1. Introduction
As a globally vital fruit crop with high economic and nutritional value, apples are primarily harvested manually [
1]. This reliance on increasingly scarce and costly labor drives significant demand for automation in agriculture [
2]. Automated harvesting systems are key to overcoming labor shortages and improving efficiency [
3], but face substantial technical challenges in complex orchard environments, such as occlusions and uneven fruit distribution. Accurate fruit detection and instance segmentation are thus critical prerequisites for full automation. Advances in AI and computer vision have consequently made fruit instance segmentation a major research focus, providing essential technology for efficient automated harvesting [
4].
Early image segmentation methodologies predominantly utilized low-level image characteristics, encompassing color properties, edge information, and texture features. Representative techniques include color thresholding, region growing, and edge detection algorithms. While computationally efficient, these traditional methods exhibit limited robustness, particularly under variable illumination conditions or in the presence of complex background clutter [
5]. Subsequently, the integration of machine learning paradigms led to the application of classifiers, such as Support Vector Machines (SVMs) and Random Forests, typically coupled with handcrafted feature descriptors (e.g., color histograms) for segmentation tasks. Although these approaches demonstrated efficacy in constrained scenarios, their performance was fundamentally constrained by the reliance on manual feature engineering, thereby limiting their generalization capabilities across diverse application domains [
6]. In recent years, the advent of deep learning has significantly advanced the field. Semantic segmentation models, exemplified by architectures like Fully Convolutional Networks (FCNs), DeepLab, and U-Net, leverage learned hierarchical features to perform pixel-level classification, yielding substantial improvements in segmentation accuracy [
7]. Nevertheless, a principal limitation of semantic segmentation is its inherent inability to differentiate between distinct object instances belonging to the same semantic category. This characteristic renders it insufficient for tasks demanding instance-level discrimination, such as resolving spatial ambiguities arising from overlapping or occluded fruits in automated harvesting applications.
Instance segmentation has emerged as a pivotal technique alongside the rapid advancement of deep convolutional neural networks. By integrating the strengths of object detection and semantic segmentation, it enables the precise delineation of individual object instances at the pixel level. Unlike semantic segmentation, which assigns a class label to each pixel without distinguishing between objects of the same category, instance segmentation provides both pixel-wise classification and instance-level discrimination. This allows for the extraction of detailed object contours, even when instances are overlapping or closely clustered [
8]. In the agricultural domain, instance segmentation has been widely employed in a variety of tasks, including fruit detection and segmentation, monitoring of pests and diseases, estimation of crop yields, analysis of plant growth stages, and the facilitation of automated operations in agricultural robotics [
9]. Beyond agriculture, instance segmentation also plays a critical role in diverse application areas such as autonomous driving [
10], medical image analysis [
11], and quality control in industrial robotics [
12], where accurate object localization and boundary information are essential.
Mainstream instance segmentation methods are typically classified into two categories: one-stage and two-stage approaches. Among the two-stage frameworks, Mask R-CNN is one of the most representative algorithms [
13]. Wang et al. [
14] enhanced the performance of Mask R-CNN for apple instance segmentation by incorporating attention modules, achieving excellent results under challenging conditions involving occlusion and overlap, with a reported recall of 97.1% and precision of 95.8%. Similarly, Sapkota et al. [
15] conducted a comparative study between YOLOv8 and Mask R-CNN, noting that although Mask R-CNN outperforms in segmentation accuracy, it suffers from higher inference latency, requiring 15.6 milliseconds for multi-class tasks and 12.8 milliseconds for single-class segmentation. Despite their high accuracy, two-stage methods typically incur significant computational overhead, which includes increased memory usage and longer processing times. These characteristics make them less suitable for real-time applications. In parallel, the Transformer architecture, which was originally designed for natural language processing and is based on the self-attention mechanism, has shown promising potential in image segmentation tasks due to its ability to capture global contextual dependencies [
16]. The Vanilla Transformer [
17], which serves as the foundation for Transformer-based research, adopts a dual-module encoder–decoder structure to process tokenized inputs. Each module consists of multiple stacked Transformer blocks, with each block comprising two key components: a multi-head self-attention (MHSA) mechanism [
18] and a position-wise fully connected feed-forward network (FFN) [
19].
To address the challenges associated with deploying segmentation models in real-time applications, researchers have increasingly focused on one-stage approaches for fruit segmentation. In 2015, Joseph Redmon introduced the YOLO algorithm [
20], which quickly became one of the most widely adopted methods due to its high inference speed and real-time performance. Building on this foundation, Kang and Chen [
21] proposed DaSNet-V2, a single-stage instance segmentation network that integrates a lightweight backbone with a feature pyramid structure, enabling both fruit detection and instance segmentation. In complex orchard environments, DaSNet-V2 achieved an F1 score of 0.844 for detection and a mean Intersection over Union (mIoU) of 0.858 for segmentation, demonstrating strong robustness and computational efficiency. Tang et al. [
22] enhanced the SOLOv2 framework by incorporating a lightweight spatial attention module, which significantly improved segmentation accuracy for overlapping apples. By utilizing RGB-D data for more accurate spatial localization, their method achieved a 3.6% improvement in mean average precision (mAP) and a reduction of 1.94 million parameters, making it well-suited for environments with heavy occlusion. Wang et al. [
23] introduced two novel modules—Receptive-Field Attention Convolution (RFA) and Dual-Feature Pooling (DFP)—based on the YOLOv5s architecture and combined them with the Soft-NMS algorithm. This approach enhanced the detection performance of small objects in UAV-captured images, resulting in a 6.1% increase in mAP. Fu et al. [
24] developed MSOAR-YOLOv10 (Multi-Scale Occluded Apple Recognition), which integrates multi-scale feature fusion with an Efficient Channel Attention (ECA) mechanism. This model notably improved the detection accuracy of occluded apples while maintaining a lightweight architecture suitable for deployment on embedded systems. Furthermore, Li et al. [
25] optimized YOLOv5 through a multi-task learning framework, achieving a mAP of 84.12% in occluded scenarios and enhancing real-time performance on edge devices. These advancements collectively demonstrate that YOLO-based instance segmentation methods possess strong adaptability in unstructured orchard environments, offering accurate and efficient delineation of fruit instance contours.
