Preprocessing
The successful training of the rice foreign object detection model relies on high-quality, representative, and diverse image data. To construct a reliable dataset, the rice and foreign object samples in this study were obtained from the Key Laboratory of Grain Information Processing and Control at the Ministry of Education, Henan University of Technology. Based on the Chinese national standards GB/T 1354-2018 [
17]
Rice, this study selected common types of foreign objects found in rice, including stones, clods, metal fragments, screws, corn kernels, and wheat.
In this study, approximately 5000 images for rice foreign object detection were collected, with the dataset split into a training set and a validation set in a ratio of 8:2. This ratio was chosen as a commonly accepted practice in deep learning to provide a sufficient amount of data for training while reserving enough data for reliable performance evaluation. The dataset was randomly split to ensure that both the training and validation sets are representative of the overall data distribution. All images were captured using a high-resolution camera against a uniform background and under varying lighting conditions. Manual annotation was performed using Labelme software (version 4.5.13) to ensure data accuracy and annotation quality. To enhance training efficiency and reduce computational costs, all images underwent standardized preprocessing, including resizing to 384 × 384 pixels to ensure consistency of input data. Furthermore, size normalization helps mitigate feature scale variation caused by differences in image resolution, thereby improving the model’s robustness and detection performance [
18]. On this basis, we also applied data augmentation techniques, such as converting images to grayscale, increasing brightness, adjusting image contrast, and adding Gaussian noise, to further improve the model’s generalization ability and robustness. This dataset serves as a stable and high-quality input source for training subsequent deep learning models. To demonstrate the applied preprocessing techniques,
Figure 1 presents several representative data augmentation results derived from a single image in the rice foreign object dataset.
2.2. Evaluation Index
In the task of rice foreign object detection, evaluating model performance requires a comprehensive consideration of detection accuracy, inference speed, and model complexity. Therefore, this study employs precision, recall, average precision (
AP), and mean average precision (
mAP) as evaluation metrics to assess the accuracy of the detection model. In addition, to measure the computational complexity and inference efficiency of the model, this study adopts GFLOPs and the number of parameters as metrics for model complexity, ensuring that the model maintains high computational efficiency and deployability while achieving accurate detection [
19].
Precision is the proportion of correctly predicted positive samples among all predicted positive samples, calculated using Equation (1):
Recall is the proportion of all true foreign object samples that are correctly detected and is calculated using Equation (2):
where
TP represents the number of foreign object samples correctly detected,
FP represents the number of normal rice samples incorrectly detected as foreign objects, and
FN represents the number of foreign object samples not correctly detected.
Average precision (
AP) is the area under the precision–recall curve, which measures the overall detection capability of the model across different recall levels. It is calculated using Equation (3):
Mean Average Precision (
mAP) is the average of the
AP values across all categories. In this study, it represents the mean
AP of five categories: stones, clods, screws, corn kernels, and wheat. It is calculated using Equation (4):
where
N represents the total number of categories, which, in this study, includes various types of foreign objects in rice. Additionally, this study adopts
mAP@[0.5:0:95] as the core evaluation metric. This metric calculates the average
mAP by setting different IoU thresholds (ranging from 0.5 to 0.95, with a step size of 0.05), providing a more comprehensive assessment of the model’s detection capability under varying matching criteria [
20].
To further evaluate the computational complexity of the model, this study introduces the concepts of GFLOPs and the number of parameters as evaluation metrics. GFLOPs represent the amount of computation required during inference; a lower GFLOPs value indicates lower computational cost, making the model more suitable for deployment on embedded devices or in low-computing-power environments. The number of parameters represents the total number of trainable parameters within the model. A model with fewer parameters typically achieves faster inference speed and reduced storage requirements but may compromise detection accuracy. In this study, the network structure is optimized to balance the parameter count and detection performance, ensuring that the model maintains high accuracy while minimizing computational cost [
21].