To mitigate the computational burden posed by complex segmentation models, researchers have actively explored model lightweighting techniques aimed at reducing the resource demands of computationally intensive components. Lightweight architectures such as MobileNet and ShuffleNet employ methods including depthwise separable convolutions, pruning, and quantization to significantly lower model complexity while maintaining acceptable performance levels. Hu Guangrui et al. [
26] proposed Lad-YXNet, a lightweight segmentation model that integrates Efficient Channel Attention (ECA) and Shuffle Attention (SA) modules to enhance the backbone network and feature fusion processes. This approach resulted in an 18.23% reduction in model size. Liu et al. [
27] introduced Faster-YOLO-AP, which incorporates Partial Depthwise Convolution (PDWConv) and Depthwise Separable Convolution (DWSConv) to reduce computational demands. In addition, the model employs the EIoU loss function to enhance bounding box regression accuracy. Their method achieved a mean average precision of 84.12% on edge devices, with parameters and FLOPs reduced to 22% and 28% of the baseline model, respectively. These studies represent important advances in the design of lightweight models that are suitable for deployment in resource-constrained environments such as edge computing. Nevertheless, further research is needed to optimize the trade-off between model efficiency and robustness, particularly in the context of complex and unstructured orchard environments [
28].
In order to improve the accuracy of the picking robot vision system’s understanding of the orchard environment and provide the robot with more refined picking guidance, the research objectives of this paper are to improve the model’s segmentation accuracy of fruits in complex orchard environments and to realize the lightweight design of the model so as to ensure that it can operate efficiently on resource-constrained embedded devices and realize the accurate recognition of fruits.
3. LGVM-YOLOv8n Model
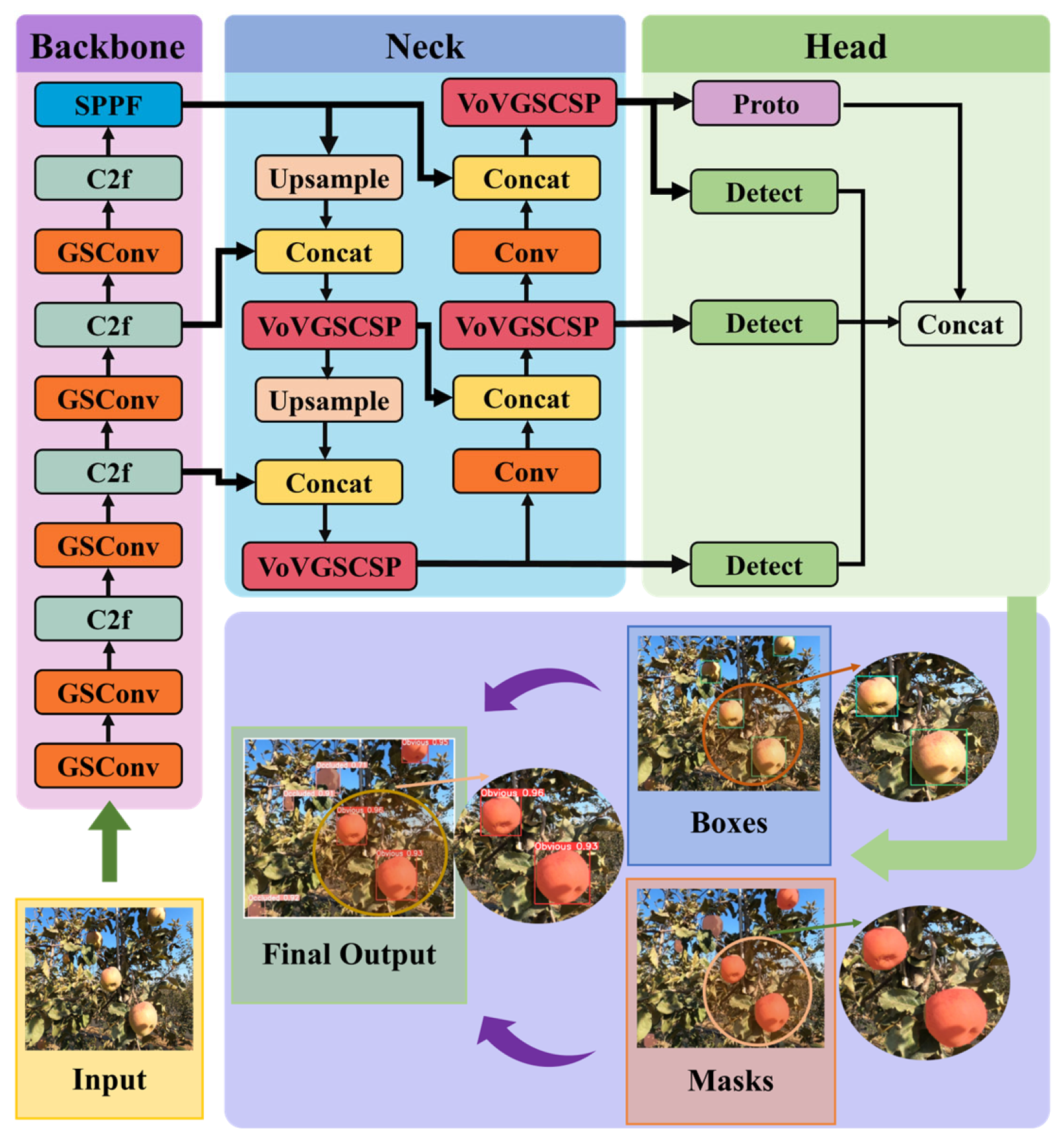
YOLOv8n is an instance segmentation network built upon the YOLO series, incorporating the strengths of earlier generations while introducing structural enhancements for improved performance. The YOLOv8 segmentation framework (YOLOv8seg) is available in five variants, differentiated by model size: YOLOv8n-seg, YOLOv8s-seg, YOLOv8m-seg, YOLOv8l-seg, and YOLOv8x-seg. As the model size increases, so do the number of network layers and the associated computational complexity. In this study, the lightweight version, YOLOv8n, serves as the base architecture. To adapt the network to the challenges of apple instance segmentation in complex, unstructured orchard environments, targeted structural optimizations were applied across several components of the network, including the backbone, neck, detection head, and segmentation head [
36].
The primary objective of these modifications was to simultaneously improve segmentation accuracy and maintain high inference speed suitable for deployment on edge computing platforms [
37]. To achieve this, three key enhancements were introduced. First, the GSConv lightweight convolution module was used to replace standard convolution operations in the backbone, reducing computational cost. Second, the C2f module in the neck was replaced with the more efficient VoVGSCSP module to optimize feature fusion. Third, a new loss function,
, was adopted to improve bounding box regression accuracy by incorporating distance-based constraints. These architectural adjustments collectively define the proposed LGVM-YOLOv8n model, whose structure is illustrated in
Figure 5. The integration of these components enhances both accuracy and speed, effectively reducing false positives and false negatives and improving the model’s overall reliability for real-time fruit instance segmentation in orchard environments.
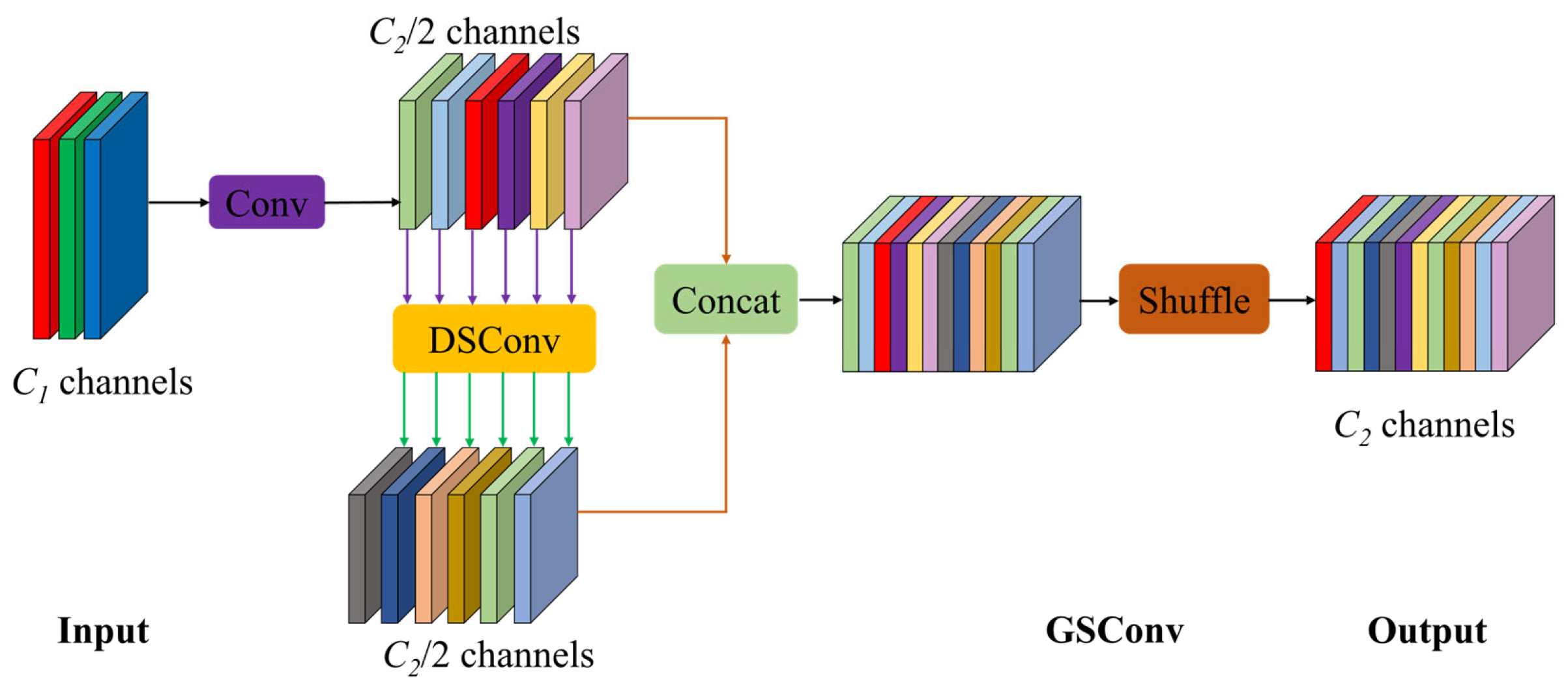
3.1. GSConv Module
GSConv is a convolution module designed for lightweight networks that effectively reduces the number of parameters and computational cost while maintaining model performance, as illustrated in
Figure 6.
It is particularly suitable for deployment in resource-constrained environments, such as mobile and embedded devices. GSConv is formulated by
where
represents the input tensor with a shape of C
1 × H × W; C
1 denotes the number of input channels; H and W represent the height and width;
denotes the final output tensor with a shape of C
2 × H × W, where C
2 represents the number of output channels;
represents the channel shuffling operation;
denotes the weight matrix of the standard convolution;
refers to the weight matrix of the depthwise separable convolution;
is the convolution operator, which performs convolution between the weight matrix and the input tensor
; and
is the channel concatenation operation, indicating that the outputs of
and
are concatenated along the channel dimension. After concatenation, the number of channels in the tensor becomes C
2.
This module facilitates efficient feature extraction by combining standard convolution with depthwise separable convolution (DSConv) and employing a channel shuffle mechanism. Although DSConv performs convolution operations independently on each channel, thereby significantly reducing computational cost compared to standard convolution, it inherently limits inter-channel information exchange. To address this limitation, a subsequent channel shuffle operation is introduced to enhance feature interactions across channels, effectively mitigating the information loss caused by channel independence in DSConv [
38]. Moreover, GSConv utilizes a concatenation (Concat) operation to integrate the complex, high-representation features generated by standard convolution with the lightweight features extracted by DSConv. This design enables a balance between computational efficiency and expressive feature extraction, making the module well-suited for lightweight segmentation networks.