2.3. YOLOv8
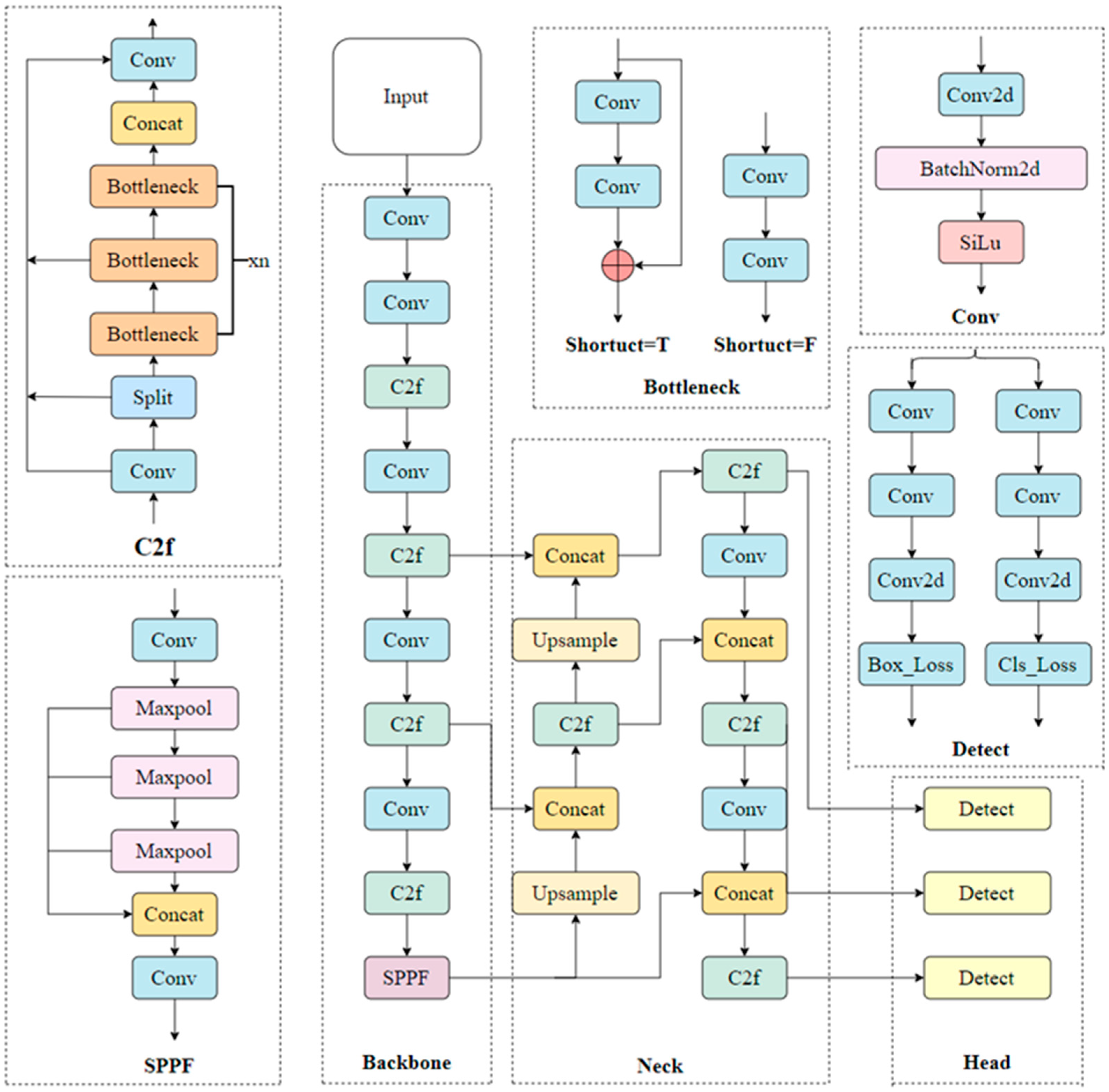
Since its introduction, the YOLO model has been a pioneering representative of object detection technology in the field of computer vision. Its outstanding performance and efficiency have led to its widespread adoption in both academia and industry. With the continuous advancement of technology, the YOLO series has undergone multiple optimizations and upgrades, with each generation of models introducing improvements in accuracy, speed, and application scenarios. In 2023, Ultralytics released YOLOv8, marking another significant milestone in the YOLO series. Compared to its predecessors, such as YOLOv5 and YOLOv7, YOLOv8 introduced breakthroughs in multiple aspects, particularly excelling in both accuracy and efficiency. As a result, it has become a leading choice in the field of object detection. YOLOv8 offers five different network architectures—YOLOv8-n, YOLOv8-s, YOLOv8-m, YOLOv8-l, and YOLOv8-x—as illustrated in
Figure 2. These architectures provide a unified and efficient solution for various computer vision tasks, including object detection, instance segmentation, and image classification [
22].