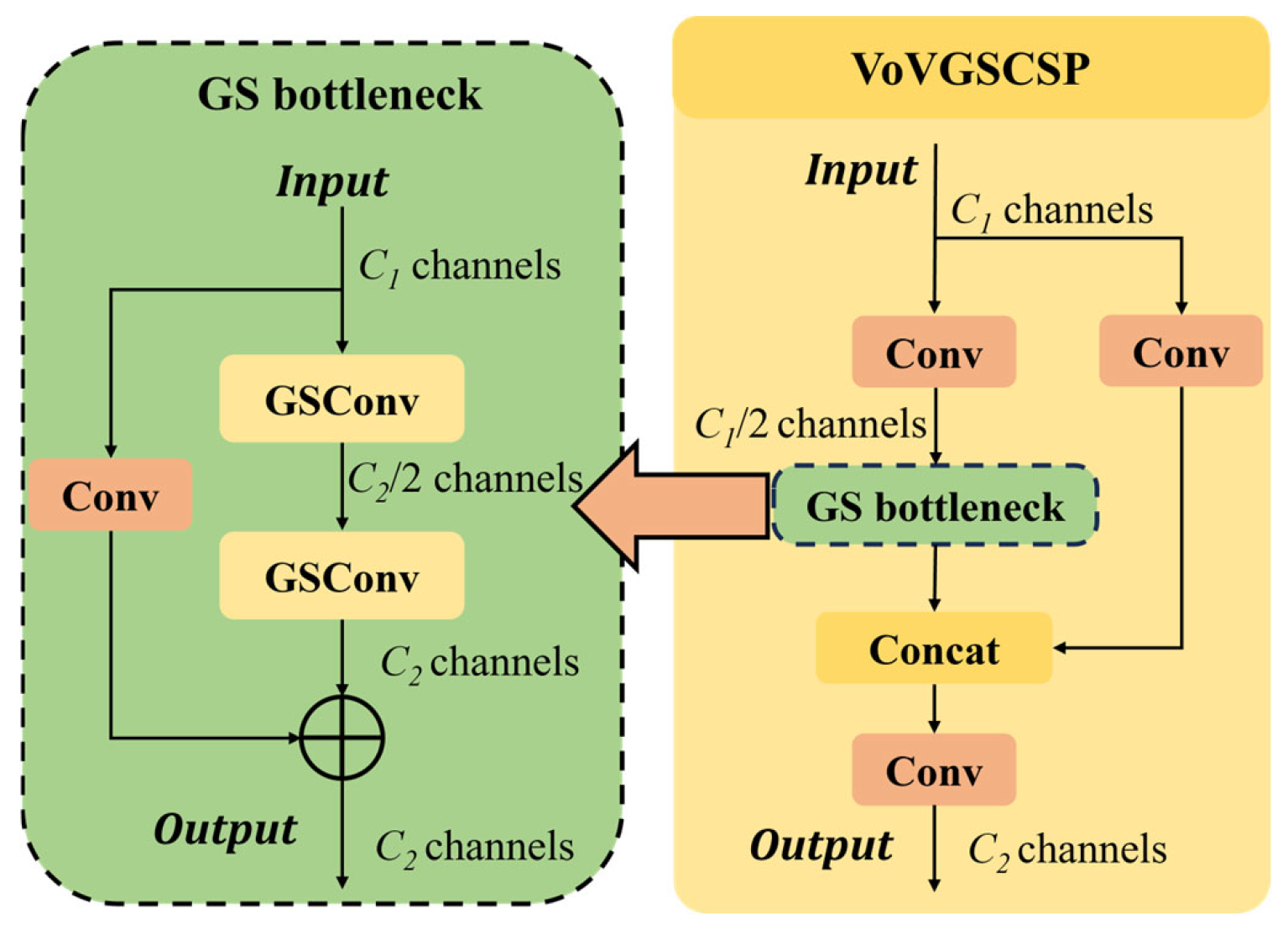
3.2. VoVGSCSP Module
The VoVGSCSP module, as illustrated in
Figure 7, optimized the feature fusion mechanism of CSPNet by incorporating the GSConv and GS Bottleneck structures, effectively reducing the model’s computational complexity and parameter count while enhancing feature representation flexibility and computational efficiency [
39].
This module incorporates group convolution and channel shuffle operations to effectively reduce redundant computations, thereby lowering computational overhead without compromising accuracy. Its streamlined architectural design ensures strong adaptability to embedded systems, significantly decreasing both memory usage and power consumption. As a result, it is particularly well-suited for real-time applications such as unmanned aerial vehicles (UAVs), vision-based sensors, and Internet of Things (IoT) devices. In addition, the VoVGSCSP module exhibits excellent multi-scale feature extraction capabilities, offering robust support for instance segmentation tasks in complex and unstructured environments. It is especially effective in capturing small objects and fine-grained details, making it a practical and efficient solution for deployment in resource-constrained settings. VoVGSCSP is formulated by
where
denotes the input tensor with a shape of C
1 × H × W; C
1 represents the number of channels; H and W represent the height and width;
,
and
are the weight matrices for three convolution operations, with each convolution operation performing calculations on the input feature map.
is the output feature map obtained after the final convolution operation, with a shape of C
2 × H × W, where C
2 is the number of output channels.
represents the convolution operator, indicating that the weight matrix is convolved with the input tensor
.
denotes the channel concatenation operation, which is used to merge two feature maps along the channel dimension.
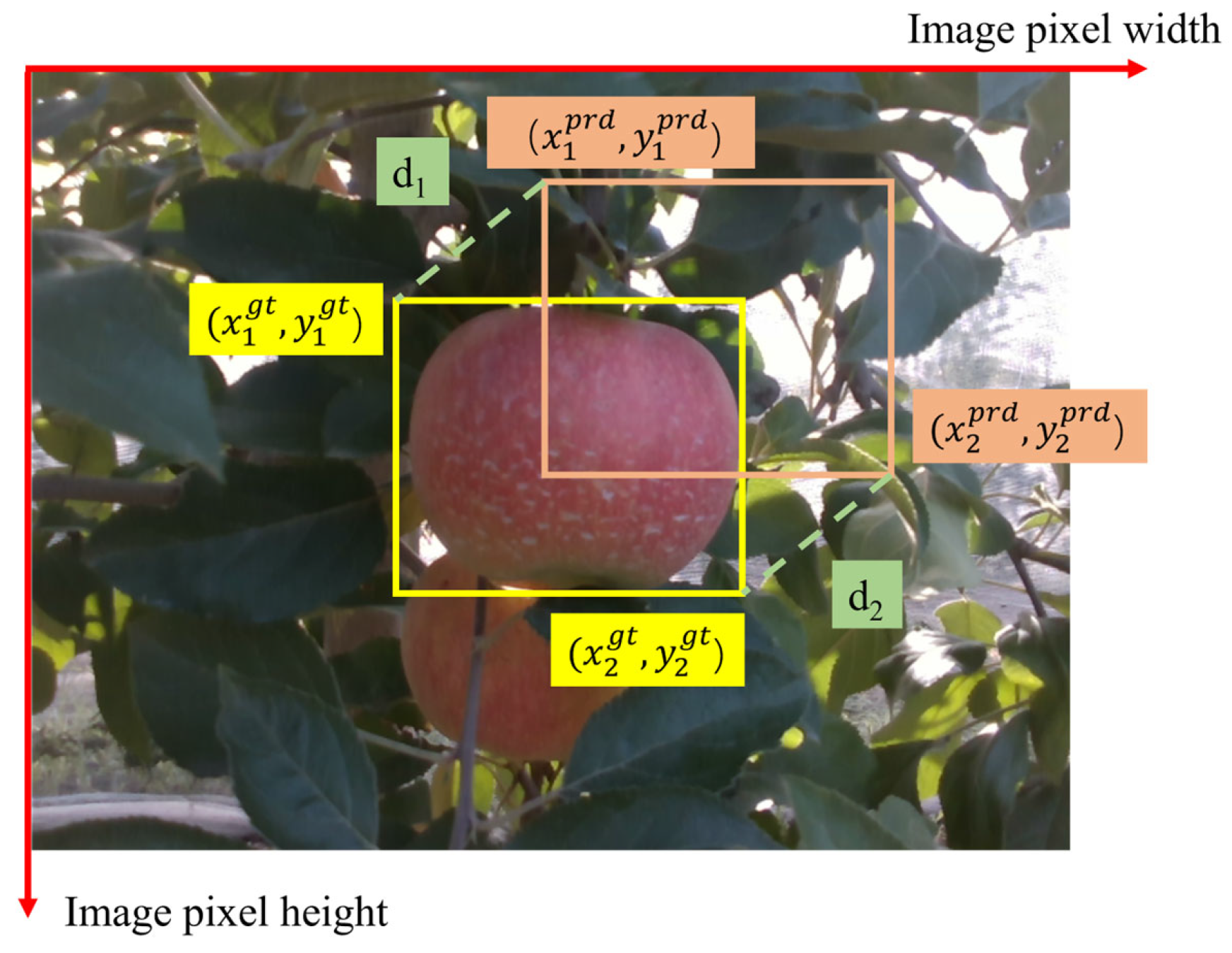
3.3. MPDIoU
Loss Function
(Minimum Points Distance Intersection over Union) is an enhanced bounding box regression loss function that enhances the accuracy of bounding box matching by incorporating the minimum corner point distance between the predicted and ground truth box, as illustrated in
Figure 8. This approach significantly reduces errors, particularly when the bounding boxes have minimal overlap, thereby improving object localization accuracy [
40]. It is derived from Equations (3)–(5).
where
and
represent the euclidean distances between the top-left and bottom-right corners of the predicted and ground truth box;
,
and
,
denote the coordinates of the top-left and bottom-right corners of the predicted box; and
,
and
,
represent the coordinates of the top-left and bottom-right corners of the ground truth box.
where
represents the ratio of the intersection area to the union area between the predicted and ground truth box;
and
, which denote the width and height of the predicted box.
Compared to traditional , provides a more refined evaluation of corner point distances, reducing matching deviations and demonstrating superior performance in non-overlapping segmentation tasks. In addition to considering the relative position and shape information of bounding box, simplifies the computational process, reducing complexity and minimizing resource consumption, making it well-suited for resource-constrained environments such as embedded devices, enabling efficient deployment. Furthermore, exhibits strong robustness when dealing with complex object shapes and irregular boundaries, achieving an optimal balance between accuracy and efficiency. This further enhances the model’s adaptability and reliability in real-world applications.
3.4. Model Evaluation Metrics
To evaluate the performance of the segmentation model, the following metrics were selected as evaluation criteria: precision (P), recall (R), mean average precision (mAP@0.5), model Giga Floating-Point Operations per Second (GFLOPS), weight size, and inference speed [
41]. GFLOPS represents the number of billions of floating-point operations the model can perform per second. Weight size refers to the memory space occupied by the trained model weights and inference speed indicates the time required for the model to process a single image during inference.
Precision refers to the proportion of correctly identified apple instances among all predicted apple instances. It measures the model’s accuracy in recognizing positive targets and is calculated using Equation (6).
Recall refers to the proportion of successfully segmented apple targets among all actual apple targets. It evaluates the model’s capability to identify objects and is computed using Equation (7).
where TP represents the number of apples correctly identified as apples by the model; FP represents the number of non-apple instances incorrectly classified as apples; and FN represents the number of apple instances incorrectly classified as non-apples.
Mean average precision (mAP@0.50) refers to the average precision of the model at different recall levels under an
threshold of 0.50. It represents the overall performance of the model under specific matching conditions and is calculated using Equations (8) and (9).
where AP represents the area enclosed by the precision–recall (PR) curve, with recall (R) on the x-axis and precision (P) on the y-axis; APᵢ denotes the average precision for the i-th class; and N represents the total number of classes.
3.5. Model Training Platform
The experimental training platform utilized in this study is a dedicated deep learning workstation configured with a Precision 7920 Tower. The system specifications are detailed in
Table 1. The operating system is Ubuntu 18.04 and the hardware includes an Intel Xeon
® Silver 4210 CPU and an NVIDIA GeForce RTX 2080 Ti GPU (PCIe/SSE2) with 11 GB of video memory. The deep learning environment is built on PyTorch 1.12.0, with Python 3.8, Torchvision 0.13, Ultralytics 8.2, CUDA version 10.2, and cuDNN version 8.2.0.
The initial learning rate during model training is set to 0.01, with a weight decay rate of 0.0005 and a momentum factor of 0.937. The learning rate is adjusted using the warmup strategy for the first three epochs. Stochastic Gradient Descent (SGD) with momentum is employed for parameter updates. The model is trained for 300 epochs, with a batch size of 24 and an image input size of 640 × 640. The Intersection over Union () threshold is set to 0.5 and the confidence threshold is also set to 0.5. Additionally, a cosine annealing scheduler is utilized to optimize the learning rate throughout the training process.
4. Experimental Results
4.1. Ablation Experiments
To evaluate the effectiveness of the three improvements applied to the original model, an ablation study is conducted on the same apple dataset under identical configuration settings. Using YOLOv8n as the baseline model, the three improvement methods are sequentially introduced to assess the combined impact of different modules. The experimental results are presented in
Table 2. Method A refers to the incorporation of the
loss function, Method B involves the integration of the lightweight convolutional module GSConv into the backbone network, and Method C denotes the addition of the VoVGSCSP module.