The architecture of the YOLOv8 model consists of four core components: the input layer, backbone network layer, neck structure layer, and output layer. The input layer is optimized through various data augmentation techniques, such as mosaic augmentation, dynamic anchor box calculation, and grayscale padding, enhancing the model’s robustness across diverse environments and data variations. Next, the backbone network extracts high-level feature information from the input image. It incorporates techniques such as convolutional modules (Conv), the C2f module, and Spatial Pyramid Pooling Faster (SPPF). These components enable the capture of both global context and local details, providing a comprehensive feature representation for subsequent processing. The neck structure layer serves as a bridge between the backbone network and the output layer. It effectively integrates multi-scale information through structures such as the feature pyramid network (FPN) and the path aggregation network (PAN), enhancing the model’s adaptability to multi-scale objects and thereby improving detection accuracy. Finally, the output layer generates the final detection results and applies the non-maximum suppression (NMS) algorithm to eliminate redundant bounding boxes, ensuring precise and reliable outputs. The deep learning framework of YOLOv8 leverages the powerful capabilities of convolutional neural networks (CNNs) to comprehensively analyze input images and accurately generate object locations, classifications, and confidence scores.
2.4. Improved YOLOv8 Network
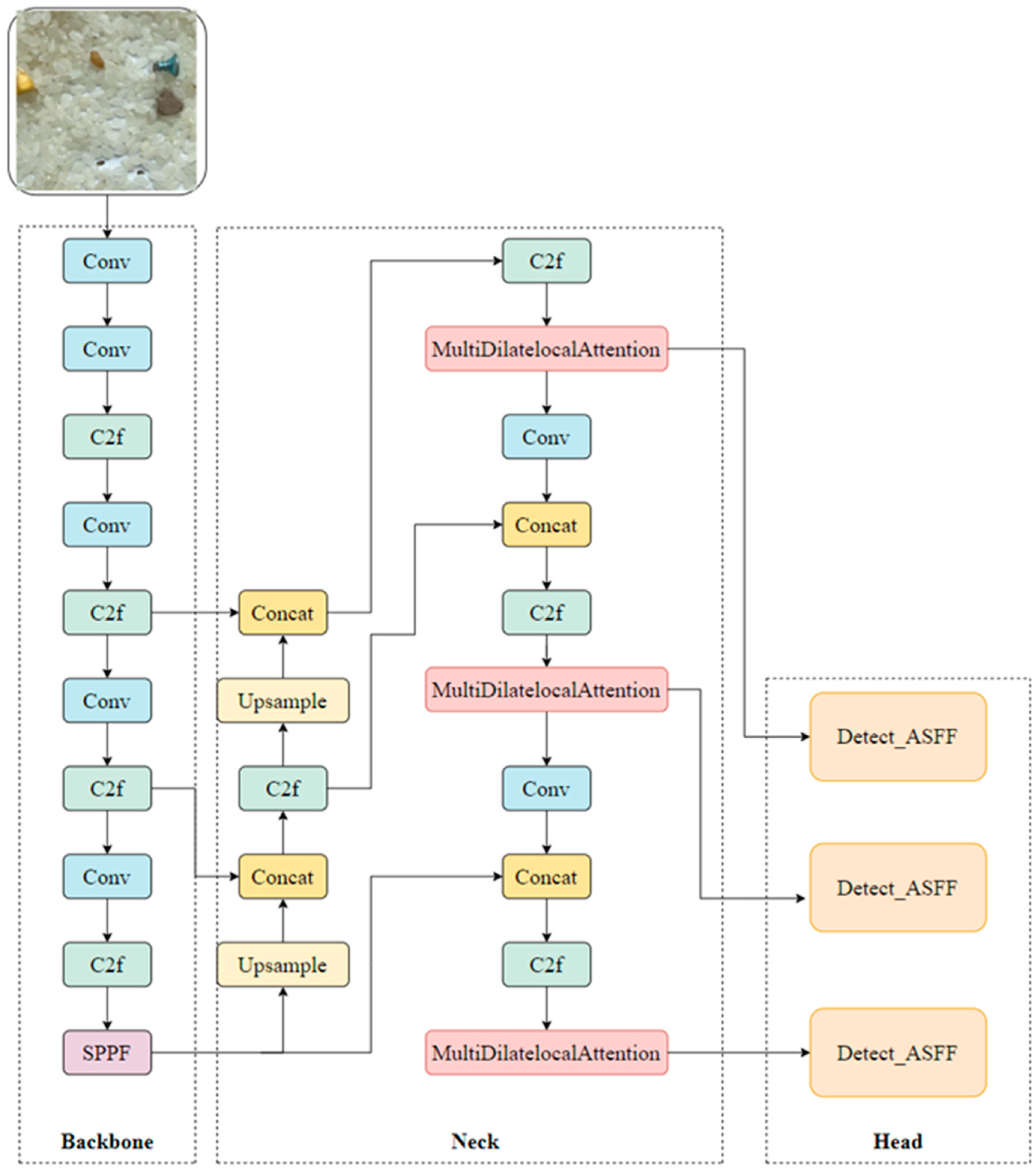
Although YOLOv8 has demonstrated outstanding accuracy and efficiency in object detection tasks, making it one of the leading detection models, it still faces challenges in specific scenarios. Taking rice foreign object detection as an example, the wide variety of foreign objects, their significant size differences, and the complex background create challenges. YOLOv8 occasionally fails to detect small targets or misclassifies low-contrast objects. These issues may affect the accuracy and reliability of detection results in real-world applications. To address these limitations, this study proposes an improved method based on YOLOv8 by introducing the multi-scale dilated attention (MSDA) mechanism and the adaptive spatial feature fusion (ASFF) module. These enhancements aim to improve object detection accuracy and strengthen feature fusion in complex backgrounds. The structure of the improved YOLOv8 network is shown in
Figure 3.