The experimental results demonstrate that the introduction of the modules significantly impacts the model’s performance. The baseline model exhibits balanced performance in terms of both Box and Mask accuracies, with Box mAP50 at 73.4% and Mask mAP50 at 73.5%. After the introduction of the loss function, both Box mAP50 and Mask mAP50 increased by 0.2%, while the model’s computational complexity decreased by 4.17%. Replacing the standard convolution in the YOLOv8n network with the lightweight GSConv convolution module allows for an improvement in accuracy while reducing complexity. Specifically, Box mAP50 and Mask mAP50 improved by 0.8% and 0.3%, respectively, highlighting its advantages in accuracy optimization. The introduction of the VoVGSCSP module led to even more significant performance improvements, with Box mAP50 and Mask mAP50 increasing by 1.4% and 1.0%, respectively, and a notable 15.3% improvement in inference speed, demonstrating its dual optimization of accuracy and efficiency. The combination of multiple modules further reinforces these advantages, especially when both the GSConv convolution module and the VoVGSCSP module are introduced. This combination results in a 0.8% improvement in Box mAP50 and a 1.0% improvement in Mask mAP50, while reducing inference speed by 11.9%. Finally, the simultaneous application of all three improvements to the baseline YOLOv8n model achieves a 1.2% improvement in Box mAP50, a 0.9% improvement in Mask mAP50, a 9.17% reduction in computational complexity, and a 16.9% reduction in inference time, demonstrating the optimal balance between accuracy and inference speed.
4.2. Comparison Experiments
In this experiment, the enhanced YOLOv8n instance segmentation network serves as the base model, replacing mainstream lightweight feature extraction backbone networks such as MobileNetV3, MobileNetV2, GhostNet, and ShuffleNetV2. By keeping all parameters constant except for the backbone network, we compare the training performance of different backbone networks using the same apple dataset.
The experimental results, as shown in
Table 3, demonstrate that the proposed LGVM-YOLOv8n model outperforms other lightweight backbone networks in key metrics such as Box mAP50 and Mask mAP50. Notably, in terms of Mask mAP50, LGVM-YOLOv8n achieves improvements of 6.90%, 8.50%, 9.10%, and 14.10% over MobileNetV2, MobileNetV3, GhostNet, and ShuffleNetV2, respectively, highlighting its superior segmentation capability. In terms of inference speed, LGVM-YOLOv8n improves by 62.9% compared to MobileNetV2 and 26.9% compared to GhostNet, while the differences with MobileNetV3 and ShuffleNetV2 are relatively small. Although LGVM-YOLOv8n exhibits slightly higher computational complexity than the other lightweight networks, it delivers better performance in both detection and segmentation accuracy while maintaining higher inference efficiency. These results indicate that while lightweight strategies effectively reduce model size and computation, excessive lightweighting can compromise feature extraction capability, negatively affecting segmentation performance. LGVM-YOLOv8n achieves significant advancements in lightweighting while preserving high segmentation performance, strikes an optimal balance between efficiency and effectiveness, and demonstrates superior performance in comparison to other lightweight feature extraction networks.
Additionally, performance comparison experiments are conducted between the proposed improved model and several common models, including the two-stage model Mask R-CNN and the single-stage models SOLOv2, YOLACT, and YOLOv8n. These experiments are carried out on the same apple dataset under identical configuration settings to further assess the segmentation performance of the improved model. The results of these comparison experiments are presented in
Table 4.
Although the classical two-stage instance segmentation network, Mask R-CNN, demonstrates strong segmentation capabilities, its inference speed of 213 ms results in low inference efficiency, making it unsuitable for real-time applications such as fruit-picking robots. In contrast, single-stage instance segmentation networks exhibit faster inference speeds, with YOLOv8n and LGVM-YOLOv8n achieving inference times of 5.9 ms and 4.9 ms, respectively. The improved model also shows significant advancements in segmentation performance, particularly in precision, recall, and Mask mAP50, which reach 73.1%, 67.0%, and 74.1%, respectively. Notably, the Mask mAP50 of the improved model surpasses that of Mask R-CNN, SOLOv2, YOLACT, and YOLOv8n by 21%, 18.4%, 19.7%, and 0.6%, respectively. Regarding the evaluation metrics for lightweight models, the GFLOPS and weight size of LGVM-YOLOv8n are 10.9 and 5.95M, respectively, outperforming the other compared models. Overall, the improved model strikes a superior balance between inference speed and accuracy, making it well-suited for deployment on edge computing platforms.
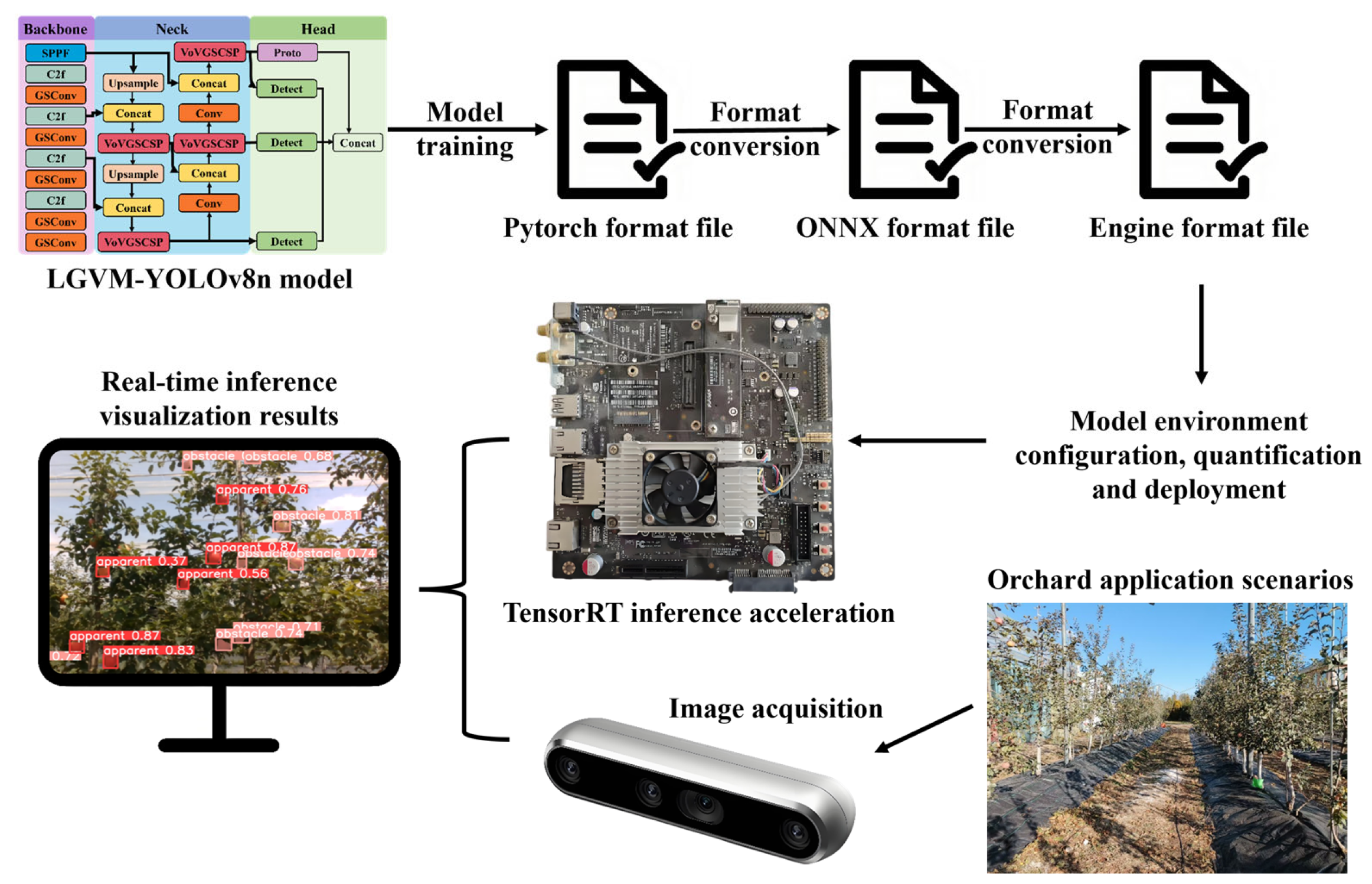
4.3. Deployment on Edge-Computing Platform
The NVIDIA Jetson TX2 is an embedded AI computing platform built on the NVIDIA Pascal™ architecture, designed for smart devices. It delivers robust GPU and CPU performance, equipped with 8 GB of RAM and 32 GB of storage, enabling it to meet the requirements of real-time image processing and deep learning tasks [
42]. As a modular AI device, the Jetson TX2 is widely utilized in edge computing applications and is particularly suited for scenarios that demand a balance between computational performance and energy efficiency [
43].
In this study, NVIDIA TensorRT is utilized for optimization and acceleration to further enhance the inference efficiency of the improved model. TensorRT is a high-performance inference optimization tool specifically designed for NVIDIA GPUs and Jetson hardware, supporting a wide range of deep learning frameworks. It significantly reduces model latency and increases throughput through techniques such as layer fusion, accuracy optimization, and memory management [
44]. The deployment process involves converting the trained PyTorch 1.12.0 model to ONNX format and generating an optimized inference engine using TensorRT on the Jetson TX2, as illustrated in
Figure 9. The generated engine files support serialized storage, allowing for deserialization and loading at any time for inference on real-time video data [
45]. With these optimization steps, the improved model is capable of achieving low-latency, high-efficiency real-time inference on resource-constrained edge devices, thereby demonstrating its practical feasibility in real-world applications.
To evaluate the performance of the improved model in real orchard environments, this study deploys the proposed LGVM-YOLOv8n model alongside the YOLOv8n baseline model and YOLACT, which demonstrates the best performance among models outside the YOLO series on the dataset, on the TX2 edge computing platform. The models’ inference accuracy is assessed in various scenarios during dual-armed apple-picking robot operations [
46]. The performance comparison results of the different models during robot operation are presented in
Table 5. The test results indicate that YOLACT exhibits the lowest FPS and detection speed. Compared to YOLOv8n, LGVM-YOLOv8n improves inference speed by 0.018 s, GPU occupancy by 2.26%, and FPS by 3.38, demonstrating that LGVM-YOLOv8n achieves higher detection accuracy and superior real-time responsiveness in the real-time robot detection system.
Additionally, to further assess the segmentation accuracy of the model, this study randomly selects fruit images under typical lighting conditions (smooth light, back-light, and occlusion) from the real-time inference results. For each scene, 100 frames are evaluated for segmentation accuracy. During the evaluation, unrecognized fruits, repeated recognition frames, and misclassified apple objects are considered as incorrect segmentations and the segmentation accuracy of the model is manually calculated. This evaluation index objectively and accurately reflects the model’s real-time fruit segmentation performance in orchard environments. A statistical analysis of the segmentation results of the LGVM-YOLOv8n model shows that the model correctly segmented 932 fruits, with 13 missed detections, resulting in a missed detection rate of 1.4%. Additionally, there were 17 false detections, corresponding to a false detection rate of 1.8%. The segmentation performance of the model is illustrated in
Figure 10.
Figure 10a shows the results under front lighting conditions, where the total number of fruits in the field of view is 30, with 3 missed detections and no false detections.
Figure 10b presents the results under back-lighting conditions, with a total of 30 fruits, one missed detection, and two false detections.
Figure 10c shows the results in scenarios with occlusions from leaves and branches, where the total number of fruits is 32, with three missed detections and four false detections.
As shown in
Table 6, the inference accuracy of LGVM-YOLOv8n outperforms both YOLOv8n and YOLACT across all test scenarios. Specifically, the segmentation accuracies in smooth light, back-light, leaf-shading, and branch-shading scenarios are improved by 3.89%, 4.31%, 3.87%, and 3.28%, respectively, compared to YOLOv8n. These results demonstrate that LGVM-YOLOv8n exhibits strong robustness and adaptability under complex lighting conditions and partial target occlusion, significantly improving fruit segmentation accuracy to meet the real-time task requirements in orchard environments.
5. Discussion
Traditional research on apple detection and segmentation primarily focuses on the precision and accuracy of apple segmentation. However, real-time fruit detection and segmentation are essential for the practical operation of picking robots. Consequently, it is critical to develop real-time, high-performance vision systems for apple recognition and segmentation in complex orchard environments [
47]. To address these challenges, the LGVM-YOLOv8n lightweight instance segmentation model proposed in this study incorporates three module-level optimization strategies—GSConv, VoVGSCSP, and
—at key network nodes, enabling a synergistic enhancement of both accuracy and efficiency. Each module plays a distinct role: the
loss function primarily enhances the model’s target localization accuracy, the GSConv module effectively balances accuracy and speed, and the VoVGSCSP module significantly improves segmentation capability while maintaining high inference efficiency. The joint optimization of these three modules not only improves computational efficiency but also ensures a high mask average accuracy and achieves the fastest inference speed among all the improved approaches. Experimental results demonstrate that the proposed method significantly enhances fruit segmentation in complex orchard environments, achieving an optimal balance between inference speed, computational efficiency, and segmentation accuracy.