This study primarily focuses on optimizing the detection head of the YOLOv8 model. The original YOLOv8 model relies on conventional concatenation operations (Concat) and a standard detection module (Detect); however, it often exhibits insufficient detection accuracy when handling multi-scale objects, particularly in the detection of small and low-contrast targets. To address this issue, this study introduces two key enhancements to the model’s Neck and Head sections: the multi-scale dilated attention (MSDA) mechanism and the adaptive spatial feature fusion (ASFF) module.
First, the MSDA mechanism is incorporated into the Neck section. This mechanism combines dilated convolutions with an attention mechanism to enhance the feature representations of multi-scale targets across small, medium, and large object detection layers adaptively. By applying the MSDA mechanism at various detection scales, the model is able to capture the details of different targets more precisely, significantly improving its ability to detect objects, particularly under low-contrast conditions and complex backgrounds.
Secondly, in the Head section, the conventional Detect module is replaced with the Detect_ASFF module. The ASFF module adaptively learns the fusion weights of feature maps at different scales, addressing the issue of inconsistent feature scales inherent in traditional methods. This process significantly enhances detection accuracy for multi-scale objects. This improvement is particularly notable in scenarios with large variations in object sizes and complex backgrounds.
2.4.1. Multi-Scale Dilated Attention (MSDA)
Traditional convolutional neural networks are constrained by a fixed receptive field in object detection, making it challenging to capture multi-scale targets effectively, particularly for small and low-contrast objects [
23]. The multi-scale dilated attention (MSDA) mechanism is a hybrid module that combines dilated convolution with multi-head self-attention. It is designed to enhance feature representation in complex scenarios through multi-scale receptive field modeling and a sparse attention mechanism [
24]. Its core improvement mechanisms are as follows:
Traditional convolution operations are limited by a fixed-size local receptive field (e.g., 3 × 3 or 5 × 5), which hinders the simultaneous capture of local details and global semantics. MSDA addresses this limitation by introducing differentiated dilation rates in different attention heads to construct multi-scale feature extraction branches.
For the input feature map
, a query (
Q), key (
K), and value (
V) matrix is first generated by linear projection. The channel dimension is divided into n heads, and each head independently processes a subset of features. Different expansion rates
are set for the convolution operation in each head. The mathematical form of the dilated convolution is shown in Equation (5).
where
is the convolutional kernel weight, and
is the dilation rate. For example, three different dilation rates (r = 1, 2, 3) correspond to different receptive field sizes (3 × 3, 5 × 5, 7 × 7). A 3 × 3 kernel at r = 2 is equivalent to the receptive field of a standard 5 × 5 convolution, but only requires 9 parameters. This approach expands the receptive field and significantly reduces the amount of computation, allowing the model to capture details while enhancing global semantic expression. The model principle of MSDA is shown in
Figure 4.
- 2.
Sparse Attention Mechanism and Sliding Window
To reduce the computational complexity of global self-attention,
, MSDA proposes the sliding window dilated attention (SWDA), which calculates attention weights only within local windows. For position
, a sliding window
is defined centered at this position, and attention scores are computed only for the keys (
) and (
) within the window, as shown in Equation (6).
In this way, MSDA reduces the complexity of the calculation to (where is the window size) while retaining the semantic relevance of local regions.
- 3.
Channel–Spatial Dual-Path Attention Enhancement
MSDA introduces dual-path attention (DPA), which integrates channel attention and spatial attention mechanisms to further enhance feature representation capability.
Channel attention: channel weights are generated using global average pooling (GAP) to suppress irrelevant channels.
Spatial attention: spatial dependencies are extracted using dilated convolutions to focus on the target region.
The final output is as follows:
Here, represents the Sigmoid function, while denotes element-wise multiplication. By simultaneously incorporating channel and spatial attention mechanisms, MSDA optimizes feature representation across multiple dimensions, enhancing the model’s focus on important feature regions. This approach demonstrates significant advantages, particularly in object detection tasks involving complex backgrounds.