The LGVM-YOLOv8 model proposed in this study achieves an inference speed of 4.9 ms and a computational volume of 10.9 GFLOPS per image, demonstrating both high inference efficiency and computational performance. These results align with the real-time operational requirements of fruit-picking robots. However, experimental results indicate that the model’s accuracy varies under different lighting conditions, with performance in back-lit environments being slightly lower than in front-lit and occlusion scenarios. This phenomenon may be attributed to the significant contrast variations and shadow effects in back-lit conditions, which complicate the extraction of target boundary information, thereby leading to a reduction in segmentation accuracy [
48]. Although the overall error is still within the acceptable range, constructing specialized datasets for different environments (e.g., smooth light, back-light, motion blur, etc.) can enhance the diversity of the data, thus improving the model’s adaptability. Meanwhile, combining migration learning to train targeted models also helps to further improve their performance and robustness in specific scenarios [
49]. However, this approach increases the costs associated with data collection, annotation, and computational resources [
50]. Therefore, when deploying the model in practical applications, it is crucial to strike a balance between data acquisition costs, model adaptability, and computational resources to ensure the system’s practicality and scalability.
Although optimization tools such as TensorRT can significantly enhance inference efficiency and improve computational resource utilization, the deployment of deep learning models on embedded platforms, particularly in real-time robotic systems, remains challenging [
51]. One of the primary obstacles is the memory limitation inherent to embedded devices, which often lack sufficient storage capacity to handle high-resolution input data or run multiple models simultaneously. This can result in memory overflow and compromise system stability, particularly in computationally demanding visual tasks. Additionally, embedded robotic systems typically execute multiple processes in parallel, such as visual perception, path planning, and sensor data fusion. The constrained computational resources available may lead to task contention, reduced responsiveness, and decreased reliability of time-sensitive operations [
52]. Another critical issue is the trade-off between power consumption and thermal performance. Most embedded platforms are battery-powered, and high computational loads can lead to excessive energy usage. Combined with limited heat dissipation capabilities, this may trigger thermal protection mechanisms, which restrict the device’s ability to sustain prolonged, stable operation [
53]. Moreover, deep learning models that have undergone training and general optimization often fail to meet real-time performance requirements when deployed directly on embedded hardware. Therefore, further refinement of network structures, reductions in computational complexity, and the integration of hardware acceleration are necessary to achieve a balance between inference speed and system efficiency [
37]. Given these challenges, future research should focus on low-power and high-efficiency optimization strategies to improve the practical deployment and long-term stability of deep learning models in resource-constrained environments.
The application of deep learning in agriculture continues to expand, and the LGVM-YOLOv8 model demonstrates strong potential for extension to a range of related tasks, including environmental monitoring [
54], plant growth analysis [
55], pest and disease detection [
56], and yield estimation [
57], through the use of transfer learning techniques. By constructing task-specific datasets and retaining the majority of pre-trained parameters, the model’s adaptability and generalization capability can be significantly improved through fine-tuning of selective layers or key feature extraction modules [
58]. In addition, for scenarios requiring higher task specificity, neural architecture search (NAS) can be employed to automatically explore optimal network configurations, while parameter-sharing strategies may be leveraged to facilitate the efficient transfer of pre-trained models across different agricultural tasks. These approaches help to reduce the computational cost and time associated with training while maintaining or even enhancing model performance [
59]. Collectively, such strategies not only exploit the inherent advantages of the LGVM-YOLOv8 architecture but also broaden its applicability, contributing to the advancement of intelligent agricultural systems.
In response to the challenges and future development trends discussed above, future research will focus on several key directions. One important area involves constructing specialized datasets and conducting targeted model training tailored to diverse application scenarios, in order to optimize the trade-off between inference accuracy and computational efficiency in complex agricultural environments. Another focus will be the incorporation of lightweight model optimization techniques, including model pruning, weight quantization, and knowledge distillation, to improve the model’s suitability for deployment on resource-constrained embedded platforms while maintaining high accuracy. Additionally, transfer learning will be utilized to extend the model framework proposed in this study to other agriculture-related domains, enabling flexible adaptation to a range of tasks and supporting multi-functional applications. In conclusion, while challenges remain in the application of deep learning to robotic perception systems in agriculture, continued advancements in model structure optimization, computational resource management, and adaptive learning strategies will contribute to the development of more accurate, efficient, and robust fruit recognition and analysis systems, thereby accelerating progress toward intelligent agricultural solutions.
6. Conclusions
In this study, we propose LGVM-YOLOv8n, a lightweight apple instance segmentation model that improves upon YOLOv8 by introducing the GSConv and VoVGSCSP modules, as well as the loss function. Compared to the original YOLOv8n-seg model, LGVM-YOLOv8n achieves a 0.70 percentage point improvement in mask mAP50, a 16.9% increase in inference speed, a 7.89% reduction in model weight, and a 9.16% decrease in computational cost, striking an effective balance between accuracy and efficiency. Modular ablation experiments further validate the impact of each enhancement: the GSConv module reduces model weight by 4.95% and improves box mAP50 by 0.80 percentage points; the VoVGSCSP module enhances multi-scale feature fusion, increasing mask mAP50 by 1.30 percentage points while maintaining a lightweight design; and the loss function significantly optimizes bounding box regression accuracy, demonstrating robust performance in complex scenarios. Furthermore, the embedded real-time performance and robustness of the LGVM-YOLOv8n model under challenging conditions are validated through deployment tests on edge computing platforms. The results indicate that the model improves segmentation accuracy by 3.89%, 4.31%, 3.87%, and 3.28% in front-light, back-light, leaf occlusion, and branch occlusion scenarios, respectively. The primary contributions of this work are as follows:
- (1)
We propose LGVM-YOLOv8n, a novel lightweight instance segmentation model developed for complex orchard environments. This model innovatively integrates the GSConv module, the VoVGSCSP module, and the loss function into the YOLOv8n baseline, achieving a significant reduction in parameters and computational cost while maintaining high segmentation accuracy for fruit detection.
- (2)
We demonstrate the practical viability of LGVM-YOLOv8n for real-time applications on resource-constrained edge devices. Our experiments show a substantial improvement in computational efficiency, achieving an inference speed of 28.73 FPS, significantly outperforming baseline models and confirming its suitability for deployment on embedded platforms like orchard-picking robots.
- (3)
We conduct a systematic evaluation establishing the enhanced robustness and adaptability of LGVM-YOLOv8n under challenging, previously under-investigated orchard conditions. The proposed model shows significant accuracy improvements over the baseline YOLOv8n specifically in scenarios involving varying illumination (front-light and back-light) and occlusions (leaf and branch), ensuring more reliable fruit segmentation performance in complex real-world agricultural settings.



 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}