- 4.
Head Feature Aggregation and Pruning Optimization
In multi-head feature aggregation, the outputs from each head,
, are integrated through concatenation and linear projection.
Meanwhile, MSDA applies channel pruning, performing dynamic channel pruning on the features after dilated convolution (with a pruning rate of 15%). This significantly reduces computational cost while preserving model accuracy.
2.4.2. Adaptive Spatial Feature Fusion (ASFF)
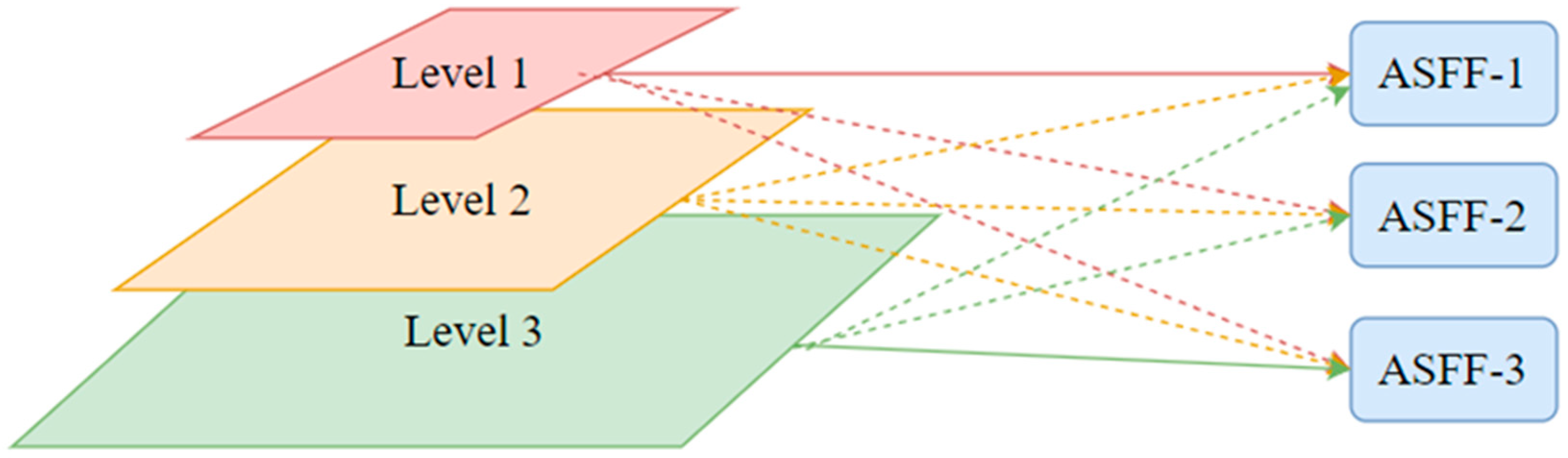
In the YOLOv8 model, the path aggregation network (PANet) typically serves as the feature fusion module, employing both bottom-up and top-down pathways to facilitate information exchange and integration. This enables the effective utilization of semantic information from feature maps at different levels to enhance object detection accuracy. However, this method only fuses the feature maps by making them uniform in size, which limits the full utilization of feature information across different scales and imposes certain constraints on multi-scale object detection. To solve this problem, this paper introduces the adaptive spatial feature fusion (ASFF) mechanism [
25].
Unlike conventional multi-scale feature fusion methods that rely on element-wise operations or cascaded approaches, the core concept of ASFF is to adaptively learn the spatial fusion weights for feature maps at different scales, thereby dynamically adjusting the fusion strategy for features at various levels. Specifically, ASFF can spatially filter out conflicting information and suppress inconsistencies between features at different scales, thereby enhancing scale invariance. This significantly enhances YOLOv8’s object detection capabilities in complex scenarios, particularly in multi-scale and low-contrast object detection. In addition, ASFF not only significantly improves detection accuracy and robustness but also maintains the model’s computational efficiency, enhancing performance with minimal additional inference overhead. This makes ASFF an exceptionally effective feature fusion strategy, especially in application scenarios that require real-time inference, showing its strong advantages. The structure of ASFF is shown in
Figure 5.
2.5. Experimental Environment
This study is based on the open-source machine learning framework PyTorch 1.13.1, using Windows 11, 11th Gen Intel(R) Core(TM) i7-11800H @2.30 GHz, 16 GB of RAM, RTX3060 with 6 GB of RAM, and CUDA 11.8 for GPU acceleration. The Python version used is 3.8. The training parameters are set as shown in
Table 1.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}